
1
POJĘCIE DANYCH, BAZY DANYCH I SYSTEMU
BAZY DANYCH
Dane to fakty, koncepcje i instrukcje reprezentowane przez wartości,
liczby, ciągi znaków, symbole, obrazy itp.
Baza danych to zbiór zapamiętanych w urządzeniach pamięciowych
(dyski, dyski optyczne, taśmy) danych wykorzystywanych przez
organizację.
Baza danych stanowi element większej całości, którą jest system bazy
danych. System ten tworzą:
•bazy danych,
•sprzęt komputerowy do gromadzenia i manipulowania danymi
zgromadzonymi w bazie danych,
•oprogramowanie do wyszukiwania, aktualizacji, wprowadzania i
usuwania danych oraz utrzymania integralności danych.
Oprogramowanie składające się na system bazy danych obejmuje:
•zbiór programów wsadowych operujących na danych zgromadzonych w
bazie,
•zbiór
programów
interakcyjnych
operujących
na
danych
zgromadzonych w bazie,
•oprogramowanie systemowe (system operacyjny komputera, na
którym jest zrealizowana baza danych).
Oprogramowanie pozwalające na stworzenie oraz utrzymanie bazy
danych nazywa się system zarządzania bazą danych.

2
ZBIORY DANYCH
Organizacja
danych
w
systemie
komputerowym,
rozpatrywana w kierunku wstępującym oparta jest o
następującą sekwencję:
•bit (binary digit), czyli cyfra dwójkowa (0 lub 1),
•bajt (byte), czyli osiem bitów oznaczających literę, cyfrę
lub znak specjalny,
•pole (field), czyli ciąg bajtów zapisujących konkretną
daną,
•rekord, czyli sekwencja logicznie powiązanych ze sobą
pól, stanowiących łącznie komunikat typu cecha. Rekord
opisuje określoną encją (entiti), czyli nazwę obiektu
będącego przedmiotem zainteresowania. Każdy rekord
może zawierać w sobie dowolną liczbę jego wystąpień. Ze
względu na podstawowe znaczenie rekordu, musi on być
jednoznacznie identyfikowany przez co najmniej jeden
klucz,
•zbiór (file), czyli grupa rekordów dotyczących
jednorodnej tematyki.

3
MODELE ORGANIZACJI DANYCH W
BAZACH DANYCH
Dane zgromadzone w bazie danych mogą
zostać
zorganizowane
zgodnie
z
możliwościami
reprezentacji
danych
w
systemach komputerowych. W praktyce
rozróżnia
się
następujące
podstawowe
modele baz danych:
•hierarchiczny,
•sieciowy,
•relacyjny,
•obiektowy,
•obiektowo-relacyjny

4
MODEL HIERARCHICZNY BAZ
DANYCH
W
modelu
hierarchicznym
dane
są
gromadzone
w
postaci
rekordów
występujących
w
roli
podrzędnej
lub
nadrzędnej. Rekordy podrzędne mają jedno
powiązanie
z
rekordem
nadrzędnym,
natomiast rekord nadrzędny może mieć
dowolną
liczbę
powiązań
z
rekordami
podrzędnymi (w szczególności zero). Struktura
hierarchiczna (zwana również drzewiastą)
charakteryzuje się tym, że nie może istnieć
żaden rekord podrzędny bez przypisanego mu
jednoznacznie rekordu nadrzędnego
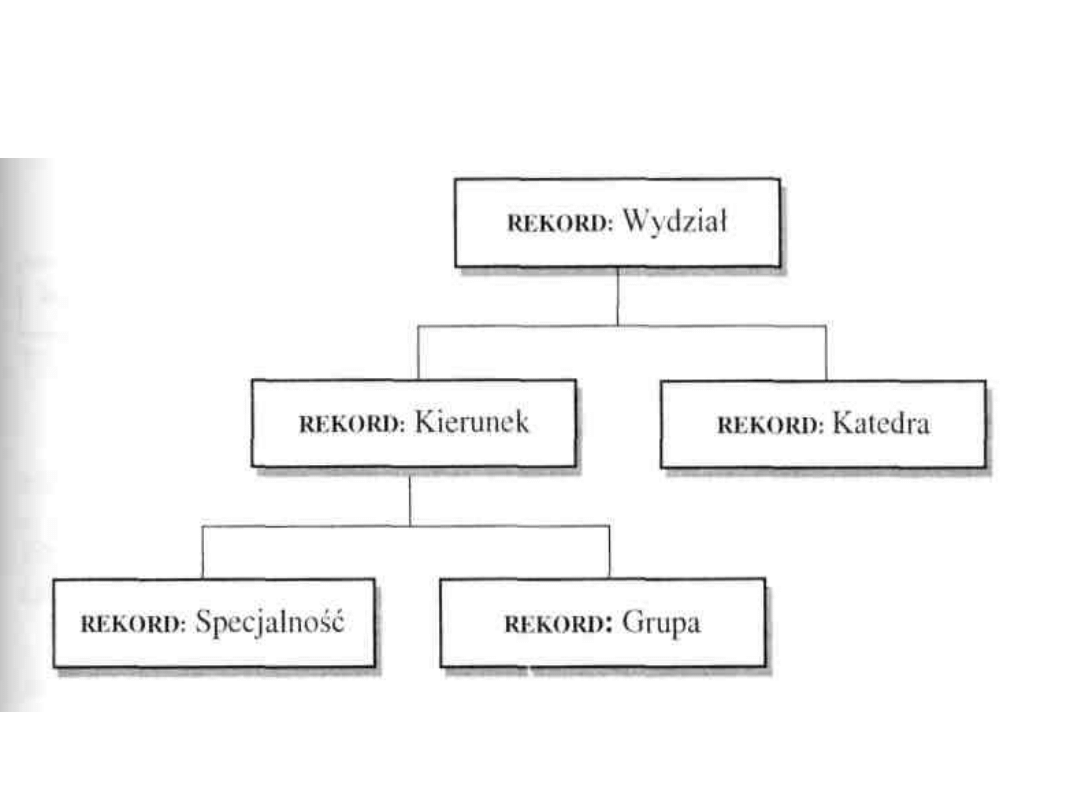
5
MODEL HIERARCHICZNY BAZ
DANYCH

6
MODEL SIECIOWY BAZ DANYCH
Model sieciowy bazy danych stanowi naturalne
rozwinięcie i uogólnienie modelu hierarchicznego.
Tak, jak w modelu hierarchicznym dane są
reprezentowane przez rekordy, jednak w sieciowych
bazach danych rekordy mogą być powiązane z
dowolną
liczbą
innych
rekordów,
zarówno
nadrzędnych, jak i podrzędnych .
Sieciowe bazy danych są bardziej złożone niż
hierarchiczne. Dzięki temu można w bardziej
naturalny
sposób
odzwierciedlać
zależności
wieloznaczne. Zazwyczaj model sieciowy jest bardziej
zbliżony do rzeczywistości niż model hierarchiczny.
Podstawową wadą modelu sieciowego jest zbytnia
złożoność tego modelu oraz związanego z nim języka
manipulowania danymi.
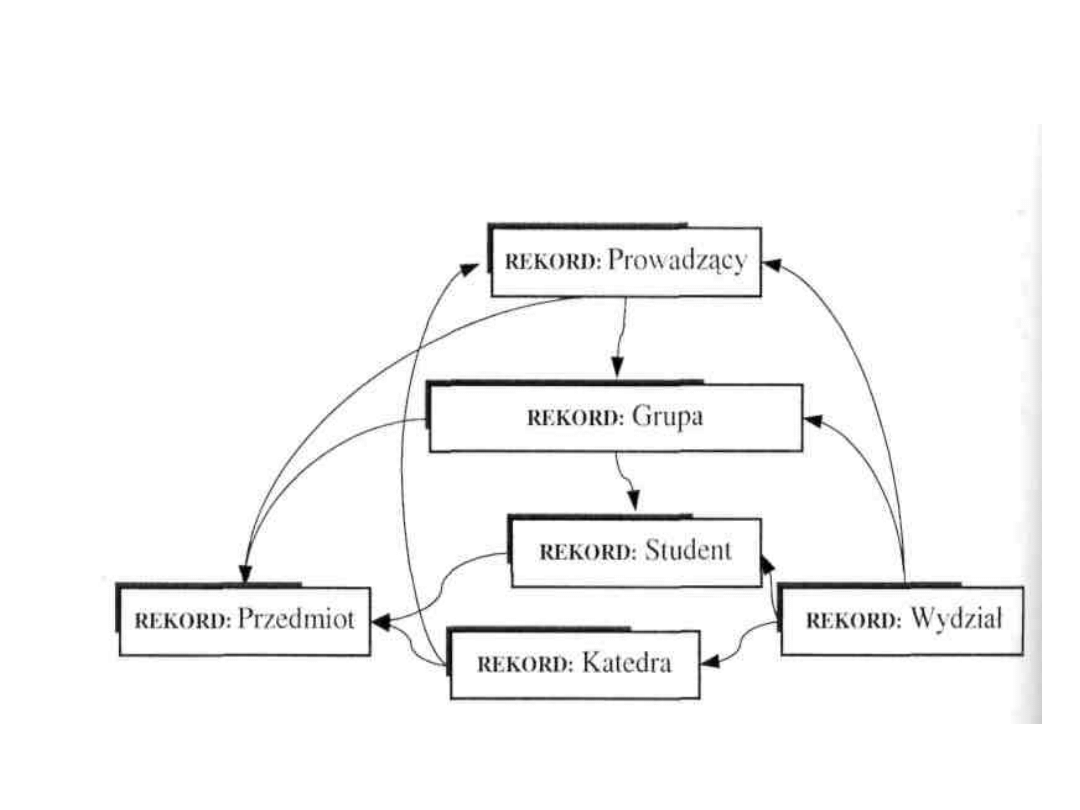
7
MODEL SIECIOWY BAZ DANYCH

8
MODEL RELACYJNY BAZ DANYCH
Najbardziej rozpowszechnionym obecnie modelem danych
jest model relacyjny. Powstał on jako alternatywa dla
modeli hierarchicznego i sieciowego. Podejście relacyjne
zakłada, że tradycyjne pliki (wykorzystywane w modelach
sieciowym i hierarchicznym) mogą zostać potraktowane
jako relacje matematyczne, dzięki czemu można
zastosować w stosunku do nich mechanizmy znane z teorii
relacji.
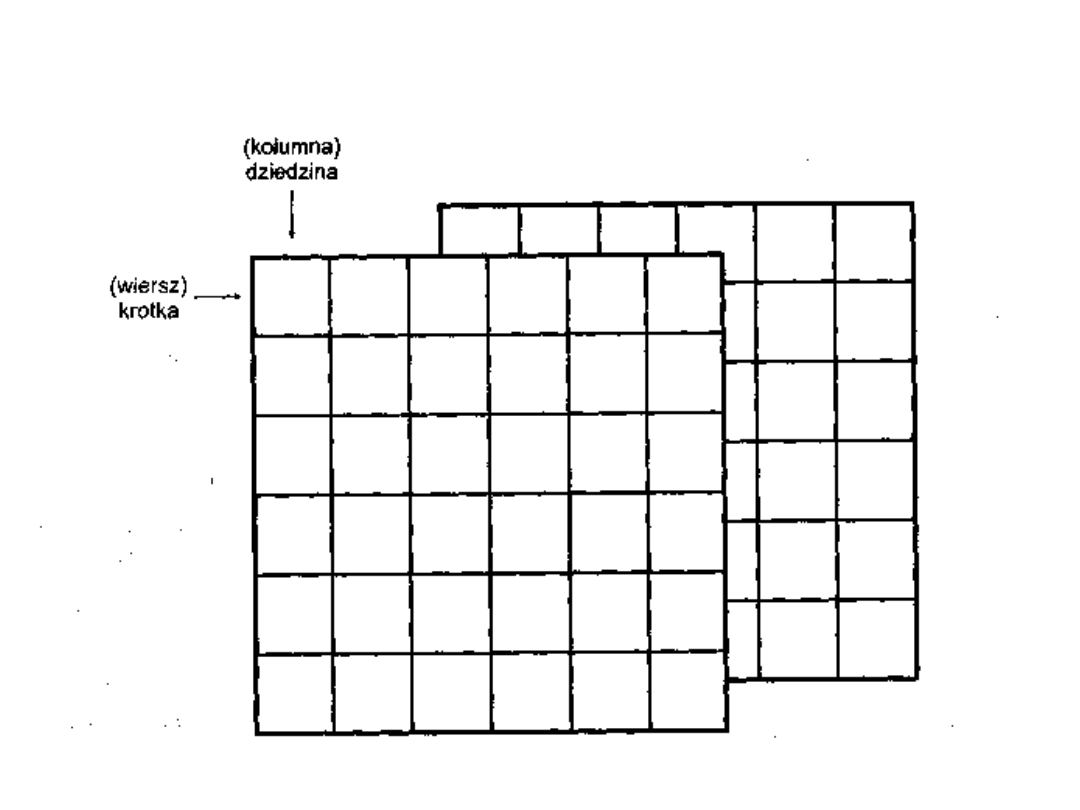
Relacje R nad zbiorami Di, D
2
,...,D
n
nazywamy dowolny
podzbiór iloczynu kartezjańskiego D
1
x D
2
x...x D
n
. Relacja
jest więc zbiorem n-elementowych ciągów. Najczęściej
relacja przedstawia się w postaci tablicy, a relacyjną bazą
danych jako zbiór tablic.
Tablica (relacja) w modelu relacyjnym odpowiada plikowi w
tradycyjnym przetwarzaniu danych. Pojedynczy wiersz
relacji
nazywamy
krótką
(rekord
w
tradycyjnym
przetwarzaniu danych). Można więc powiedzieć, że relacją
jest dowolny skończony podzbiór zbioru krotek.

9
MODEL RELACYJNY BAZ DANYCH
Relacyjna baza danych składa się z kilku powiązanych ze sobą
tablic (relacji), które otrzymuje się w wyniku przeprowadzonego
procesu normalizacji.
Na otrzymanych relacjach można wykonywać określone operacje,
które są kwalifikowane do jednej z następujących grup:
- operacje mnogościowe
z faktu, że relacja jest
zbiorem,
- operacje relacyjne, do których zaliczamy:
- operację projekcji,
- operację selekcji,
- operację złączenia.
Zaletą modelu relacyjnego jest to, że jest on dobrze osadzony w
matematycznej teorii relacji i łatwo posługiwać się nim. W
praktyce jednak można napotkać pewne ograniczenia w jego
stosowaniu wynikające m.in. z tego że:
- systemy relacyjne wymagają zazwyczaj bardzo dużych zasobów
pamięci,
- wykonanie skomplikowanych zapytań może być czasochłonne,
systemy nie zawsze dostarczają pełnego zakresu
operacji algebry relacji.
10
MODEL RELACYJNY BAZ DANYCH

11
OBIEKTOWY I OBIEKTOWO-RELACYJNY
MODELE
Omówione
wcześniej
modele
reprezentacji
danych
mogą
się
okazać
niewystarczające w sytuacjach, gdy należy zapamiętać informacje o bardziej
złożonych strukturach danych, takich jak: obraz, dźwięk, sekwencje wideo. Do
reprezentacji tego typu danych przydatny może się okazać model obiektowy. Jako
obiekt należy rozumieć reprezentację stanu i zachowań wyróżnionego fragmentu
rzeczywistości. Obiekt jest zbiorem atrybutów oraz metod, czyli operacji, które na
nim mogą zostać wykonane.
Obiektowe bazy danych wykorzystują w modelu danych paradygmat obiektowy
dotychczas stosowany w nowoczesnych językach programowania. Obiektowa baza
danych umożliwia przechowywanie i zarządzanie klasami, obiektami i ich metodami
zachowując jednocześnie możliwości posiadane przez nowoczesne systemy
relacyjne (np. przetwarzanie transakcji, kontrola dostępu, optymalizacja zapytań).
Zalety obiektowych baz danych :
- przechowywanie danych oraz operacji na danych w jednej bazie,
- bardziej elastyczne odwzorowanie rzeczywistości w porównaniu z innymi
modelami danych,
- dziedzinę atrybutów klas może stanowić dowolny typ wbudowany bądź
zdefiniowany przez użytkownika.
W teorii i praktyce baz danych są rozwijane również inne koncepcje organizacji baz
danych. Dość mocno akcentują swoją obecność rozwiązania powstałe w wyniku
połączenia modelu relacyjnego i obiektowego - obiektowo-relacyjne bazy
danych.

12
TRANSAKCYJNE BAZY DANYCH (TBD)
W ujęciu informatycznym transakcja jest to ciąg nierozerwalnych,
następujących działań:
•wczytanie danych wejściowych,
•aktualizcja danych,
•zatwierdzenie/odrzucenie,
•kontrola danych,
•transmisja danych.
Jednocześnie tak pojęta transakcja powinna mieć następujące cechy,
zwane skrótowo ACID, tj.:
•nierozrywalności,
•spójności,
•odizolowania od innych transakcji,
•trwałości.
Transakcyjna baza danych (TBD) jest to kolekcja danych i ich
zbiorów zorganizowana w ten sposób, że mogą one obsługiwać w
efektywny sposób wiele ich zastosowań, zadanych jednocześnie przez
wielu użytkowników, w oparciu o centralne sterowanie danymi, o
zminimalizowanie ich redundancji oraz o uniezależnienie ich od
programów użytkowych.
Główne elementy TBD
•model TBD (zewnętrzny, koncepcyjny i wewnętrzny),
•system zarządzania bazą danych (SZBD),
•administrator bazy danych.
13
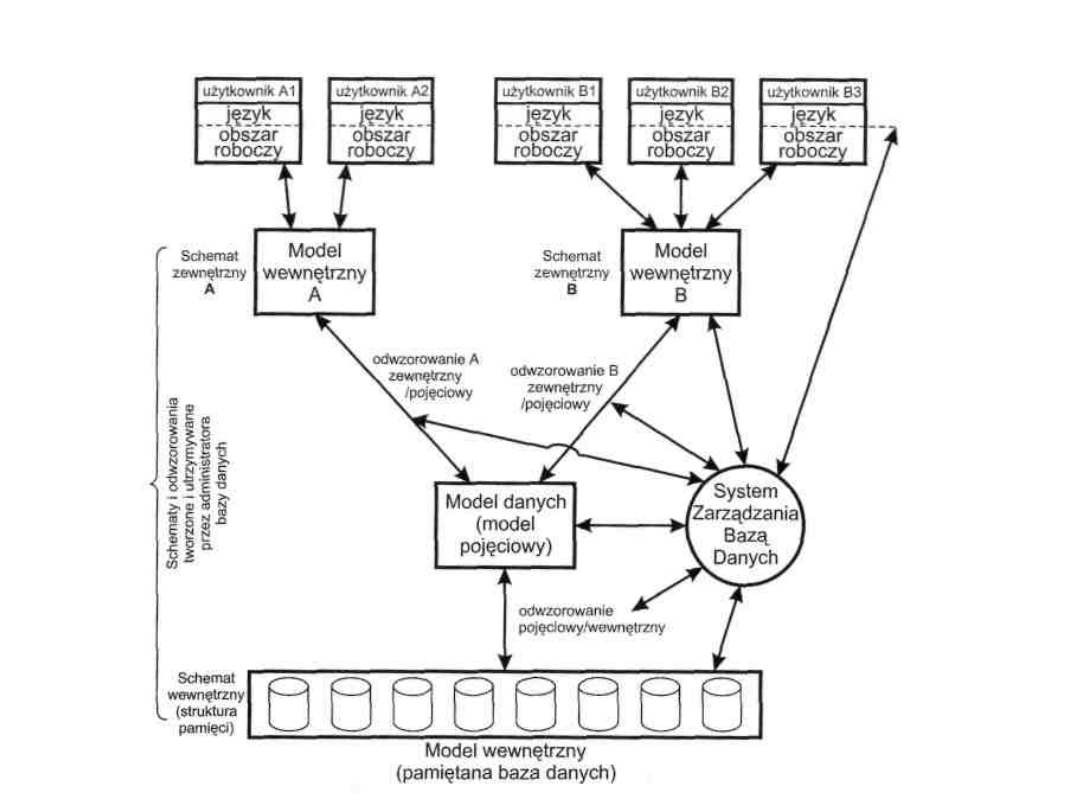
OGÓLNA KONCEPCJA TBD
14
ARCHITEKTURA TBD

15
MODELE TBD
Architektura TBD składa się z trzech powiązanych ze sobą
modeli
takiej
bazy,
tj:
modelu
zewnętrznego,
koncepcyjnego (zwanego również pojęciowym) oraz
wewnętrznego.
Model zewnętrzny TBD odzwierciedla sposób widzenia
bazy danych przez poszczególnych jej użytkowników. Jest to
więc odzwierciedlenie obszaru roboczego użytkownika TBD
w postaci np. ekranów, na których pojawiają się dane i/lub
rekordy żądane przez korzystającego z bazy danych. Model
zewnętrzny składa się z wielu wystąpień różnych typów
rekordów zewnętrznych, przy czym nie zakłada się aby był
on identyczny z rekordem pamiętanym w TBD. Każdy model
zewnętrzny
jest
wyspecyfikowany
przez
schemat
zewnętrzny, zawierający opisy każdego żądanego rekordu
zewnętrznego. Opis taki zawierać może np. określenie ilości
znaków dla odwzorowania nazwiska pracownika, jego
stanowiska itd.

16
MODELE TBD
Model koncepcyjny (pojęciowy) TBD odzwierciedla pełną
zawartość informacyjną bazy danych, która różni się na ogół od
oglądu jej przez konkretnego użytkownika. Model składa się z
wielu wystąpień rekordów pojęciowych, takich jak np. pracownik,
dostawca, odbiorca. Rekord pojęciowy może nie być identyczny z
rekordem zewnętrznym oraz z rekordem pamiętanym. Model
pojęciowy jest wyspecyfikowany przez schemat pojęciowy
definiujący każdy typ rekordu pojęciowego, z tym że definicje
takie nie dotyczą ich fizycznego uporządkowania, stosowanych
metod dostępu, adresowania, indeksowania itp.
W szczególności schemat pojęciowy:
•charakteryzuje encje i ich cechy,
•ustala strukturę logiczną oraz relacje zachodzące między
encjami,
•ustala uprawnienia oraz ograniczenia semantyczne,
•podaje formaty czyli fizyczną reprezentację rekordów,
•ustala fizyczną lokalizację danych na nośnikach magnetycznych,
•ustala parametry integralności danych, takie, jak uprawnienia
dostępu do danych, lub zasady kopiowania danych

17
MODELE TBD
Model wewnętrzny TBD zawiera w sobie wystąpienia różnych typów
rekordu wewnętrznego, czyli rekordu pamiętanego. Model ten różni się od
poziomu fizycznego, gdyż nie jest konstruowany w zrozumieniu rekordów
fizycznych (bloków). Model wewnętrzny jest sprecyzowany w ramach
schematu wewnętrznego, który określa poszczególne typy rekordów
pamiętanych, specyfikuje indeksy, sposób reprezentacji pól pamiętanych, ich
uporządkowanie fizyczne itp.
Między trzema powyższymi modelami zachodzą dwa rodzaje odwzorowań:
między poziomem zewnętrznym i pojęciowym oraz między poziomem
pojęciowym a wewnętrznym.
Odwzorowanie:
poziom
zewnętrzny
-
pojęciowy
specyfikuje
odpowiedniości zachodzące między poszczególnymi modelami zewnętrznymi
a modelem pojęciowym. Jest to istotne m.in. ze względu na fakt, iż modeli
zewnętrznych może być wiele, i że są one nie zawsze rozłączne między sobą
(mogą zachodzić na siebie) oraz baza danych obsługiwać może jednocześnie
wielu użytkowników. Ponadto pola mogą mieć różne typy danych, zaś rekordy
mogą być różnie uporządkowane.
Odwzorowanie: poziom pojęciowy - wewnętrzny określa sposoby
odwzorowywania rekordów i pól pojęciowych na ich pamiętane odpowiedniki.
Jeśli np. zmienia się strukturę pamiętanej bazy danych, to należy dokonać
odpowiednich zmian w tym odwzorowaniu, aby schemat pojęciowy pozostał
nie naruszony.

18
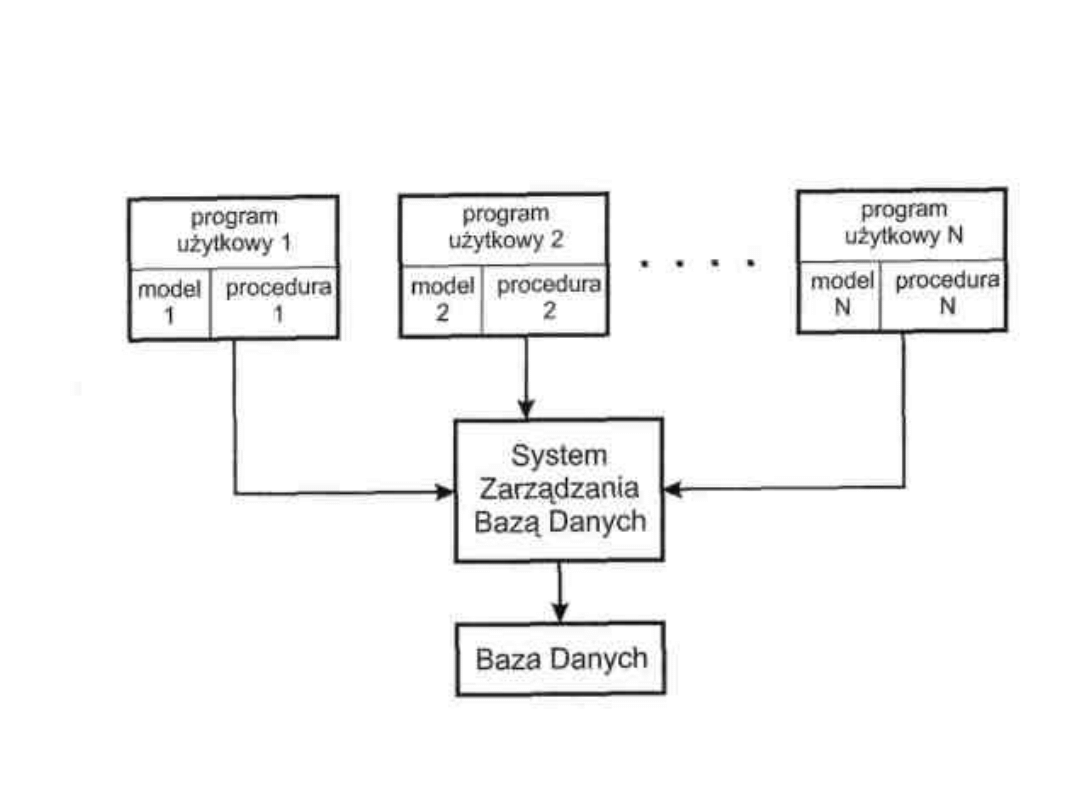
SYSTEM ZARZĄDZANIA BAZĄ
DANYCH (SZBD)
System Zarządzania Bazą Danych jest to pakiet
specjalistycznego oprogramowania, przy pomocy którego
następuje scentralizowane zarządzanie danymi, gromadzonymi
w TBD, umożliwiające dostęp do tych danych, które są żądane w
programie użytkowym. Jest to więc pomost między programami
użytkowymi a fizycznymi zbiorami danych. Jeśli np. TBD ma
wygenerować określony rekord zewnętrzny, to zwykle żądane
pola takiego rekordu będą pochodzić z różnych wystąpień
rekordu pojęciowego, te zaś z kolei mogą wymagać włączenia
pól z kilku wystąpień rekordu pamiętanego. W takim wypadku
SZBD musi odnależć żądane wystąpienia rekordu pamiętanego,
z nich zbudować odpowiednie wystąpienia rekordu pojęciowego
i w końcu wygenerować żądany rekord zewnętrzny.
W SZBD wyodrębnić można jego trzy główne części składowe:
język definicji danych, język manipulacji danymi oraz
słownik danych (zwany również bazą metadanych lub
metabazą danych).

19
SYSTEM ZARZĄDZANIA BAZĄ
DANYCH (SZBD)
Język definicji danych - jest to język formalny,
używany przez programistów. Jego zadaniem jest
definiowanie każdego pola, które figuruje w bazie
danych, zanim pole to zostanie użyte w modelu
zewnętrznym, szerzej, w programie użytkowym.
Inaczej mówiąc język ten określa treść i strukturę bazy
danych;
Język manipulacji danymi - jest językiem
wyspecjalizowanym, stosowanym wraz z językami
programowania trzeciego lub czwartego poziomu
(języki proceduralne lub nieproceduralne). Zadaniem
tego języka jest wydobywanie danych z bazy danych,
służących do budowy odpowiedzi na pytania
kierowane przez użytkowników pod adresem bazy
danych oraz do tworzenia programów użytkowych.

20
SYSTEM ZARZĄDZANIA BAZĄ
DANYCH (SZBD)
Słownik danych (data dictionary) jest wyspecjalizowanym systemem,
zbudowanym z tzw. metadanych, opisujących zawartość TBD. Metadane
są to takie dane, przy pomocy których opisuje się dane zawarte w TBD.
Metadane mogą tworzyć sobą metainformację, czyli informacje o
informacjach, dotyczących zawartości TBD. Konieczność budowy takiego
słownika wynika z faktu, że TBD zawiera w sobie bardzo duży wolumen
danych, wymagających wielokryteryjnego ich opisu, biorąc pod uwagę
zarówno potrzeby użytkowników bazy danych, jak i projektantów tych
baz, programistów oraz administratora bazy danych.
Podstawową funkcją słownika danych jest funkcja informacyjna,
dostarczająca użytkownikom bazy danych metainformacji na temat:
•jakie dane zgromadzone są w bazie danych, jakie komunikaty można z
danych tych utworzyć oraz na jaki temat,
•co oznaczają poszczególne dane,
•gdzie przechowywane są te dane,
•w jaki sposób zorganizowany jest dostęp do danych, jak można je
przetwarzać i jakie rodzaje danych znajdują się w zasobach bazy danych,
•kto jest użytkownikiem danych, kto odpowiada za ich jakość i
udostępnienie oraz kto dostarcza dane do bazy danych.

21
ADMINISTRATOR BAZY DANYCH (ABD)
Administrator bazy danych jest to osoba lub organizacyjnie
wydzielony zespół osób odpowiedzialny za efektywne zarządzanie
zasobami danych, gromadzonych w TBD oraz za jej stałą gotowość
eksploatacyjną, w oparciu o prawidłowe stosowanie podstawowego
narzędzia, jakim jest SZBD, w tym słownik.
Podstawowymi funkcjami ABD są:
•definiowanie, wprowadzanie i usuwanie danych, zgodnie z
żądaniami użytkowników baz danych,
•dostarczanie narzędzi i sposobów dostępu oraz aktualizacji
danych, jak też do tworzenia raportów, generowanych przez TBD,
•informowanie użytkowników na temat interesujących ich
problemów, związanych z TBD i uczestniczenie w procesach
planowania i użytkowania zasobów danych w bazie danych,
•nadzorowanie poprawności przeprowadzanych operacji z
wykorzystaniem TBD,
•nadzór nad integralnością danych, tj. nad ich jakością
(kompletnością, aktualnością oraz niedopuszczeniem do ich
uszkodzenia), sposobami kopiowania bazy danych, metodami
odzyskiwania danych oraz nad sterowaniem dostępem do danych
(wraz z ich utajnianiem) itp.

22
OKREŚLENIE HURTOWNI DANYCH
Hurtownia
danych
-
jest
to
baza
danych
wspomagająca procesy analiz i podejmowania decyzji
na wyższych poziomach zarządzania, służących do
podejmowania decyzji strategicznych związanych z
zarządzaniem organizacją. Gromadzone są w niej dane
pochodzące z różnych źródeł, takich, jak:
•systemy transakcyjne dzialające w danej organizacji,
•bazy danych istniejące w otoczeniu organizacji,
•zasoby systemu WWW,
•arkusze kalkulacyjne lub pliki w formacie XML.
W hurtowni są przechowywane kopie danych z
systemów operacyjnych oraz wyliczone na ich
podstawie agregaty (średnie, sumy itp.) o różnym
stopniu agregacji.

23
WŁASNOŚCI HURTOWNI DANYCH
Hurtownia danych charakteryzująca się następującymi
własnościami:
•jest uporządkowana tematycznie,
•jest zintegrowana,
•zawiera wymiar czasowy,
•jest nieulotna.
Uporządkowanie tematyczne oznacza zbiorczą
postać danych, dotyczących tego samego zagadnienia,
a rozproszonych w różnych bazach (zbiorach) danych. I
tak np. wystąpić może w SG zbiór transakcji zawartych
z klientami indywidualnymi i osobny zbiór takich
transakcji
zawartych
z
odbiorcami
zinstytucjonalizowanymi. W hurtowni danych występuje
suma transakcji obu typów odbiorców w danym
momencie lub przedziale czasu.

24
WŁASNOŚCI HURTOWNI DANYCH
Integracja dotyczy ujednolicenia nazw, sposobów
pomiaru wartości oraz sposobów kodowania.
Wymiar
czasowy
związany
jest
z
szerokim
uwzględnieniem w hurtowni zagregowanych danych
historycznych, które z zasady nie występują w TBD.
Ponadto w TBD dane za poszczególne okresy mogą być
uaktualniane, natomiast w hurtowni danych dane za okres
X są te same, bez względu na moment, w którym są
żądane.
Nieulotność dotyczy tego, że w hurtowni danych dane są
stałe, czyli nie są wrażliwe na częste aktualizacje, co ma
miejsce w TBD. Stąd, o ile w TBD wprowadza się każdą
transakcję osobno, o tyle w hurtowni danych, dane
wprowadza się okresowo, w trybie wsadowym. Tak więc, o
ile dane w TBD „napędzają" SG, to w hurtowni danych
otrzymujemy informacje, jak SG jest „napędzana".
25
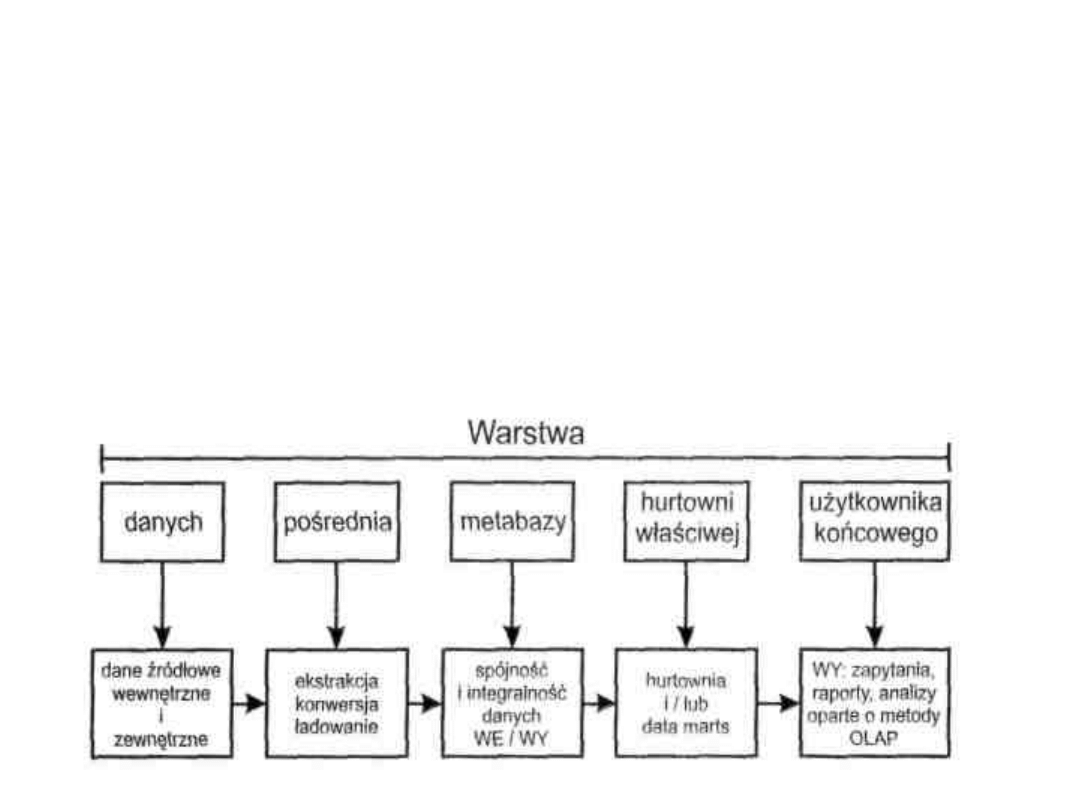
STRUKTURA HURTOWNI DANYCH
W strukturze hurtowni danych wyodrębnić można pięć jej
warstw:
1.warstwa danych źródłowych,
2.warstwa pośrednia,
3.metabaza,
4.warstwa hurtowni właściwej,
5.warstwa użytkownika końcowego.
Powiązanie tych warstw

26
WARSTWY DANYCH
1. Warstwa danych źródłowych obejmuje źródła zasilające
hurtownię danych. Do tych źródeł zliczyć należy: dane
historyczne SG, dane pochodzące z aktualnie eksploatowanych
TBD oraz różnego typu dane o otoczeniu SG. Takie dane są w
stosunku wzajemnym w różnym stopniu redundantne, a
ponadto nie wszystkie są potrzebne w hurtowni danych.
Oznacza to, że przed przystąpieniem do budowy hurtowni
danych należy określić, jakie dane będą znajdować się w
hurtowni danych, czyli jakie cele i zadania hurtownia taka
powinna spełniać.
2. Warstwa pośrednia ma na celu przygotowanie wybranych
zbiorów danych, pobieranych ze zbiorów danych źródłowych,
do przeniesienia ich do hurtowni danych. Warstwa ta dokonuje
operacje: ekstrakcji i konwersji danych. Do tej warstwy,
spełniającej funkcje pomocnicze, użytkownik hurtowni danych
nie ma możliwości kierowania zapytań. Warstwa pośrednia ma
zatem charakter roboczy, czyli jest miejscem, gdzie dane z
warstwy danych źródłowych są składowane, czyszczone oraz
kontrolowana jest ich poprawność.

27
WARSTWY DANYCH
3. Metabaza danych jest tym elementem hurtowni
danych, która jest istotnym narzędziem administrowania
hurtownią, umożliwiającym zapewnienie integralności
oraz spójności językowej i informacyjnej hurtowni
(podhurtowni) danych. Metabaza opisuje struktury
danych, wprowadzanych i przechowywanych w hurtowni
danych, specyfikację wymiarów, źródeł pochodzenia
danych, reguł transformacji, reguł i procedur czyszczenia,
zasilania, archiwizacji, bezpieczeństwa danych w hurtowni
itp.
4.
Warstwa
hurtowni
właściwej
może
być
budowana w różny sposób. Głównie chodzi tu o
odpowiedź na pytania, czy hurtownia danych ma być
jednolitą, scentralizowaną hurtownią, czy też ma być
oparta na podhutowniach danych oraz czy i w jaki sposób
powiązać ze sobą te podhurtownie z hurtownią.

28
WARSTWY DANYCH
5. Podhurtownie danych - są to odpowiednie części
wydzielone z globalnej hurtowni danych, albo wyciągi z
transakcyjnych baz danych, ukierunkowane na obsługę
lokalnych potrzeb informacyjnych, zgłaszanych przez
określone grupy użytkowników. W stosunku do hurtowni
danych, podhurtownie dysponują mniejszym wolumenem
danych, są łatwiejsze w eksploatacji i wymagają mniejszych
nakładów. Biorąc pod uwagę oba elementy (hurtownię i
podhurtownie danych) możliwe są następujące rozwiązania:
• dane źródłowe po przejściu przez warstwę pośrednią, są
ładowane do jednej, globalnej hurtowni danych. Zalety
takiego rozwiązania polegają na możliwości odpowiedzi na
wszelkie pytania, w ramach poszczególnych tematów,
interesujących użytkownika. Wadą jest tu operowanie na
dużym wolumenie danych, na budowie wielu programów
ekstrakcji danych itp.
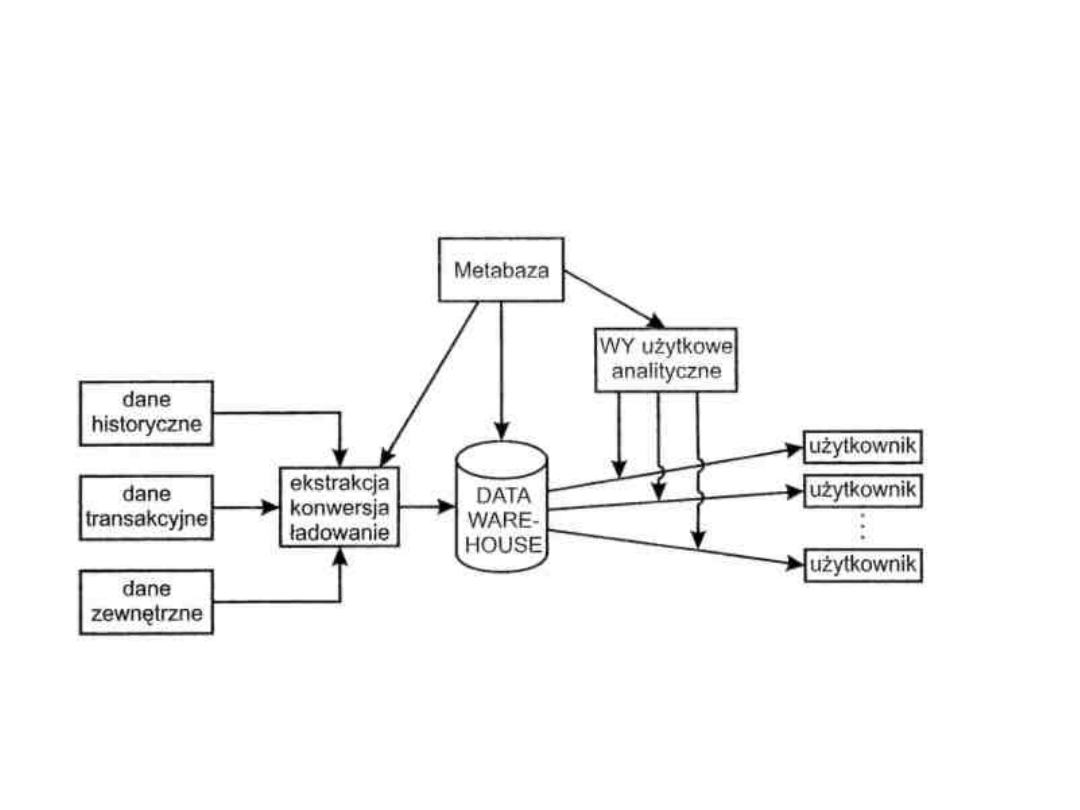
29
GLOBALNA HURTOWNIA DANYCH
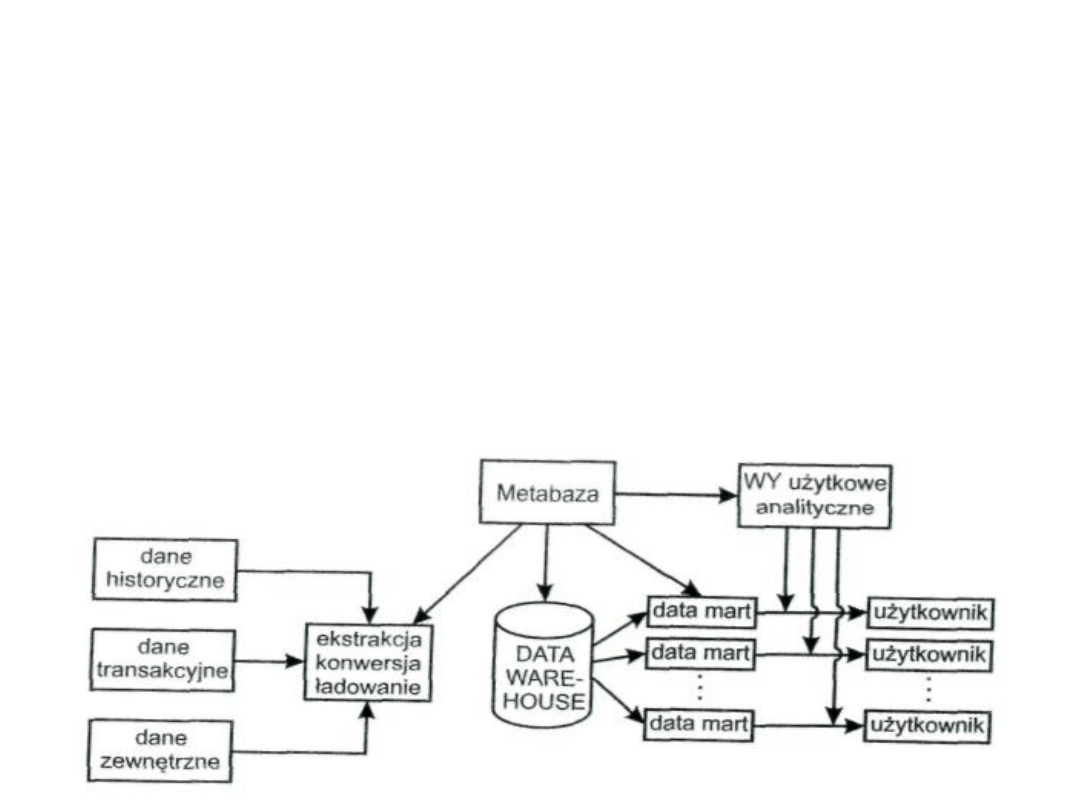
30
ROZWIĄZANIA HURTOWNI DANYCH
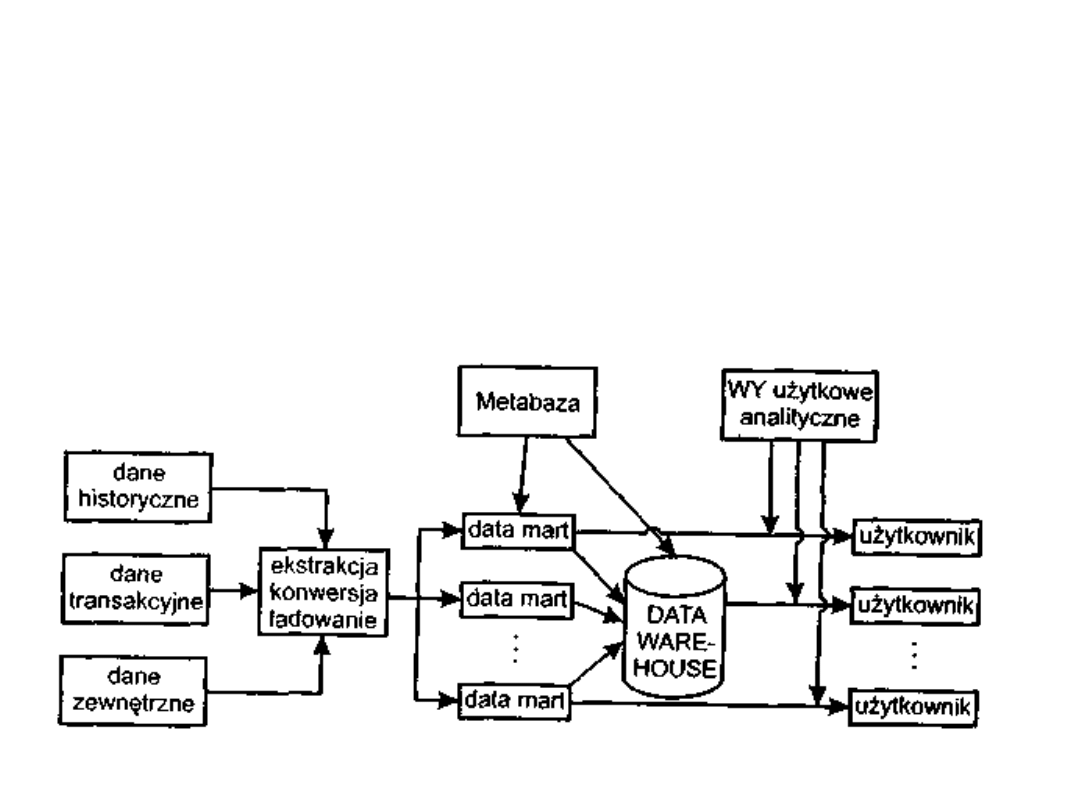
• dane źródłowe po przejściu przez warstwę pośrednią, są
ładowane do globalnej hurtowni danych, powiązanych
następnie z określoną ilością podhurtowni. Użytkownik
ma możliwości odwołania się albo do globalnej
hurtowni, albo do odpowiedniej podhurtowni. Zaletą
takiego rozwiązania jest możliwość zbudowania
podhurtowni, co jest łatwiejsze i prostsze. Wadą jest
możliwość
powstania
niezgodności
między
podhurtowniami, a hurtownią. Schemat tego typu
hurtowni:
31
ROZWIĄZANIA HURTOWNI DANYCH
• dane źródłowe, po przejściu przez warstwę pośrednią są
najpierw ładowane do podhurtowni, te zaś tworzą
hurtownie. Jest to więc schemat odwrotny od
poprzedniego. Zalety i wady są podobne jak w
wariancie
poprzednim.
Taki
schemat,
o
„wstępującym„ charakterze przedstawia rys.:
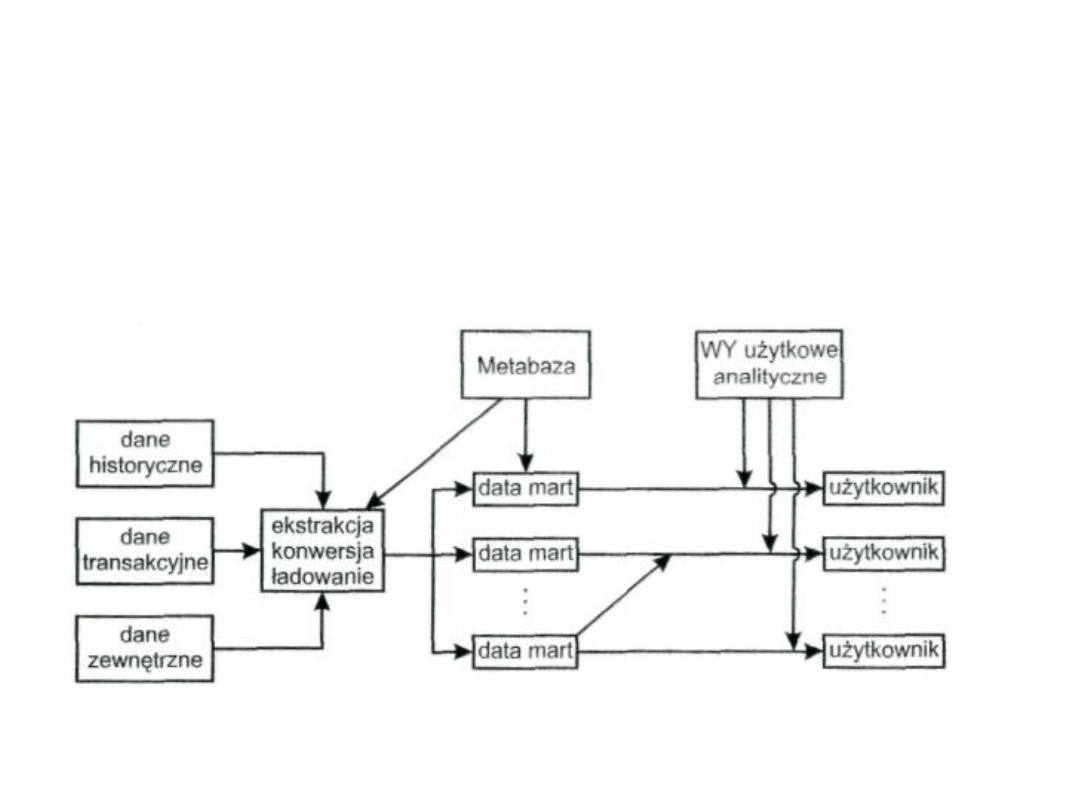
32
ROZWIĄZANIA HURTOWNI DANYCH
• dane źródłowe po przejściu przez warstwę pośrednią, są
ładowane jedynie do podhurtowni danych, co oznacza
brak hurtowni globalnej. Ten model jest obecnie
stosowany coraz częściej. Schemat takiej hurtowni:

33
KORZYŚCI HURTOWNI DANYCH
Korzyści ze stosowania hurtowni danych dotyczą
głównie:
• możliwości
scalania
informacji
z
odmiennych
tematycznie systemów transakcyjnych w jeden, pełny
obraz
SG,
ułatwiający
podejmowanie
decyzji
racjonalnych;
• wykorzystywanie dla celów podejmowania decyzji oraz
różnego typu analiz, danych historycznych SG,
zwłaszcza dla celów predykcji i prognozowania w
średnich i długich okresach;
• stworzenie godnego zaufania jednoznacznego źródła
informacji o SG, umożliwiające jednolite rozumienie
prowadzonych w SG przedsięwzięć gospodarczych
(jednolitość interpretacji danych o SG);
• oddzielenie danych transakcyjnych od procesu
podejmowania decyzji.

34
UWARUNKOWANIA HURTOWNI DANYCH
Uwarunkowania stosowania hurtowni danych dotyczą
głównie:
• określenia celów, które spełnić ma hurtownia danych dla
potrzeb wyższych poziomów zarządzania;
• zidentyfikowania danych, które będą przenoszone z TBD
do hurtowni danych;
• standaryzacji pojęć i definicji, które będą obowiązujące
dla całego SG.
Jednocześnie należy zwrócić uwagę na to, że:
• hurtownia danych absorbuje znaczne zasoby pamięci,
• hurtownia jest o połowę droższa niż standardowa TBD,
• hurtownia wymaga bardziej złożonych interfejsów niż to
ma miejsce w relacyjnej bazie danych.
Budowa hurtowni danych nie jest przedsięwzięciem łatwym,
zazwyczaj wiąże się z dużym ryzykiem i kosztami. jednak
w sytuacji, gdy projekt budowy hurtowni kończy się
sukcesem można oczekiwać szybkiego zwrotu kosztów i
wymiernych efektów wynikających z jej stosowania.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
Wyszukiwarka
Podobne podstrony:
Hurtownie danych Juranek
Hurtownia danych serwis samochodowy
03 Projekt fizyczny hurtowni danych
bd 02 03 Hurtownie danych Ix
hurtownie danych 1 id 207288 Nieznany
bd 02 04 Hurtownie danych IIx
bd 02 03, Hurtownie danych Ix
HDA przykladowy test z teorii, Studia WIT - Informatyka, HDA - Hurtownie Danych
Hurtownie Danych(2)
zadania hurtownie 2b, WSB Poznań, Hurtownie Danych
hurtownie danych
04 hurtownia danych PLOUG
01 Hurtownie danych
warsztat hurtownie 1, WSB Poznań, Hurtownie Danych
więcej podobnych podstron