
XHTML
Jêzyk HTML
Rozwój języka HTML został wstrzymany w roku 1999. Wtedy ukazała się
jego ostatnia specyfikacja, zatytułowana
HTML 4.01 Specification
, opisują-
ca język HTML w wersji 4.01. Dokument ten sygnalizował trendy, które
zaczynały obowiązywać w dziedzinie publikacji internetowych. Głównie cho-
dzi o oddzielenie prezentacyjnych cech witryny od jej struktury (poprzez
stosowanie stylów).
Specyfikacja definiuje trzy dialekty języka: strict, transitional oraz frame-
set. Wprawdzie w żadnym miejscu dokumentu nie jest to jasno powiedziane,
ale moim zdaniem należy się skupić na języku HTML 4.01 w wersji strict.
Jest to szczególnie ważne, gdy myślimy o tworzeniu witryn WWW i planuje-
my publikowanie stron zgodnych ze standardami. Treść dokumentów HTML
4.01 strict oraz XHTML 1.0 strict różni się ośmioma szczegółami.
Jêzyk XHTML
Specyfikacja języka XHTML 1.0 jest datowana na 26 stycznia 2000 roku.
Język XHTML nie jest nowym językiem, a jedynie modyfikacją języka HTML.
We wstępie specyfikacji XHTML stwierdzono, że w specyfikacji języka
XHTML nie opisano żadnego ze znaczników. Szukając opisu elementów,
ich atrybutów oraz zdarzeń musimy zajrzeć do specyfikacji języka HTML.
Specyfikacja XHTML 1.0 definiuje jedynie zmiany, które należy wprowadzić
w dokumencie HTML, by stał się on dokumentem XHTML.
Podobnie jak HTML 4.01, również język XHTML 1.0 zawiera trzy dialek-
ty: strict, transitional oraz frameset (najlepiej stosować wersję strict).
Dostępne wersje języka XHTML to: 1.0, 1.1 oraz 2.0. Z racji na surowe
wymagania (każdy dokument XHTML 1.1 musi być wysyłany jako applica-
tion/xhtml+xml, XHTML 2.0 nie jest zgodny w dół z poprzednimi językami)
powszechnie stosowana jest wyłącznie wersja 1.0 języka XHTML.
XHTML zgodny z HTML-em
Powszechnie stosowanym rozwiązaniem (zalecanym również przez W3C)
jest przygotowywanie dokumentów w języku XHTML w taki sposób, by były
one – na ile to możliwe – poprawnymi dokumentami HTML. Wprawdzie pełna
zgodność nie jest możliwa, jednak w zasadniczej części (czyli pomiędzy znacz-
nikami <body> oraz </body>) dokumenty w języku XHTML 1.0 strict róż-
nią się od dokumentów HTML 4.01 strict ośmioma szczegółami. Podane roz-
wiązania możemy stosować zarówno w językach XHTML, jak i HTML.
WielkoϾ liter
W języku HTML nazwy znaczników oraz atrybutów mogły być zapisywane do-
wolnymi literami. Wszystkie poniższe przykłady są poprawne w języku HTML:
Specyfikacja HTML stosuje konsekwentnie do zapisu nazw znaczników duże
litery, a do atrybutów małe. Nie jest to jednak wymóg; decydują o tym jedynie
względy estetyczne i upodobanie autorów specyfikacji. W języku XHTML na-
zwy znaczników oraz atrybutów muszą być zapisywane małymi literami:
Obecnie w internecie obowiązują dwa języki: starzejący się już HTML oraz zastępujący go
XHTML. Którego z nich używać? Jak przygotowywać strony WWW zgodne ze standardami?
W³odzimierz Gajda
W
EB
M
AS
TE
RI
N
G
HTML
czy
XHTML?
CZEGO SIÊ DOWIESZ Z TEGO ARTYKU£U:
l
na czym polega ró¿nica w przygotowywaniu doku-
mentów HTML oraz XHTML
l
jak przygotowywaæ strony XHTML zgodnie z zale-
ceniami specyfikacji publikowanych przez W3C
l
jakie s¹ korzyœci przejœcia z HTML-a na XHTML
WYMAGANA WIEDZA:
l
znajomoœæ jêzyka HTML
l
znajomoœæ arkuszy stylów CSS
98
INTERNET.lipiec.2006
www.mi.com.pl
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
<strong>white</strong>
<STRONG>black</STRONG>
<strong>gray</STRONG>
<stRONG>silver</STrong>
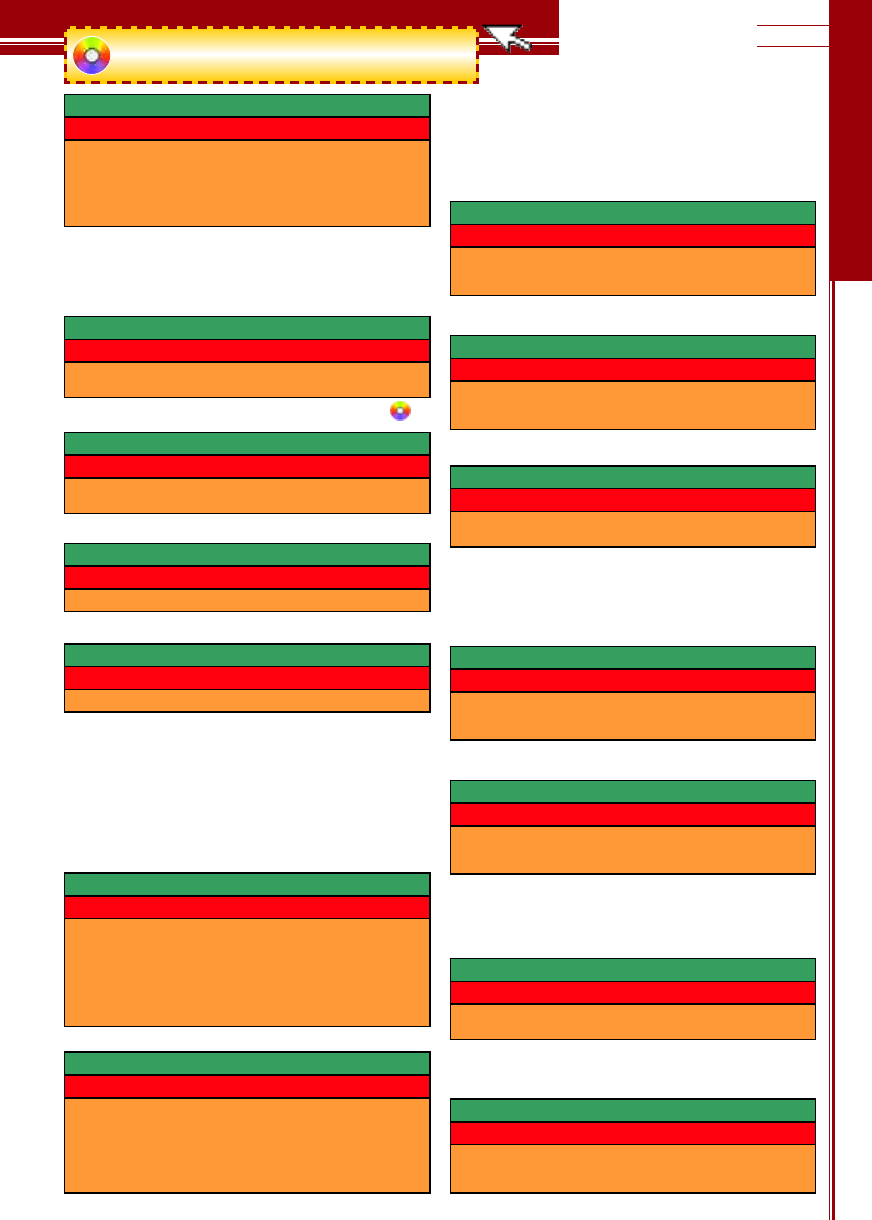
XHTML
W
EB
M
AS
TE
RIN
G
Wartości atrybutów, takich jak
id
czy
href
, mogą być zapisywane litera-
mi dowolnej wielkości. Jednak to ograniczenie dotyczy również wartości
atrybutów wyliczeniowych. Na przykład typ elementu
input
należy koniecz-
nie zapisywać małymi literami:
Poniższy zapis jest poprawny wyłącznie w HTML-u (patrz tabela 1 –
):
Trzeba także uważać na wielkość liter w encjach heksadecymalnych. Zapis:
jest niepoprawny w XHTML-u. Należy stosować małą literę x:
Jako ciekawostkę warto zapamiętać, że jednym z niewielu miejsc, gdzie
wielkość liter odgrywa rolę są – w języku HTML – właśnie encje. Znak
Å
jest różny od
å
!
Elementy puste i niepuste
W języku HTML pojawiło się pojęcie elementu pustego. Elementami pusty-
mi są między innymi
img
,
br
,
hr
,
link
oraz
meta
. Przykłady elementów nie-
pustych to
p
,
em
,
span
czy
table
. Elementy puste należy w języku XHTML
kończyć dwoma znakami /> zamiast pojedynczego
>
. Zatem należy pisać:
zamiast:
Zwróćmy uwagę na spację występującą przed znakami />. W XHTML-u,
który ma być zarazem poprawnym HTML-em, jest ona konieczna (część
przeglądarek HTML-owych nie zrozumie zapisu
<br/>
). Natomiast pomię-
dzy końcowymi znakami / oraz > nie może wystąpić spacja.
Elementy niepuste nie mogą być pisane w taki sposób. Nawet jeśli ich
zawartość jest pusta. Zatem zapisem poprawnym jest:
Zapisami niepoprawnymi są:
Element pusty nie może być zapisywany jako:
Znaczniki opcjonalne
W języku HTML niektóre znaczniki, na przykład
</p>
oraz
</li>
, były op-
cjonalne. W języku XHTML nie ma znaczników opcjonalnych. Wszystkie
znaczniki są obowiązkowe. Zatem przykład:
jest niepoprawny w języku XHTML. Należy dodać znaczniki zamykające
</li>
:
Cudzys³owy otaczaj¹ce wartoœci atrybutów
Wartości atrybutów w języku HTML możemy pisać otaczając je znakami
cudzysłowu lub apostrofami:
W języku HTML, w niektórych sytuacjach, cudzysłowy i apostrofy są
zbędne. Poniższy przykład jest poprawny w języku HTML:
Omówione w tym artykule przykłady oraz część cytowa-
nych specyfikacji znajdują się na płycie CD oraz
w naszym serwisie internetowym:
www.mi.com.pl
.
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<strong>white</strong>
<em id=”op”>black</em>
<a href=”index.html”>Indeks</a>
<strong onmouseover=”fun1();”>nothing</strong>
<a id=”STR” href=”MENU.HTML”>Menu</a>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<input type=”text” name=”IMIE” />
<form action=”index.php” method=”post”>
HTML 4.01 strict – niepoprawny
XHTML 1.0 strict – niepoprawny
<br></br>
<hr></hr>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<a href=”index.html”>Indeks</a>
<a href=’nowa.html’>Nowa</a>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<p></p>
<strong></strong>
<div></div>
HTML 4.01 strict – niepoprawny
XHTML 1.0 strict – niepoprawny
<p />
<strong />
<div />
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
<li>Red
<li>Green
<li>Blue
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<li>Red</li>
<li>Green</li>
<li>Blue</li>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
<input type=”TEXT” name=”IMIE” />
<form action=”index.php” method=”POST”>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
A
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
A
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<img src=”” alt=”” />
<br />
<hr />
<link rel=”stylesheet” type=”text/css” href=”style.css”
Ã
/>
<meta http-equiv=”Content-Type” content=”text/html;
Ã
charset=iso-8859-2” />
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
<img src=”” alt=””>
<br>
<hr>
<link rel=”stylesheet” type=”text/css” href=”style.css”>
<meta http-equiv=”Content-Type” content=”text/html;
Ã
charset=iso-8859-2”>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
<a href=index.html>Indeks</a>
<a href=nowa.html>Nowa</a>
<td rowspan=4 colspan=5 id=opis>

Pamiętajmy jednak, że
CDATA
nie może się pojawić w dokumencie HTML
(ani w XHTML wysyłanym jako text/html). Jeżeli zastosujemy
CDATA
w statycznym dokumencie .html, to bez względu na to, czy go przygotuje-
my w języku HTML czy XHTML, takie style nie będą działały (pierwsza regu-
ła będzie ignorowana przez MSIE). Jedynym rozwiązaniem, które zadziała
zarówno w HTML-u, jak i XHTML-u są zewnętrzne pliki .css oraz .js.
Encje
Znaki wykorzystywane do zapisu kodu HTML, czyli <, > oraz &, należy za-
pisywać wyłącznie w postaci encji <, > oraz &. W języku HTML
również było to wymagane, jednak przeglądarki w wielu różnych sytuacjach
potrafiły poprawnie zinterpretować znaki <, > oraz &. W XHTML-u może-
my stosować wyłącznie encje. Pamiętajmy o adresach definiujących zmien-
ne w PHP!
Powyższy przykład należy zapisać jako:
Pamiętajmy również, że encje nazwane mogą w XHTML-u przysporzyć wie-
lu kłopotów. Zawsze poprawnymi znakami są jedynie <, >, & oraz
". Zamiast pozostałych najlepiej stosować unikod lub encje numeryczne.
B³êdy HTML 4.01 strict
Już w języku HTML 4.01 strict wprowadzono liczne obostrzenia, które
przybrały formę nakazu (patrz tabela 3 – ). Są nimi:
4
stosowanie wyłącznie dopuszczonych znaczników – w kodzie nie może
pojawić się żaden przestarzały czy nieznany znacznik (np.
font
,
center
),
4
stosowanie wyłącznie dopuszczonych atrybutów – w kodzie nie może
pojawić się żaden przestarzały czy nieznany atrybut (np.
align
),
4
znaczniki muszą być poprawnie zamykane, nie mogą na siebie nachodzić,
4
niektóre zagnieżdżenia elementów, na przykład
table
w
h1
czy
hr
w
pre
, są niedozwolone. (Niestety, takie ograniczenia były możliwe
w języku SGML. Język XML nie ma możliwości wykluczenia zagnieżdża-
nia elementów. W tym względzie XML jest krokiem wstecz w stosun-
ku do języka SGML.)
Ponadto w formie zaleceń pojawiły się wymogi:
4
rezygnacji ze stosowania elementów
b
,
i
,
tt
,
big
,
small
,
4
otaczania wartości atrybutów znakami cudzysłowu,
4
rezygnacji z wykorzystania tabel do tworzenia układu strony.
(cdn.)
XHTML
100
INTERNET.lipiec.2006
www.mi.com.pl
Specyfikacja HTML 4.01 wyraźnie zalecała stosowanie cudzysłowów, nie
był to jednak wymóg, a jedynie zalecenie. W języku XHTML cudzysłowy lub
apostrofy są zawsze konieczne (w odniesieniu do każdego atrybutu!):
Minimalizacja atrybutów logicznych
Niektóre atrybuty są nazywane atrybutami logicznymi. Należy do nich, na
przykład, atrybut
selected
elementu
option
(patrz tabela 2 –
). W ję-
zyku HTML atrybuty logiczne mogą być zapisywane w zminimalizowanej
postaci:
Z racji na zgodność ze starszymi przeglądarkami, specyfikacja HTML
4.01 zalecała stosowanie zminimalizowanej postaci atrybutów logicznych.
W języku XHTML atrybuty logiczne należy zawsze zapisywać w pełnej po-
staci, tzn. jako parę atrybut=”wartosc”:
Identyfikator fragmentu
W języku HTML możemy stosować dwa rodzaje atrybutów do identyfikacji
fragmentu dokumentu. Atrybut
id
(dowolnego elementu) oraz
name
(elementu
a
):
W języku XHTML atrybut
name
jest niepoprawny. Stosujemy wyłącznie
atrybut
id
:
Style i skrypty
Style CSS oraz skrypty JavaScript zawierające jedną z czterech poniż-
szych kombinacji znaków: <, &, ]]>, - - należy w języku XHTML zapisywać
w zewnętrznych plikach .css, .js lub stosować
CDATA
:
<style type=”text/css”>
<![CDATA[
div {
color : yellow;
background : red;
}
]]>
</style>
W
EB
M
AS
TE
RI
N
G
Chcesz wiedzieć więcej? Odwiedź nasze forum:
http://forum.mi.com.pl
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<a id=”ind” href=”index.html”>Indeks</a>
<a href=’nowa.html’>Nowa</a>
<td rowspan=”4” colspan=”5” id=”opis”>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
<option selected value=”pink”>Pink colour</option>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
index.php?imie=Jan&nazwisko=Nowak
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
index.php?imie=Jan&nazwisko=Nowak
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<a id=”i2” href=”info.html”>...</a>
<h1 id=”wstep”>...</h1>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – poprawny
<option selected=”selected” value=”pink”>Pink
Ã
colour</option>
HTML 4.01 strict – poprawny
XHTML 1.0 strict – niepoprawny
<a name=”info” href=”info.html”>...</a>
<a id=”i2” href=”info.html”>...</a>
Wyszukiwarka
Podobne podstrony:
KRZYŻ CZY PAL CZ 2
HTML zaawansowane możliwości tabel 05 2006
''Kawa czy herbata'' (''Chemia w Szkole'' 4 2006 r )
I,II,III termin cz Ö Ť ç II 2006,07
2008 02 Extreme Programming i CMMI – kreatywność czy dyscyplina (Cz 3) [Inzynieria Oprogramowania]
Fw cz 1, PYTANIA 2006, 192
kacala przywarty trawinski html dom xhtml cel i charakterystyka
KRZYŻ CZY PAL CZ 1
HTML układ stałej szerokości 05 2006
Jezus Adon Jah a Trójca Święta mit czy rzeczywistość (cz I Ewangelia Łukasza) Trynitarianie
PASCAL PO PROSTU GOTUJ (Newsletter 107 2006)
2006 02 Terapia manualna w leczeniu zmian zwyrodnieniowych cz 1
2006 02 Czy udar mozgu mozna mierzycid 25445
ABC jezyka html i xhtml
więcej podobnych podstron