
BAZY DANYCH
OPRACOWANIE PYTAŃ NA BUJNOWE KOŁO
BY ITCompozer
1.Co to jest model danych? Wymień poznane modele danych. Scharakteryzuj jeden z nich.
Model danych jest to zbiór zasad posługiwania się danymi:
- zbiór reguł określających strukturę danych (definicja danych),
- zbiór reguł określających operacje na danych (operowanie
danymi),
- zbiór reguł określających poprawne stany bazy danych
(integralność danych).
Model danych jest to zintegrowany zbiór wymagań dotyczących
danych dla określonej aplikacji.
Poznane modele danych:
-proste modele danych,
-klasyczne modele danych,
-semantyczne modele danych,
Bardziej szczegółowo:
-płaski,
-prosty,
-hierarchiczny,
-obiektowy,
-sieciowy,
-obiektowo-relacyjny,
Charakterystyka wybranego:
Podstawą hierarchicznego model danych jest struktura danych określana
jako drzewo. Począwszy od węzła (wierzchołka) podstawowego, będącego
korzeniem drzewa (np. "c:\" w systemie plików) poprzez krawędzie -
rozgałęzienia (np. foldery) dochodzimy do ostatnich zbiorów danych - liści
(np. pliki). System hierarchiczny jest często przedstawiany poprzez związek
„rodzic-potomek”. Rodzic posiada pewną liczbę potomków, potomkowie Ci mogą mieć swoich potomków i
tak dalej.
2. Wyjaśnij pojęcia: dane, struktury danych , model danych, krotka, encja, atrybut, typ danych .
Dane - to zapis/reprezentacja faktów.
Struktury danych - sposób uporządkowania informacji w komputerze.
Model danych – zbiór zasad posługiwania się danymi.
Krotka - uporządkowana kolekcja stałych wartości.
Encja - reprezentacja wyobrażonego lub rzeczywistego obiektu
Atrybut - cecha osoby lub rzeczy, która może wyróżniać ją spośród innych; własność, właściwość tej osoby
lub rzeczy.
Typ danych - opis rodzaju, struktury i zakresu wartości, jakie może przyjmować dany literał,zmienna,stała,
argument, wynik funkcji lub wartość.
3. Co to jest normalizacja danych? Czemu ona służy?
Ogólnie, sprowadzenie danych do pewnego określonego formatu uwzględniającego ograniczenia
nakładane na dopuszczalne struktury danych. Najczęściej tym terminem określa się proces sprowadzenia
danych do postaci nadającej się do przechowywania w systemie relacyjnym.
4.
Dokonaj podziału składni języka SQL. Scharakteryzuj wybraną grupę poleceń.
➔ SQL DML – manipulowanie danymi.
➔ SQL DDL - definicja danych.
➔ SQL DCL - kontrola nad danymi.
DML - wykonywanie operacji – umieszczanie, kasowanie, przeglądanie itp.
DDL – operacje na strukturach.
DCL – nadawanie uprawnień do obiektów bazodanowych.

5. Co to są wyzwalacze ? Jak tworzy się I korzysta z wyzwalaczy w relacyjnych bazach
danych ?
Wyzwalacze(trigger) – są zdarzeniami, które można przypisać w określonym miejscu do tabeli.
W przypadku występowania warunku określonego do wyzwolenia triggera wywołana zostanie określona
funkcja.
|Create TRIGGER nazwa (BEFORE|AFTER} ON tablica [FOR[EACH] (Row|Statement|) EXECUTE PROCEDURE
nazwa funkcji (argumenty).|
6. XML a bazy danych . Rozwiń zagadnienie.
XML – uniwersalny język formalny przeniesiony do reprezentowania różnych danych.
XML sam z siebie ma budowę hierarchiczną co usprawnia jego konwersję do bazy danych.
Jest również coraz popularniejszym sposobem na przechowywanie, zapisywanie i prezentacje danych.
Wiele DBMS potrafi zawarte dane konwertować do tego formatu , jak i również z niego te dane pobierać.
7. Co to są funkcje w bazach danych. Jak funkcje się tworzy i jak z nich korzysta.
Do tworzenia własnych funkcji służy polecenie CREATE FUNCTION. Zostało ono zdefiniowane w
normie SQL:1999 i późniejszych. Składnia stosowana w PostgreSQL jest podobna, ale nie w pełni
kompatybilna. Atrybuty nie są przenaszalne, jak również odmienne są języki programowania.
Tworzenie:
CREATE [ OR REPLACE ] FUNCTION
name ( [ [ argmode ] [ argname ] argtype [, ...] ] )
[ RETURNS rettype ]
{ LANGUAGE langname
| IMMUTABLE | STABLE | VOLATILE
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| COST execution_cost
| ROWS result_rows
| SET configuration_parameter { TO value | = value | FROM CURRENT }
| AS 'definition '
| AS 'obj_file ', 'link_symbol '
} ...
[ WITH ( attribute [, ...] ) ]
8. Co to są funkcje agregacji ? Podaj przykłady.
Za pomocą nich możemy badać różne statystyki dla zbiorów wartości.
Przykłady: Count, Min, Max, Avg.
9. W jaki sposób przydziela się i odbiera uprawnienia w bazach danych ?
Loguje się na konto administratora i wpisujemy:
grant select on nazwa_tabeli to nazwa_usera; - przeglądanie
grant insert on nazwa_tabeli to nazwa_usera; - wpierdalanie danych do tabeli
Do usuwanie uprawnień służy komenda REVOKE.
10.Co to są struktury danych?
Jest sposób uporządkowania informacji w komputerze. Na strukturach danych operują algorytmy.
Przykładowe struktury danych to:
➔
➔
➔
➔
➔
drzewo i jego liczne odmiany (np. drzewo binarne)
➔
➔
rekord

11.Co to są związki w bazach danych. Opisz podstawowe rodzaje związków.
Związek - jest to powiązanie między dwiema lub kilkoma encjami. Związki na diagramie można opisać
poprzez liczebność, opcjonalność i relację między encjami.
12. Co to jest normalizacja danych ? Jakie są podstawowe cele normalizacji ?
Ogólnie, sprowadzenie danych do pewnego określonego formatu uwzględniającego ograniczenia
nakładane na dopuszczalne struktury danych. Najczęściej tym terminem określa się proces sprowadzenia
danych do postaci nadającej się do przechowywania w systemie relacyjnym.
13. Wymień operacje w algebrze relacyjnej. Krótko scharakteryzuj wybraną (zadana przez
prowadzącego).
Algebra relacyjna, proceduralny model operowania danymi, zbiór relacji bazy danych rozpatrywany z
ośmioma działaniami określonymi na następujących relacjach: selekcja, rzut, złączenie oraz suma, iloczyn,
przecięcie, różnica i iloraz.
Selekcja bierze jedną relacje jako swój argument i produkuje w wyniku jedną relację, wydobywa z
wejściowej relacji wiersze, które pasują do podanego warunku, i przekazuje je do relacji wynikowej,może
być uważana za „poziomą maszynę do cięcia”.
Rzut bierze jedną relacje jako swój argument i produkuje w wyniku jedną relację. Rzut jest „pionową
maszyną do cięcia”. Rzut usuwa z wejściowej relacji kolumny, a pozostałe umieszcza w relacji wyjściowej.
Iloczyn - argumentami są dwie relacje i produkowana jedna relacja wynikowa złożona ze wszystkich
możliwych kombinacji wierszy z wejściowych tabel. Operator rzadko używany ze względu na możliwość
generowania „eksplozji informacyjnej”.
Równo złączenie jest iloczynem kartezjańskim, po którym jest wykonywana selekcja - zostają tylko te
wiersze, których wartości w kolumnach złączenia są takie same.
Suma, przecięcia oraz różnica:
Argumentami operatorów są dwie zgodne relacje, wynikiem relacja wynikowa.
Relacje zgodne – to relacje, które mają taką samą strukturę – te same kolumny określone na tych samych
dziedzinach.
W wyniku sumy otrzymujemy relację zawierającą wiersze (krotki) z obu relacji.
W wyniku przecięcia uzyskujemy wiersze wspólne dwóch relacji.
W wyniku różnicy otrzymujemy wiersze należące do pierwszej relacji i nie należące do drugiej.
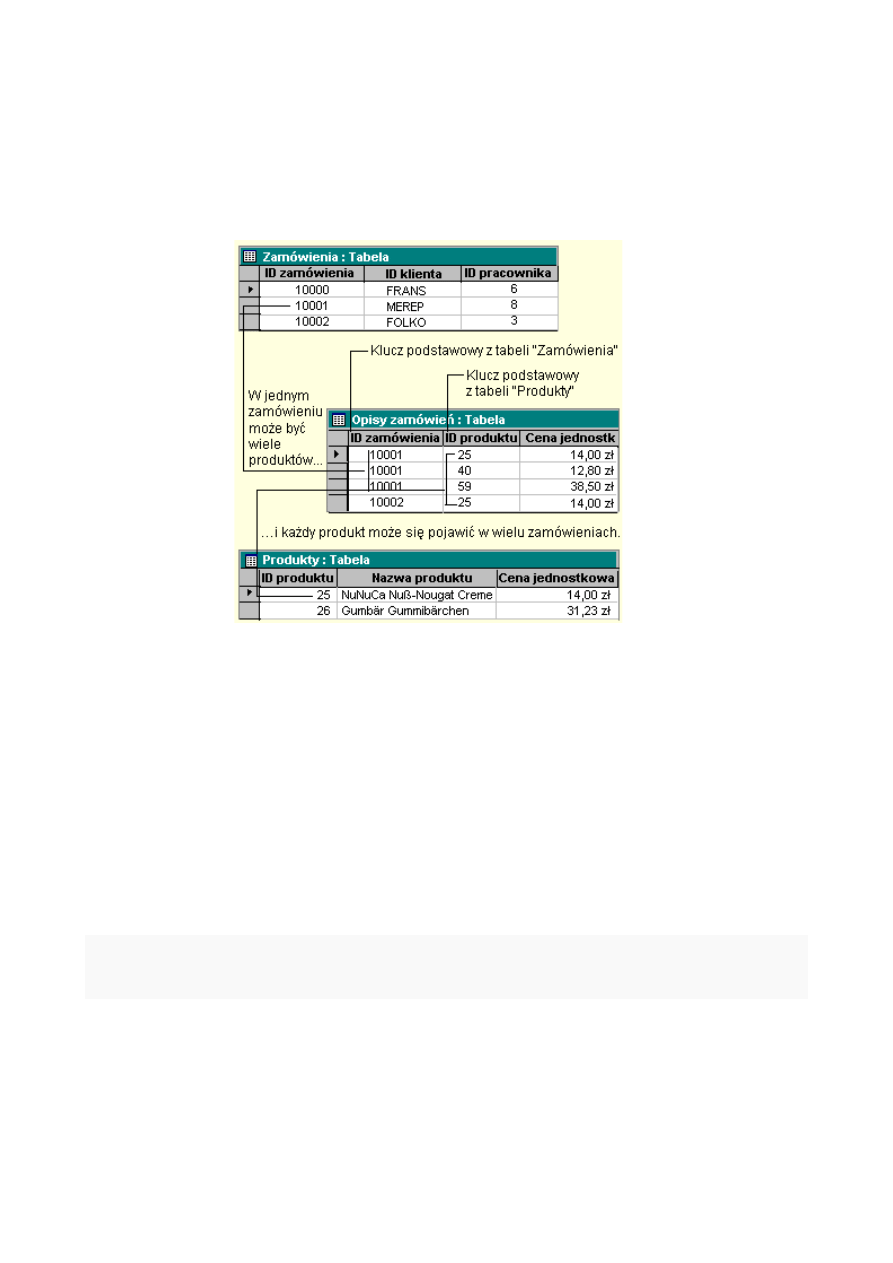
14. W jaki sposób zapisuje się relacje wiele-do-wielu w relacyjnych bazach danych ?
W relacji wiele-do-wielu, rekord w tabeli A może mieć wiele dopasowanych do niego rekordów z tabeli B i
tak samo rekord w tabeli B może mieć wiele dopasowanych do niego rekordów z tabeli A. Jest to możliwe
tylko przez zdefiniowanie trzeciej tabeli (nazywanej tabelą łącza), której klucz podstawowy składa się z
dwóch pól z kluczy obcych z tabel A i B. Relacja wiele-do-wielu jest w istocie dwiema relacjami jeden-do-
wielu z trzecią tabelą. Na przykład, tabele "Zamówienia" i "Produkty" są powiązane relacją wiele-do-wielu
zdefiniowaną przez utworzenie dwóch relacji jeden-do-wielu z tabelą "Opisy zamówień".
15. Co to są postacie normalne? Jakich zależności dotyczą ?
Postać normalna - postać relacji w bazie danych, w której nie występuje redundancja (nadmiarowość) czyli
powtarzanie się tych samych informacji. Doprowadzeniu relacji do postaci normalnej służy normalizacja
bazy danych.
Dotyczy zależności funkcyjnych.
16. Co to są widoki? Do czego służą ?
Widok (perspektywa) to logiczna struktura, wirtualna tabela tworzona przez serwer baz danych w czasie
rzeczywistym, określona przez zapytanie SQL. Umożliwia dostęp do podzbioru kolumn i wierszy tabel lub
tabeli. Przy pobieraniu wyników z bazy danych do widoku należy odwoływać się identycznie jak w
przypadku tabeli. Operacje wstawiania, modyfikowania oraz usuwania rekordów nie zawsze są możliwe
( np. w sytuacji gdy widok udostępnia część kolumn dwóch tabel tb_A oraz tb_B bez kolumny z kluczem
głównym tabeli tb_B i jest podjęta próba wstawienia nowego wiersza do widoku ). W niektórych SZBD
widok służy tylko i wyłącznie do pobierania wyników i ograniczania dostępu do danych.
Składnia SQL do utworzenia widoku:
CREATE VIEW nazwa_widoku [(kolumna1, kolumna2, ..., kolumnaN )]
AS
SELECT ...
17. Co to są transakcje ? Jakie reguły powinny być spełnione przy korzystaniu z transakcji?
Transakcje to zbiór operacji na bazie danych, które stanowią w istocie pewną całość i jako takie powinny
być wykonane wszystkie lub żadne z nich. Powinny być spełnione reguły ACID(Atomowości, spójności,
trwałości).

18.Co to jest poziom izolacji transakcji ? Jakie znasz poziomy ? Jakie poziomy
zaimplementowano w PostrgeSQL-u ?
Poziom izolacji transakcji (transaction isolation levels) to stopień uniezależnienia się transakcji od siebie
nawzajem. Im wyższy poziom izolacji tym większa pewność, że podczas wykonywania jednej transakcji
zmiany dokonywane w tym samym czasie przez inne transakcje nie wpłyną na nią.
Wyróżniamy obecnie 4 poziomy:
➔ Odczyt niezatwierdzonych,
➔ Odczyt zatwierdzonych,
➔ Odczyt powtarzalny,
➔ Szeregowalność,
19. Omówić wybrany poziom izolacji transakcji (odczyt zatw. / odczyt niezatw. / powtarzalny
odczyt/ szeregowalne ).
Odczyt niezatwierdzonych
Zasadniczo jest to po prostu brak izolacji. Wszelkie zmiany, w tym także te jeszcze niezatwierdzone (!) są
widzialne przez inne transakcje. Czyli transakcja odczytująca dane może odczytać dane błędne.
Odczyt_zatwierdzonych
Podstawowa izolacja, w której transakcja zawsze widzi tylko dane zatwierdzone. W dalszym ciągu jednak
nie jest to sytuacja zbyt komfortowa, ponieważ długa transakcja będzie odczytywać dane zmieniane w
czasie jej trwania przez inne transakcje. W szczególnym przypadku transakcja odczytując dwa razy te same
dane może otrzymać inne wyniki (jeśli w międzyczasie inna transakcja zatwierdzi zmiany w tych danych).
Odczyt_powtarzalny
Przy tym poziomie izolacji transakcja w dalszym ciągu widzi zmiany zatwierdzane już po jej rozpoczęciu
przez inne transakcje, ale ma zapewnioną powtarzalność odczytów, czyli nie dojdzie do sytuacji, w której
czytając te same dane kilka razy otrzyma inne wyniki. Czyli przy tym poziomie izolacji transakcja ma
wrażenie, że dane w bazie się nie zmieniają - ma dostęp tylko do ich jednej wersji. W dalszym ciągu jednak
pozostaje problem tego, że w zależności od różnych czynników wpływających na szybkość wykonywania tej
i innych transakcji, nie można przewidzieć, jakie dane transakcja odczyta. Co tutaj najistotniejsze: z punktu
widzenia tej transakcji inne transakcje mogą się wydawać NIESPÓJNE, NIEPEŁNE.
Na przykładzie: mamy transakcję raportową, która czyta dane zagregowane z dużej tabeli. W czasie
generowania raportu inne krótkie transakcje modyfikują dane w tej tabeli w ten sposób, że każda
modyfikuje dwa rekordy (np. dwa konta księgowe). Transakcja raportowa zaś podczas generowania raportu
zapamiętuje wartości rekordów, które odczytuje. Może się więc zdarzyć, że przy odczycie kolejnego
rekordu uwzględni zmianę w nim, ale nie uwzględni zmiany w drugim rekordzie (wcześniejszym - odczytała
go wcześniej i zmian w nim już nie rejestruje). Na przykładzie kont księgowych: transakcja raportowa
zauważy zmianę tylko jednego konta (i np. stwierdzi dodatnie saldo na wyższym poziomie syntetyki
zamiast zerowego).
Szeregowalność
W tym poziomie izolacji mamy rozwiązany problem pozornej niespójności innych zatwierdzanych transakcji.
Transakcja raportowa widzi stan bazy z momentu swojego rozpoczęcia, a wszelkie zmiany dokonywane
przez inne transakcje po tym momencie są niewidzialne. Czyli transakcja dostaje do swojej dyspozycji
zamrożony obraz bazy danych z dokładnego punktu w czasie - z momentu swojego rozpoczęcia. Skąd
nazwa "szeregowalne"? Ano właśnie stąd, że przy tym poziomie izolacji liczą się tylko momenty
rozpoczynania transakcji. Można je więc szeregować wg. czasu rozpoczęcia. Taki szereg transakcji zawsze
zaowocuje takim samym stanem bazy po ich zakończeniu, niezależnie od tego, jak szybko się one
wykonywały i które wcześniej się zakończyły (zatwierdziły swoje dane). Nie ma znaczenia, w jakiej
kolejności transakcje zatwierdzają dane. Przy tym poziomie izolacji trzeba pamiętać o konfliktach. Przy tym
poziomie izloacji bowiem konflikty między transakcjami odwołującymi się do tych samych danych są
najbardziej prawdopodobne. Warto jednak pomyśleć o tym, że w wielu wypadkach dla prostych transakcji
modyfikujących wystarczy poziom izolacji Read Commited, natomiast tylko wrażliwe na niespójności
transakcje złożone, które odczytują dane, np. raportowe (uwaga: należy uważnie przeanalizować także
proste transakcje odczytująco-modyfikujące) wymagają przełączenia do poziomu Serializable.
Ten poziom izolacji nastręcza bazom danych sporo kłopotu. Sposoby realizacji są dwa: poprzez
odwoływanie się do danych historycznych lub przez złożone blokady.
Metoda zakładania złożonych blokad ma bardzo krótkie nogi, ponieważ nie gwarantuje sukcesu - po prostu
przy tym poziomie izolacji pewnych rzeczy nie można już wykonać post factum - dane zostały zatwierdzone

później, trafiły do bazy i koniec. Stąd przy dużym obciążeniu drobnymi transakcjami modyfikującymi
wykonanie złożonego raportu korzystającego z bieżących danych przy poziomie Serializable jest
praktycznie niemożliwe.
Metoda odtwarzania danych historycznych daje gwarancję sukcesu. Dane historyczne mogą być
otrzymywane np. przez odwoływanie się do logów transakcyjnych lub poprzez tworzenie kopii
modyfikowanych rekordów (tę drugą strategię stosuje np. baza danych PostgreSQL i jest to strategia
najpewniejsza, ale też kosztowna). Przy korzystaniu z logu transakcyjnego potknąć się można przy zbyt
małej wielkości tego logu (czyli wtedy, gdy np. transakcja raportowa trwa bardzo długo i musi sięgać
głęboko wstecz, a w tym czasie log szybko przyrasta na skutek intensywnych operacji modyfikujących
dane) - nie dotyczy to bazy PostgreSQL.
20. W jaki sposób można dokonywać blokad w bazach danych i po co się stosuje blokady ?
Blokady stanowią mechanizm strzegący integralności danych w sytuacji wielodostępu, poprzez
zapewnienie określonemu klientowi wyłączności dostępu do modyfikowanych przez niego danych, gdy jest
to niezbędne aby zapobiec błędom które mogłyby wyniknąć z ,,przemieszania'' modyfikacji danych
wykonywanych przez różnych klientów. Blokady stosowane są zarówno do struktur danych widocznych dla
użytkownika (tabele, wiersze), jak i do wewnętrznych struktur danych systemu.
System Oracle stosuje blokady automatycznie, w sposób niewidoczny dla użytkownika, w ramach obsługi
transakcji. W szczególnych przypadkach może być potrzebne (i jest możliwe) jawne deklarowanie blokad
lub zmiana przez użytkownika blokad stosowanych implicite, sytuacje takie są jednak wyjątkiem. Przykłady
takich sytuacji: pewna transakcja wykonuje jedynie odczyt danych z pewnych tabel (instrukcjami SELECT) --
co nie wiąże się automatycznie z blokadą dostępu, lecz musi mieć zagwarantowaną niezmienność tych
tabel w ramach transakcji; pewna transakcja musi mieć zagwarantowany wyłączny dostęp do potrzebnych
jej danych, ponieważ nie może z jakichś względów czekać na zwolnienie blokad które mogą być nałożone
na te dane przez innych klientów. Do takich celów istnieje m. in. instrukcja LOCK TABLE.
Przykładowo, instrukcja
LOCK TABLE tabela IN SHARE MODE
uniemożliwia innym, jednocześnie wykonywanym transakcjom dokonywanie modyfikacji danych w podanej
tabeli, oraz nakładanie blokad wyłącznych (p. poniżej). Pozwala natomiast na nałożenie analogicznych
blokad (SHARE MODE) przez inne transakcje -- wówczas żadna z transakcji nie będzie mogła dokonać
modyfikacji danych.
Z kolei
LOCK TABLE tabela IN EXCLUSIVE MODE
dopuszcza inne transakcje jedynie do odczytu danych z zablokowanej tabeli, uniemożliwiając im
jakiekolwiek inne operacje (łącznie z nakładaniem własnych blokad).
21. Zasady tworzenia interfejsu użytkownika w bazach danych.
Istnieje kilka głównych wytycznych, którymi powinieneś się kierować w trakcie projektowania interfejsu:
➔ Używaj programowania obiektowego z zachowaniem wszelkich jego zasad i przesłanek.
➔ Czyń interfejs niezależnym i wyspecjalizowanym.
➔ Oprzyj interfejs na standardowej budowie.
22. Podstawowe metody dostępu do danych z poziomu aplikacji .
➔ Prosty menadżer plików
➔ Terminal
➔ Putty
➔ Tak naprawdę to za bardzo nie wiem :)
BAZY DANYCH KURWA!
Wyszukiwarka
Podobne podstrony:
Opracowanie Pytan Bazy danych M Nieznany
BDII Opracowania egzamin, Bazy danych II
BDII Opracowania egzamin, Bazy danych II
Access2 Projektowanie bazy danych, Ogrodnictwo 2011, INFORMATYKA, Informatyka, MS Access
pakiety, Studia PŚK informatyka, Semestr 4, Bazy Danych 2, Wyklady 2011
Przewodnik Relacyjne bazy danych 2008-2009, Ogrodnictwo 2011, INFORMATYKA, informatyka sgg, MS Acces
25. Modelowanie bazy danych - rodzaje połączeń relacyjnych, gotowe opracowania
tworzenie bazy danych, do uczenia, materialy do nauczania, rok2010-2011, 24.10.2010, baza danych
BD kol 2011, studia wsiz, semestr 4, bazy danych, bazy danych, BD T M1
Bazy danych SQL Teoria i praktyka bdsql
Wytyczne do przygotowania prezentacji BDII SQL dzienne 2011, Wit, Semestr4, Bazy Danych II
bazy danych - pytania na egzamin, sem. 3, Teoria obwodów i systemów
Bazy danych opracowanie zagadnie , Automatyka i Robotyka, Semestr 3, Bazy danych, BD, BD, Bazy Danyc
Bazy danych SQL Teoria i praktyka bdsql
Bazy danych SQL Teoria i praktyka bdsql
więcej podobnych podstron