
Przykładowe pytania z “Architektury systemów komputerowych”
część 1
Poniższe opracowanie ma charakter często "twórczości własnej" – dlatego polecam korzystanie z
poniższych materiałów raczej w formie powtórki...
NIE POLECAM KUCIA NA PAMIĘĆ!!!
A. Podstawowe zasady działania komputera.
1. Omówić koncepcje programu w modelu komputera wg. von Neumanna.
Przyjęty pewien podstawowy zbiór operacji i każdej operacji przypisano ustalony kod w
postaci ciągu zero-jedynkowego.
Operacje zdefiniowane na ciągu podstawowym nazywane są rozkazami lub instrukcjami
procesora. Każdy rozkaz ma przypisany kod zerojedynkowy . Podstawowy zbiór operacji
procesora jest zazwyczaj nazywany listą rozkazów procesora.
W takim ujęciu algorytm obliczeń przedstawiony jest za pomocą operacji ze zbioru
podstawowego. Algorytm zakodowany jest w postaci sekwencji ciągów zero-jedynkowych
zdefiniowanych w podstawowym zbiorze operacji – tak zakodowany algorytm nazywa się
programem w języku maszynowym
Program przechowywany jest w pamięci, wykonywanie programu polega na przesyłaniu
kolejnych ciągów zerojedynkowych z pamięci głównej do układu sterowania procesora.
Zadaniem układu sterowania, po odczytaniu takiego ciągu, jest wygenerowanie
odpowiedniej sekwencji sygnałów kierowanych do poszczególnych podzespołów, tak aby w
rezultacie wykonać wymaganą operacje.
KONCEPCJA PROGRAMU PRZECHOWYWANEGO W PAMIĘCI STANOWI
KLUCZOWY ELEMENT MODELU VON NEUMANNA.
2. Wyjaśnić znaczenie terminu lista rozkazów procesora.
Lista rozkazów procesora jest to podstawowy zbiór rozkazów realizowanych przez procesor.
3. Na czym polega różnica pomiędzy pamięcią fizyczną a pamięcią wirtualną
Pamięć fizyczna to pamięć bezpośrednio zainstalowana w komputerze, natomiast pamięć
wirtualna oznacza pamięć udostępnioną przez system operacyjny. Pamięć wirtualna to
pewne odwzorowanie, “iluzja” pamięci rzeczywistej (fizycznej).
W szczególności pamięć wirtualna może być większa od pamięci fizycznej, pamięć
wirtualna jest również spójna – dzięki mechanizmowi stronicowania – nie podlega
problemom fragmentacji. (?)
4. Jaką rolę w trakcie wykonywania programu przez procesor pełni wskaźnik instrukcji
(licznik rozkazów)?
Wskaźnik instrukcji określa położenie w pamięci położenie aktualnie wykonywanego
rozkazu. Służy on zatem do określania który rozkaz jest wykonywany – po zakończeniu
danego rozkazu wskaźnik instrukcji jest zwiększany o długość danego rozkazu. (?)
5. W jaki sposób zmienia się zawartość wskaźnika instrukcji w trakcie wykonywania różnych
rozkazów.
Zawartość wskaźnika instrukcji jest zwiększana o długość (rozmiar rozumiany jako ilość
zajętej przez rozkaz pamięci) rozkazu.
Rozkazy mają różną długość – mogą być jednobajtowe (inc), lub kilkubajtowe (mov) (?)

6. Omówić funkcje dwóch dowolnych znaczników spośród zainstalowanych w rejestrze
znaczników (rejestrze flag)
CF – (carry flag) – znacznik przeniesienia ustawiany w przypadku wystąpienia nadmiaru
przy operacjach arytmetycznych na liczbach bez znaku (suma - przeniesienie, różnica –
pożyczka)
ZF – (zero flag) – znacznik zera – ustawiany kiedy wynik operacji arytmetycznej jest równy
zeru.
7. Omówić podstawowe elementy architektury koprocesora arytmetycznego
Osiem 80-dziesięcio bitowych rejestrów, tworzących stos. Odwołania do rejestrów:
SP(0) .. SP(7). Koprocesor arytmetyczny operacji dokonuje na liczbach
zmiennopozycyjnych. Koprocesor musi być zainicjowany (rozkaz: "finit"). Rozkazy
operacji wykonywanych przy pomocy koprocesora mają własną składnie – przykładowo
"fld" – odłożenie na stos komprocesora, "fmul sp(0), sp(0)" pomnożenie liczby znajdującej
się na szczycie stosu przez samą siebie. Możliwe obliczenia przy użyciu wartości
specjalnych.
(?)
B. Kodowanie danych i instrukcji
1. Omówić różne rodzaje kodowania liczb binarnych.
całkowite:
- binarne(unsigned)
- znak moduł
- U2
- BCD - Binary Coded Decimals
z przecinkiem:
- stałoprzecinkowe, format na bitach:
znak | część całkowita, bity o wagach 2
9
do 2
0
| część ułamkowa, 2
-1
do 2
-5
- zmienno przecinkowe, formaty 32, 64 i 80 bitowe:
32: znak | 8 bitów wykładnika | 23 bity mantysy ; znak*(mantysa + 1)*2
wykładnik-127
64: znak | 11 bitów wykładnika | 52 bity mantysy ; znak*(mantysa + 1)*2
wykładnik-1023
80: znak | 15 bitów wykładnika | 64 bity mantysy ; znak*mantysa*2
wykladnik-16383
uwagi:
1. w wykładniku odejmuje się podane wartości, aby nie trzeba było wprowadzać
dodatkowego bitu na znak wykładnika
2. w formacie 80 bitowym część całkowita mantysy występuje w postaci jawnej nie musimy
więc dodawać 1
2. Porównać w przybliżeniu zakresy liczb, które mogą być kodowane w postaci binarnej jako
liczby bez znaku na 16 lub 32 bitach
16 bit --> [ 0 ; 65536 ]
32 bit --> [ 0 ; 4294967296 ]
3. W jaki sposób w procesorach Pentium sygnalizowane jest wystąpienie nadmiaru w
operacjach dodawania, odejmowania ?
W przypadku liczb liczb bez znaku przy wystąpieniu nadmiaru ustawiany jest znacznik CF
Dla liczb ze znakiem ustawiany jest znacznik OF
4. Przedstawić w postaci graficznej schemat konwersji liczb 32 – bitowych zapisanych w

pamięci wg. reguły mniejsze wyżej na postać mniejsze niżej.
|32 . . 24 | 23 . . 16 | 15 . . 8 | 7 . . 0 |
Czyli tak: (?)
| 0 . . 7 | 8 . . 15 | 16 . . 23 | 24 . . 32 | ======> |32 . . 24 | 23 . . 16 | 15 . . 8 | 7 . . 0 |
5. Omówić technikę porównywania liczb stałoprzecinkowych stosowaną w procesorach
Pentium.
Przy odejmowaniu liczb następuje ustawienie odpowiednich znaczników. Testując te
znaczniki można uzyskać informację czy nastąpiła pożyczka, czy wynik jest równy zero itd.
Na tej podstawie można określić czy dana liczba była większa, mniejsza czy równa.
Do ustawienia znaczników – dokładniej wykonania odejmowania bez wpisania wyniku
służy rozkaz CMP. Np. CMP AX, BX – porównanie zawartości rejestrów ax i bx i
ustawienie flag. Po powyższym rozkazie następuje często rozkaz skoku warunkowego np.
JE etykieta (JE - skok gdy równe).
6. Dlaczego obliczenia na liczbach stałoprzecinkowych są kłopotliwe jeżeli działania
wykonywane są na wartościach bardzo dużych i bardzo małych?
Ponieważ zachodzi problem ustalenia miejsca umownego przecinka oddzielającego część
całkowitą liczby od części ułamkowej. Dla liczb bardzo małych liczba bitów
przypadających na część ułamkową powinna być względnie duża, w przypadku liczb
dużych natomiast duża powinna być ilość bitów przypadających na część całkowitą. Przy
obliczeniach zachodzi potrzeba kompromisu – co jest problematyczne.
7. Co oznacza termin 'wartości specjalne' używane w kontekście koprocesora arytmetycznego
Podczas wykonywania obliczeń czasami konieczne jest posługiwanie się takimi wartościami
jak zero i nieskończoność – wystąpienie takich wartości czasami powinno nie wiązać się z
załamaniem programu (wygenerowania wyjątku przez procesor). Dlatego zero jak i
nieskończoność określono jako wartości specjalne. Charakteryzują się one występowaniem
samych zer lub samych jedynek w polu mentysy. Obliczenia prowadzone z wykorzystaniem
wartości specjalnych nie prowadzą do wygenerowania wyjątku procesora (przy ustawionym
zezwoleniu na wykonywanie takich operacji). Wynik obliczeń, w których została
wykorzystana liczba określana jako wartość specjalna jest też wartością specjalną.
8. Omówić format 32-bitowych liczb zmiennopozycyjnych (pole mentysy zawiera 23bity, pole
wykładnika 8bitów)
Liczby zmiennopozycyjne zapisywane są jako | bit znaku | wykładnik | mentysa | gdzie
mentysa
=
transformowana liczba
2
wykładnik
a wykładnik wielkością tak dobraną aby mentysa zawierała się w przedziale
(-2, -1> lub <1, 2)
Zastosowanie liczb zmiennopozycyjnych pozwala na prowadzenie obliczeń na liczbach

zarówno bardzo małych jaki i bardzo dużych – nie zachodzi tutaj problem ustalenia pozycji
umownego przecinka i kompromisów związanych z ustaleniem tej pozycji.
9. Omów zasady wykonywania operacji arytmetycznych na stałoprzecinkowych liczbach
wielokrotnej długości.
Liczby wielokrotnej długości – liczby kodowane na ilości bitów będącej wielokrotnością
rozmiarów rejestrów używanych przy obliczeniach.
Wykonywanie obliczeń na liczbach wielokrotnej długości opiera się na podzieleniu ich na
fragmenty o długości odpowiadającej poszczególnym rejestrom, oraz przeprowadzenia
obliczeń na tych fragmentach przy użyciu flagi przeniesienia (CF) jako rejestru
zawierającego najmniej znaczący bit przy kolejnych operacjach.
Przykładowo, jeżeli chcielibyśmy przeprowadzić obliczenia na liczbach 24bitowych:
mov al, mniej_znacząca_część_pierwszej_liczby
mov ah, środkowa_część_pierwszej_liczby
mov bl, bardziej_znacząca_część_pierwszej_liczby
mov bh, mniej_znacząca_część_drugiej_liczby
mov cl środkowa_część_drugiej_liczby
mov ch bardziej_znacząca_część_drugiej_liczby
add al, bh
adc ah, cl
(Uwaga! adC nie adD – adc automatyczne dodanie wartości flagi
adc bl, ch
przeniesienia (CF) do najmniej znaczącego bitu wyniku)
10. Dlaczego w formatach liczb zmiennoprzecinkowych zgodnych z normą 754 nie występuje
bit znaku wykładnika?
Ponieważ wykładnik jest "przenoszony o wartość minus 127" – tzn. wartość 0 w wykładiku
oznacza '-127'. Zapis taki pozwala na rezygnacje z bitu znaku.
11. Jakie są zalety i wady kodowania w systemie UNICODE?
Zalety:
- 65 tyś. Znaków – zatem rozwiązanie problemu brakujących kodów na potrzebne symbole
wady:
- większa zajętość pamięci przy zapisie tekstu (jeżeli na znak przypadają 2 bajty to
dwukrotnie większa niż w przypadku kodowania ASCII)
(to wziąłem całkiem z głowy czyli z niczego... tak więc nie wiem na ile mam racji... po
prostu wydaje mi sie to sensowne więc napisałęm...)
C. Mechanizmy adresowania:
1. Omówić podstawowe mechanizmy modyfikacji adresowych
Modyfikacje adresowe – adres lokacji pamięci, na której wykonywane jest działanie
określany jest nie tylko przez pole adresowe, ale zależy również od zawartości jednego lub
dwóch wskazanych rejestrów.
Mechanizmy modyfikacji adresowych:
- modyfikatorami mogą być 16bitowe rejestry: BX, SI, DI, BP, a także ich pary: (BX, SI),
(BX, DI), (BP, SI), (BP, DI)
-modyfikatorami mogą być dowolne 32bitowe rejestry: EAX, EBX, ECX, EDX, ESI, EDI,
EBP, ESP
- drugi rejestr modyfikacji może być skojarzony z tzw. współczynnikiem skali, który
podawany jest w postaci: *1, *2, *4, *8 – podana liczba wskazuje przez ile zostanie

pomnożona zawartość drugiego rejestru modyfikacji podczas obliczania adresu.
W literaturze zawartość pierwszego rejestru modyfikacji nazywana jest adresem bazowym,
a drugiego adresem indeksowym.
2. Wyjaśnić zasady adresowania pośredniego
Adresowanie pośrednie – przy pomocy rejestrów – do odpowiedniego rejestru zapisywana
jest lokacja pamięci, odwołania pod lokacje pamięci z wykorzystaniem rejestru.
Przykładowo:
mov ax, word PTR [ebp]
- załadowanie do ax wartości wskazywanej przez pomocniczy
wskaźnik stosu
Przy adresowaniu pośrednim:
- rejestr zawierający adres musi być podany w nawiasach kwadratowych – oznacza to że
chodzi o lokacje pamięci której adres jest zapisany w danym rejestrze, a nie o rejestr
- przy adresowaniu pośrednim należy sie posługiwać dyrektywą PTR – określa ona rozmiar
danej pobieranej/zapisywanej w pamięci – jest to ważne ponieważ bez takiej deklaracji nie
wiadomo o jaki typ chodzi – 8, 16, czy może 32 bity...
3. Jaka wartość zostanie wprowadzona do rejestru DX po wykonaniu podanego niżej
fragmentu programu:
dane3a
SEGMENT
line
dw
421, 422, 443, 442, 444, 427, 432
----------------------------------------
polacz
SEGMENT
ASSUME
cd:polacz, ds:dane
--------------------------------------
mov esi, OFFSET linie + 4
mov exb, 4
mov dx, [ebx][esi]
Do rejetsru dx wprowadzona zostanie wartość "444" – ponieważ łącznie do adresu początku
bufora 'linie' dodawane jest 8 – a ponieważ linie składa się ze zmiennych zadeklarowanych
jako word (dw – 2 bajty) oznacza to przesunięcie o 4-ry pozycje.
D. Programowanie w asemblerze:
1. Wyjaśnij na czym polega różnica pomiędzy językiem maszynowym a językiem asemblera.
Język maszynowy przeznaczony jest dla maszyny – składa się on z kolejnych rozkazów
zapisanych w formie liczbowej. Język asemblera natomiast to język zrozumiały dla
człowieka (nie dla maszyny) – opiera sie o mnemoniki – kilkuliterowe symbole rozkazów
maszynowych, zawiera możliwość deklaracji etykiet, procedur, dopisywania komentarzy.
Język asemblera musi być przetłumaczony na kod zrozumiały dla procesora – służą temu
odpowiednie programy (zwane asemblerami?).
2. Omówić dyrektywy używane do definiowania danych na poziomie asemblera:
db - definicja bajtu
(8 bit)
dw - definicja słowa
(16 bit)
dd - definicja podwójnego słowa
(32 bit)
df - definicja 6 bajtów
(48 bit)
dq - definicja poczwórnego słowa (64 bit)
dt - definicja 10 bajtów
(80 bit)

3. Co oznacza znak "?" podany zamiast wartości danej w kodzie asemblerowym
Znak "?" stosuje się przy definicji obszaru pamięci i oznacza on niezainicjowanie danej
sprecyzowaną wartością – w praktyce zmienna po takiej inicjacji zawiera przypadkową
wartość – zależną od wcześniejszej zawartości pamięci. Deklaracje takie są często
stosowane kiedy nie jest znana wartość początkowa zmiennej a nie ma to znaczenia dla
algorytmu. Stosowane zwłaszcza w przypadkach deklaracji buforów.
4. Dalczego rozkaz add [edi], 3 jest traktowany przez asembler jako błędny?
Ponieważ nie został określony typ wartości zapisywanej do pamięci (zapis [edi] oznacza
odwołanie do pamięci o adresie zawartym w rejestrze edi). Poprawny rozkaz wygląda
następująco:
add byte PTR [edi], 3
- zamiast byte (8 bitów) może być np. word (16 bit) , dword (32
bit) – zależnie od potrzeb programu.
5. Jak należy rozumieć termin licznik lokacji w kontekście programu asemblerowego?
Licznik lokacji określa do której zostanie przesłany aktualnie tłumaczony rozkaz lub dana.
Po załadowaniu rozkazu lub danej licznik lokacji zostaje zwiększony o ilość bajtów
zajmowanych przez ten rozkaz lub daną. Licznik lokacji jest rejestrtem programowym –
zdefiniowanym przez asembler. W asemblerach dla procesorów Pentium licznik lokacji
wskazuje położenie względem początku segmentu. W trakcie tłumaczenie pierwszego
wiersza segmentu licznik lokacji zawiera 0. W wyrażeniach adresowych licznik lokacji
reprezentowany jest przez symbol $. Jeżeli asembler napotka definicję symbolu, to rejestruje
go w słowniku symboli jednocześnie przypisując temu symbolowi wartość równą aktualnej
zawartości licznika lokacji. Ponadto zapisywane są także atrybuty symbolu takie jak np. far,
byte itp.
6. Jakie działania wykonuje asembler w pierwszym i drugim przebiegu asemblacji?
Pierwszy przebieg – sprawdzenie i wyłapanie błędów składniowych, stworzenie słownika
symboli (nazwy etykiet, procedur)
Drugi przebieg – tłumaczenie rozkazów na kod maszynowy, obliczanie adresów i
zastępowanie nazw etykiet adresami (w rozkazach oczywiście – sama etykieta służy tylko
dla zaznaczenia miejsca w programie – zaznaczenia przydatnego programiście – z punktu
widzenia kodu maszynowego etykieta jako taka "nie istnieje")
(to może być dobrze–ale wcale nie musi... i prawdopodobnie nie jest – napisane "z głowy" ;)
7. W jaki sposób asembler oblicza pola adresowe rozkazów sterujących (skokowych)?
Oblicza jako odległość od rozkazu do odpowiedniej etykiety – jeżeli etykieta poprzedza
rozkaz wartość ta jest ujemna, jeżeli następuje po rozkazie, wartość jest dodatnia.
8. Napisać rozkaz w asemblerze realizujący operację sumowania AX <== AX + [0040026AH]
ADD AX, WORD PTR [0040026AH]
E. Operacje stosu i podprogramy
1. W jaki sposób interpretuje się zawartość rejestru wskaźnika stosu ESP w procesorze
Pentium?
Wskaźnik stosu ESP określa odległość (w bajtach) od początku stosu. Należy pamiętać że
stos rośnie w kiedunku mniejszych adresów.
2. Co oznacza sformuowanie: "stos rośnie w kiedunku malejących adresów"?
Oznacza to że kolejne wartości odkładane na stosie lądują na coraz niższych adresach

pamięci. Zatem stos zwiększa się w kierunku mniejszych adresów.
3. Omówić drogi i sposoby przekazywania parametrów do podprogramów:
Sa dwie główne drogi:
– przekazywanie przez wartość – do podprogramu przekazywana jest bezpośrednio
potrzebna dana (liczba, tablica liczb, łańcuch znaków idt.)
– przekazywanie przez adres – do podprogramu przekazywany jest adres pod którym leżą
potrzebne dane (taki sposób pozwala na modyfikację danych przez podprogram, pozwala
również zaoszczędzić – w porównaniu do poprzedniego sposobu – na przekazywaniu wielu
wartości w przypadku tablic)
Drogi przekazywania parametrów:
- przez rejestry
- przez stos (najpowszechniej stosowana metoda)
- przez ślad
- przez bufory (wymagają stałego zainicjowania – mało elastyczne, rzadkie choć spotykane
rozwiązanie)
4. Omówić zasady działania rozkazów CALL i RET
CALL – odłożenie na stos adresu następnego rozkazu po CALL, położenie rejestru flag na
stos, skok do lokacji pamięci
RET – zdjęcie rejestru flag ze stosu – przywrócenie flag, zdjęcie ze stosu lokacji pamięci-
powrotu - skok do tej lokacji (powrót)
Rozkazy call i ret są chętnie stosowane do wywoływania podprogramów – ze względu na
stosunkowo proste wywołanie i brak problemów związanych z powrotem do wywołującego
programu.
5. W jakim celu rozkaz wywołania podprogramu pozostawia ślad na stosie?
Aby umożliwić powrót do programu wywołującego (ślad zawiera adres powrotu – czyli
lokacji pamięci zawierającej następny rozkaz). Ślad zawiera również rejestr flag który jest
przywracany przy powrocie z podprogramu – pozwala to na uniknięcie kłopotów
związanych ze zmianą tego rejestru podczas wykonywania podprogramu.
6. Dlaczego wiele programów generowanych przez kompilatory języków wysokiego poziomu
używa stosu do przechowywania wartości zmiennych lokalnych?
Ponieważ pozwala to na tymczasową alokację pamięci i zwolnienie jej po zakończeniu
programu/podprogramu. Podczas zajmowania pamięci w inny sposób nie może ona być
zwolniona aż do zakończenia programu – było by to więc rozwiązanie niewygodne.
7. Jaką rolę w trakcie odczytywania wartości parametrów przekazywanych do podprogramu
pełni pomocniczy wskaźnik stosu EBP?
Przy przekazywaniu parametrów przez stos bardzo wygodne jest zapamiętanie na początku
podprogramu wartości wierzchołka stosu. Stos podczas wykonywania podprogramu może
sie zmieniać (w sensie zwiększania i zminiejszania rozmiaru). Dlatego sensowne jest
posługiwanie się drugim wskaźnikiem stosu który wskazuje wierzchołek stosu z momentu
wywoływania podprogramu. Rejestr EBP może być traktowany tak jak ESP z tą tylko
różnicą iż nie jest on automatycznie zmieniany podczas operacji na stosie. Może być zatem
wykorzystany jako "stały punkt" według którego będą określane lokacje parametrów
przekazanych do podprogramu.
8. Na czym polegają różnice standardów wywoływania podprogramów: Pascall, C, StdCall?
Pascal – przekazywanie od lewej do prawej, zdejmuje program wywoływany
C – od prawej do lewej, program wywołujący

StdCall – od prawej do lewej, program wywoływany (złożenie Pascall i C)
9. W jaki sposób w programie wywołuje się funkcje usługowe systemu operacyjnego?
W systemach Dos oraz Linux – przy pomocy instrukcji: "int numer_funkcji" – numer
"podfunkcji" przekazywany przy pomocy rejestrów.
W systemach Windos – przy pomocy: "call"
10. Wyjaśnić znaczenie terminu interfejs programowania aplikacji.
Interfejs programowania aplikacji – zbiór funkcji usługowych systemu operacyjnego
pozwalający na komunikację pomiędzy programem a sysemem oraz programem a sprzętem
(użytkownikiem). Dzięki tym funkcjom program sygnalizuje pewne sytuacje a ich obsługa
należy do systemu operacyjnego – przykładowo wyświetlenie okienka (MessageBox) nie
jest realizowane bezpośrednio przez program ale przez system operacyjny który otrzymał
polecenie wyświetlenia takiego okienka. Podobnie komunikacja ze sprzętem odbywa się za
pośrednictwem systemu – system w ten sposób zapewnia programowi środowisko pracy.
(Twórczość własna...)
11. Omówić podstawowe zasady programowania hybrydowego
Podstawową zasadą jest zapewnienie zgodności wywoływania procedór dla modułów
stworzonych w odmiennych językach (asembler i język wysokiego poziomu). W
szczególności należy stosować tą samą technikę przekazywania parametrów jak też
odpowiednie nazwy segmentów (i ich atrybutów).
F. Lista rozkazów procesora:
1. Czym różnią się rozkazy sterujące warunkowe od bezwarunkowych?
Warunkowe testują rejestr flag – skok następuje jedynie jeżeli są ustawione (lub zgaszone)
odpowiednie flagi (różne dla różnych rozkazów)
Bezwarunkowe – skok bez testowania rejestru flag (zawsze)
2. Scharakteryzować grupę rozkazów procesora określanych jako operacje bitowe
Wykonują operacje na odpowiadających sobie bitach operandów, rezultat zapisywany w
operandzie docelowym (dla rozkazu TEST brak zapisu), jednocześnie ustawiane znaczniki
ZF, SF, PF, przy czym CF i OF zerowane (TEST ustawia znaczniki, tylko nie zapisuje
wyniku).
Rozkazy wykonujące operacje bitowe to: TEST, AND, OR, XOR, NOT
3. Jak zmieni sie zawartość rejestu EBX po wykonianiu rozkazu XOR EBX, 7
3 najmłodsze bity rejestr EBX zostaną zanegowane, reszta pozostanie bez zmian.
4. Omówić technikę wyodrębniania pól bitowych
Wyodrębnianie pól bitowych polega na nakładaniu odpowiedniej maski. Do nałożenia
maski służy rozkaz iloczynu bitowego (AND). Przykładowo wyodrębnienie 3ech
najbardziej znaczących bitów liczby znajdującej się w rejestrze ax:
AND AX, 11100000b
do uzyskabnia wartości liczbowej można użyć rozkazu przesunięcia logicznego. W naszym
przypadku będzie to:
MOV CL, 5
SAR AX, CL (SAR – przesunięcie w prawo, z lewej wprowadzane zera – ew. może być
SHR AX, CL – w tym wypadku bity z lewej były by powielane najstarszym
bitem liczby w AX)

5. Czym różnią się przesunięcia cykliczne od logicznych?
- logiczne – zerowany, lub powtarzany najmniej znaczący bit (przesunięcia w lewo) lub
najbardziej znaczący (przesunięcia w prawo), reszta bitów przesuwana (bity które
"wypadają" z rejestru przy przesunięciu tracone)
- cykliczne – liczba zawarta w rejestrze jest "zawijana" - dla przesunięcia w lewo bity z
pozycji 7 trafiają na pozycje 0, zawracane bity kopiowane do CF (reszta bitów przesuwana),
w przypadku przesunięcia w prawo bity z pozycji 0 trafiają do 7, najmłodszy wpisywany do
CF (a reszta przesuwana).
Możliwe są także przesunięcia przez CF – wtedy CF jest traktowane jako dodatkowy bit
rejestru.
6. W jaki sposób są kodowane mnemoniki (skróty literowe) rozkazów wykonujących działania
na liczbach zmiennoprzecinkowych?
Mnemoniki te dotyczą koprocesora arytmetycznego i są kodowane jako zwykłe rozkazy
poprzedzone literą f (zazwyczaj). Dodatkowo są dostępne funkcje pozwalające na
wyznaczenie wartości pierwiastka, funkcji trygonometrycznych. Przykładowo:
fmul st(0), st(0) - pomnożenie liczby znajdującej sie na szczycie stosu
koprocesora przez samą siebie
Należy pamiętać że koprocesor musi zostać najpierw zainicjowany – rozkaz "finit"
Inne rozkazy koprocesora:
fld
- odłożenie na stos koprocesora
fsubp st(1), st(0)
- wykonanie odejmowania
fsqrt
- obliczenie pierwiastka stopnia drugiego
ftan
- instrukcje powodują obliczenie wartości funkcji tg
fdiv
MUSZĄ WYSTĄPIĆ RAZEM, JEDNA PO
DRUGIEJ
G. Sterowanie urządzeniami zewnętrznymi:
1. Wyjaśnić różnice w sposobie komunikacji procesora z urządzeniami zewnętrznymi poprzez
pamięć i poprzez porty.
Poprzez pamięć – rejestry urządzenia są dostępne w przestrzeni adresowej pamięci –
komunikacje realizowana poprzez rozkazy MOV. (współadresowalne ukłądy
wejścia/wyjścia)
Poprzez porty – rejestry urządzenia znajdują sie w odrębnej przestrzeni adresowej zwanej
przestrzenią adresową wejścia/wyjścia lub przestrzenią adresową portów. (izolowane
wejście/wyjście) – komunikacja z urządzeniem realizowana przy pomocy rozkazów IN i
OUT – należy tutaj zaznaczyć że powyższe rozkazy nie są dostępne przy pracy z systemami
operacyjnymi typu Windows/Linux – komunikacja z urządzeniami odbywa sie przy pomocy
funkcji systemowych (IN i OUT są rozkazami niedozwolonymi dla programu i ich
wykonanie powoduje zgłoszenie nieprawidłowej operacji i zakończenie programu. Rozkazy
te mogą być wykonywane przez system oparacyjny – pracujący na wyższym poziomie
uprzywilejowania)
2. Jak zorganizowana jest pamięć ekranu w trybie teksowym?
W trybie tekstowym pamięć ekranu zaczyna się od adresu B8000H. Znaki reprezentowane
są przez dwa bajty – bajt o adresie parzystym zawiera numer koloru(16 kolorów), bajt o
adresie nieparzystym zawiera kod znaku (ASCII). Kolejne pola pamięci (rosnące adresy)
odwzorowują kolejne znaki na ekranie przy porządku od pierwszej linii (góra ekranu) i od
lewej do prawej (czyli kolejność tak jak przy zwykłym zapisie "na papierze").
3. Omówić różne techniki skojarzenia rejestrów urządzenia z portami.
- jeden rejestr z jednym portem:

(rejestry – R, porty – P)
R ===> P
R <=== P
R <=== P
R ===> P
- jeden port, wiele rejetrów – kolejne dane kierowane na port przesyłane do kolejnych
rejestrów
P =+==> R
|==> R
|==> R
\==> R
- za pośrednictwem dwuch portów – portu adresowego i portu danych – każda operacja
zapisu/odczytu poprzedzana wysłaniem adresu rejestru na którym ma być przeprowadzone
działanie
Port adresowy: P
adresu
R
Port danych: P
danych
--- \ R
\-----> R
R
- ten sam port odczytu rejestru i zapisu innego rejestru (często używane do rejestru stanu i
rejestru sterującego)
P =========> R
^========== R
4. Omówić organizacje pamięci ekranu w trybie graficznym 13h (raster 320*200)
Pamięć zawiera 65000 bajtów i rozpoczyna się od adresu A0000H. Kolejne bajty opisują
kolory kolejnych pikseli wg. Standardowej palety VGA (palete można zmienić – tzn. można
zdefiniować własne kolory RGB)
5. Omówić podstawowe elementy systemu przerwań stosowanego w komputerach PC
"Urządzenei sygnalizuje zakończenie operacji (albo niezdolność do dalszego jej
wykonywania) za pomocą sygnału przerwania skierowanego do procesora; sygnał
przerwania powoduje przerwanie wykonywania aktualnego programu i przejście do
wykonywania podprogramu obsługi urządzenia, właściwego dla przyjętego przerwania [...]
przerwanie powinno być niewidoczne dla aktualnie wykonywanego programu powodując
jedynie jego chwilowe zatrzymanie. [...] Stosowane są różne systemy obsługi przerwań;
niekiedy zainstalowana jest wspólna linia przerwań dla wszystkich urządzeń – po nadejściu
przerwania procesor sprawdza stany poszczególnych urządzeń identyfikując urządzenie
które wysłało przerwanie (metoda odpytywania); w innych systemach linia przerwań
przechodzi przez wszystkie zainstalawane urządzenia ustawione wg. priorytetów; w
komputerach PC priorytet przerwania ustalany jest poprzez odpowiednie skonfigurowanie
układów PIC lub APIC".
6. Jaką rolę w obsłudze przerwań pełni sprzętowych pełni tablica deskryptorów przerwań?
"omawiana tablica zawiera 256 elementów nazywanych deskryptorami; każdy deskryptor
zajmuje 8bajtów. Wyróżnia się trzy rodzaje deskryptorów: furtki przerwania (używane przy
obsłudze przerwań sprzętowych), furtki potrzasku (używane przy obsłudze wyjątków
procesora i wywołań za pomocą rozkazu INT) oraz furtki zadania (używane w sytuacjach
awaryjnych). Furtki przerwania i potrzasku zawierają adresy odpowiednich podprogramów
obsługujących przerwania i wyjątki; deskryptory znajdujące się na pozycjach 0 – 31
używane są do obsługi wyjątków generowanych przez procesor. Pozostawłe deskryptory
mogą zawierać adresy podprogramów obsługujących przerwania sprzętowe i wywołania

systemowe. Położenie tablicy deskryptorów przerwań w pamięci głównej komputera
wskazane jest przez zawartość rejestru IDTR".
H. Hierarcha pamięci:
1. Co ozanacza termin trafienie i chybienie w odniesieniu do pamięci podręcznej?
Zgodnie z zasadą lokalności prawdopodobne jest że kolejne potrzebne rozkazy czy dane
znajdować się będą w bezpośrednim sąsiedztwie. Dlatego też konstruktorzy procesorów
zaczeli stosować niewielką ale bardzo szybką pamięć zdefiniowaną wewnątrz procesora
(tzw. "cache") do której przegrywane są fragmenty pamięci głównej. W takim przypadku
sytuację jeżeli potrzebne dane znajdują się w przegranym bloku nazywamy trafieniem, jeżeli
potrzebnych danych (rozkazów) nie ma – chybieniem. W przypadku chybienia do pamięci
podręcznej kopiowany jest cały blok pamięci głównej zawierający potrzebną daną – zgodnie
z zasadą lokalności istnieje duże prawdopodobieństwo że dane potrzebne w dalszych
operacjach będą znajdowały się w sąsiedztwie chwilowo potrzebnej danej.
2. Na czym polega technika dostępu do pamięci podręcznej z odwzorowaniem bezpośrednim?
32 bitowy adres jest dzielony na 3 pola: pole etykiedy (16bitów), pole obszaru (12bitów),
pole słowa (4bity). W przypadku zajścia konieczności odczytu podejmowane są działania:
- wyznaczenie liczby z pola etykiety i pola obszaru
- z odpowiedniego wiersza pamięci podręcznej zostanie odczytane pole etykiety i
porównane z polem etykiety adresu 32-bitowego
- jeżeli porównane wartości są identyczne to zostanie odczytany indeksowany wiersz, w
którym na drugiej pozycji znajduje się potrzebny bajt (pamięć podręczna), natomiast jeżeli
wartości nie są identyczne zachodzi potrzeba odczytania bajtu z pamięci RAM
3. Omówić schemat współdzielenia różnych rodzajów pamięci w komputerze znany jako
hierarchia pamięci.
Pamięci wbudowane w procesor (rejestry, pamięć podręczna) są bardzo szybkie ale drogie –
w związku z czy niewielkie, pamięci masowe natomiast są tanie (przez co mogą być
znacznie większe) ale powolne. Zatem zachodzi potrzeba usystematyzowania pamięci pod
względem potrzeb związanych z szybkością ale też wielkością i ceną.
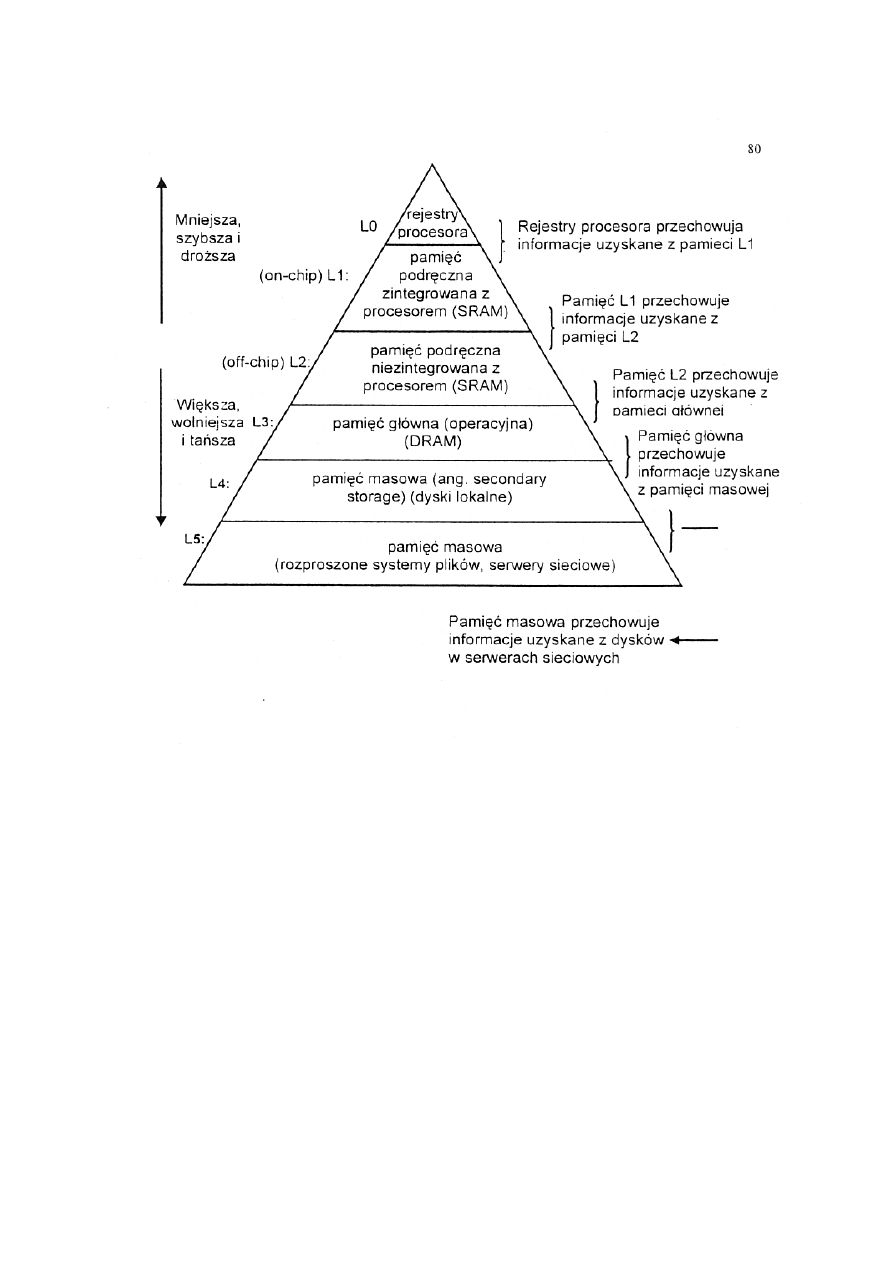
Hierarcha pamięci: (skrypt do wykładów)
Ważne pojęcia:
Strona – pewien obszar pamięci fizycznej wskazywany po transformacji starszych bitów adresu
pierwotnego. W obszarze tym położenie konkretnej lokacji pamięci określa młodsza,
nietransformowana część adresu pierwotnego. Zazwyczaj rozmiar jednej strony jest ustalany jako
4kB ale może być też 2 lub 4 MB.
Tablica TLB – bufor wewnątrz procesora w którym rejestrowane są ostatnio przeprowadzone
transformacje adresów. Tablica ta zawiera pewną ilość wierszy, zazwyczaj 32, a każdy wiersz
zawiera 20 najbardziej znaczących bitów adresu wirtualnego oraz 20 najbardziej znaczących bitów
adresu fizycznego (który został otrzymany poprzez odczyt katalogu tablic stron i tablicy stron).
Jeżeli opis pewnej stony znajduje się w TLB, to procesor pobiera niformacje o adresie fizycznym
bezpośrednio z tablicy stron. Przeglądanie TLB zrealizowane jest poprzez układy równoległe,
dzięki czemu możliwe jest natychmiastowe stwierdzenie czy potrzebny adres znajduje się w TLB
czy nie.
Ze względu na zasadę lokalności większość transformacji adresów odbywa się przez odczyt z TLB
(około 98%) - co korzystnie wpływa na wydajność systemu (nie jest tracony czas na znalezienie
fizycznego adresu strony)
Wyszukiwarka
Podobne podstrony:
pytania marzec 2006
Pytania z ortopedii 2006, medycyna zabrze SUM lekarski, ortopedia testy
pytania rozwojowa 2006-2007, PEDAGOGIKA i PSYCHOLOGIA, PSYCHOLOGIA - materiały, Psychologia Rozwoju
Chirurgia pytania z egzaminu 2006, Stomatologia, III rok, chirurgia ogólna
Folie 04 PKB Czynniki marzec 2006
Chirurgia pytania z egzaminu 2006-2dd, Stomatologia, III rok, chirurgia ogólna
Pytania Rat 2006, Rok II, Med. ratunkowa wieku dziecięcego
wykłady, Układ autonomiczny głowy i szyi., 22 marzec 2006
Pytania marzec
pytania z fundamentow-2006(1), budownictwo, semestr IV
pytania z fundamentow-2006, Egzamin(1)
pytania z fundamentow-2006, Studia PG, Semestr 08, Fundamenty Specjalne, Egzamin
Pytania z mikrobw 2006 - Julka, BIO, MIKRO, MIKROBY
Pytania z higieny 2006, IV rok, IV rok CM UMK, HIGIENA I EPIDEMIOLOGIA, giełdy, giełdy hig
pytania z fundamentow-2006 IT, Studia PG, Semestr 08, Fundamenty Specjalne, Egzamin
Pytania z egzaminu 2006, Choroby skórne i weneryczne, Dermatologia, giełdy
wykłady, Newry czaszkowe. Nerw trójdzielny., 8 marzec 2006
Pytania z biochemii 2006[1], biochemia
więcej podobnych podstron