
1
Architektura Komputerów i Programowanie
Niskopoziomowe
1. Historia ewolucji komputerów
Generacje komputerów:
!!!!"
"
"
" 1 generacja
1946-1957
lampa próżniowa
ok. 40 000 operacji na sekundę
!!!!"
"
"
" 2 generacja
1958-1964
tranzystor
ok. 200 000 operacji na sekundę
!!!!"
"
"
" 3 generacja
1965-1971
mała i średnia skala integracji
ok. 1 000 000 operacji na sekundę
!!!!"
"
"
" 4 generacja
1972-1977
wielka skala integracji
ok. 10 000 000 operacji na sekundę
!!!!"
"
"
" 5 generacja
1978-…
bardzo wielka skala integracji
ok. 100 000 000 operacji na sekundę
ENIAC
ENIAC (ang. Electronic Numerical Integrator And Computer) został ukończony w roku
1946. Był pierwszym na świecie elektronicznym komputerem cyfrowym o ogólnym
przeznaczeniu. ENIAC był maszyną raczej dziesiętną niż binarną. Liczby były
reprezentowane w formie dziesiętnej i arytmetyka była realizowana w systemie
dziesiętnym. Jego pamięć składała się z 20 „akumulatorów”, z których każdy
mógł przechowywać 10-cyfrową liczbę dziesiętną. Każda cyfra była
reprezentowana przez pierścień złożony z 10 lamp próżniowych. Główną wadą ENIAC-
a było to, że musiał on być programowany ręcznie przez ustawianie przełączników
oraz wtykanie i wyjmowanie kabli.
Maszyna von Neumanna
W roku 1946 rozpoczęto projektowanie nowego
komputera wykorzystującego
program przechowywany w pamięci. Miało to miejsce w Princeton Institute for
Advanced Studies, a sam komputer określono skrótem
IAS. Głównymi jego
składnikami są:
!" Pamięć główna, w której są przechowywane zarówno dane jak i rozkazy
!" Jednostka arytmetyczno-logiczna (ALU), mogąca wykonywać działania
na danych binarnych
!" Jednostka sterująca, która interpretuje rozkazy z pamięci i powoduje
ich wykonanie
!" Urządzenia wejścia-wyjścia, których pracą kieruje jednostka sterująca

2
Komputer IAS działał przez powtarzalne wykonywanie cyklu rozkazu. Z rzadkimi
wyjątkami wszystkie dzisiejsze komputery mają tę samą ogólną strukturę i funkcje,
są wobec tego określane jako maszyny von Neumanna.
2. Pojęcia organizacji i architektury komputerów
Architektura komputera – opis budowy systemu komputerowego, który odnosi się
do atrybutów systemu widzialnych dla programisty takich jak liczba bitów
reprezentacji danych, organizacja jednostki arytmetyczno-logicznej, lista rozkazów,
metody organizacji pamięci, mechanizmy wejścia-wyjścia.
Organizacja komputera – opis budowy systemu komputerowego, który odnosi się
do atrybutów niewidzialnych dla programisty takich jak rozwiązania sprzętowe
wynikające z zastosowanej technologii elektronicznej, sygnały i układy sterujące,
interfejsy między komputerem a urządzeniami peryferyjnymi.
Struktura komputera – opis wzajemnego, hierarchicznego powiązania składników
systemu komputerowego.
3. Podstawowe podzespoły komputera
Funkcje komputera:
!!!!"
"
"
" przetwarzanie danych
!!!!"
"
"
" przechowywanie danych
!!!!"
"
"
" przenoszenie danych
!!!!"
"
"
" sterowanie
Procesor – jednostka centralna (CPU) przetwarza dane i steruje działaniem
komputera. Składa się m.in. z:
!" Jednostki arytmetyczno-logicznej – realizuje funkcje przetwarzania danych
przez komputer (dokonuje obliczeń)
!" Rejestrów podręcznych – przechowują chwilowe dane przetwarzane przez
procesor
!" Jednostki sterującej – pobiera i dekoduje rozkaz, generuje odpowiednie sygnały
sterujące dla innych elementów procesora
!" Magistral procesora – zapewniają łączność pomiędzy składnikami procesora
Pamięć główna – przechowuje dane i instrukcje
Urządzenia wejścia-wyjścia – odpowiadają za komunikację komputer – otoczenie
Połączenia systemowe – (magistrale) – zapewniają łączność pomiędzy
poszczególnymi elementami komputera
4. Pojęcia hardware, firmware i software
Hardware – zestaw urządzeń elektronicznych do automatycznego przetwarzania
informacji. Fizyczne komponenty komputera, elementy peryferyjne i akcesoria.
Firmware – oprogramowanie układowe, umieszczone przez producenta sprzętu
w pamięci ROM, dostarczane razem ze sprzętem i traktowane jako jego element.
Software – oprogramowanie umieszczane w pamięci komputera w postaci sekwencji
rozkazów, wykonywanych przez jednostkę centralną.

3
5. Pojęcia mikroprocesor, mikrokontroler, mikrokomputer
Mikroprocesor – steruje działaniem komputera i realizuje jego funkcje
przetwarzania danych. Układ scalony, którego działanie polega na wykonywaniu
instrukcji programów zapisanych w pamięci. Nadzoruje i synchronizuje pracę
wszystkich urządzeń w komputerze. Głównymi zespołami procesora są: jednostka
arytmetyczno-logiczna ALU, jednostka sterująca, rejestry. Procesory mogą się
wyróżniać: architekturą (RISC lub CISC), liczbą bitów przetwarzanych w jednym
cyklu, częstotliwość taktowania w MHz.
Mikrokontroler – układ scalony o bardzo wielkiej skali integracji, w skład którego
wchodzi: mikroprocesor, pamięć przechowująca rozkazy dla mikroprocesora, dane
oraz wyniki operacji, układy wejścia-wyjścia umożliwiające wprowadzenie do pamięci
rozkazów, danych i wyprowadzenie wyników. Mikrokontrolery są kompletnymi,
programowalnymi, autonomicznymi układami (do pracy wystarczają im urządzenia
zewnętrzne zawarte w mikrokontrolerze), mogącymi realizować wszystkie operacje
składające się na przetwarzanie informacji cyfrowej łącznie z jej wymianą
z określonym otoczeniem.
Mikrokomputer – jednoukładowy komputer, którego wszystkie bloki funkcjonalne
(procesor, pamięć, urządzenia wejścia-wyjścia) są umieszczone w jednym układzie
scalonym. Mikrokomputery znajdują zastosowanie głównie w komputerach
wbudowanych, np. w sterownikach.
6. Procesory sygnałowe
Sygnały można podzielić na:
!!!!"
"
"
" Analogowe - są przebiegami konkretnej wielkości fizycznej np. napięcia
elektrycznego, ciśnienia, temperatury.
!!!!"
"
"
" Cyfrowe - jeśli użyta do reprezentacji sygnałów wielkość fizyczną odgrywa
rolę drugorzędną i kwantuje się ją, to próbki interesującego nas sygnału
można zakodować za pomocą ustalonych zestawów symboli. Takie kwantowe
i kodowane sygnały nazywają się cyfrowymi.
!!!!"
"
"
" Ciągłe - takie, że ich wartości są istotne dla każdej wartości zmiennej
niezależnej z pewnego przedziału np. każdej chwili czasu
!!!!"
"
"
" Dyskretne - jeśli istotne są tylko ich wartości w pewnych (dyskretnych)
punktach przestrzeni zmiennej niezależnej np. w wybranych, dyskretnych
chwilach czasu. Sygnały dyskretne są opisywane jako ciągi (sekwencje) liczb
tzw. próbek sygnału
!!!!"
"
"
" Jednowymiarowe
!!!!"
"
"
" Wielowymiarowe
Sygnał skwantowany
Sygnał skwantowany to taki sygnał, który nie jest rejestrowany dokładnie, lecz
rozróżnia się jedynie skończoną liczbę możliwych poziomów (wartości) wielkości
fizycznej użytej do reprezentacji sygnału.
Najważniejsze cechy procesorów sygnałowych:
!" Długie formaty danych (np. 16 bitów, 32 bity i więcej)
!" Sprzętowa realizacja mnożenia z możliwością zapisu dokładnego wyniku
w tzw. długim akumulatorze
!" Rozdzielanie toru programu od toru danych (architektura harwardzka)
!" Szybkie działanie
!" Niski pobór mocy
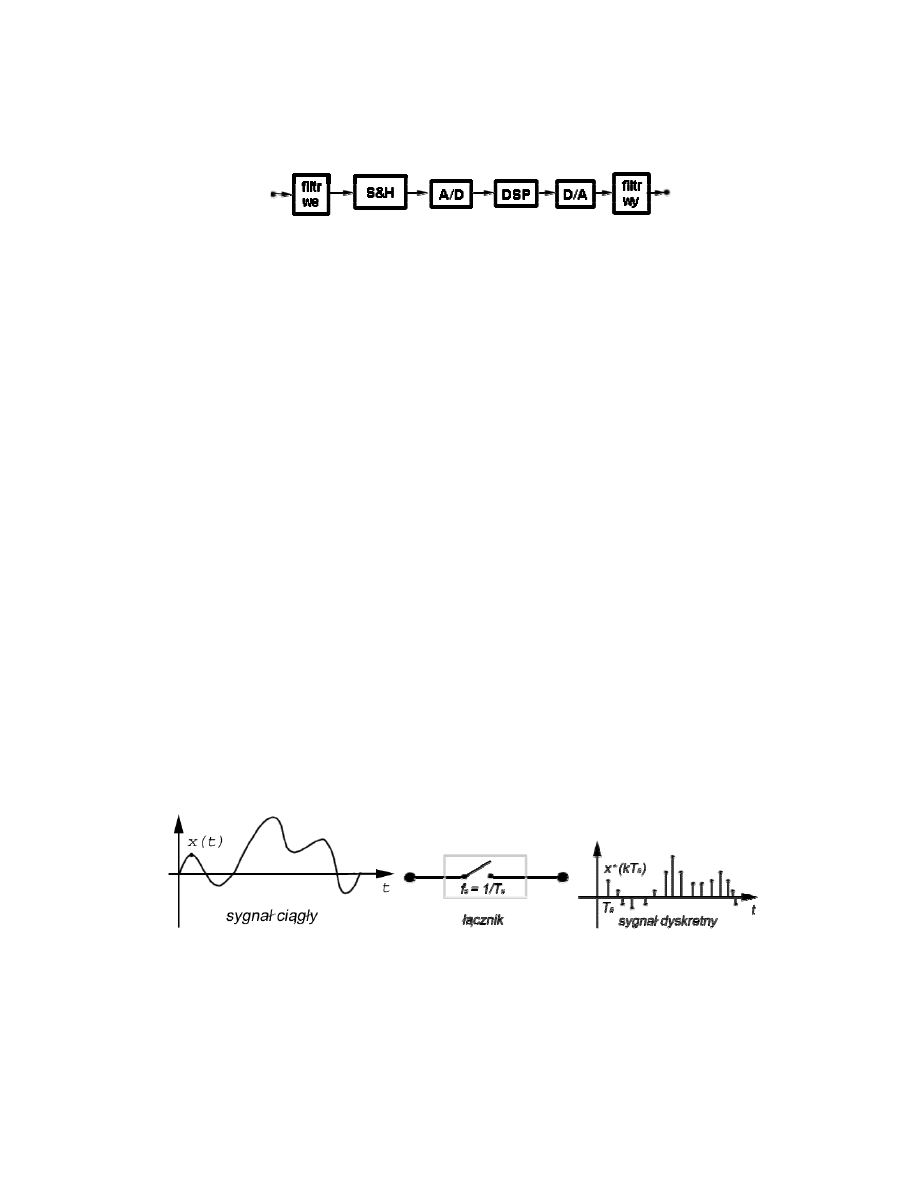
4
Przebieg obróbki sygnału
Stosujemy czujniki do przetworzenia temperatury, ciśnienia, wibracji w odpowiednie
sygnały elektryczne. Tak uzyskane sygnały są zazwyczaj analogowe i ciągłe. Z reguły
poddawane są na wstępie pewnej filtracji analogowej, ograniczającej jej pasmo
(tzw. filtracji anty-aliasingowej) [filtr we], następnie próbkowaniu np. w układzie
próbkująco-pamiętającym [S&H] (sample & hdd - próbkuj i trzymaj) i wreszcie
przetwarzaniu analogowo-cyfrowemu [A/D] (analog to digital). Teraz następuje
proces główny czyli etap cyfrowego przetwarzania sygnału, np. za pomocą procesora
sygnałowego [DSP] (digital signal processor). Otrzymane w wyniku sygnał użyteczny
podlega przetwarzaniu cyfrowo-analogowemu [D/A] i wygładzeniu w filtrze
wyjściowym [filtr wy].
Układy analogowe:
!" Ograniczona dokładność, zależna od precyzji pomiaru wielkości fizycznej
zastosowanej reprezentacji sygnału.
!" Zależne w działaniu od temperatury, warunków atmosferycznych, rozrzutu
i starzenia się elementów (brak powtarzalności działania układu i różnice
w działaniu poszczególnych egzemplarzy).
Układy cyfrowe:
!" Wraz ze wzrostem ilości bitów słowa rośnie dokładność, ale rosną również
koszty i maleje szybkość próbkowania.
!" Działają w sposób dokładnie powtarzalny i nie podlegają starzeniu.
!" Brak bezpośredniej zależności od zjawisk fizycznych (realizacja dowolnych
algorytmów obliczeniowych).
!" Możliwość zastosowania układów programowalnych (np. procesorów
sygnałowych) - możliwość zmiany właściwości układu jedynie przez program,
bez modyfikacji sprzętu.
!" Występowanie hazardów danych i sterowania.
!" Występowanie błędów statycznych: „przywarta jedynka”, „przywarte zero”.
Koncepcja próbkowania
Sygnał ciągły transmitowany za pośrednictwem łącznika, co jakiś czas zamykany jest
łącznik, co daje krótki impuls o amplitudzie równej wartości sygnału w chwili
próbkowania. Odstępy między chwilami próbkowania mogą być równe, np. Ts, wtedy
jest to próbkowanie równomierne o okresie Ts albo szybkości fs=1/Ts. Jeśli nie to
próbkowanie takie nazywamy próbkowaniem nierównomiernym.

5
7. Architektura von Neumanna i architektura harwardzka
Architektura von Neumanna:
!" Dane i rozkazy są przechowywane w tej samej pamięci umożliwiającej zapis
i odczyt
!" Zawartość pamięci może być adresowana przez wskazanie miejsca, bez
względu na rodzaj przechowywanych danych
!" Wykonywanie rozkazów w sposób szeregowy, rozkaz po rozkazie
Urządzenie realizuje różne operacje w zależności od doprowadzonych sygnałów
sterujących. System przyjmuje dane i sygnały sterujące, po czym dostarcza wyniki.
Cały program jest sekwencją kroków. W każdym kroku wykonywana jest pewna
operacja arytmetyczna lub logiczna.
Architektura harwardzka:
!" Zastosowanie osobnych pamięci i magistral dla programu i danych
!" Program nie może zapisać do pamięci programu
!" Ułatwia projektowanie procesorów
!" Adres danej można podawać do pamięci danych już w czasie podawania
adresu następnej instrukcji pamięci programu - przyspiesza przetwarzanie
potokowe
8. Magistrale i połączenia magistralowe
Magistrala jest drogą zapewniającą komunikację między urządzeniami.
Główną charakterystyczną cechą magistrali jest to, że jest ona wspólnym
nośnikiem transmisji (ang. shared transmission medium). Do magistrali dołącza się
wiele urządzeń, a sygnały wysyłane przez którekolwiek z nich mogą być
odbierane przez wszystkie pozostałe urządzenia. Jeśli dwa urządzenia nadawałyby
w tym
samym czasie, ich sygnały nakładałyby się i ulegały zakłócaniu.
W określonym czasie może więc nadawać tylko jedno urządzenie. Często magistrala
składa się z wielu dróg (linii) komunikacyjnych. Każdą linią mogą być przesyłane
sygnały reprezentujące binarne 0 i 1. W ciągu pewnego czasu przez pojedynczą linię
może być przekazana sekwencja cyfr binarnych. Wiele linii zawartych w magistrali
można wykorzystywać razem do jednoczesnego (równoległego) transmitowania cyfr
binarnych. Na przykład 8-bitowa jednostka danych może być przesyłana przez 8 linii
magistrali. System komputerowy zawiera pewną liczbę różnych magistrali, które
łączą zespoły komputera na różnych poziomach hierarchii. Magistrala łącząca
główne zespoły komputera (procesor, pamięć, wejście-wyjście) nazywana jest
magistralą systemową. Najczęściej spotykane struktury połączeń
komputera wykorzystują jedną lub więcej magistrali systemowych.
Struktura magistrali
Zawarte w magistralach linie można podzielić na trzy grupy funkcjonalne:
linie danych, adresów i sterowania. Ponadto mogą występować linie służące do
zasilania dołączonych modułów.
Linie danych są ścieżkami służącymi do przenoszenia danych między modułami
systemu. Wszystkie te linie łącznie są określane jako szyna danych (ang. data bus).
Szyna danych składa się typowo z 8, 16 lub 32 oddzielnych linii, przy czym liczba linii
określa szerokość tej szyny. Ponieważ w danym momencie każda linia może przenosić
tylko 1 bit, z liczby linii wnika, ile bitów można jednocześnie przenosić. Szerokość
szyny danych jest kluczowym czynnikiem określającym wydajność całego systemu.
Jeśli na przykład szyna danych ma szerokość 8 bitów, a każdy rozkaz ma długość 16
bitów, to procesor musi łączyć się z modułem pamięci dwukrotnie w czasie każdego
cyklu rozkazu.

6
Linie adresowe są wykorzystywane do określania źródła lub miejsca przeznaczenia
danych przesyłanych magistralą. Jeśli na przykład procesor ma zamiar odczytać słowo
(8, 16 lub 32 bity) danych z pamięci, umieszcza adres potrzebnego słowa na linii
adresowej. Jest jasne, że szerokość szyny adresowej determinuje maksymalną
możliwą pojemność pamięci systemu. Ponadto linie adresowe są również używane do
adresowania portów wejścia-wyjścia. Najczęściej najbardziej znaczące bity służą do
wybrania określonego modułu na magistrali, natomiast najmniej znaczące bity
określają lokację w pamięci lub port wejścia-wyjścia wewnątrz modułu.
Linii sterowania używa się do sterowania dostępem do linii danych
i linii adresowych, a także do sterowania ich wykorzystaniem. Ponieważ linie danych
i adresowe służą wszystkim zespołom, musi istnieć sposób sterowania ich
używaniem. Sygnały sterujące przekazywane między modułami systemu
zawierają zarówno rozkazy, jak i informacje regulujące czas (taktujące). Sygnały
czasowe określają ważność danych i adresów. Sygnały rozkazów precyzują operacje,
które mają być przeprowadzone. Typowe linie sterowania to linie:
!" Zapis w pamięci. Sprawia, że dane z magistrali zostają zapisane pod
określonym adresem.
!" Odczyt z pamięci. Sprawia, że dane spod określonego adresu są
umieszczane w magistrali.
!" Zapis do wejścia-wyjścia. Sprawia, że dane z magistrali są kierowane do
zaadresowanego portu wejścia-wyjścia.
!" Odczyt z wejścia-wyjścia. Sprawia, że dane z zaadresowanego portu
wejścia-wyjścia są umieszczane w magistrali.
!" Potwierdzenie przesyłania
(transfer ACK). Wskazuje, że dane
zostały przyjęte z magistrali lub na niej umieszczone.
!" Zapotrzebowanie na magistralę (bus request). Wskazuje, że moduł zgłasza
zapotrzebowanie na przejęcie sterowania magistralą.
!" Rezygnacja z magistrali (bus grant). Wskazuje, że moduł rezygnuje ze
sterowania magistralą.
!" Żądanie przerwania (interrupt request). Wskazuje, że przerwanie jest
zawieszone.
!" Potwierdzenie przerwania
(interrupt ACK). Potwierdza, że
zawieszone przerwanie zostało rozpoznane.
!" Zegar. Wykorzystywany do synchronizowania operacji.
!" Przywrócenie (reset). Ustawia wszystkie moduły w stanie początkowym.
Działanie magistrali jest następujące. Jeśli jeden z modułów zamierza wysłać
dane do drugiego, to musi wykonać dwie rzeczy: (1) uzyskać dostęp do magistrali
i (2) przekazać dane za pośrednictwem magistrali. Jeśli natomiast zamierza uzyskać
dane z innego modułu, to musi: (1) uzyskać dostęp do magistrali i (2) przekazać
zapotrzebowanie do tego modułu przez odpowiednie linie sterowania i adresowe. Musi
następnie czekać, aż drugi moduł wyśle dane.
9. Magistrale w komputerach klasy PC
MAGISTRALA PCI
System połączeń urządzeń peryferyjnych PCI (skrót od ang. Peripheral Component
Interconnect) jest współczesną, szerokopasmową magistralą niezależną od procesora.
W porównaniu z innymi, powszechnie spotykanymi magistralami PCI umożliwia
uzyskanie większej wydajności systemu, jeśli są wykorzystywane szybkie podsystemy
wejścia-wyjścia
(np. sterowniki interfejsów sieciowych, sterowniki dysków i
inne).
Magistrala PCI pracująca w trybie 33 MHz pozwala na osiągnięcie teoretycznej
maksymalnej przepustowości 132 MB/s. Jej 64 bitowe rozszerzenie (pracujące
z częstotliwością 66 MHz) umożliwia transfer z maksymalną prędkością 264 MB/s.
Magistrala PCI została zaprojektowana jako ekonomiczne
rozwiązanie spełniające
wymagania wejścia-wyjścia w nowoczesnych systemach. Wymaga niewielu mikroukładów

7
i wspomaga działanie innych magistrali,
związanych z magistralą PCI.
Do magistrali PCI mogą być podłączone dwa rodzaje urządzeń: inicjatory (initiator)
mogące przejmować kontrolę nad magistralą oraz jednostki podporządkowane (slave)
zdolne tylko do transmisji danych. Transmisja może przebiegać między dwoma
inicjatorami lub inicjatorem i jednostką podporządkowaną.
MAGISTRALA AGP
AGP (z ang. Accelerated Graphics Port) nie jest magistralą jako taką, stanowi jedynie
pewne przedłużenie magistrali PCI. Specyfikacja AGP bazuje na specyfikacji PCI w wersji
2.1 (zegar 66 MHz), rozszerzając ją o dodatkowe funkcje, dodając nowe niektórych
zmieniając znaczenie niektórych dotychczasowych sygnałów. Złącze AGP posiada 132
kontakty (po 66 z każdej strony) o wysokiej gęstości pól kontaktowych (1 mm).
Magistrala AGP może pracować w różnych trybach:
!" Tryb 1X – Proste rozszerzenie standardu PCI polegające na przyspieszeniu
zegara do 66 MHz. Maksymalny transfer to 264 MB/s.
!" Tryb 2X – Częstotliwość zegara wynosi nadal 66 MHz, ale wymiana danych
odbywa się w momentach wyznaczanych przez obydwa zbocza impulsów
taktujących (tryb DDR). W efekcie mamy „pozorny” wzrost częstotliwości
zegara do 133 MHz. Teoretyczna przepustowość magistrali sięga więc 532
MB/s. Transfer w trybie 2X może być inicjowany wyłącznie przez kontroler
graficzny. Napięcie obniżono z 5V na 3,3V w celu złagodzenia wymagań na
stromość zboczy coraz krótszych sygnałów.
!" Tryb 4X – pracuje na znacznie obniżonych poziomach napięć (1,5V). Tak
spłaszczone przebiegi mają dostatecznie strome zbocza aby podołać wymogom
bardzo szybkiej transmisji. Magistrala AGP w trybie 4X przesyła w porównaniu
z trybem 2X podwójną ilość danych, pomiędzy dwoma zboczami zegara mają
miejsce dwie transakcje. Teoretyczna przepustowość wynosi 1064 MB/s.
10. Klasyfikacja pamięci w komputerach
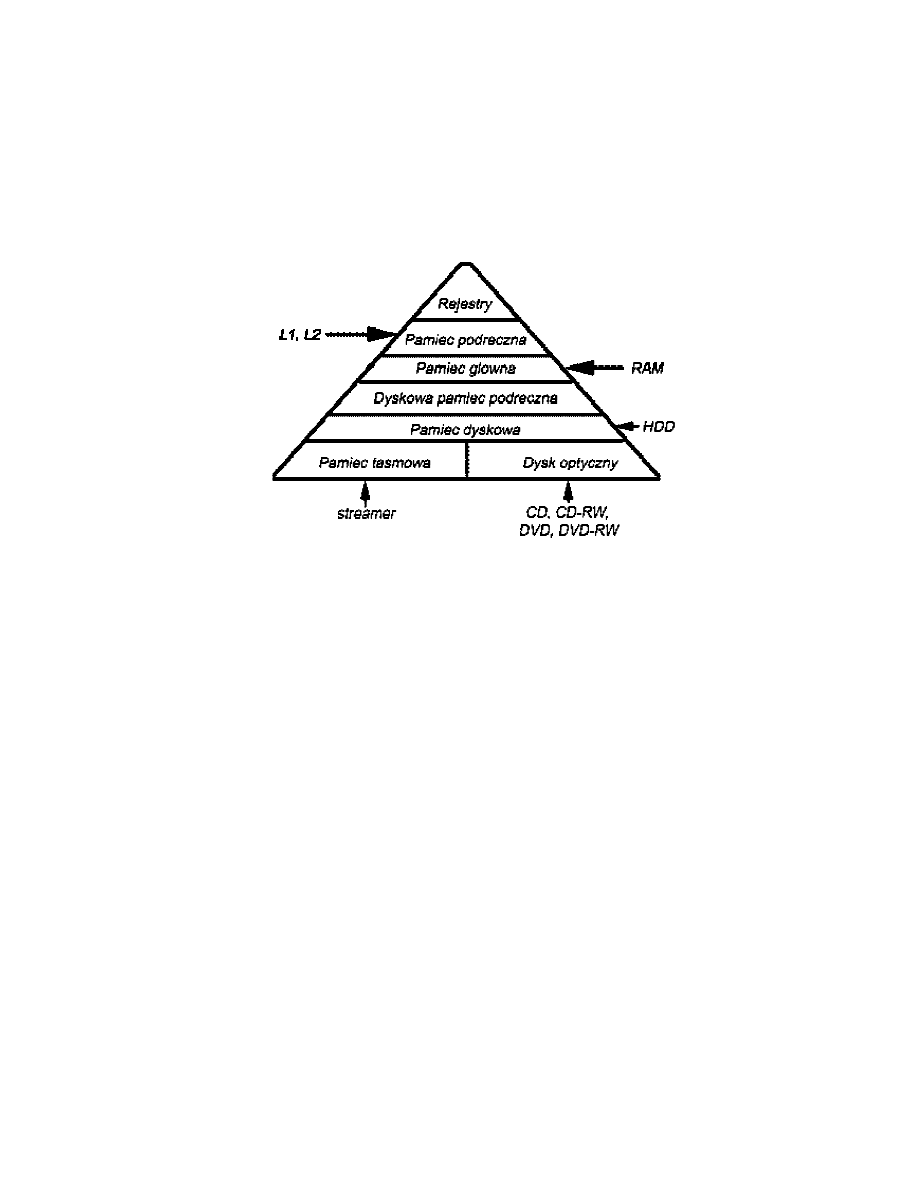
Typowy system komputerowy zwiera hierarchię podsystemów pamięci: niektóre z nich są
wewnętrzne w stosunku do systemu (bezpośrednio dostępne dla procesora), a inne
zewnętrzne (dostępne dla procesora przez moduł wejścia-wyjścia).
Pamięć wewnętrzna jest często identyfikowana z pamięcią główną. Są jednak także inne
formy pamięci wewnętrznej. Procesor wymaga własnej pamięci lokalnej w postaci
rejestrów, a jego jednostka sterująca może również potrzebować własnej pamięci
wewnętrznej.
Pamięć zewnętrzna składa się z peryferyjnych urządzeń pamięciowych, takich jak pamięć
dyskowa i taśmowa, które są dostępne dla procesora poprzez sterowniki wejścia-wyjścia.
Własności pamięci:
!" Pojemność - w przypadku pamięci wewnętrznej wyrażona w bajtach lub
słowach (najczęściej 8, 16, 32 bity)
!" Jednostka transferu - liczba bitów jednocześnie odczytywanych z pamięci,
równa liczbie linii danych doprowadzonych do modułu pamięci.
Można wyróżnić cztery rodzaje dostępu do pamięci:
!" Dostęp sekwencyjny - dostęp jest możliwy w określonej sekwencji liniowej.
Odczyt i zapis dokonywane są za pomocą tego samego mechanizmu, przy
czym proces ten musi się przenosić z pozycji bieżącej do pożądanej
przepuszczając i odrzucając wszystkie rekordy pośrednie (np. pamięci
taśmowe). Czas dostępu do rekordów może być bardzo różny, w zależności od
położenia żądanego rekordu.
!" Dostęp swobodny - każda adresowalna lokacja w pamięci ma unikatowy
fizycznie wbudowany mechanizm adresowania. Czas dostępu do danej lokacji
8
nie zależy od sekwencji poprzednich operacji dostępu i jest stały. Dowolna
lokacja może być wybierana swobodnie i jest adresowana i dostępna
bezpośrednio (np. pamięć główna).
!" Dostęp skojarzeniowy - jest to rodzaj dostępu swobodnego, który umożliwia
porównywanie i specyficzne badanie zgodności wybranych bitów wewnątrz
słowa, przy czym jest to czynione dla wszystkich słów jednocześnie.
Hierarchia pamięci:
11. Pamięć operacyjna
Pamięć operacyjna - podstawowy rodzaj pamięci o dostępie swobodnym,
przechowujący całość lub część bieżącego wykonywanego programu.
Pamięć operacyjna pozostaje w stałym kontakcie z procesorem, dla którego logicznie
przedstawia uporządkowany ciąg komórek zaadresowanych od 0 do 2n, przy czym
n oznacza liczbę bitów rejestru adresowego procesora. Pamięć operacyjna może być
realizowana jak pamięć stała lub pamięć zapisywalna. Cecha wyróżniająca RAM
(ang. Random Access Memory) spośród innych jest to, że możliwe jest zarówno
odczytanie danych z pamięci jak też łatwe i szybkie zapisanie do niej nowych danych.
Zarówno odczyt jak i zapis są deklarowane za pomocą sygnałów elektrycznych. Inną
własnością wyróżniającą jest ich ulotność. Pamięć RAM musi mieć źródło stałego
zasilania. Jeśli zasilanie jest przerwane, dane są tracone. Pamięć RAM może być
używana tylko do przechowywania czasowego. Pamięć RAM można podzielić na
statyczną i dynamiczną. Dynamiczna pamięć RAM jest wykonywana z komórek, które
przechowują dane podobnie jak kondensatory przechowują ładunek elektryczny.
Obecność lub brak ładunku w kondensatorze są interpretowane jako binarne 1 lub 0.
Ponieważ kondensatory mają naturalną tendencję do rozładowywania się, dynamiczne
pamięci RAM wymagają okresowego odświeżania ładunku w celu zachowania danych.
W statycznej pamięci RAM wartości binarne są przechowywane za pomocą
przerzutników. Statyczne pamięci RAM zachowują dane tak długo jak długo są
zasilane. Zarówno statyczne jak i dynamiczne pamięci RAM są ulotne. Dynamiczna
komórka pamięci jest prostsza i dzięki temu mniejsza niż statyczna. W rezultacie
dynamiczna pamięć RAM jest gęściej upakowana i tańsza niż odpowiadająca jej
statyczna. Z drugiej strony dynamiczna pamięć RAM wymaga układów odświeżania.
Statyczne pamięć RAM są dużo szybsze od dynamicznych.
9
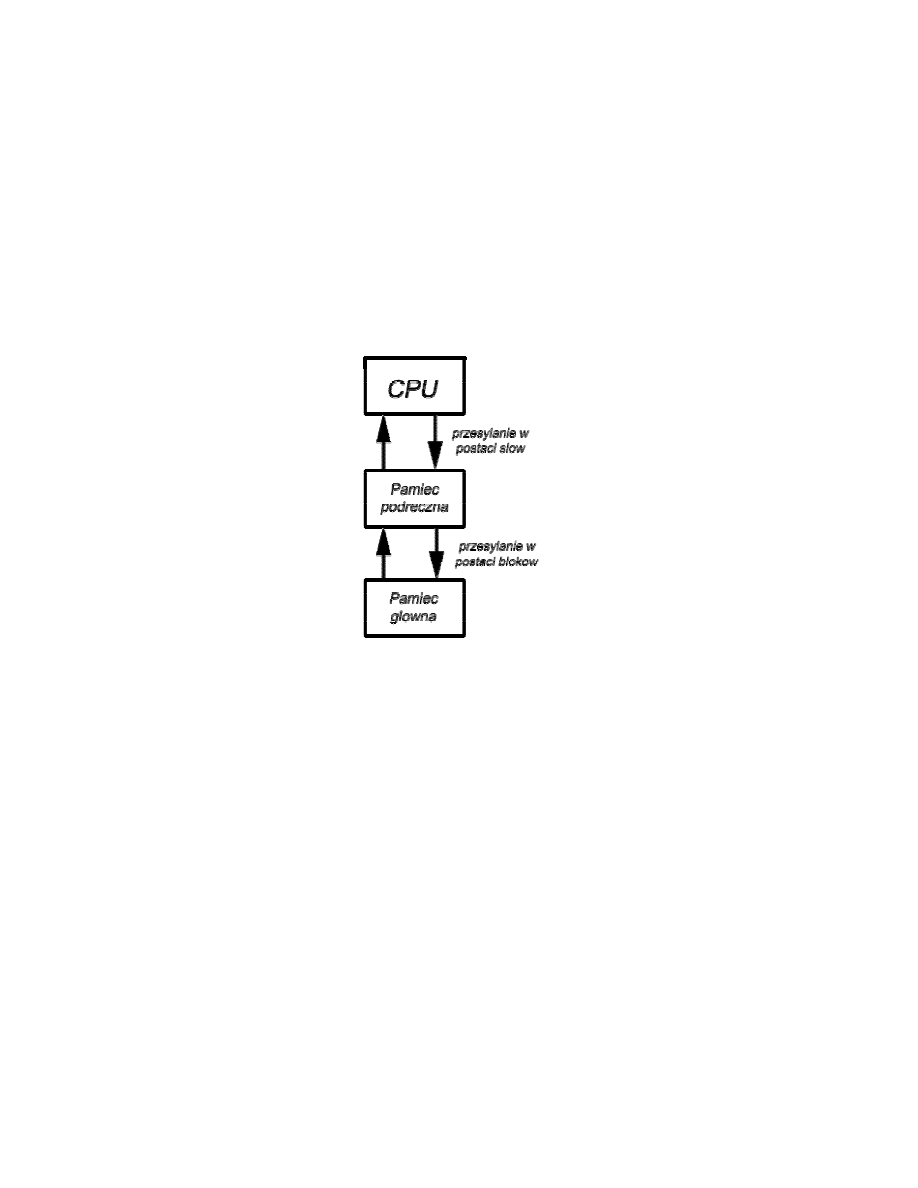
12. Pamięć podręczna
Pamięci podręczne stosuje się w celu uzyskania pamięci o takiej szybkości, jaką maja
najszybsze osiągalne pamięci, z jednoczesnym uzyskaniem dużego rozmiaru pamięci
w cenie tańszych pamięci półprzewodnikowych. Pamięć podręczna zawiera kopię części
zawartości pamięci głównej. Gdy procesor zamierza odczytać słowo w pamięci, najpierw
następuje sprawdzenie, czy słowo to nie znajduje się w pamięci podręcznej. Jeśli tak, to
słowo jest dostarczane do procesora. Jeśli nie to blok pamięci głównej zawierająca
ustaloną liczbę słów jest wczytywany do pamięci podręcznej, a następnie słowo jest
dostarczane do procesora. Ze względu na zjawisko lokalności odniesień, jeśli blok danych
został pobrany do pamięci podręcznej w celu zaspokojenia pojedynczego odniesienia do
pamięci, jest prawdopodobne, że przyszłe odniesienia będą dotyczyły innych słów
zawartych w tym samym bloku.
Obecnie systemy komputerowe, często dysponują wieloma poziomami pamięci
podręcznej. Jako przykład może służyć wewnętrzna i zewnętrzna procesorowa pamięć
podręczna - odpowiednio cache L1 i L2. Przy czym zazwyczaj L1 < L2.
13. Pamięci zewnętrzne
Urządzenia i systemy pamięci zewnętrznej:
!" dysk magnetyczny
!" pamięci RAID
!" pamięć optyczna
!" taśma magnetyczna
!" Dysk magnetyczny
Dysk magnetyczny
Zasada działania: Dysk to okrągła, metalowa lub plastikowa płyta pokryta
materiałem magnetycznym. Dane są zapisywane i odczytywane za pomocą
przewodzącej cewki - głowicy. Nieruchoma głowica umieszczona jest nad
obracającym się dyskiem. Sposób zapisu danych - przez cewkę płynie prąd
wytwarzający pole magnetyczne co powoduje zapis wzorów magnetycznych na
powierzchni dysku różnych dla prądu dodatniego i ujemnego. Sposób odczytu - wzory
magnetyczne na dysku indukują w cewce taki prąd ( o tej samej biegunowości +/-)
jaki zostawiły do zapisu.
Organizacja i formatowanie danych: Dane są zorganizowane na dysku w postaci
ścieżek - koncentrycznych okręgów o szerokości głowicy. ścieżki oddzielone są
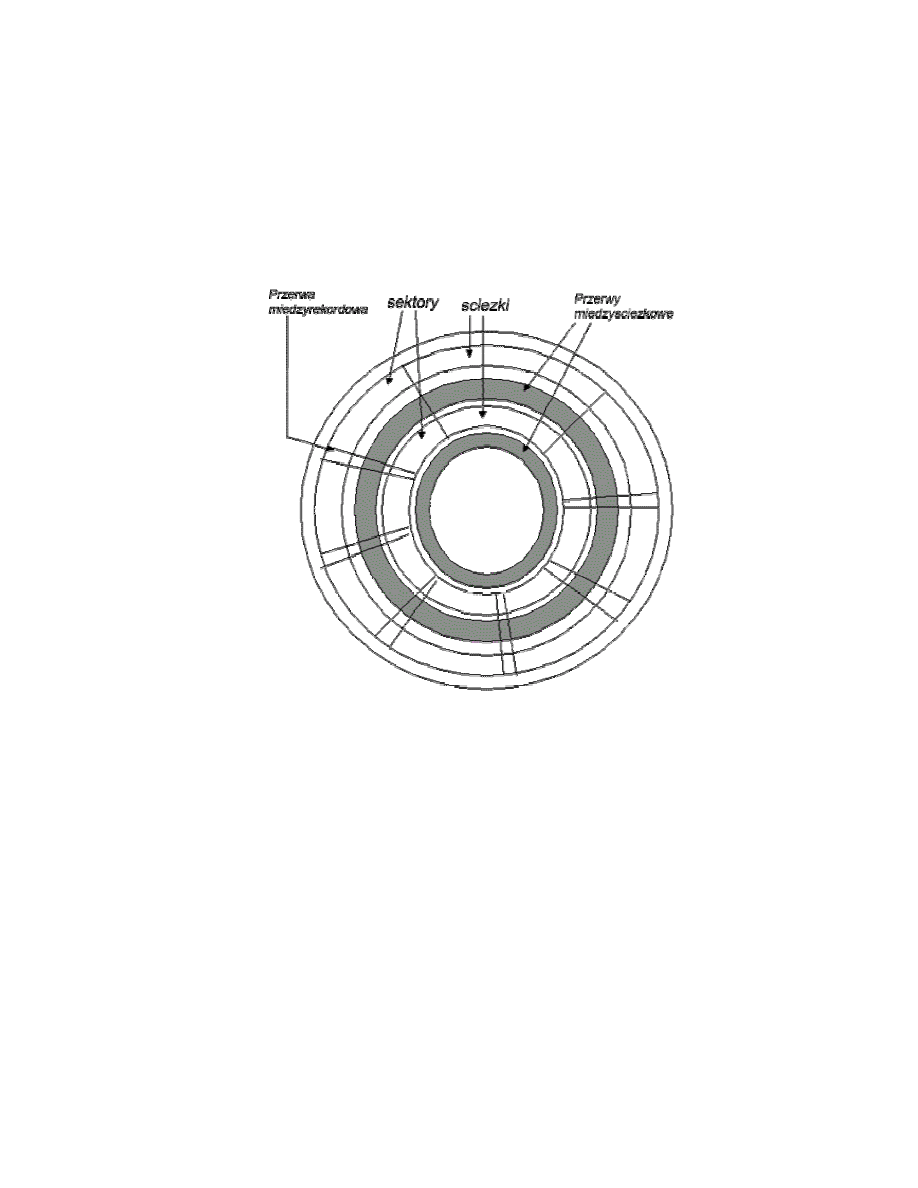
10
przerwami aby uniknąć błędów powstałych przez niewłaściwe ustawienie głowicy lub
interferencje pól magnetycznych. ścieżka dzieli się na sektory, zwykle od 10 do 100.
Na każdej ścieżce przechowuje się taką sama liczbę bitów, więc gęstość danych
(bit/cal) wzrasta od brzegu do środka dysku. Aby rozpoznać gdzie zaczyna i kończy
się ścieżka i poszczególne sektory stosowane są dane kontrolne zapisane na dysku,
wykorzystywane przez napęd, niedostępne dla użytkownika. W każdym sektorze są
bajty przeznaczone na dane i kilka bajtów przeznaczonych na informacje kontrolne
wykorzystywane przez sterownik dysków to znaczy identyfikatory wykorzystywane do
lokalizacji określonego sektora, wyznaczające początek pola, ścieżki itd. Ponadto
w identyfikatorach i polach danych zawarty jest kod służący do wykrywania błędów.
Rozkład danych na dysku.
Rodzaje dysków
podział:
1. ze względu na ruch głowicy
!" głowica nieruchoma (jedna na ścieżkę) wszystkie na sztywnym ramieniu
!" głowica ruchoma (jedna na powierzchnie) ramię można wydłużać i
skracać
2. ze względu na wymienność dysku
!" niewymienny czyli na stale umocowany w napędzie (napęd = ramię +
wałek obracający dysk + układy elektroniczne do wprowadzania i
wyprowadzania danych binarnych)
!" wymienny czyli taki, który można wyjąć i zastąpić innym dyskiem
3. ze względu na wykorzystanie stron
!" jednostronny (warstwa magnetyczna naniesiona po jednej stronie płyty -
rzadko stosowane)
!" dwustronny (warstwę magnetyczną naniesiono po obu stronach płyty -
częściej stosowane)
4. ze względu na liczbę dysków
!" jednodyskowy (gdy w napędzie na raz tylko 1 dysk)

11
!" wielodyskowy (gdy w napędzie wiele płyt ustawionych pionowo
w odległościach ok.2,5 cm) tzw.pakiet dysków
5. ze względu na mechanizm głowicy
!" kontaktowy (głowica ma bezpośredni kontakt z płytą podczas
odczytu/zapisu - mechanizm stosowany przy napędzie dyskietek)
!" ustalona przerwa (głowica umieszczona w ustalonej odległości nad płytą
z pozostawieniem przerwy powietrznej - rozwiązanie tradycyjne)
!" przerwa aerodynamiczna-Winchester (patrz tekst pod spodem).
Zależność miedzy gęstością danych a rozmiarem przerwy powietrznej: im węższa
głowica tym bardziej musi być zbliżona do płyty, żeby wytwarzać lub wykrywać
odpowiednio duże pole elektromagnetyczne. Im węższa głowica tym węższe
ścieżki (bo ścieżki musza mieć szerokość taką jak głowica) a wiec większą gęstość
zapisu. Ale z drugiej strony im mniejsza odległość miedzy głowicą a dyskiem tym
większe prawdopodobieństwo błędów spowodowanych zanieczyszczeniami lub
niedokładnościami. W wyniku ulepszenia technologii wprowadzono dysk typu
Winchester. Głowicę dysku W. pracują w zamkniętych zespołach napędowych,
które są niemal wolne od zanieczyszczeń. Zostały zaprojektowane do działania
w mniejszej odległości od powierzchni dysków niż konwencjonalne głowice, co
umożliwiło większą gęstość upakowania danych. Głowica ta to aerodynamiczny
pasek folii, spoczywający lekko na powierzchni płyty w czasie, gdy dysk jest
nieruchomy. Ciśnienie powietrza wytwarzane przez wirujący dysk unosi folie nad
powierzchnia. Dzięki temu można wykorzystać węższe głowice, które pracują
bliżej powierzchni płyty niż konwencjonalne sztywne głowice dysków.
Czas dostępu do dysków
Aby odczytać lub zapisać dane na dysku głowica musi się ustawić na początku
odpowiedniej ścieżki i sektora. Ustawianie na odpowiednia ścieżkę to w przypadku
głowicy ruchomej fizyczne przesuniecie ramienia (czas potrzebny na to, to czas
przeszukiwania, ang. seek time). W przypadku nieruchomej, elektroniczny wybór
jednej z głowic. Potem głowica musi się znaleźć nad odpowiednim sektorem, więc
musi czekać, aż ten sektor się pod nią znajdzie. Czas jaki się na to zużywa to
opóźnienie obrotowe (ang. rotational latency). Suma czasu przeszukiwania (jeśli
występuje) i opóźnienia obrotowego to czas dostępu.
Pamieć RAID
RAID – (ang. Redundant Array of Independent Disks) wynaleziono w celu
zamknięcia poszerzającej się luki miedzy szybkimi procesorami a stosunkowo
wolnymi elektromechanicznymi napędami dysków.
14. Urządzenia wejścia-wyjścia
Urządzenia, których zadaniem jest komunikacja komputera z otoczeniem (zwykle
bezpośrednio z użytkownikiem). Do najczęściej spotykanych urządzeń wejścia
należą klawiatura, mysz czy skaner, zaś urządzenia wyjścia to np. drukarka lub
monitor. Urządzenie zewnętrzne współpracuje z komputerem poprzez łącze
z modułem wejścia-wyjścia. Łącze jest używane do wymiany sygnałów sterowania
i stanu oraz danych między modułem wejścia-wyjścia a urządzeniem
zewnętrznym. Urządzenie zewnętrzne połączone z modułem wejścia-wyjścia jest
często określane jako peryferyjne. Możemy sklasyfikować urządzenia zewnętrzne
na trzy kategorie:
!" Przeznaczone do odczytywania przez człowieka. Odpowiednie do
komunikowania się z użytkownikiem komputera.
!" Przeznaczone do odczytywania przez maszynę. Odpowiednie do
komunikowania się ze sprzętem.
!" Komunikacyjne. Odpowiednie do komunikowania się z odległymi urządzeniami.

12
Przykładami urządzeń przeznaczonych dla człowieka są terminale wizyjne i drukarki
a dla maszyny są dyski magnetyczne, systemy taśmowe oraz czujniki i urządzenia
wykonywania wykonawcze wykorzystywane w robotach. Najbardziej powszechnym
środkiem współpracy między komputerem a użytkownikiem jest zespół
klawiatura/monitor. Użytkownik wprowadza dane za pomocą klawiatury. Dane
wyjściowe są następnie transmitowane do komputera i mogą być również
zobrazowane na monitorze. Monitor pokazuje również dane dostarczone przez
komputer. W przypadku wejścia z klawiatury naciśnięcie klawisza przez użytkownika
powoduje wygenerowanie sygnału elektrycznego, który jest interpretowany przez
przetwornik w klawiaturze i tłumaczony na wzór bitowy odpowiedniego kodu ASCII.
Wzór bitowy jest następnie transmitowany do modułu wejścia-wyjścia w komputerze.
W przypadku wejścia, kody ASCII znaków są transmitowane z modułu wejścia-wyjścia
do urządzenia zewnętrznego. Przetwornik w tym urządzeniu interpretuje kod i wysyła
niezbędne sygnały elektryczne do urządzenia wyjściowego w celu albo wyświetlenia
wskazanego znaku albo wykonania wymaganej funkcji sterującej.
15. System operacyjny
System operacyjny jest programem, który steruje wykonywaniem programów
użytkowych i działa jako interfejs między użytkownikiem, a sprzętem komputerowym.
Można uważać, że system operacyjny ma dwa cele lub realizuje dwie funkcje:
!" Wygoda. System operacyjny czyni system komputerowy wygodniejszym
w użytku.
!" Sprawność. System operacyjny umożliwia sprawne eksploatowanie zasobów
systemu komputerowego.
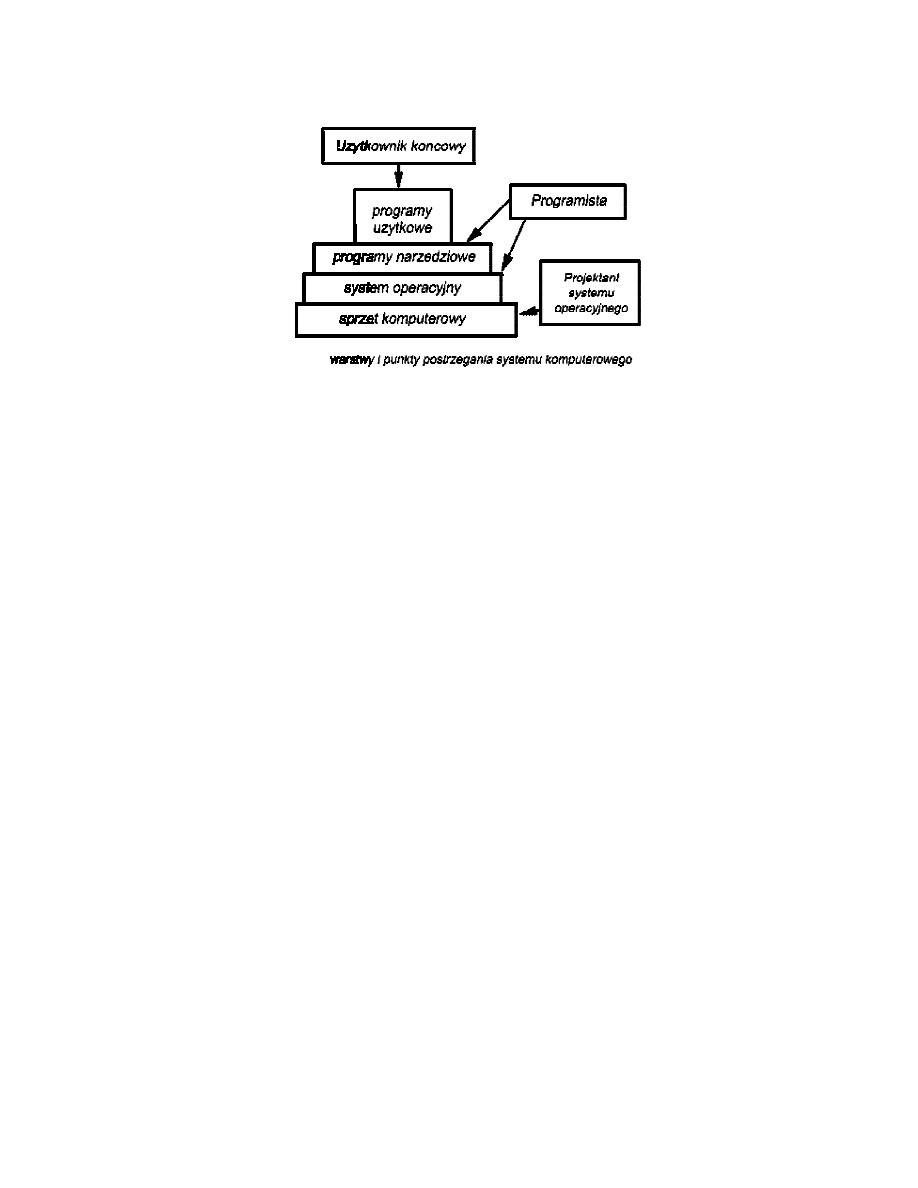
System operacyjny jako interfejs użytkownik – komputer
W większości przypadków ostatecznym przeznaczeniem komputerów jest
wykonywanie jednego lub wielu programów użytkowych (aplikacji). Użytkownik tych
aplikacji jest nazywany użytkownikiem końcowym i na ogół nie interesuje go
architektura komputerów. Użytkownik końcowy patrzy na system komputerowy
poprzez swój program użytkowy. Program ten może być wyrażony w języku
programowania i jest przygotowywany przez programistę tworzącego
oprogramowanie użytkowe. Nie robi on tego przy pomocy rozkazów maszynowych,
w pełni odpowiedzialnych za sterowanie sprzętem komputerowym, tylko przy pomocy
programów systemowych. Niektóre spośród nich - programy narzędziowe umożliwiają
realizowanie często używanych funkcji, które wspomagają tworzenie programów,
zarządzanie plikami oraz sterowanie urządzeniami wejścia - wyjścia. Programista
wykorzystuje te ułatwienia, przygotowując program użytkowy, a program ten podczas
pracy uruchamia programy narzędziowe w celu wykonania pewnych funkcji.
Najważniejszym programem systemowym jest system operacyjny. Maskuje on przed
programistą szczegóły sprzętowe i dostarcza mu wygodnego interfejsu z systemem
komputerowym.
13
Mówiąc w skrócie, system operacyjny zapewnia zwykle usługi należące do
następujących obszarów:
!" Tworzenie programów. System operacyjny dostarcza wielu ułatwień i usług
wspomagających programistę przy tworzeniu programów. Są to tzw. programy
narzędziowe (ang. utilites).
!" Wykonywanie programów. Aby program był wykonany musi być
zrealizowanych wiele zadań. Rozkazy i dane muszą być załadowane do pamięci
głównej; urządzenia we-wy i pliki muszą być zainicjowane, potrzebne jest tez
przygotowanie pozostałych zasobów. Tym wszystkim zajmuje się system
operacyjny.
!" Dostęp do urządzeń wejścia-wyjścia. Każde urządzenie we-wy do działania
wymaga własnego, specyficznego zestawu rozkazów lub sygnałów sterowania.
System operacyjny zajmuje się tymi szczegółami, dzięki czemu programista
może myśleć w kategoriach prostych odczytów i zapisów.
!" Kontrolowany dostęp do plików. W przypadku plików musi być
dostosowane nie tylko do natury urządzeń wejścia-wyjścia (napędów
dyskowych, napędów taśmowych itp.), lecz także do formatów plików na
nośniku przechowującym. I znów, o szczegóły troszczy się system operacyjny.
Ponadto, w przypadku systemów z wieloma jednoczesnymi użytkownikami,
system operacyjny może zapewnić mechanizmy kontrolujące dostęp do
wspólnych zasobów, takich jak pliki.
!" Dostęp do systemu. W przypadku systemów wspólnych lub publicznych
system operacyjny kontroluje dostęp do systemu jako całości oraz do
określonych zasobów systemu.
System operacyjny jako program zarządzający zasobami
System operacyjny w pewnym sensie steruje przenoszeniem, przechowywaniem
i przetwarzaniem danych. Mechanizm sterowania nie jest tu jednak czymś
zewnętrznym w stosunku do sterowanego obiektu. System operacyjny funkcjonuje
w taki sam sposób jak zwykłe oprogramowanie komputera i tam jest on programem
wykonywanym przez procesor. System operacyjny często wyrzeka się sterowania
i musi polegać na procesorze aby odzyskać sterowanie - system operacyjny kieruje
procesorem w zakresie używania pozostałych zasobów systemu oraz
synchronizowaniem wykonywania przez procesor innych programów. Żeby to zrobić,
musi jednak zaprzestać realizowania programu systemu operacyjnego i zacząć
wykonywać inne programy. W systemie operacyjnym wykorzystuje się więc
sterowania procesorem, umożliwiając mu wykonanie użytecznej pracy, po czym
wznawia sterowanie z wyprzedzeniem wystarczającym do przygotowania następnej
pracy.
14
Rodzaje systemów operacyjnych
Podział pierwszy:
!" Wsadowy - programy wielu użytkowników są łączone, powstaje wsad, który
jest uruchamiany przez operatory. Po zakończeniu wyniki są drukowane
i przekazywane użytkownikom. W dzisiejszych czasach - bardzo rzadkie czyste
systemy wsadowe.
!" Konwersacyjny – (ang. interactive), ma miejsce konwersacja między
użytkownikiem (programistą), a komputerem, zwykle za pośrednictwem
terminala klawiatura/monitor mająca na celu zgłaszanie zapotrzebowania na
wykonanie określonej pracy lub przeprowadzenie transakcji. Ponadto
użytkownik może komunikować się z komputerem podczas wykonywania.
Podział drugi:
!" Wieloprogramowy (wielozadaniowy) - czynione są starania o maksymalne
możliwe obciążenie procesora praca, poprzez jednoczesne wykonywanie więcej
niż jednego programu. Do pamięci ładuje się kilka programów, a procesor
"przeskakuje" szybko między nimi.
!" jednoprogramowy (jednozadaniowy) - w określonym czasie wykonuje
tylko jeden program.
wsadowy konwersacyjny
jednozadaniowy
pojedynczy wsad
system wyspecjalizowany
wielozadaniowy
złożony wsad
z podziałem czasu
Szeregowanie czasowe
Głównym celem nowoczesnych systemów operacyjnych jest wieloprogramowanie
(wielozadaniowość). W przypadku wieloprogramowania wiele zadań lub programów
użytkowych pozostawia się w pamięci. Każde zadanie jest przełączane między
używaniem centralnego procesora, a oczekiwaniem na realizacje operacji wejścia-
wyjścia. Procesor pozostaje zajęty, wykonując jedno z zadań, podczas gdy inne
oczekują. Kluczem do wieloprogramowania jest szeregowanie. Stosowane są zwykle 3
rodzaje szeregowania:
Szeregowanie
wysokiego poziomu
Decyzja dotycząca dodania do puli programów
przeznaczonych do wykonania
Szeregowanie
krótkookresowe
Wybór tego spośród dostępnych procesów, który będzie
wykonywany przez procesor
Szeregowanie operacji
wejścia-wyjścia
Wybór tego spośród zawieszonych żądań we-wy, które
ma być realizowane przez dostępne urządzenie wejścia-
wyjścia
Szeregowanie wysokiego poziomu - działa rzadko i podejmuje ogólne decyzje.
Program szeregujący wysokiego poziomu określa, które programy są dopuszczone do
przetwarzania przez system. Po dopuszczeniu program lub zadanie jest ustawiane
w kolejce zarządzającej przez krótkookresowy program szeregujący. Im więcej
procesów tym mniej czasu na realizację każdego z nich, więc niektóre nie są
dopuszczone przez długookresowy program szeregujący - ograniczenie stopnia
wieloprogramowości. W przypadku systemu wsadowego nowe zadania są kierowane
na dysk i trzymane w kolejce. Zwykle po zakończeniu każdego procesu program
szeregujący decyduje czy można przyjąć następne oraz które z zadań mają być
w ogóle zaakceptowane i zamienione na procesy. Stosowane kryteria: priorytet, czas
realizacji, wymagania co do we-wy. W przypadku podziału czasu zapotrzebowanie na
proces jest generowane przez użytkownika, który chce się dołączyć do systemu.
System operacyjny akceptuje wszystkich użytkowników aż do nasycenia systemu
a reszcie każe poczekać i spróbować później.
15
Szeregowanie krótkookresowe - program szeregujący (inaczej dyspozytor)
podejmuje bardziej szczegółowe decyzje, które zadanie ma być realizowane jako
następne.
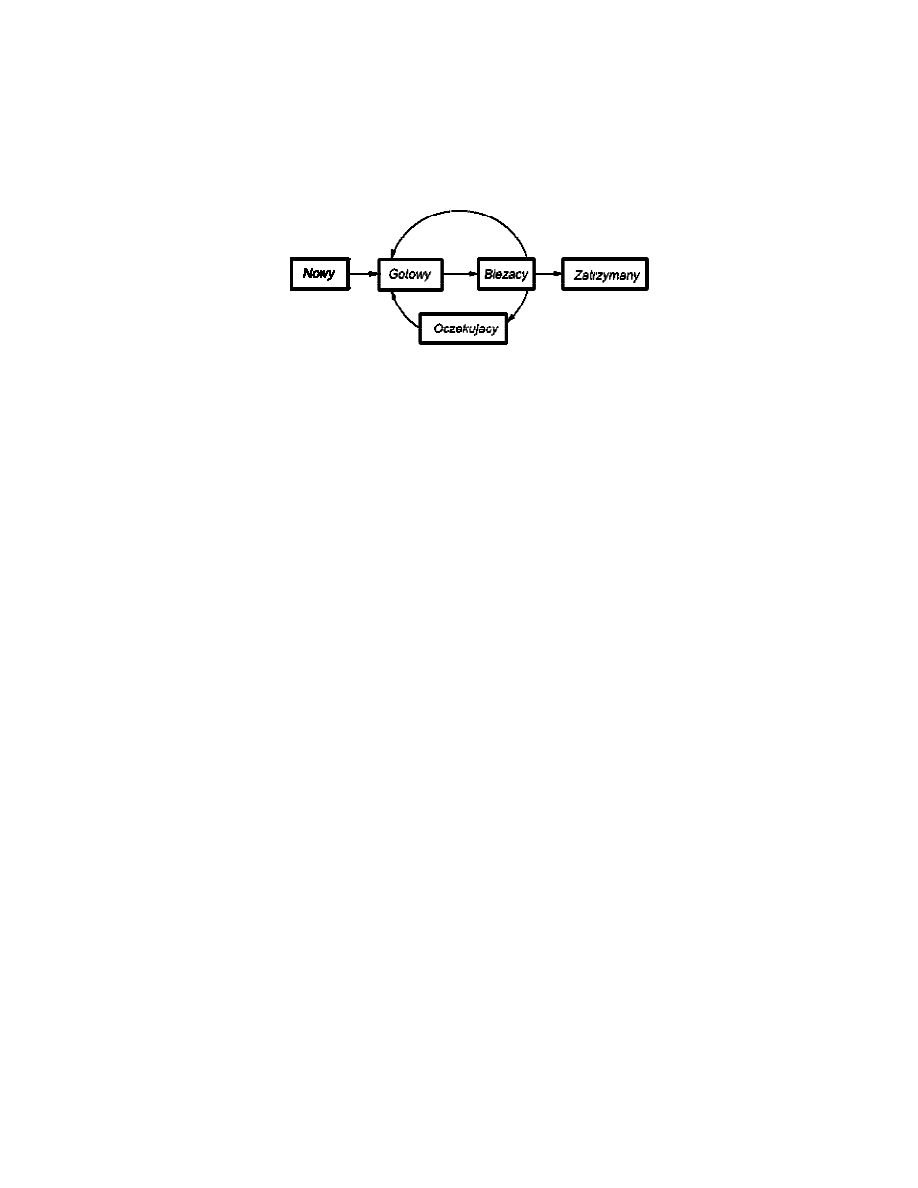
Stany procesu:
!" Nowy - program jest przyjęty przez program szeregowania wysokiego
poziomu ale nie gotowy do realizacji. System operacyjny inicjuje proces,
przesuwając go w ten sposób do stanu gotowości.
!" Gotowy - proces jest gotowy do wykonania i czeka na dostęp do procesora.
!" Bieżący - proces jest realizowany przez procesor.
!" Oczekujący - realizacja procesu jest zawieszona podczas oczekiwania na
pewne zasoby systemu np. wejścia-wyjścia.
!" Zatrzymany - proces został zakończony i zostanie zniszczony przez system
operacyjny.
Blok kontrolny procesu
Blok kontrolny procesu jest to informacja o statusie procesu i inne cechy istotne do
jego realizacji. Podane są tu dane:
Identyfikator, Stan (gotowy, nowy itd.), Priorytet, Licznik programu (adres
następnego rozkazu), Znaczniki pamięci (początek i koniec zajmowanej pamięci),
Dane dotyczące kontekstu, Informacja o stanie we-wy, Informacja ewidencyjna
(wymagany czas procesora, zegara, ograniczenie czasowe, liczby ewidencyjne itd.)
Przykład szeregowania
Mamy dwa aktywne procesy A i B. Procesor wykonuje rozkazy z pamięci przydzielonej
do A. W pewnym momencie przerywa (możliwe różne powody np. przerwanie
spowodowane procesem A lub innym zdarzeniem, wywołanie obsługi przez A np.
żądanie wejścia-wyjścia), zapisuje bieżące dane kontekstowe i licznik A w bloku
kontrolnym A, po czym przystępuje do działania w systemie operacyjnym. System
operacyjny wykonuje pewną prace np. zainicjowanie operacji wejścia-wyjścia. Potem
należący do systemu operacyjnego program szeregowania krótkookresowego
decyduje, który proces powinien być realizowany następny. Załóżmy, że wybiera B.
System operacyjny poleca procesorowi odnowienie danych kontekstu B i przystępuje
do realizowania B w punkcie, w którym został pozostawiony.
Kolejka - lista procesów czekających na pewne zasoby, przekazana do systemu
operacyjnego.
!" Kolejka długookresowa - lista zadań czekających na użycie systemu. Gdy
warunki pozwolą, program szeregowania wysokiego poziomu dokona alokacji
pamięci i utworzy proces z jednej z czekających jednostek.
!" Kolejka krótkookresowa - składa się ze wszystkich procesów będących
w stanie gotowości. Któryś z nich wybiera krótkookresowy program
szeregowania na podstawie algorytmu cyklicznego (każdy po kolei) lub
poziomu priorytetu.
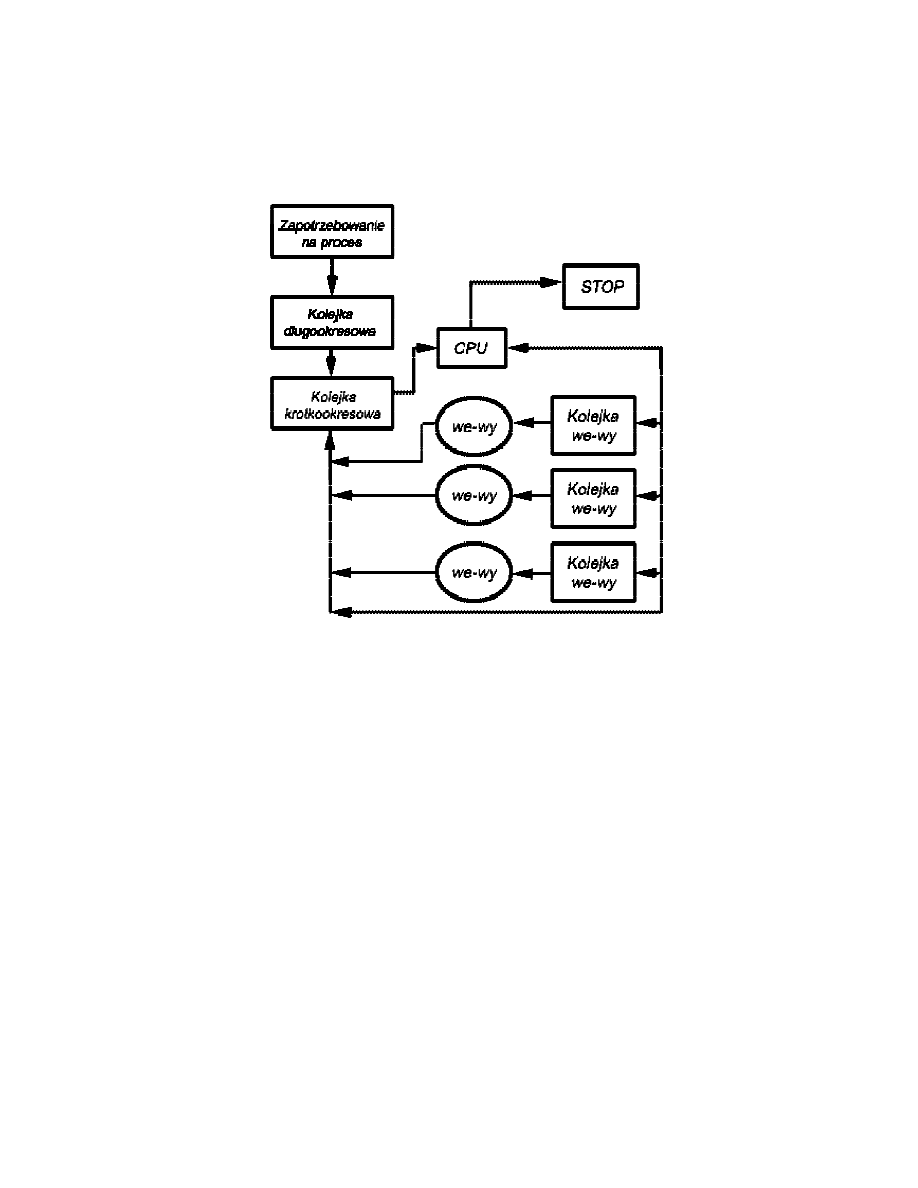
16
!" Kolejka wejścia-wyjścia - związana z każdym urządzeniem we-wy. Wiele
procesów może domagać użycia tego samego urządzenia - ustawia się
w kolejce.
Diagram kolejek związanych z szeregowaniem pracy procesora:
16. Pamięć wirtualna
Przestrzeń pamięci, która może być traktowana przez użytkownika systemu
komputerowego jako adresowalna pamięć główna i w której adresy wirtualne są
adresowane w zbiorze adresów rzeczywistych. Rozmiar pamięci wirtualnej jest
ograniczony przez schemat adresowania systemu komputerowego oraz przez wielkość
dostępnej pamięci pomocniczej nie zaś przez rzeczywistą liczbę lokacji w pamięci
głównej. Rozważmy duży proces składający się z długiego programu oraz z pewnej
liczby zespołów danych. Przez pewien czas wykonywanie programu może być
ograniczone do malej jego części (np. do podprogramu standardowego) i mogą być
używane jeden lub dwa zespoły danych. Byłoby oczywiście rozrzutnością ładowanie
wielu stron procesu, gdy tylko kilka stron będzie używane przed zawieszeniem
programu. Lepiej wykorzystamy pamięć ładując tylko kilka stron. Następnie, jeśli
program rozgałęzi się do rozkazu znajdującego się na stronie poza pamięcią lub, gdy
program odwoła się do danych znajdujących się na stronie poza pamięcią, zostanie
zasygnalizowany błąd strony. Skłoni to system operacyjny do dostarczenia żądanych
stron. Tak więc, w określonym momencie tylko kilka stron danego procesu znajduje
się w pamięci i dzięki temu więcej procesów może pozostawać w pamięci. System
operacyjny musi potrafić zarządzić tym schematem. Gdy wprowadza jedna stronę,
musi wyrzucić inną. Jeśli wyrzuci stronę, która wkrótce ma być użyta musi ją prawie
natychmiast wprowadzić ponownie. W istocie system operacyjny próbuje zgadnąć na
podstawie najnowszej historii, które strony najprawdopodobniej będą użyte w bliskiej
przyszłości. Ponieważ proces jest realizowany tylko w pamięci głównej, pamięć ta jest
określona jako pamięć rzeczywista. Jednak programista lub użytkownik dysponuje
o wiele większa pamięcią – ta, która znajduje się na dysku zwana pamięcią

17
wirtualną. Umożliwia ona bardzo efektywne wieloprogramowanie i uwalnia
użytkownika od niepotrzebnie ciasnych ograniczeń pamięci głównej.
Pamięć wirtualna może przekraczać rozmiary fizycznej pamięci operacyjnej, gdyż jest
implementowana z użyciem pamięci zewnętrznej (dyskowej) z zastosowaniem
sprzętowego stronicowania i algorytmów stronicowania na zadanie, zastępowania
stron i stronicowania wstępnego. Czas działania programów wykonywanych
w systemie pamięci wirtualnej może zależeć od programowego sposobu organizacji
danych oraz zmieniać się od wykonania do wykonania, toteż pamięć wirtualną nie
stosuje się w systemach czasu rzeczywistego. Poza tym wyjątkiem pamięć wirtualna
jest wielkim udogodnieniem programowania, gdyż zdejmuje z osób programujących
ostre ograniczenia na ilość dostępnej pamięci i uwalnia je od niejednolitego
zarządzania pamięciami fizycznymi w aplikacjach.
17. Formaty reprezentacji liczb i arytmetyki komputerów
Jednostka arytmetyczno logiczna (ALU) jest tą częścią komputera, która realizuje
operacje arytmetyczne i logiczne na danych. Wszystkie inne elementy sytemu
komputerowego – jednostka sterująca, rejestry, pamięć, urządzenia wejścia-wyjścia –
istnieją głownie po to, żeby dostarczać dane do ALU w celu przetworzenia,
a następnie odebrać wynik. Dane są przedstawiane ALU w rejestrach i wyniki operacji
są przechowywane też w rejestrach. Rejestry są miejscami tymczasowego
przechowania danych wewnątrz procesora i są połączone ścieżkami sygnałów z ALU.
ALU wstawia również znacznik (flagi) będące wynikiem operacji.
Reprezentacja liczb całkowitych
Jeśli n–bitowy ciąg cyfr binarnych a
n-1
, a
n-2
,…, a
1
, a
0
jest interpretowany jako
pozbawiona znaków liczba całkowita A to jej wartość oblicza się ze wzoru:
∑
−
=
=
1
0
2
n
i
i
i
a
A
Używanie liczb całkowitych bez znaku jest niewystarczające w wielu przypadkach. Np.
wtedy, kiedy wymagane jest reprezentowanie również liczb ujemnych. Istnieje kilka
wersji, które można zastosować. Wszystkie z nich polegają na traktowaniu najbardziej
znaczącego (położonego po lewej stronie) bitu słowa jako znaku, jeśli „0” to liczba
dodatnia, jeśli „1” to liczba ujemna. Najprostszą formą reprezentacji jest znak-moduł.
Reprezentacja uzupełnienia do dwóch została opracowana dla wyeliminowania dwóch
głównych niedogodności reprezentacji znak-moduł nieefektywnego dodawania
i odejmowania oraz dwóch reprezentacji zera.
Konwersja między różnymi długościami bitowymi
Jest czasem pożądane przechowanie liczby n-bitowej w postaci m bitów, gdzie m > n.
W przypadku notacji znak-moduł można tego dokonać z łatwością: po prostu trzeba
przesunąć bit znaku do najdalszej lewej pozycji oraz wypełnić pozostałe wolne
pozycje zerami. Procedura taka nie działa w przypadku całkowitych liczb ujemnych
w reprezentacji uzupełnienia do dwóch. Tu stosuje się następującą regułę:
Wykonuje się przesunięcie bitu znaku do najdalszej lewej pozycji, poczym wypełnia
się powstałe puste pozycje kopiami bitu znaku. W przypadku liczb dodatnich wypełnia
się zerami, w przypadku ujemnych - jedynkami.
Reprezentacja stałopozycyjna
Zwróćmy uwagę na to, że reprezentacje analizowane w tym punkcie są
czasem określane jako stałopozycyjne. Jest tak, ponieważ położenie przecinka
pozycyjnego (przecinka binarnego) jest ustalone i zakładamy, że znajduje się on
na prawo od cyfry położonej najdalej na prawo. Programista może używać tej
samej reprezentacji dla ułamków binarnych, posługując się skalowaniem liczb tak,
że przecinek binarny przez implikację znajduje się w pewnym innym położeniu.

18
ARYTMETYKA LICZB CAŁKOWITYCH
Negowanie
W przypadku reprezentacji znak-moduł reguła negowania liczby całkowitej
jest prosta: odwrócić bit znaku. W notacji uzupełnienia do dwóch negowanie
liczby całkowitej może być dokonywane za pomocą następujących reguł:
1. Weź uzupełnienie Boole'a każdego bitu liczby całkowitej (łącznie
z bitem znaku).
2. Traktując wynik jako liczbę całkowitą pozbawioną znaku, dodaj 1.
Reguła przepełnienia - Jeśli są dodawane dwie liczby dodatnie lub dwie ujemne, to
przepełnienie następuje wtedy i tylko wtedy, gdy wynik ma znak przeciwny.
Reguła odejmowania - W celu odjęcia od jednej liczby (odjemnej) drugiej liczby
(odjemnika) weź uzupełnienie do dwóch odjemnika i dodaje do odjemnej.
Mnożenie
1. Mnożenie obejmuje tworzenie iloczynów cząstkowych, po jednym dla każdej
cyfry mnożnika. Iloczyny cząstkowe są następnie sumowane
w celu otrzymania iloczynu końcowego.
2. Iloczyny cząstkowe są łatwe do określenia. Gdy bit mnożnika jest równy
0, iloczyn cząstkowy jest równy 0. Gdy bit mnożnika jest równy 1,
iloczyn cząstkowy jest równy mnożnej.
3. Iloczyn końcowy jest otrzymywany przez sumowanie iloczynów cząstkowych.
W przypadku tej operacji każdy kolejny iloczyn cząstkowy jest przesuwany
o jedną pozycję w lewo względem poprzedniego iloczynu cząstkowego.
4. Wynikiem mnożenia dwóch n-bitowych binarnych liczb całkowitych jest liczba
o długości do 2n bitów.
Dzielenie
Po pierwsze, bity dzielnej są badane od lewej do prawej, aż zespół zbadanych bitów
będzie reprezentował liczbę większą lub równą dzielnikowi; jest to określane jako
sprawdzanie, czy dzielnik może podzielić liczbę. Aż do wystąpienia tego zdarzenia
w ilorazie są umieszczane zera od lewej do prawej. Gdy wystąpi już to zdarzenie,
w ilorazie umieszczana jest 1, a dzielnik jest odejmowany od dzielnej cząstkowej.
Wynik jest określany jako reszta cząstkowa. Począwszy od tego punktu, dzielenie
powtarza się cyklicznie. W każdym cyklu dodatkowe bity dzielnej są dołączane do
reszty cząstkowej, aż wynik będzie większy lub równy dzielnikowi. Jak poprzednio,
dzielnik jest odejmowany od tej liczby, przez co powstaje nowa reszta cząstkowa.
Proces jest kontynuowany, aż wszystkie bity dzielnej zostaną zużyte.
REPREZENTACJA ZMIENNOPOZYCYJNA
Zasady
W przypadku notacji stałopozycyjnej (np. uzupełnienia do dwóch) możliwe
jest reprezentowanie zakresu dodatnich i ujemnych liczb całkowitych ze środkiem
w zerze. Przy założeniu ustalonego przecinka pozycyjnego format ten
umożliwia również reprezentację liczb ze składnikiem ułamkowym. Podejście to ma
ograniczenia. Nie mogą być reprezentowane ani bardzo duże liczby, ani bardzo małe
ułamki. Ponadto, ułamkowe składniki ilorazu przy Dzieleniu dwóch dużych liczb mogą
być utracone. W przypadku liczb dziesiętnych obchodzi się to ograniczenie stosując
notację naukową. Wtedy 976 000 000 000 000 może być reprezentowana jako 9,76 x
10
14
, a 0,0000000000000976 jako 9,76 x 10
-14
. To, co zrobiliśmy, jest w rezultacie
dynamicznym przesunięciem przecinka dziesiętnego do wygodnego
położenia
i użyciem potęgi 10 do określania rzeczywistego położenia tego przecinka. Umożliwia
to reprezentowanie bardzo dużych i bardzo małych liczb za pomocą tylko kilku cyfr.

19
ARYTMETYKA ZMIENNOPOZYCYJNA
W przypadku dodawania i odejmowania konieczne jest zapewnienie, żeby oba
argumenty miały taki sam wykładnik. Może to wymagać przesunięcia przecinka
pozycyjnego w jednym z argumentów. Mnożenie i dzielenie są pod tym względem
prostsze. Problemy mogą się pojawić jako wynik tych operacji. Należą do nich:
!" Przepełnienie wykładnika. Dodatni wykładnik przekracza
maksymalną dopuszczalną wartość. W pewnych systemach może to być
oznaczane jako +∞ lub -∞.
!" Niedomiar wykładnika. Ujemny wykładnik przekracza maksymalną
dopuszczalną wartość. Oznacza to, że liczba jest zbyt mała, aby mogła być
reprezentowana. Może być traktowana jako 0.
!" Niedomiar mantysy. W procesie wyrównywania mantys cyfry mogą
„wypłynąć" poza prawy koniec mantysy. Wymagana jest pewna
forma zaokrąglenia.
!" Przepełnienie mantysy. Wynikiem dodawania mantys o takim samym znaku
może być wyprowadzenie najbardziej znaczącego bitu. Można to naprawić
przez powtórne wyrównywanie.
Dodawanie i odejmowanie
W arytmetyce zmiennopozycyjnej dodawanie i odejmowanie są bardziej złożone niż
mnożenie i dzielenie. Jest tak z powodu konieczności wyrównywania. Są cztery
podstawowe etapy algorytmu dodawania i odejmowania:
1. Sprawdzenie zer
2. Wyrównanie mantys
3. Dodanie lub odjęcie mantys
4. Normalizowanie wyniku
Mnożenie
Najpierw, jeśli którykolwiek z argumentów jest równy 0, to 0 jest zgłaszane jako
wynik. Następnym krokiem
jest dodanie wykładników. Jeśli wykładniki są
przechowywane w postaci przesuniętej, to suma wykładników spowodowałaby
podwojenie przesunięcia. Wobec tego wartość przesunięcia musi być odjęta od
sumy. Wynikiem może być przepełnienie lub niedomiar wykładnika, co powinno być
zgłoszone i co stanowi kończenie algorytmu.
Jeśli wykładnik iloczynu jest we właściwym zakresie, to następnym krokiem jest
mnożenie mantys z uwzględnieniem ich znaków. Mnożenie jest realizowane w ten
sam sposób, jak w przypadku liczb całkowitych. Mamy tu do czynienia z reprezentacją
znak-moduł, jednak szczegóły są podobne do mnożenia liczb wyrażonych w notacji
uzupełnienia do dwóch. Iloczyn ma długość dwukrotnie większą od długości mnożnej
i mnożnika. Dodatkowe bity będą utracone podczas zaokrąglania.
Po obliczeniu iloczynu wynik jest normalizowany i zaokrąglany, podobnie jak przy
dodawaniu i odejmowaniu. Zauważmy, że normalizacja może spowodować niedobór
wykładnika.
Dzielenie
Znów pierwszym krokiem jest sprawdzanie zer. Jeśli dzielnik jest równy 0, to jest
zgłaszany błąd lub wynik jest ustalany jako nieskończoność, zależnie od
implementacji. Dzielna równa 0 daje wynik 0. Następnie wykładnik
dzielnika jest odejmowany od wykładnika dzielnej. Powoduje to usunięcie
przesunięcia, które wobec tego musi być dodane. Wykonywane są testy w celu
wykrycia przepełnienia lub niedomiaru wykładnika.
Następnym krokiem jest dzielenie mantys. Po tym następuje zwykła normalizacja
i zaokrąglanie.

20
ANALIZA DOKŁADNOŚCI
Zaokrąglanie
!" Zaokrąglanie do najbliższej. Wynik jest zaokrąglany do najbliższej
reprezentowalnej liczby.
!" Zaokrąglanie w kierunku +∞. Wynik jest zaokrąglany w górę,
w kierunku plus nieskończoności.
!" Zaokrąglanie w kierunku -∞. Wynik jest zaokrąglany w dół,
w kierunku minus nieskończoności.
!" Zaokrąglanie w kierunku 0. Wynik jest zaokrąglany w kierunku zera.
18. Listy rozkazów: własności
Każdy rozkaz musi zawierać informacje wymagane przez procesor do jego wykonania.
Przez implikacje etapy te definiują elementy rozkazu maszynowego. Elementami tymi
są:
!" Kod operacji. Określa operację jaka ma być przeprowadzona (np. ADD).
Operacja jest precyzowana za pomocą kodu binarnego.
!" Odniesienie do argumentów źródłowych. Operacja może obejmować
jeden lub wiele argumentów źródłowych. Są one danymi wejściowymi operacji.
!" Odniesienie do wyniku. Operacja może prowadzić do powstania wyniku.
!" Odniesienie do następnego rozkazu. Mówi ono procesorowi skąd ma on
pobrać następny rozkaz po zakończeniu wykonywania bieżącego rozkazu.
Argumenty źródłowe i wyniki mogą się znajdować w jednym z trzech obszarów:
!" Pamięć główna lub wirtualna. Podobnie jak w przypadku odniesienia do
następnego rozkazu musi być dostarczony adres pamięci.
!" Rejestr procesora. Jeśli więcej niż jeden każdy musi być ponumerowany.
!" Urządzenia wejścia-wyjścia. Rozkaz musi określać moduł wejścia-wyjścia
oraz urządzenia wejścia-wyjścia używane w operacji. Jeśli używane jest
wejście-wyjście adresowane w pamięci jest to jeszcze jeden adres pamięci
głównej lub wirtualnej.
Reprezentacja rozkazu. Rozkaz jest dzielony na pole odpowiadające elementom
składowym rozkazu. Ten obraz nazywany jest formatem rozkazu. Powszechną
praktyka stało się używanie symbolicznej reprezentacji rozkazów maszynowych. Kody
operacji są zapisywane za pomocą skrótów zwanych mnemonikami. Do powszechnie
znanych należą:
!" ADD – dodaj
!" SUB – odejmij
!" MPY – pomnóż
!" LOAD – ładuj dane do pamięci
!" STOR – zapisz dane w pamięci
Komputer powinien dysponować listą rozkazów, które umożliwiają użytkownikowi
formułowanie dowolnych zadań dotyczących przetwarzania danych. Innym sposobem
widzenia tego problemu jest rozważenie możliwości języka wysokiego poziomu.
Dowolny program napisany w języku wysokiego poziomu musi być przetłumaczony na
język maszynowy, aby mógł być wykonany. Wobec tego lista rozkazów maszynowych
musi być wystarczająca do wyrażenia
dowolnych instrukcji języka wysokiego
poziomu. Mając to na uwadze, możemy podzielić rozkazy na następujące rodzaje:
!" Przetwarzanie danych. Rozkazy arytmetyczne i logiczne.
!" Przechowywanie danych. Rozkazy pamięciowe.
!" Ruch danych. Rozkazy wejścia-wyjścia.
!" Sterowanie. Rozkazy testowania i rozgałęzienia.

21
Rozkazy arytmetyczne zapewniają zdolność obliczeniową przetwarzania danych
numerycznych. Rozkazy logiczne (Boole'a) operują na bitach słowa raczej jako na
bitach niż na liczbach; wobec tego zapewniają one zdolność przetwarzania dowolnych
innych rodzajów danych, jakie użytkownik może chcieć wykorzystywać. Operacje te
są wykonywane głównie na danych znajdujących się w rejestrach procesora. Wobec
tego muszą istnieć rozkazy pamięciowe służące do przenoszenia danych między
pamięcią a rejestrami. Rozkazy wejścia-wyjścia są potrzebne do przenoszenia
danych i programów do pamięci oraz wyników obliczeń do użytkownika. Rozkazy
testowania są używane do sprawdzania wartości słów danych lub stanu obliczeń.
Rozkazy rozgałęzienia są używane do przeskoczenia do innego zestawu rozkazów
zależnie od podjętych decyzji.
Rozkazy dzielą się na:
!" Zeroadresowe – do sterowania działaniem komputera (nie potrzebują
argumentów).
!" Jednoadresowe – wymagają jednego argumentu lub jeden z argumentów
jest domyślny.
!" Dwuadresowe – wymagają większej ilości argumentów, np. operacje
arytmetyczno-logiczne
!" Trójadresowe
19. Komputery RISC i CISC
RISC (ang. Reduced Instruction Set Computing) – architektura procesora wywodząca
się z Berkeley, charakteryzująca się między innymi zredukowaną liczbą krótkich
rozkazów, mających niewiele formatów i trybów adresowania przy dużej ilości
rejestrów uniwersalnych (nawet powyżej 100). Operacje kontaktu z pamięcią są
sprowadzone do czytania i pisania, działanie procesora przyśpieszają dodatkowe
ulepszenia w postaci przetwarzania potokowego i pamięci podręcznej. RISC jest
popularną architekturą procesorów 32- i 64-bitowych. Przykładem architektury RISC
jest mikroprocesor PowerPC.
CISC (ang. Complex Instruction Set Computing) – architektura procesora
charakteryzująca się między innymi znaczną liczbą rozkazów i trybów adresowania
przy małej ilości rejestrów uniwersalnych. Przykładem architektury CISC jest
mikroprocesor Pentium.
20. Język asemblera
Mikroprocesor wykonuje program zapisany w pamięci programu. Zawartość pamięci
to zestaw bitów. Przygotowanie przez człowieka programu bezpośrednio w takiej
postaci jest praktycznie nie możliwe. Dlatego dla każdego procesora istnieje jego
asembler. Asembler to język programowania (tzw. niskiego poziomu), w którym
jednemu rozkazowi napisanemu przez programistę odpowiada jeden rozkaz
procesora. Rozkazy zapisuje się w postaci symbolicznej, znacznie czytelniejszej dla
człowieka niż jest to w przypadku całej masy zer i jedynek.
Każdemu rozkazowi odpowiada jego symbol (mnemonik) składający się z kilku liter.
Asembler umożliwia również stosowanie symboli do oznaczania zarówno danych
liczbowych jak i adresów. Symbol określający adres w pamięci programu nosi nazwę
etykiety. Program napisany przez programistę w postaci symbolicznej jest nazywany
kodem źródłowym programu.
Asembler to program, który tłumaczy kod źródłowy programu (zapisany
w asemblerze danego mikroprocesora) na postać binarną (zestaw bitów). Taki proces
tłumaczenia nosi nazwę asemblacji.
W wyniku asemblacji program zapisywany jest w pliku w formacie umożliwiającym
jego wpisanie do pamięci programy. W czasie asemblacji powstaje również listing.

22
Jest to plik tekstowy zawierający kod źródłowy programu uzupełniony o różne
informacje wytworzone przez asembler (numery linii, kody rozkazów, komunikaty
o błędach itp.). Plik ten jest przeznaczony dla programisty i umożliwia mu wyszukanie
oraz usunięcie błędów.
Poza mnemonikami, ich parametrami, etykietami i wartościami symbolicznymi
w treści programu w asemblerze mogą wystąpić dyrektywy asemblera. Są to
specjalne polecenia asemblera (programu) niezwiązane z asemblerem procesora.
Poszczególne dyrektywy wykonują różne funkcje sterowania procesem asemblacji.
21. Formaty adresowania
Trybem adresowania nazywamy sposób przetworzenia adresu wirtualnego lub
logicznego w celu wyznaczenia adresu liniowego. Jeśli dostępna pamięć jest mniejsza
od tej, która jesteśmy w stanie zaadresować, to adres liniowy podlega dodatkowej
translacji.
Tryby adresowania ze względu na liczbę składowych wskaźnika adresu:
!" Adresowania zero elementowe - jest to adresowanie bezpośrednie,
w którym adres jest niejawny. Można je podzielić na:
#" zwarte - jeden lub wszystkie operandy są domniemane
#" błyskawiczne - krótki kod danej umieszczony w wyróżnionym polu
bitowym słowa kodu operacji jest częścią tego kodu.
#" natychmiastowe - za pomocą licznika rozkazów PC, słowo kodu danej
stanowi rozszerzenie kodu rozkazu.
!" Adresowanie jednoelementowe - bezpośrednie lub pośrednie, jeden jawnie
podany wskaźnik. Wyróżnia się adresowanie:
#" bezwzględne - skrócony adres danej jest umieszczony w polu słowa
kodu operacyjnego rozkazu lub pełny adres jest polem rozszerzenia
kodu.
#" bezwzględne pośrednie - adres adresu danej jest słowem
rozszerzenia kodu rozkazu.
#" rejestrowe bezpośrednie - argument jest umieszczony we
wskazanym rejestrze, identyfikowanym w słowie kodu rozkazu.
#" rejestrowe pośrednie - adres danej jest umieszczony w rejestrze,
identyfikowanym w słowie kodu rozkazu.
#" rejestrowe pośrednie z modyfikacja - adres umieszczany
w rejestrze jest automatycznie zwiększany (+1) po użyciu lub
zmniejszany (-1) przed użyciem.
!" Adresowania wieloelementowe - jest zawsze adresowaniem pośrednim.
Wskaźnik adresu jest wyznaczany jako funkcja dwóch lub większej liczby
składowych adresu.
W adresowaniu jednopoziomowym suma składowych adresu wyznacza lokacje danej
w pamięci. W adresowaniu dwupoziomowym niektóre składowe adresu są użyte do
wskazania lokacji w pamięci zawierającej adres odniesienia (bazę pośrednia), który
jest dodawany do pozostałych składowych. Po prostu niektóre składowe nie są
dodawane, ale jedynie wskazują inna dana i to ona właśnie ma być użyta
w sumowaniu. Szczególnym typem adresowania wieloargumentowego jest
adresowanie względne, w którym adresem bazowym jest zawartość licznika
rozkazów. Najprostszym rodzajem adresowania wieloargumentowego jest
adresowanie dwuelementowe, które można podzielić na:
#" bazowe z przemieszczeniem
#" indeksowe z przemieszczeniem
#" bazowo-indeksowe
#" względne z przemieszczeniem
#" względne indeksowe

23
W architekturze Intel 80x86 zaadresowanie każdej danej w pamięci wymaga
dwóch wskaźników: segmentu i adresu względnego wewnątrz segmentu
o wartości nie przekraczającej rozmiaru segmentu. Wskaźnik segmentu,
umieszczony w rejestrze, wyznacza adres liniowy początku segmentu (bazę
odniesienia). Najbardziej złożonym trybem adresowania w Inlet 80x86 jest dwu-
wskaźnikowe skalowane adresowanie bazowo-indeksowe z przemieszczeniem:
Adres liniowy = (wskaźnik segmentu])+(baza)+(indeks)*skala przemieszczenie
W Motorolach używany jest m.in. mechanizm adresowania dwupoziomowego,
używający bazy pośredniej jako odniesienia dla innych składowych. Stosuje się
również:
!" adresowanie preindeksowe - indeks jest użyty do wyliczenia adresu
bazy pośredniej, a adres logiczny jest obliczany ze wzoru:
LA = [(baza)+przemieszczenie+(indeks)*skala]+relokacja
[na podstawie bazy, przemieszczenia, indeksu i skali wyznaczany jest
drugi adres bazy (baza pośrednia) i potem jest ona traktowana jak
zwyczajna baza - dodajemy do niej relokacje (odpowiednik
przeniesienia).
!" adresowania postindeksowe - indeks służy do modyfikacji bazy
pośredniej, a adres logiczny jest obliczany ze wzoru:
LA = [(baza)+przemieszczenie]+(indeks)*skala+relokacja
[baza pośrednia jest wyliczana na podstawie bazy i przemieszczenia -
i ta suma jest traktowana jako nowa baza, do której później dodawana
jest relokacja(przesuniecie) oraz skalowany indeks.
Adresowanie opisowe (deskryptorowe) - jest to metoda adresowania
wieloelementowego (adresowanie pośrednie). Role bazy pośredniej pełni tutaj
deskryptor (realizowany przez wskaźnik) i to do niego dodawana jest baza,
przemieszczenie i skalowany indeks. Oprócz adresu bazowego (pośrednia baza)
deskryptor zawiera również informacje umożliwiające realizowanie selektywnego
dostępu do bloku.. Adresowanie opisowe ułatwia elastyczne adresowanie
zmiennych strukturalnych przy jednoczesnym zachowaniu prywatności
(np. w pamięci wirtualnej. Podstawowo różnica miedzy adresowaniem post-
indeksowym, a deskryptorowym jest to, ze w dwupoziomowym adresowaniu
pośrednim adres bazowy zawarty jest rejestrze, a w deskryptorowym jest to pełny
adres wirtualny danej. Adresowanie wieloelementowe jest charakterystyczne dla
architektury CISC. W maszynach RISC najbardziej złożonym trybem jest
adresowania skalowane bazowo-indeksowe.
Adresowanie danych strukturalnych - w praktyce sprowadza się do
adresowanie stosu i kolejki. W przypadku stosu do adresowania wykorzystywany
jest wskaźnik wierzchołka stosu. Takie adresowanie wymaga modyfikacji
wskaźnika po działaniach na stosie. Mamy tu dwie sytuacje - jeśli stos jest
rozbudowywany w kierunku adresów malejących to mamy tryb predekrementacji
wskaźnika (dla przesłań na stos) i postinkrementacji (dla odczytu ze stosu)
[ogólnie rzecz biorą stos rośnie w dół]. Mechanizm odwroty jest używany
w obrębie stosu tworzonego w kierunku adresów rosnących. [stos rośnie w górę]
Drugim typem strukturalnym jest kolejka (bufor LIFO). Jej adresowanie wymaga
dwóch wskaźników - początku i końca kolejki (lub rozmiaru kolejki). Mechanizm
ten jest stosowany jedynie przy tworzeniu tzw. bufora rozkazów. Inne
mechanizmy wspomagające adresowanie danych strukturalnych: sprawdzanie
uprawnień dostępu do danych, testowanie zakresu, (gdy mieści się w nim adres),
adresowanie pól w rekordach.

24
22. Cykl rozkazowy
Cykl rozkazu - przetwarzanie wymagane dla pojedynczego rozkazu. Cykl ten jest
podzielony na dwa etapy, określane jako cykl pobierania i cykl wykonywania.
Wykonywanie programu jest wstrzymywane tylko po
wyłączeniu maszyny, po
wystąpieniu pewnego rodzaju nieodwracalnego błędu lub, jeśli wystąpi w programie
rozkaz zatrzymania komputera.
Na początku każdego cyklu rozkazu procesor pobiera rozkaz z pamięci. W typowym
procesorze do śledzenia, który rozkaz ma być pobrany, służy rejestr zwany licznikiem
programu (PC). Jeśli procesor nie otrzyma innego polecenia,
to powoduje
inkrementację licznika PC po każdym pobraniu rozkazu i wykonuje następny rozkaz
w ciągu (to znaczy rozkaz zlokalizowany w pamięci pod najbliższym adresem
o kolejnym wyższym numerze). Pobrany rozkaz jest następnie ładowany do rejestru
w procesorze zwanego rejestrem rozkazu (IR). Rozkaz ten ma formę kodu binarnego
określającego działanie, które ma podjąć procesor. Procesor interpretuje rozkaz
i przeprowadza wymagane działanie. Ogólnie działania te można podzielić na cztery
kategorie:
!" Procesor-pamięć. Dane mogą być przenoszone z procesora do pamięci lub
z pamięci do procesora.
!" Procesor-wejście-wyjście. Dane mogą być przenoszone z otoczenia lub
do niego, przez przenoszenie ich między procesorem a modułem wejścia-
wyjścia.
!" Przetwarzanie danych. Procesor może wykonywać pewne operacje
arytmetyczne lub logiczne na danych.
!" Sterowanie. Rozkaz może określać, że sekwencja wykonywania ma
być zmieniona. Na przykład: procesor może pobrać rozkaz z pozycji 149,
z którego wynika, że następny rozkaz ma być pobrany z pozycji 182. Procesor
zapamięta ten fakt przez ustawienie licznika programu na 182. Dzięki temu
w następnym cyklu pobrania rozkaz zostanie pobrany z pozycji 182, a nie 150.
Oczywiście wykonywanie rozkazów może zawierać kombinacje tych działań. Tak więc
cykl wykonania określonego rozkazu może wykorzystywać więcej niż jedno
odniesienie do pamięci.
23. Przetwarzanie potokowe
Przetwarzanie potokowe - równoległe wykonywanie w procesorze poszczególnych
faz cyklu rozkazowego. Jeden z układów procesora potokowego wykonuje rozkaz,
a drugi, niezależny układ w tym samym czasie pobiera następny rozkaz z pamięci, co
podwaja wydajność procesora. Stopień równoległości konstrukcji procesorów
w architekturze RISC wynosi od trzech do siedmiu niezależnych bloków
funkcjonalnych wykonujących jednocześnie pobranie rozkazu, jego zdekodowanie,
obliczenie adresu argumentu, pobranie argumentu, wykonanie operacji
i przechowanie wyniku.
Potok przebiega w dwóch niezależnych etapach. W pierwszym następuje pobranie
i zbuforowanie rozkazu. Gdy drugi etap jest wolny, następuje przekazanie do niego
zbuforowanego rozkazu. Podczas gdy w drugim etapie wykonywany jest rozkaz,
w pierwszym wykorzystuje się jeden z nieużywanych cykli pamięci w celu pobrania
i zbuforowania następnego rozkazu. Nazywa się to pobieraniem rozkazu
z wyprzedzeniem (ang. instruction prefetch) lub pobieraniem na zakładkę (ang. fetch
overlap). Jeżeli etapy pobierania i wykonywania zajmowałyby tyle samo czasu, cały
proces skróciłby się 2 razy. Jednak wykonywanie jest na ogół dłuższe niż pobieranie,
więc etap pobierania musi zawierać pewien czas oczekiwania na opróżnienie bufora.
Poza tym rozkaz skoku warunkowego powoduje, że adres następnego rozkazu

25
przewidzianego do pobrania jest nieznany. Wobec tego realizacja pobierania może
nastąpić dopiero po otrzymaniu adresu następnego rozkazu, który zostanie określony
po zakończeniu wykonywania. Natomiast na etapie wykonywania następuje
oczekiwanie na pobranie kolejnego rozkazu.
Strata czasu może być zmniejszona przez zgadywanie. Gdy rozkaz rozgałęzienia
warunkowego przechodzi z etapu pobierania do wykonywania na etapie pobierania
następuje pobranie następnego rozkazu po rozkazie rozgałęzienia. (Rozkaz jest
pobierany, niezależnie czy jego warunek jest spełniony. Tego na razie nie wiemy, ale
jeśli się okaże, że warunek spełniony, to nie straciliśmy czasu i "obrabiamy" ten
rozkaz dalej. Jeśli się okaże, że warunek nie jest spełniony, to wyrzucamy ten rozkaz
i pobieramy nowy).
Aby jeszcze zwiększyć tempo potok musi mieć więcej etapów:
!" Pobranie rozkazu - wczytanie następnego spodziewanego rozkazu do bufora.
!" Dekodowanie rozkazu - określenie kodu operacji i specyfikatorów
argumentu.
!" Obliczanie argumentów - obliczanie efektywnego adresu każdego
argumentu źródłowego. Może to obejmować obliczanie adresu z przesunięciem
adresu rejestrowego pośredniego, adresu pośredniego lub innych form.
!" Pobieranie argumentów - pobranie każdego argumentu z pamięci.
Argumenty w rejestrach nie muszą być pobierane.
!" Wykonywanie rozkazu - przeprowadzenie wskazanej operacji
i przechowanie wyniku (jeśli jest) w ustalonej lokacji docelowej.
!" Zapisanie argumentu - zapisanie wyniku w pamięci.
Przy założeniu, że czasy trwania poszczególnych etapów są równe, czas wykonania
rozkazów zmniejsza się z 54 do 14 jednostek czasu. Dla uproszczenia zakładamy, że
każdy rozkaz przechodzi przez wszystkie etapy potoku i że wszystkie etapy mogą być
realizowane równolegle - nie ma konfliktów dostępu do pamięci.
Ograniczenia poprawy wydajności:
!" Jeśli czasy trwania 6 etapów nie są równe występuje oczekiwanie.
!" Możliwość unieważnienia przez rozkaz rozgałęzienia wartości kilku pobranych
rozkazów.
!" Nieprzewidywalność przerwań.
!" Konflikty rejestrów i pamięci.
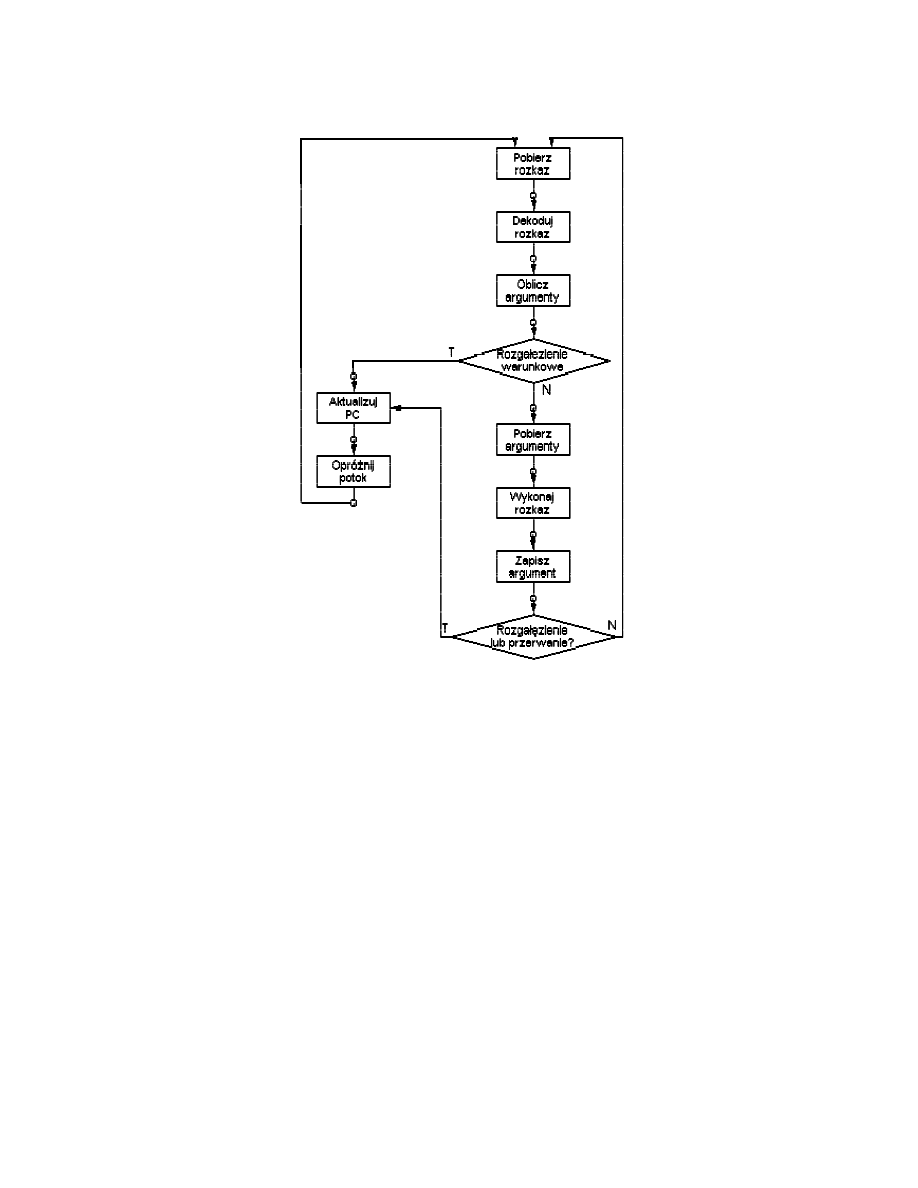
26
Sześcioetapowy potok rozkazów procesora:
Mogłoby się wydawać, że im więcej etapów tym szybsze wykonywanie rozkazów. Są
jednak czynniki, które zaburzają ten sposób zwiększania wydajności:
!" Na każdym etapie potoku występuje pewien narzut związany z przenoszeniem
danych z bufora oraz z wykonywaniem różnych działań przygotowawczych, co
może wydłużyć całkowity czas wykonania rozkazu, szczególnie jeśli rozkazy
sekwencyjne są logicznie zależne albo przez częste rozgałęzianie, albo przez
uzależniony dostęp do pamięci.
!" Wraz z liczbą etapów wzrasta znacząco liczba układów logicznych potrzebnych
do zapobiegania konfliktom rejestrów i pamięci - może się zdarzyć, że układy
logiczne sterujące przejściami między etapami są bardziej złożone niż same
etapy.
Metody postępowania z rozgałęzieniami warunkowymi
Rozgałęzienie warunkowe jest zasadnicza przeszkoda dla stałego napływu rozkazów
do początkowych etapów potoku - aż do zakończenia wykonywania tego rozkazu nie
jest możliwe stwierdzenie, czy rozgałęzienie nastąpi, czy nie. Istnieją różne sposoby
postępowania:
!" Zwielokrotnienie strumienia - powielanie początkowych części potoku
i umożliwianie równoczesnego pobrania obu rozkazów za pomocą dwóch
strumieni np. IBM 370/168, IBM 3033.
!" Pobieranie docelowego rozkazu z wyprzedzeniem - gdy rozpoznawany
jest rozkaz rozgałęzienia warunkowego, następuje wyprzedzające pobranie
rozkazu docelowego razem z rozkazem następującym po rozgałęzieniu. Rozkaz

27
docelowy jest następnie zachowywany, aż do czasu wykonania rozkazu
rozgałęzienia. W momencie rozgałęzienia rozkaz docelowy jest już pobrany np.
IBM 360/91.
!" Bufor pętli - mała, bardzo szybka pamięć związana z etapem pobierania,
zawiera kolejno n ostatnio pobranych rozkazów. Jeśli ma nastąpić
rozgałęzienie, sprawdza się najpierw, czy cel rozgałęzienia znajduje się
wewnątrz bufora. Jeśli tak, następny rozkaz jest pobierany z bufora.
!" Przewidywania rozgałęzień - można np. zakładać zawsze, że rozgałęzienie
nie nastąpi i kontynuować kolejne pobieranie rozkazów, albo zakładać zawsze,
że rozgałęzienie nastąpi i pobierać rozkaz w celu rozgałęzienia. Można tez
podejmować decyzję na podstawie kodu operacji rozkazu rozgałęzienia.
Procesor zakłada, że rozgałęzienie nastąpi w przypadku pewnych kodów
operacji, a w przypadku innych nie. Można też rejestrować historię rozkazów
względem warunku. W programie i na podstawie już przebytych rozkazów
wyciągnąć wnioski w powtarzających się przypadkach (tzw. Przełącznik
nastąpiło/nie nastąpiło lub tablica historii rozgałęzień).
!" Opóźnione rozgałęzienie - automatyczna zmiana porządku rozkazu
wewnątrz programu, tak żeby rozkazy rozgałęzienia występowały później.
24. Struktura i działanie jednostki centralnej
Podstawowymi elementami funkcjonalnymi procesora są jednostka arytmetyczno-
logiczna, rejestry wewnętrzne, ścieżki danych, zewnętrzne ścieżki danych, jednostka
sterująca.
ALU jest funkcjonalną istotą komputera. Rejestry są używane do
przechowywania danych wewnętrznych w procesorze. Niektóre rejestry zawierają
informacje o stanie potrzebne do zarządzania porządkowaniem rozkazów (np. słowo
stanu programu). Pozostałe zawierają dane przeznaczone dla ALU, pamięci, modułów,
wejścia-wyjścia, lub przekazane przez te jednostki. Wewnętrzne ścieżki danych są
używane do przenoszenia danych między rejestrami oraz między rejestrem a ALU.
Zewnętrzne ścieżki danych łącza wejście z pamięcią i modułami wejścia-wyjścia,
często za pomocą magistrali systemowej. Jednostka sterującą powoduje
wykonywanie operacji wewnątrz procesora. Zadania, które realizuje procesor:
!" Pobieranie rozkazów. Procesor musi odczytywać rozkazy z pamięci
!" Interpretowanie rozkazów. Rozkazy musza być zdekodowane w celu,
okreslenia jakie działania są wymagane
!" Pobieranie danych. Wykonywanie rozkazów może wymagać odczytania
danych, z pamieci lub modułu wejścia-wyjścia
!" Przetwarzanie danych. Wykonywanie rozkazów może wymagać
przeprowadzania na danych pewnych operacji arytmetycznych lub logicznych
!" Zapisanie danych. Wyniki operacji mogą wymagać zapisania danych
w pamięci lub w module wejścia-wyjścia
25. Procesory superskalarne
Procesor oparty o technologię superskalarności posiada nie jeden, lecz więcej
potoków typu pipeline, w których przetwarza równocześnie większą liczbę instrukcji.
Według ścisłych przepisów zaimplementowanych sprzętowo procesor przydziela
polecenia wolnym w danym momencie potokom. Pomysłowe metody usuwają
zależności pomiędzy poszczególnymi instrukcjami, aby uniknąć niepotrzebnych
zatorów, a niniejszym zbędnego oczekiwania. Dzięki tym metodom żadna z instrukcji
znajdująca się w potoku nie musi wyczekiwać na wynik polecenia realizowanego
w innym potoku i wstrzymywać w ten sposób przetwarzanie pozostałych poleceń.
26. Mikrokomputery jednoukładowe rodziny 8051 i 8052 (MCS-51)
Rodzina mikrokomputerów jednoukładowych MCS-51 powstała w firmie Intel
Corporation. Podstawowymi układami rodziny MCS-51 są: mikrokomputer 8051, od

28
którego pochodzi nazwa rodziny, oraz nieco rozbudowany mikrokomputer 8052.
Ośmiobitowa jednostka centralna może wykonywać 111 rozkazów (49 jedno-, 45
dwu- i 17 trzybajtowych). Lista rozkazów zawiera m.in. rozkazy arytmetyczne
i logiczne, rozkazy dotyczące operacji logicznych na bitach (procesor boolowski) oraz
rozbudowane grupy rozkazów skoków warunkowych i wejścia-wyjścia.
Zegar taktujący jest stabilizowany zewnętrznym rezonatorem
kwarcowym,
o częstotliwości maksymalnej 12 MHz. Czas cyklu maszynowego jest więc równy 1 μs.
Wewnętrzna pamięć programu, typu ROM, ma pojemność 4096 (4K.) słów 8-
bitowych. Może być rozszerzona do 64K bajtów przez dołączenie pamięci zewnętrznej.
Wewnętrzna pamięć danych, typu RAM, ma pojemność 128 bajtów. Możliwe jest
dołączenie zewnętrznej pamięci danych o pojemności do 64K słów (w ramach osobnej
przestrzeni adresowej).
Układ czasowo-licznikowy zawiera dwa 16-bitowe liczniki, które mogą zliczać
wewnętrzne impulsy zegarowe lub impulsy zewnętrzne. Oba liczniki mogą pracować
w jednym z czterech, ustawianych indywidualnie, trybów.
Linie wejścia-wyjścia, których jest 32, są zorganizowane w cztery 8-bitowe porty.
Część z tych linii (zwłaszcza linie portu P3) może być wykorzystana do realizacji
specjalnych funkcji.
Port szeregowy umożliwia niezależne nadawanie i odbieranie transmisji szeregowej.
Może pracować w czterech trybach.
Układ przerwań (dwupoziomowy) może obsługiwać dwa przerwania zewnętrzne
i dwa z układu czasowo-licznikowego oraz przerwanie z układu szeregowego wejścia-
wyjścia (razem 5).
Mikrokomputer 8052 jest wersją układu 8051 o nieco powiększonych zasobach,
a mianowicie:
!"
wewnętrzna pamięć programu jest powiększona do 8K bajtów,
!"
wewnętrzna pamięć danych jest powiększona do 256 bajtów,
!"
układ czasowo-licznikowy zawiera dodatkowy 16-bitowy licznik
impulsów
zegarowych lub zewnętrznych.
Mikrokomputery rodziny MCS-51 są obecnie najpopularniejszymi układami na świecie
w klasie ośmiobitowych mikrokomputerów jednoukładowych.
27. Procesor Pentium
Procesory tej rodziny stanowią bardzo liczną grupę. Pierwsze modele - od dawna
nieobecne na rynku - zasilane napięciem 5 V osiągały częstotliwość do 66 MHz.
Kolejna grupa (oznaczana symbolem P54C) pracowała już przy zasilaniu 3,3 V,
a częstotliwość taktowania jądra procesora sięgała 200 MHz. Procesor posiada
dynamiczny system przepowiadania rozgałęzień. Bufor BTB mieści 256 rekordów
i zorganizowany jest w systemie poczwórnej asocjacji. Strata czasu, którą ponosi
procesor w wypadku błędnej przepowiedni, wynosi od 3 do 4 cykli
zegarowych. Pamięć podręczna danych (Data Cache) pracuje w bardzo efektywnym
trybie WB (Write Back), ale dla zachowania zgodności z procesorami 486 może dać
się przełączyć na tryb WT (Write Through). W jej skład wchodzi 8 banków, każdy po
32 linijki. Jedna linijka ma wymiar 32 bajtów. Cache jest dwuportowy i może być
udostępniany równolegle dla potrzeb U i V, jeśli tylko odwołania odnoszą się do
różnych banków. Próba jednoczesnego dostępu do danych złożonych w tym samym
banku kończy się przyznaniem pierwszeństwa U. Potok V zmuszony jest do
oczekiwania przez czas trwania
jednego cyklu zegarowego.
Jakkolwiek rejestry
dostępne programowo są 32-bitowe, wewnętrzne ścieżki mają 128, a nawet 256
bitów szerokości. Przyczynia się to z pewnością do zwiększenia
prędkości wewnętrznych transferów. Cechy architektury pozwalają zaliczyć Pentium
do grupy CISC. Jądro procesora jest superskalarne i wyposażone w dwa potoki
przetwarzające instrukcje stałoprzecinkowe oraz jednostkę zmiennoprzecinkową. Jeśli
spełnione są wymogi narzucone przez mechanizm parowania, procesor przetwarza
w każdym cyklu zegarowym dwie instrukcje: każdy z potoków (U i V) kompletuje po
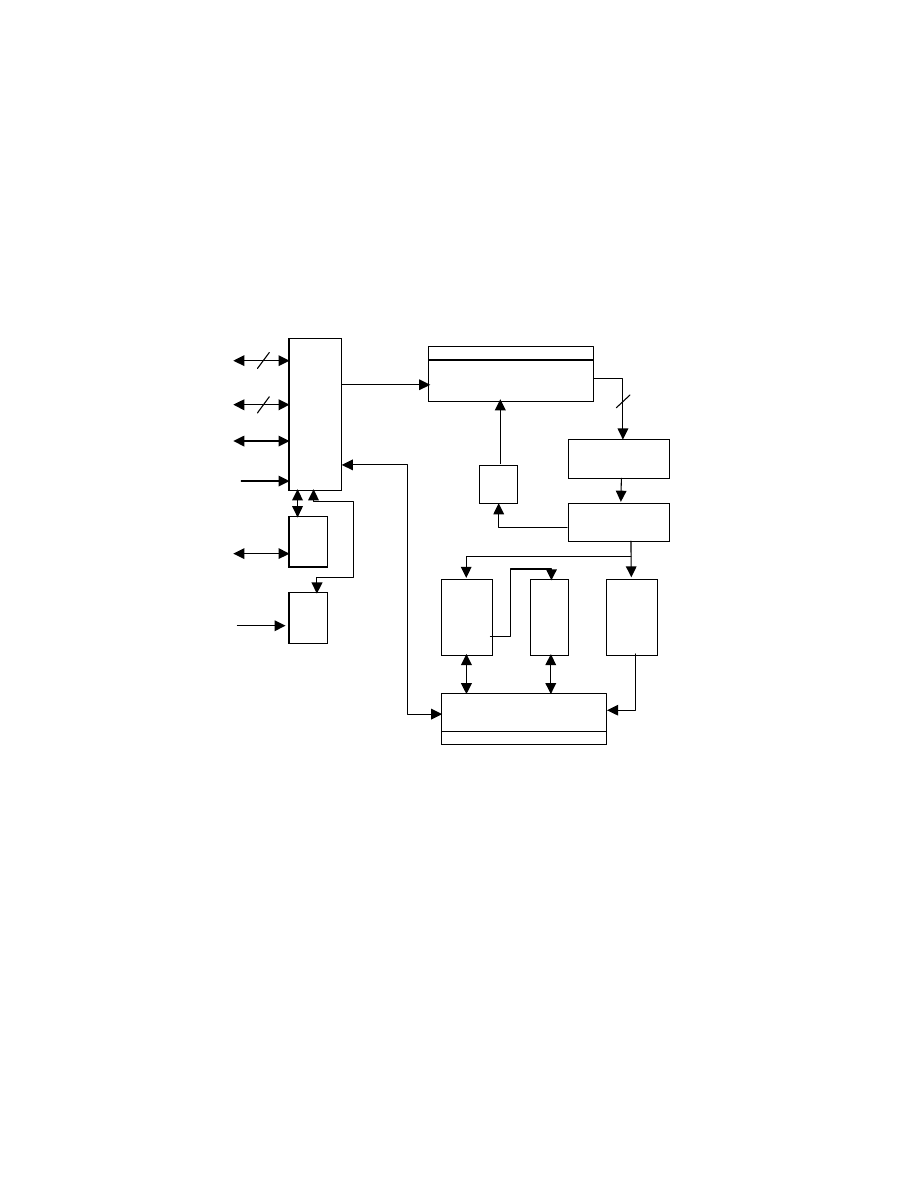
29
jednej z nich. Należy jednak podkreślić, iż potoki są bardzo silnie ze sobą powiązane
i pracują wyłącznie w trybie synchronicznym. Żaden z nich nie może wybiegać
naprzód w procesie przetwarzania. Jakiekolwiek zahamowanie w jednej z linii
powoduje natychmiastowe zatrzymanie drugiego potoku. Pamięć podręczna kodu jest
dwudrożna (2-Way Set) i zorganizowana w 8 banków. Również w tym przypadku
rozmiar linijki wynosi 32 bajty. Pentium przygotowany jest do pracy w systemach
wieloprocesorowych, a konkretnie w parze z drugim identycznym procesorem (Dual
System). Dla potrzeb takiej konfiguracji dodany został kontroler APIC (Advanced
Programmable Interrupt Controller) oraz kilka dodatkowych końcówek sterujących,
a pamięć podręczna danych sygnalizuje swój stan zgodnie z protokołem MESI.
28. Mikroprogramowanie
Mikroprogramowanie jest powszechnie stosowaną metodą technicznej realizacji
komputerów CISC. Ciąg mikrorozkazów tworzy mikroprogram realizujący określony
rozkaz. Stosowanie mikroprogramowania pozwoliło, w stosunkowo łatwy sposób,
zrealizować sterowanie wykonaniem złożonych rozkazów wymagających różnych
okresów czasu, zależnie od stopnia ich złożoności. Wzrosła też liczba taktów
zegarowych potrzebnych do wykonania pełnego cyklu rozkazowego. W miarę wzrostu
złożoności mikroprogramów pojawił się też problem racjonalnego wykorzystania
zasobów procesora. W czasie wykonywania jednego mikrorozkazu, wykonującego
proste operacje elementarne, wykorzystywana jest tylko niewielka część zasobów
procesora, podczas gdy inne pozostają nieczynne. Mikroprogramy są z reguły
przechowywane w pamięci stałej.
TLB
TLB
BTB
PREFETCH
DECODE
L1 Data Casche:8kB
MP
APIC
L1 Code Casche:8kB
BUS
Interface
Unit
Pipeline
V
Pipeline
U
P
ipe
li
n
e F
P
∑
×
÷
Address
Data
Control
Clock
Dual – CPU
BUS
Dual – CPU
System
IRQ
256
32
64

30
29. Systemy wieloprocesorowe
W pogoni za coraz to większą mocą obliczeniową komputerów poszukuje się stale
nowych rozwiązań. Jednym z nich jest rozdział ogólnych zadań całego systemu
pomiędzy pewną liczbę współpracujących ze sobą procesorów.
Wyróżnić należy dwa podstawowe punkty podejścia do tego zagadnienia:
!" Każdy z procesorów stanowi niezależną jednostkę obliczeniową
i dysponuje własną pamięcią operacyjną. Koordynacja pracy poszczególnych
podsystemów odbywa się na drodze wymiany wiadomości, najczęściej
w formie pakietów. Czas dostępu do danych może się znacznie wydłużać, jeżeli
leżą one w obszarze zarządzanym przez inny procesor.
!!!!"
"
"
" Cała pamięć systemowa jest ogólnodostępna i leży w zasięgu działania
każdego z procesorów (ang. Shared Memory). Czas dostępu do danych jest
jednakowy dla każdej z jednostek, jednakowoż protokół dostępu musi
uwzględniać możliwość występowania kolizji.
Architektura MPP
(ang. Massive Parallel Processing) Model z pamięcią rozproszoną ma wiele zalet.
Pozwala między innymi na łączenie ze sobą dowolnie wielu bloków procesorowych.
Poszczególne moduły połączone są ze sobą przez specjalne magistrale (np. GTL+) lub
adaptowane do tego celu rozwiązania sieciowe. Równoległe połączenie setek lub
nawet tysięcy procesorów prowadzi do osiągnięcia fenomenalnej mocy obliczeniowej,
która może jednak być wykorzystana jedynie w nielicznych przypadkach. Konieczność
częstej komunikacji między procesorami pochłania moc obliczeniową
i blokuje wspólną magistralę. Cały proces obliczeniowy musi więc być rozpisany na
wątki operujące na niezależnych danych.
Architektura UMA
U podstaw architektury UMA (ang. Uniform Memory Access) leży idea wspólnej
pamięci globalnej, którą może adresować w całym zakresie każdy z procesorów.
Wspólne pozostają również układy I/0 (czyli wszelkie porty, złącza i dyski).
Wspólna magistrala pamięciowa staje się wąskim gardłem skutecznie tamującym
wymianę danych. Jak zawsze w takim przypadku, pewne rozładowanie przynosi
zastosowanie pamięci podręcznej (Cache). W małą pamięć podręczną pierwszego
poziomu (L1 Cache) wyposażone są wszystkie współczesne procesory. Istotną rolę
odgrywa jednak w tym przypadku pamięć podręczna wyższego poziomu.
Wszelkie żądania odczytu z pamięci głównej przechodzą przez kontroler pamięci
podręcznej. Jeżeli kontroler uzna, iż żądana informacja zawarta jest w pamięci
podręcznej, przekazuje ją procesorowi natychmiast, w przeciwnym razie kieruje
odwołanie do kontrolera magistrali, który inicjuje cykl dostępu do pamięci głównej.
Nieco inaczej obsługiwane są cykle zapisu. Mogą one odbywać się za
pośrednictwem pamięci podręcznej lub być kierowane bezpośrednio do pamięci
operacyjnej. Sytuacja komplikuje się znacznie, jeżeli w systemie pracuje kilka
procesorów (lub innych układów mających prawo dostępu do pamięci), a każdy z nich
ma swoją pamięć podręczną. Dla zachowania spójności zawartości pamięci należy
przedsięwziąć pewne działania dodatkowe. W tym celu wszystkie zainteresowane
strony stale podsłuchują (Snooping), co dzieje się na magistrali pamięciowej.
Wyszukiwarka
Podobne podstrony:
Architektura Komputerow wiedza
ARCHITEKTURA KOMPUTEROW1A
architektury komputerow v1 1
Architektura Komputera, Informatyka, Płyta Główna
Architektury Komputerów zagadnienia
Architektura komputerów I 16 12 2008
gulczas 2001 opracowanie, Politechnika Wrocławska - Materiały, architektura komputerow 2, egzamin, o
wiedzasp, ppl wiedzosp, WIEDZA OGÓLNA O SAMOLOCIE lic
Architektura komputerów I 09 12 2008
Architektura komputerów i systemy operacyjne
ak projekt, Studia, PWR, 4 semestr, Architektura komputerów 2, projekt
Tematy cwiczen, Architektóra komputerów
ako pytania zadania cz2 2010, Studia - informatyka, materialy, Architektura komputerów
Architektura komputerów I 25 11 2008
więcej podobnych podstron