CYFROWE
CYFROWE
ŚLADY
ŚLADY
Jest się
Jest się
czego bać
czego bać
Leszek
Leszek
IGNATOWICZ
IGNATOWICZ
Warszawa, październik 2014
Ebookpoint.pl kopia dla: kp89@riseup.net

Na szukanie lepszego świata
nie jest jeszcze za późno.
Alfred Tennyson
Leszek IGNATOWICZ
Cyfrowe ślady.
Jest się czego bać
ISBN: 978-83-7853-403-7
Wydanie I, październik 2014
Projekt okładki: Leszek IGNATOWICZ
Korekta: Agnieszka Kwiatkowska
Autor zezwala na bezpłatne kopiowanie i przekształcanie na inne
formaty niniejszej publikacji pod warunkiem zachowania całości i
niezmienności treści oraz Copyright© 2014 by Leszek IGNATOWICZ
Copyright© 2014 by Leszek IGNATOWICZ
Ebookpoint.pl kopia dla: kp89@riseup.net

Spis Treści
........................................................................................
PODSTAWY CYFROWEGO PRZETWARZANIA INFORMACJI
........................................................................
Bity, bajty i systemy liczbowe
...................................................
...................................................................
Pamięć RAM i trwałe nośniki informacji
.......................................
......................................................................
Zapisywanie danych na dyskach magnetycznych
CYFROWE ŚLADY W SYSTEMACH WINDOWS
..............................
........................................................................
Kasowanie/odzyskiwanie danych w systemach plików Windows
Cyfrowe ślady w Koszu systemu Windows
...................................
Ślady ostatniej aktywności na komputerze (ang. MRU lists)
....................................................
ŚLADY AKTYWNOŚCI ONLINE W PRZEGLĄDARKACH WWW
......................................................................
Adres IP komputera podłączonego do Internetu
Ciasteczka (ang. HTML cookies)
...............................................
Historia odwiedzanych stron, URL oraz autouzupełniania
WYKORZYSTYWANIE CYFROWYCH ŚLADÓW W INTERNECIE
......................................................................
Sposoby gromadzenia danych o użytkownikach
Reklama behawioralna (ang. OBA, Online
..........................................
Ebookpoint.pl kopia dla: kp89@riseup.net

Wstęp
4
Wstęp
Cyfrowy świat już nieodwołalnie wkroczył w nasze życie, lecz czy
przyniósł same korzyści? Wydawało się, że wraz z rozwojem Internetu
będzie się poszerzać sfera wolności, lecz stało się coś wręcz przeciwnego.
Ujawniona przez Edwarda Snowdena
skala powszechnego szpiegostwa z
wykorzystaniem globalnej sieci Internet wskazuje, że wolności jest coraz
mniej. Jest to tym groźniejsze, że ta elektroniczna inwigilacja jest
niewidoczna, tak jak niewidoczne są cyfrowe ślady. Łatwo jest uznać to, co
niewidoczne za nieistniejące i za jakiś czas obudzimy się w świecie
Orwella. Jeszcze można temu przeciwdziałać. Najpierw jednak trzeba
zobaczyć, jak pozostawiane przez nas w komputerach i coraz częściej
wykorzystywanych urządzeniach mobilnych cyfrowe ślady zdradzają naszą
aktywność i ułatwiają szpiegowanie.
Okazuje się, że powszechnie wykorzystywane systemy z rodziny
Microsoft Windows zapisują bez naszej wiedzy i zgody mnóstwo
informacji, na podstawie których można ustalić, co i kiedy robiliśmy na
komputerze. Na przykład, jakie pliki i kiedy zostały skasowane. Zresztą
takie „zwykłe” skasowanie (i usunięcie z kosza) niewiele znaczy. Bardzo
często te pliki można odczytać i ujawnić to, czego chcieliśmy się pozbyć.
Kolejnym źródłem cyfrowych śladów są przeglądarki WWW, które zapisują
całą naszą aktywność online. A co gorsze, są wykorzystywane przez
cyberkorporacje do tzw. profilowania użytkowników, czyli przetwarzania
naszej aktywności w internecie na coraz większe zyski z reklam. Czy i jak
to ogranicza naszą wolność? Przeczytaj tego ebooka i sam(a) przekonaj
się, czy jest się czego bać...
1
Glenn Greenwald, „Snowden. Nigdzie się nie ukryjesz”, Warszawa 2014
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Podstawy cyfrowego przetwarzania informacji
5
Podstawy cyfrowego
przetwarzania informacji
Wprowadzenie
Cyfrowe ślady nie są intelektualnym konceptem, lecz realnym
zjawiskiem fizycznym. Mogą, po spełnieniu rygorystycznych warunków,
stanowić dowód w procesie sądowym. Wprawdzie są informacją, lecz
zapisaną na materialnych nośnikach. Stąd też niezbędne jest zrozumienie
technicznych podstaw technologii cyfrowych. W tym celu, skrótowo i
przystępnie, omówione zostaną poniżej kluczowe pojęcia, procesy i
komponenty sprzętowe komputerowego przetwarzania informacji.
Bity, bajty i systemy liczbowe
Komputery, jakkolwiek wydają się skomplikowane, faktycznie są w
stanie przetwarzać wyłącznie dwie cyfry 0 i 1. Te dwie cyfry zwane są
binarnymi, czyli w systemie o podstawie „dwa” reprezentują informację o
wartości jednego bita. A wiec 1 bit to cyfra 0 lub 1. Zbitka ośmiu bitów
nazywana bajtem (ang. byte) jest podstawową jednostką informacji,
używaną w cyfrowym świecie. Przykładowo może to być: 01101001.
Binarny, czyli dwójkowy system liczbowy posługuje się tylko dwoma
cyframi 0 i 1, natomiast ludzie posługują się systemem dziesiętnym
zwierającym dobrze nam znane cyfry 0, 1, 2, 3, 4, 5, 6, 7, 8 i 9. Podany
powyżej bajt zapisuje w systemie binarnym liczbę o wartości dziesiętnej
105. Cyfry, litery i znaki przestankowe są reprezentowane przez jedno-
bajtowe liczby binarne. Jest to tzw. kodowanie w systemie ASCII.
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Podstawy cyfrowego przetwarzania informacji
6
Pliki komputerowe
Plik komputerowy jest dużą porcją informacji składająca się z bitów i
bajtów. Tak naprawdę wszystkie informacje zawarte w komputerze są
zapisane w rożnych plikach. Pliki są identyfikowane przez unikatowe
nazwy oraz rozszerzenia nazw, w systemach Windows określające typ
pliku. Na przykład plik Raport.txt jest plikiem tekstowym zawierającym
informacje zapisane jawnym tekstem. Są również pliki binarne, czyli
zwierające nieczytelny strumień bitów. Mogą to być pliki programów (np.
Notepad.exe), graficzne (np. Foto.jpg), wideo (np. Film.avi), muzyczne
(np. Nujazz.mp3) itp. W systemach Windows rozszerzenia znanych typów
plików domyślnie są niewidoczne, co jest sporym zagrożeniem
bezpieczeństwa. Typ pliku jest obrazowany specyficzną ikoną, lecz może
być ona łatwo sfałszowana. W systemach Unix/Linux typy plików są
rozpoznawane za pomocą tzw. sygnatury, czyli specyficznego nagłówka.
Pamięć RAM i trwałe nośniki informacji
Cyfrowe przetwarzanie informacji jest realizowane przy wykorzystaniu
procesorów, ulotnej pamięci swobodnego dostępu tzw. RAM oraz pamięci
trwałej, połączonych odpowiednimi komponentami. Procesor i nietrwała
pamięć RAM (jej zawartość znika po wyłączeniu zasilania) nie są istotne z
punktu widzenia cyfrowych śladów. Skupimy się więc na nieulotnych (ich
zawartość nie znika po wyłączeniu zasilania) nośnikach cyfrowej
informacji. Najistotniejsze są magnetyczne (lub elektroniczne typu flash)
dyski twarde (HDD lub SSD) zamontowane w komputerach lub
urządzeniach mobilnych. Oczywiście, cyfrowe ślady występują także na
przenośnych nośnikach typu dyski USB, pendrive'y, karty pamięci oraz
nośniki optyczne (CD, DVD, BlueRay). Nie można również zapominać o
wszelkiego rodzaju wirtualnych dyskach sieciowych czy też „chmurach”
internetowych (ang. cloud computing).
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Podstawy cyfrowego przetwarzania informacji
7
Systemy plików
Komputery przetwarzają miliony, a nawet miliardy plików. Efektywną
realizację tego zadania umożliwiają systemy plików. Zarządzają one
alokacją plików oraz wolną przestrzenią na dyskach wbudowanych lub
nośnikach przenośnych. Wolna przestrzeń, zwana również nieprzydzieloną,
oznacza niezapisany obszar dysku lub też obszar po skasowanych plikach.
Stosowane są różne systemy plików, wśród których najważniejsze to:
•
FAT (ang. File Allocation Table) – najstarszy system plików,
dawniej stosowany w systemach Windows; obecnie stosowany
powszechnie jako system plików nośników przenośnych (FAT32),
•
NTFS (ang. New Technology File System) – stosowany w
systemach Windows począwszy od XP; bardziej efektywny i
odporniejszy na błędy niż FAT; umożliwia szyfrowanie oraz
zarządzanie prawami dostępu na poziomie folderów i plików,
•
inne stosowane w komputerach Apple, czy też systemach Linux.
Zapisywanie danych na dyskach magnetycznych
Komputery przechowują dane w wyznaczonych obszarach dysku,
mogących pomieścić maksymalnie 512 bajtów, zwanych sektorami.
Natomiast w systemie plików najmniejszą jednostką alokacji jest tzw.
klaster. Może zajmować od jednego do nawet kilkudziesięciu sektorów.
Pliki zapisywane na dysku muszą zajmować całkowitą liczbę klastrów i
oczywiście sektorów. Lecz rzadko się zdarza, że plik wpasuje się dokładnie
w całkowitą liczbę klastrów. Ostatni klaster może być tylko częściowo
zajęty przez zapisywany plik, lecz jest przydzielony do tego pliku. To, co
nie zostało nadpisane (w ostatnim klastrze) przez aktualnie składowany
plik, zawiera dane z poprzedniego zapisu (ang. slack space), które mogą
być odczytane.
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Cyfrowe ślady w systemach Windows
8
Cyfrowe ślady w systemach
Windows
Wprowadzenie
Systemy z rodziny Windows opanowały około 90% komputerów
osobistych. Są przyjazne dla użytkowników, lecz można mieć wątpliwości,
czy są niezawodne i bezpieczne. Ich cechą jest to, że w czasie działania
zapisują niejako „w tle” mnóstwo informacji obrazujących aktywność
użytkownika, czyli co i kiedy robił na komputerze. Te cyfrowe ślady nie są
widoczne bezpośrednio, zwykle głęboko ukryte w systemie, lecz mogą być
łatwo uzyskane przy pomocy specjalistycznego oprogramowania. Są to
tzw. artefakty (ang. artifacts) systemu Windows. Natomiast w plikach
utworzonych przez aplikacje systemu Windows są umieszczane ukryte
tzw. metadane („dane o danych”), które mogą zawierać informacje,
których nie chcielibyśmy ujawniać, zwłaszcza publikując je w Internecie.
Kasowanie/odzyskiwanie danych w systemach plików Windows
Przeciętny użytkownik komputera po prostu kasuje zbędne pliki i nie
zastanawia się, czy ktoś może je odzyskać i zobaczyć co zawierają.
Bardziej świadomy dodatkowo opróżni kosz Windows (albo użyje
kombinacji klawiszy Shift+Delete). Niestety nie zapewnia to bezpiecznego
skasowania plików, ponieważ faktycznie nie są one usunięte z dysku – są
tylko oznaczone jako usunięte i miejsce przez nie zajmowane może być
użyte do zapisania innych plików. Współczesne dyski są bardzo pojemne i
system operacyjny może nie skorzystać z tego zwolnionego miejsca.
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Cyfrowe ślady w systemach Windows
9
Co to oznacza w praktyce? Dla wielu z nas jest to zaskakujące, lecz taki
nienadpisany plik łatwo odzyskać i odczytać zawarte w nim informacje. Do
tego celu wystarczy użyć odpowiedniego oprogramowania. Niekoniecznie
musi to być płatne, profesjonalne oprogramowanie. Dostępne w Internecie
bezpłatne programy sprawnie odzyskują nienadpisane, skasowane pliki.
Natomiast zaawansowane oprogramowanie używane w informatyce
śledczej (ang. computer forensics) umożliwia odzyskanie nawet częściowo
nadpisanych plików. Czasami w tych nienadpisanych sektorach jest
zawarta istotna informacja, której nie chcielibyśmy ujawnić – jak na
przykład w pliku poniżej (odzyskany plik graficzny prawie całkowicie jest
nadpisany, lecz to co pozostało zawiera istotną informację).
Źródło: materiały własne autora
Cyfrowe ślady w Koszu systemu Windows
Przypadkowe skasowanie ważnego pliku lub foldera może się
przydarzyć każdemu. Na szczęście z niemałego kłopotu w takim przypadku
wybawi nas Kosz systemu Windows. Zapewnia on, że kasowane pliki i
foldery tak naprawdę pozostają na swoim miejscu, a tylko logicznie są
przenoszone do ukrytego foldera $recycle.bin na tym samym dysku
komputera. Usunięty obiekt można łatwo przywrócić do oryginalnej
lokalizacji. Warto jednak zauważyć, że intencjonalnie usunięty plik lub
folder też może być łatwo przywrócony i odczytany, przez każdego, kto
ma dostęp do naszego komputera (może to być oczywiście dostęp zdalny,
np. przy pomocy złośliwego oprogramowania typu RAT – ang. Remote
Administration Trojan/Tool). Tak więc kosz Windows jest miejscem, w
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Cyfrowe ślady w systemach Windows
10
którym potencjalnie mogą się znajdować istotne cyfrowe ślady, łatwe do
uzyskania bez żadnego specjalistycznego oprogramowania.
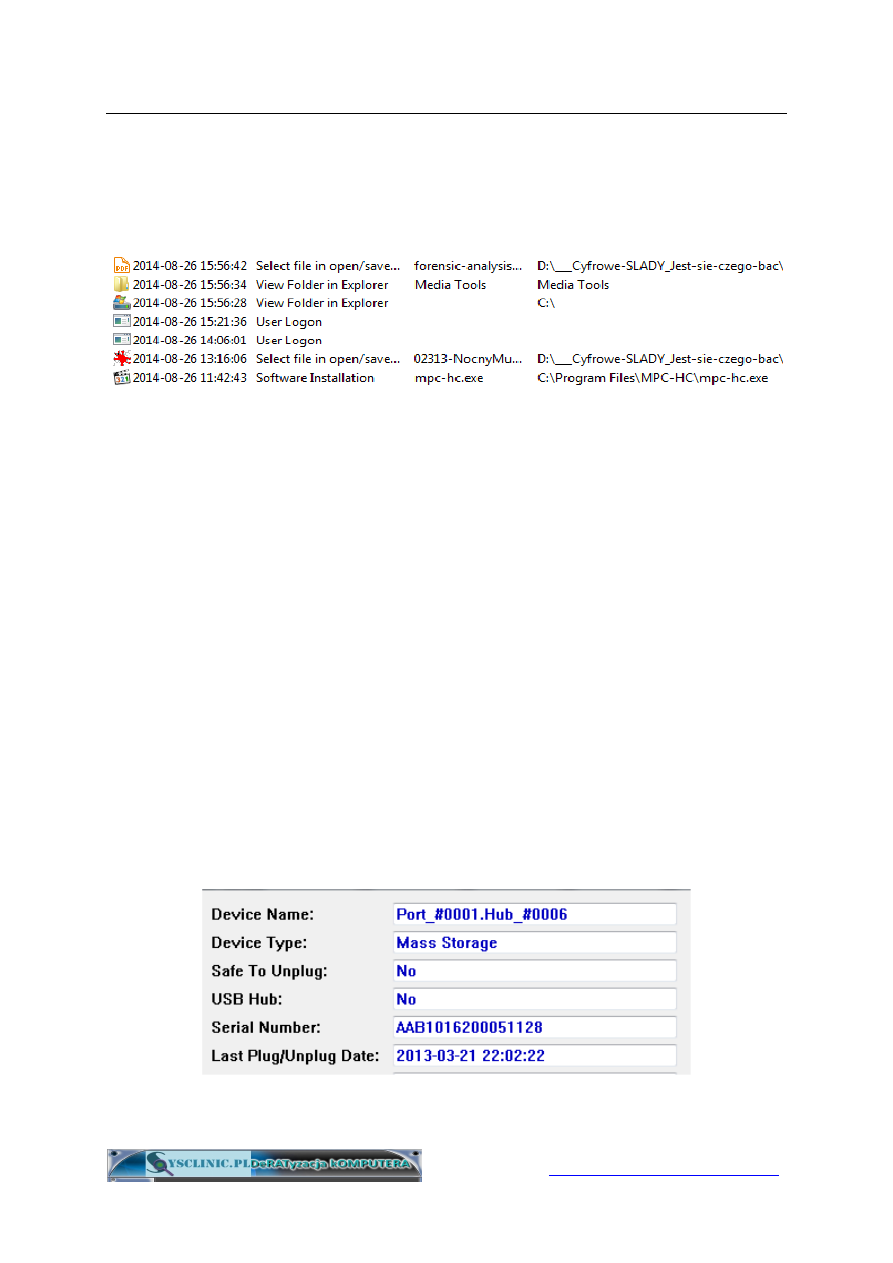
Ślady ostatniej aktywności na komputerze (ang. MRU lists)
Systemy Windows zapisują historię ostatniej aktywności użytkownika
na komputerze. Tworzą tzw. MRU listy (ang. Most Recent Used lists).
Rejestrują one ostatnio otwarte dokumenty, pliki, foldery, instalacje
oprogramowania itp. Powyżej widzimy przykład analizy aktywności
użytkownika. W pierwszej kolumnie mamy datę i godzinę czynności
określonej w kolumnie drugiej. Dalej mamy nazwę pliku i pełną ścieżkę
dostępu do tego pliku. Nie ma więc problemu, aby przy pomocy
specjalistycznego oprogramowania stwierdzić, czy jakiś plik był
otwierany/zapisywany (Select file in open/save dialog-box) lub czy był
otwierany folder (View Folder in Explorer). To samo dotyczy instalacji
programu (Software Installation). Proszę również zauważyć, że jest
zapisywane zalogowanie użytkownika (User Logon). To samo dotyczy
wylogowania (User Logoff). A więc jak widać nie ma problemu z
ustaleniem jaki użytkownik, kiedy i co zrobił na komputerze. A co się
stanie, jak podłączysz pendrive'a? Windows to zapamięta!
Zauważ, że każdy pendrive ma numer seryjny (Serial Number).
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Cyfrowe ślady w systemach Windows
11
Schowek systemu Windows
Systemy Windows oferują dobrze wszystkim znany mechanizm
kopiuj/wklej. Umożliwia on przenoszenie skopiowanej informacji z jednej
aplikacji Windows do drugiej (opcja wklej). Operacja jest realizowana przy
pomocy schowka (ang. clipboard), który tymczasowo przechowuje to, co
zostało ostatnio skopiowane. Mogą to być wszelkie informacje tekstowe,
graficzne, jak również nazwy plików lub folderów. Skopiowany obiekt
pozostaje w schowku tak długo, aż zostanie zastąpiony przez inny.
Kopiujemy róże informacje, nawet tak istotne jak hasło, numer karty
kredytowej, czy numer rachunku. Może to być niebezpieczne, bowiem
takie informacje mogą być przejęte i wykorzystane w dowolny sposób.
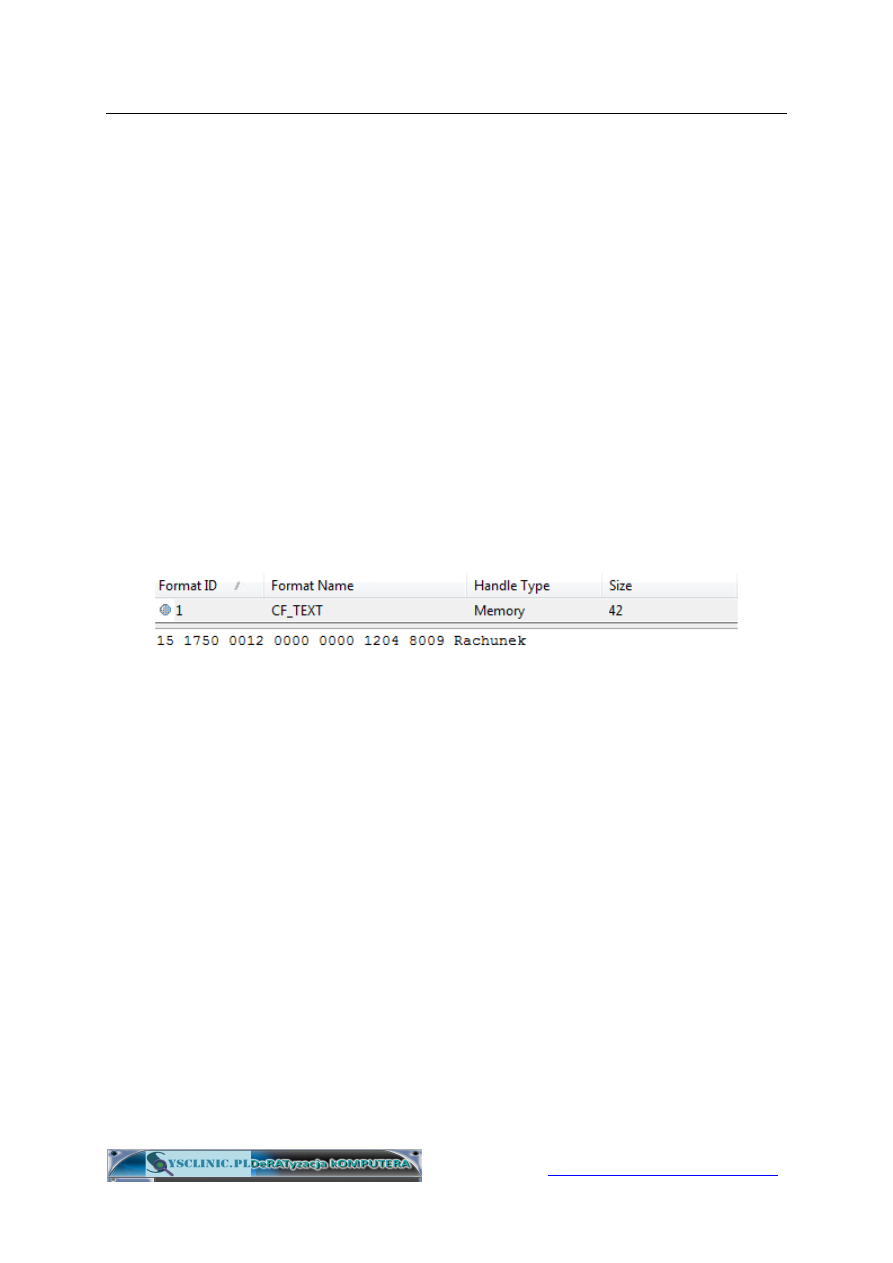
Poniżej przykładowy odczyt zawartości schowka z numerem rachunku.
Trojan bankowy VBKlip atakujący polskich użytkowników perfidnie
wykorzystuje schowek Windows do okradania ofiar. Działa bardzo prosto –
po prostu monitoruje zawartość schowka i jeżeli wykryje tekst w formacie
rachunku bankowego zamienia go w locie na inny. Efekt jest taki, że w
przelewie wklejamy inny numer rachunku niż ten, który skopiowaliśmy. A
teraz proszę zgadnąć, do kogo trafi nasz przelew? Nie jest istotne jaka
jest nazwa i adres odbiorcy – banki tego nie sprawdzają. Istotny jest tylko
poprawny numer rachunku. No właśnie, nasz przelew trafi więc do
cyberprzestępców. Jest to bardzo skuteczna forma okradania , ponieważ z
powodu swojej prostoty trojan VBKlip jest trudno wykrywalny.
Zawartość schowka może być również łatwo odczytana przez skrypty
umieszczone na stronach WWW. Jest to więc taki schowek bez zamka, do
którego każdy może zajrzeć i wykraść (lub podmienić!) jego zawartość.
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Ślady aktywności online w przeglądarkach WWW
12
Ślady aktywności online w
przeglądarkach WWW
Wprowadzenie
Przeglądarka WWW (ang. web browser) jest jedną z najważniejszych
aplikacji w komputerach i urządzeniach mobilnych. Służy nie tylko do
przeglądania zasobów Internetu, lecz również do korzystania z
różnorodnych usług. W dobie Web 2.0 są to przede wszystkim różne
serwisy społecznościowe, lecz także poczta, czy też bankowość
elektroniczna. Działa w modelu klient-serwer, co w uproszczeniu oznacza,
że wysyła do serwerów webowych żądania dostarczenia zawartości ich
serwisów. Następnie przeprowadza interpretację (renderowanie) danych
uzyskanych z serwerów w celu ich zobrazowania. W pewnych przypadkach
serwery również „nieproszone” przesyłają do przeglądarki dane, które są
zapisywane w komputerze. Mogą również „wyciągnąć” z naszego
komputera wiele istotnych informacji, zwłaszcza wykorzystując w tym celu
„zawartość aktywną” (ang. active web contents), najczęściej skrypty Javy.
Adres IP komputera podłączonego do Internetu
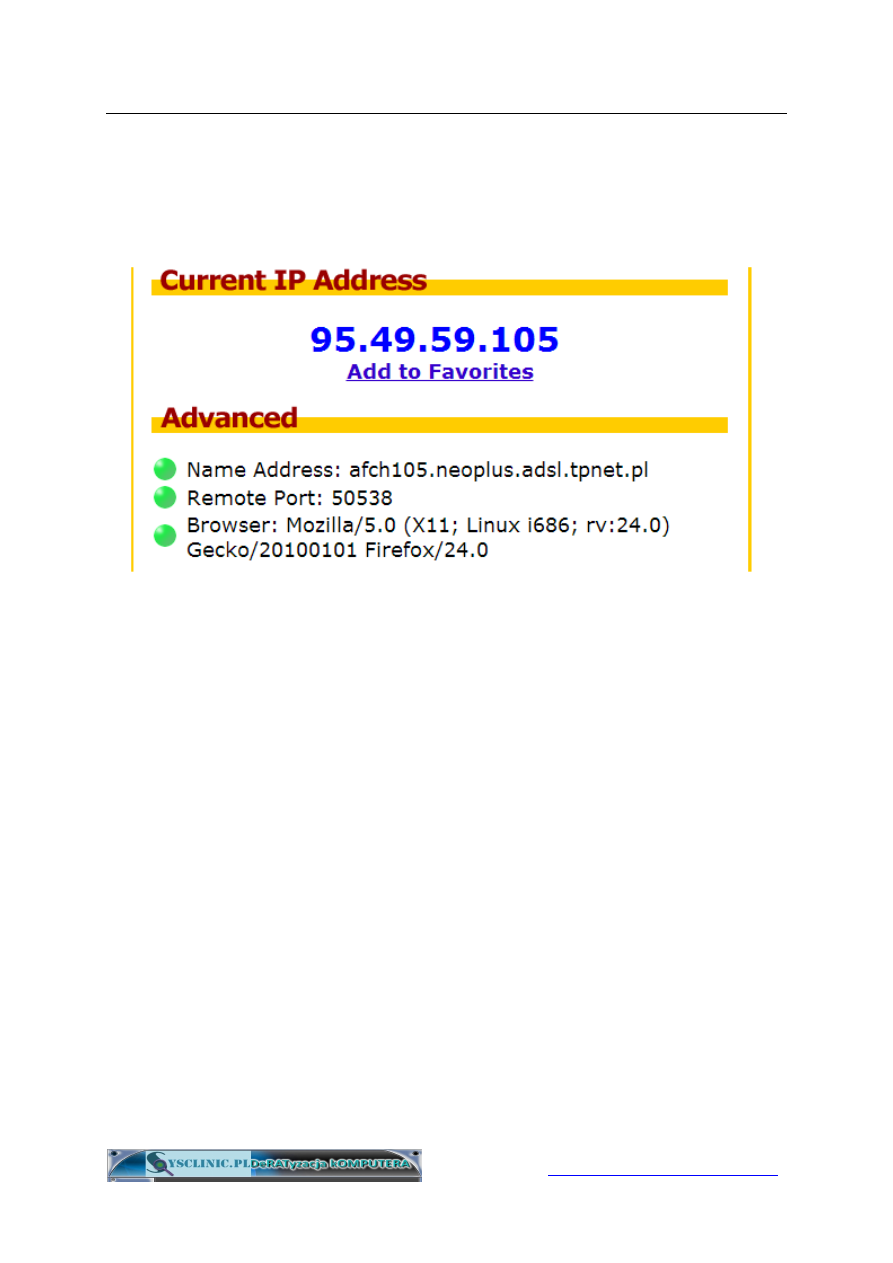
Każdy komputer czy też serwer podłączony do Internetu ma przypisany
unikatowy cyfrowy adres, zwany adresem IP (skrót od Internet Protocol).
Jest on faktycznie liczbą binarną, lecz w celu umożliwienia łatwego
odczytywania przez ludzi zapisuje się go w postaci czterech liczb
oddzielonych kropkami (każda do 0 do 255). Komputery mogą podzielić
się jednym adresem IP, zwanym w takim przypadku adresem publicznym.
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Ślady aktywności online w przeglądarkach WWW
13
Nazywa się to translacją adresów (ang. Network Address Translation,
NAT). Jednak i w takim przypadku, nasz dostawca usług internetowych
może jednoznacznie zidentyfikować komputer za NAT'em (przeglądarka
wykorzystuje konkretny port).
Zródło: IPChicken.com
Dlaczego adres IP jest tak ważnym cyfrowym śladem? Dlatego, że jest
on zapisywany w logach wszystkich serwerów, z których korzystamy
serfując po Internecie. Może być także ujawniany w naszych wpisach na
forach internetowych. Nawet jeśli jest to tzw. adres przypisywany
dynamicznie, policja może uzyskać od dostawcy usług internetowych
adres zamieszkania osoby, której ten adres IP w danym momencie był
przydzielony. Oznacza to, że anonimowość w Internecie jest dość
iluzoryczna, aczkolwiek są dobre sposoby ukrywania swojego prawdziwego
adresu IP.
Ciasteczka (ang. HTML cookies)
Ciasteczka są to małe pliki tekstowe zapisywane w twoim komputerze
przez rożne wyświetlane w przeglądarce strony WWW. Dzielą się na:
•
ciasteczka bezpośrednie (ang. first-party), zapisywane przez serwer,
na którym umieszczona (hostowana) jest dana strona
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Ślady aktywności online w przeglądarkach WWW
14
•
ciasteczka pośrednie (ang. third-party), zapisywane przez inne
serwery, do których odwołuje się wyświetlana strona, np. przez
banery reklamowe czy też różne ikony serwisów społecznościowych,
•
tymczasowe, usuwane automatycznie po zakończeniu surfowania lub
stałe, czyli długotrwale pozostające w przeglądarce.
Ciasteczka mogą zawierać dowolną treść, jaką zechcą zapisać
odwiedzane przez ciebie serwery. Zostały wymyślone po to, aby ułatwiać
nawigację na stronie. Są to tzw. ciasteczka sesyjne (ang. session cookies),
z reguły automatycznie kasowane po zamknięciu przeglądarki. Są
niezbędne w serwisach wymagających zalogowania, czy też do
zapisywania stanu tzw. koszyka w sklepach internetowych. Ogólnie można
stwierdzić, że ciasteczka sesyjne są niezbędne do prawidłowego
wyświetlania stron. Zdecydowanie nie można tego powiedzieć o tzw.
ciasteczkach śledzących (ang. tracking cookies), służących najogólniej
mówiąc do śledzenia aktywności użytkowników w czasie surfowania po
internecie. Więcej na ten temat w następnym rozdziale.
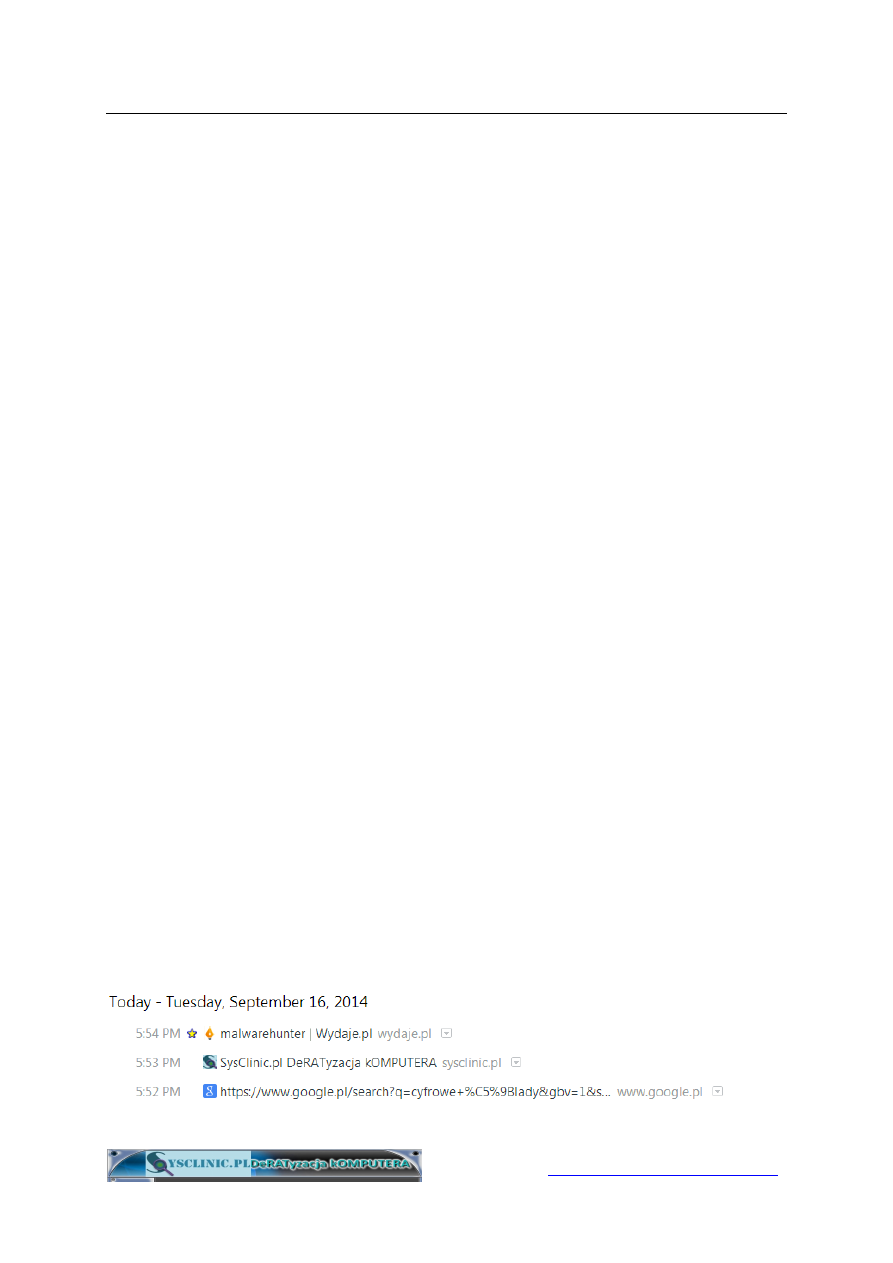
A oto przykład pośredniego ciasteczka śledzącego:
Zawartość ciasteczka (ang. Content) to unikatowy identyfikator
użytkownika przeglądarki oraz adres domenowy (ang. Domain) sewera,
który je zapisał. Proszę zwrócić uwagę na datę ważności (ang. Expires)
ciasteczka 24 styczeń 2019 roku! Jakie to ma znaczenie i czy jest się
czego bać? Otóż oznacza to, że ciasteczko będzie przechowywane w
komputerze przez prawie 5 lat i przez te 5 lat będzie możliwe śledzenie
oznakowanej przez to ciasteczko przeglądarki, czyli de facto jej
użytkownika. Ciasteczka można usuwać, lecz prawie nikt tego nie robi.
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Ślady aktywności online w przeglądarkach WWW
15
Historia odwiedzanych stron, URL oraz autouzupełniania
Przeglądarki WWW zapisują i przechowują adresy wyświetlanych stron,
adresy internetowe wpisywane ręcznie w pasku adresowym, jak również
historię autouzupełniania formularzy i haseł. Funkcjonalności te ułatwiają
przeglądanie zasobów Internetu. Można łatwo wrócić do już odwiedzonej
strony, nawet po zamknięciu przeglądarki. W czasie wpisywania adresu,
zwanego również URL (ang. Uniform Resource Locator) przeglądarka po
wpisaniu kilku liter podpowiada, na podstawie zapisanej historii, właściwy
adres. Jeszcze większe ułatwienia oferuje funkcjonalność
autouzupełniania. Polega to na tym, że przeglądarka przechowuje dane
do wypełniania formularzy, nazwy użytkowników i hasła. Zostaną one
automatycznie wstawione po powrocie na stronę, gdzie te dane były
wpisywane. Również odwiedzane strony są zapisywane dla wygody
tymczasowo na twardym dysku. Dotyczy to również pobieranych plików.
W zależności od wielkości obszaru dysku przeznaczonego na ich
przechowywanie (ang. browser cache), tymczasowo może oznaczać
całkiem długo. Zresztą nawet jak już zostaną skasowane, żeby zwolnić
miejsce dla nowych mogą być łatwo odzyskane.
Jak widać przeciętna przeglądarka WWW „dobrze wie” co i kiedy
przeglądaliśmy w Internecie. A przeglądarka Google Chrom zapisuje
również wszystkie nasze google'owania – lokalnie, na twardym dysku
komputera. Czy jest więc się czego bać? Myślę, że to zależy od
okoliczności. Oczywiście można te cyfrowe ślady skutecznie usunąć.
A oto przykład historii odwiedzanych stron (materiały własne autora).
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Wykorzystywanie cyfrowych śladów w Internecie
16
Wykorzystywanie cyfrowych
śladów w Internecie
Wprowadzenie
Surfując po Internecie pozostawiamy mnóstwo różnorodnych cyfrowych
śladów, które mogą być automatycznie gromadzone, przechowywane i
analizowane. Powstały cyberkorporacje, które wyspecjalizowały się w
tworzeniu na ich podstawie olbrzymich baz indywidualnych profili
użytkowników (konsumentów). Służą one do personalizowania reklam, czy
też wyników wyszukiwania w Internecie. Największą cyberkorporacją,
której model biznesowy opiera się na gromadzeniu i analizie danych o
użytkownikach jest Google. Oferując bezpłatnie różnorodne atrakcyjne
usługi (najbardziej znana jest wyszukiwarka) osiąga ona 96 % swoich
dochodów ze spersonalizowanych reklam (dane z 2009 r.)
Sposoby gromadzenia danych o użytkownikach
Efektywne pozyskiwanie danych na temat określonego użytkownika,
wymaga użycia wyrafinowanych sposobów śledzenia, bowiem nie zawsze
jest on zalogowany w serwisie internetowym typu Google+. Jakie cyfrowe
ślady są wykorzystywane do śledzenia i profilowania użytkowników? Co
ujawniają śledzącym nas cyberkorporacjom? Poniżej krótki przegląd.
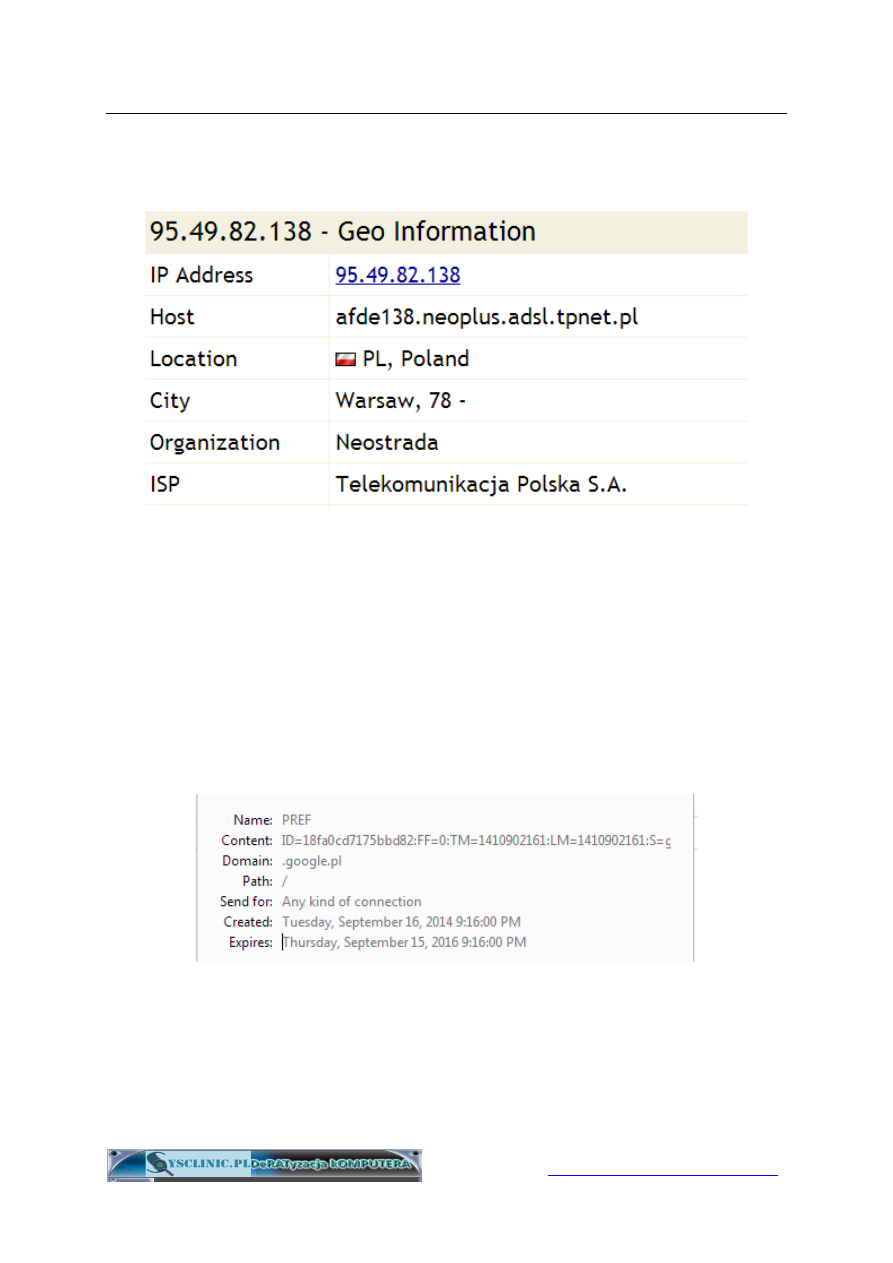
Adres IP komputera ujawnia:
•
kraj, miasto/region w którym znajduje się śledzony komputer,
przeglądarka, de facto użytkownik – jest to tzw. geolokalizacja
2
http://anonymous-proxy-servers.net/en/help/wwwprivacy.html
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Wykorzystywanie cyfrowych śladów w Internecie
17
•
nazwę naszego dostawcy usług internetowych (ang. ISP, Internet
Service Provider), np. Telekomunikacja Polska S.A.
•
czasami również nazwę firmy, jeśli korzystamy z Internetu w pracy.
Ciasteczka śledzące – służą do identyfikacji i zapamiętania
użytkownika serwisów WWW (unikatowy ID). Są zapisywane w
przeglądarce i przechowywane do ich daty ważności (ang. Expires).
Zapewniają jednoznaczne rozpoznanie użytkownika, jeśli korzysta z
jakichkolwiek stron o adresie określonym w polu Domain. Poniżej
przykładowe ciasteczko Google'a, który dla adresów IP rozpoznanych jako
zlokalizowane w Polsce posługuje się adresem google.pl
Supercookies, Evercookies i Zombie cookies – są to specjalne
ciasteczka, stosowne przez cyberkorporacje wyspecjalizowane w
agresywnym śledzeniu użytkowników, trudniejsze do usunięcia, niż
„zwykłe” ciasteczka (ang. HTML cookies).
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Wykorzystywanie cyfrowych śladów w Internecie
18
Identyfikator (ang. fingerprint) przeglądarki – umożliwia unikatowe
lub prawie unikatowe rozpoznanie każdej przeglądarki, niezależnie od
plików cookies, które dość łatwo mogą być usuwane. Jak to możliwe? W
tym przypadku wykorzystywana jest podstawowa zasada działania
przeglądarek – wysyłają one do serwera WWW nie tylko żądanie
wyświetlenia strony WWW, lecz również dodatkowe informacje. Są to
najczęściej: język przeglądarki, jej nazwa i wersja, nazwa i wersja
systemu operacyjnego, a także inne charakterystyczne dane, takie jak
zainstalowane czcionki, wtyczki itp. Na podstawie tych danych, w oparciu
o rożne algorytmy, są wyliczane identyfikatory przeglądarek. Jest to na
tyle skuteczny mechanizm, że umożliwia śledzenie ponad 80%
przeglądarek, czyli de facto użytkowników. Sytuacja staje się jeszcze
gorsza, jeśli przeglądarka obsługuje Javascript, aplety Javy lub Flash'a. A
najczęściej obsługuje, bowiem jest to niezbędne do poprawnego
wyświetlenia większości stron WWW. W takim przypadku efektywność
śledzenia zwiększa się do 94% (źródło: JonDos GmbH, wrzesień 2014).
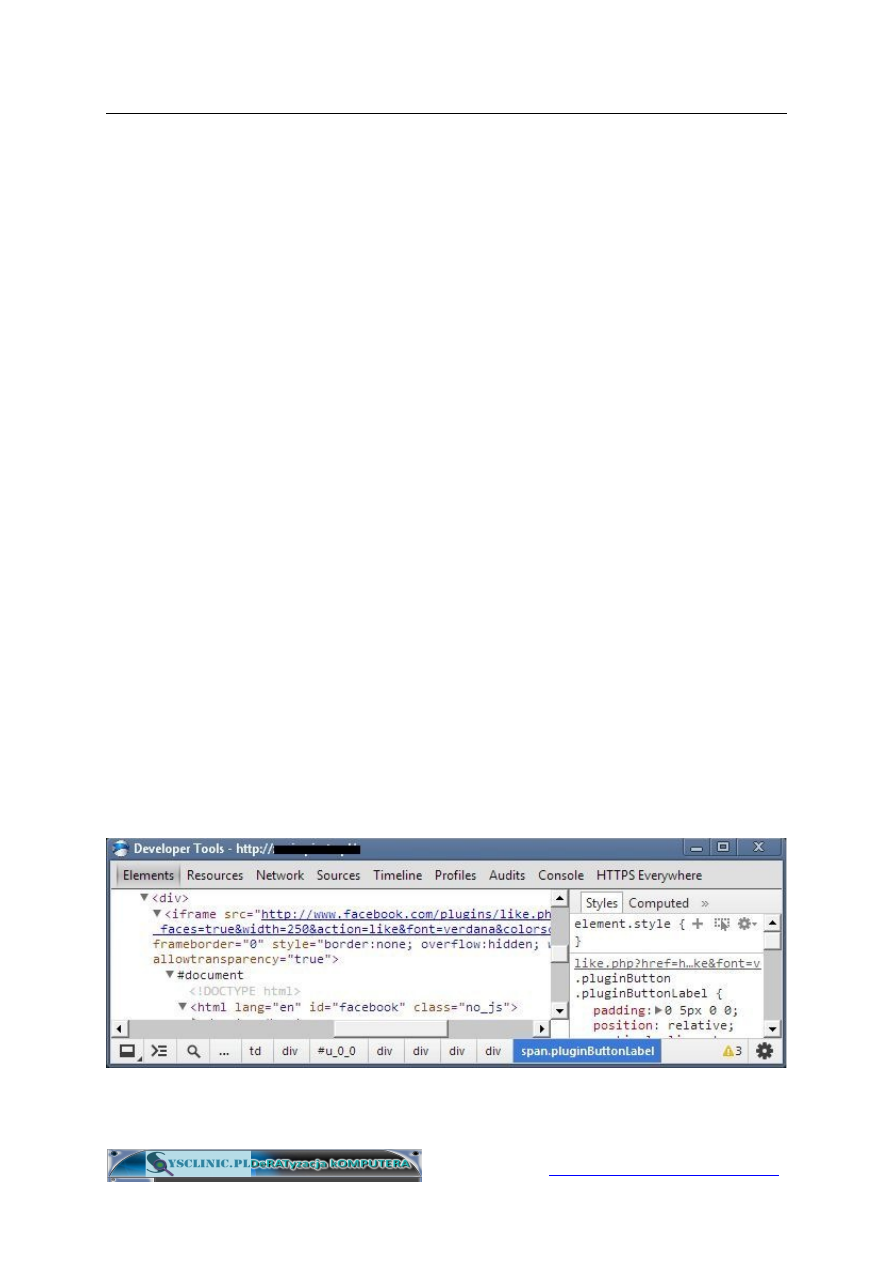
Czy jest się czego bać? Przecież nie wszystkie strony nas śledzą.
Okazuje się jednak, że nie trzeba odwiedzać śledzącej strony, aby być
przez nią śledzonym. Śledzą nas różne bannery reklamowe oraz przyciski
mediów społecznościowych i nie trzeba nawet na nie nawet klikać! Śledzą
nas za pomocą tzw. iFrame'a, który zresztą może być także niewidoczny.
A oto przykład przycisku fejsbukowego lajka (materiały własne autora).
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Wykorzystywanie cyfrowych śladów w Internecie
19
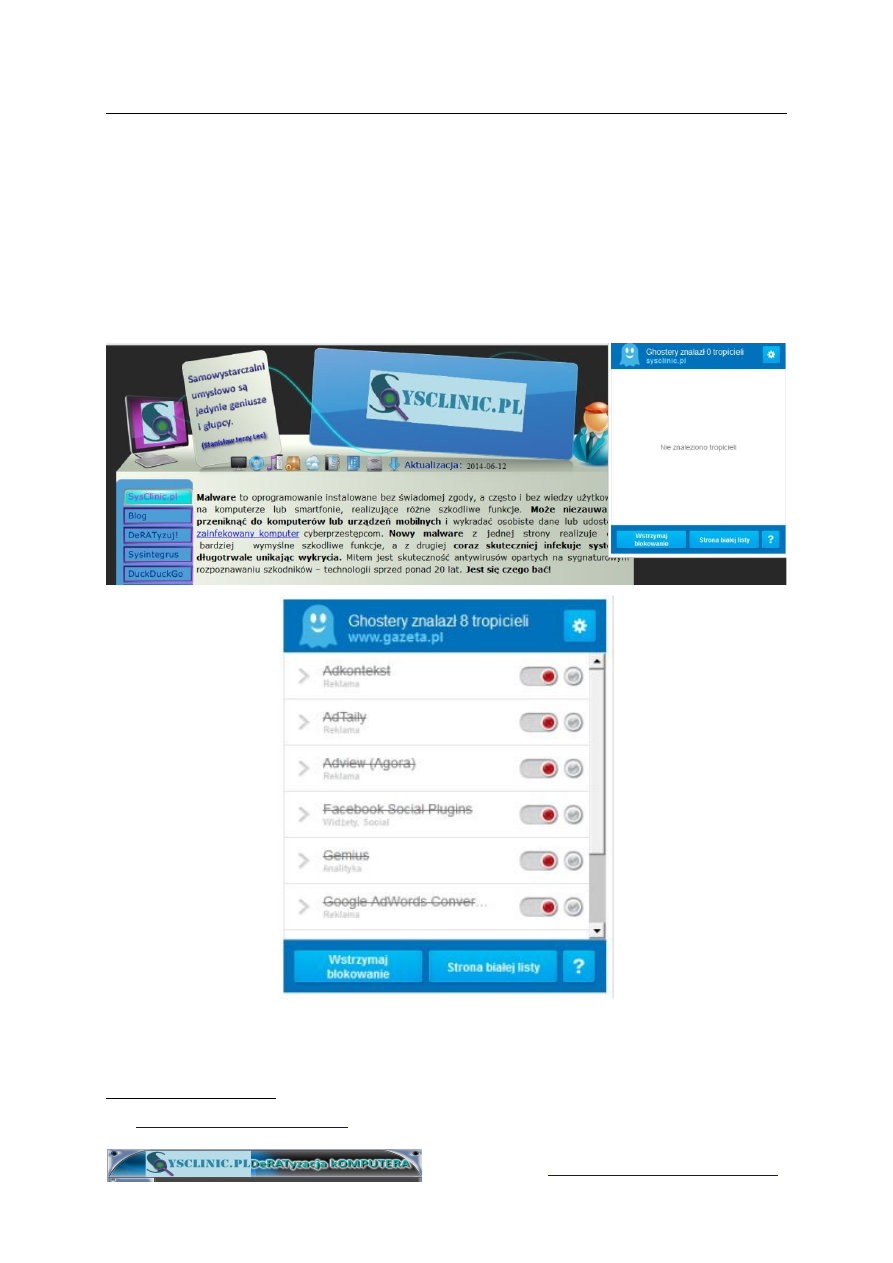
Tropiciele (ang. trackers) na stronach WWW
Ponad 80% stron WWW używa jednego lub kilku omówionych na
poprzednich stronach mechanizmów śledzenia użytkowników. Odwiedzenie
50-ciu największych serwisów WWW spowoduje zainstalowanie w twoim
komputerze pond 3 tysięcy różnorodnych plików śledzących – tropicieli
Powyżej zamieszczono przykład strony, nie zawierającej żadnych
tropicieli oraz jednej z największych polskich stron WWW (Google
PageRank: 7). Źródło: materiały własne autora.
3
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Wykorzystywanie cyfrowych śladów w Internecie
20
Reklama behawioralna (ang. OBA, Online behavioral ads)
Modele biznesowe większości cyberkorporacji opierają się głównie na
dochodach z reklam zachęcających do zakupu towarów lub usług. Dochody
te są tym większe, im skuteczniejsza jest reklama. A jej skuteczność jest
tym większa, im bardziej adekwatne reklamy są pokazywane
odwiedzającym daną stronę WWW. Internauci niezbyt lubią reklamy, a te,
którymi nie są w ogóle zainteresowani powodują ich irytację. Nie
przekłada się to korzystnie na wyniki sprzedaży. Rozwiązaniem tego
problemu jest reklama skierowana do konkretnego użytkownika -taka,
która go zainteresuje, co może zaowocować tak pożądaną sprzedażą.
Skąd się dowiedzieć, jakie reklamy komu wyświetlać? Trzeba śledzić, w
dłuższym okresie czasu aktywność, czyli zachowanie określonego
użytkownika w Internecie i na podstawie tej wiedzy wyświetlać na „jego”
stronie WWW reklamy, które z pewnością go zainteresują.
Reklama behawioralna opiera się na tzw. profilowaniu użytkowników,
czyli zbieraniu wszelkich informacji o konkretnej osobie, które mogą być
przydatne z punktu widzenia personalizacji usług. Oczywiście, samo w
sobie to nie musi być coś negatywnego, czy też niekorzystnego dla
profilowanych użytkowników. Rzeczywiście może to umożliwić lepsze
dopasowanie prezentowanych treści, w tym reklam, do konkretnej osoby.
Zresztą to jest podstawowy argument uzasadniający reklamę
behawioralną. Lecz z drugiej strony, warto się zastanowić, jakie są
negatywne konsekwencje profilowania użytkowników? Z pewnością jest to
pewne zagrożenie naszej prywatności, lecz profile użytkowników nie są
powiązane z konkretną osobą określoną z imienia i nazwiska lub
identyfikowaną przez inne dane osobowe. Przynajmniej tak twierdzą
korporacje internetowe profilujące swoich użytkowników i świadczące
usługi reklamy behawioralnej. A jednak jest powód do zaniepokojenia.
Okazuje się, że sprofilowanie powoduje ograniczenie dostępu do pełnej
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Wykorzystywanie cyfrowych śladów w Internecie
21
informacji, nie tylko zresztą na temat dostępnych towarów i usług. To
samo dotyczy wszelkich informacji, które możemy uzyskać za pomocą
wyszukiwarki Google. W konsekwencji Internet staje się coraz bardziej
rozwarstwiony w tym sensie, że nie prezentuje takich takich samych treści
dla każdego użytkownika. Czy to nie ogranicza mojej i twojej wolności?
Czy nie jest tak, że to Google decyduje, jakie treści w Internecie są dla
mnie odpowiednie? A w konsekwencji, czy mogę się dowiedzieć, tylko
tego, co już wiem? Bo wcześniej szukałem podobnych informacji...
Przykład połączeń tropicieli. Źródło: materiały własne autora.
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net

Źródła, ebooki, zasoby online
22
Źródła, ebooki, zasoby online
Źródła:
The World Wide Web and your privacy
, Internet 5.10.2014
, Internet 5.10.2014
, Internet 5.10.2014
Samuel Daniel „An Internet Of Nosy Insects”, Tufts University 2013
Gutwirth, S., Leenes, R., de Hert, P., Poullet, Y. (Eds.)
„European Data Protection: In Good Health?”, Springer 2012
John Sammons „The Basics of Digital Forensics”, © 2012 Elsevier, Inc.
Ebooki:
Leszek IGNATOWICZ "Cyfrowe ślady. Tropienie i zacieranie.
Poradnik ochrony prywatności”
(w opracowaniu)
Leszek IGNATOWICZ "Cyfrowe ślady. Zabezpieczanie,
wykrywania i analiza. Podstawy informatyki śledczej"
(w oprac.)
Zasoby online:
Electronic Frontier Foundation
HTTP cookie – Wikipedia, wolna encyklopedia
What is Online Behavioral Advertising (OBA)
C
Leszek.Ignatowicz@SysClinic.pl
Ebookpoint.pl kopia dla: kp89@riseup.net
Document Outline
- Wstęp
- Podstawy cyfrowego przetwarzania informacji
- Cyfrowe ślady w systemach Windows
- Ślady aktywności online w przeglądarkach WWW
- Wykorzystywanie cyfrowych śladów w Internecie
- Źródła, ebooki, zasoby online
Wyszukiwarka
Podobne podstrony:
cyfrowe slady jest sie czego bac pl
Slowianskie zle moce jest sie czego bac
Mity bezpieczenstwa IT Czy na pewno nie masz sie czego bac mibeit
Mity bezpieczenstwa IT Czy na pewno nie masz sie czego bac mibeit
informatyka mity bezpieczenstwa it czy na pewno nie masz sie czego bac john viega ebook
jest się czy chwalić
Jak powiedzieć szefowi ,że jest się w ciąży
02 Aborcja czym jest i do czego prowadzi
B. kaniewska I tak taki jest się jaki jest– wokół kategorii podmiotu, Uniwerek, Seminarium
Najważniejsze jest to, czego nie widać, rozmowa z Wojciechem Eichelbergerem
potwierdzenie ze jest sie malym przedsiebiorca nie podlegajacym pod Mwst (Vat)
ekonomia giełda, Bilans handlowy, Co to jest bilans i z czego wynika
więcej podobnych podstron