Spróbujemy teraz wykorzystać w praktyce zdobyte dotychczas umiejętności. Jedną z ważniejszych cech Perla jest jego elastyczność i zgodnie z powiedzeniem dotyczącym tego języka każdy problem można w Perlu rozwiązać na co najmniej dwa sposoby. Dlatego też w niniejszej instrukcji przedstawiony zostanie jedynie pseudokod lub ogólny plan rozwiązania problemów programistycznych, którymi będziemy się zajmować tak, aby nie ograniczać inwencji twórczej programisty ☺
Poszukiwanie motywów w sekwencji
Brzmi znajomo, jednak tym razem zajmiemy się poszukiwaniem motywów, które pobierzemy z pliku oraz ustalimy ich ranking na podstawie ilości trafień w sekwencji DNA.
Oto w jaki sposób zabierzemy się do tego. W pierwszej kolejności powinniśmy wczytać odpowiednią sekwencję DNA z pliku. Pamiętajmy o obsłudze błędów, to znaczy skonstruujmy nasz program w taki sposób, aby zabezpieczyć się przed możliwymi pojawiającymi się błędami (np. brak pliku, który chcemy otworzyć). Oczywiście nie jest to konieczne dla funkcjonowania danego skryptu, jednak zadbanie o prawidłową obsługę błędów jest eleganckie i należy do dobrej praktyki programistycznej.
Dla większej łatwości operowania sekwencją odpowiednią tablicę zamieniamy w jeden ciąg.
Teraz możemy zabrać się za motywy, których będziemy poszukiwać w naszej sekwencji DNA. Podobnie jak powyżej wczytujemy motywy z odpowiedniego pliku i umieszczamy je w tablicy. Zwracam uwagę na konieczność pozbycia się znaków nowej linii, które występować będą na końcach poszczególnych motywów.
Tak przygotowaniu możemy zacząć właściwą część skryptu, która będzie poszukiwać motywów w sekwencji DNA i zliczać ilość trafień. W tym celu wykorzystamy pętlę foreach, za pomocą której pobierać będziemy motywy i przeszukiwać sekwencję DNA. Trafienia będziemy zliczać za pomocą pętli while, podobnie jak miało to miejsce w przykładzie dotyczącym obliczania ilości odpowiednich zasad w sekwencji DNA. Ostatnią operacją jakiej dokonamy w pętli foreach będzie zapisanie wyników zliczania trafień w odpowiedniej tablicy. Tutaj uwaga, elementy tej tablicy powinny odpowiadać kolejnym elementom w tablicy zawierającej motywy.
Ostatnim etapem będzie wydrukowanie wyników na ekranie. W tym celu znowu korzystamy z pętli foreach i drukujemy kolejne motywy z tablicy motywów oraz odpowiadające im trafienia z tablicy trafień.
Brzmi być może trochę skomplikowanie, ale w gruncie rzeczy jest to bardzo prosty program. Oto jego pseudokod:
#zainicjuj zmienne
$plik_dna = ‘dna.txt’;
$plik_motywy = ‘motywy.txt’
wczytaj sekwencję DNA z pliku $plik_dna do tablicy @DNA
zamień tablicę @DNA na łańcuch $DNA
#wczytaj motywy z pliku $plik_motywy do tablicy @motywy
while(<PLIKMOTYWY>) {
usuń znak nowej linii
zapisz w tablicy @motywy
}
# szukaj motywów w sekwencji DNA
Trochę praktyki…
Strona 1
foreach(@motywy) {
resetuj licznik
while(trafienia w $DNA) {
powiększ licznik o jeden
}
zapisz licznik w tablicy @wyniki
}
# drukujemy wyniki
foreach(@wyniki) {
drukuj odpowiedni motyw – element tablicy @motywy
drukuj odpowiadający mu wynik poszukiwań
}
exit;
Teraz tylko trzeba dobrać odpowiednie instrukcje kodu i sprawdzić działanie skryptu. Oczywiście program ten można skonstruować w inny sposób, to jest po prostu jedna z możliwości na napisanie której pozwalają nam poznane dotychczas informacje. Skrypt można by wzbogacić o kod, który pozwalałby na posortowanie wyników. Tylko uwaga!
Musimy pamiętać, że nasze motywy i wyniki znajdują się w osobnych tablicach, więc trzeba by dobrze przemyśleć całą operację sortowania.
Najprostsza grafika
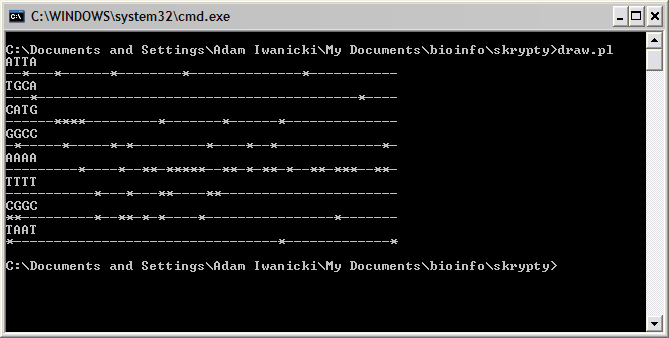
Grafika to może trochę za mocno powiedziane. Spróbujemy teraz napisać skrypt, który przedstawiałby w formie graficznej wyniki naszych poszukiwań motywów. Wynik działania takiego skryptu mógłby wyglądać na przykład tak:
|------*---*--|
gdzie myślniki reprezentują fragmenty sekwencji przedstawione w jakiejś skali (trudno, żebyśmy mieli drukować na ekranie na przykład fragment DNA o długości 12 tysięcy par zasad), natomiast gwiazdki to położenie motywów.
Oczywiście to bardzo zgrubna prezentacja graficzna, jednak pozwala ona na szybkie zorientowanie się gdzie w interesującym nas fragmencie DNA znajduje się poszukiwany przez nas motyw. Oto przykładowy wynik wygenerowany przez skrypt:
Trochę praktyki…
Strona 2
W programie możemy wykorzystać część kodu napisanego w poprzednim przykładzie, ponieważ część zadań, jakie mają zostać wykonane jest dokładnie taka sama. Zatem po inicjalizacji zmiennych i wczytaniu danych z odpowiednich plików rozpoczynamy poszukiwanie motywów. Tym razem, zamiast zapisywania w tablicy samych ilości trafień dla odpowiednich motywów zapamiętujemy pozycje poszczególnych trafień dla każdego z motywów. Do tego celu korzystamy z funkcji pos(). Zatem kod:
while($dna =~ /$_/ig) {
push(@positions, pos($dna));
}
pozwala nam na przeszukanie sekwencji przechowywanej w zmiennej $dna i zapisanie w tablicy @positions pozycji znalezionych motywów.
Oto plan naszego programu. Rozpoczynamy od zainicjowania zmiennych i otwarcia pliku zawierającego sekwencję.
Tablicę zawierającą linie sekwencji zamieniamy na zmienną tekstową. Pamiętajmy o zdefiniowaniu zmiennej określającej skalę, w jakiej rysować będziemy nasze wyniki poszukiwań. Następnie wczytujemy z pliku motywy, pamiętając o usuwaniu znaku końca linii. Motywy zapamiętujemy w odpowiedniej tablicy. Teraz przystępujemy do poszukiwania motywów i rysowania wyników na ekranie. Do tego celu wykorzystujemy pętlę foreach, która wykonywana jest dla wszystkich elementów tablicy zawierającej motywy. Korzystając z pętli while i funkcji pos, zapisujemy w czasowej tablicy pozycje kolejnych trafień dla danego motywu.
Teraz zaczynamy tworzyć tablicę, na podstawie której wygenerujemy nasz rysunek. Stosujemy prosty trick, w którym kolejne elementy tablicy odpowiadać będą kolejnym myślnikom reprezentującym naszą sekwencję. Oczywiście najpierw przeliczamy długość sekwencji na jej długość w skali i cała tablicę rysunku wypełniamy myślnikami.
Przydatna może być funkcja int(), która zwraca część całkowita danej liczby. Następnie korzystając z pętli foreach, którą wykonujemy dla wszystkich elementów tablicy zawierającej pozycje trafień dla bieżącego motywu i przeliczamy tą pozycję w odpowiedniej skali. Uzyskany wynik jest dla nas wskazówką w którym miejscu tablicy rysunku należy umieścić znak gwiazdki, odpowiadający trafieniu. Teraz pozostaje już tylko zamiana tablicy rysunku na jedną zmienną i wyświetlenie jej na ekranie. Jako ostatni krok resetujemy tablice pozycji oraz rysunku.
A oto odpowiedni pseudokod programu:
#zainicjuj zmienne
$plik_dna = ‘dna.txt’;
$plik_motywy = ‘motywy.txt’
$skala
wczytaj sekwencję DNA z pliku $plik_dna do tablicy @DNA
zamień tablicę @DNA na łańcuch $DNA
#wczytaj motywy z pliku $plik_motywy do tablicy @motywy
while(<PLIKMOTYWY>) {
usuń znak nowej linii
zapisz w tablicy @motywy
}
# szukaj motywów i rysuj wynik
foreach(@motywy) {
while(trafienia w $DNA) {
zapisz pozycję trafienia w tablicy @pozycje
}
Trochę praktyki…
Strona 3
przelicz długość sekwencji na długość skali i zapisz w $caly
# twórz tablicę rysunku
for($licznik = 0; $licznik < $caly; ++$licznik) {
zapisz myślnik w elemencie $rysunek[$licznik]
}
# wstaw gwiazdki w miejsca trafień w sekwencji
foreach(@pozycje) {
wyraź pozycję w skali i zapisz w $pozycja
zapisz gwiazdkę w elemencie $rysunek[$pozycja]
}
# rysuj
zamień tablicę @rysunek na zmienną
drukuj zmienną rysunku na ekranie
# reset tablic
zresetuj tablicę @pozycje
zresetuj tablicę @rysunek
}
exit;
Po uzupełnieniu powyższego pseudokodu odpowiednimi instrukcjami i uruchomieniu programu powinniśmy otrzymać wynik zbliżony do wyniku przedstawionego na początku tego przykładu.
Sekwencja consensus
A teraz zadanie. Proszę napisać skrypt, który generować będzie sekwencję consensus na podstawie dwóch sekwencji zapisanych w odpowiednich plikach. Wynik powinien wyglądać na przykład tak:
------A--CG-----TG----C------ACGTG-----
Myślnik oznacza pozycję w sekwencji, dla której brak jest zgodności zasad, natomiast litery to sekwencje consensusowe.
Trochę praktyki…
Strona 4
Wyszukiwarka
Podobne podstrony:
praktyki cz 2
mellibruda sobolewska integracyjna psychoterapia uzaleznien teoria i praktyka cz 1 i 2
Przygotowanie do stosowania wyrażeń dwumianowanych w praktyce cz I notatka, edukacja matematyczna z
Geometria w praktyce, cz 1 Dach pulpitowy i dwuspadowy
Przygotowanie do stosowania wyrażeń dwumianowanych w praktyce cz II referat, edukacja matematyczna z
Geometria w praktyce, cz 2 ?ch czterospadowy i kopertowy
Sprawozdanie z praktyk cz.2, Praktyki w Akzo Nobel Coatings Sp ZOO
Geometria w praktyce, cz 2 Dach czterospadowy i kopertowy
Geometria w praktyce, cz 1 ?ch pulpitowy i dwuspadowy
(MIDI w praktyce cz 5 Zmiana kanałów (śladów)
Pomiary oscyloskopowe okiem praktyka cz 04
Metasploit w praktyce cz II
Edycja zdjęć w praktyce, cz III krótki przewodnik po programach
więcej podobnych podstron