Katedra Architektury Systemów Komputerowych
Laboratorium
Architektury Komputerów
Materiały pomocnicze do ćwiczeń laboratoryjnych cz. I
S p i s t r e ś c i
Asemblacja i konsolidacja programu w asemblerze
Przetwarzanie tekstów z wykorzystaniem modyfikacji adresowych
Konwersje dziesiętno-dwójkowa i dwójkowo-dziesiętna
Dodatek A: Uruchamianie programów z wykorzystaniem debuggera
Opracował dr inż. Andrzej Jędruch
Gdańsk 2007
Laboratorium Architektury Komputerów
Ćwiczenie 1
Asemblacja i konsolidacja programu w asemblerze
Wprowadzenie do programowania w asemblerze
Mimo intensywnego rozwoju rozmaitych języków programowania, ciągle spotyka się systemy oprogramowania, których bardziej wyrafinowane fragmenty konstruowane są na poziomie rozkazów procesora. Ponieważ jednak bezpośrednie kodowanie rozkazów procesora byłoby bardzo żmudne i kłopotliwe, od wielu lat stosuje się języki programowania, które łączą w sobie możliwość programowania na poziomie pojedynczych rozkazów procesora, uwalniając jednocześnie programistę od żmudnych czynności binarnego kodowania i adresowania rozkazów. Języki te, zazwyczaj odrębne dla każdej rodziny procesorów, przyjęto nazywać asemblerami. Asemblery oferują szereg rozmaitych opcji, czyniąc programowanie maksymalnie elastycznym i wygodnym. Dla komputerów PC używane są najczęściej: asembler MASM firmy Microsoft, którego najnowsza wersja oznaczona jest numerem 8.0 oraz asembler TASM firmy Borland. W sieci Internet dostępnych jest wiele innych asemblerów, spośród których najbardziej znany jest asembler NASM, udostępniany w wersjach dla systemu Windows i Linux.
W początkowym okresie rozwoju informatyki asemblery stanowiły często podstawowy język programowania, na bazie którego tworzono nawet złożone systemy informatyczne. Obecnie asembler stosowany jest przede wszystkim do tworzenia modułów oprogramowania, działających jako interfejsy programowe. Należy tu wymienić moduły służące do bezpośredniego sterowania urządzeń i podzespołów komputera. W asemblerze koduje się też te fragmenty oprogramowania, które w decydujący sposób określają szybkość działania programu. Wymienione zastosowania wskazują, że moduły napisane w asemblerze występują zazwyczaj w połączeniu z modułami napisanymi w innych językach programowania.
Asembler możemy też uważać jako narzędzie, za pomocą którego można zbadać podstawowe mechanizmy wykonywania programów przez procesor na poziomie rejestrowym. Taki właśnie punkt widzenia przyjęto w niniejszym opracowaniu.
Samodzielne programy w asemblerze
Niekiedy jednak tworzymy samodzielne programy w asemblerze. W tego rodzaju programach, w przypadku komputerów PC, istotnym problemem jest odpowiednie zakodowanie komunikacji programu ze światem zewnętrznym. Współczesne systemy operacyjne nie pozwalają bowiem na bezpośrednie sterowanie urządzeniami, lecz wymagają zawsze obowiązkowego pośrednictwa systemu operacyjnego. W szczególności oznacza to, że program, który zamierza wyświetlić tekst na ekranie musi zwrócić się z prośbą do systemu operacyjnego o wyświetlenie tego tekstu.
Systemy operacyjne oferują dla programów najrozmaitsze funkcje usługowe, które realizują wprowadzenie danych z klawiatury, wyświetlanie tekstu i grafiki, zapis i odczyt plików, przesyłanie informacji do/z sieci komputerowych i wiele innych. Opisy usług udostępnianych przez system operacyjny zebrane są w formie dokumentu oznaczanego skrótem API (ang. application program interface), co tłumaczymy jako interfejs programowania aplikacji. API dla 32-bitowych wersji systemu MS Windows oznaczane jest skrótem Win32 API i zawiera opisy ponad 1000 funkcji usługowych. Opisy te zostały zdefiniowane na poziomie języka C. W praktyce dokumentacja API umieszczona jest w plikach, np. WIN32API.HLP.
W konsekwencji wywołanie funkcji usługowej Win32 API na poziomie asemblera musi być przeprowadzone wg standardów stosowanych przez kompilatory języka C. Wymaga to znajomości techniki przekazywania parametrów przez stos i innych szczegółów interfejsu. Na razie omówimy sposoby wywoływania typowych funkcji, a szczegóły związane z mechanizmem przekazywania parametrów przedstawimy w dalszej części opracowania.
Obok interfejsu Win32 API, system Windows udostępnia nadal inny interfejs, odziedziczony po systemie DOS, zdefiniowany na poziomie 16-bitowego kodu asemblerowego. Interfejs ten nie jest jednak dostępny w najnowszych, 64-bitowych wersjach systemu Windows. W omawianym interfejsie podprogramy usługowe systemu operacyjnego wywoływane są za pomocą rozkazu INT, a parametry wywołania przekazywane są najczęściej przez rejestry procesora. W literaturze tego rodzaju wywołania nazywane są często (nieściśle!) przerwaniami DOSu lub BIOSu.
Przykładowy program asemblerowy
Autorzy 32-bitowego interfejsu programowego systemu Windows, kierując się zamiarem implementacji systemu operacyjnego na różne typy procesorów, zdefiniowali operacje wejścia/wyjścia na poziomie języka C. Stąd wyprowadzenie znaków na ekran wymaga wywołania funkcji języka C na poziomie asemblera.
Poniżej podano krótki program przykładowy w asemblerze wraz z opisem sposobu translacji i wykonania. W pierwszej chwili, dla mniej zorientowanego czytelnika, podany niżej program może wydawać się dość skomplikowany. Mimo tego, czytelnik powinien dość uważnie go przeanalizować, korzystając z podanych dalej objaśnień. Objaśnienia mają charakter wstępny i mają przede wszystkim na celu przedstawienie podstawowych elementów programu.
Wykonanie podanego niżej programu powoduje wyświetlenie na ekranie komputera tekstu:
Nazywam się ...
Mój pierwszy program asemblerowy działa już poprawnie!.
; program przykładowy (wersja dla środowiska Microsoft)
.686
extrn _ExitProcess@4 : near
extrn __write : near ; (dwa znaki podkreślenia)
public _main
_DATA SEGMENT dword public 'DATA' use32
tekst db 10, 'Nazywam się . . . ' , 10
db 'Mój pierwszy (?) program asemblerowy '
db 'działa już poprawnie!', 10
koniec_t db ?
_DATA ENDS
_TEXT SEGMENT dword public 'CODE' use32
ASSUME cs:_TEXT, ds:_DATA
_main:
mov ecx, koniec_t - tekst
; wywołanie funkcji ”write” z biblioteki języka C
push ecx ; liczba znaków wyświetlanego tekstu
push dword PTR OFFSET tekst ; położenie obszaru
; ze znakami
push dword PTR 1 ; uchwyt urządzenia wyjściowego
call __write ; wyświetlenie znaków
; (dwa znaki podkreślenia _ )
add esp, 12 ; usunięcie parametrów ze stosu
; zakończenie wykonywania programu
push dword PTR 0 ; kod powrotu programu
call _ExitProcess@4
_TEXT ENDS
END
Zauważmy, że w podanym programie występują dwie charakterystyczne części zwane segmentami. Każdy z nich zaczyna się od dyrektywy SEGMENT i kończy się dyrektywą ENDS. Zarówno dyrektywa SEGMENT jak i dyrektywa ENDS poprzedzona jest nazwą segmentu. Pierwszemu segmentowi nadano nazwę _DATA, a drugiemu - nazwę _TEXT. Czytelnik zapewne domyśla się, że nazwy nadane segmentom korespondują z rolą, jakie segmenty te pełnią w programie. I tak pierwszy segment zawiera dane potrzebne do realizacji programu: łańcuch znaków "Mój pierwszy program ...". W drugim segmencie umieszczone są rozkazy programu. Cały program kończy dyrektywa END.
W każdym z segmentów występują różne typy wierszy programu, a wśród nich rozkazy procesora (ściślej: mnemoniki rozkazów), dyrektywy, etykiety i komentarze. Nietrudno zauważyć, że komentarze poprzedzone są zawsze średnikiem. Zwróćmy uwagę na wiersz
tekst db 10, 'Nazywam się . . . ' , 10
umieszczony w segmencie _DATA. Mamy tutaj dyrektywę db (ang. define byte) stanowiącą opis bajtów. Podany wiersz stanowi polecenie zarezerwowania w programie kilkunastu bajtów, przy czym pierwszy z nich będzie zawierał liczbę 10. Następne bajty zawierać będą kody ASCII znaków tworzących wyrazy Nazywam się, itd.
Dyrektywy db jednoznacznie określają zawartość bajtów. Jednak w sytuacji, gdy początkowa zawartość bajtów jest nieistotna, (bajty zostaną zapisane dopiero w trakcie wykonywania programu), można zarezerwować bajty nie precyzując ich zawartości. W takim przypadku zamiast liczb lub znaków ujętych w apostrofy podaje się znaki zapytania. Przykład takiej rezerwacji można znaleźć w segmencie danych (koniec_t db ?).
Spróbujmy teraz przeanalizować działanie programu. Jako pierwszy zostanie wykonany rozkaz wskazany przez etykietę _main.
mov ecx, koniec_t - tekst
Rozkaz ten powoduje wpisanie do rejestru ECX liczby znaków wyświetlanego tekstu.
Następne rozkazy przygotowują parametry potrzebne do wywołania funkcji wyświetlającej znaki na ekranie. Można przypuszczać, że wyświetlenie znaków na ekranie wymaga po prostu wpisania odpowiednich kodów do pamięci umieszczonej na karcie graficznej komputera. Rzeczywiście, w pierwszych komputerach PC metoda taka była powszechnie stosowana, jednak rozwój sprzętu i oprogramowania spowodował, że zapis taki jest obecnie dość kłopotliwy, i co najważniejsze może powodować zakłócenia w pracy systemu. Dlatego też współczesne systemy operacyjny nie zezwalają na bezpośrednie sterowanie urządzeniami komputera (np. kartą graficzną), ale wymagają obowiązkowego pośrednictwa systemu operacyjnego. Próba ominięcia tego pośrednictwa jest natychmiast sygnalizowana przez procesor i powoduje zazwyczaj zakończenie wykonywania programu.
Zatem wyświetlenie znaków na ekranie wymaga użycia odpowiedniej funkcji usługowej, która udostępniana jest przez system operacyjny. Funkcje usługowe systemu Windows opisane są na poziomie interfejsu języka C, czyli zakłada się (chociaż nie jest to obowiązkowe), że będą one wywoływane z poziomu języka C. W rezultacie, wywołując funkcję usługową systemu operacyjnego w kodzie asemblerowym musimy przeprowadzić to wywołanie, tak jak gdyby zostało ono wykonane na poziomie języka C.
Musimy teraz odwołać się do znanej z języka C funkcji write, która zapisuje dane znajdujące się w obszarze pamięci (określonym przez drugi parametr) do pliku lub urządzenia. W naszym przypadku dane, w postaci znaków w kodzie ASCII, przesyłamy na ekran, czyli do urządzenia, które identyfikowane jest przez pierwszy parametr (uchwyt). Wywołanie funkcji write w języku C ma postać (zob. np. opis podany w podręczniku Kernighana i Ritchie „Język C”)
write (uchwyt, adres_obszaru_danych, liczba_znaków);
Funkcja ta ma trzy parametry, i zgodnie ze przyjętymi standardami powinny one zostać zapisane w specjalnym segmencie danych dynamicznych, który nazywany jest stosem. Zapisywanie danych na stosie wykonywane jest przez rozkazy push. Dodajmy, że parametry funkcji write zapisywane są na stos w kolejności od prawej do lewej, a więc najpierw zostanie zapisana liczba znaków, potem adres obszaru danych i wreszcie uchwyt, który w tym przypadku ma wartość 1.
Po wyświetleniu znaków parametry zapisane wcześniej na stosie są już niepotrzebne i muszą zostać usunięte za pomocą rozkazu add esp, 12.
Wywołanie funkcji ExitProcess kończy wykonywanie programu i oddaje sterowanie do systemu.
Na początku segmentu zawierającego rozkazy programu umieszczona jest dyrektywa ASSUME. Informuje ona asembler o przewidywanych zawartościach rejestrów procesora CS i DS. Ponieważ w programach 32-bitowych rejestry te ustawiane są przez system operacyjny przed uruchomieniem programu, więc praktycznie nie ma potrzeby zajmowania się tymi rejestrami. Trzeba tu wyraźnie podkreślić, że sama dyrektywa ASSUME nie wpływa w jakikolwiek sposób na zawartości rejestrów. Dodajmy, że sens i znaczenie omawianej dyrektywy budzi zazwyczaj wiele wątpliwości wśród początkujących programistów.
Edycja i uruchamianie programów z wykorzystaniem asemblera zewnętrznego
Tworzenie pliku źródłowego
Komputery zainstalowane w Międzykatedralnym Zespole Laboratoriów Komputerowych (MKZL) na Wydziale ETI PG pracują w systemie MS Windows 2000, Windows XP i Windows Vista. W niektórych laboratoriach zainstalowany jest także system Linux.
W przypadku systemu Windows 2000 lub XP, po uruchomieniu komputera lub po zakończeniu pracy przez poprzedniego użytkownika należy odczekać aż pojawi się komunikat Naciśnij Ctrl Alt Del. Przy jednoczesnym naciśnięciu tych klawiszy na ekranie pojawi się okienko dialogowe, do którego należy wprowadzić nazwę użytkownika (student albo student1) i nazwę domeny (MKZLLAB). Po naciśnięciu przycisku OK system będzie przygotowany do pracy.
W przypadku systemu MS Windows Vista, po uruchomieniu komputera wystarczy tylko kliknąć na ikonę student.
W tym podrozdziale pokażemy sposób translacji programu asemblerowego za pomocą asemblera i konsolidatora (linkera), które nie są zintegrowane z edytorem. Z tego względu wygodnie jest przeprowadzać translację w okienku konsoli (dawniej nazywanym oknem DOSowym). Używane jest również określenie wiersz poleceń. Jeśli na pulpicie nie została umieszczona odpowiednia ikona, to okienko konsoli można otworzyć wydając polecenie
Start / Uruchom / cmd
W przypadku systemu Vista wystarczy tylko wpisać cmd do pola nad przyciskiem startu.
Ponieważ użytkownicy student (lub student1) posiadają uprawnienia do zapisu plików wyłącznie w katalogu
d:\studenci
więc w okienku konsoli konieczna jest zmiana bieżącego katalogu na d:\studenci — w tym celu należy najpierw wpisać d: i nacisnąć klawisz Enter, a następnie wpisać polecenie cd studenci, również zakończone naciśnięciem klawisza Enter. Wskazane jest by każdy użytkownik utworzył podkatalog roboczy w tym katalogu, np. d:\studenci\proby. Przed zakończeniem zajęć pliki źródłowe należy skopiować na dyskietkę (lub inny nośnik), zaś wcześniej utworzony podkatalog powinien zostać skasowany.
W trakcie uruchamiania programu wielokrotnie wprowadza się te same polecenia — wszystkie wydane wcześniej polecenia można przeglądać posługując się klawiszami strzałek i . Identyczny mechanizm dostępny jest w systemie Linux.
Program źródłowy można napisać korzystając z dowolnego edytora, który nie wprowadza znaków formatujących. Może to być więc Notatnik (ang. Notepad) czy np. Crimson Editor (słowa kluczowe języka programowania wyświetla w innym kolorze), ale Word czy Write nie jest odpowiedni. Istotne jest także by edytor wyświetlał numer wiersza — własność tę ma m.in. nowsza wersja Notatnika. Nazwa pliku zawierającego kod źródłowy powinna posiadać rozszerzenie ASM. Ze względu na używane asemblery, nazwy plików nie powinny zawierać liter specyficznych dla alfabetu polskiego (ą, ć, ę ...), spacji, a w przypadku asemblerów pochodzących z lat dziewięćdziesiątych nazwy plików mogą zawierać co najwyżej 8 znaków. Praktyczne jest wywoływanie edytora z nazwą pliku podaną w linii zlecenia, np.
notepad zdanie.asm
Dla wygody dalszego opisu przyjmijmy, że program źródłowy znajduje się w pliku zdanie.asm
Po utworzeniu pliku źródłowego należy poddać go asemblacji i konsolidacji (linkowaniu). W wyniku asemblacji uzyskuje się plik z rozszerzeniem .OBJ (o ile program nie zawierał błędów formalnych). Kod zawarty w pliku .OBJ (tzw. kod półskompilowany) zawiera już instrukcje programu zakodowane w języku maszyny, ale nie jest jeszcze całkowicie przygotowany do wykonywania przez procesor. Ostateczne przygotowanie kodu, a także włączenie programów bibliotecznych czy innych programów, jeśli jest to konieczne, następuje w fazie zwanej konsolidacją lub linkowaniem. Wykonuje to program zwany konsolidatorem lub linkerem (np. link), w wyniku czego powstaje plik z rozszerzeniem .EXE, zawierający program gotowy do wykonania.
W laboratoriach MKZL dostępne są między innymi 32-bitowe asemblery i konsolidatory (linkery) firmy Microsoft: ML.EXE (asembler) i LINK.EXE (konsolidator).
Asemblacja i konsolidacja za pomocą oprogramowania firmy Microsoft
Potrzebne oprogramowanie firmy Microsoft zainstalowane jest laboratoriach MKZL, natomiast studenci mogą je uzyskać w ramach programu Microsoft Academic Alliance (bliższe informacje podane są na stronie internetowej Wydziału ETI PG).
Najpierw należy skonfigurować ścieżki dostępu do asemblera i konsolidatora. W tym celu w okienku konsoli należy wywołać plik wsadowy VCVARS32.BAT (wpisać w jednym wierszu):
"c:\Program Files (x86)\Microsoft Visual
Studio 8\VC\bin\VCVARS32.BAT"
albo dla MS Visual Studio 2003:
″c:\Program Files\Microsoft Visual
Studio .Net 2003\VC7\bin\VCVARS32.BAT″
Ponieważ wiersz jest dość długi, a niekiedy trzeba go kilkakrotnie wpisywać, warto utworzyć plik wsadowy VC.BAT zawierający jedno z podanych wyżej poleceń. Wówczas wprowadzenie do okienka tekstu VC spowoduje wykonanie podanego polecenia.
Od tej chwili, w dalszych działaniach, wywołanie asemblera MASM (ml.exe) lub konsolidatora LINK (link.exe) nie wymaga podawania ścieżek dostępu. Ustalenie to dotyczy tylko okienka konsoli, w którym wywołano plik VCVARS32.BAT (lub VC.BAT). Jeśli w trakcie pracy zostanie otwarte inne okienko konsoli, to niezbędne jest ponownym wywołanie pliku VCVARS32.BAT (lub VC.BAT) w nowym okienku.
Przyjmujemy, że program znajduje się w pliku zdanie.asm . Polecenie asemblacji ma postać:
ml -c -Cp -coff -Fl zdanie.asm
Jeśli w trakcie asemblacji nie zostały wykryte błędy składniowe, to asembler utworzy plik zdanie.obj zawierający kod programu w języku pośrednim. Ponadto zostanie utworzony plik zdanie.lst zawierający raport z przebiegu asemblacji. W raporcie tym obok przedrukowanego tekstu źródłowego programu podane jest położenie rozkazów i liczb w segmencie i ich reprezentacja szesnastkowa. Na końcu raportu podane jest zestawienie użytych symboli i przyporządkowanych im wartości. Z kolei w celu przeprowadzenia konsolidacji (linkowania) należy napisać polecenie:
link -subsystem:console -out:zdanie.exe
(ciąg dalszy poprzedniego wiersza) zdanie.obj libcmt.lib user32.lib
W rezultacie powstanie plik zdanie.exe, zawierający program gotowy do wykonania.
Uwaga: ze względu na zmiany konfiguracji, w niektórych komputerach, znak minus „-„ przed nazwą opcji trzeba zastąpić znakiem „/„, np. zamiast -c należy pisać /c.
Zazwyczaj uruchamiany program zawiera kilka błędów składniowych, co wymaga wielokrotnego powtarzania opisanych operacji. Z tego powodu można napisać prosty plik wsadowy (z rozszerzeniem .bat), który automatyzuje wykonywanie ww. czynności. Przykładowy plik tm.bat może mieć postać:
ml -c -Cp -coff -Fl %1.asm
if errorlevel 1 goto koniec
link -subsystem:console -out:%1.exe
(ciąg dalszy poprzedniego wiersza) %1.obj libcmt.lib user32.lib
:koniec
Korzystając z tego pliku, przetłumaczenie pliku źródłowego zdanie.asm wymaga wprowadzenia polecenia
tm zdanie
Instrukcja if errorlevel 1 goto koniec testuje kod powrotu asemblera i jeśli jest on większy od zera (tj. gdy wystąpiły błędy składniowe), to operacja konsolidacji zostaje pominięta.
Usuwanie błędów formalnych
Często program poddany asemblacji wykazuje błędy, podawane przez asembler. Usunięcie takich błędów, w przeciwieństwie do opisanych dalej błędów wewnętrznych zakodowanego algorytmu, nie przedstawia na ogół większych trudności. Wystarczy tylko odnaleźć w programie źródłowym błędny wiersz i dokonać odpowiedniej poprawki. Przykładowo, jeśli w trakcie asemblacji sygnalizowane były błędy na ekranie:
zdanie.asm(17) : error A2070: invalid instruction operands
zdanie.asm(24) : error A2005: symbol redefinition : ptl
to ich odnalezienie nie przedstawia większych trudności. W wierszu 17 występuje instrukcja, w której pojawiła się niezgodność typów operandów — po odszukaniu w pliku źródłowym okazało się, że instrukcja ta ma postać:
add bh, ax
Okazało, że autor programu planował pierwotnie dodać do rejestru BH liczbę 8-bitową przechowywaną w rejestrze AL. Po wprowadzeniu zmian wiersz przyjął postać:
add bh, al
Podobnie, przyczyną następnego błędu (wiersz 24) było powtórzenie definicji etykiety ptl.
Typowe błędy kodowania programów w języku asemblera
Kolejność sekwencji rozkazów POP musi być odwrotna w stosunku do sekwencji rozkazów PUSH. Liczba wykonanych rozkazów PUSH i POP musi być jednakowa.
Należy przechowywać zawartości rejestrów przy wywoływaniu podprogramów, chyba że rejestry przechowywane są wewnątrz podprogramu. Rejestr EBP często pełni rolę pomocniczego wskaźnika stosu i trzeba zachować ostrożność, jeśli stosowany jest jako zwykły rejestr do przechowywania wyników pośrednich.
Należy pamiętać o strukturze rejestrów, np. zmiana rejestru BH powoduje jednocześnie zmianę rejestru EBX, a wyzerowanie rejestru ESI powoduje także wyzerowanie rejestru SI.
W wyrażeniach języka asembler należy precyzyjnie odróżniać adresy i wartości zmiennych.
Jeśli kod asemblerowy jest łączony z kodem w języku C++, to funkcję zdefiniowaną w asemblerze należy deklarować jako extern ”C”. Eliminuje to problem wynikający z automatycznych zmian nazw funkcji w celu zakodowania informacji o parametrach (ang. name mangling). Często wymagane jest poprzedzenie nazwy funkcji w kodzie asemblerowym znakiem podkreślenia.
W kodzie podprogramu musi wystąpić co najmniej jeden rozkaz RET.
W systemach 64-bitowych przed wykonaniem rozkazu skoku do podprogramu wskaźnik stosu musi wskazywać adres podzielny przez 16. Należy także pamiętać o rezerwacji „shadow space”. Konwencje wywoływania funkcji w 64-bitowych wersjach systemu Windows i Linux nie są jednakowe.
W operacjach zmiennoprzecinkowych przed zakończeniem podprogramu należy oczyścić rejestry tworzące stos koprocesora, z wyjątkiem ST(0), jeśli służy on do przekazywania wyniku funkcji.
Edycja i uruchamianie programów w środowisku zintegrowanym Microsoft Visual Studio .Net 2005
Tworzenie i uruchamianie programów w środowisku zintegrowanym, np. MS Visual Studio znacznie ułatwia pracę programisty, aczkolwiek w przypadku dużej liczby plików źródłowych może powodować pewne opóźnienia w stosunku do trybu niezintegrowanego.
Zakładamy, że program źródłowy w asemblerze znajduje się pliku zdanie.asm. W celu przeprowadzenia asemblacji i konsolidacji należy wykonać niżej opisane działania.
Najpierw należy utworzyć katalog d:\studenci\pierwszy. Przed uruchomieniem MS Visual Studio 2005 do tego katalogu należy skopiować plik zdanie.asm.
Po uruchomieniu MS Visual Studio należy wybrać opcje: File / New / Project
W oknie projektu (zob. rys.) wybieramy opcje General / Empty Project. Do pola Name wpisujemy nazwę programu (tu: pierwszy) i naciskamy OK. W polu Location powinna znajdować się ścieżka d:\studenci. Znacznik Create directory for solution należy ustawić w stanie nieaktywnym.
W rezultacie wykonania opisanych wyżej operacji pojawi się niżej pokazane okno
Następnie prawym klawiszem myszki należy kliknąć na Source File i wybrać opcje Add / Existing Item.
W ślad za tym pojawi się kolejne okno, w którym należy zaznaczyć plik zdanie.asm i nacisnąć OK.
Kolejne okno prezentuje opcje wywołania asemblera MASM (ml.exe) — zaznaczamy MASM i naciskamy OK.
W kolejnym kroku należy skorygować ustawienia konsolidatora (linkera)
Rozwijamy menu konsolidatora i wybieramy opcję Command line. Następnie w polu Additional options podajemy nazwę biblioteki libcmt.lib
Przy okazaji warto ustawić opcje aktywizujące debugger. W tym celu wybieramy opcję Debugging i pole Generate Debug Info ustawiamy na YES. Następnie naciskamy OK.
W celu wykonania asemblacji i konsolidacji programu wystarczy nacisnąć klawisz F7. Opis przebiegu tych operacji pojawi się w oknie umieszczonym w dolnej części ekranu. Przykładowa postać takiego opisu pokazana jest poniżej.
Jeśli nie zidentyfikowano błędów (0 errors) ani ostrzeżeń (0 warnings), to można uruchomić program naciskając kombinację klawiszy Ctrl F5. Na ekranie pojawi się okno programu, którego przykładowy fragment pokazany jest poniżej.
Laboratorium Architektury Komputerów
Ćwiczenie 2
Przetwarzanie tekstów
z wykorzystaniem modyfikacji adresowych
Reprezentacja tekstu w pamięci komputera
Początkowo komputery używane były do obliczeń numerycznych. Okazało się jednak, że doskonale nadają się także do edycji i przetwarzania tekstów. Wyłoniła się więc konieczność ustalenia w jakiej formie mają być przechowywane w komputerze znaki używane w tekstach. Ponieważ w komunikacji dalekopisowej (telegraficznej) ustalono wcześniej standardy kodowania znaków używanych w tekstach, więc sięgnięto najpierw do tych standardów. W wyniku różnych zmian i ulepszeń około roku 1968 w USA ustalił się sposób kodowania znaków znany jako kod ASCII (ang. American Standard Code for Information Interchange). Początkowo w kodzie ASCII każdemu znakowi przyporządkowano unikatowy 7-bitowy ciąg zer i jedynek, zaś ósmy bit służył do celów kontrolnych. Wkrótce zrezygnowano z bitu kontrolnego, co pozwoliło na rozszerzenie podstawowego kodu ASCII o nowe znaki, używane w alfabetach narodowych (głównie krajów Europy Zachodniej).
Ponieważ posługiwanie się kodami złożonymi z zer i jedynek jest kłopotliwe, w programach komputerowych kody ASCII poszczególnych znaków zapisuje się w postaci liczb dziesiętnych lub szesnastkowych. Znaki o kodach od 0 do 127 przyjęto nazywać podstawowym zestawem ASCII, zaś znaki o kodach 128 do 255 rozszerzonym kodem ASCII. Przykładowe kody ASCII niektórych znaków podano w tablicy.
a |
0110 0001 |
61H |
||
b |
0110 0010 |
62H |
||
c |
0110 0011 |
63H |
||
d |
0110 0100 |
64H |
||
e |
0110 0101 |
65H |
||
f |
0110 0110 |
66H |
||
— — — — — |
|
|
||
y |
0111 1001 |
79H |
||
z |
0111 1010 |
7AH |
||
A |
0100 0001 |
41H |
||
B |
0100 0010 |
42H |
||
C |
0100 0011 |
43H |
||
D |
0100 0100 |
44H |
||
E |
0100 0101 |
45H |
||
F |
0100 0110 |
46H |
||
— — — — — |
||||
Y |
0101 1001 |
59H |
||
Z |
0101 1010 |
5AH |
||
! |
0010 0001 |
21H |
||
" |
0010 0010 |
22H |
||
# |
0010 0011 |
23H |
||
$ |
0010 0100 |
24H |
||
— — — — — |
|
|
||
{ |
0111 1011 |
7BH |
||
| |
0111 1100 |
7CH |
||
0 |
0011 0000 |
30H |
||
1 |
0011 0001 |
31H |
||
2 |
0011 0010 |
32H |
||
3 |
0011 0011 |
33H |
||
— — — — — |
|
|||
8 |
0011 1000 |
38H |
||
9 |
0011 1001 |
39H |
||
Kody od 0 do 31 oraz kod 127 zostały przeznaczone do sterowania komunikacją dalekopisową. Niektóre z nich pozostały w informatyce, chociaż zatraciły swoje pierwotne znaczenie, inne zaś są nieużywane. Do tej grupy należy m.in. znak powrotu karetki (CR) o kodzie 0DH (dziesiętnie 13). W komunikacji dalekopisowej kod ten powodował przesunięcie wałka z papierem na skrajną lewą pozycję. W komputerze jest często interpretowany jako kod powodujący przesunięcie kursora do lewej krawędzi ekranu. Bardzo często używany jest także znak nowej linii (LF) o kodzie 0AH (dziesiętnie 10).
Problem znaków narodowych
Z chwilą szerszego rozpowszechnienia się komputerów osobistych w wielu krajach wyłonił się problem kodowania znaków narodowych. Podstawowy kod ASCII zawiera bowiem jedynie znaki alfabetu łacińskiego (26 małych i 26 wielkich liter). Rozszerzenie kodu ASCII pozwoliło stosunkowo łatwo odwzorować znaki narodowe wielu alfabetów krajów Europy Zachodniej. Podobne działania podjęto także w odniesieniu do alfabetu języka polskiego. Działania te były prowadzone w sposób nieskoordynowany. Z jednej polscy producenci oprogramowania stosowali kilkanaście sposobów kodowania, z których najbardziej znany był kod Mazovia. Jednocześnie firma Microsoft wprowadziła standard kodowania znany jako Latin 2, a po wprowadzeniu systemu Windows zastąpiła go standardem Windows 1250. Dodatkowo jeszcze organizacja ISO (ang. International Organization for Standardization) wprowadziła własny standard (zgodny z polską normą) znany jako ISO 8859-2, który jest obecnie często stosowany w Internecie. Należy mieć nadzieję, że stopniowo standard ISO 8859-2 stanie się podstawowym standardem kodowania znaków alfabetu języka polskiego. Podana niżej tablica zawiera kody litery ą w różnych standardach kodowania.
Znak |
Mazovia |
Latin 2 |
Windows 1250 |
ISO 8859-2 |
Unicode |
ą |
86H |
A5H |
B9H |
B1H |
0105H |
Ą |
8FH |
A4H |
A5H |
A1H |
0104H |
Uniwersalny zestaw znaków
Kodowanie znaków za pomocą ośmiu bitów ogranicza liczbę różnych kodów do 256. Z pewnością nie wystarczy to do kodowania liter alfabetów europejskich, nie mówiąc już o alfabetach krajów dalekiego wschodu. Z tego względu od wielu prowadzone są prace na stworzeniem kodów obejmujących alfabety i inne znaki używane na całym świecie.
Prace nad standaryzacją zestawu znaków używanych w alfabetach narodowych podjęto na początku lat dziewięćdziesiątych. Początkowo prace prowadzone były niezależnie przez organizację ISO (International Organization for Standardization), jak również w ramach projektu Unicode, finansowanego przez konsorcjum czołowych producentów oprogramowania w USA. Około roku 1991 prace w obu instytucjach zostały skoordynowane, aczkolwiek dokumenty publikowane są niezależnie. Ustalono jednak, że tablice kodów standardu Unicode i standardu ISO 10646 są kompatybilne, a w wszelkie dalsze rozszerzenia są dokładnie uzgadniane.
Standard międzynarodowy ISO 10646 definiuje Uniwersalny Zestaw Znaków USC - ang. Universal Character Set. Można uważać, że UCS pokrywa wszystkie istniejące dotychczas standardy kodowania znaków. Oznacza to, że jeśli przekodujemy pewien tekst do USC, po czym ponownie przekodujemy na format pierwotny, to żadna informacja nie zostanie stracona.
UCS zawiera znaki potrzebne do reprezentacji tekstów praktycznie we wszystkich znanych językach. Obejmuje nie tylko znaki alfabetu łacińskiego, greki, cyrylicy, arabskiego, ale także znaki chińskie, japońskie i wiele innych. Co więcej, niektóre kraje (np. Japonia, Korea) przyjęły standard UCS jako standard narodowy, ewentualnie z pewnymi uzupełnieniami.
Formalnie rzecz biorąc omawiany standard definiuje zestaw znaków 31-bitowych. Jak dotychczas używany jest 16-bitowy podzbiór obejmujący 65534 początkowych pozycji (czyli 0x0000 do 0xFFFD), oznaczany skrótem BMP (ang. Basic Multilingual Plane). Czasami używany jest termin "Plane 0". Znaki UCS o kodach U+0000 do U+007F są identyczne ze znakami kodu ASCII (standard ISO 646 IRV). Z kolei znaki z przedziału U+0000 do U+00FF są identyczne ze znakami kodu ISO 8859-1 (kod Latin-1).
Współczesne języki programowania definiują typy danych przeznaczone do przechowywania 16-bitowych znaków UCS („wide character”), np. w języku C++ stosowany jest typ wchar_t. Związane z tym problemy kodowania będą omawiane w dalszej części opracowania.
Modyfikacje adresowe
W wielu problemach informatycznych mamy do czynienia ze zbiorami danych w formie różnego rodzaju tablic, które przeglądać, odczytywać, zapisywać, sortować itd. Na poziomie rozkazów procesora występują powtarzające się operacje, w których za każdym razem zmienia się tylko indeks odczytywanego lub zapisywanego elementu tablicy. Takie powtarzające się operacje koduje się w postaci pętli. W przypadku operacji na elementach tablic muszą być dostępne mechanizmy pozwalające na dostęp do kolejnych elementów tablicy w trakcie obiegów pętli. Ten właśnie rozwiązywany jest za pomocą modyfikacji adresowych.
Współczesne procesory udostępniają wiele rodzajów modyfikacji adresowych, dostosowanych do różnych problemów programistycznych. Między innymi pewne modyfikacje adresowe zostały opracowane specjalnie dla odczytywania wielobajtowych liczb, inne wspomagają przekazywanie parametrów przy wywoływaniu procedur i funkcji.
Wprowadzenie modyfikacji adresowej powoduje, że końcowy adres rozkazu (instrukcji), zwany adresem efektywnym, obliczany jest jako suma zawartości pola adresowego rozkazu i zawartości jednego lub dwóch rejestrów (spośród rejestrów ogólnego przeznaczenia). W ten sposób, zwiększając w każdym obiegu pętli zawartość rejestru modyfikacji o 1, 2, 4 lub 8, powodujemy, że kolejne wykonania tego samego rozkazu spowodują przeprowadzenie wymaganych działań (np. odczytu, zapisu, porównania, itp.) na kolejnych elementach tablicy. Jeśli pojedynczy element tablicy zajmuje jeden bajt, to zawartość rejestru modyfikacji w każdym obiegu pętli zwiększa się o 1, jeśli element tablicy zawiera dwa bajty, to zawartość rejestru modyfikacji zwiększa się o 2, itd.
Przykład programu przekształcającego tekst
; wczytywanie i wyświetlanie tekstu wielkimi literami (inne znaki
; się nie zmieniają)
.686
extrn _ExitProcess@4 : near
extrn __write : near ; (dwa znaki podkreślenia)
extrn __read : near ; (dwa znaki podkreślenia)
public _main
_DATA SEGMENT dword public 'DATA' use32
tekst_pocz db 10, 'Proszę napisać jakiś tekst `
db `i nacisnac Enter', 10
koniec_t db ?
magazyn db 80 dup (?)
nowa_linia db 10
liczba_znakow dd ?
_DATA ENDS
_TEXT SEGMENT dword public 'CODE' use32
ASSUME cs:_TEXT, ds:_DATA
_main:
; wyświetlenie tekstu informacyjnego
mov ecx, koniec_t - tekst_pocz ; liczba znaków tekstu
push ecx
push OFFSET tekst_pocz ; adres tekstu
push 1 ; nr urządzenia (tu: ekran - nr 1)
call __write ; wyświetlenie tekstu początkowego
add esp, 12 ; usuniecie parametrów ze stosu
; czytanie wiersza z klawiatury
push 80 ; maksymalna liczba znaków
push OFFSET magazyn
push 0 ; nr urządzenia (tu: klawiatura - nr 0)
call __read ; czytanie znaków z klawiatury
add esp, 12 ; usuniecie parametrów ze stosu
; kody ASCII napisanego tekstu zostały wprowadzone
; do obszaru `magazyn'
; funkcja read wpisuje do rejestru EAX liczbę wprowadzonych znaków
mov liczba_znakow, eax
; rejestr ECX pełni rolę licznika obiegów pętli
mov ecx, eax
mov ebx, 0 ; indeks początkowy
ptl: mov dl, magazyn[ebx] ; pobranie kolejnego znaku
cmp dl, 'a'
jb dalej ; skok, gdy znak nie wymaga zamiany
cmp dl, 'z'
ja dalej ; skok, gdy znak nie wymaga zamiany
sub dl, 20H ; zamiana na wielkie litery
mov magazyn[ebx], dl ; odesłanie znaku do pamięci
dalej: inc ebx ; inkrementacja modyfikatora
loop ptl ; sterowanie pętlą
; wyświetlenie przekształconego tekstu
push liczba_znakow
push OFFSET magazyn
push 1
call __write ; wyświetlenie przekształconego tekstu
add esp, 12 ; usuniecie parametrów ze stosu
push 0
call _ExitProcess@4 ; zakończenie programu
_TEXT ENDS
END
Fragment programu, który oblicza liczbę wystąpień podanego znaku w tablicy
Podany fragment wyszukuje liczbę wystąpień znaku a w tablicy znaki. Tablica zawiera 22 bajty wypełnione różnymi kodami ASCII. Wyznaczona liczba wystąpień zostaje wpisana do DL.
znaki db 'w', 'abc', '$171', 'P', 'Z', '7081', 'abcdefgh'
wzorzec db 'a'
— — — — — — — — — — — — — — —
mov dl, 0 ; wyzerowanie rejestru DL, w którym
; będzie wpisany wynik
mov dh, wzorzec ; poszukiwany znak
xor ebx, ebx ; wyzerowanie modyfikatora
mov ecx, 22 ; licznik bajtów
petla_wystapien:
cmp dh, znaki [ebx] ; porównywanie
sete al ; ustaw AL=1, jeśli porównywane
; wartości są równe,
; w przeciwnym razie AL=0
add dl, al ; zwiększ liczbę wystąpień o 0, gdy
; poszukiwany znak nie wystąpił,
; albo o 1, gdy wystąpił
inc bx ; inkrementacja modyfikatora
loop petla_wystapien
Laboratorium Architektury Komputerów
Ćwiczenie 3
Konwersje dziesiętno-dwójkowa i dwójkowo-dziesiętna
Algorytmy konwersji
Komputery wykonują operacje przetwarzania danych na wartościach binarnych, podczas gdy współczesna cywilizacja posługuje się systemem dziesiętnym. Zachodzi więc potrzeba dokonywania konwersji dziesiętno-dwójkowej lub dwójkowo-dziesiętnej. W niniejszym punkcie zostaną rozpatrzone sposoby rozwiązania tego zadania na przykładzie programu wykonującego działania arytmetyczne na liczbach naturalnych. Przyjęto, że wprowadzane liczby mieszczą się na 32 bitach, jak również wynik operacji nie zajmuje więcej niż 32 bity.
Konwersja dziesiętno-dwójkowa
Zadanie konwersji dziesiętno-dwójkowej pojawia się, np. przy wczytywaniu liczb z klawiatury. Wczytywane są wtedy kody ASCII kolejnych cyfr wielocyfrowej liczby dziesiętnej. Operacje wykonujemy na wartościach rejestrów, w których naturalną reprezentacją jest postać dwójkowa.
Sposób konwersji może być następujący. Wartość pewnej liczby dziesiętnej zapisanej za pomocą cyfr
można zapisać następująco:
W praktyce programowania wygodniej jednak posługiwać się schematem iteracyjnym:
Przykładowo, w trakcie wprowadzania liczby 5804 użytkownik wprowadza kolejno cyfry 5, 8, 0, 4, czyli wartość wprowadzanej liczby wynosi:
W ten właśnie sposób, dysponując cyframi dziesiętnymi liczby możemy obliczyć jej wartość.
Kodowanie algorytmu będzie nieco łatwiejsze, jeśli przyjąć że użytkownik wcześniej wprowadził już cyfrę 0 (co oczywiście nie wpływa na wynik końcowy). W tej sytuacji, po wprowadzeniu cyfry 5 przez użytkownika, mnożymy wcześniej uzyskany wynik przez 10 i dodajemy 5. Jeśli użytkownik wprowadzi cyfrę 8, to tak jak poprzednio, mnożymy dotychczas uzyskany wynik przez 10 i dodajemy 8. Tak samo postępujemy przy kolejnych cyfrach.
Zauważmy, że w podanym algorytmie nie określa się z góry ilości cyfr — wymaga się jedynie aby reprezentacja binarna wprowadzonej liczby dała się zapisać na 32 bitach.
Poniżej podano fragment programu, w którym przeprowadzana jest omawiana konwersja.
; wczytywanie liczby dziesiętnej z klawiatury - liczba po konwersji
; na postać binarną zostaje wpisana do rejestru EAX
; po wprowadzeniu ostatniej cyfry należy nacisnąć klawisz Enter
; deklaracja tablicy do przechowywania wprowadzanych cyfr
; (w segmencie _DATA)
obszar db 12 dup (?)
— — — — — — — — — — — —
push dword PTR 12 ; max ilość znaków wczytywanej liczby
push dword PTR OFFSET obszar ; adres obszaru pamięci
push dword PTR 0 ; numer urządzenia (0 dla klawiatury)
call __read ; odczytywanie znaków z klawiatury
; (dwa znaki podkreślenia przed read)
add esp, 12 ; usunięcie parametrów ze stosu
; zamiana cyfr w kodzie ASCII na liczbę binarną
mov esi, 0 ; bieżąca wartość przekształcanej
; liczby przechowywana jest
; w rejestrze ESI; przyjmujemy 0
; jako wartość początkową
mov ebx, OFFSET obszar ; adres obszaru ze znakami
nowy:
mov al, [ebx] ; pobranie kolejnej cyfry w kodzie ASCII
inc ebx ; zwiększenie indeksu
cmp al,10 ; sprawdzenie czy naciśnięto Enter
je byl_enter ; skok, gdy naciśnięto Enter
sub al, 30H ; zamiana kodu ASCII na wartość cyfry
movzx edi, al ; przechowanie wartości cyfry
; w rejestrze EDI
mov eax, 10 ; mnożna
mul esi ; mnożenie wcześniej obliczonej
; wartości razy 10
add eax, edi ; dodanie ostatnio odczytanej cyfry
mov esi, eax ; dotychczas obliczona wartość
jmp nowy
byl_enter:
mov eax, esi ; przepisanie wyniku konwersji
; do rejestru EAX
; wartość binarna wprowadzonej liczby znajduje się teraz w rejestrze EAX
Konwersja dwójkowo-dziesiętna
W tym przypadku problem jest odwrotny, tj. mamy reprezentację binarną liczby w rejestrze (lub rejestrach) i należy znaleźć jej kolejne cyfry w reprezentacji dziesiętnej. Patrząc jeszcze raz na wyrażenie
można zauważyć, że dzieląc liczbę kolejno przez 10 otrzymamy kolejne reszty będące cyframi w reprezentacji dziesiętnej w odwróconej kolejności, tj. kolejno
Przykładowo, w wyniku dzielenia liczby binarnej 0001 0110 1010 1100 (=5804) uzyskamy kolejne reszty:
Pierwotna liczba i kolejne ilorazy z dzielenia przez (0000 1010)2 =(10)10 |
Kolejne reszty z dzielenia przez (0000 1010)2 =(10)10 |
0001 0110 1010 1100 (=5804) |
0100 (=4) |
0000 0010 0100 0100 (=580) |
0000 (=0) |
0000 0000 0011 1010 (=58) |
1000 (=8) |
0000 0000 0000 0101 (=5) |
0101 (=5) |
0000 0000 0000 0000 (=0) |
|
W ten właśnie sposób działa przeprowadzana jest konwersja w poniższym fragmencie programu. Możliwe jest wyświetlenie liczby 32-bitowej, która reprezentowana będzie przez 10 cyfr w systemie dziesiętnym.
; deklaracja tablicy do przechowywania
; tworzonych cyfr (w segmencie _DATA)
znaki db 12 dup (?)
— — — — — — — — — — — —
mov esi, 11 ; indeks w tablicy 'znaki'
mov ebx, 10 ; dzielnik równy 10
od_nowa:
mov edx, 0 ; zerowanie starszej części dzielnej
div ebx ; dzielenie przez 10,
; reszta w EDX, iloraz w EAX
add dl, 30H ; zamiana reszty z dzielenia na kod ASCII
mov znaki [esi], dl ; zapisanie cyfry w kodzie ASCII
dec esi ; zmniejszenie indeksu
cmp eax, 0 ; sprawdzenie czy iloraz = 0
jne od_nowa ; skok, gdy iloraz niezerowy
; wypełnienie pozostałych bajtów spacjami
; i wpisanie znaku nowego wiersza
wypeln:
mov byte PTR znaki [esi], 20H ; kod spacji
dec esi ; zmniejszenie indeksu
jnz wypeln
mov byte PTR znaki [esi], 0AH ; kod nowego wiersza
; wyświetlenie cyfr na ekranie
push dword PTR 12 ; liczba wyświetlanych znaków
push dword PTR OFFSET znaki ; adres wyśw. obszaru
push dword PTR 1 ; numer urządzenia (ekran ma numer 1)
call __write ; wyświetlenie liczby na ekranie
add esp, 12 ; usunięcie parametrów ze stosu
Kodowanie BCD
Rozpatrzmy prosty przykład. W komputerach PC zainstalowany jest zegar, zasilany z małej baterii, który pracuje także po wyłączeniu komputera. Za pomocą odpowiednich instrukcji można odczytać datę i czas z tego zegara, przy czym dane kodowane są w systemie BCD. Tak więc, jeśli kod aktualnej godziny wpisany do rejestru AL ma postać 00100001, to oznacza że jest godzina 21. Dodajmy, że zegar podaje rok w postaci w dwóch ostatnich cyfr, co było przyczyną trudności niektórych komputerów ze zmianą daty na 1.01.2000.
Wyświetlenie na ekranie aktualnego czasu i daty wymaga zamiany wartości odczytanych w kodzie BCD na znaki w kodzie ASCII. Ponieważ taka zamiana musi przeprowadzona oddzielnie dla liczby sekund, minut, godzin, dni, miesięcy i roku, warto więc zbudować podprogram, który by realizował zamianę kodu. Znaki w kodzie ASCII kodowane są na ośmiu bitach, przy czym znakom cyfr zostały przypisane kody: 0 — 30H, 1 — 31H, 2 — 32H, . . ., 9 — 39H. Zatem godzina 21 zapisana w postaci dwóch cyfr w kodzie ASCII będzie opisana przez dwa bajty: 00110010 00110001. Podany niżej podprogram wykonuje zamianę liczby w kodzie BCD zapisanej w rejestrze AL na dwa znaki ASCII, które zostają wpisane do rejestrów DH i DL.
W asemblerze początek podprogramu wskazuje dyrektywa PROC, a koniec podprogramu dyrektywa ENDP. Dyrektywy te nie generują żadnych dodatkowych instrukcji, ale jedynie polepszają czytelność programu. Podprogram ten może być z dowolnego miejsca w programie za pomocą instrukcji
call BCD2ASCII
Dodatkowo, w początkowej i końcowej części podprogramu wprowadzono instrukcje push eax, pop eax, które zapamiętują i odtwarzają zawartość rejestru AX. W rezultacie, korzystając z podprogramu mamy pewność, że zawartości rejestrów ogólnego przeznaczenia nie zostaną zmienione, z wyjątkiem DH, DL, przez które wyprowadzane są wyniki.
BCD2ASCII PROC near
; podprogram zamienia liczbę w kodzie BCD znajdującą się
; w rejestrze AL na dwie cyfry w kodzie ASCII
; i wpisuje je do rejestrów DH i DL
; podprogram nie zmienia zaw. rejestrów z wyjątkiem DH i DL
push ax
mov ah, al ; przechowanie AL
shr al, 4 ; przesunięcie wszystkich bitów AL.
; o 4 poz. w prawo
add al, 30H ; zamiana na kod ASCII
mov dh, al ; odesłanie starszej cyfry do rejestru DH
xchg al, ah ; zamiana zawartości rejestrów AL i AH
and al, 00001111B ; wyzerowanie 4 starszych bitów AL
add al, 30H ; zamiana na kod ASCII
mov dl, al ; odesłanie młodszej cyfry do rejestru DL
pop ax
ret
BCD2ASCII ENDP
Dodatek A
Uruchamianie programów z wykorzystaniem debuggera
Nieodłącznym elementem praktyki programowania jest występowanie różnych typów błędów. Nawet doświadczonym programistom zdarza się popełniać omyłki. Z tego powodu we współczesnej informatyce rozwinięto szereg zasad i reguł postępowania w zakresie tworzenia oprogramowania, tak by ograniczyć błędy do minimum. Stosunkowo najprostsze do znalezienia są błędy formalne polegające na niezgodności kodu programu ze składnią języka. Kompilatory sygnalizują takie błędy podając numer wiersza w programie, co pozwala na szybkie ich odnalezienie i usunięcie. Trudniejsze do wykrycia są błędy wykonania programu (ang. run-time errors), jak też błędy logiczne. Błędy wykonania programu ujawniają się dopiero podczas wykonywania jego wykonywania — próba wykonania niedozwolonej operacji jest wykrywana przez sprzęt lub oprogramowanie, a ślad za tym wykonywanie programu zostaje zawieszone, czemu towarzyszy odpowiedni komunikat. Błędy logiczne nie są sygnalizowane przez system operacyjny, ale ich objawami jest niepoprawne działanie programu, np. program podaje błędne wartości, wykres na ekranie ma niewłaściwy kształt, dźwięki odtwarzane są nieprawidłowo, itp.
Zidentyfikowanie błędu może być znacznie łatwiejsze jeśli dysponujemy programem narzędziowym pozwalającym na wykonywanie pod nadzorem poszczególnych fragmentów analizowanego programu, czyli debuggerem. Debuggery umożliwiają krokowe uruchamianie programów, obserwację wykonywania rozkazów zawartych w segmencie kodu, oglądanie zmiennych znajdujących się w segmencie danych, i inne operacji.
Dostępnych jest wiele różnych debuggerów, o różnym stopniu złożoności i zakresie zastosowań. Zazwyczaj debugger stanowi integralną część środowiska programistycznego, np. w systemie MS Visual Studio. Dostępne są także debuggery zewnętrzne — jednym z nich jest m.in. niżej opisany, udostępniany w Internecie (http://www.ollydbg.de), program OllyDbg, wyróżniający się stosunkowo nieskomplikowanym interfejsem użytkownika. Podobne możliwości ma także Turbo-debugger (TD32.EXE). Oba wymienione debuggery nie wymagają instalacji, od razu są gotowe do użycia.
Śledzenie programów w środowisku MS Visual Studio C++
Debuggowanie programu jest wykonywane po naciśnięciu klawisza F5. Przedtem należy ustawić punkt zatrzymania (ang. breakpoint) poprzez kliknięcie na obrzeżu ramki obok rozkazu, przed którym ma nastąpić zatrzymanie. Po uruchomieniu debuggowania, można otworzyć potrzebne okna, wśród których najbardziej przydatne jest okno prezentujące zawartości rejestrów procesora. W tym celu wybieramy opcje Debug / Windows / Registers. W analogiczny sposób można otworzyć inne okna. Ilustruje to poniższy rysunek.
Po naciśnięciu klawisza F5 program jest wykonywany aż do napotkania (zaznaczonego wcześniej) punktu zatrzymania. Można wówczas wykonywać pojedyncze rozkazy programu poprzez wielokrotne naciskanie klawisza F10. Podobne znaczenie ma klawisz F11, ale w tym przypadku śledzenie obejmuje także zawartość podprogramów.
Wybierając opcję Debug / Stop debugging można zatrzymać debuggowanie programu. Prócz dostępnych jest jeszcze wiele innych opcji, które można wywołać w analogiczny sposób.
Śledzenie programów za pomocą debuggera OllyDbg
Debugger OllyDbg należy do grupy debuggerów zewnętrznych, nie zintegrowanych ze środowiskiem programistycznym. W szczególności stosowany jest w przypadkach, gdy kod programu zapisany jest w języku wysokiego poziomu, a jego realizacja budzi wątpliwości.
Program, który zamierzamy śledzić za pomocą debuggera OllyDbg wymaga uprzedniego przygotowania. W tym celu w kodzie źródłowym programu, w fragmencie, który przypuszczalnie jest odpowiedzialny za błędne działanie programu, należy wprowadzić rozkaz INT 3. Następnie należy przeprowadzić asemblację i konsolidację (linkowanie) w zwykły sposób — w rezultacie powstanie plik z rozszerzeniem .EXE. Następnie, po uruchomieniu śledzenia debugger zatrzyma się bezpośrednio za rozkazem INT 3, co pozwoli na dokładne prześledzenie działania kolejnych rozkazów programu.
Po usunięciu błędów w programie rozkaz INT 3 należy usunąć z kodu źródłowego i ponownie przetłumaczyć program.
W celu szybkiego uruchomienia debuggera OllyDbg wygodnie jest utworzyć krótki plik wsadowy, podobny do używanego podczas asemblacji. Plik, nazwany przykładowo d.bat, zawiera tylko jeden wiersz:
c:\programy\masm\OllyDbg\Ollydbg %1.exe
W celu uruchomienia debuggera wystarczy tylko uruchomić powyższy plik wsadowy z odpowiednim parametrem. Przykładowo, jeśli plik przetłumaczony program znajduje się pliku w pliku pierwszy.exe, to wywołanie ma postać
d pierwszy
W wyniku powyższej operacji zostanie uruchomiony debugger, który na ekranie pojawi się w postaci kilku okien. Naciśnięcie klawisza F9 spowoduje rozpoczęcie wykonywania programu, który zatrzyma się po napotkaniu rozkazu INT 3. Poniższy rysunek przedstawia okna debuggera w trakcie śledzenia programu przykładowego zdanie.exe, który został opisany na poprzednich stronach.
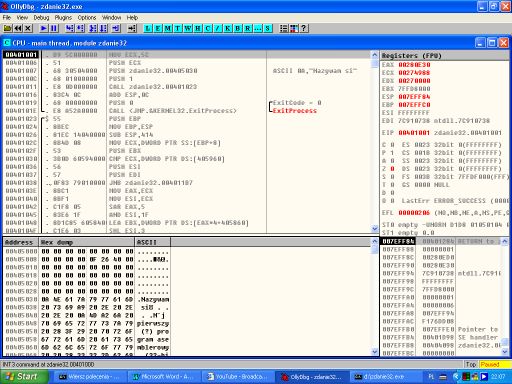
Wartości liczbowe kodowane są w systemie szesnastkowym. W lewym górnym oknie wyświetlane są rozkazy programu, a poniżej wyświetlany jest obszar danych programu (sposób wyświetlania danych można zmienić). W prawym górnym oknie podana jest zawartość rejestrów i znaczników procesora, przy czym na czerwono zaznaczone są rejestry, które zmieniły swoją zawartość po wykonaniu ostatniego rozkazu. W prawym dolnym oknie wyświetlany jest obszar stosu.
Dostępnych kilka różnych sposobów wykonywania programów. W najprostszym przypadku można nacisnąć klawisz F9, co spowoduje rozpoczęcie wykonywania programu w konwencjonalny sposób. Taka metoda jest zwykle mało przydatna (chyba, że używane są pułapki), ponieważ nie pozwala na dokładną obserwację działania poszczególnych rozkazów programu.
Znacznie częściej posługujemy się klawiszem F7, którego naciśnięcie powoduje wykonanie pojedynczego rozkazu, który zaznaczony jest przez poziomy, szary pasek. Skutkiem jej wykonania może być zmiana zawartości rejestru, zmiana zawartości komórki pamięci lub inna operacja. Identyczny skutek ma naciśnięcie klawisza F8, o ile wykonywany rozkaz nie wywołuje podprogramu (CALL). W takim przypadku naciśnięcie F8 powoduje wykonanie całego podprogramu.
Jeśli w trakcie śledzenia programu zachodzi konieczność uruchomienia go od nowa, to program można przełączyć (ang. reset) do stanu początkowego poprzez naciśnięcie kombinacji klawiszy Ctrl F2. Uwaga: jeśli konieczna jest ponowna translacja (asemblacja i konsolidacja) programu, to trzeba zakończyć debuggowanie poprzez wybranie opcji Debug ! Close lub poprzez zamknięcie debuggera.
Przesuwanie "zaznaczonego" rozkazu za pomocą klawiszy strzałek nie powoduje wykonywania rozkazów. W takim przypadku naciśnięcie klawisza F7 powoduje wykonanie kolejnego rozkazu programu, a nie rozkazu zaznaczonego. Poprzez naciśnięcie klawisza F4 można jednak spowodować wykonanie kolejnych rozkazów programu aż do rozkazu aktualnie zaznaczonego (wyłącznie).
W oknie rejestrów (u góry po prawej stronie) wyświetlane są zawartości rejestrów procesora. Poprzez kliknięcie (w tym oknie) prawym klawiszem myszki na wybrany rejestr, można zmienić jego zawartość: zwiększyć lub zmniejszyć, wpisać inną wartość, wpisać kod ASCII znaku. itp.
W oknie danych wyświetlana jest zawartość obszaru danych programu. Zawartość tego dostosować do specyfiki programu poprzez kliknięcie (w tym oknie) prawym klawiszem myszki. W rezultacie pojawi się menu konfiguracyjne, za pomocą którego można określić format wyświetlanych danych. Opcja „Go to ...” pozwala wskazać adres początkowy wyświetlanego obszaru danych. Wyświetlane dane można dowolnie zmieniać poprzez zaznaczenie danej i naciśnięcie klawiszy Ctrl E.
Omawiany debugger realizuje jeszcze wiele innych operacji wspomagających uruchamianie programów. Interfejs debuggera jest intuicyjny i w dużym stopniu zgodny z powszechnie znanym interfejsem Turbo-debuggera firmy Borland.
Debuggowanie programów zawierających informacje symboliczne
Opisane techniki debuggowania programów dotyczą dowolnych programów zakodowanych w postaci pliku wykonywalnego (z rozszerzeniem .exe). Debuggowanie będzie jednak bardziej efektywne, jeśli jednocześnie dostępny będzie kod źródłowy programu a nie tylko sekwencja wykonywanych rozkazów. Typowe asemblery i konsolidatory opcjonalnie wprowadzają do generowanego kodu informacje symboliczne, które później pozwalają na śledzenie programu na poziomie kodu źródłowego. Każdy producent oprogramowania stosuje własne systemy kodowania, co powoduje że do asemblacji, konsolidacji i debuggowania trzeba stosować produkty tej samej firmy, np. asembler TASM, konsolidator ILINK32, debugger TD32 firmy Borland.
7
Wyszukiwarka
Podobne podstrony:
AKO Lab2007 cw4 7
AKO Lab2012 cw1
Matlab cw1 2 zaoczni
ćw1 Maszyna turinga
MZ TZrokII cw1(1)
ćw1
fizyka lab20090221 00006
cw1 modelowanie id 122786 Nieznany
cw1
Ćw1 Punkty pomiarowe
Ćw1 Budowa i geometria ostrzy skrawających jakieś opracowanko
Tabelka do lab-cw1, Studia Budownictwo PB, 5 semestr, laborki metal
cw1
ĆW1 doc biochemia
cw1 (2)
GRI cw1 id 195763 Nieznany
Biochemia(ŻCz)Ćw1 Właściwości fizyko chemiczne aminokwasów
cw1
więcej podobnych podstron