MODUŁ 4 - WYBRANE ROZKŁADY ZMIENNYCH LOSOWYCH
Wstęp do modułu
W praktyce i badaniach naukowych spotykamy się z obserwacjami, które mogą być powtarzane w identycznych lub prawie identycznych warunkach. Różne wyniki możliwe do uzyskania w powtarzalnych doświadczeniach to zdarzenia, a zdarzenie losowe, to zdarzenie, które w wyniku przeprowadzonego doświadczenia może wystąpić lub nie. Zmienne losowe, to funkcje, których argumentami są zdarzenia elementarne, a wartościami - liczby rzeczywiste. Niektóre z rozkładów zmiennej losowej mają duże znaczenie (między innymi dla wnioskowania statystycznego). Stąd wynika potrzeba omówienia rozkładów zmiennych losowych (co jest celem modułu „Wybrane rozkłady zmiennych losowych”).
Spis treści:
Podstawowe pojęcia
Wybrane rozkłady dyskretne
Wybrane rozkłady ciągłe
Tablice statystyczne
1. PODSTAWOWE POJĘCIA:
ZMIENNĄ LOSOWĄ X nazywamy każdą funkcję o wartościach liczbowych (rzeczywistych),
określoną na zbiorze zdarzeń elementarnych o wartościach ze zbioru liczb rzeczywistych.
X: ω∈Ω → X(ω)∈R
zdarzenia→ liczby
ZMIENNA LOSOWA X TYPU SKOKOWEGO (zmienna losowa dyskretna)
przyjmuje wartości x1, x2, ... z prawdopodobieństwami p1, p2, ...
FUNKCJĄ PRAWDOPODOBIEŃSTWA ZMIENNEJ LOSOWEJ SKOKOWEJ X
nazywamy przyporządkowanie
xi → P(xi)=pi, i=1, 2, ...
gdzie P(xi) jest prawdopodobieństwem wystąpienia wartości xi oraz
dla zmiennych osiągających skończoną liczbę wartości
dla zmiennych osiągających przeliczalną liczbę wartości.
DYSTRYBUANTĄ ZMIENNEJ LOSOWEJ SKOKOWEJ X
nazywamy funkcję F(x) określoną dla wszystkich liczb rzeczywistych w następujący sposób:
Własności dystrybuanty:
F(x) jest funkcją niemalejącą i lewostronnie ciągłą.
WARTOŚCIĄ OCZEKIWANĄ ZMIENNEJ LOSOWEJ SKOKOWEJ X
nazywamy wartość
dla zmiennych osiągających skończoną liczbę wartości
dla zmiennych osiągających przeliczalną liczbę wartości
WARIANCJĄ ZMIENNEJ LOSOWEJ SKOKOWEJ X
nazywamy wartość
FUNKCJĄ GĘSTOŚCI PRAWDOPODOBIEŃSTWA ZMIENNEJ LOSOWEJ CIĄGŁEJ X
nazywamy funkcję f(x), określoną na zbiorze liczb rzeczywistych i spełniającą warunki:
Dla przedziałów: (a, b), <a, b), (a, b>, <a, b> mamy:
DYSTRYBUANTĄ ZMIENNEJ LOSOWEJ CIĄGŁEJ X
nazywamy funkcję F(x) określoną dla wszystkich liczb rzeczywistych w następujący sposób:
Własności dystrybuanty:
F(x) jest funkcją niemalejącą i ciągłą.
WARTOŚCIĄ OCZEKIWANĄ ZMIENNEJ LOSOWEJ CIĄGŁEJ X
nazywamy wartość
WARIANCJĄ ZMIENNEJ LOSOWEJ CIĄGŁEJ X
nazywamy wartość
Własności wartości oczekiwanej ( a, b, c- stałe, X, Y - zmienne losowe):
E(c)=c
E(aX)=aE(X)
E(X+b)=E(X)+b
E(X-E(X))=0
E(X+Y)=E(X)+E(Y)
E(X·Y)=E(X)·E(Y) dla zmiennych niezależnych
Własności wariancji:
D2(c)=0
D2(aX)=a2 D2(X)
D2(X+b)=D2(X)
D2(X+Y)= D2(X)+D2(Y) dla zmiennych niezależnych
D2(X-Y)= D2(X)+D2(Y) dla zmiennych niezależnych
2. WYBRANE ROZKŁADY DYSKRETNE
ROZKŁAD DWUPUNKTOWY
P(X=x1)=p; P(X= x2)=q (gdzie p+q=1)
Szczególnym przypadkiem rozkładu dwupunktowego jest rozkład ZERO-JEDYNKOWY
P(X=1)=p; P(X=0)=q (gdzie p+q=1)
Dla rozkładu ZERO-JEDYNKOWEGO:
ROZKŁAD DWUMIANOWY
gdzie k=0, 1, ..., n oraz p+q=1
Zmienna losowa o rozkładzie dwumianowym opisuje eksperyment znany pod nazwą prób Bernoulliego: przeprowadzamy n doświadczeń (n*2). Wynikiem każdego doświadczenia może być tylko jeden z dwóch stanów: sukces albo porażka. Prawdopodobieństwo sukcesu jest takie samo w kolejnych doświadczeniach. Między prawdopodobieństwem sukcesu (p) oraz prawdopodobieństwem porażki (q) zachodzi związek p+q =1. Doświadczenia są niezależne. Jeśli przeprowadzimy n niezależnych doświadczeń, to liczba sukcesów w tych doświadczeniach ma rozkład dwumianowy.
ROZKŁAD POISSONA
Zmienna losowa X, która przyjmuje wartości 0, 1, 2, ... z prawdopodobieństwami określonymi wzorem
gdzie m jest stałą dodatnią nazywa się zmienną losową o rozkładzie Poissona. Wartość oczekiwana i wariancja tej zmiennej są odpowiednio równe E(X)=m i D2(X)=m.
Rozkładem Poissona można przybliżać rozkład dwumianowy, gdy spełnione są następujące warunki:
duża liczba doświadczeń (co najmniej 20)
stały iloczyn np=m
wartość parametru p<0,2.
WYBRANE ROZKŁADY CIĄGŁE
ROZKŁAD JEDNOSTAJNY W PRZEDZIALE <a, b〉
Rys. Funkcja gęstości rozkładu jednostajnego w przedziale <a, b>.
Źródło: opracowanie własne.
ROZKŁAD WYKŁADNICZY
Rys. Funkcja gęstości rozkładu wykładniczego.
Źródło: opracowanie własne.
ROZKŁAD NORMALNY
Wyrażenie „zmienna losowa X ma rozkład normalny z parametrami m i σ” zapisać można następująco: X∼N(m,σ).
Wykresem gęstości rozkładu normalnego jest tzw. krzywa Gaussa. Krzywa Gaussa ma następujące własności:
kształt funkcji gęstości zależy od wartości dwóch parametrów: m i σ (m decyduje o przesunięciu krzywej, natomiast σ o smukłości krzywej)
jest symetryczna względem prostej x=m
w punkcie x=m osiąga wartość maksymalną (jednomodalność)
w x=m-σ oraz x=m+σ ma punkty przegięcia.
Rys. Funkcja gęstości rozkładu normalnego.
Źródło: opracowanie własne.
Rys. Funkcje gęstości rozkładu normalnego o różnych parametrach.
Źródło: opracowanie własne.
Reguła trzech sigm: P (m - 3 σ ≤ X ≤ m + 3σ) = 0,997 ≈ 1
Prawdopodobieństwo, że zmienna losowa ciągła X przyjmie wartości z przedziału <m-3σ, m+3σ〉 wynosi w przybliżeniu 1.
Przy wykorzystaniu rozkładu normalnego w procedurze wnioskowania statystycznego często dokonuje się przekształcenia, zwanego standaryzacją, tak aby uniezależnić się od parametrów m i σ. Zamiast obserwowanej zmiennej losowej X wprowadzamy tzw. zmienną standaryzowaną T∼N(0,1), która jest zdefiniowana jako:
Dystrybuanta standaryzowanego rozkładu normalnego standaryzowanego jest stablicowana.
ROZKŁAD CHI-KWADRAT
Rozkładem χ2 z k stopniami swobody nazywamy rozkład następującej sumy: X12+ X22+ ...+ Xk2, gdzie X1, X2, ..., Xk są niezależnymi zmiennymi losowymi o rozkładzie normalnym Xi∼N(0,1) dla i=1, 2, ..., k. Zmienna losowa χ2 przyjmuje wartości dodatnie i ma rozkład określony przez liczbę stopni swobody k.
Rys. Funkcja gęstości rozkładu chi-kwadrat.
Źródło: opracowanie własne.
ROZKŁAD T-STUDENTA
Jeżeli zmienna losowa X ma rozkład N(0,1), zmienna losowa Y ma rozkład χ2 o k stopniach swobody, a zmienne losowe X i Y są niezależne, to zmienna losowa
przyjmuje rozkład t-Studenta o k stopniach swobody. Rozkład tego typu po raz pierwszy otrzymał Goosset (pseudonim Student - stąd nazwa rozkładu).
Rys. Funkcja gęstości rozkładu t-Studenta.
Źródło: opracowanie własne.
Tablice statystyczne
Tabela. Wartości dystrybuanty rozkładu normalnego standaryzowanego
P(X<uα)=α
|
0 |
0,01 |
0,02 |
0,03 |
0,04 |
0,05 |
0,06 |
0,07 |
0,08 |
0,09 |
0,0 |
0,5000 |
0,5040 |
0,5080 |
0,5120 |
0,5160 |
0,5199 |
0,5239 |
0,5279 |
0,5319 |
0,5359 |
0,1 |
0,5398 |
0,5438 |
0,5478 |
0,5517 |
0,5557 |
0,5596 |
0,5636 |
0,5675 |
0,5714 |
0,5753 |
0,2 |
0,5793 |
0,5832 |
0,5871 |
0,5910 |
0,5948 |
0,5987 |
0,6026 |
0,6064 |
0,6103 |
0,6141 |
0,3 |
0,6179 |
0,6217 |
0,6255 |
0,6293 |
0,6331 |
0,6368 |
0,6406 |
0,6443 |
0,6480 |
0,6517 |
0,4 |
0,6554 |
0,6591 |
0,6628 |
0,6664 |
0,6700 |
0,6736 |
0,6772 |
0,6808 |
0,6844 |
0,6879 |
0,5 |
0,6915 |
0,6950 |
0,6985 |
0,7019 |
0,7054 |
0,7088 |
0,7123 |
0,7157 |
0,7190 |
0,7224 |
0,6 |
0,7257 |
0,7291 |
0,7324 |
0,7357 |
0,7389 |
0,7422 |
0,7454 |
0,7486 |
0,7517 |
0,7549 |
0,7 |
0,7580 |
0,7611 |
0,7642 |
0,7673 |
0,7704 |
0,7734 |
0,7764 |
0,7794 |
0,7823 |
0,7852 |
0,8 |
0,7881 |
0,7910 |
0,7939 |
0,7967 |
0,7995 |
0,8023 |
0,8051 |
0,8078 |
0,8106 |
0,8133 |
0,9 |
0,8159 |
0,8186 |
0,8212 |
0,8238 |
0,8264 |
0,8289 |
0,8315 |
0,8340 |
0,8365 |
0,8389 |
1,0 |
0,8413 |
0,8438 |
0,8461 |
0,8485 |
0,8508 |
0,8531 |
0,8554 |
0,8577 |
0,8599 |
0,8621 |
1,1 |
0,8643 |
0,8665 |
0,8686 |
0,8708 |
0,8729 |
0,8749 |
0,8770 |
0,8790 |
0,8810 |
0,8830 |
1,2 |
0,8849 |
0,8869 |
0,8888 |
0,8907 |
0,8925 |
0,8944 |
0,8962 |
0,8980 |
0,8997 |
0,9015 |
1,3 |
0,9032 |
0,9049 |
0,9066 |
0,9082 |
0,9099 |
0,9115 |
0,9131 |
0,9147 |
0,9162 |
0,9177 |
1,4 |
0,9192 |
0,9207 |
0,9222 |
0,9236 |
0,9251 |
0,9265 |
0,9279 |
0,9292 |
0,9306 |
0,9319 |
1,5 |
0,9332 |
0,9345 |
0,9357 |
0,9370 |
0,9382 |
0,9394 |
0,9406 |
0,9418 |
0,9429 |
0,9441 |
1,6 |
0,9452 |
0,9463 |
0,9474 |
0,9484 |
0,9495 |
0,9505 |
0,9515 |
0,9525 |
0,9535 |
0,9545 |
1,7 |
0,9554 |
0,9564 |
0,9573 |
0,9582 |
0,9591 |
0,9599 |
0,9608 |
0,9616 |
0,9625 |
0,9633 |
1,8 |
0,9641 |
0,9649 |
0,9656 |
0,9664 |
0,9671 |
0,9678 |
0,9686 |
0,9693 |
0,9699 |
0,9706 |
1,9 |
0,9713 |
0,9719 |
0,9726 |
0,9732 |
0,9738 |
0,9744 |
0,9750 |
0,9756 |
0,9761 |
0,9767 |
2,0 |
0,9772 |
0,9778 |
0,9783 |
0,9788 |
0,9793 |
0,9798 |
0,9803 |
0,9808 |
0,9812 |
0,9817 |
2,1 |
0,9821 |
0,9826 |
0,9830 |
0,9834 |
0,9838 |
0,9842 |
0,9846 |
0,9850 |
0,9854 |
0,9857 |
2,2 |
0,9861 |
0,9864 |
0,9868 |
0,9871 |
0,9875 |
0,9878 |
0,9881 |
0,9884 |
0,9887 |
0,9890 |
2,3 |
0,9893 |
0,9896 |
0,9898 |
0,9901 |
0,9904 |
0,9906 |
0,9909 |
0,9911 |
0,9913 |
0,9916 |
2,4 |
0,9918 |
0,9920 |
0,9922 |
0,9925 |
0,9927 |
0,9929 |
0,9931 |
0,9932 |
0,9934 |
0,9936 |
2,5 |
0,9938 |
0,9940 |
0,9941 |
0,9943 |
0,9945 |
0,9946 |
0,9948 |
0,9949 |
0,9951 |
0,9952 |
2,6 |
0,9953 |
0,9955 |
0,9956 |
0,9957 |
0,9959 |
0,9960 |
0,9961 |
0,9962 |
0,9963 |
0,9964 |
2,7 |
0,9965 |
0,9966 |
0,9967 |
0,9968 |
0,9969 |
0,9970 |
0,9971 |
0,9972 |
0,9973 |
0,9974 |
2,8 |
0,9974 |
0,9975 |
0,9976 |
0,9977 |
0,9977 |
0,9978 |
0,9979 |
0,9979 |
0,9980 |
0,9981 |
2,9 |
0,9981 |
0,9982 |
0,9982 |
0,9983 |
0,9984 |
0,9984 |
0,9985 |
0,9985 |
0,9986 |
0,9986 |
3,0 |
0,9987 |
0,9987 |
0,9987 |
0,9988 |
0,9988 |
0,9989 |
0,9989 |
0,9989 |
0,9990 |
0,9990 |
3,1 |
0,9990 |
0,9991 |
0,9991 |
0,9991 |
0,9992 |
0,9992 |
0,9992 |
0,9992 |
0,9993 |
0,9993 |
3,2 |
0,9993 |
0,9993 |
0,9994 |
0,9994 |
0,9994 |
0,9994 |
0,9994 |
0,9995 |
0,9995 |
0,9995 |
3,3 |
0,9995 |
0,9995 |
0,9995 |
0,9996 |
0,9996 |
0,9996 |
0,9996 |
0,9996 |
0,9996 |
0,9997 |
3,4 |
0,9997 |
0,9997 |
0,9997 |
0,9997 |
0,9997 |
0,9997 |
0,9997 |
0,9997 |
0,9997 |
0,9998 |
3,5 |
0,9998 |
0,9998 |
0,9998 |
0,9998 |
0,9998 |
0,9998 |
0,9998 |
0,9998 |
0,9998 |
0,9998 |
Tabela. Tablice rozkładu t-Studenta P(|X|>tα)=α
|
0,99 |
0,98 |
0,95 |
0,9 |
0,8 |
0,7 |
0,3 |
0,2 |
0,1 |
0,05 |
0,02 |
0,01 |
1 |
0,016 |
0,031 |
0,079 |
0,158 |
0,325 |
0,510 |
1,963 |
3,078 |
6,314 |
12,706 |
31,821 |
63,657 |
2 |
0,014 |
0,028 |
0,071 |
0,142 |
0,289 |
0,445 |
1,386 |
1,886 |
2,920 |
4,303 |
6,965 |
9,925 |
3 |
0,014 |
0,027 |
0,068 |
0,137 |
0,277 |
0,424 |
1,250 |
1,638 |
2,353 |
3,182 |
4,541 |
5,841 |
4 |
0,013 |
0,027 |
0,067 |
0,134 |
0,271 |
0,414 |
1,190 |
1,533 |
2,132 |
2,776 |
3,747 |
4,604 |
5 |
0,013 |
0,026 |
0,066 |
0,132 |
0,267 |
0,408 |
1,156 |
1,476 |
2,015 |
2,571 |
3,365 |
4,032 |
6 |
0,013 |
0,026 |
0,065 |
0,131 |
0,265 |
0,404 |
1,134 |
1,440 |
1,943 |
2,447 |
3,143 |
3,707 |
7 |
0,013 |
0,026 |
0,065 |
0,130 |
0,263 |
0,402 |
1,119 |
1,415 |
1,895 |
2,365 |
2,998 |
3,499 |
8 |
0,013 |
0,026 |
0,065 |
0,130 |
0,262 |
0,399 |
1,108 |
1,397 |
1,860 |
2,306 |
2,896 |
3,355 |
9 |
0,013 |
0,026 |
0,064 |
0,129 |
0,261 |
0,398 |
1,100 |
1,383 |
1,833 |
2,262 |
2,821 |
3,250 |
10 |
0,013 |
0,026 |
0,064 |
0,129 |
0,260 |
0,397 |
1,093 |
1,372 |
1,812 |
2,228 |
2,764 |
3,169 |
11 |
0,013 |
0,026 |
0,064 |
0,129 |
0,260 |
0,396 |
1,088 |
1,363 |
1,796 |
2,201 |
2,718 |
3,106 |
12 |
0,013 |
0,026 |
0,064 |
0,128 |
0,259 |
0,395 |
1,083 |
1,356 |
1,782 |
2,179 |
2,681 |
3,055 |
13 |
0,013 |
0,026 |
0,064 |
0,128 |
0,259 |
0,394 |
1,079 |
1,350 |
1,771 |
2,160 |
2,650 |
3,012 |
14 |
0,013 |
0,026 |
0,064 |
0,128 |
0,258 |
0,393 |
1,076 |
1,345 |
1,761 |
2,145 |
2,624 |
2,977 |
15 |
0,013 |
0,025 |
0,064 |
0,128 |
0,258 |
0,393 |
1,074 |
1,341 |
1,753 |
2,131 |
2,602 |
2,947 |
16 |
0,013 |
0,025 |
0,064 |
0,128 |
0,258 |
0,392 |
1,071 |
1,337 |
1,746 |
2,120 |
2,583 |
2,921 |
17 |
0,013 |
0,025 |
0,064 |
0,128 |
0,257 |
0,392 |
1,069 |
1,333 |
1,740 |
2,110 |
2,567 |
2,898 |
18 |
0,013 |
0,025 |
0,064 |
0,127 |
0,257 |
0,392 |
1,067 |
1,330 |
1,734 |
2,101 |
2,552 |
2,878 |
19 |
0,013 |
0,025 |
0,064 |
0,127 |
0,257 |
0,391 |
1,066 |
1,328 |
1,729 |
2,093 |
2,539 |
2,861 |
20 |
0,013 |
0,025 |
0,063 |
0,127 |
0,257 |
0,391 |
1,064 |
1,325 |
1,725 |
2,086 |
2,528 |
2,845 |
21 |
0,013 |
0,025 |
0,063 |
0,127 |
0,257 |
0,391 |
1,063 |
1,323 |
1,721 |
2,080 |
2,518 |
2,831 |
22 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,390 |
1,061 |
1,321 |
1,717 |
2,074 |
2,508 |
2,819 |
23 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,390 |
1,060 |
1,319 |
1,714 |
2,069 |
2,500 |
2,807 |
24 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,390 |
1,059 |
1,318 |
1,711 |
2,064 |
2,492 |
2,797 |
25 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,390 |
1,058 |
1,316 |
1,708 |
2,060 |
2,485 |
2,787 |
26 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,390 |
1,058 |
1,315 |
1,706 |
2,056 |
2,479 |
2,779 |
27 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,389 |
1,057 |
1,314 |
1,703 |
2,052 |
2,473 |
2,771 |
28 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,389 |
1,056 |
1,313 |
1,701 |
2,048 |
2,467 |
2,763 |
29 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,389 |
1,055 |
1,311 |
1,699 |
2,045 |
2,462 |
2,756 |
30 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,389 |
1,055 |
1,310 |
1,697 |
2,042 |
2,457 |
2,750 |
31 |
0,013 |
0,025 |
0,063 |
0,127 |
0,256 |
0,389 |
1,054 |
1,309 |
1,696 |
2,040 |
2,453 |
2,744 |
32 |
0,013 |
0,025 |
0,063 |
0,127 |
0,255 |
0,389 |
1,054 |
1,309 |
1,694 |
2,037 |
2,449 |
2,738 |
33 |
0,013 |
0,025 |
0,063 |
0,127 |
0,255 |
0,389 |
1,053 |
1,308 |
1,692 |
2,035 |
2,445 |
2,733 |
34 |
0,013 |
0,025 |
0,063 |
0,127 |
0,255 |
0,389 |
1,052 |
1,307 |
1,691 |
2,032 |
2,441 |
2,728 |
35 |
0,013 |
0,025 |
0,063 |
0,127 |
0,255 |
0,388 |
1,052 |
1,306 |
1,690 |
2,030 |
2,438 |
2,724 |
36 |
0,013 |
0,025 |
0,063 |
0,127 |
0,255 |
0,388 |
1,052 |
1,306 |
1,688 |
2,028 |
2,434 |
2,719 |
37 |
0,013 |
0,025 |
0,063 |
0,127 |
0,255 |
0,388 |
1,051 |
1,305 |
1,687 |
2,026 |
2,431 |
2,715 |
38 |
0,013 |
0,025 |
0,063 |
0,127 |
0,255 |
0,388 |
1,051 |
1,304 |
1,686 |
2,024 |
2,429 |
2,712 |
39 |
0,013 |
0,025 |
0,063 |
0,126 |
0,255 |
0,388 |
1,050 |
1,304 |
1,685 |
2,023 |
2,426 |
2,708 |
40 |
0,013 |
0,025 |
0,063 |
0,126 |
0,255 |
0,388 |
1,050 |
1,303 |
1,684 |
2,021 |
2,423 |
2,704 |
50 |
0,013 |
0,025 |
0,063 |
0,126 |
0,255 |
0,388 |
1,047 |
1,299 |
1,676 |
2,009 |
2,403 |
2,678 |
60 |
0,013 |
0,025 |
0,063 |
0,126 |
0,254 |
0,387 |
1,045 |
1,296 |
1,671 |
2,000 |
2,390 |
2,660 |
70 |
0,013 |
0,025 |
0,063 |
0,126 |
0,254 |
0,387 |
1,044 |
1,294 |
1,667 |
1,994 |
2,381 |
2,648 |
80 |
0,013 |
0,025 |
0,063 |
0,126 |
0,254 |
0,387 |
1,043 |
1,292 |
1,664 |
1,990 |
2,374 |
2,639 |
90 |
0,013 |
0,025 |
0,063 |
0,126 |
0,254 |
0,387 |
1,042 |
1,291 |
1,662 |
1,987 |
2,368 |
2,632 |
100 |
0,013 |
0,025 |
0,063 |
0,126 |
0,254 |
0,386 |
1,042 |
1,290 |
1,660 |
1,984 |
2,364 |
2,626 |
Tabela. Tablice rozkładu chi-kwadrat P(X>tα)=α
|
0,99 |
0,98 |
0,95 |
0,9 |
0,8 |
0,2 |
0,1 |
0,05 |
0,02 |
0,01 |
1 |
0,000 |
0,001 |
0,004 |
0,016 |
0,064 |
1,642 |
2,706 |
3,841 |
5,412 |
6,635 |
2 |
0,020 |
0,040 |
0,103 |
0,211 |
0,446 |
3,219 |
4,605 |
5,991 |
7,824 |
9,210 |
3 |
0,115 |
0,185 |
0,352 |
0,584 |
1,005 |
4,642 |
6,251 |
7,815 |
9,837 |
11,345 |
4 |
0,297 |
0,429 |
0,711 |
1,064 |
1,649 |
5,989 |
7,779 |
9,488 |
11,668 |
13,277 |
5 |
0,554 |
0,752 |
1,145 |
1,610 |
2,343 |
7,289 |
9,236 |
11,070 |
13,388 |
15,086 |
6 |
0,872 |
1,134 |
1,635 |
2,204 |
3,070 |
8,558 |
10,645 |
12,592 |
15,033 |
16,812 |
7 |
1,239 |
1,564 |
2,167 |
2,833 |
3,822 |
9,803 |
12,017 |
14,067 |
16,622 |
18,475 |
8 |
1,646 |
2,032 |
2,733 |
3,490 |
4,594 |
11,030 |
13,362 |
15,507 |
18,168 |
20,090 |
9 |
2,088 |
2,532 |
3,325 |
4,168 |
5,380 |
12,242 |
14,684 |
16,919 |
19,679 |
21,666 |
10 |
2,558 |
3,059 |
3,940 |
4,865 |
6,179 |
13,442 |
15,987 |
18,307 |
21,161 |
23,209 |
11 |
3,053 |
3,609 |
4,575 |
5,578 |
6,989 |
14,631 |
17,275 |
19,675 |
22,618 |
24,725 |
12 |
3,571 |
4,178 |
5,226 |
6,304 |
7,807 |
15,812 |
18,549 |
21,026 |
24,054 |
26,217 |
13 |
4,107 |
4,765 |
5,892 |
7,042 |
8,634 |
16,985 |
19,812 |
22,362 |
25,472 |
27,688 |
14 |
4,660 |
5,368 |
6,571 |
7,790 |
9,467 |
18,151 |
21,064 |
23,685 |
26,873 |
29,141 |
15 |
5,229 |
5,985 |
7,261 |
8,547 |
10,307 |
19,311 |
22,307 |
24,996 |
28,259 |
30,578 |
16 |
5,812 |
6,614 |
7,962 |
9,312 |
11,152 |
20,465 |
23,542 |
26,296 |
29,633 |
32,000 |
17 |
6,408 |
7,255 |
8,672 |
10,085 |
12,002 |
21,615 |
24,769 |
27,587 |
30,995 |
33,409 |
18 |
7,015 |
7,906 |
9,390 |
10,865 |
12,857 |
22,760 |
25,989 |
28,869 |
32,346 |
34,805 |
19 |
7,633 |
8,567 |
10,117 |
11,651 |
13,716 |
23,900 |
27,204 |
30,144 |
33,687 |
36,191 |
20 |
8,260 |
9,237 |
10,851 |
12,443 |
14,578 |
25,038 |
28,412 |
31,410 |
35,020 |
37,566 |
21 |
8,897 |
9,915 |
11,591 |
13,240 |
15,445 |
26,171 |
29,615 |
32,671 |
36,343 |
38,932 |
22 |
9,542 |
10,600 |
12,338 |
14,041 |
16,314 |
27,301 |
30,813 |
33,924 |
37,659 |
40,289 |
23 |
10,196 |
11,293 |
13,091 |
14,848 |
17,187 |
28,429 |
32,007 |
35,172 |
38,968 |
41,638 |
24 |
10,856 |
11,992 |
13,848 |
15,659 |
18,062 |
29,553 |
33,196 |
36,415 |
40,270 |
42,980 |
25 |
11,524 |
12,697 |
14,611 |
16,473 |
18,940 |
30,675 |
34,382 |
37,652 |
41,566 |
44,314 |
26 |
12,198 |
13,409 |
15,379 |
17,292 |
19,820 |
31,795 |
35,563 |
38,885 |
42,856 |
45,642 |
27 |
12,879 |
14,125 |
16,151 |
18,114 |
20,703 |
32,912 |
36,741 |
40,113 |
44,140 |
46,963 |
28 |
13,565 |
14,847 |
16,928 |
18,939 |
21,588 |
34,027 |
37,916 |
41,337 |
45,419 |
48,278 |
29 |
14,256 |
15,574 |
17,708 |
19,768 |
22,475 |
35,139 |
39,087 |
42,557 |
46,693 |
49,588 |
30 |
14,953 |
16,306 |
18,493 |
20,599 |
23,364 |
36,250 |
40,256 |
43,773 |
47,962 |
50,892 |
31 |
15,655 |
17,042 |
19,281 |
21,434 |
24,255 |
37,359 |
41,422 |
44,985 |
49,226 |
52,191 |
32 |
16,362 |
17,783 |
20,072 |
22,271 |
25,148 |
38,466 |
42,585 |
46,194 |
50,487 |
53,486 |
33 |
17,074 |
18,527 |
20,867 |
23,110 |
26,042 |
39,572 |
43,745 |
47,400 |
51,743 |
54,776 |
34 |
17,789 |
19,275 |
21,664 |
23,952 |
26,938 |
40,676 |
44,903 |
48,602 |
52,995 |
56,061 |
35 |
18,509 |
20,027 |
22,465 |
24,797 |
27,836 |
41,778 |
46,059 |
49,802 |
54,244 |
57,342 |
36 |
19,233 |
20,783 |
23,269 |
25,643 |
28,735 |
42,879 |
47,212 |
50,998 |
55,489 |
58,619 |
37 |
19,960 |
21,542 |
24,075 |
26,492 |
29,635 |
43,978 |
48,363 |
52,192 |
56,730 |
59,893 |
38 |
20,691 |
22,304 |
24,884 |
27,343 |
30,537 |
45,076 |
49,513 |
53,384 |
57,969 |
61,162 |
39 |
21,426 |
23,069 |
25,695 |
28,196 |
31,441 |
46,173 |
50,660 |
54,572 |
59,204 |
62,428 |
40 |
22,164 |
23,838 |
26,509 |
29,051 |
32,345 |
47,269 |
51,805 |
55,758 |
60,436 |
63,691 |
50 |
29,707 |
31,664 |
34,764 |
37,689 |
41,449 |
58,164 |
63,167 |
67,505 |
72,613 |
76,154 |
60 |
37,485 |
39,699 |
43,188 |
46,459 |
50,641 |
68,972 |
74,397 |
79,082 |
84,580 |
88,379 |
70 |
45,442 |
47,893 |
51,739 |
55,329 |
59,898 |
79,715 |
85,527 |
90,531 |
96,388 |
100,425 |
80 |
53,540 |
56,213 |
60,391 |
64,278 |
69,207 |
90,405 |
96,578 |
101,879 |
108,069 |
112,329 |
90 |
61,754 |
64,635 |
69,126 |
73,291 |
78,558 |
101,054 |
107,565 |
113,145 |
119,648 |
124,116 |
100 |
70,065 |
73,142 |
77,929 |
82,358 |
87,945 |
111,667 |
118,498 |
124,342 |
131,142 |
135,807 |
Kontrola wiadomości
Pytania kontrolne:
Co to jest zmienna losowa?
Co to jest zmienna losowa skokowa (dyskretna)?
Co to jest zmienna losowa ciągła?
Podaj przykłady rozkładów dyskretnych.
Podaj przykłady rozkładów ciągłych.
Jakie własności ma dystrybuanta zmiennej losowej skokowej?
Jakie własności ma dystrybuanta zmiennej losowej ciągłej?
Podaj własności wartości oczekiwanej.
Podaj własności wariancji.
Które wykresy funkcji gęstości rozkładów ciągłych są symetryczne względem prostej x=0?
Które wykresy funkcji gęstości rozkładów ciągłych są prawostronnie asymetryczne?
Co to jest krzywa Gaussa? Jakie ma własności?
Co to jest rozkład normalny standaryzowany?
Czy są tablice statystyczne z dystrybuantą rozkładu normalnego N(2, 8)?
Zapoznaj się z tablicami statystycznymi (dystrybuanta rozkładu normalnego standaryzowanego, rozkład χ2, rozkład t-Studenta). Przypomnij jakie własności miały poszczególne wykresy funkcji gęstości.
Szacowany czas wykonania: 45 min.
Słownik
Doświadczenie losowe - każdy proces, którego wyniku nie jesteśmy w stanie dokładnie przewidzieć
Zdarzenie elementarne - każdy wynik doświadczenia losowego
Przestrzeń zdarzeń elementarnych - zbiór wszystkich możliwych wyników doświadczenia (zbiór wszystkich zdarzeń elementarnych
Zdarzenie losowe - Podzbiór przestrzeni zdarzeń elementarnych, zawierający wyróżnione ze względu na daną cechę zdarzenia elementarne
Zmienna losowa - funkcja X, przyporządkowująca każdemu zdarzeniu losowemu ω dokładnie jedną liczbę rzeczywistą X(ω), co można zapisać X: ω∈Ω → X(ω)∈R
BIBLIOGRAFIA:
Hellwig Z., Elementy rachunku prawdopodobieństwa i statystyki matematycznej, PWN, Warszawa 1970
Krysicki W., Bartos J., Królikowska K., Wasilewski M., Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, tom 1, Wydawnictwo PWN, Warszawa 1995, s. 7-135.
Luszniewicz A., Statystyka nie jest trudna. Metody wnioskowania statystycznego, Państwowe Wydawnictwo Ekonomiczne, Warszawa 1994
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, 59-70, 89-91.
Metody statystyczne w zarządzaniu, pod red. D. Witkowskiej, Wydawnictwo „Menadżer”, Łódź 1999, 9-42.
Ostasiewicz S, Rusnak Z., Siedlecka U., Statystyka. Elementy teorii i zadania, Wydawnictwo Akademii Ekonomicznej, Wrocław 1997
Sobczyk M., Statystyka, Wydawnictwo Naukowe PWN, Warszawa 1998, s.2783-105.
Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 166-227.
Wieczorkowska G., Kochański P., Eljaszuk M., Statystyka. Wprowadzenie do analizy danych sondażowych i eksperymentalnych. Wydawnictwo Naukowe Scholar, Warszawa 2004.
MODUŁ 5 - ELEMENTY TEORII ESTYMACJI
Wstęp do modułu
Uogólnianie wyników próby losowej na całą populację, z której pochodzi próba, to wnioskowanie statystyczne. Estymacja, której poświęcony jest moduł „Elementy teorii estymacji” jest procesem wnioskowania o numerycznych wartościach nieznanych wielkości charakteryzujących populację generalną na podstawie danych próbkowych.
Spis treści:
Podstawowe pojęcia
Estymacja punktowa
Estymacja przedziałowa
Minimalna liczebność próby
Podstawowe pojęcia
Proces uogólniania zaobserwowanych w próbie losowej wyników na całą zbiorowość statystyczną nazywamy wnioskowaniem statystycznym. Metody wnioskowania statystycznego obejmują estymację parametrów zbiorowości generalnej oraz weryfikację hipotez statystycznych.
Wnioskowanie statystyczne jako oparte na częściowej informacji dostarcza jedynie wniosków wiarygodnych. Dowolne dwie n-elenentowe próby z populacji są na ogół różne. Wygodnie jest zatem traktować ciąg liczbowy x1, x2, …, xn jako realizację ciągu X1, X2, …, Xn, gdzie Xi, i=1, 2, …, n, jest zmienną losową, której zbiorem możliwych wartości są wartości i-tego spośród n wylosowanych elementów. Ciąg zmiennych losowych X1, X2, …, Xn nazywa się n-elementową próbą losową, natomiast jeśli zmienne X1, X2, …, Xn są niezależne i każda z nich ma rozkład taki jak rozkład badanej cechy populacji, to próbę nazywamy PRÓBĄ PROSTĄ.
Jednym z rodzajów wnioskowania jest estymacja. ESTYMACJA (szacowanie, ocenianie) jest procesem wnioskowania o numerycznych wartościach nieznanych wielkości charakteryzujących populację generalną na podstawie danych próbkowych.
ESTYMATOREM parametru ![]()
nazywa się statystykę
(1)
służącą do oszacowania nieznanej wartości parametru zbiorowości generalnej ![]()
.
Wyróżnia się dwa rodzaje estymacji:
ESTYMACJĘ PUNKTOWĄ, czyli metodę szacunku za pomocą której jako wartość parametru zbiorowości generalnej przyjmuje się konkretną wartość estymatora wyznaczonego na podstawie n-elementowej próby
ESTYMACJĘ PRZEDZIAŁOWĄ, za pomocą której wyznacza się przedział liczbowy, który z ustalonym prawdopodobieństwem zawiera nieznana wartość szacowanego parametru zbiorowości generalnej. Prawdopodobieństwo to nosi nazwę WSPÓŁCZYNNIKA (POZIOMU) UFNOŚCI i oznaczane jest jako 1-α, a znaleziony przedział nazywany jest PRZEDZIAŁEM UFNOŚCI.
Interpretacja poziomu ufności jest następująca: przy wielokrotnym pobieraniu prób n-elementowych i wyznaczaniu na ich podstawie granic przedziałów ufności, średnio w (1-α)⋅100% przypadków otrzymujemy przedziały pokrywające nieznaną wartość ![]()
.
ESTYMACJA PUNKTOWA
Wartość liczbową ![]()
estymatora ![]()
policzoną na podstawie realizacji (x1, x2, …, xn) próby prostej (X1, X2, …, Xn) nazywamy oceną parametru Q.
Wyrażenie ![]()
nazywa się błędem szacunku, a jego miarą jest zwykle ![]()
. Wielkość błędu szacunku zależy od doboru próby i od wyboru możliwie najlepszego estymatora.
O wykorzystaniu estymatora dla dokonania oszacowania decydują jego własności, spośród których szczególnie pożądane są:
nieobciążoność
zgodność
efektywność.
Estymatorem zgodnym nazywamy estymator stochastycznie zbieżny do parametru estymowanego, tzn. taki, który dla każdego ε>0 spełnia równość:
(2)
Estymator nieobciążony to taki estymator, którego wartość oczekiwana jest równa estymowanemu parametrowi, tzn. ![]()
. Jeśli równość ta nie zachodzi, to estymator nazywa się obciążonym.
Obciążeniem estymatora nazywamy wyrażenie ![]()
. (3)
Estymator, dla którego nazywamy estymatorem asymptotycznie nieobciążonym.
Estymator nieobciążony o najmniejszej wariancji nazywamy estymatorem najefektywniejszym. Efektywnością estymatora ![]()
nazywamy wyrażenie
(4)
gdzie ![]()
oznacza estymator najefektywniejszy. Estymator, dla którego ![]()
nazywamy estymatorem asymptotycznie najefektywniejszym.
Estymator![]()
jest dostateczny, jeżeli zawiera wszystkie informacje o parametrze ![]()
, które występują w próbie.
Korzystanie z estymatora posiadającego własności zgodności, nieobciążoności i będącego najbardziej efektywnym pozwala najlepiej oszacować nieznany parametr ![]()
, ponieważ z dużym prawdopodobieństwem można przyjąć, że wyznaczona ocena estymatora jest bliska rzeczywistej wartości.
Podstawowymi parametrami, które szacowane są dla populacji generalnej są: wartość oczekiwana (średnia), wariancja, odchylenie standardowe, frakcja.
Nieobciążonym, zgodnym i efektywnym estymatorem wartości oczekiwanej (średniej) m w populacji jest średnia w próbie
(5)
Estymatorem zgodnym, ale obciążonym wariancji σ2 w populacji jest wariancja w próbie
(6)
Nieobciążonym i zgodnym estymatorem wariancji σ2 w populacji jest wyrażenie
(7)
W badaniach statystycznych często pojawia się problem oszacowania prawdopodobieństwa wystąpienia danego wariantu cechy (zwanego sukcesem) lub oszacowania, jaki procent zbiorowości generalnej posiada wyróżnioną cechę (ewentualnie wariant cechy). Jest to szczególnie ważne w przypadkach, gdy cecha opisująca zbiorowość jest cechą niemierzalną i podstawową charakterystyką populacji jest frakcja (procent) wyróżnionych elementów, zwana też wskaźnikiem struktury w populacji. Zadanie sprowadza się do estymacji parametru p w rozkładzie dwumianowym
(8)
W przypadku, gdy szacujemy p na podstawie n-elementowej próby prostej, estymatorem zgodnym, nieobciążonym i efektywnym jest częstość względna
(9)
gdzie k - liczba elementów wyróżnionych, zaobserwowanych w n-elementowej próbie.
3.ESTYMACJA PRZEDZIAŁOWA
Przypomnijmy, że interpretacja poziomu ufności jest następująca: przy wielokrotnym pobieraniu prób n-elementowych i wyznaczaniu na ich podstawie granic przedziałów ufności, otrzymujemy średnio w (1-α)⋅100% przypadków przedziały pokrywające nieznaną wartość ![]()
(porównaj rysunek.
Rys. Interpretacja (1-α)⋅100% realizacji przedziałów ufności dla parametru ![]()
.
Źródło: Opracowanie własne.
Wzrostowi deklarowanego poziomu ufności odpowiada wzrost przedziału ufności, co prowadzi do znanego paradoksu statystycznego, że im chcemy być bardziej ufni, tym jesteśmy mniej precyzyjni i odwrotnie. Wzrostowi ufności odpowiada wzrost długości przedziałów, a zatem spadek precyzji oszacowania parametru ![]()
. Dlatego też nie należy ustalać przesadnie wysokich prawdopodobieństw 1-α, bowiem może odpowiadać im zbyt niska precyzja oszacowań parametrów. Deklarowany poziom ufności zawiera się zazwyczaj w granicach od 0,90 do 0,99.
Przedziały ufności dla wartości przeciętnej m
Średnia wartość badanej cechy jest najczęściej stosowanym parametrem populacji generalnej. Estymatorem wartości przeciętnej jest średnia arytmetyczna z próby. Jest ona zmienną losową, ma swój rozkład i spełnia wszystkie własności dobrego estymatora. Konkretna wartość liczbowa średniej arytmetycznej jest punktową oceną wartości oczekiwanej. Dlatego też, wykorzystując rozkład średniej i deklarując poziom ufności 1-α, konstruujemy przedział ufności dla wartości przeciętnej. W zależności od przyjętych założeń, otrzymuje się konkretne przedziały ufności w oparciu o rozkład normalny lub rozkład t-Studenta.
Populacja generalna ma rozkład N(m, σ); σ - znane
Przedział ufności wyznaczamy na podstawie wzoru:
(10)
gdzie uα - wartość odczytana z tablic dystrybuanty rozkładu normalnego standaryzowanego tak, aby był spełniony warunek
(11)
Uwaga!
W zależności od typu tablic zawierających dystrybuantę rozkładu normalnego może zajść potrzeba skorzystania z innej zależności. Na przykład dla tablic zamieszczonych w S. Ostasiewicz, Z. Rusnak, U. Siedlecka, Statystyka. Elementy teorii i zadania, Wydawnictwo Akademii Ekonomicznej im. Oskara Langego, Wrocław 1997, wartość uα odczytuje się z tablic dystrybuanty rozkładu normalnego standaryzowanego tak, aby był spełniony warunek
(12)
Populacja generalna ma rozkład N(m, σ); σ - nie jest znane, próba - mała
Przedział ufności wyznaczamy na podstawie wzoru:
(13)
gdzie tα,n-1 - wartość odczytana z tablic rozkładu t-Studenta dla poziomu istotności α oraz n-1 stopni swobody, tak aby spełniony był warunek
(14)
Uwaga!
W zależności od typu tablic może zajść potrzeba skorzystania z innej zależności. Jeżeli korzystamy z tablic zbudowanych wyłącznie dla obszaru dwustronnego, chcąc ustalić wartość krytyczną dla obszaru jednostronnego, bierzemy podwojoną wartość poziomu istotności 2α.
Rozkład dowolny, σ - nie jest znana, próba - duża
Przedział ufności wyznaczamy na podstawie wzoru:
(15)
gdzie uα - wartość odczytana z tablic dystrybuanty rozkładu normalnego standaryzowanego tak, aby był spełniony warunek
(16)
Przedziały ufności dla wariancji i odchylenia standardowego
W badaniach statystycznych ze względu na cechę mierzalną do najczęściej szacowanych parametrów populacji obok średniej należy wariancja (lub odchylenie standardowe) badanej cechy. W zależności od przyjętych założeń, otrzymuje się konkretne przedziały ufności w oparciu o rozkład normalny lub rozkład χ2.
Populacja generalna ma rozkład N(m, σ); próba - mała
Przedział ufności wyznaczamy na podstawie wzoru:
(17)
(18)
gdzie:
wartości odczytane z tablic rozkładu chi-kwadrat dla n-1 stopni swobody w ten sposób, aby spełniały równości:
(19)
(20)
Populacja generalna ma rozkład N(m, σ); próba - duża
Przedział ufności wyznaczamy na podstawie wzoru:
(21)
(22)
gdzie uα - wartość odczytana z tablic dystrybuanty rozkładu normalnego standaryzowanego tak, aby był spełniony warunek
(23)
Przedziały ufności dla wskaźnika struktury (prawdopodobieństwa sukcesu, procentu, odsetka, frakcji)
Nie zawsze badanie statystyczne jest prowadzone ze względu na cechę mierzalną. Czasami badana cecha ma charakter jakościowy. Wtedy, zamiast wartości liczbowej badanej cechy, z badania próbnego uzyskujemy jedynie informację o tym, czy dany element populacji generalnej ma badaną, wyróżnioną cechę jakościową, czy też jej nie ma. Elementy możemy podzielić wówczas na dwie klasy:
posiadające daną cechę (tj. elementy wyróżnione)
nie posiadające danej cechy (tj. elementy niewyróżnione).
Podstawowym parametrem szacowanym w przypadku badań statystycznych ze względu na cechę niemierzalną jest frakcja elementów wyróżnionych w populacji, zwana także wskaźnikiem struktury w populacji. Wskaźnik struktury (frakcję) oznacza się zwykle literą p.
Podstawą konstrukcji przedziału ufności dla prawdopodobieństwa sukcesu p jest częstość występowania tego sukcesu, czyli k/n, gdzie k - liczba wystąpień sukcesu w n-elementowej próbie.
Przedział ufności wyznaczamy tylko na podstawie dużej próby (przyjmuje się nawet n≥100) ze wzoru:
(24)
gdzie uα - wartość odczytana z tablic dystrybuanty rozkładu normalnego standaryzowanego tak, aby był spełniony warunek
(25)
4. WYZNACZANIE MINIMALNEJ LICZEBNOŚCI PRÓBY
Wyznaczenie niezbędnej liczebności próby należy do podstawowych problemów badawczych. Chodzi bowiem o wyznaczenie takiej liczebności próby, która pozwala oszacować podstawowe parametry populacji generalnej z zakładaną dokładnością.
Można wskazać następujące sposoby określania liczebności próby:
badacz wybiera próbę na podstawie własnych osądów
liczebność próby jest określona poprzez minimalne liczby potrzebnych w tablicy kontyngencji obserwacji (porównaj testowanie hipotez nieparametrycznych - test niezależności χ2)
liczebność próby zostaje ograniczona w związku z kosztami (ograniczenia budżetowe)
ustalenie liczebności próby na podstawie określonego z góry poziomu precyzji (konstruowanie przedziałów ufności).
Praktyczna użyteczność wyznaczonych przedziałów ufności zależy od popełnianego maksymalnego błędu szacunku. Z kolei długość przedziału zależy od współczynnika ufności 1-α oraz liczebności próby n. W calu zapewnienia odpowiedniej dokładności estymacji przy zadanym poziomie ufności istnieje konieczność obliczania niezbędnej liczebności próby dla konstruowanych przedziałów ufności.
Niech cecha X na rozkład normalny N(m, σ). Minimalną liczebność próby, niezbędną do oszacowania wartości m na poziomie ufności 1-α, z maksymalnym błędem szacunku nie przekraczającym ![]()
, przy założeniu, że σ2 jest znane, obliczamy ze wzoru:
gdzie
uα - wartość odczytana z tablic dystrybuanty rozkładu normalnego standaryzowanego tak, aby był spełniony warunek
Jeżeli σ2 nie jest znane, to na podstawie wstępnej próby liczącej n0 elementów, przedstawionych w postaci szeregu szczegółowego wyznacza się:
Z tablic rozkładu t-Studenta odczytujemy tα,n0-1 dla n0-1 stopni swobody, tak aby spełniony był warunek
Wówczas:
Uwagi!
Jeżeli n nie jest liczbą całkowitą, to wynik należy zaokrąglić w górę.
Jeżeli obliczona liczebność próby jest ze względów praktycznych za duża, to mniejszą liczebność otrzymamy zwiększając maksymalny błąd szacunku, a więc zmniejszając dokładność oszacowania.
Kontrola wiadomości
Pytania kontrolne:
Co to jest wnioskowanie statystyczne? Jakie metody obejmuje?
Co oznacza pojęcie „estymacja”?
Jakie są rodzaje estymacji?
Jakie własności estymatora uznawane są za pożądane?
Co to jest estymator zgodny?
Co to jest estymator nieobciążony?
Co to jest estymator efektywny?
Co to jest estymator dostateczny?
Podaj przykład estymatora zgodnego.
Podaj przykład estymatora efektywnego.
Podaj przykład estymatora nieobciążonego.
Podaj przykład estymatora obciążonego.
Uzupełnij zdanie: „Do najczęściej szacowanych parametrów populacji należą:…”.
Problemy do dyskusji:
Od czego zależy praktyczna użyteczność wyznaczonych przedziałów ufności?
Dlaczego nie należy ustalać przesadnie wysokich poziomów ufności 1-α?
Szacowany czas wykonania: 60 min.
Słownik
Estymacja punktowa - sposób szacunku nieznanej wartości parametru Q populacji, w którym jako wartość tego parametru przyjmuje się wartość estymatora q otrzymaną na podstawie wyników n-elementowej próby losowej
Estymacja przedziałowa - sposób szacunku nieznanej wartości parametru Q populacji za pomocą przedziału liczbowego zwanego przedziałem ufności
Estymator - dowolna statystyka q zastosowana do oszacowania (estymacji) nieznanej wartości parametru Q populacji generalnej
Estymator najefektywniejszy - estymator q parametru Q charakteryzujący się najmniejszą ariancją
Estymator nieobciążony - estymator q mający tę własność, że E(q)=o, tzn., że estymator q pozwala na oszacowanie nieznanej wartości parametru Q bez błędu systematycznego
Estymator zgodny - estymator, który wykazuje zbieżność stochastyczną do parametru Q
Populacja generalna (zbiorowość generalna) - zbiór elementów podlegających badaniu ze względu na jedną lub więcej właściwości (cech), mający przynajmniej jedną właściwość (cechę) wspólną dla wszystkich jego elementów (kwalifikującą je do tego zbioru) oraz przynajmniej jedną właściwość ze względu na którą elementy zbioru mogą się różnić między sobą.
Poziom ufności (współczynnik ufności) - prawdopodobieństwo 1-α oznaczające prawdopodobieństwo z jakim nieznana wartość parametru Q objęta jest (pokryta) przez ten przedział
Próba (próbka) - podlegający badaniu skończony podzbiór populacji generalnej
Przedział ufności - przedział liczbowy charakteryzujący się tym, że z dużym (przyjętym z góry prawdopodobieństwem) pokrywa wartość estymowanego parametru
Bibliografia
Aczel A.D., Statystyka w zarządzaniu, Wydawnictwo Naukowe PWN, Warszawa 2000.
Balicki A., Makać W., Metody wnioskowania statystycznego, Wydawnictwo Uniwersytetu Gdańskiego, Gdańsk 2000, s. 105-133.
Greń J., Modele i zadania statystyki matematycznej, PWN, Warszawa 1970, s. 19-50.
Krysicki W., Bartos J., Królikowska K., Wasilewski M., Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, Wydawnictwo Naukowe PWN, Warszawa 1995, 38-77.
Luszniewicz A., Słaby T., Statystyka stosowana, PWE, Warszawa 1997, s. 118-178.
Luszniewicz A., Słaby T., Statystyka z pakietem komputerowym STATISTICA TM PL, Wydawnictwo C.H. BECK, Warszawa 2001, s. 154-175.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s. 99-118.
Mansfield E., Statistics for Business & Economics. Methods and Applications, Norton&Company, New York, London 1987.
Metody statystyczne w zarządzaniu, pod red. D. Witkowskiej, Wydawnictwo „Menadżer”, Łódź 1999, s. 227-310.
Ostasiewicz S., Rusnak Z., Siedlecka U., Statystyka. Elementy teorii i zadania, Wydawnictwo Akademii Ekonomicznej im. Oskara Langego, Wrocław 1997.
Sej-Kolasa M., Zielińska A., Excel w statystyce. Materiały do ćwiczeń, Wydawnictwo Akademii Ekonomicznej im. Oskara Langego, Wrocław 2004.
Sobczyk M., Statystyka, Wydawnictwo Naukowe PWN, Warszawa 1998, s.118-124, 131-151.
Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 228-246.
MODUŁ 6 - TESTOWANIE HIPOTEZ STATYSTYCZNYCH
Wstęp do modułu
Uogólnianie wyników próby losowej na całą populację, z której pochodzi próba to wnioskowanie statystyczne. Kolejnym rodzajem wnioskowania statystycznego (po estymacji) jest weryfikacja hipotez. Termin ten oznacza sprawdzanie sądów (przypuszczeń) o populacji, sformułowanych bez zbadania jej całości. Zagadnienie weryfikacji hipotez zostało zaprezentowane w module „Testowanie hipotez statystycznych”.
Spis treści:
Wiadomości ogólne
Weryfikacja hipotez parametrycznych
Weryfikacja hipotez nieparametrycznych
1. WIADOMOSCI OGÓLNE
Proces uogólniania zaobserwowanych w próbie losowej wyników na całą zbiorowość statystyczną nazywamy wnioskowaniem statystycznym. Metody wnioskowania statystycznego obejmują estymację parametrów zbiorowości generalnej oraz weryfikację hipotez statystycznych.
Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie pobranej próbki. Hipotezą zerową H0 nazywamy hipotezę sprawdzaną (testowaną, weryfikowaną). Hipotezą alternatywną H1 nazywamy hipotezę, którą jesteśmy skłonni przyjąć, gdy odrzucamy hipotezę H0.
Poniżej zaprezentowano przebieg procedury weryfikacyjnej:
Źródło: Opracowanie własne na podstawie A. Balicki, W. Makać, Reguły wnioskowania statystycznego, Wydawnictwo Uniwersytetu Gdańskiego, Gdańsk 2000, s. 136.
Proces weryfikacji hipotezy przebiega według pewnego schematu postępowania, nazywanego testem statystycznym. Weryfikując daną hipotezę ponosimy zawsze pewne ryzyko podjęcia błędnej decyzji. Sytuację wobec jakiej stajemy można ilustruje poniższa tabela.
Test, który przy ustalonym prawdopodobieństwie błędu I rodzaju minimalizuje prawdopodobieństwo błędu II rodzaju nazywamy testem najmocniejszym dla hipotezy zerowej względem prostej hipotezy alternatywnej.
Tabela poniżej prezentuje możliwe decyzje w procesie testowania hipotez:
Decyzja |
Hipoteza H0 jest prawdziwa |
Hipoteza H0 jest fałszywa |
Brak podstaw aby odrzucić weryfikowaną hipotezę H0 |
decyzja poprawna |
decyzja błędna - błąd II rodzaju |
Odrzucić weryfikowaną hipotezę H0 |
decyzja błędna - błąd I rodzaju |
decyzja poprawna |
Źródło: W. Krysicki, J. Bartos, W. Dyczka, K. Królikowska, M. Wasilewski, Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, tom II, Wydawnictwo Naukowe PWN, Warszawa 1995, s. 79.
Poziomem istotności α nazywamy prawdopodobieństwo popełnienia błędu I rodzaju. Przyjmujemy je arbitralnie (najczęściej α=0,01 lub α=0,05 lub α=0,1).
Sprawdzianem hipotezy nazywamy taką statystykę T (o znanym rozkładzie), której wartość t policzona na podstawie próby losowej, pozwala na podjęcie decyzji czy odrzucić hipotezę H0.
Zbiorem (obszarem) krytycznym nazywamy zbiór tych wartości sprawdzianu hipotezy, które przemawiają za odrzuceniem hipotezy H0. Rozkład sprawdzianu hipotezy określa z jakich tablic należy odczytać wartość krytyczną wyznaczającą obszar krytyczny. Obszar krytyczny może być w zależności od hipotezy alternatywnej zbiorem jednostronnym (prawostronnym lub lewostronnym) bądź zbiorem dwustronnym.
Testy statystyczne są zróżnicowane ze względu na:
rodzaj porównywanych charakterystyk
skale pomiaru
liczbę badanych prób
zależność bądź niezależność w obrębie prób.
Hipotezy, które dotyczą wyłącznie wartości parametru określonej klasy rozkładów nazywamy HIPOTEZAMI PARAMETRYCZNYMI. Każdą hipotezę, która nie jest parametryczna nazywamy NIEPARAMETRYCZNĄ.
Wykorzystanie parametrycznych testów statystycznych do opracowywania wyników badań naukowych jest ograniczone określonymi założeniami (zmienne mierzalne o rozkładzie normalnym, jednorodność zbioru itd.). Warunkiem użycia tych testów jest więc sprawdzenie założeń. Jeśli nie zostały one spełnione, wyciągnięte wnioski nie są w pełni poprawne lub tracą wiarygodność. Testy te stają się też bezużyteczne dla danych jakościowych i danych typu porządkowego. W tych wszystkich przypadkach stosuje się odpowiednie testy nieparametryczne.
W przypadku pojedynczej próby losowej testy statystyczne ograniczają się w zasadzie do porównywania zgodności charakterystyk z próby z odpowiednimi parametrami populacji (testy parametryczne) bądź do porównywania rozkładów empirycznych z próby z odpowiednimi rozkładami hipotetycznymi w populacji (testy nieparametryczne). W przypadku większej liczby prób, ze względu na charakter zależności między próbami, tworzy się znacznie większe zróżnicowanie w grupie testów parametrycznych i nieparametrycznych.
Próby niezależne to próby nie związane ze sobą żadnymi relacjami czasowymi bądź przestrzennymi. Najczęściej są to próby różnoliczne, na których dokonuje się pomiarów jednokrotnych i niezależnych w czasie i w przestrzeni. W odróżnieniu od prób niezależnych, próby zależne są powiązane ze sobą pewnymi relacjami. Na próbach tych dokonuje się najczęściej pomiarów wielokrotnych (powtarzalnych w różnych odcinkach czasu). Systematykę testów, uwzględniającą poszczególne kryteria (rodzaj porównywanych charakterystyk, skale pomiaru, liczbę badanych prób, zależność bądź niezależność w obrębie prób) przedstawia poniższy rysunek.
Rys. Podział testów statystycznych
Źródło: S. Mynarski, Analiza danych rynkowych i marketingowych z wykorzystaniem programu STATISTICA, Wydawnictwo Akademii Ekonomicznej w Krakowie, Kraków 2003, s. 21.
Testy statystyczne mogą być szeroko stosowane w analizach danych uzyskanych w badaniach ankietowych. Dzięki testom statystycznym można między innymi weryfikować sądy oraz przypuszczenia odnośnie:
kształtowania się sytuacji rynkowej przedsiębiorstw (itp. przychodów),
występowania ewentualnych różnic istotnych statystycznie pomiędzy przedsiębiorstwami (itp. współpracującymi z sektorem B+R oraz przedsiębiorstwami niewspółpracującymi),
występujących zależności (itp. skuteczności oddziaływania instytucji otoczenia biznesu na możliwość korzystania z funduszy UE, zależności między spektrum wprowadzanych innowacji a łączną liczbą tworzonych specjalistycznych stanowisk pracy)
określenie wpływu czynnika klasyfikującego (itp. rodzaju działalności przedsiębiorstwa) na skalę zmienności zmiennej (itp. przychodów) itp.
Przypomnijmy stosowane wcześniej wzory (wariancja w próbie):
(1)
(2)
2. WERYFIKACJA WYBRANYCH HIPOTEZ PARAMETRYCZNYCH
Testy parametryczne najczęściej weryfikują sądy o takich parametrach populacji jak średnia arytmetyczna, wariancja i wskaźnik struktury. W testach tych hipoteza H0 jest hipotezą „o równości” . Hipoteza alternatywna, w zależności od pytania sformułowanego w zadaniu, może być prostym zaprzeczeniem hipotezy H0 tzw. hipotezą bezkierunkową lub może być hipotezą „o większości” lub „o mniejszości”, tzw. hipotezą kierunkową.
H0: Θ1=Θ2
H1: Θ1≠Θ2 lub H1: Θ1<Θ2 lub H1: Θ1>Θ2
testy parametryczne dla wnioskowania o własnościach populacji jednowymiarowej - testy dla średniej
W testach tych hipoteza H0 jest hipotezą „o równości”. Hipoteza alternatywna, w zależności od pytania sformułowanego w zadaniu, może być prostym zaprzeczeniem hipotezy H0, może być hipotezą „o większości” lub „o mniejszości”.
H0: m=m0
H1: m≠m0 lub H1: m<m0 lub H1: m>m0
Populacja generalna ma rozkład N(m, σ); σ- znane
Obliczamy statystykę testową
(3)
Porównujemy ją z wartością krytyczną (lub wartościami krytycznymi) odczytaną z tablic standaryzowanego rozkładu normalnego, przy założonym poziomie istotności α.
Dla H1: m≠m0 wartość statystyki obliczona z próby t≤ - uα/2 lub t≥ uα/2 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: m<m0 wartość statystyki obliczona z próby t≤ - uα powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: m>m0 wartość statystyki obliczona z próby t≥ uα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
Rozkład populacji - dowolny, wariancja nie jest znana, próba - duża
Obliczamy statystykę testową
(4)
Porównujemy ją z wartością krytyczną (lub wartościami krytycznymi) odczytaną z tablic standaryzowanego rozkładu normalnego, przy założonym poziomie istotności α.
Dla H1: m≠m0 wartość statystyki obliczona z próby t≤ - uα/2 lub t≥ uα/2 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: m<m0 wartość statystyki obliczona z próby t≤ - uα powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: m>m0 wartość statystyki obliczona z próby t≥ uα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
Populacja generalna ma rozkład N(m, σ); σ - nie jest znane, próba - mała
Obliczamy statystykę testową
(5)
Porównujemy ją z wartością krytyczną (lub wartościami krytycznymi) odczytaną z tablic rozkładu t-Studenta dla poziomu istotności α oraz n-1 stopni swobody.
Dla H1: m≠m0 wartość statystyki obliczona z próby t≤ - tα/2,n-1 lub t≥ tα/2,n-1 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: m<m0 wartość statystyki obliczona z próby t≤ - tα,n-1 powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: m>m0 wartość statystyki obliczona z próby t≥ tα,n-1 powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
Rys. Zbiory krytyczne dla różnych postaci hipotezy alternatywnej (rozkład normalny).
Źródło: opracowanie własne.
Rys. Zbiory krytyczne dla różnych postaci hipotezy alternatywnej (rozkład t-Studenta).
Źródło: opracowanie własne.
testy parametryczne dla wnioskowania o własnościach populacji jednowymiarowej - testy dla wariancji
W testach tych hipoteza H0 jest hipotezą „o równości”. Hipoteza alternatywna, w zależności od pytania sformułowanego w zadaniu, może być prostym zaprzeczeniem hipotezy H0, może być hipotezą „o większości” lub „o mniejszości”.
H0: σ2=σ02
H1: σ2≠σ02 lub H1: σ2<σ02 lub H1: σ2>σ02
Populacja generalna ma rozkład N(m, σ); m - znane
Obliczamy statystykę testową
(6)
gdzie
(7)
Porównujemy ją z wartością krytyczną (lub wartościami krytycznymi) odczytaną z tablic rozkładu chi-kwadrat, dla n stopni swobody oraz dla założonego poziomu istotności α.
Dla H1: σ2≠σ02 odczytujemy dwie wartości krytyczne. Wartość statystyki obliczona z próby ![]()
lub ![]()
powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: σ2<σ02 odczytujemy jedną wartość krytyczną. Wartość statystyki obliczona z próby χ2≤ χα2 powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: σ2>σ02 odczytujemy jedną wartość krytyczną. Wartość statystyki obliczona z próby χ2≥ χα2 powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
Populacja generalna ma rozkład N(m, σ); m - nie jest znane, próba - mała
Obliczamy statystykę testową
(8)
Porównujemy ją z wartością krytyczną (lub wartościami krytycznymi) odczytaną z tablic rozkładu chi-kwadrat, dla n-1 stopni swobody oraz dla założonego poziomu istotności α.
Dla H1: σ2≠σ02 odczytujemy dwie wartości krytyczne. Wartość statystyki obliczona z próby ![]()
lub ![]()
powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: σ2<σ02 odczytujemy jedną wartość krytyczną. Wartość statystyki obliczona z próby χ2≤ χα22 powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: σ2>σ02 odczytujemy jedną wartość krytyczną. Wartość statystyki obliczona z próby χ2≥ χα12 powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
Rys. Zbiory krytyczne dla różnych postaci hipotezy alternatywnej (test χ2)
Źródło: opracowanie własne.
Populacja generalna ma rozkład N(m, σ); m - nie jest znane; próba - duża
Obliczamy statystykę testową
(9)
Porównujemy ją z wartością krytyczną testu uα odczytaną z tablic standaryzowanego rozkładu normalnego, przy założonym poziomie istotności α.
Dla Ha: σ2≠σ02 wartość statystyki obliczona z próby t≤ - uα/2 lub t≥ uα/2 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla Ha: σ2<σ02 wartość statystyki obliczona z próby t≤ - uα powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla Ha: σ2>σ02 wartość statystyki obliczona z próby t≥ uα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
Populacja generalna ma rozkład N(m, σ); m - znane; próba - duża
Obliczamy statystykę testową
(10)
Porównujemy ją z wartością krytyczną testu uα odczytaną z tablic standaryzowanego rozkładu normalnego, przy założonym poziomie istotności α.
Dla Ha: σ2≠σ02 wartość statystyki obliczona z próby t≤ - uα/2 lub t≥ uα/2 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla Ha: σ2<σ02 wartość statystyki obliczona z próby t≤ - uα powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla Ha: σ2>σ02 wartość statystyki obliczona z próby t≥ uα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
testy parametryczne dla wnioskowania o własnościach populacji jednowymiarowej - testy dla wskaźnika struktury
W testach tych hipoteza H0 jest hipotezą „o równości”. Hipoteza alternatywna, w zależności od pytania sformułowanego w zadaniu, może być prostym zaprzeczeniem hipotezy H0, może być hipotezą „o większości” lub „o mniejszości”.
H0: p=p0
H1: p≠p0 lub H1: p<p0 lub H1: p>p0
Niech populacja generalna ma rozkład dwupunktowy z parametrem p oznaczającym prawdopodobieństwo, że badana cecha przyjmie wyróżnioną wartość. Chcemy zweryfikować na podstawie n-elementowej próby (n≥100) hipotezę zerową wobec postawionej hipotezy alternatywnej.
Obliczamy statystykę testową
(11)
gdzie k- liczba jednostek o wyróżnionej wartości cechy w n-elementowej próbie.
Porównujemy ją z wartością krytyczną (wartościami krytycznymi) testu uα odczytaną z tablic standaryzowanego rozkładu normalnego, przy założonym poziomie istotności α.
Dla H1: p≠p0 wartość statystyki obliczona z próby t≤ - uα/2 lub t≥ uα/2 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: p<p0 wartość statystyki obliczona z próby t≤ - uα powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: p>p0 wartość statystyki obliczona z próby t≥ uα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
testy parametryczne dla wnioskowania o własnościach dwóch populacji generalnych - testy dla dwóch średnich
W testach tych hipoteza H0 jest hipotezą „o równości”. Hipoteza alternatywna, w zależności od pytania sformułowanego w zadaniu, może być prostym zaprzeczeniem hipotezy H0, może być hipotezą „o większości” lub „o mniejszości”.
H0: m1=m2
H1: m1≠m2 lub H1: m1<m2 lub H1: m1>m2
Dane są dwie zbiorowości generalne o rozkładach normalnych N(m1, σ1) i N(m2, σ2). Chcemy zweryfikować hipotezę zerową wobec hipotezy alternatywnej. Niech n1, n2 oznaczają wielkości prób prostych, wylosowanych z każdej zbiorowości, a ![]()
oraz ![]()
oznaczają odpowiednio średnie arytmetyczne i wariancję S2 z prób. W zależności od założeń dotyczących zbiorowości generalnych oraz od liczebności prób - sprawdzian hipotezy H0 ma różną postać i jest związany z rozkładem normalnym lub rozkładem t-Studenta.
σ1 - znane; σ2 - znane; n1 ≤30; n2 ≤30
σ1 - znane; σ2 - znane; n1 >30; n2 >30
σ1, σ2 - nie są znane; n1 >30; n2 >30, to ![]()
Obliczamy statystykę testową
(12)
Porównujemy ją z wartością krytyczną (lub wartościami krytycznymi) odczytaną z tablic standaryzowanego rozkładu normalnego, przy założonym poziomie istotności α.
Dla H1: m1≠m2 wartość statystyki obliczona z próby t≤ - uα/2 lub t≥ uα/2 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: m1<m2 wartość statystyki obliczona z próby t≤ - uα powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: m1> m2 wartość statystyki obliczona z próby t≥ uα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
σ1, σ2 - nie są znane; σ1=σ2 ; n1 ≤30; n2 ≤30
Obliczamy statystykę testową
(13)
Porównujemy ją z wartością krytyczną (lub wartościami krytycznymi) odczytaną z tablic t-Studenta o r=n1+n2-2 stopniach swobody i przy założonym poziomie istotności α.
Dla Ha: m1≠m1 wartość statystyki obliczona z próby t≤ - tα/2,r lub t≥ tα/2,r powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla Ha: m1<m2 wartość statystyki obliczona z próby t≤ - tα,r powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla Ha: m1> m2 wartość statystyki obliczona z próby t≥ tα,r powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
testy parametryczne dla wnioskowania o własnościach dwóch populacji generalnych - testy dla dwóch wariancji
W testach tych hipoteza H0 jest hipotezą „o równości”. Hipoteza alternatywna jest hipotezą „o większości” .
H0: σ12=σ22
H1: σ12>σ22
populacje generalne mają rozkłady normalne N(m1, σ1) i N(m2, σ2); σ1, σ2 - nie są znane; n1 ≤30; n2 ≤30
Chcemy zweryfikować hipotezę zerową wobec hipotezy alternatywnej. Niech n1, n2 oznaczają liczebności prób prostych, wylosowanych z każdej zbiorowości, a ![]()
oznaczają wariancję S12 z prób. Ze względu na postać hipotezy alternatywnej tak numerujemy zbiorowości, żeby ![]()
Obliczamy statystykę testową
(14)
Porównujemy ją z wartością krytyczną Fα odczytaną z tablic F-Snedecora dla r1=n1-1 i r2=n2-1 stopni swobody, przy założonym poziomie istotności α.
Dla H1: σ12>σ22 wartość statystyki obliczona z próby f≥ Fα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
Uwaga!
Przedstawiony powyżej test wykorzystuje się najczęściej do sprawdzenia prawdziwości założenia, że σ1= σ2, które jest konieczne, aby można było testować hipotezę o równości wartości przeciętnych w dwóch populacjach.
testy parametryczne dla wnioskowania o własnościach dwóch populacji generalnych - testy dla dwóch wskaźników struktury
W testach tych hipoteza H0 jest hipotezą „o równości”. Hipoteza alternatywna, w zależności od pytania sformułowanego w zadaniu, może być prostym zaprzeczeniem hipotezy H0, może być hipotezą „o większości” lub „o mniejszości”.
H0: p1=p2
H1: p1≠p2 lub H1: p1<p2 lub H1: p1>p2
Niech badana cecha ma w dwóch populacjach generalnych rozkład dwupunktowy z parametrami p1 i p2. Z obu populacji losujemy próby proste o liczebnościach n1 ≥100; n2 ≥100. Niech k1/n1 i k2/n2 oznaczają wskaźniki struktury z pierwszej i drugiej próby. Chcemy zweryfikować hipotezę zerową wobec postawionej hipotezy alternatywnej.
Obliczamy statystykę testową
(15)
gdzie
(16)
Porównujemy ją z wartością krytyczną (wartościami krytycznymi) uα odczytaną z tablic standaryzowanego rozkładu normalnego, przy założonym poziomie istotności α.
Dla H1: p1≠p2 wartość statystyki obliczona z próby t≤ - uα/2 lub t≥ uα/2 powoduje odrzucenie H0 (zbiór krytyczny dwustronny).
Dla H1: p1< p2 wartość statystyki obliczona z próby t≤ - uα powoduje odrzucenie H0 (zbiór krytyczny lewostronny).
Dla H1: p1> p2 wartość statystyki obliczona z próby t≥ uα powoduje odrzucenie H0 (zbiór krytyczny prawostronny).
3. WERYFIKACJA WYBRANYCH HIPOTEZ NIEPARAMETRYCZNYCH
TESTY NIEPARAMETRYCZNE służą do weryfikacji hipotez dotyczących zgodności rozkładu cechy w populacji z określonym rozkładem teoretycznym, losowości doboru próby czy też zgodności rozkładów w dwóch populacjach.
H0: F(x) = F0(x)
H1: F(x) ≠ F0(x)
test zgodności χ2
Testy zgodności służą do weryfikacji hipotez odnoszących się do postaci rozkładu badanej cechy w populacji. Ich budowa opiera się na ocenie zgodności rozkładu empirycznego, otrzymanego w próbie losowej z rozkładem teoretycznym o określonej postaci.
H0: F(x) = F0(x) dystrybuanta badanej cechy F(x) jest zgodna z hipotetyczną dystrybuantą określonego typu F0(x)
H1: F(x) ≠ F0(x) dystrybuanta badanej cechy F(x) nie jest zgodna z hipotetyczną dystrybuantą określonego typu F0(x)
Do najczęściej stosowanych testów zgodności należy test zgodności χ2 . Test zgodności χ2 może być stosowany zarówno do zmiennych skokowych, jak i ciągłych. Próba - duża, a jej wyniki pogrupowane w szereg rozdzielczy o k przedziałach, tak aby ni≥5. Szereg ten przedstawia rozkład empiryczny badanej zmiennej. Na podstawie rozkładu empirycznego dokonuje się aproksymacji (przybliżenia) założonego w H0 rozkładu teoretycznego. Dla każdej klasy ustala się prawdopodobieństwo pi. W przypadku zmiennej ciągłej prawdopodobieństwo pi oblicza się jako różnicę dystrybuanty dla granic przedziałów:
pi=P(xi0<X<xi1)=F(xi1) - F(xi0) (17)
a następnie oblicza się liczebności teoretyczne hipotetycznego rozkładu (jakie powinny wystąpić w n-elementowej próbie, gdyby rozkład był zgodny z określonym w H0).
Obliczamy wartość statystyki:
(18)
Wyznaczamy prawostronny obszar krytyczny. Wartość krytyczną χα2 odczytujemy z tablic rozkładu chi-kwadrat, dla k-r-1 stopni swobody (gdzie r jest liczbą parametrów określających rozkład hipotetyczny, które należy wstępnie obliczyć na podstawie próby) oraz dla założonego poziomu istotności α. Wartość statystyki obliczona z próby χ2≥ χα2 powoduje odrzucenie H0.
test niezależności χ2
Test niezależności χ2 pozwala na sprawdzenie, czy dwie badane cechy (niekoniecznie mierzalne) są niezależne. Wymogiem jest duża liczebność próby, której wyniki zostały podzielone na odpowiednie grupy wartości (kategorie) ze względu na obie cechy jednocześnie. Sporządza się zatem tzw. tablicę wielodzielczą (lub inaczej tablicę niezależności / kontyngencji).
H0: X i Y są cechami niezależnymi
H1: X i Y są cechami zależnymi
Ocena skojarzenia cech opiera się na statystyce χ2, która pokazuje odchylenie zaobserwowanych liczebności dla wyodrębnionych klas obu cech od liczebności, których należałoby oczekiwać, gdyby cechy były niezależne. Statystykę χ2 oblicza się dla tablicy o wymiarach r × s, która powstaje w wyniku grupowania badanej zbiorowości według dwóch cech i składa się z r wierszy odpowiadających wariantom jednej cechy oraz s kolumn odpowiadających wariantom drugiej cechy (najmniejsze wymiary tablicy wynoszą 2 × 2 - jest to tzw. tablica czteropolowa). Ze względu na wymaganą liczebność w każdej klasie, zachodzi czasem konieczność połączenia za pomocą spójnika „lub” dwóch kategorii danej cechy w jedną.
Tabela . Możliwe decyzje w procesie testowania hipotez - tablica wielodzielcza.
yj xi |
y1 |
y2 |
... |
ys |
ni. |
x1 |
n11 |
n12 |
... |
n1s |
n1. |
x2 |
n21 |
n22 |
... |
n2s |
n2. |
… |
… |
… |
… |
… |
… |
xr |
nr1 |
nr2 |
... |
nrs |
nr. |
n.j |
n.j |
n.j |
... |
n.j |
n |
Źródło: opracowanie własne.
Prawdopodobieństwa brzegowe: pi.=ni./n oraz p.j=n.j/n (19)
Prawdopodobieństwo pij=pi.p.j (20)
Dla każdego pola tablicy wyznacza się liczebności teoretyczne
(21)
Po ustaleniu liczebności teoretycznych, zakładających niezależność cech, statystykę oblicza się według wzoru:
(22)
Obszar krytyczny (prawostronny) w tym teście określa relacja P{χ2≥χ2α}=α, gdzie χ2α jest wartością krytyczną odczytaną z tablicy rozkładu χ2 dla zadanego poziomu istotności α oraz dla (r-1)(s-1) stopni swobody.
Jeżeli χ2≥χ2α to hipotezę H0 o niezależności badanych cech należy odrzucić na rzecz hipotezy alternatywnej, natomiast gdy χ2<χ2α to nie ma podstaw do odrzucenia hipotezy H0.
Miarą zależności jest współczynnik zbieżności T-Czuprowa (bazujący na wartości statystyki χ2) postaci:
(
23)
Gdy r=s to 0≤T≤1. Gdy r≠s to T może być znacznie mniejsze od 1.
Kontrola wiadomości
Pytania kontrolne:
Co nazywamy hipotezą statystyczną?
W jakim celu stosuje się testowanie hipotez?
Jaki jest schemat procedury weryfikacyjnej?
Jakiego typu obszary krytyczne mogą wystąpić w hipotezach parametrycznych? Od czego to zależy?
Jakiego typu obszar krytyczny występuje w teście zgodności χ2?
Jakiego typu obszar krytyczny występuje w teście niezależności χ2?
Od czego zależy wybór testu statystycznego?
Jakie znasz przykłady testowania hipotez nieparametrycznych?
Co to jest poziom istotności? Jaki jest jego związek z błędem I rodzaju?
Czego dotyczą hipotezy parametryczne?
Czego dotyczą hipotezy nieparametryczne?
W jakim celu stosuje się test zgodności χ2?
W jakim celu stosuje się test niezależności χ2?
Problemy do dyskusji:
Zapoznaj się z różnymi typami tablic statystycznych zawartych w podręcznikach do statystyki (dystrybuanta rozkładu normalnego standaryzowanego, rozkład chi-kwadrat, rozkład t-Studenta, rozkład F-Snedecora). Jakie poziomy istotności spotyka się najczęściej?
Czy poziom istotności może przyjąć wartość α=2? Dlaczego? Jakie wartości może przyjmować α?
Szacowany czas wykonania: 60 min.
Słownik
Błąd pierwszego rodzaju - błąd polegający na tym, że w trakcie weryfikacji hipotezy statystycznej podjęto decyzję o odrzuceniu hipotezy prawdziwej
Błąd drugiego rodzaju - możliwy do popełnienia przy sprawdzaniu hipotezy statystycznej błąd polegający na przyjęciu hipotezy fałszywej
Hipoteza statystyczna - dowolne przypuszczenie dotyczące rozkładu populacji generalnej
Hipoteza parametryczna - hipoteza statystyczna sformułowana w stosunku do wartości parametru w rozkładzie populacji generalnej znanego typu
Hipoteza nieparametryczna - hipoteza statystyczna precyzująca typ rozkładu populacji generalnej
Hipoteza zerowa (H0) - hipoteza statystyczna (parametryczna lub nieparametryczna) bezpośrednio sprawdzana za pomocą testu
Hipoteza alternatywna (H1) - hipoteza statystyczna konkurująca w teście z hipotezą zerową w ten sposób, że ilekroć podejmuje się decyzję o odrzuceniu hipotezy zerowej, tyle razy przyjmuje się hipotezę alternatywną
Obszar krytyczny testu - obszar mający tę właściwość, że ilekroć uzyskana w teście wartość odpowiedniej statystyki trafi do tego obszaru, podejmuje się decyzję o odrzuceniu hipotezy zerowej i przyjęciu hipotezy alternatywnej
Poziom istotności α - prawdopodobieństwo mierzące szansę popełnienia podczas weryfikacji hipotezy statystycznej błędu pierwszego rodzaju. Najczęściej bierze się pod uwagę następujące wartości poziomu istotności: 0,1; 0,05; 0,01 i 0,001.
Test statystyczny - „narzędzie statystyczne”, za pomocą którego dokonuje się weryfikacji hipotez statystycznych. Wynikiem zastosowania testu statystycznego jest decyzja o przyjęciu lub odrzuceniu sprawdzanej hipotezy statystycznej. Test statystyczny to reguła postępowania, która na podstawie wyników próby ma doprowadzić do decyzji przyjęcia lub odrzucenia postawionej hipotezy statystycznej.
Wnioskowanie statystyczne polega na uogólnianiu wyników uzyskanych dla próby na całą populację generalną z wykorzystaniem metod probabilistycznych.
Bibliografia
Aczel A.D., Statystyka w zarządzaniu, Wydawnictwo Naukowe PWN, Warszawa 2000.
Balicki A., Makać W., Metody wnioskowania statystycznego, Wydawnictwo Uniwersytetu Gdańskiego, Gdańsk 2000, s. 134-187.
Greń J., Modele i zadania statystyki matematycznej, PWN, Warszawa 1970, s. 51-152.
Krysicki W., Bartos J., Królikowska K., Wasilewski M., Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, Wydawnictwo Naukowe PWN, Warszawa 1995, s. 78-148.
Luszniewicz A., Słaby T., Statystyka stosowana, PWE, Warszawa 1997, s. 138-178.
Luszniewicz A., Słaby T., Statystyka z pakietem komputerowym STATISTICA TM PL, Wydawnictwo C.H. BECK, Warszawa 2001, s. 176-221.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s. 119-180.
Mansfield E., Statistics for Business & Economics. Methods and Applications, Norton&Company, New York, London 1987.
Metody statystyczne w zarządzaniu, pod red. D. Witkowskiej, Wydawnictwo „Menadżer”, Łódź 1999, s. 179-226.
Mynarski S., Analiza danych rynkowych i marketingowych z wykorzystaniem programu STATISTICA, Wydawnictwo Akademii Ekonomicznej w Krakowie, Kraków 2003.
Mynarski S. , Badania rynkowe w warunkach konkurencji, Oficyna Wydawnicza Fogra, Kraków 1995.
Mynarski S., Praktyczne metody analizy danych rynkowych i marketingowych, Kantor Wydawniczy Zakamycze, Zakamycze 2000.
Ostasiewicz S., Rusnak Z., Siedlecka U., Statystyka. Elementy teorii i zadania, Wydawnictwo Akademii Ekonomicznej im. Oskara Langego, Wrocław 1997.
Sej-Kolasa M., Zielińska A., Excel w statystyce. Materiały do ćwiczeń, Wydawnictwo Akademii Ekonomicznej im. Oskara Langego, Wrocław 2004.
Sobczyk M., Statystyka, Wydawnictwo Naukowe PWN, Warszawa 1998, s.125-128, 152-189.
Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 247-284.
Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 166.
Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 167.
Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 167.
Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 167.
Por. Starzyńska W., Statystyka praktyczna, Wydawnictwo Naukowe PWN, Warszawa 2000, s. 188 oraz Balicki A., Makać W., Metody wnioskowania statystycznego, Wydawnictwo Uniwersytetu Gdańskiego, Gdańsk 2000, s. 42.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.94.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.94.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.93.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.94.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.94.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.94.
Por. Krysicki W., Bartos J., Królikowska K., Wasilewski M., Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, Wydawnictwo Naukowe PWN, Warszawa 1995, s. 5; Luszniewicz A., Słaby T., Statystyka z pakietem komputerowym STATISTICA TM PL, Wydawnictwo C.H. BECK, Warszawa 2001, s. 6.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.94.
Krysicki W., Bartos J., Królikowska K., Wasilewski M., Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, Wydawnictwo Naukowe PWN, Warszawa 1995, s. 5.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.94.
Zob. W. Krysicki, J. Bartos, W. Dyczka, K. Królikowska, M. Wasilewski, Rachunek prawdopodobieństwa i statystyka matematyczna w zadaniach, tom II, Wydawnictwo Naukowe PWN, Warszawa 1995, s. 81.
Zob. A. Stanisz, Przystępny kurs statystyki w oparciu o program STATISTICA PL na przykładach z medycyny, Kraków 1998, s. 263-292. Por. S. Mynarski, Badania rynkowe w warunkach konkurencji, Oficyna Wydawnicza Fogra, Kraków 1995, s. 55-61.
Należy jednak pamiętać, że klasy, na jakie dzieli się wyniki próby powinny być odpowiednio liczne. Większość autorów określa liczność klas na „co najmniej 5”, ale J. Greń podaje już „co najmniej 8”. Por. J. Greń, Modele i zadania statystyki matematycznej, PWN, Warszawa 1970, s. 104; A. Luszniewicz, T. Słaby, Statystyka z pakietem komputerowym STATISTICA TM PL, Wydawnictwo C.H. BECK, Warszawa 2001, s. 210.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Greń J., Modele i zadania statystyki matematycznej, PWN, Warszawa 1970, s. 15.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.96.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Greń J., Modele i zadania statystyki matematycznej, PWN, Warszawa 1970, s. 15.
Maliński M., Statystyka matematyczna wspomagana komputerowo, Wydawnictwo Politechniki Śląskiej, Gliwice 2000, s.95.
Greń J., Modele i zadania statystyki matematycznej, PWN, Warszawa 1970, s. 15.
Balicki A., Makać W., Metody wnioskowania statystycznego, Wydawnictwo Uniwersytetu Gdańskiego, Gdańsk 2000, s.7.
11
-uα
lewostronny zbiór krytyczny
α
0
x
f(x)
dwustronny zbiór krytyczny
uα/2
-uα/2
α/2
α/2
0
x
f(x)
![]()
![]()
![]()
![]()
![]()
Odrzucić H0
Nie odrzucać H0
Podjęcie decyzji
Wyznaczenie obszaru krytycznego testu
Określenie poziomu istotności
Obliczenie statystyki na podstawie próby
Wybór statystyki testowej
Sformułowanie hipotezy zerowej H0 i alternatywnej H1
f(x)
x
0
α
prawostronny zbiór krytyczny
uα
f(x)
x
0
α/2
α/2
-tα/2
tα/2
dwustronny zbiór krytyczny
f(x)
x
0
α
lewostronny zbiór krytyczny
-tα
f(x)
x
0
α
prawostronny zbiór krytyczny
tα
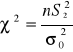
![]()
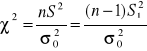
x
dwustronny zbiór krytyczny
f(x)
x
χα2
α
lewostronny zbiór krytyczny
f(x)
α/2
α/2
![]()
![]()
f(x)
x
α
prawostronny zbiór krytyczny
χα2
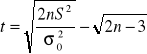
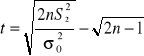
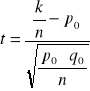
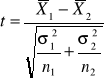
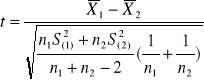
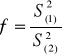
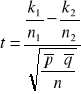
![]()
![]()
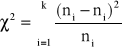
![]()
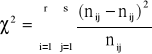
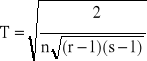
Test z
Test t
Test F
(ilorazu wariancji)
Wilcoxona
Friedmana
Znaków
Mediany
Kruskala- Wallisa
U Manna-Whitneya
Walda-Wolfowitza
Kołmogorowa-Smirnowa
Mc Nemara
Q Cochrana
Niezależności Chi-kwadrat
Test z
Test t
Kołmogorowa
Serii
Test zgodności
Chi-kwadrat
NIEZALEŻNE
NIEZALEŻNE
ZALEŻNE
ZALEŻNE
ZALEŻNE
NIEZALEŻNE
DWIE I WIĘCEJ
DWIE I WIĘCEJ
JEDNA
DWIE I WIĘCEJ
JEDNA
PRZEDZIAŁOWA I ILORAZOWA
PORZĄDKOWA
NOMINALNA
PARAMETRYCZNE
TESTY STATYSTYCZNE
S K A L E
NIEPARAMETRYCZNE
Z M I E N N E
![]()
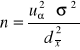
![]()
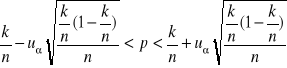
![]()
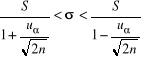
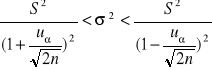
![]()
![]()
![]()
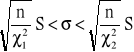
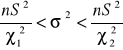
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
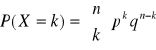
![]()
![]()
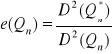
![]()
![]()
![]()
![]()
![]()
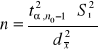
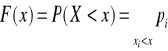
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
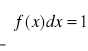
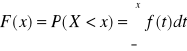
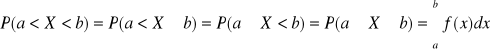
![]()
![]()
![]()
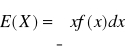
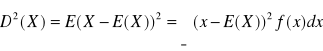
![]()
![]()
![]()
![]()
f(x)
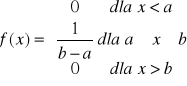
![]()
b
x
a
f(x)
x
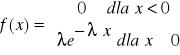
f(x)
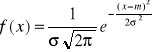
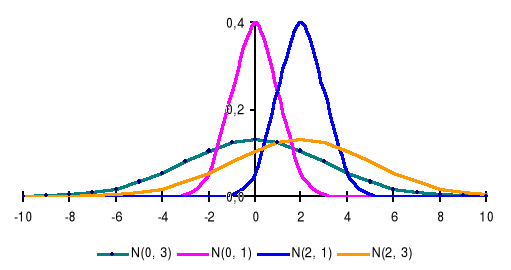
![]()
f(x)
x
![]()
f(x)
x
0