Prezentacja języka opisu
układów cyfrowych
VHDL
Trochę historii...
Język VHDL jest jednym z nowszych języków opisu i projektowania układów cyfrowych. Już w lipcu 1983 roku zespół złożony z przedstawicieli firm Intermetrics, IBM oraz Texas Instruments rozpoczął pierwszy etap pracy nad nowym językiem opisu i projektowania układów VLSI. Po roku pracy zaimplementowano dany język, dzięki czemu w grudniu 1985 otrzymano pierwszą wersję narzędzia napisanego w języku Ada dla komputerów klasy VA 11/780 i IBM 370.
Projekt VHDL był częścią programu Departamentu Obrony USA o nazwie VHSIC, którego zadaniem było opracowanie metod projektowania oraz wykorzystanie najbardziej złożonych i bardzo szybkich układów scalonych. W roku 1987 VHDL stał się obowiązującym standardem w dziedzinie języków opisu i projektowania układów VLSI. Ulepszona wersja języka pojawiła się dopiero w 1993 roku i obecnie jest stosowana przez większość projektantów układów cyfrowych na świecie (niestety jednak, w Polsce język VHDL nie jest jeszcze zbyt popularny).
1. Podstawowe cechy języka VHDL
Język VHDL spełnia podobną funkcję w dziedzinie projektowania sprzętu, jak język C++ w dziedzinie programowania. Ma on następujące właściwości:
wspiera hierarchiczność projektowanego sprzętu,
umożliwia opis projektu i jego sprawdzenie w całym procesie jego powstania,
umożliwia tworzenie nowych wersji projektowych realizowanych w nowych technologiach na postawie rozwiązań projektowych przechowywanych w bibliotece projektów - jest zatem niezależny od konkretnej technologii, metody projektowania, narzędzi wspomagających projektowanie,
umożliwia reprezentację dynamiki układu cyfrowego oraz współbieżnych operacji w sprzęcie - można stworzyć równoważne modele funkcjonalne,
ułatwia dokumentowanie projektu, a najlepsze rozwiązania można gromadzić w bibliotekach projektów,
ułatwia wymianę informacji między projektantami oraz całymi zespołami projektowymi,
W języku VHDL można reprezentować układy cyfrowe na poziomach: od bramkowego do systemowego. Oznacza to, że najmniejszym elementem naszego projektu jest bramka logiczna. Nie mamy więc dostępu do poziomu analogowego (topografii bramki logicznej), chociaż w kolejnych wersjach języka VHDL prawdopodobnie się to zmieni.
2. Zasady reprezentowania gramatyki języka VHDL
Dla opisu składni używanej w języku VHDL używa się podstawowej notacji BNF o następujących cechach:
1. elementy syntaktyczne języka są przedstawione w postaci słów połączonych znakiem podkreślenia,
część_deklaracyjna_jednostki
2. każda "produkcja" gramatyki języka VHDL składa się z:
części lewej reprezentującej wybrany element syntaktyczny języka,
symbolu "::=",
części prawej przedstawiającej sposób rozkładu elementu syntaktycznego na części składowe,
znaku ";"
jednostka_podstawowa ::= identyfikator ;
3. znak "|" występujący między dwoma elementami gramatyki oznacza, że możemy wybrać albo jeden, albo drugi element syntaktyczny,
literał_wyliczeniowy ::= identyfikator | literał znakowy ;
4. nawias klamrowy "{...}" oznacza, że elementy syntaktyczne występujące wewnątrz nawiasu mogą tworzyć listę tych elementów,
lista_czułości ::= nazwa_sygnału { , nazwa_sygnału } ;
5. słowa wytłuszczone oznaczają słowa kluczowe języka VHDL,
definicja_typu_rzeczywistego ::= range zakres_prosty ;
6. nawias kwadratowy "[...]" oznacza, że elementy gramatyczne języka będące wewnątrz nawiasu mogą nie występować w produkcji,
instrukcja_założenia ::= [ etykieta: ] założenie ;
7. komentarze umieszczamy po dwóch myślnikach "--''.
-- funkcja zwracająca wartość A ;
3. Budowa projektu układu cyfrowego w języku VHDL
Każda jednostka projektowa (ang. desing entity) w języku VHDL składa się z:
sprzęgu jednostki projektowej,
Sprzęg jednostki projektowej nazywany jest interfejsem (ang. interface) lub deklaracją jednostki projektowej. Składnia sprzęgu jest następująca:
deklaracja_jednostki_projektowej ::=
entity identyfikator is
[generic ( lista_parametrów); ]
[port ( lista_portow); ]
część_deklaracyjna_jednostki
[begin
instrukcje_współbieżne ]
end [entity] [nazwa_jednostki_projektowej] ;
Jak widać z syntaktycznej postaci interfejsu, udostępnia on porty wejściowe i wyjściowe oraz parametry formalne innym jednostkom.
Sprzęg jednostki projektowej składa się zatem z:
identyfikatora jednostki projektowej - reprezentującego jednostkę w środowisku projektowym,
nagłówka jednostki projektowej - zawierającego listę parametrów i listę portów,
części deklaracyjnej jednostki projektowej - zawierającej typy i obiekty używane w danej jednostce projektowej,
pasywnych instrukcji współbieżnych - działań opisujących zachowanie się (funkcjonowanie) jednostki projektowej, ale nie zmieniających wartości sygnałów.
Oprócz identyfikatora wszystkie pozostałe części interfejsu mogą wystąpić opcjonalnie. Zatem najprostszy sprzęg jednostki projektowej może wyglądać następująco:
entity Dekoder is end;
Lista portów
Porty to inaczej sygnały zewnętrzne, które połączone są z wyprowadzeniami naszego projektu. Innymi słowy, jeżeli naszą jednostkę projektową potraktujemy jako "czarną skrzynkę", to wszelkie jej wyprowadzenia nazywamy portami. Charakter takiego portu (tzn. kierunek przepływu danych) określamy przy deklaracji portu.
Przykład:
entity Dekoder is
port (
wejscie : in bit_vector
wyjscie : out bit_vector );
end entity Dekoder;
Deklaracja portów jest jednoznaczna z deklaracją sygnałów. Sygnały te różnią się jednak od zwykłych sygnałów "rodzajem" umieszczanym przed wskaźnikiem typu sygnału.
rodzaj ::= in | out | inout | buffer | linkage ;
Wyróżniamy pięć typów portów:
1. wejściowe - charakteryzujące się:
słowem kluczowym "in";
jednokierunkowym przepływem informacji do jednostki projektowej;
gą być tylko i wyłącznie odczytywane;
nie można odczytywać ich atrybutów takich jak: stable, quiet, delayed, transaction;
wejscie1 : in bit_vector (0 to 3) ;
2. wyjściowe - charakteryzujące się:
słowem kluczowym "out";
jednokierunkowym przepływem informacji z jednostki projektowej;
wartości ich są wyliczane wewnątrz danej jednostki;
mogą być tylko uaktualniane;
nie można odczytywać ich atrybutów takich jak: stable, quiet, delayed, transaction, event, active, last_event, last_active, last_value;
wyjscie1 : out bit ;
3. wejściowo-wyjściowe z wieloma źródłami - charakteryzujące się:
słowem kluczowym "inout";
dwukierunkowym przepływem informacji z i do jednostki projektowej (możliwy jest np. odczyt sygnału a potem jego aktualizacja);
mogą być uaktualniane przez więcej niż jedno źródło;
nie można odczytywać ich atrybutów takich jak: stable, quiet, delayed, transaction;
sgnA : inout bit_vector ;
4. wejściowo-wyjściowe z jednym źródłami - charakteryzujące się:
słowem kluczowym "buffer";
dwukierunkowym przepływem informacji z i do jednostki projektowej;
mogą być uaktualniane tylko przez jedno źródło;
można odczytywać ich wszystkie atrybuty;
sgnB : buffer bit_vector (5 downto 1) ;
5. wejściowo-wyjściowe o nie określonym kierunku przepływu informacji - charakteryzujące się:
słowem kluczowym "linkage";
stosuje się je do komunikacji z jednostkami projektowymi definiowanymi w innym środowisku niż język VHDL;
Lista parametrów
Parametry to rodzaj zmiennych globalnych, które zasadniczo wpływają na działanie jednostki projektowej. Różnią się od innych zmiennych tym, że deklaruje się je po słowie kluczowym "generic", a także tym że parametry mogą być mapowane (tzn. przyporządkowane) przez inne jednostki projektowe przy pomocy konfiguracji. Innymi słowy, są pewnego rodzaju zmiennymi wejściowymi.
Parametry w jednostkach projektowych stosujemy głównie po to, aby tworzone przez nas jednostki projektowe były bardziej wszechstronne, a także aby przyśpieszyć proces projektowania. Chodzi o to, aby jeden projekt z parametrem zastąpił co najmniej dwa inne projekty bez parametru, ale o bardzo zbliżonym działaniu. Przykładem mogą być wszelkiego rodzaju dekodery, których sposób dekodowania jest taki sam (np. z kodu BCD na postać umożliwiającą sygnalizację na diodach LED), jednak są one w stanie zdekodować tylko i wyłącznie sygnał wejściowy o określonej długości słowa. Zastosowanie parametru umożliwia stworzenie jednego, uniwersalnego dekodera, który nie jest uzależniony od długości sygnału wejściowego. Projekt taki z odpowiednio zmapowanymi parametrami staje się konkretnym dekoderem, który może być samodzielnym projektem lub też stanowić element jakiegoś projektu.
ciała architektonicznego jednostki projektowej.
Ciało architektoniczne jednostki projektowej zawiera własności funkcjonalne (behawioralne) i strukturalne układu cyfrowego. Składnia ciała architektonicznego jednostki projektowej wygląda następująco:
ciało_architektoniczne ::=
architecture identyfikator of nazwa_jednostki_projektowej is
część deklaracyjna_ciała
begin
instrukcje współbieżne
end [ architecture ] [ nazwa_ciała ] ;
Ciało architektoniczne jednostki projektowej składa się zatem z:
identyfikatora - reprezentującego ciało jednostki w środowisku projektowym,
nazwy jednostki projektowej - wiążącej dane ciało z określonym interfejsem (sprzęgiem jednostki projektowej),
części deklaracyjnej ciała jednostki projektowej - zawierającej m.in typy, obiekty, podprogramy używane w danym ciele jednostki projektowej,
instrukcji współbieżnych - działań opisujących funkcjonalne i/lub strukturalne własności ciała jednostki projektowej.
Oprócz identyfikatora i nazwy jednostki projektowej wszystkie pozostałe części interfejsu mogą wystąpić opcjonalnie.
Ciało architektoniczne może wyglądać różnie. W zależności od jego struktury ciała architektoniczne dzielimy na:
ciało strukturalne - zawierające strukturę danej jednostki projektowej (czyli skonkretyzowane i połączone ze sobą składniki)
ciało behawioralne (funkcjonalne) - zawierający opis działania danej jednostki projektowej,
ciało mieszane - zawierające zarówno strukturę jak i opis działania danej jednostki projektowej.
Różnice między tymi typami ciał można zademonstrować na prostym przykładzie sumatora:
Dany sumator można przedstawić w języku VHDL w postaci ciała:
a. strukturalnego
architecture Budowa_Sumatora1 of Sumator is
signal S1, S2 : bit;
begin
Bramka_Not1 : entity Work.Gate_Not port map (wej1, S1);
Bramka_Not2 : entity Work.Gate_Not port map (wej2, S2);
Bramka_And1 : entity Work.Gate_And port map (S1, S2, wyj);
end Budowa_Sumatora1;
Ciało architektoniczne zawiera skonkretyzowane składniki, które wcześniej zostały zadeklarowane i umieszczone w bibliotece "Work". Zastosowanie tego typu ciała pozwala na wykorzystanie wcześniej stworzonych projektów i tym samym przyśpieszenie procesu projektowania. Jego wadą natomiast jest to, że aby dowiedzieć się czegokolwiek o działaniu poszczególnych składników należy odwołać się do konkretnej jednostki projektowej.
b. funkcjonalnego
architecture Budowa_Sumatora2 of Sumator is
signal S1, S2 : bit;
begin
process (wej1, wej2)
S1 <= not wej1 after 2 ns;
S2 <= not wej2 after 2 ns;
wyj <= S1 and S2 after 2 ns;
end process;
end Budowa_Sumatora2;
Ciało architektoniczne zawiera dokładny opis działania (zachowania się) układu, dzięki czemu możemy go wnikliwie analizować. Nie jest on jednak bardzo czytelny przy projektowaniu skomplikowanych i rozbudowanych układów.
c. mieszanego
architecture Budowa_Sumatora3 of Sumator is
signal S1, S2 : bit;
begin
process (wej1, wej2)
S1 <= not wej1 after 2 ns;
S2 <= not wej2 after 2 ns;
end process;
Bramka_And1 : entity Work.Gate_And port map (S1, S2, wyj);
end Budowa_Sumatora3;
Ciało mieszane zawiera częściowy opis działania układu, a także konkretyzację składnika "Bramka_And1". W bardziej skomplikowanych układach jest to dużą zaletą, gdyż jest to w pewnym sensie kompromis między czytelnością funkcjonowania układu i szybkością projektowania. Niezbędne okazują się tu także komentarze, które poprawiają w znacznym stopniu przejrzystość programu.
Zależność między nimi jest ściśle określona. Do jednego sprzęgu może być przypisanych kilka ciał architektonicznych. A z kolei jedno ciało architektoniczne może być powiązane tylko i wyłącznie z jednych sprzęgiem. Dzięki takiemu rozwiązaniu jeden projekt, np.: dekodera, może działać w różny sposób w zależności od użytego ciała architektonicznego jednostki projektowej.
Najprostszy projekt układu cyfrowego musi zawierać jeden sprzęg i jedno ciało jednostki projektowej. Jednak w bardziej skomplikowanych projektach znaleźć można kilka jednostek projektowych tj. więcej niż jeden sprzęg i ponad dwa ciała architektoniczne. Projekty takie mogą także dodatkowo zawierać:
pakiety,
W języku VHDL część deklaracji wspólnych dla różnych projektów może być przechowywana w pakietach, które są umieszczane tak, jak i całe projekty, w bibliotekach. Dzięki nim możliwe jest znaczne przyśpieszenie procesu projektowania. Zawartość raz określonego pakietu i umieszczonego w konkretnej bibliotece można wykorzystać w dowolnej części własnego projektu. Warunkiem użycia danego pakietu jest odpowiednia deklaracja w postaci zakresu dostępu do pakietu i biblioteki.
Każdy pakiet składa się z dwóch części:
części deklaracyjnej - zawierająca tylko nagłówki deklaracji (mogą tu się znaleźć m.in. deklaracje podprogramów, typy, podtypy, obiekty i aliasy, składniki i atrybuty);
deklaracja_pakietu ::=
package identyfikator is
część_deklaracyjna_pakietu
end [ package ] [ nazwa_pakietu ] ;
ciała pakietu - zawierająca głównie ciała podprogramów, czyli instrukcje sekwencyjne opisujące działanie podprogramów (mogą tu się znaleźć także elementy wchodzące w skład części deklaracyjnej pakietu np. typy, podtypy, deklaracje podprogramów);
ciało_pakietu ::=
package body nazwa_pakietu is
część_deklaracyjna_ciała_pakietu
end [ package body ] [ nazwa_pakietu ] ;
Zależność między częścią deklaracyjną i ciałem pakietu nie jest taka sama jak w przypadku sprzęgu jednostki projektowej i jej architekturą. Oznacza to, że do jednej części deklaracyjnej pakietu można przyporządkować tylko i wyłącznie jedno ciało pakietu.
W języku VHDL (dokładniej w bibliotece STD) są predefiniowane (wbudowane) dwa pakiety:
pakiet Standard - zawierający predefiniowane typy i operatory języka VHDL,
pakiet TextIO - zawierający operacje zapisu i odczytu plików tekstowych przy komunikacji ze środowiskiem zewnętrznym.
deklaracje konfiguracji.
Deklaracje konfiguracji są stosowane do łączenia ze sobą poszczególnych składników. W wyniku połączenia otrzymujemy jednostkę projektową z ciałem strukturalnym projektu. Deklaracja konfiguracji wyznacza jednostkę projektową i ciało architektoniczne dla każdego komponentu, który został utworzony przy pomocy instrukcji konkretyzacji (przyporządkowanie bezpośrednie).
deklaracja_konfiguracji ::=
configuration identyfikator of nazwa_jednostki_projektowej is
część_deklaracyjna_konfiguracji
konfiguracja_bloku
end [ configuration ] [ nazwa_konfiguracji ];
Deklaracja konfiguracji rozpoczyna się od podania nazwy konfiguracji (identyfikatora) oraz skojarzenia jej z daną nazwą jednostki projektowej. Trzeba tu jednak zauważyć, że jedna deklaracja konfiguracji może być związana tylko i wyłącznie z jedną wybraną jednostką projektową i z jednym ciałem architektonicznym tej jednostki. Deklaracja konfiguracji dla określonej jednostki projektowej musi także być w tej samej bibliotece co dana jednostka projektowa. Kolejnym elementem deklaracji konfiguracji jest część deklaracyjna, która może zawierać informacje dotyczące: zakresu widzialności bibliotek, specyfikacji atrybutów oraz deklaracji grup.
Wyróżniamy dwa typy konfiguracji: konfiguracja bloku i konfiguracja składnika.
Konfiguracja bloku
Konfiguracja bloku określa blok lub ciało architektoniczne jednostki projektowej, którą konfigurujemy. Postać składniowa konfiguracji bloku wygląda następująco:
konfiguracja_bloku ::=
for specyfikacja_bloku
{ zakres_widzialności }
{ konfiguracja_bloku | konfiguracja_składnika }
end for ;
Występująca "specyfikacja bloku" wskazuje na ciało architektoniczne jednostki projektowej lub instrukcję bloku. Mogą tu także występować deklaracje zakresu widzialności oraz jednostki konfigurowalne. Konfiguracja bloku może więc zawierać też inne konfiguracje bloku lub konfiguracje składnika.
Konfiguracje bloku dzielimy na:
konfigurację hierarchiczną - gdy konfiguracja bloku zawiera inne konfiguracje bloku reprezentujące ciało architektoniczne,
konfigurację podstawową - gdy konfiguracja bloku nie zawiera innych konfiguracji bloku reprezentujących ciało architektoniczne.
Konfiguracja składnika
Konfiguracja składnika przyporządkowuje konkretną jednostkę projektową do składnika występującego w danym bloku lub ciele architektonicznym. Postać składniowa konfiguracji składnika wygląda następująco:
konfiguracja_składnika ::=
for specyfikacja_składnika
[ wiązanie_składnika ]
[ konfiguracja_bloku ]
end for ;
Konfiguracja składnika składa się ze specyfikacji składnika oraz część wiążącej składnik z jednostką projektową. Specyfikacja składnika określa składnik w bloku lub ciele architektonicznym, który konfigurujemy. Część wiążąca składnika wskazuje, którą jednostkę projektową wybraliśmy, aby przyporządkować ją do danych składnika.
wiązanie_składnika ::=
[ use entity nazwa_jednostki_projektowej [(nazwa_ciała_architektonicznego)]
| use configuration nazwa_konfiguracji
| use open ]
[ generic map (mapowanie_parametrów) ]
[ port map (mapowanie_portów) ]
Jak widać, wiązanie składnika może się odbyć na trzy sposoby:
bezpośrednio; w przypadku, gdy wskazujemy bezpośrednio na wybraną jednostkę projektową, w miejsce składnika przyporządkowana zostaje dana jednostka projektowa (nazwa jej może być złożona tzn. że jednostka może znajdować się w dowolnej bibliotece),
za pomocą innej konfiguracji; nasza konfiguracja wykorzystuje inną, wcześniej zdefiniowaną konfigurację, która wiąże wybrany składnik,
za pomocą słowa kluczowego "null", które oznacza, że składnik nie jest połączony z żadną jednostką projektową; taką sytuację nazywamy opóźnionym wiązaniem składnika.
Dzięki nim można znacznie przyśpieszyć proces projektowania wykorzystując w swoim projekcie poszczególne części innych projektów gromadzonych w bibliotekach.
4. Biblioteki
Język VHDL pozwala tworzyć biblioteki projektowe. Biblioteki są to, jak sama nazwa wskazuje, pewne zbiory elementów bibliotecznych, które możemy wykorzystać. Mogą one zawierać zarówno całe jednostki projektowe (także z wieloma architekturami) jak i wszelkiego rodzaju pakiety.
Biblioteki i elementy biblioteczne nie są bezpośrednio udostępnione w innych jednostkach projektowych. Dlatego też aby skorzystać z zawartości danej biblioteki należy posłużyć się klauzulą biblioteczną i klauzulą dostępu.
klauzula_biblioteczna ::=
library lista_nazw_bibliotek ;
klauzula_dostępu ::=
use nazwa_wybrana { , nazwa wybrana } ;
Klauzula biblioteczna zapewnia nam dostęp do konkretnej biblioteki lub grupy bibliotek. Ich nazwy umieszczamy po słowie kluczowym "library". Natomiast klauzula dostępu umożliwia nam wybranie konkretnych lub wszystkich elementów określonej biblioteki. Ich nazwy umieszczamy w postaci aliasu (nazwy złożonej, ścieżki) po słowie kluczowym "use". Na dostęp do wszystkich elementów bibliotecznych danej biblioteki pozwala klauzula dostępu ze słowem kluczowym "all".
Działanie klauzul można pokazać na następujących przykładach:
a. dostęp do wszystkich elementów biblioteki "Biblioteka1" i całych ich zawartości:
library Biblioteka1 ;
use STD.all ;
b. dostęp do konkretnego elementu bibliotecznego Biblioteka1 (np. pakietu Pakiet_biblioteki1) i całej jego zawartości:
library Biblioteka1 ;
use Biblioteka1.Pakiet_biblioteki1.all ;
c. dostęp do konkretnego elementu bibliotecznego Biblioteka1 (np. pakietu Pakiet_biblioteki1) i określonej jego zawartości (np. procedury Test):
library Biblioteka1 ;
use Biblioteka1.Pakiet_biblioteki1.Test ;
Klauzulę biblioteczną i dostępu umieszczamy przed jednostką projektową, w której wykorzystujemy określone elementy biblioteczne.
library ... ;
use ... ;
entity ... is
...
end;
W języku VHDL wbudowane są dwie podstawowe biblioteki:
biblioteka Work - do której zwykle dołączane są nasze projekty oraz pakiety, i do których to (dzięki tej bibliotece) mamy dostęp w innych projektach i pakietach,
biblioteka STD - zawierająca predefiniowane pakiety, w których znajdują się deklaracje typów i procedur podstawowych, wykorzystywanych przy definiowaniu operacji arytmetycznych, logicznych oraz zapisu i odczytu danych.
W/w biblioteki nie wymagają żadnych klauzul, ponieważ dostęp do nich jest nieograniczony w każdym elemencie definiowanym w języku VHDL.
5. Typy i podtypy
W języku VHDL, podobnie jak w przypadku innych języków programowania, można definiować typy i podtypy. Są to niezbędne elementy języka, dzięki którym mamy pewność co do poprawności działania projektu tj. np. zgodności parametrów aktualnych, portów wejściowych lub wyjściowych. Typy określają zatem własności deklarowanych w projekcie obiektów (tzn. stałych, zmiennych, sygnałów i plików). Innymi słowy, typ to odpowiednio nazwany zbiór wartości o wspólnych charakterystycznych cechach. Z typami wiążą się także ściśle określone operacje, które mogą być wykonywane tylko i wyłącznie na danych obiektach konkretnego typu.
Każdy typ możemy zdeklarować w dwojaki sposób stosując: pełną lub niepełną deklarację typu. Różnica w tych deklaracjach polega na tym, że nie trzeba od razu określać własności danego typu, a jedynie zasygnalizować jego istnienie. Taki typ musi być jednak później (w naszym projekcie) precyzyjnie zdefiniowany. Deklarację pełną i niepełną tworzymy w następujący sposób:
pełna_deklaracja_typu ::=
type identyfikator is definicja_typu ;
np.: type typ_danych1 is bit_vector (0 to 9);
niepełna_deklaracja_typu ::=
type identyfikator ;
np.: type typ_danych2 ;
Ze składni wynika, że niezbędnym elementem typu jest identyfikator. Może być nim dowolna nazwa, która nie została wcześniej użyta w projekcie, ponieważ od momentu przypisania jej określonemu typowi, będzie ona reprezentować dany typ w środowisku projektowym. Dzięki niej możemy określać później obiekty, które charakteryzować się będą właściwościami zdefiniowanymi po słowie kluczowym "is". Definicję typu określa odpowiednia składnia, zależna od konkretnego typu.
Mając już określony typ możemy wykorzystać go do stworzenia podtypu, który będzie posiadał tylko niektóre właściwości danego typu. Inaczej mówiąc podtypy to jakby "podzbiory typów". Podtyp tworzymy za pomocą:
deklaracja_podtypu ::=
subtype identyfikator is wskaźnik_typu ;
Występujący tu wskaźnik typu określa nam typ bazowy, na którym tworzymy podtyp, np.:
np.: subtype podtyp_typu_danych is typ_danych1 ;
Jednak oprócz samej nazwy typu bazowego może on także zawierać pewne ograniczenie, które chcemy zastosować, np.:
np.: subtype podtyp_typu_danych is typ_danych1 (0 to 4) ;
W ten sposób powstał przykładowy podtyp jednowymiarowej tablicy, przy pomocy którego możemy tworzyć sygnały w postaci słowa 5-bitowego.
Typy, które możemy zdefiniować dzielimy na:
skalarne,
złożone,
wskaźnikowe,
plikowe.
W języku VHDL (w pakiecie Standard) są już predefiniowane typy, podtypy i operacje podstawowe, z których można korzystać przy definiowaniu nowych typów i podtypów. Są to:
Tabela. Predefiniowane typy i podtypy języka VHDL
Rodzaj predefiniowanego typu lub podtypu Opis
Bit wartości "0" i "1"
Bit_Vector typ tablicowy złożony z elementów typu Bit
Boolean wartości logiczne False i True (Fałsz i Prawda) Character znaki kodu ASCII Delay_Length podtyp typu Time, w którym ograniczono zakres File_Open_Kind rodzaj dostępu do pliku File_Open_Status status w jakim znajduje się plik Integer liczby całkowite określone przez implementację Natural liczby całkowite nieujemne Positive liczby całkowite większe od zera Real liczby rzeczywiste określone przez implementację Severity_Level poziomy ważności komunikatu String typ tablicowy złożony ze znaków kodu ASCII Time typ fizykalny definiujący jednostki czasu
Typ skalarny
Wartości typu skalarnego są uporządkowane wg określonej skali, co pozwala na określenie zależności między nimi. Podstawową własnością typów skalarnych jest ich zakres, który określa granice zbioru wartości oraz kierunek zmian wartości w tym zbiorze. Zakres najłatwiej określić przy pomocy zakresu prostego:
zakres_prosty ::= wyrażenie_proste kierunek wyrażenie_proste ;
kierunek ::= to | downto ;
Należy zauważyć, że kierunek jest ściśle określony z granicami zakresu. W ten sposób kierunek określony słowem "to" zawsze wskazuje od wartości najniższej do najwyższej. A kierunek "downto" odwrotnie. Podanie kierunku w innym kontekście spowoduje określenie zbioru pustego.
Praca z typami skalarnymi jest możliwa przez wykorzystanie operatorów i atrybutów predefiniowanych w pakiecie Standard.
Typy skalarne mogą być składnikami innych typów np.: złożonych oraz typów wskaźnikowych.
Wśród typów skalarnych wyróżniamy:
a. typ skalarny wyliczeniowy
Jest to typ definiowany przez wartości nienumeryczne złożone z identyfikatorów i znaków ASCII. Jest on definiowany w następujący sposób:
definicja_typu_wyliczeniowego ::= (literał_wyliczeniowy { , literał_wyliczeniowy }) ;
W całym zakresie typu nie może się powtórzyć żaden element zbioru. Definicję typu wyliczeniowego tworzymy za pomocą wypisania kolejnych elementów zbioru w nawiasach okrągłych.
Każdy element w zbiorze posiada przyporządkowaną liczbę naturalną, dzięki czemu możliwym jest odwołanie do tej liczby jak do konkretnego elementu. Kierunek tak utworzonego ciągu liczb naturalnych (zakres typu wyliczeniowego) jest zawsze narastający.
Zdarzyć się może, że ten sam element (np.: '1' lub '0') powtarza się w wielu typach. Następuje wtedy tzw. przeciążenie tych literałów, a co za tym idzie ich typ wynika z kontekstu w jakim ten literał wystąpił.
Przykłady:
type Bity is ('0', '1');
type Alfabet is (A, B, C, D, E, F);
b. typ skalarny całkowity
Jest to typ numeryczny, który składa się z liczb całkowitych należących do zakresu określonego przez implementacje (standardowo od -2147483647 do +2147483647). Jest on definiowany w następujący sposób:
definicja_typu_całkowitego ::= range zakres_prosty ;
Typ całkowity tworzony przez nas, to inaczej podtyp liczb całkowitych z użyciem zakresu. Są to nadal liczby całkowite z tym, że ich wybór ograniczony zostaje przez określony przez nas przedział.
Typ ten można także zmieniać poprzez zastosowanie wyrażenia lokalnie statycznego (tzn. przed próbą wykorzystania takiego typu, wartość zakresu musi być wyliczona, a co za tym idzie parametr użyty przez nas musi być wartością stałą).
Przykłady:
type liczbaABC is range 1 to 3;
type wyraz is range 10 downto 0;
type liczby_plus_minus is range -10 to 10;
type typ_wyliczany is range -10 to 7;
c. typ skalarny rzeczywisty
To kolejny typ numeryczny. Zawiera on liczby rzeczywiste z zakresu określonego przez implementację (standardowo od -1.0E38 do +1.0E38). Definiuje się go tak jak typ całkowity:
definicja_typu_całkowitego ::= range zakres_prosty ;
Typ ten ma takie same własności jak typ całkowity z tą różnicą, że liczby występujące w typie rzeczywistym zawierają symbol kropki.
Dopuszcza się także aby zakres był wyliczany (podobnie jak w typie całkowitym). Pamiętać jednak należy aby użyty parametr był wyrażeniem stałym przed operacją wyliczania.
Przykłady:
type typ_Liczba_A is range 3.5 to 10.3 ;
type Poziom_Halasu is range -0.01 downto -10.66 ;
d. typ skalarny fizykalny
Umożliwia zdefiniowanie jednostek miary dla zadanej wielkości występującej w badanym procesie fizycznym, tj. długości, czasu, napięcia, itp.. W deklaracji występuje jednostka podstawowa oraz kilka jednostek będących wielokrotnością jednostki podstawowej.
definicja_typu_fizykalnego ::= range zakres_prosty
units jednostka_podstawowa {jednostka_wielokrotna}
end units [nazwa_typu_fizykalnego];
W pakiecie Standard jest predefiniowany typ fizykalny TIME. Typ ten posiada przyporządkowany zestaw operatorów. Te same operatory są określone także dla typów zadeklarowanych przez użytkownika: =, /=, <, <=, >, >=, +, -, abs, *, /
Przykład:
type typ_Napiecie is range 0 to 1E18
units
nV;
uV = 1000 nV;
mV = 1000 uV;
V = 1000 mV;
KV = 1000 V;
end units typ_Napiecie;
Typ złożony
Są to typy, dzięki ktorym możemy tworzyć obiekty złożone. Wśród tych typów wyróżniamy:
a. typ złożony tablicowy
Typ ten grupuje elementy tego samego typu, każdy element przyporządkowany ma swój indeks, dzięki któremu możemy odwołać się do niego w naszym programie. Typ ten możemy podzielić na typ tablicowy ograniczony (gdy podamy jego zakres) i typ tablicowy nieograniczony (gdy nie znamy wielkości przyszłej tablicy).
definicja_typu_tablicowego_ograniczonego ::=
array ( ograniczenie_indeksowe )
of wskaźnik_typu_elementu_tablicy ;
definicja_typu_tablicowego_nieograniczonego ::=
array ( definicja_podtypu_indeksu_tablicy {, definicja_podtypu_indeksu_tablicy} )
of wskaźnik_typu_elementu_tablicy ;
W pakiecie Standard zdefiniowano dwa typy jednowymiarowe nieograniczone: STRING (nieograniczony ciąg znaków) i BIT_VECTOR (nieograniczony ciąg bitów).
Przykłady:
type bajt is array (7 downto 0) of bit ;
type pamiec is array (natural range <>) of bit_vector ;
b. typ złożony rekordowy
Jest typem za pomocą którego możemy łączyć ze sobą różne inne typy. Pomocny jest np. w sytuacji gdy chcemy używając jednego typu zapisać dane personalne jakiejś osoby. Stworzony obiekt typu rekordowego może zawierać zatem "Imię" (ciąg znaków - string), "Nazwisko" (ciąg znaków - string), "Wiek" (liczba naturalna - natural).
definicja_typu_rekordowego ::= record lista_identyfikatorów :
wskaźnik_typu {, lista_identyfikatorów : wskaźnik_typu}
end record ;
Ważnym jest, że kolejność występowania poszczególnych identyfikatorów jest ustalana raz - przy deklaracji - a w związku z tym dostęp do nich musi być tak samo precyzowany.
Przykład:
type dane_personalne is record
Imie, Nazwisko : string ;
Wiek : natural ;
end record ;
Typ wskaźnikowy
Powstaje z typu skalarnego, złożonego lub innego wskaźnikowego. Dużą zaletą tego typu jest to, że obiekt typu wskaźnikowego jest wyliczany w procesie alokacji. Zmienia się zatem dynamicznie.
definicja_typu_wskaźkowego ::= access wskaźnik_typu ;
Obiektami typu wskaźnikowego są tylko zmienne. Początkowa wartość takiego obiektu określona jest jako "null", a dopiero w programie za pomocą operatora "new" tworzymy jego nową wartość.
Przykłady:
type parametry is access parametry_temp1 ;
new parametry_temp1 (x, y) ;
Typ plikowy
Pozwala na deklarację obiektów reprezentujących w środowisku pliki. W plikach mogą być przechowywane wartości typu, który został podany w deklaracji.
definicja_typu_plikowego ::= file of nazwa_typu ;
Typ podany w deklaracji może być tylko typem skalarnym lub złożonym (bez typów wskaźnikowego i plikowego).
Posługując się obiektami typu plikowego, niejawnie generujemy procedury związane z ich obsługą. Są to procesy otwierania, odczytywania, zapisywania, zamykania plików.
Przykład:
type plik_16bit is file of bit_vector range 15 downto 0 ;
6. Wyrażenia
Wyrażenia w języku VHDL określają głównie operatory, nazwy i operandy. Inaczej mówiąc słowy są to wszystkie te elementy języka, które towarzyszą słowom kluczowym, ale pełnią one nie mniej ważną funkcję.
Operatory
Operatory w języku VHDL są bardzo zróżnicowane. Znajdziemy tu wiele popularnych operatorów z algebry (dodawanie to "+", mniejszość to "<") ale i wiele charakterystycznych dla tego języka (przesunięcie logiczne w prawo to "srl", sklejanie to "&"). Kolejność wykonania zależy od priorytetu jaki posiada dany operator.
Tabela. Priorytety operatorów
1. Operatory różne ** abs not
2. Operatory multiplikatywne * / mod rem
3. Operatory znaku + -
4. Operatory dodawania + - &
5. Operatory przesunięć sll srl sla sra rol ror
6. Operatory relacji = \= < <= > >=
7. Operatory logiczne and or nand nor xor xnor
Zmiana kolejności wykonania może nastąpić po zastosowaniu nawiasów okrągłych "( )", których liczba zagęszczenia jest dowolna (należy jednak pamiętać, że zbyt rozległe stosowanie nawiasów prowadzi do braku czytelności projektu).
a. operatory logiczne
Realizują działania logiczne. Operatory logiczne są zdefiniowane dla typów BIT ('0' lub '1') oraz BOOLEAN (True lub False).
not Neguje wartość logiczną
and Wynik jest prawdą gdy wszystkie czynniki są prawdą
or Wynik jest prawdą gdy przynajmniej jeden ze składników jest prawdą
xor Wynik jest prawdą gdy występuje nieparzysta ilość składników będących prawdą
nand Wynik jest fałszem gdy wszystkie czynnik nie jest prawdą
nor Wynik jest fałszem gdy przynajmniej jeden ze składników jest prawdą
nxor Wynik jest fałszem gdy występuje nieparzysta ilość składników będących prawdą
Przykłady:
Y <= not A;
Signal <= G and H;
Op := A nxor B;
b. operatory relacji
Porównują dwa argumenty (lewy i prawy). Operandy zawsze muszą być tego samego typu, natomiast wynik jest zawsze typu BOOLEAN (True lub False); Operator '=' i '/=' są zdefiniowane dla wszystkich dostępnych typów oprócz typu plikowego.
= Określa równość dwóch operandów
/= Określa nierówność dwóch operandów
< Określa mniejszość pierwszego operandu od drugiego
<= Określa mniejszość równość pierwszego operandu od drugiego lub ich równość
> Określa większość pierwszego operandu od drugiego
>= Określa większość pierwszego operandu od drugiego lub ich równość
Przykłady:
10 < 19 -- True;
"10" >= "11" -- False;
c. operatory przesunięć
Służą do wykonywania działań na jednowymiarowych tablicach (z elementami typu BIT lub BOOLEAN); Lewy operand to dana tablica; Prawy operand to liczba pozycji do przesunięcia lub obrócenia.
sll Przesuwa logicznie w lewo (miejsca zwolnione zapisywane są wartością '0')
srl Przesuwa logicznie w prawo (miejsca zwolnione zapisywane są wartością '0')
sla Przesuwa arytmetycznie w lewo (miejsca zwolnione zapisywane są wartością '1')
sra Przesuwa arytmetycznie w prawo (miejsca zwolnione zapisywane są wartością '1')
rol Obraca logicznie w lewo (pierwszy bit staje się drugim, drugi - trzecim, itd.)
ror Obraca logicznie w prawo (pierwszy bit staje się ostatnim, drugi - pierwszym, itd.)
Przykłady:
A <= "0110" ;
A sll 2 - A <= "1000";
A sra 1 - A <= "1011";
d. operatory addytywne
Realizują działania arytmetyczne, z wyjątkiem operatora sklejania, który "łączy" bity tworząc jednowymiarowe tablice; Typy operandów mogą być dowolnego typu numerycznego;
+ Dodaje arytmetycznie operandy
- Odejmuje arytmetycznie operandy
& Skleja operandy
Przykłady:
Q := 2 + W;
Y := I - J;
U := '0' & '1'; -- U := "01"
e. operatory znaku
Określają znak argumentu. Typy operandów mogą być dowolnego typu numerycznego; Ze względu na niski priorytet tego operatora zalecane jest stosowanie ich w nawiasach okrągłych.
+ Określa dodatni znak operandu
- Określa ujemny znak operandu
Przykłady:
Z := A ** (-B);
X := -Z;
f. operatory multiplikatywne
Realizują działania mnożenia. Operandami są wszystkie typy całkowite, zmiennoprzecinkowe oraz fizykalne; Natomiast operatory mod oraz rem zostały zdefiniowane tylko dla całkowitych.
* Mnoży operandy
/ Dzieli operandy
mod Oblicza moduł operandu
rem Oblicza resztę z dzielenia
Przykłady:
C := 2 * 2;
A := B mod 2;
g. operatory różne
Operator potęgowania jest przeznaczony dla typu całkowitego i zmiennoprzecinkowego; Prawy operand musi być typu całkowitego.
** Potęguje operandy
abs Oblicza wartość bezwzględną operandu
Przykłady:
2 ** 3 = 8
abs 6.8 = 6
Nazwy
W deklaracjach jednostek języka VHDL występują identyfikatory, które następnie określają daną jednostkę. Dostęp do takiej jednostki jest możliwy poprzez użycie nazwy, która wskazuje tę jednostkę. Nazwy mogą również wskazywać na obiekty typu wskaźnikowego, elementy obiektu typu złożonego, części obiektów typu złożonego lub atrybuty jednostki, która w swej deklaracji posiada identyfikator.
Wśród nazw wyróżniamy:
a. nazwa prosta
b. symbol operatora
c. nazwa wybrana
d. nazwa indeksowa
e. nazwa wyciskowa
f. nazwa atrybutowa
a. nazwa prosta
Składa się tylko z identyfikatora, który został przyporządkowany w czasie deklaracji nazwy.
Przykłady:
variable X : integer -- nazwą prostą jest X
X := 2 * 2;
b. symbol operatora
Nazwa ta ma postać napisu i wskazuje na funkcję, która została zadeklarowana z takim symbolem operacji
Przykłady:
function "+"(a,b : integer) return real; -- nazwą jest symbol dodawania
Y := "+"(2,3);
c. nazwa wybrana
Wskazuje na jednostkę, która została zadeklarowana w innej jednostce lub bibliotece projektów. Składa się z trzech części: prefiksu (określającego dowolną jednostkę), kropki (.), sufiksu (precyzującego wybór elementu w danej jednostce). Gdy chcemy wybrać wszystkie elementy jednostki, w części sufiksu używamy słowa "all".
Przykłady:
Work.FunkcAnd;
Std_Logic.all;
Work.AA.Band;
d. nazwa indeksowa
Wskazuje na element tablicy, który wyznaczany jest za pomocą listy wyrażeń będących indeksami tablicy. Składa się z prefiksu (j.w.) i wyrażenia w nawiasach okrągłych za pomocą którego następuje wybór.
Przykłady:
TablicaA(6);
TabZ(4);
e. nazwa wycinkowa
Wskazuje na część obiektu jednowymiarowych tablic. Budową jest ona bardzo podobna do nazwy indeksowej. Różnica tkwi w podaniu zakresu w części precyzującej wybór.
Przykłady:
Tabela(7 downto 5);
TblO(4 to 6);
f. nazwa atrybutowa
Wskazuje na pewne własności jednostki (np.: wartości, funkcje, typy, zakresy, sygnały lub stałe). Składnią jest podobna do nazwy wybranej. Różnica to apostrof zamiast kropki.
Przykłady:
Clk'event;
WartoscX'left(2);
7. Obiekty
Język VHDL jest wyposażony w następujące obiekty: stałe, zmienne, sygnały i pliki. Każdy obiekt ma przyporządkowany określony typ oraz może mieć przypisaną wartość początkową (jeśli nie jest ona przypisana, przypisywana jest automatycznie najniższa wartość określonego typu). Charakterystycznym dla obiektów jest ich jawność (tzn. niektóre z obiektów generują się bez wiedzy projektującego - obiekty niejawne).
a. stała
Obiekt, którego wartość jest zawsze stała.
deklaracja_stałej ::= constant lista_identyfikatorów : wskaźnik_typu [ := wyrażenie ];
Przykłady:
constant A : integer := 7 ;
constant GJ : bit;
b. zmienna
Obiekt ten może przyjmować wartości, które mogą być zmieniane w czasie symulacji. Służą do przechowywania informacji lokalnych w procesach i podprogramach.
deklaracja_zmiennej ::= variable lista_identyfikatorów : wskaźnik_typu [ := wyrażenie ];
Przypisanie wartości do zmiennej jest realizowane natychmiast po instrukcji przypisania.
Przykłady:
variable delay : time;
variable x : real := 2.5;
c. sygnał
Obiekt ten może przyjmować wartości, które mogą być zmieniane w trakcje symulacji. Wykorzystuje się je do połączenia pomiędzy składnikami projektu.
deklaracja_sygnału ::= signal lista_identyfikatorów : wskaźnik_typu [rodzaj_sygnału] [ := wyrażenie ];
Rodzaj sygnału może przyjąć wartość "register" (dla sygnałów typu rejestrowego) i "bus" (dla sygnałów typu magistralowego). Różnica polega na możliwości wykorzystania niejawnego sygnału GUARD dla sygnału typu "register" (Przypisanie sygnału nastąpi dopiero gdy GUARD = True).
Przypisanie wartości do sygnału może być opóźnione o żądany czas.
Przykłady:
signal SgnA : bit;
signal SgnB : bit_vector (7 downto 0);
d. plik
Obiekt ten reprezentuje w programie pliki fizyczne, w których mogą być przechowywane wartości określonego typu.
deklaracja_pliku ::= file lista_identyfikatorów : wskaźnik_typu
[ [ open rodzaj_dostępu_do_pliku ] is logiczna_nazwa_pliku ];
Przykłady:
file plik1 : bit_vector;
file plik2 : bit_vector open WRITE_MODE is file of "\vhdl\test.hgj"
8. Instrukcje sekwencyjne
Wszystkie operacje realizowane przez nasz projekt mogą być definiowane przy pomocy instrukcji sekwencyjnych. Podstawowe cechy tych instrukcji to:
są one wykonywane sekwencyjnie, czyli kolejno, jedno po drugim w porządku, w jakim zostały one zapisane w projekcie,
mogą być stosowane tylko w procesach lub podprogramach,
mogą być poprzedzone etykietą.
Wśród instrukcji sekwencyjnych wyróżniamy:
a. instrukcja sekwencyjna jeżeli
b. instrukcja sekwencyjna następna
c. instrukcja sekwencyjna oczekiwania
d. instrukcja sekwencyjna pętli
e. instrukcja sekwencyjna powrotu
f. instrukcja sekwencyjna przypadku
g. instrukcja sekwencyjna przypisania sygnału
h. instrukcja sekwencyjna przypisania zmiennej
i. instrukcja sekwencyjna pusta
j. instrukcja sekwencyjna raportu
k. instrukcja sekwencyjna wyjścia
l. instrukcja sekwencyjna wywołania procedury
m. instrukcja sekwencyjna założenia
a. instrukcja sekwencyjna jeżeli
Można nią sterować kolejnością wykonywania innych instrukcji sekwencyjnych.
instrukcja_jeżeli ::= [etykieta :] if warunek then
instrukcje sekwencyjne
{elsif warunek then
instrukcje sekwencyjne}
[else instrukcje sekwencyjne]
end if [etykieta] ;
W swej budowie zawiera może zawierać szereg warunków umożliwiających wykonanie odpowiedniej sekwencji poleceń. Warunki te umieszczamy po słowach: pierwszy warunek - słowo "if", każdy kolejny - słowo "elsif". Operacja nie spełniająca żadnego ze zdefiniowanych warunków, powoduje wykonanie sekwencji po słowie "else", lub w przypadku jego braku kończy wykonywanie instrukcji przechodząc do kolejnych instrukcji po słowach "end if".
Przykłady:
if Sgn = A then
X := 1;
end if;
if Clk = '1' then
Sg <= SgA and SgB else Sg <= '0'
end if;
if signal = '01' then
Y <= A after 2ns;
elsif signal = "10" then
Y <= B after 2ns;
else
Y <= C;
end if;
b. instrukcja sekwencyjna następna
Pozwala zmienić kolejność wykonywania instrukcji zadeklarowanych w pętli.
instrukcja_następna ::= [etykieta :] next [etykieta_pętli] [when warunek];
Gdy występuje słowo "when" i warunek, to dopiero spełnienie warunku spowoduje wykonanie danej instrukcji wyjścia. Gdy występuje po słowie "next" etykieta, to niespełnienie warunku spowoduje przejście do tej etykiety i realizacje instrukcji po niej;
Przykład:
X0 : for i in 1 to 3 loop
X1 : SgnA(i) <= '0';
next X0 when warunek1 = '1'; -- jeśli warunek1 = False, to wykonane
X2 : SgnB(i) <= '1'; -- zostaną instr. po etykiecie X0, jeśli True - po X2
end loop X0;
c. instrukcja sekwencyjna oczekiwania
Powoduje zawieszenie wykonywania procesu lub procedury do czasu gdy zostanie spełniony warunek wznowienia działania.
instrukcja_oczekiwania ::= [etykieta :] wait [until warunek_logiczny]
[for wyrażenie_czasu] [on nazwa_sygnału { , nazwa_sygnału}] ;
Wznowienie może nastąpić po spełnieniu warunku po słowie "until" lub upłynięciu czasu podanym po słowie "for" lub zmianie sygnałów zadeklarowanych po słowie "on". W przypadku braku jakiegokolwiek warunku wznowienia proces zostanie zawieszony na czas nieokreślony - nigdy nie zostanie wznowiony;
Przykłady:
wait until clk = '1';
wait for 10ns;
wait on SgnA, SgnB, SgnC;
wait;
d. instrukcja sekwencyjna pętli
Wielokrotnie uruchamia sekwencję instrukcji zawartych w pętli.
instrukcja_pętli ::= [etykieta :] [schemat_iteracji] loop
instrukcje sekwencyjne
end loop [etykieta];
Liczba powtórzeń zależy od schematu iteracji poprzedzającego słowo "loop". Jeśli schemat iteracji jest nie określony pętla będzie cały czas realizowana.
schemat_iteracji ::= while warunek | for identyfikator in zakres_dyskretny
Przy schemacie iteracji ze słowem "while" pętla będzie realizowana do czasu spełnienia warunku. Przy schemacie iteracji ze słowem "for" liczba powtórzeń jest określona przez zakres dyskretny.
Przykłady:
L1 : loop
clk <= not clk after 1us;
end loop L1;
L2 : while x = 2 loop
SgnA <= '1';
end loop L2;
L3 : for z in 1 to 4
Tbl(z) = '0';
end loop L3;
e. instrukcja sekwencyjna powrotu
Umożliwia zakończenie wykonywania nawet najbardziej zagnieżdżonego podprogramu.
instrukcja_powrotu ::= [etykieta :] return [wyrażenie] ;
Może ona być użyta tylko w procedurach lub funkcjach.
Przykłady:
return;
return rezultat;
f. instrukcja sekwencyjna przypisania zmiennej
Umożliwia zmianę wartości wybranej zmiennej. Nowa wartość zostaje wyliczana z wyrażenia po prawej stronie i przypisana bezpośrednio w chwili zakończenia wyliczania.
instrukcja_przypisania_zmiennej ::= [etykieta :] cel_przypisania := wyrażenie ;
Cel przypisania musi być identyczny co wyrażenia.
Przykłady:
X := 5;
S(2) := '1';
G(7 downto 3) := 9;
RekordA.f := 34;
g. instrukcja sekwencyjna przypisania sygnału
Umożliwia zmianę wartości wybranego sygnału. Nowa wartość zostaje wyliczana z wyrażenia po prawej stronie i przypisana w momencie zdefiniowanym przez projektanta.
instrukcja_przypisania_sygnału ::=
[etykieta :] cel_przypisania <= [rodzaj opóźnienia] kształt_przebiegu;
Cel przypisania musi być identyczny co wyrażenia.
rodzaj_opóźnienia ::= transprt | [reject wyrażenie_czasowe] inertial
Rodzaj opóźnienia uzależniony od słowa "transprt", które powoduje nadanie tego samego opóźnienia niezależnie od szerokości sygnału. Natomiast "inertial" powoduje nadanie opóźnienia uzależnionego od szerokości sygnału (np.: gdy impuls jest mniejszy od 1ns, jest on w sygnale wynikowym pomijany). Dodatkowe zastosowanie słowa "reject" umożliwia dowolną regulację warunku szerokości sygnału. W przypadku nie wystąpienia słów "transprt" lub "inertial" zakłada się, że jest słowo "inertial";
kształt_przebiegu ::= wyrażenie [after wyrażenie czasowe] | null
Wyrażenie, które jest przypisywane może być opóźnione o zadany czas umieszczony po słowie "after". Możliwe jest zastosowanie w jednej instrukcji przypisania sygnału kilku wartości z zadanym różnym opóźnieniem.
Przykłady:
SgnA <= '1';
SgnB <= SgnA after 1ns;
SgnC <= SgnA after 2ns, SgnB after 3ns;
SgnD <= "011" after 2ms;
SgnD <= transport S_in after 1ns;
SgnE <= inertial S_in after 1ns;
SgnF <= reject 1us inertial S_in after 1ns;
h. instrukcja sekwencyjna przypadku
Steruje kolejnością sekwencji instrukcji w zależności od wartości zadanego warunku.
instrukcja_przypadku ::= [etykieta :] case wyrażenie is
when wartości_wyboru => instrukcje sekwencyjne
{ when wartości_wyboru => instrukcje_sekwencyjne }
end case [etykieta] ;
Wyrażenie, które podlega warunkowi musi być typu dyskretnego lub może być jednowymiarową tablicą, której elementy są typu złożonego ze znaków kodu ASCII (character, string, bit_vector). Wartości wyboru muszą obejmować wszystkie możliwości. W przypadku gdy interesujące nas wartości wyboru zostały określone, i mimo to zostały nam jeszcze wolne możliwości, określamy sytuację określamy sytuację ze słowem "others". Ważnym jest aby słowo to było wymienione jako ostania możliwość wyboru.
Przykład:
case A is
when "00" => ster <= '1' after 1ps;
when "01" => ster <= '0';
when others => null;
end case;
i. instrukcja sekwencyjna pusta
Nic nie wykonuje.
instrukcja_pusta ::= [etykieta :] null ;
Przykład:
null;
j. instrukcja sekwencyjna raportu
Służy do wyświetlania komunikatów w czasie procesu symulacji.
instrukcja_raportu ::= [etykieta :] report wyrażenie [severity wyrażenie] ;
Pole "report" służy do umieszczenia zawartości komunikatu, a pole "severity" służy do określenia ważności danego komunikatu. Są cztery poziomy severity_level: note (notatka), warning (ostrzeżenie), failure (błąd), error (błąd krytyczny). W przypadku zaistnienia błędu krytycznego zatrzymywany jest proces symulacji. W przypadku nie wystąpienia słowa "severity" uznaje się poziom ważności jako "note".
Przykłady:
report "Koniec pętli";
report "Liczba A mniejsza od zera" severity FAILURE;
k. instrukcja sekwencyjna wyjścia
Przerywa wykonanie instrukcji pętli, w której jest zagnieżdżona.
instrukcja_wyjścia ::= [etykieta :] exit [etykieta_pętli] [when warunek] ;
Przerwanie następuje po spełnieniu warunku po słowie "when". Nie podanie etykiety pętli powoduje przerwanie tylko tej pętli, w której instrukcja wyjścia się znajduje. Jeśli chcemy przerwać pętle zagnieżdżone, musimy podać etykietę.
Przykłady:
exit when clk = '1';
exit L3 when reset = '1'; -- jeśli warunek będzie równy True nastąpi skok do etykiety L3;
l. instrukcja sekwencyjna wywołania procedury
Służy do uruchamiania ciała procedury w trakcie procesu symulacji
instrukcja_wywołania_procedury ::=
[etykieta :] nazwa_procedury [(paramentry_aktualne)] ;
Występowanie i typ parametrów aktualnych jest ściśle uwarunkowane od definicji danej procedury.
Przykłady:
Procedura2000 (a, b, c);
StoLatProcedura ;
m. instrukcja sekwencyjna założenia
Sprawdza podany warunek i w przypadku jego spełnienia wyświetla komunikat. Instrukcja ta jest bardzo podobna do instrukcji raportu.
instrukcja_założenia ::=
[etykieta :] assert warunek [report wyrażenie] [severity wyrażenie] ;
(Informacje o częściach instrukcji ze słowem "report" i "severity" tak jak w instrukcji raportu)
Przykłady:
assert test = "11" report "Sygnał posiada wartość 11" severity NOTE;
assert Bum = 1 report "Przeciążenie sygnału" severity ERROR;
9. Instrukcje współbieżne
Instrukcje współbieżne umożliwiają modelowanie struktury i zachowania projektowanych układów cyfrowych. Podstawowe cechy tych instrukcji to:
są one wykonywane asynchronicznie, niezależnie od siebie, w nieokreślonej kolejności,
nie mogą wystąpić w podprogramach,
mogą być poprzedzone etykietą,
Każda z instrukcji współbieżnej może być zastąpiona równoważną instrukcją sekwencyjną. Dlatego też wydawać by się mogło, że są one zbędne. W praktyce tak nie jest. Różnica między instrukcjami współbieżnymi polega na tym, że instrukcje współbieżne są na wyższym szczeblu hierarchii języka niż instrukcje sekwencyjne. Instrukcje współbieżne dotyczą bezpośrednio operacji na jednostkach projektowych. Określają ich działanie (instrukcja procesu z wykorzystaniem instrukcji sekwencyjnych, instrukcja wywołania procedury, założenia, przypisania sygnału) i zależności (instrukcja konkretyzacji składnika). Instrukcje współbieżne także ułatwiają projektowanie (instrukcja konkretyzacji składnika, instrukcja powielania) i poprawiają czytelność projektu (instrukcja bloku).
Wśród instrukcji współbieżnych wyróżniamy:
a. instrukcja współbieżna bloku
b. instrukcja współbieżna konkretyzacji składnika
c. instrukcja współbieżna powielania
d. instrukcja współbieżna procesu
e. instrukcja współbieżna przypisania sygnału
f. instrukcja współbieżna wywołania procedury
g. instrukcja współbieżna założenia
a. instrukcja współbieżna bloku
Grupuje inne instrukcje współbieżne, definiuje fragment ciała jednostki projektowej, który zawarty jest pomiędzy słowami "block" oraz "end block".
instrukcja_bloku ::= etykieta block [(wyrażenie_dozoru)] [is]
nagłówek_bloku
jednostka_deklaracyjna_bloku
begin
instrukcje_współbieżne
end block [etykieta];
Stosuje się ją głównie po to aby polepszyć czytelność projektu.
Przykłady:
B1 : block (clk'event and clk = '1')
signal S : bit;
begin
S <= '1' after 2ns;
Y <= A and S;
end block B1;
b. instrukcja współbieżna konkretyzacji składnika
Umożliwia tworzenie projektu w postaci strukturalnego opisu jednostki projektowej.
instrukcja_konkretyzacji_składnika ::= etykieta : jednostka_konkretyzacji
[generic map aktualne_wartości_parametrów] [port map aktualne_porty] ;
Instrukcja ta może przybierać różne formy w zależności od tego co stanowi jednostkę konkretyzacji.
intantacja bezpośrednia - występuje gdy jednostka konkretyzacji jest poprzedzona słowem "entity"
entity nazwa_jednostki_projektowej [(nazwa_ciała_jedostki_projektowej)]
Jej dużą zaletą jest prostota budowy. Ma on jednak poważną wadę - uniemożliwia ona ingerowanie wewnątrz konkretyzowanej jednostki z poziomu naszego projektu.
Brak nazwy ciała jednostki projektowej spowoduje konkretyzację do tej architektury jednostki projektowej, która była ostatnio kompilowana.
Przykład:
Dec1 : entity Work.DecBcdLed (DecBody) port map (S1, S2);
specyfikacja konfiguracji - występuje gdy jednostka konkretyzowana jest wskazywana pośrednio przez składnik.
[component] nazwa_składnika
Aby jednak zastosować ten rodzaj konkretyzacji musimy zadeklarować składnik w naszym projekcie.
deklaracja_składnika ::= component identyfikator [is]
[sekcja_parametrów]
[sekcja_portów]
end component [identyfikator] ;
Strukturą deklaracja składnika jest bardzo zbliżona do sprzęgu jednostki projektowej i w taki sam sposób należy wypełniać odpowiednie sekcje w deklaracji składnika.
Przykład:
component AND_AB is
port (a, b : in bit; y : out bit);
end component AND_AB;
A1 : AND_AB port map (In1, In2, Out1);
A2 : AND_AB port map (In3, In4, In5, Out2);
Gdy już mamy składnik możemy go użyć w specyfikacji konkretyzacji.
specyfikacja_konfiguracji ::=
for lista_składników : nazwa_składnika wiązanie_składnika ;
Przykład:
for A1 : AND_AB use entity Work.AND2 (AND2_arch);
for others : AND_AB use entity Work. AND3;
Zastosowanie składnika znacznie poprawia wszechstronność naszego projektu, ponieważ każdy składnik raz zadeklarowany można w różnoraki sposób konkretyzować. Zaletą takiej metody konkretyzacji jest to, że raz określone parametry i porty jednostki konkretyzowanej możemy zmieniać za pomocą zmiany parametrów i portów składnika.
konfiguracja - występuje gdy jednostka konkretyzowana jest wskazywana pośrednio przez konfigurację.
configuration nazwa_konfiguracji
Jest to bardziej skomplikowana struktura od konkretyzacji z wykorzystaniem komponentów (patrz wyżej), lecz posiada te same zalety co i ona.
Przykład:
Cnt : configuration Work.Count port map (clk, Q);
c. instrukcja współbieżna powielania
Umożliwia szybsze i łatwiejsze tworzenie struktur projektowych, których ilość w projekcie jest znaczna. Dotyczyć to może np.: liczników zbudowanych z kilku takich samych przerzutników.
instrukcja_powielania ::= etykieta : schemat_generacji generate
[część_deklaracyjna
begin]
isnstrukcje_współbieżne
end generate [etykieta];
Mamy dostępne dwa typy generacji:
schemat pętlowy - wykorzystujemy gdy powielane struktury są w pełni regularne.
schemat_generacji_pętlowy ::= for identyfikator in zakres_dyskretny
schemat warunkowy - wykorzystujemy gdy powielane struktury nie są w pełni regularne.
schemat_generacji_warunkowy ::= if warunek
Przykłady:
G1 : for i in 1 to 8 generate
P1 : Przerz port map (S(i), S(i+1));
end generate;
G2 : if x = 1 generate
P2 : Przerz port map (S(x), S(x-1));
end generate;
d. instrukcja współbieżna procesu
Jest to podstawowa instrukcja współbieżna. Definiuje niezależny sekwencyjny proces reprezentujący zachowanie pewnej części projektu za pomocą instrukcji sekwencyjnych.
instrukcja_procesu ::= [etykieta :] [posponed] process [(lista_czułości)][is]
część_deklaracyjna_procesu
begin
instrukcje_sekwencyjne
end [posponed] process [etykieta] ;
Słowo "posponed" lub jego brak określa proces, którego wznowienie jest możliwe dopiero w następnym cyklu symulacji. Wznowienie w tym samym cyklu symulacji jest możliwe przez użycie słowa "nonpostponed".
Lista czułości opisuje w jakich przypadkach dany proces się wznowi. Można to zrobić np.: za pomocą listy sygnałów (dowolna zmiana któregoś z nich powoduje wzbudzenie). Lista ta może znajdować się po słowie "process" lub w miejscu instrukcji sekwencyjnych - jako polecenie "wait" (patrz sekwencyjna instrukcja oczekiwania).
Przykłady:
process (a)
signal x : integer ;
begin
y <= x and '1' after 1ns;
z <= y or x after 2ns;
end process;
e. instrukcja współbieżna przypisania sygnału
Działa analogicznie do sekwencyjnej instrukcji przypisania sygnału.
instrukcja_przypisania_sygnału ::=
[etykieta :] [postponed] warunkowe_przypisanie_sygnału
| [etykieta :] [postponed] selektywne_przypisanie_sygnału ;
Jak widać współbieżne przypisanie sygnału jest bardziej złożone od sekwencyjnego.
warunkowe_przypisanie_sygnału ::=
cel_przypisania <= [guarded] [mechanizm_opóźnienia]
{charakterystyka_przypisania when warunek else }
charakterystyka_przypisania [when warunek] ;
selektywne_przypisanie_sygnału ::=
with wyrażenie select
cel_przypisania <=
{charakterystyka_przypisania when wyrażenie_wyboru , }
charakterystyka_przypisania when wyrażenie_wyboru ;
Może się ono odbyć na cztery sposoby:
podstawowe przypisanie sygnału - jest to uproszczone warunkowe przypisanie sygnału (brak w nim sekcji warunkowej ze słowem "when"), ogranicza się zatem tylko do podania celu przypisania i wartości jaka ma być przypisana (opóźnienie po słowie "after" może wystąpić opcjonalnie).
Przykłady:
Syg12 <= '1';
Gap1 <= "011" after 1ns;
Gap2 <= "101" after 2ns, "010" after 6ns;
warunkowe przypisanie sygnału - jest to przypisanie sygnału uzależnione od podanych warunków po słowach "when".
Przykłady:
S4 <= '1' when clk = '1';
S99 <= "01" after 1us when clk = '0';
Sg0 <= '0' when clk = '1', '1' when clk ='0';
selektywne przypisanie sygnału - przypisywany sygnał wybierany jest z listy wyszczególnionych przypadków i odpowiadającym im warunkom.
Przykład:
with Sg_in select
y <= a and b when "001",
a or b when "010",
a xor b when "100",
'0' after 1us when others;
dozorowane przypisanie sygnału - przypisanie sygnału jest uwarunkowane od niejawnego sygnału GUARD, który jest wyliczany zawsze dla każdej instrukcji przypisania sygnału. Gdy wartość GUARD jest równa True następuje normalne przypisanie sygnału, gdy False nośnik sygnału jest odłączany od wartości (przypisanie wartości null). Zastosowanie tego typu przypisania jest możliwe po zastosowaniu słowa "guarded" (patrz warunkowe przypisanie sygnału)
Przykład:
SG_dozor <= guarded A nxor B when C = '1' ;
f. instrukcja współbieżna wywołania procedury
Działa i wygląda analogicznie do sekwencyjnej instrukcji wywołania procedury.
instrukcja_wywołania_procedury ::= [etykieta :] [posponed]
nazwa_procedury [(paramentry_aktualne)] ;
Jedyna różnica tkwi w możliwości zastosowania słowa "posponed" lub "nonposponed" (patrz współbieżna instrukcja procesu).
Przykłady:
procedura77 (Sgn1, A);
nonposponed DzialanieNaSyg (6, D, '1');
g. instrukcja współbieżna założenia
Działa i wygląda analogicznie do sekwencyjnej instrukcji założenia.
instrukcja_założenia ::= [etykieta :] [posponed]
assert warunek [report wyrażenie] [severity wyrażenie] ;
Jedyna różnica tkwi w możliwości zastosowania słowa "posponed" lub "nonposponed" (patrz współbieżna instrukcja procesu).
Przykład:
nonposponed assert Z = 13 report "Zmienna Z jest równa 13";
10. Podprogramy
Pewne działania projektu mogą się powtarzać. Aby uniknąć żmudnego powtarzania całych fragmentów programu opracowano takie struktury jak podprogramy. Raz zadeklarowane i zdefiniowane można wykorzystać w dowolnym miejscu naszej jednostki projektowej za pomocą odpowiedniej instrukcji wywołania sekwencyjnej lub współbieżnej (należy zauważyć że wywołanie funkcji odbywa się analogicznie do wywołania procedury).
W podprogramach używamy tylko i wyłącznie instrukcji sekwencyjnych.
Podprogramy możemy podzielić na procedury i funkcje.
a. procedura
Jest to podprogram, który może opisywać dowolne zachowanie się projektu (dotyczy to operacji na wszelkiego typu obiektach). Dużą zaletą procedury jest możliwość zastosowania w niej nieograniczonej liczby parametrów wejściowych i wyjściowych. Możliwe to jest dzięki strukturze procedury, która przypomina odrębną jednostkę projektową.
Każda procedura składa się z deklaracji procedury i ciała procedury.
deklaracja_procedury ::= procedure identyfikator
[(lista_parametrów_formalnych)] ;
Na liście parametrów formalnych mogą się znaleźć wszystkie typy obiektów. Dodatkowo dla stałych, zmiennych i sygnałów definiuje się kierunek przepływu informacji ("in", "out", "inout") oraz decyduje się o tym, jakie parametry formalne mogą być dostępne wewnątrz procedury. Procedura może także wystąpić bezparametrowo.
ciało_procedury ::= procedure identyfikator
[(lista_parametrów_formalnych)] is
część_deklaracyjna_podprogramu
begin
instrukcje_sekwencyjne
end [procedure] [identyfikator] ;
Jak widać ciało procedury ma początek identyczny ze składnią deklaracji procedury. Dlategoteż pisząc procedury można pominąć deklarację procedury unikając tym samym powtórzeń.
W części deklaracyjnej możemy zadeklarować wszystkie dodatkowe obiekty, których będziemy używać tylko i wyłącznie w procedurze.
Czasem zdarza się, że zaistnieją w projekcie procedury o tej samej nazwie, lecz różnych pod względem listy parametrów formalnych. Mówimy wtedy, że dane procedury są przeciążone. W wyniku próby realizacji takiej procedury kompilator wybierze tę procedurę, której wywołanie jest zgodne z liczbą i typami parametrów użytych w procedurze.
Przykład:
procedure Dekoder (sg_wej : in bit_vector; sg_wyj : out bit_vector) is
begin
case sg_wej is
when "001" => sg_wyj <= "100";
when "010" => sg_wyj <= "010";
when "011" => sg_wyj <= "001";
when others => sg_wyj <= "000";
end case;
end procedure;
b. funkcja
Jest to podprogram stosowany głównie do obliczeń. Wynika to budowy funkcji, która może mieć dowolną liczbę parametrów wejściowych i jedną wartość wyjściową.
deklaracja_funkcji ::= [pure | impure] function nazwa_funkcji
[(lista_parametrów_formalnych)]
return nazwa_typu ;
Nazwą funkcji może być zarówno identyfikator jak i symbol operatora.
Listę parametrów formalnych określamy tak jak w procedurach. Należy jednak zauważyć, że dostępny jest tu tylko kierunek określony słowem "in".
Charakterystycznym jest także opcjonalne występowanie słów "pure" (funkcja która dla tych samych podanych parametrów wejściowych zawsze zwraca tą samą wartość) i "impure" (funkcja która dla tych samych parametrów wejściowych może zwracać różną wartość; dzieje się tak gdy wartość zwracana jest zależna od obiektów wyliczanych poza funkcją, mogących mieć różne wartości w różnym czasie).
ciało_funkcji ::= [pure | impure] function nazwa_funkcji
[(lista_parametrów_formalnych)] is
część_deklaracyjna_podprogramu
begin
instrukcje_sekwencyjne
end [function] [nazwa_funkcji] ;
Ponieważ większość elementów deklaracji funkcji występują w ciele funkcji można się nie powtarzać i użyć ich jeden raz w ciele funkcji (tak jak w procedurze).
Podobnie do procedur, funkcje także mogą być przeciążone. Kompilator w takich przypadkach zachowuje się analogicznie jak w przypadku procedur.
Ponieważ nazwę funkcji może stanowić także symbol operatora, w przypadku funkcji przeciążane mogą być operatory. Oznacza to że zdefiniowanie funkcji np. o nazwie "+", zmusi kompilator do wybrania odpowiedniej funkcji do zrealizowania, ponieważ funkcja o tej nawie jest predefiniowana i realizuje sumę dwóch argumentów. Wybór funkcji przez kompilator odbywa się na takiej samej zasadzie co przy przeciążaniu zwykłych funkcji.
Przykłady:
function "+" (a, b : in integer; return integer) is
begin
y := (a + b) / a;
return y ;
end function;
Przykłady
Projekty tu prezentowane są to jedne z najprostszych i najpopularniejszych struktur, toteż lepiej można poznać funkcjonowanie języka VHDL w opisywaniu układów cyfrowych. A mając do dyspozycji wiedzę na temat tworzenia tak prostych struktur, możemy pokusić się o tworzenie bardziej lub bardzo zaawansowanych struktur (język VHDL znalazł zastosowanie do opisu mikroprocesorów, pamięci, itp.)
Projekty te zostały tak stworzone, aby pokazać jednocześnie drogę jaką podążała technologia, od prostych bramek logicznych do jednostki arytmetyczno- logicznej. Droga ta może pokrywać się z programem nauczania dla Pracowni Elektrycznej i Elektronicznej.
Dla ułatwienia zrozumienia działania projektów, dostępne są także animacje przedstawiające ich funkcjonowanie. Działanie projektów można także samemu przetestować w części obok animacji.
Słowem wstępu...
bramki logiczne
Bramkami nazywane są kombinacyjne układy cyfrowe, realizujące proste funkcje logiczne jednej lub wielu zmiennych logicznych. W praktyce są one realizowane przez specjalne układy, które zwykle zawierają w sobie cztery bramki jednego typu. Z pomocą języka VHDL jesteśmy w stanie stworzyć projekt układu cyfrowego, który zastąpiłby szereg różnych układów specjalistycznych i realizował wszystkie najpopularniejsze funkcje logiczne.
Projekt 'BramkiLogiczne' został tak zaprojektowany, aby spełniał dowolną funkcję logiczną na dwóch wejściowych zmiennych logicznych 'A' i 'B' (wyjątkiem jest negacja jednej zmiennej 'A') i prezentował wynik na wyjściu 'Y'. W jednej, określonej chwili projekt może realizować tylko jedną operację, którą wybieramy na podstawie wartości sygnału 'wybierz'. Dodatkowo każdy z projektów został wyposażony w sygnał 'reset', który pozwala na sterowanie nim przez inną jednostkę projektową np.: mikroprocesor.
W projekcie zostały zaprezentowane następujące bramki logiczne:
a. bramka NOT
b. bramka AND
c. bramka NAND
d. bramka OR
e. bramka NOR
f. bramka XOR
g. bramka NXOR
a. bramka NOT
Bramka ta (dostępna w projekcie 'Bramki' po podaniu wartości "000" na port 'wybierz') jest układem o jednym wejściu realizującym operację negacji zmiennej wejściowej tzn. zmieniającym wartość zmiennej na jej dopełnienie. Negacja oznacza, że gdy sygnał wejściowy ma wartość 0, to wyjściowy 1, i odwrotnie: gdy sygnał wejściowy jest 1 to wyjściowy 0.
A Y
0 1 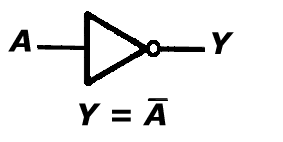
1 0
b. bramka AND
Bramka ta (dostępna w projekcie 'Bramki' po podaniu wartości "001" na port 'wybierz') jest układem o dwu lub większej liczbie wejść, realizującym funkcję iloczynu logicznego zmiennych wejściowych. Funkcja iloczynu przyjmuje wartość 1 gdy wszystkie składniki mają wartość 1. W pozostałych przypadkach wartość funkcji wynosi 0.
A B Y 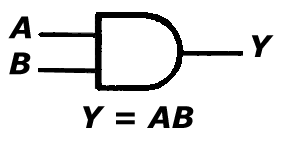
0 0 0
0 1 0
1 0 0
1 1 1
c. bramka NAND
Bramka ta (dostępna w projekcie 'Bramki' po podaniu wartości "010" na port 'wybierz') jest układem realizującym funkcję negacji iloczynu logicznego zmiennych wejściowych, a więc zgodnie z prawem de Morgana również funkcje sumy negacji zmiennych wejsciowych. Funkcja negacji iloczynu przyjmuje wartość 1 gdy wszystkie składniki mają wartość 0. W pozostałych przypadkach wartość funkcji wynosi 1.
A B Y 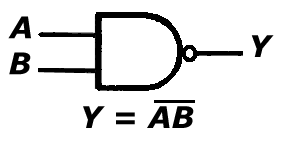
0 0 1
0 1 1
1 0 1
1 1 0
d. bramka OR
Bramka ta (dostępna w projekcie 'Bramki' po podaniu wartości "011" na port 'wybierz') jest układem o dwu lub większej liczbie wejść, realizującym funkcję sumy logicznej zmiennych wejściowych. Funkcja sumy logicznej przyjmuje wartość 1 gdy którykolwiek składnik funkcji (sygnał wejściowy) ma wartość 1; 0 - gdy wszystkie składniki maja wartość 0.
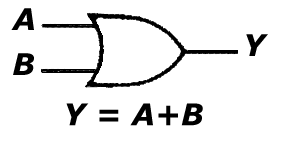
A B Y
0 0 0
0 1 1
1 0 1
1 1 1
e. bramka NOR
Bramka (dostępna w projekcie 'Bramki' po podaniu wartości "100" na port 'wybierz') ta jest układem realizującym funkcję negacji sumy logicznej zmiennych wejściowych, a więc zgodnie z prawem de Morgana również funkcje iloczynu negacji zmiennych wejsciowych. Funkcja negacji sumy logicznej przyjmuje wartość 1 gdy którykolwiek składnik funkcji (sygnał wejściowy) ma wartość 0; 1 - gdy wszystkie składniki maja wartość 0.
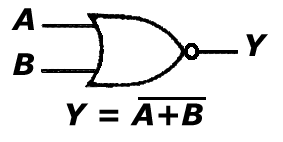
A B Y
0 0 1
0 1 0
1 0 0
1 1 0
f. bramka XOR
Bramka ta (dostępna w projekcie 'Bramki' po podaniu wartości "101" na port 'wybierz') realizuje dodawanie mod 2, tj. na jej wyjściu pojawi się '1'-ka logiczna wtedy i tylko wtedy, gdy suma arytmetyczna zmiennych wejściowych będzie równa '1'.
A B Y 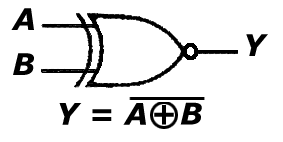
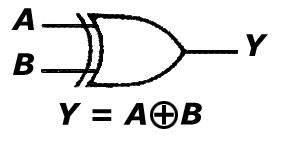
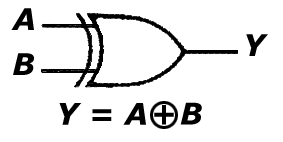
0 0 0
0 1 1
1 0 1
1 1 0
g. bramka NXOR
Bramka ta (dostępna w projekcie 'Bramki' po podaniu wartości "110" na port 'wybierz') jest negacją bramki XOR, zatem na jej wyjściu pojawi się '1'-ka logiczna wtedy i tylko wtedy, gdy suma arytmetyczna zmiennych wejściowych będzie równa '0'.
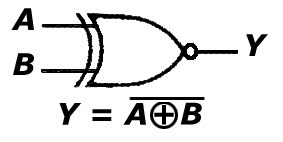
A B Y
0 0 1
0 1 0
1 0 0
1 1 1
Kod źródłowy
entity BramkiLogiczne is
port ( reset, A, B : in bit; wybierz : in bit_vector (2 downto 0) ; Y : out bit );
end entity;
architecture ArchBramkiLogiczne of BramkiLogiczne is
begin
process (reset, A, B, wybierz)
begin
if (reset = '0') then
case wybierz is
-- realizacja bramki NOT ;
when "000" => Y <= not A;
-- realizacja bramki AND ;
when "001" => Y <= A and B;
-- realizacja bramki NAND ;
when "010" => Y <= A nand B;
-- realizacja bramki OR ;
when "011" => Y <= A or B;
-- realizacja bramki NOR ;
when "100" => Y <= A nor B;
-- realizacja bramki XOR ;
when "111" => Y <= A xor B;
-- realizacja bramki NXOR ;
when "110" => Y <= not (A xor B);
-- opcja dla pozostałych wartości sygnału wybierz ;
when others => null;
end case;
else
Y <= '0';
end if;
end process;
end architecture;
przerzutniki asynchroniczne
Przerzutnik to podstawowy element układów sekwencyjnych, którego podstawową funkcją jest pamiętanie jednego bitu informacji. Posiada on conajmniej dwa wejścia i z reguły dwa wyjścia. Wejścia mogą być:
zegarowe, zwane synchronizującymi albo wyzwalającymi - gdy impul zegarowy występuje, przerzutnik reaguje na informację wejściową; w przypadku braku wejścia zegarowego, przerzutnik reaguje zawsze gdy zmieni się informacja wejściowa,
informacyjne - w zależności od nich przerzutnik odpowiednio generuje sygnały wyjściowe,
programujące - są to zwykle dwa wejścia: ustawiające S (gdy występuje to przerzutnik jest włączony), zerujące R (gdy występuje to przerzutnik zostaje wyzerowany).
Istnieje wiele typów przerzutników, a co za tym idzie wiele różnych układów cyfrowych realizujących określony typ przerzutnika. Dlategoteż można pokusić się o stworzenie jednego uniwersalnego układu, który pokazywałby działanie wszystkich najpopularniejszych przerzutników.
W ten sposób, dzięki językowi VHDL, możemy zrealizować projekt 'Przerzutniki', który zawierałby w sobie:
a. przerzutnik RS
b. przerzutnik JK
c. przerzutnik D
d. przerzutnik T
a. przerzutnik asynchroniczny RS
Przerzutnik RS (dostępny w projekcie 'Przerzutniki' po podaniu wartości "00" na port 'wybierz') jest najprostszym przerzutnikiem. Posiada on dwa wejścia informacyjne R i S (w projekcie 'Przerzutniki' odpowiednio Y i X przy wybierz = "00") i zależnie od trzech dozwolonych kombinacji ich stanów, przerzutnik może spełniać trzy funkcje:
nie zmienić stanu na wyjściach Q i nieQ, jeśli R = S = '0',
przyjąć na wyjściu Q stan '0' i na wyjściu nieQ stan '1', jeśli R = '1' i S = '0',
przyjąć na wyjściu Q stan '1' i na wyjściu nieQ stan '0', jeśli R = '0' i S = '1'.
Przy stanie R = S = '1' stan wyjściowy przerzutnka jest nieokreślony co oznacza, że może zaistnieć albo stan Q = '0' i nieQ = '1', albo Q = '1' i nieQ = '0'.
Sn Rn Qn+1
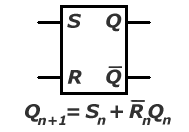
0 0 Qn
0 1 0
1 0 1
1 1 ?
b. przerzutnik asynchroniczny JK
Przerzutnik ten (dostępny w projekcie 'Przerzutniki' po podaniu wartości "01" na port 'wybierz') różni się od przerzutnika RS tym, że stan J = '1' i K = '1' (w naszym projekcie odpowiednio X = '1' i Y = '1' przy wybierz = "01") jest dozwolony. Przerzutnik JK jest przerzutnikiem najbardziej uniwersalnym funkcjonalnie. Warto zauważyć, że jeśli J = K = '1', to stany na wyjściach Q i nieQ zmieniają się na przeciwne. Przypadek ten odpowiada dzieleniu liczby impulsów zegarowych przez dwa - jest to dwójka licząca.
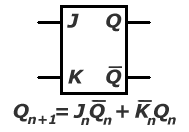
Jn Kn Qn+1
0 0 Qn
0 1 0
1 0 1
1 1 nieQn
c. przerzutnik asynchroniczny D
Przerzutnik D (dostępny w projekcie 'Przerzutniki' po podaniu wartości "10" na port 'wybierz') jest dość prostym przerzutnikiem, posiadającym tylko jedno wejście informacyjne D (w naszym projekcie X przy wybierz = "10"). Działanie jego polega na wpisaniu '0' na wyjście Q i '1' na nieQ, gdy sygnał wejściowy D jest równy '0', a wpisanie '1' na wyjście Q i '0' na nieQ, gdy sygnał wejściowy D jest równy '1'. Należy tu zauważyć, że informacje wyjściowe (Qn+1 i nieQn+1) nie są zależne od wsześniejszych (Qn i nieQn).
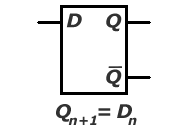
Dn Qn+1
0 0
1 1
d. przerzutnik asynchroniczny T
Przerzutnik T (dostępny w projekcie 'Przerzutniki' po podaniu wartości "11" na port 'wybierz') jest także prostym przerzutnikiem. Posiada tylko jedno wejście informacyjne T (w naszym projekcie X przy wybierz = "11"). Działanie jego polega na zmianie sygnałów wyjściowych na przeciwne przy T = '1', a pozostawieniu ich bez zmian przy T = '0'. Podobnie jak w przypadku przerzutnika JK realizuje on dwójkę liczącą.
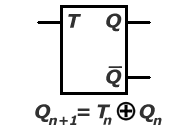
Tn Qn+1
0 Qn
1 nieQn
Kod źródłowy
entity Przerzutniki is
port ( reset, X, Y : in bit ; wybierz : in bit_vector (1 downto 0) ; Q, nieQ: out bit );
end entity;
architecture ArchPrzerzutniki of Przerzutniki is
signal wynik : bit_vector (1 downto 0);
signal temp : bit;
begin
process (reset, X, Y, wybierz, wynik)
begin
if (reset = '0') then
case wybierz is
-- realizacja przerzutnika RS ;
when "00" =>
wynik(1) <= X or (not Y and wynik(1));
wynik(0) <= not wynik(1);
-- realizacja przerzutnika JK ;
when "01" =>
wynik(1) <= (not wynik(1) and X) or (not Y and wynik(1));
wynik(0) <= not wynik(1);
-- realizacja przerzutnika D ;
when "10" =>
wynik(1) <= X;
wynik(0) <= not wynik(1);
-- realizacja przerzutnika T ;
when "11" =>
wynik(1) <= wynik(1) xor X;
wynik(0) <= not wynik(1);
end case;
else
wynik <= "00";
end if;
Q <= wynik(1);
nieQ <= wynik(0);
end process;
end architecture;
układy rejestrowe
Rejestrem nazywamy układ służący do przechowywania informacji. Ze względu na sposób wprowadzania i wyprowadzania informacji rejestry dzielą się na:
szeregowe, umożliwiające szeregowe wprowadzenie i wyprowadzenie informacji, tzn. kolejno, bit po bicie,
szeregowo-równoległe, umożliwiające szeregowe wprowadzenie i równoległewyprowadzenie informacji,
równoległo-szeregowe, umożliwiające równoległe wprowadzenie i szeregowe wyprowadzenie informacji,
równoległe, umożliwiające równoległe wprowadzenie i wyprowadzenie informacji jednocześnie do wszystkich i ze wszystkich pozycji rejestru.
Jeśli zatem chcemy skonstruować jakieś urządzenie wykorzystujące rejestry, jesteśmy "uzależnieni" od konkretnego typu rejestru. Dzięki językowi VHDL można ten problem rozwiązać projektując jeden uniwersalny projekt 'Rejestry', który w zależności od podanej wartości sygnału 'wybierz' zastąpi nam wybrany rejestr (dla 'wybierz' = "00" - szeregowy, "01" - szeregowo-równoległy, "10" - równoległo-szeregowy, "11" - równoległy).
Obsługa takiego uniwersalnego rejestru jest stosunkowo prosta.
Zapis do rejestru: Najpierw wybieramy typ rejestru, którego chcemy użyć. Następnie dane wejściowe, które podamy na port 'wej' (dla rejestrów z wprowadzaniem szeregowym używamy tylko jednej linii sygnału 'wej'). Pozostaje nam tylko wybrać opcję zapisu na porcie 'ster' i uruchomić układ. Zauważyć należy, że wszelkie operacje realizowane przez projekt 'Rejestry' są wykonywane w obecności sygnału zegarowego 'clk' (wyjątkiem jest asynchroniczny sygnał 'reset', który zeruje cały rejestr).
Odczyt rejestru: Już zapisany rejestr możemy odczytać. Robimy to za pomocą zmiany sygnału 'ster' na opcję odczytu. Wynik odczytu pojawi się na porcie wyjściowym 'wyj' w postaci charakterystycznej dla danego typu rejestru.
Uwaga: W między czasie możemy obserwować sygnał wewnętrzny 'rejestr', ale jest to możliwe tylko w procesie symulacji projektu. Po zaprogramowaniu układu cyfrowego oczywiście nie będzie on dostępny.
Kod źródłowy
entity Rejestry is
port ( reset, clk, ster : in bit;
wybierz : in bit_vector(1 downto 0);
wej : in bit_vector(3 downto 0);
wyj : out bit_vector(3 downto 0) );
end entity;
architecture ArchRejestry of Rejestry is
signal rejestr : bit_vector(3 downto 0);
begin
process (reset, clk, ster)
begin
if reset = '0' then
case wybierz is
-- realizacja rejestru szeregowego ;
when "00" =>
if ster = '1' and clk = '1' and clk'event then
rejestr(0) <= wej(0);
elsif ster = '1' and clk = '0' and clk'event then
rejestr <= rejestr sll 1;
elsif ster = '0' and clk = '1' and clk'event then
wyj(0) <= rejestr(0);
elsif ster = '0' and clk = '0' and clk'event then
rejestr <= rejestr rol 1;
end if;
wyj(3 downto 1) <= "000";
-- realizacja rejestru szeregowo-równoległego ;
when "01" =>
if ster = '1' and clk = '1' and clk'event then
rejestr(0) <= wej(0);
elsif ster = '1' and clk = '0' and clk'event then
rejestr <= rejestr sll 1;
elsif ster = '0' and clk = '1' and clk'event then
wyj <= rejestr;
end if;
-- realizacja rejestru równoległo-szeregowego ;
when "10" =>
if ster = '1' and clk = '1' and clk'event then
rejestr <= wej;
elsif ster = '0' and clk = '1' and clk'event then
wyj(0) <= rejestr(0);
elsif ster = '0' and clk = '0' and clk'event then
rejestr <= rejestr rol 1;
end if;
-- realizacja rejestru równoległego ;
when "11" =>
if ster = '1' and clk = '1' and clk'event then
rejestr <= wej;
elsif ster = '0' and clk = '1' and clk'event then
wyj <= rejestr;
end if;
end case;
else
rejestr <= "0000";
wyj <= "0000";
end if;
end process;
end architecture;
4. liczniki asynchroniczne
Licznikiem nazywany jest sekwencyjny układ cyfrowy służący do zliczania i pamiętania liczby impulsów podawanych w określonym przedziale czasu na jego wejście zliczające. Jeśli chcelibyśmy sklasyfikować liczniki, możemy to zrobić np. pod względem ich długości cyklu, która to może być stała lub programowalna.
Działanie projektu 'Liczniki' polega na zliczaniu impulsów wejściowych i prezentowaniu wyniku na porcie wyjściowym. Proces zliczania jest jednak uzależniony od dwóch sygnałów: sterującego 'wybierz' (który określa typ wykorzystywanego licznika) i zerującego 'reset' (który zeruje wyjścia licznika).
Projekt 'Liczniki' został przystosowany do pracy jako trzy różne liczniki:
a. licznik modulo 2
b. licznik modulo 3
c. licznik modulo 4
a. licznik asynchroniczny modulo 2
Licznik asynchroniczny modulo 2 jest realizowany przez projekt 'Liczniki' po podaniu wartości "00" na port 'wybierz'. Działanie jego polega na zliczaniu imulsów wejściowych do dwóch, tzn. wynikiem zliczania jest wartość 0 lub 1 zapisana w postaci bitowej (0 = "00", 1 = "01") na portach wyjściowych.
b. licznik asynchroniczny modulo 3
Licznik asynchroniczny modulo 3 jest realizowany przez projekt 'Liczniki' po podaniu wartości "01" na port 'wybierz'. Działanie jego polega na zliczaniu imulsów wejściowych do trzech, tzn. wynikiem zliczania jest wartość 0, 1 lub 2 zapisana w postaci bitowej (0 = "00", 1 = "01", 2 = "10") na portach wyjściowych.
c. licznik asynchroniczny modulo 4
Licznik asynchroniczny modulo 4 jest realizowany przez projekt 'Liczniki' po podaniu wartości "10" na port 'wybierz'. Działanie jego polega na zliczaniu imulsów wejściowych do czterech, tzn. wynikiem zliczania jest wartość 0, 1, 2 lub 3 zapisana w postaci bitowej (0 = "00", 1 = "01", 2 = "10", 3 = "11") na portach wyjściowych.
Kod źródłowy
entity Liczniki is
port ( reset, wej : in bit; wybierz : in bit_vector (1 downto 0); wyjA, wyjB : out bit );
end entity;
architecture ArchLiczniki of Liczniki is
signal wynik : bit_vector (1 downto 0);
begin
process (reset, wynik, wej)
begin
if reset = '0' then
case wybierz is
-- realizacja licznika modulo 2
when "00" =>
if wej = '0' and wej'event then
wynik(0) <= ('1' and not wynik(0)) or ('0' and wynik(0));
end if;
wynik(1) <= '0';
-- realizacja licznika modulo 3
when "01" =>
if wej = '0' and wej'event then
wynik(0) <= (not wynik(1) and not wynik(0)) or ('0' and wynik(0));
wynik(1) <= (wynik(0) and not wynik(1)) or ('0' and wynik(1));
end if;
-- realizacja licznika modulo 4
when "10" =>
if wej = '0' and wej'event then
wynik(0) <= ('1' and not wynik(0)) or ('0' and wynik(0));
if wynik(0) = '1' then
wynik(1) <= ('1' and not wynik(1)) or ('0' and wynik(1));
end if;
end if;
-- opcja dla pozostałych wartości sygnału wybierz ;
when others => null;
end case;
else
wynik <= "00";
end if;
wyjA <= wynik(0);
wyjB <= wynik(1);
end process;
end architecture;
układy arytmetyczne
Sumator jest to podstawowy układ arytmetyczny. Jego zasadniczym zadaniem jest dodawanie liczb, ale zastosowanie sumatora można także wykorzystać do odejmowania liczb. Dzieje się tak ponieważ odejmowanie to także rodzaj dodawania. Sumatory realizujące funkcję odejmowania liczb nazywają się subtraktorami.
Projekt 'Arytmetyka' realizuje funkcję sumatora i subtraktora 4-bitowych liczb. Działanie jego polega na podaniu wartości sygnałów wejściowych ('wejA', 'wejB') i wyborze funkcji ('wybierz' = '0' - dodawanie, '1' - odejmowanie). Wynik zostaje prezentowany na porcie wyjściowym ('wyj'). Dodatkowy port wyjściowy 'przen' służy do określenia, czy operacja spowodowała przepełnienie tzn. dla dodawania wystąpiło przeniesienie, a dla odejmowania potrzebna jest pożyczka.
a. sumator
Sumator (dostępny w projekcie 'Arytmetyka' po podaniu wartości '0' na port 'wybierz') realizuje dodawanie, które wykonuje się według tych samych zasad, jakimi posługujemy się przy dodawaniu liczb dziesiętnych. W przypadku dodawania wielobitowych liczb dwójkowych należy uwzględnić przeniesienie z pozycji sąsiedniej mniej znaczącej od rozpatrywanej. Funkcje, które realizuje sumator wyglądają następująco:
Si = Ai xor Bi xor Ci-1
Ci = Ai.Bi + (Ai xor Bi)Ci-1
Dodajna Ai 0 0 0 0 1 1 1 1
Dodajnik Bi 0 0 1 1 0 0 1 1
Przeniesienie Ci-1 0 1 0 1 0 1 0 1
Suma Si 0 1 1 0 1 0 0 1
Przeniesienie Ci 0 0 0 1 0 1 1 1
b. subtraktor
Subtraktor (dostępny w projekcie 'Arytmetyka' po podaniu wartości '1' na port 'wybierz') realizuje odejmowanie. Tak jak w przypadku dodawania, funkcja odejmowania wielobitowych liczb dwójkowych także odbywa się na zasadach normalnego odejmowania liczb dziesiętnych i podobnie jak tam należy uwzględnić pożyczkę z pozycji mniej znaczącej od rozpatrywanej. Funkcje, które realizuje subtraktor wyglądają następująco:
Di = Ai xor Bi xor Vi-1
Vi = notAi.Bi + (notAi xor Bi)Vi-1
Odjemna Ai 0 0 0 0 1 1 1 1
Odjemnik Bi 0 0 1 1 0 0 1 1
Pożyczka Vi-1 0 1 0 1 0 1 0 1
Różnica Di 0 1 1 0 1 0 0 1
Pożyczka Vi 0 1 1 1 0 0 0 1
Kod źródłowy
entity Arytmetyka is
port ( reset, wybierz : in bit; wejA, wejB : bit_vector (3 downto 0);
wyj : out bit_vector (3 downto 0); przep : out bit );
end entity;
architecture ArchArytmetyka of Arytmetyka is
signal dane, wynik : bit_vector (7 downto 0);
signal zapas : bit;
begin
process (reset, wejA, wejB, dane, wynik)
begin
dane <= wejA & wejB;
if (reset = '0') then
case wybierz is
-- realizacja dodawania 4-bitowych liczb (sumator) ;
when '0' =>
wynik(4) <= dane(0) xor dane (4);
wynik(0) <= dane(0) and dane(4);
wynik(5) <= (not wynik(1) and (dane(1) or dane(5) or wynik(0))) or (dane(1) and dane(5) and wynik(0));
wynik(1) <= (dane(1) and dane(5)) or (dane(1) and wynik(0)) or (dane(5) and wynik(0));
wynik(6) <= (not wynik(2) and (dane(2) or dane(6) or wynik(1))) or (dane(2) and dane(6) and wynik(1));
wynik(2) <= (dane(2) and dane(6)) or (dane(2) and wynik(1)) or (dane(6) and wynik(1));
wynik(7) <= (not wynik(3) and (dane(3) or dane(7) or wynik(2))) or (dane(3) and dane(7) and wynik(2));
wynik(3) <= (dane(3) and dane(7)) or (dane(3) and wynik(2)) or (dane(7) and wynik(2));
-- realizacja odejmowania 4-bitowych liczb (subtraktor) ;
when '1' =>
if wejA < wejB then
zapas <= '1';
else
zapas <= '0';
end if;
wynik(0) <= (not dane(4) and dane(0)) or ((not dane(4) xor dane(0)) and zapas);
wynik(1) <= (not dane(5) and dane(1)) or ((not dane(5) xor dane(1)) and wynik(0));
wynik(2) <= (not dane(6) and dane(2)) or ((not dane(6) xor dane(2)) and wynik(1));
wynik(3) <= (not dane(7) and dane(3)) or ((not dane(7) xor dane(7)) and wynik(2));
wynik(4) <= dane(4) xor dane(0) xor zapas;
wynik(5) <= dane(5) xor dane(1) xor wynik(0);
wynik(6) <= dane(6) xor dane(2) xor wynik(1);
wynik(7) <= dane(7) xor dane(3) xor wynik(2);
end case;
else
wynik <= "00000000";
end if;
wyj <= wynik (7 downto 4);
przep <= wynik (3);
end process;
end architecture;
5. konwertery kodów
Konwertery kodów służą przede wszystkim do komunikacji między dwoma urządzeniami lub też urządzeniem i człowiekiem. Przedstawiony projekt 'Konwertery' jest przystosowany do pracy w różnych kodach, zatem jego zastosowanie może być bardziej wszechstronne. Projekt może pełnić funkcję trzech różnych konwerterów. Może pracować jako:
a. dekoder
b. enkoder
c. transkoder
Wybór odpowiedniego trybu pracy odbywa się przez podanie odpowiedniej wartości na port 'wybierz'. Dodatkowo w prezentacji został umieszczony przykład zastosowania traskodera, który jest możliwy do zrealizowania po podłączeniu zestawu diod LED do zaprojektowanego układu cyfrowego.
a. dekoder
Jest to konwerter, w którym kod wyjściowy jest kodem pierścieniowym, tzn. "1 z n". W projekcie 'Konwertery' jest on dostępny po podaniu wartości "00" na port 'wybierz'.
wej wyj
00000000 00000001
00000001 00000010
00000010 00000100
00000011 00001000
00000100 00010000
00000101 00100000
00000110 01000000
00000111 10000000
inny 00000000
b. enkoder
Jest to konwerter, w którym kod wejściowy jest kodem pierścieniowym, tzn. "1 z n". W projekcie 'Konwertery' jest on dostępny po podaniu wartości "01" na port 'wybierz'.
wej wyj
00000001 00000000
00000010 00000001
00000100 00000010
00001000 00000011
00010000 00000100
00100000 00000101
01000000 00000110
10000000 00000111
inny 11111111
c. transkoder
Jest to konwerter, w którym kod wejściowy i wyjściowy nie jest kodem pierścieniowym. W projekcie 'Konwertery' jest on dostępny po podaniu wartości "10" na port 'wybierz'.
wej wyj
00000000 11111100
00000001 01100000
00000010 11011010
00000011 11110010
00000100 01100110
00000101 10110110
00000110 00111110
00000111 11100000
00001000 11111110
00001001 11100110
inny 00000001
Kod źródłowy
entity Konwertery is
port ( reset : in bit; wybierz : in bit_vector(1 downto 0);
wej : in bit_vector (7 downto 0);
wyj : out bit_vector (7 downto 0) );
end entity;
architecture ArchKonwertery of Konwertery is
begin
process (reset, wej)
begin
if (reset = '0') then
case wybierz is
-- realizacja dekodera ;
when "00" =>
case wej is
when "00000000" => wyj <= "00000001";
when "00000001" => wyj <= "00000010";
when "00000010" => wyj <= "00000100";
when "00000011" => wyj <= "00001000";
when "00000100" => wyj <= "00010000";
when "00000101" => wyj <= "00100000";
when "00000110" => wyj <= "01000000";
when "00000111" => wyj <= "10000000";
when others => wyj <= "00000000";
end case;
-- realizacja enkodera ;
when "01" =>
case wej is
when "00000001" => wyj <= "00000000";
when "00000010" => wyj <= "00000001";
when "00000100" => wyj <= "00000010";
when "00001000" => wyj <= "00000011";
when "00010000" => wyj <= "00000100";
when "00100000" => wyj <= "00000101";
when "01000000" => wyj <= "00000110";
when "10000000" => wyj <= "00000111";
when others => wyj <= "11111111";
end case;
-- realizacja transkodera ;
when "10" =>
case wej is
when "00000000" => wyj <= "11111100";
when "00000001" => wyj <= "01100000";
when "00000010" => wyj <= "11011010";
when "00000011" => wyj <= "11110010";
when "00000100" => wyj <= "01100110";
when "00000101" => wyj <= "10110110";
when "00000110" => wyj <= "00111110";
when "00000111" => wyj <= "11100000";
when "00001000" => wyj <= "11111110";
when "00001001" => wyj <= "11100110";
when others => wyj <= "00000001";
end case;
-- opcja dla pozostałych wartości sygnału wybierz ;
when others => null;
end case;
else
wyj <= "00000000";
end if;
end process;
end architecture;
7. jednostka arytmetyczno-logiczna
Jednostki arytmetyczne są to uniwersalne, programowalne układy realizujące szereg różnych operacji arytmetycznych i logicznych. Zademonstrowany projekt 'ALU' realizuje szesnaście operacji arytmetycznych i szesnaście logicznych na dwu 4-bitowych słowach wejściowych ('wejA', 'wejB'), które realizowane są w zależności od sygnałów sterujących. Są to sygnały:
'rodzaj_pracy' - służy do wyboru realizowanych operacji, dla '0' - arytmetycznych, dla '1' - logicznych,
'wej_przenieś' - służy do określenia przeniesienia wejściowego (sygnał dostępny tylko dla operacji arytmetycznych),
'ster' - służy do precyzyjnego określenia jednej z 16 operacji wybranych uprzednio przy pomocy sygnałów 'rodzaj_pracy' i 'wej_przenies',
Wynik jest prezentowany na porcie 'wyj'. Warto dodać, że pojawi się on tam tylko przy braku sygnału zerującego 'reset'.
A oto jakie operacje są realizowane przez projekt 'ALU':
(dodawanie arytmetyczne jest oznaczone jako "plus", logiczne "+")
'rodzaj_pracy'
'wej_przenies'
'ster'
realizowana funkcja
0 0 0000 F = A
0 0 0001 F = A+B
0 0 0010 F = A+nieB
0 0 0011 F = minus 1 (uzup. do 2)
0 0 0100 F = A plus AnieB
0 0 0101 F = A+B plus AnieB
0 0 0110 F = A minus B minus 1
0 0 0111 F = AnieB minus 1
0 0 1000 F = A plus AB
0 0 1001 F = A plus B
0 0 1010 F = (A+nieB) plus AB
0 0 1011 F = AB minus 1
0 0 1100 F = A plus A
0 0 1101 F = (A+B) plus A
0 0 1110 F = (A+nieB) plus A
0 0 1111 F = A minus 1
0 1 0000 F = A plus 1
0 1 0001 F = A+B plus 1
0 1 0010 F = A+nieB plus 1
0 1 0011 F = zero
0 1 0100 F = A plus AnieB plus 1
0 1 0101 F = (A+B) plus AnieB plus 1
0 1 0110 F = A minus B
0 1 0111 F = AnieB
0 1 1000 F = A plus AB plus 1
0 1 1001 F = A plus B plus 1
0 1 1010 F = (A+nieB) plus AB plus 1
0 1 1011 F = AB
0 1 1100 F = A plus A plus 1
0 1 1101 F = (A+B) plus A plus 1
0 1 1110 F = (A+nieB) plus A plus 1
0 1 1111 F = A
1 X 0000 F = nieA
1 X 0001 F = nie(A+B)
1 X 0010 F = nieAB
1 X 0011 F = 0
1 X 0100 F = nie(AB)
1 X 0101 F = nieB
1 X 0110 F = AxorB
1 X 0111 F = AnieB
1 X 1000 F = nieA+B
1 X 1001 F = nie(AxorB)
1 X 1010 F = B
1 X 1011 F = AB
1 X 1100 F = 1
1 X 1101 F = A+nieB
1 X 1110 F = A+B
1 X 1111 F = A
Uwaga: W powyższej prezentacji przedstawiono tylko najważniejsze elementy funkcjonowania ALU. W projekcie przewidzianych jest jeszcze kilka dodatkowych funkcji. Są to: określenie przeniesienia wyjściowego ('wyj_przenies'), przeniesienia wyjściowego generowanego ('wyj_przenies_g'), przeniesienia wyjściowego propagowanego ('wyj_przenies_p'), a także wyjścia komparatora słów danych ('AB').
Kod źródłowy
entity ALU is
port ( reset, wej_przenies, rodzaj_pracy : in bit;
wejA, wejB, ster : in bit_vector (3 downto 0);
wyj : out bit_vector (3 downto 0);
wyj_przenies, wyj_przenies_p, wyj_przenies_g, AB : out bit
);
end entity;
architecture ArchALU of ALU is
signal temp : bit_vector (15 downto 0);
signal wynik : bit_vector (3 downto 0);
begin
process (reset, wejA, wejB, ster, wej_przenies, rodzaj_pracy, temp, wynik)
begin
if reset = '0' then
temp(0) <= (wejB(3) and ster(3) and wejA(3)) nor (wejA(3) and ster(2) and not wejB(3));
temp(1) <= not ((not wejB(3) and ster(1)) or (ster(0) and wejB(3)) or wejA(3));
temp(2) <= (wejB(2) and ster(3) and wejA(2)) nor (wejA(2) and ster(2) and not wejB(2));
temp(3) <= not ((not wejB(2) and ster(1)) or (ster(0) and wejB(2)) or wejA(2));
temp(4) <= (wejB(1) and ster(3) and wejA(1)) nor (wejA(1) and ster(2) and not wejB(1));
temp(5) <= not ((not wejB(1) and ster(1)) or (ster(0) and wejB(1)) or wejA(1));
temp(6) <= (wejB(0) and ster(3) and wejA(0)) nor (wejA(0) and ster(2) and not wejB(0));
temp(7) <= not ((not wejB(0) and ster(1)) or (ster(0) and wejB(0)) or wejA(0));
temp(8) <= not temp(0) nor temp(1);
temp(9) <= not temp(2) nor temp(3);
temp(10) <= not temp(4) nor temp(5);
temp(11) <= not temp(6) nor temp(7);
temp(12) <= not (temp(1) or (temp(0) and temp(3)) or (temp(0) and temp(2) and temp(5)) or (temp(0) and temp(2) and temp(4) and temp(7)));
temp(13) <= not ((not wej_przenies and temp(6) and temp(4) and temp(2) and not rodzaj_pracy) or (temp(4) and temp(2) and temp(7) and not rodzaj_pracy) or (temp(2) and temp(5) and not rodzaj_pracy) or (temp(3) and not rodzaj_pracy));
temp(14) <= not ((not wej_przenies and temp(6) and temp(4) and not rodzaj_pracy) or (temp(4) and temp(5) and not rodzaj_pracy) or (temp(5) and not rodzaj_pracy));
temp(15) <= (not wej_przenies and temp(6) and not rodzaj_pracy) nor (temp(7) and not rodzaj_pracy);
wyj_przenies_g <= temp(12);
wyj_przenies_p <= not (temp(0) and temp(2) and temp(4) and temp(6));
wyj_przenies <= temp(12) nand not (temp(0) and temp(2) and temp(4) and temp(6) and wej_przenies);
AB <= wynik(3) and wynik(2) and wynik(1) and wynik(0);
wynik(3) <= temp(8) xor temp(13);
wynik(2) <= temp(9) xor temp(14);
wynik(1) <= temp(10) xor temp(15);
wynik(0) <= temp(11) xor (not wej_przenies nand not rodzaj_pracy);
elsif reset = '1' then
wynik <= "0000"; wyj_przenies <= '0';
wyj_przenies_p <= '0'; wyj_przenies_g <= '0';
AB <= '0';
end if;
wyj <= wynik;
end process;
end architecture;
8. pamięć
Pamięć RAM umożliwia zapis informacji i jej odczyt bez niszczenia zapisanej uprzednio informacji. Podstawową komórką pamięci RAM stanowi przerzutnik RS sterowany sygnałem adresu ('adres') oraz sygnałem danych ('dane'). Istnieje jeszcze jeden sygnał charakterystyczny dla rejestrów pamięci. Jest to oczywiście sygnał sterujący odczytem i zapisem ('ster').
Działanie prostej pamięci RAM realizuje projekt 'Pamiec4x4', który zawiera cztery 4-bitowe rejestry równoległe. W zależności od sygnałów sterujących będą zapisywane dane do rejestrów. I tak, jeśli sygnał 'ster' będzie równy '0' nastąpi zapis, jesli '1' - odczyt. Operacje te muszą jednak być poprzedzone wyborem odpowiedniej komórki pamięci. Robi się to za pomocą sygnału 'adres'. Jeśli 'adres' będzie równy "00" to operacje będą się odbywały na rejestrze 'pamiec(0)', jeśli "01" - 'pamiec(1)', jeśli "10" - 'pamiec(2) i w końcu "11" - pamiec(3). Należy jednak pamiętać, że wszystkie operacje mogą być zrealizowane tylko w obecności sygnału zegarowego 'clk' i wyłączonym sygnale zerującym 'reset'.
Kod źródłowy
entity Pamiec4x4 is
port ( reset, clk, ster : in bit; adres : in bit_vector (1 downto 0);
dane : in bit_vector (3 downto 0);
wyj : out bit_vector (3 downto 0) );
end entity;
architecture ArchPamiec4x4 of Pamiec4x4 is
type rejestry is array (3 downto 0) of bit_vector (3 downto 0);
signal pamiec : rejestry;
begin
process (reset, clk, ster, dane)
begin
if reset = '0' and ster = '1' and clk = '1' and clk'event then
case adres is
when "00" => pamiec(0) <= dane;
when "01" => pamiec(1) <= dane;
when "10" => pamiec(2) <= dane;
when "11" => pamiec(3) <= dane;
end case;
elsif reset = '0' and ster = '0' and clk = '1' and clk'event then
case adres is
when "00" => wyj <= pamiec(0);
when "01" => wyj <= pamiec(1);
when "10" => wyj <= pamiec(2);
when "11" => wyj <= pamiec(3);
end case;
elsif reset = '1' then
for wybor in 0 to 3 loop
pamiec(wybor) <= "0000";
end loop;
wyj <= "0000";
end if;
end process;
end architecture;
Wyszukiwarka
Podobne podstrony:
Eisenhower Briefing Document, 18 November 1952
DU19941100532 konwencja Brukselska z 10 05 1952
Lutoslawski Bucolics (1952)
Dz U 2005 93 775 Konwencja (nr 102) dotycząca minimalnych norm zabezpieczenia społecznego Genewa 19
Ściągi, Historia 4, 1956 przyczyny tych wydarzeń stalinowska konstytucja obowiązująca w polsce od 19
1952
6 marca 1952 r, Antypolonizm , antysemityzm , rasizm
1952
Deportacje w ZSRR 1930-1952. Podstawy prawne i organizacyjne, AV dokumentalny, Syberia
Konstytucja PRL z 1952 - tekst wlasny, Bezpieczeństwo Narodowe, inne
Konstytucje Polskie, Konst. PRL 1952
K 1952
Konstytucja PRL z 22 lipca 1952 roku
1952
Eisenhower Briefing Document, 18 November 1952
więcej podobnych podstron