img072

238 V. Metoda reprezentacyjna
powtórnie wylosowany do próby- Gdy populacja generalna ma skończoną liczbę N elementów i stosuje się losowanie zależne próby, to estymatory mają wariancje określone innymi wzorami niż przy losowaniu niezależnym. przy czym wariancje estymatorów w losowaniu zależnym są mniejsze niż w losowaniu niezależnym. Wprawdzie gdy populacja jest bardzo duża, to różnica la nie ma praktycznego znaczenia, ale przy małych populacjach, np. rzędu setek czy mniejszych, zysk na efektywności danego estymatora przy stosowaniu losowania zależnego może być znaczny w stosunku do losowania niezależnego. Gdy szacujemy średnią wartość m w populacji generalnej* zwykły estymator tej średniej, czyli średnia z próby x, ma w przypadku schematu losowania zależnego wariancję określoną wzorem
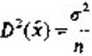
N-n ;Y-f ’
(5-1)
gdzie cń jest wariancją populacji* Arjest liczebnością populacji, a n liczebnością próby.
W metodzie reprezentacyjnej, gdzie rozważa się populacje skończone, wygodnie jest zamiast wariancji er1 w populacji, użyć wariancji S2 określonej wzorem
(5.2)
S2 = jV <r2= —
,V-I iV-Uxi
V (Xk-tn)z.
Wzór na wariancję D*(x) przyjmuje wtedy postać
u
(5-3)
Gdy populacja ma rozkład zbliżony do normalnego (ze względu nąj skończoną liczbę N elementów populacji jej rozkład nie może być dokład-j nie normalny), wtedy można 2budować przedział ufności dla średniej m| w populacji. W poniższych modelach podane będą wzory na przedział] ufności dla średniej m w populacji dla losowania zależnego oraz na trzebną liczebność próby do oszacowania średniej m z żądaną z góry kład nością. Wzory te oparte są na rozkładzie normalnym i rożki t Studenta.
Model I, Populacja generalna ma skończoną liczbę N elementów. Rozkład badanej cecby mierzalnej X w populacji jest zbliżony do normalnego o średniej m i znanej wariancji S2. Z populacji tej wylosowano zależnie próbę n elementową, na podstawie której należy1 oszacować wartość średnią m w populacji.
Przedział ufności dla średniej m wyznacza się ze wzoru
( S 1 n 5 f" n)
(5.4) P |l--<m<x^łT 'h-Ul-a,
(. v- n \ jN v n \ Aj
gdzie Sjest średnią uzyskaną z wyników n elementowej próby, a um jest wartością odczytaną z tablicy rozkładu -¥(0, I) dla ustalonego z góry współczynnika ufności 1 —a w taki sposób, by U<ua}= \ -a.
Uwaga. Ze wzoru podanego wyżej na przedział ufności można korzystać także, gdy populacja nie ma wprawdzie rozkładu zbliżonego do normalnego, ale próba jest duża.
Model IL Populacja generalna ma skończoną liczbę N elementów. Rozkład badanej cechy X w populacji jest zbliżony do normalnego o średniej z« i nieznanej wariancji Sz. Z populacji tej wylosowano zależnie próbę rt-elementową, z wyników które] obliczono średnią x oraz wariancję
**-A i
n — i i-i
Przedział ufności dla szacowanej średniej m populacji wyznacza się wtedy ze wzoru <5-5'
gd2ie ś ^-JT2, a /„jest wartością odczytaną z tablicy rozkładu t Studenta dla u - ł stopni swobody i dla ustalonego z góry współczynnika ufności 1—a w taki sposób, by P{—/ł<f<r*}= 1 — a.
Gdy próba jest duża (n> 120), wtedy w modelu tym zamiast wartości tK używamy jak w modelu I wartości ua odczytanej z tablicy rozkładu normalnego.
Wyszukiwarka
Podobne podstrony:
img073 240 V. Metoda reprezentacyjna Model UL Populacja generalna ma skończoną liczbę JV elementów.
DSCF1031 Następny rozkład z próby, to rozkład t-Studenta. Okazuje się, gdy populacja generalna ma&nb
DSCF1032 m Następny rozkład ii próby, to rozkład t-Studenta. Okazuje się, te gdy populacja generalna
statystyka (8) Xi * w Ilu studentów studiów dziennych należałoby niezależnie wylosować do próby, by
statystyka (21) Zadani^^ ) De żarówek należy niezależnie wylosować do próby, aby z dokładnością do 1
statystyka (8) Xi * w Ilu studentów studiów dziennych należałoby niezależnie wylosować do próby, by
Egzamin pisemny ze statystyki matematycznej wrzesień 2002 r. Zad 1. Ile osób należy wylosować do pró
Egzamin pisemny ze statystyki matematycznej wrzesień 2002 r. Zad 1. Ile osób należy wylosować do pró
Egzamin pisemny ze statystyki matematycznej wrzesień 2002 r. Zad 1. Ile osób należy wylosować do pró
Egzamin pisemny ze statystyki matematycznej wrzesień 2002 r. Zad 1. Ile osób należy wylosować do pró
43927 statystyka (28) J Ilu studentów studiów dziennych należałoby niezależnie wylosować do próby, b
statystyka (8) Ilu studentów studiów dziennych należałoby niezależnie wylosować do próby, by z dopus
1id&492 Zadanie 5 WSiOd kobiet i ius*2czyzn wylosowanych do próby zostały obliczone odsetki osób otr
WYZNACZANIE BEZWZGLĘDNEGO WSPÓŁCZYNNIKA LEPKOŚCI CIECZY METODĄ STOKESA. tarcia, aż do momentu, gdy s
Rozkład średniej arytmetycznej z próby *=*P‘ . Cecha X w populacji generalnej ma rozkład N(p.o). o z
MINIMALNA LICZEBNOŚĆ PRÓBY 4. Gdy szacujemy wskaźnik struktury niezbędną liczbę elementów n w próbie
więcej podobnych podstron