9157474422
zagrożeniami z Internetu. Dlatego te zastosowania będą poruszone i rozważone w dalszej części pracy.
2. Inteligentna przeglądarka
Internet stanowi niemalże nieograniczone źródło wiedzy. Niestety informacje zawarte w nim nie są w zbyt dogodnej dla komputera postaci. Co prawda może on bez problemu odnaleźć niektóre wyrażenia, nawet rozproszone w całym dokumencie, jednak np. wyznaczenie najkrótszej trasy podróży za pomocą dowolnych środków transportu, wyliczenie przy tym kosztów i potrzebnego czasu na pokonanie dystansu, bez specjalnego oprogramowania, jest dla niego zadaniem nie do rozwiązania. Co gorsza nie wszystkie materiały dostępne w Internecie są przydatne do użycia. Niektóre z nich są fałszywe i mogą jedynie wprowadzić w błąd, a cześć może być po prostu przestarzała lub kompletnie nie związana z szukanym tematem.
Firma Cycorp dostrzegła ogromne możliwości w rozwoju Internetu, który był szansą na przeskoczenie głównego problemu CYC: ilości wiedzy i sposobu jej pozyskiwania. Do tej pory bowiem baza wiedzy była uzupełniania jedynie przez ludzi, co oczywiście jest procesem czasochłonnym i bardzo nieefektywnym. Gdyby jednak system nauczył się zbierać dane z stron www, wówczas w błyskawicznym tempie można by zrobić duży postęp.
Ponieważ już w tamtych czasach Google zaczął dominować w indeksowaniu stron internetowych, projekt został oparty na ich interfejsie. Głównymi założeniami było wykorzystać posiadaną już wiedzę w KB do pozyskiwania nowych informacji z sieci, wprowadzanie nowych danych w odpowiedniej formie, aby później mogły być one zweryfikowane przez Google i pracownika, a w końcu wykorzystane przez użytkownika. Proces nauki systemu przebiegać miał następująco:
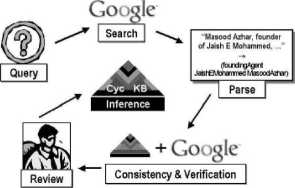
rys. 2.1: Schemat pozyskiwania wiedzy przez system CYC
(rysunek z artykułu 1, patrz literatura)
4
Wyszukiwarka
Podobne podstrony:
Wprowadzenie do MatLab (28) Typy złożono będą omówione w dalszej części pracy. Formowanie zmiennych
194 X. Zastosowania rachunku całkowego Rozważania te odnoszą się w pełni do wszystkich trzech
PTDC0091 288 kasińskiego musiałoby się pojawić, załamując napięcie, niwecząc końcowy efekt. Dlatego
Jakość - Rozwój - Współpraca Te trzy stówa wyznaczały rozważania uczestników seminarium
IMGr96 Ćyłwruzaleźnlenl® • przeciwdziałanie uzeloinlonlom od komputera I Internet Wszystkie te trzy
PTDC0091 288 kasińskiego musiałoby się pojawić, załamując napięcie, niwecząc końcowy efekt. Dlatego
ii Niech te święta będą jak zwykle NIEZWYKŁE. Bądźmy mniej smutni, bardziej
DLA WSZYSTKICH NASZYCH STUDENTÓWWesołychSioiąt! Niech te święta będą dla Was radosne. Dobrego czasu
8. 2/60 ^Kancelaria Scimu_ Wszystkich, którzy dla dobra Trzeciej Rzeczypospolitej tę Konstytucje będ
^Kancelaria Scimu_g, 2/2 Wszystkich, którzy dla dobra Trzeciej Rzeczypospolitej tę Konstytucję będą
ScanImage86 (2) Maksymalna ochr< kradzieżą danych osobowi i zagrożeniami internatowi fcimUAu
ZAGROŻENIAW INTERNECIE rozwój poznawczy, emocjonalny i społeczny • Wpływają pozytywnie
więcej podobnych podstron