5441337054
ASSOCIATION METHODS IN DATA CLEANING
ŁUKASZ CISZAK: APPLICATION OF CLUSTERING.
corrcction is conccmed. dala cleaning Solutions are only as good as the reference data they use. Reference data is a set of yalues which are considcrcd to be valid for a givcn attribute. e.g. list of States, countries.car modcls. etc.
The aim of rcscarch led by the author of this article was to examine if data mining methods may be used to solve tasks mentioned in the above paragraph. As data inining is the process of discovcring previously unknown knowledge from data. it can be used to discover data validation niles and reference data directly from the data set. Table I con-tains possible application of data mining methods within the area of data cleaning..
The main focus of this article is attribute correction. Other data cleaning tasks are subject to fuither research. This article presents two applications of data mining techniques in the area of attribute correction: conte.\t-independent attribute correction implemented using clustering tecltniques and con-te\t-dependent attribute correction using associations. The next sections of this cliapter present two algorithms created by the author tliat are supposed to exainine the possibility of application of data mining tcchniqucs in data cleaning. Both algorithms are intcndcd for use in the application of text-based address and personnel data cleaning.
A. Context independent attribute correction
As mentioned in the prcvious section. attribute correction Solutions require reference data in order to provide satisfying results. The algorithm described in tliis section is used to ex-amine if a data set may be a source of reference data tliat could be used to identify incorrect entries and enable to correct them. The algorithm aims at correcting text attributes in address and personal data.
Context-independent attribute correction means that all the record attributes are examined and cleaned in isolation without regard to values of other attributes of a given record.
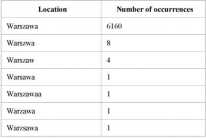
The key idea of the algorithm is based on an observation tliat in most data sets there is a certain number of values hav-ing a large number of occurrences within the data set and a very large number of attributes with a veiy Iow number of occurrences. Therefore, the most-representative values may be the source of reference data. The values with Iow number of occurrences are noise or misspelled instances of the reference data. Table D shows an excerpt from the distribution with values sortcd alphabctically and thcn dcsccnding ac-cording to the number of occurrences. The attribute being examined comes from the sample data set used in this experi-mcnt and is derived from an Internet survey. As it may be noticed. there are many (6160) rccords that have the value "Warszawa'' and veiy few that have a value tliat closely re-sembles “Warszawa”. Therefore, the value “Warszawa” is most likely the correct value of the attribute and should entcr the reference data set while the remaining values are misspelled and should be corrected to “Warszawa".
The aim of the algorithm is to create a reference data set and a set of substitution niles that could be used to correct misspelled values.
Table II.
Location attribute distribution
1) Algorithm definition
The algorithm utilizes two data mining tcchniqucs: clustering and classification using the “k-nearest neiglibours" method.
The algorithm lias two parameters: distance tlireshold -distThresh being the minimum distance between two values allowing them to be maiked as similar, and occurrence rela-tion - occRel, used to determine whether both compared val-ues belong to the reference data set. This parametcr was in-troduced because it is possible that there are two values tliat may seem similar terms of the distance but that may repre-sent two different objects of the real world that should create separate entries in the reference data set.
To measure the distance between two values a modified Levenshtein distance [5] was used. Levenshtein distance for
Association rulcs
Data standardization/attrihutc co
Duplicatc mat. Yalidation rulcs g.
Wyszukiwarka
Podobne podstrony:
ASSOCIATION METHODS IN DATA CLEANING ŁUKASZ CISZAK: APPLICATION OF CLUSTERING. [4]
ASSOCIATION METHODS IN DATA CLEANING ŁUKASZ CISZAK: APPLICATION OF
114 MAŁGORZATA GRUCHOŁA CULTURE IN SOCIOLOGICAL DEPICTION Summary The goal of the publication is to
The role of accounting in an anti-crisis prevention in smali businesses Summary: The purpose of this
00215 ?0e621dbf006c49e21a7837633685a1 217 Applications of the EWMA This paper (1) describes a metho
00219 a6d333666646e915e39fbc117115f5 221 Applications of the EWMA The Control Algorithm In this al
00233 ?994b263585678f9e7929f08dc27281 235 Applications of the EWMA Closed-loop sigma (ar) is calcul
case, Quantitative Methods in Economics, Vydavatelstvo EKONOM, Bratislava, 141-160.Michalski Grzegor
Granty Europejskie FP5 Research Training NetWork Projectdama nr csDevelopment and Application of Met
The Nobel Prize in Chemistry 2005"for the development of the metathesis method in organie
This provides space for the application of AHP method that offers the possibility of pairwise compar
Katarzyna Maruszewska The Application of Correspondence Analysis in Research on Determinants of IWig
497 on SWB. The analysis was conducted with the application of an ordered logit model. The dala used
E L LE R I Prolessor P 4 H ł O H S Medium ais dessen Schiilerin ahmt seine Methoden in der Voraussag
2009: Third International Conference in Combinatorics, Graph Theory and Applications, 23-27 marzec 2
APPLICATION OF FLAYOUR COMPOUNDS IN FOOD Lecture: dr Aneta Jastrzębska Seminar: dr Aneta Jastrzębska
więcej podobnych podstron