
Transmisja danych
dr hab. inż. Jerzy Kisilewicz, prof.
Katedra Systemów i Sieci Komputerowych
www.kssk.pwr.wroc.pl
C-3, pok. 107
TD1-1 / 22
Konsultacje:
•Wt. godz. 13-15
•Sr. godz. 15-17
Wymagania
1. Zdanie egzaminu testowego,
2. Zaliczenie i projektu,
1. Punkty z testu zaliczeniowego,
2. Punkty z projektu,
3. Punkty za obecności na wykładach.
Co wpływa na ocenę
1. Ocenę określa lokata na liście
uszeregowanej według sumy punktów. Progi
odcinają kolejno 10%-5, 25%-4,5, 30%-4,
25%-3,5 i 10%-3 z osób, które zaliczyły
przedmiot.
Uwagi
TD1-2 / 22
Literatura
1. Simmonds A., Wprowadzenie do transmisji
danych, Warszawa, WKŁ, 1999
2. Kula S., Systemy teletransmisyjne,
Warszawa, WKŁ, 2004
3. Rutkowski J., Theory of information and
coding,
Katowice, Wyd. Uniwersytetu
Śląskiego, 2006
4. Haykin S., Systemy telekomunikacyjne,
Warszawa, WKŁ, 2004
5. Forouzan B.A., Data communications and
networking, New York, McGraw-Hill, 2007
6. Piecha J., Transmisja danych i sieci
komputerowe, Katowice, Wyd.
Uniwersytetu Śląskiego, 2006
Literatura pomocnicza
TD1-3 / 22

Tematyka wykładów
1. Informacja i jej ilość.
2. Kanały i ich przepustowość.
3. Dyskretyzacja. Interpolacja.
4. Kodowanie wiadomości.
5. Detekcja i korekcja błędów. Podstawy
modulacji.
6. Modulacje dyskretne i widma sygnałów.
7. Łącza transmisyjne. Skrętki i światłowody
8. Łącza radiowe. Transmitancja kanału.
9. Kanał binarny i jego parametry. Styki.
10.Styki szeregowe i ich okablowanie.
11.Modemy.
12.Zwielokrotnianie kanałów.
13.Okablowanie strukturalne.
14.Sterowanie modemami.
15.Zagadnienia wybrane. Test zaliczeniowy.
TD1-4 / 22
E-Portal KSSK
TD1-5 / 22
Materiały dydaktyczne
http://www.kssk.pwr.wroc.pl/
Dla studentów
e-KSSK
Transmisja danych -
wykład
1. Zalogować się w e-Portalu KSSK (system
Moodle).
2. Zapisać się na kurs „Transmisja danych -
wykład”, hasło:
ISK3W#JK

Wykład 1
Miara informacji
1. Wstęp
2. Entropia dyskretnej zmiennej
losowej
3. Właściwości entropii
4. Ilość informacji
5. Źródła z pamięcią
6. Źródła rozszerzone
TD1-6 / 22

Wstęp
Pojęcie ilości informacji
Entropia
TD1-7 / 22
Informacja
TD1-8 /
22
Komunikat o zajściu zdarzenia niesie tym więcej informacji,
im więcej zmienia nasz stan niewiedzy.
Przykłady:
Jutro też będzie dzień.
Zero informacji – jest
pewne, że jutro będzie
dzień
Pies pogryzł chłopca.
Mało informacji –
zdarzenie
prawdopodobne
Chłopiec pogryzł psa.
Dużo informacji –
zdarzenie
nieoczekiwane
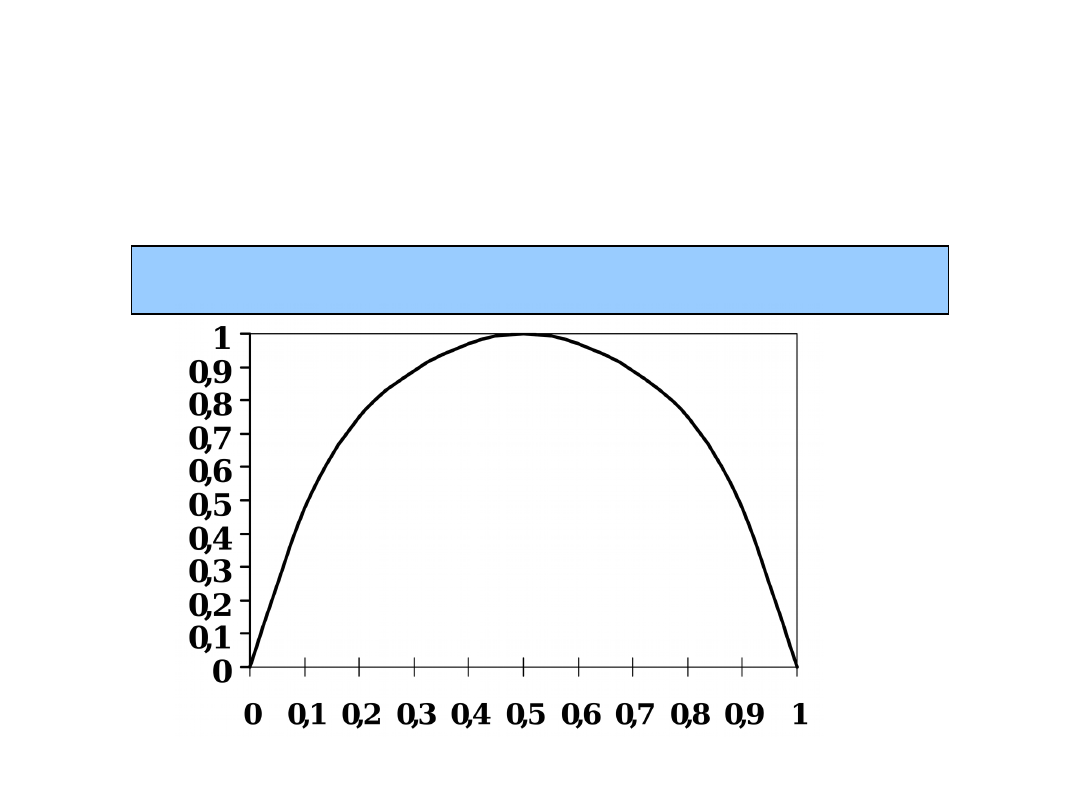
Informacja a
prawdopodobieńst
wo
p
1
log
informacji
Ilość
TD1-9 / 22
•Komunikat, że zaszło zdarzenie pewne nie niesie informacji.
•Im mniejsze prawdopodobieństwo, tym więcej informacji.
p=1 Ilość informacji = 0
p0 Ilość informacji
Entropia dyskretnej zmiennej
losowej
TD1-10 / 22
X – dyskretna zmienna losowa
x
i
– zdarzenie, X przyjmuje wartość x
i
p
i
– prawdopodobieństwo zdarzenia x
i
i = 1, 2, ..., q (q – liczba stanów
zmiennej X)
H(X) – entropia zmiennej losowej
q
i
i
i
q
i
i
i
p
p
p
p
X
H
1
1
log
1
log
)
(
Podstawa
logarytmu
2
e
10
Jednostka
entropii
bit
nat hartle
y
Entropia - interpretacja
Entropia dyskretnej zmiennej losowej
X to:
• wartość oczekiwana ilości
informacji, którą niesie wiadomość o
tym, jaki stan przyjęła zmienna losowa
X,
• miara niewiedzy o tym, jaki stan
przyjmie zmienna losowa X.
TD1-11 / 22
Zmienna losowa
dwustanowa
q = 2
P(X
=
x
1
)
=
p, P(X
=
x
2
)
=
1
–
p
H(
X
)
=
–
p
log( p)
–
(1
–
p)log(1
–
p)
p
H
TD1-12 / 22
Właściwości entropii (1)
0 H(X
)
log q
0
log
lim
0
p
p
p
H(X) = 0 gdy p
1
=1,
p
2
=p
3
=...=p
q
=0
zatem H(X) 0
max H(X) = log q gdy
p
1
=p
2
=...=p
q
=1/q
bo dla F(X) = H(X) + (1 – p
1
– p
2
–... – p
q
)
mamy
q
const
r
p
c
p
p
X
F
c
i
i
i
1
0
log
)
(
Dowód:
Gdy 0 < p 1 to –p
log(p) 0
TD1-13 / 22
e
c log

Właściwości entropii (2)
Niech x
i
oraz y
i
(i=1, 2, ...q) będą prawdopodobień-
stwami kolejno zmiennych losowych X oraz Y
oraz niech
q
i
i
i
q
i
i
i
y
x
Y
X
F
x
x
X
H
1
1
1
log
)
,
(
1
log
)
(
Zachodzi:
H(X) F( X, Y )
oraz
H(X) = F( X, X )
TD1-14 / 22
Właściwości entropii (2) -
dowód
1
ln
i
i
i
i
x
y
x
y
1
2
ln
1
)
,
(
)
(
1
i
i
q
i
i
x
y
x
Y
X
F
X
H
i
i
q
i
i
i
i
q
i
i
i
i
q
i
i
x
y
x
x
y
x
y
x
x
Y
X
F
X
H
ln
2
ln
1
log
1
log
1
log
)
,
(
)
(
1
1
1
1
1
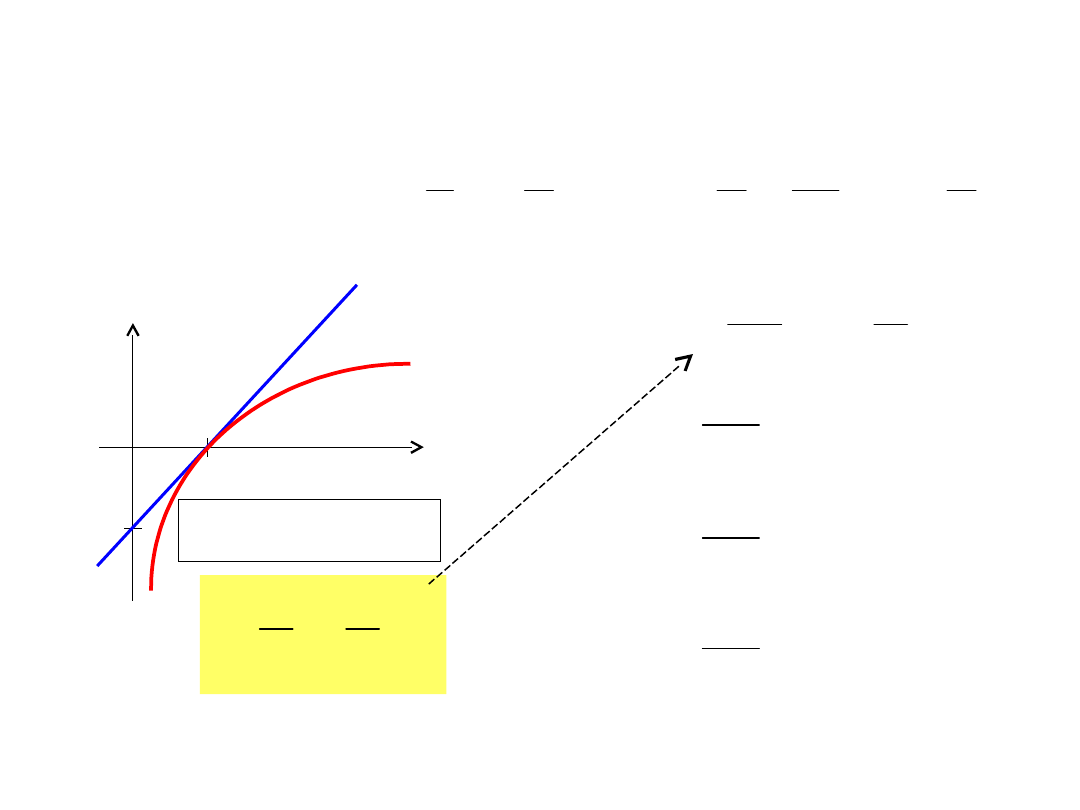
y=x
-1
y
x
y=ln x
ln x
x –1
TD1-15 / 22
0
1
1
2
ln
1
2
ln
1
2
ln
1
1
1
1
q
i
i
q
i
i
q
i
i
i
x
y
x
y
Ilość informacji
I(A) = H(X
) – H(X
|
A)
Zdarzenie A niesie tyle informacji o zmiennej losowej X,
o ile zmienia naszą niewiedzę o tej zmiennej, czyli
o ile zmienia entropię.
Zatem
TD1-16 / 22
H(X|A) – entropia zmiennej X po zajściu zdarzenia A

Ilość informacji
H(X
) = log 6 = 1 + log 3 2,58496 bita
H(X
|
A) =
I(A) = H(X ) – H(X | A) 2,58496 – 2,35846 =
0,2265 bita
Przykład
Zdarzenie A mówi, że kostka do gry jest
fałszywa, bo 2, 3 lub
4 oczka wypadają po 2 razy częściej niż 1
oczko, 5 oczek
wypada 3 razy częściej, a 6 oczek 6 razy
częściej niż 1 oczko.
Niech zdarzenie x
i
polega na wyrzuceniu
liczby i oczek.
Prawdopodobieństwa zdarzeń wynoszą:
•dla zwykłej kostki
p(x
i
) = {
1
/
6
,
1
/
6
,
1
/
6
,
1
/
6
,
1
/
6
,
1
/
6
}
•dla kostki fałszywej p(x
i
|A) = {
1
/
16
,
2
/
16
,
2
/
16
,
2
/
16
,
3
/
16
,
6
/
16
}
TD1-17 / 22
3
log
16
9
4
1
3
6
16
log
16
6
3
16
log
16
3
2
16
log
16
2
3
1
16
log
16
1

Źródła z pamięcią
H(X
) =
H(X |x
j1
, …
x
jn
)
x
j1
, … x
jn
TD1-18 / 22
Entropia źródła Markova n-tego rzędu
p(x
i
|x
j1
, x
j2
, … x
jn
)
H(X |x
j1
, … x
jn
) = – p(x
i
|x
j1
, … x
jn
) log p(x
i
|
x
j1
, … x
jn
)
q
i 1
E

Źródła stowarzyszone
q
i
i
i
x
p
x
p
X
H
1
~
log
~
~
jn
j
j
i
x
x
x
i
x
x
x
x
p
x
p
E
jn
j
j
,...
,
|
~
2
1
,...
,
2
1
TD1-19 / 22
Źródło stowarzyszone ze źródłem Markova n-
tego rzędu
to źródło bezpamięciowe o
prawdopodobieństwach
X
H
X
H
~

Przykład
TD1-20 / 22
Oblicz entropię źródła Markova pierwszego
rzędu, które po bicie 0 generuje bit 1 z
prawdopodobieństwem p, a po bicie 1 generuje
bit 0 z prawdopodobieństwem q.
Oblicz entropię źródła stowarzyszonego.
0
p(0|0) = 1– p
1
p(1|1) = 1– q
p(1|0) = p
p(0|1) = q
q
p
p
p
q
p
q
p
1
,
0
H(X | 0) = – p log p – (1– p)log(1– p)
H(X | 1) = – q log q – (1– q)log(1– q)
H(X ) = p(0) H(X | 0) + p(1) H(X | 1)
H(X ) = – p(0) log p(0) – p(1)log p(1)
~
Dla: p = 0,5 oraz q = 0,25
H(X | 0) = 1
H(X | 1) = 0,811
p(0) = 0,333
p(1) = 0,667
H(X ) = 0,874
H(X ) = 0,918
~

Rozszerzenie źródła
TD1-21 / 22
bezpamięciowego
Ciąg n symboli źródła podstawowego X traktujemy jako
pojedynczy symbol źródła rozszerzonego X
n
σ
i
= x
i1
, x
i2
, … x
in
p(σ
i
) = p(x
i1
) p(x
i2
) … p(x
in
)
H(X
n
) = nH(X )

Entropia źródła
rozszerzonego
TD1-22 / 22
X
nH
X
H
X
H
X
H
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
p
X
H
q
in
in
in
q
i
i
i
q
i
i
i
q
in
in
in
q
i
i
q
i
i
q
in
in
i
q
i
i
q
i
i
q
in
in
q
i
i
q
i
i
i
in
i
i
q
in
in
i
i
q
i
q
i
in
i
i
q
in
in
i
i
q
i
q
i
q
i
i
i
n
n
...
log
...
log
log
log
...
...
...
log
...
log
log
...
log
log
...
...
...
log
...
...
log
1
1
2
2
2
1
1
1
1
1
1
2
2
1
1
1
1
2
1
2
2
1
1
1
1
1
2
2
1
1
1
1
2
1
1
2
1
1
2
1
1
2
1
1
2
1
1
2
1
1
1
Oznaczając p
i
= p(x
i
) mamy
1
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
Wyszukiwarka
Podobne podstrony:
Ubytki,niepr,poch poł(16 01 2008)
01 E CELE PODSTAWYid 3061 ppt
01 Podstawy i technika
01 Pomoc i wsparcie rodziny patologicznej polski system pomocy ofiarom przemocy w rodzinieid 2637 p
zapotrzebowanie ustroju na skladniki odzywcze 12 01 2009 kurs dla pielegniarek (2)
01 Badania neurologicz 1id 2599 ppt
01 AiPP Wstep
ANALIZA 01
01 WPROWADZENIA
TD 09
TD 05
01 piątek
choroby trzustki i watroby 2008 2009 (01 12 2008)
syst tr 1 (2)TM 01 03)13
Analiza 01
więcej podobnych podstron