
WOJSKOWA AKADEMIA TECHNICZNA
IM. JAROSŁAWA DĄBROWSKIEGO
W WARSZAWIE
HURTOWNIE DANYCH
Sprawozdanie
Temat: Rentowność Klienta
Prowadzący:
mgr inż. Andrzej Rozmus
Wykonawcy:
Błażej Bubrowiecki
Łukasz Giro
Mirosław Klimek
Kamil Krajewski

Grupa I8C1S1
1) Uzasadnienie biznesowe dla realizowanego projektu.
Celem zadania laboratoryjnego było stworzenie hurtowni danych, która
przeprowadzi analizę rentowności klienta. Dzięki tej analizie użytkownik hurtowni będzie
mógł w prosty, szybki i przyjemny sposób przejrzed dane na temat poszczególnego klienta.
Zestawienia będą wyglądały następująco: ile towarów za jaką cenę, w jakim czasie zakupił i
lokalizacje poszczególnych nabywców produktów. Posiadając taką wiedzę będą mogły zostad
podjęte odpowiednie działania promocyjne względem odbiorców (np. promocje, rabaty).
Celem wdrożenia hurtowni danych jest umożliwienie analizy rentowności klienta.
Brak takiej analizy powoduje straty dla przedsiębiorstwa(np. ulotki, „książeczki reklamowe”).
Znając taki profil klienta można dopasowad produkty do jego wymagao co pozwoli na
zwiększenie zysków.
Korzyści wynikające z realizacji projektu to:
- zwiększenie wglądu w rynek
- stworzenie społeczności wokół usług
- usprawnienie pracy analityków
- ocenę strategii rynkowej
- podniesienie jakości świadczonych usług
- utrzymanie dobrych relacji z poszczególnymi grupami klientów
- zdobycie nowych rynków zbytu
- zwiększenie sprzedaży

2) Koncepcja hurtowni wspomagającej działalnośd
przedsiębiorstwa w odniesieniu
do postawionego problemu.
Dzięki hurtowniom danych istnieje możliwośd śledzenia najistotniejszych punktów
organizacji. Hurtownia jest centralnie zarządzaną i zintegrowaną bazą danych, zawierającą
dane organizacji. Użytkownicy mogą mied bezpośredni dostęp do źródła analiz zawartych w
hurtowni danych na której się opiera bazę. Hurtownie można „odświeżyd”(wprowadzid
nowe, zmodyfikowad lub usunąd dane) w dowolnej chwili bez odłączania systemów
operacyjnych lub produkcyjnych firmy. Taka możliwośd istnieje dzięki zaimplementowaniu
procesu ETL. Zapewniona jest integrację danych z heterogenicznych źródeł. Hurtownia
przechowuje pełną historię zmian, które nie są usuwane tylko nadpisywane. Zaprojektowana
hurtownia danych jest podstawą systemu wspomagania decyzji. Struktura aplikacji, która
generuje dane nie wpływa na strukturę przechowywanych danych. Hurtownia danych jest
specjalnie tworzoną dla danej organizacji bazą danych posiadającą historyczne, szczegółowe,
stałe i spójne dane, które mogą zostad poddane analizie w zależności od czasu.

3) Opis środowiska wytwórczego, w którym realizowany jest
projekt.
a) System operacyjny: Windows XP.
b) Baza danych: Oracle Database 11g Release 2
c) Klient: Oracle Warehouse Builder 11g Release 2
Środowisko projektowe
Podstawowym składnikiem systemu OWB jest w pełni skalowalne
repozytorium metadanych. Repozytorium jest to zestaw tabel umieszczonych w bazie
danych Oracle, do których dostęp jest możliwy dzięki graficznym aplikacjom
klienckim.
Przepływ danych pochodzących z różnych systemów źródłowych zasilających
repozytorium OWB zapewniony jest dzięki zastosowaniu tzw. integrantów. Są one
komponentami przeznaczonymi do pobierania metadanych i danych z określonych
źródeł. W trakcie zachodzących zmiany źródeł, OWB zapewnia aktualizację
metadanych zgromadzonych w repozytorium. Do sprawdzenia jakości i kompletności
metadanych Oracle zapewnia narzędzie do sprawdzenia danych (valiadatory). Chroni
on przed błędami i umożliwia uszczegółowienia błędu. Elementem środowiska
umożliwiającego tworzenie raportów, jest Impact Analysis oprogramowanie
pozwalające badad wpływ zmian w systemie przed ich propagacją.
Środowisko wykonawcze
Posiadając już logiczną strukturę mechanizmów ETL zostaje ona przeniesiona
na fizyczne środowisko bazy danych. Do operowania danymi podczas procesu
gromadzenia danych z systemów źródłowych OWB posługuje się instrukcjami języka
SQL DDL. Kod umieszczony jest w pliku tekstowym lub w bazie danych. Podczas
wykonywania funkcji ETL dane źródłowe są przesyłane do docelowej bazy danych.
Procedury monitorujące zapewniają proces raportowania wczytywanych danych.
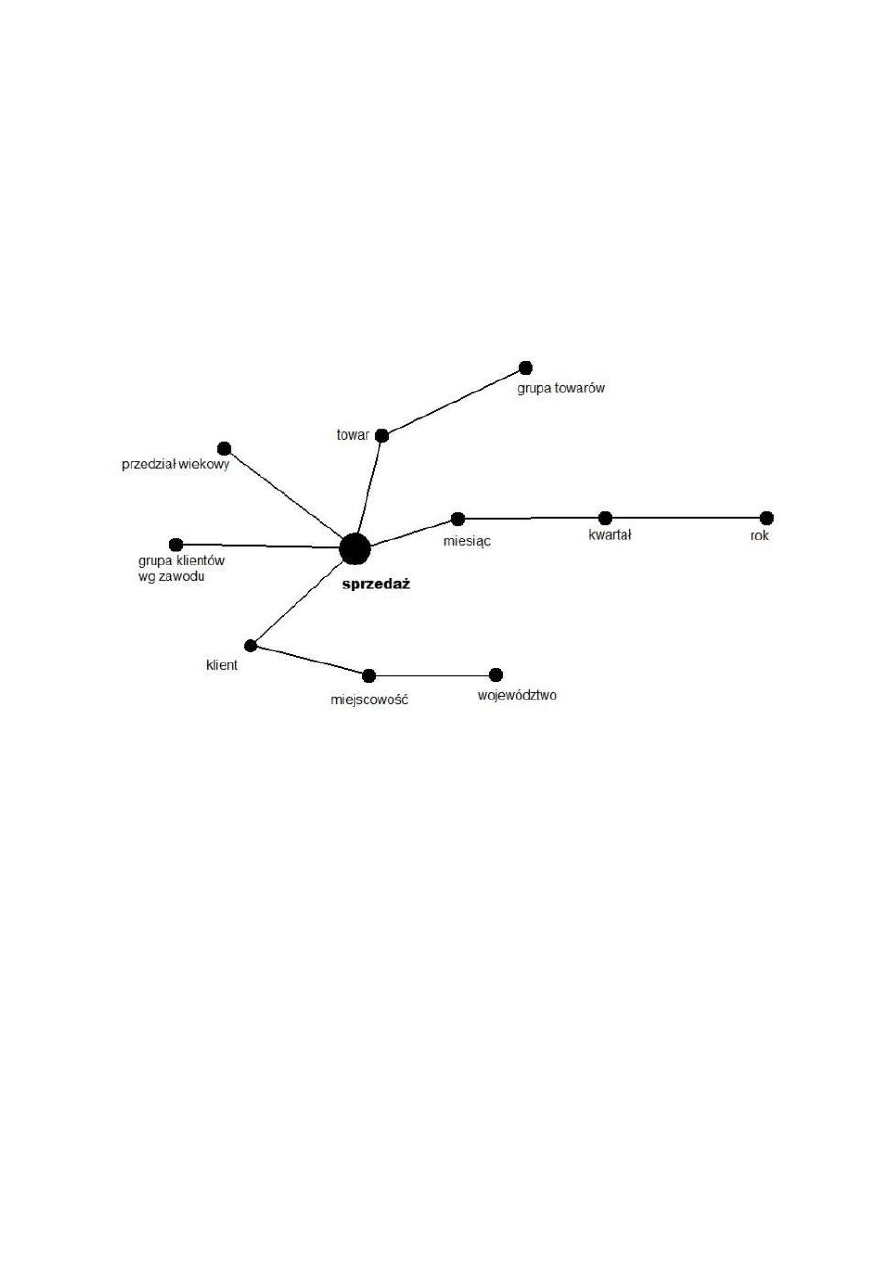
4) Model punktowy wraz z opisem.
Rys.1. Model punktowy.
Fakty:
- sprzedaż - zdarzenie, o którym informacja jest przechowywana w hurtowni danych,
podlega analizie.
Wymiary – atrybuty opisujące kontekst wystąpienia faktu:
1. Klient
Poziom szczegółowości:
a) Klient
b) Miejscowośd

c) Województwo
2. Grupa klientów według zawodów
3. Przedział wiekowy
4. Towar
Poziom szczegółowości:
a) Towar
b) Grupa towarów
5. Czas
Poziom szczegółowości:
a) Miesiąc
b) Kwartał
c) Rok
5) Architektura hurtowni danych wraz z uzasadnieniem wyboru.
Tworząc projekt hurtowni danych postanowiliśmy zbudowad ją w oparciu o technologię
ROLAP, czyli relacyjnych baz danych. Hurtownie danych zaimplementowaliśmy w postaci
tabel wykorzystując do tego strukturę gwiazdy.
Wybraliśmy technologię ROLAP ze względu na możliwośd łatwiejszej aktualizacji
danych, czy też możliwości wprowadzania zaistniałych poprawek. Istotną cechą
przemawiającą za wyborem był także czas ładowania danych do hurtowni, który w
przypadku ROLAP jest prawie 2,5 razy krótszy niż w przypadku technologii MOLAP. Ponadto
ROLAP charakteryzuje się krótszym czasem odpowiedzi niż MOLAP.
Cechą charakterystyczną struktury gwiazdy jest jedna duża tabela faktów i pewna
liczba dużo mniejszych tabel wymiarów. Każda tabela wymiarów powiązana jest z tabelą
faktu za pomocą związku klucz główny – klucz obcy. Struktura gwiazdy charakteryzuje się
tym, że:

- jest modelem łatwo rozszerzalnym,
- poprawia wydajnośd hurtowni danych,
- wspiera wielowymiarową analizę,
- poszerza możliwośd wyboru narzędzi dostępu do danych
6) Charakterystyka źródła (źródeł) danych.
Rys.2. Model danych zaimportowany z źródłowej bazy danych.
Klient
Id_klienta
Pesel
Imie
Nazwisko
Miejscowosc
Ulica
Numer_domu
Kod_pocztowy
Data_urodzenia
integer
character
character
character
char
character
integer
character
date
<pk>
Zamowienie
Id_zamowienia
Data_zamowienia
Id_klienta
Id_pracownika
Data_realizacji
integer
date
integer
integer
date
<pk>
<fk1>
<fk2>
Pracownik
Id_pracownika
Pesel
Imie
Nazwisko
Miejscowosc
Ulica
Numer_domu
Kod_pocztowy
Data_urodzenia
Uposażenie
integer
character
character
character
character
character
integer
character
date
money
<pk>
Faktura
Id_faktury
Kod_platnosci
Data_wystawienia
Data_zaplaty
Kod_sprzedawcy
Id_zamowienia
Id_kanalu
Id_towaru
integer
integer
date
date
integer
integer
integer
integer
<pk>
<fk1>
<fk2>
<fk3>
Kanal_sprzedazy
Id_kanalu
Nazwa
integer
character
<pk>
Pozycja_zamowienia
Id_zamowienia
Id_towaru
Liczba
integer
integer
integer
<pk,fk1>
<fk2>
Pozycja_faktury
Id_zamowienia
Id_towaru
Id_faktury
Cena_sprzedazy
Liczba
integer
integer
integer
money
integer
<pk,fk2>
<pk,fk3>
<fk1>
Dostawca
Id_dostawcy
Nazwa
Miejscowosc
Ulica
Nmer_lokalu
Kod_pocztowy
NIP
integer
character
character
character
integer
character
character
<pk>
Towar
Id_towaru
Nazwa
Wymiary
Liczba
integer
character
character
integer
<pk>
Ilosc_dostawy
Id_dostawcy
Id_towaru
Id_dostawy
Id_pracownika
Liczba
integer
integer
integer
integer
integer
<fk3>
<fk2>
<fk4>
<fk1>
Dostawa
Id_dostawy
Data_dostawy
integer
date
<pk>

Informacje o zamówieniach, klientach, pracownikach, dostawcach i towarach
pozyskujemy ze źródłowej bazy danych. Nasza hurtownia wykorzystuje tabele:
- Klient,
- Zamówienie,
- Towar,
- Pozycja_faktury,
- Pozycja_zamówienia
7) Charakterystyka procesu ETL.
Głównym zadaniem procesu ETL jest integracja danych źródłowych, a tym
samym zmiana źródłowych danych w wartościową informację. Proces
integracji, jak sama nazwa wskazuje, składa się z trzech etapów: ekstrakcji,
transformacji i ładowania danych
a) Ekstrakcja danych pozwala na uzyskanie dostępu do danych,
przechowywanych w systemach informatycznych organizacji, w celu ich
ładowania do hurtowni danych,
b) Transformacja danych polega na sprowadzeniu danych do wspólnego
formatu,
obliczeniu
wszystkich
potrzebnych
agregatów,
oraz
zidentyfikowaniu danych brakujących lub powtarzających się,
c) Ładowanie danych jest procesem, który zapewnia poprawne zasilanie
systemu docelowego zintegrowanymi i oczyszczonymi danymi.
Opracowanie projektu procesu ETL:
1. Odwzorowanie modelu logicznego źródeł danych na model logiczny HD.
2. Model struktury tymczasowych datastage.
3. Specyfikacja niestandardowych algorytmów transformacji danych.
4. Specyfikacja procedur obsługi błędnych danych
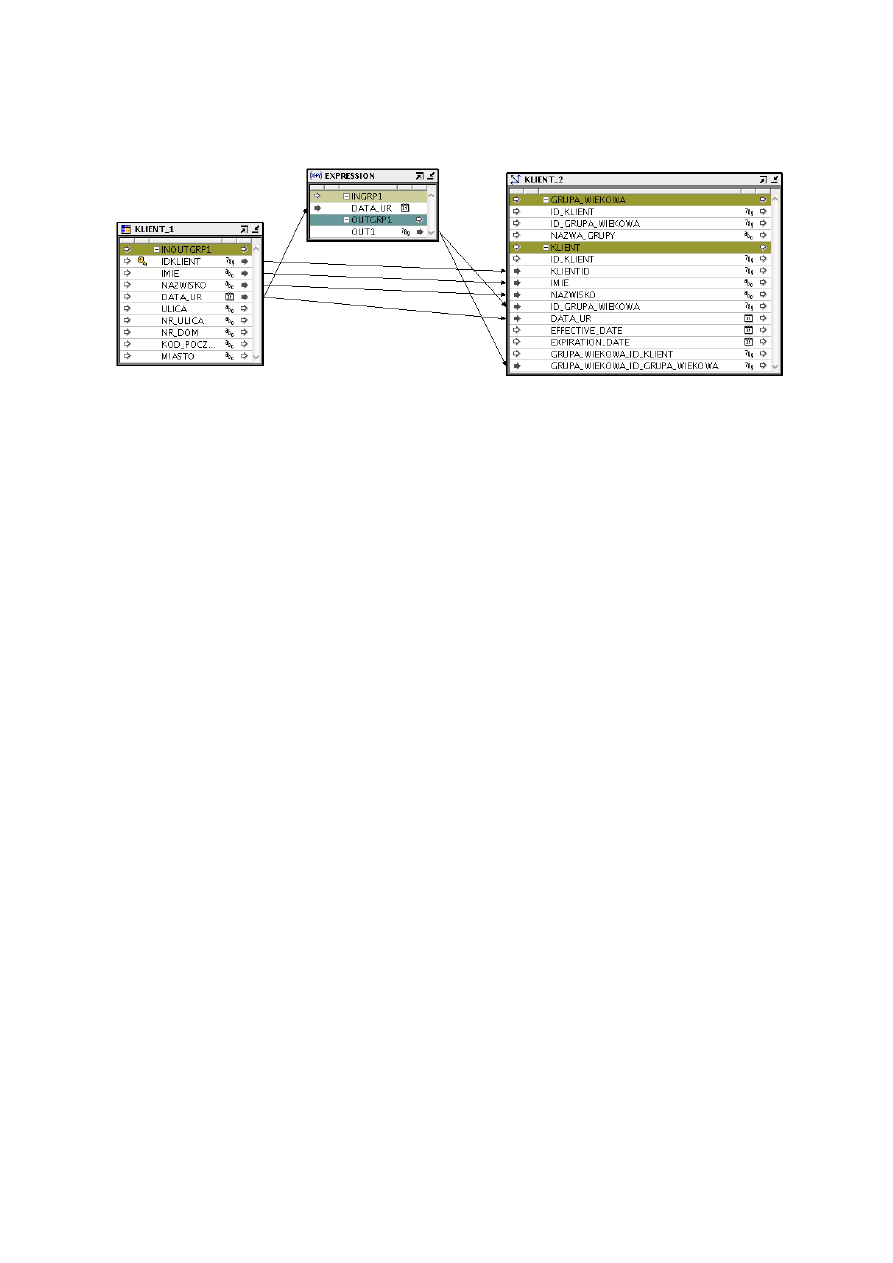
KLIENT
Rys. 01 – Mapowanie klienta
Mapowanie klienta – z tabeli KLIENT_1 wiersz DATA_UR łączymy z tabelą
KLIENT_2 przy wykorzystaniu operatora EXPRESSION. Wyjście operatora
łączymy
z
wierszami
ID_GRUPA_WIEKOWA
oraz
GRUPA_WIEKOWA_ID_GRUPA_WIEKOWA w tabeli KLIENT_2. Zadaniem
operatora jest pogrupowanie klientów w grupy wiekowe według ich dat
urodzenia. Pozostałe wiersze (IDKLIENT, IMIE, NAZWISKO, DATA_UR)
przechodzą bezpośrednio do tabeli KLIENT_2.
Expression OUTPUT1:
CASE
WHEN TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) >= 1990 THEN 1
WHEN TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) < 1990 AND
TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) >= 1980 THEN 2
WHEN TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) < 1980 AND
TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) >= 1970 THEN 3
WHEN TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) < 1970 AND
TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) >= 1960 THEN 4
WHEN TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) < 1960 AND
TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) >= 1950 THEN 5
WHEN TO_NUMBER(TO_CHAR(INGRP1.DATA_UR,'YYYY')) <= 1950 THEN 6
END
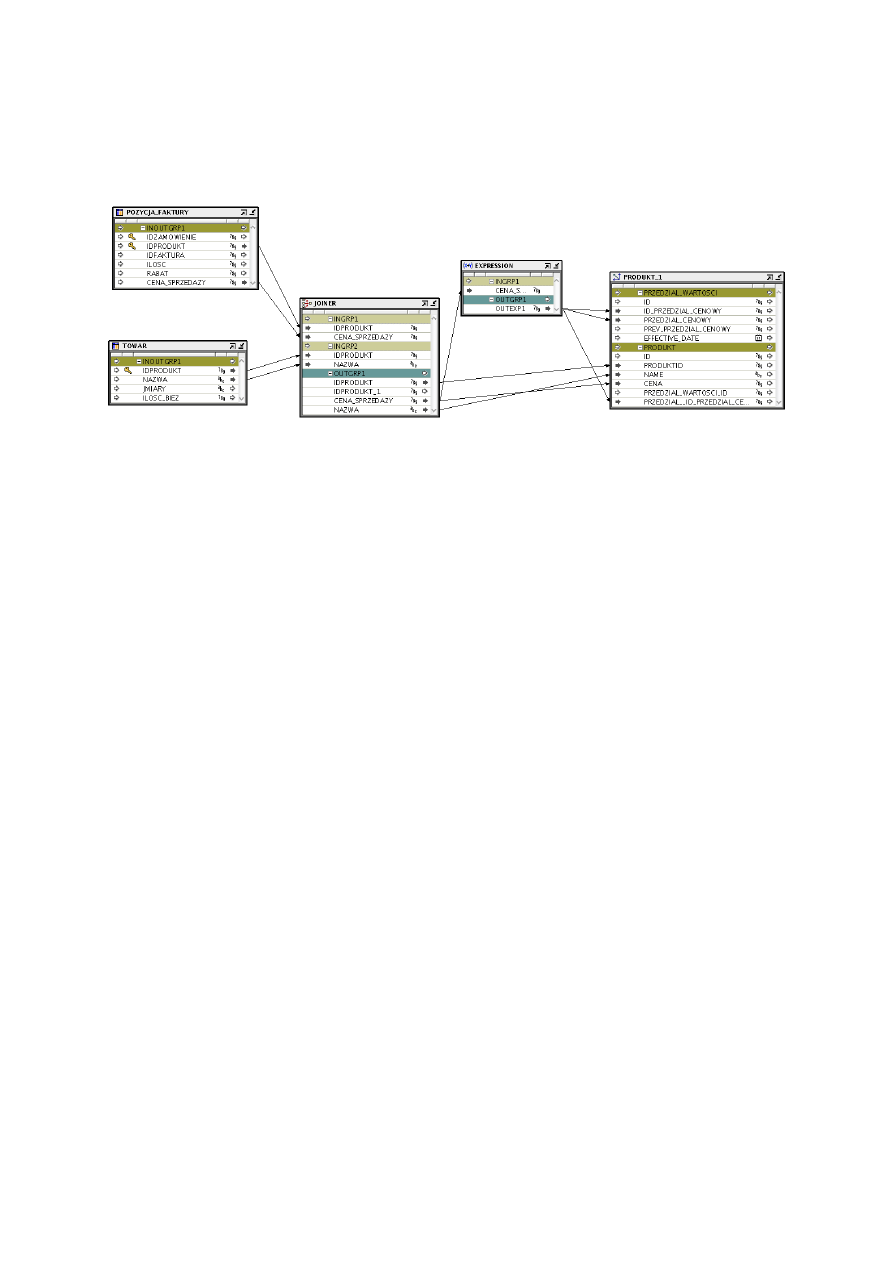
PRODUKT
Rys. 02 – Mapowanie produktu
Mapowanie produktu – z tabeli POZYCJA_FAKTURY wiersze IDPRODUKT i
CENA_SPRZEDAZY, oraz tabeli TOWAR wiersze IDPRODUKT i NAZWA, łączymy
za pomocą operatora JOINER oraz EXPRESSION z tabelą PRODUKT_1. Wyjście z
operatora JOINER łączymy z operatorem EXPRESSION, oraz z wymiarem
PRODUKT tabeli PRODUKT_1. Natomiast wyjście z operatora EXPRESSION
łączymy
z
wymiarem
PRZEDZIAŁ_WARTOSCI
z
wierszami
ID_PRZEDZIAL_CENOWY, PRZEDZIAL_CENOWY, oraz wymiarem PRODUKT z
wierszem
PRZEDZIAL_ID_PRZEDZIAL_CENOWY.
Zadaniem
operatora
EXPIRESSION jest pogrupowanie cen w przedziały cenowe według cen
sprzedaży.
EXPRESSION OUTPUT1:
CASE
WHEN INGRP1.CENA_SPRZEDAZY >= 8000 THEN 9
WHEN INGRP1.CENA_SPRZEDAZY < 8000 AND INGRP1.CENA_SPRZEDAZY >= 7000 THEN 8
WHEN INGRP1.CENA_SPRZEDAZY < 7000 AND INGRP1.CENA_SPRZEDAZY >= 6000 THEN 7
WHEN INGRP1.CENA_SPRZEDAZY < 6000 AND INGRP1.CENA_SPRZEDAZY >= 5000 THEN 6
WHEN INGRP1.CENA_SPRZEDAZY < 5000 AND INGRP1.CENA_SPRZEDAZY >= 4000 THEN 5
WHEN INGRP1.CENA_SPRZEDAZY < 4000 AND INGRP1.CENA_SPRZEDAZY >= 3000 THEN 4
WHEN INGRP1.CENA_SPRZEDAZY < 3000 AND INGRP1.CENA_SPRZEDAZY >= 2000 THEN 3

WHEN INGRP1.CENA_SPRZEDAZY < 2000 AND INGRP1.CENA_SPRZEDAZY >= 1000 THEN 2
WHEN INGRP1.CENA_SPRZEDAZY <= 1000 THEN 1
END
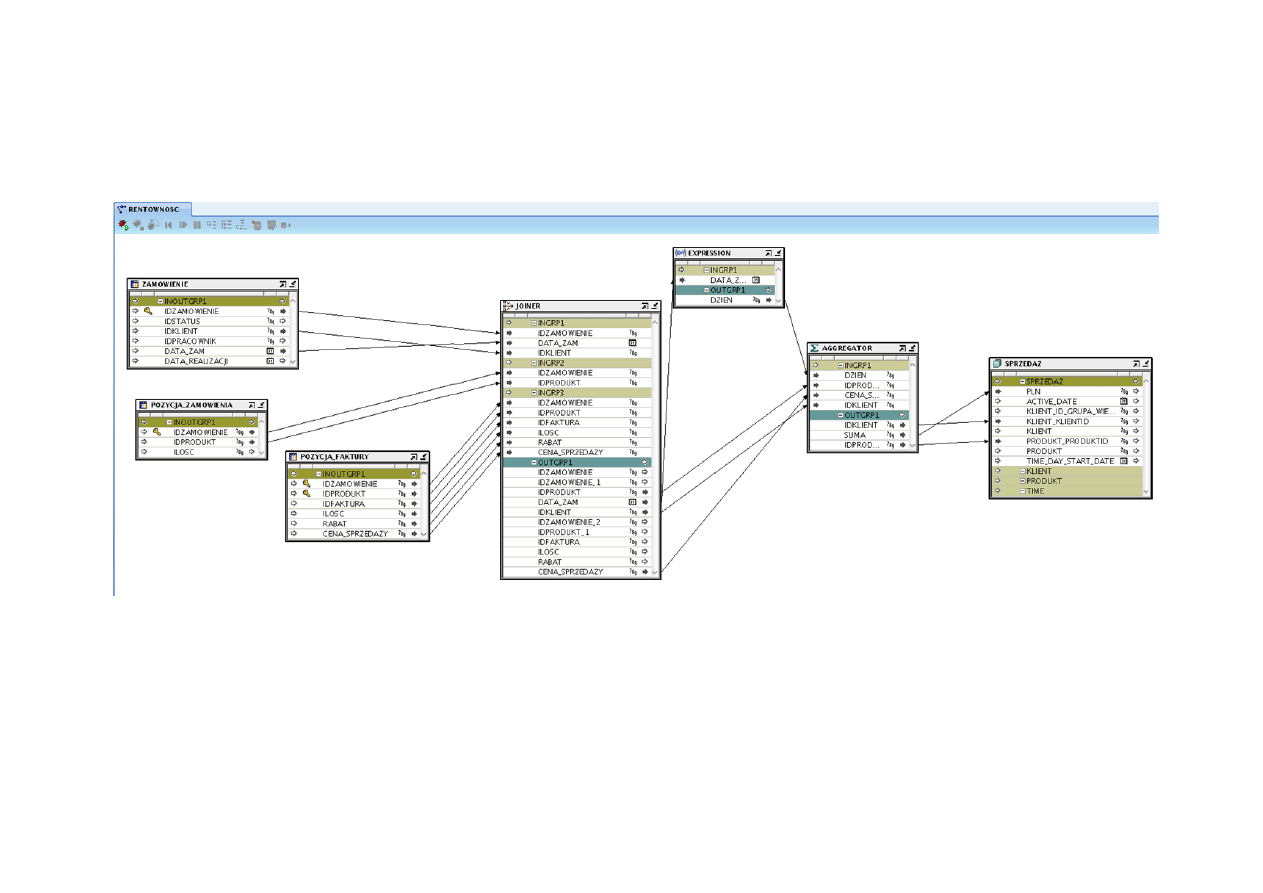
RENTOWNOŚĆ
Rys. 03 – Mapowanie rentowności

Mapowanie rentowności – celem tego mapowania jest przesłanie
z bazy źródłowej do hurtowni wartości sprzedaży z danego miesiąca dla danego
klienta i produktu, czyli przesłanie zagregowanej wartości sprzedaży i kluczy
biznesowych produktu, czasu i klienta.
JOINER został użyty w celu zebrania wartości faktur, kluczy biznesowych
produktu, czasu i klienta w jednej tabeli. Z tabel ZAMOWIENIE,
POZYCJA_ZAMOWIENIA, POZYCJA_FAKTURY łączymy za pomocą JOINERA
wybrane rekordy. Wyjście z JOINER jest wejściem do operatora EXPRESSION.
Jego zadaniem jest usunięcie informacji o konkretnym dniu, gdyż nie jest nam
to potrzebne.
Wyjście z JOINER i operatora EXPRESSION jest wejściem do operatora
AGGREGATOR. Agregator został użyty w celu zsumowania wszystkich wartości z
danego miesiąca dla danego klienta i produktu.
Wyjście z AGGREGATORA jest wejściem do głównej tabeli SPRZEDAZ.
Klucz biznesowy do czasu wstawia się automatycznie i dla tego nie ma przejścia
między kluczem biznesowym w agregatorze i tabeli SPRZEDAZ.
EXPRESSION OUTPUT1:
CASE
WHEN INGRP1.CENA_SPRZEDAZY >= 8000 THEN 9
WHEN INGRP1.CENA_SPRZEDAZY < 8000 AND INGRP1.CENA_SPRZEDAZY >= 7000 THEN 8
WHEN INGRP1.CENA_SPRZEDAZY < 7000 AND INGRP1.CENA_SPRZEDAZY >= 6000 THEN 7
WHEN INGRP1.CENA_SPRZEDAZY < 6000 AND INGRP1.CENA_SPRZEDAZY >= 5000 THEN 6
WHEN INGRP1.CENA_SPRZEDAZY < 5000 AND INGRP1.CENA_SPRZEDAZY >= 4000 THEN 5
WHEN INGRP1.CENA_SPRZEDAZY < 4000 AND INGRP1.CENA_SPRZEDAZY >= 3000 THEN 4
WHEN INGRP1.CENA_SPRZEDAZY < 3000 AND INGRP1.CENA_SPRZEDAZY >= 2000 THEN 3
WHEN INGRP1.CENA_SPRZEDAZY < 2000 AND INGRP1.CENA_SPRZEDAZY >= 1000 THEN 2
WHEN INGRP1.CENA_SPRZEDAZY <= 1000 THEN 1
END

8) Podsumowanie i wnioski.
Głównym przeznaczeniem i motywem wytworzenia hurtowni danych jest
wspomaganie zarządzania firmą. Osiąga się to poprzez analizę wycinka rzeczywistości pod
kątem interesujących nas aspektów (np. liczba zawartych umów w ostatnim roku w podziale
na regiony). Dane potrzebne do utworzenia raportu są zintegrowane i pochodzą najczęściej z
wielu źródeł (zazwyczaj jest to kilka relacyjnych baz danych).
W naszym przypadku stworzenie hurtowni danych miało pomóc potencjalnemu
analitykowi w odpowiedzi na pytanie dotyczące rentowności klienta. Zdobyta przez niego
wiedza o kontrahencie pozwoliłaby decydowad o zasadach dalszej współpracy z firmą.
Jednak aby tego dokonad należałoby udostępnid analitykowi raporty zawierające
interesujące go dane. Niestety nasze rozwiązanie przedstawione w poprzednich punktach
jest niedokooczone i nie pozwala na generowanie raportów. Udało nam się wykonad częśd
procesu ETL.
Wyszukiwarka
Podobne podstrony:
I8C1S1 HD Sprawozdanie
I8C1S1 HD Sprawozdanie
I8C1S1 Bubrowiecki sprawozdanieOrr
sprawozdanie SPG Mirosław Klimek I8C1S1, WAT, SEMESTR VI, system pracy grupowej
2 definicje i sprawozdawczośćid 19489 ppt
PROCES PLANOWANIA BADANIA SPRAWOZDAN FINANSOWYC H
W 11 Sprawozdania
Wymogi, cechy i zadania sprawozdawczośći finansowej
Analiza sprawozdan finansowych w BGZ SA
W3 Sprawozdawczosc
1 Sprawozdanie techniczne
Karta sprawozdania cw 10
eksploracja lab03, Lista sprawozdaniowych bazy danych
2 sprawozdanie szczawianyid 208 Nieznany (2)
więcej podobnych podstron