
Informatyka
Thread Building Blocks
Biblioteka Open Source firmy Intel
Instalacja, konfigurowanie, podstawowe konstrukcje
Programowanie współbieżne
1

2
•
Konfigurowanie VS 2010 do współpracy z TBB
•
Tworzenie i konfigurowanie aplikacji TBB
•
Uruchamianie przykładów z firmy Intel
•
Programowanie w TBB bez wyrażeń funkcyjnych lambda
•
Symulacja domknięć z wykorzystaniem technik
programowania obiektowego
•
Konwersja pomiędzy 2 notacjami (i.e. lambda i operator)
•
Optymalizacja kodu: dynamiczne szeregowanie i dystrybucja
zadań, korzystanie z łączność i przemienności redukcji
Zagadnienia

Intel® Threading Building Blocks
Tutorial
Document Number 319872-010US
World Wide
3
Dokumenty dostępne na utrzymywanej przez Intel stronie WWW biblioteki TBB,
m.in.:
•
Getting Started
•
Tutorial
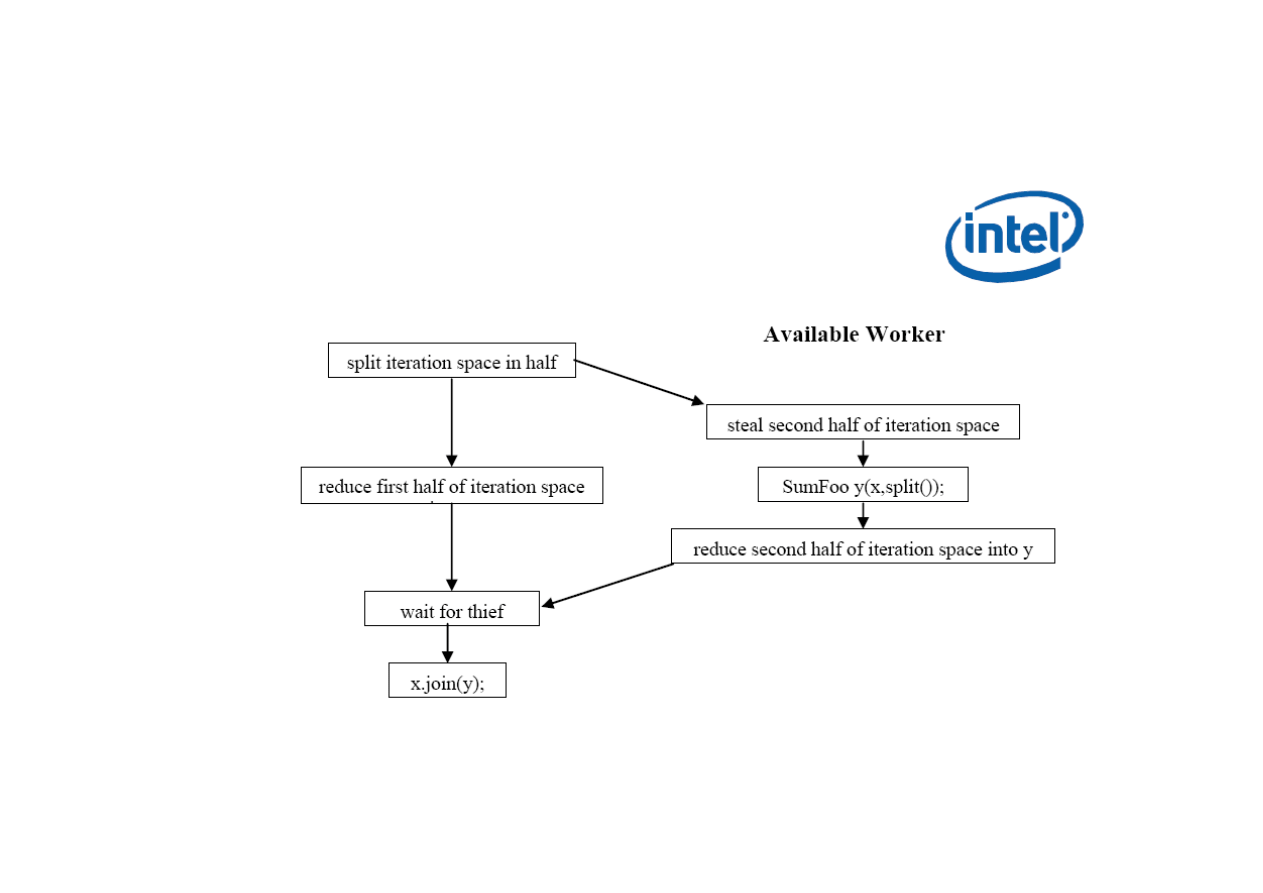
Dynamiczne zrównoleglenie procesu
Wariant „Available worker”: decyzja w trakcje wykonania
4

#include
"stdafx.h"
int
_tmain(
int
argc, _TCHAR* argv[])
{
return
0;
}
Punkt wyjścia (1)
(konsolowa aplikacja Win32, C++)
Zadanie: odtworzyć proces tworzenia aplikacji tbb pod Linux’em, wskazówki w dokumencie
Getting Started
5
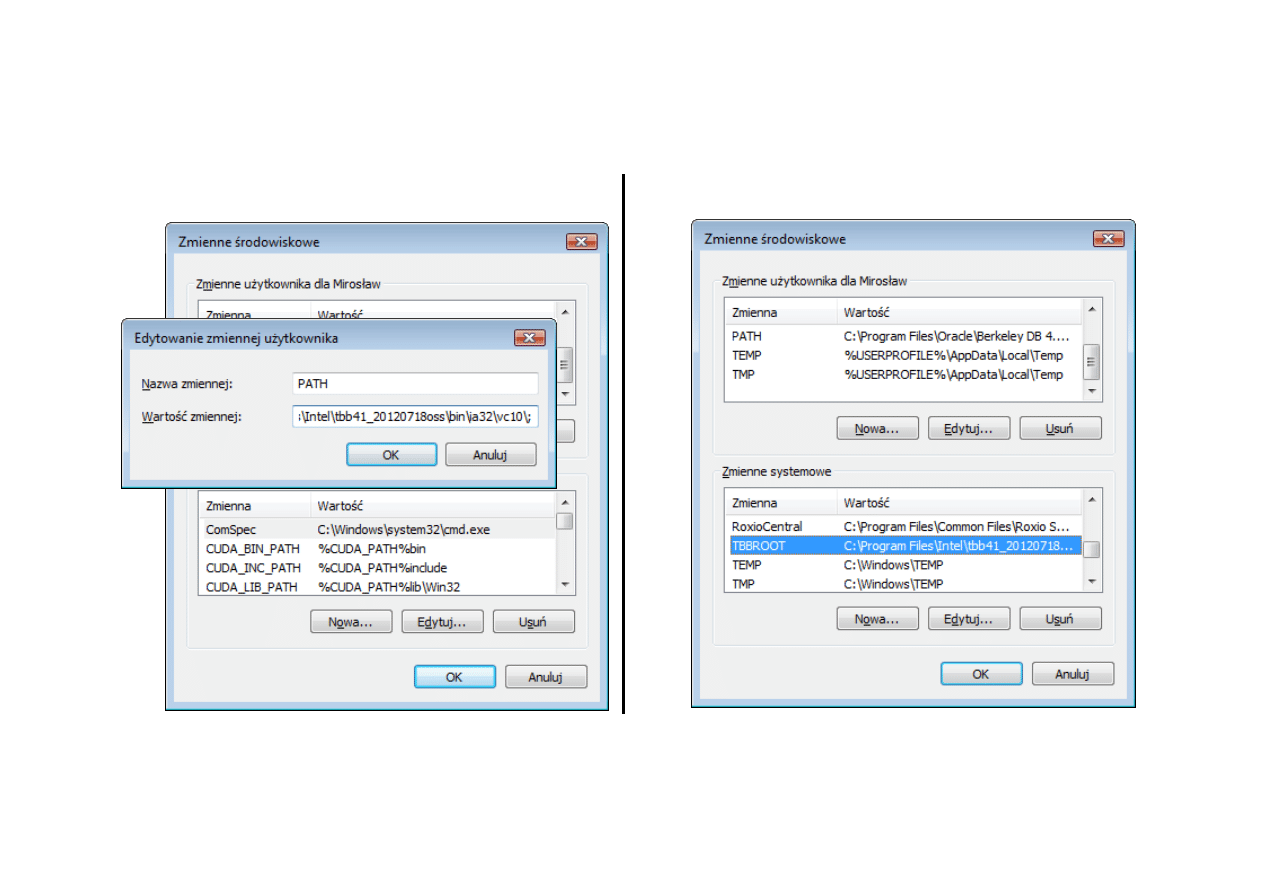
Punkt wyjścia (2)
Prosta konfiguracja (można na różne sposoby)
C:\Program Files\Oracle\Berkeley DB 4.7.25\bin;C:\Program Files\Oracle\Berkeley DB
4.7.25\bin\debug;c:\sedna\bin;c:\nałka\db xml\dbxml-
2.4.16\bin\debug;c:\ruby186\bin;C:\FPC\2.4.0\bin\i386-Win32;
C:\Program Files\Intel\tbb41_20120718oss\bin\ia32\vc10\;
6
1) Dostępność DLL
2) Parametr używany w VS
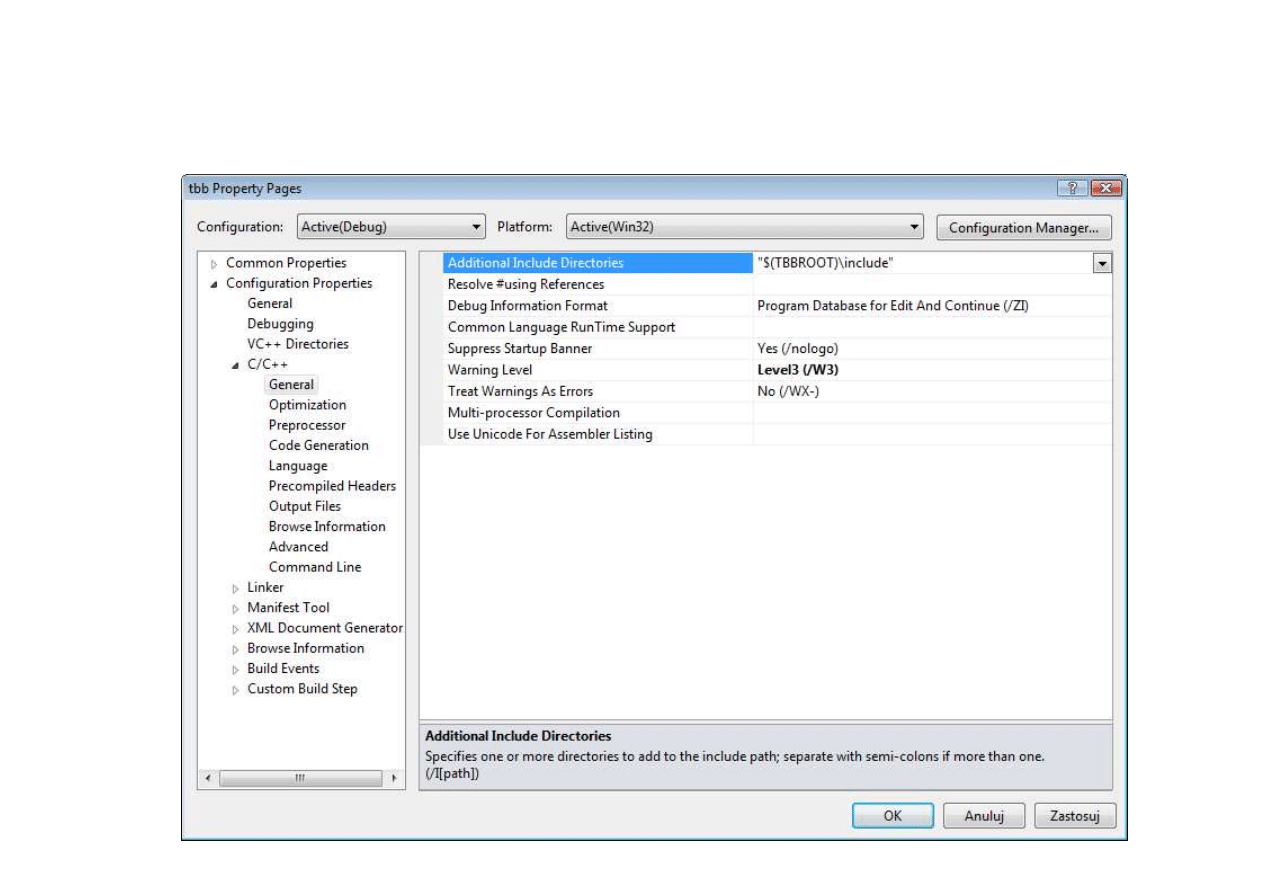
Punkt wyjścia (2a)
7
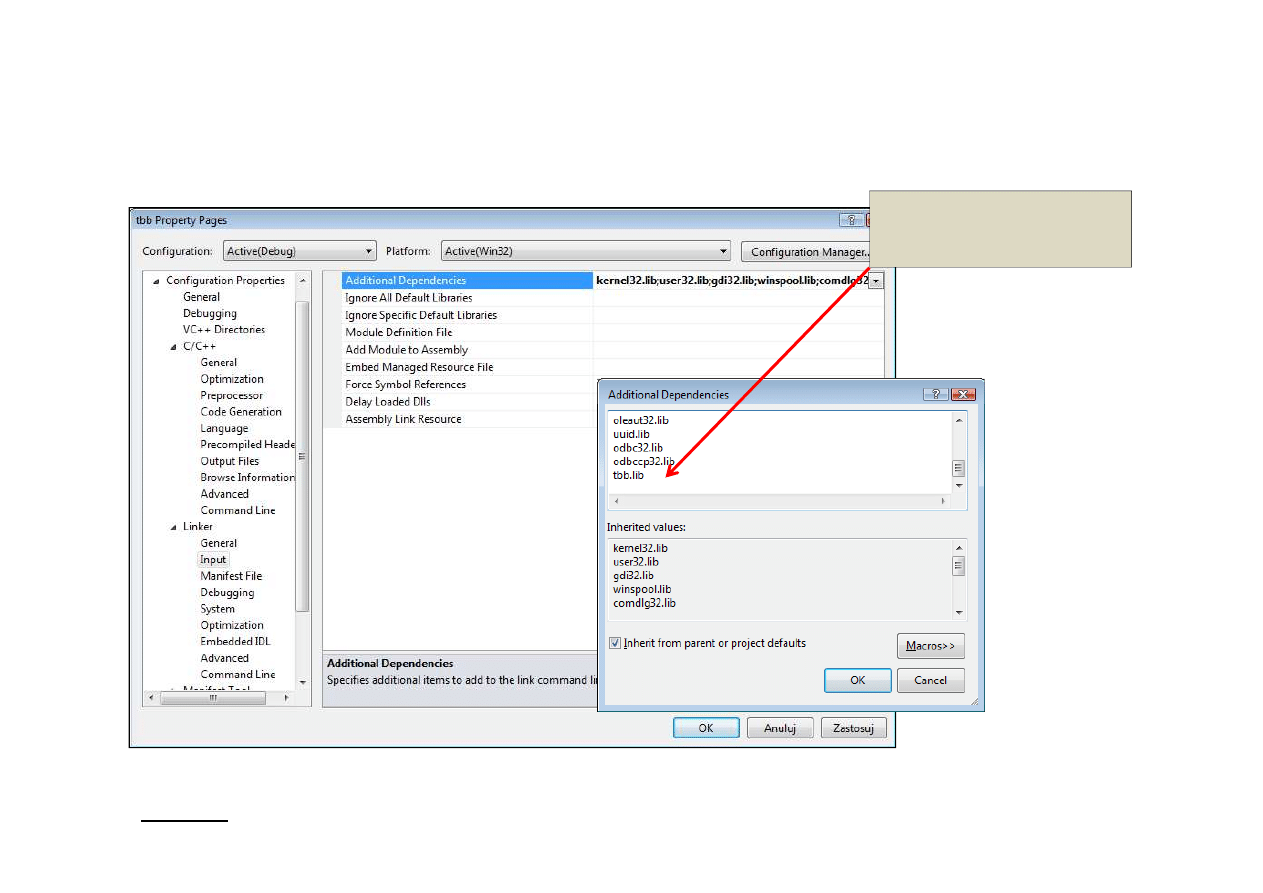
Punkt wyjścia (2b)
Biblioteka
tbb.lib lub tbb_debug
Uwaga: właściwy kod tbb jest w dll – trzeba potem zadbać by jakoś był widoczny
8
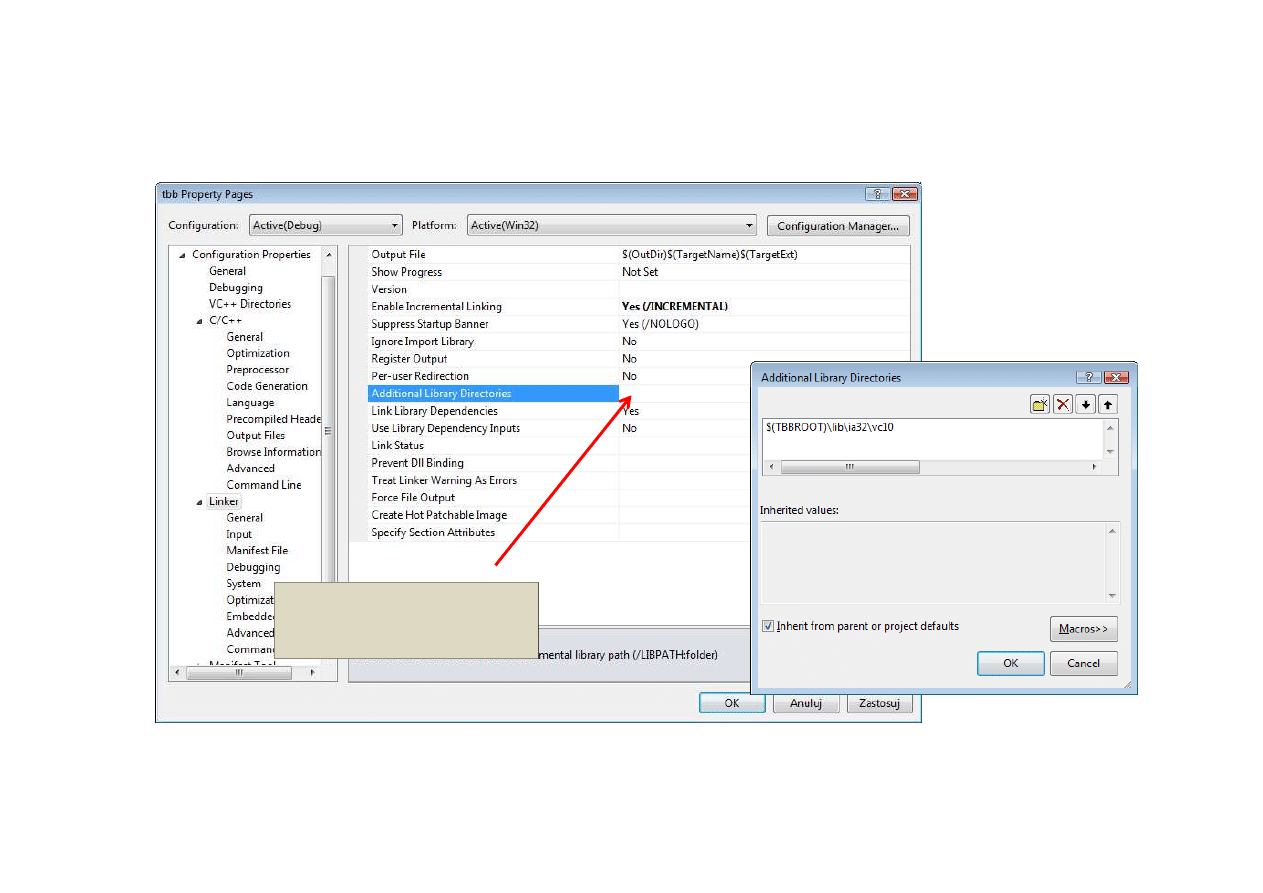
Punkt wyjścia (2d)
Katalogi gdzie linker
ma szukać bibliotek
Uwaga: Linker a nie aplikacja o dll trzeba „zadbać” oddzielnie
9

Punkt wyjścia (3)
#include
"stdafx.h"
int
_tmain(
int
argc, _TCHAR* argv[])
{
return
0;
}
07:
using namespace tbb;
36:
int main() {
50:
return 0;
51:
}
Uwaga: getting started Intela jest najbardziej „ogólne” – tutaj wszystko w kontekście VS2010
10
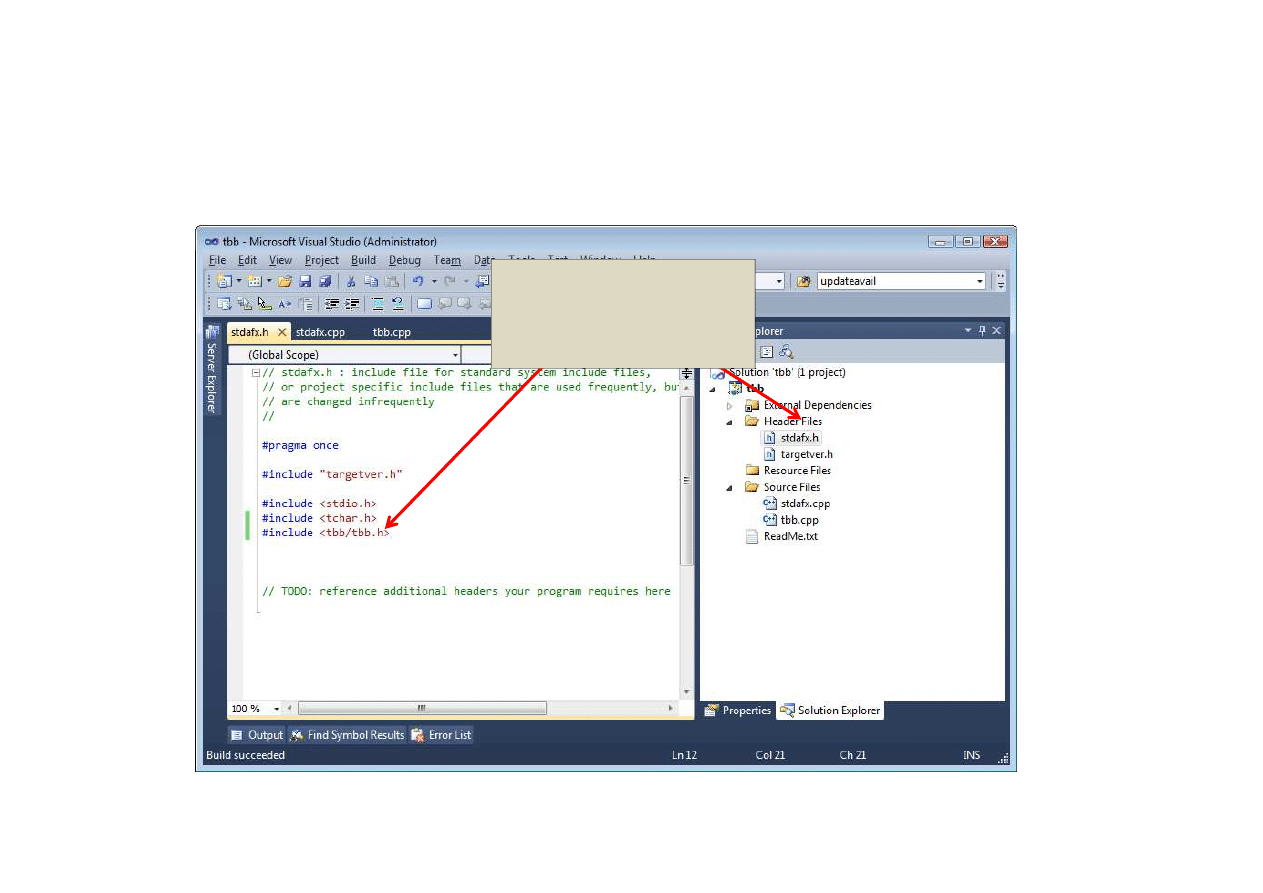
Punkt wyjścia (4a)
Standardowa
struktura aplikacji C++
w środowisku VS
To samo co w OpenMP: prekompilowane nagłówki
11

Punkt wyjścia (4b)
#include
"stdafx.h"
using namespace
tbb;
int
_tmain(
int
argc, _TCHAR* argv[])
{
combinable<
double
> c;
return
0;
}
Wstępny test: skompilować i uruchomić, wtedy wiadomo że OK. Choć program nie
robi nic sensownego.
12

#include "targetver.h"
#include <stdio.h>
#include <tchar.h>
#include <tbb/tbb.h>
#include <iostream>
#include <string>
Prekompilowany nagłówek <stdafx.h>
Nowe rzeczy
Znowu drobna różnica. Bo dodawane do stdafx. Pliki stl dostępne pod Linux.
Uwaga: kod dalej nieco starszy niż „c++ z lambdami” – tbb pojawiło się już wcześniej.
Kolejny dowód na ścisły związek domknięcia i funkcji anonimowych z programowaniem
współbieżnym.
13
14
Problem do rozwiązania (1)

15
Problem do rozwiązania (2)
Wyszukiwanie wzorca w tekście.
babbababbabba
babbababbabbababbabab
F7
F8
Tutaj z definicji
For each position in a string, the program displays the length and location of the
largest matching substring elsewhere in the string.
Dla każdej pozycji w zadanym tekście (string) Fibonacciego znaleźć najdłuższe pasujące
pod-słowo.

16
Problem do rozwiązania (3)
Zapis sekwencyjny. Bez dodatkowych „kombinacji obiektowych”.
for
(
int
i=0;i<N;i++)
{
int
pos1=0, max=0;
for
(
int
j=i+1;j<N;j++)
{
int
k;
for
(k=0;str[i+k]==str[j+k];k++);
if
(k>max) {max=k; pos1=j;}
}
len[i]=max;
pos[i]=pos1;
}

int
_tmain(
int
argc, _TCHAR* argv[])
{
string str[N] = { string(
"a"
), string(
"b"
) };
for
(size_t i = 2; i < N; ++i)
str[i] = str[i-1]+str[i-2];
string &to_scan = str[N-1];
size_t num_elem = to_scan.size();
size_t *max =
new
size_t[num_elem];
size_t *pos =
new
size_t[num_elem];
// will add code to populate max and pos here
for
(size_t i = 0; i < num_elem; ++i)
cout <<
" "
<< max[i] <<
"("
<< pos[i] <<
")"
<< endl;
delete
[] pos;
delete
[] max;
return
0;
}
Przykład z Intela : łańcuchy/teksty Fibonacci (1)
Fibonacci
17
18
void
FibText(
int
n)
{
int
f1=1,f2=1;
for
(
int
i=0;i<n-2;i++)
{
int
t=f2; f2=f1+f2; f1=t;}
str=
new char
[f2+1];str[f2]=(
char
)0;
int
i;
//these represent our f2 & f1, in this order
str[0]=
'b'
;str[1]=
'a'
; f1=1;f2=1;
for
(
int
i=0;i<n-3;i++)
{
int
t=f2; f2=f1+f2; f1=t;
memcpy(str+f2,str,f1);
}
}
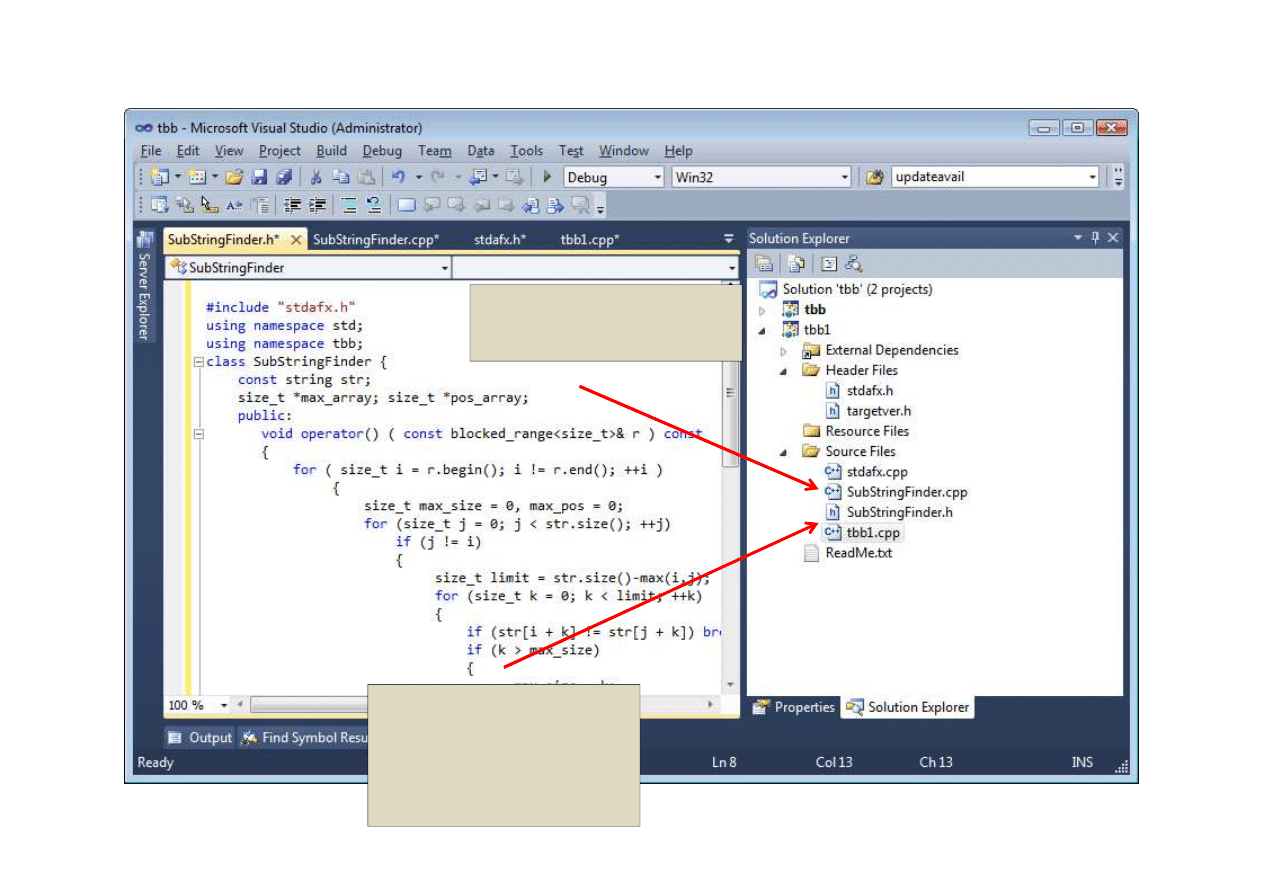
Przykład z Intela : łańcuchy/teksty Fibonacci (1a)
Można szybciej
wzorem Cassiniego.
Jak robi to Intel a jak zawodowcy - w epoce ajfonów i dotacji musiało do czegoś takiego dojść.
Zadanie: przeczytać kim był Chuck Peddle. (trochę poszukać nie tylko Wiki)
19
class
SubStringFinder {
const
string str;
size_t *max_array; size_t *pos_array;
public
:
void operator
() (
const
blocked_range<size_t>& r )
const
{
// tu wejdzie wszystko co się nie zmieściło czyli
// właściwa aplikacja
}
SubStringFinder(string &s, size_t *m, size_t *p) :
str(s), max_array(m), pos_array(p) { }
};
Przykład z Intela : łańcuchy/teksty Fibonacci (2)
Zamiast domknięcia
Zamiast lambdy
Później zostaną porównane obie notacje.
Ważne: jak domykać gdy nie ma domknięć. Będzie przy omawianiu modeli pamięci pod
Windows (Windows Memory Model, Joe Duffy)
20
Przykład z Intela (2a)
void operator
() (
const
blocked_range<size_t>& r )
const
{
for
( size_t i = r.begin(); i != r.end(); ++i )
{
size_t max_size = 0, max_pos = 0;
for
(size_t j = 0; j < str.size(); ++j)
if
(j != i)
{
size_t limit = str.size()-max(i,j);
for
(size_t k = 0; k < limit; ++k)
{
if
(str[i + k] != str[j + k])
break
;
if
(k > max_size)
{
max_size = k;
max_pos = j;
}
}
}
max_array[i] = max_size;
pos_array[i] = max_pos;
}
}
Taa
Intel☺
cóż…
Implementacja
operatora
„Zamiast lambdy”
21
Przykład z Intela (3)
#include
"SubStringFinder.h"
using namespace
std;
static const
size_t N = 23;
int
_tmain(
int
argc, _TCHAR* argv[])
{
string str[N] = { string(
"a"
), string(
"b"
) };
for
(size_t i = 2; i < N; ++i) str[i] = str[i-1]+str[i-2];
string &to_scan = str[N-1]; size_t num_elem = to_scan.size();
size_t *max =
new
size_t[num_elem];
size_t *pos =
new
size_t[num_elem];
parallel_for(blocked_range<size_t>(0, num_elem ),
SubStringFinder( to_scan, max, pos ) );
for
(size_t i = 0; i < num_elem; ++i)
cout <<
" "
<< max[i] <<
"("
<< pos[i] <<
")"
<< endl;
delete
[] pos;
delete
[] max;
return
0;
}
wywołanie
Operatora ()
„Zamiast lambdy”
Co trafia do
Stdafx a co do
„zwykłych” include☺
22
Wszystko w nagłówku
bo operator
zdefiniowany jako
inline
Pusty plik.
Wszystko publiczne.

23
Rozmiar
problemu O(n
3
) =
ok. 4 10
12
(sporo)

24
Porównanie 2 notacji (lambda i obiektowa).
•
Operator () odpowiednik lambda
•
Klasa implementująca operator używana jako argument dla 1 z przeciążonych
wariantów
•
Ciekawostka – dlaczego czasem intellisense zawodzi? i.e. Edytor VS nie podkreśla
a potem jest błąd kompilacji.
•
Inżynieria oprogramowania: czy można wymusić poprawność argumentu poprzez
określenie typu?
•
Zmienne instancyjne to odpowiednik domknięcia.

25
int
_tmain(
int
argc, _TCHAR* argv[])
{
string str[N] = { string(
"a"
), string(
"b"
) };
for
(size_t i = 2; i < N; ++i) str[i] = str[i-1]+str[i-2];
string &to_scan = str[N-1]; size_t num_elem = to_scan.size();
size_t *max =
new
size_t[num_elem];
size_t *pos =
new
size_t[num_elem];
parallel_for(blocked_range<size_t>(0, num_elem ),
[=](
const
blocked_range<size_t>& r){} );
for
(size_t i = 0; i < num_elem; ++i)
cout <<
" "
<< max[i] <<
"("
<< pos[i] <<
")"
<< endl;
delete
[] pos;
delete
[] max;
return
0;
}
Notacja lambda (1)
Pusta lambda!
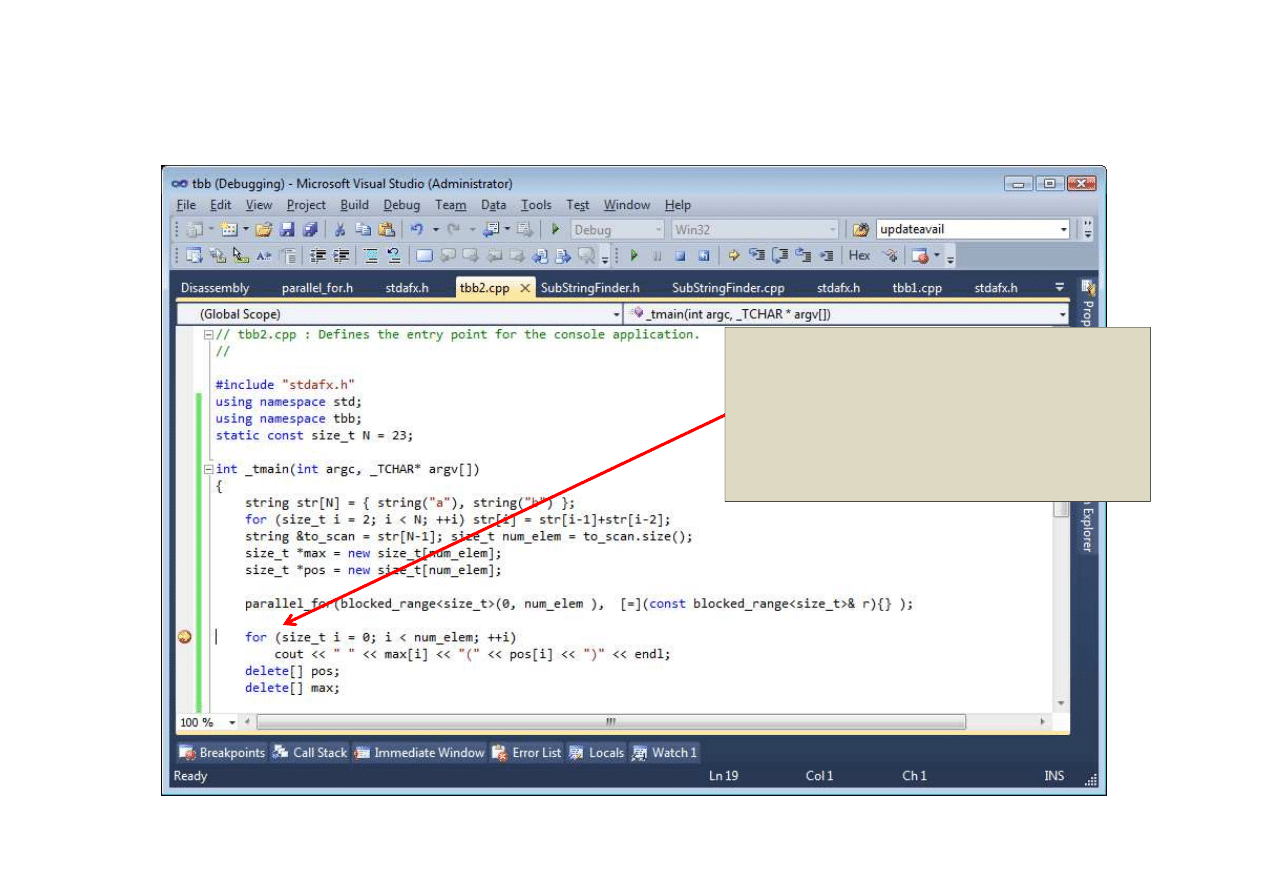
26
Notacja lambda (2)
Dla pustej lambdy
1) Natychmiastowe zakończenie
2) Liczba wątków prawdopodobnie
równa 1 (jak sprawdzić?)
3) Zalety dynamicznego przydziału

27
parallel_for(blocked_range<size_t>(0, num_elem ),
[=](
const
blocked_range<size_t>& r)
{
for
( size_t i = r.begin(); i != r.end(); ++i )
{
size_t max_size = 0, max_pos = 0;
for
(size_t j = 0; j < to_scan.size(); ++j)
if
(j != i)
{
size_t limit = to_scan.size()-max(i,j);
for
(size_t k = 0; k < limit; ++k)
{
if
(to_scan[i + k] != to_scan[j + k])
break
;
if
(k > max_size)
{
max_size = k;
max_pos = j;
}
}
}
max[i] = max_size;
pos[i] = max_pos;
}}
);
Notacja lambda (3)

28
Notacja lambda (4)
Zadania:
1. Dokonać pomiarów czasu wykonania dla różnych rozmiarów problemu. W
przykładzie Intela parametr N ustawiony na 23.
2. Zaimplementować rozwiązanie w OpenMP. Dokonać pomiarów i porównać. Czy
potrzebne będzie domknięcie? Jak „realizowane” są domknięcia w OpenMP?
3. (Proste) W kodzie na poprzedniej planszy użyto wyrażenia lambda domykającego w
trybie kopiowania i.e. [=](
const
blocked_range<size_t>& r){…} Jakie ma to znaczenie
w przypadku omawianego problemu? – Kod wykonywany równolegle modyfikuje
przecież globalną tablicę.
4. Zaimplementować wyznaczanie liczby pi za pomocą tbb.
5. Zadania 2 oraz 4 dodatkowo premiowane.
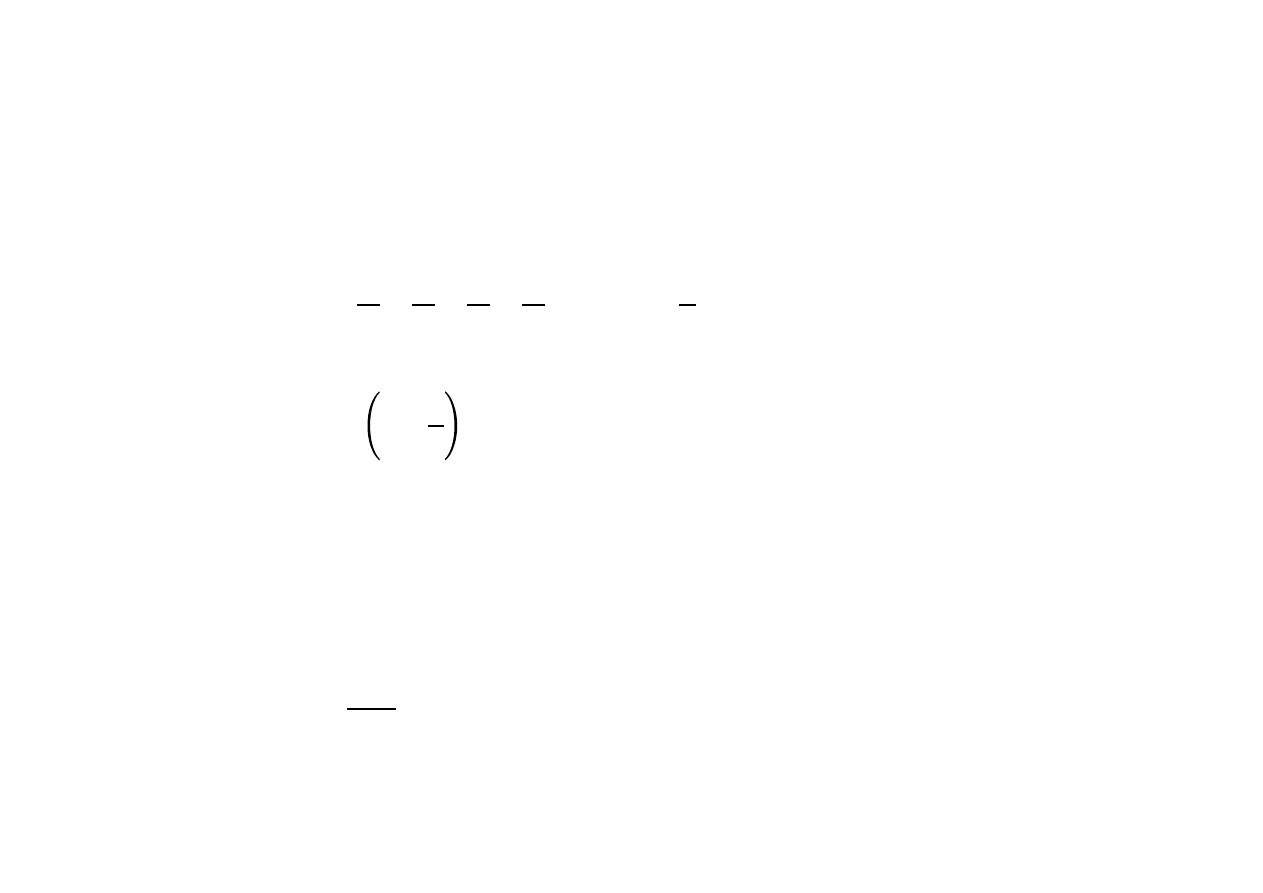
29
Wyznaczanie przybliżenia e
Było OpenMP powtórka definicji:
݁ = 1 +
1
1! +
1
2! +
1
3! +
1
4! + … =
1
݅!
ஶ
ୀ
Na potrzeby obliczeń:
݁ = ݔ
ଵ
+ ݔ
ଶ
+ ݔ
ଷ
+ ݔ
ସ
… = ݔ
ஶ
ୀଵ
ݔ
=
ݔ
ିଵ
݅
Gdzie:
(Taylor/MacLaurin)
݁ = lim
→ஶ
1 +
1
݊
(Bernoulli)
Redukcja nieprzemienna! (dla pi akurat przemienna więc prościej)

30
Pomocnicza Klasa – nie działało na OpenMP
class
natural
{
public
:
double
x,e;
natural(
double
p1,
double
p2){ x=p1;e=p2;}
natural
operator
+(natural & val);
};
natural natural::
operator
+(natural& n1)
{
e+=n1.e*x;
x=x*n1.x;
return
natural(x,e);
}
Klasa – operator wykonuje redukcję wg znanego schematu.

31
[](
const
tbb::blocked_range<size_t> &r,natural n)->natural
{
double
x=1.0,e=0;
for
(size_t i=r.begin();i<r.end();i++)
{
x=x/i;
e=e+x;
}
return
n+natural(x,e);
}
Wyrażenie lambda – wyznaczające sekwencyjnie fragment przybliżenia

32
Redukcja nieprzemienna (1)
[](natural n1,natural n2) {
return
n1+n2;}
natural natural::
operator
+(natural& n1)
{
e+=n1.e*x;
x=x*n1.x;
return
natural(x,e);
}
Tak prosto, bo korzysta z wyrażenia:
Operator miał być wykorzystany w OpenMP. Tutaj można prościej
33
Redukcja nieprzemienna (2)
[](natural n1,natural n2)
{
return
natural(n1.x*n2.x,n1.e+n2.e*n1.x);
}
•
Bez przeciążonego operatora.
•
Przeciążanie operatora: Bardziej defensywne.
•
Przykład programowania defensywnego. Defensywa: obrona przed wiadomo czym.
•
Operator pojawia się w 2 miejscach więc też ma jakieś zalety.
Przejrzystość kontra. Defensywa.
Zamiast operatora – bezpośrednie wyznaczenie wartości.
Klasa jednak potrzebna
bo „coś” trzeba zwrócić.
Tu opakować 2 double.
34
Wyznaczanie przybliżenia e - całość
int
_tmain(
int
argc, _TCHAR* argv[])
{ natural res=
tbb::parallel_reduce(
tbb::blocked_range<size_t>(1,100),
natural(1.0,0.0),
[](
const
tbb::blocked_range<size_t> &r,natural n)->natural
{
double
x=1,e=0;
for
(size_t i=r.begin();i!=r.end();i++)
{
x=x/i;
e=e+x;
}
return
n+natural(x,e);
},
[](natural n1,natural n2){
return
n1+n2;}
);
return
0;
}
W 2 miejscach.
Zadanie: czy inline?

35
Forma parallel_reduce, notacja obiektowa (1)
int
_tmain(
int
argc, _TCHAR* argv[])
{ T res=
tbb::parallel_reduce(
tbb::blocked_range<size_t>(1,100),
T(),
[](
const
tbb::blocked_range<size_t> &r,natural n)->natural
{…},
[](T t1,T t2){…}
);
return
0;
}
Ogólna postać aplikacji wzorca parallel_reduce.
Potrzebne są 2 metody – przedtem tylko operator().
Ćwiczymy różne znaczenia słowa aplikacja, aplikować pochodzące od apply.
Podstawa języka: „implement &apply”
36
Forma parallel_reduce, notacja obiektowa (2)
#include
"stdafx.h"
#include
"tbb/parallel_reduce.h"
#include
"tbb/blocked_range.h"
Nie wszyscy mają
szczęście używać
Windowsa i VS
Ciekawostka: pliki pch były już w Visual C++ © Microsoft 1993!
Borland jeszcze wcześniej (#pragma symfile).
int
_tmain(
int
argc, _TCHAR* argv[])
{
return
0;
}
Przykład z dokumentacji, aplikacja konsolowa + ustawienia properties.

37
Forma parallel_reduce, notacja obiektowa (3a)
struct
Object {
Object() {…}
Object( Object& s, split ) {…}
void operator
()(
const
blocked_range<
float
*>& r )
{
…
}
void
join( Object& rhs )
{…}
};
Implementacja operatora (), funkcja składowa o nazwie join i odpowiedniej sygnaturze.
Konstruktor o sygnaturze (T&, split) – po co split? Argument nigdy nie wykorzystywany.
Technika typowa dla C++. Wymuszenie (coercion) – tu akurat nie potrzebne (dlaczego?)
38
Forma parallel_reduce, notacja obiektowa (3b)
struct
Sum {
float
value; Sum() : value(0) {}
Sum( Sum& s, split ) {value = 0;}
void operator
()(
const
blocked_range<
float
*>& r )
{
float
temp = value;
for
(
float
* a=r.begin(); a!=r.end(); ++a )
{
temp += *a;
}
value = temp;
}
void
join( Sum& rhs )
{value += rhs.value;}
};
Tego intellisense nie
sprawdzi
Identity
39
float
ParallelSum(
float
arr[], size_t n )
{
Sum total;
parallel_reduce( blocked_range<
float
*>( arr, arr+n ), total );
return
total.value;
}
Forma parallel_reduce, notacja obiektowa (3c)
•
Wzorzec blocked_range może operować na różnych typach podstawowych.
•
Obiekt typu Sum zadeklarowany i utworzony z wykorzystaniem konstruktora
domyślnego.
•
Zadanie: zapisać przykłady wyznaczania liczb e oraz z wykorzystaniem notacji
obiektowej (do wyboru).
•
Dodatkowe zadanie zoptymalizować obliczanie
π
oparte na całkowanie pochodnej
atan. Wiadomo (lata 70-te 8 klasa szkoły podstawowej) że atan(1)=
π
/4
template
<
typename
Range,
typename
Body>
void
parallel_reduce(
const
Range& range,
const
Body& body
[, partitioner[, task_group_context& group]] );
referencja

40
Z dokumentacji Intela
Dzielenie na podzakresy i tworzenie nowych zadań – jeżeli dzielony jest zakres to tylko
wtedy tworzone i uszeregowane jest nowe zadanie (ale niekoniecznie).
A body is split only if the range is split, but the converse is not necessarily so.
Zdanie z dokumentacji:
Stwierdzenie odwrotne (nieprawdziwe): jeżeli zakres jest dzielony to tworzone jest
nowe zadanie.
Body , body split: terminologia którą operuje TBB – nie ma wątków ani zadań.
41
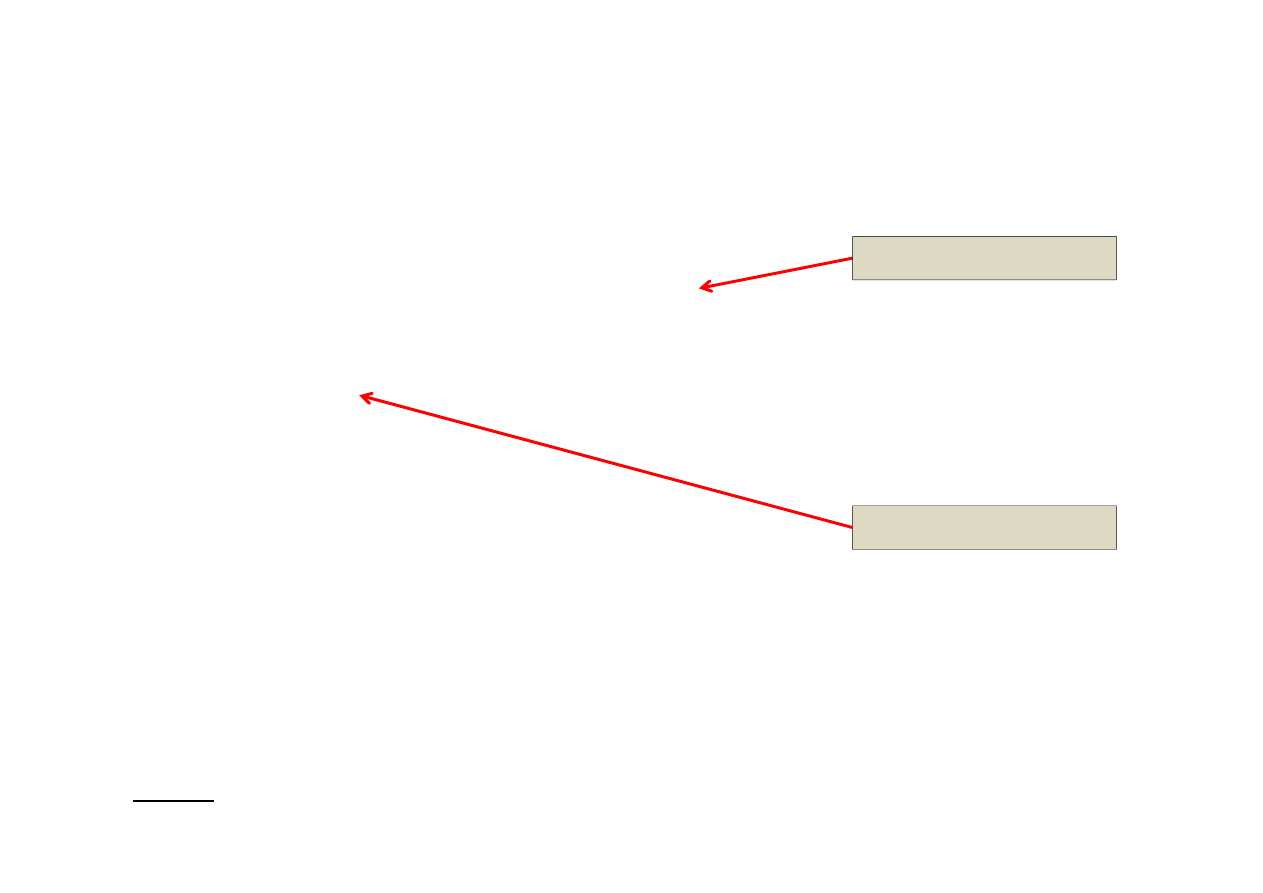
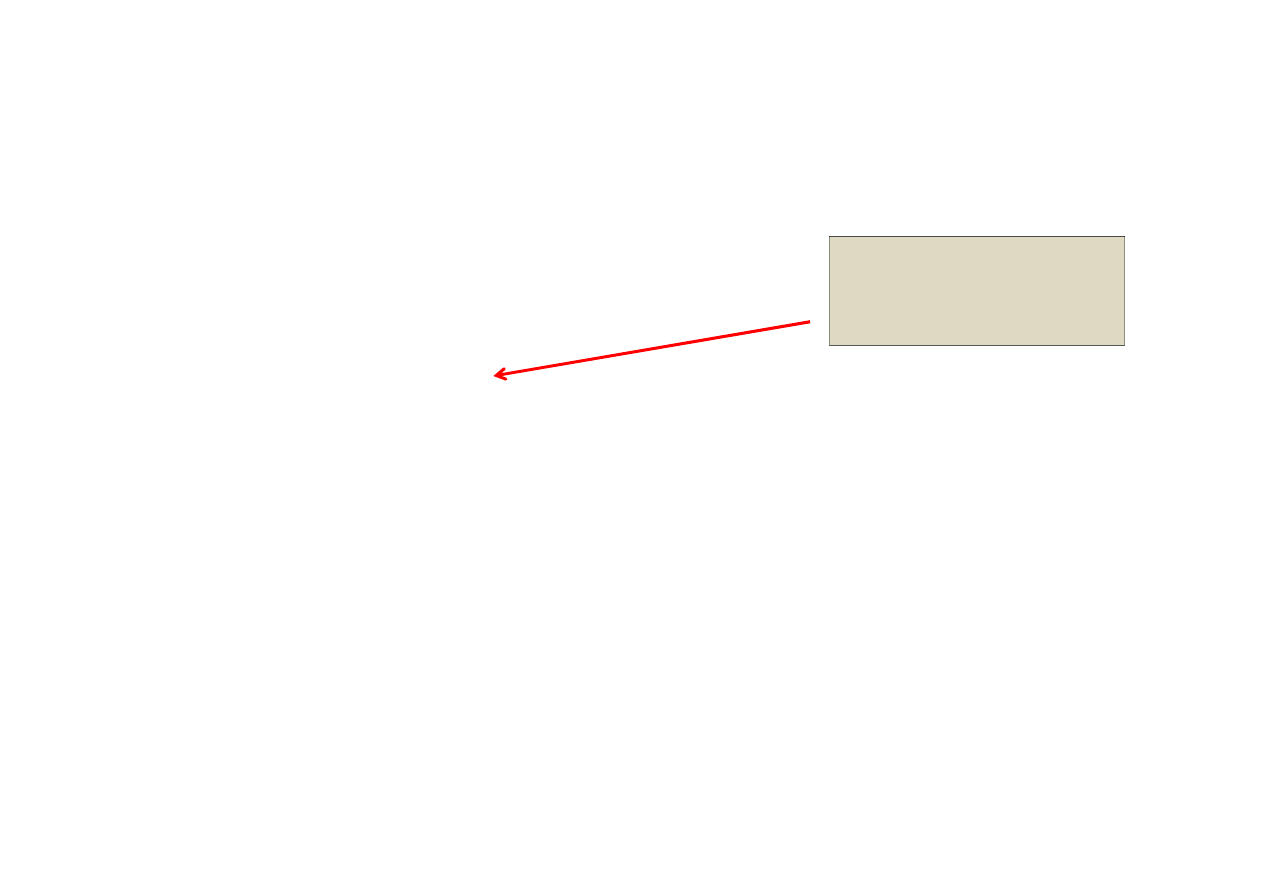
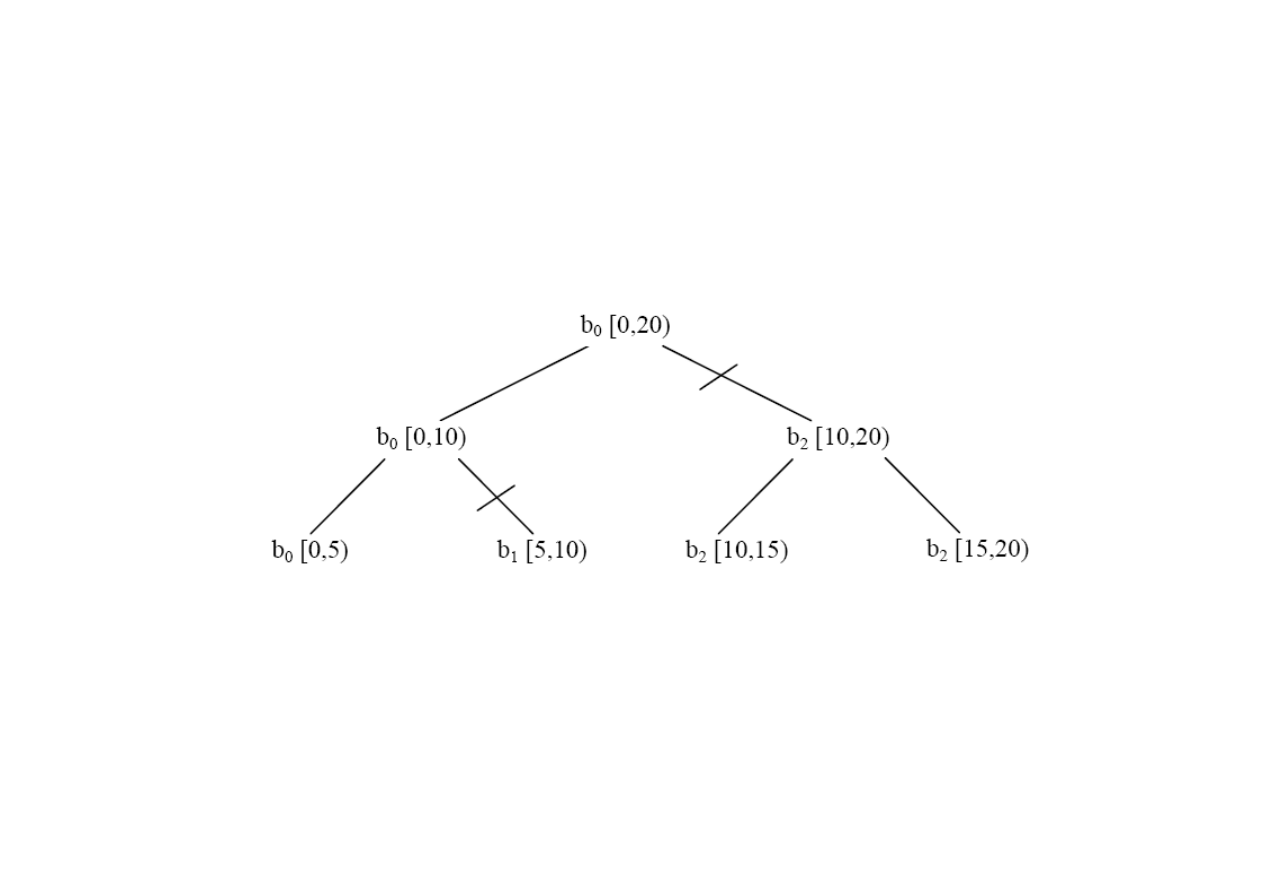
Z dokumentacji Intela (1)
Figure 1: Execution of parallel_reduce over blocked_range<int>(0,20,5)
W sumie 4 zakresy ale tylko 3 zadania (mogły by być 4 warunek konieczny)
42
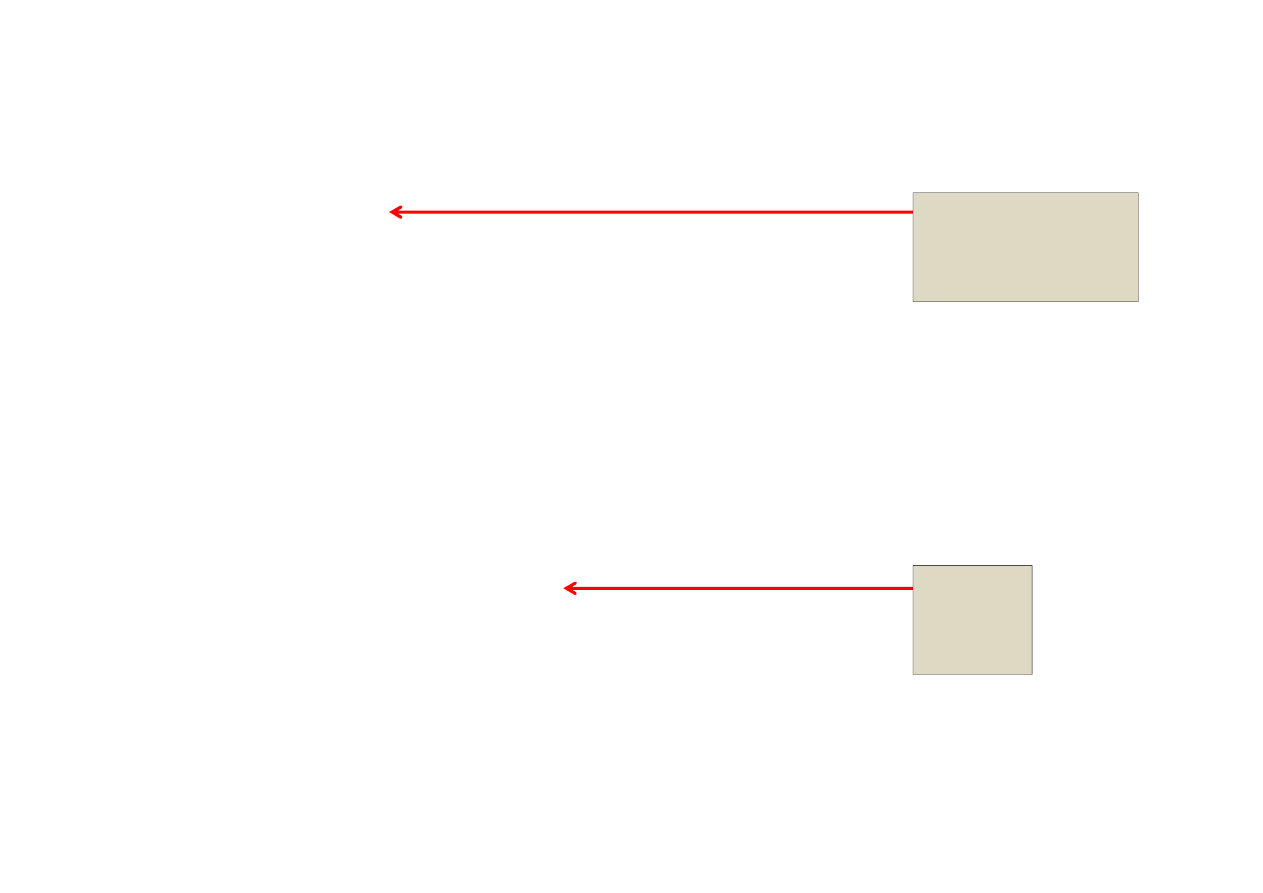
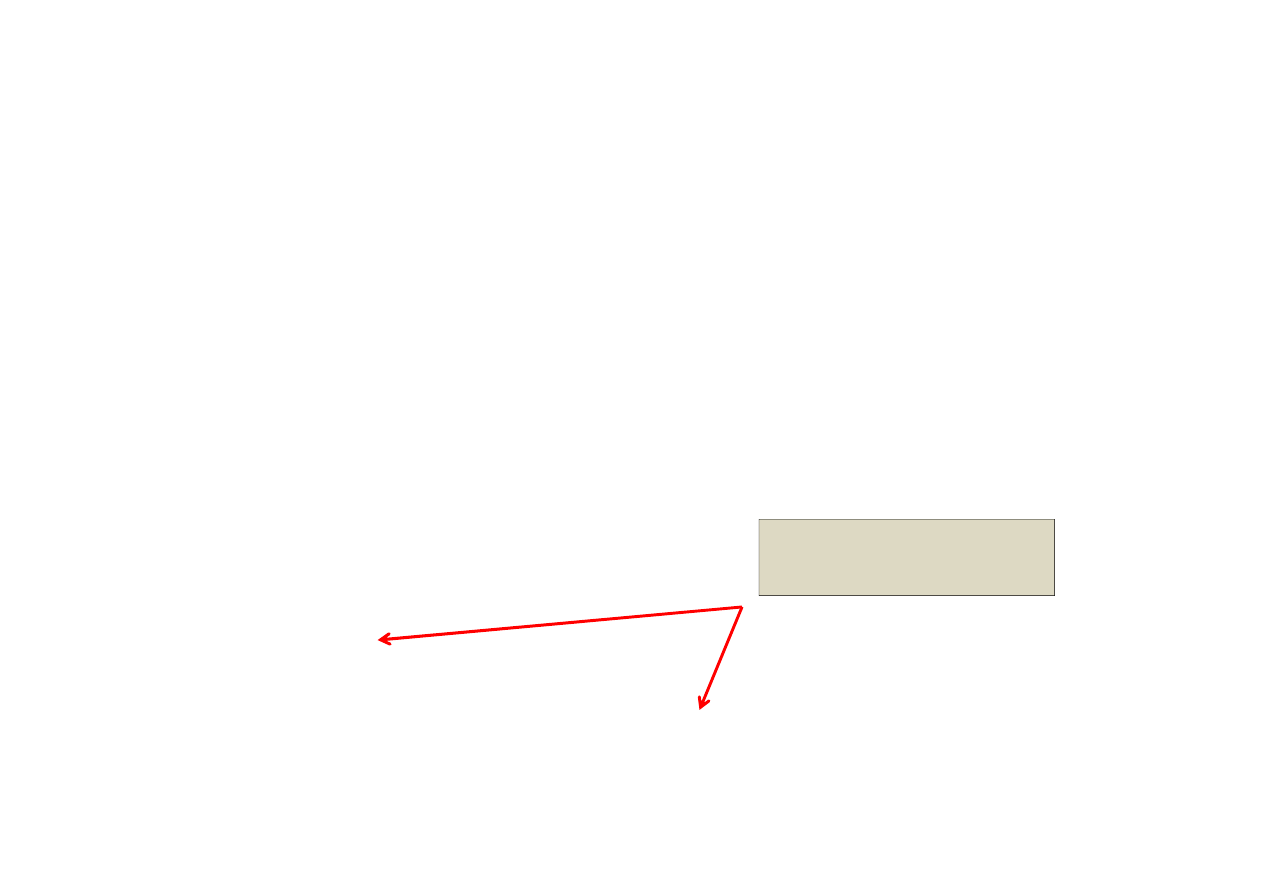
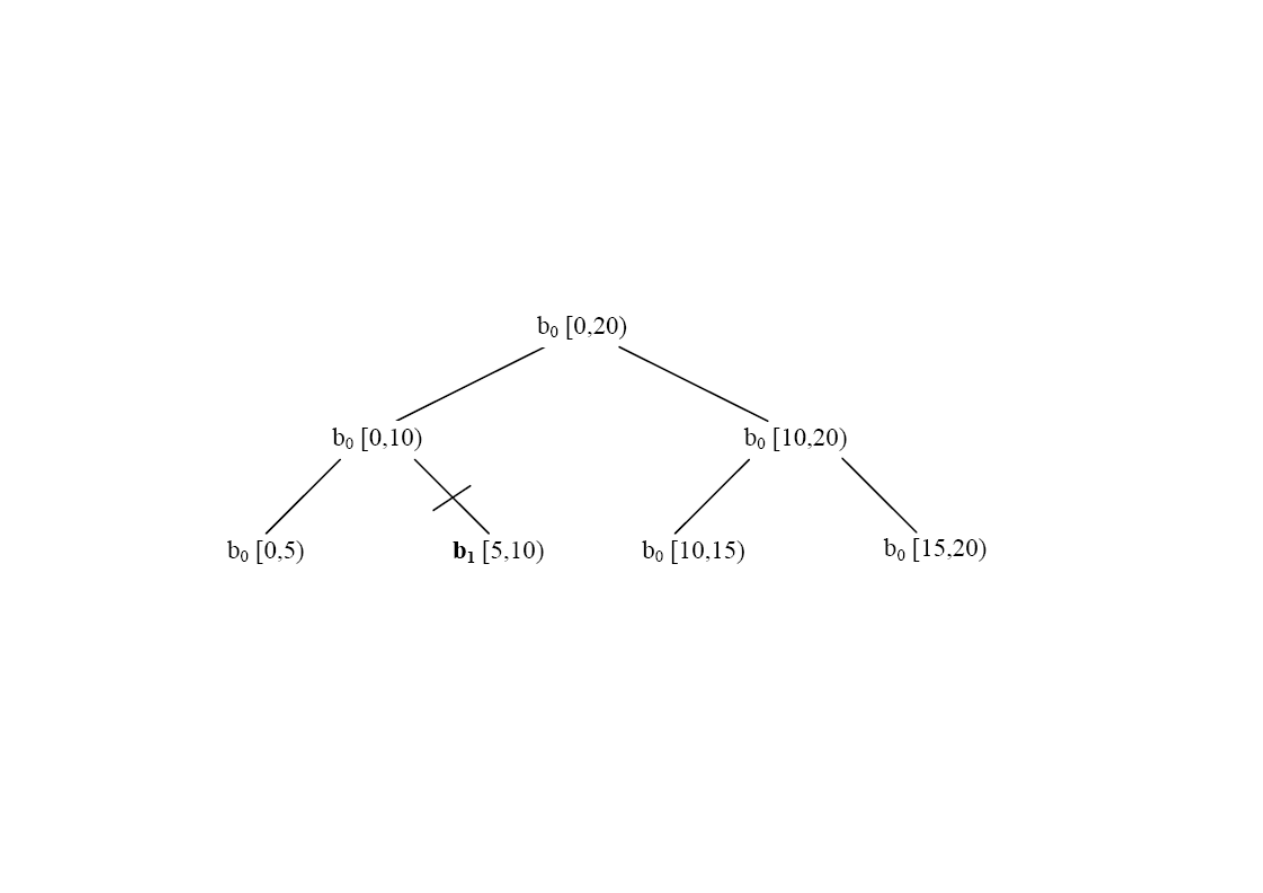
Z dokumentacji Intela (2)
Figure 2: Example Where Body b0 Processes Non-consecutive Subranges.
W sumie 4 zakresy ale tylko 2 zadania.
Decyzja podejmowana dynamicznie przez TBB.
Wyszukiwarka
Podobne podstrony:
lab11 3 2
lab11 3
Lab11 RapidPrototyping id 25910 Nieznany
za, Elektrotechnika AGH, Semestr II letni 2012-2013, Fizyka II - Laboratorium, laborki, laborki fizy
lab11 (5)
lab11
lab11
AiP Lab11
LAB11 BB beta2, Wydział Fizyki i Techniki
MiI MT lab11
LAB11
LAB11
lab11 3
LAB11
JP LAB11
lab11
lab11 lab6x
lab11 metrologia
lab11 3 5
więcej podobnych podstron