
1
Wprowadzenie do
programowania w SAS-ie
oraz estymacji rozkładów
Henryk Maciejewski
hmac@ict.pwr.wroc.pl
PWr, 2002/2003
2
Plan
♦
Co to jest SAS System
– Moduły
– Środowisko
– Organizacja danych przetwarzanych w SAS
♦
Programowanie w języku SAS 4GL
♦
Estymacja parametryczna rozkładów zmiennych
losowych

3
Co to jest SAS System
♦
Historycznie SAS = Statistical Analysis System
♦
Obecnie (a) platforma do budowania systemów wspomagania
decyzji (DSS) (zbiór modułów do analizy danych), (b) zbiór
specjalizowanych aplikacji DSS
♦
Przykładowe moduły
• Base SAS
język do przetwarzania danych, procedury analityczne)
• STAT
procedury analizy statystycznej
• ACCESS
dostęp do danych w różnych formatach (DBMS)
• GRAPH
• AF, webAF
środowiska budowania aplikacji OLAP
• EIS
• ...
• OR, QC, ETS,...
specjalizowane procedury (badania operacyjne,
niezawodność i kontrola jakości, szeregi czasowe, etc.
• Enterprise Miner
aplikacja data mining
• Data Warehouse Administrator
4
Środowisko programu SAS
♦
MVA (MultiVendor Architecture): programy SAS wykonują się
na VMS, CMS, OS/390, Unix, Windows, OS/2 bez modyfikacji
♦
Dane przetwarzane przez programy SAS:
– Pliki SAS (SAS files)
Np. SAS data sets, views, MDDBs
– Które przechowywane są w bibliotekach SAS (SAS libraries)
Referencja (LIBREF) do folderu, kartoteki itp. systemu operacyjnego, np.
LIBNAME projekt ‘c:\dane\projekt’;

5
Biblioteki (SAS Libraries)
♦
Biblioteki tworzone automatycznie przez SAS
SASHELP
-- SAS system files
SASUSER
-- user profile files
WORK
-- Biblioteka tymczasowa (pozostałe s
ą
permanentne)
♦
Odwołania do plików SAS –kwalifikowane nazwy
libraryname.filename, e.g.,
projekt.dane
-- plik w bibliotece projekt
dane
-- plik w bibliotece WORK
6
Pliki danych SAS (SAS Data Sets)
♦
SAS data sets, dwa typy:
– DATA
– tablica fizycznie przechowująca dane
– VIEW
– kod (query), który tworzy logiczny data set
♦
Konwencje nazw
– Wiersze nazywają się obserwacjami
– Kolumny nazywają się zmiennymi (variables)
♦
SAS data set składa się z:
– Deskryptora
- zawiera atrybuty data set-u i jego zmiennych
– Części zawierającej dane

7
Pliki danych SAS (SAS Data Sets)
♦
Wyświetlanie deskryptora SAS data set-u
PROC CONTENTS DATA=projekt.test;
RUN;
-----Alphabetic List of Variables and Attributes-----
# Variable Type Len Pos Format
Informat Label
ƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒƒ
1 sex Char 2 16 $3. $3. sex
4 teach_duration Num 8 8 11. 11. teach_duration
2 teacher_Code Num 8 0 11. 11. teacher_Code
3
titel_code Char 12 18 $12. $12.
titel_code
♦
Typy zmiennych w SAS
– character
– numeric
♦
Atrybuty zmiennych
– Length
- długość zmiennej: numeric: 3-8, character 1-32767 (MS Windows)
– Format
- jak wyświetlać (drukować) wartości zmiennej
– Informat
- jak konwertować (skanować) „input string” do wartości zmiennej
– Label
- opis zmiennej
8
Pliki danych SAS (SAS Data Sets)
♦
Wyświetlanie wartości w data set
PROC PRINT DATA= projekt.test;
RUN;
Obs sex teacher_Code
titel_code teach_duration
1 M 1 006 1
2 M 2 502 1
3 M 3 .
4 M 4 1
5 M 5 022 1
6 M 6 006 1
7 W 7 1
8 M 8 006 1
♦
„Missing value” – brak danych
– Wskazuje że w danej obserwacji nie przechowujemy wartoći dla danej zmiennej
– „missing numeric value” reprezentowana przez . (kropka)
– „missing character value” reprezentowana przez spację
9
Programowanie w SAS – Pierwszy
Program
DATA STEP
tworzy data set test
Tworzy zmienne w test
Wykonuje data step
PROC STEP
Wy
ś
wietla data set test
data test;
teachers=283;
students=853;
all=teachers+students;
s_per_t=students/teachers;
run;
proc print data=test;
run;
Data Set WORK.FHS
Obs teachers students all s_per_t
1 283 853 1136 3.01413
10
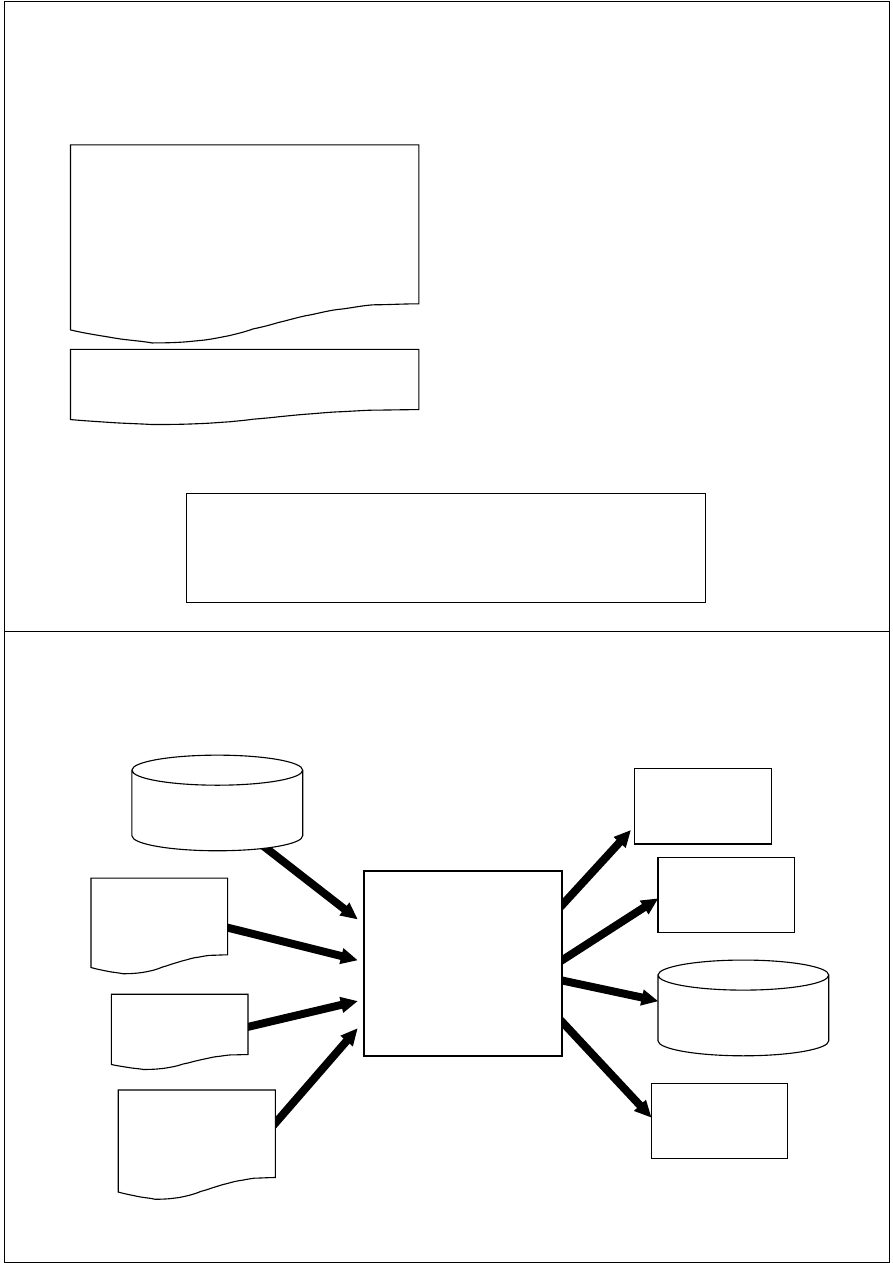
Przetwarzanie danych w programach
SAS
Program w SAS
Raport
Plik zewnętrzny
SAS Log
SAS Data Set
SAS Data Set
Raw data file
DBMS tables
(e.g., .mdb)
Remote access
(ftp, TCP/IP
socket, etc.)
...
DATA Step
PROC Step
...
DATA Step
...
11
Części programu: DATA Step,
PROC Step
♦
DATA Step
– Wczytuje dane wejściowe
• Np. data set,
• Pliki zewnętrzne itd.
– Przetwarza dane
– Tworzy wyjście
• Np. data sets,
• Plik zewnętrze
• Raporty
♦
PROC Step
– Analiza danych,
– Tworzenie raportów (tekst,
graf, HTML, PDF, itd.)
12
Algorytm
DATA Step
data students;
input name $ sex $ note1 note2;
avg=mean(note1,note2);
datalines;
Anna
F 4 5
Ian
M 3 .
Eva
F 1 4
;
run;
Obs name sex note1 note2 avg
1
Anna
F
4
5
4.5
2
Ian
M
3
.
3.0
3
Eva
F
2
1
1.5

13
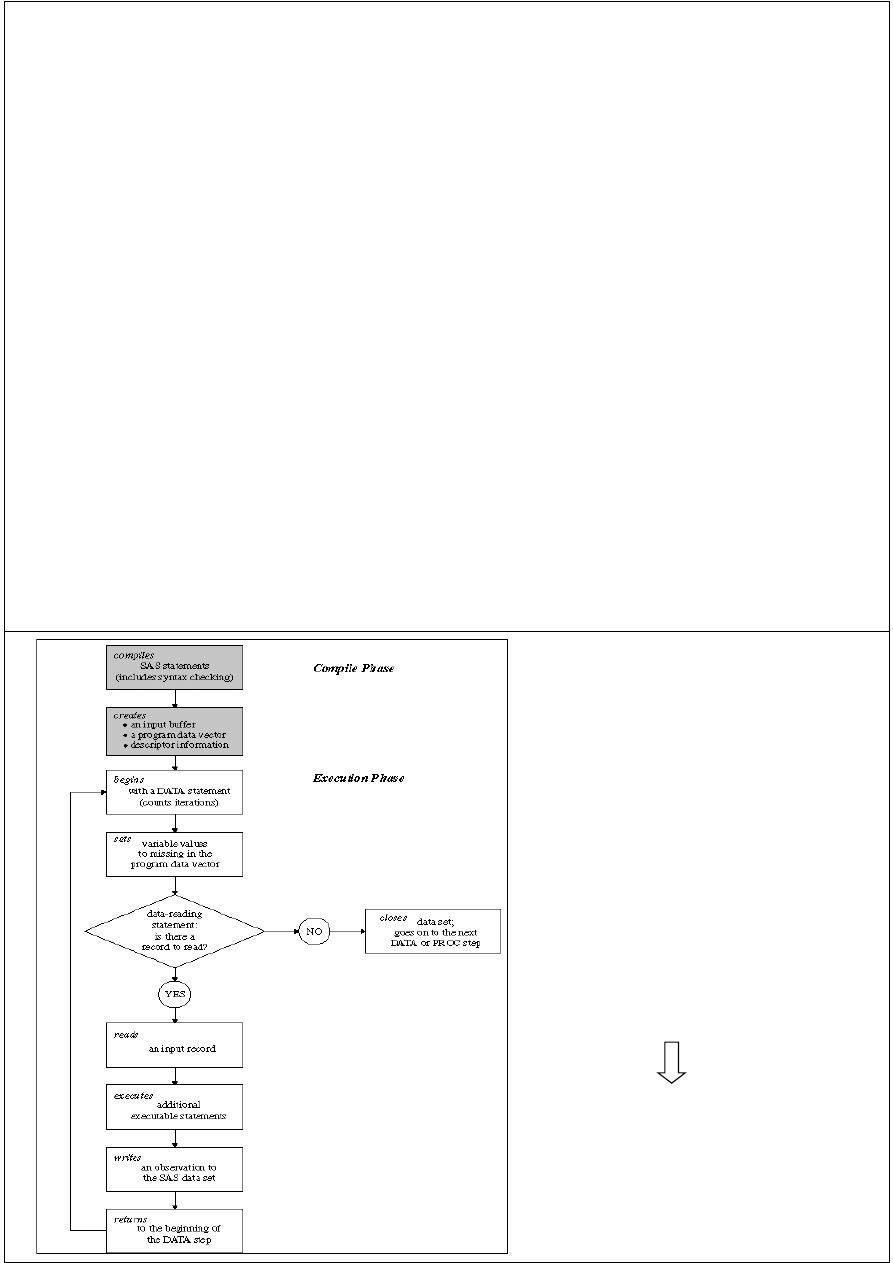
Algorytm DATA Step-u
♦
Główna pętla DATA step:
– data step wczytuje jedną obserwację,
– Dane są umieszczane w PDV = Program Data Vector;
– PDV jest inicjowany na wartości missing na początku każdej iteracji data step
– Wykonuje instrukcje (statements) zapisane w DATA step (na danej
obserwacji),
– Zapisuje obserwację do wynikowego data set (implicit OUTPUT)
♦
Uwaga: Implicit OUTPUT nie działa jeśli jawnie użyjemy
OUTPUT statement w DATA step
♦
Dane wejściowe dla DATA step wskazujemy np. instrukcją:
– SET statement – czytaj dane we z data set
– INPUT statement – wczytaj linię z pliku zewnętrznego (np. wskazanego
przez instrukcję INFILE)
14
Wybrane „idiomy” programisty
♦
Wybieramy obserwacje
♦
Wybieramy zmienne
♦
Tworzenie i modyfikowanie zmiennych
♦
Instrukcja OUTPUT
♦
Łączenie data set-ów (stacking, merging)
♦
BY-group processing
♦
Czytanie, pisanie plików zewnętrznych

15
Wybieramy obserwacje
data male;
set students;
if sex=‘F’ then delete;
run;
data male;
set students;
if sex=‘M’;
run;
or:
data male;
set students;
where sex=‘M’;
run;
data male;
set students (where=(sex=‘M’));
run;
Zapisz wybrane obserwacje
Używając subsetting IF:
→
usuń obserwację jeśli wyrażenie true;
→
zapisz obserwację jeśli wyrażenie true;
Używając WHERE (instrujację lub „data
set option”)
→
instrukcja WHERE
→
WHERE „data set option”
16
Wybieramy obserwacje
data male;
set students;
if sex=‘F’ then delete;
run;
data male;
set students;
if sex=‘M’;
run;
or:
data male;
set students;
where sex=‘M’;
run;
data male;
set students (where=(sex=‘M’));
run;
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian
M 3 . 3.0
3 Eva
F 2 1 1.5
Obs name sex note1 note2 avg
1 Ian
M 3 . 3

17
Wybieramy zmienne
data avg_only;
set students;
drop sex note1 note2;
run;
data avg_only;
set students;
keep name avg;
run;
or:
data avg_only;
set students (drop= sex note1
note2);
run;
data avg_only;
set students (keep= name avg);
run;
Zapisz tylko wybrane zmienne
Używając instrukcji DROP, KEEP
Używając „data set options” DROP, KEEP
18
Wybieramy zmienne
data avg_only;
set students;
drop sex note1 note2;
run;
data avg_only;
set students;
keep name avg;
run;
or:
data avg_only;
set students (drop= sex note1
note2);
run;
data avg_only;
set students (keep= name avg);
run;
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian
M 3 . 3.0
3 Eva
F 2 1 1.5
Obs name avg
1 Anna
4.5
2 Ian
3.0
3 Eva
1.5

19
Tworzymy nowe zmienne
data pass (drop= sex note1 note2
avg);
set students;
if avg < 2 then
result='passed';
else result='failed';
run;
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian
M 3 . 3.0
3 Eva
F 2 1 1.5
Obs name result
1
Anna failed
2
Ian
failed
3
Eva
passed
20
Tworzymy nowe zmienne
ŻLE:
data pass;
set students (drop= sex note1
note2 avg);
if avg < 2 then
result='passed';
else result='failed';
run;
Uwaga: W przykładzie zmienne sex, note1,2 i
avg nie są czytane w wejściowego data
set, stąd wartość avg jest
niezainicjowana w DATA step (czyli jest
missing)
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian
M 3 . 3.0
3 Eva
F 2 1 1.5
Obs name avg result
1
Anna
. passed
2
Ian
. passed
3
Eva
. passed

21
Instrukcja OUTPUT
data males females;
set students;
if sex='F' then output females;
if sex='M' then output males;
drop sex;
run;
Zapisuje aktualną obserwację do
wyjściowego data set
Uwaga: jeśli OUTPUT jest użyty jawnie
w DATA step, „implicit OUTPUT”
nie działa w data stepie (patrz
algorytm DATA step)
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian
M 3 . 3.0
3 Eva
F 2 1 1.5
females
males
1
Anna
1 Ian
2
Eva
22
Instrukcja OUTPUT– generacja
danych
data generator;
do x=1 to 100;
y=rannor(-1);
output;
end;
run;
Uwaga: nie ma instrukcji podającej źródło
danych we (np. SET lub INPUT), stąd
wykona się jedna iteracja gł. pętli
DATA step
Wynik: 100 liczb losowych z rozkładu
normalnego N(0,1)
Obs x
y
1
1
0.52813
2
2
0.51177
...
...
99
99 -0.23971
100 100 0.92665
23
Łączenie Data Set-ów (instrukcja
SET)
data all;
set males females;
run;
data all2;
set males(in=m) females(in=f);
if m then sex=‘M’;
if f then sex=‘F’;
run;
Przetwarzaj obserwacje z pierwszego data
set, potem z drugiego itd.
Rozróżnianie z którego zbioru pochodzi
dana obserwacja:
–
males(in=m)
tworzy zmienną
automatyczną
m
(
m
=1 dla obserwacji ze
zbioru
males
;
m
=0 w przeciwnym
przypadku)
–
Uwaga: zmienne automatyczne (m and
f) nie są zapisywane do wyjściowego
data set
Obs name note1 note2 avg sex
1 Ian
3 . 3.0 M
2 Anna 4 5 4.5 F
3 Eva
2 1 1.5 F
24
Łączenie Data Set-ów (instrukcja
MERGE)
data lib;
input name $ @8 date yymmdd10. title
$20. ;
datalines;
Anna
2000/12/14 Hamlet
Anna
2000/12/14 SAS Programming
Witek
2001/07/12 XML
;
run;
proc sort data=students
out=students_sort;
by name;
run;
data st_books;
merge students_sort lib;
by name;
keep name sex title;
run;
„Match-merging” data sets:
Data set STUDENTS:
Obs name sex note1 note2 avg
1 Anna F 4 5 4.5
2 Ian
M 3 . 3.0
3 Eva
F 2 1 1.5
Data set LIB:
Obs name date title
1 Anna
2000-12-14 Hamlet
2 Anna
2000-12-14 SAS Programming
3 Witek 2001-07-12 XML
Result data set:
Obs name
sex
title
1 Anna
F
Hamlet
2 Anna
F
SAS Programming
3 Eva
F
4 Ian
M
5 Witek
XML

25
„BY-group Processing” w DATA
Stepie
data best_note worst_note;
set exam;
by st_code;
if first.st_code then
output best_note;
if last.st_code then
output worst_note;
keep st_code sem note;
run;
„BY-group” jest podzbiorem obserwacji ze
wspólną wartością zmiennej „BY-
variable” (data set musi być
posortowany wg tej zmiennej)
Użycie instrukcji BY w DATA step tworzy
zmienne automatyczne, np.
FIRST.st_code
LAST.st_code
ustawiane przez DATA step na 1 dla
pierwszej (ostatniej) obserwacji w „BY-
group-ie”
Data set EXAM:
st_code sem
note
1
WS96/97
1
1
WS96/97
4
1
WS95/96
6
2
WS99/00
1
2
WS00/01
3
3
WS99/00
1
3
WS99/00
1
...
BY-group
BY-group
26
Zmienne automatyczne
Przykład – sprawdzamy czy nie ma błędnych
danych wejściowych:
data results err_log;
infile ‘C:\temp\results.txt’;
input name $ jump date yymmdd8.;
if _error_ then output err_log;
else output results;
run;
Tworzone przez DATA step; nie są
częścią Program Data Vectora; nie
są zapisywane do wynikowego data
set, np.
_N_ - nr iteracje DATA stepu
_ERROR_ - ustawiane na 1 jeśli jest błąd
przetwarzania danych (błędne dane
we, błąd w operacji matematycznej)
FIRST.by_variable
LAST. by_variable – patrz BY-group
processing

27
Czytanie plików zewnętrznych
data results err_log;
infile ‘C:\temp\results.txt’;
input name $ 1-10 jump @24 date
yymmdd8.;
if _error_ then output err_log;
else output results;
run;
Instrukcja INFILE – wskazuje plik do
czytania (może być fizyczna ścieżka
lub FILEREF przypisane przez
FILENAME fileref ‘path’;
INPUT
–
Wczytaj (przynajmniej jedną) linię
z pliku
–
Konwertuj linię do wartości
zmiennych wg:
•
Specyfikacji zmiennych, np.
–
name $ -
character variable
–
jump, date
– numeric variables
•
Specyfikacji kolumn, np.
–
name $ 1-10
– zakres kolumn
•
Informaów, np.
–
date yymmdd.
– informat daty
28
Czytanie plików zewnętrznych
data xy;
input x y;
datalines;
1 2 3
4
5 6 7 8
;
run;
data xy_ok;
input x y @@;
datalines;
1 2 3
4
5 6 7 8
;
run;
Modyfikacja funkcjonalności INPUT:
INPUT var1 var2 var3 @@;
INPUT nie czyta nowej linii jak długo w
buforze linii są jeszcze dane nie
skonwertowane do zmiennych
Obs x y
1
1 2
2
4 5
Obs x y
1
1 2
2
3 4
3
5 6
4
7 8

29
Zapis plików zewnętrznych
data _null_;
*no data set;
set exam;
file 'c:\temp\exam.txt';
put student_code 1-4 ', ' sem
@24 note 3.1 ;
run;
Instrukcja FILE – wskaż plik do którego
nastąpi zapis
Instrukcja PUT – zapisz jedną linię do
pliku wy, używając FORMAT-ów
zmiennych lub FORMAT-ów
podanych w instrukcji PUT
data _null_
– nie twórz wyjściowego
data set-u
30
Instrukcja RETAIN
data wzrosty_miesieczne;
set gielda;
*data kurs mies;
BY mies;
RETAIN pocz;
IF FIRST.mies then pocz=kurs;
IF LAST.mies then DO;
Wzrost=kurs-pocz;
Output;
end;
run;
Składnia polecenia RETAIN:
RETAIN var
initial_val;
Zmienna var nie będzie inicjowana na
‘missing’ na początku kolejnych
iteracji DATA step (wartość będzie
zachowana z poprzedniej iteracji)
Również:
var+expression;
Co jest równoważne:
RETAIN var 0;
var=SUM(var,expression);

31
Estymacja parametryczna rozkładów
zmiennych losowych
♦
Estymacja na podstawie prób pełnych za pomocą
procedur:
– PROC CAPABILITY (z modułu SAS/QC)
– PROC UNIVARIATE (z modułu Base SAS)
♦
Estymacja na podstawie prób obciętych
– PROC RELIABILITY (z modułu SAS/QC)
32
PROC CAPABILITY
proc capability data=test;
var t;
histogram t /
weibull (color=blue fill)
cfill=yellow;
run;
Wykonaj analizę parametryczną
rozkładu zmiennej t (zmienna
numeryczna w zbiorze test)
Polecenie
histogram
z opcją
weibull
realizuje dopasowanie rozkładu
Weibulla do danych
W wyniku dostajemy estymowane
parametry rozkładu (patrz np.
wykres histogramu z nałożoną
funkcją gęstości) oraz wyniki testów
zgodności rozkładów
Możemy również użyć polecenia
cdfplot
oraz
probplot
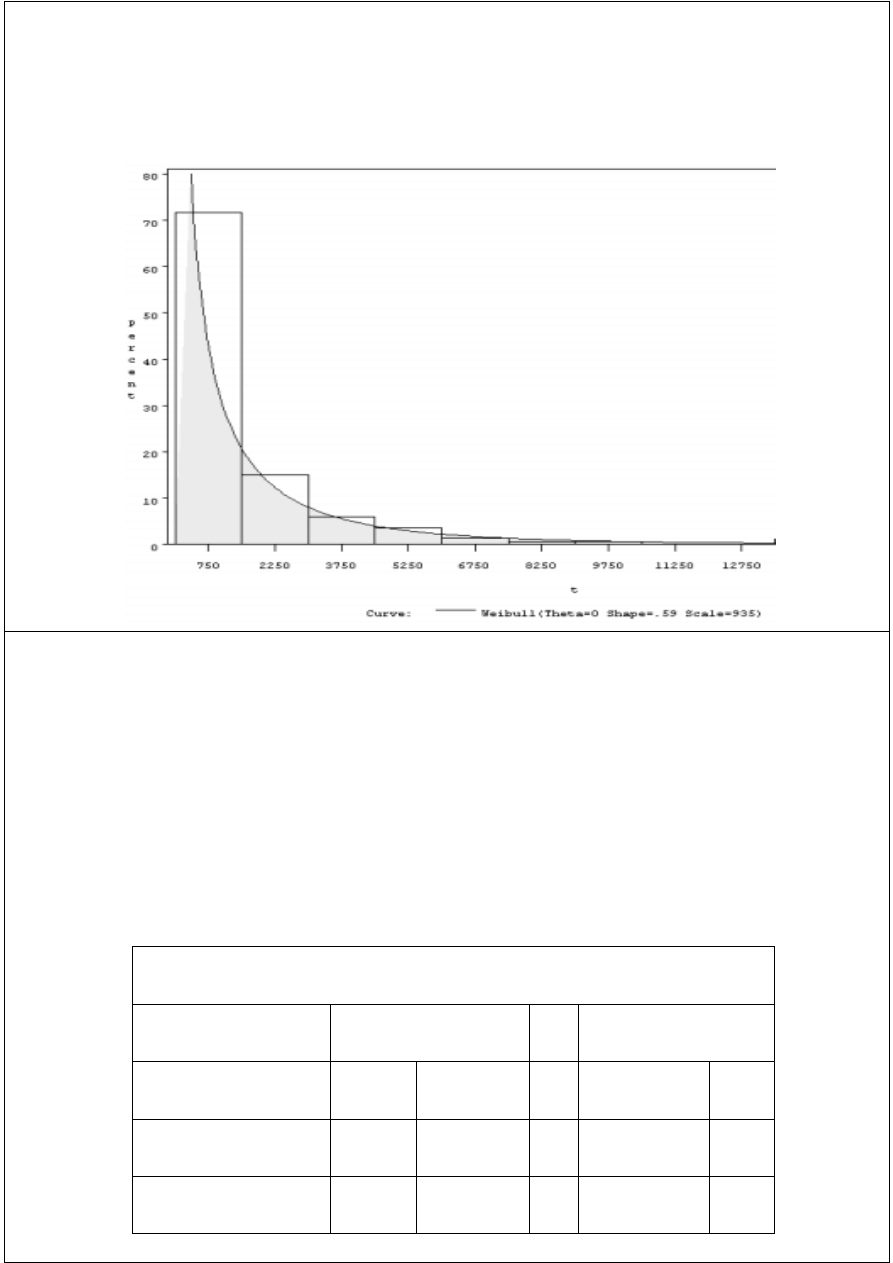
33
PROC CAPABILITY – histogram i
estymowana funkcja gęstości
34
PROC CAPABILITY – test
zgodności rozkładów
Goodness-of-Fit Tests for Weibull Distribution
Test
Statistic
DF
p Value
Cramer-von Mises
W-Sq
0.1169997
Pr > W-Sq
0.063
Anderson-Darling
A-Sq
0.8760160
Pr > A-Sq
0.024
Chi-Square
Chi-Sq
20.3972448
9
Pr > Chi-Sq
0.016
♦
Jeśli p Value jest mniejsze niż założony poziom istotności testu
(np. 0.05), wówczas odrzucamy hipotezę zerową o zgodności
rozkładów (czyli badana zmienna t nie ma rozkładu Weibulla)
35
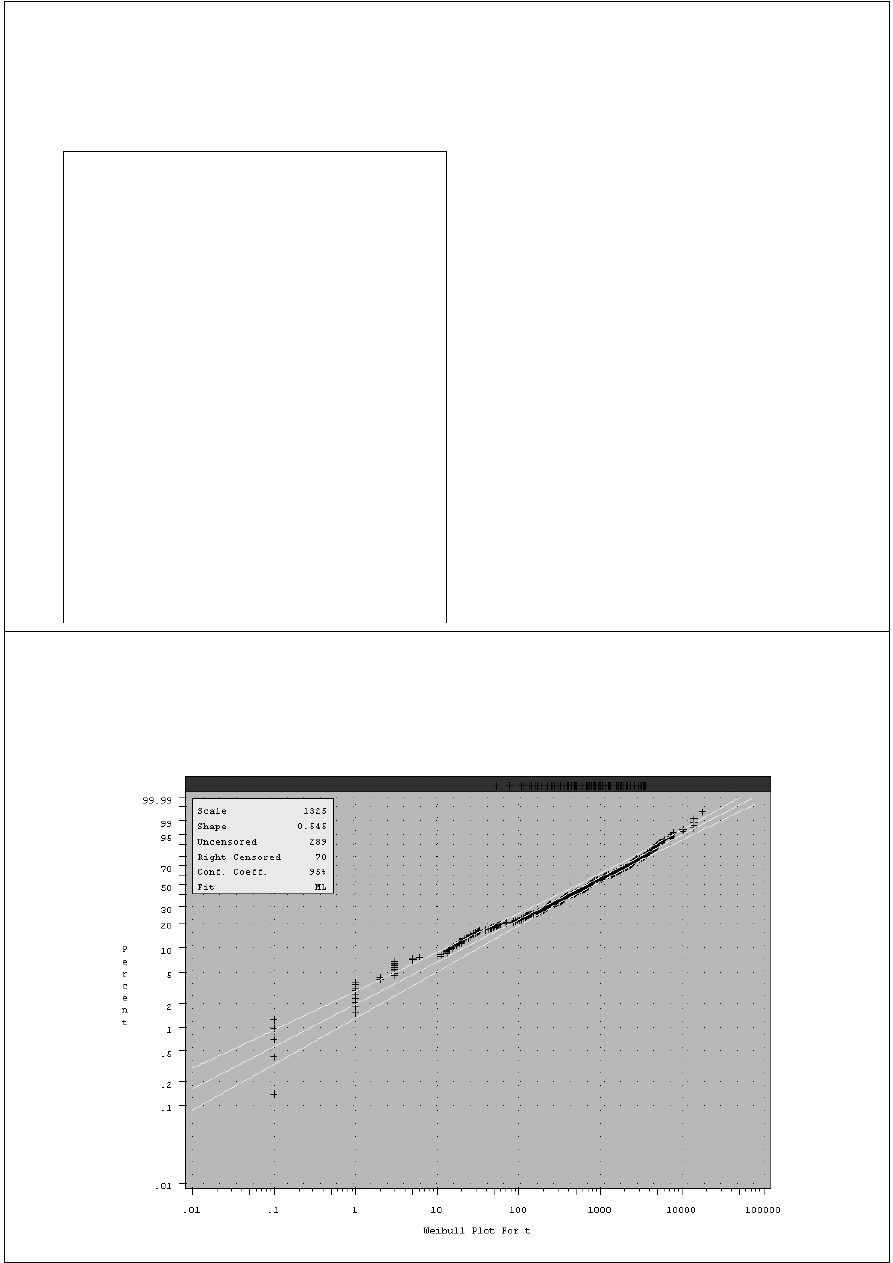
PROC RELIABILITY
proc reliability data=test;
distribution Weibull;
pplot t*censor( 1 ) /
covb
cfit
= yellow
cframe
= ligr
ccensor = red;
inset / cfill = ywh;
run;
Wykonaj analizę parametryczną
rozkładu zmiennej t, przy czym
obserwacje w zbiorze test, w
których zmienna censor przyjmuje
wartość 1 należy traktować jako
próby obcięte
Polecenie
distribution
realizuje
dopasowanie wskazanego rozkładu
do danych
W wyniku dostajemy parametry
rozkładu estymowane na podst.
próby obciętej oraz wykres pplot,
na podstawie którego oceniamy
zgodność rozkładów (jeśli próba
pochodzi z rozkładu Weibulla, dane
powinny układać się wzdłuż
prostej).
36
PROC RELIABILITY - pplot
Wyszukiwarka
Podobne podstrony:
Program umiarkowany id 395519 Nieznany
Narodowy Program Zdrowia1 id 31 Nieznany
Narodowy Program Zdrowia id 314 Nieznany
Program cw3 id 395618 Nieznany
Programowanie GUI id 395885 Nieznany
Program zjazdu id 395614 Nieznany
Program cw2 id 395617 Nieznany
Program cw5 id 395619 Nieznany
Program cz1 id 395054 Nieznany
Program cz10 id 395055 Nieznany
program zajec id 395592 Nieznany
Programowanie Usb C id 396388 Nieznany
Program wykladu id 395571 Nieznany
Program zajec 2 id 395593 Nieznany
program arteterapii 3 id 394997 Nieznany
program pedagogika id 395372 Nieznany
Program studiow 2 id 395472 Nieznany
Programowanie pilotow id 396293 Nieznany
Podstawy programu FDS id 368033 Nieznany
więcej podobnych podstron