
2009-06-03
1
1
EKSTRAKCJA WIEDZY Z DANYCH 12
2
EKSTRAKCJA WIEDZY
Wprowadzenie
W większości firm występuje poważny problem informacyjny związany z nadmiarem
bezużytecznych danych, zbieranych w systemach informatycznych przy jednoczesnym braku
możliwości dotarcia do ważnych informacji.
Systemy księgowe, transakcyjne to systemy gromadzące dane dzień po dniu, wykonujące te
same rutynowe działania i nastawione na masowe przetwarzanie. To właśnie one zdominowały
dzisiejsze środowisko biznesowe.
Nie są one jednak w stanie dostarczyć niezbędnej do zarządzania wiedzy.
Powszechna potrzeba informacji zwiększa zapotrzebowanie na systemy dostarczające
odpowiedzi na podstawowe pytania biznesu, nastawione na potrzeby użytkownika, zdolne
wesprzeć długoterminową strategię i uzyskać konkurencyjną przewagę.
3
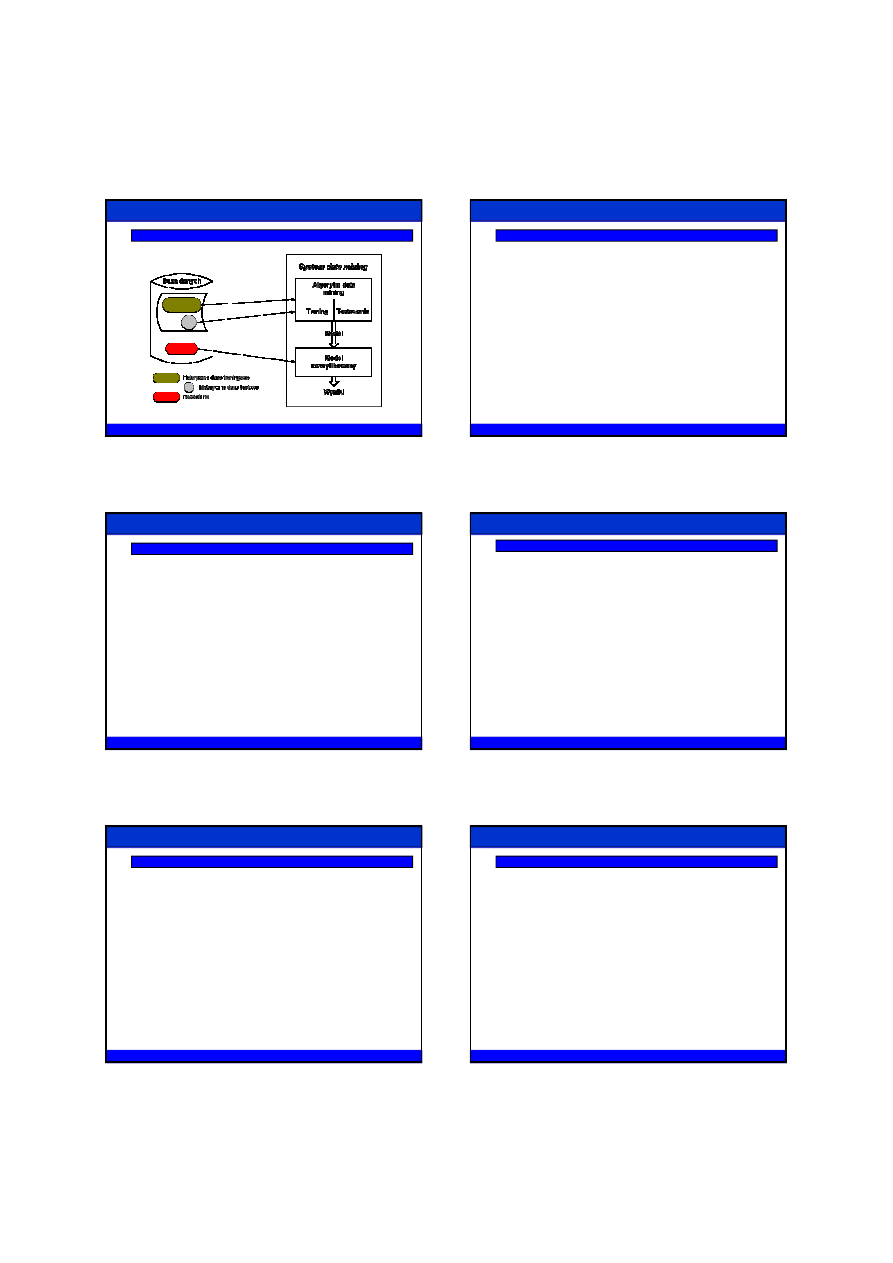
EKSTRAKCJA WIEDZY
Obszary działalno
ś
ci
Obecna sytuacja na rynku, zdominowanym przez silną konkurencję, wymusza na
organizacjach gospodarczych skupienie się na zasadniczych obszarach:
Zwiększeniu przychodów dzięki lepszej wiedzy o wymaganiach klientów,
Lepszej obsłudze klienta,
Obniżce kosztów własnych działalności, zarządzaniu ryzykiem i innych ważnych
aspektach zależnych od profilu przedsiębiorstwa.
4
EKSTRAKCJA WIEDZY
Systemy DSS
Wszystkie te aspekty działalności przedsiębiorstwa mogą być wspomagane odpowiednimi
systemami informatycznymi, które na bazie danych gromadzonych przez systemy
transakcyjnie pozwoliłyby na efektywniejsze wykorzystanie istniejącego potencjału
firmy oraz zdecydowane wsparcie procesu zarządzania. Zwłaszcza to ostanie zagadnienie
stało się domeną DSS (z ang. Decision Support Systems - Systemy Wspomagania Decyzji),
których działanie zaczyna opierać się na nowych rozwiązaniach, jakimi są hurtownie danych
wraz z metodami ekstrakcji wiedzy.
Cechy danych, które były niemożliwe do osiągnięcia w tradycyjnych systemach
transakcyjnych spowodowały powstanie nowych mechanizmów i technik pozyskiwania
informacji i wiedzy z danych gromadzonych w hurtowni.
5
EKSTRAKCJA WIEDZY
Przetwarzanie danych
Do najistotniejszych metod przetwarzania danych zaliczyć można:
□
OLAP (On-Line Analytical Processing)
□
przeszukiwanie w głąb (z ang. Drill Down)
□
odkrywanie wiedzy (z ang. Knowledge Data Discovery)
□
drążenie danych (z ang. Data Mining).
Dane zgromadzone w hurtowni danych są zoptymalizowane pod kątem ich
wyszukiwania przez analityków wykorzystujących przetwarzanie analityczne na bieżąco
(OLAP).
W związku z tym dane są zorganizowane albo w oparciu o wielowymiarową bazę
danych (MOLAP – z ang. Multidimensional On-Line Analytical Processing) lub w
oparciu o relacyjną bazę danych (ROLAP – z ang. Relational On-Line Analytical
Processing.
6
EKSTRAKCJA WIEDZY
Metody KDD
Techniki ekstrakcji wiedzy są ze sobą ściśle związane – drążenie danych (DM – z ang.
Data Mining) jest składową odkrywania wiedzy (KDD – z ang. Knowledge Data
Discovery). Pozyskiwanie wiedzy z baz danych jest stosunkowo młodą interdyscyplinarną
dziedziną badań, łączącą ze sobą doświadczenia z dziedziny statystyki, baz danych oraz
systemów uczących się i systemów odkryć.
Przedmiotem badań dziedziny pozyskiwania wiedzy w bazach danych są nietrywialne
procesy identyfikacji poprawnych, nowych, potencjalnie użytecznych i zrozumiałych
regularności w danych bez potrzeby podawania z góry listy hipotez regularności.
Data Mining stosuje technologie sieci neuronowych, drzew decyzyjnych oraz
standardowych technik statystycznych do przeszukiwania dużych ilości danych.
W procesie tym tworzone są modele, które przykładowo mogą służyć do przewidywania
zachowań klientów. Najprostszą definicją Data Mining jest automatyczne wykrywanie
zależności w bazie danych.
2009-06-03
2
7
EKSTRAKCJA WIEDZY
Integracja z bazą danych
8
EKSTRAKCJA WIEDZY
Przykłady
Przykładowo może to być stwierdzenie faktu iż, prawdopodobieństwo prowadzenia określonego
sportowego samochodu przez zamężne kobiety z dziećmi jest dwa razy większe niż przez
bezdzietne mężatki. Oczywiście przykład ten istotny będzie dla producenta lub sprzedawcy
samochodów, który może te informacje wykorzystać odpowiednio kierunkując swoją ofertę.
Samo poszukiwanie wiedzy nie jest oczywiście nowością – od lat statystycy przeszukiwali
ręcznie zasoby baz danych w celu odnalezienia istotnych zależności. Data Mining dodatkowo
stosuje techniki uczenia maszynowego i proces ten wykonuje się automatycznie
wykorzystując ogromne zbiory danych, czyli hurtownie danych. Wciąż jednak uczestnictwo
człowieka jest konieczne – odpowiednio wyszkolony analityk może podjąć decyzję o
poprawności i użyteczności uzyskanego modelu oraz o stopniu wykorzystania jego rezultatów.
9
EKSTRAKCJA WIEDZY
Nadmiar danych
Większość organizacji gospodarczych można śmiało określić jako „bogate w dane” z powodu
ogromnych ilości danych o działalności i zasobach gromadzonych przez systemy operacyjne.
Po przetworzeniu nadają się one do przedstawiania typowych faktów i wykresów np.
firma posiada 200 klientów lub dostawca X zapewnia 60% surowca Y. Niestety takie fakty
nie reprezentują istotnej wiedzy i mogą prowadzić do przeładowania informacjami.
Pomimo bogactwa danych, większość przedsiębiorstw jest „uboga w wiedzę”. Procesy KDD
oraz DM służą właśnie wypełnieniu luki w „wiedzy” o działalności przedsiębiorstwa poprzez
odpowiednie przetworzenie „bogactwa danych”.
10
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Metody KDD
Odkrycie istotnych zależności w danych dotyczących przeszłych stanów organizacji
gospodarczej pomoże polepszeniu przyszłości dzięki wykorzystaniu pozytywnych powiązań
oraz unikanie tych niekorzystnych dla firmy.
Przykładami zastosowań DM w praktycznej działalności przedsiębiorstwa może być przewidywanie
skali reakcji klientów na określoną formę marketingu, popytu na polisy ubezpieczeniowe w
zależności od wielu czynników czy też konsumpcji określonych produktów. Większość ludzi jest
lepsza w wykrywaniu anomalii niż znajdowaniu związków i relacji w dużych zbiorach danych,
dlatego właśnie odkrywanie wiedzy może stać się tak przydatne w działalności przedsiębiorstwa.
Zamiast polegać na ludzkiej intuicji można przy pomocy odpowiedniego narzędzia wykryć,
sprawdzić i wykorzystać różne powiązanie między badanymi zjawiskami.
Popularność tego nowatorskiego rozwiązanie stale wzrasta, głównie z powodu trafności i
przydatności uzyskiwanych rezultatów oraz coraz większej ilości dostępnych narzędzi. Jednak
przedsiębiorstwo decydując się na wprowadzenie metod KDD wraz z Data Mining musi rozważyć
trzy podstawowe zagadnienia: metodologię, łatwość stosowania oraz reprezentacja danych i
skalowalność. Pierwsza pojęcie czyli metodologia dotyczy kroków realizacji projektu DM. Ich
przestrzeganie ma na celu osiągnięcie podobnych
korzyści przez przedsiębiorstwo, jakie udało
osiągnąć innym po wdrożeniu DM.
11
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Terminologia
Do metod wykorzystywanych w celu zdobycia jak największej wiedzy na temat klienta należą
między innymi rozwijane w latach dziewięćdziesiątych metody wspomagania decyzji określane
jako odkrywanie wiedzy w bazach danych (ang. KDD – knowledge discovery in databases).
Obejmują one rozwiązania w zakresie automatycznego odkrywania uogólnionych reguł
i wiedzy zawartej w bazach danych. W literaturze przedmiotu spotyka się również inne
określenia na przykład metody eksploracji danych (ang. data mining), ekstrakcji wiedzy,
archeologia danych, drążenie danych. Odkrywanie wiedzy ma na celu "Pozyskanie wiedzy
wcześniej nie znanej, ale potencjalnie użytecznej".
12
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Systemy KDD
Podstawową cechą odróżniającą metody tej klasy od innych metod jest model odkrywczy
przetwarzania danych, podczas gdy tradycyjny model przetwarzania danych jest modelem
weryfikacyjnym, w którym tworzone przez analityków hipotezy są formułowane z użyciem na
przykład języków zapytań i weryfikowane na podstawie danych.
U podstaw metod odkrywania wiedzy leżą rozwiązania z zakresu uczenia maszynowego,
statystyki,
rozpoznawania
wzorców,
wnioskowania,
systemów
ekspertowych,
sztucznej
inteligencji. Technologia baz danych dostarcza narzędzi, które zapewniają gromadzenie i
manipulowanie danymi.
Coraz częściej wykorzystywane są tzw. hurtownie danych zintegrowane z narzędziami
przetwarzania danych klasy OLAP (ang. Online Analytical Processing ) umożliwiającymi
wielowymiarowe przetwarzanie. W skład procesu odkrywania wiedzy wchodzą etapy takie jak
przygotowanie danych, wybór danych, eliminacja danych błędnych, uzyskanie wiedzy,
interpretacja wyników, a do ich realizacji wykorzystuje się wymienione wcześniej dziedziny.

2009-06-03
3
13
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Metody KDD
Kolejność kroków wdrażania systemów KDD
Analiza problemu – realizacja tego etapu ma odpowiedzieć na pytanie czy dany problem
może być badany przy pomocy DM. Jeśli tak, to czy dostępne są odpowiednie dane i
technologia DM oraz w jaki sposób rezultaty poszukiwań zostaną wykorzystane biorąc pod
uwagę całość rozwiązania.
Przygotowanie danych – etap polega na ekstrakcji odpowiednich danych i transformacji
ich na wymagany format (agregacja, łączenie tabel, dodawanie pól, czyszczenie danych
itd.).
Eksploracja danych – etap ten poprzedza moment poszukiwania powiązań i relacji między
danymi. Przeprowadzana jest wizualizacja danych (tak aby użytkownik miał ich jasny
obraz) oraz sprawdzanie czy poprzednie etapy nie zawierały błędów.
14
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Metody KDD
Generowanie hipotez – przy pomocy reguł wywoływania (automatycznych lub
interaktywnych) oraz algorytmów odkrywania powiązań generowane są hipotezy, których
poprawność jest rozważana, a następnie są one interpretowane.
Rozmieszczanie hipotez – etap ten polega na umieszczeniu uzyskanych hipotez w
odpowiednich etapach analizy. Są one głownie stosowane w systemach SWD do generowania
raportów lub filtrowania danych do dalszego przetwarzania.
Monitorowanie hipotez – główną przesłanką rozmieszczania hipotez jest założenie, że
przyszłość przypomina przeszłość, więc hipotezy „historyczne” mogą mieć zastosowanie w
przyszłych sytuacjach. Jednak strategia ta jest bezpieczne tylko w momencie stałego
monitorowania hipotez „historycznych” na podstawie nowych danych i odpowiednio
szybkiego wykrywania wahań. Zbyt duże odchylenia prowadzą do konieczności porzucenia
dotychczasowych hipotez i poszukania nowych.
15
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Posta
ć
pozyskanej wiedzy
Ogólna postać reguły:
r = p => q, gdzie: p - zbiór atrybutów warunkujących
(przesłanki),q - zbiór atrybutów warunkowanych (konkluzje). Gdy R jest zbiorem atrybutów
to p
∈
R , q
∈
R – p
Częstotliwością (frequency) występowania podzbioru atrybutów X w tabeli T nazywamy
stosunek liczby wierszy (m), które zawierają atrybutu należącego do X, do liczby
wszystkich wierszy w tabeli (dbsize), co zapisujemy następująco:
c(X,T) = m/dbsize
Zbiór atrybutów X jest częsty jeśli c (X,T) >= z, gdzie z jest zadanym przez użytkownika
progiem częstotliwości występowania podzbioru atrybutów w tabeli. Częsty zbiór atrybutów
X jest maksymalny jeśli nie istnieje taki nadzbiór tego zbioru, który jest częsty .
Tzn. jeżeli dodamy dowolny atrybut do zbioru X to zbiór X przestanie być zbiorem
częstym.
16
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Posta
ć
pozyskanej wiedzy
Poparciem (support) reguły P nazywamy stosunek liczby wierszy, które zawierają
wszystkie atrybuty zawarte w przesłankach i konkluzjach, do liczby wszystkich wierszy
w tabeli.
Poparcie dla reguły X => Y odpowiada częstotliwości występowania sumy podzbiorów X U
Y w tabeli T.
po(P,T) = c(X U Y,T).
Poparcie może być również określone jako liczba wierszy w tabeli zawierających wszystkie
atrybuty zawarte w przesłankach i konkluzjach reguły
Poziom poparcia reguły - Reguła P jest na zadanym poziomie poparcia - d jeśli:
po(P,T) = q = d
17
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Posta
ć
pozyskanej wiedzy
Pewność reguły P nazywamy stosunek częstotliwości występowania sumy podzbiorów
atrybutów X U Y do częstotliwości występowania podzbioru atrybutów X.
pe(P,T) = c(X U Y,T) / c(X,T)
Reguła P jest na zadanym poziomie pewności - b jeśli
pe(P,T) = q = b
18
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Proces eksploracji danych
selekcja
przekształcenia
poszukiwanie/
odkrywanie
zależności
wizualizacja/
interpretacja
hurtownia
danych
wybrane
dane
przekształcone
dane
wydobyta
informacja
WIEDZA
Proces eksploracji baz danych
(źródło: Cezary Głowiński „Sztuka wysokiego składowania”)

2009-06-03
4
19
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Klasy problemów
Eksploracja danych posługuje się różnymi technikami, które budują specyficzne rodzaje
wiedzy. W zależności od przeznaczenia odkrywanej wiedzy, może ona odwzorowywać
klasyfikacje, regresje, klastrowanie, charakterystyki, dyskryminacje, asocjacje itp.
•KLASYFIKACJA
•REGRESJA
•KLASTROWANIE
•ODKRYWANIE CHARAKTERYSTYK
•DYSKRYMINACJA
•ODKRYWANIE ASOCJACJI
20
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY - Klasyfikacja
Klasyfikacja jest metodą analizy danych, której celem jest predykcja wartości
określonego atrybutu w oparciu o pewien zbiór danych treningowych.
Obejmuje metody odkrywania modeli (tak zwanych klasyfikatorów) lub funkcji opisujących
zależności pomiędzy zadaną klasyfikacją obiektów a ich charakterystyką. Odkryte modele
klasyfikacji są, następnie, wykorzystywane do klasyfikacji nowych obiektów o nieznanej
klasyfikacji
21
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY - Grupowanie
Grupowanie (klastrowanie) - obejmuje metody analizy danych i znajdowania skończonych
zbiorów klas obiektów posiadających podobne cechy. W przeciwieństwie do metod
klasyfikacji i predykcji, klasyfikacja obiektów (podział na klasy) nie jest znana a-priori, lecz
jest celem metod grupowania. Metody te grupują obiekty w klasy w taki sposób, aby
maksymalizować podobieństwo wewnątrzklasowe obiektów i minimalizować podobieństwo
pomiędzy klasami obiektów. Grupowanie znalazło szereg zastosowań w różnych dziedzinach
ż
ycia np. grupowanie dokumentów, grupowanie klientów czy określenia segmentacji rynku.
22
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY – Odkrywanie asocjacji
Odkrywanie asocjacji jest jedną z najciekawszych i najbardziej popularnych technik
eksploracji danych. Celem procesu odkrywania asocjacji jest znalezienie interesujących
zależności lub korelacji, nazywanych ogólnie asocjacjami, pomiędzy danymi w dużych
zbiorach danych. Wynikiem procesu odkrywania asocjacji jest zbiór reguł asocjacyjnych
opisujących znalezione zależności lub korelacje między danymi. Sztandarowym przykładem
reguły asocjacyjnej jest reguła wygenerowana w odniesieniu do bazy danych supermarketu:
„klienci, którzy kupują pieluszki, kupują również piwo”. Celem tej analizy jest znalezienie
naturalnych wzorców zachowań konsumenckich klientów poprzez analizę produktów, które są
przez klientów supermarketu kupowane najczęściej wspólnie np.: „klienci, którzy kupują
chleb, masło i ser, kupują również wodę mineralną i ketchup”.
W odniesieniu do reguł asocjacyjnych znalezionych w bazie supermarketu reguły te można
wykorzystać przykładowo do opracowania akcji promocyjnych, programów lojalnościowych,
planowaniu
kampanii
promocyjnych,
planowanie
rozmieszczeń
stoisk
sprzedaży
w
supermarketach, opracowania koncepcji katalogu oferowanych produktów i wiele innych.
23
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY – Odkrywanie asocjacji 2
Market Basket Analysis znajduje zastosowanie wszędzie tam, gdzie „klienci” nabywają
łącznie pewien zbiór dóbr lub usług: może to być analiza pogody, w której koszykiem będzie
zbiór zdarzeń pogodowych, występujących w danym przedziale czasu. Telekomunikacja, gdzie
koszykiem będzie zbiór rozmów telefonicznych, oraz wiele innych dziedzin życia np.:
diagnostyka medyczna czy też bankowość.
Modelując koszyk zakupów, możemy odnieść się do pewnej abstrakcji umożliwiającej
modelowanie relacji
wiele-do-wiele pomiędzy wspomnianymi
encjami
„Produkty” i
„Koszyki”. Model koszyka zakupów modelujemy najczęściej w postaci tzw. tablicy
obserwacji.
Wynik analizy koszyka zakupów przedstawiany jest w formie zbioru reguł asocjacyjnych
Przykład: „jeżeli klient kupił produkty Ai1, Ai2, ..., Aik, to prawdopodobnie kupił
również produkty Aik+1, Aik+2, ..., Aik+l”.
Z każdą binarną regułą asocjacyjną są związane dwie miary określające statystyczną ważność
i siłę reguły: {wsparcie} reguły (ang. support) oraz {ufność} reguły (ang. confidence).
24
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY – Odkrywanie asocjacji 3
Z punktu widzenia typu przetwarzanych danych wyróżniamy dwa rodzaje reguł asocjacyjnych:
(1) {binarne reguły asocjacyjne} (ang. binary lub Boolean association rules) oraz (2)
{ilościowe reguły asocjacyjne} (ang. quantitative association rules).
Regułę asocjacyjną nazywamy {binarną regułą asocjacyjną}, jeżeli dane występujące w regule
są danymi (zmiennymi) binarnymi, to znaczy, danymi, które mogą przyjmować tylko dwie
wartości: '1' ({true}) lub '0' ({false}).
Regułę asocjacyjną nazywamy {ilościową regułą asocjacyjną}, jeżeli dane występujące w
regule są danymi ciągłymi i\lub kategorycznymi. Ilościowe reguły asocjacyjne reprezentują,
najogólniej mówiąc, współwystępowanie wartości niektórych danych.

2009-06-03
5
25
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY – Odkrywanie asocjacji 4
Binarne reguły asocjacyjne reprezentują współwystępowanie danych. Przykładem binarnej
reguły asocjacyjnej może być reguła: „pieluszki=1 -> piwo=1”; Reguła ta wywiedziona w
ramach analizy koszyka zakupów klientów supermarketu, stwierdza, że produkt 'pieluszki'
często występuje w koszykach klientów łącznie z produktem 'piwo'.
Przykładem ilościowej reguły asocjacyjnej jest reguła: „wiek =’30…40’ ? wykształcenie =
‘wyższe’ -> opcja_polityczna = ‘demokrata’. Ilościowe reguły asocjacyjne reprezentują
współwystępowanie wartości niektórych danych. Reguła wywiedziona z analizy danych
osobowych, stwierdza, że jeżeli wiek pracownika należy do przedziału wartości '30...40' i
pracownik posiada wykształcenie wyższe, to, często, jego poglądy polityczne zwrócone są w
kierunku demokracji. Atrybut {wiek} jest atrybutem ciągłymi, natomiast atrybuty
{wykształcenie oraz opcja_polityczna} są atrybutami kategorycznym.
W procesie odkrywania ilościowych reguł asocjacyjnych, atrybuty ciągłe podlegają
dyskretyzacji. Stąd, w regule wartością atrybutu {wiek} jest pewien przedział wartości.
26
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY – Odkrywanie wzorców sekwencji
Odkrywanie wzorców sekwencji polega na analizie bazy danych zawierającej informacje o
zdarzeniach, które wystąpiły w określonym przedziale czasu, w celu znalezienia zależności
pomiędzy występowaniem określonych zdarzeń w czasie. Przykładem wzorca sekwencji, który
można znaleźć w bazie danych wypożyczalni filmów video, jest następujący wzorzec
zachowania klientów wypożyczalni: ‘Klient, który wypożyczył tydzień temu film pod tytułem
Gwiezdne wojny, w ciągu tygodnia wypożyczy film pt.Imperium kontratakuje, a następnie, w
ciągu kolejnego tygodnia, wypożyczy film pt. Powrót Jedi'. Zauważmy, że zdarzenia
wchodzące w skład wzorca sekwencji nie muszą występować bezpośrednio jedno po drugim -
mogą być przedzielone wystąpieniem innych zdarzeń. W odniesieniu do przedstawionego
powyżej wzorca sekwencji, oznacza to, że klient, pomiędzy wypożyczeniem filmu pt.
Imperium kontratakuje a Powrót Jedi, wypożycza zwykle jeszcze inny film, ale podana
sekwencja opisuje typowe zachowanie większości klientów wypożyczalni.
27
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY – Odkrywanie wzorców sekwencji 2
Metoda odkrywania wzorców sekwencji znalazła zastosowanie w wielu dziedzinach: analiza
koszyka
zakupów,
telekomunikacja,
medycyna
(znajdowanie
skutecznej
terapii),
ubezpieczenia i bankowość, planowanie inwestycji giełdowych, przewidywanie sprzedaży,
WWW, itd. W przypadku analizy koszyka zakupów, metodę odkrywania wzorców sekwencji
stosuje się w celu znalezienia typowych wzorców zachowań klientów w czasie. Dotyczy to
handlu hurtowego lub półhurtowego, gdy potrafimy zidentyfikować pojedynczego klienta i
jego koszyk zakupów. W takim przypadku, z każdym rekordem opisującym zakupy
pojedynczego klienta jest związana, dodatkowo, informacja o kliencie (identyfikator klienta) i
o dacie zakupów (etykieta czasowa rekordu). Na podstawie danych opisujących zakupy danego
klienta, uporządkowanych zgodnie z wartościami etykiet czasowych można uzyskać profil
klienta i próbować przewidzieć jego zachowanie w czasie.
28
EKSTRAKCJA WIEDZY Z BAZ DANYCH
METODY – Odkrywanie charakterystyk
Metoda odkrywania charakterystyk. Metoda ta polega na znajdowaniu zwięzłych opisów
(charakterystyk) podanego zbioru danych, czy też znajdowaniu zależności funkcyjnych
pomiędzy zmiennymi opisującymi zbiór danych. Przykładem wykorzystania odkrywania
charakterystyk może być opis pacjentów chorujących na anginę. Celem jest określanie
powszechnych symptomów wskazanej choroby, czyli w przypadku anginy możemy podać
następującą charakterystykę ‘pacjenci chorujący na anginę cechują się temperaturą ciała
większą
niż
37.5C,
bólem
gardła
i
osłabieniem
organizmu’
29
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Problemy odkrywania wiedzy
W dużych bazach danych czy też hurtowniach danych mogą zostać odkryte tysiące reguł, a ich
analiza jest bardzo czasochłonna często niemożliwa do realizacji w rozsądnym czasie.
Czynnik ludzki, człowiek nie potrafi zrozumieć i przeanalizować dużych zbiorów informacji.
Specyficzne wymagania użytkowników, różni użytkownicy systemu bazy danych są
zainteresowani różnymi typami reguł z różnych relacji.
Problemy efektywnościowe - odkrywanie reguł jest procesem bardzo złożonym obliczeniowo i
wymaga dużego nakładu pracy.
30
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Klasy problemów
Data mining stosuje się w każdej gdzie z dużych ilości danych należy wydobyć użyteczną
informację.
•
Bankowość
•
Telekomunikacja
•
Ubezpieczenia
•
Logistyka
•
Planowanie strategii inwestycyjnych
•
Opieka zdrowotna
•
Zarządzanie przedsiębiorstwem
•
Marketing
•
Badania naukowe

2009-06-03
6
31
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Zastosowania
Stosowanie systemów odkrywania wiedzy w bazach danych pozwala na znaczącą poprawę
jakości produkcji oraz podniesienie poziomu zysków. Poniżej przedstawiono kilka
najpopularniejszych „sukcesów” odkrywania wiedzy w bazach danych dużych przedsiębiorstw:
Database Marketing
„Database Marketing” polega na analizie danych o klientach w celu znajdowania schematów ich
preferencji i następnie wykorzystywania tych schematów dla precyzyjnej selekcji kolejnych
klientów.
„Database Marketing” w American Express doprowadził do 10-15% wzrostu zakupów z
wykorzystaniem kart kredytowych.
32
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Zastosowania
Weryfikacja poprawności danych
Reuters stosuje techniki eksploracji danych dla weryfikacji poprawności i wykrywania
prawdopodobnych przekłamań w wysokości publikowanych kursów wymiany walut.
Profil klienta
BBC przy pomocy systemu eksploracji danych przewiduje profil widowni programów
telewizyjnych w celu wyboru optymalnych pór ich nadawania.
33
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Zastosowania
Wykrywanie oszustw finansowych
Polega na znajdowaniu transakcji finansowych, których cechy odbiegają od
statystycznie dominującej charakterystyki finansowej bazy danych.
34
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Zastosowania
Na przykład zmniejszenie liczby odchodzących klientów do konkurencji
WINTERTHUR INSURANCE - 1 milion klientów
1996 – początek utraty klientów
BAZA DANYCH – dane o klientach (250 cech)
30 CECH – cechy wpływające na decyzję
SKUTECZNOŚĆ – 66,7%
35
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Oprogramowanie
Na rynku dostępne są zintegrowane środowiska programowe, które umożliwiają odkrywanie
wiedzy w najbardziej popularnych systemach zarządzania bazami danych.
Intelligent Miner, IBM
Zestaw narzędzi realizujących algorytmy odkrywania klasyfikacji i asocjacji, klastrowania,
wykrywania odchyleń itp. Pozwala na eksplorację danych zgromadzonych w bazach DB2,
Oracle lub Sybase, współpracując z IBM DataJoiner dla przygotowania danych.
Jest zorientowany na realizację następujących zastosowań odkrywania wiedzy: segmentacja
klientów, analiza koszyka i wykrywanie oszustw finansowych. Intelligent Miner pracuje
m.in. w systemach AIX, AS/400, OS/390, korzystając z architektury klient-serwer.
36
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Oprogramowanie
MineSet, Silicon Graphics
Ś
rodowisko, które dostarcza narzędzi dla przygotowywania danych, eksploracji danych i
wizualizacji wiedzy. Wspierane metody eksploracji to: odkrywanie reguł asocjacyjnych,
klasyfikacja za pomocą drzew decyzyjnych, klasyfikacja na podstawie niepełnych
danych i szacowanie klasyfikującej siły atrybutów relacji.
MineSet umożliwia animację i trójwymiarową wizualizację danych, drzew
decyzyjnych i reguł. Środowisko pracuje na komputerach SGI O2, Octane, Onyx, Origin 200,
Origin 2000, Indy, Indigo2, Onyx I Challenge. Dane mogą być pobierane bezpośrednio z
systemów baz danych Oracle, Informix i Sybase.

2009-06-03
7
37
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Oprogramowanie
Clementine, Integral Solutions
Pakiet umożliwiający znajdowanie klasyfikacji w danych pobieranych z baz typu Oracle,
Ingres, Sybase i Informix, z plików tekstowych lub z arkuszy kalkulacyjnych. Możliwa jest
szeroka selekcja danych,łączenie krotek, definiowanie atrybutów wywiedzionych. Dane mogą
być przedstawiane w postaci graficznej.
System wykorzystuje sieci neuronowe, drzewa decyzyjne i reguły.
Jest wyposażony w interfejs programowania graficznego: użytkownik przy pomocy budowy
graficznego schematu przetwarzania danych definiuje, w jaki sposób Clementine będzie
pobierać dane, eksplorować i prezentować wyniki.
38
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Oprogramowanie
Data Mining Suite, Information Discovery
Przeznaczony jest do odkrywania wiedzy w bardzo dużych zbiorach danych.
Automatycznie znajduje reguły, schematy i anomalie w bazach danych. Proces
odkrywania wiedzy może przebiegać automatycznie, bądź też może być nadzorowany
i kierowany przez użytkownika.
System buduje raporty w języku naturalnym.
Dodatkowo, środowisko wyposażone jest w moduł Predictive Modeler, służący do
predykcji na podstawie odkrytych reguł i schematów. Wspierane są następujące techniki
eksploracjidanych: klasyfikacja, klastering, odkrywanie charakterystyk, analiza
zależności, wykrywanie odchyleń. Data Mining Suite korzysta z baz danych poprzez
interfejs SQL.
39
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Oprogramowanie
Weka
Zbiór algorytmów uczenia maszynowego i bibliotek Java opracowany na Uniwersytecie
Waikato (Nowa Zelandia).
Zaimplementowano algorytmy ekstrakcji wiedzy m.in., klasyfikacji, grupowania,
regresji wykrywania reguł asocjacyjnych oparty na algorytmie Apriori.
Pakiet obliczeniowy dostępny w oparciu o licencję Open Source dla różnych platform
sprzętowo programowych. Zawiera graficzny interfejs i narzędzia wizualizacji danych i
wyników obliczeń.
40
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
@relation heart-disease-simplified
@attribute age numeric
@attribute sex { female, male}
@attribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina}
@attribute cholesterol numeric
@attribute exercise_induced_angina { no, yes}
@attribute class { present, not_present}
@data
63,male,typ_angina,233,no,not_present
67,male,asympt,286,yes,present
67,male,asympt,229,yes,present
38,female,non_anginal,?,no,not_present
41
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
42
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
2009-06-03
8
43
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
44
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
45
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
46
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
47
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Pakiet obliczeniowy WEKA
48
EKSTRAKCJA WIEDZY Z BAZ DANYCH
Przykłady wizualizacji z innych pakietów
Wyszukiwarka
Podobne podstrony:
bd w12
KZ BD w12 id 256669 Nieznany
bd w12
BD w12
BD 2st 1 2 w12 tresc 1 1
bd cz 2 jezyki zapytan do baz danych
bd normalizacja
W12 mod
model BD
w12
wde w12
Handout w12 2011
BD Wykład 3 2011
Eurasia topsoil Bd
więcej podobnych podstron