
The Predictive Value of Subjective
Labour Supply Data:
A Dynamic Panel Data Model
with Measurement Error
Rob Euwals
Aneta Dzik
Anna Kalinowska
Ekonometria II: modele panelowe

2
1. Modele panelowe.
Termin dane panelowe odnosi się do zbioru obserwacji określonych jednostek
(tych samych) w kolejnych okresach czasu.
Gromadzenie tego rodzaju danych rozpoczęto w latach 60. w Stanach
Zjednoczonych. W latach 80. zaczęły być gromadzone także w Europie.
Przykłady:
• USA: Panel Study of Income Dynamics (PSID), National Longitudinal
Surveys of Labor Market Experience (NLS)
• Kanada: Survey of Labour Income Dynamics (SLID)
• Europa :
o
Niemiecki panel socjo-ekonomiczny (GSEOP),
o
Francuski panel gospodarstw domowych (1985-1990),
o
Węgierski panel gospodarstw domowych (1992-1996),
o
Brytyjski panel gospodarstw domowych (BHSP) od 1991,
o
EuroStat -The European Community Household Pane (ECHP) od 1994.
Wykorzystanie danych panelowych umożliwia kontrolę indywidualnej
heterogeniczności. W porównaniu do szeregów czasowych i danych przekrojowych
panele zawierają więcej informacji, dzięki temu są lepsze do badanie dynamiki
dostosowań, umożliwiają identyfikacje i zmierzenie większej ilości efektów, a także
pozwalają konstruować i testować bardziej złożone modele zachowań. Dane
panelowe są gromadzone na poziomie mikro, dzięki czemu unika się błędów
związanych z agregacją.
Z wykorzystaniem danych panelowych wiążą się również pewne ograniczenia,
związane są one przede wszystkim z procesem gromadzenia danych – długim
okresem obserwowania poszczególnych jednostek (braki danych, błędy pomiaru,
samoselekcja).
2. Przedmiot badania.
Przedmiotem badanie jest subiektywna podaż pracy oraz kwestia czy na jej
podstawie da się w jakiś sposób przewidzieć przyszłą podaż pracy jednostki.
Problemem jest fakt w jakim stopniu subiektywna odpowiedź na pytanie „ile
chciałbyś pracować” ma odbicie w rzeczywistych decyzjach jednostki.
Według tradycyjnej metodologii należ badać tylko preferencje ujawnione poprzez
działania, gdyż deklarowane obciążone są dużym błędem pomiaru. Jednakże dane

3
dotyczące subiektywnych preferencji mogą nieść pewne ważne informacje, dotyczące
między innymi kwestii elastyczności rynku pracy, czy preferencji osób bezrobotnych.
Wobec tego kluczową kwestią staje się kategoria błędu pomiaru wynikającego
zarówno z indywidualnych cech jednostki, jak i czysto losowego.
3. Kategorie czasu pracy:
hc
it
– zakontraktowany czas pracy (wynikając z kontraktu)
ht
it
– całkowity czas pracy =hc+ nadgodziny
or
it
– w jaki sposób wynagradzane są nadgodziny
(A) dodatkowa zapłata
(B) kompensowane dodatkowym czasem wolnym
(C) częściowo zapłata, częściowo czas wolny
(D) nie wynagradzane w żaden sposób
hd
it
– pożądany czas pracy przy zalozeniu, odpowiednich zmian w dochodzie z pracy
hp
it
(paid actual working hours) – czas pracy, za który otrzymuje się wynagrodzenie.
hp
it
= hc
it
+ I(or
it
=‘A’)(ht
it
-hc
it
)+½ I(or
it
=‘C’)(ht
it
-hc
it
)
4. Dynamiczne modele panelowe.
W przypadku modeli dynamicznych, skorelowanie zmiennych objaśniających z
błędem losowym, powoduje obciążenie większości typowych estymatorów.
Estymatory Random Effect i First Diffrence są obciążone zawsze, estymator Fixed
Effect jest nieobciążony jedynie w przypadku gdy tÆnieskończoności (w praktyce w
przypadku bardzo długich paneli).
W takim wypadku stosuje się zwykle metodę zmiennych instrumentalnych,
wykorzystującą zmienne skorelowane ze zmiennymi objaśniającymi, a nie
skorelowane z błędem losowym.
Arellano
i
Bond (1991) proponują wykorzystanie wszystkich możliwych
instrumentów, których liczba różni się w kolejnych okresach.
Przykład: dysponujemy panelem o długości 5 okresów (T=5), czyli t=1,...,5.
t=1 i t=2 Æ brak instrumentów
t=3
Æ
(
)
{
}
0
y
ε
ε
E
i,1
i,2
i,3
=
−
t=4
Æ
(
)
{
}
0
y
ε
ε
E
i,2
i,3
i,4
=
−
ale także
Æ
(
)
{
}
0
y
ε
ε
E
i,1
i,3
i,4
=
−
t=5 Æ
(
)
{
}
0
y
ε
ε
E
i,3
i,4
i,5
=
−

4
ale także Æ
(
)
{
}
0
y
ε
ε
E
i,2
i,4
i,5
=
−
i Æ
(
)
{
}
0
y
ε
ε
E
i,1
i,4
i,5
=
−
Przykład instrumentu: y
i, t-2
- skorelowane z (y
i,t-1
-y
i,t-2
)ale niezależne od ε
i,t
- ε
i,t-1
(o ile składnik losowy nie wykazuje autokorelacji, co zakładamy).
5. Postaci estymowanych modeli.
Model na poziomach
Zmienne z * - rzeczywiste wartości, bez * - obserwowane.
Mamy dynamiczny model panelowy z dość nietypową postacią błędu –
wynika to z uwzględnienia błędu pomiaru postaci v = v
i
+v
it
(v
i
– błąd właściwy dla
danej jednostki i stały w czasie, v
it
–taki klasyczny błąd ).
Autorzy
artykułu chcieli sprawdzić możliwość przewidywania na podstawie
subiektywnej podaży pracy (parametr beta 2) , hipotezą zerową jestbrak możliwości
przewidywania rzeczywistego czasu pracy na podstawie subiektywnego czasu pracy z
poprzedniego okresu (to co ludzie mówią nie ma żadnego wpływu na to co robią).
Wykorzystano uogólnioną metodę momentów (zmiennych instrumentalnych) i
procedurę bardzo zbliżoną do metody Arelano – Bonda. Jedyna różnica wynikała z
tego, że nie można było jako instumentu użyć drugiego opóźnienia (ha
it-2
skorelowany
z υ
a
it-2
) a dopiero trzeciego (ha
it-3
)
• Pierwsze różnice (aby pozbyć się efektów indywidualnych):
• Postać estymatora:
βGMM = ([∆ha
-1
,∆hd
-1
]’Z WN Z’[∆ha
-1
,∆hd
-1
])-1 ([∆ha
-1
,∆hd
-1
]’Z W
N
Z’∆ha)
Δha - wektor pierwszych opóźnień , Z-Macierz instrumentów (Z=[Z1’,...,Zn’], gdzie
Zi - macierz blokowo-diagonalna, każdy wiersz zawiera instrumenty prawidłowe dla
danego okresu).
)
(
)
(
)
)
1
(
(
1
2
1
1
2
1
1
2
1
1
0
*
*
*
1
2
*
1
1
0
*
d
it
a
it
d
it
it
d
i
a
i
i
it
it
it
d
it
d
i
it
it
a
it
a
i
it
it
it
i
it
it
it
v
v
v
v
v
hd
ha
ha
v
v
hd
hd
v
v
ha
ha
hd
ha
ha
−
−
−
−
−
−
−
−
+
+
−
−
+
+
+
+
=
+
+
=
+
+
=
+
+
+
+
=
β
β
ε
β
β
ε
β
β
β
ε
ε
β
β
β
)
(
)
(
)
(
)
(
)
(
)
(
2
1
2
2
1
1
1
1
2
1
2
2
1
1
1
d
it
d
it
a
it
a
it
a
it
a
it
it
it
it
it
it
it
it
it
v
v
v
v
v
v
hd
hd
ha
ha
ha
ha
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
+
+
−
+
−
+
−
=
−
β
β
ε
ε
β
β
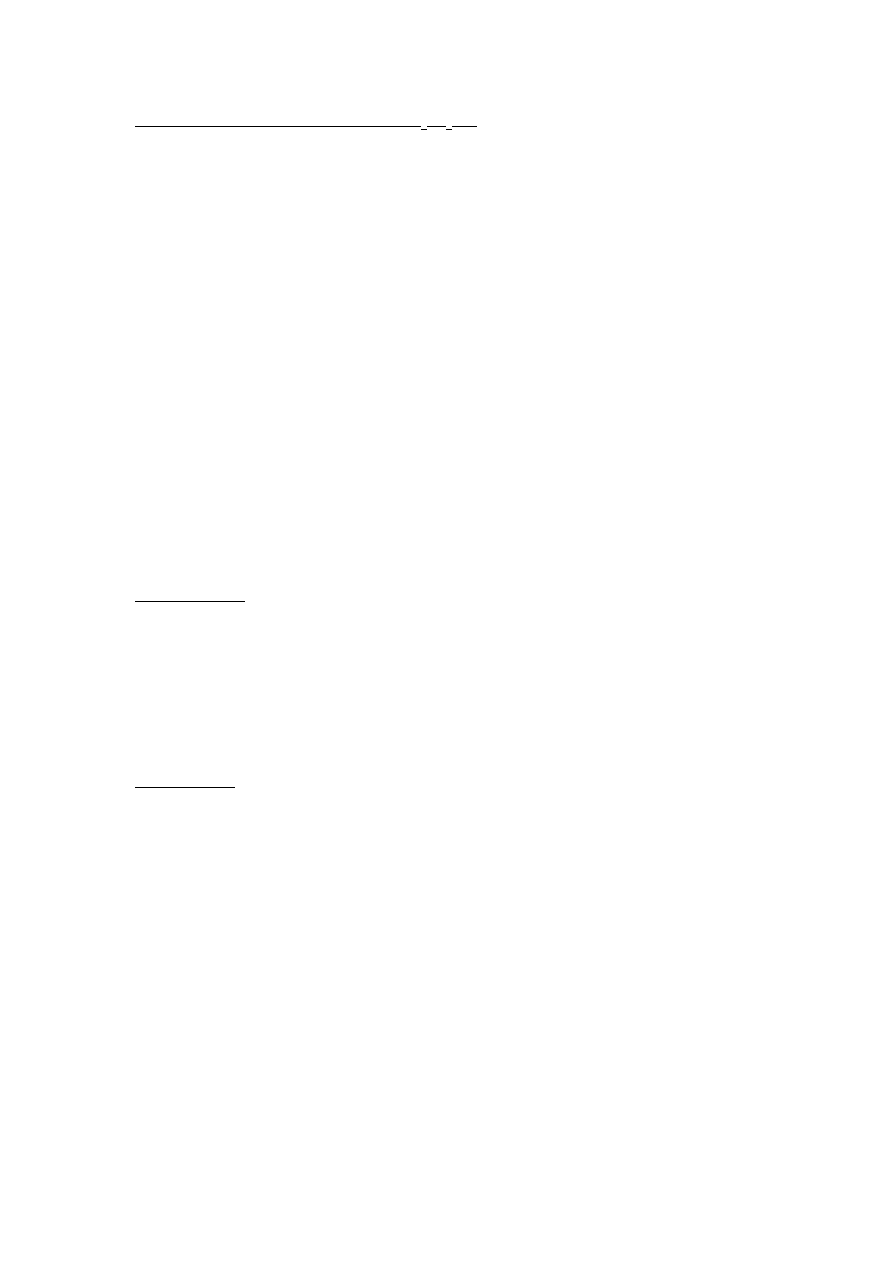
5
Model na różnicach (z ograniczeniem β
1
+β
2
=1)
Czy różnica między pożądanym a rzeczywistym czasem pracy dobrze
prognozuje zmianę czasu pracy w następnym okresie?
Sens ograniczenia- model rozdziela zdolność do prognozowania pomiędzy
pożądany i rzeczywisty (opóźniony) czas pracy. Ograniczenie to wyklucza
możliwość, ze aktualny czas pracy wynika jedynie z efektów indywidualnych.
W tym modelu, mimo że nie jest to typowy model dynamiczny (nie zawiera
opóźnionej zmiennej zależnej), występuje problem endogeniczności, mimo, że nie jest
to typowy model dynamiczny. Wobec tego można zastosować estymacje analogiczna
jak w przypadku modelu na poziomach.
6. Wykonane estymacje.
Na poziomach:
6.1. LEV-OLS – klasyczny model liniowy nieuwzględniający „dynamiczności”
modelu.
6.2. LEV-ME – GMM, jako instrumenty wykorzystane są opóźnienia o 3 i więcej
okresów (wykorzystane wszystkie możliwe instrumenty) – omówiona w
poprzednim punkcie.
Na różnicach:
• DIF-FE – model stałych efektów indywidualnych
• DIF-AB – model Arellano
i
Bonda, jako instrumenty wykorzystane
opóźnienia o dwa i więcej okresów
• DIF-ME – omówiona wcześniej metoda GMM
7. Dane.
Dane pochodzą z niemieckiego panelu socjo-ekonomicznego (GSOEP). Respondenci
to zatrudnieni w wieku 18-60 lat z wykluczeniem imigrantów. Badanie dotyczy lat
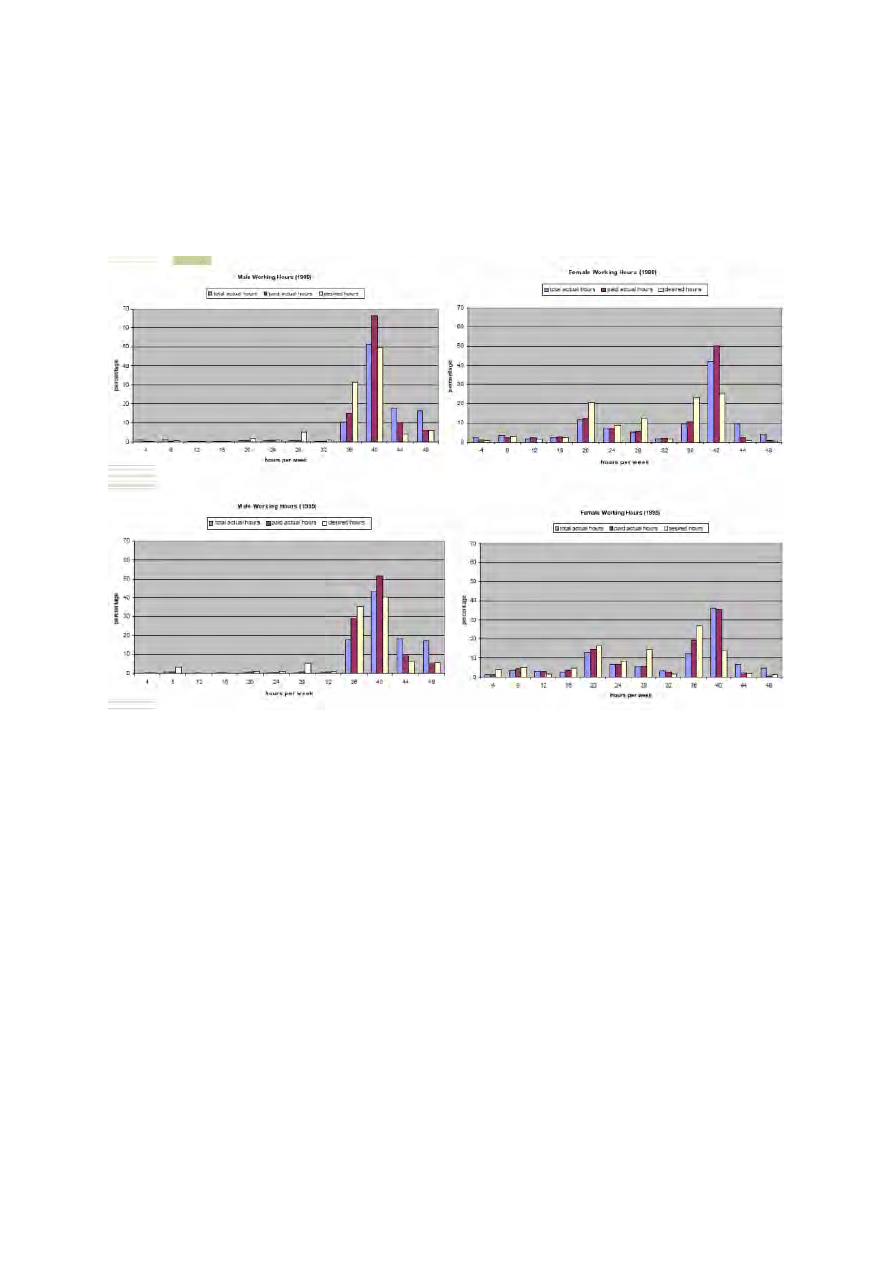
1988-1996. Artykuł zawiera tablicę ze statystykami opisowymi. Na jej podstawie
można stwierdzić, że dla mężczyzn istnieje spadkowy trend w opłacanym czasie
pracy (paid working hours). Aczkolwiek całkowite godziny pracy wydają się
)
(
)
(
)
(
)
(
)
(
1
2
1
2
1
2
1
1
2
0
1
*
1
*
1
2
0
*
1
*
a
it
d
it
a
it
a
it
it
a
i
d
i
it
it
it
it
it
it
it
it
it
v
v
v
v
v
v
ha
hd
ha
ha
ha
hd
ha
ha
−
−
−
−
−
−
−
−
−
−
−
−
+
+
−
+
−
+
=
−
+
−
+
=
−
β
β
ε
β
β
β
ε
β
β
6
nieobjęte tym spadkiem. Dla kobiet w obu przypadkach mamy trend spadkowy.
Autorzy uznają to jako konsekwencję rozprzestrzeniania się redukcji czasu pracy w
tamtych latach i rosnącą liczbą przypadków part-time zatrudnienia (zwłaszcza wśród
kobiet).
Powyższe wykresy pokazują rozkład aktualnych i planowanych godzin pracy. To co
można zauważyć na pierwszy rzut oka to redukcja czasu pracy. Liczba mężczyzn
pracujących 40 godzin tygodniowo spada na przestrzeni lat 1988-1995 z około 66%
do 51%. Rośnie natomiast liczba mężczyzn pracujących oraz chcących pracować 36
godzin tygodniowo. Wykresy dla kobiet również wykazują tendencję do ograniczania
godzin pracy. Widać tendencję do podejmowania pracy part-time. Okazuje się jednak,
że podaż pracy kobiet przy 28 godzinach tygodniowo znacznie przekracza popyt.
Artykuł zawiera tabelę pokazującą sukces predykcji mierzony średnią ważoną. Dla
mężczyzn: 41,9% dla płatnych godzin pracy, 41,6% dla łącznych godzin pracy. A dla
kobiet 42,1% dla płatnych godzin pracy, 44% dla łącznych godzin pracy. Co
oznaczałoby, że kobietom częściej udaje się robić to, co sobie zaplanowały
(zwiększać, zmniejszać lub nie zmieniać godzin pracy). Ale by potwierdzić te
wczesne uwagi konieczna jest estymacja modelu.

7
8. Wyniki estymacji.
• Wyniki dla modeli dynamicznych z błędem pomiaru.
LEV-OLS
W przypadku braku efektów indywidualnych i błędów pomiaru ta metoda daje
estymator zgodny i efektywny. Współczynniki, zarówno dla łącznych jak i
opłacanych godzin pracy, są dodatnie i istotne. Ale mamy tu autokorelację
pierwszego rzędu, co oznacza, że estymator nie jest zgodny. Nie możemy zatem
interpretować wyników.
LEV-ME
Model uwzględnia autokorelację. Brak autokorelacji drugiego rzędu oznacza, że
zostały użyte dobre instrumenty. Współczynniki okazują się jednak mało różne od
zera.
DIF-FE
Współczynniki, zarówno dla łącznych jak i opłacanych godzin pracy, są dodatnie i
istotne.
DIF-AB
Dwa razy opóźnione zmienne są dobrymi instrumentami, współczynniki dodatnie, ale
mało różne od zera.
DIF-ME
Współczynniki są nieistotne.
Na podstawie testu Hausmana należy odrzucić H0 mówiącą o nieobecności efektów
indywidualnych.
Autor podsumowuje wyniki różnych estymacji stwierdzeniem, że są one sprzeczne i
na ich podstawie nie można orzec, że subiektywne dane mogą służyć do predykcji.
Wniosek ten dotyczy zarówno mężczyzn jak i kobiet.
• Wyniki dla modeli z ograniczeniem.
LEV-ME
Model uwzględnia autokorelację. Brak autokorelacji drugiego rzędu oznacza, że
zostały użyte dobre instrumenty. Współczynniki, zarówno dla łącznych jak i
opłacanych godzin pracy, są dodatnie i istotne. Jeśli zatem założenie o braku efektów

8
indywidualnych jest prawdziwe, to można stwierdzić, że subiektywne dane mogą
służyć do predykcji.
Test Hausmana na brak efektów indywidualnych: nie ma podstaw do odrzucenia H0
DIF-ME
Współczynniki są nieistotne.
Dla kobiet Test Hausmana wskazuje na istnienie efektów indywidualnych dla
opłacanych godzin pracy, a brak dla łącznych.
9. Podsumowanie.
Autor badał zdolność danych subiektywnych (planowane godziny pracy) do
prognozowania rzeczywistego czasu pracy w następnym okresie. Użył do estymacji
modelu dynamicznego tłumaczącego aktualną liczbę godzin pracy opóźnioną
planowaną i opóźnioną aktualną liczbą godzin pracy. Autor posłużył się również
modelem z ograniczeniem tłumaczącym zmiany (dostosowania) w aktualnych
godzinach pracy na podstawie opóźnionych różnic między planowanym a aktualnym
czasem pracy. Użyty został estymator GMM, zaproponowany przez Arellano i
Bonda, gdzie błąd pomiaru jest wzięty pod uwagę przez użycie odpowiednio
opóźnionych zmiennych jako instrumentów.
Wniosek:
Opóźnione planowane godziny nie mają zdolności do przewidywania
wartości poziomu aktualnych godzin pracy.
Wyszukiwarka
Podobne podstrony:
gmm v1 streszczenie
markov v1-streszczenie
markov v1 streszczenie
nieparametryczne v1 streszczenie
panele v1 prezentacja id 348812 Nieznany
duration analysis v1-streszczenie
panele v3-streszczenie
panele v3 streszczenie
panele v2 streszczenie
duration analysis v1 streszczenie
gmm v1 streszczenie
więcej podobnych podstron