
Akademia Górniczo-Hutnicza
im. Stanisława Staszica w Krakowie
Wydział Elektrotechniki, Automatyki,
Informatyki i Elektroniki
Katedra Informatyki
Kierunek studiów: Informatyka
Specjalność: Systemy komputerowe
Praca Dyplomowa
Obiektowe bazy danych –
przegląd i analiza rozwiązań
Promotor:
Autorzy:
prof. dr hab. inż. Antoni Ligęza
Paweł Józwik
Maciej Mazur
Kraków 2002

Podziękowania
Pragniemy złożyć serdeczne podziękowania dla
Promotora naszej pracy, prof. dr hab. inż. Antoniego Ligęzy.
Praca ta powstała z jego inicjatywy, a jej zrealizowanie
było możliwe dzięki jego wsparciu i życzliwości.
Paweł Józwik
Maciej Mazur
2

Spis treści
EFINICJE DOTYCZĄCE OBIEKTOWOŚCI
........................................................................................ 9
ORÓWNANIE RELACYJNYCH I OBIEKTOWYCH BAZ DANYCH
...................................................... 45
3

ROZSZERZENIA OBIEKTOWE W RELACYJNYCH BAZACH DANYCH......................... 85
Kluczowe cechy obiektowe modelu relacyjno-obiektowego w Oracle ............................... 86
Dodatkowe narzędzia ułatwiające obsługę rozszerzeń obiektowych ................................. 97
4

....................................................................................... 105
......................................................................................... 126
5

1 Wstęp
Obiektowe bazy danych spotyka się obecnie coraz częściej w rozmaitych
zastosowaniach. Zdobywają one coraz to nowe obszary, gdzie ich właściwości dają im
przewagę nad systemami relacyjnymi. Dużym atutem obiektowych baz danych jest
struktura, która naturalnie odpowiada strukturze modelującej rzeczywiste zjawiska i
która jest z powodzeniem stosowana w obecnych językach programowania. Badania
nad modelem obiektowym w bazach danych są obecnie prowadzone intensywnie w
wielu ośrodkach naukowych; rozwijane są również komercyjne implementacje.
1.1 Cel
pracy
W chwili obecnej brak jest w literaturze pozycji, która obejmowałaby tematykę
obiektowych baz danych w sposób całościowy, z uwzględnieniem najnowszych
tendencji zarówno jeżeli chodzi o podstawy teoretyczne i przegląd istniejących
standardów, jak i o systemy działające w praktyce. Niniejsza praca ma za zadanie
wypełnić tę lukę.
W kolejnych rozdziałach będziemy starali się przybliżyć problematykę obiektowych
baz danych. W pierwszej części pracy zostaną omówione teoretyczne podstawy
obiektowości oraz algebry obiektowej. Później zostanie zaprezentowany rys historyczny
rozwoju baz danych, zaczynając od płaskich plików, poprzez modele hierarchiczne,
sieciowe, relacyjne, aż po obiektowe. W następnej części pracy zostaną omówione
istniejące standardy obiektowych baz danych. W niniejszej pracy zostaną przedstawione
przede wszystkim trzy główne standardy, czyli SQL:1999, ODMG oraz JDO.
Praca ma w zamierzeniach przedstawić problematykę obiektowych baz danych w
sposób kompleksowy, tak aby osoba będąca nawet laikiem w tej dziedzinie mogła
wyrobić sobie ogólny pogląd w tym temacie oraz poznać najbardziej rozpowszechnione
obecnie standardy.
Praca ta ma również na celu propagować zagadnienia związane z obiektowymi
bazami danych. Zastanawiając się, dlaczego obiektowe bazy danych tak trudno torują
sobie drogę na rynku zdominowanym przez relacyjne bazy, można dojść do wniosku, że
jednym z powodów na pewno jest niedoinformowanie. Wynikiem tego jest stosowanie
6

produktów innych niż obiektowe bazy danych w zastosowaniach, gdzie właśnie
obiektowe bazy danych byłyby najwłaściwszym rozwiązaniem.
Bez rzetelnej informacji na temat tych produktów niewielu inżynierów uwierzy, iż
bardziej korzystne może być zainwestowanie w obiektowe bazy danych. Tymczasem
zostało wielokrotnie dowiedzione, że na przykład do zastosowań związanych ze
składowaniem multimediów obiektowe bazy danych nadają się lepiej niż na przykład
relacyjne. Również czas tworzenia aplikacji jest krótszy gdy nie ma potrzeby
mapowania modelu obiektowego, wykorzystywanego w procesie projektowania i
programowania aplikacji, do modelu relacyjnego w jakim dane są najczęściej
przechowywane w bazach.
Niniejsza praca przedstawia ogólne omówienie problematyki obiektowych baz danych.
Może ona posłużyć jako podstawa do dalszych studiów związanych z wybranym
aspektem, bądź konkretnym produktem.
1.2 Zawartość pracy
Rozdział drugi ma na celu przedstawienie teoretycznych podstaw obiektowości i
algebry obiektowej. Omówione zostały podstawowe pojęcia obiektowości, takie jak:
obiekt, identyfikator obiektu, tożsamość obiektu, klasa, atrybut, metoda, komunikat,
hermetyzacja, hierarchia klas i dziedziczenie. W rozdziale tym porównane zostały różne
definicje pojawiające się w literaturze. Dodatkowo przedstawiono wybrane pojęcia
wykraczające poza model podstawowy, takie jak: polimorfizm, obiekty złożone oraz
zarządzanie wersjami.
W związku z tym, iż nie istnieje jedna ogólnie przyjęta algebra obiektowa, w pracy
skupiono się na propozycji algebry obiektowej określonej mianem AQUA. Jej autorami
są dobrze znani na tym polu naukowcy, co pozwala uważać tę algebrę za w dużym
stopniu reprezentatywną. W pracy przedstawiono składnię oraz podstawowe operatory
algebry.
Kolejny rozdział omawia etapy w rozwoju baz danych. Przegląd rozpoczęto od
najstarszych systemów przechowywania danych, działających w oparciu o
przetwarzanie płaskich plików. Następnie przybliżono działanie baz danych opartych na
hierarchicznym modelu danych, potem na modelu sieciowym CODASYL, aby wreszcie
7

zaprezentować najpopularniejsze obecnie relacyjne bazy danych. Ostatecznie
przedstawiono obiektowe bazy danych, będące tematem niniejszej pracy. Rozdział ten
zawiera także prezentację systemów będących swoistym pomostem pomiędzy
relacyjnymi a obiektowymi bazami danych, czyli obiektowo-relacyjnych baz danych.
Zaprezentowane zostało także porównanie relacyjnych i obiektowych baz danych.
Następny rozdział zawiera prezentację standardów w zakresie obiektowych baz
danych. Omówione zostały trzy najważniejsze obecnie standardy. Pierwszym z nich jest
SQL:1999 (SQL3), rozwinięcie standardu relacyjnego języka SQL, efekt współpracy
organizacji ANSI oraz ISO. Następnie omówiono propozycje standaryzacyjne ODMG
(Object Database Management Group). Jest to grupa, której głównym celem jest
opracowywanie standardów dla obiektowych baz danych, które to standardy bardzo
często są implementowane w produktach komercyjnych. Ostatnim przedstawionym
standardem jest JDO (Java Data Object). Jest to najnowsza propozycja, stworzona i
promowana przez firmę Sun Microsystems, będąca interfejsem Javy do baz danych.
W kolejnym rozdziale przedstawione zostały rozszerzenia obiektowe
wprowadzone w relacyjnych bazach danych: Oracle oraz PostgreSQL. Baza danych
Oracle to bardzo zaawansowana i najbardziej ceniona baza na świecie. Natomiast
PostgreSQL jest bardzo popularnym, niekomercyjnym systemem zarządzania bazą
danych. Wprowadzone rozszerzenia pozwalają zaliczyć opisywane systemy do rodziny
obiektowo-relacyjnych baz danych, jednakże ich rdzeń nadal stanowi model relacyjny.
Następny rozdział stanowi przegląd dostępnych obecnie na rynku najbardziej
popularnych systemów obiektowych baz danych. Przedstawione zostały następujące
produkty: ObjectStore, Objectivity/DB, Versant, FastObjects, GemStone/J,
GemStone/S, Matisse, Jasmine, GOODS, Titanium, Orient oraz EyeDB. Przy każdym z
tych produktów zaprezentowano jego historię, budowę, udostępniane usługi i
możliwości zastosowań.
8

2 Teoria
2.1 Definicje
dotyczące obiektowości
Zagadnienie obiektowych baz danych powstało jako efekt prac w wielu
dziedzinach. Wpływ na jego rozwój miały nowe tendencje, jakie pojawiały się w
obiektowych językach programowania, inżynierii oprogramowania, a także w pracach
dotyczących systemów rozproszonych, systemów multimedialnych oraz komunikacji
przez WWW. Nowe kierunki rozwoju zarysowały się również w technologii
tradycyjnych, relacyjnych baz danych.
Obecnie występuje pewnego rodzaju zamieszanie związane ze znaczeniem
obiektowości w ogóle, a znaczeniem obiektowych baz danych w szczególności. Wiele
osób traktuje termin „zorientowany obiektowo” jako rodzaj modnego sformułowania,
mieszczącego w sobie wiele znaczeń. Wielu ekspertów stara się określić silne,
techniczne kryteria związane z terminem obiektowości, aby umożliwić rozróżnienie
systemów zorientowanych obiektowo od pozostałych.
Co przemawia za wykorzystaniem obiektowości w bazach danych? Istnieje kilka
koncepcji. Najbardziej popularna mówi, iż bazy danych składają się raczej z obiektów
niż relacji, tabel czy innych struktur. Pojęcie „obiektu” jest rodzajem metafory,
odnoszącej się do ludzkiej psychiki, sposobu w jaki ludzie myślą i postrzegają świat
rzeczywisty. Ewolucja wykształciła w umysłach ludzkich mechanizmy umożliwiające
nam wyodrębnianie obiektów w naszym środowisku, nazywanie ich i
przyporządkowywanie im pewnych cech i zachowań. Obiektowość w technologii
komputerowej, z psychologicznego punktu widzenia, jest więc oparta na wrodzonych
mechanizmach ludzkiego umysłu.
Kolejnym zagadnieniem jest potrzeba obiektowości w technologii
komputerowej. Przez wiele lat eksperci wskazywali na negatywny syndrom, określany
mianem kryzysu oprogramowania (ang. software crisis). Kryzys oprogramowania może
być przedstawiany jako efekt wzrastających kosztów produkcji oprogramowania i jego
utrzymania, problemów związanych z oprogramowaniem spadkowym (ang. legacy
9

software), ogromnym ryzykiem związanym z niepowodzeniem projektów
informatycznych, niedojrzałością metod projektowania i konstrukcji oprogramowania,
brakiem niezawodności, różnego rodzaju frustracjami projektantów oprogramowania i
programistów i wielu tym podobnych czynników. Jednocześnie wraz z
przedstawionymi zagrożeniami stale wzrasta rola systemów informatycznych jako
czynników krytycznych w misji konkretnego przedsiębiorstwa.
Kryzys oprogramowania jest więc powodowany przez skomplikowanie
oprogramowania i złożoność metod jego wytwarzania.
Obiektowość, będąca próbą naśladowania naturalnej psychiki człowieka, jest
postrzegana jako sposób na zmniejszenie złożoności oprogramowania, a w efekcie na
zredukowanie negatywnych zjawisk związanych z kryzysem oprogramowania. Ma to
zostać uczynione poprzez skrócenie dystansu pomiędzy ludzkim postrzeganiem
dziedziny problemu, abstrakcyjnym modelem konceptualnym dziedziny problemu
(wyrażonym przykładowo za pomocą diagramu klas), a podejściem programisty
zorientowanym na struktury danych i operacje. Zmniejszenie dystansu pomiędzy
postrzeganiem problemu przez projektantów, a myśleniem programistów, jest uważane
za najważniejszy czynnik zmniejszający złożoność analizy, projektowania, konstrukcji i
utrzymania oprogramowania.
Obiektowe modele dostarczają pojęć umożliwiających analitykom i
projektantom lepsze odwzorowanie problemu w abstrakcyjny schemat konceptualny. W
skład tych pojęć wchodzą między innymi: złożone obiekty, klasy, dziedziczenie,
kontrola typów, metody powiązane z klasami, hermetyzacja i polimorfizm. Istnieje
kilka notacji i metodologii (przykładowo OMT, UML, OPEN), które pozwalają na
wydajne odwzorowywanie problemu w zorientowany obiektowo model konceptualny.
Z drugiej strony, systemy obiektowych baz danych oferują podobne pojęcia odnośnie
struktur danych, tak więc odwzorowywanie pomiędzy modelem konceptualnym a
strukturami danych jest dużo łatwiejsze, niż w przypadku tradycyjnych systemów
relacyjnych.
Model obiektowy przede wszystkim dostarcza wyższego poziomu abstrakcji w
sposób bardziej skuteczny, konsekwentny i jednorodny. Dotyczy on głównie struktur
danych przechowywanych w obiektowej bazie danych. Wyznacza intelektualną i
10

ideologiczną bazę pozwalającą na budowę modeli obiektowych struktur danych oraz na
komunikację. Jest on spójnym zestawem własności, pojęć, terminologii, notacji i
formalizmów służących do:
− porozumiewania się profesjonalistów,
− uczenia i objaśniania metod i technik obiektowych,
− budowy języków, systemów, interfejsów,
− budowy i objaśniania zasad analizy i projektowania obiektowego.
W stosunku do modelu relacyjnego, obiektowość wprowadza znacznie więcej
pojęć, często o niezbyt precyzyjnej semantyce. Z jednej strony obiektowość stara się
uogólnić i rozszerzyć ideologiczne założenia modelu danych, z drugiej strony stara się
objąć nimi te pojęcia, które w modelu relacyjnym nie dały się wyrazić.
W chwili obecnej nie istnieje jeden, ogólnie przyjęty, standard jednoznacznie
definiujący pojęcia obiektowe. Trwają prace nad ustandaryzowaniem pojęć
obiektowych w dziedzinie baz danych, prowadzone między innymi przez ODMG.
Brak powszechnie akceptowalnych definicji modelu obiektowego w dziedzinie
baz danych wynika z faktu, iż rozwój podejścia obiektowego następował w trzech
różnych obszarach:
− językach programowania,
− sztucznej inteligencji,
− bazach danych.
W różnych językach programowania i reprezentacji wiedzy przyjęto różne
interpretacje pojęć obiektowych. Jednak mimo to, obiektowe języki programowania i
reprezentacji wiedzy zawierają wiele spójnych pojęć obiektowych, na podstawie
których można stworzyć podstawowy, obiektowy model danych.
Przedstawione poniżej pojęcia są podstawowymi dla obiektowości i według
[Kim 1996] wchodzą w skład podstawowego modelu obiektowego:
− obiekt,
− identyfikator obiektu,
11

− tożsamość obiektu,
− klasa,
− atrybut,
− metoda,
− komunikat,
− hermetyzacja,
− hierarchia klas i dziedziczenie.
W kolejnych rozdziałach pracy zostaną przybliżone przedstawione powyżej pojęcia.
2.1.1 Obiekt
Obiekt (ang. object) jest podstawowym pojęciem dla obiektowości. W pracy
[Subieta 1999a] obiekt jest definiowany jako abstrakcyjny byt, reprezentujący lub
opisujący pewną rzecz lub pojęcie obserwowane w świecie rzeczywistym. Obiekt jest
odróżnialny od innych obiektów, ma nazwę i dobrze określone granice.
Obiektem może być także pewna abstrakcja programistyczna. Mogą istnieć obiekty
programistyczne, które nie posiadają swoich odpowiedników w świecie rzeczywistym.
Obiektem może być pewien zamknięty fragment oprogramowania (dana, procedura,
moduł itp.), którymi programista może operować jak pewną zwartą bryłą. Obiektom
przypisuje się cechy takie jak: tożsamość, stan i operacje. Obiekt posiada nazwę,
jednoznaczną identyfikację, określone granice, atrybuty i inne własności.
Tenże autor uważa, iż wiele prac nie różnicuje pojęcia obiektu jako pewnej
abstrakcji pojęciowej lub informacyjnej, struktury danych określanej jako „obiekt”
przechowywanej wewnątrz komputera oraz konkretnego obiektu istniejącego w świecie
rzeczywistym. Stwierdza on jednak, iż z metodologicznego punktu widzenia takie
rozróżnienie jest konieczne i wynika zwykle z kontekstu.
Przykładami obiektów ze świata rzeczywistego są: miasto Kraków, faktura,
konkretna osoba czy model samochodu. Obiektami nie są przykładowo: śnieg, woda,
piasek.
1
W literaturze istnieje pojęcie nieobiektu (ang. non-object). W pracy [Subieta 1999a] jest ono
przedstawione jako „coś, co nie jest obiektem”. Autor ten stwierdza, iż nieobiektowość w informatyce
wciąż czeka na swego odkrywcę, ideologa i guru.
12

RYSUNEK 2.1. GRAFICZNA PREZENTACJA OBIEKTU.
2.1.2 Identyfikator obiektu
Opierając się na definicji przedstawionej przez [Subieta 1999a], identyfikator
obiektu (ang. object identifier) jest to unikalna wewnętrzna nazwa obiektu, nadawana
automatycznie przez system i nie posiadająca znaczenia w świecie zewnętrznym. Służy
on do odróżnienia obiektu od innych obiektów oraz do budowy odwołań prowadzących
do obiektu.
[Lausen 2000] stwierdza, iż identyfikator przypisany do obiektu pozostaje
niezmienny w całym cyklu jego życia. W konsekwencji identyfikator obiektu jest różny
od jego wartości, która może ulegać zmianom.
W pracy [Subieta 1999a] poruszony jest także problem unikalności
identyfikatorów. Autor uważa, iż pojęcie unikalnego identyfikatora obiektu staje się
dość trudne w przypadku istnienia wielu kopii tego samego obiektu, lub w przypadku
istnienia wielu wersji obiektu. Istnienie unikalnych identyfikatorów obiektów czyni w
zasadzie zbędnym pojęcie klucza
, występujące w modelu relacyjnym.
Zdarza się, że identyfikator obiektu jest związany logicznie z adresem miejsca
przechowywania obiektu. Jednakże związek tego rodzaju jest uważany za niekorzystny
jeśli chodzi o elastyczność w zakresie ulokowania obiektu, z drugiej jednak strony bywa
konieczny z uwagi na wymaganą wydajność.
13
2
Klucz jest atrybutem, bądź zestawem atrybutów, których wartości są wykorzystywane w celu unikalnej
identyfikacji. Jest to zbiór minimalny.

[Ludwikowska 2000] dodaje, iż identyfikator obiektu jest ważnym elementem
semantyki języków dostępu i manipulacji obiektami. W praktyce nie występuje
bezpośrednie posługiwanie się wartością identyfikatora obiektu, lecz wykorzystywane
jest pewne oznaczenie symboliczne, przykładowo nazwa obiektu, które następnie w
procesie wiązania jest zmieniane na jego identyfikator.
2.1.3 Tożsamość obiektu
Tożsamość obiektu (ang. identity) jest pojęciem ściśle wiążącym się ze
zdefiniowanym wcześniej pojęciem identyfikatora obiektu.
Oznacza ono, iż obiekt istnieje i jest odróżnialny od innych obiektów niezależnie od
jego aktualnego stanu, który może się zmieniać. Tożsamość obiektu jest kategorią
filozoficzną, która nie jest wiązana z jakimkolwiek zestawem atrybutów obiektu lub
jego aktualnym stanem. Dopuszczalne jest istnienie dwóch różnych obiektów o
identycznych wartościach atrybutów. W praktyce tożsamość oznacza istnienie
unikalnego wewnętrznego identyfikatora, nie ulegającego zmianom w trakcie życia
obiektu. Tożsamość obiektu jest niezależna od jego lokacji w świecie rzeczywistym lub
w przestrzeni adresowej komputera [Subieta 1999a].
2.1.4 Klasa
Wszystkie obiekty mające ten sam zbiór atrybutów i metod, mogą zostać
zgrupowane w jednej klasie. Obiekt należy do klasy jako jej instancja (wystąpienie).
Klasa stanowi wzorzec dla tworzonego obiektu. Klasa jest również bytem
semantycznym, rozumianym jako miejsce przechowywania, specyfikacji i definicji
takich cech grupy podobnych obiektów, które są dla nich niezmienne: atrybuty, metody,
ograniczenia dostępu, dozwolone operacje na obiektach, wyjątki.
W systemach obiektowych klasa jest traktowana jako obiekt klasowy w celu
zagwarantowania jednolitego posługiwania się komunikatami. W związku z tym, z
klasą mogą być związane atrybuty i metody klasowe (statyczne). W atrybutach takich
przechowywane są wartości wspólne dla wszystkich obiektów tej klasy [Ludwikowska
2000].
14

Istnieje wiele rodzajów klas. Do najważniejszych z nich można zaliczyć: klasę
abstrakcyjną oraz klasę konkretną.
Pojęcie klasy abstrakcyjnej (ang. abstract class) jest uważane za jedno z
podstawowych dla obiektowości, wzmacniające zarówno mechanizmy abstrakcji
pojęciowej, jak i możliwości ponownego użycia. Klasa abstrakcyjna zawiera własności,
które są dziedziczone przez jej podklasy, ale jednocześnie nie posiada bezpośrednich
wystąpień obiektów. Stanowi ona wyższy poziom abstrakcji podczas rozpatrywania
pewnego zestawu obiektów. Najczęściej wykorzystuje się klasy abstrakcyjne do
zdefiniowania wspólnego interfejsu dla pewnej liczby podklas. Klasa abstrakcyjna
może posiadać metody, które są wyspecyfikowane w jej wnętrzu, a których
implementacja jest oczekiwana w jej bezpośrednich lub pośrednich podklasach.
W odróżnieniu od klasy abstrakcyjnej, klasa konkretna (ang. concrete class)
może posiadać bezpośrednie wystąpienia obiektów.
RYSUNEK 2.2. GRAFICZNA PREZENTACJA KLASY.
2.1.5 Atrybut
Atrybuty (ang. attributes), będące częścią definicji klasy, poprzez przypisywane
im wartości tworzą stan obiektu. Atrybuty obiektu są analogiczne do atrybutów
(kolumn) krotki relacji w relacyjnych bazach danych. Dziedziną atrybutu może być
jakakolwiek klasa, wliczając w to klasy wartości pierwotnych (np. integer, string itp.). Z
powyższego faktu wynika zagnieżdżona struktura definicji klasy. Klasa składa się ze
zbioru atrybutów, dziedzinami których mogą być inne klasy z ich własnymi zbiorami
15

atrybutów, itd. W wyniku tego definicja klasy określa skierowany graf klas o korzeniu
w tej klasie [Kim 1996].
W literaturze pojawia się wiele rodzajów atrybutów. Wśród nich można
wyróżnić [Subieta 1999a]:
− atrybut prosty (ang. simple attribute, atomic attribute) – przechowuje dokładnie
jedną wartość, będącą z punktu widzenia użytkownika wartością niepodzielną
(atomową).
− atrybut złożony (ang. complex attribute, composite attribute) – przechowuje
wiele wartości niepodzielnych (atomowych). Atrybut taki może posiadać
strukturę hierarchiczną.
− atrybut klasowy (ang. class attribute) – nazywany także statycznym. Nazwa i
wartość takiego atrybutu jest wspólna dla wszystkich wystąpień danej klasy.
− atrybut powtarzalny (ang. repeating attribute) – przechowuje zestaw wartości o
nieokreślonej i zmiennej w czasie liczbie elementów.
− atrybut pochodny (ang. derived attribute) – nazywany także wyliczalnym.
Przechowuje wartość, która jest wyliczana na podstawie innych atrybutów, bądź
też innych danych.
− atrybut wskaźnikowy (ang. pointer attribute) – atrybut, którego wartością jest
wskaźnik prowadzący zwykle do pewnego obiektu.
− atrybut opcyjny (ang. optional attribute) – atrybut, którego wartość może być
pusta, lub który może być nieobecny w konkretnym wystąpieniu obiektu.
Opcyjność może dotyczyć atrybutu dowolnego rodzaju. Atrybut ten można
uważać za specjalny przypadek atrybutu powtarzalnego, w którym liczba
elementów zestawu wartości wynosi zero lub jeden.
− atrybut domyślny (ang. default attribute) – atrybut ten wiąże się pojęciowo z
przedstawionym wcześniej atrybutem opcyjnym. Oznacza on wartość
przyjmowaną domyślnie, o ile nie została wstawiona żadna inna wartość.
2.1.6 Metoda
Metoda (ang. method) to procedura, funkcja lub operacja przypisana do klasy
obiektów i dziedziczona przez jej podklasy. Identyfikacja stanu obiektu oraz
16

identyfikacja zmiany stanu obiektu są możliwe dzięki metodom związanym z danym
obiektem. W przypadku idealnym, metody zdefiniowane przez programistę powinny
być jedynym sposobem dostępu do obiektu.
Metoda jest abstrakcją programistyczną tej samej kategorii co procedura lub
procedura funkcyjna. Metoda, w przeciwieństwie do procedury, działa w środowisku
obiektu po wysłaniu do niego komunikatu zawierającego nazwę tej metody. Metoda
wykorzystuje wewnętrzne informacje tego obiektu, jakimi są przede wszystkim
wartości atrybutów.
Z koncepcyjnego punktu widzenia miejscem przechowywania metody jest
odpowiednia klasa. Oznacza to, że metoda takowa może zostać zastosowana do
dowolnego obiektu będącego instancją tej klasy.
Istnieje kilka charakterystycznych metod posiadających odrębne nazewnictwo.
Zaliczyć do nich można następujące rodzaje metod:
− metoda abstrakcyjna (ang. abstract method) – jest to metoda, której specyfikacja
znajduje się w danej klasie, ale której implementacje znajdują się w podklasach.
− metoda fabrykująca (ang. factory method) – nazywana inaczej konstruktorem.
Służy do tworzenia nowych obiektów.
− metoda klasowa (ang. class method) – metoda ta nie działa na pojedynczych
wystąpieniach danej klasy (obiektach), lecz na całej ekstensji klasy.
2.1.7 Komunikat
Komunikat (ang. message) jest sygnałem skierowanym do obiektu,
wywołującym określoną metodę lub operację, którą należy wykonać na obiekcie.
Nazwa użyta w komunikacie jest nazwą wywoływanej metody. Źródłem komunikatu
jest działający aktualnie program, w szczególności może to być wykonywana aktualnie
metoda. Komunikat może posiadać parametry; zwykle jest ich co najwyżej kilka, w
każdym razie parametry komunikatu nie służą do przenoszenia większej ilości
informacji.
Obiekt otrzymujący komunikat wykonuje odpowiednią metodę, która to
metoda może zmienić jego stan. W efekcie wykonania metody na obiekcie, który
otrzymał komunikat, może zostać zwrócona odpowiedź do nadawcy komunikatu.
17

W wielu opracowaniach uważa się, że zarówno komunikat, jak i nazwy
występujące w ciele metody są dynamicznie wiązane, w związku z czym ten sam
komunikat może zostać wysłany do różnych obiektów i może wywołać różne metody.
Fakt ten posiada istotne znaczenie dla metod oraz technik projektowania i
programowania [Subieta 1999a].
2.1.8 Hermetyzacja
Hermetyzacja (ang. encapsulation) polega na grupowaniu elementów
składowych w obrębie jednej bryły i umożliwieniu manipulowania tą bryłą jako
całością. Hermetyzacja wiąże się z ukrywaniem pewnych informacji dotyczących
struktury i implementacji wnętrza tej bryły [Ludwikowska 2000].
Hermetyzacja jest podstawową techniką abstrakcji, czyli ukrycia wszelkich
szczegółów danego przedmiotu lub bytu programistycznego, które na danym etapie
rozpatrywania (analizy, projektowania, programowania) nie stanowią jego istotnej
charakterystyki [Subieta 1999a].
Pojęcie hermetyzacji, jako jedna z zasad inżynierii oprogramowania, zostało
sformułowane przez D. Parnasa w roku 1975.
Można wyróżnić dwie koncepcje hermetyzacji: hermetyzacja ortodoksyjna oraz
hermetyzacja ortogonalna.
Pierwsza z nich, hermetyzacja ortodoksyjna, jest dość popularnym stereotypem
w obiektowości. Ten rodzaj hermetyzacji został zaimplementowany między innymi w
języku Smalltalk. W tym podejściu wszelkie operacje, jakie można wykonać na
obiekcie, są określone przez metody do niego przypisane (znajdujące się w jego klasie i
nadklasach). Bezpośredni dostęp do atrybutów obiektu jest niemożliwy.
Drugim rodzajem jest hermetyzacja ortogonalna, zaimplementowana między
innymi w językach C++ i Eiffel. W tym przypadku dowolny atrybut i metoda obiektu
mogą być prywatne (czyli niedostępne z zewnątrz), bądź też publiczne.
2.1.9 Hierarchia klas i dziedziczenie
Klasy w systemie tworzą hierarchię klas (ang. class hierarchy). Oznacza to, że
dla pewnej klasy A może istnieć inna klasa (jedna lub więcej) B, znajdująca się na
18
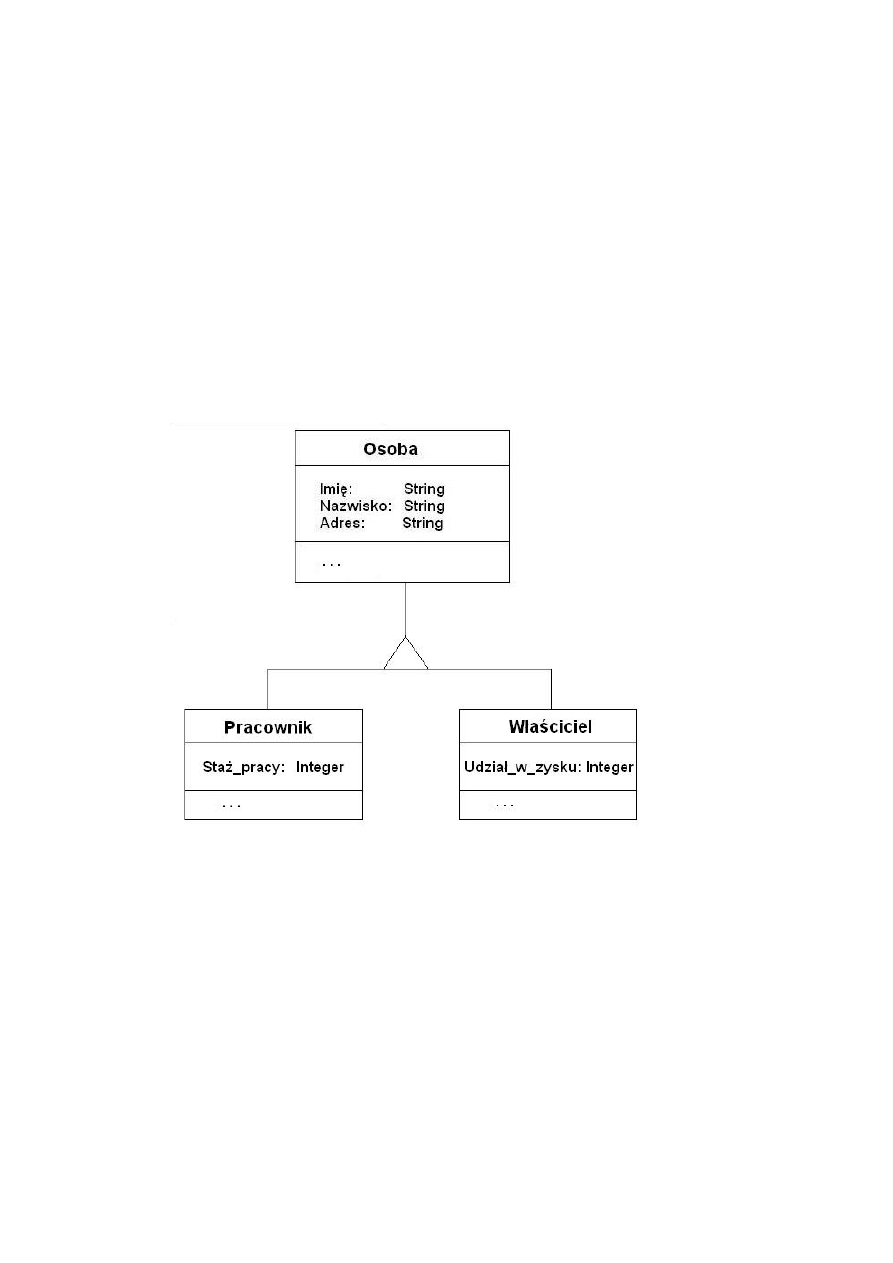
niższym poziomie, która jest uszczegółowieniem (specjalizacją) klasy B. Natomiast
klasa A, będąca na wyższym poziomie w hierarchii, jest uogólnieniem (generalizacją)
klasy (klas) B. Klasa B dziedziczy wszystkie atrybuty i metody klasy A, mogąc
jednocześnie posiadać własne atrybuty i metody. Określone dla klasy A atrybuty i
metody są rekurencyjnie dziedziczone przez wszystkie jej podklasy (rys. 2.3).
Większość systemów obiektowych posiada predefiniowaną przez system klasę,
stanowiącą jedyny korzeń dla wszystkich klas w systemie. Hierarchia klas jest spójna,
co oznacza, że nie istnieją odizolowane węzły, natomiast do każdego węzła (klasy)
istnieje dostęp z korzenia.
RYSUNEK 2.3. HIERARCHIA KLAS I DZIEDZICZENIE.
Cechą wspólną dla wszystkich bez wyjątku systemów obiektowych jest to, że
klasa może posiadać dowolną liczbę podklas. Jednakże w pewnych systemach klasy
mogą mieć tylko jedną nadklasę, natomiast w innych klasy mogą mieć dowolną liczbę
nadklas.
19

Pierwszy przypadek, kiedy klasa dziedziczy atrybuty i metody od tylko jednej
klasy, nazywany jest dziedziczeniem pojedynczym (ang. single inheritance). W sytuacji
takiej każda klasa ma co najwyżej jedną nadklasę.
Drugi przypadek dotyczy klasy, która dziedziczy atrybuty i metody od więcej
niż jednej nadklasy. Sytuacja taka nosi nazwę dziedziczenia wielokrotnego (ang.
multiple inheritance). Jeżeli system umożliwia wielokrotne dziedziczenie, wówczas
klasy tworzą zakorzeniony spójny skierowany graf acykliczny, nazywany czasem kratą
klas. Nie ma porozumienia odnośnie tego, czy wielokrotne dziedziczenie jest naprawdę
konieczne. Jednakże pomimo tego, iż ten rodzaj dziedziczenia komplikuje model
danych, wydaje się, że jest ono potrzebne i jego zaakceptowanie jest nieuniknione [Kim
1996].
Metody odziedziczone mogą zostać przeciążone. Oznacza to, iż podklasa może
zmodyfikować działanie odziedziczonej metody nie zmieniając jej nazwy.
Pojęcie dziedziczenia stwarza pewne problemy, takie jak: konflikty nazw, zasięg
dziedziczenia, naruszenia hermetyzacji. Są to jednak sytuacje charakterystyczne dla
programowania obiektowego, dlatego nie należy ich traktować jako wady rzutujące
negatywnie na decyzje, czy stosować dziedziczenie.
2.1.10 Pojęcia wykraczające poza model podstawowy
Przedstawione powyżej pojęcia wchodzące w skład podstawowego modelu
obiektowego w większości przypadków zaspokajają podstawowe wymagania dotyczące
modelowania danych. Istnieje jednak wiele ważnych pojęć, które są istotne w wielu
przypadkach, ale które nie należą do pojęć podstawowych.
W tym rozdziale postaramy się przedstawić trzy z takich pojęć. Są to:
polimorfizm, obiekty złożone oraz zarządzanie wersjami.
Polimorfizm (ang. polymorphism) w terminologii obiektowej oznacza
możliwość istnienia wielu metod o takiej samej nazwie, powiązaną z możliwością
wyboru konkretnej metody podczas czasu wykonania (dynamicznego wiązania).
Wybór nazwy jest określany wyłącznie jej zewnętrznym, pojęciowym znaczeniem w
ramach danej klasy obiektów. Wybór ten nie jest uwarunkowany własnościami lub
20

istnieniem innych klas. Identyczny komunikat wysłany do różnych obiektów może
wywołać różne metody.
Obiekt złożony (ang. complex object, composite object) składa się z innych
obiektów. Obiekty takowe wywodzą się z obiektów atomowych lub już
skonstruowanych za pomocą pewnych konstruktorów. W celu obsługi obiektów
złożonych muszą zostać dostarczone odpowiednie operatory na nich operujące. W
szczególności, musi istnieć możliwość działania na całych obiektach lub też tylko na ich
części.
Obiekty złożone posiadają wewnętrzną strukturę, czyli składają się z prostszych
składników. Wartości składników mogą być częścią wartości obiektu lub wiązać się z
obiektem za pomocą odwołań. Zaletą tej ostatniej procedury jest możliwość powtórnego
użycia informacji poprzez dzielenie obiektów.
Obiekty złożone w naturalny sposób występują w większości dziedzin
zastosowania systemów baz danych. Dostępne obecnie obiektowe systemy baz danych
w szerokim zakresie obsługują obiekty złożone [Lausen 2000].
Trzecim z kolei pojęciem jest zarządzanie wersjami.
Funkcjonalność systemu
obiektowych baz danych musi objąć szereg żądań o szerszym zakresie niż stawiane
systemom konwencjonalnym. Wynika to głównie z nowych obszarów, w których może
mieć zastosowanie ten nowy typ baz danych. Przykładowo w aplikacjach CAD lub
CASE, występują wersje poszczególnych obiektów projektu, które są tworzone i
ewentualnie odrzucane podczas procesu projektowania. Wersje obiektów są łączone w
konfiguracje, które w efekcie mogą dać produkty do wytworzenia. Jeśli system bazy
danych ma właściwie obsługiwać taki rodzaj środowiska, musi oferować zarządzanie
wersjami [Lausen 2000].
3
Wersją nazywany jest zarejestrowany stan obiektowej bazy danych w przeszłości lub równorzędny,
alternatywny stan bazy danych dotyczący pewnego projektu. Wersja obiektu oznacza zarejestrowany stan
obiektu w przeszłości [Subieta 1999a].
21

2.2 Algebra
obiektowa
Algebra obiektowa jest z założenia matematyczną podstawą semantyki
obiektowych języków zapytań, wzorującą się na algebrze relacji. W odróżnieniu od
algebry relacyjnej, operatory wprowadzane przez algebrę obiektową działają na
zbiorach obiektów i zwracają zbiory obiektów. Celem prac nad algebrami obiektowymi
jest potrzeba takiego sformalizowania modelu obiektowego i semantyki języków
zapytań, ażeby możliwe było przeprowadzanie dowodów poprawności technik
optymalizacji zapytań.
Jak stwierdza autor [Subieta 1999a], cel ten nie został jak dotąd osiągnięty.
Tenże autor uważa, iż obecnie istniejące propozycje algebr obiektowych są niespójne
koncepcyjnie, dość skomplikowane, niedostatecznie uniwersalne i mają luźne związki z
rygorystyczną matematyką.
Pomimo takowych opinii, istnieje wiele prób stworzenia algebry obiektowej. W
niniejszej pracy oparto się na algebrze zaproponowanej w [Leung 1993]. Autorami tej
algebry są dobrze znani na tym polu naukowcy. Jako że byli oni współtwórcami kilku
wcześniejszych algebr, proponowana przez nich algebra AQUA jest efektem
doświadczeń zdobytych podczas poprzednich prac.
2.2.1 Składnia
Wyrażenia w algebrze są reprezentowane przez termy. Term jest zmienną, stałą,
symbolem funkcji (ang. function symbol), lambda abstrakcją (ang. lambda abstraction)
formy
λ (x
1
: T
1
, x
2
: T
2
, ... , x
n
: T
n
) t : R,
lub aplikacji (ang. application)
t
0
(t
1
: T
1
, ... , t
k
: T
k
) (t
k+1
: T
k+1
, ... , t
n
: T
n
) : R,
gdzie t
0
, t
1
, ... , t
n
są termami, a t
0
musi mieć typ funkcyjny (ang. function type).
Lambda abstrakcja może posiadać nazwę.
Przykładowo, niech nazwany term Names ma następującą postać:
Names = apply(
λ(p)select_field(name)(p))(Persons),
term ten zwraca zbiór zawierający nazwiska każdej z osób ze zbioru Persons.
22

Apply (zdefiniowany w dalszej części pracy), select_field oraz name są symbolami
funkcji,
p jest zmienną, natomiast
λ(p)select_field(name)(p) jest lambda abstrakcją.
Predykaty są funkcjami zwracającymi typ boolean. Są one tworzone z
wykorzystaniem wbudowanych operatorów algebry AQUA i jej języka termów,
opartego na rachunku lambda. Są one normalnie przekazywane jako parametry do
operatorów takich jak: select, join, exists, czy foreall. Wszystkie zapytania w rezultacie
tworzą nowy obiekt algebry.
Poniżej zaprezentowano oznaczenia wykorzystywane w dalszej części pracy do
definiowania operatorów:
− A oraz B odnoszą się do wejściowych zbiorów lub wielozbiorów (ang. multisets).
− R jest wykorzystywane do oznaczenia wyjściowego zbioru lub wielozbioru, bądź
też wynikowego zbioru lub wielozbioru.
− a służy do reprezentacji elementu wejściowego zbioru lub wielozbioru A.
− f, g oraz h służą do reprezentacji funkcji.
− id reprezentuje funkcję tożsamości (ang. identity function).
− p oznacza predykat.
− T oznacza typ wynikowy operatora.
− Krotki są oznaczane jako < >.
− L jest nazwą pola krotki.
− a/L oznacza wartość krotki a minus pole oznaczone L.
Inne oznaczenia będą definiowane w miarę potrzeb.
2.2.2 Typ parametrów
Parametryzowane konstruktory typu i wymagania związane z podtypami
zaprojektowano tak, ażeby obsługiwały statyczną kontrolę typów. Rozwiązanie, które w
tym celu przyjęto jest związane z wyraźnym podawaniem typu wynikowego jako
parametru jednej z operacji algebry.
Wiele operacji opisywanej algebry tworzy instancje nowych typów jako wyniki.
W związku z tym, wywnioskowanie typu wynikowego nie jest łatwym zadaniem, biorąc
23

pod uwagę, że algebra zezwala na wielokrotne nadtypy i unie. Ażeby rozwiązać tę
trudność i zapewnić elastyczność, algebra pobiera typ wynikowy jako parametr
wejściowy operatorów, w których nie jest wymagany unikalny nadtyp przy
występowaniu dwóch wejść o kompatybilnych (lecz nie identycznych) typach.
2.2.3 Równość
Niektóre typy mogą posiadać więcej niż jedną definicję pojęcia równości (ang.
equality). Od każdego typu jest wymagane posiadanie domyślnej równości, która
oznacza tożsamość. Wbudowane typy prymitywne (integer, float, boolean czy string)
posiadają standardową definicję równości. W przypadku definiowania przez
użytkownika nowego typu, musi zostać określona domyślna równość dla tego typu.
Sensowne równości definiowane przez użytkownika powinny wywoływać relacje
równości na wszystkich instancjach tego typu.
Równość jest niezbędna do zdefiniowania niektórych operatorów, jak na
przykład unii.
Tożsamość stanowi domyślną równość dla elementów zbioru. Jeśli użytkownik
chce narzucić na zbiór dodatkowe pojęcie równości, może je odpowiednio zdefiniować
i dołączyć przykładowo do operatora dup_elim. Istotne jest, aby użytkownik w
pierwszej kolejności wykonał operacje wymagające równości domyślnej. Warunek ten
jest spowodowany tym, iż równość zdefiniowana przez użytkownika jest słabsza od
równości domyślnej.
2.2.4 Operatory
W tym rozdziale przedstawione zostaną operatory algebry. Część z tych
operatorów może zostać wyrażona poprzez użycie innych, co prowadzi do wielu
redundancji w zbiorze operatorów. Zostały one jednak pozostawione częściowo dlatego,
że pozwalają na tworzenie wyrażeń bardziej zwięzłych i przejrzystych, co byłoby
niemożliwe po ich usunięciu, a częściowo dlatego, iż nadają się do specjalizowanych
implementacji i optymalizacji, które są bardziej wydajne, niż gdyby zostały stworzone z
wykorzystaniem operatorów bardziej ogólnych.
24

2.2.4.1 Operatory
zbiorowe
Podrozdział ten przedstawia operatory zbiorowe (ang. set operators) omawianej
algebry. Większość z tych operatorów wywodzi się z podobnych operatorów
przedstawianych w literaturze. Autorzy algebry dokonali pewnych kombinacji,
mających na celu uczynienie obecnego podejścia bardziej elastycznym w porównaniu z
poprzednimi próbami.
Poniżej przedstawiona została lista wszystkich operatorów dla zbiorów, wraz z
krótką definicją każdego z nich.
Pierwszą grupą operatorów są zbiorowe operatory jednoargumentowe (ang.
unary set operators). Zostały one zdefiniowane następująco:
∅
≠
∅
=
=
⊕
∈
=
∈
∀
=
∈
∃
=
∈
=
∈
=
⊕
∈
A
a
f
A
u
A
f
u
A
a
A
a
a
p
A
a
A
p
a
p
A
a
A
p
a
p
A
a
a
A
p
A
a
a
f
A
f
A
a
),
(
,
)
)(
,
,
(
)
)(
(
)
(
.
)
)(
(
)
(
.
)
)(
(
)}
(
,
|
{
)
)(
(
}
|
)
(
{
)
)(
(
fold
mem
forall
exists
select
apply
Operator fold jest mocnym operatorem. Wyrażenie fold(u,f,
⊕)(A) redukuje zbiór
A do pojedynczej wartości poprzez zastosowanie funkcji f do każdego jego elementu i
iteracyjne łączenie otrzymanego wyniku z operatorem
⊕. Zastosowanie fold do pustego
zbioru w efekcie daje u.
Operatory exists, forall oraz mem zwracają wartość typu boolean. Mogą być
więc wykorzystywane jako rodzaj predykatów.
Kolejną grupę stanowią zbiorowe operatory dwuargumentowe (ang. binary set
operators):
)}
(
|
{
)
,
)(
(
}
|
{
)
,
)(
(
}
|
{
)
,
)(
(
B
x
and
A
x
x
B
A
T
B
x
and
A
x
x
B
A
T
B
x
or
A
x
x
B
A
T
∈
¬
∈
=
∈
∈
=
∈
∈
=
diff
intersect
union
25

Operatory zbiorowe dwuargumentowe union, intersect oraz diff są operatorami znanymi
z teorii zbiorów. Mimo tego przedstawione definicje są bardziej skomplikowane z
uwagi na konieczność uwzględnienia typów. Podczas stosowania operatora
dwuargumentowego nie jest wymagane, ażeby rozpatrywane zbiory były tego samego
typu. Wystarczy, aby ich elementy miały przynajmniej jeden wspólny nadtyp, jako że
domyślna równość tego nadtypu jest używana do porównań. Operatory te wykorzystują
dodatkowy argument T, określający typ wynikowy. Typem wynikowym operatora
union musi być nadtyp typów zbiorów wejściowych. W przypadku operatora intersect
typ wynikowy może być zarówno nadtypem typów wejściowych, jak i jednym z tych
typów. Ostatecznie, w przypadku operatora diff, typ wynikowy musi być albo typem
pierwszego zbioru wejściowego, albo jego nadtypem.
Operatory określane mianem zbiorowych operatorów przekształcających (ang.
set restructuring operators) to:
Wielozbiór
jako
A
A
L
a
s
and
A
a
s
L
L
a
A
L
A
a
L
a
L
b
and
A
b
L
b
L
L
a
A
L
y
x
eq
że
taki
R
y
A
x
and
y
x
eq
R
y
x
że
taki
A
R
A
eq
a
f
a
f
A
a
a
a
eqclass
gdzie
A
a
a
eqclass
a
f
A
f
A
a
jakieś
(A)
a
a
=
∈
∈
>
<
=
∈
>
=
∈
<
=
∈
∃
∈
∀
¬
∈
∀
⊆
=
=
∈
=
∈
=
∈
=
=
convert
tup_concat
unnest
tup_concat
nest
dup_clim
group
choose
set
)
(
}
.
|
)
:
,
/
(
{
)
)(
(
}
|
)
}
/
/
|
.
{
:
,
/
(
{
)
)(
(
)
,
(
.
,
,
)),
,
(
(
,
,
,
)
)(
(
)}
'
(
)
(
,
'
|'
{
)
(
},
|
))
(
),
(
{(
)
)(
(
}
{
)
(
Na pewną uwagę zasługują tutaj dwa operatory, a mianowicie zagnieżdżania (nest) oraz
rozgnieżdżania (unnest).
Zostały one zdefiniowane jako wykorzystujące
pojedyncze pole krotki L. Jednakże definicja ta może zostać w łatwy sposób
rozszerzona do listy pól. W takim przypadku a/L odnosi się do wartości krotki a minus
pola w liście L, natomiast a.L jest konkatenacją wartości wszystkich pól listy L.
26

Poniżej przedstawiono definicje operatorów złączenia (ang. join operators):
)}
,
(
.
,
|
)
(
{
)}
,
(
.
,
|
)
(
{
)}
,
(
,
,
|
)
,
(
{
)
,
)(
,
,
,
,
(
)
,
)(
,
(
)
,
)(
(
)}
,
(
,
,
|
)
,
(
{
)
,
)(
,
(
b
a
p
A
a
B
b
b
h
b
a
p
B
b
A
a
a
g
b
a
p
B
b
A
a
b
a
f
B
A
T
h
g
f
p
B
A
p
B
A
p
b
a
p
B
b
A
a
b
a
f
B
A
f
p
¬
∈
∀
∈
∪
¬
∈
∀
∈
∪
∈
∈
=
=
∈
∈
=
outer_join
tup_concat
join
tup_join
join
Operatory złączenia wymagają uwagi ze względu na ich ogólność. Operator join
przyjmuje jako parametr funkcję, umożliwiając przez to użytkownikowi na
definiowanie funkcji „łączącej”. Pozostałe operatory złączenia są podobnymi
uogólnieniami wymagającymi predykatu i funkcji.
Typ wynikowy T operatora outer_join musi być nadtypem typów wynikowych funkcji
f, g oraz h, ażeby umożliwić powiązanie rezultatów funkcji.
Znane operatory złączeniowe, takie jak: natural_join, equijoin, semijoin czy antijoin,
nie zostały zdefiniowane jako prymitywy (ang. primitives) w omawianej algebrze, lecz
w łatwy sposób mogą zostać wyrażone z wykorzystaniem zdefiniowanych operatorów.
Ostatnim przedstawianym operatorem zbiorowym jest operator najmniej stałego
punktu (ang. least fixed point operator):
U
∞
=
∅
=
=
0
0
)
(
)),
(
(
)
)(
,
(
i
i
A
f
gdzie
A
f
A
f
T
LFP
W przypadku tego operatora należy przyjąć następujące założenia w stosunku do
funkcji f . Jest ona funkcją T
ÆT, gdzie T jest typem zbioru A, a także musi być
monotoniczna.
Poniżej zaprezentowano krótki przykład ilustrujący wykorzystanie operatorów.
Rozważono zapytanie, które znajduje wszystkie osoby mieszkające w tym samym
mieście w którym pracują, a następnie grupuje je w oparciu o nazwę tego miasta.
Przedstawione rozwiązanie wykorzystuje pole employer obiektu Person.
Wyrażenie A.B jest skrótem oznaczającym wywołanie metody B na obiekcie A.
27

Omówione zapytanie wygląda następująco:
LiveWhereWorkPeople =
select(
λ(x)x.address = x.employer.address)(Persons)
Następnie należy zastosować operator group w celu pogrupowania osób z
LiveWhereWorkPeople według ich miejsca zamieszkania.
Prezentuje to poniższy przykład:
group(
λ(x)x.address)(LiveWhereWorkPeople)
W efekcie otrzymano zbiór uporządkowanych par postaci (city, people), gdzie city jest
nazwą miasta w którym przynajmniej jedna osoba mieszka i pracuje, natomiast people
jest zbiorem obiektów Person, reprezentujących wszystkie osoby mieszkające i
pracujące w tym mieście.
2.2.4.2 Operatory
wielozbiorowe
W przypadku wielozbiorów obsługiwane są praktycznie te same operacje, co w
przypadku zbiorów, w większości przypadków z bardzo podobną semantyką.
Różnica pomiędzy wielozbiorami oraz zbiorami polega na tym, że wielozbiór może
zawierać wielokrotne wystąpienia tego samego elementu. Notacją wykorzystywaną do
oznaczenia wielozbiorów jest: {*e
1
, e
2
, ..., e
n
*}, gdzie e
i
oznacza elementy wielozbioru.
Zdefiniowano także pojęcie „krotności elementu” (ang. cardinality of an element)
wielozbioru, jako liczbę wystąpień tego elementu w wielozbiorze. Zapis |A|
a
oznacza
„krotność elementu a w wielozbiorze A”. Można mówić także o „liczności wielozbioru”
|A|, oznaczającej całkowitą ilość elementów, z uwzględnieniem wszystkich powtórzeń
elementów.
Większość operatorów wielozbiorowych jest podobna do odpowiadających im
operatorów zbiorowych, za wyjątkiem tego, że typami wejściowymi i wyjściowymi
zamiast zbiorów są wielozbiory. Większość z przedstawionych dotychczas definicji jest
prawdziwa także dla wielozbiorów.
28

Wyjątki stanowią zdefiniowane poniżej operatory:
Zbiór
jako
A
id
A
a
a
)
)(
(
)
(
*}
{*
)
(
dup_elim
convert
multiset
=
=
R
y
B
y
and
A
y
że
takiego
y
również
B
A
R
R
x
że
taki
R
B
A
T
R
y
B
y
and
A
y
że
takiego
y
również
B
A
R
R
x
że
taki
R
B
A
T
R
y
B
y
or
A
y
że
takiego
y
również
B
A
R
R
x
że
taki
R
B
A
T
R
y
B
y
or
A
y
że
takiego
y
również
B
A
R
R
x
że
taki
R
B
A
T
x
x
x
x
x
x
x
x
x
x
x
x
∈
∈
¬
∈
∀
−
=
∈
∀
=
∈
∈
∈
∀
=
∈
∀
=
∈
∈
∈
∀
+
=
∈
∀
=
∈
∈
∈
∀
=
∈
∀
=
))).
(
(
)
((
,
)
|
|
|
|,
0
max(
|
|
.
,
)
,
)(
(
)).
(
)
((
,
)
|
|,
|
min(|
|
|
.
,
)
,
)(
(
)).
(
)
((
,
|
|
|
|
|
|
.
,
)
,
)(
(
)).
(
)
((
,
)
|
|,
|
max(|
|
|
.
,
)
,
)(
(
diff
intersect
nion
additive_u
union
Operatory multiset oraz convert są to wielozbiorowe operatory przekształcające
(ang. multiset restructuring operators). Natomiast operatory union, additive_union,
intersect oraz diff to wielozbiorowe operatory dwuargumentowe (ang. binary multiset
operators).
W przypadku wielozbiorowych operatorów dwuargumentowych występuje
największe odstępstwo od odpowiadających im operatorów zbiorowych. Wszystkie te
operatory w przypadku wielozbiorów bazują na pojęciu liczności elementów.
2.2.4.3 Operatory innych typów
Poza zbiorami i wielozbiorami, omawiana algebra obsługuje mnóstwo innych
typów.
Unia jest typem, który wraz ze swym konstruktorem pozwala na tworzenie unii z
dyskryminatorem (ang. discriminated union). Operacje zdefiniowane dla tego typu to:
union, tagcase oraz typecase. Operacja union(U, tag, e) tworzy instancję unii U i
inicjalizuje jej zawartość jako jednostkę e z etykietą tag. Zarówno tagcase(e), jak i
typecase(e) selektywnie wykonują zbiór termów bazujący albo na etykiecie, albo na
typie instancji unii e.
Typy funkcyjne reprezentują funkcje, które pobierają kilka typowanych
parametrów i zwracają pojedynczą wartość typowaną. Nie istnieje wyraźny konstruktor
29

typów funkcyjnych. Zamiast tego, instancje typów funkcyjnych są tworzone z
wykorzystaniem typowanych wyrażeń lambda.
Typ boolean jest wykorzystywany do reprezentowania wartości prawdy i fałszu.
Jest on wykorzystywany przy porównaniach i testowaniu wyrażeń warunkowych. Na
typie boolean można wykonywać operacje and, or oraz not.
Ostatecznie, abstrakcyjne typy danych są to typy zbiorowe, których elementy są
dostępne tylko poprzez użycie specjalnych funkcji, nazywanych interfejsem. Funkcje są
dostępne poprzez operator invoke(I, f), który wywołuje funkcję f na instancji I.
30

3 Rozwój baz danych
3.1 Rys
historyczny
Aby w pełni docenić obiektowy model baz danych, należy poznać i zrozumieć
wszystkie kolejne etapy w rozwoju baz danych. W rozdziale tym przedstawiono
rozwiązania stosowane w technologii baz danych i zaprezentowano w jaki sposób
kolejne architektury wprowadzały nowe cechy. Ten historyczny przegląd pomoże w
późniejszym zgłębieniu architektury obiektowych baz danych. Niniejszy rozdział
powstał w oparciu o [Burleson 1999].
3.1.1 Przetwarzanie płaskich plików
Wraz z wprowadzeniem komputerów do komercyjnego użytku, organizacje
zaczęły zdawać sobie sprawę z możliwości jakie oferuje przechowywanie danych.
Wczesne komputery były bardzo duże i nieefektywne w utrzymaniu, lecz były
idealnymi maszynami do wykonywania powtarzających się zadań. Cecha ta została
szybko dostrzeżona przez użytkowników.
Przed wprowadzeniem komercyjnych systemów baz danych, istniały systemy
będące niczym innym, jak zbiorami płaskich plików (ang. flat files). Nazwa „płaski
plik” wiąże się z tym, iż pliki nie były ze sobą połączone, więc nie istniała możliwość
stworzenia relacji pomiędzy danymi.
Płaskie pliki były sekwencyjnymi plikami, przechowującymi dane w sposób
liniowy, w związku z tym, aby odszukać konkretny rekord należało za każdym razem
przeglądać plik od początku.
Idealnym nośnikiem dla przechowywania płaskich plików jest taśma
magnetyczna. Przechowywanie danych na taśmie jest kilkaset razy tańsze, niż
wykorzystywanie w tym celu pamięci dyskowej, a dodatkowo taśma, podobnie jak
płaski plik, posiada strukturę liniową.
Płaskie pliki są nadal wykorzystywane przez niektóre przedsiębiorstwa do
przechowywania dużych ilości danych, które są bardzo rzadko zmieniane i używane.
31

3.1.1.1 BDAM – Podstawowa metoda bezpośredniego dostępu
Wraz ze wzrostem ilości przechowywanych danych, organizacje usiłowały
obchodzić liniową naturę płaskich plików. Podczas przechowywania rekordów na
dysku, każdy blok może zostać zidentyfikowany przez unikalny adres dyskowy. Znając
adres konkretnego rekordu, możemy bardzo szybko uzyskać do niego dostęp.
Powyższa cecha znalazła odzwierciedlenie w metodzie bezpośredniego dostępu
BDAM (Basic Direct Access Method). Metoda ta, w przeciwieństwie do plików
sekwencyjnych, wykorzystuje algorytm mieszający (ang. hashing algorithm) w celu
określenia adresu konkretnego rekordu na dysku. Algorytm na podstawie dostarczonego
klucza, będącego zazwyczaj częścią przechowywanego rekordu, generuje unikalny
adres dyskowy, lokalizujący rekord. W związku z tym, iż dzięki metodzie BDAM
uzyskuje się bezpośredni dostęp do rekordów, ich przetwarzanie i dostęp do nich są
dużo szybsze.
W metodzie BDAM po raz pierwszy nastąpiło oddzielenie metod dostępu
fizycznego od metod dostępu logicznego. Oznacza to, iż rekord może zostać wyszukany
na podstawie klucza, a użytkownik nie musi się interesować, gdzie fizycznie rekord
znajduje się na dysku.
Ważną cechą algorytmu mieszającego jest jego powtarzalność, czyli
generowanie dla konkretnego klucza zawsze identycznego adresu. Niezbędne jest także
zapewnienie, iż algorytm nie wygeneruje identycznego adresu dla dwóch różnych
kluczy, gdyż prowadziłoby to do kolizji. Jeśli prosty klucz nie zapewnia jednoznacznej
identyfikacji rekordu, wówczas wykorzystywana jest kombinacja kilku wartości.
Należy jednak zaznaczyć, iż metoda BDAM poza swoimi niewątpliwymi
zaletami posiada wady. Największą z nich jest koszt związany z ilością
wykorzystywanej przestrzeni dyskowej. Wiąże się to z tym, iż rekordy są rozproszone
po całym dysku, a wolna przestrzeń pomiędzy nimi nie może zostać wykorzystana,
gdyż w przyszłości nowy rekord może zostać tam przyporządkowany przez algorytm
mieszający.
Pomimo problemów związanych z wykorzystaniem przestrzeni dyskowej i
unikalnością kluczy, metoda BDAM pozostaje nadal jednym z najszybszych sposobów
do przechowywania i przetwarzania informacji.
32

3.1.1.2 ISAM – Metoda indeksowanego dostępu sekwencyjnego
Kolejną metodą wykorzystywaną dla płaskich plików jest metoda
indeksowanego dostępu sekwencyjnego ISAM (Indexed Sequential Access Method).
Działanie tej metody opiera się na istnieniu pliku z indeksami. W najprostszej
postaci indeks składa się z dwóch pól. Pierwsze pole jest symbolicznym kluczem,
natomiast drugie pole zawiera adres dyskowy powiązanego z tym kluczem rekordu. W
większości systemów, plik z indeksami jest przechowywany jako całkowicie oddzielny
plik. W celu odszukania rekordu, system przeszukuje indeks w celu odnalezienia
klucza, a następnie pobiera rekord z określonej pozycji na dysku.
Metoda ISAM, podobnie jak w przypadku fizycznych plików sekwencyjnych,
bardzo efektywnie wykorzystuje przestrzeń dyskową, gdyż rekordy przechowywane są
obok siebie. Jednakże w przeciwieństwie do fizycznych plików sekwencyjnych, które
mogą być przechowywane na taśmie, pliki w systemu ISAM muszą być składowane na
dysku, gdyż adresy dyskowe są niezbędne do stworzenia indeksów.
ISAM umożliwia stworzenie kilku różnych indeksów, pozwalających na
przetwarzanie plików na różne sposoby.
Inna popularna metoda dostępu do plików została stworzona przez firmę IBM.
Jest to metoda VSAM (Virtual Storage Access Method), będąca połączeniem
najlepszych cech metod ISAM oraz QSAM (Queued Sequential Access Method). Jest to
metoda bardzo podobna do przedstawionej w tym rozdziale metody ISAM.
3.1.1.3 Mankamenty
płaskich plików
Sprawą oczywistą jest mnogość wad związanych z systemami płaskich plików.
Przede wszystkim pojawiały się problemy związane z dzielonym przez kilka aplikacji
dostępem do danych, co w efekcie prowadziło do duplikowania tych samych informacji
i bardzo utrudniało ich aktualizację.
Nie są to niestety jedyne wady. W przypadku zmiany struktury plików,
wymagana była aktualizacja wszystkich programów działających w oparciu o nie.
Dodatkowo płaskie pliki nie posiadały mechanizmów zabezpieczających, takich jak
kopie zapasowe, czy metody odzyskujące dane.
Ostatnim problemem był brak jednolitego formatu przechowywania danych, co
znacznie ograniczało możliwości przetwarzania przez różne systemy.
33

3.1.2 Początek formalnego zarządzania bazami danych
Bazy danych powstały jako bezpośredni rezultat niedoskonałości systemów
płaskich plików. Przed powstaniem systemów zarządzania bazami danych, dane
przechowywane były w wielu różnych formatach i nie istniał jeden spójny system do
zarządzania nimi. Należy zaznaczyć, iż systemy zarządzania bazami danych są czymś
więcej niż tylko jednolitym repozytorium dla informacji. Wszystkie systemy
zarządzania bazami danych posiadają następujące cechy:
− odtwarzanie niekompletnych transakcji,
− mechanizm odtwarzania transakcji po awarii dysku,
− wewnętrzne narzędzia do zarządzania relacjami pomiędzy danymi,
− obsługę dostępu przez wielu użytkowników jednocześnie,
− język dostępu do danych, który może zostać osadzony w kodzie proceduralnym.
Obecne systemy zarządzania bazami danych dostarczają dodatkowo następujące
mechanizmy:
− obsługę integralności odwołań (ang. referential integrity),
− spójność odczytu dla długo działających zapytań,
− obsługę rozproszonych aktualizacji,
− obsługę modelowania złożonych obiektów,
− przypisywanie zachowań do danych.
Wczesne systemy zarządzania dostępem do baz danych bazowały na metodach
BDAM oraz VSAM. W roku 1960 firma IBM wprowadziła prototyp komputerowej
bazy danych w celu pokazania jak dane mogą być przechowywane, przetwarzane i
aktualizowane z wykorzystaniem jednolitego formatu. Ta baza danych znana jest jako
System Zarządzania Informacją – IMS (Information Management System). IMS był
rewolucyjnym pomysłem, gdyż umożliwiał dostęp do danych przez kilka programów
napisanych w różnych językach, a także pozwalał na obsługę przez wielu
użytkowników jednocześnie. Powstanie systemu IMS sprawiło, iż organizacje
zrozumiały, jak ważnym zagadnieniem jest przechowywanie danych, a także spójne
zarządzanie i kontrolowanie danych.
34

3.1.3 Hierarchiczny model danych
Hierarchiczny model bazy danych został zapoczątkowany przez wspomniany
system IMS. Model ten wykorzystuje wskaźniki jako logiczne połączenia pomiędzy
jednostkami danych.
Hierarchiczne bazy danych są bardzo dobrym rozwiązaniem do przedstawiania
relacji będących w naturalny sposób hierarchicznymi. Zasadniczo, hierarchia jest
metodą organizowania danych w schodzące w dół relacje jeden-do-wielu, gdzie każdy
poziom hierarchii ma pierwszeństwo w stosunku do znajdującego się poniżej. Polega
ona na układaniu danych w struktury zwane węzłami i łączeniu ich między sobą przy
pomocy tak zwanych gałęzi. Najwyższy węzeł nosi miano korzenia. Wszystkie
zapytania muszą mieć swój początek w korzeniu i przechodzić w dół hierarchii. Każdy
węzeł, z wyjątkiem korzenia, jest połączony w górę z tylko jednym węzłem „rodzicem”.
Jako trzy główne zalety hierarchicznych baz danych można uznać:
− łatwość zastosowania modelu hierarchicznego,
− bardzo duża szybkość działania,
− są to systemy, które okazały się na tyle dobre, że są nadal wykorzystywane.
Do wad zaliczyć można:
− ścisłe reguły dotyczące relacji,
− wstawianie i kasowanie danych może okazać się bardzo skomplikowane,
− dostęp do niższych warstw jest możliwy tylko poprzez warstwy nadrzędne,
− trudności w modelowaniu relacji typu wiele-do-wielu.
3.1.4 Sieciowy model CODASYL
W latach sześćdziesiątych powstało kilka systemów zarządzania bazami danych,
wykorzystujących sieciowy system zarządzania bazą danych, stworzony przez
organizację CODASYL (Conference On Data Systems Languages). Czynny udział w
rozwoju nowego modelu brały także dwie podgrupy CODASYL’u, mianowicie: DBTG
(Database Task Group) oraz DDLC (Data Description Language Committee).
35

Specyfikacje wydane przez CODASYL nazywały stworzony model
„sieciowym” modelem danych. Model ten stał się podstawą dla wielu późniejszych
systemów, jak na przykład wprowadzonego w 1970 roku IDMS firmy Cullinet.
Specyfikacje CODASYL zawierały definicje schematu bazy danych, języka
kontroli urządzeń DMCL (Device Media Control Language) oraz języka manipulacji
danymi DML (Data Manipulation Language). W skład specyfikacji wchodził także opis
fizycznej struktury plików z danymi. Logiczna struktura bazy danych definiowana była
za pomocą języka definiowania danych DDL (Data Definition Language).
W sieciowym modelu danych CODASYL dane posiadają wewnętrzne
identyfikatory (lub adresy), zaś związki semantyczne pomiędzy danymi reprezentowane
są poprzez powiązania referencyjne lub wskaźnikowe. Struktura danych tworzy więc
graf, czyli sieć.
Zaproponowany model obarczony był niestety wieloma wadami. Model ten jest
bardzo złożony i skomplikowany w użyciu. Sieciowe bazy danych, podobnie jak
hierarchiczne, są bardzo trudne w nawigacji. Implementacja strukturalnych zmian jest
niezwykle trudna w przypadku baz danych tego typu.
Daje się jednakże zauważyć, że w ostatnich latach nastąpił renesans
podstawowych założeń modelu sieciowego w obiektowych bazach danych.
3.1.5 Relacyjne bazy danych
W roku 1970 dr Edgar Ted Codd z firmy IBM zaprezentował relacyjny model
danych. W modelu tym dane miały być przechowywane w prostych plikach liniowych,
które to pliki nazywane są „relacjami” bądź „tabelami”. Jedną z największych zalet
modelu relacyjnego w stosunku do poprzedników jest jego prostota. Zamiast
konieczności poznawania mnóstwa komend języka DML, model relacyjny wprowadził
język SQL w celu ułatwienia dostępu do danych i ich modyfikacji.
Tabele są dwuwymiarowymi tablicami składającymi się z wierszy i kolumn.
Wiersze nazywane są czasami krotkami (ang. tuples), natomiast kolumny atrybutami.
Rekord jest wierszem tabeli, a pole jest kolumną w wierszu tabeli. Tabela posiada
zawsze pole lub kilka pól, tworzące dla niej klucz główny (ang. primary key). W
relacyjnych bazach danych tabele są niezależne, w przeciwieństwie do modeli
hierarchicznego i sieciowego, gdzie występują połączenia wskaźnikowe. Tabele
36

relacyjne mogą zawierać tylko jeden typ rekordu, natomiast każdy rekord posiada stałą
liczbę wyraźnie nazwanych pól.
Klucz główny jednoznacznie identyfikuje wiersz w tabeli. Klucz ten może
zostać stworzony na podstawie jednego lub kilku pól. Klucz obcy (ang. foreign key),
którego wartością jest wartość pewnego klucza głównego, pozwala na łączenie tabel
między sobą.
Relacyjne bazy danych wprowadziły następujące ulepszenia w stosunku do
hierarchicznych i sieciowych baz danych:
− Prostota.
Podejście bazujące na tabelach z wierszami i kolumnami jest niezwykle proste i
łatwe do zrozumienia. Końcowi użytkownicy mają prosty model danych.
Złożone diagramy, wykorzystywane w przypadku hierarchicznych i sieciowych
baz danych, nie występują w przypadku relacyjnych baz danych.
− Niezależność danych.
Niezależność danych pozwala na modyfikowanie struktury danych bez wpływu
na istniejące programy. Jest to możliwe głównie dlatego, że tabele nie są ze sobą
połączone na sztywno. Do tabel mogą być dodawane kolumny, tabele mogą być
dołączane do bazy danych, a nowe relacje mogą być tworzone bez konieczności
wprowadzania istotnych zmian do tabel. Relacyjne bazy danych dostarczają
dużo wyższy poziom niezależności danych, niż hierarchiczne i sieciowe bazy
danych.
− Deklaratywny język dostępu do danych.
Dzięki wykorzystaniu języka SQL, użytkownik określa jedynie warunki
odnośnie poszukiwanych danych, system natomiast zajmuje się pobraniem
danych spełniających żądanie. Nawigacja w bazie danych jest ukryta przed
użytkownikiem końcowym, w odróżnieniu od języka DML w systemie
CODASYL, gdzie użytkownik musi znać wszelkie szczegóły określające
ścieżkę dostępu do danych.
3.1.6 Manifesty baz danych
Pisząc o historii baz danych nie sposób pominąć pojawiających się co pewien
czas manifestów prezentujących nowe koncepcje w tematyce baz danych.
37

Historia manifestów związanych z bazami danych rozpoczęła się w połowie lat
osiemdziesiątych, kiedy E. F. Codd, ojciec modelu relacyjnego, opublikował dwanaście
reguł prawdziwego systemu relacyjnego. Jak dotychczas, żaden komercyjny system
zarządzania relacyjną bazą danych nie jest w pełni zgodny z przedstawionymi przez
niego założeniami. Obecne systemy komercyjne wciąż oddalają się od
zaproponowanego „ideału”.
Kolejne manifesty dotyczyły obiektowych baz danych. Istotną rolę w ich
rozwoju spełnił manifest „The Object-Oriented Database System Manifesto”.
Zanim on powstał, jednym z silnych argumentów wykorzystywanych przez
zwolenników systemów relacyjnych baz danych, przy krytyce systemów obiektowych
baz danych, był brak sensownego zdefiniowania pojęcia obiektowej bazy danych.
Przedstawiony manifest określił podstawowe zasady systemów obiektowych baz
danych. Właściwości takich systemów zostały przedstawione z podziałem na trzy
grupy:
− Cechy obowiązkowe: obiekty złożone, tożsamość obiektu, typy oraz klasy,
dziedziczenie, przesłanianie z późnym wiązaniem, rozszerzalność, kompletność
obliczeniowa, trwałość, zarządzanie pamięcią pomocniczą, współbieżność,
odtwarzanie oraz zapytania ad hoc.
− Cechy opcjonalne: wielokrotne dziedziczenie, kontrola typów, rozproszenie,
transakcje projektowe i wersje.
− Cechy otwarte (pozostawione do decyzji projektantów): paradygmat
programowania, system reprezentacji, system typów i jednolitość.
Manifest obiektowych baz danych był nie do zaakceptowania przez
konserwatystów związanych z modelem relacyjnym. Konkurencyjny manifest „The
Third Generation Database Systems Manifesto”
postuluje pozostawienie wszystkich
praktycznie sprawdzonych cech systemów relacyjnych baz danych (zwłaszcza języka
SQL) i skromne ich rozszerzenie o nowe cechy, pośród których znalazłyby się cechy
4
Manifest opublikowany w roku 1989 przez następujących autorów: M. Atkinson, F. Bancilhon, D.
DeWitt, K. Dittrich, D. Maier, S. Zdonik.
5
Manifest opublikowany w roku 1990 przez następujących autorów: M. Stonebraker, L. A. Rowe, B.
Lindsay, J. Gray, M. Carey, M. Brodie, P. Bernstein, D. Beech.
38

obiektowe. Manifest ten zakłada także, iż bazy danych trzeciej generacji muszą być
otwarte dla innych systemów.
Ostatni manifest, „The Third Manifesto”
, postuluje odrzucenie zarówno
obiektowości jak i języka SQL (który według autorów zniszczył ideały relacyjnego
modelu) i powrót do pierwotnej postaci modelu relacyjnego wraz z jego dwunastoma
zasadami. Przedstawione przez autorów argumenty są jednak dość naiwne i bardzo
trudne do zaakceptowania przez większość ekspertów z dziedziny baz danych.
3.2 Obiektowe bazy danych
Technologia obiektowa rozwija się i rozprzestrzenia w bardzo szybkim tempie.
W ostatnich latach również w technologii baz danych wyraźnie obserwuje się ogólny
trend w kierunku koncepcji obiektowej.
Pierwszym językiem proceduralnym łączącym dane z ich zachowaniem był
język Simula, który był wykorzystywany w zadaniach naukowych do symulowania
zachowania jednostek. Obiekty, w sensie zarządzania danymi, zostały wprowadzone po
raz pierwszy na początku lat siedemdziesiątych przez Palo Alto Research Center z
firmy Xerox.
Podejście obiektowe podkreśla bardziej naturalną reprezentację danych. W
dzisiejszym środowisku modele danych są dużo bardziej wymagające. Ich zadaniem jest
przetwarzanie dźwięku, obrazu, tekstu, grafiki itp. Potrzeby te wymagają dużo bardziej
elastycznego formatu przechowywania danych niż hierarchiczne, sieciowe, czy
relacyjne bazy danych mogą zapewnić. Jedynie obiektowe bazy danych będą mogły
sprostać tym wymaganiom.
Obiektowa baza danych jest zbiorem obiektów, których zachowanie się i stan
oraz związki są określone zgodnie z obiektowym modelem danych. Obiektowy system
zarządzania bazą danych (OSZBD) jest systemem wspomagającym definiowanie,
zarządzanie, utrzymywanie, zabezpieczanie i udostępnianie obiektowej bazy danych.
Systemy obiektowych baz danych były rozwijane w celu dostarczenia
elastycznego modelu danych bazującego na tym samym paradygmacie, co obiektowe
języki programowania. Obiektowe bazy danych dają możliwość silniejszego powiązania
6
Manifest opublikowany w roku 1995 przez następujących autorów: H. Darwen oraz C. J. Date.
39

z aplikacjami obiektowymi, niż było to w przypadku relacyjnych baz danych. Dzięki
temu można zminimalizować ilość operacji związanych z przechowywaniem i
dostępem do danych zorientowanych obiektowo. Zaleta ta staje się szczególnie cenna w
przypadku, gdy obiektowy model danych jest naprawdę skomplikowany.
Obiektowe systemy zarządzania bazą danych zapewniają tradycyjną
funkcjonalność baz danych, lecz bazują na modelu obiektowym.
Do klasycznych funkcji obsługiwanych przez OSZBD można zaliczyć:
− zarządzanie pamięcią zewnętrzną,
− zarządzanie schematem,
− sterowanie współbieżnością,
− zarządzanie transakcjami,
− odtwarzalność,
− przetwarzanie zapytań,
− kontrolę dostępu.
Do przedstawionych powyżej funkcji, OSZBD dokładają dodatkowo:
− złożone obiekty,
− typy definiowane przez użytkownika,
− tożsamość obiektów,
− hermetyzację,
− typy i/lub klasy oraz ich hierarchię,
− przesłanianie, przeciążanie, późne wiązanie,
− kompletność obliczeniową (pragmatyczną).
Poza bezsprzecznymi zaletami OSZBD, istnieje wiele powodów
powstrzymujących ich dynamiczny rozwój i powodujących, iż systemy relacyjnych baz
danych wciąż posiadają znacznie większy udział w rynku. Do powodów tych zaliczyć
można:
− Niedojrzałość technologii – wiele organizacji wykorzystuje obecnie OSZBD do
aplikacji o mniejszym znaczeniu, z uwagi na ryzyko wiążące się z
wykorzystaniem nowej technologii.
40

− Niestabilność producentów – producenci OSZBD wydają się być relatywnie
małymi firmami, co powstrzymuje niektóre organizacje przed inwestowaniem w
te systemy z obawy, że w niedalekiej przyszłości firmy te mogą zniknąć z rynku.
− Brak wykwalifikowanego personelu – niestety wciąż brakuje informatyków
wykwalifikowanych w obsłudze obiektowych systemów zarządzania bazami
danych.
− Koszty konwersji – niebagatelną przeszkodę stanowią koszty konwersji na nowy
system. Należy tu wziąć pod uwagę koszty nowego oprogramowania i jego
instalacji, a także w przypadku firm już istniejących na rynku, inwestycje
poczynione dotychczas w systemy relacyjnych baz danych.
3.2.1 Trwałość obiektu
Trwałość obiektu (ang. object persistence) jest jedną z najważniejszych usług
dostarczanych przez obiektowe systemy zarządzania bazami danych. Przez trwałość
rozumie się zachowanie polegające na tym, że obiekt jest stale dostępny, a jego stan
pozostanie niezmieniony pomiędzy kolejnymi wywołaniami.
Obiekty, które nie są stale dostępne nazywane są ulotnymi. Zależnie od
aplikacji, niektóre obiekty muszą zmieniać swój stan z ulotnego na trwały, a zadaniem
OSZBD jest zarządzanie tą konwersją. OSZBD przyporządkowuje każdemu obiektowi
unikalny identyfikator, który jest wykorzystywany głównie do ustalenia powiązań
pomiędzy trwałymi obiektami. OSZBD posiada procedury odzyskiwania zapewniające,
że trwałe obiekty przetrwają wszelkie awarie systemu.
Istnieją dwie metody wykorzystywane przez OSZBD w celu uzyskania dostępu
do trwałych obiektów. Są to wirtualne wskaźniki adresu pamięci oraz tablice z
kodowaniem mieszającym.
Trwałe obiekty są stale gotowe do wywołania. Są one przechowywane na dysku,
natomiast obiekty ulotne istnieją w pamięci RAM. W OSZBD obiekty mogą
przechodzić z jednego stanu w drugi, mając swoją reprezantację w pamięci RAM, a
także na dysku.
41

Poniżej przedstawiono niektóre z działań, które OSZBD musi wykonywać w
związku z zarządzaniem trwałością obiektów:
− wyszukiwanie obiektów na dysku i przyporządkowywanie im nowych
identyfikatorów w pamięci RAM,
− przyporządkowywanie i alokowanie przestrzeni w składzie trwałych obiektów,
− automatyczne zwiększanie przestrzeni w razie potrzeby,
− zarządzanie wolną przestrzenią w składzie trwałych obiektów,
− interfejs pomiędzy systemem wejścia-wyjścia a składem trwałych obiektów,
− zapewnienie, że trwałe obiekty mogą być odzyskane,
− zarządzanie buforami bazy danych,
− zarządzanie mapowaniem pomiędzy fizycznymi adresami a identyfikatorami
obiektów.
3.2.2 Architektura
Istnieje kilka koncepcji odnośnie architektury obiektowego systemu zarządzania
bazą danych. Najbardziej abstrakcyjną jest architektura zaproponowana przez komitet
ANSI/SPARC. Wyróżnia ona trzy poziomy:
− poziom pojęciowy systemu, wspólny dla wszystkich jego użytkowników,
− poziom zewnętrzny, specyficzny dla konkretnego użytkownika,
− poziom fizyczny, który odnosi się do implementacji bazy danych.
Kolejnym rodzajem jest architektura klient-serwer, gdzie występuje podział na
dwie części: serwer bazy danych, wykonujący przykładowo wyrażenia SQL wysyłane
przez klientów oraz druga część, którą stanowi jeden lub kilku klientów wysyłających
żądania do serwera.
Bardziej zaawansowane są architektury trzywarstwowa oraz wielowarstwowa.
Jak sama nazwa wskazuje, architektura trzywarstwowa charakteryzuje się podziałem na
trzy warstwy: interfejs użytkownika, logikę przetwarzania oraz bazę danych. Warstwy
te są zaprojektowane i istnieją niezależnie, co ma duże znaczenie dla utrzymania całego
systemu ze względu na możliwość zmian w dowolnej warstwie bez konieczności
42
interwencji w pozostałych warstwach. Warstwa środkowa może być złożona z kilku
warstw i mamy wówczas do czynienia z architekturą wielowarstwową.
Poniższy rysunek pokazuje typową architekturę obiektowego systemu
zarządzania bazą danych ujętą z funkcjonalnego punktu widzenia (rys. 3.1).
Przedstawione zostały zależności pomiędzy podstawowymi funkcjonalnymi
komponentami systemu [Subieta 1999b].
RYSUNEK 3.1. PRZYKŁADOWA ARCHITEKTURA OBIEKTOWEGO SYSTEMU ZARZĄDZANIA
BAZĄ DANYCH (OSZBD).
3.2.3 Obiektowo-relacyjne bazy danych
Obiektowo-relacyjne bazy danych są najnowszym osiągnięciem w rozwoju
hybrydowych architektur baz danych. Systemy te pojawiły się między innymi z
powodu ogromnych inwestycji poczynionych przez różne organizacje w systemy
relacyjnych baz danych. Bezpośrednie przekwalifikowanie z relacyjnych na obiektowe
systemy baz danych wiązałoby się z dodatkowymi kosztami, natomiast obiektowo-
relacyjne bazy danych stanowią swoisty kompromis.
43

Obiektowe bazy danych nie posiadają niektórych cech, do których przywykli
użytkownicy poprzednich systemów. Dodatkowo, w chwili obecnej obiektowe systemy
baz danych nie mają odpowiedniej infrastruktury, aby przejąć rynek relacyjnych baz
danych, podobnie jak bazy relacyjne uczyniły to z systemami hierarchicznymi i
sieciowymi.
Rozwiązaniem dla firm takich jak Oracle, Informix, Sybase, czy IBM jest
rozwój ich systemów polegający na przekształcaniu ich w systemy obiektowo-
relacyjnych baz danych.
Systemy obiektowo-relacyjne są wyposażane w wiele cech umożliwiających
efektywną produkcję aplikacji. Wśród nich można wymienić przystosowanie do
multimediów (duże obiekty BLOB, CLOB i pliki binarne), dane przestrzenne,
abstrakcyjne typy danych (ADT), metody (funkcje i procedury) definiowane przez
użytkownika w różnych językach, kolekcje (zbiory, wielozbiory, sekwencje,
zagnieżdżone tablice, tablice o zmiennej długości), typy referencyjne, przeciążanie
funkcji, późne wiązanie i inne. Systemy te zachowują jednocześnie wiele technologii,
które sprawdziły się w systemach relacyjnych (takie jak architektura klient/serwer,
mechanizmy buforowania i indeksowania, przetwarzanie transakcji, optymalizacja
zapytań) [Subieta 1999a].
Obiektowo-relacyjne bazy danych zdobywają uznanie, gdyż wiele organizacji
dostrzega, że relacyjne bazy danych nie są wystarczające do obsługi ich złożonych
wymagań. Zamiast więc bezpośredniego przejścia na systemy czysto obiektowe,
podejście obiektowo-relacyjne pozwala organizacjom na zapoznanie się z technologią
obiektową w rozsądnym tempie. Dodatkową zaletą jest uniknięcie konwersji aktualnych
baz danych do nowego, obiektowego formatu danych, co oszczędza czas i pieniądze.
Obiektowo-relacyjne bazy danych stanowią zatem pomost pomiędzy relacyjnymi a
obiektowymi bazami danych.
44

3.3 Porównanie relacyjnych i obiektowych baz danych
Celem niniejszego rozdziału jest próba porównania relacyjnych i obiektowych
baz danych w oderwaniu od konkretnych produktów. Dokonanie rzetelnego porównania
napotyka jednak na wiele trudności, związanych przede wszystkim z tendencyjnością
publikowanych prac, które w zależności od ich autorstwa prezentują bardzo odmienne
opinie.
Systemy obiektowych baz danych są dobrze przystosowane do obsługi danych
mających złożoną, zagnieżdżoną strukturę, tworzących hierarchię, czy też dynamicznie
zmieniających rozmiar. Podczas gdy relacyjne bazy danych dobrze sprawdzają się w
zastosowaniach wykorzystujących proste, nie zagnieżdżone dane, dające się łatwo
umieścić w tablicy.
Dla wielu zastosowań struktury relacyjne okazują się zbyt sztywne. Odwzorowanie
struktur pojęciowych (np. struktury klas i asocjacji) na struktury relacyjne wiąże się ze
znacznym wzrostem złożoności, która może podważyć osiągalność celów projektu. W
związku z tym, a także z konieczności poszukiwania nisz, które nie zostały dotąd
zagospodarowane przez wcześniejsze technologie, potencjalnym polem zastosowań
obiektowych baz danych są multimedia, dziedziny wymagające bardziej
rozbudowanych struktur danych, takie jak CAD (Computer Aided Design), CAM
(Computer Aided Manufacturing), CASE (Computer Aided Software Engineering), lub
dziedziny implikujące nieregularne, niesformatowane struktury danych, takie jak
zastosowania pełnotekstowe, hurtownie danych, zastosowania biurowe [Subieta 1998d].
Ogromną zaletą obiektowych baz danych jest bezpośrednia, bardzo szeroko
rozumiana współpraca z obiektowymi językami programowania. Jest to bardzo duża
przewaga nad systemami relacyjnymi, gdzie programiści muszą dostosowywać program
obiektowy do potrzeb relacyjnej bazy danych. Niedogodności te są częściowo
eliminowane w systemach obiektowo-relacyjnych.
Zagadnieniem bardzo interesującym, lecz zarazem kontrowersyjnym, jest
wydajność obiektowych baz danych w porównaniu z bazami relacyjnymi. Bez
wątpienia wyniki te są zależne od rodzaju przetwarzanych danych i niestety, od zespołu
45

przeprowadzającego testy. Można jednak stwierdzić, iż obiektowe bazy danych stają się
coraz bardziej wydajnymi systemami. Sprzyja temu zastosowanie między innymi
techniki przemiany wskaźników
, indeksów ścieżkowych
oraz nowych mechanizmów
indeksacji i buforowania umożliwiających istotne przesunięcie przetwarzania na stronę
klienta w architekturze klient-serwer.
Kolejnym problemem często pojawiającym się przy porównaniach jest
twierdzenie, iż obiektowe języki zapytań nie posiadają sprawnych metod
optymalizacyjnych. [Subieta 1998d] podważa prawdziwość tego stwierdzenia. Uważa
on, iż:
− Podstawowym celem metod optymalizacyjnych w systemach relacyjnych jest
kosztowna operacja złączenia. Ponieważ w systemach obiektowych złączenie
jest najczęściej zmaterializowane w postaci wskaźników, zapotrzebowanie na tę
operację jest znacznie zredukowane.
− Testy wykazują, iż optymalizacja relacyjnych języków zapytań nie zawsze jest
tak sprawna, jak jest to podkreślane w literaturze.
− Metody oparte na przepisywaniu działają tak samo dla języków relacyjnych i
obiektowych.
− Nie istnieją powody, dla których metod sprawnych w systemach relacyjnych nie
można zastosować w systemach obiektowych.
− Ortogonalność i bardziej precyzyjna semantyka języka OQL (w stosunku do
SQL) stwarza większy potencjał dla metod optymalizacyjnych.
Pomimo wielu pozytywnych opinii, słychać także głosy krytyczne odnośnie
obiektowych baz danych. Wśród wad najczęściej wymienia się:
− Istnienie wskaźników w strukturach obiektowych cofa rozwój do czasów
systemów sieciowych.
7
Przemiana wskaźników (ang. pointer swizzling) - technika implementacji obiektowych baz danych
polegająca na tym, że w buforze obiektów (w pamięci operacyjnej) następuje zamiana trwałych
wskaźników (identyfikatorów obiektów) prowadzących do obiektów przechowywanych w bazie danych
na wskaźniki danego języka programowania, prowadzące do kopii tych obiektów w pamięci operacyjnej.
Technika ta, w porównaniu do relacyjnych baz danych, pozwala na podwyższenie wydajności niektórych
aplikacji nawet tysiąckrotnie [Subieta 1999a].
8
Indeks ścieżkowy (ang. path index) – indeks, w którym jedna pozycja składa się z pewnej wartości oraz
lokalizacji pewnej liczby obiektów powiązanych w hierarchię lub poprzez wskaźniki. Indeksy ścieżkowe
znacznie polepszają czas ewaluacji wyrażeń ścieżkowych. Ich wadą jest kłopotliwa aktualizacja w
odpowiedzi na aktualizację zapamiętanych danych [Subieta 1999a].
46

− Brak opracowanych mechanizmów zarządzania dużą bazą obiektów, sterowania
wersjami, rejestrowania zmian, zapewnienia stabilności interfejsów.
− Duża liczba tematów związanych z obiektowością znajduje się wciąż w fazie
laboratoryjnej, co powoduje, że wiele technologii jest mało stabilnych.
− Przejście na technologie obiektowe może zagrozić funkcjonowaniu obecnie
działających i sprawnych systemów, które są krytyczne dla misji organizacji.
47

4 Standardy
W rozdziale tym przyjrzano się wysiłkom podejmowanym w celu osiągnięcia
standaryzacji w zakresie obiektowych baz danych. Niektórzy twierdzą, że brak
przyjętych standardów jest jedną z przyczyn, dla których systemy te nie mogą odegrać
dominującej roli na rynku. Dlatego opracowanie standardów stało się priorytetem, a
nawet więcej, wykazano ich pozytywny wpływ na produkty zaraz po wprowadzeniu
systemów obiektowych.
W kolejnych podrozdziałach przedstawione zostały trzy standardy. Najpierw
opisano SQL:1999 (SQL3), rozwinięcie standardu relacyjnego języka SQL, w którym
po raz pierwszy zostały odzwierciedlone własności obiektowe. Następnie omówiono
propozycje standaryzacyjne przedstawione przez ODMG. Grupę stworzoną przez
konsorcjum sprzedawców, której głównym celem jest opracowanie standardów
obiektowych baz danych. Ostatnim omówionym standardem jest JDO (Java Data
Objects). Jest to standard korzystania z obiektowych baz danych z poziomu języka Java.
Standard ten został opracowany pod patronatem firmy Sun Microsystems, która
stworzyła język Java.
4.1 Język SQL:1999
SQL:1999 jest długo oczekiwanym standardem, który podczas procesu
tworzenia był nazywany SQL3. Planowaną datą opublikowania nowego standardu,
który miał znacznie rozszerzać możliwości SQL’a drugiej generacji (SQL-92), był rok
1996. Niestety, rzeczywistość rozminęła się z planami i zamiast planowanych trzech do
czterech lat, rozwój nowego standardu zajął twórcom siedem lat. Jak wskazuje nazwa,
SQL trzeciej generacji został opublikowany w 1999 roku.
SQL3 był charakteryzowany jako „SQL zorientowany obiektowo”. W dalszej
części pracy pokazano, iż SQL:1999 jest czymś więcej, niż tylko językiem SQL-92
wzbogaconym o technologię obiektową. Nowy standard wzbogacono także o
dodatkowe cechy, które można uważać za rozszerzenia relacyjnych cech SQL’a,
poddano także całkowitej restrukturyzacji dokumentację standardu, aby ułatwić jego
rozwój w przyszłości.
48

4.1.1 Rozwój standardu
Dwie organizacje aktywnie uczestniczące w tworzeniu standardu i rozwoju
języka SQL:1999 to ANSI oraz ISO.
Dokładniej, społeczność międzynarodowa współpracuje poprzez ISO/IEC JTC1 (Joint
Technical Committee 1), komitet stworzony przez ISO (International Organization for
Standardization) wraz z IEC (International Electrotechnical Commission).
Zadaniem JTC1 jest rozwój i nadzór nad standardami związanymi z ogólnie pojętą
informatyką (ang. Information Technology).
W obrębie JTC1 został stworzony komitet SC32 (Data Management and Interchange).
Jego zadaniem było przejęcie standaryzacji kilku standardów związanych z bazami
danych, które to standardy były rozwijane przez inne organizacje (jak na przykład
rozwiązany SC21). Z kolei SC32 stworzył kilka grup zajmujących się stroną techniczną.
Przykładowo WG3 (Working Group 3) jest grupą odpowiedzialną za standard SQL,
podczas gdy WG4 (Working Group 4) zajmuje się rozwojem SQL/MM (SQL
MultiMedia).
W Stanach Zjednoczonych standardy informatyczne rozwijane są przez komitet
NCITS (National Committee for Information Technology Standardization), będący
częścią ANSI (American National Standards Institute). Komitet NCITS (uprzednio
„X3H2”) jest odpowiedzialny za kilka standardów związanych z zarządzaniem danymi,
między innymi SQL oraz SQL/MM.
Kiedy projektowana była pierwsza generacja SQL’a (SQL-86 i jego rozszerzenie
SQL-89), większość prac została wykonana w Stanach Zjednoczonych przez X3H2, a
także przez społeczność międzynarodową, która aktywnie uczestniczyła w
recenzowaniu propozycji ANSI. Zanim standard SQL-89 został opublikowany,
społeczność międzynarodowa stawała się coraz bardziej aktywna w zgłaszaniu nowych
propozycji, które znalazły odzwierciedlenie w standardzie SQL-92. Podobnie wyglądał
proces rozwoju obecnego standardu SQL:1999. Z całą pewnością można zatem
stwierdzić, iż SQL jest efektem międzynarodowej współpracy.
W dalszej części pracy przedstawione zostały rozszerzenia wprowadzone do
standardu SQL:1999.
Informacje zawarte w kolejnych podrozdziałach pochodzą w dużej mierze z
opracowania [Eisenberg 1999], którego autorzy brali czynny udział w rozwoju
49

standardu. Podobnie jak we wspomnianej pracy, także tutaj nowe cechy SQL’a zostały
podzielone na cechy relacyjne i obiektowe.
4.1.2 Cechy relacyjne
Opisane poniżej cechy zostały nazwane cechami relacyjnymi, choć bardziej
poprawne wydaje się nazwanie ich cechami odnoszącymi się do tradycyjnej roli i
modelu danych SQL’a. Cechy opisane poniżej nie są ograniczone jedynie do modelu
relacyjnego, lecz nie są także powiązane z obiektowością jako taką.
Cechy te zazwyczaj są dzielone na pięć grup: nowe typy danych, nowe predykaty,
poprawiona semantyka, dodatkowe bezpieczeństwo oraz aktywność bazy danych.
Poniżej przedstawiono poszczególne grupy.
4.1.2.1 Nowe typy danych
SQL:1999 posiada cztery nowe typy danych.
Pierwszym z nich jest typ LARGE OBJECT (LOB). Typ ten posiada dwa
warianty: CHARACTER LARGE OBJECT (CLOB) oraz BINARY LARGE OBJECT
(BLOB). Typy te zostały zdefiniowane w celu obsługi bardzo dużych obiektów.
Typ CLOB zachowuje się podobnie jak ciąg znaków, lecz posiada ograniczenia
uniemożliwiające jego wykorzystywanie w wyrażeniach UNIQUE jako klucza
podstawowego, klucza obcego oraz w porównaniach innych niż testy równości i
nierówności.
Typ BLOB posiada podobne ograniczenia.
Tym samym typ LOB nie może być także wykorzystywany w wyrażeniach GROUP BY
oraz ORDER BY. Aplikacje nie przekazują właściwych wartości LOB do i z bazy
danych, lecz manipulują nimi poprzez specjalny typ, znajdujący się po stronie klienta,
zwany LOB lokalizator (ang. locator). W SQL:1999 lokalizator jest unikalną wartością
binarną, która zachowuje się jak zastępca wartości przechowywanej w bazie danych.
Lokalizator może być wykorzystywany w różnych operacjach bez konieczności
występowania dodatkowego nakładu związanego z przekazywaniem właściwej wartości
LOB pomiędzy klientem i serwerem.
Kolejnym nowym typem danych jest typ BOOLEAN, który umożliwia
bezpośrednie wskazywanie wartości true, false oraz unknown.
50

SQL:1999 posiada także dwa nowe typy zbiorowe: ARRAY oraz ROW.
Typ ARRAY umożliwia przechowywanie zbioru wartości bezpośrednio w kolumnie
tabeli bazy danych. Przykładowo:
WEEKDAYS VARCHAR(10) ARRAY[7]
Powyższa definicja pozwala na przechowywanie nazw wszystkich siedmiu dni tygodnia
w jednym wierszu tabeli.
Nasuwa się tutaj pytanie, czy SQL:1999 pozwala na tworzenie baz danych, które
nie spełniają założeń pierwszej postaci normalnej.
Jest tak rzeczywiście, w sensie
zezwalania na „powtarzane grupy”, które nie są dopuszczane przez pierwszą postać
normalną. Jednakże słychać opinie, iż typ ARRAY pozwala jedynie na
przechowywanie informacji, które mogą być dekomponowane (podobnie jak funkcja
SUBSTRING dekomponuje ciągi znaków), dlatego też nie łamie w pełni założeń
pierwszej postaci normalnej.
Typ ROW w SQL:1999 udostępnia twórcom możliwość przechowywania
wartości strukturalnych w pojedynczych kolumnach bazy danych. Przy rozpatrywaniu
tego typu także mogą nasunąć się wątpliwości odnośnie zasad pierwszej postaci
normalnej, jednakże są one rozpatrywane podobnie jak dla opisanego powyżej typu
ARRAY.
Ostatnim typem jest typ rozróżniony (ang. distinct type). Umożliwia on
tworzenie deklaracji powodujących, że dwie normalnie równoważne deklaracje typu są
traktowane jako różne typy danych.
Jakiekolwiek próby traktowania instancji jednego typu jako instancji drugiego będą
skutkowały wystąpieniem błędu, pomimo tego, iż oba typy posiadają taką samą
reprezentację.
4.1.2.2 Nowe
predykaty
SQL:1999 wprowadził trzy nowe predykaty. Dwa z nich to predykaty SIMILAR
oraz DISTINCT, które przedstawione zostały poniżej.
9
Pierwsza postać normalna oznacza warunek, że każda składowa w każdej krotce ma wartość
atomową.
51

Predykat SIMILAR umożliwia użycie wyrażeń regularnych przy porównywaniu
wzorców, podobnie jak ma to miejsce w systemie UNIX. Niestety, składnia wyrażeń
używanych w tym predykacie nie jest identyczna ze składnią wyrażeń regularnych
UNIX’a. Jest to spowodowane tym, iż niektóre ze znaków wykorzystywanych w tym
celu w UNIX’ie miały już inne zastosowanie w języku SQL.
Kolejnym nowym predykatem jest DISTINCT, który w zastosowaniu jest
bardzo podobny do predykatu UNIQUE. Ważną różnicą pomiędzy tymi predykatami
jest traktowanie wartości NULL.
Dwie wartości NULL są uważane jako nierówne i w
związku z tym spełniają predykat UNIQUE. Jednak nie zawsze takie zachowanie jest
pożądane. Predykat DISTINCT traktuje dwie wartości NULL jako nie różniące się
między sobą i w związku z tym te dwie wartości NULL nie będą spełniały predykatu
DISTINCT.
4.1.2.3 Nowa
semantyka
Długo oczekiwanym przez twórców aplikacji elementem jest aktualizacja
perspektyw (ang. view updating). Wiele środowisk wykorzystuje perspektywy jako
mechanizm bezpieczeństwa, bądź też jako uproszczenie aplikacyjnego widoku bazy
danych. Jednakże jeśli perspektywy nie mogą być aktualizowane, wówczas aplikacje
muszą rezygnować z wykorzystywania perspektyw i polegać na bezpośredniej
aktualizacji tabel, co jest rozwiązaniem niezadowalającym.
SQL:1999 znacząco zwiększył zakres perspektyw, które mogą być
aktualizowane przy wykorzystaniu tylko dodatkowych funkcji dostarczonych w
standardzie. Działanie tego mechanizmu w dużym stopniu opiera się na funkcjonalnych
zależnościach, od których zależy, jakie perspektywy mogą być aktualizowane, a także w
jaki sposób należy wykonywać zmiany w tabelach bazy odwzorowujące owe
uaktualnienia.
Kolejnym rozszerzeniem są zapytanie rekurencyjne. Stworzenie takiego
zapytania polega na określeniu wyrażenia, które chcemy poddać rekurencji i nadaniu
mu odpowiedniej nazwy. Następnie wykorzystuje się tę nazwę w skojarzonym
zapytaniu. Obrazuje to poniższy przykład:
10
Wartość NULL (ang. null value) jest to specjalna wartość występująca w języku SQL. Jest ona
wpisywana w miejsce składowych o nieokreślonych wartościach. Wartości tej nie można traktować tak
jak zwykłych wartości liczbowych lub logicznych. Porównanie jakiejkolwiek innej wartości z NULL daje
w wyniku wartość logiczną UNKNOWN.
52

WITH RECURSIVE
Q1 AS SELECT...FROM...WHERE...,
Q2 AS SELECT...FROM...WHERE...,
SELECT...FROM Q1, Q2 WHERE...
W rozdziale o nowych typach danych wspomniano o lokalizatorach jako
wartościach, które reprezentują znajdujące się po stronie serwera wartości typu LOB.
Lokalizatory mogą być wykorzystywane w taki sam sposób do reprezentacji wartości
tablicowych (ARRAY) w związku z tym, iż tablice bardzo często są zbyt duże, aby
przesyłać je pomiędzy aplikacją i serwerem. Ostatnim wykorzystaniem lokalizatorów
może być reprezentowanie wartości typów definiowanych przez użytkownika,
omawiane w dalszej części pracy, które to typy także mogą być znacznych rozmiarów.
Ostatnim elementem, który zostanie zaprezentowany jest pojęcie określane jako
punkt składowania (ang. savepoint). Jest to mechanizm będący rodzajem podtransakcji,
polegający na tym, iż aplikacja może cofnąć operacje wykonane po ustawieniu punktu
składowania,
bez konieczności anulowania wszystkich operacji w obrębie transakcji.
SQL:1999 zezwala na wykonywanie zapytań postaci ROLLBACK TO SAVEPOINT
oraz RELEASE SAVEPOINT, które działają podobnie jak podtransakcje.
4.1.2.4 Dodatkowe
bezpieczeństwo
Rozszerzeniem bezpieczeństwa w języku SQL:1999 jest zastosowanie
mechanizmu określanego mianem roli (ang. role). Do ról mogą być przypisywane
przywileje, w taki sam sposób jak do indywidualnych użytkowników. Role mogą być
przypisywane do poszczególnych użytkowników, a także do innych ról. Zastosowanie
tego elementu znacznie upraszcza definiowanie złożonych zbiorów przywilejów.
4.1.2.5 Aktywność bazy danych
Element ten jest dostarczany poprzez zastosowanie wyzwalaczy (ang. triggers).
Jest to mechanizm pozwalający twórcy bazy danych na zaprogramowanie jej w ten
sposób, ażeby system bazy wykonywał pewne specyficzne operacje za każdym razem,
gdy aplikacja wykona określone działania na pewnych tabelach.
53

Wyzwalacze czasami nazywane są regułami zdarzenie-warunek-akcja (ang. ECA rules).
Instrukcja wyzwalacza udostępnia wiele opcji w zakresie każdego elementu: zdarzenia,
warunku i akcji. Podstawowe właściwości są następujące:
− Akcja może być wykonana przed, po oraz w chwili zajścia zdarzenia.
− Akcja może korzystać zarówno z wartości sprzed zajścia zdarzenia, jak i z
wartości nowych, powstałych w efekcie wstawienia, modyfikacji lub usunięcia
krotki w trakcie zdarzenia.
− Zdarzenia mogą wprowadzać zmiany do określonej kolumny lub do zbioru
kolumn.
− Istnieje możliwość określenia, czy akcja ma być wykonana zawsze dla każdej
modyfikowanej krotki, czy też raz dla wszystkich modyfikowanych krotek w
pojedynczej operacji w bazie danych.
4.1.3 Cechy obiektowe
Oprócz cech opisanych do tej pory, rozwój SQL:1999 koncentrował się głównie
na wzbogaceniu języka o cechy obiektowości.
Część z cech opisywanych w tej kategorii została po raz pierwszy zdefiniowana w
standardzie SQL/PSM, opublikowanym w roku 1996.
4.1.3.1 Strukturalne typy definiowane przez użytkownika
Najbardziej fundamentalnym udogodnieniem wspierającym obiektowość w
języku SQL:1999, jest strukturalny typ definiowany przez użytkownika (ang. Structured
User-Defined Type). Słowo „strukturalny” odróżnia ten typ od typu rozróżnionego,
który także jest typem definiowanym przez użytkownika, lecz w obecnej wersji języka
musi on bazować na typach wbudowanych SQL’a i w związku z tym nie posiada
skojarzonej struktury.
Typy strukturalne posiadają wiele cech, z których najważniejsze to:
− Mogą być definiowane tak, aby posiadać jeden lub więcej atrybutów, z których
każdy może być dowolnym typem SQL’a, włączając typy wbudowane jak
INTEGER, typy zbiorowe jak ARRAY lub inne typy strukturalne.
54

− Wszystkie aspekty ich zachowań są dostarczane poprzez metody, funkcje i
procedury.
− Ich atrybuty są hermetyzowane poprzez użycie generowanych systemowo
funkcji: obserwator (ang. observer) oraz modyfikator (ang. mutator). Funkcje te
umożliwiają dostęp do wartości. Obserwator działa jak funkcja pobierająca
„get”, natomiast modyfikator ustawia wartość jak funkcja „set”. Te generowane
systemowo funkcje nie mogą być przeciążone. Wszystkie inne funkcje i metody
mogą być przeciążone.
− Porównania ich wartości odbywają się poprzez funkcje zdefiniowane przez
użytkownika.
− Mogą być częścią hierarchii typu, w której to typy specjalizowane (podtypy)
posiadają wszystkie atrybuty i używają wszystkich metod powiązanych z typami
generalizowanymi (nadtypami). Typy specjalizowane mogą także dodawać
nowe atrybuty i metody.
Przykładowa definicja typu strukturalnego może wyglądać następująco:
CREATE TYPE emp_type
UNDER person_type
AS (EMP_ID INTEGER,
SALARY REAL)
INSTANTIABLE
NOT FINAL
REF (EMP_ID)
INSTANCE METHOD
GIVE_RAISE
(ABS_OR_PCT BOOLEAN,
AMOUNT REAL)
RETURNS REAL
Zdefiniowany powyżej nowy typ emp_type jest podtypem innego typu strukturalnego
person_type, ogólnie opisującego osoby. Zdefiniowany powyżej typ posiada nowe
atrybuty takie jak ID pracownika oraz jego pensję (EMP_ID, SALARY). Typ ten został
zadeklarowany jako INSTANTIABLE, co oznacza, że mogą być tworzone wartości
55

tego typu. Oznaczenie NOT FINAL informuje, że typ ten może posiadać podtypy.
Powyższa definicja informuje także, iż referencje do tego typu wywodzą się z wartości
ID pracownika (EMP_ID). Ostatecznie zadeklarowana została metoda mogąca działać
na instancjach tego typu. W dalszej części pracy referencje i metody zostały omówione
dokładniej.
Po wielu próbach odnośnie dziedziczenia, kiedy to podtypy mogły posiadać
więcej niż jeden bezpośredni nadtyp, SQL:1999 prezentuje model dziedziczenia
podobny do pojedynczego dziedziczenia w języku Java.
Podczas definiowania typu można określić, czy dany typ jest INSTANTIABLE, czyli
jak wspomniano wyżej, mogą być tworzone konkretne wartości tego typu, czy też jest
to typ NOT INSTANTIABLE, co stanowi analogię do typów abstrakcyjnych w innych
językach programowania.
Wszystkie miejsca, takie jak przykładowo kolumna, dopuszczające występowanie
wartości konkretnego typu strukturalnego muszą zezwalać na pojawianie się tam
wartości jego dowolnego podtypu.
W tym miejscu należy wspomnieć o jeszcze jednym istotnym zagadnieniu.
Większość obiektowych języków programowania pozwala na definiowanie stopnia
hermetyzacji typu. Hermetyzacja na poziomie PUBLIC oznacza, że atrybut jest w pełni
dostępny. Modyfikator PRIVATE oznacza, iż poza metodami zadeklarowanymi w
obrębie typu, żadne inne nie mają dostępu do tak oznaczonego atrybutu. Ostatecznie
PROTECTED informuje, że dostęp do atrybutu posiadają tylko metody danego typu i
wszystkich jego podtypów.
Język SQL:1999, pomimo prób zdefiniowania powyższego mechanizmu,
ostatecznie go nie posiada. Przewiduje się, iż element ten zostanie rozważony w
przyszłych wersjach standardu.
4.1.3.2 Metody a funkcje
SQL:1999 bardzo wyraźnie rozróżnia zwyczajne funkcje SQL’a od metod. W
bardzo dużym uproszczeniu, metoda jest funkcją z pewnymi ograniczeniami i
rozszerzeniami.
56

Poniżej zebrane zostały różnice pomiędzy funkcjami i metodami:
− Metody, w przeciwieństwie do funkcji, są ściśle powiązane z konkretnym typem
zdefiniowanym przez użytkownika.
− Funkcje mogą być polimorficzne, lecz określona funkcja jest wybierana w
czasie kompilacji, poprzez analizowanie zadeklarowanych typów każdego
argumentu w jej wywołaniu i wybranie funkcji najlepiej dopasowanej. Metody
także mogą być polimorficzne, lecz wybór właściwej metody do wywołania
odbywa się w czasie wykonywania. Wybór ten opiera się na jednym z
argumentów, a mianowicie tym, którego typ jest najbardziej specyficzny.
Wszystkie pozostałe argumenty są określane w trakcie kompilacji na podstawie
ich zadeklarowanych typów.
− Metody muszą być przechowywane w tym samym schemacie, co powiązane z
nimi typy strukturalne. Ograniczenie to nie odnosi się do funkcji.
Zarówno funkcje, jak i metody mogą być pisane w języku SQL, lub też w
jednym z kilku bardziej tradycyjnych języków programowania, między innymi w Javie.
4.1.3.3 Zapis funkcjonalny i kropkowy
Dostęp do atrybutów typów definiowanych przez użytkownika może być
dwojakiego rodzaju, poprzez zapis funkcjonalny lub kropkowy. W wielu przypadkach
bardziej naturalne wydaje się użycie zapisu kropkowego:
WHERE emp.salary > 10000
są jednak przypadki, gdy zapis funkcjonalny jest odpowiedniejszy:
WHERE salary(emp) > 10000
SQL:1999 obsługuje oba zapisy. W rzeczywistości są one zdefiniowane jako
syntaktyczne odmiany tej samej funkcjonalności semantycznej, tak długo jak emp jest
przechowywaną jednostką, której typem jest jakiś typ strukturalny z atrybutem o nazwie
salary, bądź też istnieje funkcja nazwana salary z jednym argumentem typu
strukturalnego emp.
Metody w tym przypadku są mniej elastyczne od funkcji. Dla wywoływania
metod może być wykorzystywany tylko zapis kropkowy. Jeśli salary jest metodą
57

związaną z typem employee, który jest typem kolumny o nazwie emp, wówczas metoda
może być wywołana tylko w poniższy sposób:
emp.salary
Pewna inna metoda o nazwie make_raise może korzystać zarówno z zapisu
kropkowego jak i funkcjonalnego:
emp.make_raise(amount)
4.1.3.4 Obiekty oraz typ REF
Jak dotychczas unikano używania określenia obiekt w stosunku do typów
strukturalnych. Jest to związane z tym, iż poza kilkoma właściwościami, takimi jak
hierarchiczność czy hermetyzacja, instancje typów strukturalnych języka SQL:1999 są
po prostu wartościami, podobnie jak instancje typów wbudowanych. Oczywiście
wartość zdefiniowanego wcześniej typu opisującego pracownika jest dużo bardziej
złożona, niż na przykład instancja typu INTEGER, lecz mimo tego jest to nadal wartość
nie posiadająca swoistej tożsamości.
Aby jednak SQL:1999 mógł dostarczać obiekty posiadające swoją tożsamość,
dzięki której możliwe są odwołania do nich w różnych sytuacjach, dodano kolejne
rozszerzenie. Rozwiązanie to pozwala twórcom baz danych na specyfikowanie, że
określone tabele są zdefiniowane jako tabele typowane (ang. typed tables). Oznacza to,
że definicje ich kolumn wywodzą się z atrybutów typu strukturalnego. Obrazuje to
poniższy przykład:
CREATE TABLE empls OF emp_type
Tabele takie posiadają jedną kolumnę dla każdego atrybutu odpowiadającego
typowi strukturalnemu. Funkcje, metody i procedury zdefiniowane do operowania na
instancjach typu działają teraz na wierszach tabeli. Wiersze tabeli są zatem wartościami
(instancjami) typu. Każdemu wierszowi jest przyporządkowany unikalny identyfikator,
zachowujący się jak identyfikator obiektu. Identyfikator ten jest unikalny w obrębie
bazy danych.
SQL:1999 dostarcza specjalny typ referencyjny, oznaczany jako REF, którego
wartościami są te unikalne identyfikatory. Dany typ REF jest zawsze skojarzony z
58

określonym typem strukturalnym. Przykładowo, definicja tabeli zawierającej kolumnę o
nazwie manager, której wartościami są referencje do wierszy w typowanej tabeli
pracowników, wygląda następująco:
manager REF(emp_type)
Wartość typu REF identyfikuje wiersz w tabeli typowanej, lub też nie
identyfikuje nic, jeśli usunięto wiersz, który był uprzednio przez nią identyfikowany.
Tabela, na którą wskazuje typ REF musi być znana już w fazie kompilacji. W trakcie
tworzenia standardu SQL:1999 podejmowano próby stworzenia typów REF jako
bardziej ogólnych. Niestety działania te spotkały się z dużymi trudnościami, których
rozwiązanie wymagałoby dalszego opóźnienia publikacji standardu. W związku z tym
wprowadzono powyższe ograniczenie. Jednym z korzystnych jego efektów jest
ułatwienie implementacji tego mechanizmu w niektórych produktach
Typy REF mogą być oczywiście wykorzystywane w bardziej zaawansowany
sposób niż przedstawiony powyżej.
SQL:1999 dostarcza składnię pozwalającą na dostęp do atrybutów wartości typu
strukturalnego.
SELECT emps.manager->last_name
Zapis wskaźnikowy jest stosowany do wartości typu REF i prowadzi do wartości
skojarzonego typu strukturalnego, który w rzeczywistości jest wierszem typowanej
tabeli będącej w zasięgu typu REF.
4.1.4 Opinie o standardzie
Z pewnością nowy standard SQL’a wprowadza dość rewolucyjne zmiany do
języka. Pomimo wielu bezsprzecznych ulepszeń, SQL:1999 wprowadza także
modyfikacje, które są odbierane dość krytycznie. Poniżej przedstawione zostały uwagi
zawarte w pracy [Subieta 1998a].
Autor stwierdza między innymi, że:
− Twórcy nowego standardu starają się wyeliminować wszystkie wady jego
poprzedników, jednocześnie próbując wszystko z nich pozostawić.
59

− Występuje tendencja do uniwersalizmu, nie przeoczenia jakiejkolwiek
własności, która mogłaby mieć znaczenie dla organizacji bazy danych lub
interfejsu programistycznego.
− Silnie zaznacza się wpływ modnych pojęć obiektowości, które nakładają się na
wymienione (sprzeczne) tendencje. Jednocześnie obiektowość jest okrojona i
wtłoczona w obce mechanizmy.
− Standard stworzono bez troski o możliwie zwięzłą postać języka. Duża liczba
konstrukcji to konstrukcje redundantne, od strony syntaktycznej, semantycznej
lub koncepcyjnej.
− Podejście do programowania ogólnego (SQL/CLI) zachowuje wady
dynamicznego SQL. Brakuje takich pojęć jak typy/klasy parametryczne, funkcje
wyższego rzędu, itd.
− W rezultacie powstała konstrukcja dość monstrualna. Jest mało prawdopodobne,
aby producenci systemów implementowali ją w całości.
4.2 Standard
ODMG
4.2.1 Powstanie grupy ODMG
Brak standardu obiektowych baz danych był główną przeszkodą ich masowego
użycia. Relacyjne bazy danych swój sukces zawdzięczają nie tylko wyższemu
poziomowi zaawansowania oraz prostszemu modelowi w porównaniu z wcześniejszymi
systemami. Do sukcesu tego w dużej mierze przyczyniła się właśnie standaryzacja.
Akceptacja standardu SQL pozwoliła tworzyć systemy baz danych w wysokim stopniu
kompatybilne ze sobą, co w efekcie dało wiele korzyści. Korzyści wynikające ze
standaryzacji są istotne także w przypadku obiektowych systemów baz danych.
Wnioski te spowodowały, iż Rick Cattel zdecydował się zainicjować próbę
stworzenia standardu dla obiektowych systemów baz danych. W lecie 1991 roku na
zaimprowizowanym śniadaniu z producentami obiektowych systemów bazodanowych
przedstawił swoje frustracje na temat braku postępu w kształtowaniu się właśnie takiego
60

standardu. Zaowocowało to pierwszym spotkaniem w tej sprawie już jesienią 1991
roku.
Kolejne ważne zdarzenia związane z grupą ODMG można przedstawić w
następujących punktach:
− Pierwszy rys standardu został opublikowany w roku 1991. Nosi on nazwę
ODMG 93 (1.0).
− Stworzona została grupa do prac nad standardem. Została ona nazwana Object
Database Management Group. Grupa zaczęła działać formalnie jako organizacja
i przeniosła się do własnego biura. Grupa ta podzieliła się na zespoły robocze,
każdy zespół zajmuje się swoimi podzadaniami. Zakres zagadnień do
ustandaryzowania okazał się daleko większy niż w relacyjnych bazach danych.
− W roku 1993 nastąpiło stowarzyszenie z OMG (Object Management Group).
− Publikacja ODMG wersja 1.2 miała miejsce w roku 1996.
− ODMG 2.0 został opublikowany w roku 1997.
− ODMG 3.0, skończony w 1999, został opublikowany w roku 2000.
Wysiłek ODMG daje przemysłowi obiektowych baz danych standard, który
ułatwia szybki start, zamiast mozolnego kształtowania standardu przez lata. ODMG
umożliwia wielu producentom wykorzystanie jednolitego interfejsu do obiektowych baz
danych, co pozwala klientom na pisanie ich własnych aplikacji.
Kolejne podrozdziały prezentujące standard powstały w oparciu o [Cattell 2000,
Haase 1999, Subieta 1998c] oraz stronę WWW grupy: http://www.odmg.com.
4.2.1.1 Cele
Głównym celem jest przedstawienie zestawu standardów, pozwalających
klientom systemów baz danych na pisanie przenośnych aplikacji, czyli takich, które
mogą współpracować z więcej niż jednym produktem bazodanowym. Układ danych,
język definiowania i manipulowania danymi oraz język zapytań muszą być przenośne.
Kolejnym celem jest to, że wypracowane propozycje będą przydatne w operowaniu
61

systemami bazodanowymi, również wersjami rozproszonymi, komunikującymi się za
pomocą OMG Object Request Broker.
Systemy bazodanowe mogą być bardzo różne, lecz ważne jest, aby umożliwiały
przenośność na poziomie kodu źródłowego. Nie można również zapomnieć o
pozostawieniu miejsca na innowacje w przyszłości. Z pewnością rzeczywiste systemy
będą różnorodne dla wielu klas odbiorców, z odmiennymi cechami, bibliotekami itp.,
jednak muszą one współpracować ze sobą na poziomie określonym właśnie przez
standard.
Istotnym zagadnieniem jest określenie zakresu działań związanych z tworzeniem
propozycji standardu. Obiektowe systemy baz danych mają architekturę, która jest
znacząco inna od pozostałych systemów bazodanowych. Zatem przejście z relacyjnego
systemu na obiektowy jest zmianą bardziej rewolucyjną niż ewolucyjną. Bardziej, niż
stworzenie języka w rodzaju SQL’a do manipulowania danymi, obiektowe systemy
przezroczyście integrują możliwości baz danych z językami programowania. Ta
przezroczystość eliminuje konieczność translacji danych między reprezentacją w bazie
danych, a reprezentacją w języku programowania. Model ten także umożliwia zapytania
rodem z relacyjnych systemów ale posiada większe możliwości, gdyż na przykład
umożliwia przechowywanie list, tablic i rezultatów dowolnego typu.
Podsumowując, zdefiniowanie obiektowego systemu baz danych, oznacza
stworzenie systemu bazodanowego, który integruje potencjał zorientowanych
obiektowo języków programowania. System taki tworzy obiekty w bazie, wyglądające
tak samo jak obiekty w języku programowania. Dodatkowo niezauważalnie monitoruje
dane, zapewnia równoległy dostęp, ochronę danych oraz inne tym podobne cechy
systemów bazodanowych.
4.2.1.2 Architektura
Przedstawione poniżej części składają się na zaproponowaną przez standard
architekturę:
62

− Model obiektowy.
Jako podstawa użyty został model obiektu zaproponowany przez OMG. Rdzeń
modelu OMG został zaprojektowany jako wspólny mianownik dla ORB (Object
Request Broker), systemów bazodanowych, obiektowych języków
programowania oraz innych aplikacji. Trzymając się architektury OMG, ODMG
zaprojektowało własny profil tego modelu, zawierający dodatkowe cechy (na
przykład relacje), aby zagwarantować możliwość realizacji swoich zamierzeń.
− Język specyfikacji obiektu ODL.
Język specyfikacji jako podstawę przyjął IDL (Interface Definition Language) z
OMG. Wersja 2.0 dodała obsługę innych języków, które umożliwiają na
przykład wymianę obiektów pomiędzy rozproszonymi bazami danych
− Obiektowy język zapytań OQL.
Język zapytań został pomyślany jako język deklaratywny. Służy on do
pobierania oraz uaktualniania obiektów w bazie. Jako podstawa został użyty
język SQL, wzbogacony o nowe możliwości.
− Wiązanie do języka C++.
Określa ono zasady połączenia ODL i OQL z językiem C++ oraz specyfikuje
zestaw klas umożliwiających takie połączenie. C++ jest językiem bardzo
popularnym, będąc jednocześnie mocno krytykowanym za cechy niskiego
poziomu. Pozwala to przypuszczać, że w przyszłości wiązanie do C++ straci na
znaczeniu, na korzyść rozbudowy języka OQL oraz wiązań do języków takich
jak Smalltalk i Java.
− Wiązanie do języka Smalltalk
ODMG starało się stworzyć standard wiązania, co było o tyle kłopotliwe, że nie
ma jeszcze oficjalnego standardu tego języka. Wiązanie pozwala na pełne
wsparcie ODL oraz OQL dla Smalltalk’a zgodnego z rozwojową wersją
standardu ANSI.
− Wiązania do języka Java.
Wersja wiązania ODMG 3.0 wymaga języka Java w wersji co najmniej 1.2.2.
Umożliwia wiązanie pomiędzy Javą oraz językami ODL i OQL, a także zawiera
bibliotekę do operacji na bazie oraz transakcji. Wiązanie to w ostatnim czasie
doczekało się wielkiego konkurenta. Firma Sun Microsystems, twórca języka
Java, zaproponowała ostatnio własny standard komunikacji tego języka z bazami
63

danych zwany Java Data Objects. Standard ten został przedstawiony w dalszej
części pracy.
Istnieje możliwość korzystania z bazy jednocześnie przy pomocy wiązań C++,
Smalltalk’a oraz Javy, jeśli tylko programista zadba o używanie typów danych
wspieranych przez wszystkie te języki. Wsparcie dla kolejnych języków jest planowane
w późniejszym czasie. Należy zauważyć, że w przeciwieństwie do relacyjnych
systemów obsługiwanych przez SQL’a, dane w systemach obiektowych są silnie
związane z danym językiem programowania. Dzieje się tak, aby zapewnić jedno spójne
środowisko dla programu oraz dla jego danych.
4.2.2 Model obiektu
Model obiektu w obiektowych bazach danych określa rodzaje semantyk, za
pomocą których mogą być definiowane obiekty. Semantyka mówi między innymi o
charakterystyce obiektu, o tym w jakiej relacji jest obiekt z innymi obiektami, jak obiekt
jest nazywany oraz jak identyfikowany. Model obiektu specyfikuje także, jakie
konstrukcje są możliwe w systemach.
Podstawą modelowania jest obiekt oraz literał. Każdy obiekt posiada swój
unikalny identyfikator. Literał natomiast nie posiada identyfikatora. Obiekty oraz
literały mogą być dzielone na kategorie ze względu na swoje typy. Wszystkie elementy
danego typu posiadają dany zakres stanów oraz dane zachowanie (czyli zdefiniowane
operatory, które pozwalają na operowanie elementami).
Stan obiektu jest definiowany przez zestaw wartości, które przybierają różne
właściwości obiektu. Właściwościami mogą być albo atrybuty danego obiektu, albo
powiązania obiektu z innymi obiektami. Zazwyczaj właściwości obiektu mogą być
zmieniane w czasie.
Zachowanie się obiektu jest definiowane przez zestaw operacji, które mogą być
wykonane przez lub na obiekcie. Operacje mogą posiadać listę parametrów
wejściowych oraz listę danych wyjściowych określonego typu. Dodatkowo każda
operacja może zwracać wynik również określonego typu.
64

Baza przechowuje obiekty pozwalając im na bycie dzielonymi przez wielu
użytkowników oraz wiele aplikacji. Baza jest oparta na schemacie zdefiniowanym w
ODL’u.
Model obiektu w rozumieniu ODMG specyfikuje to, co jest rozumiane przez
obiekt, literał, typ, operację, właściwości, atrybuty, powiązania itd. Programista
tworzący aplikacje używa konstruktorów dostarczonych przez model obiektu ODMG,
do tworzenia modelu obiektów dla danej aplikacji. Aplikacyjny model obiektu
specyfikuje określone typy oraz operacje i właściwości każdego z tych typów. Obiekt
aplikacyjny jest schematem bazodanowym.
Analogicznie do modelu obiektu ODMG dla obiektowych baz danych, istnieje
relacyjny model dla relacyjnych baz danych, który jest zaimplementowany w SQL’u.
Model relacyjny jest fundamentem zarządzania funkcjonalnością systemów relacyjnych
baz danych. Podobnie model obiektu ODMG jest fundamentalną definicją dla
funkcjonalności obiektowych systemów baz danych. Model ten ma znacznie bogatszą
semantykę niż model relacyjny.
4.2.3 Języki programowania
Opisane poniżej języki programowania są używane do programowania baz
danych zgodnych z systemami obiektowymi ODMG. Głównym celem powstania tych
języków jest ułatwienie przenoszenia danych pomiędzy systemami różnych
producentów.
4.2.3.1 ODL
ODL (Object Definition Language) jest językiem używanym do definiowania
specyfikacji obiektu zgodnie z modelem obiektu ODMG. ODL jest używany do
wspierania przenośności schematu danych pomiędzy różnymi systemami.
Głównymi zasadami, które wytyczały rozwój ODL’a są:
− ODL powinien zawierać całą semantykę konstrukcji obiektu, która ma
umożliwiać tworzenie obiektu zgodnie z modelem ODMG.
− ODL nie będzie językiem ogólnego przeznaczenia, a jedynie językiem
definiującym specyfikację obiektu.
65

− ODL powinien być niezależny od innych języków programowania.
− ODL powinien być kompatybilny z językiem IDL grupy OMG.
− ODL powinien mieć możliwość późniejszego rozwoju.
ODL w zamierzeniach nie ma być pełnym językiem programowania. Jest to
język do definiowania specyfikacji obiektu. Za pomocą tego języka można zdefiniować
charakterystykę typów, włącznie z ich danymi oraz operacjami na tych danych. ODL
tworzy jedynie sygnatury operacji, ale nie mówi nic na temat implementacji tych
operacji.
ODL ma w zamierzeniach definiować typy obiektów, które mogą być
implementowane w różnych językach programowania. Zatem język ten nie próbuje
bezpośrednio nawiązywać do składni żadnego z języków programowania ogólnego
przeznaczenia. Użytkownicy mogą użyć ODL’a, aby zdefiniować swój schemat bazy
danych w sposób niezależny od konkretnej implementacji programu korzystającego z
tej bazy.
Biblioteki do wiązania z językami takimi jak C++, Smalltalk i Java zostały
zaprojektowane tak, aby umożliwić także deklaratywną składnię, osiągalną w tych
językach. W związku z różnicami w modelu obiektów tych języków, nie zawsze jest
możliwe osiągniecie spójnej semantyki w ODL’u dostępnym z bibliotek. Podejmowane
były starania, aby minimalizować tę niespójność.
Składnia ODL’a jest rozszerzeniem IDL’a, który jest rozwijany przez OMG jako
część CORBA (Common Object Request Broker Architecture). IDL był tworzony pod
wpływem języka C++, co również wywarło wpływ na ODL.
ODL umożliwia także integrację schematów baz danych stworzonych innymi
metodami. Przykładowymi językami, które łatwo mogą być przekonwertowane do
specyfikacji ODL są: SQL (ANSI X3H2), EXPRESS (STEP/PDES), Object
Information Management (ANSI X3H7), CAD Framework Initiative. Umożliwia to
integrację z istniejącymi już rozwiązaniami.
66

Przykładowy interfejs klasy w ODL’u:
interface Student {
key student_id;
attribute string name;
attribute string student_id;
relationship Set<Course> takes;
take (in Course);
}
4.2.3.2 OIF
OIF (Object Interchange Language) jest językiem, który umożliwia wymianę
obiektów za pomocą plików tekstowych.
Następujące cechy są uwzględniane w celu scharakteryzowania stanu obiektu:
− identyfikator obiektu,
− typ wiązania do języka programowania,
− wartości atrybutów,
− powiązania z innymi obiektami.
Struktura pliku OIF zawiera definicję obiektu, włączając w to specyfikację
typów, wartości atrybutów oraz relacje z innymi obiektami. Identyfikatory są
specyfikowane razem z tzw. tag name, który zapewnia unikalność nazwy. Jest on
widoczny w całym zestawie plików OIF i jednoznacznie identyfikuje dany obiekt.
4.2.3.3 OML
OML (Object Manipulation Language) oznacza język manipulacji obiektami.
Standard obiektowych baz danych ODMG nie zawiera specyficznego języka do tego
zadania. Modyfikacje obiektów mają odbywać się za pomocą zwyczajnych języków
programowania, które mogą komunikować się z bazą danych za pomocą odpowiednich
wiązań do tych języków. Dodatkowe cechy związane z manipulacją obiektami takie jak
zarządzanie trwałością obiektu, transakcje itp., zrealizowane są w bibliotece
67

zapewniającej wiązanie do danego języka programowania. OML jest więc zależny od
konkretnego języka programowania i nie może być rozpatrywany w oderwaniu od
konkretnego wiązania. W obecnym standardzie ODMG 3.0 znajdują się wiązania do
trzech języków (C++, Smalltalk, Java), z czego wynika istnienie trzech odmian OML’a.
4.2.3.4 OQL
OQL (Object Query Language) jest językiem umożliwiającym stawianie
zapytań do obiektowego systemu bazy danych.
Do głównych zasad, które wytyczały rozwój OQL’a można zaliczyć:
− OQL opiera się na założeniach modelu obiektu ODMG.
− OQL jest oparty na języku SQL-92. Rozszerzenia dotyczą notacji związanej z
obiektowością.
− OQL dostarcza wysokiego poziomu prymitywów do operacji z zestawem
obiektów, ale umożliwia także operacje na strukturach, listach, tablicach i
pozwala na ich wykorzystywanie z taką samą efektywnością.
− OQL jest językiem funkcjonalnym, w którym operatory mogą być dowolnie
tworzone, tak aby tylko operandy odpowiadały typom w systemie. Jest to
konsekwencją faktu, że rezultat każdego zapytania posiada typ, który należy do
modelu typów ODMG, zatem może być podstawą do kolejnych zapytań.
− OQL nie jest językiem ogólnego przeznaczenia. Jest to prosty w użyciu język
zapytań, umożliwiający dostęp do systemu obiektowych baz danych.
− OQL może być wywoływany z języków programowania, do których stworzone
jest wiązanie ODMG. OQL może także wykonywać operacje tych języków.
− OQL nie dostarcza operatorów do modyfikacji danych, ale zamiast tego
umożliwia wywoływanie obcych operacji w tym celu. Tym samym nie łamie
metodologii obiektowej mówiącej, że obiekty są zarządzane przez metody
będące ich częścią.
− OQL umożliwia deklaratywny dostęp do obiektów. Umożliwia to łatwą
optymalizację zapytań z racji takiej natury deklaratywności.
− Formalna semantyka OQL może być łatwo definiowana.
68

Przykładowe zapytania (do klasy przytoczonej w przykładzie do ODL’a) mogą
być następujące:
SELECT s.name
FROM s IN students
WHERE s.student_id = "4711"
SELECT s.name
FROM s IN students
WHERE EXISTS c IN s.takes: c.code = "CME-DB"
4.2.4 Wiązania do języków programowania
W kolejnych rozdziałach pracy zostały zaprezentowane wiązania do
następujących języków programowania: C++, Smalltalk oraz Java. Ogólny schemat
wiązania na przykładzie wiązania do języka C++ został przedstawiony na poniższym
rysunku (rys. 4.1).
Wiązanie ODL do języka C++ zostało zrealizowane jako biblioteka dla tego
języka. W bibliotece tej można znaleźć klasy oraz funkcje, pozwalające
zaimplementować model obiektu zgodny z modelem ODMG. Wiązanie OML nie jest
konieczne, gdyż syntaktyka oraz semantyka OML są w całości zawarte w standardzie
C++ oraz standardowej bibliotece klas.
ODL/OML specyfikują jedynie logiczną charakterystykę obiektów oraz operacje
używane do manipulacji na nich. Celem jest dążenie do ideału, gdzie wszystko jest
przezroczyste dla programisty, czyli jest on niezależny od sposobu adresowania
obiektów, zarządzania pamięcią, fizycznej reprezentacji obiektu, struktur dostępu jak
indeksy itp. Niestety w rzeczywistym świecie nie jest tak znakomicie. Istnieją powody,
dla których został stworzony zestaw konstrukcji nazwanych „physical pragmas”. Daje
on programiście w niektórych przypadkach kontrolę nad elementami z niższych warstw,
lub przynajmniej daje możliwość dawania systemowi bazodanowemu wytycznych w
celu optymalizacji jego pracy. Mechanizm ten istnieje wewnątrz ODL’a oraz OML’a.
69
Ponieważ mechanizm ten nie jest standardowym elementem języka, a jedynie
dodatkiem zależnym od implementacji, dlatego można o nim mówić jedynie w
odniesieniu do konkretnego wiązania z językiem wyższego poziomu.
Schemat
danych
Wykonywana
aplikacja
Dostęp do danych
Pliki do konsolidacji
Biblioteki
ODMG
Baza danych
Linker
Wygenerowane pliki
Kompilator
Preprocesor ODL
- rozwinięcie makr
Pliki źródłowe oraz
pliki nagłówkowe z
wykorzystaniem OML
Deklaracje w ODL
4.2.4.1 Wiązanie do języka C++
RYSUNEK 4.1. OGÓLNY SCHEMAT WIĄZANIA NA PRZYKŁADZIE JĘZYKA C++.
70

4.2.4.2 Wiązanie do języka Smalltalk
Z powodu braku oficjalnego standardu języka Smalltalk, członkowie organizacji
ODMG jako podstawę przyjęli rozwojową wersję standardu X3J20 ANSI Smalltalk.
U podstaw tworzenia wiązania do języka Smalltalk stały następujące zasady:
− Używanie języka ODL powinno być możliwe w języku Smalltalk w sposób
naturalny dla tego języka, co oznacza, że nie będą tworzone żadne rozszerzenia
ani modyfikacje tego języka, które ułatwiłyby integrację z obiektowymi bazami
danych. Należy mieć przy tym na uwadze, że Smalltalk jest językiem, w którym
typy ustalane są dynamicznie.
− Wiązanie uwzględnia dynamiczne zarządzanie pamięcią w Smalltalk’u. Obiekty
utrzymują się w pamięci, dopóki istnieje referencja z innych istniejących
obiektów i są kasowane, kiedy znika ostatnie odwołanie.
− Wiązanie ma umożliwiać korzystanie ze wszystkich możliwości języka ODL.
4.2.4.3 Wiązanie do języka Java
Wiązanie ODMG do języka Java opiera się na następujących założeniach:
− Programista powinien pracować w jednym języku, który umożliwia operacje
zarówno na bazie danych, jak i zwykłe czynności programistyczne.
− Wiązanie uwzględnia dynamiczne zarządzanie pamięcią w Javie. Obiekty
utrzymują się w pamięci, dopóki istnieje referencja z innych istniejących
obiektów i są kasowane, gdy ostatnie odwołanie przestaje istnieć. W przypadku
wywołania komendy COMMIT wszystkie obiekty, które są osiągalne z
korzenia, zostaną zapisane w bazie danych.
4.3 Java Data Objects
JDO (Java Data Objects) to nowy standard, który został stworzony przez firmę
Sun Microsystems. Standard ten ma na celu zdefiniowanie sposobu łączenia aplikacji
napisanych w języku Java z obiektowymi bazami danych. JDO jest na razie bardzo
„świeżą” specyfikacją, co powoduje, że nie można znaleźć działających zgodnie z nią
71

systemów. Mając jednakże na uwadze, że to właśnie firma Sun Microsystems jest
twórcą Javy, można się spodziewać, że standard ten szeroko się rozpowszechni.
Informacje przedstawione w kolejnych podrozdziałach zostały wybrane z
opracowań [Bobzin 2000, Criag 2001, Criag 2002, Echelpoel 2002, Jordan 2000,
Jordan 2001, OpenFusion 2002].
4.3.1 Rozwój standardu
Zanim powstało JDO, Sun Microsystems stworzył dwie metody umożliwiające
przechowywanie danych. Pierwszą jest JDBC
, drugą zaś serializacja obiektów. Jako
że JDBC jest adresowane do tych, którzy chcą korzystać z relacyjnych baz danych, a
serializacja dla tych, którzy chcą przesyłać obiekty, JDO nie jest metodą, która miałaby
z nimi konkurować. JDO ma je uzupełniać, lub nawet rozszerzać ich możliwości. JDO
może być samodzielnym interfejsem języka Java do obiektowych baz danych, może
także być zaimplementowane ponad warstwą JDBC i emulować cechy obiektowe w
relacyjnych bazach danych.
Pierwsze plany stworzenia nowej specyfikacji pojawiły się na początku 1999
roku. W sierpniu 1999 uformowała się pod kierownictwem Criaga Russel’a grupa
robocza mająca prowadzić prace nad JDO. W maju 2000 roku ukazał się dokument
zawierający ogólny zarys koncepcji JDO, natomiast w maju kolejnego roku wydana
została w dokumencie [Criag 2001] proponowana specyfikacja JDO. 25 marca 2002
roku koncepcja ta z małymi zmianami stała się oficjalnym standardem [Criag 2002]
firmy Sun Microsystems dotyczącym łączenia aplikacji Javy z obiektowymi bazami
danych.
Główne cele, jakie przyświecały twórcom JDO to:
− zbudowanie interfejsu między aplikacją napisaną w Javie a obiektowymi bazami
danych, który to interfejs działa bez potrzeby mapowania struktury obiektowej
do relacyjnej ani żadnej innej,
11
JDBC (Java Database Connectivity) – jest to standard dostępu do relacyjnych baz danych z poziomu
języka Java.
72

− pozwolenie programiście na używanie składni Javy do modelowania schematu
bazy, a także zarządzania danymi w bazie,
− zbudowanie standardu, który będzie odpowiadał szerokiemu gronu odbiorców i
będzie mógł spełniać swoją rolę zarówno w urządzeniach przenośnych, jak i w
wielkich systemach, włączając w to serwery aplikacji,
− uproszczenie budowania aplikacji korzystających z baz danych,
− danie możliwości implementacji różnorodnych serwerów baz danych zgodnych
z JDO,
− zapewnienie dodatkowej optymalizacji przez serwery bazodanowe (na przykład
optymalizacja zapytań),
− danie możliwości rozszerzania standardowego zestawu klas oraz interfejsów
JDO przez producentów serwerów bazodanowych.
4.3.2 Architektura JDO
4.3.2.1 Schemat bazy danych
Aby system zarządzania obiektową bazą danych mógł przechowywać dane,
musi znać strukturę samej bazy danych. Struktura bazy danych to nic innego, jak
struktura klas w programie. Struktura ta określana jest mianem metadane (ang.
metadata). Owe metadane zapisywane są w plikach formatu XML. Każda klasa zdolna
do trwałości, posiada swój własny plik o nazwie „<nazwa-klasy>.jdo”.
Metadane, oprócz serwera baz danych, wykorzystywane są także przez JDO
Enhancer do modyfikacji B-kodu plików „class”.
Obowiązek tworzenie plików ze schematem bazy danych spoczywa bądź to na
programiście, bądź na dodatkowych narzędziach, potrafiących wygenerować metadane
z deklaracji klas zawartych w kodzie źródłowym aplikacji.
Poniżej przedstawiono przykład pliku zawierającego metadane dla klasy
Employee.
73

Deklaracja klasy:
package com.xyz.hr;
class Employee {
String name;
Float salary;
Department dept;
Employee boss;
}
Zawartość pliku:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE jdo SYSTEM "jdo.dtd">
<jdo>
<package
name="com.xyz.hr">
<class name="Employee" identity-type="application"
objectid-class= "EmployeeKey">
<field
name="name"
primary-key="true">
<extension
vendor-name="sunw"
key="index"
value="btree"/>
</field>
<field
name="salary"
default-fetch-
group="true"/>
<field
name="dept">
<extension
vendor-name="sunw"
key="inverse"
value="emps"/>
</field>
<field
name="boss"/>
</class>
</package>
</jdo>
74

4.3.2.2 Trwałe obiekty w Javie - interfejs PersistenceCapable.
Jednym z problemów postawionych przed grupą tworzącą standard JDO była
potrzeba umożliwienia istnienia obiektów, które nie są już osiągalne przez wskazania z
żadnej innej klasy, czyli tzw. trwałych obiektów (ang. persistent objects). Normalnie,
obiekty takie są niszczone przez odśmiecacz pamięci (ang. garbage collector) w
wirtualnej maszynie Javy. Istnienie obiektów zdolnych do trwałości osiągnięto na dwa
sposoby. Pierwszym sposobem jest dodanie przez programistę do odpowiednich klas
interfejsu PersistenceCapable. Drugim jest modyfikacja B-kodu Javy przez specjalne
narzędzie zwane JDO Enhancer. Stosowanie takiego rozwiązania nie wymaga
ingerencji programisty, ponieważ obiekty większości standardowo zadeklarowanych
klas, mogą być zamienione na trwałe przez JDO Enhancer. W bazie danych mogą być
umieszczane tylko klasy zdolne do trwałości.
Według modelu obiektu JDO, klasy można podzielić na dwa rodzaje: takie,
które implementują interfejs PersistenceCapable oraz takie, które go nie implementują.
Pierwszym rodzajem nie mogą być klasy, których stan zależy od innych odległych
obiektów, czyli na przykład takich, które dziedziczą po java.net.SocketImpl lub
implementują interfejs java.net.SocketOptions.
Klasy, które implementują interfejs PersistenceCapable można z kolei podzielić
na dwie grupy. Pierwsza grupa obejmuje klasy, których instancje posiadają swój
unikalny identyfikator zwany JDO Identity. Takie obiekty nazywają się First Class
Object. Druga grupa zawiera klasy, których instancje nie posiadają owego
identyfikatora, ich obiekty nazywają się Second Class Object. Obiekty klasy typu FCO
można bez problemów przechowywać w bazie, a później je pobrać, zadając serwerowi
zapytania. Instancje klasy typu SCO nie mogą samodzielnie istnieć w bazie, jednakże
mogą się tam znajdować jako części składowe obiektu FCO.
Obiekty klas zdolnych do trwałości w czasie swojego życia, można
scharakteryzować za pomocą następujących cech określających ich stan:
− ulotny (ang. transient) – obiekt ulotny to obiekt, który mimo, iż jest zdolny do
trwałości, aktualnie nie wykazuje takich cech i jest traktowany przez odśmiecacz
pamięci jako zwykły obiekt.
75

− brudny (ang. dirty) – obiekt brudny to obiekt, który w aktualnej transakcji został
zmieniony.
− transakcyjny (ang. transactional) – obiekt transakcyjny to obiekt, który bierze
udział w aktualnej transakcji.
− nowy (ang. new) – obiekt nowy to obiekt, który w aktualnej transakcji został
zmieniony ze stanu trwały na ulotny lub odwrotnie.
− skasowany (ang. deleted) – obiekt skasowany to obiekt, który został skasowany
w aktualnej transakcji. Aby usunąć obiekt zdolny do trwałości, należy go
skasować. Jest to nowość w języku Java, gdyż do tej pory programista nie
troszczył się o usuwanie obiektów. Cechy dodane przez interfejs
PersistenceCapable powodują, że tradycyjna metoda automatycznego usuwania
obiektów przez odśmiecacz pamięci nie ma zastosowania w przypadku obiektów
zdolnych do trwałości.
4.3.2.3 Modyfikator kodu binarnego JDO Enhancer.
Jak już wcześniej wspomniano, trwałe klasy można deklarować w kodzie
programu. Można również używać narzędzia zwanego JDO Enhancer, aby uczynić dane
klasy klasami trwałymi. JDO Enhancer na podstawie metadanych z odpowiednich
plików „jdo” modyfikuje kod binarny zawarty w plikach „class”. Głównym jego
zadaniem jest przekształcanie klas do postaci trwałych klas. Przekształcenie to polega
na zmianie odpowiednich klas tak, aby implementowały interfejs PersistenceCapable
oraz na dodaniu kodu związanego z metodami zawartymi w tym interfejsie. Dodatkowo
narzędzie to może dokonywać innych koniecznych modyfikacji. Przykładem takiej
modyfikacji może być dodanie do klasy atrybutu typu Integer, który będzie
wykorzystywany przez bazę jako klucz główny. Enhancer będzie ignorował klasy, które
zostały obdarzone przez programistę interfejsem PersistenceCapable. Enhancer nie
będzie związany z konkretnym serwerem bazodanowym. Jest to zgodne z głównym
założeniem języka Java, czyli przenośnością kodu binarnego. Powoduje to, iż
zmodyfikowane pliki „class” będą mogły komunikować się z dowolną obiektową bazą
danych, zgodną ze specyfikacją JDO. Aby zmienić serwer na inny, nie będzie potrzeby
modyfikowania plików „class” odpowiednio innym Enhancer’em.
76
Poniższy schemat prezentuje kompilację aplikacji korzystającej z JDO z
użyciem JDO Enhancer’a (rys. 4.2).
B-kod
Wirtualna
maszyna Javy
Schemat
danych
Baza danych
Dostęp do danych
Rozszerzone pliki
.class
JDO Enhancer
Wygenerowane pliki
.class
Kompilator
ew. generator
plików .jdo
pliki z metadamymi
.jdo
Pliki źródłowe
.java
RYSUNEK 4.2. KOMPILACJA APLIKACJI KORZYSTAJĄCEJ Z JDO Z UŻYCIEM JDO ENHANCER’A.
77

4.3.2.4 Dostęp do bazy danych - język JDOQL
Java Data Objects zrywa z dotychczasowymi standardami dostępu do baz
danych opartych na języku SQL. Twórcy standardu JDO stworzyli interfejsy
PersistenceManager oraz Query, za pomocą których można wykonywać operacje, jakie
w relacyjnych bazach danych specyfikowało się w języku SQL.
Nowy sposób dostępu do bazy danych nazwano JDOQL (Java Data Objects
Query Language).
W przykładach poniższych wykorzystywana będzie definicja następującej klasy
Person:
class Person implements PersistenceCapable{
String name;
int age;
public void setName(String name){
this.name=name;
}
public void setAge(int age){
this.age=age;
}
}
4.3.2.4.1 Umieszczanie obiektów w bazie danych
Umieszczenie obiektu w bazie danych to nic innego niż spowodowanie, aby stał
się on obiektem trwałym. W poniższym przykładzie stworzono instancję klasy Person
zawierającą informacje o pewnej osobie (tutaj informacje te to imię i wiek).
fCon.beginTransaction();
Person p = new Person();
fPm.makePersistent(p);
p.setName("John");
p.setAge(20);
fCon.commitTransaction();
78

4.3.2.4.2 Pobieranie obiektów z bazy
Język zapytań JDOQL oparty jest na selekcji według wartości atrybutów
obiektów. Warunki zawarte w zapytaniach opierają się na wyrażeniach logicznych,
które muszą być spełnione, aby dany obiekt został pobrany z bazy. Nowością jest
ustalanie parametrów pobranego zestawu obiektów po zadaniu zapytania. W poniższym
przykładzie pobierane są z bazy wszystkie te instancje klasy Person, które reprezentują
osoby mające powyżej 10 lat. Dodatkowo zestaw ten zostanie posortowany rosnąco
według wieku.
String filter - "age > 10";
Query q = fPM.newQuery(Person.class, filter);
q.setOrdering ("age ascending");
Collection result = (Collection)q.execute();
4.3.2.4.3 - Modyfikacja obiektów w bazie
Język JDOQL nie posiada możliwości takich jak słowo kluczowe UPDATE
znane z języka SQL. Modyfikacja obiektów w bazie danych odbywa się zawsze w
dwóch etapach. Pierwszym jest zadanie zapytania do bazy, aby pobrać interesujący nas
zestaw instancji klas. Drugim krokiem jest modyfikacja owego zestawu. W poniższym
przykładzie zmieniany jest każdy obiekt, który reprezentuje osobę o liczbie lat równej
20. Po pobraniu takiego zestawu obiektów, drugim krokiem jest ustawienie w nich
liczby lat na 21.
fCon.beginTransaction();
String filter - "age == 20";
Query q = fPM.newQuery(Person.class, filter);
Collection result = (Collection)q.execute();
Iterator iter = result.iterator();
while(iter.hasNext()){
Person p = (Person)iter.next();
p.setAge(21);
}
fCon.commitTransaction();
79

4.3.2.4.4 Kasowanie obiektów z bazy
Podobnie jak modyfikacje danych, kasowanie danych również przebiega
dwuetapowo. Kasowanie obiektów wykonuje się w sposób nietypowy dla Javy, a
mianowicie poprzez wywołanie funkcji kasującej. Skasowany obiekt zostaje usunięty z
bazy, jak również z pamięci operacyjnej. Usuwanie z pamięci operacyjnej następuje w
sposób analogiczny do zwykłych klas w Javie. W poniższym przykładzie kasowane są
wszystkie obiekty typu Person, które odpowiadają osobom niepełnoletnim (o liczbie lat
mniejszej niż 18).
fCon.beginTransaction();
String filter - "age < 18";
Query q = fPM.newQuery(Person.class, filter);
Collection result = (Collection)q.execute();
Iterator iter = result.iterator();
while(iter.hasNext()){
Person p = (Person)iter.next();
fPm.deletePersistent(p);
p = null;
}
fCon.commitTransaction();
4.3.3 Java Data Objects a Enterprise Java Beans
Istnieją dwa typy ziaren EJB (Enterprise Java Beans): Entity Beans oraz Session
Beans. Ze względu na specyfikę komponentów, sposoby przechowywania każdego z
tych typów w bazie za pomocą JDO różnią się od siebie.
4.3.3.1 Ziarna typu Entity Beans
Entity Beans to komponenty, które mogą być używane w tym samym czasie
przez wielu klientów. Serwer aplikacji zgodny ze specyfikacją j2ee (Java 2 Enterprise
Edition) dostarcza dwie metody, które zapewniają trwałość ziaren EJB. Metody te
nazywane są: BMP (Bean Managed Persistence) i CMP (Container Managed
80

Persistence). Te dwie metody nie pozwalają niestety na uzyskanie pełnej
funkcjonalności płynącej z JDO. Sugerowanym sposobem na umożliwienie stosowania
trwałości komponentów Entity Beans zgodnym z JDO jest stworzenie dostępu do nich
zgodnie ze specyfikacją DAO (Data Access Object). Trwałość komponentów można
zaszyć w implementacji DAO. Konsekwentne odwoływanie się do Entity Beans za
pomocą DAO pozwoli uzyskać żądany efekt, czyli możliwość umieszczania Entity
Beans w obiektowych bazach danych.
4.3.3.2 Ziarna typu Session Beans
Session Beans to komponenty, których instancje tworzą się niezależnie dla
każdego klienta z osobna. Aby osiągnąć trwałość tych komponentów wymaganą przez
JDO, należy skojarzyć każdy z nich z instancją klasy PersistenceManagerFactory,
która pochodzi z JDO. Jedna instancja PersistenceManagerFactory powinna być
dzielona przez wszystkie ziarna korzystające z jednej bazy danych. Każda metoda
znajdująca się w owych ziarnach powinna otrzymać dostęp do instancji
PersistenceManager pochodzącej z PersistenceManagerFactory.
4.4 Porównanie
standardów
Po przedstawieniu trzech głównych standardów proponowanych dla
zorientowanych obiektowo systemów baz danych: SQL:1999, ODL/OQL oraz JDO,
omówione zostaną główne podobieństwa oraz różnice pomiędzy nimi. Pomimo tego, iż
standardy te pochodzą z bardzo różnych modeli: języków relacyjnych baz danych oraz
języków programowania zorientowanych obiektowo, podobieństwa przeważają nad
różnicami. Jest to efektem między innymi tego, iż każdy ze standardów w efektywny
sposób adaptuje pojęcia z obcego mu modelu.
Główne różnice pomiędzy opisanymi standardami, są to przede wszystkim
różnice dotyczące następujących obszarów:
− Podstawa dla specyfikacji:
Standard SQL:1999 powstał w wyniku naturalnej ewolucji standardu
SQL-92.
81

Standard ODMG czerpie z różnych źródeł. Model obiektu został
zapożyczony z modelu zaproponowanego przez grupę OMG. Podobnie język
definicji schematu obiektowego, bierze dużo z języka definicji interfejsu IDL,
który jest dziełem OMG. Operacje na obiektach spoczywają na językach
programowania, czyli według standardu na C++, Smalltalk’u i Javie.
Standard JDO został stworzony tylko dla języka Java. Powoduje to, iż
Java jest językiem z którego owa specyfikacja czerpie najwięcej. Wszystkie
operacje włączając w to zapytania do bazy, które co prawda są specyficzne i
zostały nazwane JDOQL, są pisane w języku Java. Wyjątkiem od tej reguły
jest definicja schematu bazy, która jest zapisana w języku XML.
− Język zapytań do bazy
SQL:1999 jest niezależnym językiem zapytań od środowiska
programistycznego. Podobnie jak w pozostałych implementacjach SQL’a,
także tutaj istnieje wąski interfejs, umożliwiający przekazywanie wartości
między strukturami danych SQL’a a zmiennymi środowiskowymi. Dodatkowo
do zwykłego interfejsu między językiem SQL a językiem podstawowym, w
standardzie SQL:1999 powstała koncepcja funkcji zewnętrznych.
W systemie OQL istnieje założenie, iż jego instrukcje są osadzone w
języku programowania, mającym z nim wspólne środowisko programowania i
model danych. Zakłada się również, że jest to język programowania
zorientowany obiektowo, na przykład Java, C++ lub Smalltalk.
Język zapytań JDOQL to wręcz język Java, plus osadzone jako
parametry funkcji, filtry. W języku tym, w przeciwieństwie do poprzednich,
składnia jest bardzo prosta i nie ma potrzeby tworzenia złożonych zapytań.
− Język definicji danych
W standardzie SQL:1999 wszystkie operacje czyli również definiowanie
danych odbywa się za pomocą języka SQL.
W specyfikacji ODMG wyróżnia się specjalny język ODL, który ma
służyć, do definiowania schematu bazy. Język ten rozszerza możliwości języka
IDL opracowanego przez grupę OMG.
82

Zgodnie
ze
specyfikacją JDO, dane są definiowane w programie w
języku Java. Serwer natomiast korzysta z definicji danych zapisanych w
formacie XML.
− Język modyfikacji danych
W systemach zgodnych z SQL:1999 do modyfikacji danych używa się
języka SQL, który może być osadzony w innym języku.
Modyfikacje danych zgodnie z ODMG odbywają się w językach
programowania. Aktualnie mogą to być języki C++, Java lub Smalltalk.
Zgodnie z JDO wszystkie modyfikacje zawartości bazy są wykonywane
w języku Java.
− Rola relacji
W modelu danych języka SQL:1999 pojęcie relacji odgrywa główną rolę.
Typy wiersza w rzeczywistości są opisem relacji.
W języku OQL dominującą rolę odgrywają zbiory i wielozbiory
obiektów lub struktur. Podobną rolę w JDO odgrywają znane z Javy kolekcje
obiektów. Zbiory obiektów w systemie ODL/OQL oraz JDO są bardzo
zbliżone do pojęcia relacji języka SQL:1999, ze względu na pełnione funkcje
w różnych instrukcjach.
− Zasięg klasy
W języku SQL:1999 można by stosować podobną kontrolę nad
zasięgiem typu wiersza, czyli relacją, która zawiera wszystkie istniejące w
bazie krotki tego typu. Jednakże działanie takie nie jest konieczne.
W
języku OQL zakłada się, że każda klasa posiada określony zasięg.
Referencje wskazują elementy z zasięgu.
Zasięg klasy w JDO odpowiada zasięgowi klasy w języku Java.
− Identyfikator obiektu
Zarówno w języku ODL, jak i w SQL:1999 stosuje się konwencjonalną
interpretację identyfikatora obiektu. Jest to tworzona przez system jednostka,
83

do której użytkownik nie posiada dostępu. Zasada ta nie stosuje się do typu
wiersza w SQL:1999.
Obiekty w bazach zgodnych z JDO są rozróżniane ze względu na
posiadanie lub nieposiadanie identyfikatora zwanego JDO Identity. Jeśli obiekt
posiada identyfikator to jest on dostępny dla użytkownika.
84

5 Rozszerzenia obiektowe w relacyjnych bazach danych
5.1 Oracle
Baza danych Oracle powstała w roku 1977 w firmie Relational Software
Incorporated. Pierwszym klientem był rząd Stanów Zjednoczonych. W roku 1979 firma
zmieniła nazwę na Oracle, czyli na taką jak jej główny produkt. Baza zyskała szeroką
popularność w swej szóstej wersji z roku 1989. Produkt ten posiadał już rozwinięte
mechanizmy zwiększające efektywność i niezawodność systemu oraz potrafił
wykorzystać potencjał systemów wieloprocesorowych. Kolejna wersja z 1993 roku
oferowała wzbogacone możliwości deklaratywnego definiowania więzów integralności
oraz ich weryfikacji w trakcie pracy oprogramowania aplikacyjnego. Dodatkowo,
istniała możliwość definiowania funkcji użytkowych w języku PL/SQL, które są
dołączane do bazy danych i wykorzystywane jak funkcje systemowe. Podwyższona
została efektywność systemu przez równoległe operacje, takie jak: wykonywanie
zapytań, tworzenie indeksów, ładowanie danych oraz przez replikowanie danych
znacznie redukujące kodowanie przy tworzeniu rozproszonych aplikacji.
Obecnie serwer Oracle to bardzo zaawansowana i najbardziej ceniona baza
danych na świecie. Posiada ona największy udział na rynku baz danych, szacowany
przez firmę DataQuest na 41%.
W wersjach 8i oraz 9i nabyła wiele cech, które mogą zbliżać ją do obiektowych
baz danych. Co prawda rdzeń stanowi nadal model relacyjny, jednakże rozszerzenia
obiektowe tworzą z niej hybrydową bazę relacyjno-obiektową. Oznacza to, iż bazę tę
można traktować jako bazę stricte relacyjną, zapominając o jej obiektowych
rozszerzeniach, natomiast nie można jej uznać jako bazę czysto obiektową ze
wszystkimi jej zaletami. Obiektowe modyfikacje bazy nie zaburzyły dotychczasowej
relacyjnej funkcjonalności, takiej jak zapytania (SELECT FROM WHERE), szybkie
potwierdzenia, partycjonowane tabel, równoległe zapytania, klastrowane składowanie
danych, eksport/import, itp.
SQL oraz różnorodne programistyczne interfejsy do Oracle włączając w to
PL/SQL, Java, Oracle Call Interface, Pro*C/C++, OO4O zostały wzbogacone o
wsparcie nowych cech obiektowych. Przedstawione poniżej informacje pochodzą w
85

większości z dostarczonego przez producenta opracowania „Oracle 9i Application
Developers Guide - Object-Relational Features” [Gietz 2001].
5.1.1 Kluczowe cechy obiektowe modelu relacyjno-obiektowego w Oracle
5.1.1.1 Dziedziczenie
typów
Dziedziczenie typów zostało dodane, aby umożliwić tworzenie hierarchii typów,
przez zdefiniowanie kolejnych poziomów coraz bardziej specjalizowanych podtypów,
wywodzących się od ogólniejszych przodków. Zasada jest analogiczna jak w przypadku
dziedziczenia obiektów w obiektowych językach programowania.
5.1.1.2 Modyfikacje
typów
Przy użyciu polecenia ALTER TABLE można modyfikować (rozwijać)
istniejące typy i czynić następujące zmiany:
− dodawać i usuwać atrybuty,
− dodawać i usuwać metody,
− modyfikować atrybuty, aby osiągnąć żądany zakres, precyzję lub skalę,
− zmieniać właściwości FINAL oraz INSTANTIABLE.
5.1.1.3 Mechanizm obiektowej perspektywy
Oprócz przechowywania „prawdziwych” obiektów w bazie, Oracle pozwala na
tworzenie obiektowych abstrakcji wykorzystując istniejące dane relacyjne. Poprzez
mechanizm obiektowej perspektywy (ang. object view) istnieje dostęp do relacyjnych
danych w taki sam sposób jakby to były obiekty. Wykorzystując tę cechę, można
używać bazy w formie obiektowej bez konieczności modyfikowania jej schematu.
Obiektowa perspektywa pozwala także na wykorzystanie polimorfizmu, który
jest możliwy w hierarchii typów.
86

5.1.1.4 Rozszerzenia obiektowe SQL’a
Aby obsłużyć nowe, obiektowo zorientowane cechy bazy, rozszerzono nieco
składnię języka SQL. Dodano nowy DDL
oraz składnie zapytań, aby tworzyć,
zmieniać oraz kasować typy obiektowe, referencje oraz kolekcje. Dodano także cechy,
które pozwalają obiektowo operować na relacyjnych danych, poprzez mechanizm
obiektowej perspektywy.
5.1.1.5 Rozszerzenia obiektowe PL/SQL’a
PL/SQL jest językiem programowania baz danych firmy Oracle. Język ten jest
mocno zintegrowany z językiem SQL. Wraz z dodaniem typów definiowanych przez
użytkownika, język ten został rozszerzony o operacje z tym związane. Obecnie
programiści mogą używać języka PL/SQL, aby wykorzystać całą nową funkcjonalność.
5.1.1.6 Java a obiektowość w bazie Oracle
Wersja wirtualnej maszyny Javy, stworzona przez Oracle, jest mocno
zintegrowana z systemem bazy danych, aby zapewnić dostęp do rozszerzeń
obiektowych, poprzez wzbogacenie JDBC. Korzystając z bazy w wersji 8i istnieje
możliwość definiowania własnych typów obiektowych z poziomu Javy, natomiast
wersja 9i pozwala także na tworzenie typów bazodanowych bezpośrednio z istniejących
klas Javy. Dzięki temu, programiści Javy mogą traktować bazę danych Oracle jako
obiektową.
5.1.1.7 Zewnętrzne procedury
Funkcje bazodanowe, procedury lub metody z typów obiektowych, mogą być
implementowane w językach PL/SQL, Java lub C, jako zewnętrzne procedury.
Procedury takie są bardzo pożądane do zadań, które mają być wykonane szybko w
niskopoziomowym języku takim jak C, który jest bardzo efektywny. Zewnętrzne
procedury są zawsze wykonywane w bezpiecznym trybie, poza przestrzenią adresową
systemu bazodanowego.
12
DDL (Data Definition Language) - język definicji danych.
13
DML (Data Manipulation Language) - język manipulacji danymi.
87

5.1.1.8 Translator typów obiektowych
Translator typów obiektowych (ang. Object Type Translator) umożliwia
mapowanie obiektów do schematów obiektowych, które później są używane do
generowania plików nagłówkowych zawierających klasy Javy lub struktury w C. Owe
pliki nagłówkowe mogą zostać użyte przez programistów w swoich programach do
zapewnienia przezroczystego dostępu do obiektów bazodanowych, bez konieczności
jakiejkolwiek konwersji. Aby translator typów obiektowych mógł pracować, musi mieć
dostęp do Oracle Data Dictionary, skąd pobiera niezbędne informacje.
5.1.1.9 Podręczny zbiór obiektów po stronie klienta
W celu zwiększenia szybkości dostępu do obiektów znajdujących się w bazie
danych, został stworzony podręczny skład obiektów (ang. object cache). Kopie
obiektów mogą być przechowywane w podręcznym składzie od momentu gdy zostaną
pierwszy raz ściągnięte przez użytkownika. Dzięki temu można osiągnąć duże
przyspieszenie działania aplikacji. Wszystkie zmiany dokonane na obiektach w składzie
mogą być zapisane w bazie poprzez Oracle Call Interface Object Extensions.
5.1.1.10 Oracle Call Interface Object Extensions
Oracle Call Interface Object Extensions to obiektowy interfejs między
aplikacjami oraz narzędziami programistycznymi a bazą danych. Za jego pomocą
można uzyskać dostęp do obiektów w bazie, możliwość modyfikowania obiektów oraz
ich atrybutów. Technicznie rzecz biorąc OCIOE ściąga obiekty z bazy do podręcznego
zbioru i tam dopiero istnieje możliwość modyfikacji.
OCIOE jest zorganizowany jako środowisko czasu wykonania, które posiada funkcje do
połączeń z serwerem bazodanowym Oracle. Funkcje te umożliwiają także uzyskanie
informacji na temat struktury bazy oraz poszczególnych obiektów.
5.1.1.11 Rozszerzenia obiektowe Pro*C/C++
Oracle Pro*C/C++ to prekompilator, który dostarcza osadzony interfejs
programistyczny SQL wewnątrz języka C++ oraz zapewnia wyższy poziom abstrakcji,
niż Oracle Call Interface Object Extensions. Podobnie jak OCIOE, prekompilator
88

Pro*C/C++ umożliwia programistom użycie podręcznego zbioru obiektów po stronie
klienta oraz translatora typów obiektowych. Pro*C/C++ umożliwia sprawdzanie
zgodności typów programu z typami zdefiniowanymi w bazie danych.
5.1.1.12 Rozszerzenia obiektowe OO4O
OO4O (Oracle9i Objects For OLE) jest zestawem komponentów COM, których
zadaniem jest komunikacja z serwerem Oracle9i, a także wykonywanie zapytań oraz
zarządzanie zwróconymi wynikami. OO4O umożliwia łatwe i efektywne wykorzystanie
cech serwera Oracle9i. Interfejs ten może być użyty w dowolnym języku
programowania, obsługującym technologię COM firmy Microsoft. Obecnie jest to
możliwe między innymi w rodzinie kompilatorów zawartych w MS Visual Studio, IIS
Active Server Pages oraz kompilatorach firmy Borland.
5.1.2 Koncepcja obiektowości w bazie danych Oracle
5.1.2.1 Typy
obiektowe
Typ obiektowy nie jest szczególnym rodzajem typów w Oracle. Można używać
ich w ten sam sposób, jak używa się typów dostępnych w czysto relacyjnych bazach.
Przykładowo można wyspecyfikować daną klasę jako typ kolumny w relacyjnej tabeli i
deklarować obiekty tej klasy. Typy obiektowe mają jednakże kilka istotnych różnic w
porównaniu z tradycyjnymi typami bazodanowymi. Są to przede wszystkim:
− Zestawy obiektów nie mogą być tworzone przez bazę danych.
− Istnieje możliwość definiowania dowolnych typów obiektowych w zależności
od potrzeb.
− Obiekty nie są jednostkami atomowymi. Obiekty posiadają części: atrybuty oraz
metody. Atrybuty przechowują dane zawarte w obiekcie. Atrybut posiada swój
typ, który może być nawet typem obiektowym. Wszystkie atrybuty razem
zawierają dane obiektu. Metody, czyli procedury lub funkcje, umożliwiają
aplikacji wykonanie użytecznych operacji na atrybutach klasy. Metody to
opcjonalny element klasy. Metody definiują zachowanie obiektu, czyli wszystko
to, co obiekt potrafi zrobić.
89

− Klasy są mniej ogólnymi typami niż wbudowane typy obiektowe. Zazwyczaj
dobrze wiadomo, co może być przechowywane w obiektach danej klasy i do
czego będą one używane. Jest to ich główna zaleta, gdyż mogą swoją strukturą
odzwierciedlać rzeczywisty układ rzeczy, nad którą pracuje dany program.
Obiekty umożliwiają prostsze i bardziej intuicyjne zarządzanie danymi, niż ma
to miejsce w tradycyjnym modelu.
O typach obiektowych (klasach) można myśleć jako o wzorze, natomiast o
obiekcie (instancji klasy) jako o czymś, co zostało zbudowane według tego wzoru.
5.1.2.2 Dziedziczenie typów obiektowych
Istnieje możliwość specjalizowania klasy poprzez tworzenie podtypów, które
mają jakieś dodatki, inne cechy itp. w stosunku do typu będącego ich przodkiem.
Podtypy oraz typy macierzyste są powiązane przez swoją hierarchię. Podtyp to
specjalizowana wersja przodka. Typ potomny posiada wszystkie atrybuty i metody,
które posiadał przodek oraz dodatkowe, dodane przez klasę potomną. Wszystkie typy
macierzyste oraz typy potomne, razem tworzą swoistą hierarchię.
5.1.2.3 Obiekty
Podczas tworzenia zmiennej typu obiektowego, tworzy się instancję klasy, czyli
obiekt. Ponieważ instancja klasy jest czymś konkretnym, można nadawać atrybutom
specjalne wartości (jeśli metody na to pozwalają), odczytywać je oraz wywoływać
metody klasy.
5.1.2.4 Metody
Metody to funkcje lub procedury, które zostały zadeklarowane w danej klasie.
Metody określają zachowanie danej klasy. Jednym z głównych zadań metod jest
zapewnienie dostępu do danych zawartych w obiekcie.
90

5.1.2.5 Tabele
obiektowe
Tabela obiektowa jest specjalnym rodzajem tabeli, w której każdy wiersz
reprezentuje jeden obiekt.
Dla przykładu poniższy kod tworzy klasę OSOBA:
CREATE TYPE osoba AS OBJECT (
imie VARCHAR2(30),
telefon VARCHAR2(20) );
Teraz, mając już definicję klasy OSOBA, można zdefiniować tabelę obiektową dla
obiektów typu OSOBA:
CREATE TABLE tabela_osoba OF osoba;
Tabelę taką można traktować teraz na dwa różne sposoby:
− Jako tabelę z jedną kolumną, w której każdy wiersz to obiekt typu OSOBA.
Takie spojrzenie pozwoli pobierać całe obiekty i używać ich później do
wykonywania operacji w językach zorientowanych obiektowo.
Przykład zapytania obiektowego, które zwróci wiersz jako instancję klasy (o ile
taki istnieje w bazie):
SELECT VALUE(p) FROM tabela_osoba p
WHERE p.imie = "Jan Kowalski";
− Jako wielokolumnową tabelę, gdzie każdy parametr klasy OSOBA reprezentuje
jedną kolumnę. W przykładzie istnieją dwie kolumny nazwane imie
oraz
nazwisko. Spojrzenie takie, umożliwi wykonywanie relacyjnych operacji.
Przykład zapytania
relacyjnego (dodawanie danych do tabeli):
INSERT INTO tabela_osoba VALUES (
"Jan Kowalski",
"0-12-123-4567" );
91

5.1.2.6 Typ bazodanowy REF
REF jest specjalnym pierwotnym typem bazodanowym bazy Oracle. Jest to
logiczny wskaźnik do wiersza tabeli obiektowej. Typy REF mogą być używane do
modelowania związków pomiędzy obiektami, szczególnie relacji wiele-do-jeden.
Pozwala to zredukować potrzebę używania obcych kluczy w tabelach. Aby korzystać z
typów REF używa się notacji kropkowej.
Typy REF mogą być używane do uzyskania dostępu do obiektów, na które
wskazują. Za ich pomocą można dostać również kopię danego obiektu. Można zmieniać
REF, aby wskazywał na inny obiekt niż obecny, jednakże musi to być obiekt takiego
samego typu. Istnieje także możliwość przypisania do REF’a wartości NULL.
5.1.2.7 Kolekcje
W celu utworzenia relacji jeden-do-wielu, Oracle udostępnia dwa typy kolekcji:
VARRAY oraz tabele zagnieżdżone (ang. nested tables). Typy kolekcji mogą być użyte
wszędzie tam, gdzie używane są inne typy danych.
5.1.3 Użycie rozszerzeń obiektowych w bazie danych Oracle9i
5.1.3.1 Definiowanie klas oraz typów kolekcji
Do tworzenia typów obiektowych oraz typów kolekcji używa się słowa
kluczowego CREATE TYPE.
Przykłady tworzenia typów obiektowych:
CREATE TYPE osoba AS OBJECT (
imie VARCHAR2(30),
telefon VARCHAR2(20)
);
92

CREATE TYPE produkt AS OBJECT (
produkt VARCHAR2(30),
ilosc NUMBER,
cena NUMBER(12,2)
);
CREATE TYPE tabela_magazyn AS TABLE OF produkt;
CREATE TYPE zamowienie AS OBJECT (
id NUMBER,
kontakt osoba,
produkty tabela_magazyn,
MEMBER FUNCTION
get_value RETURN NUMBER
);
W powyższym kodzie zostały zdefiniowane typy obiektowe: osoba, produkt,
tabela_magazyn oraz zamowienie.
Typ tabela_magazyn jest typem kolekcji. Klasa zamowienie posiada atrybut produkty
właśnie typu tabela_magazyn. Każdym wierszem tej kolekcji jest obiekt typu produkt.
Przykład powyższy jest uproszczony, gdyż nie pokazuje, w jaki sposób zdefiniować
ciało metody get_value.
5.1.3.2 Metody
Głównym przeznaczeniem metod jest umożliwienie dostępu do danych
przechowywanych w instancjach klas. Definiuje się oddzielnie metody dla każdej
operacji, jaka
jest
wywołana
do wykonywania przez obiekt.
Poniżej zaprezentowano przykład definiowania metody w języku PL/SQL:
CREATE TYPE Ulamek AS OBJECT (
licznik INTEGER,
93

mianownik INTEGER,
MEMBER PROCEDURE skroc
);
CREATE TYPE BODY Ulamek AS
MEMBER PROCEDURE skroc IS
g INTEGER;
BEGIN
g := nwd(licznik, mianownik);
licznik := licznik / g;
mianownik := mianownik / g;
END skroc;
END;
5.1.3.2.1 Metody specjalne
Istnieje kilka charakterystycznych metod, do których można zaliczyć:
− Metody MAP
Metody tego typu umożliwiają porównywanie obiektów poprzez mapowanie ich
do jednego z typów skalarnych takich jak: DATE, NUMBER, VARCHAR2,
CHARACTER lub REAL. Tak zmapowane obiekty porównuje się później za
pomocą standardowych operatorów porównania, przykładowo:
obj_1.map() > obj_2.map()
− Metody ORDER
Metody typu ORDER umożliwiają porównywanie obiektu macierzystego z
innym obiektem, który jest przekazywany jako parametr. Jeśli metoda taka uzna,
że obiekt przekazany jako parametr jest „większy” od obiektu macierzystego
powinna zwrócić liczbę ujemną, jeśli uzna że obiekty są sobie równe to zwraca
zero, natomiast jeśli obiekt macierzysty jest „większy” to zwraca liczbę
dodatnią.
94

− Metody statyczne
Metody statyczne są wywoływane z klasy, a nie z jej instancji. Używa się ich dla
operacji, które są globalne i nie potrzebują referencji do danej instancji obiektu.
− Konstruktory
Każdy obiekt posiada zdefiniowany przez system konstruktor. Jest to metoda,
która tworzy nowy obiekt i
nadaje wartości jego atrybutom. Konstruktor jest
funkcją, która przy wywołaniu zwraca obiekt. Nazwa konstruktora jest taka
sama, jak nazwa klasy. Parametry konstruktora mają takie same nazwy jak
atrybuty klasy. Wywołanie konstruktora jest równoznaczne z wykonaniem
instrukcji INSERT języka SQL.
5.1.3.3 Dziedziczenie
5.1.3.3.1 Modyfikacje obiektów macierzystych
Jak już wspomniano wcześniej, baza danych Oracle9i umożliwia tworzenie
typów obiektowych, które dziedziczą po już istniejącym typie obiektowym.
Klasa potomna może różnić się od klasy macierzystej w trzech podstawowych
kwestiach:
− może dodawać nowe atrybuty,
− może dodawać nowe metody,
− może tworzyć własne implementacje istniejących metod.
5.1.3.3.2 Słowa kluczowe FINAL oraz NOT FINAL
Programista tworząc nową klasę musi zdecydować, czy będzie ona mogła być
później podstawą do tworzenia klasy potomnej. Aby to umożliwić, należy na końcu
deklaracji klasy dodać słowo kluczowe NOT FINAL. Decyzję można potem zmienić
poleceniem ALTER TYPE (zmieniając klasę na FINAL).
Bardzo podobnie sprawa wygląda w przypadku metod; można określić czy dana
metoda będzie mogła być zmieniana w typach potomnych.
95

5.1.3.3.3 Tworzenie typów potomnych
Aby stworzyć klasę potomną, używa się polecenia CREATE TYPE, w którym
specyfikuje się klasę macierzystą:
CREATE TYPE Student UNDER Osoba (
rok_studiow NUMBER,
wydzial VARCHAR2(30)
) NOT FINAL;
Powyższy kod tworzy typ obiektowy Student, który jest podtypem klasy Osoba.
Jako podtyp, klasa Student posiada wszystkie atrybuty i
metody zadeklarowane w klasie
Osoba oraz te, które klasa Osoba odziedziczyła ze swojego przodka, jeśli taki istniał.
Dodatkowo klasa Student posiada dwa nowe atrybuty. Nowe atrybuty deklarowane w
typach potomnych muszą mieć nazwy różne od tych, które zostały odziedziczone.
5.1.3.3.4 Typy wirtualne
Typy wirtualne nie posiadają konstruktora, co uniemożliwia tworzenie ich
instancji. Klasy takie mogą być jedynie typami macierzystymi. Aby zadeklarować klasę
jako wirtualną, używa się słowa kluczowego NOT INSTANTIABLE.
Metody również mogą być zadeklarowane jako wirtualne. Pozwala to na
deklarowanie metod, bez konieczności implementowania ich. Metody takie tworzymy,
kiedy spodziewamy się, iż każda klasa dziedzicząca będzie przesłaniać swoją metodą
działanie metody obecnej. Jeśli klasa potomna nie zawiera implementacji każdej z
metod, którą odziedziczyła jako wirtualną, sama musi być wirtualna.
5.1.3.3.5 Dziedziczenie i przeciążanie metod
Klasa potomna automatycznie dziedziczy wszystkie metody przodka. Metody te
można przedefiniować, można także dodać nowe metody. Można nawet dodać metodę,
która posiada taką samą nazwę jak metoda którą się już odziedziczyło. Definiowanie
wielu metod posiadających taką samą nazwę określane jest jako przeciążanie metod.
96

Kiedy klasa posiada wiele metod o takich samych nazwach, kompilator używa sygnatur
metod, aby móc je rozróżniać. Sygnatura zawiera nazwę metody, jej numer, typ oraz
listę jej parametrów.
Przesłanianie metod polega na przedefiniowaniu metody dziedziczonej. Jeśli
klasa przesłania jakąś metodę, to nowa wersja będzie wykonywana zamiast starej.
Metoda będzie przesłonięta, jeśli nowa wersja posiada dokładnie taką samą sygnaturę.
Metody nie mogą być przesłanianie w następujących przypadkach:
− metoda przodka jest zadeklarowana jako FINAL,
− metoda przodka jest typu ORDER,
− metoda potomka jest statyczna, a przodka nie,
− metoda przodka jest statyczna,
− metoda potomka ma inne wartości domyślne niż metoda przodka.
5.1.4 Dodatkowe narzędzia ułatwiające obsługę rozszerzeń obiektowych
5.1.4.1 Business Components for Java (BC4J)
BC4J to zestaw komponentów w standardzie EJB oraz CORBA, które mają za
zadanie uprościć
tworzenie, rozpowszechnianie oraz dostosowywanie biznesowych
aplikacji w języku Java. Zestaw ten jest pomyślany jako szkielet (ang. framework)
dostarczający programistom komponentów mających za zadanie:
− uprościć tworzenie oraz testowanie logiki biznesowej w komponentach
integrujących aplikacje z bazami danych,
− umożliwić wielokrotne używanie istniejących komponentów, poprzez
różnorodne, oparte na SQL’u przeglądanie danych,
− umożliwić dostęp
do danych oraz ich modyfikację z serwletów, JSP (Java
Server Pages) oraz klientów opartych na JavaSwing,
− umożliwić dostosowywanie warstwy aplikacji odpowiedzialnej za kontakt z
użytkownikiem, bez konieczności zmiany wnętrza.
97

5.1.4.2 JPublisher
JPublisher jest narzędziem, napisanym w całości w języku Java, które potrafi
generować klasy Javy, reprezentujące następujące elementy bazodanowe:
− typy obiektowe,
− typy wskaźnikowe REF,
− typy kolekcji,
− pakiety PL/SQL.
JPublisher pozwala na wiele możliwości konfiguracji, aby móc dostosować wynik
mapowania bazy danych do potrzeb klienta.
5.1.4.3 JDeveloper
JDeveloper jest zintegrowanym narzędziem programistycznym do tworzenia
wieloużytkownikowych aplikacji w języku Java. Środowisko to pozwala na
programowanie, usuwanie błędów oraz testowanie aplikacji. Korzystając z tego
narzędzia można tworzyć aplikacje klienckie, aplikacje przez WWW, aplikacje oraz
komponenty serwerów aplikacji.
JDeveloper działa w środowisku Windows NT, jest dobrze zintegrowany z
serwerem aplikacji Oracle oraz bazą danych Oracle.
5.1.4.4 Import/Eksport typów obiektowych
Narzędzie pozwala na przemieszczanie danych z oraz do bazy danych Oracle.
Umożliwia także na tworzenie kopii zapasowych, archiwizację danych oraz późniejsze
ewentualne odtwarzanie z kopii.
Import/Eksport obsługuje typy obiektowe. Przy eksportowaniu zapisywane są
definicje typów wszystkich danych. Przy imporcie możliwe jest tworzenie klas
potomnych, zanim jeszcze definicja klasy macierzystej zostanie zaimportowana.
Możliwe jest przeglądanie hierarchii klas z plików utworzonych w czasie eksportu
danych.
98

5.1.4.5 SQL*Loader
Narzędzie SQL*Loader pozwala na przenoszenie danych z zewnętrznych plików
do tabel w bazie danych Oracle. Pliki mogą zawierać dane składające się z
podstawowych typów bazodanowych, jak również dane w złożonych, zdefiniowanych
przez użytkownika typach, takich jak obiekty, kolekcje oraz LOB’y.
SQL*Loader używa plików kontrolnych, które zawierają opisy danych w języku DDL.
5.2 PostgreSQL
PostgreSQL jest obiektowo-relacyjnym systemem zarządzania bazą danych,
bazującym na systemie POSTGRES, rozwijanym na Uniwersytecie Kalifornijskim na
wydziale informatyki (Berkeley Computer Science Department). Projekt POSTGRES,
który prowadził profesor Michael Stonebraker był sponsorowany przez następujące
instytucje: DARPA (Defense Advanced Research Projects Agency), ARO (Army
Research Office), NSF (National Science Foundation) oraz ESL.
PostgreSQL wywodzi się z tego projektu. Dostarcza on wsparcie dla języków SQL-92
oraz SQL:1999 i posiada inne nowoczesne cechy.
W chwili obecnej najnowsza wersja systemu to PostgreSQL 7.2.
POSTGRES wprowadził wiele obiektowo-relacyjnych pojęć, które są obecnie
zaimplementowane w niektórych komercyjnych systemach baz danych. Tradycyjny,
relacyjny system obsługuje model danych składający się ze zbiorów nazwanych relacji,
zawierających atrybuty określonego typu. W obecnych systemach komercyjnych,
dopuszczalne typy zawierają liczby zmiennoprzecinkowe, liczby całkowite, ciągi
znaków, waluty oraz daty. Powszechnie uważa się, iż model ten jest niewystarczający
dla przyszłych aplikacji przetwarzających dane.
PostgreSQL dostarcza dodatkowych możliwości poprzez zastosowanie między
innymi poniższych mechanizmów, dzięki którym użytkownicy mogą w łatwy sposób
rozszerzać system:
− dziedziczenie,
− typy danych,
− funkcje.
99

Pozostałe cechy zwiększające elastyczność to:
− ograniczenia,
− wyzwalacze,
− reguły,
− integralność transakcji.
Cechy powyższe czynią z PostgreSQL’a system zaliczany do kategorii obiektowo-
relacyjnych. Pomimo jednak cech obiektowych, PostgreSQL jest silnie osadzony w
kręgu relacyjnych baz danych.
W kolejnych podrozdziałach zostaną przybliżone najważniejsze rozszerzenia
wprowadzone w systemie PostgreSQL. Pomimo, iż wprowadzone zmiany czynią z
niego system obiektowo-relacyjny, nie są to zmiany tak rewolucyjne jak w
przedstawionym poprzednio systemie oferowanym przez firmę Oracle.
Informacje zaprezentowane w dalszej części pracy pochodzą z opracowania
[PostgreSQL].
5.2.1 Wielkie Obiekty
W systemie PostgreSQL aż do wersji 7.1, wielkość wiersza w bazie danych nie
mogła przekraczać wielkości strony danych. Ponieważ rozmiar strony danych wynosi
8192 bajty (wartość domyślna, która może zostać zwiększona do 32768), górny limit
rozmiaru danych był więc relatywnie niski. Aby obsłużyć przechowywanie większych
wartości atomowych, PostgreSQL został wyposażony w interfejs wielkich obiektów
(ang. large objects). Interfejs ten udostępnia plikowo zorientowany dostęp do danych
użytkownika zadeklarowanych jako wielkie obiekty.
POSTGRES 4.2, bezpośredni przodek systemu PostgreSQL, obsługiwał trzy
standardowe implementacje wielkich obiektów: jako zewnętrzne pliki dla serwera
POSTGRES, jako zewnętrzne pliki zarządzane przez serwer POSTGRES, bądź też jako
dane przechowywane wewnątrz bazy POSTGRES. Powodowało to znaczne
komplikacje dla użytkowników. W rezultacie, w systemie PostgreSQL pozostało
jedynie wsparcie dla wielkich obiektów jako danych przechowywanych w obrębie bazy
100

danych. Pomimo wolniejszego dostępu, metoda ta zwiększa integralność danych.
Począwszy od wersji PostgreSQL 7.1, wszystkie wielkie obiekty są umieszczane w
jednej tablicy systemowej o nazwie pg_largeobject.
PostgreSQL 7.1 wprowadził także mechanizm (nazwany „TOAST”), który
pozwala aby wiersze danych były dużo większe niż pojedyncze strony danych. Czyni
on interfejs wielkich obiektów częściowo przestarzałym, jednakże pozostającą zaletą
interfejsu jest nadal możliwość swobodnego dostępu do danych np. istnieje możliwość
odczytu i zapisu małych kawałków dużych wartości. Planowane jest dodanie tej cechy
do mechanizmu TOAST w przyszłości.
5.2.2 Interfejs JDBC
JDBC jest rdzennym API Javy. Dostarcza on standardowy zbiór interfejsów do
baz danych obsługiwanych przez SQL.
PostgreSQL dostarcza sterownik JDBC typu 4. Oznacza to, że został on
stworzony z użyciem czystej Javy i komunikuje się wykorzystując własny protokół
sieciowy bazy danych. W związku z tym, sterownik jest niezależny od platformy.
5.2.2.1 Przechowywanie danych binarnych
PostgreSQL dostarcza dwie różne metody przechowywania danych binarnych.
Dane binarne mogą być przechowywane w tabeli wykorzystując binarny typ danych
PostgreSQL’a bytea, lub też z wykorzystaniem właściwości wielkich obiektów, która
pozwala na przechowywanie danych binarnych w oddzielnej tabeli o specjalnym
formacie, a odwołania do tych danych odbywają się z wykorzystaniem specjalnej
wartości typu OID.
W celu określenia właściwej metody do konkretnego przypadku należy
zrozumieć ograniczenia każdej z nich. Typ bytea nie jest dobrze przystosowany do
przechowywania bardzo dużych ilości binarnych danych. Kolumna typu bytea może
pomieścić dane binarne o rozmiarze nawet 1 GB, jednakże wiąże się to z ogromnym
zapotrzebowaniem na pamięć operacyjną RAM. Metoda działająca w oparciu o wielkie
101

obiekty jest dużo lepiej przystosowana do przechowywania bardzo dużych wartości
binarnych, jednakże ona także posiada wady. Usunięcie rekordu zawierającego wielki
obiekt nie powoduje likwidacji tego obiektu. Likwidacja ta jest oddzielną operacją,
która musi zostać wykonana dodatkowo.
Aktualna wersja PostgreSQL 7.2 po raz pierwszy wprowadza sterownik JDBC
obsługujący dane typu bytea. Wprowadzenie tej funkcjonalności wiąże się z pewnymi
zmianami w stosunku do poprzednich wersji systemu. Obecnie metody: getBytes(),
setBytes(), getBinartStream() oraz setBinaryStream() działają na danych typu bytea. W
wersji 7.1 metody te działały na typie OID, który był skojarzony z konkretnym wielkim
obiektem. Istnieje możliwość przestawienia sterownika na zachowanie znane z
poprzedniej wersji.
5.2.3 Rozszerzanie języka SQL
Istnieje możliwość rozszerzania języka zapytań PostgreSQL SQL poprzez
dodawanie:
− funkcji,
− typów danych,
− operatorów,
− agregatów.
PostgreSQL jest rozszerzalny ponieważ jego działanie jest sterowane
katalogowo (ang. catalog-driven). Standardowe relacyjne systemy baz danych
przechowują informacje o bazie, tabelach, kolumnach, itp. w systemie katalogowym.
Katalogi są widoczne dla użytkownika jak inne tabele, lecz system zarządzania bazą
danych przechowuje w nich swoje wewnętrzne informacje. Jedną z kluczowych różnic
pomiędzy systemem PostgreSQL a standardowymi systemami relacyjnymi jest to, że
PostgreSQL przechowuje dużo więcej informacji w swoich katalogach. Nie tylko
informacje o tabelach i kolumnach, lecz także dane o ich typach, funkcjach, metodach
dostępu, itd. Tabele te mogą być modyfikowane przez użytkownika, a skoro
PostgreSQL opiera swoje wewnętrzne działanie na tych tabelach, oznacza to iż może
być on rozszerzany przez użytkownika. Przez porównanie, konwencjonalne systemy
102

baz danych mogą być rozszerzane tylko przez zmianę wbudowanych w system procedur
lub też poprzez ładowanie modułów napisanych specjalnie przez dostawcę systemu.
PostgreSQL w odróżnieniu od innych systemów pozwala na włączanie do
serwera kodu pisanego przez użytkownika poprzez dynamiczne ładowanie. Oznacza to,
iż użytkownik może określić plik, który implementuje nowy typ lub funkcję, a
PostgreSQL włączy je w razie potrzeby. Zdolność modyfikowania działania „w locie”
czyni z PostgreSQL’a system bardzo dobrze dostosowany do prototypowania nowych
aplikacji i struktur składowania danych.
5.2.3.1 Funkcje
Częścią definiowania nowego typu jest definicja funkcji opisujących jego
zachowanie. W rezultacie, istnieje możliwość zdefiniowania nowej funkcji bez
definiowania nowego typu, jednakże działanie odwrotne nie jest możliwe.
PostgreSQL dostarcza cztery rodzaje funkcji:
− funkcje języka zapytań (funkcje napisane w języku SQL),
− funkcje języka proceduralnego (funkcje napisane w np. PL/Tcl lub PL/pgSQL),
− funkcje wewnętrzne,
− funkcje języka C.
Każdy rodzaj funkcji może pobierać typ podstawowy, zbiorowy, lub pewną ich
kombinację. Dodatkowo, każdy rodzaj funkcji może zwrócić typ podstawowy lub
zbiorowy.
Funkcje mogą być przeciążane, czyli może istnieć kilka funkcji o takiej samej
nazwie lecz różniących się pobieranymi argumentami.
5.2.3.2 Typy
Istnieją dwa rodzaje typów w systemie PostgreSQL: typy podstawowe i typy
zbiorowe. Istnieje możliwość zdefiniowania nowego typu podstawowego.
103

Typ zdefiniowany przez użytkownika musi zawsze posiadać funkcje wejściową i
wyjściową. Określają one reprezentację typu w ciągach znakowych oraz jego
organizację w pamięci.
PostgreSQL w pełni obsługuje tablice typów podstawowych. Dodatkowo
obsługiwane są także tablice typów zdefiniowanych przez użytkownika. Podczas
definiowania nowego typu PostgreSQL automatycznie dodaje obsługę tablic tego typu.
104

6 Obiektowe bazy danych w praktyce
6.1 Bazy danych dostępne na rynku
Jeszcze kilka lat temu, kiedy po wielkiej rewolucji odeszły w zapomnienie
języki strukturalne, a na ich miejsce pojawiły się języki zorientowane obiektowo,
wszyscy spodziewali się, że historia powtórzy się także na polu baz danych. Wzrost roli
Internetu oraz danych multimedialnych, z którymi relacyjne bazy danych radzą sobie
nienajlepiej, prorokował świetlaną przyszłość dla systemów obiektowych. Niestety,
rzeczywistość okazała się inna. Jak podaje [Leavitt 2000], dzisiejszy udział systemów
obiektowych baz danych w rynku komercyjnych baz danych sięga jedynie kilku
procent.
W dalszej części pracy zostaną zaprezentowani wiodący obecnie producenci
systemów obiektowych baz danych oraz oferowane przez nich rozwiązania.
6.1.1 eXcelon (dawniej Object Design) – produkt ObjectStore
6.1.1.1 Historia firmy w skrócie
Firma Object Design została założona w roku 1988 w Burlington w USA.
Pierwsza wersja bazy danych ObjectStore została wydana w roku 1990. W roku 1988
firma zaczęła tworzenie swojego drugiego, po bazie ObjectStore, sztandarowego
produktu o nazwie eXcelon. Pierwsza wersja owego systemu została wydana w roku
1999. Stał się on na tyle ważny dla firmy, że w roku 2000 zmieniła ona swoją nazwę na
eXcelon. Dział zajmujący się obiektowymi bazami danych stał się autonomiczną
częścią firmy, zachowując swoją nazwę Object Design. W chwili obecnej dostępna jest
baza ObjectStore w wersji 6.0. Informacje zawarte w niniejszym rozdziale pochodzą z
[eXcelon 2002a-c] oraz następujących stron WWW:
http://www.exceloncorp.com
http://www.odi.com
http://www.objectdesign.com
105

6.1.1.2 Ogólne
informacje
Produkt ObjectStore jest wiodącą bazą obiektową na rynku. Jej udział jest
szacowany na 40% wszystkich komercyjnych obiektowych serwerów baz danych.
Produkt ten jest najczęściej wykorzystywany do zadań związanych z telekomunikacją
oraz e-biznesowych rozwiązaniach z dostępem przez WWW. Baza ta była również
wykorzystywana na uniwersytecie MIT do badań nad genomem ludzkim (http://www-
genome.wi.mit.edu). Firma eXcelon oferuje również jednostanowiskową wersję zwaną
ObjectStore PSE for Java, bądź ObjectStore PSE for C++, w zależności od
wykorzystywanego języka. Wersja PSE pomyślana jest jako produkt do różnego
rodzaju urządzeń elektronicznych. Aby sprostać wymaganiom stawianym przez takie
urządzenia, ma on bardzo niewielki rdzeń, możliwy do umieszczenia w pamięciach typu
(EP)ROM.
Cały produkt składa się z następujących elementów: Baza ObjectStore, Active
Toolkit, Database Designer, Inspector, ObjectForms, Performance Analyzer, Object
Manager.
6.1.1.3 Przegląd produktów z rodziny ObjectStore
− ObjectStore Server – System ten jest w pełni obiektową bazą. Produkt ów może
pracować w dwóch trybach. W pierwszym jego działalność obejmuje wszystkie
aspekty pracy bazy, natomiast w drugim (ang. cache forward) produkt pracuje
jako proxy. Właściwą bazą jest wtedy inna, relacyjna baza, natomiast
ObjectStore ma za zadanie z jednej strony być widzianą jako obiektowa baza
danych przez aplikacje, natomiast z drugiej strony być widzianą jako relacyjny
klient przez właściwą bazę. Interfejs zewnętrzny bazy jest jednakowy tak, że
aplikacja klienta nie ma możliwości rozróżnienia w którym trybie pracuje
ObjectStore. Baza ta może przechowywać klasy języków Java oraz C++.
Wiązanie do Javy jest zgodne ze standardem ODMG 3.0, natomiast wiązanie z
językiem C++ oparte jest na własnym rozwiązaniu.
− Active Toolkit – Narzędzie to pozwala na łączenie bazy danych ObjectStore z
dowolnym językiem umożliwiającym wykorzystanie ActiveX.
106

− Component Wizard – Narzędzie to umożliwia tworzenie nagłówków klas oraz
interfejsów komponentów w językach C++ lub Java na podstawie schematu
danych zawartego w bazie.
− Database Designer – Graficzne narzędzie do budowania modelu obiektowego
bazy danych. Narzędzie jest niezależne od żadnego konkretnego języka
programowania. Zbudowany schemat można potem zapisać w postaci
nagłówków klas w konkretnym już języku.
− Inspector – Graficzna konsola do bazy danych. Za pomocą tego narzędzia
użytkownik może przeglądać, edytować i zadawać zapytania do bazy. Inspector
umożliwia także eksport danych oraz tworzenie raportów.
− ObjectForms – Za pomocą ObjectForms można automatycznie generować
dynamiczne strony WWW. Na stronach tych można oczywiście prezentować
dane pochodzące z bazy ObjectStore
− Performance Analyzer – Za pomocą tego narzędzia można automatycznie
przeprowadzać analizy działania bazy, tworzyć raporty statystyczne oraz
archiwizować wyniki analiz. Narzędzie ułatwia dopracowywanie konfiguracji
bazy.
− Object Manager – Narzędzie zarządzające predefiniowanymi, gotowymi do
wykorzystania komponentami, które zostały napisane z myślą o
przechowywaniu danych takiego typu jak: dźwięk, obraz, pliki PDF, teksty,
wideo.
ObjectStore obsługuje następujące platformy:
− Microsoft Windows 2000, NT, 98
− Sun Solaris SPARC, Intel
− Hewlett-Packard HP-UX
− Silicon Graphics IRIX
− IBM AIX
− Compaq Tru64 UNIX
107

6.1.2 Objectivity – produkt Objectivity/DB
6.1.2.1 Historia firmy w skrócie
Firma Objectivity została założona w roku 1988. Jej działalność jest głównie
skierowana na rozwijanie obiektowej bazy danych Objectivity. Wcześniejsze wydania
tego produktu miały miejsce w roku 1997 (wersja 5.0) oraz w roku 2000 (wersja 6.0).
Obecnie najbardziej aktualną wersją jest 7.0. Firma oferuje ją od roku 2002.
Zaprezentowane w dalszej części pracy informacje pochodzą z [Objectivity 2001] oraz
strony WWW producenta:
http://www.objectivity.com
6.1.2.2 Ogólne informacje o produkcie
Objectivity jest rozproszonym systemem obiektowych baz danych. Objectivity
przechowuje dane w formacie natywnym dla aplikacji. Architektura rozproszona
zapewnia skalowalność, a co za tym idzie, możliwość dostosowania pojemności i
wydajności systemu dla danego przedsięwzięcia.
Serwer ten można integrować z aplikacjami w sposób obiektowy, czyli przesyłać dane
do/z bazy za pomocą wiązań do odpowiednich języków, a także w tradycyjny sposób,
czyli za pomocą SQL’a.
Produkt Objectivity składa się z wielu programów, wśród których można wyróżnić
następujące grupy:
− baza danych, czyli: Objectivity/DB, Objectivity/DB Fault Tolerant Option,
Objectivity/DB Data Replication, Objectivity/DB In-Process Lock Server,
Objectivity/DB Open File System, Objectivity/DB Secure Framework,
− wiązanie do języka C++, czyli: Objectivity/C++, Objectivity/C++ Data
Definition Language oraz Objectivity/C++ Standard Template Library,
− wiązanie do języka Java: Objectivity/Java,
− wiązanie do języka Smalltalk: Objectivity/Smalltalk,
− narzędzia zgodne z SQL-92: Objectivity/SQL++.
108
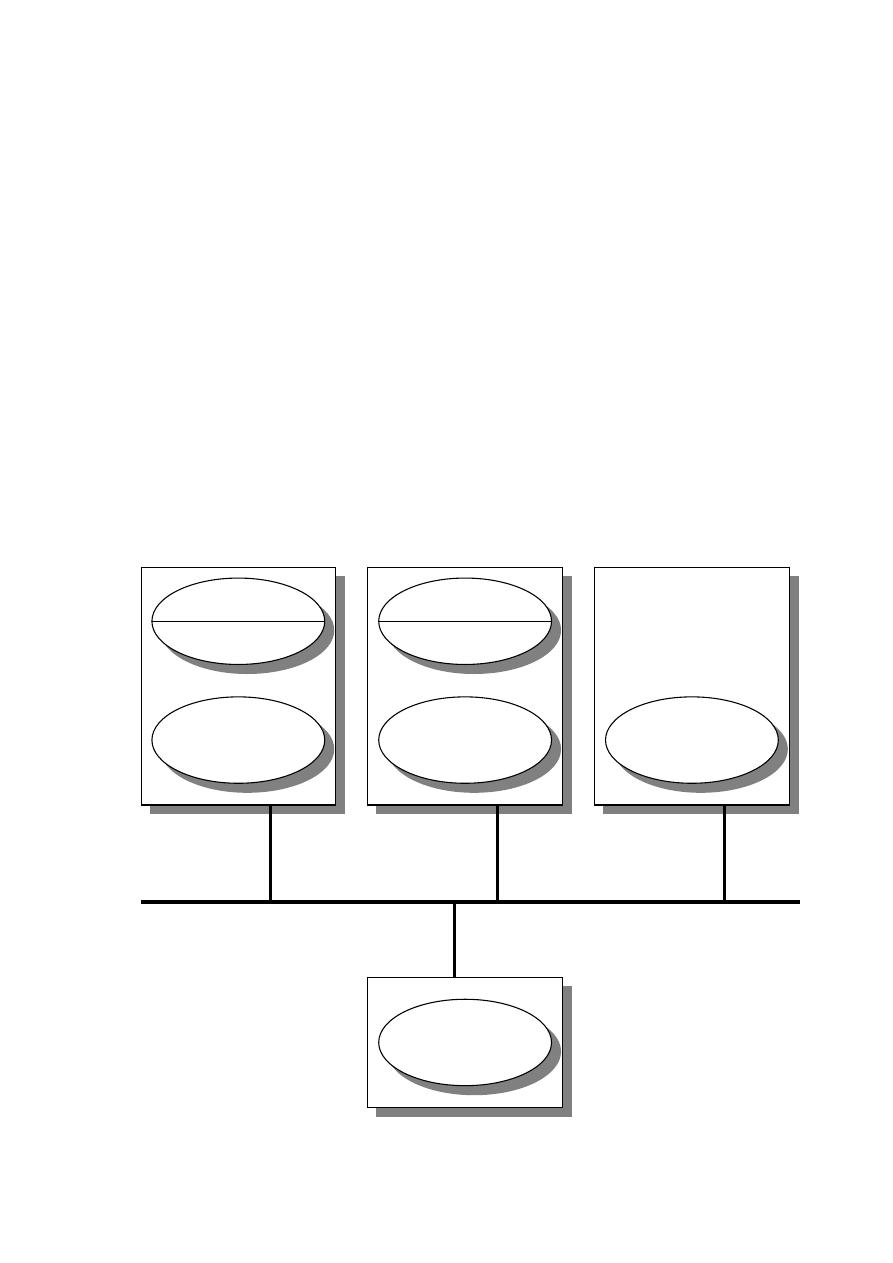
6.1.2.3 Przegląd produktów z rodziny Objectivity
− Objectivity/DB – Jest to serwer bazodanowy. Jego wyróżniającą się cechą jest
rozproszona architektura. Zamiast jednego centralnego serwera, w
rozwiązaniach opartych na Objectivity/DB można spotkać trzy typy serwerów:
serwery blokujące, serwery lokalne oraz serwery odległe (rys. 6.1). Serwery
blokujące gwarantują spójność danych, serwer lokalny to serwer, który jest
bezpośrednio połączony z aplikacją korzystającą z danych w bazie. Serwery
odległe to właściwe aplikacje przechowujące obiekty. Serwer odległy to
oddzielny proces, który w praktyce wcale nie musi znajdować się na odległej
maszynie. Dwa typy odległych serwerów mogą pracować w rodzinie
Objectivity. Pierwszy, nazywany Objectivity/DB Advanced Multithreaded
Server (AMS) jest wielowątkową aplikacją oferującą szybki dostęp do danych.
Drugim typem jest serwer udostępniający dane poprzez Network File Servers
(NFS).
serwer blokujący
RYSUNEK 6.1. SCHEMAT POŁĄCZEŃ MIĘDZY TRZEMA TYPAMI SERWERÓW Z RODZINY
OBJECTIVITY ORAZ APLIKACJĄ.
odległy serwer
odległy serwer
aplikacja
lokalny serwer
odległy serwer
aplikacja
lokalny serwer
109

− Objectivity/DB Fault Tolerant Option – Produkt ten ma za zadanie zapobiegać
sytuacjom krytycznym, oraz jeśli już się zdarzą, obsługiwać je. Do jego
głównych zadań należy: poprawianie dostępności do danych poprzez
odpowiednie rozkładanie obiektów między serwerami; pomoc w zarządzaniu
blokowaniem obiektów po awariach w sieci; replikacja schematu danych. Przy
użyciu Fault Tolerant Option administrator może podzielić bazę na kilka
autonomicznych części. Działanie tego narzędzia jest niewidoczne dla aplikacji
korzystających z bazy.
− Objectivity/DB Data Replication – Narzędzie to umożliwia replikacje danych
pomiędzy serwerami bazodanowymi. Replikacje pomagają w rozłożeniu
obciążenia serwerów oraz eliminują pojedyncze punkty, których awaria może
unieruchomić całą bazę.
− Objectivity/DB In-Process Lock Server – W uzupełnieniu do standardowego
serwera blokującego, Objectivity oferuje serwer blokujący, który może być
podłączony do danej aplikacji. Serwer ten może okazać się przydatny w
przypadku, kiedy aplikacja jest wielowątkowa. Nie istnieje wówczas potrzeba
każdorazowego odwoływania się do ogólnego serwera blokującego, co znacznie
przyspiesza dostęp do danych.
− Objectivity/DB Open File System – Narzędzie to umożliwia łączenie
, a także tworzenie interfejsów do innych
hierarchicznych systemów składowania danych.
− Objectivity/DB Secure Framework – Narzędzie, które pracuje wspólnie z
Objectivity/DB Open File System i ma za zadanie umożliwiać autoryzowany
dostęp do danych.
− Wiązanie do języka C++ – Wiązanie to jest częściowo zgodne z ODMG 3.0.
Zapytania tworzy się, zamiast w języku OQL jak w ODMG, w SQL++, który
jest własnym rozwiązaniem firmy ODMG.
− Wiązanie do języka Java – Wiązanie to jest w pełni zgodne z ODMG 3.0.
− Wiązanie do języka Smalltalk – Wiązanie to jest w pełni zgodne z ODMG 3.0.
Wiązanie to dodatkowo rozszerza język znany z produktu VisualWorks firmy
ObjectShare o cechy wymagane przy projektowaniu aplikacji związanych z bazą
14
HPSS (High Performacne Storage Systems) - wielka hierarchiczna baza danych rozwijana przez firmy
IBM oraz Sun Microsytems.
110

Objectivity.
− Objectivity/SQL++ – Język SQL++ jest językiem do tworzenia, uzyskiwania
oraz kasowania obiektów przechowywanych w bazie Objectivity/DB. SQL++
jest w pełni zgodny z SQL-89 Entry Level Standard oraz częściowo zgodny z
SQL-92 Intermediate Level Standard. Języka tego można używać jako
osadzonych zapytań w języku C++. W porównaniu z językiem SQL, SQL++
wzbogacono o możliwość manipulowania obiektami. Te rozszerzenia obejmują
dziedziczenie obiektów, dostęp do danych składowych obiektów oraz obsługę
danych takich jak tablice. Język SQL++ umożliwia także wykonywanie metod
zawartych w obiektach języka C++. Jako dodatek do SQL++ rozprowadzany
jest sterownik ODBC, który umożliwia aplikacjom zgodnym z ODBC
manipulowanie danymi w bazie Objectivity/DB przy pomocy SQL++.
Platformy wspierane przez system to:
− Linux
− Solaris
− HP-UX
− IRIX
− AIX
− Tru64
− Windows
6.1.3 Versant – produkt Versant
6.1.3.1 Historia firmy w skrócie
Firma Versant została założona w roku 1998 w USA. Głównym celem firmy
było rozwijanie jej obiektowej bazy danych. W roku 2000 zalety tej bazy doceniła firma
IBM, kiedy to rozpoczęła się współpraca mająca na celu integrację serwera aplikacji
WebSphere firmy IBM oraz bazy danych Versant. Obecnie firm Versant oferuje swój
produkt w wersji 6.0.5. Wersja ta została zaprezentowana po raz pierwszy w roku 2002.
111

Informacje przedstawione w kolejnych podrozdziałach zostały wybrane z [Versant
2002a-d] oraz strony WWW producenta:
http://www.versant.com/
6.1.3.2 Ogólne informacje o produkcie
Produkt Versant Developer Suite jest jednym z najpopularniejszych na rynku
obiektowych baz danych. Z jego usług korzystają między innymi takie firmy i
organizacje jak: AT&T, Alcatel, British Airways, Departament obrony USA, Ericsson,
Siemens.
Produkt Versant Developer Suite jest całym środowiskiem programistycznym, a
nie tylko obiektową bazą danych. W skład pakietu wchodzą: Versant ODBMS,
wiązania do języków C++ oraz Java, XML Toolkit i Asynchronous Replication
Framework. Produkt jest częściowo zgodny z ODMG 3.0, wprowadza także własny
język zapytań VQL.
Na lato 2002 roku firma Versant planuje wydanie nowej wersji swojej bazy, w
której dodana zostanie obsługa standardu Java Data Objects.
6.1.3.3 Przegląd produktów z rodziny Versant Developer Suite
− Versant ODBMS – Wewnętrznie baza jest złożona z kilku modułów. Modułem,
który odpowiada za komunikację z otoczeniem jest Versant Manager. Moduł ten
ma za zadanie umożliwiać komunikację pomiędzy interfejsami z językami
programowania a rdzeniem bazy, czyli modułem Versant Server. Versant
Manager zarządza zapytaniami, a także schematem bazy. Moduł ten pomaga w
wykonywaniu transakcji, a także zarządza działaniem podręcznego bufora (ang.
cache). Versant Server to rdzeń bazy, jego zadanie sprowadza się do
wykonywania zapytań, modyfikacji danych w bazie, wypełniania bufora
podręcznego, tworzenia indeksów, zarządzania transakcjami, blokowania, a
także logowania zdarzeń. Moduł Virtual System Layer to łącze pomiędzy
systemem operacyjnym a resztą produktów z Developer Suite. Jego istnienie
ułatwia rozwijanie produktu na wielu platformach sprzętowych. Zapytania do
bazy wykonuje się przy pomocy języka VQL (Versant Query Language). Język
ten czerpie dużo z języka SQL-92 oraz OQL 3.0.
112

− Wiązanie do języka C++ – Wiązanie to jest zgodne ze standardem ODMG 3.0 z
dokładnością do języka zapytań, który został zmieniony z OQL na VQL.
Wiązanie to zostało zorganizowane w postaci biblioteki klas oraz typów.
Dodatkowo w skład wiązania wchodzą: Schema Capture Utility - tworzące
nagłówki klas na podstawie schematu bazy, Drop Classes Utility - usuwające
klasy ze schematu bazy, Drop Instances Utility - usuwające obiekty z bazy oraz
Check Facility - sprawdzające poprawność syntaktyczną kodu.
− Wiązanie do języka Java – Wiązanie to jest zgodne ze standardem ODMG 3.0, a
także wprowadza własne, dodatkowe cechy. Wiązanie to podzielone jest na dwa
poziomy. W jednym poziomie można zarządzać działaniem całej bazy,
natomiast drugi poziom ma za zadanie umożliwić przenoszenie obiektów Javy
z/do bazy oraz operacje bazodanowe według ODMG.
− XML Toolkit – Produkt ten ma za zadanie mapować definicje klasy oraz dane z
obiektów do postaci XML’a oraz w drugą stronę. Umożliwia to
przechowywanie obiektów w bazie w postaci XML, co dla niektórych rozwiązań
jest bardzo korzystne. Narzędzie działa z wiązaniem do C++ oraz Java.
− Asynchronous Replication Framework – Jest to narzędzie służące do replikacji
danych zawartych w bazach Versant. Możliwa jest replikacja synchroniczna
także asynchroniczna
Wśród obsługiwanych platform znajdują się:
− Solaris
− Windows
− AIX
− HP
− Linux
− SGI
− Tru64
15
replikacja synchroniczna – Polega na tym, że wszystkie kopie bazy mają jednakową zawartość. Jej
niekorzystną cechą jest długi czas wykonywania transakcji.
16
replikacja asynchroniczna – Polega na tym, że kopie bazy różnią się między sobą. Jej niekorzystną
cechą jest istniejące prawdopodobieństwo pracy na nieaktualnych danych.
113

6.1.4 Poet Software – produkt FastObjects
6.1.4.1 Historia firmy w skrócie
Firma Poet Software została założona w roku 1993 w Hamburgu. W roku 1995
siedziba została przeniesiona do San Mateo w Kalifornii. Głównym produktem firmy
jest obiektowa baza danych FastObjects. Ostatnia wersja oznaczona numerem 9.0
została wydana w roku 2002. Kolejne podrozdziały opierają się na informacjach
wybranych z [Chase 2001, Meyer 2001a-b, Poet 2001a-b] oraz następujących stron
WWW:
http://www.poet.com
http://www.fastobjects.com
6.1.4.2 Ogólne informacje o produkcie
Firma Poet Software oferuje swoją bazę danych FastObjects w kilku wersjach,
zależnie od potrzeb klienta. Baza ta może pracować zarówno jako wielodostępny
serwer, jak i baza funkcjonująca w urządzeniach elektronicznych.
6.1.4.3 Przegląd produktów z rodziny FastObjects
− FastObjects t7 – Wersja t7 to sztandarowy produkt firmy Poet Software. Jest to
wielodostępny obiektowy serwer baz danych. Standardowo jest on pomyślany
do współpracy z językami C++ oraz Java. Produkt jest częściowo zgodny ze
standardem ODMG. Językiem zapytań do bazy jest OQL w wersji 2.0. Wiązanie
do C++ zmienia trochę standard wiązania z ODMG (wspólny język zapytań),
natomiast wiązanie do języka Java jest w pełni zgodne z ODMG 3.0. Obecne
(maj 2002) wersje beta produktu posiadają zaimplementowany standard Java
Data Objects, zatem można się spodziewać, że kolejne wydania produktu
FastObjects będą umożliwiały dostęp do bazy z poziomu Javy również w ten
sposób. Serwer umożliwia prowadzenie wielu równoczesnych transakcji
zarówno przez klientów C++ jak i Java. Dodatkowo posiada wbudowane
mechanizmy automatycznego sprawdzania i ewentualnej naprawy danych.
Istnieje możliwość eksportu oraz późniejszego importu klas oraz obiektów do
postaci XML.
114

− FastObjects j1 – FastObjects j1 jest okrojoną wersją t7. Można jej używać
bezpłatnie w zastosowaniach niekomercyjnych. Produkt ma na celu
popularyzowanie marki, posiada jednak możliwość łatwej rozbudowy do wersji
t7. FastObjects j1 może współpracować jedynie z obiektami języka Java.
− FastObjects e7 – Wersja e7 bazy FastObjects została pomyślana jako serwer do
zastosowań osadzonych w urządzeniach elektronicznych. Baza ta może
przechowywać obiekty języków C++ oraz Java.
− FastObjects j2 – Wersja j2, podobnie jak wersja e7, ma za zadanie pracować w
urządzeniach elektronicznych. Serwer ten potrafi przechowywać jedynie obiekty
języka Java. Mniejsze możliwości niż wersja e7 rekompensuje mniejszą
zajętością zasobów sprzętowych, co w zastosowaniach osadzonych ma
szczególne znaczenie.
Do wspieranych platform zaliczają się:
− Windows
− Linux
− HP-UX
− Sun Solaris
− Novel Netware
6.1.5 GemStone – produkty: GemStone/J, GemStone/S
6.1.5.1 Historia firmy w skrócie
Firma GemStone została założona w roku 1982 w USA. W roku 1985 została
wydana pierwsza wersja systemu GemStone/S. Obecnie głównymi produktami firmy
są: GemStone/S, GemStone/J, GemFire, GemStone Facets. Ostania wersja GemStone/S
została wydana w roku 2002 i została oznaczona numerem 6.0. Ostania wersja
GemStone/J została wydana w roku 2002 i została oznaczona numerem 4.0. Informacje
przedstawione w kolejnych podrozdziałach pochodzą z [GemStone 2000a-b,
GemStone 2001] oraz strony WWW producenta:
http://www.gemstone.com
115

6.1.5.2 Ogólne informacje o produktach
Firma GemStone oferuje produkty: GemStone/S oraz GemStone/J. Są one
skierowane do klientów, którzy chcą rozwijać swoje produkty w Smalltalk’u, Javie lub
C/C++. Nie są to tylko obiektowe bazy danych, lecz całe serwery aplikacji. W niniejszej
pracy omówiony został jedynie aspekt obiektowego przechowywania danych przez te
serwery.
6.1.5.3 Cechy
produktów
− Persistent Cache Architecture – baza danych zawarta w pakiecie GemStone/J
pozwala na przechowywanie klas języka Java. Baza ta nie czerpie, jak
większość innych produktów, ze standardu ODMG, ale wzoruje swój interfejs
na standardowym API języka Java. W bazie można efektywnie przechowywać
tablice oraz kolekcje znane z pakietu java.util w typach zdefiniowanych przez
GemStone. Standardowa biblioteka jest nieefektywna kiedy przechowuje się
bardzo duży zestaw danych, gdyż wszystko jest trzymane w pamięci
operacyjnej. Używanie do tego celu biblioteki bazy z GemStone/J nie niesie ze
sobą takich niedogodności. Baza wspiera tworzenie indeksów, blokowanie
danych, a także automatyczne wykrywanie zakleszczeń.
Dostęp do obiektów Persistent Cache Architecture może odbywać się w sposób
znany z java.util, a także za pomocą języka zapytań GemStone/J Query
Language. Język ten jest oparty na SQL-92, ale posiada również własne
rozszerzenia obiektowe.
− Gemstone/S – produkt pierwotnie był projektowany jako środowisko dla
aplikacji napisanych w języku Smalltalk, później jednak został rozszerzony o
wsparcie dla języków C++ oraz Java. W pakiecie tym zawarta jest baza dla
języka Smaltalk zwana Personal Information Manager. Baza ta jest oparta na
rozwiązaniach firmy GemStone. W pakiecie tym jest również zawarta baza
Persistent Cache Architecture, taka sama jak w pakiecie GemStone/J.
Platformy wspierane przez GemStone/S to:
− Solaris
− HP-UX
116

− AIX
− Windows
Z kolei GemStone/J może działać na:
− Solaris
− Windows
6.1.6 Fresher Information Software – produkt Matisse
6.1.6.1 Historia produktu w skrócie
Pierwsza wersja bazy danych Matisse powstała na Uniwersytecie Technicznym
w Compiegne (Francja). Po krótkim czasie produkt się skomercjalizował i był dalej
rozwijany dla potrzeb francuskiej agencji energii nuklearnej. W roku 1995 produktem
zainteresowali się specjaliści z USA. Zainteresowanie to wzrosło na tyle, że w roku
1998 rozwój projektu przeniesiono do Stanów Zjednoczonych. Powołano w tym celu
firmę Fresher. Obecnie firma ta oferuje bazę Matisse w wersji 6.0. Wersja ta została
pierwszy raz zaprezentowana w roku 2001. Przedstawione w kolejnych podrozdziałach
informacje zostały wybrane z [Fresher 2001, Fresher 2002] oraz strony WWW:
http://www.fresher.com
6.1.6.2 Ogólne informacje o produkcie
Matisse to baza w pełni obiektowa, potrafiąca jednak także przechowywać dane
w postaci relacyjnej. Od ponad dziesięciu lat jest z powodzeniem używana przez
francuską agencję energii nuklearnej, a także w wielu francuskich firmach i
organizacjach, m.in. koncernach farmaceutycznych, kolei, armii.
6.1.6.3 Cechy
produktów
− Serwer Matisse – jest bazą, której siła tkwi w interfejsach do bardzo wielu
języków programowania. Wśród tych języków można znaleźć na przykład: Java,
C++, Perl, Python, PHP, C, Eiffel. Z tych języków można korzystać z bazy w
standardowy sposób za pomocą języka SQL, jak również w sposób obiektowy.
Matisse rozszerzyła język SQL o możliwość obsługi obiektów. Właśnie język
117

zapytań do bazy jest jedyną przyczyną niepełnej zgodności z ODMG 3.0.
Matisse wspiera ODL 3.0, a także wiązania do C++ oraz języka Java zgodne z
ODMG.
− mt_xml – Matisse udostępnia specjalne udogodnienia oraz narzędzia do języka
XML. XML może być przechowywany w bazie, możliwe są także konwersje
danych do tego języka i z powrotem.
− mt_dba – jest to narzędzie administratorskie pozwalające na konfigurowanie,
start, monitorowanie i wstrzymywanie bazy. Umożliwia także tworzenie kopii
danych oraz zarządzanie poziomem bezpieczeństwa bazy.
− mt_editor – narzędzie to pozwala na przeglądanie bazy, ręczne modyfikowanie
obiektów oraz eksport schematu bazy do postaci ODL.
− mt_sql – narzędzie podobne do mt_editor’a, jednakże używa się go w celu
operowania na danych zapisanych relacyjnie.
− mt_monitor – umożliwia monitorowanie pracy serwera. Jest on pomocny w
dopracowywaniu konfiguracji serwera.
Wśród obsługiwanych platform znajdują się:
− Windows
− Linux
− Sun Solaris
− FreeBSD
6.1.7 Computer Association oraz Fujitsu – produkt Jasmine
6.1.7.1 Historia produktu w skrócie
Baza danych Jasmine powstała na mocy porozumienia firmy Computer
Association oraz Fujitsu. Firmy te zadeklarowały wspólną chęć rozwijania obiektowej
bazy danych. Pierwsza wersja produktu została zaprezentowana w roku 1996. Kolejne
ważne wydanie produktu przypadło na rok 1998. Obecnie firmy oferują wersję wydaną
w roku 2000. Fujitsu nazywa ją „Jasmine 2000”, natomiast Computer Association
„Jasmine ii”.
118

Kolejne podrozdziały prezentują informacje pochodzące z [CA 2001, Fallon 1998,
Fujitsu 2001, Ketabchi 1998] oraz następujących stron WWW:
http://www.cai.com/
http://www.fujitsu.co.jp/en/
6.1.7.2 Ogólne
informacje
Jasmine to produkt rozwijany równolegle przez dwie firmy: Computer
Association oraz Fujitsu. Computer Association oferuje bazę Jasmine jako część
większego produktu Jasmine ii The eBusiness Platform i nazywa ją „Jasmine ODB The
Object Database”, natomiast Fujitsu oferuje bazę pod nazwą „Jasmine 2000”. W skład
bazy Jasmine wchodzą następujące moduły: Object Database, Browser, Builder,
WebLink, Extendable Class Libraries oraz pakiet wiązań do języków programowania.
Nie wszystkie wyżej wymienione części wchodzą w skład pakietu każdego z
producentów.
6.1.7.3 Przegląd produktów
− Object Database – Obiektowa baza danych Jasmine wspiera wszystkie
obiektowe cechy, czyli: klasy abstrakcyjne, hermetyzację, dziedziczenie (w tym
wielokrotne), unikalną identyfikację obiektów, polimorfizm oraz agregację.
Oprócz obiektów może przechowywać w czystej postaci dane multimedialne.
Do korzystania z bazy stworzony został specjalny język ODQL (Object
Definition and Query Language). Język ten umożliwia tworzenie klas,
dokonywanie zmian w bazie, zapytania do bazy, a także zestaw konstrukcji
programistycznych nieznanych z klasycznych języków zapytań.
Języka ODQL można używać jako samodzielnego języka, a także wywoływać
go z innych języków programowania.
− Programming Language Support – Jest to pakiet wiązań do opisanych niżej
języków programowania, a także narzędzia ułatwiające korzystanie z języka
XML.
• Wiązanie do C++ – Język C++ jest obok ODQL głównym językiem, który
uwzględniano podczas projektowania bazy. Jasmine zapewnia pełną
119

zgodność z tym językiem. Oprócz przechowywania klas C++ istnieje
możliwość pisania rozszerzeń do Jasmine w tym języku.
• Java Proxies – Java Proxies jest wiązaniem obiektowej bazy danych Jasmine
do języka Java. Wiązanie to składa się z biblioteki klas umożliwiającej
korzystanie z bazy Jasmine. Aby z poziomu języka Java pobrać istniejące
dane z bazy, używa się języka ODQL. Chcąc dodać obiekty Javy do bazy,
wywoływane jest dodatkowe narzędzie zwane JPCG (Java Proxies Class
Generator), które ma za zadanie stworzyć semantyczny ekwiwalent definicji
klas Javy w postaci ODQL.
• Persistent Java – Persistent Java umożliwia wiązanie bazy Jasmine do
języka Java zgodne ze standardem ODMG. Produkt ten składa się z dwóch
części: Java Persistence Processor oraz Java Persistence Runtime. Narzędzie
to umożliwia przechowywanie obiektów Javy w bazie, a także
automatycznie tworzy definicje klas potrzebnych do schematu bazy.
Zapytania do bazy formułuje się w przypadku Persistent Java w języku
OQL, zamiast, jak to było w przypadku Java Proxies, w ODQL.
• Jasmine Java Beans – Jest to trzecia możliwość dostępu do bazy Jasmine z
poziomu języka Java. Produkt ten to zestaw ziaren Javy, które otwierają
drogę do korzystania z Jasmine. Komponenty te zawierają także dodatkową
funkcjonalność możliwą do wykorzystania przez programistów.
• API do języka C – Jest to biblioteka do języka C umożliwiająca działanie
tylko przy używaniu kompilatorów potrafiących obsłużyć biblioteki „dll”.
Biblioteka zapewnia możliwość wpisania kodu ODQL do funkcji
interpretujących.
• ActiveX Development – Zestaw kontrolek ActiveX, które umożliwiają dostęp
do bazy z poziomu języków zgodnych z ActiveX. Jest to dość uboga
biblioteka, większość rzeczy osiąga się poprzez wpisanie odpowiedniego
kodu ODQL do funkcji interpretujących.
− Browser – Produkt ten udostępnia możliwość graficznego przeglądania
zawartości bazy. Za jego pomocą można także modyfikować obiekty i klasy
zawarte w bazie, a także wykonywać zadania administratorskie w stosunku do
bazy.
120

− Builder – Graficzne narzędzie do budowania aplikacji korzystającej z bazy.
Produkt ten jest zintegrowany z Browser’em, co usprawnia tworzenie schematu
bazy.
− WebLink – Graficzne narzędzie do tworzenia dynamicznych stron WWW, które
mogą odwoływać się do bazy Jasmine. Weblink może generować aplikacje
WWW w trzech formatach: CGI dla serwerów typu Apache, ISAPI dla
Microsoft IIS oraz NSAPI dla serwerów Netscape.
− Extendable Class Libraries – Biblioteki dodatkowych klas i komponentów,
które rozszerzają możliwości programisty korzystającego z bazy Jasmine.
Jasmine obsługuje dwie platformy: Windows oraz Sun Solaris.
6.1.8 Uniwersytet Moskiewski – produkt GOODS
6.1.8.1 Ogólne informacje o produkcie
Baza GOODS (Generic Object-Oriented Database System) powstała w roku
1998 na uniwersytecie w Moskwie. Projektem kieruje Konstanty Kniżnik. Kolejne
podrozdziały powstały w oparciu o [Kniżnik 1999a-b] oraz stronę domową bazy:
http://www.ispras.ru/~knizhnik/goods.html
Serwer został tak pomyślany, aby wykonywał jedynie operacje związane z
przechowywaniem i wyszukiwaniem obiektów, zarządzaniem transakcjami,
blokowaniem, a także wykonywaniem kopii zapasowych. Cała reszta pracy
przeniesiona jest na klientów bazy. Komunikacja pomiędzy serwerem a klientami
odbywa się za pomocą specjalnego protokołu zwanego „Metaobject Protocol”.
GOODS ma architekturę rozproszoną. Baza może składać się z wielu węzłów, z których
każdy może znajdować się w dowolnym miejscu sieci. Fizyczne rozlokowanie obiektów
nie ma znaczenia dla klienta. Klient nie musi wiedzieć, gdzie są potrzebne mu dane,
jednakże może sobie zażyczyć, gdzie mają być usytuowane obiekty, które właśnie
zamierza składować. Serwer pomimo rozproszonej architektury potrafi obsługiwać
transakcje oraz zmiany schematu bazy.
Obiekty w bazie mogą pochodzić z dowolnego języka programowania, dla którego
zaimplementowano protokół „Metaobject Protocol”. Dostępne są także biblioteki dla
języków C++ oraz Java.
121

Serwer jest dostępny wraz z dwoma dodatkowymi narzędziami, monitorem serwera i
przeglądarką danych. Przeglądarka dostępna jest w dwóch wersjach konsolowych, a
także z dostępem przez WWW.
Do wspieranych platform systemowych należą:
− Windows
− Linux
− Sun Solaris
− FreeBSD
− Digital Unix
6.1.9 Micro Database Systems – produkt Titanium
6.1.9.1 Historia firmy w skrócie
Firma Micro Database Systems została założona w roku 1979 przez profesorów
z uniwersytetu Purdue. Firma była pionierem w tworzeniu baz danych na
mikrokomputery. Obecnie głównym produktem firmy jest Titanium. Firma MDBS
oferuje go w wersji 8.1, która została wydana w roku 2000. Informacje zaprezentowane
w kolejnych podrozdziałach pochodzą z [MDBS 2000] oraz strony WWW producenta:
http://www.mdbs.com
6.1.9.2 Ogólne
informacje
Titanium jest bazą danych, która potrafi obsługiwać relacyjne, obiektowe oraz
sieciowo/nawigacyjne modele danych. Baza pod względem swoich obiektowych cech
jest zgodna ze standardem ODMG 3.0.
Produkt Titanium składa się z wielu modułów, najważniejsze z nich to:
− TITANIUM Database Engine – główny moduł. Ma on za zadanie wykonywać
wszystkie operacje typowe dla bazy danych, takie jak: przechowywanie danych,
wykonywanie zapytań, obsługa transakcji, itp.
− TITANIUM Interactive SQL Module – konsola języka SQL umożliwiająca
wykonywanie zapytań.
122

− TITANIUM Data Definition Module – narzędzie służące do projektowania
struktury danych oraz późniejszego zakładania bazy na podstawie stworzonego
schematu. Definicja obiektowych baz danych odbywa się przy użyciu języka
ODL 3.0.
− TITANIUM Language Interfaces – wiązania do języków programowania. W
skład obsługiwanych języków wchodzą: C, C++, Cobol, Visual Basic, Delphi.
Wiązanie do języka C++ jest w pełni zgodne z ODMG 3.0, włączając w to ODL
oraz OML.
W chwili obecnej Titanium wspiera tylko platformę Windows. W przyszłości
planowane jest dodanie wsparcia dla systemu Linux.
6.1.10 Orient Technologies – produkt Orient
6.1.10.1 Historia produktu w skrócie
Baza danych Orient jest nowym projektem. Został on zapoczątkowany w roku
2000 we Włoszech. Także w roku 2000 wydano pierwszą wersję produktu. Obecnie
firma oferuje wersję 2.0, która została pierwszy raz zaprezentowana w roku 2001.
Więcej informacji o firmie Orient Technologies oraz produkcie Orient można znaleźć
na stronie WWW: http://www.orientechnologies.com, która zawiera informacje
stanowiące podstawę dla niniejszego rozdziału.
6.1.10.2 Ogólne informacje o produkcie
Orient Technologies oferuje bazę danych Orient w dwóch wersjach: Orient
Enterprise Edition oraz Orient Just Edition. Baza Just Edition jest dostępna za darmo
dla zastosowań niekomercyjnych.
Bazy Orient oferują niepełną zgodność ze standardem ODMG. Definicja
schematu danych odbywa za pomocą języka ODL. Zapytania do bazy odbywają się w
języku Orient Query Language, który czerpie swoje konstrukcje z SQL-92 oraz ODMG
OQL.
Wraz z bazą dostarczane jest wiązanie do języka C++ zgodne ze standardem ODMG.
Planowane jest wiązanie do języka Java zgodne ze standardem JDO.
123

W skład produktu, oprócz serwera bazodanowego, wchodzą: kompilator ODL, konsola
do wydawania poleceń oraz narzędzia do wykonywania kopii zapasowych.
Baza wspiera platformy systemowe: Windows oraz Linux.
6.1.11 Sysra Informatique – produkt EyeDB
6.1.11.1 Ogólne informacje
EyeDB była obiektową bazą danych rozwijaną przez Sysra Informatique przy
współpracy z Infobiogen, ANVAR oraz Conseil Regional d'Ile de France. Więcej
informacji o projekcie EyeDB można znaleźć na stronie WWW:
http://www.sysra.com/eyedb/. Zawiera ona informacje wykorzystane w kolejnych
podrozdziałach niniejszej pracy.
6.1.11.2 Historia projektu w skrócie
Pierwszy prototyp systemu, nazwany IDB był rozwijany przez Genethon
Laboratories dla potrzeb projektu „Genome View”. Projekt „Genome View” został
rozpoczęty w roku 1992 i miał na celu stworzenie kompletnej mapy ludzkiego genomu.
Od kwietnia 1994 roku nową wersją zajęła się Sysra Informatique. Nowa wersja bazy
została przepisana od początku. Ostatnie informacje o pracach nad EyeDB pochodzą z
roku 2000.
6.1.11.3 Cechy produktu
EyeDB był systemem, który miał wszystkie cechy obiektowych baz danych
według ODMG 3.0. System bazował na modelu klient/serwer. Umożliwiał transakcje
oraz równoległy dostęp. Model obiektu w tej bazie zawierał:
− obiekty jako instancje klas,
− polimorficzność,
− kolekcje takie jak: set, bag, array, wielowymiarowe oraz zmiennowymiarowe
tablice.
124

W skład systemu bazodanowego wchodziły:
− język zapytań oparty na OQL z ODMG 3.0,
− język definiowania danych oparty na ODL z ODMG 3.0,
− wiązanie do języka Java,
− wiązanie do języka C++,
− generator kodu Java oraz C++ na podstawie ODL.
6.1.11.4 Zastosowanie
Baza EyeDB była obiektową bazą ogólnego zastosowania, jednakże była
tworzona z myślą o przechowywaniu informacji związanych z genami ludzkimi.
Największa baza danych, jaka została stworzona za pomocą EyeDB to HuGeMap.
Jedyną obsługiwaną platformą jest Solaris.
125

7 Podsumowanie i wnioski ogólne
Mamy nadzieję, iż niniejsza praca będzie użyteczna dla osób zainteresowanych
problematyką obiektowych baz danych. Stanowi ona próbę uzupełnienia luki, jaka
istnieje w literaturze polskojęzycznej zajmującej się tematyką zastosowań obiektowości
w bazach danych. W związku z bardzo dynamicznym rozwojem technologii
obiektowych baz danych, większość publikacji jest częściowo zdezaktualizowana.
Opracowanie nasze stanowi spojrzenie na aktualnie rozwijane standardy, produkty i
kierunki rozwoju obecnych systemów.
Zamierzeniem naszym było stworzenie opracowania, które dawałoby podstawy
wiedzy na temat obiektowości i obiektowych baz danych. Wybraliśmy najbardziej
obecnie rozpowszechnione standardy i produkty i przedstawiliśmy je starając się nie
faworyzować żadnego z nich. Praca ta była próbą obiektywnego spojrzenia na to co
dotychczas zostało wypracowane w tej dziedzinie. Staraliśmy się także porównać
poszczególne rozwiązania z wyszczególnieniem ich wad i zalet.
Mamy nadzieję, że niniejsza praca będzie służyć pomocą każdemu, kto chciałby
zapoznać się z obecnymi trendami w dziedzinie obiektowych baz danych lub też
uzupełnić swoją wiedzę na ten temat. Chodzi tu przede wszystkim o pracowników
naukowych zajmujących się wykorzystaniem obiektowości w bazach danych. Praca ta
stanowi kompendium wiedzy na ten temat, może być więc pomocna wszystkim
zainteresowanym opisywaną tematyką.
Zastosowane w tej pracy podejście ma też swoje negatywne strony. Siłą rzeczy
poszczególne standardy i produkty zostały przedstawione pobieżnie, gdyż dokładne ich
omówienie wykraczałoby poza ramy tego opracowania.
7.1 Perspektywy rozbudowy pracy
Przedmiotem osobnej analizy mogłyby być inne spojrzenia na obiektowość i
algebrę obiektu, niż to zostało przedstawione w naszej pracy w oparciu o algebrę zwaną
AQUA.
Pracę można by także rozszerzyć o opisy mniej popularnych standardów związanych z
obiektowymi bazami danych. Przykładem może być standard SQLJ, który traktuje o
126

specjalnej wersji języka SQL:1999 osadzonego w Javie. Na pewno nie został do końca
wyczerpany temat związany ze standardem JDO. Jest to zupełnie nowe zagadnienie, co
powoduje, że na razie brak jest publikacji oraz produktów zgodnych z tym standardem.
Jeśli chodzi o produkty dostępne na rynku, można by pokusić się o dodanie informacji o
tych mniej znanych, a także wspomnieć o projektach, które nie są już rozwijane. Oprócz
tego, rozdział traktujący o obiektowych bazach danych w praktyce jest elementem
pracy najbardziej narażonym na dezaktualizację. Ewentualny rozwój pracy w
przyszłości należałoby uzupełnić o informacje o najnowszych produktach.
127

8 Literatura
[Bartels 2001] D. Bartels, G. Chase „A Comparison Between Relational and Object-
Oriented Database Systems for Object-Oriented Application Development”,
Poet Software GmbH, 2001.
[BenDaniel 1999] M. BenDaniel „Building Scalable ODBMS Applications”, 1999.
[Bobzin 2000] H. Bobzin „Java Data Objects Specification (JDO), Transparent
Interface for Persistent Data Storage”, Czerwiec 2000.
[Burleson 1999] D. K. Burleson „Inside the Database Object Model”, CRC Press LLC,
1999.
[CA 2001] „Jasmine ODB The Object Database - Database Design and Implementation
2.02”, Computer Association, 2001.
[Cattell 2000] R.G.G. Cattell, D. K. Barry „The Object Data Standard: ODMG 3.0”,
Morgan Kaufmann Publishers, 2000.
[Chase 2001] G. Chase „FastObjects j2”, 2001.
[Criag 2001] R. Criag „Java Data Objects - Version 1.0 - Proposed Final Draft”, Sun
Microsystems, Maj 2001.
[Criag 2002] R. Criag „Java Data Objects Version 1.0”, Sun Microsystems, Marzec
2002.
[Echelpoel 2002] K. Van Echelpoel „Java Data Objects: Een Revolutie voor Java
Databank Applicaties”, Uniwersytet w Antwerpii, Kwiecień 2002.
[Eisenberg 1999] A. Eisenberg, J. Melton „SQL:1999, formerly known as SQL3”,
1999.
[eXcelon 2002a] „ObjectStore High-Performance Data Managment Solution”, eXcelon
Corporation, 2002.
[eXcelon 2002b] „Embedding ObjectStore PSE Pro for Java”, eXcelon Corporation,
2002.
[eXcelon 2002c] „Component-Based Computing and the ObjectStore Cache-Forward
Architecture”, eXcelon Corporation, 2002.
[Fallon 1998] P. Fallon, P. Piko „Object Databases and Jasmine Development
Options”, Kwiecień 1998.
[Figura 1996] D. Figura „Obiektowe bazy danych”, Akademicka Oficyna Wydawnicza
PLJ, 1996.
128

[Franklin 2002] S. Franklin „Choosing the Right OODB Solution”,
http://www.devx.com/dbzone/, 2002.
[Fresher 2001] „The Emergence of the Object-SQL Database”, Fresher Information
Software, 2001.
[Fresher 2002] „Getting Started with MATISSE”, Fresher Information Software, 2002.
[Fujitsu 2001] „Jasmine 2000 Overview”, Fujitsu, 2001.
[GemStone 2000a] „Introduction to GemStone/J", GemStone Systems, Wrzesień 2000.
[GemStone 2000b] „GemStone/J System Administration", GemStone Systems,
Wrzesień 2000.
[GemStone 2001] „GemStone/S Programming Guide", GemStone Systems, Grudzień
2001.
[Gietz 2001] B. Gietz "Oracle 9i Application Developers Guide - Object-Relational
Features", Oracle Corporation, 2001.
[Górski 2000] J. Górski „Inżynieria oprogramowania w projekcie informatycznym”,
Wydawnictwo Informatyki MIKOM, (czerwiec 2000): 251-284.
[Haase 1999] O. Haase „ODMG – Object Database Management Group”, NEC Europe,
1999.
[Harrington 2001] J. L. Harrington „Obiektowe bazy danych”, Wydawnictwo
Informatyczne MIKOM, luty 2001.
[Jordan 2000] D. Jordan „An overview of Sun's Java Data Objects specification”,
Czerwiec 2000.
[Jordan 2001] D. Jordan „The JDO object model”, Czerwiec 2001.
[Ketabchi 1998] M. Ketabchi „Jasmine Perfect Platform To Build Java Applications”,
Santa Clara University, Kwiecień 1998.
[Kim 1996] W. Kim „Wprowadzenie do obiektowych baz danych”, Wydawnictwo
Naukowo-Techniczne, 1996.
[Kniżnik 1999a] K. Kniżnik „Generic Object-Oriented Database System”, Marzec
1999.
[Kniżnik 1999b] K. Kniżnik „Generic Object-Oriented Database System JavaAPI”,
Marzec 1999.
[Lausen 2000] G. Lausen, G. Vossen „Obiektowe bazy danych – modele danych i
języki”, Wydawnictwo Naukowo-Techniczne, 2000.
[Leavitt 2000] N. Leavitt „Whatever Happened to Object-Oriented Databases?”,
Sierpień 2000.
129

[Lechleitner 2001] C. Lechleitner „Lechleitner’s Related Work Book”, University of
Linz, Austria, Listopad 2001.
[Leung 1993] T. W. Leung, G. Mitchell, B. Subramanian, B. Vence, S. L. Vandenberg,
S. B. Zdonik „The Aqua Data Model And Algebra”, Technical Report No. CS-
93-09, Marzec 1993.
[Ludwikowska 2000] A. Ludwikowska „Obiektowe bazy danych”, http://javasoft.pl,
2000.
[McClure 1997] S. McClure „Object Database vs. Object-Relational Databases”,
Biuletyn IDC nr 14821E, Sierpień 1997.
[MDBS 2000] „Titanium Database Engine - Technical Synopsis”, Micro Database
Systems, 2000.
[Meyer 2001a] D. Meyer „FastObjects t7”, 2001.
[Meyer 2001b] D. Meyer „FastObjects e7”, 2001.
[Objectivity 2001] „Objectivity Technical Overview”, Objectivity, Styczeń 2001.
[OpenFusion 2002] „Java Data Objects - A White Paper”, OpenFusion, Luty 2002.
[Poet 2001a] „FastObjects j1”, Poet Software Corporation, 2001.
[Poet 2001b] „FastObjects Application Deployment Guide FastObjects t7”, Poet
Software Corporation, 2001.
[PostgreSQL] „PostgreSQL 7.2 Programmer’s Guide”, The PostgreSQL Global
Development Group, 2002.
[Subieta 1995] K. Subieta, J. Leszczyłowski „A Critique of Object Algebras”, 1995.
[Subieta 1998a] K. Subieta „SQL3 – Nowy standard języka SQL”, Luty 1998.
[Subieta 1998b] K. Subieta „Obiektowość w projektowaniu i bazach danych”,
Akademicka Oficyna Wydawnicza PLJ, 1998.
[Subieta 1998c] K. Subieta „Standard obiektowych baz danych ODMG 2.0”, 1998.
[Subieta 1998d] K. Subieta „Obiektowe Bazy Danych kontra Relacyjne Bazy Danych”,
1998.
[Subieta 1999a] K. Subieta „Słownik terminów z zakresu obiektowości”, Akademicka
Oficyna Wydawnicza PLJ, 1999.
[Subieta 1999b] K. Subieta „Object Database Systems”, Luty 1999.
[Ullman 2000] J. D. Ullman, J. Widom „Podstawowy wykład z systemów baz danych“,
Wydawnictwo Naukowo-Techniczne, 2000.
[Versant 2002a] „VERSANT Database Fundaments Manual”, Versant Corporation,
Marzec 2002.
130

131
[Versant 2002b] „C++/VERSANT Usage Manual”, Versant Corporation, Marzec 2002.
[Versant 2002c] „Java/VERSANT Interface Usage Manual”, Versant Corporation,
Marzec 2002.
[Versant 2002d] „VERSANT XML Toolkit Usage Manual”, Versant Corporation,
Marzec 2002.
Wyszukiwarka
Podobne podstrony:
iv rok formacji odb
rekolekcje ewangelizacyjne, Ruch Światło-Życie (oaza), Materiały formacyjne, Różne dodatkowe materia
p odb, Na temat rusztowań
Kon. - odb. sp gór. i dol.-syt na 3(siata), AWF, Konspekty, Siatkówka
nadajnik odb Aga
ODB II rekolekcje rysunki do 4 spotkania
odb ii°20 dziecieca krucjata milosci
elebot odb
PL-Piotrek-dogovor, 1---Eksporty-all, 1---Eksporty---, 1---akt.-odb.-SNG+UE+world, akt.-KZ-Uralsk-Ża
iii rok formacji odb
Obsługa i wykorzystanie funkcji nawi odb RS
Obsługa i wykorzystanie funkcji nawi odb Lei
Obsługa i wykorzystanie funkcji nawi odb Shi
AVT502 Odb 430MHz
2k odb ster modeli
ODB II rekolekcje, tematyka, II Rok Formacji - kl
ODB I stopień - Tabelka
odb i pomoce
spiewnik, Ruch Światło-Życie (oaza), Materiały formacyjne, Różne dodatkowe materiały formacyjne - gł
więcej podobnych podstron