
/* Protokoły komunikacyjne to zbiór ścisłych reguł i kroków postępowania, które są automatycznie
wykonywane przez urządzenia komunikacyjne w celu nawiązania łączności i wymiany danych. Dzięki temu, że
połączenia z użyciem protokołów odbywają się całkowicie automatycznie typowy użytkownik zwykle nie zdaje
sobie sprawy z ich istnienia i nie musi o nich nic wiedzieć (szkoda że nie jesteśmy typowymi użytkownikami :D).
Klasyczne protokoły, których prawzorem był protokół telexu składają się z trzech części:
•
procedury powitalnej (tzw. "handshake") która polega na przesłaniu wzajemnej podstawowej informacji o
łączących się urządzeniach, ich adresu (nr. telefonu), szybkości i rodzaju transmisji itd, itp,
•
właściwego przekazu danych,
•
procedury analizy poprawności przekazu (np: sprawdzania sum kontrolnych) połączonej z procedurą
pożegnania lub powrotu do procedury powitalnej.
*/
31. Właściwości protokołu Internet Protocol (IP wersja 4).
IP jest bezpołączeniowym protokołem komunikacyjnym (warstwy sieci), generującym
usługi datagramowe. Datagramy są to pakiety, zawierające między innymi adres źródła i miejsca
przeznaczenia oraz całość lub fragment danych przekazywanych między źródłem a miejscem
przeznaczenia. Przepływ datagramów w sieci odbywa się bez kontroli kolejności dostarczania ich do
miejsca przeznaczenia, kontroli błędów i bez potwierdzania odbioru (best-effort, niegwarantowany
transport). Istnieje możliwość fragmentacji datagramów na łączach różnej wielkości MTU
(maximum-transmission unit)
/*Pakiet (inaczej datagram, są to synonimy, chociaż w pewnych kontekstach rozróżnia się subtelne
różnice) jest podstawową jednostką nośnika informacji w nowoczesnych sieciach telekomunikacyjnych.
Pakiet składa się z nagłówka i obszaru danych. Nagłówek pakietu zawiera informacje wymagane do przesłania
pakietu od nadawcy do odbiorcy. Obszar danych zawiera informacje, które mają zostać przesłane za pomocą
pakietu. Można się posłużyć analogią do listu - nagłówek jest kopertą, a obszar danych tym, co nadawca włożył
do koperty.
Połączenie zawiera zwykle serię pakietów; w niektórych rodzajach sieci pakiety składające się na połączenie nie
muszą być przesyłane tą samą trasą przez sieć. Wiele architektur sieci nie zapewnia mechanizmu
zapobiegającego utracie pakietów, duplikacji lub ogólnie nieprawidłowemu dostarczeniu pakietu. Możliwe jest
jednak umieszczenie protokołu transportowego w warstwie powyżej protokołu pakietowego, który udostępnia
takie zabezpieczenia. Przykładem takiego protokołu jest TCP.
Datagramem określa się samodzielny pakiet - zawierający w nagłówku ilość informacji wystarczającą do
przesłania go przez sieć od nadawcy do odbiorcy niezależnie od innych pakietów. Dzięki temu nie są konieczne
żadne przygotowania zanim komputer prześle datagram do innego komputera, z którym wcześniej się nie
komunikował.
Niektóre systemy oparte o pakiety (na przykład sieci ATM) Wymagają przygotowania połączenia przed
wysyłaniem pakietów. Z tego względu wprowadza się rozróżnienie pomiędzy tymi pojęciami. Inne, jak na
przykład protokół IP, nie wymagają żadnych przygotowań, i w takim przypadku terminów pakiet i datagram
używa się zamiennie.
Czasami w odniesieniu do pakietów przesyłanych bezpośrednio w sieciach radiowych lub przewodowych (np.
Ethernet) używany jest równiż termin ramka.*/
32.Format datagramu IP
- Version – wersja protokołu IP (4 bity)
- IHL - IP Header Length - długość nagłówka w bajtach - 4bity,
-Type-of service – określa sposób traktowania przez wyższy
protokół, poziom ważności (QoS) - 8 bitów,
- Total length - całkowita długość (w bajtach) pakietu IP -16 bitów
- Indentification - numer identyfikujący kolejność - 16 bitów,
- Flags - bit nieużywany=0, bit zezwalający na fragmentację (=0),
bit oznaczający ostatni z fragmentów (=0),
- Fragment Offset - wskazuje względną pozycję (64-bitowe elementy)
danych fragmentu w stosunku do oryginalnego datagramu -13 bitów,
- Time-to-Live (TTL) - licznik zmniejszany przez każdy kolejny
router, jeśli równy zero to datagram jest usuwany - 8 bitów,
- Protocol - wskazuje docelowy protokół wyższego rzędu - 8 bitów,
- Header Checksum - suma kontrolna nagłówka - 16 bitów,
- Source Address - adres węzła źródłowego - 32 bity,
- Destination Address - adres węzła docelowego - 32 bity,
- Options - specyfikuje różne opcje n.p. security, source-routing,
- Data - dane zawierające segmenty wyższych protokołów.

32. Format datagramu IP.
00 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
wersja
długość
nagłówka
(IHL)
typ usługi
długość całkowita
identyfikacja
DF MF xx przesunięcie fragmentów
TTL
protokół
suma kontrolna nagłówka
Adres źródłowy
Adres docelowy
opcje
dane
wersja - wersja IP, obecnie 4, [4 bity]
długość nagłówka - wyrażana w bajtach [4 bity]
typ usługi okresla sposób traktowania przez wyższy protokół, poziom ważnosci – [8 bitów]
długość całkowita - podawana w bajtach [16 bitow]
identyfikacja - numer identyfikujacy kolejnosc -/// podczas fragmentowania danych wszystkie
fragmenty mają to pole jednakowe, [16 bitów]
Flagi służą do kontroli i organizacji fragmentów.
DF - Don't Fragment pole zabraniające fragmentowania datagramu,(gdy DF=0 wtedy datagram
można fragmentować)
MF - More Fragments - pole bit oznaczający ostatni z fragmentów,
xx- bit nieużywany =0
przesunięcie fragmentów - przesunięcie fragmentu względem początku całości, [13 bitow]
TTL - licznik zmniejszany przez każdy kolejny router, jesli równy zero to datagram jest usuwany [
8 bitów] (długość drogi jaką może przebyć pakiet)
protokół - wskazuje docelowy protokół wyższego rzedu (np. ICMP, UDP) – [8 bitów]
suma kontrolna nagłówka - dotyczy tylko nagłówka, nie dotyczy poprawności danych [16 bitów]
adres źródłowy
- adres pojedynczego komputera - nadawcy pakietu,
adres docelowy - adres wezła docelowego – [32 bity]
opcje
- specyfikuje różne opcje n.p. security, source-routing może zawierać zapis trasy - ścieżkę
po której przechodzi pakiet,
dane - dane właściwe, pochodzącee z wyższych warstw.
33. Klasy adresów IP.
Adres IP jest 32-bitową liczbą całkowitą zawierającą informacje o tym do jakiej sieci
włączony jest dany komputer, oraz jednoznaczny adres w tej sieci.

Zapisywany jest on w postaci czterech liczb dziesiętnych oddzielonych kropkami, przy czym każda
liczba dziesiętna odpowiada 8 bitom adresu IP. Istnieje 5 klas adresowych: A, B, C, D, E.
Ilość hostow i
sieci
Bity
początkowe
struktura
Najniższy
adres
Najwyższy adres
A 126 sieci, 16
mln hostów
0
Net
Host
Host
Host
0.1.0.0
126.0.0.0
B 65 tys. sieci i
hostów
10
Net
Net
Host
Host
128.0.0.0 191.255.0.0
C 16 mln sieci,
254 hostów
110
Net
Net
Net
Host
192.0.1.0 223.255.255.0
D multicast
1110
1110xxxx xxxxxxxx xxxxxxxx xxxxxxxx 224.0.0.0 239.255.255.255
E zarezerwowane 1111
1111xxxx xxxxxxxx xxxxxxxx xxxxxxxx 240.0.0.0 247.255.255.255
A- adresów klasy A jest niewiele (2
7
=128), ale w każdej z sieci tej klasy może być aż 65535
maszyn. Używany w kilku dużych organizacjach.
B - Klasa B to 2
14
sieci i 2
16
komputerów. Używany w średniej wielkości organizacjach.
C – sieć adresowana jest za pomocą 21 bitów - daje to 2
21
sieci, ale w każdej z nich może być co
najwyżej 2
8
=256 maszyn.
D - ma specjalne znaczenie - jest używany w sytuacji gdy ma miejsce jednoczesna transmisja do
większej liczby urządzeń
E – zarezerwowana pula numerów
34. Definicja, formaty i zastosowania podsieci.
Podsieci:
- stosowane w celu bardziej optymalnej gospodarki przydzielona pula adresowa,
- powstają w wyniku podziału części adresu reprezentującej węzeł na numer podsieci i numer węzła
(w podsieci).
Typy podsieci:
- statyczne - wszystkie węzły maja taka sama maskę,
- o zmiennej długości (wymagają routerów przystosowanych do takiej konfiguracji).
Maska podsieci:
32-bitowa liczba, w której cyfry 1 oznaczają część adresu reprezentującą numer sieci (łącznie z
podsiecią), a cyfry 0 część reprezentującą numer węzła w podsieci.
35. Metody dostarczania datagramów IP.
Adresy specjalne:
- all bits 0 = ten węzeł (tylko źródłowy),
- all bits 1 = wszystkie sieci lub wszystkie węzły (broadcast),
- Klasa A: 127.0.0.0 = loopback = interfejs wewnętrzny (pętla).
Unicast
-Point to point
Broadcast
- ograniczony (255.255.255.255) - do wszystkich węzłów podsieci, nigdy jako źródło, nie jest
rutowany (z wyj. BOOTP fowarding),
- skierowany do sieci (np. 128.2.255.255) - jest rutowany do wszystkich węzłów sieci (używany
przez ARP),
- skierowany do podsieci - zawiera numer sieci i podsieci, nadawca musi znać maskę docelowa,
realizuje go router docelowy,
- skierowany do wszystkich podsieci (np. 128.2.255.255) - w sieci z podsieciami, zwykle nie jest
rutowany, niepożądany.
Multicast
- na adresy klasy D,
- bezpołączeniowy,
- zero lub więcej odbiorców pod jednym adresem,
- węzły docelowe samodzielnie zgłaszają się do grup multicastowych informując o tym routery,

- każdy węzeł może nadawać na adres multicastowy.
Anycast
- rozłożenie usługi miedzy wiele serwerów,
- zdefiniowany dopiero w IP v. 6.
36. Klasy adresy prywatnych i ich zastosowanie
Kilka adresów sieci jest zarezerwowane do szczególnych celów. Dwa takie adresy to:
0.0.0.0 i 127.0.0.0, pierwszy nazywamy domyślnym routingiem (ang. default route), a drugi
adresem pętli zwrotnej (ang. loopback address). Domyślny routing jest związany ze sposobem
kierowania datagramów IP. Sieć 127.0.0.0 jest zarezerwowana dla ruchu IP lokalnego względem
lokalnego hosta. Zwykle adres 127.0.0.1 zostaje przypisany specjalnemu interfejsowi lokalnego
hosta - interfejsowi pętli zwrotnej, który działa jak obwód zamknięty. Dowolny pakiet IP
skierowany na ten interfejs z TCP lub UDP zostanie do niego zwrócony tak, jakby właśnie nadszedł
z jakiejś sieci. Dzięki temu można testować oprogramowanie sieciowe bez wykorzystywania
"rzeczywistej" sieci. Sieć pętli zwrotnej pozwala także na używanie oprogramowania sieciowego na
pojedynczym hoście.
Pewne zakresy adresów zostały odłożone na bok i określone jako "zarezerwowane" lub "prywatne"
zakresy adresów. Adresy te są przeznaczone do użytku w sieciach prywatnych i nie są przekazywane do
Internetu. Zwykle korzystają z nich organizacje tworzące własny intranet (sieć wewnętrzną), ale także małe
sieci. Są to adresy od 10.0.0.0 do 10.255.255.255 (sieci ich używające mogą mieć nawet ponad 16 milionów
hostów), od 172.16.0.0 do 172.31.0.0 (sieci ich używające mogą mieć do 65534 hostów) oraz od 192.168.0.0
do 192.168.255.0 (sieci ich używające mogą mieć do 254 hostów). Czasami stosuje się skrócony zapis adresu
IP wraz z maską sieci postaci: {adres IP}/{liczba bitów mających wartość jeden w masce}.
- trasy do nich nie są rozgłaszane w Internecie,
- węzły nie są bezpośrednio widoczne z poziomu IP,
- stosowane w sieciach wewnętrznych (korporacyjnych),
- dostęp przez bramy aplikacyjne (proxy) lub NAT (Network Address Translation).
Zarezerwowane klasy (prefiksy) adresowe:
jedna klasa A – ( 10.0.0.0 – 10.255.255.255
16 klas B – od 172.16.0.0 do 172.31.255.255
256 klas C – od 192.168.0 do 192.168.255
37.
Agregacja adresów wg Classless Inter-Domain Routing (CIDR).
Każdy adres IP składa się z dwóch części. Jedna część adresu identyfikuje sieć, a druga -
konkretny system host w tej sieci. Gdyby stosować wyłącznie systemy adresowania klasy A, to w
całym systemie routingu występowałoby tylko 126 sieci. Oznacza to, że każdy router musiałby
śledzić lokalizację tylko tej ograniczonej liczby sieci. Jednak obecnie przydziela się coraz więcej
sieci klasy C i dzisiejszy Internet składa się z milionów sieci. Powoduje to olbrzymie obciążenie
routerów. Poza tym routery muszą wymieniać między sobą tabele tras. Obszerne tabele mogą
zajmować dużą część pasma transmisyjnego sieci i są podatne na błędy transmisji.
Mechanizm CIDR, zdefiniowany w dokumencie RFC 1519, chwilowo oddala kryzys, związany
z adresowaniem sieci i systemów w Internecie. Proponowany pomysł polega zasadniczo na
przydzielaniu ośrodkom bloków adresów klasy C, przy czym liczba przydzielonych bloków zależy od
liczby adresów hostów, jakiej dany ośrodek potrzebuje. Zapobiega to marnotrawieniu adresów,
występującemu w sieciach klasy B. Ponadto przestrzeń adresowa klasy C podzielona została na
cztery strefy geograficzne (Europa, Ameryka Płn., Ameryka Środkowa i Płd. oraz obszar Azji i
Pacyfiku). Każdej strefie przydzielono 32 miliony adresów. Dzięki temu routery mogą funkcjonować
bez tak bardzo obszernych tabel tras. Jeśli do amerykańskiego routera dotrze datagram z
azjatyckim adresem, to zostanie po prostu przesłany do azjatyckiej bramy.
Korzysta z bitów maski do ustalenia zmiennej części 32 bitowego adresu IP sieci, podsieci
lub hosta. CIDR wykonuje "agregację trasy" na różnych poziomach hierarchi sieci, dzięki czemu
routery mogą przechowywać tylko pojedynczą tablicę routingu, zapewniając dostęp do wielu
niższych warstw sieci.
Agregację trasy oznacza iż pojedyńczy wpis w tabeli routingu może reprezentować
przestrzeń adresową kilkutysięcy tradycyjnych tras opartych na klasach, przez co redukuje liczbę
wpisów w tabelach routingu.

CIDR umożliwia bardziej wydajny sposób dla przydziału przestrzeni adresowej IPv4, przez
eliminację tradycyjnej koncepcji klas A, B i C. Pozwala to na rozwinięcie dowolnej wielkości sieci
przez co nie ogranicza standardowymi 8-mio, 16-to lub 24-ro bitowymi numerami sieciami
skojarzonymi z klasami. W modelu CIDR, każda część informacji routingu jest rozgłaszana z
długością prefiksu, która określa liczbę bitów (licząc od lewej strony) używanych dla części
sieciowej adresu IP. CIDR pomaga tylko osłabić problem adresacji, ale go nie likwiduje.
CIDR nie gwarantuje sprawnej i skalowalnej hierarchii. W celu uniknięcia osobnego wpisu
dla każdej trasy, jest ważne aby routery w niższej hierarchi sieci (które naturalnie mają dłuższe
przedrostki numeru) były "zbierane" razem w mniejsze i mniej specyficzne trasy, na wyższym
poziomie w hierarchi routingu.
Przykład: <192.32.136.0 255.255.248.0> - reprezentuje zakres od 192.32.136.0 do
192.32.143.0 jako jedna pozycja w tabeli tras routera.
38.
Podstawowe operacje routera i algorytm trasowania.
Podstawowe zadnia routera:
- przesyłanie komunikatów (pakietów, datagramów, segmentów) w warstwie trzeciej
(sieci), miedzy sieciami o różnej budowie;
- umożliwia łączenie sieci heterogenicznych.
Algorytmy trasowania (Routing Algorithms):
- cele projektowe:
- optymalność - zdolność wyboru najlepszej trasy,
- prostota - niskie wymagania sprzętowe i narzut komunikacyjny,
- niezawodność - odporność na zakłócenia, przeciążenia, błędy.
- szybka zbieżność - koordynacja, zapobiegająca pętlom,
- elastyczność - przystosowanie do zmiennych parametrów sieci.
Algorytmy trasowania są różne pod względem wielu parametrów. Po pierwsze -
zróżnicowanie zależy od celów określonych przez konstrukcję algorytmu. Po drugie - istnieją różne
typy algorytmów trasowania i każdy z nich ma inny wpływ na sieć i zasoby routerów. Wreszcie po
trzecie - algorytmy trasowania używają różnych miar mających wpływ na obliczenie trasy
optymalnej.
Optymalizacja odnosi się do możliwości algorytmu trasowania co do wyboru najlepszej trasy, a to zależy od przyjętej
do obliczeń miary trasowania i wagi przypisanej poszczególnym miarom. Na przykład jeden algorytm może używać liczby hop i
opóźnień, ale w kalkulacjach waga związana z opóźnieniami może być większa. Oczywiście protokoły trasowania muszą
dokładnie definiować algorytmy kalkulacji miar.
Algorytmy trasowania powinny być zaprojektowane tak, by były możliwie najprostsze. Inaczej mówiąc, algorytm
trasowania musi mieć bardzo efektywnie zaprojektowaną warstwę funkcjonalną przy minimalnych nakładach na
oprogramowanie i eksploatację. Efektywność jest szczególnie ważna w sytuacji, gdy oprogramowanie algorytmu trasowania
musi działać na komputerze z ograniczonymi zasobami sprzętowymi.
Algorytmy trasowania muszą być odporne i stabilne, co oznacza ich poprawne działanie nawet w niezwykłych
okolicznościach i trudnych do przewidzenia warunkach, np. przy uszkodzeniach sprzętu czy niewłaściwej eksploatacji. Routery
pracujące w punktach stykowych sieci mogą powodować poważne kłopoty w razie uszkodzenia. Dlatego najlepszymi
algorytmami trasowania okazują się te, które wytrzymały próbę czasu i okazały się stabilne w różnych warunkach pracy sieci.
Ponadto algorytmy trasowania muszą charakteryzować się krótkim czasem konwergencji. Konwergencja jest
procesem uzgadniania optymalnych tras między wszystkimi routerami w sieci. Jeśli wydarzenia w sieci powodują naprzemian
zanikanie lub dostępność tras, to routery obwieszczają ten fakt rozgłaszając komunikaty aktualizujące, przenikające całą sieć,
stymulujące ponowną kalkulację optymalnych tras i uzgodnienie tych tras. Algorytmy o długim czasie konwergencji mogą
powodować powstawanie pętli trasowania, a nawet zaniki pracy sieci.
Zasada jest dość prosta. Pakiet jest wysyłany do pierwszego routera jeżeli ma bezpośrednie
połączenie to przekazuje go do niego, jeżeli nie to pyta się czy jest jakieś niebezpośrednie
połączenie poprzez inne routery. Jeżeli tego też nie ma to sprawdza czy jest jakaś ścieżka
defaultowa, jeżeli też jej nie ma to wysyła wiadomość ICMP że sieć jest nieosiągalna,
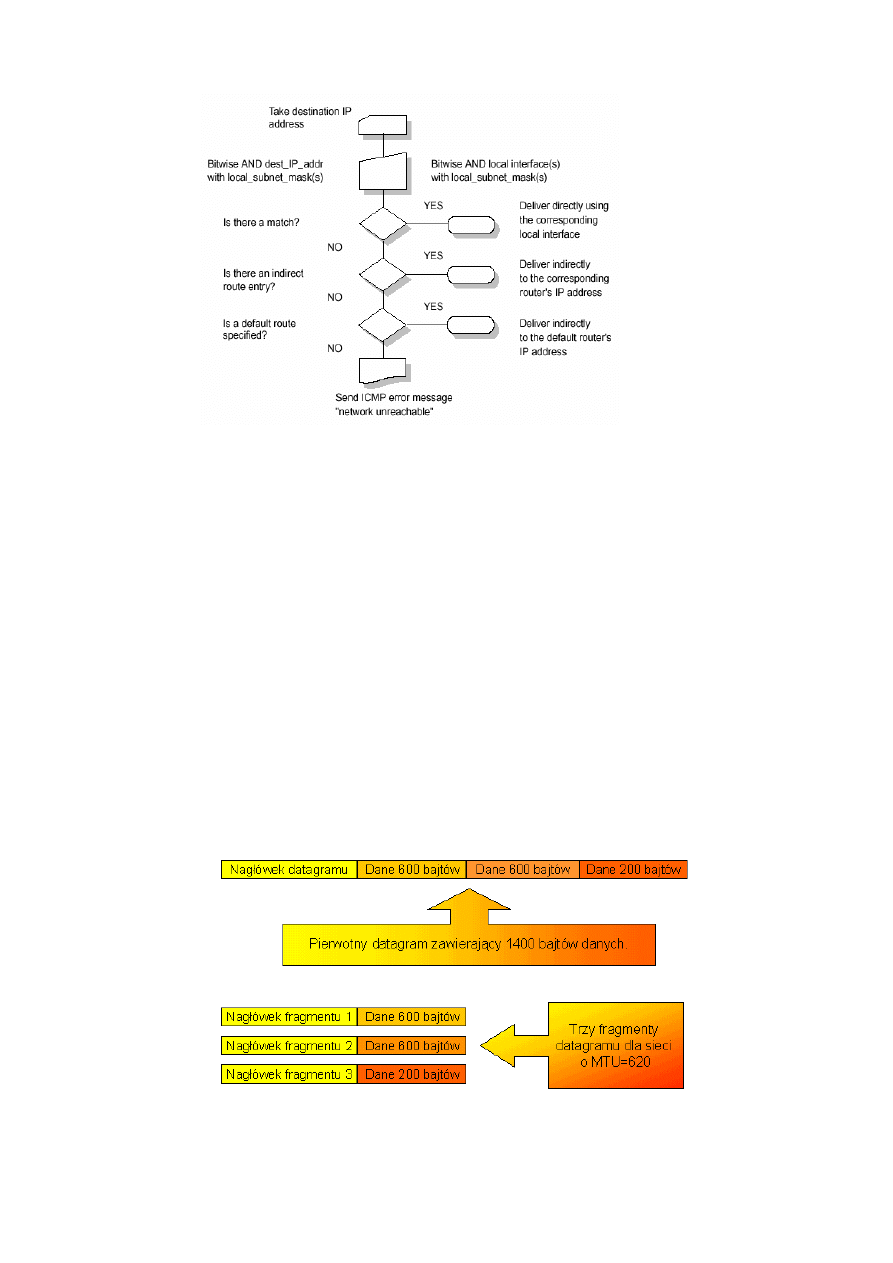
39.
Fragmentacja datagramu IP (algorytm).
W idealnym przypadku cały datagram mieści się w jednej ramce fizycznej. Nie zawsze
jednak jest to możliwe.
Dzieje się tak dlatego, że datagram może przemieszczać się przez różne sieci fizyczne. Każda z
nich ma ustaloną górną granicę ilości danych, które mogą być przesłane w jednej ramce. Np. w
sieci Ethernet “porcja” danych jest ograniczona do 1500 bajtów, natomiast w sieci FDDI można
przesłać ok. 4470 bajtów w jednej ramce.
Ten parametr sieci nosi nazwę maksymalnej jednostki transmisyjnej danej sieci -MTU (ang.
Maximum Transfer Unit).
Wielkość MTU może być całkiem mała, np. niektóre rodzaje sprzętu ograniczają porcje danych
do 128 i mniej bajtów. Ograniczenie wielkości datagramów, tak aby pasowały do najmniejszego
MTU, byłoby nieefektywne w przypadku przechodzenia przez sieci, które mogą przenosić większe
ramki. Jednak zezwolenie, aby datagramy były większe niż minimalne sieciowe MTU sprawia, że
datagram może nie zawsze zmieścić się w pojedynczej ramce sieciowej.
Wobec tego zamiast projektować datagramy, które spełniają ograniczenia sieci fizycznych,
oprogramowanie TCP/IP dobiera wygodny początkowy rozmiar datagramu i oferuje sposób
dzielenia datagramu na mniejsze części, kiedy datagram musi przejść przez sieć, która ma małe
MTU.
Mniejsze kawałki, na które jest dzielony datagram nazywane są fragmentami, a proces ten
nazywa się fragmentacją. Gdy takie pofragmentowane datagramy dotrą do odbiorcy podlegają
procesowi odwrotnemu czyli defragmentacji.
Rysunek przedstawia wynik fragmentacji. Każdy z fragmentów zawiera nagłówek, w którym jest powielona większość
zawartości nagłówka pierwotnego datagramu (nie licząc bitu w polu ZNACZNIKI, który wskazuje, że jest to fragment), a za
którym jest tyle danych, ile może być przeniesione we fragmencie, tak aby długość całkowita nie przekroczyła MTU sieci, przez
którą musi on przejść.

Algorytm:
- sprawdzenie flagi DF (jeśli =1 to datagram jest odrzucany, wysyłany jest komunikat
ICMP.
- podział datagramu na części (zależnie od MTU), o długości danych n*8 bajtów za
wyjątkiem ostatniego,
- kopiowanie danych: ustawianie bitu MF (za wyjątkiem ostatniego), ustawienie pola offset,
kopiowanie wymaganych opcji (wg bitu najbardziej znaczącego, ustawienie pola IHL,
ustawienie pola całkowitej długości datagramu, obliczenie sumy kontrolnej,
- transmisja podzielonych datagramów, każdy indywidualnie.
Odbiór: licznik czasu rekonstrukcji zależy od implementacji.
/*
Datagram wędruje od nadawcy przez różne sieci i routery aż do końcowego odbiorcy. Jeżeli router nie
potrafi ani wyznaczyć trasy ani dostarczyć datagramu, albo gdy wykrywa sytuacje mającą wpływ na możliwość
dostarczenia datagramu np. Przeciążenie sieci, wyłączenie maszyny docelowej, wyczerpanie się licznika czasu
życia datagramu to musi poinformować pierwotnego nadawcę, aby podjął działania w celu uniknięcia skutków
tej sytuacji.
Protokół komunikatów kontrolnych internetu ICMP (ang. Internet Control Message Protocol) powstał
aby umożliwić routerom oznajmianie o błędach oraz udostępnianie informacji o niespodziewanych sytuacjach.
Chociaż protokół ICMP powstał, aby umożliwić routerom wysyłanie komunikatów to każda maszyna może
wysyłać komunikaty ICMP do dowolnej innej.
Z technicznego punktu widzenia ICMP jest mechanizmem powiadamiania o błędach.
Gdy datagram powoduje błąd, ICMP może jedynie powiadomić pierwotnego nadawcę o przyczynie. Nadawca
musi otrzymaną informację przekazać danemu programowi użytkownika, albo podjąć inne działanie mające na
celu uporanie się z tym problemem.
Każdy komunikat ICMP ma własny format, ale wszystkie zaczynają się trzema takimi samymi polami:
-
8-bitowe pole TYP komunikatu identyfikuje komunikat,
-
8-bitowe pole KOD daje dalsze informacje na temat rodzaju komunikatu,
-
Pole SUMA KONTROLNA (obliczane podobnie jak suma IP, ale suma kontrolna ICMP odnosi się tylko do
komunikatu ICMP).
Oprócz tego komunikaty ICMP oznajmiające o błędach zawsze zawierają nagłówek i pierwsze 64 bity danych
datagramu, z którym były problemy.
ICMP (ang. Internet Control Message Protocol - internetowy protokół komunikatów kontrolnych)
wykorzystywany jest przy diagnostyce oraz routingu. */
40.
Charakterystyka protokołu Internet Control Message Protocol (ICMP).
Charakterystyka:
-
ICMP używa IP, ale jest jego integralna częścią,
-
ICMP sygnalizuje niektóre błędy, nie zapewnia niezawodności!
-
ICMP nie może sygnalizować błędów transmisji ICMP,
-
komunikaty ICMP mogą dotyczyć tylko fragmentu zero,
-
ICMP nigdy nie dotyczy broadcast, multicast, loopback, this-net,
-
ICMP może być wysłany jako odpowiedz na ICMP Query,
-
w praktyce routery wysyłają komunikaty ICMP o błędach, węzły końcowe zależnie od
implementacji.
Każdy komunikat ICMP podróżuje przez intersieć w części datagramu IP przeznaczonej na
dane, a ten jak wiemy przemieszcza się przez sieć fizyczną w części dla danych ramki.
Chociaż komunikaty ICMP przenoszone przy użyciu IP, nie są protokołem wyższego rzędu lecz
wymaganą częścią IP.
42. Użytkowe aplikacje ICMP
Ping - wysyła jeden lub więcej datagramów ICMP na podany adres z żądaniem odpowiedzi i mierzy
czas obiegu (round trip time). Używa komunikatów ICMP Echo i Echo Reply.
Traceroute - wykorzystuje datagramy ICMP i UDP. Wysyła datagramy UDP na nieużywany port,
najpierw z TTL=1, w kolejnych zwiększa TTL o jeden. Pierwszy datagram jest usuwany przez
najbliższy router, który zwraca komunikat ICMP Time Exceeded. Kolejne datagramy są usuwane
przez coraz dalsze routery. Datagram odebrany przez węzeł docelowy jest sygnalizowany
komunikatem ICMP Port Unreachable. Na podstawie odebranych komunikatów ICMP określana jest
droga datagramu od węzła źródłowego do docelowego.

43. Działanie protokołu Address Resolution Protocol (ARP).
ARP (ang. Address Resolution Protocol) - protokół komunikacyjny przekształcania 32-
bitowych adresów IP (ustalanych autorytarnie przez użytkownika/administratora) na fizyczne, 48-
bitowe adresy MAC (przypisane fizycznie m.in. do kart sieciowych) w komputerowych sieciach
lokalnych typu Ethernet.
Każdy komputer w sieci powinien posiadać tzw. tablicę ARP. Znajduje się w niej adres IP i przypisany
do niego adres MAC. Dzięki temu komputery mogą się ze sobą komunikować za pośrednictwem adresu MAC,
ale tylko w obrębie danej sieci LAN. Jeśli jakieś informacje mają być przesłane do innej sieci (lub podsieci w
sieci złożonej, sieci oddzielonej routerem, itp.),to adres MAC musi być zastąpiony adresem IP.
ARP jest protokołem pracującym na drugiej warstwie modelu ISO/OSI, czyli warstwie łącza danych,
ponieważ pracuje ona na ramkach i może je analizować tzn. np. sprawdzać ich poprawność.
Protokół ARP stosowany jest zawsze wówczas, gdy jeden z węzłów sieci TCP/IP musi znać adres MAC
innego węzła w tej samej sieci lub w sieci złożonej. Najogólniej mówiąc, ARP umożliwia komputerowi wysłanie
żądania: "proszę komputer o adresie IP w.x.y.z o podanie mi swojego adresu MAC". Taki komunikat ARP
rozgłaszany jest w sieci lokalnej, tak że dociera do wszystkich węzłów. Odpowiada nań jednak tylko węzeł o
żądanym adresie IP. Poniżej przedstawiono proces odwzorowania adresów:
Algorytm:
-
najpierw sprawdzana jest tablica ARP Cache,
-
jeśli brak skojarzenia datagram IP jest odrzucany (konieczna retransmisja) a w sieć zostaje
wysłany ARP Request jako broadcast,
-
węzeł który rozpozna swój adres IP odsyła ARP Reply zawierając swój adres MAC
(sprzętowy) jako unicast, a także aktualizuje swój ARP Cache o adres MAC węzła
pytającego,
-
węzeł pytający odbiera ARP Reply i aktualizuje swój ARP Cache, jest gotowy do transmisji
IP.
44. Zastosowanie portów (Ports) i gniazdek (Sockets).
Porty protokołu są oznaczone za pomocą liczb całkowitych z zakresu od 1 do 65535. Niektóre porty (od
1 do 1023) są zarezerwowane na standardowe usługi takie jak WWW albo poczta elektroniczna. Przykładowo
jeśli jakiś host jest serwerem WWW i poczty elektronicznej to program chcący otworzyć stronę WWW na tym
hoście musi otworzyć port 80 a chcąc wysłać email musi otworzyć port 25. Różne usługi mogą używać tych
samych numerów portów pod warunkiem, że korzystają z innego protokołu TCP albo UDP chociaż niektóre
usługi korzystają jednocześnie z danego numeru portu i obudwu protokołów np. DNS korzysta z portu 53 za
pomocą TCP i UDP jednocześnie. Poszczególne numery portów przydzielone są przez IANA.
Port - 16-bitowy numer służący do identyfikacji aplikacji lub protokołu wyższego poziomu
komunikujących się za pomocą protokołu niższego poziomu.
Nie zależy od numeru identyfikacyjnego procesu w systemie operacyjnym (process ID).
Typy portów:
well-known (dobrze znane) - przydzielane przez IANA (STD 2), w zakresie do 1023 identyfikują
standardowe serwery usług np. telnet (23), FTP (20,21), które oczekują na zgłoszenia z sieci,
ephemeral (efemeryczne) - przydzielane aplikacjom użytkowników w zakresie 1023-65535, na czas
ich pracy.
W przyłączonym do sieci komputerze, który oferuje swoim użytkownikom różne usługi,
zazwyczaj realizowanych jest kilka różnych procesów. W środowisku protokołów TCP/IP usługi
udostępniane są poprzez porty. Gdy chcący skorzystać z pewnej usługi komputer łączy się z inną
maszyną, nawiązuje z nimi połączenie typu end-to-end. Ponadto w obu maszynach tworzone jest
tzw. gniazdo (socket). Jest ono związane z portem o określonym, zależnym od aplikacji numerze.
Gniazda można traktować jak swego rodzaju aparaty telefoniczne znajdujące się na końcach łącza
telefonicznego, a porty - jak numery telefonów
45. Właściwości i zastosowania protokołu User Datagram Protocol (UDP).
UDP (ang. User Datagram Protocol - Datagramowy Protokół Użytkownika) to jeden z
podstawowych protokołów internetowych. Umieszcza się go w warstwie czwartej (transportu)
modelu OSI.
Podczas gdy protokół TCP jest połączeniową usługą transportową, realizującą niezawodną
transmisję danych, UDP (User Datagram Protocol) jest bezpołączeniową usługą transportową (nie
zapewniającą takiej niezawodności jak TCP). Jak wcześniej wspomniano, każda aplikacja
potrzebuje interfejsu do protokołu IP. Takim interfejsem jest protokół UDP. Pozwala on na
zaadresowanie procesu uruchomionego na komputerze pełniącym rolę hosta, przez podanie
numeru portu, bez potrzeby zestawiania fizycznego połączenia. Takie rozwiązanie zazwyczaj
przyczynia się do zwiększenia wydajności komunikacji - a to dzięki temu, że kompletna informacja
może zostać przesłana przy użyciu jednego lub dwóch datagramów UDP. Z pewnością zestawienie
połączenia TCP - w celu przesłania tej samej informacji - zajęłoby o wiele więcej czasu.
Port jest adresem, pod którym na danym komputerze jest dostępna konkretna aplikacja. Datagramy
docierające do komputera trafiają do niego na podstawie adresów IP. Zawartość nadsyłanych datagramów
przekazywana jest do właściwego procesu zgodnie z podanym adresem portu. Jeśli komputer pełni rolę
serwera, może być na nim uruchomionych wiele procesów (usług) - takich jak HTTP (port 80), ftp (port 21),
Gopher (port 70). Wykorzystując protokół UDP aplikacja może wysłać datagram do procesu bez potrzeby
zestawiania połączenia, jak to ma miejsce w przypadku protokołu TCP.
Pakiety UDP (zwane też datagramami) zawierają oprócz nagłówków niższego poziomu, nagłówek UDP.
Składa się on z pól zawierających sumę kontrolną, długość pakietu oraz porty: źródłowy i docelowy.
Podobnie jak w TCP, porty UDP zapisywane są na dwóch bajtach (szesnastu bitach), więc każdy adres
IP może mieć przypisanych 65535 różnych zakończeń. Z przyczyn historycznych, porty 0-1023 zarezerwowane
są dla dobrze znanych usług sieciowych - dla aplikacji użytkownika przydziela się porty od 1024.
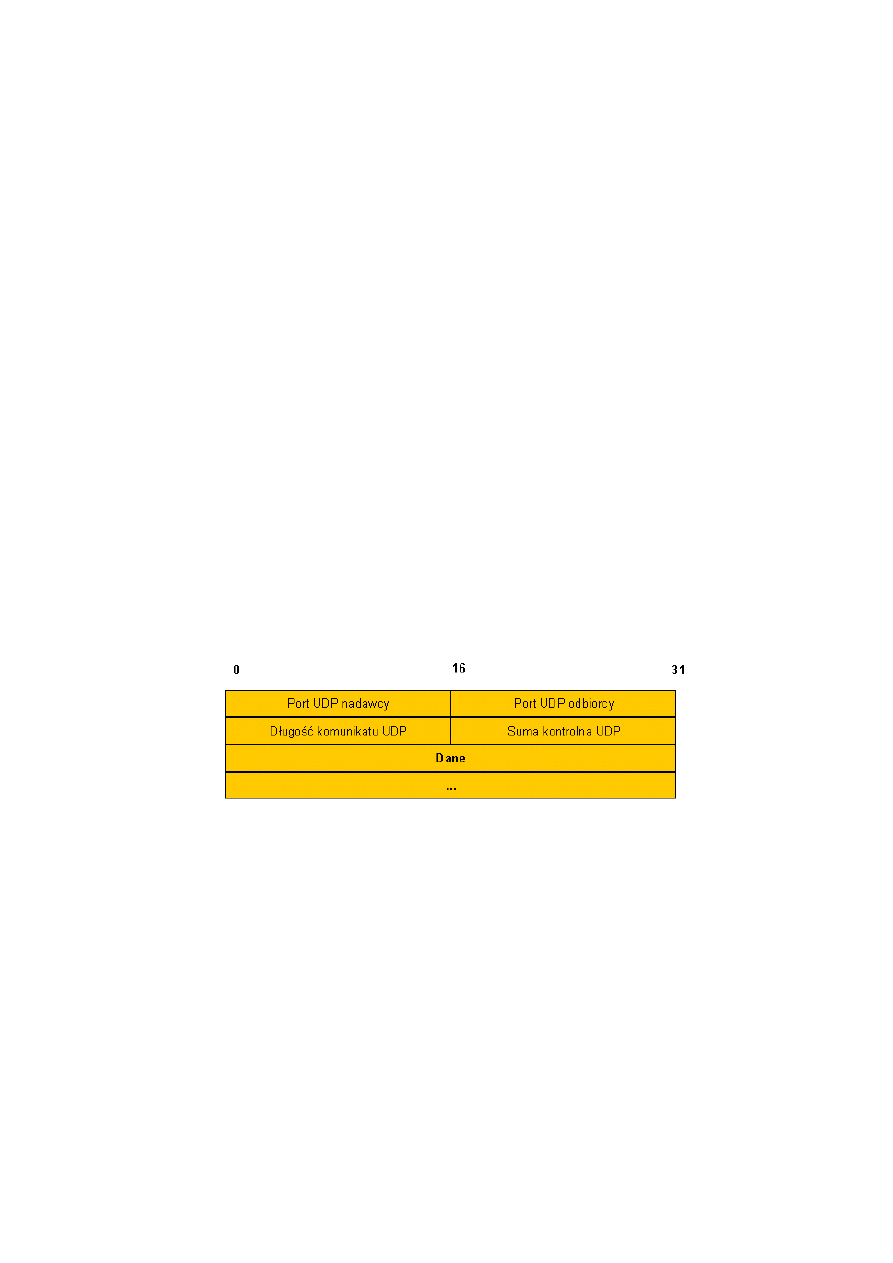
46. Format datagramu UDP.
Każdy komunikat UDP nazywa się datagramem użytkownika. Datagram taki można podzielić na
dwie części: nagłówek UDP i obszar danych UDP.
Nagłówek datagramu użytkownika składa się z czterech 16-bitowych pól.
Pola PORT NADAWCY i PORT ODBIORCY zawierają 16-bitowe numery portów UDP używane do
odnajdywania procesów oczekujących na dany datagram. Pole PORT NADAWCY jest opcjonalne.
Pole DŁUGOŚĆ zawiera wartość odpowiadającą liczbie bajtów datagramu UDP wliczając nagłówek i dane.
Minimalna więc wartość tego pola wynosi więc 8, czyli jest długością samego nagłówka.
Pole SUMA KONTROLNA jest opcjonalne. Ponieważ jednak IP nie wylicza sum kontrolnych dla danych,
suma kontrolna UDP jest jedyną gwarancją, że dane nie zostały uszkodzone.
/* Protokół IP nie troszczy się tak naprawdę o dostarczenie datagramu do adresata, lecz w przypadku
odrzucenia datagramu sygnalizuje ten fakt jako błąd maszynie-nadawcy i uznaje sprawę za załatwioną.
Używanie zawodnego dostarczania bez użycia połączenia do przesyłania dużych porcji danych jest więc nużące i
wymaga od programistów, aby wbudowywali do każdego programu użytkowego wykrywanie i korekcję błędów.
Teraz zajmiemy się przesyłaniem niezawodnymi strumieniami TCP (ang. Transmission Control Protocol), które
istotnie zwiększa funkcjonalność omawianych do tej pory protokołów, biorąc odpowiedzialność za wiarygodne
dostarczenie datagramu. Okupione jest to jednak skomplikowaniem protokołu.
Protokół TCP będąc drugą najważniejszą usługą w sieci, wraz z IP dał nazwę całej rodzinie protokołów TCP/IP.
Pomimo związku z protokołem IP - TCP jest protokołem w pełni niezależnym i może zostać zaadaptowany do
wykorzystania z innymi systemami dostarczania.
Możliwe jest używanie go zarówno w pojedynczej sieci takiej jak ethernet jak i w skomplikowanej intersieci.
*/
47. Właściwości protokółu Transmission Control Protocol (TCP).
TCP (ang. Transmission Control Protocol) to strumieniowy protokół komunikacji między
dwoma komputerami. Jest on częścią większej całości określanej jako stos TCP/IP. W modelu OSI
TCP odpowiada warstwie Transportowej.
W przeciwieństwie do UDP, TCP zapewnia wiarygodne połączenie dla wyższych warstw
komunikacyjnych przy pomocy sum kontrolnych i numerów sekwencyjnych pakietów, w celu
weryfikacji wysyłki i odbioru. Brakujące pakiety są obsługiwane przez żądania retransmisji. Host
odbierający pakiety TCP porządkuje je według numerów sekwencyjnych tak, by przekazać wyższym
warstwom modelu OSI pełen, złożony segment.
Charakterystyczny dla TCP jest moment nawiązania połączenia, nazywany ang. three-way handshake.
Host inicjujący połączenie wysyła pakiet zawierający segment TCP z ustawioną flagą SYN (Synchronize). Host
odbierający połączenie, jeśli zechce je obsłużyć odsyła pakiet z ustawionymi flagami SYN i ACK (Acknowledge -
potwierdzenie). Inicjujący host powinien teraz wysłać pierwszą porcję danych, ustawiając już tylko flagę ACK
(gasząc SYN). Jeśli host odbierający połączenie nie chce lub nie może odebrać połączenia, powinien
odpowiedzieć pakietem z ustawioną flagą RST (Reset).
Aplikacje, w których zalety TCP przeważają nad wadami (większy koszt związany z utrzymaniem sesji TCP przez
stos sieciowy) to między innymi HTTP, SSH, FTP czy SMTP/POP3 i IMAP4.
•
Połączenie TCP realizowane jest w trybie full-duplex
Połączenia w TCP są realizowane w trybie full-duplex poprzez dwukierunkowe kanały wirtualne, co
pozwala każdemu z systemów końcowych przesyłać dane w dowolnej chwili. W związku z tym połączenie
sprawia wrażenie realizowanego poprzez dwa niezależne kanały nadawania i odbioru. Dane wysyłane i
odbierane są buforowane, więc proces komunikacji nie wpływa na żadne inne procesy.
•
Odbiorca może potwierdzić odebrane datagramy (ACK)
Odbiorca może potwierdzać (acknowledge) odebranie datagramów, aby nadawca mógł być pewny, że
dotarły one na miejsce.
•
Kontrola przepływu (flow control)
Kontrola przepływu daje możliwość aktywnej współpracy dwóch systemów w czasie transmisji danych i
pozwala zapobiec nadmiarom i utracie datagramów, które to sytuacje powodowane są poprzez szybkich
nadawców. Cecha ta pozwala systemom transmitującym szybko dostosować się do poziomu ruchu w sieci
oraz/lub ustalić odpowiednią wielkość bufora u odbiorcy.
•
Porządkowanie numeracji datagramów (sequencing)
Porządkowanie jest techniką numerowania datagramów, która pozwala odbiorcy ułożyć je we
właściwym porządku i ewentualnie określić brakujące elementy.
•
Generowanie sum kontrolnych (checksumming)
Generowanie sumy kontrolnej pozwala integralność pakietów.
48. Zasada ruchomego okna (Sliding Window) w TCP.
Jak widać na poprzednich rysunkach, dane pomiędzy maszynami płyną w danym momencie
tylko w jednym kierunku i to nawet wtedy, kiedy sieć umożliwia jednoczesną komunikację w obu
kierunkach. Ponadto sieć nie będzie używana, kiedy maszyny będą zwlekać z odpowiedziami np.
podczas wyliczania sum kontrolnych. Takie rozwiązanie powoduje znaczne marnowanie
przepustowości sieci.
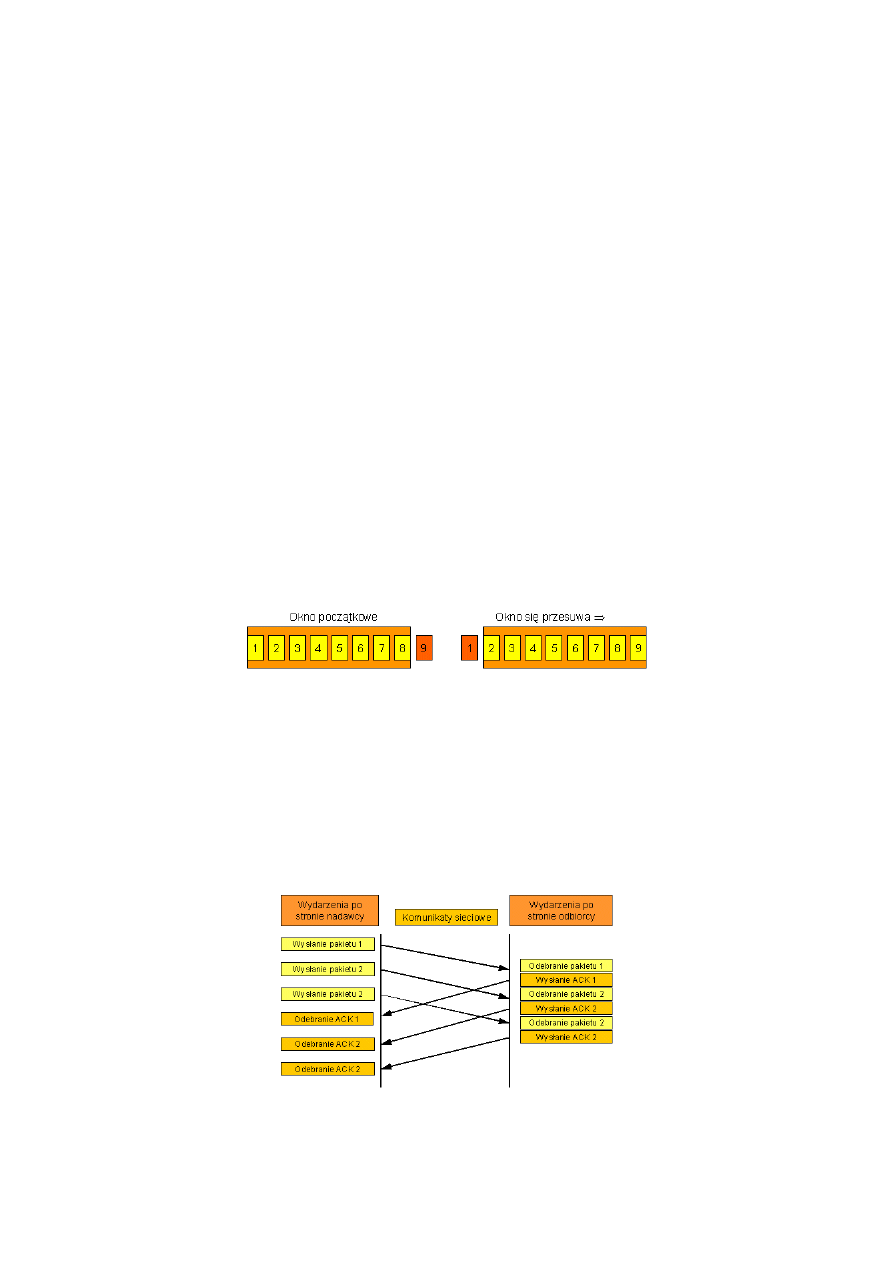
Technika przesuwającego się okna lepiej wykorzystuje przepustowość sieci, gdyż umożliwia
wysyłanie wielu pakietów przed otrzymaniem potwierdzenia. W rozwiązaniu tym protokół zaleca
umieszczenie na ciągu pakietów ustalonego rozmiaru okna i przesłanie wszystkich pakietów, które
znajdują się w jego obrębie. Mówimy, że pakiet jest niepotwierdzony, jeżeli został wysłany, a nie
nadeszło dla niego potwierdzenie. Liczba pakietów niepotwierdzonych w danej chwili jest
wyznaczona przez rozmiar okna.
Dla protokołu z przesuwającym się oknem , którego rozmiar jest np. równy 8, nadawca ma możliwość
wysłania przed otrzymaniem potwierdzenia do 8 pakietów. Gdy nadawca odbierze potwierdzenie dla pierwszego
pakietu, okno przesuwa się i zostaje wysłany następny pakiet. Okno przesuwa się dalej gdy przychodzą kolejne
potwierdzenia.
Pakiet dziewiąty może zostać wysłany gdy przyszło potwierdzenie dotyczące pierwszego pakietu.
Retransmitowane są tylko te pakiety, dla których nie było potwierdzenia. Oczywiście protokół musi pamiętać,
które pakiety zostały potwierdzone i utrzymuje oddzielny zegar dla każdego nie potwierdzonego pakietu. Gdy
pakiet zostanie zgubiony lub zostaje przekroczony czas nadawca wysyła ten pakiet jeszcze raz.
Poprawa uzyskiwana przy protokołach z przesuwającymi się oknami zależy od rozmiaru okna i szybkości, z
jaką sieć akceptuje pakiety.
Gdy rozmiar okna wynosi 1, protokół z przesuwającym się oknem jest tym samym, co nasz zwykły protokół z
potwierdzaniem.. Zwiększając rozmiar okna, możemy w ogóle wyeliminować momenty nieaktywności sieci.
Oznacza to, że w sytuacji stabilnej nadawca może przesyłać pakiety tak szybko, jak szybko sieć może je
przesyłać.
Poniższy rysunek pokazuje przykład przesyłania trzech pakietów przy użyciu protokołu z przesuwającym się
oknem. Istotne jest tutaj, że nadawca może przesłać wszystkie pakiety z okna bez oczekiwania na
potwierdzenie.
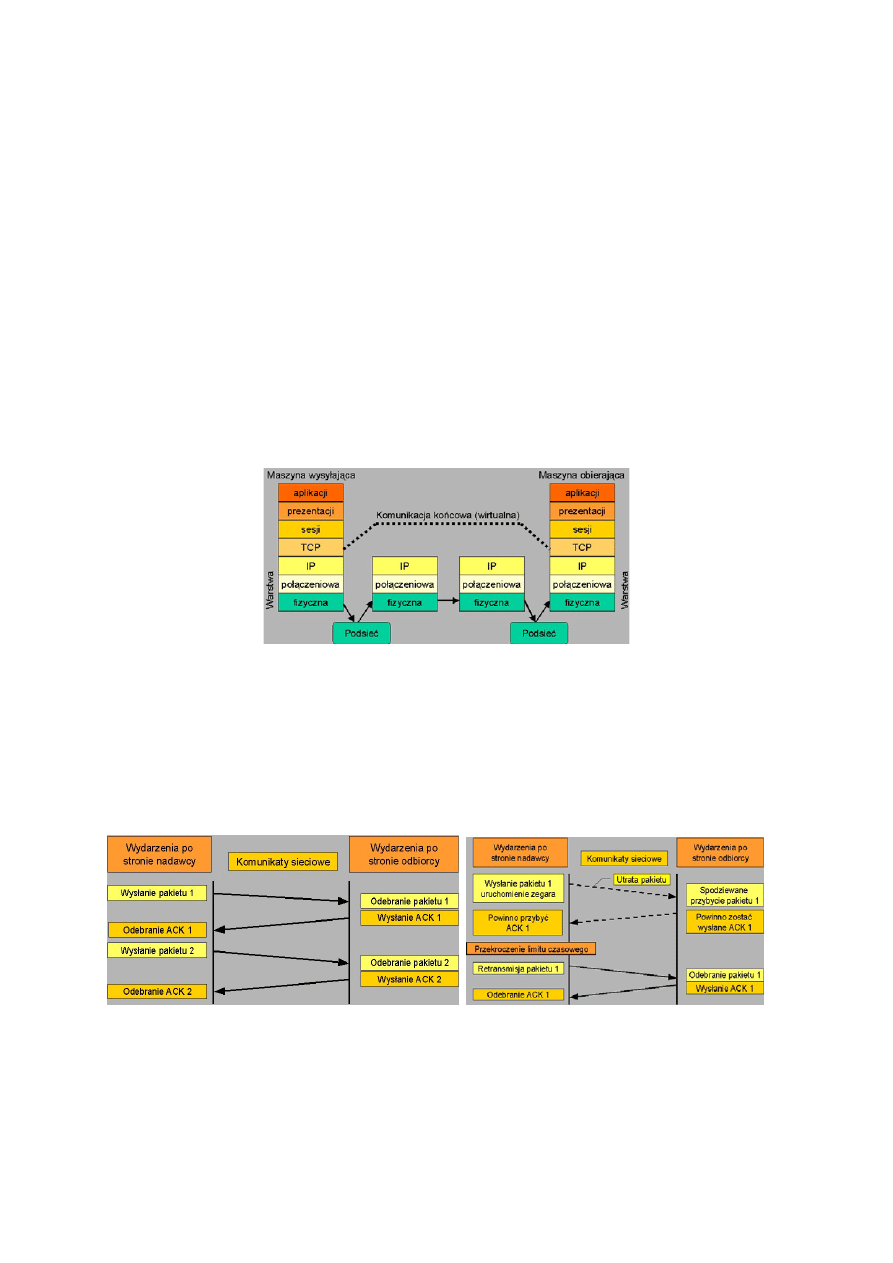
49. Pojęcie czasu obiegu pakietu i timeout’u w TCP.
Po fazie ustalenia połączenia obydwa komputery mogą zacząć wysyłać dane między sobą.
Nadawca wysyła pakiet z danymi do odbiorcy, włącza licznik i w ustalonym czasie
(TimeOut’u) czeka na potwierdzenie odbioru pakietu od odbiorcy. Jeśli potwierdzenie nie przyjdzie
w czasie ustalonego TimeOut’u od odbiorcy, nadawca retransmituje ponownie pakiet, który nie
został potwierdzony, włącza licznik i ponownie zaczyna odmierzać czas (TimeOut).
TCP reguluje TimeOut na podstawie RTT(Road Trip Time- czas obiegu pakietu), a raczej
na podstawie jego przybliżonej wartości SRTT, która jest mierzona od momentu wysłania pakietu
do momentu potwierdzenia jego odebrania.
SRTT[i] = (1-a) * SRTT[i-1] + a * RTT
0 < a < 1; za zwyczaj a = 1/8
RTO = 2 * SRTT - Retransmit TimeOut
RTT - Round Trip Time; czas obiegu pakietu
Timeout - limit czasu oczekiwania na potwierdzenie odbioru segmentu
Jeśli „timeout” jest za mały występują zbędne retransmisje; jeśli za duży to zbyt wolna reakcja na
utratę segmentu
SampleRTT - bieżący czas między wysłaniem segmentu i odbiorem ACK
SampleRTT - może znacznie fluktuować
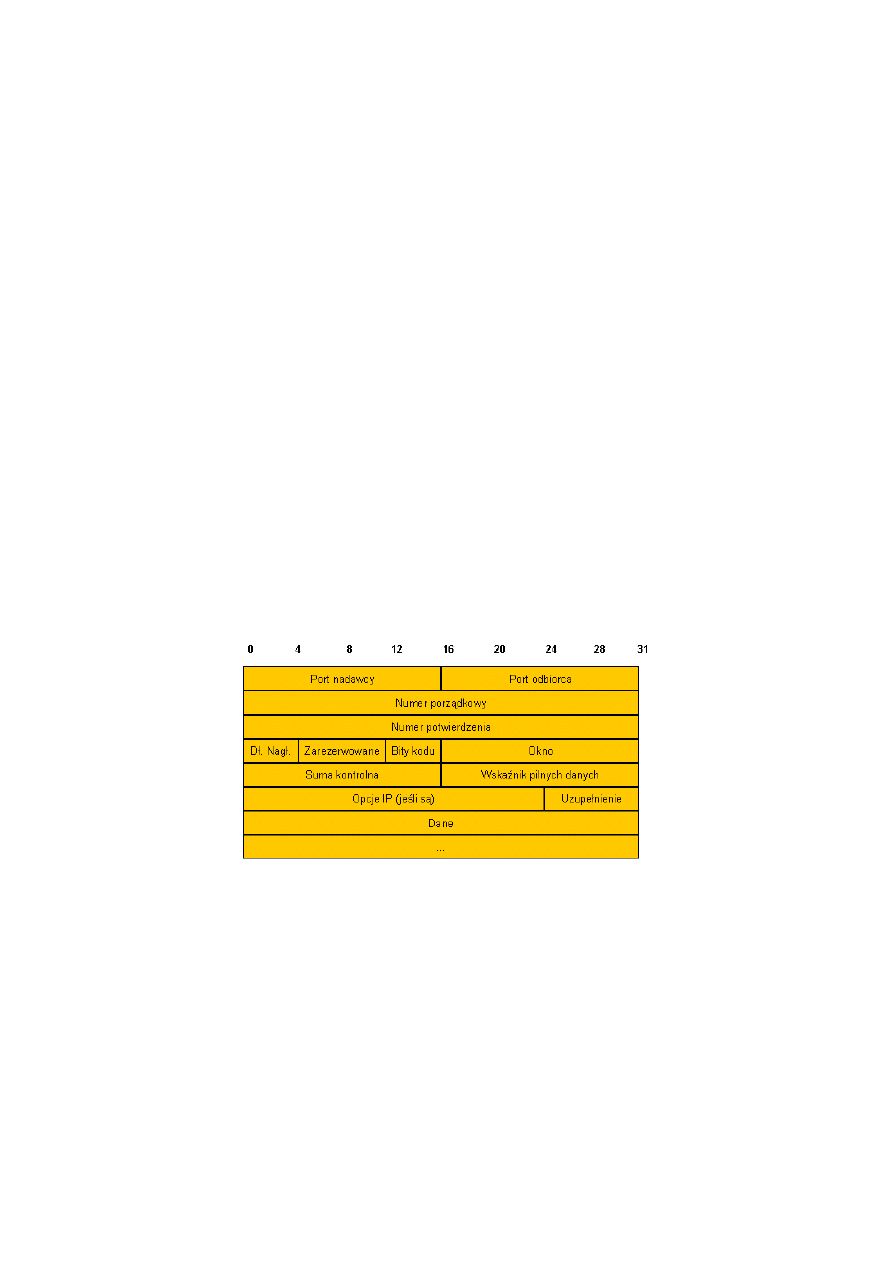
50.Format segmentu TCP (w tym wybrane opcje).
Mianem segmentu określa się jednostkową porcję danych przesyłanych między
oprogramowaniem TCP na różnych maszynach. Segmentów używa się również do ustanawiania
połączenia, do przesyłania danych, do potwierdzania, do wysyłania propozycji okien oraz do
zamykania połączeń. W związku z tym, że TCP korzysta z możliwości “jazdy na barana”,
potwierdzenie przepływające z maszyny A do maszyny B może podróżować w tym samym
segmencie, co dane z maszyny A do B i to nawet wtedy, gdy potwierdzenie odnosi się do danych
przesyłanych z B do A.
Poniższy rysunek pokazuje format segmentu TCP.
Każdy segment podzielony jest na dwie części: nagłówek i dane, które się za nim znajdują. Nagłówek,
nazywany nagłówkiem TCP, zawiera spodziewane informacje identyfikacyjne oraz kontrolne.
•
Pola PORT NADAWCY i PORT ODBIORCY zawierają numery portów TCP, które identyfikują
programy użytkowe na końcach połączenia.
•
Pole NUMER PORZĄDKOWY wyznacza pozycję danych segmentu w strumieniu bajtów nadawcy.
•
Pole NUMER POTWIERDZENIA wyznacza numer oktetu, który nadawca spodziewa się otrzymać w
następnej kolejności. Zwróćmy uwagę, że NUMER PORZĄDKOWY odnosi się do strumienia płynącego w
tym samym kierunku co segment, zaś NUMER POTWIERDZENIA odnosi się do strumieni płynących w
kierunku przeciwnym.
•
Pole DŁUGOŚĆ NAGŁÓWKA zawiera liczbę całkowitą, która określa długość nagłówka segmentu
mierzoną w wielokrotnościach 32 bitów. Jest ono konieczne gdyż pole OPCJE ma zmienną długość.
•
Pole ZAREZERWOWANE jest pozostawione do wykorzystania w przyszłości.
•
Ponieważ niektóre segmenty mogą przenosić tylko potwierdzenia, inne również dane, inne zaś
zawierają prośby o ustanowienie lub zamknięcie połączenia - pole BITY KODU zawiera informację o
przeznaczeniu zawartości segmentu.
•
Przy każdym wysłaniu segmentu oprogramowanie TCP proponuje ile danych może przyjąć,
umieszczając rozmiar swojego bufora w polu OKNO. Pole to zawiera 16-bitową liczbę całkowitą bez
znaku, zapisaną w sieciowym standardzie uporządkowania bajtów. Propozycje wielkości okna to
kolejny przykład jeżdżenia “na barana”, gdyż towarzyszą one wszystkim segmentom, w tym
segmentom zawierającym dane i przenoszącym samo potwierdzenie.
51.Właściwości i elementy interfejsu sieci IEEE/802.3u (Fast Ethernet).
Cechy:
- technologia łącza oparta o rozwiązania FDDI,
- wsteczna zgodność z IEEE/802.3 10Mbps (CSMA/CD MAC, slot
time 512-bit, max. i min. długość ramki 64B-1518B, IFG 96 bit),
- poprawna interpretacja 10/100 i autonegocjacja,
- praca w trybie full-duplex (dwukierunkowym),
- topologia fizyczna gwiazdy - łącza typu active link.
•Reconcilliation Sublayer - translacja szeregowo/równoległa
(4-bit) między MAC i MII
• Media Independent Interface - złącze 40-stykowe między
MAC i PHY (szyna danych 4-bitowa
po 25 Mbps, kabel do 0.5 m)
• Physical Coding Sublayer - kodowanie danych, obsługa
CSMA/CD, transmisja i odbiór
• Physical Medium Attachment - przenoszenie sygnałów
między PCS i łączem,
• Physical Medium Dependent - definicja parametrów łącza
fizycznego
• Media Dependent Interface - złącze elektromech.
52.Parametry funkcjonalne 100Base-FX, 100Base-TX, 100Base-T4.
(popatrz do wykładu 6 ☺ )
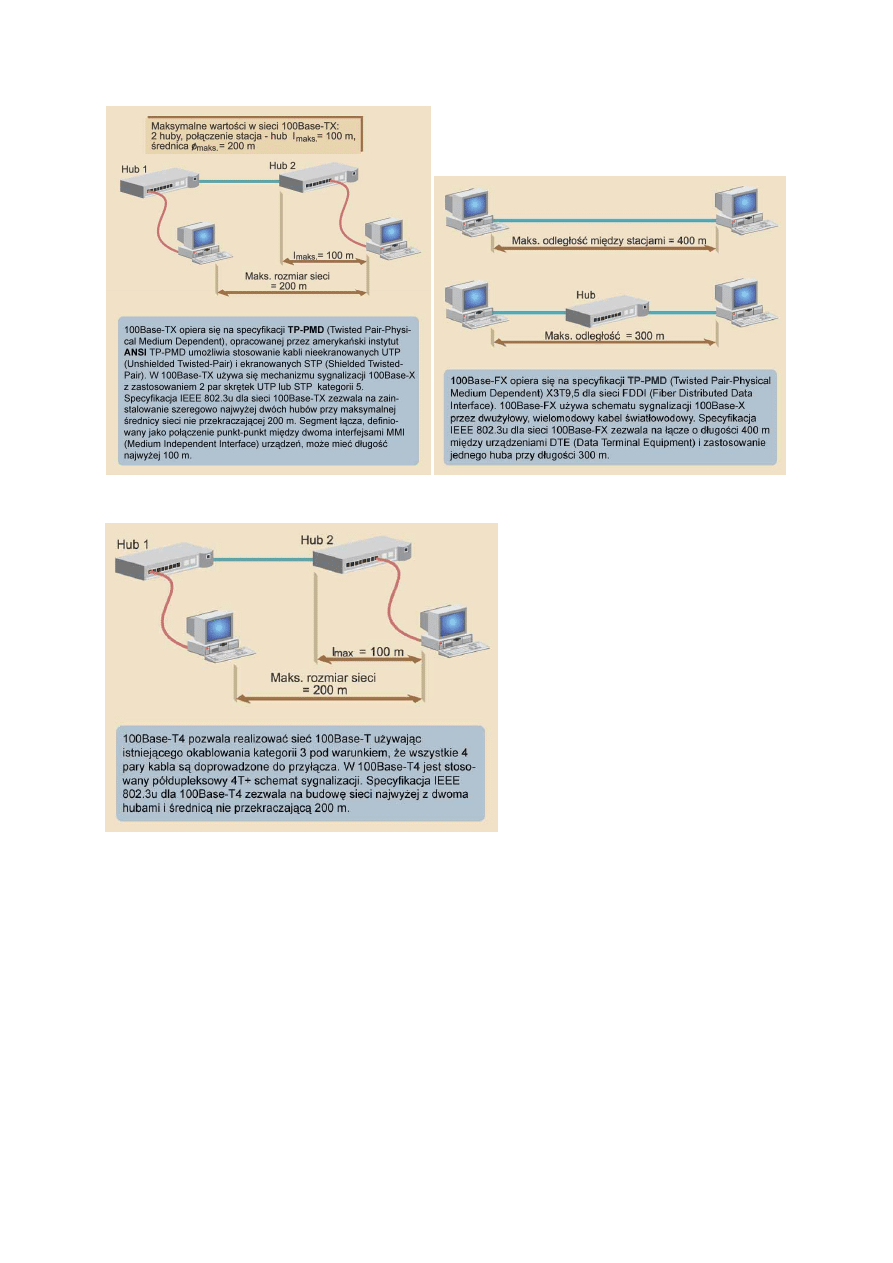
W technologii 100Base-T w celu
osiągnięcia zwiększonej przepływności w
stosunku do przepływności technologii
10Base-T rozmiar domeny kolizyjnej
musi zostać zmniejszony. Po prostu
stacja transmitująca 10 razy szybciej
musi pracować na kablu 10 razy
krótszym. W rezultacie każda stacja w
pierwszych 64 bajtach dowiaduje się o
wystąpieniu ewentualnej kolizji
spowodowanej przez inną stacji.
53.Typy koncentratorów Fast Ethernet i ich zastosowanie.
•Class I - przeznaczone do łączenia segmentów o różnej budowie (FX,TX,T4), dokonują konwersji
formatów kodowania, jest to powodem generowania większych opóźnień, dopuszczalnie tylko
jeden w domenie kolizyjnej,
•Class II - przeznaczone do łączenia segmentów o identycznej budowie, dokonują tylko
przenoszenia/wzmacniania impulsów, dopuszczalnie dwa w kaskadzie w domenie kolizyjnej
54.Właściwości wariantu Full-Duplex Ethernet / IEEE 802.3x.
•Dwukierunkowa niezależna i jednoczesna transmisja
z pominięciem metody CSMA/CD.
•Łącza typu punkt-punkt (link) z oddzielnymi torami przesyłowymi 10Base-T,FL, 100Base-TX,FX,
itp.
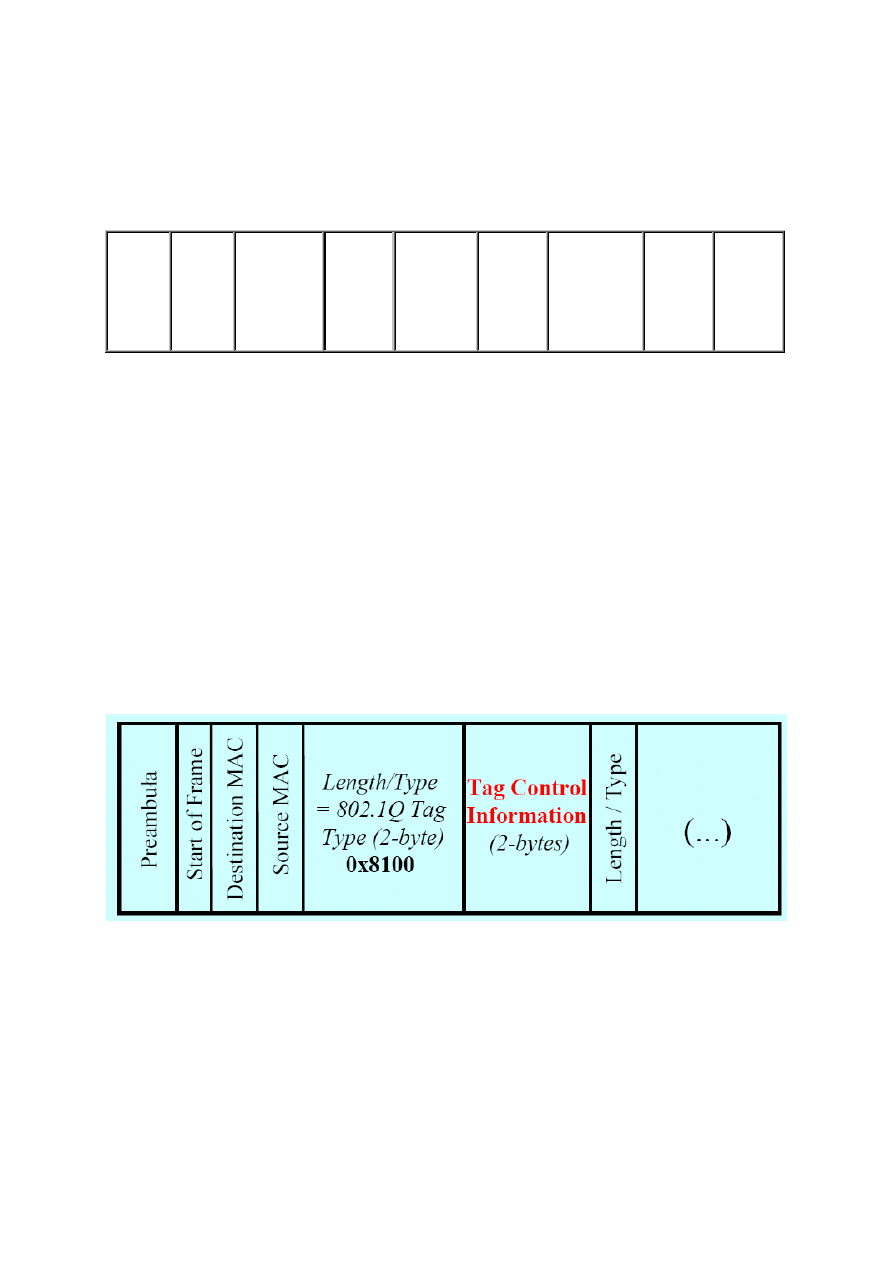
•Brak ograniczenia na czas propagacji, tylko na czas między ramkami, większa wydajność, brak
kolizji.
•Kontrola przepływu za pomocą ramek PAUSE (opcjonalna): pole MAC Control Parameters zawiera
ilość 512-bitowych okresów, którą należy odczekać przed wznowieniem transmisji (0 =
wznowienie).
Preamble
(7-bytes)
Start
Frame
Delimiter
(1-byte)
Dest. MAC
Address (6-
bytes)
= (01-80-
C2-
00-00-01)
or unique
DA
Source
MAC
Address
(6-bytes)
Length/Type
(2-bytes)
= 802.3
MAC
Control
(88-08)
MAC
Control
Opcode
(2-bytes)
= PAUSE
(00-01)
MAC Control
Parameters
(2-bytes)
= (00-00
to
FF-FF)
Reserved
(42-
bytes)
= all
zeros
Frame
Check
Sequence
(4-bytes)
55.Identyfikacja i zastosowanie sieci wirtualnych VLAN IEEE 802.1Q.
Sieć wirtualna (ang. Virtual Local Area Network, VLAN) jest siecią komputerową wydzieloną
logicznie w ramach innej, większej sieci fizycznej.
Do tworzenia VLAN-ów wykorzystuje się konfigurowalne lub zarządzalne przełączniki,
umożliwiające podział jednego fizycznego urządzenia na większą liczbę urządzeń logicznych,
poprzez separację ruchu pomiędzy określonymi grupami portów. Komunikacja między VLAN-ami
jest możliwa tylko wtedy, gdy w VLAN-ach tych partycypuje port należący do routera.
W przełącznikach konfigurowalnych zwykle spotyka się tylko najprostszą formę VLAN-ów,
wykorzystującą separację grup portów.
W przełącznikach zarządzalnych zgodnych z IEEE 802.1q możliwe jest znacznikowanie ramek
(tagowanie) poprzez doklejenie do nich informacji o VLAN-ie, do którego należą. Dzięki temu
możliwe jest transmitowanie ramek należących do wielu różnych VLAN-ów poprzez jedno fizyczne
połączenie. W przypadku urządzeń zgodnych z ISL ramki są kapsułkowane w całości.
Protokoły: IEEE 802.1q, ISL (Inter-Switch Link, rozwiązanie Cisco).
Identyfikacja:
-
IEEE 802.1Q / 802.1p (802.1ac)
-
Pierwsze 3 bity to User Priority Field – opisuje priorytet ramki Ethernet.
-
Następny bit to Canonical Format Indicator (CFI) wskazuje w ramce obecność pola Routing
Information Field (RIF) – patrz Token Ring.
-
Ostatnie 12 bitów stanowi VLAN Identifier (VID) – unikalny identyfikator sieci VLAN, do której
należy ramka.
56.Działanie autonegocjacji w sieciach Fast Ethernet.
Impulsy FLP (Fast-Link Pulses) w technologii 100Base-T są stosowane do sprawdzania
poprawności połączeń pomiędzy hubem a urządzeniem 100Base-T. Impulsy FLP są wstecznie
kompatybilne względem impulsów NLP (Normal-Link Pulses) stosowanych w technologii 10Base-T.

FLP zawierają więcej informacji niż NLP i są używane w procesie automatycznej negocjacji między
hubem a stacją w sieci 100Base-T.
Standard 100Base-T wspiera opcjonalny mechanizm zwany automatyczną negocjacją
(Autonegotiation), umożliwiający stacji sieciowej i hubowi wymianę informacji (przy użyciu
impulsów FLP) o ich możliwościach technicznych, co stwarza optymalne warunki dla komunikacji.
Automatyczna negocjacja wspiera szereg możliwości funkcjonalnych, takich jak: dobór szybkości
pracy dla urządzeń pracujących z przepływnością 10 Mb/s i 100 Mb/s, włączanie pełnego dupleksu
w urządzeniach o takich udogodnieniach i z automatyczną konfiguracją sygnalizacji dla stacji
100Base-T4 i 100Base-TX
.
Parallel Detection - jeśli tylko jedna strona łącza wspiera autonegocjację, to ustalenie typu
połączenia następuje po rozpoznaniu formatu sygnałów nadsyłanych przez drugą stronę łącza np.
NLP dla 10Base-T, Idle signal dla 100Base-TX,
- nie stosuje się w tej sytuacji wymiany FLP,
- dopuszczalne tylko połączenie half-duplex.
UWAGA: Auto-negocjacja nie rozpoznaje jakości okablowania!
Przesył sygnałów FLP wykorzystuje mniejsze pasmo przenoszenia niż transmisja ramek.
W 100Base-FX zamiast FLP stosuje się modulację czasu sygnału
idle (wcześniej auto-negocjacja
nie była obsługiwana).
57.Kodowanie danych w sieci Fast Ethernet.
10Base - kodowanie Manchester - nie nadaje się do szybkich transmisji - wymaga za dużego
pasma częstotliwości.
W celu ograniczenia wymaganego pasma 100Base stosuje kodowanie:
•
100Base-FX - 4B/5B + NRZI
•
100Base-TX - 4B/5B + (MLT-3) NRZI-3
•
100Base-T4 - 8B/6T (kombinacja 4B/5B i MLT-3)
Celem kodowania jest zmniejszenie ilości przesyłanych znaków w stosunku do przesyłanych
bitów i zapewnienie synchronizacji zegarów (wyeliminowanie ciągów powtarzających się zer
i jedynek)
Synchronizacja jest realizowana za pomocą kodowania 4B/5B
•
w podwarstwie PCS - każde 4 bity odebrane z MII są zamieniane na ciąg (słowo) 5-bitowy
wg predefiniowanej tabeli kodowej.
• Istnieją 32 kody 5-bitowe - wybrano 16 słów reprezentujące dane (min. 2 zmiany stanu)
plus 4 słowa sterujące, oznaczające początek i koniec każdej ramki oraz tzw. Idle signal
(max. ilość zmian).
• Idle signal jest wymieniany nieustannie między transmisjami.
4B5B Encoding Table
Data (Hex) Data (Binary) 4B5B Code
---------- ------------- ---------
0 0000 11110
1 0001 01001
2
0010
10100
... ....
.....
D 1101 11011
E 1110 11100
F 1111 11101
Kodowanie NRZI
- Non Return to Zero, Invert on One, podwarstwa PMA
Kodowanie MLT-3
- Multi-Level Transition 3-state , podwarstwa PMD
100Base-T4
Kodowanie jest realizowane algorytmem 8B/6T, który zamienia ciąg 8 bitów (znaków 2-stanowych)
na ciąg 6 kodów 3-stanowych. 36 = 729 możliwych kodów:
256 reprezentuje dane, 9 oznacza kody startu, stopu i sterujące.
Dopuszczalne są dowolne przejścia między poziomami sygnału (inaczej niż w MLT-3).
58.Właściwości sieci 100VG-AnyLAN / IEEE 802.12.
Technologię 100VG-AnyLAN opracowano w firmie Hewlett-Packard (HP) jako alternatywę
dla technologii Ethernet dla aplikacji czasowo-czułych, takich jak multimedia. Metoda dostępu w
100VG-AnyLAN różni się od stosowanej w Ethernecie. 100VG-AnyLAN można realizować stosując
następujące rodzaje okablowania: 4-parowy UTP kategorii 3, 2-parowy UTP kategorii 4 lub 5, STP,
kabel światłowodowy.
100VG-AnyLAN jest opisana w specyfikacji IEEE 802.12, określającej, że długość łącza
między hubem a stacją sieciową nie powinna przekraczać 100 m dla UTP kategorii 3 i 150 m dla
UTP kategorii 5.
W technologii 100VG-AnyLAN stosuje się metodę dostępu zwaną priorytetem żądania
(Demand Priority). W odróżnieniu od metody CSMA/CD, stosowanej w Ethernecie, metoda
priorytetu żądania jest metodą deterministyczną, dzięki czemu są eliminowane kolizje. W metodzie
priorytetu żądania hub steruje dostępem do sieci.
Stacja nadawcza, chcąca transmitować w sieci 100VG-AnyLAN, zgłasza swoje żądanie
transmisji do huba lub przełącznika 100VG-AnyLAN. Jeśli w sieci jest cisza (brak transmisji), to hub
natychmiast żądanie to akceptuje, a stacja nadawcza rozpoczyna transmisję do huba. Jeśli w tym
samym czasie wystąpi więcej niż jedno zgłoszenie żądania transmisji, to zgłoszenia te hub załatwia
kolejno, przestrzegając następującej reguły: żądania należące do grupy o wysokim priorytecie (np.
wideokonferencje) są obsługiwane przed żądaniami, którym przypisano normalny priorytet.
59.Proces zestawiania i rozłączania połączenia TCP.
Zestawianie połączenia TCP:
- proces serwera wykonuje tzw. passive OPEN call, pozostający w uśpieniu,
-
drugi proces podejmuje próbę połączenia wykonując active OPEN call.
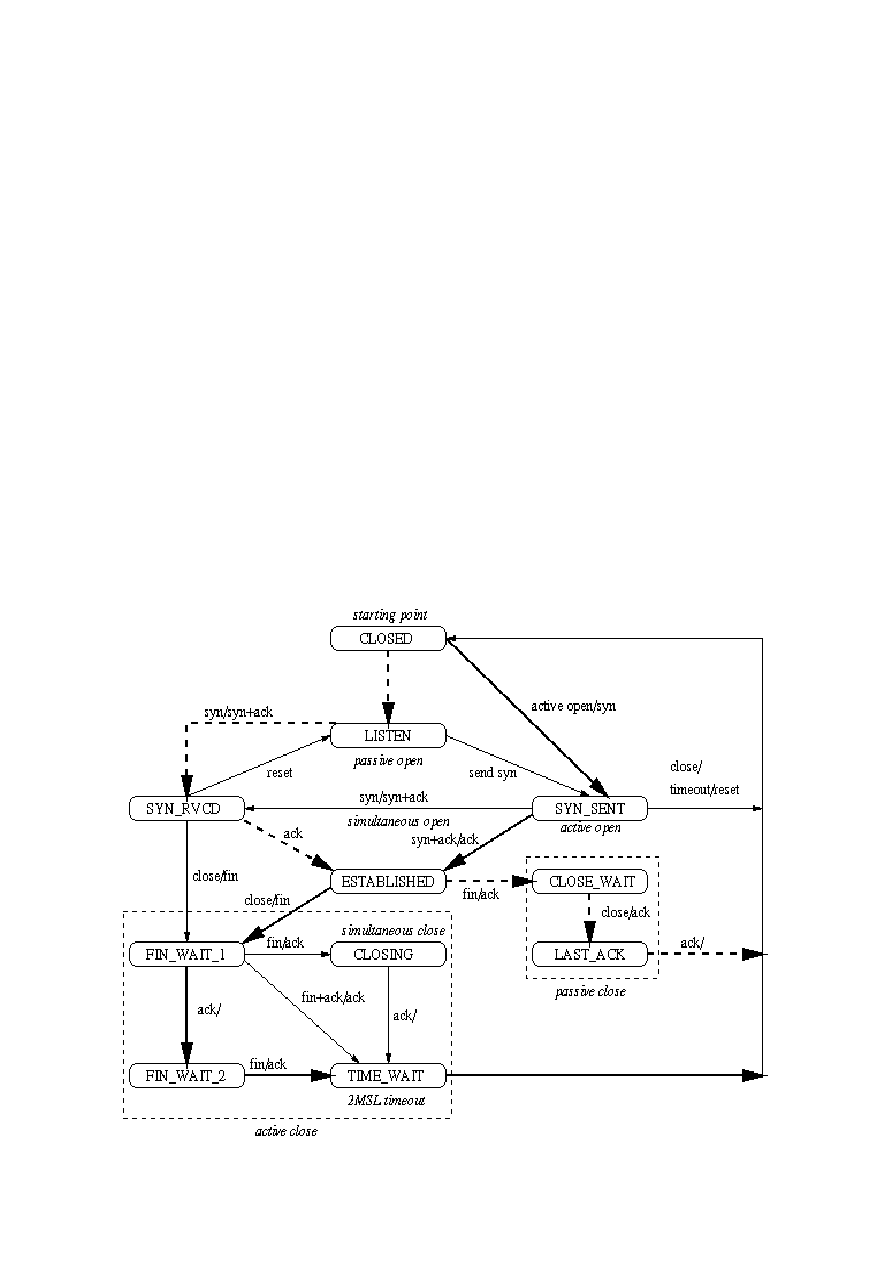
Rozłączenie połączeni
- przesłanie segmentu z bi
druga strona postę
- połączenie jest ni
0.Diagram stanów TCP.
a TCP:
tem FIN=1 zamyka transmisję w jednym kierunku,
puje podobnie (po przesłaniu wszystkich danych),
szczone po zamknięciu strumieni w obie strony.
6
Wyszukiwarka
Podobne podstrony:
operacyjne 31-60
Japanese set 31 60
biofiza cw 31
31 NIEDZIELA ZWYKŁA B
31 czwartek
31 Metody otrzymywania i pomiaru próżni systematyka, porów
(31) Leki pobudzająceid 1009 ppt
60 Rolle der Landeskunde im FSU
PN 60 B 01029
31 Księga Abdiasza (2)
31
60
Egzamin z RP2 31 stycznia 2009 p4
biznes plan (31 stron) (2)
31 36
więcej podobnych podstron