Instrukcja do przedmiotu Bazy danych – laboratorium (zajęcia 2)
1
Na poprzednich zajęciach poznaliśmy podstawy korzystania z SQL Server 2005 za pomocą SQL Server
Management Studio. W tej chwili powinniście już umieć korzystać z Eksploratora Obiektów w celu wyświetlania
dostępnych baz danych, wyświetlania i przeglądania tabel znajdujących się w bazie itp. Dzisiejsze zajęcia
rozpoczniemy od mocnego uderzenia (utworzenie nowej bazy danych), a później napięcie będzie tylko rosło
(utworzenie tabeli i wypełnienie jej danymi).
Polecenie 2.1: Uruchom SQL Server Management Studio i zaloguj się do serwera.
WAŻNE!
Przypominam, że maszyna, na której pracujecie, wykorzystywana jest przez kilka grup, a wszystkie utworzone
w niej obiekty znajdują się na lokalnym dysku twardym i działają w tej samej instancji serwera. Dla świętego
spokoju (a konkretniej, żeby uniknąć konfliktu nazw), do nazw wybranych obiektów tworzonych w SQL Server
należy dodawać przyrostek określający numer sekcji osoby, która ten obiekt utworzyła. W dalszej części tekstu
możecie natknąć się na polecenie typu "utwórz obiekt o nazwie jakasnazwa_z2XsY". Za każdym razem w
nazwie tworzonego obiektu należy podstawić pod X numer grupy, a pod Y numer sekcji. Dla naszego przykładu
dla osób z grupy Z25s1 nazwa obiektów powinna brzmieć jakasnazwa_z25s1.Przeczytaj uważnie poniższą
instrukcję i wykonaj wszystkie zawarte w niej polecenia.
Tworzenie bazy danych
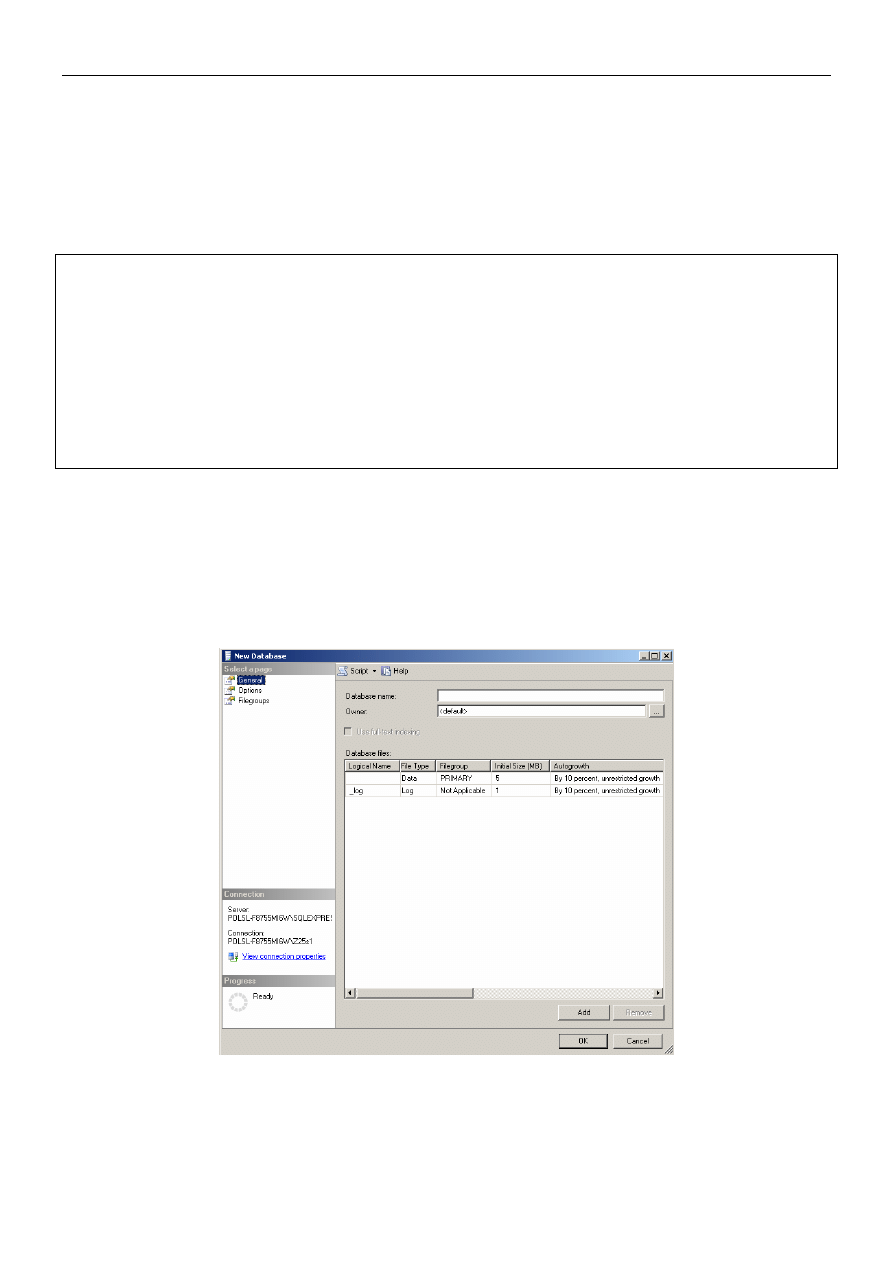
Polecenie 2.2: Kliknij prawym przyciskiem myszy na gałąź Databases w Eksploratorze Obiektów i wybierz New
Database...
Po chwili powinno pojawić się okno dialogowe, w którym możemy ustalić parametry tworzonej bazy danych.
Omówimy pokrótce kilka z nich.
Database name: nazwa bazy (możliwe jest stosowanie w nazwie polskich znaków, ale zdecydowanie zaleca się ich
unikania)
Owner: właściciel bazy (domyślnie właścicielem jest twórca bazy, ale można to zmienić)
Poniżej znajdują się charakterystyki plików, z jakich składa się baza danych. Domyślnie, każda baza składa się z
dwóch plików. W pliku bazy danych przechowywane są wszystkie zatwierdzone dane. W pliku dziennika (tzw.

Instrukcja do przedmiotu Bazy danych – laboratorium (zajęcia 2)
2
log) przechowywane są wszystkie bieżące, niezatwierdzone zmiany (pamiętacie czerwone wykrzykniki pojawiające
się przy wprowadzaniu danych? – oznaczały one, że zmiany nie zostały jeszcze wprowadzone). Takie rozwiązanie
pozwala przy pomyłce lub jakiejkolwiek awarii na wycofanie wszystkich zmian, które miały miejsce, a nie powinny
być może zostać zapisane w bazie.
Ma to związek z tzw. transakcjami (transakcja to niepodzielny ciąg operacji – jeśli jakieś operacje tworzą
transakcję, tzn. że wykonają się albo wszystkie, albo żadna z nich, innej możliwości nie ma). Jako przykład może
posłużyć transfer jakiejś kwoty z jednego konta na drugie. W takim przypadku należy wykonać (w dużym
uproszczeniu) dwie operacje: zmienić stan konta, z którego dokonuje się transfer oraz dokonać aktualizacji stanu
konta, na które wpływają pieniądze. W momencie wystąpienia awarii, po wykonaniu pierwszej operacji a przed
wykonaniem drugiej, zmiany wynikające z tej pierwszej powinny być wycofane.
Opcje związane z plikami:
Logical Name: logiczne nazwy plików, uzupełniane są automatycznie po wpisaniu nazwy bazy danych, choć można
je później zmienić
File Type: typ pliku
File Group: istotne w przypadku, gdy chcemy, aby dane przechowywane były w kilku plikach (np. w celu
zwiększenia szybkości wyszukiwania), można wtedy podzielić te pliki na grupy plików podstawowych (PRIMARY)
lub drugorzędnych (SECONDARY); w SQL Server 2005 istnieje zawsze tylko jedna podstawowa grupa plików, grup
plików drugorzędnych można zdefiniować aż 255
Initial Size: początkowy rozmiar plików
Autogrowth: sposób przyrostu wielkości plików (jeśli początkowe wielkości okażą się niewystarczające); istnieją
dwa sposoby, w jaki SQL Server może powiększać pliki bazy danych: o stałą wartość (np. zawsze o 10 MB) lub o
wartość procentową (np. o 20% aktualnego rozmiaru); możliwe jest również wyłączenie możliwości przyrostu
wielkości plików (należy odznaczyć opcję Enable Autogrowth) lub ograniczenie maksymalnego rozmiaru pliku
(zaznaczenie opcji Restricted File Growth i wpisanie maksymalnej wartości w MB)
Path: miejsce, w którym będą przechowywane pliki bazy danych
File name: rzeczywista nazwa pliku na dysku twardym (parametr opcjonalny)
Menu po lewej stronie okna dialogowego pozwala na dostęp do wielu innych, bardziej szczegółowych opcji bazy
danych oraz na tworzenie nowych grup plików. Wszystko to może być jednak zmienione już po utworzeniu samej
bazy.
Polecenie 2.3: Utwórz bazę danych o nazwie test_z2XsY. Początkowy rozmiar pliku bazy danych ustal na 3 MB.
Dodatkowo zmień sposób przyrostu wielkości pliku dziennika na stałą wartość równą 1 MB oraz ogranicz
maksymalny rozmiar wielkości plików do odpowiednio: plik bazy - 200 MB, plik dziennika - 10 MB. W
pozostałych opcjach zostaw wartości domyślne.
Jeśli nie pojawią się żadne nieprzewidziane trudności w oknie Eksploratora Obiektów powinien pojawić się efekt
twoich działań.
Gratuluję! Utworzyłeś/aś swoją pierwszą bazę danych. Przygoda właśnie się zaczyna...
Baza danych bez danych jest jak student bez… każdy może sam dopowiedzieć sobie bez czego ;) Aby wprowadzić
jakieś dane do bazy test_z2XsY należy jednak najpierw utworzyć odpowiednie tabele, w których te dane będą
przechowywane.

Instrukcja do przedmiotu Bazy danych – laboratorium (zajęcia 2)
3
Tworzenie tabel
Polecenie 2.4: W Eksploratorze Obiektów rozwiń tabele bazy danych mebelek. Kliknij prawym przyciskiem
myszy na tabelę Kierowcy i wybierz Design.
Pojawią się kolejną dwa ostrzeżenia, które informują, że nie jesteś właścicielem bazy danych oraz nie masz
uprawnień do modyfikacji tabeli Kierowcy. Kiedy już się z nimi uporasz, powinna ukazać się tabelka z
właściwościami poszczególnych kolumn tabeli Kierowcy.
Tabelka ta składa się z trzech kolumn.
•
W pierwszej znajdują się nazwy kolumn tabeli Kierowcy (kolejno: id, imie, nazwisko itd.).
•
W drugiej przedstawiono typ każdej z tych kolumn (bardziej szczegółowo jest o tym odrobinę niżej).
•
W trzeciej znajduje się informacja, czy dana kolumna może pozostać pusta podczas wstawiania nowego
rekordu (jak być może pamiętacie z poprzednich zajęć, kolumna imie nie mogła pozostać pusta - pole Allow
Nulls w jej przypadku nie jest zaznaczone).
Klucz główny
Kluczyk przy po lewej stronie wiersza z kolumną id informuje, że dana kolumna pełni rolę klucza w tabeli.
Kolumna kluczowa to taka kolumna, której wartości nie mogą się powtarzać. Jako kolumnę kluczową można
wybrać jakiś atrybut obiektów przechowywanych w tabeli. Np. w przypadku kierowców można posłużyć się
numerem dowodu osobistego albo peselem, ale nie nazwiskiem - nazwiska różnych osób po prostu mogą być
identyczne. Najczęściej stosuje się jednak dodatkową kolumnę (o nazwie id, ident, numer itp.), w której sztucznie
nadawane są numery poszczególnym rekordom w taki sposób, aby były one unikalne.
Każda tabela powinna posiadać kolumnę kluczową (jest to prawda w 99% przypadków). Tabela może mieć tylko
jeden klucz, ale klucz ten może składać się z kilku kolumn (np. możemy sobie wyobrazić, że na klucz w jakiejś
tabeli składają się imię, nazwisko, imię ojca i data urodzenia - każda z tych wartości indywidualnie może się
powtarzać, ale identyczna kombinacja wszystkich wartości jest bardzo mało prawdopodobna). Rozwiązanie takie
stosuje się najczęściej tylko w przypadku specyficznych tabel, tzw. tabel łącznikowych.
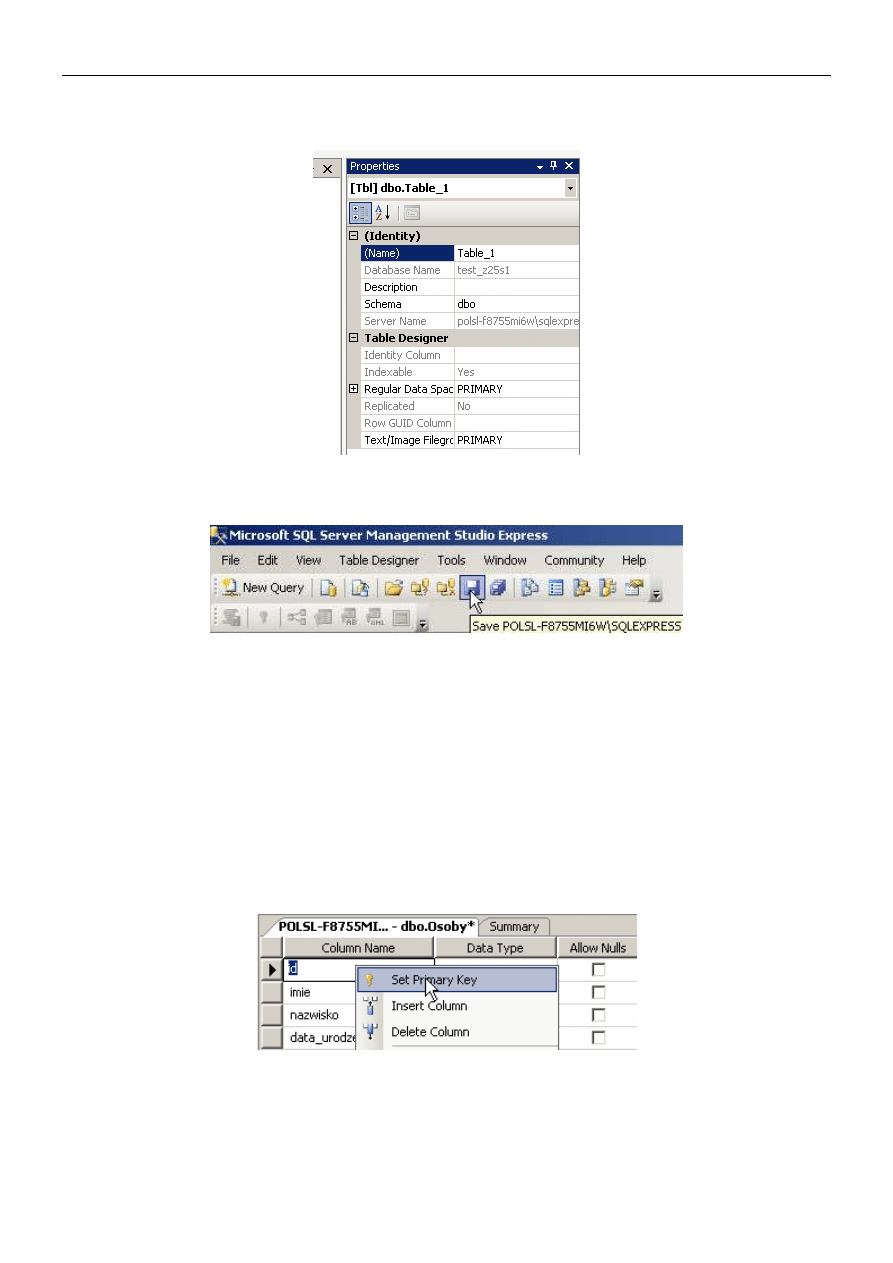
Jak pewnie pamiętacie, wartości kolumny id były uzupełniane automatycznie. Odpowiada za to właściwość
Identity.
Polecenie 2.5: Kliknij na pierwszy wiersz (z kolumną id), a następnie w oknie Column Properties znajdującym się
w dolnej części głównego okna (zob. rysunek poniżej) znajdź wartość Identity Specification i rozwiń ją.

Instrukcja do przedmiotu Bazy danych – laboratorium (zajęcia 2)
4
Pole Is Identity informuje, czy wartości w danej kolumnie będą wstawiane automatycznie. Identity Increment
ustala wielkość, o którą będzie wzrastała wartość kolumny przy wstawieniu kolejnego wiersza, natomiast Identity
Seed to początkowa wartość.
Typy kolumn
Typ kolumny określa, jakie dane mogą być w niej przechowywane. W SQL Server 2005 istnieje olbrzymia liczba
typów danych, które można nadać kolumnom, w praktyce wykorzystuje się jedynie kilka z nich. Część typów różni
się tylko zakresem wartości, które można w nich umieszczać (w przypadku liczb jest to maksymalna wielkość
wprowadzonej liczby itp.).
Polecenie 2.6: Poniżej zamieszczono pięć typów kolumn. Twoim zadaniem jest ich przyporządkowanie do opisów
zamieszczonych w tabeli poniżej (uzupełnij kolumnę "nazwa typu"). Aby wykonać to polecenie możesz przeglądać
dane lub projekt (Design) dowolnych tabel z bazy mebelek. Jeśli nie uda ci się przyporządkować wszystkich
typów, spróbuj wydedukować prawidłowe rozwiązanie. Po wykonaniu zadania pochwal się rezultatem
prowadzącemu zajęcia.
varchar(n)
int
float
datetime
char(n)
nazwa typu
opis
dane czasu i daty
liczba zmiennoprzecinkowa (np. 3,14 itp.)
dane znakowe o ustalonej długości n (wartości krótsze są uzupełniane spacjami)
liczba całkowita (np. 5 itp.)
dane znakowe o zmiennej długości, przy czym maksymalna długość może wynosić n
W tym momencie wiecie już wszystko, co potrzebne i możemy przejść do stworzenia pierwszej tabeli. Będzie to
prosta tabela o nazwie Osoby przechowująca informacje o osobach z pewnej grupy studenckiej.
Polecenie 2.7: W Eksploratorze Obiektów kliknij prawym przyciskiem myszy na folder Tables w bazie danych
test_z2XsY i wybierz New Table...
Pojawi się okno, w którym możemy definiować wszystkie kolumny i ich właściwości. W nazwach kolumn,
podobnie jak w przypadku nazwy bazy danych, dopuszczalne jest stosowanie polskich znaków (a nawet spacji),
jednak zdecydowanie się tego odradza - zamiast spacji można używać znaku podkreślenia "_".
Polecenie 2.8: Utwórz następujące kolumny oraz ustal dla nich odpowiedni typ:
id – liczba całkowita,
imie – tekst o zmiennej długości (ustal odpowiedni twoim zdaniem maksymalny rozmiar),
nazwisko – tekst o zmiennej długości (ustal odpowiedni twoim zdaniem maksymalny rozmiar),
data_urodzenia – dane daty i czasu, tylko ta kolumna może pozostawać pusta (Null)
miasto – tekst o zmiennej długości (ustal odpowiedni twoim zdaniem maksymalny rozmiar),
nr_indeksu – tekst o stałej długości równej 6
Instrukcja do przedmiotu Bazy danych – laboratorium (zajęcia 2)
5
Polecenie 2.9:
W okienku Properties po prawej stronie (jeśli nie jest ono widoczne, w menu View wybierz
Properties Window lub wciśnij klawisz F4) zmień nazwę tabeli (właściwość Name) zamiast Table_1 wpisując
Osoby.
Polecenie 2.10:
Kliknij w ikonę dyskietki znajdującą się na pasku narzędzi i zapisz utworzoną tabelę. Następnie
zamknij okno z projektem tabeli.
Pierwsza tabela w bazie test_z2XsY została właśnie utworzona. To jednak nie wszystko – przydałoby się jeszcze
sprawić, aby wartości w kolumnie id przy wstawianiu danych były ustalane automatycznie oraz ustawić tę
kolumnę jako kluczową.
Modyfikacja tabel
Polecenie 2.11: W Eksploratorze Obiektów kliknij prawym przyciskiem myszy na tabelę Osoby i wybierz Design.
Następnie zmień właściwość kolumny id tak, aby jej wartości były uzupełniane automatycznie (Identity),
zwiększały się co 1 zaczynając od jedynki.
Polecenie 2.12: Kliknij prawym przyciskiem myszy na wiersz z kolumną id i wybierz Set Primary Key. Następnie
zapisz wprowadzone zmiany i zamknij okno z projektem tabeli.
W tym momencie możesz sobie pogratulować. Tabela Osoby jest gotowa na przyjęcie danych.
Polecenie 2.13: W tabeli Osoby wprowadź dane przynajmniej siedmiu osób z twojej grupy (zaczynając od siebie).
Oczywiście nie wszystkie wartości (np. data urodzenia czy numer indeksu) muszą być prawdziwe.
Tabele w relacyjnej bazie danych można tworzyć również za pomocą języka SQL.

Instrukcja do przedmiotu Bazy danych – laboratorium (zajęcia 2)
6
Polecenie 2.14: W Eksploratorze Obiektów kliknij prawym przyciskiem myszy na tabelę Osoby i wybierz Edit.
Otworzy się okienko zapytań, w którym znajduje się kod tworzący tabelę Osoby oraz kilka dodatkowych rzeczy
ustalających wartości pewnych zmiennych globalnych (czyli ustawień bazy danych). Fragment tworzący tabelę
rozpoczyna się od słów CREATE TABLE, później podawana jest nazwa tabeli, następnie wymieniane są po
przecinku wszystkie nazwy kolumn wraz z ich typami i ewentualnymi dodatkowymi właściwościami. Na samym
końcu znajdują się deklaracje ograniczeń na kolumny (CONSTRAINT) - w tym wypadku jedynym ograniczeniem jest
klucz główny nałożony na kolumnę id (klucz główny stanowi ograniczenie w tym sensie, że wartości tej kolumny
nie mogą się powtarzać).
SQL – podstawy c.d.
Agregaty (funkcje agregujące)
Polecenie 2.15: Kliknij prawym przyciskiem myszy na bazę mebelek i wybierz New Query. Następnie wykonaj
kolejno następujące zapytania, za każdym razem analizując otrzymany rezultat:
SELECT COUNT(*) FROM Klienci
SELECT COUNT(*) FROM Towary
SELECT COUNT(*) FROM Klienci WHERE id > 3
SELECT SUM(cena) FROM Towary
SELECT SUM(cena) FROM Towary WHERE id_dost = 1
SELECT AVG(cena) FROM Towary
SELECT AVG(cena) FROM Towary WHERE id_dost = 1
SELECT MAX(data_zatr) FROM Kierowcy
SELECT MIN(data_zatr) FROM Kierowcy
Polecenie 2.16: Odpowiedz na następujące pytania:
1.
Za pomocą jakiej funkcji można wyświetlić liczbę rekordów z danej tabeli?
2.
W jaki sposób policzyć liczbę rekordów spełniających dane kryterium?
3.
Jak funkcja zwraca sumę wartości z danej kolumny?
4.
Jaka funkcja zwraca średnią z wartości z danej kolumny?
5.
Za pomocą jakich funkcji można wyświetlić minimalną lub maksymalną wartość z danej kolumny?
Polecenie 2.17: Za pomocą poleceń SQL spróbuj:
1.
Policzyć liczbę zamówień.
2.
Policzyć liczbę sztuk zakupionego towaru.
3.
Policzyć średni rocznik ciężarówek.
4.
Podać datę najwcześniejszego zamówienia.
5.
Podać datę ostatniego zamówienia.
(dla ambitnych) Uwaga! Ponieważ kolumna rocznik z tabeli Ciezarowki ma typ całkowitoliczbowy, więc
średnia wartości z tej kolumny również zostanie zamieniona na liczbę całkowitą. Aby tak się nie stało należy
dokonać konwersji na typ zmiennoprzecinkowy np. za pomocą funkcji CONVERT w następujący sposób:
CONVERT(float, rocznik)
Polecenie 2.18: Kliknij prawym przyciskiem myszy na bazę mebelek i wybierz New Query i wykonaj następujące
zapytanie:
SELECT id_dost, COUNT(*) FROM Towary GROUP BY id_dost
Polecenie 2.19: Spróbuj odpowiedzieć na następujące pytania:
1.
Jak zinterpretować wynik zwrócony przez to zapytanie (porów. z wynikiem drugiego zapytania z polecenia 15)?
2.
Co spowodowało użycie klauzuli GROUP BY? Jaki wynik dostalibyśmy bez jej użycia?

Instrukcja do przedmiotu Bazy danych – laboratorium (zajęcia 2)
7
Polecenie 2.20: Korzystając z klauzuli GROUP BY spróbuj wykonać zapytanie do tabeli Osoby w bazie
test_z2XsY zwracające nazwy miast oraz liczbę osób pochodzących z każdego z nich.
Polecenie 2.21 (dla ambitnych i pracowitych, możliwa praca w parach): W bazie danych test_z2XsY utwórz
dodatkową tabelę. Tabela ta może służyć do przechowywania dowolnych informacji (np. o filmach, książkach,
piosenkach, zwierzętach, umowach najmu itd.). Zastanów się najpierw, jakie kolumny (i jakiego typu) powinny
znaleźć się w takiej tabeli. Nałóż na odpowiednią kolumnę klucz i wprowadź przykładowe dane. Po zakończeniu,
zawołaj prowadzącego i zaprezentuj rezultat swoich wysiłków.
Pytania kontrolne:
1.
W jaki sposób utworzyć nową bazę danych za pomocą SQL Server Management Studio?
2.
Z jakich plików składa się baza danych w SQL Server 2005?
3.
Do czego służy plik dziennika?
4.
Co to jest transakcja?
5.
W jaki sposób utworzyć tabelę w bazie danych?
6.
O czym decyduje typ kolumny?
7.
Jakie dane przechowywane są w kolumnach następujących typów: varchar(n), int, float, datetime, char(n)?
8.
Co oznacza opcja Allow Nulls w projekcie tabeli?
9.
Co to jest klucz główny i w jaki sposób nałożyć go na kolumnę w tabeli?
10.
W jaki sposób sprawić, aby wartości wybranej kolumny były automatycznie uzupełniane liczbami?
11.
Jak w języku SQL nazywa się ograniczenie nałożone na kolumny?
Po tych zajęciach powinieneś/powinnaś umieć:
•
tworzyć bazy danych (wraz z ustaleniem pewnych ich parametrów),
•
tworzyć i edytować tabele (typy kolumn, klucz główny, Identity, nazwa tabeli),
•
wykonywać proste zapytania typu SELECT przy wykorzystaniu funkcji agregujących: SUM, COUNT, AVG, MAX,
MIN,
•
korzystać z klauzuli GROUP BY do grupowania danych z tabeli według wybranego kryterium.
Wyszukiwarka
Podobne podstrony:
KZ BD w09 id 256667 Nieznany
lab2 7 id 259265 Nieznany
JPPO Lab2 id 228821 Nieznany
bd dbastudio id 81961 Nieznany (2)
AKiSO lab2 id 53766 Nieznany
BD 408e id 130025 Nieznany (2)
lab2 9 id 259271 Nieznany
KZ BD w07 id 256666 Nieznany
bsi lab2 id 93526 Nieznany
KZ BD w14 2 id 256670 Nieznany
PAiRAII Instr 2007 lab2 id 3455 Nieznany
Protokol Siko Lab2 id 402771 Nieznany
lab2(1) 4 id 259343 Nieznany
lab2 8 id 259268 Nieznany
Instrukcja Lab2 id 216873 Nieznany
BHP i lab2 id 84433 Nieznany (2)
bd w1 id 81977 Nieznany (2)
więcej podobnych podstron