
Linux
Linux
Budowa i działanie systemu
Budowa i działanie systemu
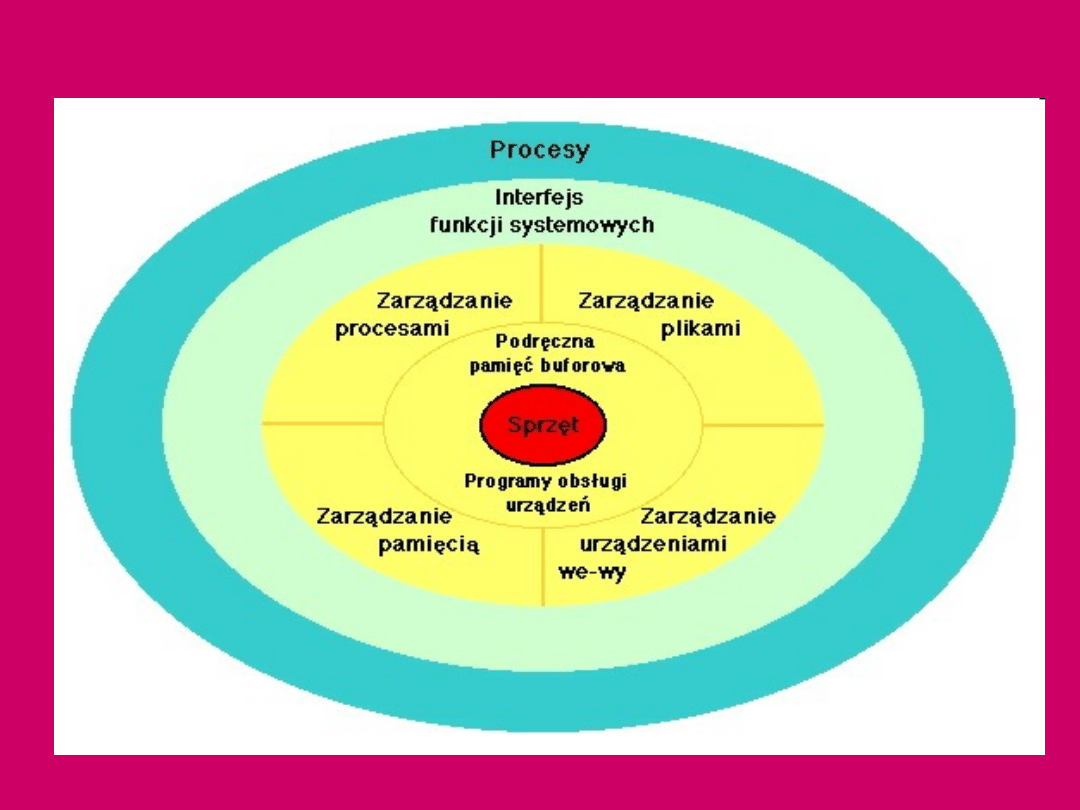
System operacyjny Unix -
System operacyjny Unix -
Model
Model
warstwowy systemu
warstwowy systemu
W modelu tym dzieli się system na 4 warstwy:
W modelu tym dzieli się system na 4 warstwy:
jądro, biblioteki, powłoka i programy
jądro, biblioteki, powłoka i programy
.
.
Jądro/Kernel
Jądro/Kernel
•
•
zawiera m.in. program szeregujący oraz
zawiera m.in. program szeregujący oraz
sterowniki urządzeń
sterowniki urządzeń
•
•
zarządza pamięcią operacyjną
zarządza pamięcią operacyjną
•
•
w nowszych systemach sterowniki rzadziej
w nowszych systemach sterowniki rzadziej
występujących urządzeń dostępne są w postaci
występujących urządzeń dostępne są w postaci
zewnętrznych modułów, które można wybiórczo
zewnętrznych modułów, które można wybiórczo
załadować do jądra - dzięki temu jego rozmiary są
załadować do jądra - dzięki temu jego rozmiary są
mniejsze
mniejsze
•
•
jądro ma bezpośredni dostęp do wszystkich
jądro ma bezpośredni dostęp do wszystkich
zasobów komputera
zasobów komputera

Biblioteki
Biblioteki
•
•
zawierają zestawy podprogramów (zwykle
zawierają zestawy podprogramów (zwykle
napisanych w języku C), wykonujących różne,
napisanych w języku C), wykonujących różne,
często stosowane, operacje (mogą to być np.
często stosowane, operacje (mogą to być np.
zestawy funkcji matematycznych, procedury,
zestawy funkcji matematycznych, procedury,
umożliwiające obsługą monitora czy też operacje
umożliwiające obsługą monitora czy też operacje
na dysku)
na dysku)
•
•
biblioteki te są zwykle dołączane do programów
biblioteki te są zwykle dołączane do programów
na etapie ich konsolidacji (program, np. w języku C,
na etapie ich konsolidacji (program, np. w języku C,
przed uruchomieniem zostaje poddany kompilacji, a
przed uruchomieniem zostaje poddany kompilacji, a
następnie konsolidacji)
następnie konsolidacji)
•
•
taka
taka
statyczna
statyczna
konsolidacja powoduje, że dana
konsolidacja powoduje, że dana
biblioteka jest dołączana do każdego z
biblioteka jest dołączana do każdego z
korzystających z niej programów - nawet wtedy,
korzystających z niej programów - nawet wtedy,
gdy uruchamiane są one jednocześnie w systemie;
gdy uruchamiane są one jednocześnie w systemie;
powoduje to znaczną zajętość pamięci operacyjnej
powoduje to znaczną zajętość pamięci operacyjnej

Powłoka
Powłoka
•
•
nazwa pochodzi stąd, że warstwa ta oddziela
nazwa pochodzi stąd, że warstwa ta oddziela
wewnętrzna część systemu operacyjnego od
wewnętrzna część systemu operacyjnego od
użytkownika
użytkownika
•
•
powłoka zawiera interpreter poleceń, który
powłoka zawiera interpreter poleceń, który
umożliwia komunikację z użytkownikiem
umożliwia komunikację z użytkownikiem
(jest to odpowiednik programu command.com z
(jest to odpowiednik programu command.com z
DOS’a)
DOS’a)
•
•
interpreter poleceń uruchamia polecenia systemu
interpreter poleceń uruchamia polecenia systemu
operacyjnego oraz programy użytkowe
operacyjnego oraz programy użytkowe

Programy
Programy
•
•
procesy uruchamiane przez użytkownika
procesy uruchamiane przez użytkownika
•
•
zarządzane przez program szeregujący jądra
zarządzane przez program szeregujący jądra
•
•
mogą być przerwane w dowolnym momencie, np.
mogą być przerwane w dowolnym momencie, np.
komendą - kill
komendą - kill
•
•
każdy ma przydzielony odpowiedni obszar
każdy ma przydzielony odpowiedni obszar
pamięci i priorytet
pamięci i priorytet
•
•
jeśli proces użytkownika próbuje dostać sie do
jeśli proces użytkownika próbuje dostać sie do
cudzego obszaru pamięci, zostaje przerwany, a
cudzego obszaru pamięci, zostaje przerwany, a
system wyświetla komunikat: segmentation fault
system wyświetla komunikat: segmentation fault
•
•
bieżąca zawartość pamięci procesu może zostać
bieżąca zawartość pamięci procesu może zostać
zapisana na dysku w pliku o nazwie core (nazwa od
zapisana na dysku w pliku o nazwie core (nazwa od
słów
słów
core dum
core dum
p, czyli zrzut pamięci)
p, czyli zrzut pamięci)
•
•
analiza zawartości tego pliku może pomóc
analiza zawartości tego pliku może pomóc
programiście w wykryciu przyczyny wystąpienia
programiście w wykryciu przyczyny wystąpienia
błędu
błędu
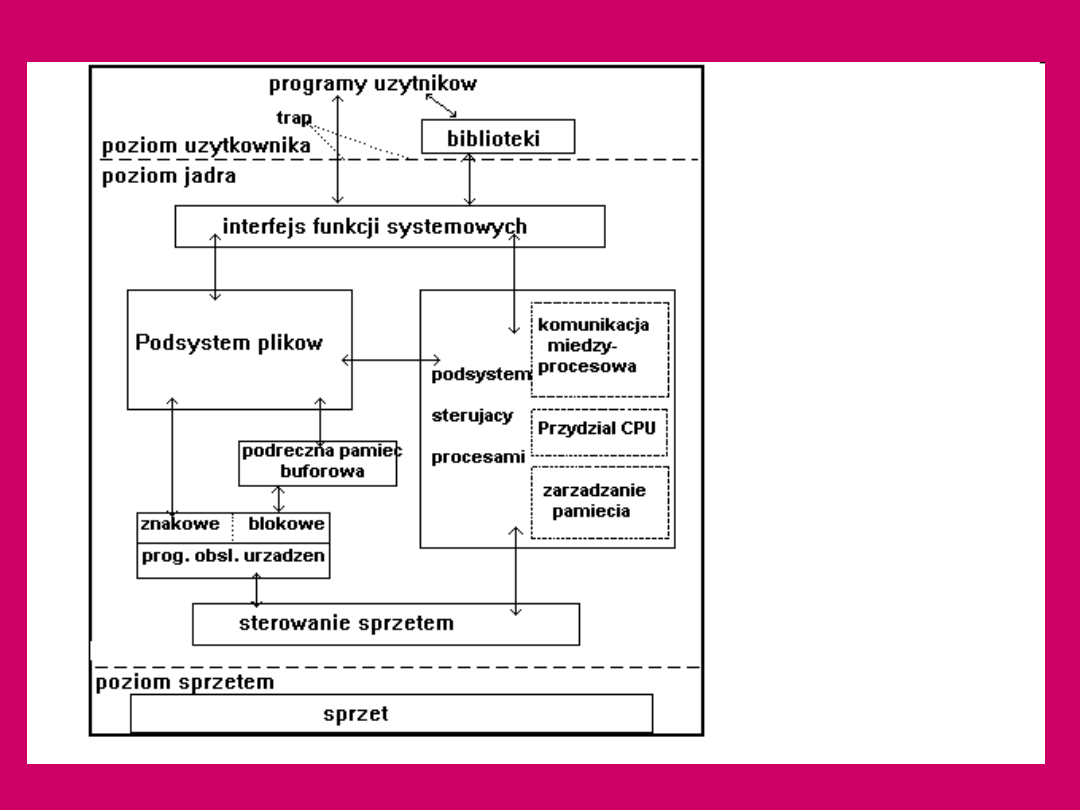
Schemat
Schemat
blokowy
blokowy

Struktura katalogów
Struktura katalogów
Rozbudowana struktura katalogów Linuxa jest
pogrupowana w logiczne części. Każdy katalog zawiera
pliki powiązane ze sobą logicznie.
Struktura katalogu głównego jest następująca:
/bin
- wykonywalne pliki binarne, niezbędne do pracy
zarówno w trybie wieloużytkownikowym, jak i w
awaryjnym trybie jednego użytkownika,
/boot
- jądro systemu oraz pliki niezbędne przy jego
uruchomieniu,
/dev
- pliki urządzeń, stanowiące interfejs do sterowników
w jądrze,
/etc
- konfiguracja systemu
/home
- katalogi domowe użytkowników

/lib
- biblioteki systemowe
/lost+found
- pliki odnalezione podczas wykonywania
testów dysku
/mnt
- katalog do którego zwykle mountowane są
tymczasowe systemy plików takie jak dyskietka czy CD-
ROM
/proc
- pseudosystem plików, odzwierciedlający stan
procesów w systemie,
/root
- katalog domowy użytkownika root,
/sbin
- wykonywalne pliki binarne, niezbędne do pracy
systemu zarówno w trybie wieloużytkownikowym, jak
również w trybie jednego użytkownika. Zawiera polecenia
administracyjne,
/tmp
- pliki tymczasowe,
/usr
- pliki użytkowników, dodatki doinstalowywane do
systemu itp.
/var
- pliki często zmieniane, np logi czy poczta

/usr/X11R6 - pliki związane z systemem XWindow,
/usr/bin - wykonywalne polecenia systemu Linux potrzebne do pracy w trybie wieloużytkownikowym,
/usr/dict - słownikowa lista wyrazów angielskich, używana m.in. przy sprawdzaniu jakości hasła
użytkownika,
/usr/doc - dodatkowa dokumentacja,
/usr/include - pliki nagłówkowe,
/usr/info - dokumentacja dla polecenia info,
/usr/lib - biblioteki systemowe,
/usr/local - struktura katalogów przeznaczona dla potrzeb elementów instalowanych przez
administratora systemu,
/usr/man - pliki pomocy kontekstowej man,
/usr/sbin - wykonywalne polecenia administracyjne systemu Linux potrzebne do pracy w trybie
wieloużytkownikowym,
/usr/share - pliki wspólne, generalnie katalog zawiera dodatkowe informacje na temat niektórych
poleceń,
/usr/src - źródła do systemu i jądra,
/usr/tmp - pliki tymczasowe.
/var/catman - preformatowane strony pomocy kontekstowej man,
/var/db - bazy danych,
/var/lock - semafory używane do komunikacji międzyprocesowej,
/var/log - logi systemowe,
/var/named - pliki serwera nazw (DNS),
/var/nis - pliki systemu NIS,
/var/run - pliki z danymi dotyczącymi numerów poszczególnych procesów w systemie,
/var/spool - kolejki poczty, wydruków itp.
/var/tmp - pliki tymczasowe.

System plików i prawa dostępu
System plików i prawa dostępu
ext2 (ang. Second Extended File System) – drugi rozszerzony system
plików dla systemu Linux. Ext2 zastąpił rozszerzony system plików
ext. Rozpoznanie uszkodzenia systemu plików (np. po załamaniu się
systemu) następuje przy starcie systemu, co pozwala na
automatyczne naprawianie szkód za pomocą oddzielnego programu
(e2fsck), uszkodzone pliki zapisywane są w katalogu lost+found.
System plików ext2 zawiera mechanizm zapobiegający znacznej
fragmentacji danych, co zdarzało się podczas używania poprzedniej
jego wersji.
Ext2 przy domyślnym rozmiarze bloku (4 KB) obsługuje partycje o
wielkości do 16384 GB i pojedyncze pliki o wielkości do 2048 GB.
Nazwy plików mogą mieć do 255 znaków długości.
Ważnym elementem systemu ext2 są wolne pola w strukturach
danych – to dzięki nim między innymi, możliwa jest konwersja „w
locie” do systemu ext3 – wykorzystuje on po prostu część z nich do
przechowywania swoich danych.

Budowa systemu plików:
blok startowy (boot block)
zawiera informacje potrzebne
Linuksowi do startu (uzyskania dostępu do systemu plików)
superblok (superblock)
zawiera informacje o strukturze systemu
plików
lista i-węzłów (inode list)
to lista adresów do tych bloków danych
na których są zapisane rzeczywiste dane pliku. Wyjaśnienie: przed
zapisaniem na dysku twardym plik jest dzielony na części określone
przez rozmiar bloku danych. Po zdefiniowaniu adresów takich bloków
w i-węzłach dane można zapisać (lub potem odczytać).
bloki danych (oraz bloki katalogów czyli data blocks)
to części
o stałym rozmiarze przestrzeni dyskowej przygotowane do
wprowadzania i odczytu danych plików (katalogów). Jeżeli plik jest
większy od jednego bloku danych, to jest dzielony i zapisany na
powierzchni kilku bloków danych - adresy do takich bloków są
notowane w i-węzłach. Natomiast, gdy wielkość pliku jest mniejsza niż
blok danych, to wolna przestrzeń bloku danych marnuje się.

chown – zmiana właściciela # chown root
/var/run/httpd.pid
ls -l
-rw-rw-r-- 1 artur artur 0 Mar 4 13:01 test
chmod <prawa> <nazwa pliku>
u-user a-all g-group o-other r-read w-write x-execute
chmod a+x test
chmod 706 test
0 to - brak praw dostępu
1 to -x wykonywanie
2 to -w- zapis
3 to -wx zapis i wykonywanie
4 to r- odczyt
5 to r-x odczyt i wykonywanie
6 to rw- odczyt i zapis
7 to rwx odczyt, zapis, wykonywanie

Dowiązania w systemie Linux
Dowiązania w systemie Linux
Dowiązania często są przyrównywane do skrótów w
systemie Windows. W rzeczywistości posiadają jednak
znacznie większe możliwości, np.: tworzenie twardych,
symbolicznych dowiązań, dowiązań do urządzeń, innych
systemów etc.
Jest jednak jedno "ale" - polecenie "ln" może być
nieobsługiwane przez niektóre systemy, na innych może
być ograniczone...
Linki twarde
posiadają te same rozmiary, te same
numery i-węzłów. Są to po prostu inne nazwy tego
samego pliku(obszaru dysku). Linki twarde są domyślnym
typem dowiązań.
Dowiązania symboliczne
pozwalają na stworzenie
dowiązań do pliku, który jest w innym systemie, na innym
urządzeniu.
Jako parametr przy wywołaniu "ln" podajemy "-s" np.:
$ ln -s /mnt/hda1/wazne wazne_c

FSCK
FSCK
fsck (skrót od
f
ile
s
ystem
c
hec
k
lub file system
consistency check) - Uniksowy program do sprawdzania
integralności systemu plików.
Zwykle fsck jest uruchamiany podczas bootowania
systemu, aby sprawdzić, czy system plików jest w dobrym
stanie. Jeżeli nie jest, na przykład w wyniku spadku
zasilania, fsck próbuje go naprawić. Na systemach plików,
które nie obsługują księgowania, jak na przykład ext2,
może to trwać nawet przez wiele godzin, w zależności od
pojemności partycji. fsck może być też uruchomiony
ręcznie przez administratora systemu, jeżeli ten uzna, że
to konieczne. Odpowiednikiem fsck dla Windows jest
Scandisk.

root (z ang., dosłownie korzeń)
to tradycyjna nazwa uniksowego
konta, które ma pełną kontrolę nad systemem. Z założenia konto root
nie powinno być używane do pracy, do której wystarczyłoby zwykłe
konto z ograniczonymi uprawnieniami. Istotną sprawą jest
zabezpieczenie tego konta silnym hasłem i zabezpieczenie przed
nieautoryzowanym dostępem.
Dobrze jest ograniczyć możliwość logowania na konto root i używać
poleceń su albo sudo.
logowanie przez ssh blokujemy w Linuksie z mieniając w zbiorze
/etc/ssh/sshd_config
parametr PermitRootLogin z "yes" na "no".
Konto root uprawnia do wykonywania takich operacji jak zmiana
właściciela pliku czy otwarcie portu TCP/UDP z numerem poniżej
1024. W innych systemach operacyjnych używa się też nazw takich
jak toor, superuser, supervisor, Administrator, czy operator. Nazwa
root funkcjonuje, jako określenie administratora systemu, zarówno w
systemach UNIX, jak i pokrewnych (FreeBSD, GNU/Linux).
Użytkownicy systemu
Użytkownicy systemu

UID (ang. User IDentifier)
- jest to identyfikator użytkownika w systemie Unix.
Reguły
• root ma UID 0,
• użytkownik nobody ma ostatni UID (zazwyczaj
32767),
• UID-y od 1 do 100 są zarezerwowane dla
systemu.

Atrybuty użytkownika
System przechowuje w pliku
/etc/passwd
następujące
atrybuty każdego zarejestrowanego użytkownika:
nazwa
- nazwa jednoznacznie identyfikująca konto użytkownika,
identyfikator użytkownika UID
- numer jednoznacznie identyfikujący użytkownika w systemie,
identyfikator grupy GID
- numer grupy, do której należy
użytkownik,
katalog domowy
- prywatny katalog użytkownika, w którym może
bezpiecznie przechowywać swoje pliki, zabezpieczone przed
dostępem innych użytkowników,
powłoka logowania
- nazwa interpretera poleceń, który jest
uruchamianypo zalogowaniu użytkownika.

Powłoki - shell
Powłoki - shell
Wyświetlenie listy powłok:
# cat /etc/shells
/bin/bash
/bin/csh
/bin/sh
/bin/tcsh
uruchamiamy np.:
csh
wychodzimy:
exit

Drobne obliczenia
Drobne obliczenia
z linii komend
z linii komend
echo $[2*3-10]
-4
a=12; b=3
c=a+b
echo $c
a+b
let c=a+b
echo $c
15
Definiowanie
Definiowanie
własnych zmiennych
własnych zmiennych
dmc=/home/user1/doc
cd $dmc

Aliasy i skrypty
Aliasy i skrypty
Wyświetlenie dostępnych aliasów:
# alias
alias cd..=‘cd ..’
alias l=‘ls -al’
...
Definiowanie aliasów:
# alias md=‘mkdir’
# alias l=‘ls -l’
# alias um=‘umount –f /mnt/floppy’
# unalias l
Dodawanie aliasów do pliku bashrc.

TREŚĆ SKRYPTU
#!/bin/sh
TEKST="Hello world!"
LICZBA=12
SUMA=$[$LICZBA+111]
echo Tekst: $TEKST
echo Liczba: $LICZBA
echo Suma: $SUMA
WYNIK SKRYPTU
Tekst: Hello world!
Liczba: 12
Suma: 123
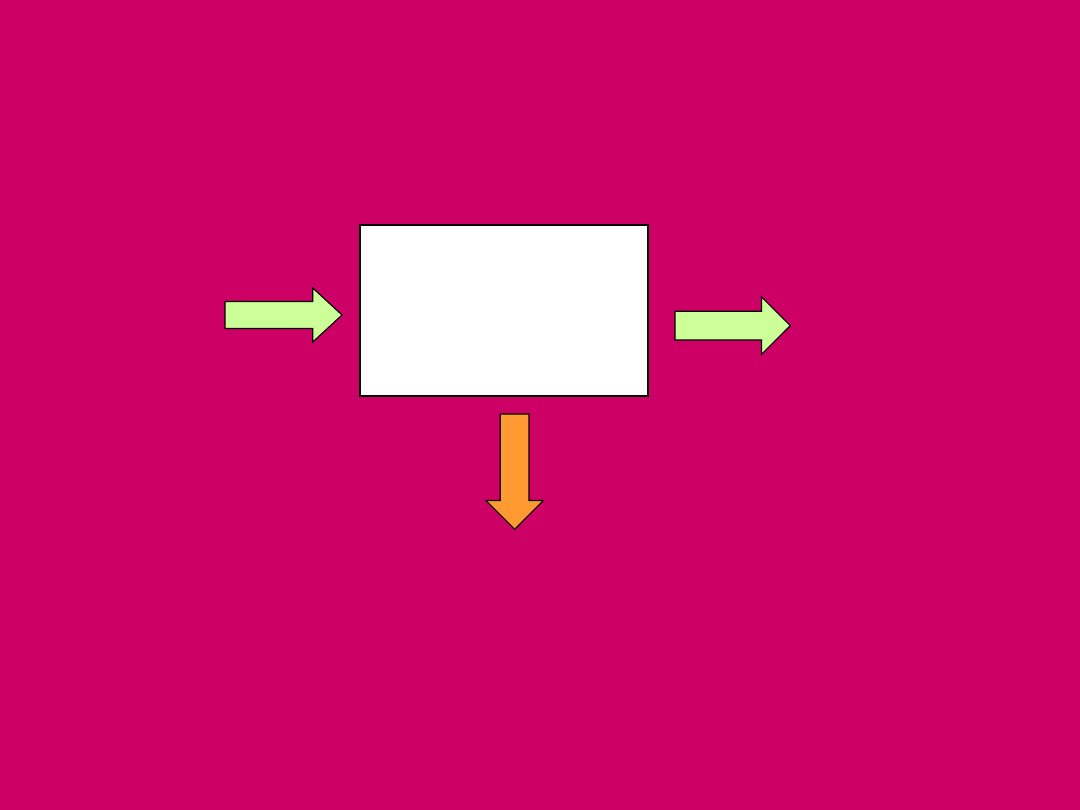
Proces i jego strumienie
Proces i jego strumienie
PROCES
WE
dane
WY
dane
Błędy
deskryptor 0 – stdin – wejście standardowe
deskryptor 1 – stdout – wyjście standardowe
deskryptor 2 – stderr – wyjście standardowe
błędów

Operatory przekierowania
> plik
- wyjście std. jest kierowane do pliku a nie na ekran
>> plik
- identyczne jak > ale dopisuje do pliku
< plik
- jako wejście standartowe (zamiast klawiatury)
zostanie otwarty plik
2 > plik
– przekierowanie stderr do pliku
1 > &2
– przekierowuje 1 w to samo miejsce co 2
Przykłady
ls -al >> lista.txt
cat > plik
ls -l /nie_istniejacy_katalog 2> /tmp/cos

Filtrowanie - grep
Filtrowanie - grep
ls -l | grep student
spowoduje wyświetlenie zawartości tylko tych pozycji katalogu, gdzie
znajduje się słowo "student" (czyli np. będących własnością studenta,
posiadających słowo "student" w nazwie itp).
cat zrodlo.c | grep include
Powyższe polecenie wyświetli wszystkie linie pliku zrodlo.c, zawierające ciąg
"include"
Podstawowe elementy wyrażeń regularnych:
. -dowolny pojedynczy znak;
$ -dopasuj poprzedzające wyrażenie do końca wiersza;
^ -dopasuj występujące po operatorze wyrażenie do początku wiersza;
* -dopasuj zero lub więcej wyrażeń znaku poprzedzający operator;
\ -oznacza ominięcie specjalnego znaczenia znaku np:"\*";
[ ] -dopasuj dowolny znak w nawiasie;
[-] -dopasuj dowolny znak z przedziału [0-9];
[^] -dopasuj znak, który nie znajduje sie w nawiasie;
Przykłady:
grep 'Ala' plik -znajduje wyraz 'Ala' w pliku;
grep 'A[lg]a' plik -znajduje wyraz 'Ala' lub 'Aga';
grep 'A.a' plik -znajduje wyrazy takie jak 'Ala' 'Aga'
itp;
grep '^Ala' plik - znajduje wyraz 'Ala' na początku
wersu;
grep 'Go*gle' plik - znajduje wyraz 'Gogle', 'Google'
itd;
grep '[0-9]' - znajduje dowolny ciąg znaków z zakresu
od 0 do 9;
Rodzaje wieloznaczników
W większości przypadków używane są dwa
wieloznaczniki:
wieloznacznik lokalny – zastępujący pojedyncze
wystąpienie dowolnego znaku (do jego oznaczania
najczęściej stosowany jest znak zapytania (?)),
wieloznacznik ogólny – zastępujący dowolną liczbę
dowolnych znaków (do jego oznaczania najczęściej
stosowany jest znak gwiazdki (*)).

Komendy shela
Komendy shela

użytkownicy /etc/passwd
zakodowane hasła /etc/shadow
dyski / partycje /etc/fstab
zamontowane sys. plików /etc/mtab
allow (dozwolone) /etc/hosts.allow
komputery niedopuszczone /etc/hosts.deny
powłoki /etc/shells
Pliki konfiguracyjne /etc
Pliki konfiguracyjne /etc

Demony
Demony
Daemon – proces w systemach UNIX
działający w tle bez konieczności
interakcji z użytkownikiem.
Zwykle nazwa takiego procesu odpowiada pełnionej
funkcji z dołączoną na końcu literą d, np.
automountd,
ftpd, httpd, inetd, lockd, powerd, rlogind, sshd, statd,
syslogd, talkd, telnetd, vold, xntpd,
W systemach MS-DOS/PC-DOS podobną funkcjonalność
oferują programy rezydentne (TSR – Terminate and Stay
Resident), natomiast w Microsoft Windows analogiem jest
usługa (service).

Instalacja pakietów
Instalacja pakietów
RPM (RPM Package Manager, dawniej Red Hat
Package Manager)
to program służący do instalacji i
zarządzania pakietami zawierającymi oprogramowanie,
oraz nazwa tych pakietów (ponieważ mają one
rozszerzenie .rpm). Pakiety RPM zawierają
skompresowane (we wczesnych wersjach gzipem, w
nowszych bzipem2) archiwum cpio zawierające
oprogramowanie. Zawierają także (w specjalnym pliku
.spec) informacje na temat zawartości, m.in. tzw.
zależności (ang. dependencies)
- czyli spis programów lub
pakietów, które są wymagane do zainstalowania i
poprawnej pracy pakietu (działa to także w druga stronę -
pakiety później zainstalowane wymagające danego
pakietu, uniemożliwiają jego odinstalowanie).
Program ten powstał na potrzeby dystrybucji Red Hat
Linux, aktualnie jest używany również w innych
dystrybucjach (np. Fedora Core, SUSE, Mandrake, PLD).

Nazwy pakietów
RPM wprowadził ujednolicone nazwy plików. Przykładowy pakiet z
GNU Gadu posiada nazwę
gg2-2.2.7-1.athlon.rpm
. Nazwa ta składa
się z czterech członów w formacie plik-wersja-
wersja_pakietu.architektura.rpm:
gg2
- nazwa programu,
2.2.7
- wersja programu,
1
- wersja pakietu (może istnieć kilka wersji pakietu dla jednej wersji
programu),
athlon
- architektura (typ procesora) dla której pakiet jest
przeznaczony (np. i386, Athlon, Alpha, PPC).
rpm -q nazwa - czy taki pakiet jest zainstalowany?
rpm -i --test nazwa.rpm - testuj
rpm -ivh nazwa.rpm - instaluj
i – instaluje v – komunikat h – zaawansowanie
rpm -Uvh nazwa.rpm - aktualizacja
rpm -e --test nazwa - deinstaluj

DEB:
dpkg -i nazwa_pakietu.deb - instalacja
apt-get remove nazwa_pakietu.deb - usunięcie
dpkg --info nazwa_pakietu.deb - wyświetla informacje o pakiecie
dpkg --reconfigure nazwa_pakietu.deb - ponowna konfiguracja
pakietu
dpkg --list nazwa_pakietu.deb - wyświatlenie listy pakietów o
podanym wzorcu nazwy
dpkg --unpack nazwa_pakietu - rozpakowanie pakietu
TGZ:
installpkg nazwa_pakietu.tgz - instalacja
removepkg nazwa_pakietu.tgz - usunięcie
DEB - Pakiety występujące w Debianie
TGZ - archiwa tara; pakiety obecne w Slackware

Instalacja programów ze źródeł
Rozpakowanie
tar -zxvf gettheport.tar.gz
gunzip plik.tar.gz
bunzip2 plik.tar.bz2
configure
sprawdza, czy w systemie zainstalowane są
wymagane biblioteki lub programy, co ustrzeże Cię przed
błędami kompilacji.
makefile
przeprowadza cały proces
kompilacji programu. Dzieli się przeważnie na trzy części:
make - sekcja kompilująca źródła
install - sekcja instalująca skompilowane pliki
uninstall - sekcja odinstalowująca pliki zainstalowane
1. Configure
2. Make
3. Make install

Linux to Kernel
(jądro systemu) plus ZBIÓR oprogramowania.
Nie ma jednego systemu Linux, a tylko Kernel jest
ustandaryzowany. W przeciwieństwie do znanego powszechnie
Windows , Linux działa bez okienek. Wynika to zreszta z historii
systemu, który pierwotnie był dostępny tylko w wersji tekstowej i
wymagał znajomości komend unixowych. Okienka (np. KDE,
Gnome) są są więc dodatkowym oprogramowaniem, tzw.
"nakładką" na powłokę tekstową (shella).
Kolejność czynności podczas
Kolejność czynności podczas
startu systemu:
startu systemu:
1. Pierwszy uruchamiany jest program LILO (ew. GRUB)
Dane tam zawarte pozwalają procesorowi na
ustawienie ekranu, uruchomienie właściwego
Kernela itp.

2. Zostaje odpalony pierwszy proces Kernela, czyli init.
Zawsze ma on identyfikator procesu PID o wartości 1.
Większość dystrybucji Linuksa używa init w oparciu o
parametry zapisane w pliku
/etc/inittab
. Proces init
odpala proces getty
3. Proces init montuje systemy plików (np. dysk twardy)
zgodnie z danymi w pliku /etc/fstab, a to co
zamontował odnotowuje w pliku
/etc/mtab
4. Następnie są czytane skrypty startowe w katalogach
/etc/rc.d/rc?.d/
(będą wówczas włączone demony w
ramach osobnych procesów) oraz plik
/etc/rc.d/sysinit
.
5. W zależności od widzimisie admina niektóre programy
mogą być uruchomione za pomocą skryptów w
katalogu
/etc/xinetd/
. Mamy wówczas do czynienia z
pracą programu nie w osobnym procesie (te zostały
włączone podczas startu systemu za pośrednictwem
w/w skryptów /etc/rc.d/rc?.d/*), a pod kontrolą
nadserwera inetd (lub xinetd)

6. Uruchamiany jest skrypt
/etc/rc.d/rc.local
. W nim
możemy (na końcu!) umieszczać odwołania do
własnych, autorskich skryptów (np. uruchomienie
połączenia SDI - patrz ostatnie wiersze pliku).
7. Gdy system zakończy ładowanie np. w 3 levelu (w
powłoce tekstowej), to automatycznie zostanie
włączony program login umożliwiający zalogowanie do
systemu. Po zalogowaniu zostaną uruchomione skrypty
konfigurujące shella.
8. Jeżeli system odpalił w 3 levelu (w powłoce tekstowej),
a użytkownik zechce pracować w okienkach np. KDE,
to wielki finał wykona
skrypt /usr/bin/X11/startx
(uruchamiany poprzez wpisanie zlecenia startx i
wciśnięcie klawisza ENTER).
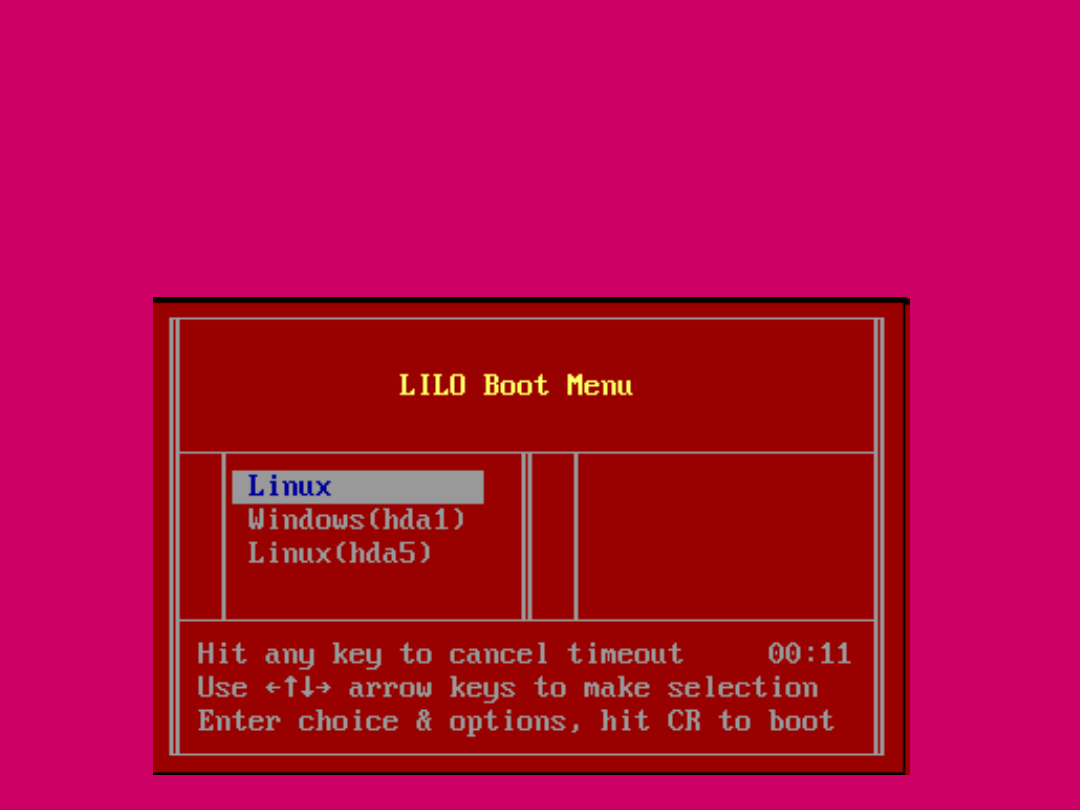
1) LILO
LILO to program (bootloader) uruchamiający system
Linux. Innym, choć na razie mniej popularnym
bootloaderem jest GRUB. LILO jest umieszczane
standardowo na dyskietce 1,44 lub w MBR dysku
twardego, zaś konfig LILO czyli plik lilo.conf na dysku
twardym, w katalogu /etc.

2) INIT
Gdy program LILO ustawi parametry startowe, nastąpi
uaktywnienie pierwszego procesu Kernela pod nazwą init,
którego opcje są zapisane w pliku
/etc/inittab
. Oto
przykład tego pliku
#(Tu decydujemy, czy załadują się okienka 5 lub czy
system zatrzyma ładowanie na powłoce tekstowej 3.
Więcej informacji umieściłem poniżej. W naszym
przykładzie system wystartuje w okienkach (5)
id:5:initdefault:
#(wskazanie miejsca położenia pliku rc.sysinit - jest to
skrypt konfigurujący niektóre parametry startowe
systemu)
si::sysinit:/etc/rc.d/rc.sysinit

Głównym zadaniem pliku /etc/inittab jest wskazanie poziomu
startowego runlevel w wierszu id:5:initdefault: . Oczywiście możemy
narzucić inny niż 5 poziom. Oto ich lista:
0 - halt, czyli zatrzymaj system (nie ustawiaj tego jako domyślny
poziom ;)
1 - system jednoużytkownikowy (będzie działać tylko pod jednym
userem), bez funkcji sieciowych
2 - wieloużytkownikowy system (tak jak poziom 3), ale z wyłączoną
funkcją sieciową
3 - wieloużytkownikowy system z funkcjami sieciowymi
4 - unused (nieużywane )
5 - tak jak poziom 3, ale w okienkach (serwer X11)
6 - reboot czyli restart systemu (nie ustawiaj tego jako domyślny
poziom ;)
Poziom 0 i 6 jest używany przez system do zwykłego restartu lub
zatrzymania, więc nie powinno się go wpisywać do pliku /etc/inittab w
wierszu id:?:initdefault: . Zobaczysz ten runlevel, gdy wydasz zwykłe
zlecenie halt, reboot lub np. init 6, telinit 6.

3) Skrypty startowe /etc/rc.d/rc?.d/*
w pracowni:
komputery startują w poziomie 3, czyli powłoka tekstowa
a okienka uruchamiamy zleceniem startx.
Należy wiedzieć, że w zależności od tego czy system załaduje się w powłoce
tekstowej, czy w okienkach (np. KDE) - są wykorzystywane inne pliki
autostartu. Jeżeli wybraliśmy domyślny poziom działania nr 3, to
automatycznie zmusiliśmy system, by w czasie startu odczytał zawartość
katalogu
/etc/rc.d/rc3.d/
(który działa podobnie jak autostart w
windowsowm menu
START- PROGRAMY- AUTOSTART
). W przypadku startu
systemu w okienkach (czyli poziomie 5), system odczyta zawartość
katalogu
/etc/rc.d/rc5.d/
. Znajdują się w nim linki do plików startowych
demonów. Mają one w nazwie literkę S (czyli plik startowy) lub K (kill - koniec,
zabity), nr oznaczający kolejność uruchomienia i nazwę demona. Skróty te
można śmiało ręcznie kasować (zamiast usuwania można zmienić nazwę,
dopisując na początku dolną kreskę "_") lub dodawać w zależności od
potrzeb. Skąd się tam biorą? Ano, podczas instalacji programu np sshd, w
katalogu /etc/rc.d/init.d/ zostanie utworzony plik sshd umożliwiający
uruchomienie danego demona. To właśnie do niego jest dowiązany skrót w
/etc/rc.d/rc3.d/.

4) Superserwer inetd (xinetd)
Superserwer inetd (xinetd) to narzędzie bardzo przydatne w systemie Linux.
Jego zaletą jest umiejętność nasłuchiwania na wybranych portach i
uruchamiania danej usługi w razie potrzeby. Weźmy przykład: sshd. Można go
odpalić jako osobny proces standalone - wówczas sshd będzie pracował jako
demon i zostanie aktywny CAŁY CZAS, nawet gdy nie będzie prób nawiązania
połączenia. Z punktu widzenia oszczędności zasobami komputera, to
rozrzutne choć umożliwiające natychmiastową reakcję rozwiązanie. Można
też uruchomić sshd pod inetd (xinetd) i wówczas nasz superserwer będzie się
czaił na porcie 22, a gdy usłyszy nawoływanie do połączenia - samoczynnie
uruchomi nieaktywnego dotychczas demona sshd. Niestety, wydłuża się
wówczas czas oczekiwania na uruchomienie i reakcję. Serwer inetd (xinetd)
ustala nr portu pobierając dane z pliku /etc/services. Plik ten zawiera listę
wszystkich usług sieciowych wraz z odpowiadającymi im portami.
Podczas instalowania demonów (np. proftpd, sshd itd.) tworzone są w
katalogu /etc/xinetd.d pliki konfiguracyjne o tytułach zawierających nazwę
demona. Po wyedytowaniu dowolnego pliku, znajdziesz parametr disable
(wyłączone). Decyduje on, czy demon będzie podporządkowany xinetd (opcja
no) lub czy włączy się jako jako samodzielny proces (opcja yes). Demona np.
sshd pracującego pod xinetd uruchomimy (po dokonaniu zmian w katalogu
/etc/xinetd.d) resetując superserwer zleceniem:
kilall -HUP xinetd
lub
/etc/rc.d/xinetd restart

5) Skrypt /etc/rc.d/rc.local
Mamy włączony system. Działają demony,
interfejsy. Został ostatni główny skrypt startowy
rc.local, w którym informatycy opiekujący się
daną dystrybucją Linuksa umieszczają ostatnie
szlifujące konfigurację zlecenia.

6) Skrypty konfigurujące shella
Proces uruchamiania shella dla danego usera jest skomplikowany.
Wspomniałem o tym na początku strony. Nas interesuje co się dzieje od
chwili, gdy program getty zaczyna proces przygotowania konsoli do użycia
uruchamiając odpowiednie programy. Program login pozwolił wpisać nazwę
usera i sprawdził hasło.
Z pliku /etc/passwd oraz passwd- jest pobierany rodzaj shella przypisany
danemu userowi (plik /etc/shells zawiera listę wszystkich, dostępnych,
systemowych shelli). Po ustaleniu rodzaju shella (w naszym przypadku bash)
jest czytany plik /etc/profile
Następnie ustalana jest zmienna PATH zgodnie z zawartością pliku ~/
.bash_profile
lub jeżeli go nie ma, to ~/bash_login
lub jeżeli ich nie ma to ~/.profile
Pozostaje jeszcze plik ~/ bashrc , który współpracuje z plikiem /etc/bashrc

7) Skrypt /usr/bin/X11/startx
Przyjmuję, że jesteśmy zalogowani w 3 levelu, czyli
działamy w powłoce tekstowej. Jeżeli mamy prawa
do odpowiednich plików, to możemy zleceniem startx
uruchomić okienka.

Źródła
Ćwiczenia z systemu Linux, Leszek Madeja, Mikom 1999
http://www.eioba.pl/c150/linux
http://zsk.tech.us.edu.pl/ogloszenia/romanek/5_7.html
http://pl.wikipedia.org/
http://rainbow.mimuw.edu.pl/SO/Linux/
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
Wyszukiwarka
Podobne podstrony:
Budowa i dzialanie komputera
budowa i dzialanie FDD id 94136 Nieznany (2)
BUDOWA I DZIAŁANIE DYSKÓW TWARDYCH, INFORMATYKA 001
Budowa i działanie sieci komputerowych
Budowa i działanie świecy zapłonowej
Dysk twardy budowa dzialanie
Ściągi z fizyki-2003 r, Budowa i działanie lasera
Budowa i dzialanie komputera, Studia, Informatyka, Informatyka, Informatyka
budowa i działanie procesora
budowa i dzialanie lasera LTF6Z4ASSKJPZYA2QILEEQQK2Y6PZM47V34DRPI
Budowa i dzialanie mechanizmow osprzetu roboczego
budowa i działanie układów rozrządu silników spalinowych
akumulator budowa i działanie
budowa i dzialanie mikroskopu metalograficznego, Nazwisko i imi˙
Budowa i działanie ekstrudera
5i6 Podział sadzarek, Budowa, działanie i obsługa
Budowa i dzialanie narzadu sluchu
Budowa i działanie wybranych elementów automatyki pneumatycznej
więcej podobnych podstron