
1
Technologie Internetu
wykład 2: XML, HTML, XHTML
Piotr Habela
Polsko-Japońska Wyższa Szkoła
Technik Komputerowych

2
Plan wykładu
• Języki znaczników
• Założenia języka XML
• Składniki dokumentu XML
• Język XHTML – motywacja i składnia

3
Języki znaczników - ogólnie

4
HTML – najpowszechniej znany język
znaczników
• Ilustruje koncepcję znaczników w elektronicznych
dokumentach tekstowych.
• Wbudowane wsparcie przez przeglądarki.
Wymaga standaryzacji znaczników HTML
=> zamknięte słownictwo => brak
rozszerzalności.
• Znaczniki określają zarówno strukturę jak i format
wyświetlania.
– Przemieszanie tych zagadnień stanowi słabość HTML,
częściowo kompensowaną przez definicje stylów (CSS).
• HTML posiada dość swobodne reguły składniowe:
– Nie wymaga cudzysłowów wokół wartości atrybutów;
– Dopuszcza pomijanie znaczników zamykających;
– Swoboda w zastosowaniu małych i wielkich liter;
=>
Łatwiejsze pisanie dokumentu
,
trudniejsze
przetwarzanie
.

5
Znaczniki – terminologia
<
p
lang=”pl”
>
Treść akapitu
</p
>
element
znacznik
otwierający
znacznik
zamykający
atrybut
zawartość elementu
<br />

6
Języki znaczników – motywacja i rozwój
• Pojęcie znacznika (jeszcze w tekstach
nieelektronicznych)
– Głównie celem wyróżnienia w tekście informacji o
zadanej docelowej formie wydruku danego
fragmentu
(np. naniesione ręcznie w maszynopisie znaki
nakazujące zastosowanie dla danego fragmentu pochylonej
czcionki).
• Bezpośrednia motywacja:
– umożliwienie formatowania treści w postaci
przetwarzalnej maszynowo;
– wsparcie w tworzeniu dużej skali publikacji
elektronicznych.
• Pierwsze przedsięwzięcia: powstałe w latach
60-tych języki GML (IBM) oraz GenCode
(GCA).
• Legły one u podstaw standardu ISO
8879:1986:
Standard Generalized Markup Language
(SGML):
– Standard grupy: Information processing -- Text
and office systems .
– Zatwierdzony standard międzynarodowy; 155
stron.

Identyfikacja znaczników ręcznych
7

Identyfikacja znaczników elektronicznych
8

9
Język znaczników – charakterystyka
• Język znaczników (markup language) –
zbiór
konwencji znaczników stosowanych do
opisywania (kodowania) tekstu
. Określa:
– znaczniki dozwolone i wymagane;
– zapewnia niezawodny sposób ich wyróżniania ze
zwykłego tekstu;
– [definiuje znaczenie poszczególnych znaczników].
• Charakter opisowy a nie proceduralny:
– w tekście umieszczone są znaczniki określające
interpretację poszczególnych elementów,
– ew. elementy proceduralne, opisujące wymagane
czynności np. sformatowania tekstu, istnieją
odrębnie – w postaci osobnych zasobów.
• Znaczniki: zamknięty zestaw (np. HTML) lub
możliwość definiowania własnych (np. SGML,
XML).
– SGML = standard opisu tekstu za pomocą
znaczników.

10
XML – Extensible Markup Language

11
Czym jest XML?
• Zbiór reguł składniowych umożliwiających
stworzenie języków specjalnego
zastosowania dla dowolnych dziedzin.
– Ma umożliwiać wymianę danych / dokumentów
pomiędzy heterogenicznymi systemami
komputerowymi; zwłaszcza w środowisku
Internetu.
• W szerszym znaczeniu termin XML może
oznaczać również:
– technologie związane z przetwarzaniem
dokumentów w składni XML,
– oparte na XML specjalizowane języki.

12
Platforma tworzenia specjalizowanych
języków
• Składnia kojarząca się z HTML-em (lecz
bardziej zdyscyplinowana).
• W przeciwieństwie do niego (i podobnie jak
SGML) nie określa „słownictwa”:
– Tj. predefiniowanych nazw elementów z ich
dozwoloną zawartością i atrybutami.
– Jest otwarty na definiowanie tego rodzaju reguł.
– Z tego względu bywa nazywany metajęzykiem.
• W istocie stanowi uproszczoną odmianę
języka SGML.
• Zatem:
HTML – język „dziedzinowy”
oparty na SGML (aplikacja SGML);
XSLT, XMI, SVG i wiele innych – języki dziedzinowe
oparte na XML (aplikacje XML);

13
XML – przykładowy dokument
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE SYSTEM pracownicy.dtd >
<!-- można umieszczać komentarze -->
<pracownicy>
<pracownik id="p1">
<nazwisko>Kowalski</nazwisko>
<placa>3000</placa>
</pracownik>
<pracownik id="p2" kierownik="p1">
<nazwisko>Nowak</nazwisko>
<placa>2000</placa>
</pracownik>
</pracownicy>
14
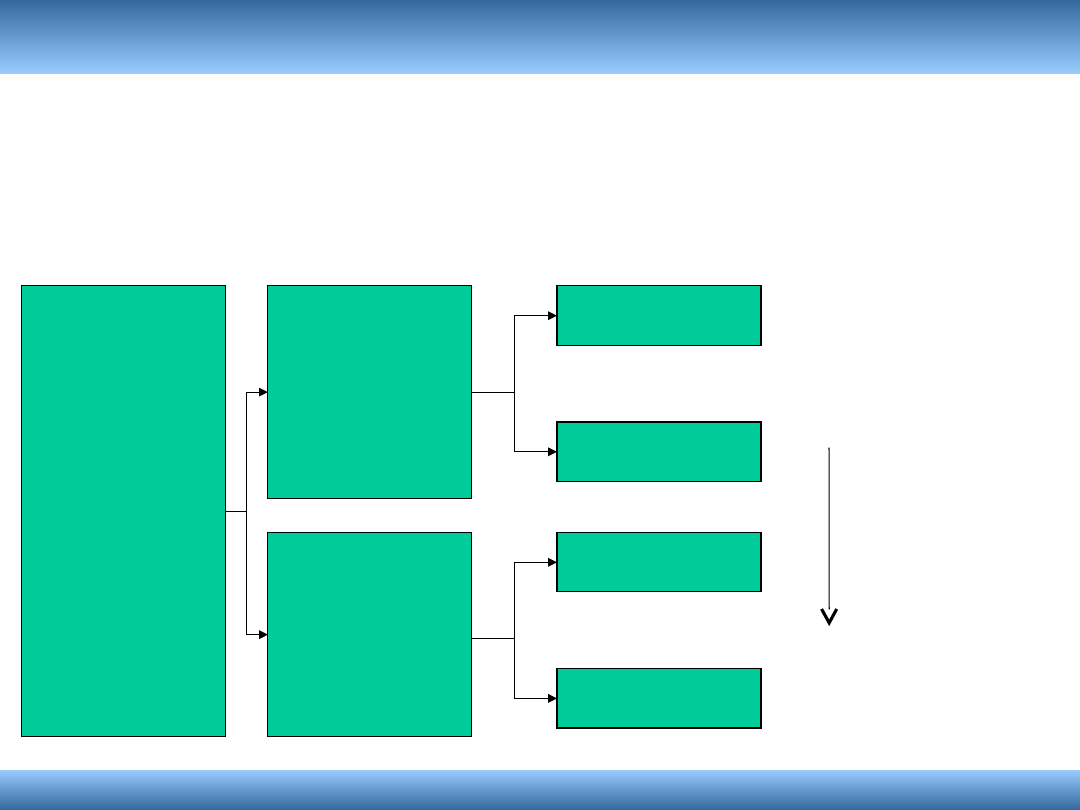
Struktura dokumentu XML
pracownicy
pracownik
pracownik
nazwisko
płaca
Hierarchia, lecz ponadto
kolejność podelementów
niesie informację.
Można zatem zilustrować
tak:
Zachowana
kolejność
nazwisko
płaca

15
Dokument XML
• Struktura fizyczna: złożenie jednostek zwanych
encjami (?) (XML entities):
– Parsowalne: dane znakowe oraz znaczniki. Encje
parsowalne zawierają tekst, czyli sekwencje znaków.
• Pojęcie znaku jest traktowane zgodnie ze standardem
ISO/IEC 10646 (Universal Multiple-Octet Coded Character
Set (UCS)).
• Za poprawne znaki są uznawane: tab, carriage return, line
feed oraz wszystkie znaki Unicode i ISO/IEC 10646;
– Nieparsowalne.
• Struktura logiczna:
– Strukturę dokumentu wyznaczają znaczniki.
• Oprogramowanie pracujące z XML:
– Procesor XML – odczytuje i udostępnia strukturę i
treść dokumentu.
– Aplikacja
– korzysta ze struktury udostępnionej
przez procesor.

16
Zawartość dokumentu XML
• Elementy:
– wyznaczane za pomocą znaczników;
– ograniczenia na nazwę – może zawierać większość
znaków, choć nie może zaczynać się od cyfry,
myślnika ani kropki; dopuszczalne na początku są
podkreślenia i dwukropki;
– dla nazw elementów rozróżnialna jest wielkość
liter;
– element niepusty składa się obowiązkowo ze
znacznika otwierającego i zamykającego:
<osoba>
Jan Kowalski
<
/
osoba>
– element pusty może składać się z jednego tylko
znacznika, zakończonego znakiem „/”:
<usuniętyWpis
/
>

17
Atrybuty XML
• Przybierają postać
nazwaAtrybutu =”wartość
atrybutu”
• Pierwotnie (DTD) wyróżniono dlań typy:
znakowy, wyliczeniowy, nazwa, identyfikator,
nazwa encji, referencja do identyfikatora…
• Składnia:
– Podobne ograniczenia na nazwę, jak w wypadku
nazw elementów;
– Zawarte w znaczniku otwierającym (albo w
znaczniku elementu pustego);
– Rozróżniana jest wielkość liter;
– Kolejność atrybutów nie jest wymagana standardem,
choć zaleca się jej konsekwentne utrzymanie;
– Znacznik może zawierać tylko jeden atrybut o danej
nazwie. Np.
<ksiazka autor = ”Jan Kochanowski”
autor=”Drugi”
>
…tutaj zawartość…
</ksiazka>

18
XML – znaki specjalne
• Znaki
<
,
>
, cudzysłów
”
, apostrof
’
– są traktowane specjalnie.
• Chcąc użyć ich jako zwykłych znaków w
miejscach, gdzie byłoby to niejednoznaczne,
należy użyć symboli zastępczych
(predefiniowanych encji):
>
,
<
oraz
"
i
'
.
• Te dwa ostatnie mogą być potrzebne w
wartościach atrybutów, jednakże można ich
uniknąć stosując jako ograniczniki wartości
tekstowej symbole apostrofu i cudzysłowu
zamiennie (tak, jak się to czyni np. w JavaScript).
• Symbole zastępcze rozwiązują problem, choć
oczywiście mogą być niewygodne
– np. przy formułowaniu w dokumentach XML warunków,
jak to ma miejsce np. w językach zapytań.

19
Zawartość elementów XML
• Wyróżniamy:
– elementy puste (pojedynczy znacznik zakończony „/”);
– elementy zawierające tylko tekst;
– elementy złożone, tj. posiadające podelementy;
– elementy o zawartości mieszanej (tj. zarówno tekst jak i
podelementy
– mogą
być
na rożne sposoby przeplecione);
• Kolejność zawieranych podelementów jest istotna dla
właściwej interpretacji dokumentu;
– jest określona definicją typu dokumentu;
• Elementy złożone (i mieszane) muszą być poprawnie
zagnieżdżone.
– W efekcie prawidłowy dokument XML posiada strukturę
hierarchiczną.
=> Reguły składniowe znane z HTML. XML odróżnia
się jednak bardziej zdyscyplinowaną składnią.

20
Deklaracja XML
• Pierwszy składnik tzw. prologu
dokumentu.
• Określa sposób interpretacji dokumentu.
• Specyfikuje:
– wersję użytego języka: parametr version;
– rodzaj kodowania znaków: parametr
encoding
(np. unicode, ISO, windows);
– określenie, czy dokument jest samodzielny:
parametr standalone.
• Np.
<?xml version=”1.0” encoding=”UTF-8”
standalone=”yes” ?>

21
Deklaracje
• W przeciwieństwie do elementów, nie są
bezpośrednio przetwarzane.
• Umieszczane w symbolach: <! … >
• Deklaracje podstawowe, obecne w zwykłych
dokumentach XML to:
– komentarze: <!-- … -->
– sekcje danych znakowych: wyznaczają obszar, w
którym można swobodnie używać znaków
zastrzeżonych:
<![CDATA[Tutaj może się znaleźć dość dowolny
tekst]]>
• O wiele szersze wykorzystanie deklaracji ma
miejsce w wypadku definicji DTD;

22
Instrukcje przetwarzania XML
• Instrukcje przetwarzania = Processing
Instructions – PI;
• umieszczane pomiędzy znakami: <? … ?>
• Określają cel (PI Target) oraz instrukcje,
które mają być wykonane.
– Cel jest słowem kluczowym (umieszczanym
bezpośrednio po otwarciu znacznika), które
identyfikuje aplikację mającą dokonać
przetwarzania.
– Preferowany styl oznaczania kodu PHP tworzy
właśnie instrukcję przetwarzania zgodną z notacją
XML:
<?php tutaj kod PHP… ?>
• Niektóre instrukcje przetwarzania (np.
związane ze stosowaniem stylów) są określone
standardem.

23
Walory XML
• Generyczność i rozszerzalność – można
wprowadzać własne pojęcia oraz definiować dla ich
opisu elementy i atrybuty.
• Hierarchiczność – umożliwia reprezentowanie
danych w postaci hierarchii elementów
(wytyczonych za pomocą znaczników).
• Łatwość przetwarzania – prosta struktura,
zdyscyplinowana składnia, dedykowane narzędzia i
interfejsy programistyczne.
• Czytelność dla człowieka – może być edytowany w
zwykłych edytorach tekstowych.
• Niezależność od platformy – dzięki oparciu języka
na czystym tekście.
• Niezależność od sposobu prezentacji.
• Możliwość walidacji dokumentu, tj. sprawdzenia
zgodności ze schematem określającym dopuszczalną
zawartość.

24
XHTML

25
Niedostatki tradycyjnego HTML
• Problem rozdzielenia treści od sposobu
prezentacji:
– Pożądane pełne wykorzystanie CSS – jednak nie jest
ono egzekwowane przez aktualną specyfikację
HTML.
• Dopuszcza usterki składniowe:
– Utrudnione przetwarzanie, większa konsumpcja
zasobów na „małych” urządzeniach.
• Stworzony z myślą o tradycyjnych
komputerach:
– Zakłada jednolitą interpretację znaczników na
różnych platformach;
– Monolityczna specyfikacja – nie przygotowana na
selektywne implementacje standardu.
• Konieczność osadzania zasobów utworzonych
w innych językach (zob. dalej).
• Utrudniona walidacja formularzy (zob. dalej).

26
XHTML – założenia
• Składnia XML – m.in. łatwiejsze transformacje
oraz prezentacja w przeglądarkach.
• Zastąpienie poleceń formatujących arkuszami
CSS – tutaj już jako wymóg języka.
• Język podzielono na moduły:
– Mogą być selektywnie implementowane na
poszczególnych platformach.
– Możliwość definiowania nowych modułów,
specyficznych dla zastosowań.
• Wsparcie przestrzeni nazwowych:
– Pozwala tworzyć strony złożone z różnych języków
rodziny XML.
<html xmlns="
http://www.w3.org/1999/xhtml
">
... </html>
<!-- domyślna przestrzeń nazwowa -->

27
XHTML a różnorodność w dokumentach
WWW
• Złożoność zwiększona przez zróżnicowanie:
– Formatowania,
– Mediów (osadzone w stronach zasoby),
– Użytych języków skryptowych (inna składnia),
– Platform (zwłaszcza upowszechnienie urządzeń
mobilnych) – różne możliwości:
1) urządzeń wyjściowych,
2) mocy obliczeniowej.
– Różne prezentacje docelowe (m.in. wydruk,
dźwięk…);
– Różni odbiorcy (m.in. udogodnienia dla
niepełnosprawnych)
– Różne języki narodowe (znaki, kierunek tekstu…)
• Koncepcja reorganizacji:
– Minimalny i uniwersalny rdzeń; moduły; zewnętrzne
style;
– Integracja z innymi językami rodziny XML.

28
Reguły poprawności pochodzące od XML
• Nazwy znaczników i atrybutów – obowiązkowo
małe litery
• Element-korzeń:
<html>
• Cudzysłowy na wartościach atrybutów
• Poprawne zagnieżdżenie znaczników;
• Deklaracja XML;
• Zawartość znakowa (np. skrypty) – w
deklaracjach
<![CDATA[…]]>
• Oznaczenia elementów pustych;
• Tzw. attribute minimization – niedopuszczalna:
<option selected>
=>
<option
selected=”selected”/>
• Wymóg określenia przestrzeni nazwowej:
<html
xmlns="http://www.w3.org/1999/xhtml"
xml:lang="pl" >

29
Reguły poprawności – c.d.
• Znane z HTML atrybuty NAME (służące m.in.
odwołaniom ze skryptów) zastąpiono
atrybutem id
– Wg definicji w DTD posiada typ ID;
– Stąd wymóg jego globalnej unikalności (w sensie
całości dokumentu)
• Obowiązek wskazania standardowego DTD:
<!DOCTYPE
html
PUBLIC
"-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-
strict.dtd"
>

30
Migracja z HTML do XHTML
•
Zdefiniowano 3 dialekty:
– Strict – wymusza wszystkie reguły;
– Transitional – mniej restrykcyjny; łatwość
przejścia z HTML;
– Frameset – służy tworzeniu stron XHTML z
ramkami.
•
Uwaga na deklarowany typ zawartości
(Content type):
– text/html
– będzie traktowany jak wariant HTML.
– application/xml
lub
application/xhtml+xml
–
traktowany jak XML
=> istnieją drobne różnice w przetwarzaniu
(wartości domyśle, wielkość znaków w
nazwach tagów itp.)
•
U
trudnione tworzenie dokumentów – niektóre
założenia krytykowane jako nadmiernie
idealistyczne.

31
Dalsza ewolucja – propozycje XHTML 2.0
• Dość radykalne założenia ukierunkowane na:
– Kompletną eliminację poleceń o charakterze
formatującym;
– Minimalizację zestawu podstawowych znaczników;
– Kompozycyjność poleceń;
– Ograniczenie zapotrzebowania na skrypty.
• Ciekawsze zmiany:
– Brak nagłówków
h1-h6
=> zamiast tego
h
, i
zagnieżdżenia elementów
section
;
– Element
p
może mieć blokową zawartość (np. listy)
– Brak
hr
=> zast. przez
separator
– Brak
br
=> elementy
line
(można „zaczepić” CSS!)
– Brak
img
=> zast. przez
object
z atrybutami
data
i
type
;
– Brak
a
=> atrybut
href
dozwolony dla większości
znaczników; podobnie często dozwolony – atrybut
src
;
– Nowy rodzaj listy:
nl
(lista nawigacyjna). Zawiera
odnośniki tworząc w ten sposób odpowiednik menu;
Document Outline
- Slide 1
- Plan wykładu
- Slide 3
- HTML – najpowszechniej znany język znaczników
- Znaczniki – terminologia
- Języki znaczników – motywacja i rozwój
- Identyfikacja znaczników ręcznych
- Identyfikacja znaczników elektronicznych
- Język znaczników – charakterystyka
- Slide 10
- Czym jest XML?
- Platforma tworzenia specjalizowanych języków
- XML – przykładowy dokument
- Struktura dokumentu XML
- Dokument XML
- Zawartość dokumentu XML
- Atrybuty XML
- XML – znaki specjalne
- Zawartość elementów XML
- Deklaracja XML
- Deklaracje
- Instrukcje przetwarzania XML
- Walory XML
- Slide 24
- Niedostatki tradycyjnego HTML
- XHTML – założenia
- XHTML a różnorodność w dokumentach WWW
- Reguły poprawności pochodzące od XML
- Reguły poprawności – c.d.
- Migracja z HTML do XHTML
- Dalsza ewolucja – propozycje XHTML 2.0
Wyszukiwarka
Podobne podstrony:
[XML][XHTML Tutorial, tutorialspoint com]
02 xml dokumenty
02-08, Programowanie, ! Java, Java i XML
02 xml dokumenty agencja
02 xml dokumenty
Wyk 02 Pneumatyczne elementy
02 OperowanieDanymiid 3913 ppt
02 Boża radość Ne MSZA ŚWIĘTAid 3583 ppt
OC 02
PD W1 Wprowadzenie do PD(2010 10 02) 1 1
05 xml domid 5979 ppt
02 Pojęcie i podziały prawaid 3482 ppt
WYKŁAD 02 SterowCyfrowe
02 filtracja
02 poniedziałek
więcej podobnych podstron