3
LISTA ROZKAZÓW PROCESORA
Jest funkcjonalnie pełna – nie ważna jest budowa listy rozkazów, ile jest
rozkazów ani jakie są, ale każdy program da się opisać i wykonać tym
procesorem – co byśmy nie wymyślili, da się zrobić, ograniczenia to głównie
czas wykonania i brak pamięci.
Podział ze względu na budowę listy rozkazów:
- CISC, idea – jak najwięcej rozkazów (300, 500...), sporo działań na
danych -> wykonanie trwa długo;
- RISC – lista okrojona – mało rozkazów (około 30), rozkazy proste i
szybko się wykonują -> lepsze od CISC.
W 8051 jest 111 rozkazów.
GRUPY ROZKAZÓW
- rozkazy przesłań – rejestr -> rejestr, pamięć -> rejestr, ... –
przemieszczanie danych
- rozkazy arytmetyczne
- rozkazy logiczne
- rozkazy sterujące
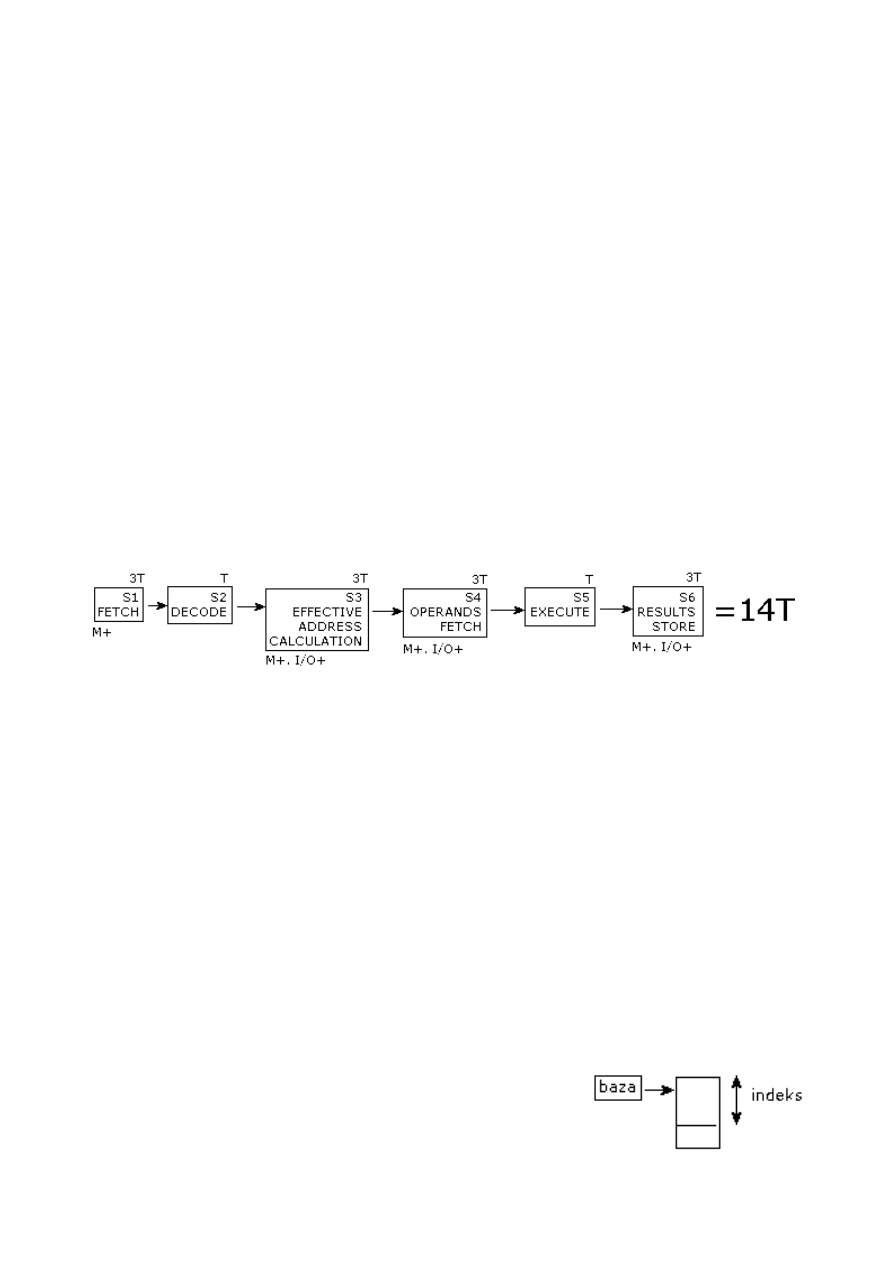
Wykonanie rozkazów w procesorze:
- pobranie rozkazu z pamięci (FETCH) – PC wskazuje, który rozkaz i
pobieramy do procesora;
- dekodowanie – co do zrobienia, skąd wziąć dane, gdzie przesłać wyniki;
- liczenie adresu efektywnego, może być dostęp do pamięci albo układów
I/O, powiązane z trybami adresowania procesora – sposób dostępu do
danych (zasobów):
tryb rejestrowy – dane są w rejestrach ogólnego przeznaczenia, wynik
może trafić do rejestru – b. szybki,
tryb rejestrowy pośredni – w rejestrze jest adres, spod którego trzeba
pobrać dane, nie trzyma adresu wprost, wynik tak samo - adres, gdzie
umieścić wynik,
tryb bezpośredni – adres podany po kodzie rozkazu, mamy dany
adres efektywny, nie trzeba go liczyć, ale odwołujemy się do innych
elementów systemu -> dłużej to trwa niż w trybie rejestrowym,
tryb natychmiastowy – dane zawarte wprost w rozkazie (dane
szczątkowe)
tryb bazowo-indeksowy – jest odmianą
trybu rejestrowego pośredniego, przydaje
się, gdy konstrukcje programistyczne są tak
poukładane (np. tablica).
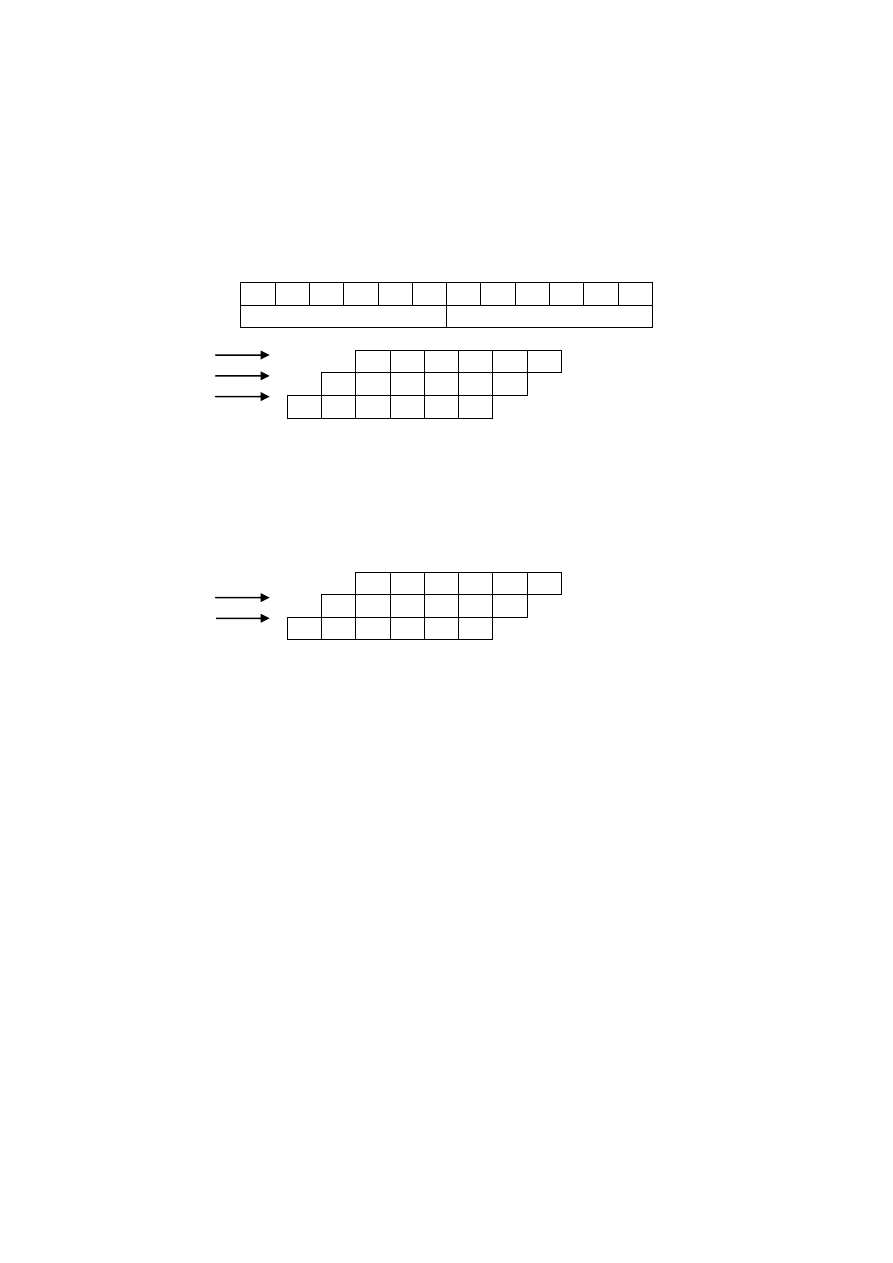
4
- pobranie operandów (operands fetch);
- wykonanie (execute);
- przechowanie rezultatów (results store).
Ile czasu jest potrzebne na wykonanie rozkazu? Tam, gdzie jest kontakt z
pamięcią, I/O – 3*T. W sumie około 14*T.
Jak to przyspieszyć?
S1 S2 S3 S4 S5 S6 S1 S2 S3 S4 S5 S6
rozkaz 1
rozkaz 2
S1 S2 S3 S4 S5 S6 3T
S1 S2 S3 S4 S5 S6
3T
S1 S2 S3 S4 S5 S6
18T
Wady – niektóre S trwają T, a inne 3T. Rozwiązanie – wszystko po 3T. Wada –
wykonanie po 18T, ale za to kolejne rozkazy są wykonywane po 3T, a to już
całkiem nieźle :)
Inny problem – PC jest tylko jeden, skąd wziąć kolejne?
S1 S2 S3 S4 S5 S6 3T
S1 S2 S3 S4 S5 S6
3T
S1 S2 S3 S4 S5 S6
18T
Rozkaz następny – ten po bieżącym wykonywanym, wtedy 1 licznik PC
wystarcza (jeśli program jest wykonywany liniowo). Jest to przetwarzanie
potokowe.
Liniowość może być zachwiana – poprzez:
- skoki:
bezwarunkowe – jeśli trzeba zmienić porządek programu, to to się
stanie
warunkowe – zmiana porządku programu zależy od warunku (np.
overflow)
- wysyłanie procedur funkcji:
warunkowe (testowanie flag, znaczników).
Skoki – kiedy znamy nowe miejsce wykonania? 3. etap – liczenie adresu
efektywnego, dla skoku warunkowego – w 5. etapie (wykonanie), najpierw
testowanie warunków.
Jeśli wystąpi skok to procesor może:
?
?
PC
PC

5
1) przeczekać – dla skoku bezwarunkowego czekamy do S3, dla
warunkowego do S5 (i tracimy takt procesora jeśli skoku nie ma);
2) nie martwię się – pobieramy dalsze rozkazy „bez zastanowienia”, bo
dla >0,5 przypadków skoków nie ma, poza tym jak jednak będzie skok i
kilka taktów pójdzie na marne to nic strasznego się nie stanie. Jednak w
tym podejściu następuje przepływ bezużytecznych informacji;
3) ORMO czuwa :) – wymagana specjalna konstrukcja procesora, procesor
wykonuje działania potokowe i jeszcze jak pozna miejsce nowego
działania programu to buforuje te rozkazy bez przetwarzania ich. Jeśli
skok się wykonał – to już mamy te rozkazy i je dekoduje, itd. –
przyspieszone działanie.
Przetwarzanie potokowe – wiele kolejnych rozkazów realizowanych nie do
końca równolegle („na zakładkę”).
Wyszukiwarka
Podobne podstrony:
mazurkiewicz,Technika Cyfrowa, system przerwań procesora
mazurkiewicz,Technika Cyfrowa, pamięci
mazurkiewicz,Technika Cyfrowa, organizacjie komputerów
mazurkiewicz,technika cyfrowa,cyfrowe układy scalone
mazurkiewicz,technika cyfrowa,Modemy i kodery multimedialne
mazurkiewicz,Technika Cyfrowa, koprocesor arytmetyczny
8086 Lista rozkazów, Akademia Morska, III semestr, technika cyfrowa, Technika Cyfrowa, TC - lab Dąbr
8080 lista rozkazów i kodów, Akademia Morska, III semestr, technika cyfrowa, Technika Cyfrowa, TC -
Technika Cyfrowa (mazurkiewicz) -wyklady, edu, el, pwr, Technika Cyfrowa (mazurkiewicz) -wyklady
mazurkiewicz,Podstawy techniki cyfrowej i mikroprocesorowej I, opracowanie zagadnień
311[51] technik cyfrowych procesow graficznych
664 technik CYFROWYCH PROCESÓW program praktyki
Technika cyfrowa opracowanie (Mazurkiewicz)
NOTAKI Z TECHNIKI CYFROWEJ
Laboratorium 4, Politechnika Koszalińska, III semestr, Laboratorium techniki cyfrowej
Lista instrukcji procesora Intel 8080
więcej podobnych podstron