
C
odziennie Âwiatowa Paj´czyna
bogaci si´ o milion nowych
stron internetowych; jej zasoby
szacowane sà na setki milionów stron.
Ta zdumiewajàca iloÊç informacji jest ze
sobà doÊç luêno powiàzana ponad mi-
liardem odnoÊników z opisem, zwanych
hiper∏àczami. Po raz pierwszy w histo-
rii miliony ludzi w domach lub w pra-
cy uzyskujà niemal natychmiastowy do-
st´p do osiàgni´ç twórczych znaczàcej
– i coraz wi´kszej – cz´Êci populacji na-
szej planety.
Poniewa˝ jednak rozwój WWW by∏
szybki i chaotyczny, Sieç nie ma logicz-
nej struktury i jest êle zorganizowana.
RzeczywiÊcie, Âwiatowa Paj´czyna pre-
zentuje globalny ba∏agan o trudnych do
wyobra˝enia rozmiarach. Strony inter-
netowe pisane sà w dowolnym j´zyku,
dialekcie i stylu, a autorem mo˝e byç ka˝-
dy, bez wzgl´du na pochodzenie, wy-
kszta∏cenie, zainteresowania czy moty-
wacj´. Strona taka zawiera od paru do
kilkuset tysi´cy znaków, a informacja na
niej podana bywa prawdziwa lub fa∏szy-
wa, màdra lub czysto propagandowa,
a nawet stanowi niekiedy zupe∏ny stek
bzdur. Jak z tego cyfrowego bagna wy-
dobyç strony zawierajàce wartoÊciowe
i istotne informacje na okreÊlony temat?
Pos∏ugiwaliÊmy si´ dotychczas prze-
szukiwarkami wy∏apujàcymi specyficz-
ne s∏owa lub wyra˝enia. Jednak cz´sto
zdarza im si´ proponowaç adresy dzie-
siàtek tysi´cy stron (w tym wielu bezu-
˝ytecznych). Jak szybko i selektywnie
zlokalizowaç potrzebnà informacj´
i w dodatku mieç zaufanie do jej wia-
rygodnoÊci i autentycznoÊci?
Uda∏o nam si´ opracowaç przeszuki-
wark´ wykorzystujàcà najcenniejszy
z zasobów WWW – niezliczone hiper-
∏àcza. Analizujàc te odnoÊniki, nasz sys-
tem automatycznie identyfikuje dwa ty-
py witryn internetowych: strony
êród∏owe z informacjà autorytatywnà,
tzw. êród∏a (authorities), oraz w´z∏y
(hubs). Te pierwsze sà najlepszymi, bo
oryginalnymi, êród∏ami informacji na
okreÊlony temat, te drugie zaÊ – zbiora-
mi odnoÊników do êróde∏. Nasze podej-
Êcie powinno u∏atwiç u˝ytkownikom
szybkie i wydajne odszukanie wi´kszo-
Êci potrzebnych informacji.
Sztuka przeszukiwania
Twarde dyski sà coraz taƒsze i po-
jemniejsze, co pozwala zgromadziç in-
formacj´ o du˝ej cz´Êci Internetu w jed-
nym miejscu. W podstawowej wersji
przeszukiwarka dysponuje dla ka˝de-
go s∏owa listà adresów wszystkich zna-
nych jej stron internetowych, na których
ono wystàpi∏o. Zbiór takich list nazywa
si´ indeksem. JeÊli interesuje nas na
przyk∏ad akupunktura, wystarczy zna-
leêç (za pomocà indeksu) s∏owo acu-
puncture, aby otrzymaç list´ wszystkich
witryn internetowych, na których ono
pada.
Tworzenie i aktualizacja takiego in-
deksu jest bardzo ˝mudnym zadaniem
[patrz: Clifford Lynch, „Przeszukujàc
Internet”; Âwiat Nauki, maj 1997], a okre-
Êlenie, jakie informacje z listy prze-
kazaç u˝ytkownikowi, pozostaje trud-
nym orzechem do zgryzienia. Roz-
wa˝my jednoznaczne pytanie o lini´ lot-
niczà Nepal Airways. Jak przeszukiwar-
ka ma zadecydowaç, które ze 100 adre-
sów witryn (tyle ich by∏o, gdy pisaliÊmy
ten artyku∏) uznaç za najlepsze, jeÊli
chcemy wyÊwietliç tylko 20 odnoÊni-
ków? Problem polega na tym, ˝e nie ma
Êcis∏ej, matematycznej definicji tego, co
jest najlepsze – zale˝y to przecie˝ od gu-
stów u˝ytkownika.
Przeszukiwarki takie jak AltaVista,
Infoseek, HotBot, Lycos i Excite po-
s∏ugujà si´ algorytmami heurystyczny-
mi do uporzàdkowania znalezionych
stron wed∏ug hierarchii wa˝noÊci. Te
empiryczne regu∏y, czyli tzw. funkcja
rankingowa, muszà sprawdzaç si´ nie
tylko w przypadku specyficznych i doÊç
prostych zapytaƒ w rodzaju Nepal Air-
ways, ale tak˝e w sytuacji, gdy has∏o jest
bardzo ogólne, na przyk∏ad samolot –
s∏owo to pada na przesz∏o milionie stron
internetowych. Jak przeszukiwarka ma
wybraç zaledwie 20 najwa˝niejszych
z tej olbrzymiej liczby?
Proste regu∏y heurystyczne mogà hie-
rarchizowaç strony na podstawie tego,
ile razy poszukiwany termin na nich
wyst´puje, lub wybieraç te, na których
pojawia si´ on najwczeÊniej. Jednak pro-
wadzi to czasami do sromotnej kl´ski:
wed∏ug powy˝szych regu∏ heurystycz-
nych ksià˝ka Toma Wolfe’a The Kandy-
-Kolored Tangerine-Flake Streamline Baby
by∏aby wa˝nym êród∏em informacji o
przepuklinie, jako ˝e na poczàtku s∏o-
wo to powtórzone jest kilkadziesiàt ra-
zy. Istniejà liczne rozwini´cia tych pro-
stych regu∏, na przyk∏ad uprzywile-
jowanie stron, na których poszukiwany
termin znajduje si´ w tytule dokumen-
tu lub akapitu, albo gdy jest jakoÊ wy-
ró˝niony w tekÊcie.
Tego typu strategia bywa rutynowo
wykorzystywana przez wiele komercyj-
nych witryn redagujàcych swoje strony
celowo tak, aby uzyskaç wysokie miej-
sce w rankingu przeszukiwarek. Spoty-
kamy wi´c strony zatytu∏owane „Tanie
bilety lotnicze, tanie bilety lotnicze, ta-
nie bilety lotnicze, tanie bilety lotnicze”.
Niektóre witryny wielokrotnie powie-
lajà specyficznie dobrane zdania, ale za
to krojem i kolorem pisma takim, ˝e nie
sà one widoczne na ekranie kompute-
ra. Tego typu praktyki, zwane spam-
mingiem*, zaÊmiecajà Sieç, przyczynia-
jàc si´ do nieefektywnego dzia∏ania
wi´kszoÊci przeszukiwarek.
52 Â
WIAT
N
AUKI
Sierpieƒ 1999
Hiperprzeszukiwanie Sieci
Lawina informacji w cyberprzestrzeni wymaga dziÊ
zdecydowanie skuteczniejszych metod wyszukiwania. Nowa technika
polega na analizowaniu powiàzaƒ stron internetowych
Uczestnicy projektu Clever
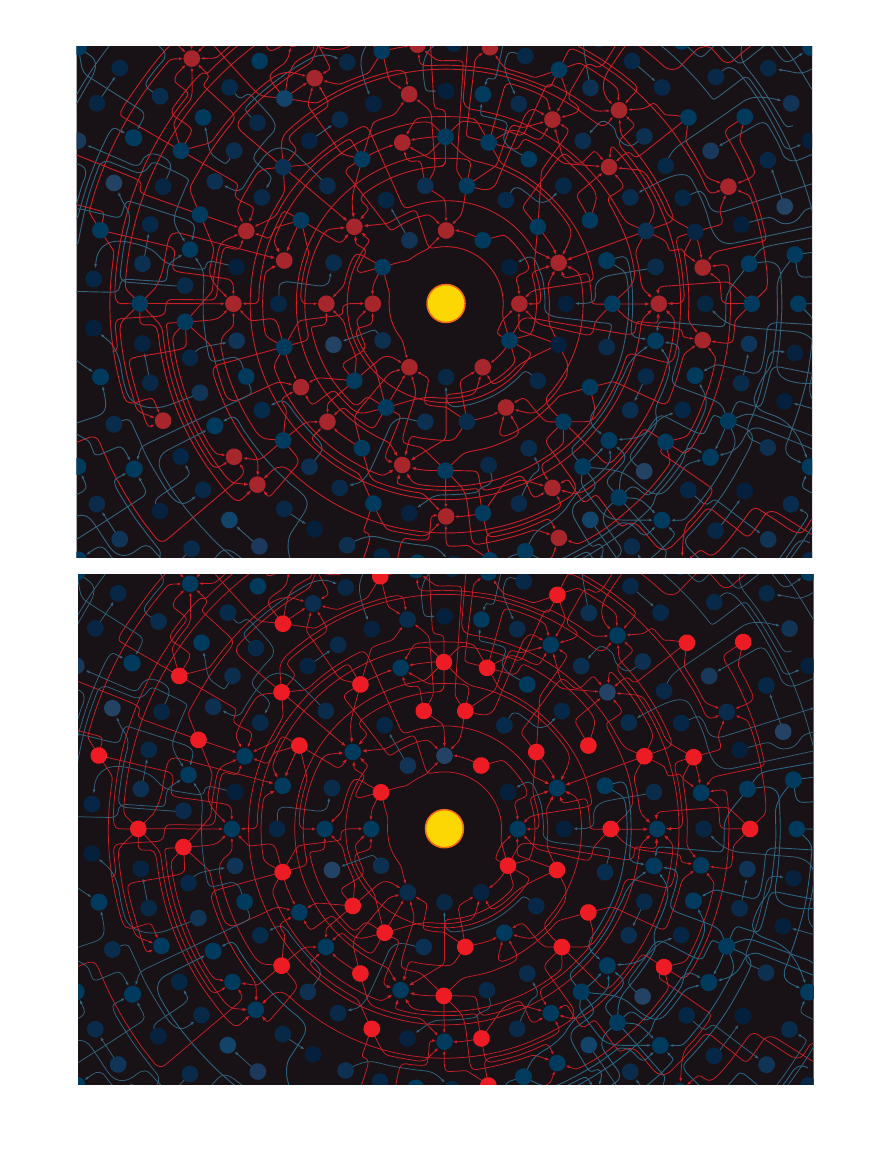
STRONY INTERNETOWE (bia∏e kropki) sà rozrzucone po Sieci w sposób chaotyczny.
U˝ytkownik w centrum tego nieuporzàdkowania ma wi´c trudnoÊci z odszukaniem tylko
tych informacji, których potrzebuje. Rysunek pokazuje par´set stron, ale WWW aktual-
nie zawiera ich ponad 300 milionów. Analizujàc, jak strony sà po∏àczone mi´dzy sobà,
znajdujemy jednak ukryty porzàdek.
Wszystkie ilustracje: BRYAN CHRISTIE

54 Â
WIAT
N
AUKI
Sierpieƒ 1999

JeÊli pominiemy spamming oszukujà-
cy przeszukiwarki, wàtpliwoÊci budzà
nawet podstawowe za∏o˝enia poszuki-
waƒ tekstowych. Albowiem na stronach
zawierajàcych istotnà informacj´ o po-
szukiwanym haÊle niekiedy nie wyst´-
puje ono w ogóle explicite, a te, na któ-
rych pojawia si´ wielokrotnie, mogà byç
bezwartoÊciowe. G∏ównym powodem
jest to, ˝e j´zyk bywa silnie polisemicz-
ny (s∏owa sà wieloznaczne, np. róg uli-
cy i róg barana) i zawiera synonimy
(ró˝ne s∏owa okreÊlajàce t´ samà rzecz).
Tak wi´c podanie has∏a samochód nie
pozwoli dostrzec licznych stron zawie-
rajàcych termin auto. Polisemia zaÊ spo-
woduje, ˝e wyszukanie terminu jaguar
przyniesie nam tysiàce stron informacji
o sportowym samochodzie, dzikim ko-
cie z d˝ungli, dru˝ynie pi∏karskiej z Na-
tional Football League i innych jeszcze
rzeczach.
Jednà z pomocnych strategii jest do-
danie informacji o zwiàzkach semantycz-
nych pomi´dzy s∏owami. Takie twory,
zwykle dzie∏o lingwistów, zwane sà cza-
sami sieciami semantycznymi. Wywo-
dzà si´ one z pionierskich prac nad
WordNet prowadzonych w Princeton
University przez zespó∏ George’a A. Mil-
lera. Przeszukiwarka pos∏ugujàca si´ in-
deksem i z dost´pem do sieci semantycz-
nej potrafi∏a stwierdziç równowa˝noÊç
s∏ów auto i samochód i wyszuka∏a wszyst-
kie strony internetowe zawierajàce te ter-
miny. Jednak ta strategia to miecz obo-
sieczny: ∏agodzi co prawda trudnoÊci
z synonimami, lecz polisemia zaczyna
sprawiaç jeszcze wi´kszy k∏opot.
Rozwiàzanie powy˝sze budzi zastrze-
˝enia nawet jako metoda na synonimy.
Stworzenie i utrzymywanie sieci seman-
tycznej, która by∏aby dostatecznie du-
˝a i uwzgl´dnia∏a powiàzania znacze-
niowe wyst´pujàce w ró˝nych kultu-
rach (WWW nie zna przecie˝ granic), to
gigantyczne przedsi´wzi´cie. Sam In-
ternet przysparza te˝ sporo problemów:
rozwija w∏asny j´zyk, powstajà nowe
s∏owa takie jak FAQ (cz´sto zadawane
pytania), zine (pisemko internetowe), bot
(programik przeszukujàcy Sieç), a inne,
takie jak ˝eglowaç lub przeglàdaç, nabie-
rajà dodatkowych znaczeƒ.
Nasze prace nad projektem Clever
w firmie IBM by∏y inspirowane tym gàsz-
czem zagmatwanych kwestii. Od poczàt-
ku zdawaliÊmy sobie spraw´, ˝e obecne
metody indeksowania i wyszukiwania
stron internetowych za pomocà wy∏àcz-
nie tekstu w nich zawartego ca∏kowicie
ignorowa∏y ponad miliard starannie do-
branych hiper∏àczy, które uwzgl´dniajà
zwiàzki pomi´dzy ró˝nymi stronami.
Tylko jak pos∏u˝yç si´ tà informacjà?
Kiedy szukamy terminu Harvard,
najcz´Êciej chodzi nam o s∏ynny uniwer-
sytet. Jednak ponad milion stron inter-
netowych zawiera s∏owo Harvard, a wi-
tryna znakomitego uniwersytetu nie jest
stronà, która u˝ywa tego s∏owa najcz´-
Êciej, najwczeÊniej – na niej s∏owo to nie
pojawia si´ w sposób, który zapewni∏by
jej wysokà pozycj´ nadanà przez trady-
cyjne funkcje rankingowe. Ta strona in-
ternetowa nie ma ˝adnej cechy, która
zdradza∏aby jej prawdziwe znaczenie.
Witryny internetowe sà w istocie
tworzone w ró˝nych celach. Na przy-
k∏ad wielkie koncerny nadajà im specy-
ficzny styl sugerujàcy pewne pozytyw-
ne wartoÊci – co niekoniecznie musi
przek∏adaç si´ na dok∏adny opis dzia-
∏alnoÊci koncernu. I tak na przyk∏ad wi-
tryna firmy IBM w ogóle nie zawiera
s∏owa komputer. W tych warunkach
zwyk∏e techniki wyszukiwania muszà
spe∏znàç na niczym.
Aby uniknàç tego typu pu∏apek,
twórcy przeszukiwarek ulegali pokusie
ingerencji w przekonaniu, ˝e wiedzà,
jak powinny wyglàdaç prawid∏owe od-
powiedzi na pewne zapytania. Stworze-
nie funkcji rankingowej, która automa-
tycznie uzyska powy˝sze odpowiedzi,
okaza∏o si´ bardzo k∏opotliwe. Tak wi´c
r´cznie tworzà list´ terminów typu Har-
vard, na które odpowiedzi nie przynosi
zwyk∏a funkcja rankingowa, lecz pod-
stawia si´ to, co autorzy uwa˝ajà za po-
prawnà odpowiedê.
To podejÊcie jest stosowane w wielu
przeszukiwarkach. Na przyk∏ad Yahoo!
podaje tylko strony kojarzone z danym
has∏em przez ludzi. Liczba mo˝liwych
zapytaƒ jest jednak nieskoƒczona. Jak
wi´c, dysponujàc skoƒczonà liczbà eks-
pertów, utrzymywaç aktualnà i pe∏nà
list´ odpowiedzi na wszystkie spodzie-
wane zapytania, jeÊli Sieç rozrasta si´
o milion stron dziennie?
Szukamy hiper∏àczami
PodeszliÊmy do sprawy inaczej.
OpracowaliÊmy technik´, która pozwa-
la automatycznie znaleêç w Internecie
najbardziej znaczàce, autorytatywne wi-
tryny dotyczàce stawianych zapytaƒ za
pomocà najcenniejszego zasobu Inter-
netu: jego hiper∏àczy. To przecie˝ one
czynià z setek milionów stron globalnà
sieç wiedzy. To w∏aÊnie hiper∏àcza po-
zwalajà nam przeglàdaç, a czasami
przypadkowo trafiaç na wartoÊciowe
informacje na podstawie zaleceƒ i ∏àczy
Â
WIAT
N
AUKI
Sierpieƒ 1999 55
èRÓD¸A I W¢Z¸Y sà pomocne w okreÊlaniu struktury informacji w Internecie; u˝yt-
kownicy Sieci tworzà je nieformalnie i cz´sto bezwiednie. èród∏a informacji (
l
) to stro-
ny, do których cz´sto odwo∏ujà si´ inne strony w przeglàdaniu informacji na okreÊlony
temat. W dziedzinie praw cz∏owieka witryna Amnesty International mo˝e byç przy-
k∏adem êród∏a informacji. W´z∏y odnoÊników (
l
) to strony, które wskazujà do wielu
êróde∏ informacji (na przyk∏ad specjalne kompilacje po˝ytecznych adresów lub te˝ „Mo-
je ulubione witryny” z amatorskiej strony internetowej.
ZNALEZIENIE èRÓDE¸ autorytatywnej informacji i w´z∏ów odnoÊników mo˝e nie byç ∏a-
twe, gdy˝ jedne definiujà drugie: êród∏o informacji to strona, którà wskazuje wiele w´z∏ów
odnoÊników, a w´ze∏ odnoÊników to strona, która zawiera hiper∏àcza do wielu êróde∏ infor-
macji. Proces wyszukiwania êróde∏ i w´z∏ów mo˝na jednak zdefiniowaç matematycznie.
Prototypowa przeszukiwarka Clever przypisuje poczàtkowe oceny stronom b´dàcym kan-
dydatami na êród∏a i w´z∏y z konkretnej dziedziny. Clever nast´pnie sukcesywnie ulep-
sza oceny, wykonujàc procedur´ iteracyjnà a˝ do uzyskania zbie˝noÊci. Koƒcowe oceny sà
podstawà do wy∏onienia najlepszych êróde∏ informacji i w´z∏ów odnoÊników.

zawartych w witrynach ludzi, których
nigdy w ˝yciu nie widzieliÊmy.
U podstaw naszego podejÊcia le˝y za-
∏o˝enie, ˝e ka˝de hiper∏àcze jest w
istocie rekomendacjà strony, do której
odsy∏a. Rozwa˝my witryn´ kogoÊ wal-
czàcego o prawa cz∏owieka zawierajà-
cà odnoÊnik do Amnesty International.
W tym wypadku jasne jest, ˝e odnoÊnik
oznacza jednoczeÊnie poparcie.
¸àcza mogà byç obecne tak˝e, aby
u∏atwiç przeglàdanie witryny („Kliknij
tu, aby powróciç do g∏ównego menu”),
w celach reklamowych („Kliknij tu,
a sp´dzisz wakacje Twoich marzeƒ”)
lub jako wyraz dezaprobaty („Kliknij
tu, aby przeczytaç, co napisa∏ ten ba-
ran”). Wydaje si´ jednak, ˝e jeÊli we-
êmiemy pod uwag´ dostatecznie du˝o
stron, hiper∏àcza kierujà przewa˝nie do
miejsc autorytatywnej informacji.
Oprócz êród∏owych w Internecie pe∏-
no jest witryn innego typu: w´z∏ów
zawierajàcych hiper∏àcza do wspo-
mnianych presti˝owych witryn, a wi´c
implicite rozprzestrzeniajàcych ich wp∏y-
wy. W´z∏y te wyst´pujà pod ró˝nymi
postaciami: hiper∏àcza znajdujemy i na
profesjonalnie utworzonych listach
w komercyjnych witrynach, i w rubry-
ce „Moje ulubione witryny WWW” na
amatorskich stronach domowych. Na-
wet jeÊli nie jest ∏atwo zdefiniowaç po-
j´cia „êród∏o autorytatywnej informa-
cji” i „w´ze∏ odnoÊników”, to mo˝emy
stwierdziç, ˝e darzymy zaufaniem takà
witryn´, do której odwo∏ujà si´ liczne
dobre w´z∏y odnoÊników; z kolei u˝y-
teczny w´ze∏ to witryna zawierajàca licz-
ne hiper∏àcza do wartoÊciowych êróde∏.
Wydaje si´ to b∏´dnym ko∏em nie pro-
wadzàcym do algorytmu numeryczne-
go pozwalajàcego na identyfikacj´ obu
typów witryn. Intuicyjnie wymyÊliliÊmy
jednak taki algorytm. Na poczàtku prze-
glàdamy zestaw witryn potencjalnie
istotnych z uwagi na dane zagadnienie
i ka˝dà z nich oceniamy subiektywnie,
czy jest dobrym êród∏em informacji, czy
te˝ u˝ytecznym w´z∏em odnoÊników.
Te estymaty sà punktem wyjÊcia do
dwufazowego procesu iteracyjnego.
W pierwszej fazie u˝ywamy aktual-
nej oceny êróde∏ informacji, aby polep-
szyç estymaty w´z∏ów odnoÊników –
identyfikujemy najlepsze aktualnie êró-
d∏a i sprawdzamy, które w´z∏y do nich
wskazujà; w ten sposób wyznaczamy
nowe najlepsze w´z∏y. W drugiej fazie
u˝ywamy ulepszonych ocen w´z∏ów,
aby polepszyç nasze estymaty êróde∏
informacji – wyznaczamy, do jakich wi-
tryn wskazujà najcz´Êciej nasze nowe
w´z∏y, co pozwala na stworzenie nowej,
bardziej wiarygodnej listy êróde∏ in-
formacji. Wielokrotne powtarzanie tej
procedury prowadzi do optymalnego
wyboru.
Algorytm powy˝szy leg∏ u podstaw
naszej prototypowej przeszukiwarki,
którà nazwaliÊmy Clever (Spryciara).
Dla konkretnego pytania, na przyk∏ad
acupuncture, Clever pobiera od standar-
dowej przeszukiwarki indeksowej (np.
AltaVista) list´ 200 stron internetowych
dotyczàcych interesujàcego nas zagad-
nienia. Program nasz dodaje do niej
wszystkie strony, powiàzane (do któ-
rych lub z których sà po∏àczenia) z tymi
200 poczàtkowymi stronami. Z naszych
doÊwiadczeƒ wynika, ˝e otrzymany
w ten sposób zbiór stron, nazywany
przez nas zbiorem podstawowym, za-
wiera od tysiàca do pi´ciu tysi´cy stron.
Ka˝dej z tych stron Clever przypisu-
je poczàtkowe oceny wskazujàce, jak do-
brym êród∏em informacji lub w´z∏em
odnoÊników jest dana strona. Nast´pnie
polepsza poczàtkowe estymaty: ocena
êród∏a jest wyznaczana jako suma ocen
wszystkich w´z∏ów, które do niego
wskazujà; nowa ocena w´z∏a jest sumà
ocen wszystkich êróde∏, do których on
kieruje. Innymi s∏owy strona – êród∏o
informacji – wysoko oceniona to taka,
do której kieruje wiele dobrze notowa-
nych w´z∏ów, a w´ze∏ zawierajàcy od-
noÊniki do wielu wysoko notowanych
êróde∏ uzyska wysokà ocen´. Clever po-
wtarza t´ procedur´ a˝ do ustabilizowa-
nia ocen, co pozwala okreÊliç najlepsze
êród∏a informacji i najwartoÊciowsze w´-
z∏y. (Zauwa˝my, ˝e ta procedura ra-
chunkowa nie wyklucza, ˝e dana stro-
na jest jednoczeÊnie dobrym êród∏em
i w´z∏em, co si´ czasami zdarza.)
Algorytm nasz najlepiej jest interpre-
towaç graficznie. Wyobraêmy sobie
WWW jako wielkà sieç niezliczonych
witryn po∏àczonych mi´dzy sobà po-
zornie w sposób przypadkowy. Pro-
gram Clever spoÊród stron zawierajà-
cych dane s∏owo lub termin wybiera te,
pomi´dzy którymi istnieje najbardziej
g´sta sieç hiper∏àczy.
Okaza∏o si´, ˝e zagadnienie iteracyj-
nego sumowania ocen êróde∏ i w´z∏ów
mo˝na analizowaç matematycznie. Al-
gebra liniowa pozwala proces sumowa-
nia ocen opisaç jako mno˝enie wektora
(ocen stron ustawionych w kolumn´)
przez macierz (tablic´ okreÊlajàcà struk-
tur´ hiper∏àczy mi´dzy stronami). Wy-
nik procedury iteracyjnej to wektor (dla
êróde∏ i w´z∏ów), który nie zmienia∏ si´
podczas iterowania – sà to w∏aÊnie oce-
ny danych witryn (w algebrze liniowej
takie wektory nazywamy wektorami
w∏asnymi macierzy).
Dalsza analiza metodami algebry li-
niowej wykaza∏a, ˝e procedura iteracyjna
b´dzie stosunkowo szybko zbie˝na.
W naszym przypadku zestaw 3000 stron
wymaga oko∏o pi´ciu iteracji. Co wi´cej,
wyniki sà niezale˝ne od poczàtkowo wy-
branych wektorów; metoda dzia∏a nawet
wtedy, gdy wszystkim stronom przypi-
szemy t´ samà maksymalnà ocen´, tzn.
jeden. Tak wi´c koƒcowe oceny êróde∏
informacji i w´z∏ów odnoÊników sà w∏a-
snoÊcià rozwa˝anych stron i nie zale˝à
od subiektywnych ocen wst´pnych.
Po˝ytecznym efektem ubocznym dzia-
∏ania algorytmu u˝ytego w Clever jest
to, ˝e w sposób naturalny dzieli on stro-
ny na gromady. Na przyk∏ad podanie
terminu aborcja ujawni istnienie dwu
grup witryn: obroƒców ˝ycia pocz´tego
i zwolenników prawa kobiety do decyzji;
dzieje si´ tak dlatego, ˝e strony jednej
grupy b´dà znacznie cz´Êciej wskazy-
waç na witryny zwolenników tej samej
opcji ani˝eli na strony przeciwników.
Z szerszej perspektywy algorytm
u˝yty w Clever ods∏ania struktur´ Âwia-
towej Paj´czyny. Albowiem mimo ˝e
Internet rozrasta si´ ˝ywio∏owo i cha-
otycznie, to panuje w nim swoisty, choç
s∏abo zorganizowany, porzàdek zapisa-
ny w strukturze hiper∏àczy.
Zwiàzek z analizà cytowaƒ
Z punktu widzenia metodologiczne-
go algorytm u˝yty w Clever ma bliskie
zwiàzki z analizà cytowaƒ, czyli bada-
niami nad tym, jak autorzy publikacji na-
ukowych cytujà inne prace. Zapewne naj-
bardziej znanà miarà znaczenia czaso-
pisma naukowego jest jego wspó∏czynnik
wp∏ywu (impact factor). Opracowany on
zosta∏ przez Eugene’a Garfielda, znane-
go specjalist´ zagadnieƒ informacji i
twórc´ Science Citation Index; ocenia war-
toÊç publikacji naukowej wed∏ug tego,
jak cz´sto jest ona cytowana.
W Internecie odpowiednikiem wspó∏-
czynnika wp∏ywu jest po prostu liczba
hiper∏àczy do danej strony. Jednak naj-
cz´Êciej takie podejÊcie si´ nie spraw-
dza, gdy˝ mo˝e ono preferowaç bardzo
popularne witryny, na przyk∏ad czaso-
pisma New York Times, niezale˝nie od
celu odwiedzin.
Nawet w dziedzinie analizy cytowaƒ
naukowcy starali si´ ulepszyç miar´
56 Â
WIAT
N
AUKI
Sierpieƒ 1999
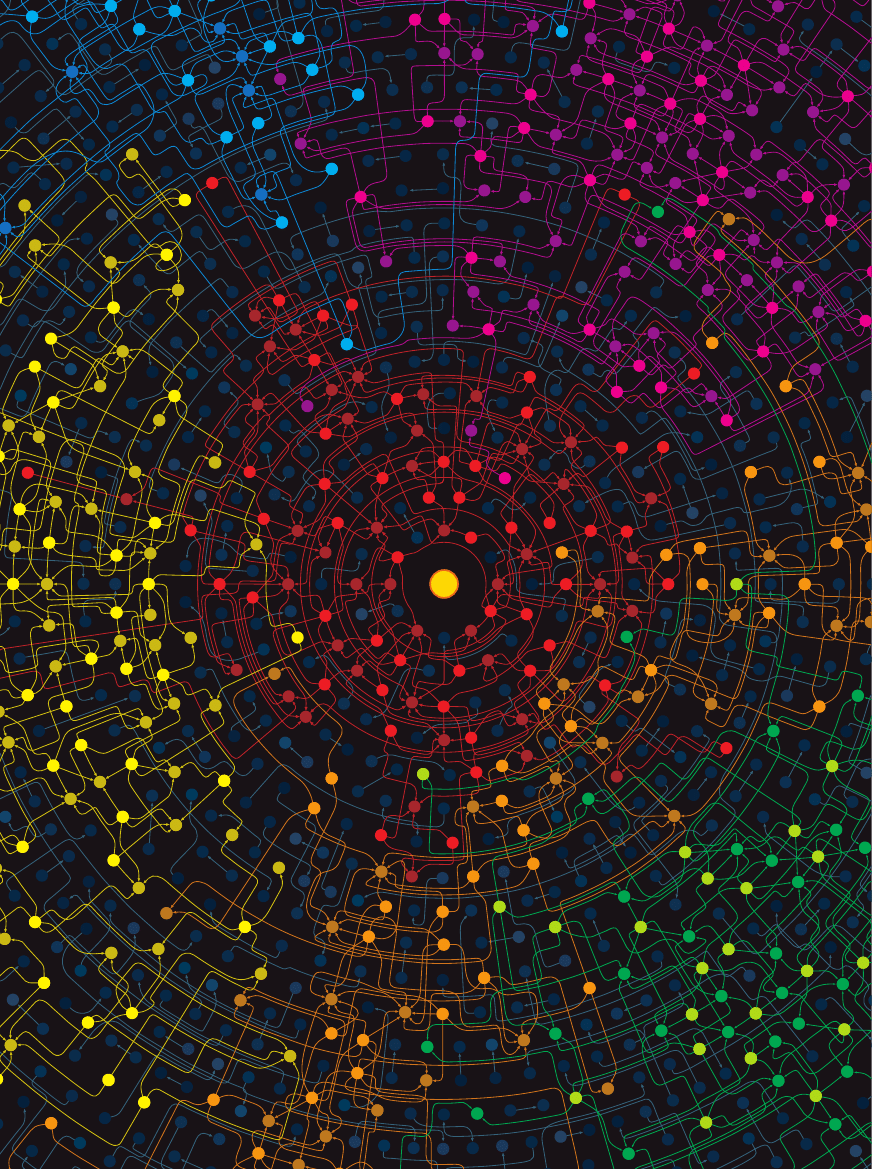
POWSTAWANIE SPO¸ECZNOÂCI INTERNETOWYCH (pokazane ró˝nymi kolorami) to
cz´ste zjawisko. Badajàc je, odkryliÊmy grupy zainteresowaƒ tak egzotycznymi temata-
mi, jak zanieczyszczenia ropà naftowà u wybrze˝y Japonii, stra˝acy w Australii czy po˝y-
teczne adresy internetowe dla Turków mieszkajàcych w USA. W Sieci sà setki tysi´cy ta-
kich ma∏ych spo∏ecznoÊci.

Garfielda, która ka˝de z nich traktuje
tak samo. Czy˝ nie by∏oby lepszà strate-
già wy˝ej ceniç powo∏ywania si´ na pra-
c´ opublikowanà w bardziej presti˝o-
wym czasopiÊmie? Oczywisty k∏opot
polega tu na zdefiniowaniu presti˝o-
wego czasopisma – ten sam problem
mieliÊmy z definicjami êróde∏ autoryta-
tywnej informacji i w´z∏ów odnoÊni-
ków. Ju˝ w 1976 roku Gabriel Pinski
i Francis Narin z CHI Research w Had-
don Heights w New Jersey przezwyci´-
˝yli t´ trudnoÊç, opracowujàc iteracyj-
nà metod´ obliczenia odpowiedniego
zestawu ocen, które nazwali wagami
wp∏ywu. Inaczej ni˝ nasz ich algorytm
nie wyró˝nia êróde∏ informacji i w´z∏ów
odnoÊników. W podejÊciu Pinskiego
i Narina jedno êród∏o autorytatywnej
informacji (tj. czasopismo) wp∏ywa bez-
poÊrednio na ocen´ pozosta∏ych.
Te odmienne podejÊcia uwypuklajà
podstawowà ró˝nic´ pomi´dzy Inter-
netem a tradycyjnymi publikacjami na-
ukowymi. W Sieci wspó∏zawodniczàce
ze sobà êród∏a (np. Netscape i Microsoft
w dziedzinie przeglàdarek) cz´sto igno-
rujà obecnoÊç konkurenta, tak wi´c da
si´ je asocjowaç wy∏àcznie za pomocà
poÊredniej warstwy w´z∏ów odnoÊni-
ków. W sferze naukowej wspó∏zawod-
niczàce czasopisma zwykle zawierajà
odnoÊniki do konkurencyjnych wydaw-
nictw, a zatem w´z∏y odnoÊników nie
odgrywajà a˝ tak du˝ej roli.
Tak˝e inne grupy badajà wykorzy-
stanie hiper∏àczy do przeszukiwania In-
ternetu. Sergey Brin i Lawrence Page ze
Stanford University opracowali prze-
szukiwark´ zwanà Google, w której za-
stosowano miar´ rankingowà zbli˝onà
do wag wp∏ywu Pinskiego i Narina.
Oparli si´ oni na modelowym internau-
cie, który podà˝a za hiperpo∏àczeniami,
ale od czasu do czasu skacze w przy-
padkowe miejsce; w rezultacie pewne
strony b´dà cz´Êciej odwiedzane ni˝ in-
ne. Korzystajàc z tego, Google znajduje
uniwersalne wa˝ne witryny – intuicja
podpowiada, ˝e sà to miejsca cz´sto od-
wiedzane podczas przypadkowego b∏à-
kania si´ po Sieci. W praktyce Google
przypisuje ka˝dej stronie ocen´ b´dàcà
sumà ocen stron, które do niej si´ od-
wo∏ujà. Tak wi´c Google mo˝e szybko
daç odpowiedê na pytanie, podajàc li-
st´ stron zawierajàcych poszukiwany
termin uporzàdkowanà wed∏ug male-
jàcych ocen.
Pomi´dzy Clever a Google sà dwie
podstawowe ró˝nice. Po pierwsze,
Google na poczàtku tworzy list´ ocen
wszystkich stron i zapami´tuje jà, a Cle-
ver za ka˝dym razem tworzy list´ pod-
stawowà i w jej ramach oceny rankin-
gowe. Google jest wi´c szybsza. Po
drugie, podstawowym za∏o˝eniem Go-
ogle jest posuwanie si´ wy∏àcznie do
przodu, od hiper∏àcza do hiper∏àcza,
a Clever tak˝e si´ cofa, sprawdzajàc, któ-
re strony kierujà do êród∏a informacji.
Clever wykorzystuje wi´c socjologicz-
ne spostrze˝enie: ludzie majà wewn´trz-
nà motywacj´ do tworzenia centrów
wiedzy na znany im temat.
Ciàg dalszy poszukiwaƒ
Rozwa˝amy ró˝ne sposoby zwi´k-
szenia mo˝liwoÊci Clever. G∏ówny na-
cisk k∏adziemy na integracj´ przeszu-
kiwaƒ tekstowych i za pomocà hiper-
∏àczy. Jednà ze strategii jest przypisanie
wi´kszej wagi niektórym hiper∏àczom
na podstawie wa˝noÊci tekstu na stronie
je zawierajàcej. Mówiàc dok∏adniej,
poddajemy analizie zawartoÊç stron ze
zbioru podstawowego, aby wyznaczyç
liczb´ i wzgl´dnà pozycj´ wystàpieƒ po-
szukiwanego terminu, a nast´pnie u˝yç
tych danych do przypisania wag nie-
którym hiper∏àczom. JeÊli na przyk∏ad
poszukiwany termin pojawia∏ si´ cz´-
sto w sàsiedztwie hiper∏àcza, to jego wa-
ga b´dzie zwi´kszona.
Nasze wst´pne próby sugerujà, ˝e to
ulepszenie znacznie poprawia koncen-
trowanie si´ przeszukiwarki na zada-
nym terminie. (Wadà Clever by∏o to, ˝e
w przypadku bardzo specyficznego ter-
minu, np. dom Fallingwater architekta
Franka Lloyda Wrighta, przeszukiwarka
ta mia∏a tendencj´ do rozszerzania te-
matu i na powy˝sze zapytanie podawa-
∏a informacje o architekturze amerykaƒ-
skiej.) Próbujemy te˝ innych ulepszeƒ
uwzgl´dniajàcych style redagowania
stron WWW i wykorzystujàcych ró˝ne
aspekty strony w procedurze nadawa-
nia wag hiper∏àczom.
Zacz´liÊmy tak˝e tworzyç listy zaso-
bów internetowych podobne do kom-
pilowanych r´cznie przez takie firmy,
jak Yahoo! i Infoseek. Wst´pne oceny
wskazujà, ˝e automatycznie tworzone
indeksy sà porównywalne z tworzony-
mi r´cznie. Co wi´cej, w trakcie realiza-
cji naszego projektu stwierdziliÊmy, ˝e
w Internecie roi si´ od grup ludzi moc-
no ze sobà powiàzanych, którzy cz´sto
majà oryginalne wspólne zainteresowa-
nia (np. amatorzy walk sumo w week-
endy walczà mi´dzy sobà dla przyjem-
noÊci, zak∏adajàc grube plastikowe
ubiory naÊladujàce monstrualnà tusz´
zawodowców). Staramy si´ teraz stwo-
rzyç algorytmy efektywnego ujawnia-
nia takich ma∏ych spo∏ecznoÊci.
Dzisiejszy Interent ró˝ni si´ zdecydo-
wanie od tego sprzed pi´ciu lat. Wyda-
je si´ wi´c, ˝e próby przewidzenia, jak
b´dzie wyglàda∏ za lat pi´ç, muszà spe∏-
znàç na niczym. Czy niebawem stanie
si´ niemo˝liwe stworzenie czegoÊ tak
podstawowego jak indeks stron WWW?
I czy wtedy nasze wyobra˝enia o prze-
szukiwaniu Sieci nie ulegnà zasadni-
czym zmianom? DziÊ czujemy si´ tylko
upowa˝nieni do stwierdzenia, ˝e nie-
pohamowany rozrost Internetu ciàgle
b´dzie êród∏em informatycznych wy-
zwaƒ dla tych, którzy chcà opracowaç
metody przedzierania si´ przez coraz
wi´kszy gàszcz informacji.
T∏umaczy∏
Aleksy Bartnik
*OkreÊlenie spamming pochodzi od s∏owa spam –
jest to amerykanska mielonka wieprzowa z puszki,
która sta∏a si´ symbolem rzeczy niesmacznej, nie-
potrzebnej i przeszkadzajàcej (przyp. t∏um.).
58 Â
WIAT
N
AUKI
Sierpieƒ 1999
Informacje o autorach
UCZESTNICY PROJEKTU CLEVER: Soumen Chakrabarti, Byron Dom,
S. Ravi Kumar, Prabhakar Raghavan, Sridhar Rajagopalan i Andrew
Tomkins, sà pracownikami naukowymi IBM Almaden Research Cen-
ter w San Jose w Kalifornii. Jon M. Kleinberg jest profesorem nadzwy-
czajnym na Wydziale Informatyki Cornell University. David Gibson
koƒczy doktorat na Wydziale Informatyki w University of California
w Berkeley. Autorzy zacz´li prace nad wykorzystaniem struktury hiper-
∏àczy trzy lata temu, kiedy starali si´ opracowaç lepsze techniki znajdo-
wania informacji w d˝ungli internetowej. Inspiracjà by∏o dla nich pyta-
nie: jeÊli dysponuje si´ dostatecznie du˝à mocà obliczeniowà, to jaki
algorytm wyszukiwania informacji jest optymalny? Innymi s∏owy, czy
mo˝na stworzyç lepszà przeszukiwark´, dopuszczajàc nie natychmia-
stowe przetwarzanie danych? Wynikiem podj´tych prac by∏ algorytm
opisany w tym artykule. Ostatnio ten zespó∏ badawczy zajmuje si´ spo-
∏ecznoÊciami internetowymi.
Literatura uzupe∏niajàca
Search Engine Watch (www.searchenginewatch.com) zawiera ak-
tualne informacje o nowych przeszukiwarkach. Projekt WordNet
opisany jest w ksià˝ce WordNet: An Electronic Lexical Database (MIT
Press, 1998). Iteracyjny algorytm wykrywania êróde∏ autorytatyw-
nej informacji i w´z∏ów odnoÊników pojawi∏ si´ po raz pierwszy
w publikacji Jona M. Kleinberga „Authoritative Sources in a Hyper-
linked Environment”, która ukaza∏a si´ w Proceedings of the 9th
ACM-SIAM Symposium on Discrete Algorithms (SIAM/ACM-
-SIGACT, 1998). Ulepszenie tego algorytmu opisane jest w witry-
nie IBM Almaden Research Center (www.almaden.ibm.com/cs
/k53/clever.html). èród∏em wiedzy ogólnej o analizie cytowaƒ
jest ksià˝ka Introduction to Informetrics (Elsevier Science Publishers,
1990) autorstwa Leo Egghe’a i Ronalda Rousseau. Informacje o pro-
jekcie Google ze Stanford University mo˝na Êciàgnàç z Internetu:
www.google.com
Wyszukiwarka
Podobne podstrony:
15 Sieć Następnej Generacjiid 16074 ppt
Sieć działań(diagram strzałkowy) v 2
Wykład12 Sieć z protokołem X 25 i Frame Relay
Wykład10a Sieć z protokołem X 25 i Frame Relay
Wykład5 sieć zintegrowana ISDN, BISDN
5.1.13 Sieć klient-serwer, 5.1 Okablowanie sieci LAN
Połączenie komputerów w sieć, DOC
progr siec, Materiały Ekonomiczna, badania operacyjne
Krajowa sieć ekologiczna?ONET
SIEĆ FTTH
Sieć krystaliczna
Co charakteryzuje sieć komputerową(1)
Sieć zakładów przetwórstwa rybnego znajduje się na wybrzeżu doc
magiczna siec cwiczenie 3
Nadprzewodniki drugiego rodzaju i sieć wirów
dobor srednic rurociagow w siec Nieznany
Bezprzewodowa sieć WiFi
Odz przekszt na siec Misiekpoprawka
więcej podobnych podstron