CELE SYSTEMÓW OPERACYJNYCH
- zasoby: procesory, pamięć, urządz. zewn., podział zasobów w kontekście kosztów,
- tworzenie maszyny wirtualnej: taka zmiana maszyny fizycznej by była przydatna dla użytkownika.

- wejście-wyjście (dostęp do urządzeń peryferyjnych),
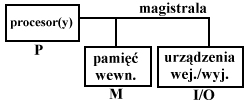
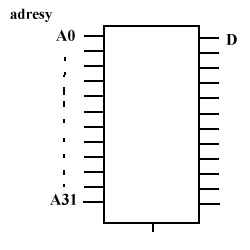
- magistrala: adresowa, danych, sterująca,
PODCEL:
- obsługa urządzeń wej/wyj,
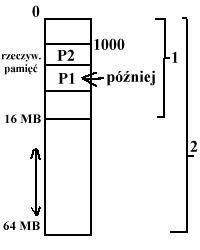
- pamięć operacyjna (tworząc pamięć wirtualną możemy stworzyć na bazie 16 MB (fizycznej) np. 64 MB (wirtualnej))
- system pliku - ma za zadanie koordynować zapis/odczyt za pomocą symboliki a nie zbioru parametrów, co jest niewygodne dla użytkownika. Musi dbać o to, aby zapis/odczyt odbywał się w sposób bezpieczny
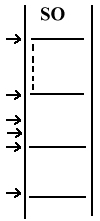
III WYMIARY CSH:
ścieżka (cylinder) na którym dane są zapisane
sektor
strona (głowica)
OCHRONA ZASOBÓW I SYSTEM BŁĘDÓW:
- syst. oper. zezwala aplikacji na dostęp do pewnych bloków pamięci (kod i dane) nie ma mowy o odwoływaniu się do innego obszaru,
- dostęp tylko wybranego użytkownika
- współdziałanie programów (udostępnianie pewnych zasobów innym aplikacjom w ściśle określony sposób)
- sterowanie poleceniami (sposób porozumiewania się człowieka z maszyną (interface))
- język poleceń
- system graficzny
RODZAJE SYSTEMÓW OPERACYJNYCH
- dla indywidualnego użytkownika MS-DOS, WINDOWS NT
- syst. przeznaczone do sterowania procesami (czasu rzeczywistego)
ich cechy:
- sprzężenie zwrotne
- niezawodność
- bezpieczne wyłączenie po awarii
Stosow. w produkcji, kontroli, bądź monitorowaniu.
Rejestruje np. pomiary i na tej podstawie stosuje odpowiednie działania.
System powinien zgłosić do obsługi fakt wystąpienia uszkodzenia i wyłączyć się.
- systemy przepytywania plików - służą do przeglądania i modyfikacji dużych baz danych, czas nie jest kryterium krytycznym.
Wykorzystywane np. w lecznictwie. Systemy policyjne.
- systemy przetwarzania transakcji (np. system rezerwacji miejsc). Szybka wymiana informacji.
- systemy ogólnego przeznaczenia - spotykane najczęściej - są przeznaczone dla szerokiego kręgu odbiorców - otwieranie jednoczesne wielu aplikacji obsłużenia jak najwięcej urządzeń zewnętrznych.
PODZIAŁ SYSTEMÓW
- systemy wsadowe
- systemy wielozadaniowe (interaktywne)
Systemy wsadowe - użytkownik zleca wykonanie pewnego zadania do systemu, system je wykonuje, wyniki przekazywane są bądź w formie wydruku, bądź pliku. Użytkownik nie ma możliwości ingerencji w wykonywaniu zadania.
Systemy interaktywne - posiadają możliwość współpracy z użytkownikiem podczas wykonywania zadania, tzn. pytanie się co robić dalej i przy jakich parametrach.
PODZIAŁ ZE WZGLĘDU NA STANOWISKOWOŚĆ
- systemy jednostanowiskowe
- systemy rozproszone (wówczas gdy na wszystkich syst. komputerowych uruchomimy jeden system operacyjny)
PODZIAŁ SYSTEMÓW ROZPROSZONYCH
- jednorodne (Wszystkie procesory takie same)
- niejednorodne (Dopuszczamy różnice pomiędzy typami procesorów na różnych maszynach. Kod wykonywany na poszczególnych procesorach jest inny (kod wynikowy))
STRUKTURY SYST. OPERACYJNYCH
- struktura jednolita (poszczególne procedury i funkcje mogą się wzajemnie wywoływać)
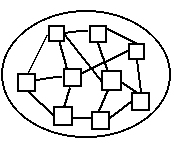
po usunięciu n-błędów pojawia się nowych
n-błędów (ilość błędów jest stała)
- struktura warstwowa (system zbudowany w postaci warstw ułożonych jedna na drugiej. Jądro, poszczególne warstwy, aplikacje dostępne dla użytkownika)
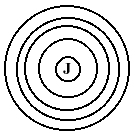
Określamy definicje poszczególnych warstw. Do poszczególnych podprogramów można się odwoływać (część może pozostać wewnętrzna - niedostępna). Warstwy leżące jedynie powyżej mogą odwoływać się do poszczególnych warstw:
do jądra - wszystkie
do pierwszej - wszystkie oprócz pierwszej itd.
Niekiedy określa się tylko pewien przedział warstw (pierścień), które mogą się odwoływać.
Łatwiej taki system tworzyć, a tym samym uniknąć błędów. Poszczególne warstwy można wymieniać i modyfikować.
- struktura typu klient-serwer
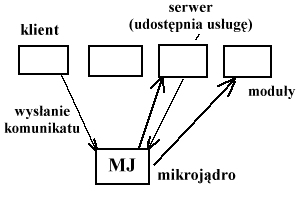
Mikrojądro zachowuje się jak „listonosz”.
Separujemy od siebie poszczególne moduły, komunikacja między nimi odbywa się poprzez mikrojądro.
Rozbijamy system na pewne moduły, które są mniej lub bardziej równorzędne. Oprócz modułów znajduje się tu mikrojądro służące do sterowania modułami. Pośredniczy w przekazywaniu informacji.
Moduł, który potrzebuje usługi jest klientem. Moduł, który usługę udostępnia jest serwerem.
Takim systemem jest np. Windows NT.
Bardzo łatwo jest zaimplementować strukturę klient-serwer w syst. rozproszonych nadając jednemu z komputerów funkcję mikrojądra.
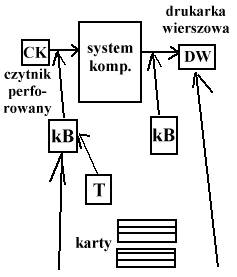
Wstawiamy komputery buforujące o niskiej mocy obliczeniowej, wystarczające do wprowadzania i wyprowadzania danych.
Zadaniem systemu oper. jest maksymalne wykorzystanie mocy obliczeniowej komputera tzn., żeby żaden komp. nie stał bezczynnie.
Komputer buforujący odczytuje dane z pierwszego zadania, po czym przesyła je do komp. głównego poprzez szybkie łącze, wyniki przesyła dalej komp. główny wykonuje zadanie.
Użytkownik łączy się poprzez terminal z komp. buforującym, wysyła kod źródłowy, który jest tam kompilowany, wynik przesyłany jest do komp. głównego, tam następuje wykonanie zadania i odesłanie rezultatu poprzez komputer buforujący.
Wykorzystywane jest to na ogół przy bardzo szybkich komputerach, których czas obliczeniowy jest zbyt drogi na wykonywanie takich czynności jak odczyt danych, czy komunikacja z urządzeniami zewn. Do tego celu służą komputery buforujące. Mają na celu przygotowywać zadania do wykonania dla komp. głównego.
Dołączenie komp. buforujących podraża cenę systemu.
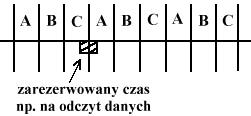
Inne metody wykorzystywania efektywn. systemu:
- przerwanie
- kanał
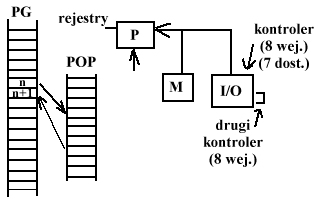
PRZERWANIA
PG - program główny
POP - podprogram obsługi przerwania
Kontrolery można łączyć kaskadowo. W naszych domowych systemach na ogół są 2 kontrolery, połączone kaskadowo, zatem mamy do dyspozycji 7 wejść kontrolera i 8 drugiego.
Mechanizm przerwania polega na tym, że urządz. zewnętrzne przesyłają do układu żądanie obsługi, układ kontrolera przesyła do procesora żądanie obsługi. Procesor kończy wykonywanie bieżącej instrukcji, a następnie przenosi sterowanie do programu obsługi przerwania. Ostatnia z instrukcji powoduje powrót z obsługi przerwań do programu głównego. Po powrocie do PG wykonywana jest n+1 instrukcja. Mechanizm powrotu do właściwego miejsca w PG zapewniany jest przez procesor. Ciąg instrukcji nie może mieć wpływu na program główny.
Podprogram obsługi przerwań nie może korzystać z rejestru procesora (gdyż uniemożliwiłoby to wykonywanie PG).
Kontroler może zgłaszać przerwania.
Linia przerwania niemaskowalnego - musi takie przerwanie zawsze być obsłużone przez procesor. Wykorzystywane do kontrolowania błędów w pamięci.
Sytuacja awaryjna - błąd systemu, błąd kontroli generowania parzystości.
Przerwania maskowalne - można wyłączać i włączać obsługę przerwań (procesor może wyłączyć obsługę przerwań jeżeli nie chcemy przerywać jakiejś aplikacji).
Sygnał RESET - tego polecenia również nie da się zamaskować.
![]()
Rys. Przerwania
Poprzez mechanizm przerwania wyeliminowaliśmy dodatkowy komputer buforujący.
Programy obsługi przerwań powinny być jak najkrótsze (najczęściej pisane są w j. niskiego poziomu - asembler).
Przy korzystanie z rejestrów procesora przed zakończeniem przerwania muszą odtworzyć stan rejestrów.
Kanał - mechanizm bezpośredniego dostępu urządzeń peryferyjnych do pamięci.
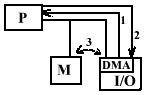
1 - sygnał z żądaniem zwolnienia magistrali
2 - potwierdzenie zwolnienia magistrali
3 - cykl bezpośredniego dostępu do pamięci
Po przeprowadzeniu transakcji układ DMA informuje o tym procesor.
Czas przerwania - kilkanaście-kilkaset μs
Cykl pracy magistrali - kilkanaście-kilkaset μs
Procesor nie ingeruje w proces transmisji w cyklu pracy magistrali, tylko ją zwalnia.
DMA nie można zamaskować (wyłączyć) tak jak w przerwaniach.
Kolejka rozkazów - posiadają ją wszystkie nowoczesne procesory:
1. rozkaz jest pobierany z pamięci do kolejki
2. wykonywany jest pierwszy rozkaz z kolejki
Niektóre rozkazy będące w pamięci mogą być wykonywane w czasie, kiedy nie mają dostępu do magistrali (pod warunkiem, że nie muszą mieć dostępu do pamięci).
Wykorzystanie przerwań i kanałów:
Np. współpraca z dyskiem twardym
- inicjalizacja mechanizmu przerwań i DMA
- przesyłanie za pomocą DMA danych
- po zakończeniu przerwania informuje system o zakończeniu transmisji i odpowiednich zdarzeniach w trakcie transmisji.
W trakcie działania programu odczytujemy dane i wysyłamy wyniki:
![]()
Jest to monitor wsadowy jednostrumieniowy.
Stos - ograniczony obszar pamięci ograniczony z dołu.
![]()
W rejestrze znajduje się wskaźnik pokazujący.
Na stosie dostęp możliwy jest tylko do danej „na wierzchu”.
Stos wykorzystywany jest do obsługi dowolnego podprogramu.
W momencie przerwania na stos wysyłany jest adres, w którym aplikacja została przerwana. Po zakończeniu podprogramu procesor wraca do miejsca, na które wskazuje adres. Adres jest zdejmowany wówczas ze stosu.
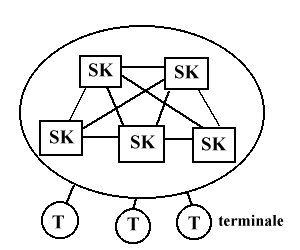
Zamiast użytkownikowi, dostęp do sytemu możemy dać kilku innym systemom.
Powstanie wówczas system wielosystemowy.
Rys. sieciowy system komputerowy
ZADANIA SYSTEMU OPERACYJNEGO
1. Szeregowanie pracy - ustawianie zadań w kolejności umożliwiającej max wykorzystanie systemu.
![]()
Rozpoczyna zadanie E bo jest wolny czas do wykorzystania
2. Sterowanie pracami, interpretowanie poleceń
3. Obsługa błędów:
np. próba odwołania się zadania bezpośrednio do urządzenia peryferyjnego:
- próba odwołania się do obszaru pamięci przeznaczonego dla innego zadania
- próba zapisania danych na uszkodzonym dysku
4. Obsługa urządzeń I/O
m.in. w celu zabezpieczenia syst. przed modyfikacją
5. Planowanie prac - czyli takie ustawienie prac, aby były wykonywane jak najszybciej
6. Sterowanie zasobami
Zasoby to m.in. zmienne, pliki, I/O, pamięć.
7. Ochrona zasobów
8. Umożliwienie dostępności - czyli przełączenie pomiędzy kilkoma użytkownikami - wielozadaniowość
9. Umożliwienie dobrej komunikacji z użytkownikiem. Dwa tryby: tekstowy, graficzny.
10. Ewidencjonowanie zasobów komputerowych. Komputer musi cały czas sprawdzać stan aktualny zasobów (np. pamięć). Komputer może również ewidencjonować różnego rodzaju zadania, np. błędy, dostęp do danych. Umożliwia to monitorowanie dostępu do danych.
WŁAŚCIWOŚCI SYST. OPERACYJNEGO
1. współbieżność (wykonywanie kilku czynności jednocześnie) - przełączanie między czynnościami
2. wzajemna ochrona
3. synchronizacja
4. wspólne korzystanie z zasobów. Jednoczesne korzystanie z zasobów.
1 - program
2 - dane dla okienka 1
3 - dane dla okienka 2
4 - dane dla okienka 3
5 - dane wspólne
5. pamięć długookresowa.
6. Dla takich samych wartości początkowych kolejność wykonywania zadań nie musi być taka sama.
POŻĄDANE CECHY SYSTEMU
1. wydajność - sposoby sprawdzania wydajności:
- średni czas pomiędzy operacjami
- niewykorzystany czas procesora
- długość cyklu przetwarzania prac wsadowych
- Czas reagowania (dla systemów interaktywnych)
- Wykorzystanie zasobów
- Przepustowość informacyjna
2. niezawodność
3. pielęgnowalny, czyli możliwość
- rozszerzenia systemu
- usuwania błędów
- modułowa budowa z określoną komunikacją międzymodułową
- dokumentacja:
a) użytkownika
b) dla administratora systemu
c) dla programistów (możliwe tworzenie
aplikacji dla danego systemu)
d) wewnętrzna producenta (opis poszczególnych
elementów, funkcji, itd.
4. mały rozmiar, czyli:
- mniej błędów
- mniej pamięci
- mniej zajętego miejsca na dysku
PROCESOR
Jest obiektem, który wykonuje rozkazy, może być całkowicie sprzętowy lub realizowane poprzez połączenie sprzętu i oprogramowania.
PROGRAM
Jest to statyczny zestaw instrukcji, wykonywanych przez jednostkę centralną
PROCES
(zadanie) dynamiczny ciąg działań wykonywanych za pośrednictwem programu lub sprzętu.
Program jest statyczny, proces dynamiczny.
Instrukcje, z których składa się program po uruchomieniu przekształcane są w proces.
Jeżeli program uruchamiany jest przez 3 użytkowników to powstają 3 procesy.
Jeden proces może korzystać z wielu programów.
Jeden program może skutkować wytworzeniem wielu procesów.
Każdy z procesów posiada własny stos i własny obszar danych.
WSPÓŁBIEŻNOŚĆ
Wykonywanie kilku procesów jednocześnie.
(musimy mieć system wieloprocesorowy)
WSPÓŁBIEŻNOŚĆ POZORNA
Występuje wówczas, gdy liczba procesów przewyższa liczbę procesorów, czyli liczba czynności jest większa od liczby wykonawców.
We wsp. pozor. system będzie dokonywał przełączeń pomiędzy procesami.
I
![]()
System jednoprocesorowy
Czas poświęcony procesom jest różny.
Należy zapamiętać stan procesu A i przywrócić stan procesu B.
Ważne jest odpowiednie przełączanie między procesami.
II
System wykonujący procesy w równych odstępach czasu.
Dokładnie równy czas poświęcony poszczególnym procesom powoduje nie wykorzystanie procesora (jest nieefektywny).
PROCESY MIĘKKIE
(wątki) - to takie procesy, które mogą odwoływać się do wspólnego obszaru pamięci (np. praca w edytorze tekstu - wątek główny, a drukowanie - wątek poboczny).
KOMUNIKACJA
Wynika z konieczności współdziałania, z drugiej strony współzawodniczenia.
ELEMENTY KOMUNIKACJI
1. wzajemne wyłączanie się - polega na zapewnieniu, by tylko jeden proces korzystał z zasobów niepodzielnych.
ZASOBY:
a) podzielne - jednocześnie może się do nich odwoływać wiele procesów, np. procesory, pliki do odczytu, bloki pamięci przeznaczone tylko do odczytu.
b). niepodzielne - tylko jeden proces w jednym czasie np. większość urządzeń zewn., pliki przeznaczone do zapisu oraz zmienne w pamięci.
2. synchronizacja procesów - procesy działają z założenia asynchronicznie. Jeżeli jakieś procesy współdziałają ze sobą, należy je zsynchronizować.
3. Blokady - wszystkie procesy zawodniczą o zasoby.
Do komunikacji między procesami można zastosować pewne mechanizmy, np.
SEMAFOR - nieujemna liczba całkowita, na której oprócz inicjalizacji można wykonać 2 niepodzielne operacje (czekaj, sygnalizuj)
System musi zapewnić, żeby semafory nie były modyfikowane równocześnie.
W przypadku, kiedy w „kolejce” oczekuje kilka operacji procesor musi w jakiś sposób zdecydować, który proces „wpuścić na tor”.
Create Semaphore - tworzenie semaforów w systemie
(pSA, wo, w max, pN) : HANDLE
pSA - wskaźnik do struktury
wo - liczba początkowa
w max - wart. max semafora (ograniczenie od góry)
pN - wskaźnik do nazwy semafora
Funkcja będzie zwracała uchwyt do semafora, musi być on przypisany do jakiejś zmiennej, aby do semafora można się było odwołać.
Open Semaphore - służy do uzyskania uchwytu do istniejącego semafora o danej nazwie.
(at, if, pN) : HANDLE
at - flaga dostępu do semafora
if - mówi czy może być dziedziczony
pN - wskaźnik do nazwy procesu
Close Handle (HANLDE) : BOOL
Zamyka semafor o podanym uchwycie.
Wait For Single Object (HANDLE, tms) : DWORD
Powoduje oczekiwanie na pewien konkretny obiekt, podajemy uchwyt do semafora oraz czas w milisekundach (max czas wykonywania).
Funkcja może zwrócić informację, czy oczekiwanie zostało zakończone sukcesem, czy nie.
Release Semaphore (HANDLE, Const, pV) : BOOL
pV - wskaźnik do miejsca w pamięci, gdzie została umieszczona poprzednia wartość semafora (przed zwiększeniem)
Podajemy o ile zwiększyć semafor.
BLOKADY (zakleszczenia)
REGIONY KRYTYCZNE - mechanizm automatycznego posługiwania się semaforami.
MONITOR - struktura zawierająca dane, procedura umożliwiająca dostęp do tych danych oraz program inicjalizujący.
Semafory są realizowane automatycznie przez kompilator, tylko jedna procedura może w danym momencie odwołać się do danych.
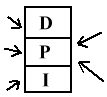
D - Dane
P - zestaw procedur mających się odwoływać do danych
I - kod inicjujący wykonuje się tylko raz
Zadania są kolejkowane nie musimy martwić się o semafory i ich właściwe ułożenie!
Procedury wyślij-odbierz
- postać blokująca proced. wyślij - proces czeka aż dany komunikat dotrze do użytkownika, podobnie jak z postacią wyślij.
- postać nieblokująca.
PROCEDURY
- bezpośrednie
- pośrednie
nadaj (P, kom)
procedura bezpośrednia: jako parametry podajemy i proces i komunikat
nadaj (A, kom)
procedura pośrednia: komunikat wysyłamy do skrzynki
Skrzynka może być buforem ograniczonym lub nieograniczonym.
![]()
W samym komunikacie możemy przesłać wartości lub wskaźniki do pamięci, gdzie znajdują się struktury.
JĄDRO SYSTEMU OPERACYJNEGO
Daje połączenie między systemem komputerowym a pozostałymi warstwami systemu operacyjnego.
Wymagania odnośnie sprzętu:
1. mechanizm przerwań
- obsługa zdarzeń zewn.
- przełączanie procesów
2. ochrona pamięci operacyjnej - powinna być wbudowana do procesora, bez niej nie jesteśmy w stanie zapewnić właściwego działania procesu.
3. zbiór rozkazów uprzywilejowanych (wykonywanych przez procesor, którymi nie może sterować użytkownik)
Tryby pracy (w intelach 4)
- włączanie i wyłączanie przerwań
- przełączanie pomiędzy procesami
- obsługa rejestrów pamięci wirtualnej
- odwoływanie się do urządzeń zewn. (rozkazy wej-wyj)
- rozkazy sterujące procesorem (np. halt)
4. występowanie zegara czasu systemowego - może np. co jakiś czas generować przerwanie i przełączać procesy.
Przełączenie trybu pracy procesora:
- odwołanie się procesu użytkownika do nadzorcy
- przełączenie procesu użytkownika w momencie odebrania przerwania
- błąd, który wystąpi w procesie użytkownika
- próba wykonania rozkazu uprzywilejowanego.
JĄDRO
1. podprogram wstępnej obsługi przerwań
2. dyspozytor procesów
3. operacje: czekaj i sygnalizuj
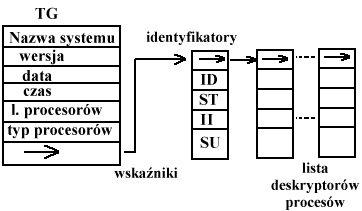
Tablica główna: zawiera wszelkiego rodzaju dane systemowe.
Jądro systemu oper. zazwyczaj pisane jest w języku niskiego poziomu (asembler).
Każdy proces musi mieć inny identyfikator (ID). Stan procesów (ST):
- wykonywany (bieżący, aktywny) uzależniony od ilości procesów
- wykonywalny - w każdej chwili może być wznowiony przez system
- niewykonywalny - proces nie może być wznowiony.
II - inne informacje, np. priorytet procesów, identyfikator użytkownika, który proces uruchomił.
SU - środowisko ulotne - zespół informacji potrzebnych do przełączania procesów.
Kolejka procesora - dodatkowe pole w tablicy głównej. Wskazuje na te deskryptory, które są wykonywalne. Kolejka może być priorytetowa - pierwotny deskryptor ma najwyższy priorytet.
Gdy któryś z procesów stanie się wykonywalny, (zostanie dołączony do kolejki na koniec lub w inne miejsce kolejki), proces niewykonywalny zostaje odłączony od kolejki.
Kolejka wielopoziomowa ze sprzężeniem zwrotnym - mamy wówczas pewien zestaw kolejek, z których każda posiada inny priorytet (pierwsza - najwyższy).
Procesy które wykonują się szybko mają podwyższony priorytet, które natomiast wykonują się długo - mają obniżony priorytet.
Minimalny priorytet - proces jest przypisany do kolejki z wartością najniższego priorytetu, może on zostać tylko podniesiony.
Implementacja operacji czekaj i sygnalizuj. Powody umieszczenia w jądrze:
- dostępność dla wszystkich
- operacja czekaj może zablokować adres
- operacja sygnalizuj może uczynić proces niewykonywalny procesem wykonywalnym.
KOLEJKA SEMAFORA
Lista procesów oczekujących na wej. semafora.
Operacja czekaj będzie odejmowała wartość semafora.
Operacja sygnalizuj będzie zwiększała wartość semafora, chyba że w kolejce semafora znajdują się procesy.
Kolejka semafora może być priorytetową np. pierwszy przyszedł pierwszy wyjdzie lub ostatni wyszedł ostatni wyjdzie.
Zjawisko głodzenia procesów - proces oczekujący w kolejce semafora, nie jest wykorzystany przez dłuższy czas. Występuje w przypadku ostatni przyszedł pierwszy wyjdzie. Dlatego trzeba pamiętać o podnoszeniu priorytetów procesów.
Operacje czekaj i sygnalizuj są niepodzielne.
Operacje zajmij (CLI) i sygnalizuj (STI)
na pocz. na końcu
operacji czekaj lub sygnalizuj
Instrukcja wymień (SWAP)
Wymienia dwie wartości w pamięci.
Proces będzie działać w pętli
tak długo aż uzyska 1.
Instrukcji procesora nie można przerwać. Wiele procesów może dążyć do uzyskania 1. Tylko jeden z procesów uzyska jedynkę od semafora. W ten sposób zapewniamy niepodzielność.
WARSTWA SŁUŻĄCA DO ZARZĄDZANIA PAMIĘCIĄ OPERACYJNĄ
CELE:
- przemieszczanie procesów, np. potrzebowanie dużego ciągłego obszaru wymusza przemieszczenie.
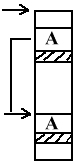
Należy zmienić wszystkie adresy wygenerowane przez procesy.
- ochrona pamięci - wymagamy aby adres generowany przez proces nie wykraczał poza przydzielony blok. Odwołanie się poza ten blok jest niedozwolone.
Nie możemy tworzyć programów samomodyfikujących się. Możemy zabronić procesowi czytania własnego kodu. Proces może się wykonywać ale przy próbie odczytu będzie zgłoszony wyjątek.
- dostęp do obszarów dzielonych - czyli obszarów, do których mogą się odwoływać różne procesy
- organizacja logiczna pamięci - dzięki temu można podzielić zadania pomiędzy różnych programistów. Bloki te mogą mieć różny rozmiar ochrony.
![]()
PG - program główny
PB - procedury bibl.
OB - obsługa błędów
OK - obsługa komunikacji
DP - dane procesów
DD - dane dodatkowe
- organizacja fizyczna pamięci - podział na pamięć główną podstawową i pamięć pomocniczą.
Pamięć główna to RAM, pamięć pomocnicza to dyski twarde itp. Chcielibyśmy aby pamięć pomocnicza była przedłużeniem pamięci głównej.
TWORZNIE ADRESÓW
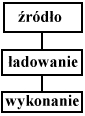
1. można tworzyć adres w czasie kompilacji po warunkiem, że znamy już miejsce gdzie będą znajdować się w pamięci poszczególne funkcje i procedury.
2. można go tworzyć w momencie ładowania. Kompilator tworzy kod wynikowy, który jest przygotowany do umieszczenia pod adresem 0.
3. możemy generować adres na etapie wykonywania.
W momencie dokonywania przesunięcia wszelkie wykonywane procesy muszą być wstrzymane.
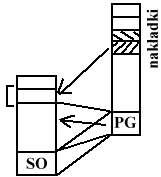
TECHNIKA NAKŁADKOWANIA
System ładuje do pamięci tylko program główny, za ładowanie pozostałych części odpowiedzialni są programiści.
Sam program może wczytywać pewne fragmenty kodu, które są mu aktualnie potrzebne. System nie ingeruje w te działania.
Nazywane jest to nakładkowaniem - nakładki mogą być dowolnie wczytywane do pamięci.
Unika się w ten sposób problemu braku pamięci.
DYNAMICZNIE ŁĄCZONE BIBLIOTEKI (DLL)
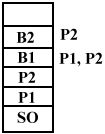
Gdy np. proces P1 zażąda funkcji z biblioteki B1, zostanie ona umieszczona w pamięci przez system. Proces może zrezygnować z danej funkcji. Wówczas system automatycznie usuwa bibliotekę z pamięci.
Tylko biblioteki w danym momencie wykorzystywane umieszczane są w pamięci.
PAMIĘĆ WIRTUALNA
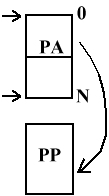
Z punktu widzenia procesów najlepiej byłoby, aby pamięć była od 0 do pewnego adresu.
W rzeczywistości posiadamy przestrzeń pamięci.
Pamięć wirtualna zapewnia, że procesy widzą swoją pamięć w taki sposób, w jaki chcą.
System w oparciu o pamięć rzeczywistą musi zapewnić przydział odpowiednich bloków pamięci do procesów.
PA może być większa od przestrzeni pamięci.
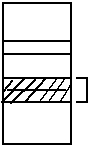
FRAGMENTACJA
Pojawiają się pewne obszary pamięci, które nie mogą być wykorzystane.
Aby tego uniknąć należy przepisać.
Proces upakowywania pamięci ma najniższy priorytet, jest wykonywany kiedy inne procesy na coś czekają.
STRONICOWANIE
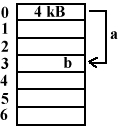
Przestrzeń pamięci adresu jest dzielona na strony.
Podział przestrzeni pamięci na ramki (po 4kB)
Nr strony jest indeksem do tablicy stron.
Uzyskujemy w rezultacie przydział pamięci nieciągły.
Z punktu widzenia procesu jest on ciągły.
Stronicowanie zapewnia takie odwzorowanie przestrzeni adresu w przestrzeń pamięci, gdzie nie musimy martwić się o ułożenie stron.
Kolejne strony umieszczamy w wolnych miejscach.
Pamięć w procesie stronicowania również podlega fragmentowaniu.
Średnio pół ramki jest tracone na 1 blok pamięci. Ostatnia strona nie jest wykorzystana w całości, niewykorzystana część jest tracona.
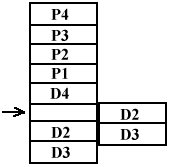
Do każdego bloku pamięci musi istnieć oddzielna tablica deskryptorów stron (TDS).
Upakowanie musi zostać wymuszone kiedy suma obszarów kawałków niewykorzystanej pamięci jest wystarczająca, aby uruchomić kolejny proces, a nie ma na niego wystarczającej ilości wolnej pamięci. To wymuszone upakowanie może zostać przerwane w przypadku uzyskania odpowiedniej ilości pamięci potrzebnej do uruchomienia procesu. Upakowanie nie musi być przeprowadzone do końca.
Wewnątrz procesora możemy umieścić pewną tablicę zawierającą wybrane deskryptory stron.
Jest to tzw. tablica asocjacyjna.
Odwołując się do strony, której nie ma w tablicy asocjacyjnej, jest ona automatycznie umieszczana w pamięci asocjacyjnej.
Może się zdarzyć że suma przestrzeni adresowej będzie większa niż przestrzeń pamięci.
Przeciwdziałanie
![]()
Utworzenie na dysku twardym partycji wymiany.
Nie można zmieścić większej przestrzeni adresowej w mniejszej przestrzeni pamięci. Tworzymy wówczas partycję wymiany (pamięci). Kiedy zaczyna nam brakować pamięci wówczas odsyłamy ramkę strony na dysk twardy.
Jeżeli proces wygeneruje np. adres strony 0, a ta znajduje się na dysku twardym, musi ona zostać przeniesiona do pamięci RAM. Należy więc zwolnić którąś z ramek przestrzeni pamięci.
Najczęściej strony najmniej używane znajdują się w przestrzeni dyskowej. Strony najczęściej używane w przestrzeni pamięci.
Ile procesów jest uruchomionych, tyle tablic deskryptorów pamięci zostanie wygenerowanych.
SEGMENTACJA PAMIĘCI
(3 sposób implementacji pamięci wirtualnej)
Adres dzielony jest na nr segmentu i przesunięcie w tym segmencie.
Segmenty mogą mieć różny rozmiar (strony miały rozmiar narzucony z góry)
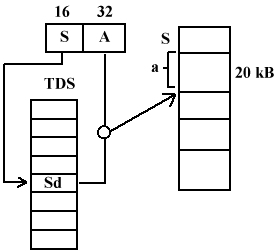
Nie możemy się odwoływać do segmentu poza jego granice (np. 20 kB) w takim przypadku zostanie wygenerowany w procesie wyjątek.
Tablica deskryptorów segmentów - przechowujemy w niej długości segmentów.
Pełny adres dzielimy na dwie części cała przestrzeń adresowa jest 48-bitowa.
Dodatkowe informacje w TDS - czy segment znajduje się na dysku, czy w pamięci. Czy dany segment jest tylko do odczytu, czy tylko do wykonania. Możemy określić prawa dostępu do wybranego segmentu.
RÓŻNICE POMIĘDZY SEGMENTACJĄ A STRONICOWANIEM
- rozmiar segmentu może być dowolny, strony są przyporządkowane do ramek o stałym rozmiarze
- jeżeli mamy adres i generujemy kolejny adres, dojdziemy do końca strony, a następnie płynnie do strony n+1. W przypadku segmentacji gdy dochodzimy do ostatniego adresu ostatniego segmentu, zostanie zgłoszony wyjątek, ponieważ nie mamy prawa wyjścia poza segment
- przy próbie odwołania się do adresu nie znajdującego się w pamięci, a na dysku, musimy ponownie wczytać go do pamięci. W przypadku segmentacji mamy możliwość określenia praw dostępu do segmentów.
Istnieje możliwość łączenia technik stronicowania i segmentacji. Uzyskamy wtedy segmentację ze stronicowaniem.
STRATEGIE PRZYDZIAŁU PAMIĘCI
1. wymiany
2. pobierania
3. rozmieszczenia
Są one zależne od tego, jaki model pamięci przyjmiemy.
![]()
Rozmieszczanie bez stronicowania.
Mamy dziury pamięci, które powinniśmy w jakiś sposób wykorzystać.
Prowadzimy ewidencję dziur w pamięci.
- wariant najlepszego przyporządkowania - zaczynając od najmniejszej dziury, przeszukujemy wolne obszary pamięci, dziury są uporządkowane od najmniejszej do największej.
- wariant najgorszego dopasowania - lista dziur ułożona jest od największej do najmniejszej.
Po przydziale w przypadku najlepszego dopasowania zostaje mały skrawek pamięci, który zostanie już bezpowrotnie stracony.
W przypadku najgorszego dopasowania pozostały skrawek pamięci jest na tyle duży, że można go jeszcze wykorzystać.
- pierwsze dopasowanie - dziury są ułożone według adresu.
algorytm bliźniaków
Bloki dzielone są na 2, jest ich 2n.
Zwalniając bloki pamięci, sprawdzamy czy jest obok blok o tym samym rozmiarze, sąsiednie bloki o tym samym rozmiarze mogą być łączone.
System będzie tak przydzielał pamięć, aby wolny blok pamięci nie był za duży. Jeśli jednak jest, podzieli go na dwa i spróbuje tam umieścić fragment programu. Jeśli wciąż jest za duży, dzieli jeszcze raz, itd.
Fragmentacja zewnętrzna - pewne bloki pamięci tracone są bezpowrotnie.
ROZMIESZCZANIE ZE STRONICOWANIEM
Wybieramy dowolny blok programu w dowolnym miejscu.
Średnio połowa ramki na jeden blok pamięci zostaje bezpowrotnie tracona - 2 kB fragmentacja wewn. (nie ma możliwości przeciwdziałania upakowaniem).
WYMIANA ZE STRONICOWANIEM
Strona, która od dłuższego czasu nie była używana, oraz strona najmniej używana są odsyłane na dysk twardy.
Również stronę najdawniej załadowaną możemy odsyłać.
WYMIANA BEZ STRONICOWANIA
(windows)
Będziemy odsyłać na dysk całe segmenty lub grupy segmentów.
Należy tak dobierać segmenty do odesłania, aby ilość i rozmiar były jak najmniejsze. W pierwszej kolejności odsyłamy segmenty najrzadziej używane.
POBIERANIE
- na żądanie - gdy generujemy adres, którego nie ma w pamięci, system ma go automatycznie wprowadzić z dysku
- pobieranie z przewidywaniem - pobierając np. stronę 1 od razu 2, ponieważ może będzie za chwilę odwołanie do niej (jest to rozwiązanie czasochłonne).
Uruchomienie zbyt wielu procesów powoduje doprowadzenie do efektu szamotania i gwałtownego spadku wydajności.
OBSŁUGA WE/WY
Różnice w działaniu urządzeń peryferyjnych
- prędkość działania (10-2 - 1010)
- jednostki przesyłania (bity, bajty, podwójne słowa - 16-bitowe, poczwórne słowa - 32-bitowe)
- reprezentacja danych w danym urządzeniu (w przypadku klawiatury, po naciśnięciu klawisza do systemu doprowadzany jest jego numer, a nie numer kodu znaku na nim się znajdujący)
- operacje uprzywilejowane - np. drukarka: przesuw do nowej strony, dysk: ustaw głowicę o nr na określonym sektorze.
- różne błędy występujące dla urządzenia: drukarka: brak papieru, dysk: błąd sumy kontrolnej.
WYMAGANIA STAWIANE SYSTEMOWI
- niezależność od kodu znaku - kod potrzebny drukarce na wydrukowanie znaku „a” może być różny od „a”
- niezależność od urządzeń we/wy - realizując dostęp do urządzenia chcemy, aby dostęp ten zrealizowany był w podobny sposób
- wydajność - chcemy, aby obsługa urządzeń była tak zrealizowana, aby procesy nie musiały zbyt długo czekać na komunikację z urz. peryferyjnym.
- jednolite traktowanie urządzeń - bez względu na rodzaj urządzenia ma być taki sam interfejs.
MECHANIZMY UŁATWIAJĄCE OBSŁUGĘ I/O
- wewnętrzny kod znaku - kody wysyłane przez klawiaturę różnią się od wewn. kodu znaku, dlatego musi być wykonane tłumaczenie, w przypadku drukarki jest na odwrót.
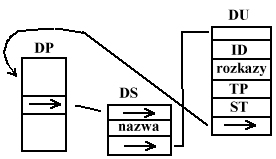
- urządzenia wirtualne - (inne nazwy: strumienie, bloki) poprzez nie następuje komunikacja z urz. fizycznymi; z punktu widzenia dowolnej aplikacji widoczne są dowolne urządzenia wirtualne.
ID - identyfikator
Rozkazy - rozkazy możliwe do wykonania na urz.
TP - tablice przekodywujące (mogą nie być jednoznaczne)
ST - stan urządzenia
- wskaźnik do deskryptora procesu, który w danym momencie korzysta z urządzenia.
DP - deskryptor procesu
DS - deskryptor strumienia (każdy ze strumieni musi mieć unikatową nazwę, związane są z danym urządzeniem fizycznym)
DU - deskryptor urządzenia
Struktura może ulec zaburzeniu. Pomiędzy deskryptorem strumienia a deskryptorem urządzenia może pojawić się deskryptor pliku. Pojawi się gdy będziemy odwoływać się do pliku lub do urządzenia poprzez plik.
PODPROGRAMY UMOŻLIWIAJĄCE KOMUNIKACJĘ Z URZĄDZ. WE/WY
Podprogramy te muszą być podprogramami wielowejściowymi, tzn. wiele procesów może się do nich odwołać.
ZADANIA:
- tworzenie bloków zamówień wejścia-wyjścia
- informowanie procesu obsługi, że został dla niego przygotowany blok zamówień
MECHANIZMY PRZYSPIESZAJĄCE DZIAŁANIE OPERACJI WE/WY
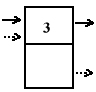
1. BUFOROWANIE
przy dwóch buforach w jednym umieszczane są informacje, a w tym czasie jest odczyt i na odwrót.
Ilość buforów może być zwiększona.
W przypadku zbyt częstego wysyłania informacji zacznie nam brakować czasu. Wówczas wykorzystywane są bufory.
Im większa ilość buforów, tym większą ilość informacji możemy wysłać.
Max szybkość uzależniona jest od szybkości komunikowania się systemu z urządzniem.
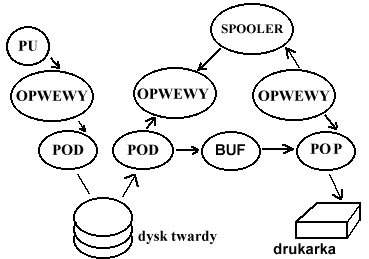
2. MECHANIZM SPOOLERA
POD - proc. obsługi dysku.
W takim mechanizmie wiele procesów może zapisywać dane i wydrukować.
Z punktu widzenia procesu zapis na dysk (dla procesu = wydruk) odbywa się natychmiast.
Spooler pobiera kolejne pliki zapisane na dysku i wysyła na drukarkę.
Nie będzie miała miejsca sytuacja, że dwa procesy wydrukują dane jednocześnie.
Drukarka jest urządzeniem niepodzielnym, ale przy udziale systemu, korzystając z dysku, z punktu widzenia procesu użytkownika staje się urządzeniem podzielnym.
Wydruki są zapamiętywane na dysku, dlatego możemy „drukować” nawet jeżeli urządzenie jest zepsute (drukarka). Rzeczywisty wydruk nastąpi gdy drukarka będzie gotowa do pracy.
SPOOLER zapewnia podzielność drukarki.
SYSTEM PLIKÓW
Wynika to z dwóch potrzeb, które są następujące:
- pamięć dostępna bezpośrednio
- wspólne korzystanie z informacji (jeśli wielu użytkowników korzysta z tych samych danych powinna być stworzona tylko 1kopia)
System plików tworzy organizację danych i pozwala z nich korzystać w sposób wygodny dla użytkownika.
Przez plik rozumiemy zbiór danych traktowanych jako jedna całość; najczęściej używany rozmiar bloku ma 4kB.
ZADANIA
- tworzenie i usuwanie plików
- dostęp do odczytu i zapisu
- zarządzanie obszarem pamięci pomocniczej
- odwoływanie się do plików poprzez nazwy symboliczne
Odwołując się do informacji musimy podać CHS
C - nr cylindra
H - nr głowicy
S - nr sektora
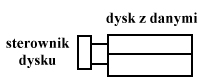
- ochrona plików przed skutkami awarii
1 sterow-nik
Dwa dyski zawierają identyczne informacje. Każdy z dysków może ulec awarii, wówczas na drugim informacje są nienaruszone.
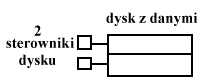
2 sterowniki
Jest to dupleksing.
Pozwala on zdublować dyski i sterowniki.
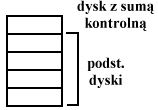
Dysk zawiera sumę kontrolną wszystkich dysków. W przypadku awarii któregoś z czterech dysków dane mogą być odtworzone na podstawie 3 pozostałych i dysku z sumą kontrolną. Macierze dyskowe (RAID).
Katalogi plików - tabele zawierające opisy poszczególnych plików.
Jedną z podstawowych informacji jest adres pliku na dysku twardym. Atrybuty. Informacje administracyjne: data, czas (utworzenia, modyfikacji, ostatniego otwarcia).
Możemy przechowywać informacje o plikach w jednym katalogu (struktura jednopoziomowa). Wada: nazwy muszą być unikalne.
Struktura dwupoziomowa - w katalogu głównym znajdują się informacje o katalogach.
Struktura wielopoziomowa - możemy mieć wiele katalogów.
Dowiązania do plików:
- trwałe
symboliczne
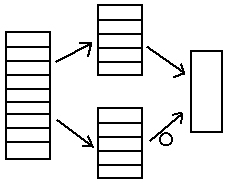
Dowiązanie trwałe
Wprowadzenie pośrednika (węzeł) w którym znajdują się informacje o ilości dowiązań.
Kasując inf. w katalogu jeżeli liczba dowiązań jest większa od zera plik pozostanie na dysku.
Dowiązanie symboliczne - wskazujemy opis w katalogu (a nie plik). Nie występuje tutaj problem wskazywania na puste miejsce lub inny od oczekiwanego.
ORGANIZACJA PAMIĘCI POMOCNICZEJ
- system plików zwarty - pliki są umieszczane na nośniku (dysku) jeden za drugim. W całości z katalogu dostajemy informacje o miejscu umieszczenia pliku i jego długości. Dostęp jest stosunkowo szybki, głowice nie muszą wykonywać wielu ruchów. W przypadku awarii łatwo jest odzyskać informacje. Wady przy kasowaniu. W zwalnianym miejscu możemy utworzyć plik o mniejszym rozmiarze.
W tej organizacji wymagane jest częste upakowywanie plików.
Mogą wystąpić problemy przy zapisie plików, bo w czasie zapisu system często nie wie, jak duży będzie plik.
- system oparty o łańcuch powiązanych bloków/ bloki mogą być zapisane w dowolnym miejscu na dysku. Unikamy w ten sposób problemu związanego z kasowaniem czy zapisywaniem.
- mapa plików (FAT)
FAT 16 - 16 bitów (jeden blok mapy plików)
FAT 32 - 32 bity (jeden blok mapy plików)
- bloki indeksów
PROCEDURA OTWIERANIA PLIKU
- wyszukiwanie nazwy pliku
- sprawdzenie, czy proces chcący otworzyć plik ma do tego prawo
- sprawdzenie, czy plik jest już otwarty
- ustalenie urządzenia, na którym znajduje się plik oraz jego lokalizacji
- utworzenie deskryptora pliku
* deskryptor centralny:
- nazwa pliku
PROCEDURA ZAMYKANIA PLIKU
- usuwanie deskryptora lokalnego
- zmniejszenie (jeśli przyjmie on wartość 0 wówczas usuwany jest deskryptor centralny)
Plik może być otwierany do zapisu tylko przez 1 proces.
Aby móc otworzyć plik w trybie do zapisu przez kilku użytkowników system oper. musi być odpowiednio skonstruowany, tak jak i aplikacje.
Na ekranie widać co dokonują inni użytkownicy w tym pliku.
Aplikacja musi przesłać informacje do systemu o modyfikacjach, musi się to dziać na bieżąco.
System rozsyła informacje o modyfikacjach do pozostałych aplikacji.
Żeby zapewnić bezpieczeństwo w systemie plików stosowane jest tzw. składowanie:
- składowanie globalne
- składowanie przyrostowe
Składowanie globalne polega na zapisaniu na taśmie całego systemu plików. Jest to proces czasochłonny, może trwać wiele godzin.
Składowanie przyrostowe - zapisujemy na taśmie tylko te pliki, które uległy modyfikacji.
W przypadku awarii najpierw odtwarzamy składowanie globalne, a następnie z kolejnych kopii przyrostowych.
Proces składowania plików ważny jest szczególnie w przypadku instytucji.
PLANOWANIE DOSTĘPU DO DYSKU
FCFS - pierwszy przyszedł, pierwszy zostanie obsłużony. Najprostsza metoda.
SSTF - najkrótszy czas odszukiwania. System wie, nad którą ścieżką znajduje się głowica. Zawsze wybieramy to zlecenie z puli zleceń, które może zostać obsłużone w najkrótszym czasie (najkrótszy czas dostępu).
SCAN - przesuwając się po drodze realizuje wszystkie napotkane zlecenia, po czym wraca (cały czas realizując wszystkie napotkane zlecenia)
![]()
C-SCAN - głowica porusza się w jedną stronę, realizując zlecenia, przenosi się na początek i dopiero wtedy ponownie rozpoczyna realizację zleceń.
![]()
Większe jest prawdopodobieństwo powstania zleceń na początku dysku niż w miejscu, gdzie głowica już była.
LOOK - głowica porusza się tak długo, aż na jej drodze nie będą znajdowały się zlecenia.
![]()
C-LOOK - głowica będzie się cofać do pierwszego miejsca na dysku.
![]()
Oprócz 2 pierwszych metod (FCFS, SSTF), optymalizują one czas dostępu do dysków. W czterech ostatnich metodach (SCAN, C-SCAN, LOOK, C-LOOK) czas dostępuj jest znacznie krótszy niż w dwóch pierwszych.
Wyszukiwarka
Podobne podstrony:
Systemy Operacyjne Wykład 2, UŁ WMiI, Wykłady SYS OP, W 2
Systemy operacyjne - wykłady, Administracja, Administracja, Administracja i samorząd, Polityka spole
1a, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Systemy operacyjne, Wykład, Systemy, Sy
TAM GDZIE PLUS TO ODPOWIEDŹ POPRAWNA, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Syste
systemy operacyjne wykłady xfafhlipgfpwdqhwx4pauokspldpoykwxr5637q XFAFHLIPGFPWDQHWX4PAUOKSPLDPOYK
Systemy Operacyjne Wykład 2
sowyk, pwr, informatyka i zarządzanie, Informatyka, Systemy operacyjne- laborki i wykład
Systemy Operacyjne Windows 10 2010 wykład 2
caban,systemy operacyjne II, opracowanie wykładu
wykłady systemy operacyjne ciąg?lszy
wykłady systemy operacyjne
Podstawy Informatyki Wykład IV System operacyjny
Sciaga Systemy wyklad kolo 27 01 2008, szkola, systemy operacyjne i mikroprocesory
Systemy operacyjne
więcej podobnych podstron