Opracowanie pytań na egzamin dyplomowy.
Mgr Teresa Podhorska
Zadania preprocesora
Rusza do pracy przed kompilatorem. Dyrektywy preprocesora oznacza się przez #. Dołącza pliki nagłówkowe. #define pozwala na definiowanie oznaczeń. Mamy możliwość tworzenia makr. Oznaczenia charakterystyczne dla danego komplitora #pragma.
Optymalizacja kodu
Pozawala przyspieszyć wykonanie danego programu kosztem rozmiaru kodu wynikowego lub przenośności.
gcc:
-O - podstawowa, najszybsza
-O2 - mocniejszy, ale jeszcze bezpieczny
-O3 - niebezpieczny
-Os - rozmiar pliku
Metody konstrukcji złożonych deklaracji
czytamy nazwę
posuwamy się w prawo (gdyż tam mogą się znajdować najsilniejsze operatory () i [] )
jeżeli w prawo już nic nie ma albo jest nawias zamykający - zaczynamy czytanie w lewo. Czytamy do końca lub do napotkania nawiasu.
Jeżeli natknęliśmy się na nawias wychodzimy z niego i rozpoczynamy czytanie w prawo (czyli od punktu 2)
typ (*twf[5])(typ,typ) - tablica wskaźników do funkcji typ fun(typ,typ)
int ( * (*fw)(int, char *) )[2] - fw jest wskaźnikiem do funkcji wywoływanej z argumentami (int, char *), a zwracającej wskaźnik do 2 elementowej tablicy typu int.
Instrukcje iteracyjne
nazywane pętlami umożliwiają powtarzanie pewnego zbioru instrukcji do momentu spełnienia warunku wyjścia z pętli
- while (warunek) instrukcja; — warunek sprawdzany na początku
- do instrukcja while(warunek); — warunek sprawdzany na końcu
- for (inicjalizacja; warunek; inkrementacja ) — inicjalizacja jest wykonywana tylko raz przed rozpoczęciem wykonywania pętli, warunek jest sprawdzany przed każdą iteracją, inkrementacja jest wykonywana po każdym obiegu.
- foreach(typ nazwa in kolekcja) — przechodzi kolejno miedzy elementami kolekcji
Instrukcje warunkowe
If, switch, operator warunkowy
Tworzenie i usuwanie zmiennych dynamicznych
Zmienne dynamiczne na stosie
Wiązane z pamięcią w chwili, gdy wykonanie programu dociera do ich deklaracji.
Pamięć zwalniana, gdy kończy się wykonanie bloku zawierającego daną zmienną.
Dla typowych zmiennych prostych (całkowite, zmiennopozycyjne) wszystkie atrybuty z wyjątkiem pamięci są wiązane statycznie.
Zalety: Mogą być używane w wywołaniach rekurencyjnych.
Wady: Mniejsza efektywność ze względu na pośrednie adresowanie, narzut związany z alokacją i dealokacją, brak „historii” (każde wywołanie podprogramu tworzy nową instancję zmiennych).
Przykład: Zmienne lokalne w funkcjach w języku C i w metodach w Javie.
Zmienne dynamiczne na stercie, jawne
Alokowane przez programistę w trakcie wykonania programu za pomocą jawnych poleceń, np. new, malloc.
Dealokowane również jawnie (w C i C++ za pomocą free i delete) lub niejawnie poprzez mechanizm odśmiecania (Java, C#).
Nie mają nazwy; dostępne są poprzez wskaźnik lub referencję.
Zalety: Mogą być używane do tworzenia dynamicznych struktur danych, np. list wiązanych i drzew.
Wady: Niska efektywność z powodu pośredniego trybu adresowania i skomplikowanego zarządzania stertą. Także duże ryzyko nadużyć ze strony nieostrożnego programisty.
Uwaga: W poniższej sytuacji wiązanie typu jest statyczne; dynamiczne jest natomiast wiązanie pamięci.
Zmienne dynamiczne - są to zmienne tworzone przez programistę w pamięci wolnej komputera (na stercie)
W języku „C++ ” do dynamicznego przydzielania pamięci wygodnie jest wykorzystywać operatory new i delete :
Operator new służy do alokacji pamięci (w C podobnie malloc i calloc) obiektom i tablicom obiektów.
Przy alokacji obiektów (ale nie tablic) możliwa jest inicjalizacja.
Operator delete służy do zwalniania przydzielonej pamięci
wskaźnik_na_obiekt = new typ_obiektu [parametry_inicjacyjne];
delete wskaźnik_na_obiekt;
np.
char *wsk;//wskaźnik na zmienną zakową
wsk = new char;//utworzenie nowego obiektu char
delete wsk;//zwolnienie obiektu
int* wsk ; // wskaźnik na zmienną typu całkowitego
wsk = new int ; // utworzenie nowego obiektu (nowej zmiennej int)
*wsk = 100 ; // przypisanie wartości (poprzez wskaźnik)
cout<<( *wsk ); // wydrukowanie zawartości zmiennej dynam.
• • •
delete wsk ; //zwolnienie obiektu
Malloc(size* n), calloc( n, size), realloc(t,size), New free ,delete
- w przeciwieństwie do malloc i free New i delete uruchamiają konstruktory i destruktory. Malloc zwraca void* new zwraca typ*.
Zmienne i zarządzanie pamięcią (słowa kluczowe: auto register static, extern)
AUTO: Wszystkie zmienne deklarowane wewnątrz funkcji są lokalne dla danej funkcji. Żadna inna funkcja nie ma do nich bezpośredniego dostępu. Każda zmienna lokalna funkcji, zaczyna żyć w chwili wywołania funkcji, a znika po jej zakończeniu.
Z tego typu obiektami wiąże się słowo kluczowe auto : auto int x;
Deklarator auto jest prawie zawsze nadmiarowy. Jest on rzadko używany, ponieważ obiekty są definiowane jako automatyczne przez domniemanie.
Modyfikator nakazujący kompilatorowi utworzenie zmiennej na stosie aplikacji (przez prostą inkrementację lub dekrementację wskaźnika stosu). Kiedyś nazywane było to automatycznym tworzeniem zmiennej. Stąd wzięła się nazwa tego modyfikatora.
Modyfikator auto kiedyś nie pozwalał kompilatorowi umieścić zmiennej w rejestrze, tak aby istniała pewność co do posiadania przez zmienną adresu w pamięci RAM. Ta ostatnia właściwość jest niezbędna jeżeli mają być do takiej zmiennej tworzone wskaźniki czyli można wykorzystać wobec niej operator &.
Dzisiaj modyfikator auto ze względu na jego domyślne stosowanie dla wszystkich zmiennych agregatowych, złożoność współczesnych kompilatorów, ich możliwości analizy oraz optymalizacji kodu - ma znaczenie wyłącznie historyczne. Użycie tego modyfikatora nie jest nadmiarowe jeżeli nie wyspecyfikuje się typu zmiennej - ponieważ domyślnie przyjmuje się wtedy typ int, a jeden modyfikator deklaracji zmiennej jest wymagany. Np.: auto indeks = 7;
REGISTER: Deklaracja register jest deklaracją auto, ale niesie więcej informacji. Informuje kompilator, że zmienna będzie często używana i należy ją umieszczać jeżli można w rejestrach przez co znacznie zwiększa sie szybkość progamu.
Kompilator może tę deklarację zignorowac jeżli np. ilość zmiennych zadeklarowanych jako register jest większa niż liczba rejestrów lub gdy w programie pobierany jest adres tej zmiennej.
Deklaracje tej zmiennej ma postać: register int x;
Nie możemy się odwoływać do zmiennej z modyfikatorem register o jej adres. Rejestr nie jest adresem pamięci, gdy usilnie próbujemy dowiadywać się jednak o jej adres, kompilator umieści zmienną w pamięci (gdzie może nam podać adres).
Jednak współczesne kompilatory na tyle optymalizują kod, że same wybierają, które zmienne mają być umieszczone w rejestrze procesora, a które nie.
Więc w praktyce to, że damy modyfikator register nie daje nam pewności, że zmienna będzie przechowywana w rejestrze.
STATIC: Są to zmienne deklarowane przy pomocy słowa kluczowego static. Można ją stosować do zmiennych globalnych i lokalnych. Są wstępnie inicjowane zerami .
Nie można zadeklarować argumentów formalnych funkcji static lub extern.
Specyfikator static można stosować do nazw obiektów i funkcji oraz unii anonimowych;
Lokalne zmienne statyczne są tak samo lokalne dla funkcji, jak zmienne automatyczne. Jednak w przeciwieństwie do automatycznych nie pojawiają się i nie znikają razem z wywołaniem funkcji, lecz istnieją między jej wywołaniami. Czyli przy powtórnym wejściu do funkcji zmienna ma wartość taką jaka miała przy opuszczaniu funkcji.
Globalne zmienne ze specyfikatorem static ogranicza dostępność zmiennej do modułu gdzie ją zdefiniowano.
EXTERN: Oznacza, że deklaracja nie jest deklaracją w sensie fizycznym, a jedynie odwołaniem do deklaracji znajdującej się w innej jednostce kompilacji (module, pliku, bibliotece - przyp. autora). Jednym słowem, jest to sposób na poinformowanie kompilatora, by nie szukał danej zmiennej globalnej w aktualnym pliku.
Specyfikatory extern i static wzajemnie się wykluczają, dlatego nie zaleca się tworzenia deklaracji zawierających obydwa te słowa jednocześnie. Ponadto zabroniona jest inicjalizacja zmiennej zadeklarowanej z użyciem modyfikatora extern!
Jeżeli extern poprzedza deklarację nie zainicjalizowanej zmiennej (globalnej lub lokalnej) albo stałej, oznacza to wówczas, że deklarowany obiekt nie zawiera się w danym pliku, a w innej jednostce kompilacji (może to być inny moduł, nagłówek, biblioteka statyczna lub dynamiczna itp.):
Jeżeli specyfikator ten poprzedza deklarację stałej zainicjalizowanej, oznacza to, że taka stała posiada łączność zewnętrzną (więc z kolei extern przed stałą niezainicjalizowaną importuje taką stałą). W odróżnieniu od zmiennych, które można powstrzymać przed eksportowaniem symbolu przez specyfikator static, stałe globalne wymagają extern, żeby eksportować symbol na zewnątrz.
Wewnątrz funkcji deklaracje ze specyfikatorem extern również wskazują, że pamięć dla deklarowanych obiektów będzie zarezerwowana gdzie indziej. Jeżeli deklaracja obiektu wewnątrz bloku (pętli, funkcji itp. - przyp. autora) nie zawiera specyfikatora extern, wówczas obiekt ten nie ma łączności i jest unikalny w funkcji. W przeciwnym wypadku, gdy w zasięgu otaczającym dany blok obowiązuje zewnętrzna deklaracja tego samego obiektu, wówczas ma on taka samą łączność, jak w deklaracji zewnętrznej i odnosi się do tego samego obiektu.
Nierzadko można natrafić na deklarację prototypu funkcji, której typ wartości zwracanej poprzedzony jest specyfikatorem extern. Oznaczać to może chociażby deklarację funkcji, której ciało (oraz pierwotna deklaracja) znajduje się w innym module. Opcjonalnie można stosować ten specyfikator przed deklaracjami prototypu funkcji w tym samym module, zwłaszcza, gdy ciało danej funkcji umieszczona zostało poniżej funkcji głównej.
Jak jednak zostało wspominane, nie jest to zabieg konieczny, a co za tym idzie, większość kompilatorów ignoruje ten specyfikator przed nazwą funkcji (każda deklaracja funkcji posiada ten kwalifikator domyślnie). Często jest to jednak wymóg w przypadkach, gdy w skład projektu wchodzą m.in. pliki asemblerowskie. Dzięki deklaracji z użyciem extern można się odwoływać do funkcji napisanych w assemblerze, a nigdzie wcześniej niezadeklarowanych (trochę więcej na ten temat w tej części artykułu).
Znaczenie zgoła inne niż dotychczas słowo kluczowe extern ma w języku C++ dla objętych specjalnym blokiem fragmentów kodu. Dzięki wspomnianemu blokowi możliwe jest jawne określenie języka nadającego reguły kompilacji dla danego bloku.
Język C może być bardzo łatwo konsolidowany (łączony) z wieloma innymi językami, które kompilowane są bezpośrednio do kodu maszynowego (m.in.: Assembler, Fortran oraz C++). Ponadto dzięki specjalnym bibliotekom można go łączyć z językami bardzo wysokiego poziomu (takimi jak np. Python czy też Ruby)
Dynamiczne struktury danych
Stos
Stos (ang. Stack) - liniowa struktura danych, w której dane dokładane są na wierzch stosu i z wierzchołka stosu są pobierane (bufor typu LIFO, Last In, First Out; ostatni na wejściu, pierwszy na wyjściu).
Kolejka
Przeciwieństwem stosu jest kolejka, bufor typu FIFO (ang. First In, First Out; pierwszy na wejściu, pierwszy na wyjściu), w którym dane obsługiwane są w takiej kolejności, w jakiej zostały dostarczone
Lista
lista - rodzaj kontenera - dynamiczna struktura danych, używana w informatyce. Składa się z podstruktur wskazujących na następniki i/lub poprzedniki.
Typowa lista jest łączona jednostronnie - komórki zawierają tylko odnośnik do kolejnej komórki. Innym przypadkiem jest lista dwustronna, gdzie komórki zawierają także odnośnik do poprzednika.
Popularna jest także lista zwana słownikową, która zazwyczaj jest wariacją listy jednostronnej. Z reguły stosuje się ją tam, gdzie elementy listy zawierają kilka pól z danymi, a kolejny element może rozszerzać pojęcie (definicję poprzedniego). Przykładem jest prosty translator tekstu, zrealizowany jako lista, gdzie każdy z elementów zawiera dane wyraz i definicja wyrazu - może się okazać, że definicja danego wyrazu ma swoje rozwinięcie (definicję) w pewnym innym elemencie, wówczas tam kieruje się dodatkowy łącznik.
lista jednokierunkowa - w każdym elemencie listy jest przechowywane odniesienie tylko do jednego sąsiada (następnika lub poprzednika).
lista dwukierunkowa - w każdym elemencie listy jest przechowywane odniesienie zarówno do następnika jak i poprzednika elementu w liście. Taka reprezentacja umożliwia swobodne przemieszczanie się po liście w obie strony.
lista cykliczna - następnikiem ostatniego elementu jest pierwszy element, a poprzednikiem pierwszego ostatni. Po liście można więc przemieszczać się cyklicznie. Nie ma w takiej liście charakterystycznego ogona (ani głowy), często rozpoznawanego po tym, że jego następnik jest pusty (NULL).
lista z wartownikiem - lista z wyróżnionym elementem zwanym wartownikiem. Jest to specjalnie oznaczony element niewidoczny dla programisty wykorzystującego listę. Pusta lista zawiera wtedy tylko wartownika. Zastosowanie wartownika znacznie upraszcza implementację operacji na listach.
tablice wskaźników
wskaźniki do funkcji
tablica wskaźników na funkcję
Oszczędzanie pamięci.
Unie anonimowe
union {
int a;
float b;
char c;
} ;
Tak zdefiniowana unia jest tzw. unia anomimową. Takie unie same nie mają nazwy, jak też nie ma nazwy jedyny egzemplarz tej unii.
Do składników tej unii odwołujemy bezpośrednio poprzez nazwę składowej.
Są dwa sposoby oszczędzania pamięci:
1.Używanie tej samej pamięci do przechowywania w różnym czasie różnych obiektów - unie
2. Umieszczenie w jednym bajcie więcej niż jednego obiektu - pola bitowe
Jest to zbiór przylegających do siebie bitów, znajdujących się w jednej jednostce pamięci zwanej słowem.
np: unsigned int odczyt :1; unsigned int zapis :3;
Pola bitowe musi to być typu całkowitego int, signed int lub unsigned int.
Każdemu polu jest przydzielona liczba bitów wynikająca z deklaracji, ale nie więcej niż 16 dla jednego pola bitowego (Borland 3.1).
Pola bitowe mogą się znaleźć tylko w strukturach, uniach i klasach.
struct dostep {
unsigned int odczyt :2;
unsigned int zapis :2;
unsigned int przeglad :4
unsigned int brak :1;
};
- stosować sizeof (zwraca długość w bajtach)
- pobierać adresu
- definiować tablic i adresów na pola bitowe
- stosować makra offsetof (podaje położenie pola w strukturze, w bajtach od początku struktury)
- pola bitowe można definiować tylko w strukturach, uniach i klasach.
- deklarować referencji do pól bitowych
Arytmetyka wskaźników
Wskaźnik - zmienna przechowująca adres jakiegoś obiektu oraz informację o jego typie (wyjątek: void)
- dodanie liczby do wskaźnika powoduje jego przesunięcie po pamięci o tyle miejsc danego typu
- nazwa zmiennej jest adresem początku pamięci
- nazwa tablicy jest wskaźnikiem na adres ale nie można go przesuwać (tab++), za to można się za jego pomocą odwoływać ( *(tab+3) )
- przy odwoływaniu się do wskaźnika za pomocą zapisu tablicowego nie jest sprawdzana legalność takiego odwołania
- odjęcie od siebie 2 wskaźników ustawionych na elementy tej samej tablicy daje w rezultacie odległość między nimi
- wskaźniki można porównywać (jeżeli 2 wskaźniki są sobie równe wówczas wskazują ten sam obiekt)
- porównanie wskaźników operatorami <> >= <= ma sens tylko dla wskaźników ustawionych na ta samą tablicę
- aby przekazać tablicę do funkcji jako tylko-do-odczytu stosujemy jako parametr formalny funkcji wskaźnik const
- wskaźnikowi można nadać konkretny adres ( wsk = 000000) lub utworzyć go na konkretnym adresie ( wsk = adr_ptr new typ )
- wskaźnik można ustawić na:
+adres: wsk = & obiekt; wsk = 3007370
+wskaźnik: wsk = wsk;
+tablicę: wsk = tab; wsk = &tab[3] ;
+funkcję: wsk = fun;
+obiekt bez nazwy: wsk = new typ(arg);
+string: wsk = „str”;
-tablica wskaźników: typ *tabw[num];
-wskaźnik do funkcji: int (*wfun)(…); - deklaracja
wfun = fun; - przypisanie
(*wfun)(...) - użycie
Sposoby przekazywania parametrów do funkcji
-Argumenty / parametry formalne - deklaracja/definicja funkcji;
-Argumenty / parametry aktualne - wywołanie funkcji;
Przez wartość: tworzone są kopie (na stosie) argumentów aktualnych.
Przez Referencję: przekazywany (i odkładany na stosie) jest adres do zmiennej
Przez wskaźnik: wskaźnik będący parametrem aktualnym jest ustawiany na podany adres
Funkcje rekurencyjne
Rekurencja, zwana także rekursją (ang. recursion, z łac. recurrere, przybiec z powrotem) to w logice, programowaniu i w matematyce odwoływanie się np. funkcji lub definicji do samej siebie.
double silnia (unsigned n) |
{ |
if (n > 0) |
return ( n * silnia (n -1)); |
else |
return 1.0; |
} |
|
Typ void
Pusty typ, wskaźnik, na który i z którego można rzutować bez utraty danych. Nie niesie informacji o typie.
Pochodne typy danych
Wyliczeniowy typ danych
enum nazwa { jeden, dwa };
Struktury
struct nazwa {
typ1 nazwa1;
typ2 nazwa2;
};
Unie
union nazwa {
typ1 nazwa1;
typ2 nazwa2;
};
Pola bitowe
typ [identyfikator] : długość;
Tablice
typ nazwa[liczba];
Wskaźniki
typ *nazwa;
typ **nazwa;
typ_zwracany (*nazwa_wsk_do_funkcji)(typ nazwa_parametru1,typ nazwa_parametru2,...);
Klasa,
dziedziczenie
Prof. Walery Rogoza
Paradygmaty programowania.
<z ważniaka>
chodzi raczej o zbiór mechanizmów, jakich programista używa, pisząc program, i o to, jak ów program jest następnie wykonywany przez komputer. Zatem paradygmat programowania to ogół oczekiwań programisty wobec języka programowania i komputera, na którym będzie działał program.
programowanie imperatywne
Programowanie imperatywne to najbardziej pierwotny sposób programowania, w którym program postrzegany jest jako ciąg poleceń dla komputera
Ściślej, obliczenia rozumiemy tu jako sekwencję poleceń zmieniających krok po kroku stan maszyny, aż do uzyskania oczekiwanego wyniku.
Stan maszyny należy z kolei rozumieć jako zawartość całej pamięci oraz rejestrów i znaczników procesora.
Ten sposób patrzenia na programy związany jest ściśle z budową sprzętu komputerowego o architekturze von Neumanna, w którym poszczególne instrukcje (w kodzie maszynowym) to właśnie polecenia zmieniające ów globalny stan.
Języki wysokiego poziomu — takie jak Fortran, Algol, Pascal, Ada lub C — posługują się pewnymi abstrakcjami, ale wciąż odpowiadają paradygmatowi programowania imperatywnego.
Przykładowo, instrukcje podstawienia działają na danych pobranych z pamięci i umieszczają wynik w tejże pamięci, zaś abstrakcją komórek pamięci są zmienne.
programowanie obiektowe
W programowaniu obiektowym program to zbiór porozumiewających się ze sobą obiektów, czyli jednostek zawierających pewne dane i umiejących wykonywać na nich pewne operacje
Ważną cechą jest tu powiązanie danych (czyli stanu) z operacjami na nich (czyli poleceniami) w całość, stanowiącą odrębną jednostkę — obiekt.
Cechą nie mniej ważną jest mechanizm dziedziczenia, czyli możliwość definiowania nowych, bardziej złożonych obiektów, na bazie obiektów już istniejących.
Zwolennicy programowania obiektowego uważają, że ten paradygmat dobrze odzwierciedla sposób, w jaki ludzie myślą o świecie
Nawet jeśli pogląd ten uznamy za przejaw pewnej egzaltacji, to niewątpliwie programowanie obiektowe zdobyło ogromną popularność i wypada je uznać za paradygmat obecnie dominujący.
programowanie funkcyjne
Tutaj program to po prostu złożona funkcja (w sensie matematycznym), która otrzymawszy dane wejściowe wylicza pewien wynik
Zasadniczą różnicą w stosunku do poprzednich paradygmatów jest brak stanu maszyny: nie ma zmiennych, a co za tym idzie nie ma żadnych efektów ubocznych.
Nie ma też imperatywnych z natury, tradycyjnie rozumianych pętli (te wymagają np. zmiennych do sterowania ich przebiegiem).
Konstruowanie programów to składanie funkcji, zazwyczaj z istotnym wykorzystaniem rekurencji. Charakterystyczne jest również definiowanie funkcji wyższego rzędu, czyli takich, dla których argumentami i których wynikami mogą być funkcje (a nie tylko „proste” dane jak liczby lub napisy).
programowanie w logice (programowanie logiczne)
Na program składa się zbiór zależności (przesłanki) i pewne stwierdzenie (cel)
Wykonanie programu to próba udowodnienia celu w oparciu o podane przesłanki.
Obliczenia wykonywane są niejako „przy okazji” dowodzenia celu.
Podobnie jak w programowaniu funkcyjnym, nie „wydajemy rozkazów”, a jedynie opisujemy, co wiemy i co chcemy uzyskać.
Programowanie strukturalne
O programowaniu strukturalnym wspominamy z kronikarskiego obowiązku, jest to bowiem bardzo dobrze znany i powszechnie stosowany „podparadygmat” programowania imperatywnego, czy ściślej — proceduralnego. Chodzi w nim o tworzenie programów z kilku dobrze zdefiniowanych konstrukcji takich jak instrukcja warunkowa if-then-else i pętla while, za to bez skoków (go to). Powinno to sprzyjać pisaniu programów przejrzystych, łatwych w rozumieniu i utrzymaniu.
Programowanie sterowane zdarzeniami
Chodzi o programowanie, w którym zamiast zasadniczego nurtu sterowania mamy wiele drobnych programów obsługi zdarzeń, uruchamianych w chwili wystąpienia odpowiedniego zdarzenia. Zdarzenia mogą być wywoływane przez urządzenia wejścia-wyjścia (np. naciśnięcie klawisza, ruch myszką) lub przez same programy obsługi zdarzeń. Oprócz zbioru programów obsługi zdarzeń potrzebny jest też zarządca, który będzie je uruchamiał.
Programowanie współbieżne
Tym razem mówimy o „nadparadygmacie”, gdyż chodzi o wykonywanie wielu zadań obliczeniowych w tym samym czasie. Istotą problemu jest koordynacja zadań, które komunikują się ze sobą i korzystają ze wspólnych zasobów, a tym samym są od siebie zależne. Pojęcie programowania współbieżnego jest ogólniejsze od programowania równoległego i od programowania rozproszonego. Równoległość oznacza równoczesne wykonywanie zadań przez wiele procesorów; współbieżność obejmuje ponadto podział czasu jednego procesora między wiele zadań — czyli to, z czym mamy do czynienia w praktycznie każdym systemie operacyjnym. O programowaniu rozproszonym mówimy, gdy mamy wiele procesorów połączonych siecią (ale nie wieloprocesorowy komputer).
programowanie liniowe (asembler)
programowanie proceduralne (sekwencyjne)
programowanie strukturalne
programowanie obiektowe (c++, ob. Pascal, smalltalk,…)
programowanie agentowe
programowanie aspektowe
programowanie komponentowe (c#)
programowanie ewolucyjne (alg. Genetyczne )
Koncepcja abstrakcyjnego typu danych.
Specyfikacja zbioru danych i operacji, które mogą być na nich przeprowadzone. Niezależne od implementacji. Stos, lista, kolejka, Mapa , Drzewo.
Abstrakcyjne typy danych
Typ abstrakcyjny to konstrukcja języka programowania, w której definiujemy typ (w dotychczasowym rozumieniu) oraz operacje na nim w taki sposób, że inne byty w programie nie mogą manipulować danymi inaczej niż za pomocą zdefiniowanych przez nas operacji.
Istotą rzeczy jest tu oddzielenie części „prywatnej” typu (czyli szczegółów reprezentacji danych i implementacji poszczególnych operacji) od części „publicznej” (tego, co można wykorzystywać w innych miejscach programu).
Ta koncepcja stała się podstawą rozwoju programowania obiektowego: instancje abstrakcyjnych typów danych (czyli konkretne wartości z typów, zwane obiektami) można postrzegać jako samodzielne byty, które współdziałają poprzez wykonywanie udostępnianych sobie operacji.
Paradygmat programowania obiektowego.
Język obiektowy musi posiadać trzy podstawowe cechy:
Abstrakcyjne typy danych.
Dziedziczenie.
Dynamiczne wiązania wywołań metod z metodami (ściślej: z definicjami metod).
Co to znaczy "obiektowy" (object-oriented)
Orientacja na obiekty, a nie na wartości
Tożsamość obiektów
Operowanie na złożonych obiektach
Abstrakcyjne typy danych
Osłonowanie (enkapsulacja, hermetyzacja)
Dziedziczenie
Polimorfizm
Model obiektowy -- cechy
Orientacja na obiekty
Zalety:
zgodna z ludzkim sposobem myślenia
bardziej dostosowana do natury opisywanej rzeczywistości
Tożsamość obiektów
Każdy obiekt ma niezmienny wewnętrzny id
Obiekty równe nie muszą być tożsame!
Zalety:
można zmieniać wszystkie atrybuty bez utraty tożsamości
zmiany struktury nie burz± integralności referencyjnej
można zmieniać położenie obiektu w strukturze bez utraty jego powiązań
ułatwione zarządzanie wersjami
nie trzeba tworzyć sztucznych kluczy
Złożone typy danych
Możliwości
definiowania złożonych typów
reprezentowania struktur: listy, zbiory itp.
Zalety:
naturalna reprezent. danych złożonych
brak ograniczeń złożoności
lepsza wydajność dla złożonych struktur
Abstrakcyjne typy danych
Dane i operacje na nich definiowane i przechowywane razem
Zalety:
możliwy kod niezależny od typów danych
możliwość samokontroli danych
Osłonowanie (encapsulation)
Idea:
ukrycie "prywatnej" części obiektu
dostęp do danych jedynie przez metody (osłonowanie "ortodoksyjne")
Komunikaty (message passing) -- wywołania metod
Zalety:
oddzielenie implementacji od specyfikacji
duża podatność aplikacji na zmiany
Wady osłonowania "ortodoksyjnego":
schemat struktury danych ukryty przed projektantem
niemożość użycia języków zapytań
problemy z przypisaniem metod dotycz±cych kilku klas
Polimorfizm
Zależność rzeczywistego działania procedur i operatorów od klasy obiektów, na których działają
Wiązanie późne i statyczne
Zalety:
możliwe pisanie kodu niezależnego od typu danych
duża podatność aplikacji na modyfikacje
Dziedziczenie (inheritance)
Dziedziczenie
strukt. danych (strukturalne)
metod (behawioralne)
wartości i wartości domyślnych
reguł integralności
cech wizualnych
zdarzeń i ich obsługi
autoryzacji dostępu
Wielodziedziczenie
Przeciążanie metod i operatorów
Zalety:
naturalna realizacja podtypów
możliwość wielkrotnego wykorzystania struktur i kodu
Smalltalk, C++, Java, C#, Ada, JavaScript
Przeciążanie funkcji i operatorów w języku C++.
Nadanie funkcjom tej samej nazwy, ale przyjmującymi inne zestawy parametrów. Podobnie z operatorami.
Typ_zwacany operator@ (Arg, …)
Polimofizm
Przeciążanie
W niektórych językach dopuszcza się możliwość definiowania w tym samym zakresie widoczności funkcji o identycznych nazwach, lecz różnych sygnaturach. Tę możliwość
wykorzystuje się zwykle w odniesieniu do funkcji o takiej samej (podobnej) semantyce, lecz różnych typach argumentów. Omawiany sposób definiowania funkcji nazywa się przeciążaniem nazw funkcji. Wybór właściwej funkcji ze zbioru wszystkich funkcji o przeciążonej nazwie odbywa się na podstawie analizy jej parametrów aktualnych i ma miejsce
na etapie kompilacji programu.
Jeśli w programie zdefiniowano dwie funkcje o tym samym identyfikatorze i jednakowych sygnaturach, to:
- kompilator sygnalizuje błąd, w wypadku, gdy funkcje są różnych typów,
- funkcja zdefiniowana później w porządku tekstowym przesłania tę wcześniejszą, w przeciwnym wypadku.
W sytuacji, gdy dla poprawnie przeciążonej funkcji nie da się dopasować (analiza list parametrów formalnych i aktualnych!) żadnej z jej wersji do przedmiotowego wywołania,
kompilator sygnalizuje błąd,
Operatory
W języku C++ oprócz nazw funkcji można przeciążyć także większość standardowych operatorów (możliwość ta nie dotyczy operatorów: ., .*, →*, ::, ?:, sizeof). Nie wolno
natomiast definiować własnych operatorów.
Przeciążanie operatorów odbywa się przy zachowaniu następujących reguł:
- definicje operatorów unarnych, operatora indeksacji [] oraz wszelkich operatorów przypisania (=, +=, *=, itd.) można przeciążyć za pomocą funkcji składowej klasy,
- definicje pozostałych dozwolonych operatorów binarnych można przeciążyć przy użyciu funkcji składowej klasy lub funkcji zaprzyjaźnionej z klasą,
- w nowej definicji przeciążonego operatora przynajmniej jeden z jego argumentów jest obiektem przedmiotowej klasy; w szczególności, w definicji sformułowanej przy
użyciu funkcji składowej klasy - lewy argument operatora (pierwszy, ukryty parametr funkcji) musi być obiektem przedmiotowej klasy,
- przeciążony operator zachowuje dotychczasowe: arność,
priorytet oraz łączność.
Nową definicję operatora @ można zadać za pomocą
funkcji składowej klasy, o nagłówku postaci:
- typ_funkcji operator @ (typ_arg arg), w wypadku, gdy
@ jest operatorem binarnym,
- typ_funkcji operator @ (), w wypadku, gdy @ jest operatorem unarnym.
Domyślnym argumentem operatora @ jest w obu powyższych wypadkach przedmiotowy obiekt (*this).
W celu przeciążenia unarnego operatora postfiksowego
(np. x++), należy funkcję określającą przeciążenie zdefiniować jako funkcję o postaci:
typ_funkcji operator @ (int arg),
z dodatkowym argumentem typu int, o znaczeniu wyłącznie rozpoznawczym.
Kapsułkowanie danych i funkcji-członków klasy w C++.
Private, protected
Sposoby inicjalizacji ukrytych danych klasy w C++.
Lista inicjalizacyjna konstruktora. Konstruktor, funkcje zaprzyjaźnione?
Sposoby rozwiązania problemu wycieki pamięci w C++.
Brak kontroli. W destruktorze. Delete.
public:
~player();
Player:: ~player()
{
}
Mechanizmy dostępu do składowych klasy tworzonych statycznie i dynamicznie.
->, . klasa::pole
Definicje systemu rozproszonego i systemu równoległego.
Grupa węzłów autonomicznych, połączonych ze sobą za pomocą sieci komputerowej. Na każdym węźle implementowane są składniki systemu. Funkcjonuje warstwa pośrednia, która pozwala składowym działać w taki sposób, że widzi ten sam system jako jednolite zintegrowany system komputerowy. System równoległy implementacja składników systemu jest wykonywana na komputerze o architekturze równoległej.
Wymagania stawiane systemom rozproszonym.
Proces projektowania oprogramowania rozpoczyna się fazą pojęciową tzn. opracowania wymagań dla systemu zgodnie z funkcjonalnymi i niefunkcjonalnymi właściwościami systemu.
Wymagania funkcjonalne mogą być jasno i ściśle określone w analizie zorientowanej obiektowo.
Wymagania niefunkcjonalne odnoszą się do jakości systemu. Trudniej je sformalizować i utożsamić z funkcjami konkretnych składników. Tymi wymaganiami są:
Współdzielenie zasobów. System rozproszony umożliwia współdzielenie zasobów umieszczonych na różnych komputerach w sieci. Zasoby to sprzęt, oprogramowanie oraz dane. Podział zasobów stosuje się w celu zwiększenia efektywnego wykorzystania kosztownych zasobów.
Otwartość systemu mierzy się łatwością rozszerzenia go o nowe nie należące do niego zasoby. Systemy rozproszone są otwarte i zwykle zawierają sprzęt i oprogramowanie różnych producentów.
Heterogeniczność jest spowodowana użyciem różnych języków programowania, systemów operacyjnych, technologii i platform sprzętowych.
Skalowalność. W zasadzie systemy rozproszone powinny być skalowalne w tym sensie, że można zwiększyć ich możliwości przez dodanie nowych zasobów w celu spełnienia nowych wymagań stawianych systemowi. Architektura systemu jest skalowalna jeżeli posiada właściwości adaptacji do zwiększonego obciążenia bez względu na to czy obciążenie istnieje czy nie.
Odporność na błędy. Odporność na błędy oznacza, że system kontynuuje pracę nawet wtedy, gdy pewne jego części zostaną zablokowane.
Przezroczystość. Polega na ukryciu przed użytkownikiem rozproszonej natury systemu. Celem projektu systemu może być zapewnienie użytkownikom całkowicie przezroczystego dostępu do usług i wykluczenie potrzeby jakiejkolwiek informacji o rozproszeniu systemu
Wymiary przezroczystości systemów rozproszonych.
Przezroczystość polega na ukryciu przed użytkownikiem rozproszonej natury systemu. Celem projektu systemu może być zapewnienie użytkownikom całkowicie przezroczystego dostępu do usług i wykluczenie potrzeby jakiejkolwiek informacji o rozproszeniu systemu. Wyróżnia się następujące wymiary przezroczystości systemów rozproszonych:
Wymiary przezroczystości nie są niezależne! Wymiary przezroczystości systemów rozproszonych są częścią międzynarodowego standardu otwartego projektowania rozproszonego (International Standard on The Open Distributed Design) ISO/EC, 1996.
Przezroczystość dostępu - ukrywa różnice w reprezentacji danych oraz w sposobie dostępu do zasobów.
Przezroczystość lokalizacji - ukrywa miejsce, w którym znajduje się zasób.
Przezroczystość replikacji - zapewnia, że użytkownicy nie mogą określić liczby istniejących kopii zasobu.
Przezroczystość współbieżnego wykonywania - zapewnia, że zasób może być współdzielony przez kilku konkurujących ze sobą użytkowników.
Przezroczystość odporności na błędy - ukrywa przed użytkownikiem błędy i awarie i odtwarza zasoby (program zostanie dokończony bez względu na awarie).
Przezroczystość przenaszalności - zapewnia niewidoczną dla użytkownika możliwość przemieszczenia zasobu do innego położenia
Przezroczystość skalowalności - zapewnia możliwość dodania dodatkowych zasobów.
Modele statyczne i dynamiczne modelu metaobiektowego systemu rozproszonego.
Statyczne:
Schematy klas
Schematy obiektów
Dynamiczne:
Schematy sekwencyjne współdziałania
Schematy współdziałania obiektów
Schematy stanów
Typy warstwy pośredniej w systemach rozproszonych bazujących na paradygmacie programowania obiektowego.
Transakcyjne zorientowana warstwa pośrednia
Wspiera transakcje w rozproszonych bazach danych
Przesyłanie komunikatów
Łączy składniki systemów za pomocą przesyłanych komunikatów. Asynchroniczna komunikacja. Grupowe przesyłanie
Obiektowa warstwa pośrednia
Dodatkowe elementy w budowie systemów rozproszonych. Język definicji interfejsów, możliwość definiowania typów obiektowych.
Poziom prezentacji, odwołanie obiektowe w format transportowy.
Sesja, zapewnia połączenie między wieloma obiektami używając jednego lub kilku połączeń, które nawiązywane są przez poziom transportowy. Przekształcenie odwołań w adresy węzłów, realizacja prymitywów aktywacji i deaktywacji obiektów, wywołanie żądanej operacji i synchronizacja klienta z serwerem.
Odwołania obiektowe w adresy węzłów
Aktywacja obiektów w adapterze
Adapter obiektowy uruchamia serwery
Zarządzanie operacjami
Synchronizacja
Najgłówniejsze składniki architektury CORBY.
Za współdziałanie między klientem a serwerem odpowiadają zapytania obiektowe za wymianę żądań odpowiada ORB. Pseudoobiekt czekający na zgłoszenia. Lokalizuje obiekty, zwraca wyniki do klienta. Statyczne i dynamiczne wywołania.
Klient:
Repozytorium interfejsów
Interfejs ORB
Interfejs wywołań dynamicznych
Pnie klienckie
ORB (IIOP) Internet Inter ORB Protocol
Serwer:
Interfejs wywołań dynamicznych
Adapter obiektowy
Repozytorium implementacji
Szkielety statyczne
IIOP - transportowanie danych, marszaling, demarszaling, adaptery obiektowe (BOA,POA)
Identyfikatory dla składników interfejsu
Składniki architektury DCOMU.
Wywołanie metody
Wywołanie między procesami
Wywołanie między innymi węzłami (rzeczywiste RPC)
Na poziomie aplikacji obiekt-serwer ma wskaźnik do przedstaw. Interfejsu i klasy DCOM.
Klient:
Reprezentant interfejsu
Reprezentant obiektu
Biblioteka DCOM
SCM
Rejestr
Analizator OXID
MS RPC
Serwer:
Realizacja interfejsu
Pień interfejsu
Pień obiektu
Biblioteka DCOM
Analizator OXID
Prezentacja:
marszling, demarszaling
Sesja:
Aktywacja obiektów
Odzwierciedlenie wskaźników
CoGetClassObject
SCM kojarzy obiekty i identyfikatory eksportera obiektów
OXID wskaźnik interfejsowy na węźle serwerowym
Przezroczystość dostępu
Przezroczystość lokalizacji
Istota problemu niejednorodności warstwy pośredniej w systemach rozproszonych, protokoły interoperabilności.
Problemy inteoperabliności:
Korzystanie z różnych języków programowania
Integracja z istniejącymi systemami
Wykorzystanie różnych platform sprzętowych
Różnice w wydajności
Interoperabliność:
Możliwość pracy przy różnej realizacji warstwy pośredniej.
Most zapewnia translacje zapytania, wbudowany i poziomu zapytania.
Prokotokoły:
GIOP
Implementacja IIOP. Dowolne produkty CORBY. Interoprabiloność na postawie formatu komunikatów.
ESIOP
Poszczególne realizacje środowiska.
Zapytanie
Wynik
Parametry
Lokalizacja
Skasowanie zapytania
Zamknięcie
Protokół interoperabliności określa wspólny format komunikatów, za pomocą których odbywa się wymiana informacji.
IIOP (RMI, CORBA) realizuje GIOP, wykorzystując do transportu TCP
Języki programowania zarządzane i nie zarządzane w środowisku Microsoft.NET.
Najgłówniejsze funkcje oprogramowania CLR w środowisku Microsoft.NET:
Definicja i wykorzystanie wspólnego systemu typów danych CTS w środowisku Microsoft.NET.
Wszystkie możliwe typy środowiska, mające swoją reprezentacje w metadanych
Specyfikacja wspólnego języka CLS w środowisku Microsoft.NET.
Ograniczony, ale musi zapewnić
Dr inż. Michał Fiodorow
Pojęcie procesu wytwarzania systemów informatycznych. Przykłady procesów i ich charakterystyka.
Metody szacowania nakładów pracy.
Zarządzanie ryzykiem w procesie wytwórczym.
Rozpoznanie ryzyka
Zasoby
Problemy
Scenariusze
Powszechne
Planowanie procesu
Określenie sposobu oceny ryzyka
Zrąb dla identyfikowania ryzyka
Analiza ryzyk zawartych w procesie
Rozwiązywanie ryzyka
Akceptacja
Ograniczenie
Eliminacja
Przeniesienie (ubezpieczenie)
Metody ustalenia wymagań stawianych oprogramowaniu.
Pojęcie komponentu. Typy komponentów i ich charakterystyka.
Wdrożenia
Wystarczające i niezbędne do scalenia działającego systemu. (biblioteki, pliki wykonywalne).
Procesu wytwórczego
Pliki z kodem, plik danych
Wykonania
Powstałe w wyniku działania systemu, takie jak obiekty COM+, ładowane z dll.
Język modelowania UML. Scharakteryzować podstawowe diagramy.
Statyczne:
Klas
Obiektów
Komponentów (uporządkowanie komponentów i zależności)
Wdrożenia (konfiguracja węzłów działania)
Dynamiczne:
Przypadków użycia
Przebiegu (kolejność przesłania komunikatów)
Kooperacji (struktura organizacyjna)
Stanów (maszyna stanowa)
Czynności (strumień kolejno wykonywanych czynności)
Proces modelowania wymagań funkcjonalnych.
jest kontraktem pomiędzy twórcami systemu a zleceniodawcami,
jest przewodnikiem dla twórców oprogramowania,
służy do weryfikacji systemu
Język naturalny;
Język ustrukturyzowany;
Tablice, formularze;
Diagramy kontekstowe;
Diagramy blokowe;
Diagramy przypadków użycia
Pojęcie architektury systemu informatycznego i jej widoki w procesie wytwórczym.
Organizacji systemu komputerowego
Wyboru elementów strukturalnych i interfejsów
Zachowania elementów
Składania elementów strukturalnych i czynnościowych w coraz większe podsystemy
Stylu architektonicznego według, którego tworzy się konstrukcję systemu tzn. charakterystycznych elementów statycznych i dynamicznych
Perspektywa przypadków (widok użytkownika)
Perspektywa projektowa (klasy, interfejsy, kooperacje)
Perspektywa procesowa (wątki, procesy synchronizacja w systemie)
Perspektywa implementacyjna (komponenty i pliki, użyte do scalenia i udostępnienia systemu fizycznego)
Perspektywa wdrożeniowa (węzły)
Pojęcie wzorca. Wzorce architektury.
Dekompozycja i jej miejsce w procesie projektowania systemów informatycznych.
Zadanie diagramów dynamicznych UML
Dynamiczne:
Przypadki użycia
Przebiegu
Kooperacji
Stanów
Czynności
Służą do specyfikowania, tworzenia zachowania systemu.
Diagramy statyczne UML i ich zadanie i ich związek z kodem
Statyczne:
Klas
Obiektów
Komponenty
Węzły
Odzwierciedlają strukturę systemu, jego szkielet.
Bezpośrednio przekładają się na kod.
Wymienić rodzaje i scharakteryzować wzorce projektowe
Wzorzec projektowy określa strukturę klas.
Czynnościowe
Upraszczają złożone przepływy sterowania, pozwalają skoncentrować się na połączeniu obiektów.
Strategia
Iterator
Metoda Szablonowa
Strukturalne
Opisują składanie obiektów lub klas w większe struktury w celu uzyskania określonej implementacji.
Dekorator
Fasada
Pyłek
Kreacyjne
Pozwalają uabstrakcyjnienie tworzenia obiektów.
Fabryka
Budowniczy
Metoda wytwórcza
Singelton
Testy alpha i beta
Testy metodą białej skrzynki
Projektowanie testów na podstawie logicznej struktury algorytmu
Wszystkie niezależne ścieżki przepływu
Wszystkie możliwe kombinacje decyzji logicznych
Jedno i wielokrotne wykonanie pętli z uwzględnieniem warunków brzegowych
Liczba błędów logicznych i błędnych założeń jest odwrotnie proporcjonalna do częstości wykonywania danego fragmentu kodu
To, co w założeniu miało być rzadko, w rzeczywistości jest bardzo często wykonywane
Pokrycie instrukcji (ang. statement coverage)
Każda instrukcja jest sprawdzana
Pokrycie gałęzi (ang. branch coverage)
Każda gałąź była odwiedzona
Instrukcja warunkowa musi być przynajmniej raz prawdziwa i przynajmniej raz fałszywa
Testy metodą czarnej skrzynki
Testowanie zachowania (behawioralne), funkcjonalne
Badanie interfejsów
Nie zwracamy uwagi na wewnętrzną strukturę logiczną
Pominiętych lub błędnie zaimplementowanych funkcji
Błędnych interfejsów
Błędów w strukturach danych lub metodach dostępu do zewnętrznych baz danych
Niewłaściwego zachowania lub zbyt małej efektywności systemu
Błędów powodujących niewłaściwe uruchamianie się lub wyłączanie systemu
Stosuje się pod koniec testowania
Pomija się strukturę sterowania
Koncentracja na dziedzinie informacyjnej
Umożliwia przygotowanie testów, które:
Zmniejszają (>1) liczbę dodatkowych testów
koniecznych do przetestowania programu
Mogą wykryć lub wykluczyć całe grupy błędów jednocześnie
Omówić paradygmat obiektowy.
Dr inż. Krzysztof Kraska
Wyjaśnij znaczenie pojęcia refaktoryzacji oprogramowania.
Wyjaśnij funkcję Aktora na diagramach przypadków użycia UML.
Wyjaśnij funkcję Przypadku Użycia na diagramach UML.
Omów pojęcia agregacji i zawierania na diagramach UML.
Scharakteryzuj wzorzec projektowy Fasada (ang. Facade).
Scharakteryzuj wzorzec projektowy Fabryka (ang. Factory).
Scharakteryzuj wzorzec projektowy Singleton.
Omów technologię Servletów oraz Java Server Pages.
Omów technologię Enterprise Java Beans.
Omów technologię Java Naming and Directory Interface (JNDI).
Omów technologię Java Messaging System (JMS).
Wymień trzy filary Szybkiego Wytwarzania Aplikacji (ang. Rapie Development) tworzące tzw. Skuteczne Wytwarzanie (ang. Efficient Development).
Wyjaśnij znaczenie trójkąta wyboru Harmonogram-Koszt-Produkt (podstawy zarządzania) dla Szybkiego Wytwarzania Aplikacji (ang. Rapid Development).
Omów kaskadowy (ang. Waterfall) model wytwarzania oprogramowania (ang. software lifecycle model), jego zalety i wady.
łatwość w zarządzaniu projektem
reagowanie na błędy dopiero po zakończeniu procesu wytwarzania oprogramowania, czyli kosztowne usuwanie błędów
mały udział klienta w procesie tworzenia programowania
sztywny harmonogram prac - część zespołu czeka na udział w pracach
Omów model wytwarzania oprogramowania (ang. software lifecycle model) określany jako Code-and-Fix, jego zalety i wady.
Prof. Włodzimierz Bielecki
Kompliatory
Formalna definicja gramatyki i języka
Gramatyki jednoznaczne i wieloznaczne
Klasyfikacja gramatyk
Gramatyki ogólnego rodzaju
Gramatyki kontekstowe
Gramatyki bezkontekstowe
Gramatyki regularne
Problem rozbioru gramatycznego
Analiza leksykalna
Analiza syntaktyczna metodami wyprowadzania
Analiza syntaktyczna metodami redukowania
Dla każdej pary symboli co najwyżej 1 relacja pierwszeństwa
Gramatyka nie zwiera produkcji o identycznych prawych stronach
Wewnętrzne postaci programu źródłowego (notacja polska, czwórki, trójki, drzewa)
Zadania analizy semantycznej
Generowanie przekładu
Techniki optymalizacji przekładu
Przetwarzanie równoległe i rozproszone
Definicja przetwarzania równoległego i rozproszonego, różnica miedzy przetwarzaniem równoległym a rozproszonym
Rodzaje zależności danych
Podstawowe transformacje pętli
Przyspieszenie i efektywność
Prawa Amdahl'a i Gustaffson'a
Paradygmaty programowania równoległego i rozproszonego (programowanie równoległości danych, Programowanie danych dzielonych, programowanie z przesyłaniem komunikatów)
„p”:n - przesunięcie planarne
„c”:n - przesunięcie cykliczne
Redukcja
ma być komutatywna
ma być asocjatywna
Mechanizmy synchronizacji dostępu do sekcji krytycznej
potrzeba powtarzania instrukcji test&set - marnowanie zasobów
brak sprawiedliwości dostępu do sekcji krytycznej
prostota
nie wymaga dodatkowych zasobów systemowych
Metodyka projektowania algorytmów równoległych
lokalna - każde zadanie może kontaktować się tylko z bezpośrednimi sąsiadami
globalna są dopuszczalne dowolne połączenia między procesami
strukturalna - tworzy struktury geometryczne (np. drzewiaste)
niestrukturalna nie można wyróżnić żadnych struktur geometrycznych
statyczna - w czasie wykonywania aplikacji równoległej lub rozproszonej połączenia między zadaniami są stałe
dynamiczna w czasie wykonywania aplikacji równoległej lub rozproszonej można zmienić połączenia między zadaniami
synchroniczna send - receive:
asynchroniczna - po instrukcji send lub receive następuje wykonanie kolejnych instrukcji.
Czas wykonania programu rozproszonego(czas obliczeń, czas komunikacji, czas przestojów)
Modele wydajności aplikacji rozproszonych
Pragmy API OpenMP C/C++
if - kompilacja warunkowa. Jest to modyfikator opcjonalny. Przed wykonaniem obliczana jest wartość wyrażenia - jeśli jest ujemna instrukcje będą wykonywane sekwencyjnie)
private - deklaracja zmiennych lokalnych
firstprivate - zmienna lokalna o określonej wartości
default(none) - kompilator będzie wymagał deklaracji wszystkich zmiennych
default(shared) - wszystkie zmienne będą traktowane jako dzielone
shared - zmienne dzielone
reduction - deklaracja jednocześnie i operacji i instrukcji zmiennych ??????
last private - deklaracja zmiennej lokalnej w ten sposób, że po wyjściu z bloku wartość zmiennej będzie wartością ostatnią
ordered - taka sama kolejność wykonywania instrukcji jak w pętli źródłowej
schedule - metody planowania iteracji:
static - metoda simple w PowerC
dynamic
guided - za każdym razem następuje zmniejszenie liczby iteracji do wykonania
runtime - określenie sposobu podziału iteracji pomiędzy procesory
nowait - bez oczekiwań - każdy wątek, który dokończy wykonywanie swojej porcji iteracji nie czeka aż wszystkie wątki skończą swoje obliczenia
Bonus
Co to jest komputer?
System komputerowy
System informacyjny a system informatyczny?
Sortowanie bąbelkowe
Co to jest informatyka?
Dane, informacje, wiedza
Co to jest baza danych?
Co to jest system zarządzania bazą danych?
J#, C#, VB.NET, MCPP, CPP
Wspólne środowisko uruchomieniowe (Common Language Runtime, w skrócie CLR) to podstawa całego systemu .NET Framework. Wszystkie języki środowiska .NET (na przykład C# czy Visual Basic .NET), a także wszystkie biblioteki klas obecne w .NET Framework (ASP.NET, ADO.NET i inne) oparte są na CLR. Ponieważ nowe, tworzone przez Microsoft oprogramowanie, także oparte jest na .NET Framework, każdy, kto chce korzystać ze środowiska Microsoft, prędzej czy później będzie musiał zetknąć się z CLR.
Środowisko CLR kompiluje i wykonuje zapisany w standardowym języku pośrednim Microsoft (MSIL) kod aplikacji zwany kodem zarządzanym (ang. managed code), zapewniając wszystkie podstawowe funkcje konieczne do działania aplikacji. Podstawowym elementem CLR jest standardowy zestaw typów danych, wykorzystywanych przez wszystkie języki oparte na CLR, a także standardowy format metadanych, służących do opisu oprogramowania wykorzystującego te typy danych. CLR zapewnia także mechanizmy umożliwiające pakowanie kodu zarządzanego w jednostki zwane podzespołami.
W CLR wbudowane są także mechanizmy kontroli bezpieczeństwa wykonywania aplikacji — bezpieczeństwo oparte na uprawnieniach kodu (Code Access Security — CAS) oraz bezpieczeństwo oparte na rolach (Role-Based Security — RBS).
Przy zachowaniu odpowiedniego poziomu abstrakcji, możliwe jest zdefiniowanie zestawu typów danych, który będzie niezależny od składni języka. Zamiast łączyć składnię i semantykę, można je określić oddzielne, co pozwoli na zdefiniowanie większej liczby języków korzystających z tych samych pojęć (typów danych). Takie właśnie podejście zastosowano w CLR. Wspólny zestaw typów danych (Common Type System— CTS) nie jest związany z żadną składnią lub słowami kluczowymi — definiuje jedynie zestaw typów danych, który może być wykorzystywany przez wiele języków. Każdy język zgodny z CLR może używać dowolnej składni, ale musi korzystać przynajmniej z części typów danych zdefiniowanych przez CTS.
Zestaw typów danych definiowany przez CTS należy do głównych składników CLR. Każdy oparty na CLR język programowania może udostępniać programiście te typy danych na właściwy sobie sposób. Twórca języka może skorzystać tylko z niektórych typów danych, może też definiować własne typy danych. Jednak większość języków wszechstronnie korzysta z CTS.
Najważniejsze typy danych zdefiniowane w CTS przedstawiono na ilustracji 2. Warto zwrócić uwagę na to, że wszystkie typy danych to albo typy skalarne (wartości), albo typy referencyjne. Innym godnym zauważenia faktem jest to, że każdy typ danych dziedziczy pośrednio lub bezpośrednio po typie Object — wszystkie typy referencyjne dziedziczą bezpośrednio po klasie Object, natomiast typy skalarne dziedziczą po klasie ValueType, która z kolei dziedziczy po Object.
Wspólny system typów (CTS) definiuje dość złożony i rozbudowany zestaw typów. Niektóre języki nie muszą obsługiwać wszystkich typów, zdefiniowanych w CTS. Jednym z głównych celów CLR jest umożliwienie napisania kodu w jednym języku i wywoływania go z kodu napisanego w innym języku. Aby było to możliwe, obydwa języki muszą w ten sam sposób obsługiwać te same typy danych. Wymóg, by w każdym języku programowania były implementowane wszystkie typy danych zdefiniowane w CTS, byłby zbyt uciążliwy dla projektantów języków programowania. Dlatego powstało rozwiązanie umożliwiające kompromis. Rozwiązaniem tym jest wspólna specyfikacja języka (Common Language Specification — CLS). CLS określa, jak duży podzbiór CTS musi zostać zaimplementowany, by język był zgodny z innymi językami wykorzystującymi CLS. CLS wymaga na przykład, by język obsługiwał większość typów skalarnych — między innymi Boolean, Byte, Char, Decimal, Int16, Int32, Int64, Single, Double. Nie jest natomiast wymagana obsługa typów takich jak UInt16, UInt32, UInt64. CTS pozwala, by najniższy indeks tablicy był dowolną liczbą całkowitą, natomiast CLS wymaga, by najniższy indeks tablicy wynosił 0. CLS określa też inne ograniczenia ułatwiające efektywną współpracę różnych języków zgodnych z CLR.
Specyfikacja wspólnego języka CLS (Common Language Specification) została opracowana i zrealizowana przez firmę Microsoft. Jest to zbiór zasad i cech jakie dany kompilator działający w .NET musi spełniać, by generować kod, który będzie mógł być akceptowany przez CLR i jednocześnie wykorzystywany w ujednolicony sposób przez wszystkie języki działające na platformie .NET. Dzięki specyfikacji CLS wszystkie języki programowania mogą współdziałać między sobą.
Zbiór czynności, które prowadzą do wytworzenia oprogramowania.
MSF 4.0. Role analityk, architekt, PM, dev, tester, RM,
Modele algorytmiczne. Wymagają opisu przedsięwzięcia przez wiele atrybutów liczbowych i/lub opisowych. Odpowiedni algorytm lub formuła matematyczna daje wynik.
Ocena przez eksperta. Doświadczone osoby z dużą precyzją potrafią oszacować koszt realizacji nowego systemu.
Ocena przez analogię (historyczna). Wymaga dostępu do informacji o poprzednio realizowanych przedsięwzięciach. Metoda podlega na wyszukaniu przedsięwzięcia o najbardziej zbliżonych charakterystykach do aktualnie rozważanego i znanym koszcie i następnie, oszacowanie ewentualnych różnic.
Wycena dla wygranej. Koszt oprogramowania jest oszacowany na podstawie kosztu oczekiwanego przez klienta i na podstawie kosztów podawanych przez konkurencję.
Szacowanie wstępujące. Przedsięwzięcie dzieli się na mniejsze zadania, następnie sumuje się koszt poszczególnych zadań.
COCOMO jest oparte na kilku formułach pozwalających oszacować całkowity koszt przedsięwzięcia na podstawie oszacowanej liczby linii kodu. Jest to główna słabość tej metody, gdyż:
liczba ta staje się przewidywalna dopiero wtedy, gdy kończy się faza projektowania architektury systemu; jest to za późno;
pojęcie “linii kodu” zależy od języka programowania i przyjętych konwencji;
pojęcie “linii kodu” nie ma zastosowania do nowoczesnych technik programistycznych, np. programowania wizyjnego.
COCOMO oferuje kilka metod określanych jako podstawowa, pośrednia i detaliczna.
Metoda podstawowa: prosta formuła dla oceny osobo-miesięcy oraz czasu potrzebnego na całość projektu.
Metoda pośrednia: modyfikuje wyniki osiągnięte przez metodę podstawową poprzez odpowiednie czynniki, które zależą od aspektów złożoności.
Metoda detaliczna: bardziej skomplikowana, ale jak się okazało, nie dostarcza lepszych wyników niż metoda pośrednia.
Metoda punktów funkcyjnych oszacowuje koszt projektu na podstawie funkcji użytkowych, które system ma realizować. Stąd wynika, ze metoda ta może być stosowana dopiero wtedy, gdy funkcje te są z grubsza znane.
Metoda jest oparta na zliczaniu ilości wejść i wyjść systemu, miejsc przechowywania danych i innych kryteriów. Te dane są następnie mnożone przez zadane z góry wagi i sumowane. Rezultatem jest liczba „punktów funkcyjnych”.
Punkty funkcyjne mogą być następnie modyfikowane zależnie od dodatkowych czynników złożoności oprogramowania.
Istnieją przeliczniki punktów funkcyjnych na liczbę linii kodu, co może być podstawą dla metody COCOMO.
Metoda jest szeroko stosowana i posiada stosunkowo mało wad.
Niemniej, istnieje wiele innych, mniej popularnych metod, posiadających swoich zwolenników.
Metoda Delphi zakłada użycie kilku niezależnych ekspertów, którzy nie mogą się ze sobą w tej sprawie komunikować i naradzać. Każdy z nich szacuje koszty i nakłady na podstawie własnych doświadczeń i metod. Eksperci są anonimowi. Każdy z nich uzasadnia przedstawione wyniki.
Koordynator metody zbiera wyniki od ekspertów. Jeżeli znacznie się różnią, wówczas tworzy pewne sumaryczne zestawienie (np. średnią) i wysyła do ekspertów dla ponownego oszacowania. Cykl jest powtarzany aż do uzyskania pewnej zgody pomiędzy ekspertami.
Metoda analizy podziału aktywności (activity distribution analysis):
Projekt dzieli się na aktywności, które są znane z poprzednich projektów.
Następnie dla każdej z planowanych aktywność ustala się, na ile będzie ona bardziej (lub mniej) pracochłonna od aktywności już wykonanej, której koszt/nakład jest znany. Daje to szacunek dla każdej planowanej aktywności. Szacunki sumuje się dla uzyskania całościowego oszacowania.
Metody oszacowania pracochłonności testowania systemu
Metody oszacowania pracochłonności dokumentacji
Metody oszacowania obciążenia sieci
Identyfikuj potencjalne problemy zanim wystąpią, tak aby działania zapobiegawcze i naprawcze mogły zostać zaplanowane z wyprzedzeniem i uruchamiane
w odpowiednim momencie życia projektu, dzięki czemu uda się ograniczyć wpływ negatywnych zdarzeń na cele projektu.
MODELOWANIE PRZEDSIĘBIORSTWA - TO TECHNIKA ANALIZY PROBLEMU UKIERUNKOWANA NA OKREŚLENIA WYMAGAŃ NA SYSTEM.
CEL MODELOWANIA PRZEDSIĘBIORSTWA: POZNANIE STRUKTURY I PROCESÓW ZACHODZĄCYCH W PROJEKTOWANYM SYSTEMIE, UJEDNOLICENIE WŚRÓD UDZIAŁOWCÓW WIEDZY I ZNAJOMOŚCI MECHANIZMÓW FUNKCJONOWANIA SYSTEMU.
PRZYPADKI UŻYCIA: IDENTYFIKUJĄ ZACHOWANIE SYSTEMU ODPOWIADAJĄC NA PYTANIA: KTO, CO, JAK? -WYKONUJE CZYNNOŚCI, OPISUJĄ INTERAKCJE MIĘDZY UŻYTKOWNIKIEM A SYSTEMEM: CO SYSTEM ROBI DLA UŻYTKOWNIKA? SŁUŻĄ DO REPREZENTACJI (NP. W JĘZYKU UML) WYMAGAŃ STAWIANYCH SYSTEMOWI.
IDENTYFIKACJA WYMAGAŃ METODĄ „ODGRYWANIA RÓL”
METODA POZNAWANIA ŚWIATA UŻYTKOWNIKA POPRZEZ „GRANIE” JEGO ROLI, TJ. WYKONYWANIA JEGO CZYNNOŚCI. UZASADNIENIE STOSOWANIA METODY: OPIS PROSTEJ PROCEDURY MOŻE BYĆ BARDZO TRUDNY, NP. WIĄZANIE SZNUROWADEŁ; UŻYTKOWNIK NIE MA ODWAGI PRZYZNAĆ SIĘ, ŻE NIE ROBI ZGODNIE Z WYTYCZNYMI SZEFA-POMIMO, ŻE ROBI DOBRZE; UŻYTKOWNIK MA WŁASNE PROCEDURY REALIZACJI ZADAŃ, KTÓRYCH NIE CHCE UJAWNIĆ; ANALITYK NIE JEST W STANIE ZAPYTAĆ O WSZYSTKO O CO POWINIEN.
Rozdział 1. Problem wymagań
Rozdział 2. Wprowadzenie do zarządzania wymaganiami
Rozdział 3. Zespół twórców oprogramowania
Umiejętność zespołowa nr 1. Analizowanie problemu
Rozdział 4. Pięć kroków podczas analizy problemu
Rozdział 5. Modelowanie przedsiębiorstwa
Rozdział 6. Inżynieria systemów informatycznych
Umiejętność zespołowa nr 2. Zrozumienie potrzeb użytkownika
Rozdział 7. Wyzwanie uzyskiwania wymagań
Rozdział 8. Cechy produktu lub systemu
Rozdział 9. Przeprowadzanie wywiadu
Rozdział 10.Warsztat wymagań
Rozdział 11.Burza mózgów i redukcja pomysłów
Rozdział 12.Wykonywanie rysunkowych szkiców ujęć
Rozdział 13.Stosowanie przypadków użycia
Rozdział 14.Odgrywanie ról
Rozdział 15.Stosowanie prototypów
Umiejętność zespołowa nr 3. Definiowanie systemu
Rozdział 16.Organizowanie informacji wymagań
Rozdział 17.Dokument wizji
Rozdział 18.Mistrz
Umiejętność zespołowa nr 4. Zarządzanie zakresem
Rozdział 19.Problem zakresu przedsięwzięcia
Rozdział 20.Ustalenie zakresu przedsięwzięcia
Rozdział 21.Zarządzanie klientem
Rozdział 22.Zarządzanie zakresem przedsięwzięcia oraz modele procesów tworzenia oprogramowania
Umiejętność zespołowa nr 5. Udoskonalanie definicji systemu
Rozdział 23.Wymagania stawiane oprogramowaniu
Rozdział 24.Udoskonalenie przypadków użycia
Rozdział 25.Nowoczesna specyfikacja wymagań stawianych oprogramowaniu
Rozdział 26.Niejednoznaczność i specyficzność
Rozdział 27.Miary jakości wymagań stawianych oprogramowaniu
Rozdział 28.Techniczne metody określania wymagań
Umiejętność zespołowa nr 6. Budowanie odpowiedniego systemu
Rozdział 29.Budowanie odpowiedniego systemu - opis ogólny
Rozdział 30.Od wymagań do implementacji
Rozdział 31.Wykorzystanie możliwości śledzenia do wspomagania weryfikacji
Rozdział 32.Zatwierdzanie poprawności systemu
Rozdział 33.Użycie zwrotu inwestycyjnego do określania wysiłku związanego z weryfikacją i zatwierdzaniem
Rozdział 34.Zarządzanie zmianą
Rozdział 35.Rozpoczęcie pracy
Fizyczna wymienna cześć systemu, która wykorzystuje i realizuje pewien zbiór interfejsów.
Język wprowadzający ujednoliconą notacje dla modelowania, normalizowany język do zapisu projektu systemu.
ETAP OKREŚLANIA WYMAGAŃ OBEJMUJE: DEFINIOWANIE SZEROKO ROZUMIANYCH WYMAGAŃ UŻYTKOWYCH SYSTEMU (ICH: IDENTYFIKACJĘ, GROMADZENIE I SPECYFIKACJĘ); ANALIZĘ I KONSTRUKCJĘ MODELU LOGICZNEGO SYSTEMU, KTÓREGO DZIAŁANIE SPEŁNI TE WYMAGANIA.
WYNIKIEM KOŃCOWYM TEGO ETAPU JEST DOKUMENT „WYMAGANIA.....” ZAWIERAJĄCY NASTĘPUJĄCE ROZDZIAŁY: WPROWADZENIE - CELE, ZAKRES I KONTEKST SYSTEMU; OPIS WYMAGAŃ FUNKCJONALNYCH OPIS WYMAGAŃ NIEFUNKCJONALNYCH OPIS EWOLUCJI SYSTEMU MODEL LOGICZNY SYSTEMU - OPRACOWANY PRZY UŻYCIU, NP. UML SŁOWNIK TERMINÓW NIEJEDNOZNACZNYCH DLA UDZIAŁOWCÓW PRZEDSIĘWZIĘCIA PROJEKTOWEGO
DOKUMENT „WYMAGANIA.....” STANOWI PODSTAWĘ DO REALIZACJI DALSZYCH PRAC PROJEKTOWYCH NAD SYSTEMEM, A W SZCZEGÓLNOŚCI DO OPRACOWANIA TESTÓW AKCEPTACYJNYCH SYSTEMU.
Architektura to zbiór decyzji dotyczących:
Widoki architektury:
Wzorzec to zwyczajowo przyjęte rozwiązanie danego problemu w danym kontekście.
Wzorzec architektury - elastyczny szablon rozwiązań z danej dziedziny. (Nadzorca czasu w systemach czasu rzeczywistego).
SOA
Klient serwer
Peer-to-peer
3 warstwowa
zasada dekompozycji oraz hierarchiczności, polegająca na wydzieleniu ze skomplikowanego problemu podproblemy, które mogą być rozpatrywane i rozwiązywane niezależnie
Minimalizowanie ryzyka niepowodzenia przez podział projektu na
mniejsze części - tzw. fazy projektowe.
Interpretacja funkcji na różnych poziomach szczegółowości:
obszary działalności, funkcje ogólne, czynności, elementarne operacje.
• Funkcja położona najwyżej w hierarchii reprezentuje całą działalność modelowanej
organizacji lub cały zakres przedsięwzięcia
• Funkcję można zdekomponować na kilka bardziej szczegółowych funkcji składowych,
które tworzą kolejny poziom w hierarchii.
• Funkcja podlegająca dekompozycji, nazywana jest funkcją nadrzędną a funkcje
znajdujące się na kolejnym poziomie, funkcjami podrzędnymi.
Interpretacja dekompozycji funkcji
• Wykonanie funkcji nadrzędnej jest realizowane przez wykonanie funkcji podrzędnych.
Alfa - testy uruchomienia aplikacji z częścią funkcjonalności
Wewnętrzne
Beta - wydane wewnątrz firmy i dla ograniczonych społeczności.
Istotą refaktoryzacji oprogramowania jest zmiana jego wewnętrznej struktury w sposób nie naruszający jego widocznego zachowania, natomiast poprawiający jego wewnętrzną strukturę [Fowler1999] . Szybko zmieniające się wymagania funkcjonalne i konieczność rozszerzania możliwości programu z jednej strony oraz wprowadzane lokalne poprawki z drugiej pogarszają jakość kodu, powodują, że staje się on nieczytelny i kosztowny w pielęgnacji. K. Beck wprowadził pojęcie przykrego zapachu, czyli działającego fragmentu kodu, który jednak wymaga poprawienia z uwagi na złą strukturę, brak elastyczności czy niebezpieczeństwo pojawienia się błędu. Wśród najczęściej spotykanych zapachów wymienia się m.in. duplikację kodu, zbyt długie metody, rozbudowane sygnatury metod, za duże klasy, błędny podział odpowiedzialności pomiędzy klasami i skomplikowane wyrażenia warunkowe. Wykrywanie tych zapachów jest w niewielkim stopniu zautomatyzowane i w wielu przypadkach zależy od intuicji programisty, co znacznie zwiększa ryzyko i konieczny nakład pracy związane z refaktoryzacją.
Ponieważ refaktoryzacja z założenia pozwala bezpiecznie wprowadzać zmiany w kodzie, jest ona kluczowym elementem tzw. zwinnych metodyk tworzenia oprogramowania (ang. agile methodologies), jak np. XP [Beck2000]. W praktyce jednak możliwość bezpiecznego przeprowadzania zmian w kodzie jest ważna niezależnie od przyjętej metodologii, gdyż samo przyjęcie założenia o stworzeniu kompletnego i spójnego projektu przed przystąpieniem do implementacji nie chroni przed tymi zmianami.
Refaktoryzacja, jako czynność nie zwiększająca funkcjonalności oprogramowania, nie przynosi szybkich korzyści, natomiast wymaga sporego nakładu pracy i jest obarczona ryzykiem wprowadzenia błędów do programu. Dlatego celem prowadzonych badań jest zmniejszenie jej pracochłonności poprzez automatyzację, przy jednoczesnym zapewnieniu bezpieczeństwa tego procesu. Refactoring Browser [Roberts1997] autorstwa D. Robertsa był pierwszym narzędziem pozwalającym na łatwą refaktoryzację programów napisanych w Smalltalku. Od tego czasu powstało wiele innych dedykowanych narzędzi, szczególnie dla języka Java, a wsparcie dla refaktoryzacji pojawiło się w popularnych środowiskach IDE, np. Eclipse, JBuilder czy TogetherJ. Niestety, w większości tych środowisk zaimplementowany jest zbiór tych samych, prostych przekształceń. Przyczyna takiego stanu leży w trudności określenia, czy dane przekształcenie faktycznie zostało wykonane poprawnie.
Reprezentuje elementy otoczenia systemu na rzecz, których są wykonywane operacje.
Przedstawia przypadki użycia, aktorów i związki między nimi.
Wyznaczanie i modelowanie zachowania systemu.
Agregacja
Jeśli mówimy, że klasa A jest zawarta w klasie B, to znaczy, że klasa A jest jednym z elementów klasy B, np. klasa Zeszyt może być zawarta w klasie Plecak. Niemniej zawieranie mówi o tym, że zarówno klasa A jak i klasa B mogą istnieć jako oddzielne elementy. W naszym przypadku jest to prawda, zarówno Zeszyt jak i Plecak są elementami nie uzależnionymi od siebie.
(Kompozycja) Zawieranie
Jest szczególnym (skrajnym) przypadkiem zawierania. Różnica polega na tym, że klasa B, która jest zawarta w A, nie może posiadać samodzielnych instancji. Innymi słowy zawsze jest składową obiektów klasy B, np. Drzwi samochodowe nie mogą istnieć jako samodzielne obiekty. Zawsze są skomponowane z obiektami klasy Samochód. Różnica w notacji w stosunku do zawierania polega na tym, że romb na zakończeniu krawędzi reprezentującej relację jest wypełniony. Rysunek zatem w tym przypadku pominiemy.
To kolejny wzorzec strukturalny, który ukrywa złożony podsystem za pomocą jednolitego interfejsu.
Wzorzec ten zapewnia interfejs umożliwiający tworzenie rodzin powiązanych ze sobą lub zależnych od siebie obiektów bez specyfikowania ich klas konkretnych.
To wzorzec kreacyjny, który gwarantuje, że klasa ma tylko 1 egzemplarz i zapewnia do niego globalny dostęp
JSP (ang. Java Server Pages) to technologia umożliwiająca tworzenie dynamicznych dokumentów WWW w formatach HTML, XHTML, DHTML oraz XML z wykorzystaniem języka Java, wplecionego w kod HTML danej strony. W tym aspekcie, jest to rozwiązanie podobne do PHP.
Jest to odmiana serwletów (aplikacji w Javie uruchamianych po stronie serwera). Przy wywołaniu, strona JSP zamieniana jest na servlet, który wykonuje właściwe działanie i każde kolejne zapytania do tej strony.
Jeśli użyta zostanie prekompilacja (kompilacja wstępna) to już podczas uruchamiania aplikacji wszystkie strony JSP zostaną przetłumaczone na servlety.
Jeśli użyta zostanie prekompilacja (kompilacja wstępna) to już podczas uruchamiania aplikacji wszystkie strony JSP zostaną przetłumaczone na servlety.
* treść statyczna - przepisywana bez modyfikacji do generowanego dokumentu
* dyrektywy JSP - informacje kontrolujące proces generowania dokumentu
* elementy skryptowe - skryplety (kod w języku Java kontrolujący proces generowania dokumentu) oraz elementy składniowe tzw. Expression Language
* akcje JSP - tagi XML wywołujące określone metody serwerowe
Serwlet - mały program wykonywany po stronie serwera WWW (nazwa powstała na wzór nazwy aplet, przez zastąpienie sylaby ap- sylabą serw-, wskazującą na wykonywanie programu na serwerze).
Serwlet otrzymuje od serwera komplet informacji zebranych z interakcyjnych elementów strony (zwykle z pól formularza) i po ich przetworzeniu dostarcza gotową stronę WWW - przesyłaną przez serwer do użytkownika. Ponieważ serwlet jest jedną z klas Javy, można w nim korzystać z całego dostępnego Java API - w tym z mechanizmów łączących z bazą danych, zdalnych wywołań metod (RMI) oraz CORBA. Parametry pobrane ze strony można przekazywać (forward) do następnego serwletu, tworząc w ten sposób kaskadę, w której każdy serwlet odpowiedzialny jest za fragment witryny. Do uruchomienia serwletów konieczne jest funkcjonowanie serwera WWW z zaimplementowanym standardem Javy.
technologia będąca jednym z elementów specyfikacji J2EE. Innymi słowy EJB to pewien podzbiór interfejsów J2EE, uważany za jeden z najbardziej zaawansowanych elementów.
Idea EJB opiera się na tworzeniu komponentów, które mogą być osadzane na serwerze (tzw. bean containerze) i wołane zdalnie poprzez protokół RMI over IIOP. Ogólnie wyróżnia się 3 rodzaje komponentów EJB:
* sesyjne EJB (ang. session EJB)
* encyjne EJB (ang. entity EJB)
* sterowane komunikatami EJB (ang. message driven EJB)
Każdy z tych rodzajów komponentów ma różne zastosowanie. Sesyjne EJB są używane do umieszczania w nich logiki aplikacji - czyli kodu, który przetwarza dane. Encyjne EJB reprezentują w sposób obiektowy dane (np. przykrywają relacyjną bazę danych). EJB sterowane komunikatami znajdują zastosowanie w przetwarzaniu asynchronicznym i w zaawansowanych modelach współpracy oprogramowania. Np. model abonent-dostawca: bean rejestruje się jako dostawca pewnej usługi, klienci mogą zarejestrować się jako abonenci.
Główną zaletą EJB jest nakierowanie projektanta na pewne sprawdzone sposoby rozwiązania typowych problemów w systemie rozproszonym: zarządzanie połączeniami, transakcja rozproszona, mapowanie danych na model obiektowy itp. Mimo to użycie niektórych elementów tej technologii wydaje się dość kontrowersyjne. Np. stosowanie encyjnych EJB oznacza rezygnację z przetwarzania danych w modelu relacyjnym. Wszelki dostęp do danych (w tym i masowy) odbywa się poprzez obiekty napisane w języku Java, a zatem niesie ze sobą ograniczenia wydajnościowe i zajętości zasobów. Mimo iż technologia EJB jest popularyzowana przez teoretyków projektowania systemów trudno doszukać się pełnego wykorzystania tej technologii w dużych systemach, w których wydajność odgrywa istotną rolę (zwłaszcza encyjnych EJB).
jest interfejsem Javy usług katalogowych, który umożliwia klientom odkrywanie i wyszukiwanie danych oraz obiektów za pomocą nazw.
Podstawy
Interfejs JNDI jest wykorzystywany przez interfejsy Java RMI oraz Java EE w celu wyszukiwania obiektów w sieci. JINI posiada swój własny serwis do wyszukiwania i nie korzysta z interfejsu JNDI.
Interfejs posiada:
* mechanizm łączący obiekt z nazwą
* interfejs wyszukiwania katalogowego, który pozwala stosować podstawowe zapytania
* interfejs zdarzeń, który pozwala klientowi na określenie wejść które zostały zmienione
* rozszerzenie LDAP, które wspiera dodatkowe możliwości protokołu LDAP
standardowy zestaw interfejsów i modeli przesyłania komunikatów w języku programowania Java. Specyfikacja JMS jest darmowa i przygotowana przez firmę Sun. Istnieję kilka implementacji tego standardu.
JMS elements
JMS consists of several elements:
JMS provider
An implementation of the JMS interface for a Message Oriented Middleware (MOM). Providers are implemented as either a Java JMS implementation or an adapter to a non-Java MOM.
JMS client
An application or process that produces and/or consumes messages.
JMS producer
A JMS client that creates and sends messages.
JMS consumer
A JMS client that receives messages.
JMS message
An object that contains the data being transferred between JMS clients.
JMS queue
A staging area that contains messages that have been sent and are waiting to be read. As the name queue suggests, the messages are delivered in the order sent. A message is removed from the queue once it has been read.
JMS topic
A distribution mechanism for publishing messages that are delivered to multiple subscribers.
[edit] JMS models
The JMS API supports two models:
* point-to-point or queuing model
* publish and subscribe model
In the point-to-point or queuing model, a producer posts messages to a particular queue and a consumer reads messages from the queue. Here, the producer knows the destination of the message and posts the message directly to the consumer's queue. It is characterized by following:
* Only one consumer will get the message
* The producer does not have to be running at the time the receiver consumes the message, nor does the receiver need to be running at the time the message is sent
* Every message successfully processed is acknowledged by the receiver
The publish/subscribe model supports publishing messages to a particular message topic. Zero or more subscribers may register interest in receiving messages on a particular message topic. In this model, neither the publisher nor the subscriber know about each other. A good metaphor for it is anonymous bulletin board. The following are characteristics of this model:
* Multiple consumers can get the message
* There is a timing dependency between publishers and subscribers. Publisher has to create a subscription in order for clients to be able to subscribe. Subscriber has to remain continuously active to receive messages, unless it has established a durable subscription. In that case, messages published while the subscriber is not connected will be redistributed whenever it will reconnect.
Using Java, JMS provides a way of separating the application from the transport layer of providing data. The same Java classes can be used to communicate with different JMS providers by using the JNDI information for the desired provider. The classes first use a connection factory to connect to the queue or topic, and then use populate and send or publish the messages. On the receiving side, the clients then receive or subscribe to the messages.
1) unikania klasycznych błędów (ang. classic
mistakes),
2) stosowania podstaw wytwarzania
(ang. development fundamentals),
3) zarządzania ryzykiem w celu zapobiegania katastroficznym komplikacjom,
tworzące tzw. Skuteczne Wytwarzanie (ang. Efficient Development).
SCHEDULE versus ECONOMY versus PRODUCT QUALITY
balances economy, schedule, and quality
1. Schedule -- faster than average
2. Economy -- costs less than average
3. Product -- better than average quality
Oparcie się na iteracjach
Tworzenie prototypów
Wykorzystanie IDE,CASE
SCHEDULE versus ECONOMY versus PRODUCT QUALITY
1. Tradeoffs determine the pace of development.
1. Efficient Development
balances economy, schedule, and quality
1. Schedule -- faster than average
2. Economy -- costs less than average
3. Product -- better than average quality
2. Sensible RAD
tilts away from economy and quality toward fastest schedule
1. Schedule -- much faster than average
2. Economy -- costs a little less than average
3. Product -- a little better than average quality
3. All-out RAD
"code like hell"
1. Schedule -- fastest possible
2. Economy -- costs more than average
3. Product -- worse than average quality
2. For RAD, something other than schedule must be negotiable.
1. RAD has a fair chance of success if the customer will negotiate
either economy or quality
2. RAD has a better chance for success if the customer will
negotiate both economy and quality
3. NOTE: Negotiating quality does NOT mean accepting a higher
defect rate. It means accepting a product that is less usable,
less fully-featured, or less efficient.
3. So, with RAD, one or more of the following goals may be
unachievable.
1. the fewest possible defects
(because developers may not have the legal right to modify the
source for some plug-in components)
2. the highest possible level of customer satisfaction
(because secondary requirements may be sacrificed to stay on
schedule)
3. the lowest development costs
(because buying reusable components may cost more than
building)
Zalety:
Wady:
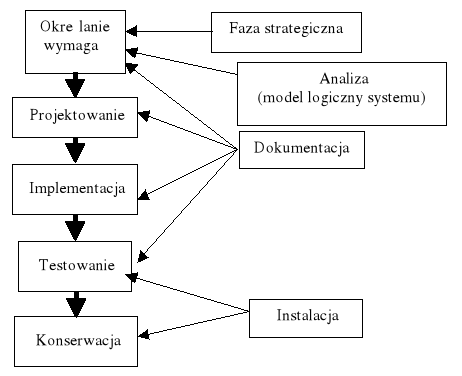
Model kaskadowy (ang. waterfall model) to jeden z kilku rodzajów procesów tworzenia oprogramowania zdefiniowany w inżynierii oprogramowania. Jego nazwa wprowadzona została przez Winstona W. Royce w roku 1970, w artykule "Managing the Development of Large Software Systems" (zarządzanie tworzeniem dużych systemów informatycznych). Polega on na wykonywaniu podstawowych czynności jako odrębnych faz projektowych, w porządku jeden po drugim. Każda czynność to kolejny schodek (kaskada):
1. Planowanie systemu (w tym Specyfikacja wymagań)
2. Analiza systemu (w tym Analiza wymagań i studium wykonalności)
3. Projekt systemu (poszczególnych struktur itp.)
4. Implementacja (wytworzenie kodu)
5. Testowanie (poszczególnych elementów systemu oraz elementów połaczonych w całość)
6. Wdrożenie i pielęgnacja powstałego systemu.
Jeśli któraś z faz zwróci niesatysfakcjonujący produkt cofamy się wykonując kolejne iteracje aż do momentu kiedy otrzymamy satysfakcjonujący produkt na końcu schodków.
Jest to dość przestarzały i rzadko używany model z następujących powodów:
* Nie można przejść do następnej fazy przed zakończeniem poprzedniej
* Model ten posiada bardzo nieelastyczny podział na kolejne fazy
* Iteracje są bardzo kosztowne - powtarzamy wiele czynności
Tego typu modelu należy używać wyłącznie w przypadku gdy wymagania są zrozumiałe i przejrzyste, ponieważ każda iteracja jest czasochłonna i wymaga dużych wydatków na ulepszanie.
The code-and-fix model contains two steps
1. Write some code
2. Fix the problems in the code
• The basic model used in earliest days of software
development
- It is not really a model, it is more “lack of a model”
- Probably the model you used in most of your
programming assignments
- It is only suitable for short programs which do not
require maintenance, unsatisfactory for large Project
Basic problems with the code-and-fix model:
1.After several fixes the code becomes poorly structured
• a design phase is necessary
2. Frequently, well-designed code is a poor match to the
customers needs
• a requirements phase is necessary
3. Code is expensive to fix because of poor preparation for
testing and modification
• testing and maintenance phases have to be planned
Gramatyką G[Z] nazywamy skończony i niepusty zbiór produkcji, przy czym Z jest pewnym symbolem występującym po lewej stronie co najmniej jednej produkcji i nazywamy go symbolem wyróżnionym. Zbiór wszystkich symboli użytych do zapisania lewych i prawych stron produkcji tworzy alfabet V.
Język jest L G[Z] jest to podzbiór wszystkich napisów podstawowych, napisów nad alfabetem podstawowym VT. Strukturę zdania określa gramatyka, ten sam język może być generowany przez różne gramatyki.
Zdanie języka generowanego przez gramatykę nazywamy wieloznacznym, jeżeli istnieje więcej niż jedno drzewo syntaktyczne wyprowadzenia tego zdania. Gramatykę nazywamy wieloznaczną, jeżeli język generowany przez tę gramatykę zawiera zdanie wieloznaczne, w przeciwnym razie gramatykę nazywamy jednoznaczną.
Nie posiadają żadnych ograniczeń na reguły generowania.
Dowolna reguła r=F'-->F'' może być utworzona przez wykorzystanie łańcuchów ze zbioru
(VtÈVa)*.
W gramatyce 0 jedna reguła może od razu zmienić kilka symboli.
Reguły wyprowadzeń mają postać:
t1 A t2 --> t1 w^ t2
gdzie t1,t2,w^ Î{VtÈVa}*, AÎVa.
Wyrazy t1 i t2 nie ulegają zmianom przy stosowaniu reguły,
dlatego nazywamy je kontekstem
(t1 - lewy kontekst, t2 - prawy kontekst).
Vt={a,b,c,d}
Va={I, A, B}
R={I --> aAI,
AI-->AA, (niepusty lewy kontekst)
I --> ABA
A-->b,
bBA-->bcdA, (zawiera oba konteksty)
bI-->ba}. (niepusty lewy kontekst)
Reguły wyprowadzeń mają postać:
<A> --> w^
gdzie w^ Î{VtÈVa}*, AÎVa.
(używane do opisów języków programowania)
Vt={a,b}
Va={<I>}
R={<I> --> aI,
<I>-->b<I>b,
<I> --> aa,
<I> --> bb}
Reguły wyprowadzeń mają postać:
<A> --> a
<A> --> a<B> albo <A> --> <B>a
gdzie a ÎVt, <A>,<B>ÎVa.
Jedna gramatyka może mieć tylko reguły (wyprowadzenia) lewostronne, lub też tylko reguły (wyprowadzenia) prawostronne.
Gramatyka prawostronna:
Vt={a,b}, Va={<I>, <A>, <Z>}
R={<I> --> a<I>, <I>-->a<A>, <A> --> b<A>,
<A> --> b<Z>,<Z> --> $},
Gramatyka lewostronna:
Vt={a,b}, Va={<I>, <A>, <Z>}
R={<I> --> <A>b, <A> --> <A>a, <A> --> <Z>a,
<Z> --> <Z>a,<Z> --> $}.
Polega na skonstruowaniu jakiegoś wyprowadzenia tej formy i - niekiedy - zbudowaniu drzewa syntaktycznego. Program wykonujący rozbiór gramatyczny nazywamy analizatorem składni lub analizatorem syntaktycznym. Zadaniem analizatora składni jest rozpoznanie zadań w celu odróżnienia ich od wielu innych napisów nad alfabetem podstawowym języka. Automatyczne rozpoznanie napisów należących do jakiegoś języka programowania.
Metody wyprowadzania
Analizator pracujący metodami wyprowadzania buduje drzewo syntaktyczne, rozpoczynając od korzenia i postępuje w kierunku wierzchołków końcowych
Analizator leksykalny czyta znaki programu źródłowego od lewej do prawej i składa z nich właściwe symbole programu. Liczby całkowite, słowa, słowa zarezerwowane. Przekazuje symbole do analizatora syntaktycznemu. Usuwa komentarze, przekazuje symbole w postaci wewnętrznej. Jest to najczęściej liczba całkowita z cytowanego przedziału (bajt, słowo itp.). Dostarcza dwie informacje: rozpoznanie jednostki leksykalnej i położenie nazwy w tablicy symboli.
Tworzone są drzewa synaktyczne w kierunku od korzenia drzewa do wierzchołków końcowych tworzących zdanie. Ojciec dołącza kolejne dzieci, aż do momentu, kiedy ostatnie dziecko zasygnalizuje sukces rozbioru ostatniego elementy produkcji danej reguły. Jeżeli każde dziecko zgłosi porażkę brana jest pod uwagę inna produkcja. Do zaprogramowania tego zachowana wykorzystywany jest stos.
Redukowanie polega na wyznaczeniu w każdym kolejnym kroku analizy tzw. argumentu u (będącego leżącą najbardziej na lewa frazą prostą aktualnej formy zdaniowej i zredukowano go do symbolu U, takiego, że U::=u jest produkcją gramatyki. Podstawowym problemem jest wyznaczenie argumentu, a następnie wyznaczenie symbolu pomocniczego zastępującego argument. Prezentujemy tutaj rozwiązanie tego problemu dla pewnej klasy gramatyk - gramatyk pierwszeństw prostych.
Gramatyka G jest gramatyką pierwszeństw prostych jeżeli,
Relacje pierwszeństwa:
R = S G zwiera U::= …RS…
R<* S G zawiera U::=…RV…, takie, że V FIRST+ S
R *> S G zawiera U::= …VW…, takie, że V LAST+ R oraz W FIRST*S
Mając napis …RS… poszukujemy algorytmu, który wykryje czy R jest końcem zdania, czy może jeszcze występuje interesujący przypadek. Jeżeli pomiędzy dwoma symbolami R oraz S zachodzi więcej niż jedna relacja pierwszeństwa, to znajomość tych relacji nie stanowi pomocy. Jeżeli jednak wiadomo, że dla każdej pary symboli zachodzi pomiędzy nimi co najwyżej jedna relacja, to relacje wyznaczają argument dowolnej formy zdaniowej.
Notacja polska:
Notacja polska służy do reprezentacji wyrażeń arytmetycznych i logicznych w sposób, który prosto i dokładnie wyznacza porządek obliczania operatorów. W dodatku nie wymaga on używania nawiasów. Operatory występują bezpośrednio po argumentach. Nazwy występują w tym samym porządku, operatory w takiej kolejności, w jakiej mają być obliczane (od lewej do prawej), operatory bezpośrednio po argumentach.
Czwórki:
<operator> <arg1> <arg2> <wynik>
Czwórki w występują w porządku, w jakim mają być wykonane
Trójki:
<operator> <arg1> <arg2>
Nie ma pola wyniku, ale wartością argumentu może być wynik poprzedniej trójki (wskazanej trójki).
Drzewa:
Drzewem dla prostej lub stałem jest ta zmienna prosta lub stała. Jeśli e1 i e2 są wyrażeniami z drzewami T1 i T2, to drzewo dla e1 + e2:
+
|
-------
| |
T1 T2
Trójki mogą być traktowane jako prosta reprezentacja drzewa.
Analiza semantyczna, sprawdza poprawność, zapamiętuje informacje w tablicy symboli lub w tekście wewnętrznej postaci programu. Analiza semantyczna opiera się na procedurach semantycznych, które są wywoływane w trakcie analizy syntaktycznej.
Wywoływane są procedura związana z produkcją U::=x. Przetwarza ona wszystkie symbole tworzące x wyprowadza odpowiedni fragment napisu w notacji polskiej. Oczekujemy, że argument redukuje się w każdym kroku zbioru.
Weryfikuje typy wyrażeń i argumentów
Wstawia niezbędne operacje konwersji typów
Dokonuje dekoracji drzewa wywodów
Sprawdza czy dane wyrażenie jest elementem języka programowania
Właściwe tłumaczenie wewnętrznej postaci programu źródłowego na język symboliczny lub kod maszynowy. Przekład w kodzie maszyny może mieć jedną z 3 postaci: rozkazy bezwzględne, umieszczone w stałych komórkach pamięci i wykonane bezpośrednio po przetłumaczeniu programu; program w języku symbolicznym maszyny, który należy jeszcze przetłumaczyć, obraz binarny programu zapamiętany w pamięci pomocniczej, który przed wykonaniem należy połączyć z innymi modułami i wprowadzić do pamięci operacyjnej.
Procedury generowania przekładu używają charakterystyk (elementów tablicy symboli lub innej tablicy) wszystkich zmiennych programu i zmiennych roboczych, gdzie zapamiętany jest typ zmiennej, adres nadany jej przez translator inne niezbędne informacje.
Jest możliwość stosowania różnorakich technik zmniejszenia liczby rozkazów, zależą one od języka maszyny, na który dokonywany jest przekład. Można zastosować pewne usprawnienie kodu dla instrukcji warunkowych, kiedy dokładnie wiemy gdzie występują i dokąd prowadzą skoki. Dołączenie procedur IFTEST, ELSE,ENDELSE, zamiast standardowych zestawów, dzięki temu będziemy mogli powiedzieć, gdzie będą się kończyć poszczególne części instrukcji.
Mając czwórkę =, A, ,B
Powinnyśmy wygenerować MOVE A,B zamiast STORE B, ale, jeśli następna czwórka to +,A,C,T1, to lepiej zostawić zawartość A w akumulatorze.
Przetwarzanie rozproszone to „nauka zajmująca się badaniem systemów sprzętowych i programowych zawierających więcej niż jeden procesor, więcej niż jeden element przechowujący dane, więcej niż jeden proces lub więcej niż jeden program, które wykonują się w sposób mniej lub bardziej powiązany.”[9] (tłum. autor). Definicja ta odpowiada zarówno systemom komputerowych realizującym przetwarzanie rozproszone, jak i równoległe. Zgodnie z nią przetwarzanie równoległe to podzbiór przetwarzania rozproszonego, w którym wykonywane elementy są mocno powiązane.
Instrukcje zależne to takie instrukcje, które nie mogą być wykonane w sposób równoległy. Formalnie wyróżniamy 3 rodzaje instrukcji zależnych: zapis-zapis, gdzie ta sama zmienna jest dwukrotnie zapisywana, odczyt-zapis, w tym przypadku najpierw odczytujemy zmienną, a potem zmieniamy jej zawartość, zapis-odczyt, w tej zależności najpierw jest ustawiana zawartość zmiennej, a potem jest ona odczytywana.
zapis - odczyt (prosta)
odczyt - zapis (odwrotna)
zapis - zapis (po wyjściu)
FAN
FAN pozwala na realizację obliczeń, w których każdy procesor wykonuje tą samą operacje, ale na różnych danych. Na samym końcu wyniki są zbierane ze wszystkich procesorów. Ponieważ każdy z procesorów najprawdopodobniej w innym czasie rozpocznie i zakończy swoje obliczenia na końcu operacji FAN musi wystąpić bariera synchronizacyjna. Operacja odpowiada realizacji modelu SPMD, a stopień równoległości odpowiada rozmiarowi licznika operacji, które zostają przekazane do zrównoleglenia. Najczęściej odpowiada to ilości iteracji w zrównoleglonej pętli. W tym podejściu nie mogą występować zależności pomiędzy zadaniami, które rozdzielamy (zależności pomiędzy poszczególnymi iteracjami), natomiast mogą występować zależności w obliczeniach prowadzonych w ramach pojedynczego zadania (zależności wewnątrz pojedynczej iteracji).
PAR
Operacja PAR rozprowadza różne fragmenty kodu, który chcemy zrównoleglić na odmienne procesory. W trakcie jednej iteracji PAR wykonuje odmienne fragmenty kodu na innym procesorze, potem następuje bariera synchronizacyjna, i tak aż do wyczerpania przestrzeni iteracji. Bariera w ramach każdej iteracji jest konieczna, gdyż najprawdopodobniej każdy procesor zakończy swoje operacje w innym czasie. Operacja PAR może być wykorzystana do zrównoleglenia dopowiadającemu podejściu MIMD. Tutaj mogą występować zależności pomiędzy poszczególnymi iteracjami (zdaniami, które zrównoleglimy), ale nie mogą występować zależności pomiędzy instrukcjami lub grupami instrukcji przypadającymi na różne procesory. Stopień równoległości to liczba instrukcji lub grup instrukcji, które mogą być wykonane równolegle w ramach pojedynczej iteracji.
FAN+PAR
Ta operacja dysponuje największym stopniem równoległości. Odpowiada podejściu MIMD, a stopień równoległości jest równy sumie wszystkich instrukcji we wszystkich operacjach. Każda operacja w każdej iteracji może być wykonana na osobnym procesorze, wobec tego nie mogą występować zależności, ani pomiędzy instrukcjami w ciele pętli ani pomiędzy iteracjami.
PIPE
Ta operacja pozwala osiąganie równoległości na poziomie instrukcji, ale co istotne synchronizacja nie następuje po każdej iteracji, ale na poziomie poszczególnych instrukcji. Rozpoczęcie wykonania iteracji bywa opóźnione w czasie w ramach wykonywania poszczególnych instrukcji. Przykładowo, rozpoczyna się wykonywanie pierwszego polecenia z pierwszej iteracji, potem zakładając, że opóźnienie pętli wynosi 1 zaczynamy wykonywać drugie polecenie z pierwszej iteracji i pierwsze polecenie z drugiej iteracji, potem można wykonywać trzecie polecenie z pierwszej iteracji, drugą instrukcje z drugiej iteracji i pierwsze polecenie z trzeciej iteracji i tak dalej. Stopień równoległości jest ograniczony do liczby iteracji, ale każdy z procesorów rozpoczyna swoje obliczenia z opóźnieniem od 0 do k - 1 w stosunku do pierwszej iteracji, gdzie k oznacza liczbę instrukcji w ciele iteracji. Charakterystyczne dla PIPE jest to, że polecenia są ponumerowane i wykonywane w kolejności, a polecenia z różnych iteracji są wykonywane jednocześnie.
ROZSZERZENIE SKALARA
for i=...
m=
zależności
iteracja i: m=...
iteracja j: m=
W pętli występują zależności zapis-zapis. Aby je wyeliminować wprowadza się tablicę m[i] zamiast skalara m.
for i=...
m[i]=...
ROZSZERZENIE TABLIC
for i=...
for j=...
a[i]=...
zależności:
a[1]=...
a[1]=...
rozszerzamy a[i] do tablicy 2-wymiarowej
a[i]a[i][j]
for i...
for j=...
a[i][j]=...
MODYFIKACJA NAZW
c=a; a=d;
|
c=a
|
PRYWATYZACJA
for i=...
m=...
a[i]=m
Aby usunąć zależność wystarczy zadeklarować zmienną m jako private. Każdy wątek, który będzie wykonywał iterację, przechowuje swoją kopię zmiennej m w osobnej komórce pamięci.
REDUKCJA
redukcje to zależności powodowane przez poniższe instrukcje:
s=s+...
s=s+...
s=s and
warunki:
Asocjacja: a+b+c+d=(a+b)+c+d=a+(b+c+d)
komutacja: a+b+c+d=a+b+d+c+ad+b+c
Redukcjami nie są dzielenie ani odejmowanie.
Przykładem zastosowania jest obliczanie sumy - każdy wątek oblicza niezależnie część sumy.
PODSTAWIENIE WYRAŻEŃ I SKALARÓW
m=1; a[m+j]=... |
for... a[1+j]=... |
m=2i+3; a[m+i]=... |
for... a[4i+3]= |
PRZYSPIESZENIE
Jest podstawową miarą programów rozproszonych i równoległych określa stosunek czasu algorytmu wykonywanego w sposób sekwencyjny do czasu algorytmu wykonywanego na P procesorach. Wyraża się dość prosto:
![]()
![]()
- czas sekwencyjnego wykonania
![]()
- czas wykonania na P procesorach
EFEKTYWNOŚĆ
O ile przyspieszenie uwzględnia tylko wyłącznie czasy wykonania, o tyle efektywność bierze także pod uwagę liczbę procesorów, które brały udział w obliczeniach. Gdyż to także jest istotny czynnik pozwalający ocenić jakość wykonania aplikacji równoległej bądź rozproszonej. Efektywność najprościej określić jako stosunek przyspieszenia uzyskanego na P procesorach do ich liczby:
![]()
![]()
- przyspieszenie uzyskanie na P procesorach
![]()
- liczba procesorów
Im większa efektywność tym lepsze zrównoleglenie/rozproszenie obliczeń, ale najczęściej ideałem, do którego się dąży jest wartość 1.
Amdahl
Zgodnie z jego twierdzeniem przyspieszenie osiągane przez aplikacje zawiera się w granicach:
![]()
![]()
- cząstka obliczeń sekwencyjnych w danej aplikacji.
Wynika to z tego, że program składa się z części, która musi być wykonana w sposób sekwencyjny i takiej, która może zostać zrównoleglona. Zgodnie z tym założeniem przyspieszenie przedstawia się w następujący sposób:
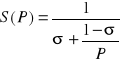
Natomiast efektywność:
![]()
W tym przypadku, dla bardzo dużej liczby procesorów efektywność będzie zbiegać do 0. Jednakże Amdahl nie uwzględnił rozmiaru problemu, który jest rozwiązywany, naprzeciwko temu wyszło prawo Gustafsona oraz definicja skalowalności.
Gustafson
Aplikację można uznać za skalowalną, jeśli wraz ze wzrostem problemu będzie rosła liczba zadań, które będzie można w sposób równoległy. Ta definicja jest wykorzystywana w prawie Gustafson'a, które mówi, że jeżeli aplikacja będzie się odpowiednio skalować to zwiększając rozmiar problemu można osiągnąć interesującą nas efektywność na dowolnej liczbie procesorów. Przykładowo zakładając, że problem na złożoność kwadratową i skaluje się w następujący sposób:
![]()
To efektywność będzie wyglądać następująco:
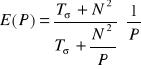
Zakładając, że rozmiar problemu (N) rośnie w nieskończoność:
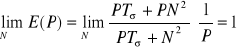
możemy osiągnąć efektywność 1, jeżeli dostatecznie zwiększymy rozmiar problemu.
Programowanie równoległości danych -
wykonywanie tej samej operacji na wszystkich danych złożonej struktury.
striding
Używany przy deklaracjach
real:: a(100, 100)
start:end:stride (początek:koniec:krok)
Przykład:
real:: a(10), b(10), c(10)
a(1:10:2)=b(2:10:2)+c(1:10:2)
oznacza:
a(1)=b(2)+c(1)
a(3)=b(4)+c(3)
...
a(9)=b(10)+c(9)
shaping
kształtowanie danych
operacje na macierzach
shape(„1”, „2”)
bez zmian
shape(„2”, „1”)
zamiana wierszy i kolumn
shape(„1”, „-2”)
lustrzane odbicie (pionowe)
operacje na wektorach
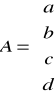
dp_shape(A, 100) lub dp_shape(A, „1”, 100)
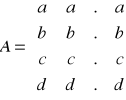
dp_shape(A, 100, „1”)
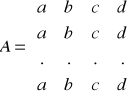
dp_shape(A, 100, 100, „1”)
rysunek najprawdopodobniej trzeba obrócić
shifting
Operacja przesunięcia
dp_shift(NAZWA, parametry)
NAZWA - nazwa tablicy/macierzy na której operujemy.
parametry - ich ilość zależy od wymiaru tablicy. Mogą przyjmować następujące wartości:
n - o ile elementów należy przesunąć
Przykład:
A=[a b c d]
dp_shift(A, „p”:2)
A=[- - a b]
dp_shift(A, „c”:2)
A=[c d a b]
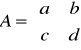
dp_shift(A, „p”:1)
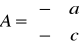
dp_shift(A, „p”:1, „p”:1)

Permutacja - mechanizm pozwalający na kształtowanie macierzy i tablic w dowolny sposób.
dp_push(„NAZWA1”, „NAZWA2”, „NAZWA3”, „OPERACJA”)
↓ ↓ ↓ ↓
nazwa tablicy nazwa tablicy nazwa tablicy +
źródłowej mapującej wynikowej -
(w jaki sposób *
kształtować AND
tablicę) OR
Przykład:
Zawartość 3 tablic:
|
|
1 |
|
|
2 |
|
|
1 |
|
|
2 |
|
|
1 |
|
|
2 |
|
|
2 |
|
|
1 |
|
|
1 |
|
1 |
|
|
3 |
|
|
2 |
|
|
2 |
|
|
3 |
|
|
1 |
|
|
3 |
|
|
1 |
|
|
3 |
|
1 |
|
|
1 |
|
|
1 |
|
|
1 |
|
|
1 |
|
|
1 |
|
|
3 |
|
|
3 |
|
|
3 |
|
|
|
|
1 |
|
|
2 |
|
|
1 |
|
|
2 |
|
|
1 |
|
|
2 |
|
|
2 |
|
|
1 |
|
|
2 |
|
1 |
|
|
3 |
|
|
2 |
|
|
2 |
|
|
3 |
|
|
1 |
|
|
2 |
|
|
2 |
|
|
1 |
|
2 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
2 |
|
|
3 |
|
|
3 |
|
|
3 |
|
|
Kompilator korzysta z czwartego argumentu, wtedy gdy tablica mapująca dla różnych elementów tablicy źródłowej zawiera takie same adresy. Operacje służą do rozwiązywania kolizji.push:
dp_pull(...)
dp_reduce(„NAME”, „OP”)
↑ ↑
nazwa tablicy operacja
Ze wszystkich wartości tablicy tworzona jest wartość skalarna.
Przykład:
dp_reduce(„A”, „+”) = 6
Operacje mogą spełniać dwa warunki:
np. a1 + a2 + a3 + a4 = (a1 + a2) + (a3 + a4) - warunki spełnione
a1 - a2 - a3 - a4 ≠ (a1 - a2) - (a3 - a4) - warunki nie spełnione
Warunki gwarantują jednoznaczność operacji redukcji.
Programowanie danych dzielonych
Operacje Fork, Join
Operacje fork i join służą do tworzenia procesów.
Procesy dzieli się na ciężkie i lekkie. Proces ciężki składa się z: procesu lekkiego, szybkiej pamięci LIFO, rejestrów, wskaźnika licznika instrukcji, danych dotyczących przerwań i plików związanych z procesem.
Operacja fork zwraca numer procesu: id=fork().
Wada: operacje fork, join często prowadzą do błędów. Alternatywna jest metoda create().
Programowanie z przesyłaniem komunikatów
PVM - maszyna uruchomiona na wielu komputerach, którą postrzega się jako 1 komputer. Model programowania to grupa zadań porozumiewających się za pomocą przesyłanych komunikatów. Komunikacja odbywa się za pośrednictwem funkcji bibliotecznych i demona. Demon, na każdej maszynie określa przeznaczenie komunikatów i przesyła je do odpowiednich zadań. Podstawą komunikacji jest komunikacja asynchroniczna, ale jest możliwość blokowania w oczekiwaniu na odpowiedź, i możliwość synchronizacji.
Test&Set
bool test&set(bool blokada)
{wynik=blokada;
blokada=true;
return wynik;}
użycie - w pustej pętli wywoływana jest funkcja test&set tak długo aż zwróci false. Wówczas następuje wejście do sekcji krytycznej, po zakończeniu blokada jest ustawiana na false.
while (test&set(blokada)) do{}
sekcja krtytyczna
blokada=false
Wady:
Zalety:
Mechanizm analogiczny do test&set, ale gwarantuje sprawiedliwość dostępu do sekcji krytycznej.
Fetch&Operate
Function fetchadd(vbl)
When .true. do
temp = vbl
vbl = vbl + 1
end when
return temp
end function
Semafor
SEMAFOR - dzielona zmienna całkowita, która po inicjalizacji dostępna jest tylko za pomocą dwóch operacji: sygnalizuj(s) i czekaj(s).
SEMAFOR BINARNY - udostępnia sekcję krytyczną tylko jednemu wątkowi. Przyjmuje 2 wartości: 0 i 1.
SEMAFOR LICZNIKOWY - przyjmuje wartość od 0 do wartości określonej przez funkcję inicjalizującą.
czekaj(s)
{
s=s-1;
if(s<0)
{
dodaj do kolejki(P);
blokuj(P);
}
}
sygnalizuj(s)
{
s=s+1;
if(s<=0)
{
usun_z_kolejki(P);
obudz(P);
}
}
zalety:
zasoby systemu komputerowego nie są marnowane - proces zablokowany „śpi” - nie ma pętli wykonywanej w czasie działania innych procesów.
Monitor
Konstrukcja językowa, która zawiera zmienne oraz procedury, które mają być umieszczone w sekcji krytycznej:
monitor nazwa_monitora
{
deklaracja zmiennych zasobu
------------------------------------------------------------------
nazwa_procedury_1(lista parametrów formalnych)
{
deklaracje zmiennych lokalnych dla procedury 1
ciało procedury 1
}
nazwa_procedury_2(lista parametrów formalnych)
{
deklaracje zmiennych lokalnych dla procedury 2
ciało procedury 2
}
...
nazwa_procedury_n(lista parametrów formalnych)
{
deklaracje zmiennych lokalnych dla procedury n
ciało procedury n
}
------------------------------------------------------------------
inicjalizacja zmiennych zasobu
}
odwołanie do procedury i: nazwa_monitora.nazwa_procedury_i(wykaz parametrów aktulanych)
Partycjonowanie
Przed podzieleniem znajdywane są zależności poprzez rozwiązanie układów równań i nierówności o rozwiązaniach w zbiorze liczb całkowitych
Nie są brane pod uwagę fizyczne elementy systemów. Trzeba szczególną uwagę na tym etapie przywiązywać do odpowiednio dużej liczby zadań i ich porównywalnego rozmiaru, gdyż to może ułatwić uzyskanie odpowiedniej skalowalności.
Komunikacja
pr1 pr2
... ...
send ...
receive
Zaletą komunikacji synchronicznej jest gwarancja wykonywania instrukcji, a wadą wydłużanie czasu wykonywania procesu.
Na tym etapie określamy komunikacje pomiędzy zadaniami zdefiniowanymi w na poprzednim etapie. Staramy się, aby każde zadanie wysyłało i odbierało zbliżoną liczbę komunikatów i komunikowało się tylko z najbliższymi sąsiadami. Ważne jest, aby komunikacja między zadaniami mogła przebiegać jednocześnie.
Aglomeracja
Na tym etapie grupujemy zadania z uwzględnieniem działania aplikacji i jej wykonania. Staramy się aby liczba grup nie była mniejsza niż liczba procesorów, staramy się utrzymać skalowalność rozwiązania, rozmiar zadań uzyskanych na tym etapie powinien być zbilansowany.
Mapowanie
Ostatnia faza polega już na przydziale zadań do poszczególnych procesorów, z uwzględnieniem czasów komunikacji i fizycznych elementów projektu, należy starać się uzyskać się model SPMD, który może zagwarantować odpowiednie zarządzanie obciążeniem.
statyczne/dynamiczne
Statyczne - podział na zadania jest wykonywany podczas kompilacji.
Dynamiczne - w czasie wykonywania programu
dokładne/heurystyczne
Dokładne - korzystamy z funkcji celu z określeniem ekstremów (cokolwiek to znaczy)
Heurystyczne - przybliża wynik. Stosowane najczęściej
globalne/lokalne
Podział stosowany dla planowania dynamicznego(tylko)
Globalne - wyniki obciążenia pobierane od wszystkich procesorów
Lokalne - tylko od sąsiednich
zcentralizowane/zdecentralizowane
Podział stosowany dla planowania dynamicznego(tylko)
Zcentralizowane - procesor - koordynator jest odpowiedzialny za podział zadań na procesory
Zdecentralizowane - brak koordynatora
Obliczeń:
Czas spędzony na wykonywaniu programu. Można zmierzyć czas wykonania zadania. Zależy od rozmiaru problemu, rodzaju procesora i pamięci.
Komunikacji:
Czas spędzony na przesyłaniu i odbieraniu komunikatów. Zadania wykonywane na różnych procesorach i zadania wykonywane na tym samym procesorze. Różnice przy komunikacji przez sieć.
Przestojów:
Trudny do określenia. Procesor nie wykonuje działania z powodu braku danych lub braku zadań, aby go uniknąć - równoważenie obciążeniem, wykonywanie obliczeń podczas oczekiwania.
Tidle = Tc (N^2 * Z) + 2ts + 2twNZ
Prawo Amdahla
T=t_{c}\frac{N^{2}Z}{P}+2t_{s}+4t_{w}NZ
Obserwacji /Modele statystyczne
Ustalenie nieznanych danych na postawie metod statystycznych w oparciu o dane eksperymentalne.
a) określić wszystkie czynniki, które mogą mieć wpływ na T i dla których da się oszacować wartości:
T=(N, P, W, O) - N wielkość prblemu, P - ilość procesorów, W - ilość wątków, O - pamięc operacyjna
b) wybrać strukturę modelu (liniowy, nieliniowy, etc.), np:
T=a_{0}+a_{1}N+a_{2}P+a_{3}W+a_{4}O
c)badanie eksperymentalne:
/---|---|---|---|---|---
| T | N | P | W | O | ...
|---+---+---+---+---+---
| x | x | x | x | x | - x - jakaś dana
|---+---+---+---+---+---
| x | x | x | x | x |
|---+---+---+---+---+---
| x | x | x | x | x |
|---+---+---+---+---+---
. . . . . .
. . . . . .
. . . . . .
d) z analizy wyników badania wygenerowane zostają współczynniki
e) wykorzystanie modelu
Asymptotyczna analiza
O(NlogN) na P procesorach
Cost(N) <= c NlogN (P)
pragma OpenMP |
Opis |
#pragma omp parallel [if, private, first private, default(shared/none), shared, reduction]
modyfikatory:
|
rozpoczęcie rejonu równoległego |
#pragma omp for [private, firstprivate, lastprivate, reduction, ordered, schedule (kind(static, dynamic, giuded, runtime[chunksize], nowait))]
modyfikatory:
|
|
#pragma omp sections [private, firstprivate, lastprivate, reduction(operators: list), nowait] |
rozpoczyna sekcję kodu niezależnego |
#pragma omp single(private, firstprivate, nowait)) |
instrukcje wykonywane są w sposób sekwencyjny (na 1 procesorze). Wszystkie pozostałe wątki czekają na zakończenie wykonywania danego wątka. |
#pragma omp parallel for |
nie ma odpowiednika w PowerC. Są dostępne wszystkie modyfikatory pragmy parallel i pragmy for poza modyfikatorem nowait. |
#pragma omp parallel omp sections |
jednoczesne określenie początku kodu równoległego i sekcji kodu niezależnego; nie ma modyfikatora nowait |
#pragma omp master |
nie ma odpowiednika w PowerC. Umożliwia realizowanie obliczeń przez 1 wątek - proces macierzysty, tzn. taki proces, który dociera do rejonu równoległego |
#pragma omp critical |
właściwy dostęp do sekcji krytycznej |
#pragma omp barrier |
synchronizacja barierowa - w PowerC odpowiednikiem jest pragma synchronize |
Maszyna cyfrowa wykonująca operacje arytmetyczne i logiczne składająca się z procesora, pamięci i urządzeń wejścia wyjścia.
Sprzęt i uruchomione na nim oprogramowanie.
System informacyjny - system służący przetwarzaniu, przekazywaniu informacji na określony temat użytkownikowi.
System informatyczny - system informacyjny zrealizowany przy pomocy środków technicznych informatyki
For (i = 0; i<n i++)
For (j = i; j<n - 1; j++)
If (t[j] < t[j + 1])
Zamień (t[j], t[j+1])
dziedzina nauki i techniki zajmująca się przetwarzaniem informacji - w tym technologiami przetwarzania informacji oraz technologiami wytwarzania systemów przetwarzających informacje, pierwotnie będąca częścią matematyki, rozwinięta do osobnej dyscypliny nauki, pozostającej jednak nadal w ścisłym związku z matematyką, która dostarcza podstaw teoretycznych przetwarzania informacji.
Dane - ciąg znaków
Informacje - znaki i interpretacja
Wiedza - informacje + wnioski
Dane + relacje - model danych
I system zarządzania
System zarządzania pozwala na modyfikacje, zarządzanie danymi, utrzymanie ich.
12
Przezr. skalowalności
Przezr. przenaszalności
Przezr. dostępu
Przezr. wydajności
Przezr. replikacji
Przezr. lokalizacji
Przezr. Odporności na błędy
Przezr. Współbieżnego wykonania
możliwość podziału na 2 wątki
A
1
2
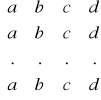
x
y
z
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
p |
q |
r |
- tablica źródłowa
- tablica mapowania
f |
d |
b |
o |
m |
k |
r |
p |
q |
a |
c |
e |
j |
l |
n |
n |
q |
c |
- tablica wynikowa
źródło
„one” |
„two” |
„three” |
„four” |
cel
„four” |
„one” |
„three” |
„two” |
4 |
1 |
3 |
2 |
źródło
„one” |
„two” |
„three” |
„four” |
cel
„two” |
„four” |
„three” |
„one” |
4 |
1 |
3 |
2 |
join join join join
fork
Wyszukiwarka
Podobne podstrony:
Opracowanie pytań na egzamin inżynierski dyplomowy Górnictwo i Geologia na semestr dyplomowy 2017 20
Maszyny Elektryczne Opracowanie Pytań Na Egzamin
pytania egz ekonimak II, OPRACOWANIE PYTAŃ NA EGZAMIN
opracowane zestawy, OPRACOWANIE PYTAŃ NA EGZAMIN
instalacje i oświetlenie elektryczne opracowanie pytań na egzamin
Pytania na egz z Ekonomiki, OPRACOWANIE PYTAŃ NA EGZAMIN
Opracowanie pytań na surowce cz. 7, Technologia Chemiczna, sem V, surowce, opracowania do egzaminu
OPRACOWANIE PYTAŃ NA KLINIKIE EGZAMIN SEM IV
Opracowanie pytań na egzamin z Systemów Sterowania Maszyn i Robotów u Salamandry
Pytania z egzaminu ekonomika KTZ ORO 2010, OPRACOWANIE PYTAŃ NA EGZAMIN
Pytania z egzaminu ekonomika KTZ ORO, OPRACOWANIE PYTAŃ NA EGZAMIN
Edukacja wczesnoszkolna pytania opracowanie pytań na egzamin
Ekonomika wziwa, OPRACOWANIE PYTAŃ NA EGZAMIN
Część opracowanych pytań na egzamin
egzamekonomika, OPRACOWANIE PYTAŃ NA EGZAMIN
Opracowanie pytań na egzamin z materiałoznawstwa , Ad29 Przemiana martenzytyczna jest przemianą bezd
Opracowanie pytań na egzamin z materiałoznawstwa
Opracowanie pytań na egzamin, AGH, WIMiC, Technologia Chemiczna, Fizyka
Opracowanie pytań na egzamin
więcej podobnych podstron