1.Statystyka- jest to nauka zajmująca się opracowaniem różnych obserwacji pomiarów, eksperymentów, ankiet w celu zbadania i liczbowego określania prawidłowości w masowych zjawiskach losowych.
2.Pojęcie populacji i próby.
Próba- (część)- podzbiór populacji, podlegający bezpośrednio badaniu ze względu na ustaloną cechę w celu wyciągnięcia wniosków o kształtowaniu się wartości tej cechy w populacji.
Populacja generalna- jest to zbiór poszczególnych elementów posiadających pewne wspólne cechy czy właściwości kwalifikujące je do tego zbioru.
3.Wnioskowanie statystyczne i wiarygodność wnioskowania
Wnioskowanie statystyczne- może wystąpić w 2 rodzajach:
-jako estymacja- czyli szacowanie parametrów rozkładu badanej cechy w populacji generalnej
-jako weryfikacja (testowanie)- hipotez statystycznych dotyczących rozkładu badanej cechy w zbiorowości generalnej
Wiarygodność wnioskowania- jest oparta na częściowej informacji i dostarcza jedynie wniosków wiarygodnych- a nie absolutnie prawdziwych.
4.Pojęcie zdarzenia elementarnego przestrzeni prób
Zdarzenie elementarne- każdy możliwy oddzielny i nie dający się rozłożyć na prostsze. Wynik obserwacji (doświadczenia) zdarzenie, które może realizować się tylko w 1 sposób.
Zdarzenie elementarne- pojedynczy niepodzielny wynik doświadczenia
Zdarzenie- jest to zbiór wyników
Przestrzeń próby- zbiór wszystkich możliwych wyników n-elementowej próby
5.Suma zdarzeń i iloczyn zdarzeń
Suma zdarzeń- A i B oznaczaną (A∪B) jest to zbiór wszystkich zdarzeń elementarnych, które należą do zdarzenia A lub B albo do obu tych zdarzeń. Przy sumie posługujemy się spójnikiem „lub” „albo”.
Iloczyn zdarzeń- A i B oznaczamy (A∩B) nazywamy zbiór wszystkich zdarzeń elementarnych, które równocześnie są elementami zdarzenia A i B.
6.Zdarzenia warunkowe, prawdopodobieństwo zdarzenia warunkowego
Prawdopodobieństwo warunkowe to podstawowe pojęcie teorii prawdopodobieństwa. W zasadzie każde zadanie z rachunku prawdopodobieństwa da się zapisać przy użyciu prawdopodobieństwa warunkowego.
Prawdopodobieństwem warunkowym zajścia zdarzenia A pod warunkiem zajścia zdarzenia B gdzie P(B)>0 nazywamy liczbę P(A/B)=P(A∩B)/P(B)
Jest to iloraz prawdopodobieństwa części wspólnej zdarzeń A i B i prawdopodobieństwa B.
7.Permutacje a kombinacje.
Permutacje- każdy możliwy sposób uporządkowania elementów danego zbioru. Liczba permutacji z n elementowego Pn=n! (silnia)!- iloczyn kolejnych liczb naturalnych np. 4 osoby można usadzić na 24 sposoby 4!=1*2*3*4=24
Kombinacja- podzbiór k elementowy ze zbioru n elementowego przy czym poszczególne kombinacje różnią się od siebie elementami natomiast ich kolejność (w odróżnieniu od wariancji) jest obojętna. Kombinacje różnią się między sobą dopiero wtedy, gdy różnią się choć jednym elementem. Liczbę kombinacji oznaczamy symbolem (nk) lub Ckn Ckn=n!/k!(n-k)!
8.Parametr populacji i statystyka z próby. Podział miar statystycznych
Parametr populacji- jest to parametr rozkładu badanej cechy w populacji. Do najczęściej używanych parametrów należą tzw. momenty.
Statystyka z próby- zmienna losowa będąca dowolną funkcją wyników próby losowej np. średnia arytmetyczna wyników z próby x-, statystyka pozycyjna rzędu 0,5 czyli mediana.
Podział miar statystycznych
1.położenia: średnie klasyczne, wartości modalne, mediana, kwantyle
2.zmienności: rozstęp (odchylenie ćwiartkowe, o przeciętne, o standardowe), wariacja, współczynnik zmienności, błąd średniej
3.Kształt: asymetrii, kurtoza, ekces
9.Charakterystyka miar położenia
Miary położenia rozkładu to taka miara rozkładu, która określa relację między dwoma identycznymi rozkładami ale przesuniętymi względem osi odciętych układu współrzędnych: najczęściej stosowana średnia arytmetyczna, średnia geometryczna, średnia harmoniczna, średnia kwantowa, mediana, kwartyl, moda
Średnia arytmetyczna- w potocznym języku nazywana średnią
Średnia geometryczna- średnią geometryczną n dodatnich liczb a, b, c nazywa się liczb
Średnia harmoniczna- średnią harmoniczną n z liczb 2,2,5,7 jest 4/1/2+1/2+1/5+1/5≈2,98
Mediana- wartość cechy w szeregu uporządkowanym powyżej i poniżej której znajduje się jednakowa liczba obserwacji
Kwartyl- definiuje się jako wartość cechy badanej zbiorowości, przedstawionej w postaci szeregu statystycznego, które dzielą się na określone części pod względem liczby jednostek, części te pozostają do siebie w określanych proporcjach
Moda- jest to wartość cechy statystycznej, która w danym rozdziale empirycznym występuje najczęściej
10.Miary zmienności
a)klasyczne: wariancja, odchylenie standardowe, odchylenie przeciętne, współczynnik zmienności
b)pozycyjne: rozstęp, odchylenie ćwiartkowe, współczynnik zmienności
rozstęp- różnica pomiędzy wartością max a min cechy
wariancja- jest to średnia arytmetyczna kwadratów odchyleń poszczególnych wartości cechy od średniej arytmetycznej zbiorowości
odchylenie standardowe- jest to pierwiastek kwadratowy z wariancji. Stanowi miarę zróżnicowania o mianie zgodnym z mianem badanej cechy, określa przeciętnie zróżnicowanie poszczególnych wartości cechy od średniej arytmetycznej
odchylenie przeciętne- jest to średnia arytmetyczna bezwzględnych odchyleń wartości cechy od średniej arytmetycznej. Określa o ile jednostek danej zbiorowości różnią się średnio, ze względu na wartość cechy, od średniej arytmetycznej
odchylenie ćwiartkowe- jest to parametr określający odchylenie wartości cechy od mediany. Mierzy poziom zróżnicowania tylko części jednostek, po odrzuceniu 25% jednostek o wartościach najmniejszych i 25 największych
współczynnik zmienności- jest iloraz bezwzględnej miary zmienności cechy i średniej wartości tej cechy, jest wielkością niemianowaną, najczęściej podawaną w %
11.Miary kształtu
Kurtoza- jest to jedna z miar rozkładu wartości cechy. Kurtoza rozkładu wynosi 0.
12.Właściwości średniej arytmetycznej
Średnia arytmetyczna- odpowiada (reprezentatywnej) dla zbiorów dość wyrównanych. Jest to iloraz sumy wartości elementów przez ich liczebność.
Właściwości- średnia arytmetyczna jest liczbą mianowaną
-jeżeli zwiększymy lub zmniejszymy wszystkie elementy o pewną wartość to x- zmieni się o tą samą wartość
-suma odchyleń od x- równa się 0 (odchylenie centralne) ∑(x1-x-)=0
-suma kwadratów odchyleń od średniej x- jest najmniejsza tzn że suma kwadratów odchyleń od innej wartości niż x- będzie zawsze większa
-jeżeli elementy szeregu x1, x2...xn zastąpimy średnią arytmetyczną to ogólny wynik (suma) będzie taki sam ∑x1=n*x-
-dla średniej arytmetycznej spełniona jest nierówność xmin<x-<xmax
-na wartość średniej arytmetycznej duży wpływ mają wielkość skrajna szeregu
13.Średnia arytmetyczna ważona, kiedy liczymy. Przykłady
Średnia arytmetyczna ważona- reprezentatywna dla zbioru danych, w którym wyróżnia się podzbiory o różnej „wadze” (stosowana w biometeorologii). Jest to suma iloczynów „waga podzbioru (n1) razy wartość podzbioru (xi)” podzielona przez sumę wag ∑n1 x-w=∑n1*xi'/∑ni
Obliczamy:
-dla dużych zbiorów gdzie niektóre wartości elementów powtarzają się
-jako średnią z kilku częściowych średnich arytmetycznych o różnej wadze
-w przypadku uporządkowania danych w szeregu rozdzielczym
16.Skale pomiarowe i przykłady pomiarów
Skale pomiarowe ze względu na relacje dzielimy na:
*nominalne relacja: różny pomiar polega na zastosowaniu liczby jako nazwy, czyli grupowaniu jednostek w klasy (kategorie) którym przypisuje się nazwy czy liczby np. studenci wg rodzaju studiów
*porządkowe relacje: większe lub mniejsze, pomiar polega na grupowaniu jednostek w klasy (kategorie) którym przypisuje się nazwy lub liczby i porządkuje się te klasy ze względu na stopień natężenia, w jakim posiadają one badaną cechę
*przedziałkowe- relacje większe o tyle pomiar występuje wtedy, gdy uporządkowany zbiór wartości cechy składa się z liczb rzeczywistych. 0 jest w tej skale ustalone dowolnie np. Farenhaita, skala pozwala określić tylko o ile coś jest wyższe
*stosunkowe (ilorazowe)- relacja: tyle razy większe spełnia wszystkie aksjomaty liczb, pomiary w tej skali charakteryzują się stałymi ilorazami i zerem bezwzględnym, tylko w tej skali możliwe jest porównanie jednostek za pomocą względnych charakterystyk np. 1 obiekt jest 2 razy cięższy od drugiego
15.Błąd bezwzględny a błąd względny
Błąd bezwzględny- i wartość błędu liczona adekwatną do danej sytuacji metodą (jako błąd max lub błąd statystyczny)
Błąd względny- wartość błędu podana jako % mierzonej wielkości. Błąd względny charakteryzuje użytą metodę pomiaru, a w mniejszym stopniu sam wynik pomiaru.
17.Pojęcie szeregu statystycznego i podział szeregów statystycznych
szereg statystyczny- ciąg wysokości statystycznych, uporządkowanych wg określonego kryterium
Podział:
Szereg szczegółowy- uporządkowany ciąg wartości badanej cechy statystycznej, stosowany gdy przedmiotem badania jest niewielka liczba jednostek
Szereg rozdzielczy- stanowi zbiorowość statystyczną, podzieloną na części (klasy), wg określonej cechy jakościowej lub ilościowej z podaniem liczebności lub częstości każdej z wyodrębnionych klas.
Rozkład empiryczny- zestawienie wyników w postaci szeregu rozdzielczego z cechą mierzalną, odzwierciedla strukturę badanej zbiorowości z punktu widzenia określonej cechy statystycznej.
20.Pojęcie zmiennej losowej i rozkładu zmiennej losowej.
Zmienna losowa- funkcja której argumentami są zdarzenia, natomiast wartościami są liczby, czyli jest to taka zmienna, która przyjmuje wartości z określonymi prawdopodobieństwami, a więc której właściwości zależą od przypadku
Rozkład prawdopodobieństwa zmiennej losowej (skokowej)- funkcja której argumentami są wartości zmiennej losowej, a wartościami prawdopodobieństwa przyjmowania przez zmienną losową tych wartości
21.Rozkład prawdopodobieństwa zmiennej losowej dyskretnej i ciągłej.
Zmienna losowa dyskretna (skokowa) przyjmuje tylko niektóre wartości (np. liczba kogutów w serii piskląt, liczba wyrzuconych oczek w rzucie kostką). Zmienna losowa ciągła może przyjmować wszystkie wartości rzeczywiste z określonego przedziału (np. wydajność mleka, wysokość osobnika)
23.Rozkład skumulowany (dystrybuanta) zmiennej losowej i ciągłej
Dystrybuanta- funkcja określająca przyjęcie przez zmienną losową wartości większe niż, t F(t)=P(x Ł t). Dystrybuanta jest więc funkcją określoną na zbiorze liczb rzeczywistych rosnącą i przyjmującą wartości od 0 do 1. Wartość dystrybuanty w punkcie t uzyskujemy sumując wartości rozkładu prawdopodobieństwa dla wartości zmiennej losowej nie przekraczających t.
24.Wartość oczekiwana i wariancja zmiennej losowej dyskretnej i ciągłej
Wartość oczekiwana
1)E(c*x)=c*E(x)
2)E(x+y)=E(x)+E(y) →jeśli nie zmienia sie niezależnie
Niech h(x) będzie f zmiennej losowej x wtedy oczekiwana wartość zmiennej losowej dyskretnej jest w postaci
Eh(x)=∑ h(x)*Pr (X-x)
Funkcją h(x) może być x2 logx h(x)=a+hx
Wariancja zmiennej losowej ciągłej
Var(x)=E[x-E(x)2]2=E(x2)-[E(x)]2
Wariancja zmiennej losowej dyskretnej jest nią wartość Var(x)=a2=f(a1)[a1-E(x)]2+f(an)[an-E(x)]2=ni=1∑f(a1)[a1-E(x)]2
Obliczenie wariancji i określenie wartości i ich prawdopodobieństw wyszczególnie określeń i-E(x) podniesienie odchyleń do kwadratu i przemnożenie przez prawdopodobieństwo i zsumowanie iloczynów
25.Charakterystyka zmiennej losowej dwumianowej- rozkład dwumianowy
Rozkład dwumianowy- jest wynikiem pojedynczego doświadczenia (losowany rzut monetą czy kostką) jest zdarzenie, które opisuje zmienną losową zero-jedynkową (sukces i niepowodzenie) to w serii n-niezależnych od siebie doświadczeń liczba sukcesów- jest tzw zmienną losową Bernoulliego.
Rozkład dwumianowy- określany jest wzorem Bernoulliego: P(k sukcesów n próbach)=P (x=k)
P(X=k)=Ckn*pk*qn-k dla k=0,1,2....
26.Charakterystyka zmiennej losowej Poissona- rozkład Poissona.
Zmienna losowa Poissona jest liczbą zdarzeń, które w jednostce czasu przestrzeni lub objętości występują rzadko. Rozkład takiej zmiennej nazywamy rozkładem Poissona.
Rozkład Poissona obejmuje tylko 1 parametr. Wystarczy znać jego wartość by obliczyć prawdopodobieństwa że zmienna losowa przybiera wartość 0,1,2,3...k
Przykłady zmiennej losowej Poissona
-liczba urodzin czworaczków w ciągu roku
-liczba wypadków śmiertelnych
-szybkość mutacji u bakterii
-liczba zachowań na rzadką chorobę na rok
27.Charakterystyka rozkładu normalnego i rozkładu normalnego standaryzowanego.
Rozkład normalny- jego wykresem jest krzywa normalna mająca kształt dzwonu, zwana również krzywą Gaussa-Laplece'a
Własności:
-powierzchnia pod krzywą równa się (1) jedności
-jest to rozkład symetryczny
-Mediana jest taka sama (=)Modalnej
-Charakteryzują go 2 parametry: średnia i odchylenie standardowe, które wyznacza kształt rozkładu
*im większe jest odchylenie standardowe badanej zbiorowości, tym krzywa normalna reprezentująca tę zbiorowość jest bardziej spłaszczona
*im mniejsze jest odchylenie tym krzywa jest bardziej wypukła (zbiorowość bardziej jednolita)
!Tutaj do odchylenia standardowego można powiedzieć o regule 3 sigm
Rozkład normalny standardowy- rozkład normalny N (0,1) tzn o funkcji gęstości. Wykresem tej funkcji jest krzywa Gaussa. Chcąc zastosować ten rozkład do jakichkolwiek danych należy przeprowadzić ich kodowanie zwane standaryzacją, standaryzując zmienną x.
28.Reguła Czybyszewa (reguła jednej, dwóch i 3 sigm)
Reguła Czybyszewa: odchylenie standardowe spełnia regułę 3 sigm wg której w przypadku rozkładu normalnego lub zbliżonego do normalnego:
1σ 68,28% wszystkich wartości x przypada na przedział u-σ do u+σ (czyli 31,7% wszystkich pomiarów różni się od średniej arytmetycznej o więcej niż Łσ
2σ 95,46% wszystkich wartości x leży w przedziale u 1,96σ u+1,96σ (czyli pomiary odbiegające od średniej o więcej niż 2 odchylenia standardowe stanowią mniej niż 5%)
3σ 99,78% wszystkich wartości zmiennej x mieści się w przedziale od u-3σ do u+3σ (czyli parametrów odbiegających od średniej o więcej niż 3 odchylenia standardowe jest zaledwie 0,27≅0,3%).
29.Centralne twierdzenie graniczne- to twierdzenie matematyczne mówiące, że jeśli x są niezależnymi zmiennymi losowymi o jednakowym rozkładzie, tej samej wartości oczekiwanej i skończonej wariancji to zmienna losowa zbiega wg rozkładu do standardowego rozkładu normalnego gdy urośnie do nieskończoności
30.Pojęcie estymacji punktowej i estymacji przedziałowej.
Estymacja punktowa metoda szacunku nieznanego parametru populacji polegająca na tym, że jako wartość parametru przyjmuje się wartość estymatora tego parametru otrzymaną z danej n elementowej próby losowej.
Estymacja przedziałowa- to grupa metod statystycznych służących do oszacowania parametrów rozkładu zmiennej losowej w populacji generalnej. Oceną parametru nie jest konkretna wartość, ale pewien przedział, do którego z określonym prawdopodobieństwem należy szacować wartość parametru. Podstawowym pojęciem estymacji przedziałowej jest przedział ufności.
31.Pojęcie estymatora i własności estymatorów
Estymator- dowolna statystyka, służąca do oszacowania nieznanej wartości parametru populacji generalnej
Własność estymatorów:
Nieobciążoność- jest to wartość oczekiwana rozkładu estymatora jest równa wartości szacowanego parametru
Asymptotyczna nieobciążoność- jeśli obciążenie estymatorem dąży do 0 rosnącej liczbie próby
Zgodność- jeśli jest stochastycznie zbieżny do szacowanego parametru
Efektywność- spośród zbioru wszystkich nieobciążonych estymatorów najefektywniejszym nazywamy estymator o najmniejszej wariancji
Asymptotyczna efektywność- estymator jest asymptotycznie najefektowniejszy jeśli przy wzrastającej liczebności próby wariancja estymatora dąży do wariancji estymatora najefektywniejszego.
32.Pojęcie estymatora obciążonego i nieobciążonego
Estymator nieobciążony- estymator spełnia równość E=0 oznaczającą, że estymator zszacuje parametr bez błędu systematycznego
Estymator obciążony- jeżeli różnica pomiędzy wartością oczekiwaną rozkładu estymatora a wartością szacowanego parametru jest zależna funkcyjnie to estymator jest obciążony ppppp różnicą nazywamy obciążeniem estymatora.
35.Przedział ufności dla średniej, poziom ufności
Przedział ufności- nazywamy przedziałem liczbowym o którym przypuszczamy, że mieści się w nim nieznany parametr populacji.
Miara ufności nazywa się poziomem ufności przedział nieprawdy zaznacza interesujący nas parametr (1-α) współczynnik ufności.
36.Pojęcie hipotezy statystycznej i testu statystycznego
Hipoteza statystyczna- każde przypuszczenie dotyczące nieznanego rozkładu lub parametru rozkładu zmiennej losowej, którego prawdziwość lub fałszywość wnioskujemy na podstawie próby losowej.
Test statystyczny- to zmienna losowa o ustalonym rozkładzie teoretycznym, określa on pewny regułę postępowania która każdej możliwej próbie losowej przyporządkowuje decyzję przyjęcia lub odrzucenia hipotezy.
37.Błędy I i II rodzaju.
Jeśli odrzucamy H0, które w rzeczywistości jest prawdziwe to popełniamy błąd I rodzaju. Jeśli odrzucamy H0, które w rzeczywistości jest fałszywe to popełniamy błąd II rodzaju.
38.Wartości P a poziom istotności
Przy założeniu, że M0 jest prawdziwa, prawdopodobieństwo, że statystyka testowa przyjmuje wartość tak ekstrymalną (lub bardziej skrajną) jak wartość obserwowana w próbie nazywa się wartością P tego testu. Im mniejsza jest wartość P tym silniejsze są argumenty przeciwko H0 dostarczane przez dane z próby
P<0,01 H0 odrzucamy wynik wysoce istotny
0,05<p<0,01 H0 odrzucamy wynik istotny
0,10<p<0,05 niejednoznaczne nie mają podstaw do odrzucenia H0 wynik istotny
40.Test Z- przykłady stosowania
-w celu stosowania H0: μ=μ0 oparta na prostej próbie losowej wielkości μ z populacji o nieznanej średniej, znanej wariancji należy wyznaczyć standaryzowaną wartość średniej próby
-dla średniej; znana wariacja z=x--μ0/r/pierwiastek n
wartość p dla dla μ:u=μ0 wobec M0:μ>μ0Pr(Z≥z)
M0:μ<μ0Pr(Z≤z)
M0:μ≠μ0Pr(Z≥z)
41.Rozkład t i test t- przykłady stosowania
-w celu testowania H0:u=μ0 w oparciu o próbę losową o wielkości n pochodzącą z populacji o mierzonej średniej n i nieznanej σ2 wyznaczamy statystykę t-studenta
-wariancja jest nieznana
t0=x-μ0/σ/pierwiastek n
wartości p dla μ0:μ=μ0 wobec H0:μ>μ0=Pr (t≥a)
H0:μ<μ0=Pr (t≤a)
H0:μ≠μ0=Pr (t≠a)
42.Rozkład F i test F- Przykłady stosowania
Jeśli s12i s22 są wariancjami wyznaczanymi z dwóch nierozdzielnych prób losowych o wielkości n1 i n2, które wylosowano z populacji o rozkładzie normalnym. F=s12/s22
Femp=średni kwadrat obiektowy/średni kwadrat błędu
43.Istota i założenia analizy wariancji
-rozkład normalnej cechy
-jednorodność wariancji (homopeniczność)
-niezależność błędów doświadczonych (nie są ze sobą związane)
-addytywność efektów (różnica w wydajności)
45.ANOVA- klasyfikacja jednokierunkowa
-badana cecha ma rozkład normalny
-nominacje porównywanych obiektów są podobne- jednorodność
-wyniki z poszczególnych poletek
46. model deterministyczny i model probabilistyczny
Model deterministyczny - model matematyczny opisujący zależność między zmienną niezależną i zmienną zależną w postaci funkcji, np. y=0,1x. uwzględnienie składnika losowego , zwanego także błędem losowym, prowadzi do modelu probabilistycznego, np. y=0,1x +e. Błąd losowy e odgrywa istotną rolę w testowaniu hipotez związanych z parametrami modelu i określeniu przedziałów ufności dla deterministycznej części modelu.
47. Pojęcie korelacji
Korelacja mierzy siłę zależności liniowej między 2 cechami X i Y. Matematyczną miarą tej siły jest współczynnik korelacji r Pearsona wyznaczony ze wzoru:
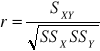
48. Pojęcie regresji:
Regresją nazywamy funkcyjną zależność zmiennej losowej od innej zmiennej z dokładnością do błędu losowego o wartości oczekiwanej równej zero.
W zapisie formalnym zależność przybiera postać Y = f(X) + ε
Gdzie Y - zmienna losowa, f(X) - funkcja regresji, X - dowolna zmienna (lub ich zespół), ε - zaburzenie losowe. E(ε)=0
50. Interpretacja współczynnika regresji prostej
Najprostszym modelem matematycznym opisującym zależności w populacji między dwoma cechami X i Y jest funkcja liniowa w postaci:
Y=β0+β1X+ ε
Gdzie: Y=β0+β1X - równanie prostej regresji; ε - błędy losowe związane z prostą regresją muszą mieć rozkład normalny o średniej 0 i wartości σ2.
W równaniu regresji wyraz wolny β0 i nachylenia β1 nazywamy współczynnikami regresji. Są to parametry populacji przyjmujące określone wartości dla analizowanej wartości populacji. Zwykle oceniamy je na podstawie próby według równań:
![]()
= β0+β1x
lub ![]()
= α+bx
Oszacowany współczynnik regresji α, zwany stałą regresji lub wyrazem wolnym określa punkt przecięcia osi wyznaczonej prostej z osią zmiennej zależnej Y. interpretacja współczynnika regresji b związanego z kątem nachylenia prostej ma znaczenie praktyczne, wskazuje bowiem, o ile zmieni się (wzrośnie lub zmaleje) zmienna zależna Y, jeśli zmienna niezależna X zmieni się (odpowiednio wzrośnie lub zmaleje) o jednostkę. Znak przy współczynniku regresji b wskazuje na kierunek zależności: jeśli współczynnik regresji jest dodatni, to prosta jest rosnąca (ze wzrostem wartości jednej ze zmiennych wartości rosną wartości drugiej zmiennej), jeśli jest ujemny, to prosta jest malejąca (ze wzrostem wartości jednej ze zmiennych maleją wartości drugiej zmiennej).
51. Interpretacja współczynnika korelacji.
Współczynnik korelacji r jest liczbą niemianowaną i zawiera się w przedziale od -1 do +1. na wartość r nie ma wpływ zmiana skali pomiarów zarówno zmiennej X, jak i zmiennej Y, a korelacja między X i Y jest taka sama jak między Y i X.
Znak współczynnika korelacji zależy od znaku kowariancji i jest on taki sam jak znak współczynnika regresji b, a zatem można przyjąć podobną jego interpretację. Gdy r>0, zależność jest dodatnia, co oznacza, że wzrostowi wartości jednej ze zmiennych towarzyszy wzrost wartości drugiej zmiennej. Gdy r<0, wtedy zależność między zmiennymi jest ujemna, tzn. że wzrostowi wartości jednej ze zmiennych towarzyszy spadek wartości drugiej. Należy podkreślić, że o sile zależności między zmiennymi decyduje wielkość współczynnika korelacji, a nie jego znak. Ekstremalne wartości -1 i +1 zdarzają się tylko wówczas, gdy wszystkie pkt leżą na linii prostej malejącej (r= -1) lub rosnącej (r= +1). Wartości r zbliżone do -1 lub +1 wskazują na niewielki rozrzut obserwacji na diagramie punktowym i silną korelację. Wartości r zbliżone do 0 wskazują na brak zależności lub słabą liniową zależność. Aby określić istotność statystyczną siły tej zależności, należy przeprowadzić testowanie hipotezy o istotności współczynnika korelacji r, przy czym jeśli wcześniej testowano istotność współczynnika regresji b, to wnioski z tego testu można także odnieść do istotności współczynnika korelacji r. Należy także pamiętać, że korelacja mierzy tylko siłę związku liniowego między 2 zmiennymi. Związek nieliniowy między cechami X i Y nie powinien być rozpatrywany w kategoriach korelacji zmiennych, ponieważ wartość liczbowa współczynnika korelacji która może być bliska 0 lub wartościom -1 i +1 nie świadczy wówczas o dobrym dopasowaniu funkcji nieliniowej.
52. interpretacja współczynnika determinacji
jeżeli przez SSY oznaczamy „ogólną zmienność Y”, która jest sumą kwadratów odchyleń poszczególnych wartości yi od średniej ![]()
, a przez SSE „niewyjaśniona zmienność Y” po dopasowaniu linii regresji ![]()
, która jest sumą kwadratów odchyleń wartość yi od średniej ![]()
i , to stosunek różnicy SSY - SSE oznaczający „wyjaśnioną zmienność Y” wynikającą z liniowego związku ze zmienną X do zmienności ogólnej nazywa się współczynnikiem determinacji R2. ma on postać:
![]()
W regresji liniowej wartość współczynnika determinacji jest kwadratem współczynnika korelacji czyli r2. w interpretacji współczynnika determinacji jego wartość wyrażamy procentowo jako 100 R2.![]()
54. Test chi-kwadrat (χ2):
Test najczęściej wykorzystywany w praktyce. Możemy go wykorzystywać do badania zgodności zarówno cech mierzalnych, jak i niemierzalnych. Jest to jedyny test do badania zgodności cech niemierzalnych.
Test χ2 można wykorzystać do testowania różnych hipotez:
-testowania niezależności w tablicy kontyngencji o braku związku między wierszami i kolumnami danych zestawionych w układzie tablicowym.
-testowania zgodności rozkładu obserwacji w próbie z określonym rozkładem , np. z rozkładem normalnym, Poissona lub innym znanym rozkładem wynikającym, np. ze spisu powszechnego.
-testowanie jednorodności frakcji: czy rozkład w populacjach jest zgodny z określonym stosunkiem ilościowym, np. 1: lub 3:1, oraz czy w kolejnych doświadczeniach założenie o określonym stosunku ilościowym jest spełnione.
-testowania zależności liniowej danych grupowych według skali porządkowej
Aby stosowanie testu χ2 było uzasadnione, należy spełnić następujące założenia:
-próba losowa jest duża - minimum 30-50 obserwacji
-odpowiednia liczebność w komórkach tablicy kontyngencji (powyżej 5-10 w tablicach 2x2 i 5 lub więcej w 80% komórek tablic większych, nie dopuszcza się komórek z zerowymi liczebnościami.
-niezależność obserwacji
-taki sam rozkład wszystkich obserwacji
-nie testuje się zależności w kategoriach przyczynowo-skutkowych
55. Tablica wielodzielcza (kontyngencji) przykłady badań przyrodniczych
wiersze w tablicy kontyngencji odpowiadają poziomom jednej kategorii klasyfikacyjnej, a kolumny - drugiej. Jeśli przyjmiemy że interesuje nas porażenie roślin pszenicy rdzą zbożową na poletkach bez ochrony chem i z ochroną chemiczną, to jedną z kategorii klasyfikacyjnych może być sposób ochrony (bez ochrony i ochrona), a drugą stan roślin (zdrowe i porażone). W takim przypadku hipoteza robocza zakłada że jedno kryterium klasyfikacji nie zależy od drugiego, tzn stan zdrowotny roślin nie zależy od sposobu ochrony roślin.
Wyszukiwarka
Podobne podstrony:
Statystyka - Warszawa - Pytania, Studia, Psychologia, SWPS, 2 rok, Semestr 04 (lato), Metodologia ze
statystyka-pytania, Studia, Psychologia, SWPS, 2 rok, Semestr 04 (lato), Metodologia ze statystyką
przykładowe pytania, studia MEiL, semestr 2mgr, semestr 9, fizyka 2
higiena-pytania, studia, wnożcik, higiena
jasiek pytania, Studia, SiMR, II ROK, III semestr, Elektrotechnika i Elektronika II, Elektra, Elektr
rr RĂłznice Indywidualne Wszytskie pytania, Studia, Psychologia, SWPS, 2 rok, Semestr 04 (lato), Psy
Przykładowe pytania, studia, semestr 1, mikroekonomia
pytania2stopień, Studia, rekrutacja
odpowiedzi pytania, Studia, WIP PW, I rok, MATERIAŁY METALOWE I CERAMICZNE, SESJA
L4 - pytania, Studia, Wytrzymałość materiałów II, lab4 wm2 studek
nieorgany-pytania2, Studia - Chemia kosmetyczna UŁ, II rok, III semestr, CHEMIA NIEORGANICZNA labora
NMW laborki pytania, Studia, AiR, SEMESTR III, Nmt
kolokwium pytania, Studia, Geofizyka, I SEMESTR, GEOFIZYKA
dobra pisze 1 grupe od 2 pytania, ★ Studia, Psychologia, Psychologia osobowości
egzamin opracowane pytania 1 , studia, Koncepcje zarządzania
więcej podobnych podstron