![]()
Hipotezy statystyczne - sformułowane przypuszczenia dotyczące rozkładu populacji:
parametryczne - precyzują wartości parametrów w rozkładzie populacji (są najczęściej stosowane)
nieparametryczne - dotyczą rozkładów badanej cechy w populacji generalnej i nie prezentują wartości parametrów tego rozkładu
h0 - podlega weryfikacji
![]()
h1 - alternatywna
Etapy testowania:
1. Przyjęcie założeń
![]()
2.Otrzymanie rozkładu z próby
3.Wyznaczenie poziomu istotności i obszaru krytycznego
4. Przeprowadzenie badań i wyliczenie statystyki testu.
5.Podjęcie decyzji.
Do weryfikacji testów używamy testów. Testy - statystyki z próby które wykorzystujemy do weryfikacji hipotez.
Test I rodzaju - h0 jest prawdziwe ale wynik testu ją obalił i przyjęto h1 popełnienie tego błędu jest związane z przyjętym poziomem istotności
Test II rodzaju - h0 jest fałszywa ale wynik testu ją potwierdził i przyjęto tę hipotezę zerową.
Test nieparametryczny - test χ2 bada zgodność rozkładu empirycznego z teoretycznym.
h0 - mówi że rozkład naszej cechy jest zgodny z rozkładem teoretycznym
h1 - mówi że rozkład naszej cechy odbiega od rozkładu teoretycznego
Test istotności - rodzaj testu na podstawie którego podejmujemy decyzję o tym czy odrzucamy czy brak jest podstaw do odrzucenia hipotezy zerowej. W tym teście bierze się pod uwagę możliwość popełnienia błędu I-go rodzaju, którego prawdopodobieństwo nosi nazwę poziomu istotności.
Zależności pomiędzy zmiennymi:
zależność funkcyjna - występuje wówczas gdy zmiana wartości jednej zmiennej powoduje ściśle określoną zmianę wartości pozostałych zmiennych.
zależność stochastyczna - gdy zmiana wartości jednej zmiennej losowej powoduje zmianę rozkładu prawdopodobieństwa drogiej zmiennej losowej czyli w miarę wzrostu wartości jednej zmiennej na ogół rosną wartości drugiej zmiennej.
Wariantem zależności stochastycznej jest zależność korelacyjna, która dotyczy tylko zmiennej zależnej mierzalnej.
brak zależności - zmiana wartości jednej zmiennej nie powoduje zmiany wartości drugiej zmiennej.
Regresja - polega na badaniu współzależności zmiennych.
Badając zależność między dwiema zmiennymi, możemy wyznaczyć dwa równania prostej regresji:
1.równanie przedstawiające zależność między zmienną Y (zmiana zależna) i zmienna X (zmienna niezależna), a więc ![]()
2.równanie przedstawiające zależność między zmienną X (zmienna zależna) i zmienną Y (zmienna niezależna), a więc
![]()
Współczynnik w równaniu regresji:
![]()
Własności prostych regresji:
Proste regresji przecinają się w punktach

.Współczynniki kierunkowe b1 i b2 prostych regresji mają taki sam znak + lub -. Gdy + to zachodz korelacja dodatnia pomiędzy cechami a więc ze wzrostem wartości jednej zmiennej rośnie wartość drugiej.
Współczynnik kierunkowy b1 wskazuje o ile zmieni się średnio wartość pierwszej zmiennej (zależnej0 gdy wartość drugiej zmiennej (niezależnej) zmieni się o jednostkę w której wyrażona jest ta zmienna. - z b2 jest analogicznie.
Gdy między zmiennymi nie występuje zależność wówczas współczynniki kierunkowe prostych są równe 0: b1 =0 i b2 =0. Wówczas proste regresji przecinają się pod kątem 900.
Jeżeli między zmiennymi występuje liniowa zależność funkcyjna, to proste regresji pokrywają się.
Jeżeli między zmiennymi występuje związek korelacyjny, to proste regresji przecinają się pod pewnym kątem. Gdy wartość tego kąta maleje do 0 to związek korelacyjny dąży do związku funkcyjnego. Im większa wartość tego kąta tym siła związku słabnie ( gdy kąt prosty - brak związku).
Współczynnik korelacji jest kowariancją dwuwymiarowej zmiennej losowej (x, y)podzieloną przez iloczyn odchyleń standardowych zmiennej x i zmiennej y.
-1≤ r≤1
![]()
gdy r =0 nie ma zależności między zmiennymi
r =sposób przybliżony
![]()
![]()
![]()
Drugi sposób
r>3εr - korelacja jest istotna
r<3εr - korelacja jest nieistotna
Korelacja-miara siły związku między analizowanymi cechami.
Błąd standardowy współczynnika korelacji = miara rozrzutu [r]
n≥50
n≤50
Własności korelacji;
Gdy r = 0 wówczas między zmiennymi nie występuje zależność liniowa, może występować zależność nieliniowa.
Gdy r = 1 lub r = -1 to zależność między zmiennymi jest funkcyjna, liniowa.
Jeżeli współczynnik korelacji przybiera wartości z przedziałów 0 < r < 1 lub-1 < r < 0 to zależność między zmiennymi jest korelacyjna.
Im bardziej współczynnik korelacji różni się od 0 więc im bliższy jest wartościom 1 lub -1 tym związek między zmiennymi jest silniejszy.
Znak współczynnika korelacji jest taki sam jak znak współczynników kierunkowych prostych regresji b1 i b2. Znak + oznacz korelację dodatnią a - ujemną.
Współczynnik determinacji r2 (tzw. Określoności) - wyjaśnia jaka część zmienności zmiennej y spowodowana jest regresją, a więc zależnością od zmiennej x.w %
Współczynnik indeterminacji 1 - r2 - podaje jaka część zmienności zmiennej y nie jest spowodowana regresją, a więc nie jest spowodowana wpływem zmiennej x. W %
Prosta próba losowa - to taka próba w której każdy element populacji ma jednakową szansę (prawdopodobieństwo) wejścia do próby, a losowanie elementów jest niezależne.
Schematy losowania:
niezależne - ze zwracaniem, - jeden element populacji może zostać wylosowany do próby więcej niż 1 raz
zależne - bez zwracania,
warstwowe - populację dzieli się na części tzw. warstwy tak że każdy element populacji należy dokładnie do jednej z warstw. Elementy dla których określa się badaną cechę A, losuje się z każdej warstwy oddzielnie, stosując losowanie zależne lub niezależne.
Systematyczne - całą populację dzielimy na n części gdzie n jest liczbą próby. Każda część populacji reprezentowana jest przez taką samą liczbę elementów, które numerujemy od 1 do k. Dla jednej części populacji losujemy 1 element z pośród k elementów. Do próby wchodzi wylosowany element oraz wszystkie te elementy z pozostałych części populacji, które mają ten sam numer.
Dwufazowe - polega na wyborze z populacji dużej próby, dla której określa się cechy B, C, D itd., W drugiej fazie pobiera się próbę do określenia cechy A, wykorzystując informację o cechach B, C, D, itd.
Wielostopniowe - populację dzielimy na duże jednostki, które losujemy, jest to losowanie pierwszego stopnia. Wylosowane jednostki dzielimy na jednostki mniejsze i przeprowadzamy losowanie drugiego stopnia. Wylosowane jednostki drugiego stopnia dzielimy na jeszcze mniejsze i ponownie przeprowadzamy losowanie. Czynności te powtarzamy do momentu uzyskania jednostek najwyższego (podstawowego) stopnia. Wylosowane jednostki najwyższego stopnia wchodzą do próby.
Estymacja punktowa - polega na wyznaczeniu parametru θ populacji generalnej na podstawie estymatora Tn będącego statystyką z próby. Szacunek taki uzupełnia się zwykle podaniem błędu estymatora. θ = Tn - Bn.
Estymacja przedziałowa - dla populacji generalnej mającej rozkład normalny wprowadzamy zmienna standaryzowaną z estymatora nieobciążonego Tn
parametru θ
![]()
![]()
i żądamy aby z prawdopodobieństwem współczynnika ufności 1-α wartość tej statystyki zawarta była w przedziale
Po przekształceniach z prawdopodobieństwem P=1-α dlaθ:
![]()
Przedział ufności to oszacowany przedział w którym z określonym prawdopodobieństwem znajduje się parametr populacji.
Poziom ufności - oznacza prawdopodobieństwo z jakim przedział ufności pokrywa nieznaną wartość parametru θ populacji generalnej.
Poziom istotności - prawdopodobieństwo że przedział ufności nie pokrywa parametru populacji generalnej.
Test zgodności χ2 pozwala na weryfikację hipotezy, że populacja ma określoną postać funkcyjną dystrybuanty. Może to być rozkład dla zmiennej losowej zarówno skokowej jak i ciągłej, a jedynym ograniczeniem jest konieczność operowania dużą próbą.
Estymacja statystyczna - rodzaj wnioskowania o wartościach parametrów populacji generalnej na podstawie statystyk określonych dla n-elementowych prób wylosowanych z populacji. Wnioskowanie to polega na tym że znając wyniki uzyskane z próby staramy się ocenić z określonym stopniem dokładności wartości parametrów zmiennej.
3 powody dla których stos. Próby:
Populacja jest nieokreślona, pop. -jest skończona ale tak liczna że jej zbadanie jest pracochłonne i czasochłonne - zbadanie jakiejś cechy - zniszczenie jednostki statystycznej.
Próba musi reprezentować populację generalną.
Próba reprezentatywna - to taka próba z której po odpowiednich przeliczeniach uzyskamy
idealny obraz populacji. Otrzymujemy ją przez losowy wybór.
Próba tendencyjna - reprezentatywna daje fałszywy obraz populacji.
Parametry z próby - to statystyki które oblicza się na podstawie wyników z próby, np. średnia arytmetyczna, wariancja
Zasady doboru próby - jeżeli próba ma służyć do oceny populacji generalnej to powinna ona być w odpowiedni sposób pobrana z tej populacji. Próbą najlepszą byłaby idealna próba reprezentatywna. Będzie to taka próba z której po przeprowadzeniu odpowiednich przeliczeń uzyskamy idealny obraz populacji. Reprezentatywność próby możemy uzyskać przez jej losowy wybór a próbę taka nazywamy próba losową. Prosta próba losowa ot taka próba, w której każdy element populacji m jednakowe prawdopodobieństwo wejścia do próby a losowanie jest niezależne. Od próby prostej możemy oczekiwać że zostaną w niej odzwierciedlone prawidłowości występujące w populacji.
Własności estymatora
nieobciążony - oznacza że przy wielokrotnym losowaniu próby średnia z wartości otrzymywanej przez estymator równa jest wartości szacowanego parametru θ w populacji generalnej.(nie będzie błędów stałych)

zgodny - jeżeli jest stochastycznie zbieżny do szacowanego parametru. Im większa próba tym estymator większy(wartość oczekiwana jest równa parametrowi)
![]()
efektywny - jeżeli mamy zbiór estymatorów nieobciążonych Tn1, Tn2 ... Tni parametru θ to estymatorem najbardziej efektywnym w tym zbiorze będzie ten który ma najmniejszą wariancję.
Efektywność estymatora - najbardziej efektywnego ma wartość =1, natomiast wszystkich pozostałych mieści się 0 < e < 1.
![]()
Odchylenie standardowe estymatora -
Wyznaczanie liczebności próby - gdy populacja generalna ma rozkład normalny N (, σ i znana jest wariancja tej populacji stosujemy wzór pozwalający na określenie liczebności próby
![]()
![]()
Dla małych prób badanie istotności różnic między średnimi możemy przeprowadzić opierając się na statystyce:
![]()
populacje z których pobieramy próby powinny mieć rozkład normalny
populacje powinny mieć jednakowe wariancje, jak w przypadku dużych prób.
Kiedy liczebność dużych prób jest jednakowa, a więc n1 = n2 =n to wzór ma postać 
Błąd standardowy dla średnich:
![]()
Błąd średni:
![]()
![]()
Dla dużych prób badanie istotności różnic między średnimi
ZAŁ:
N(0,1)![]()
TEZA ![]()
-odrzucamy hipotezę zerową
![]()
- brak podstaw do _ odrzucenia hip. zerowej
Zestaw IV
1.Miary dyspersji pokazują zakres wahań wartości badanej cechy. Rozstęp- różnica między największą i najmniejszą wartością cech.Wariancja zmiennej x- srednia arytm. Kwadratow odchylen poszczególnych wartości cechy od jej sredniej arytm. …..
Odchylenie standardowe-pierwiastek kwadratowy z wariancji …………….
Odchylenie przeciętne-………………..
Współczynnik zmienności…………….
2. P(A\/B)=P(a)+P(b) , P(A/\B)=0
- P(A/\B)>0
3.
4.Estymacja przedziałowa-metoda wnioskowania statystycznego umozliwiająca określenie przediału liczbowego o którym z pewnym prawdopodob. Można powiedzieć ze zawiera on prawdziwa wartość parametru.
5. Błąd I rodzaju - h0 jest prawdziwe ale wynik testu ją obalił i przyjęto h1 popełnienie tego błędu jest związane z przyjętym poziomem istotności
Błąd II rodzaju - h0 jest fałszywa ale wynik testu ją potwierdził i przyjęto tę hipotezę zerową.
Sposób budowy testu istotności.poziom istotności- możliwość popełnienia błędu I-rodzaju.
Zestaw
1.Miary położenia informują nas o przeciętnej wartości zmiennej.
Średnia arytm-………….
Dla szeregu
Suma odchyleń poszczególnych wartości zmiennej od średniej arytm. Jest równa zeru. Inna liczba rozna od sredniej da sume odchylen rozna od 0.
Modalna- miara wskazująca na wartość o największym prawdopodobieństwie wystąpienia, lub wartość najczęściej występująca w próbie. Mo=M-3(m-Me)
Mediana- wartość cechy w szeregu uporządkowanym, powyżej i poniżej której znajduje się jednakowa liczba obserwacji………………………….
Asym. Dodatnia= c=m-me Mo Me M
2. Załóżmy, że Ω jest zbiorem zdarzeń elementarnych ω, zaś M jest σ-ciałem na zbiorze Ω. Prawdopodobieństwem nazywamy funkcję P: M → R spełniającą następujące warunki:
P(A) ≥ 0 dla każdego A ∈ M
P(Ω) = 1
jeśli (An) jest dowolnym ciągiem podzbiorów M parami rozłącznych, to
3.rozkłaD Dwumianowy
4. Estymacja punktowa - polega na wyznaczeniu parametru θ populacji generalnej na podstawie estymatora Tn będącego statystyką z próby. Szacunek taki uzupełnia się zwykle podaniem błędu estymatora. θ = Tn - Bn.
5.krytyczny obszar tekstu- zawsze na krańcach rozkładu.jeżeli wartość statystyki testowej jest w tym obszarze to odrzucamy H0.
Zestaw 8
1.odchylenie standard.-pieriwastek kwadratowy z wariancji. Mniejsze odchylenie standardowe odpowiada większy stopień skupienia wartości zmiennej wokół sredniej.
2.P(A\/B)=P(A)+P(B)-P(a/\B). jeżeli zdarzenia a i b wyłączają się to zgodnie z aksjonatem drugim współczesnej def. Prawdop. Mamy P(a\/B)=P(a)+P(b)
3
4.błedy 1 i 2 rodzaju
5. Zależności pomiędzy zmiennymi:
zależność funkcyjna - występuje wówczas gdy zmiana wartości jednej zmiennej powoduje ściśle określoną zmianę wartości pozostałych zmiennych.
zależność stochastyczna - gdy zmiana wartości jednej zmiennej losowej powoduje zmianę rozkładu prawdopodobieństwa drogiej zmiennej losowej czyli w miarę wzrostu wartości jednej zmiennej na ogół rosną wartości drugiej zmiennej.
Wariantem zależności stochastycznej jest zależność korelacyjna, która dotyczy tylko zmiennej zależnej mierzalnej.
brak zależności - zmiana wartości jednej zmiennej nie powoduje zmiany wartości drugiej zmiennej
Zestaw 1
1.Srednia arytm.
2.współczynnik zmienności do wyznaczenia liczebności próby- CV=…..
CV=……………….
Liczebność próby wyraża się wzorem
N=(Z alfa/2
3.przedział ufnośći dla sredniej.- z populacji pobiera się n-elementowa próbę prostą. Dla proby obliczamy srednia x z krecha która jest estymatorem sredniej u. przedział dla sredniej budujemy na podstawie statystyki.
…………………………..
Przedział ufności=>
4.obszar krytyczny -- zawsze na krańcach rozkładu.jeżeli wartość statystyki testowej jest w tym obszarze to odrzucamy H0.
5.porownywanie wariancji- pobieramy z pierwszej populacji o rozkładzie normalnym n-probę dla ktorej liczymy srednia i wariancje.dla drugiej tak samo. W porównaniu wariancji opieramy się na statystyce F=s12 /s22 F>1 F<1 s2/s1
Z tablic dokonujemy odczytu Falfa na podstawie poziomu istotności alfa i liczby stopni swobody k1=n2-1
Porównujemy ho=……………………
Zestaw 5
1.populcja-zbiór jednostek wchodzących w sqad zbiorowości statystycznej będącej obiektem badania statystycznego.skończona i nieskonczona.
2.odchylenie standardowe- stopien skupienia wartości zmiennej wokół sredniej .
3.
4.wyznacz liczebność proby do minimalnej liczebności proby.
…………………………..
………………………..
5.przedział ufności przy nieznanej wariancji.
………………
……… która ma rozkład studenta z liczbą stopni swobody k=n-1
Przedział ufności wzor-
………………….
Celem wyznaczania wartości talfa/2 obliczamy dystrybuantę…………….
Na podstawie k i talfa/2 odczytujemy z tabl. Dystrybuanty studenta wartoscm talfa/2.
Zestaw 2
1.wzor na wariancje z proby-
2.wzor na odchylenie ……………
Wzor naliczebnosc proby ![]()
3. estymacja punktowa-Estymacja punktowa - polega na wyznaczeniu parametru θ populacji generalnej na podstawie estymatora Tn będącego statystyką z próby. Szacunek taki uzupełnia się zwykle podaniem błędu estymatora. θ = Tn - Bn
4.srednia hipotetyczna- srednia z próby o przypuszczalnych wartościach.
5. test x2- pozwala na weryfikację hipotezy ze populacja ma okresloną postać funkcyjną dystrybuanty. Może to być rozkład dla zmiennej losowej zarówno skokowej i ciągłej a jedyne ograniczenie to konieczność operowania duza probą.
Zestaw 6
1.cecha- własność jednostek statystycznych będącą podstawą ich różnicowania. C.zmierzalna- przyjmuje rozne wartości w określonych jednostkach miary( ciągła-wartosci to dowolne liczby i skokowa-skonczona liczba wartosci).c. niemierzalna-wyrażana słownie.
2.współczynnik zmienności- miara dyspersji wyrażana w procentach V=Sx/M *100%. Można obliczyc dla zmiennej skokowej.
3.
4.błąd standardowy estymatora- dla schematu losowania niezależnego-
…………………………………..
Dla losowania zależnego-
…………………………………….
5.przedział ufności gdy znana wariancja- z populacji norm. Pobieramy n probe dla niej liczymy srednia która jest estymatorem głównej sredniej. Przedzial ufności-……………….
…………………………
Konce przedzialu…………………………
……………………………….
Zestaw 7
1.cecha-1.cecha- własność jednostek statystycznych będącą podstawą ich różnicowania. C.zmierzalna- przyjmuje rozne wartości w określonych jednostkach miary( ciągła-wartosci to dowolne liczby i skokowa-skonczona liczba wartosci).c. niemierzalna-wyrażana słownie.
2.prawdopodobienstwo- Załóżmy, że Ω jest zbiorem zdarzeń elementarnych ω, zaś M jest σ-ciałem na zbiorze Ω. Prawdopodobieństwem nazywamy funkcję P: M → R spełniającą następujące warunki:
P(A) ≥ 0 dla każdego A ∈ M
P(Ω) = 1
jeśli (An) jest dowolnym ciągiem podzbiorów M parami rozłącznych, to
3.wlasnosci dobrego estymatora-
Nieobciążony- wartość oczekiwana jest rowna wartości parametru w populacji.
Zgodny-wraz z wzrostem liczebności proby wartość estymatora zbliza się dom wartości parametru.
Efektywny-gdy ocena parametru uzyskana dzieki estymatorowi ma najmniejsza wariancje.
Dostateczny- estymator wyczerpuje wszystkie możliwe informacje om danym parametrze.
![]()
4.małe proby- Dla małych prób badanie istotności różnic między średnimi możemy przeprowadzić opierając się na statystyce:
populacje z których pobieramy próby powinny mieć rozkład normalny
populacje powinny mieć jednakowe wariancje, jak w przypadku dużych prób.
5.korelacja- Drugi sposób
r>3εr - korelacja jest istotna
r<3εr - korelacja jest nieistotna
Korelacja-miara siły związku między analizowanymi cechami.
Błąd standardowy współczynnika korelacji = miara rozrzutu [r]
n≥50
n≤50
Własności korelacji;
Gdy r = 0 wówczas między zmiennymi nie występuje zależność liniowa, może występować zależność nieliniowa.
Gdy r = 1 lub r = -1 to zależność między zmiennymi jest funkcyjna, liniowa.
Jeżeli współczynnik korelacji przybiera wartości z przedziałów 0 < r < 1 lub-1 < r < 0 to zależność między zmiennymi jest korelacyjna.
Im bardziej współczynnik korelacji różni się od 0 więc im bliższy jest wartościom 1 lub -1 tym związek między zmiennymi jest silniejszy.
Znak współczynnika korelacji jest taki sam jak znak współczynników kierunkowych prostych regresji b1 i b2. Znak + oznacz korelację dodatnią a - ujemną.
![]()
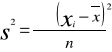
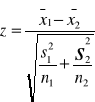
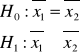

![]()
![]()
![]()
![]()
![]()
![]()
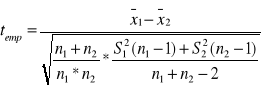

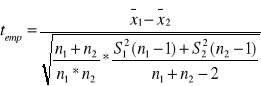
Wyszukiwarka
Podobne podstrony:
ściąga - kolokwium 1, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Statystyka, 1 semestr
wzory 3, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Statystyka, 1 semestr
odp zagadnienia egzam sciaga, Leśnictwo UWM Olsztyn, Semestr I, Gleboznawstwo, Ezgamin
Stal sciaga, Skrypty, PK - materiały ze studiów, I stopień, SEMESTR 7, Konstrukcje stalowe II, egzam
elektryczna sciaga, Skrypty, UR - materiały ze studiów, IV semestr, inżynieria
projekt zalesiania gruntów porolnych, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Hodowla, semestr 7,
ochr.przyr - ściąga, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Ochrona Przyrody
mateo ściąga str 1, SGGW, Niezbędnik Huberta, Leśnictwo, Semestr 1, Meteorologia
test H1, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Hodowla, semestr 6
podanie botanika, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Botanika, 1 semestr
pkt3 tabelaryczny opis zadrzewień, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Hodowla, semestr 7, tem
Zoologia - ściąga egzamin, SGGW, Niezbędnik Huberta, Leśnictwo, Semestr 1, Zoologia
mateo ściąga str 2, SGGW, Niezbędnik Huberta, Leśnictwo, Semestr 1, Meteorologia
ściąga meteo1, SGGW, Niezbędnik Huberta, Leśnictwo, Semestr 1, Meteorologia
plantacyjna uprawa modrzewia eurolepisa, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Hodowla, semestr
WRZOS, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Hodowla, semestr 7
drogownictwo sciaga, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Inżynieria
H5, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Hodowla, semestr 7
więcej podobnych podstron