Pojęcie zmiennej losowej; zmienna losowa skokowa i ciągła. Rozkład normalny
Zmienna losowa w dosłownym tłumaczeniu oznacza:
- zmienna - przy wielokrotnym powtarzaniu jakiejś próby uzyskamy w większości przypadków różne wartości
- losowa - nie wiemy, jaka wartość będzie przed wykonaniem próby
Definicja (jedna z możliwych):
Zmienna losowa jest to taka zmienna, która w wyniku doświadczenia przybiera jedną i tylko jedną wartość ze zbioru tych wszystkich wartości, jakie ta zmienna może przyjąć.
Zmienną losową jest zmienna, która przyjmuje różne wartości wyznaczone przez los. Jest to funkcja, która zdarzeniom losowym przypisuje liczby.
Mówimy, że X jest zmienną losową skokową (dyskretną), jeśli jej zbiór wartości jest zbiorem skończonym lub przeliczalnym.
Przykłady zmiennych losowych dyskretnych:
- liczby urodzeń w Polsce
- ocena uzyskiwana przez studentów na egzaminie z wybranego przedmiotu.
Zmiennymi losowymi ciągłymi nazywamy takie zmienne losowe, które mogą przybierać dowolne wartości liczbowe z pewnego przedziału liczbowego.
Przykłady zmiennych losowych ciągłych:
- wzrost, waga, wiek człowieka
Rozkład normalny
Rozkład normalny, jest funkcją ciągłą, a więc może przyjmować dowolne wartości x
z przedziału (-∞, +∞). Każdej wartości x przypisuje odpowiednią wielkość f(x) zwaną gęstością prawdopodobieństwa. Prawdopodobieństwo zdarzenia, że zmienna X przyjmie wartość należąca do pewnego przedziału (x1, x2), zapisujemy:
X2
P(x1 ≤ X ≤ x2) = x1∫ f(x) dx
Kształt tej funkcji zależy od dwóch parametrów: średniej m i wariancji σ2 (względnie odchylenia standardowego σ) N(m, σ). Jest to krzywa symetryczna względem swojej wartości średniej
o charakterystycznym kształcie „dzwonu”, którego spłaszczenie (wysmukłość) zależy od odchylenia standardowego. Większe odchylenie standardowe - „dzwon” bardziej smukły (przy tej samej średniej m). Większa średnia przy tym samym odchyleniu standardowym przesuwa funkcje w prawo. Punkt przegięcia krzywej znajduje się w odległości jednego odchylenia standardowego od średniej.
Rozkład normalny, zwany również rozkładem Gaussa jest jednym z najważniejszych rozkładów funkcji.
JEDNĄ Z NAJWAŻNIEJSZYCH WŁASNOŚCI ROZKŁADU NORMALNEGO JEST FAKT, ŻE PRZY PEWNYCH ZAŁOŻENIACH, ROZKŁAD SUMY DUŻEJ LICZBY ZMIENNYCH LOSOWYCH JEST
W PRZYBLIŻENIU NORMALNY (centralne twierdzenie graniczne)
Wartość średnia zmiennej losowej i wariancja zmiennej losowej
W rachunku prawdopodobieństwa wartość oczekiwana (inaczej wartość przeciętna, wartość średnia, nadzieja matematyczna)(dyskretnej) zmiennej losowej jest sumą iloczynów wartości tej zmiennej losowej oraz prawdopodobieństw, z jakimi te wartości są przyjmowane.
Formalnie, jeżeli dyskretna zmienna losowa X przyjmuje wartości x1, x2, ... odpowiednio z prawdopodobieństwami p1, p2, ..., wówczas wartość oczekiwaną E[X] zmiennej losowej X definiujemy jako:
Ogólnie, jeżeli X jest zmienną losową zdefiniowaną na przestrzeni probabilistycznej (Ω, F, P), to wartość oczekiwaną E[X] zmiennej losowej X definiujemy jako całkę :
Zatem jeśli X jest zmienną losową o funkcji gęstości prawdopodobieństwa f(x), to jej wartość oczekiwana wynosi
Wartość oczekiwana to inaczej pierwszy moment zwykły. Estymatorem wartości oczekiwanej rozkładu cechy w populacji jest średnia arytmetyczna.
Własności
Jeżeli istnieją E[X] i E[Y] to:
(liniowość);
Jeżeli zmienne X,Y są niezależne, to E[XY] = E[X]E[Y]
Wariancja to klasyczna miara zmienności.
Wariancją w zbiorze wyników nazywamy przeciętne kwadratowe odchylenie poszczególnych wyników od średniej.
Kowariancja i współczynnik korelacji
Parametrami charakteryzującymi łączny rozkład dwuwymiarowej zmiennej losowej (X,Y) są kowariancja i współczynnik korelacji, za pomocą których mierzymy zależność pomiędzy zmiennymi losowymi.
Kowariancja Cov(X,Y) jest to liczba określająca zależność liczbową między zmiennymi losowymi X,Y. Jeżeli zmienne losowe X,Y są niezależne i istnieją ich wartości oczekiwane to Cov(X,Y)=0
Kowariancja-suma iloczynów odchyleń od średniej.
X i Y zmienne losowe takie, że ∃ E(X2), E(Y2) <∞
Cov (X,Y) : = E((X-E(X))(Y-E(Y)))
Kowariancja jest miarą nieunormowaną. Unormowana kowariancja nosi nazwę współczynnika korelacji. Współczynnik korelacji to kowariancja odniesiona do iloczynu odchyleń standardowych.
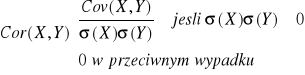
4. Pojęcie estymatora. Co to jest estymator nieobciążony, obciążony, asymptotycznie nieobciążony
Estymator jest narzędziem wnioskowania statystycznego. Estymator jest to funkcja wyników z próby, czyli statystyka służąca do oszacowania nieznanej wartości parametru populacji. Estymator jako funkcja wyników próby losowej, będących zmiennymi losowymi, jest zmienną losową.
Estymator jest nieobciążony, jeśli wartość oczekiwana rozkładu estymatora jest równa wartości szacowanego parametru.
Estymator jest obciążony, jeśli różnica pomiędzy wartością oczekiwaną rozkładu estymatora a wartością szacowanego parametru jest zależna funkcyjnie od estymatora.
Estymator nazywamy asymptotycznie nieobciążonym, jeśli obciążenie estymatora dąży do zera przy rosnącej liczebności próby.
5. Metoda momentu uzyskiwania estymatorów
Jeśli nie jest oczywiste jaką statystykę należy wybrać jako kandydata na estymator, z pomocą przychodzą różnorodne metody ich wyznaczania. Metoda momentów jest najstarszą metodą wyznaczania estymatorów. Polega ona na tym, że do szacowania parametrów populacji generalnej używamy odpowiednich momentów z próby lub ich funkcji.
Jeśli chcemy oszacować wartość średnią, to ponieważ jest to pierwszy moment, jako estymatora używamy pierwszego momentu z próby.
Chcąc oszacować wariancje, jako estymatora używamy drugiego momentu centralnego z próby. Metoda momentów odznacza się dużą prostotą, ale estymatory uzyskane przy pomocy tej metody nie mają na ogół dobrych własności.
6. Pojęcie przedziału ufności. Przedział ufności dla średniej normalnej, gdy sigma jest znana. Przedział ufności dla średniej normalnej, gdy sigma jest nieznana. Przedział ufności dla wariancji.
Przedziałem ufności nazywamy przedział (θ1, θ2), którego krańce są zmiennymi losowymi, a który zawiera nieznany parametr θ2 z prawdopodobieństwem równym 1-ά
_ _____ _____
xn - t ά √nS2n ; xn + t ά √nS2n , jest to przedział ufności dla średniej
n(n-1) n(n-1)
normalnej m na poziomie ufności 1-ά, gdy wariancja ∂2 jest nieznana.
Przedział ten ma zastosowanie w przypadku próby o małej liczebności, tj. n ≤ 30.
xn - U ά ∂ ; xn + U ά ∂ , jest to przedział ufności dla średniej normalnej, gdy
√n √n - te znaczki przed n to pierwiastki
wariancja ∂2 jest znana. Przedział ten ma zastosowanie w przypadku próby o dużej liczebności, tj. n>30.
7. Pojęcie hipotezy statystycznej. Pojęcie statystyki testowej. Pojęcie zbioru krytycznego.
Błąd I-go rodzaju, błąd II-go rodzaju.
Obok zagadnień estymacji, drugim podstawowym działem wnioskowania statystycznego jest weryfikacja (podejmowanie decyzji o prawdziwości albo fałszywości) hipotez statystycznych
Def.: Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się w oparciu o pobraną próbkę. Przypuszczenia te dotyczą najczęściej postaci rozkładu lub wartości jego parametrów. Hipotezy, które dotyczą wyłącznie wartości parametru określonej klasy rozkładów nazywamy hipotezami parametrycznymi. Każdą hipotezę, która nie jest parametryczna, nazywamy hipotezą nieparametryczną. Jeżeli hipoteza parametryczna precyzuje dokładnie wartości wszystkich nieznanych parametrów rozkładu badanej cechy, to nazywamy ją prostą. W przeciwnym wypadku mamy do czynienia z hipotezą złożoną. Weryfikację hipotezy statystycznej przeprowadzamy w oparciu o wyniki próby losowej.
Metodę postępowania, która każdej możliwej realizacji próbki x1, x 2 , x n przyporządkowuje z ustalonym prawdopodobieństwem decyzję przyjęcia lub odrzucenia sprawdzanej hipotezy nazywamy testem statystycznym. W praktyce przy weryfikacji hipotezy postępuje się tak, że oprócz weryfikacji hipotezy H0 wyróżnia się inną hipotezę H1, która najczęściej wynika z celu badania statystycznego, zwaną hipotezą alternatywną. Hipoteza H1 jest taką hipotezą, którą w danym zagadnieniu skłonni jesteśmy przyjąć, jeśli weryfikowaną hipotezę H0 należy odrzucić. W celu zbudowania testu do weryfikacji postawionej hipotezy H0 należy wybrać odpowiednią funkcję próby losowej ∂ (x1, x 2 , x n). Funkcję tę nazywamy statystyką testową. Przy pobieraniu próbek, nawet o tej samej liczności n, funkcja ta przyjmuje na ogół różne wartości, z których jedne będą świadczyły raczej o zgodności z weryfikowaną hipotezą, a inne mogą przemawiać przeciw tej hipotezie. Zachodzi więc konieczność podziału zbioru wszystkich wartości, które może przyjąć statystyka testowa na dwa dopełniające się zbiory w i w' takie, że jeśli ∂ (x1, x 2 , x n) € w, hipotezę odrzucamy. Jeśli ∂ (x1, x 2 , x n) € w', hipotezę przyjmujemy.
Zbiór W nazywamy zbiorem krytycznym lub zbiorem odrzuceń hipotezy. Zbiór W' nazywamy zbiorem przyjęć. Weryfikując daną hipotezę statystyczną w oparciu o zaobserwowane wyniki próbki, ponosimy zawsze pewne ryzyko podjęcia błędnej decyzji. Wynika to stąd, że na podstawie próbki nigdy nie mamy całkowitej informacji o zbiorowości, z której pobrano próbkę. W wyniku testowania hipotezy statystycznej możemy więc podjąć poprawną decyzję lub popełnić jeden z dwu następujących błędów:
możemy odrzucić hipotezę H0 wtedy, gdy jest ona w rzeczywistości prawdziwa
(błąd I rodzaju)
możemy przyjąć weryfikowaną hipotezę H0 jako prawdziwą, gdy jest ona fałszywa, czyli
prawdziwa jest hipoteza alternatywna (błąd II rodzaju).
Prawdopodobieństwo popełnienia błędu I rodzaju to poziom istotności, oznaczany α; prawdopodobieństwo popełnienia błędu II rodzaju oznaczamy β. Wskazane jest, by prawdopodobieństwo błędów obu rodzajów uczynić możliwie małymi. Nie można jednak zmniejszać jednocześnie obu rodzajów błędów przy ustalonej liczności próby.
Błąd pierwszego rodzaju - w statystyce pojęcie z zakresu weryfikacji hipotez statystycznych - błąd polegający na odrzuceniu hipotezy zerowej, która w rzeczywistości jest prawdziwa. Błąd pierwszego rodzaju znany też jest jako: błąd pierwszego typu, błąd przyjęcia lub alfa-błąd.
Oszacowanie prawdopodobieństwo popełnienia błędu pierwszego rodzaju oznaczamy symbolem α (mała grecka litera alfa) i nazywamy poziomem istotności testu.
Błąd drugiego rodzaju (błąd drugiego typu, błąd przyjęcia, beta-błąd) - w statystyce pojęcie z zakresu weryfikacji hipotez statystycznych - polegające na nieodrzuceniu hipotezy zerowej, która jest w rzeczywistości fałszywa.
Oszacowanie prawdopodobieństwo popełnienia błędu drugiego rodzaju oznaczamy symbolem β (mała grecka litera beta) i nazywane jest mocą testu.
Parametryczne testy istotności. Weryfikacja hipotezy dotycząca wartości średniej, testy
istotności dla wariancji.
Weryfikacją hipotezy nazywamy sprawdzenie sądów o populacji, sformułowanych bez zbadania jej całości.
Weryfikacja hipotez dotycząca wartości średniej (wykład z 7.01.2006)
MODEL I
Badana cecha X populacji generalnej ma rozkład N(m, σ), gdzie σ >0 jest znane.
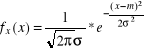
E(X)=m, D2(X)= σ2
Weryfikujemy hipotezę H0:m=m0 wobec hipotezy alternatywnej
H1:m=m1 < m0
H1:m=m1 > m0
H1:m=m1 ≠ m0
Poziom istotności α, 0<α<1
Do weryfikacji hipotezy H0 użyjemy statystyki ![]()
, która przy założeniu prawdziwości hipotezy H0:m=m0 ma rozkład N(0,1)
Postać zbioru krytycznego zależy od postaci hipotezy alternatywnej
a) jeżeli H1:m=m1 < m0
to zbiorem krytycznym W jest przedział (-∞ ),u(α)}, gdzie u(α) jest kwantylem rzędu α rozkładu N(0,1)
konstrukcja testu do weryfikacji hipotezy H0:m=m0 wobec hipotezy alternatywnej H1:m=m1 < m0 na poziomie istotności α
b) H1:m=m1 > m0
to zbiorem krytycznym W jest przedział [(1-α), +∞), gdzie u(1-α) jest kwantylem rzędu 1-α rozkładu N(0,1)
Wykres...
c) jeżeli H1:m=m1 ≠ m0 to zbiorem krytycznym W jest suma mnogościowa przedziałów (-∞, - u(1-α/2)] ∪[(1- α/2) +∞)
Wykres....
Jeśli wartość statystyki U jest obliczana dla próbki uobl należy do zbioru krytycznego W to weryfikowaną hipotezę H0 odrzucamy a przyjmujemy hipotezę alternatywną H1. W przeciwnym przypadku nie ma podstaw do odrzucenia weryfikowanej hipotezy H0.
Przyklad
Z populacji w której badana cecha X ma rozkład normalny X ~N(m,4) wylosowano próbkę o liczności n=9. Na poziomie istotności α=0,05 zweryfikować hipotezę H0: m=2 wobec hipotezy H1m=m1 < 2 jesli średnia z próbki wynosi ![]()
=1,4
![]()
![]()
H1:m=m1 < m0=2 to zbiór krytyczny W=(-∞, -u(1- )]=(-∞,-u(0,95)]= (-∞,-1,64] (1,64 z tablic)
MODEL II
Badana cecha X populacji generalnej ma rozkład N(m, σ), gdzie m, σ nieznane.
Weryfikujemy hipotezę H0:m=m0 wobec hipotezy alternatywnej
a) H1:m=m1 ≠ m0
b) H1:m=m1 > m0
c)H1:m=m1 < m0
Poziom istotności α, 0<α<1
Do weryfikacji hipotezy H0 użyjemy statystyki ![]()
, która przy prawdziwości hipotezy H0:m=m0 ma rozkład t-Studenta z n-1 stopniami swobody.
b) jeśli H1:m1 > m0 to zbiorem krytycznym jest przedział [t(1-, n-1), +∞), gdzie t(1-, n-1) jest kwantylem rzędu 1-α rozkładu t-Studenta z n-1 stopniami swobody
c) jeśli H1:m1 < m0 to zbiorem krytycznym jest przedział (-∞, - t(1-, n-1)]
a) jeśli H1:m1 ≠ m0 to zbiorem krytycznym jest suma mnogościowa przedziałów (-∞, - t(1- /2, n-1)]∪[ t(1- /2, n-1), +∞), gdzie t(1- /2, n-1) jest kwantylem rzędu 1- /2 rozkładu
t- Studenta z n-1 stopniami swobody.
Jeśli wartość tobl statystyki t obliczona dla danej próbki należy do zbioru krytycznego W wtedy weryfikowaną hipotezę H0 odrzucamy na korzyść hipotezy alternatywnej H1. W przeciwnym przypadku nie ma podstaw do odrzucenia weryfikowanej hipotezy H0.
Testy istotności dla wariancji
Niech badana cecha X populacji generalnej ma rozkład N(m, σ), gdzie m, σ nieznane.
Weryfikujemy hipotezę H0:σ 2 =σ20 wobec hipotezy alternatywnej
a) H1: σ 2 =σ21 ≠σ 20
b) H1: σ 2 =σ21 > σ 20
c)H1: σ 2 =σ21 < σ 20
Poziom istotności α, 0<α<1, n≤50
Do weryfikacji hipotezy H0 użyjemy statystyki ![]()
, która przy prawdziwości hipotezy H0 :σ 2 =σ20 ma rozkład χ2 z (n-1) stopniami swobody.
b)Jeśli H1: σ 2 =σ21 > σ 20 to zbiorem krytycznym W jest przedział [χ2(1-α, n-1), +∞)
gdzie χ2(1-α, n-1) jest kwantylem rzędu 1-α z n-1 stopniami swobody
Wykres...
[χ2(1-α, n-1)
(zbiór krytyczny z prawej strony wykresu
W
Jeśli H1: σ 2 =σ21 < σ 20 to W (0, χ2(α, n-1)
Wykres...
Jeśli H1: σ 2 =σ21 ≠σ 20 to W (0, (1/2α, n-1)] ∪ [(1-1/2α, n-1), +∞)
Jeśli obliczona z próbki wartość statystyki ![]()
należy do zbioru krytycznego W to weryfikowaną hipotezę H0 odrzucamy i przyjmujemy hipotezę alternatywną. W przeciwnym przypadku nie ma podstaw do jej odrzucenia.
UWAGA
Ponieważ tablice rozkładu χ2 podają wartości kwantyli dla n≤50 to rozpatrzony model stosujemy przy założeniu, że próbka jest o liczności n≤50
Przykład
W celu oszacowania dokładności pomiaru wykonanych pewnym przyrządem dokonano n=8 pomiarów i otrzymano następujące wyniki: 18,17; 19,21; 18,05; 18,14; 18,19; 18,22; 18,06; 18,08;
α=0,05 H0; σ 2 =σ20 przeciw hipotezie alternatywnej:
a) H1: σ 2 =σ21 ≠σ 20
b) H1: σ 2 =σ21 > σ 20
c)H1: σ 2 =σ21 < σ 20
Poziom istotności α, 0<α<1, n>50
Do weryfikacji hipotezy H0 wykorzystamy jak w poprzednim modelu statystykę ![]()
oraz fakt, że statystyka 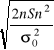
ma w przybliżeniu rozkład N(![]()
, 1)
Do weryfikacji H0 użyjemy statystyki ![]()
, która ma w przybliżeniu rozkład N(0,1)
1) jeśli H1: σ 2 =σ21 > σ 20 to zbiorem krytycznym W jest przedział [u(1-α), +∞), gdzie u(1-α) jest kwantylem rzędu 1-α rozkładu N(0,1)
2) jeśli H1: σ 2 =σ21 < σ 20 to zbiorem krytycznym W jest przedział (-∞, - u(1-α)]
3) jeśli H1: σ 2 =σ21 ≠σ 20 to zbiorem krytycznym W jest przedział ((-∞, - u(1-α/2)]∪[ u(1-α/2), +∞)
1