Wykład 1
Termin ekonometria używany jest w polskiej literaturze w dwóch znaczeniach. W szerszym znaczeniu jako zespół metod matematycznych i statystycznych stosowanych do badań ekonomicznych. W węższym znaczeniu oznacza specyficzne metody statystyczne stosowane w badaniach nieeksperymentalnych.
Ekonometria zajmuje się badaniem - mierzeniem danych ekonomicznych, badaniem obserwacji empirycznych za pomocą statystycznych metod estymacji i testowania hipotez.
Badania empiryczne i teoretyczne wzajemnie się uzupełniają. Analizy teoretyczne poddawane są weryfikacji przy pomocy danych empirycznych. Z drugiej strony do badań statystycznych potrzebne są wskazówki płynące z teorii ekonomicznych.
Podstawowym obiektem rozpatrywanym w ekonometrii jest model ekonometryczny czyli formalny zapis procesu lub zjawiska ekonomicznego. Tym formalnym zapisem jest równanie lub zespół równań wiążących rozważane zmienne.
Równanie zbudowane jest: ze zmiennych objaśnianych, objaśniających o ustalonej treści ekonomicznej; parametrów strukturalnych; składniku losowym o nieustalonej treści ekonomicznej; związku funkcyjnego łączącego te wszystkie wielkości.
Zmienna to coś co może się zmieniać, przyjmować różne wartości. Zmienne często występujące w rozważaniach ekonomicznych to: praca, zysk, koszt, dochód narodowy, import, export…
Klasyfikacja zmiennych występujących w modelu ekonometrycznym.
Ze względu na źródło zmienności:
Zmienne endogeniczne (bieżące i opóźnione, generowane od wewnątrz), zmienne określane (wyjaśniane) na podstawie modelu;
Zmienne egzogeniczne (bieżące i opóźnione, generowane z zewnątrz), wartości tych zmiennych są dane, ustalone. Zmienne nie wyjaśniane przez model.
Ze względu na rolę pełnioną przez zmienne w modelu:
Zmienne objaśniane;
Zmienne objaśniające.
Klasyfikacja modeli ekonometrycznych
Ze względu na liczbę równań
Modele jednorównaniowe
Modele wielorównaniowe
Ze względu na postać analityczną równań
Modele liniowe
Modele nieliniowe sprowadzalne do postaci liniowej - takie, które po przekształceniu przybierają postać liniową:
Modele nieliniowe i niesprowadzalne do postaci liniowej
Ze względu na rolę odgrywaną przez czas
Modele statyczne - prezentujące dane przekrojowe, dane z jednego okresu czasu
Modele dynamiczne - prezentujące zjawisko w czasie, szeregi czasowe
Model trendu
Model autoregresyjny
Ze względu na poznawcze cechy modelu.
Modele przyczynowo-skutkowe
Modele symptomatyczne
Modele trendu
Według charakteru powiązań między zmiennymi
Modele proste
Modele rekurencyjne
Modele o równaniach współzależnych.
Jeżeli za punkt odniesienia przyjmiemy cel budowy modelu to możemy wyróżnić:
Modele opisowe - budowane w celach poznawczych, głównie do celów opisowych bądź weryfikacji stawianych hipotez ekonomicznych;
Modele optymalizacyjne - klasyczne zagadnienie optymalizacji produkcji, zagadnienie diety;
Modele bilansowe - zagadnienia nakładów i wyników produkcji.
Możemy klasyfikować modele ze względu na występowanie w modelu wielkości losowej:
Modele deterministyczne - modele optymalizacyjne, modele bilansowe;
Modele stochastyczne - modele opisowe zjawisk gospodarczych.
Często stosuje się też podział modeli ze względu na zjawiska opisywane zmiennymi objaśnianymi:
Modele makroekonomiczne;
Modele mikroekonomiczne;
Branżowe
Regionalne
Gospodarki narodowej;
Handlu zagranicznego, itp…
Proces budowy modelu ekonometrycznego.
W pierwszym etapie ustalana jest mierzalna zmienna endogeniczna Y (objaśniana). Na podstawie uznawanej teorii ekonomicznej lub na podstawie zebranego materiału empirycznego formułuje się hipotezę, co do postaci modelu, zbioru zmiennych objaśniających X={X1, X2,… Xm} i zależności między zmiennymi występującymi w modelu. Tak, więc model matematyczny badanego zjawiska, czyli równanie lub układ równań wiążących rozważane przez nas zmienne są wynikiem merytorycznej analizy rozważanego zjawiska.
Zmienne mierzalne, niemierzalne, dostępne, niedostępne. Dane statystyczne: szereg czasowy, dane przekrojowe.
Przy braku teorii ekonomicznej wybieramy jako zmienne objaśniające te, które są silnie skorelowane ze zmienną objaśnianą i słabo skorelowane między sobą oraz mają związek ekonomiczny ze zmienną objaśnianą.
Y = f (X1, X2,… Xn, )
W drugim etapie zbieramy dane empiryczne, na podstawie których będziemy chcieli wyznaczyć parametry modelu i estymujemy wartości parametrów modelu.
W trzecim etapie weryfikujemy poprawność naszego modelu na podstawie nowych danych empirycznych.
W czwartym etapie stosujemy zbudowany i zweryfikowany model do celów do jakich był budowany.
Zweryfikowany model może być wykorzystywany do:
Badania ilościowych związków między badanymi zmiennymi objaśnianymi, a zmiennymi objaśniającymi;
Do prognoz;
Do poszukiwania optymalnych decyzji, itp. …
Dobór zmiennych objaśniających w modelu liniowym
Y = 0 + 1X1 + 2X2 + … + nXn +
Chcemy by zmienne objaśniające miały następujące własności:
miały wystarczająco dużą zmienność;
były silnie skorelowane ze zmienną objaśnianą;
były słabo skorelowane między sobą;
były silnie skorelowane ze zmiennymi nie występującymi w modelu, które reprezentują.
Niech y będzie wektorem obserwacji zmiennej objaśnianej, X rozszerzoną macierzą obserwacji zmiennych objaśniających X1, X2,… Xn . Dokonano m obserwacji:
Eliminowanie zmiennych quasi-stałych
Miarą poziomu zmienności zmiennej jest następujący współczynnik zmienności:
![]()
gdzie
średnia arytmetyczna zmiennej Xi ![]()
odchylenie standardowe zmiennej Xt 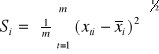
Ustalana jest pewna wartość krytyczna *. Jeśli vi ≤ v* to uznajemy zmienną za quasi-stałą i eliminujemy ze zbioru potencjalnych zmiennych objaśniających.
Przykład 1
Budujemy liniowy model ekonometryczny. Jako wartość krytyczną dla współczynnika zmienności przyjmujemy v* = 0,15.
Rok |
Y |
X1 |
X2 |
X3 |
X4 |
1993 |
12 |
6 |
11 |
5 |
35 |
1994 |
12 |
8 |
14 |
4 |
35 |
1995 |
15 |
10 |
15 |
5 |
38 |
1996 |
14 |
10 |
16 |
5 |
40 |
1997 |
16 |
8 |
18 |
4 |
41 |
1998 |
18 |
10 |
20 |
8 |
42 |
1999 |
17 |
12 |
19 |
6 |
42 |
2000 |
19 |
10 |
20 |
8 |
43 |
2001 |
20 |
12 |
15 |
7 |
44 |
2002 |
20 |
14 |
22 |
8 |
40 |
Xśri |
E(X) |
10,0 |
17,0 |
6,0 |
40,0 |
Si |
S(X) |
2,19 |
3,19 |
1,55 |
2,97 |
i |
v(X) |
0,22 |
0,19 |
0,26 |
0,07 |
Zmienna X4 jako quasi-stała musi być odrzucona.
Obliczenia do przykładu 1:
|
X4 |
X4-Xśr4 |
(X4-Xśr4)2 |
|
|
35 |
-5 |
25 |
|
|
35 |
-5 |
25 |
|
|
38 |
-2 |
4 |
|
|
40 |
0 |
0 |
|
|
41 |
1 |
1 |
|
|
42 |
2 |
4 |
|
|
42 |
2 |
4 |
|
|
43 |
3 |
9 |
|
|
44 |
4 |
16 |
|
|
40 |
0 |
0 |
|
suma |
400 |
|
88 |
|
Xśr4 |
40 |
|
8,8 |
Var(X4) |
|
|
|
2,97 |
S4 |
![]()
Wektor i macierz współczynników korelacji
Ocenę siły liniowej zależności między zmienną objaśnianą Y a zmiennymi objaśniającymi Xi dokonujemy przy pomocy współczynnika korelacji ri :
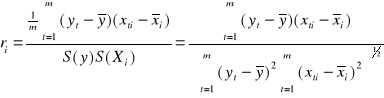
Ocenę siły liniowej zależności między zmiennymi objaśniającymi Xi Xj dokonujemy przy pomocy współczynnika korelacji rij :
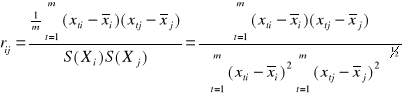
Współczynniki te przedstawiamy odpowiednio w postaci wektora i macierzy :
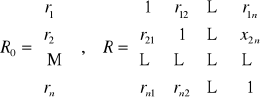
Przykład 2 (cd przykładu 1)
Obliczmy r4:
|
Y |
X4 |
Y-Yśr |
X4-Xśr4 |
(Y-Yśr)(X4-Xśr4) |
(Y-Yśr)2 |
(X4-Xśr4)2 |
|
|
|
12 |
35 |
-4,3 |
-5 |
21,5 |
18,49 |
25 |
|
|
|
12 |
35 |
-4,3 |
-5 |
21,5 |
18,49 |
25 |
|
|
|
15 |
38 |
-1,3 |
-2 |
2,6 |
1,69 |
4 |
|
|
|
14 |
40 |
-2,3 |
0 |
0 |
5,29 |
0 |
|
|
|
16 |
41 |
-0,3 |
1 |
-0,3 |
0,09 |
1 |
|
|
|
18 |
42 |
1,7 |
2 |
3,4 |
2,89 |
4 |
|
|
|
17 |
42 |
0,7 |
2 |
1,4 |
0,49 |
4 |
|
|
|
19 |
43 |
2,7 |
3 |
8,1 |
7,29 |
9 |
|
|
|
20 |
44 |
3,7 |
4 |
14,8 |
13,69 |
16 |
|
|
|
20 |
40 |
3,7 |
0 |
0 |
13,69 |
0 |
|
|
suma |
163 |
400 |
|
|
73 |
82,1 |
88 |
|
|
średnia |
16,3 |
40 |
|
|
|
|
7224,8 |
iloczyn |
|
|
|
|
|
r4 |
0,86 |
|
85,00 |
pierwiastek |
|
Obliczmy r14 :
|
X1 |
X4 |
X1-Xśr1 |
X4-Xśr4 |
(X1-Xśr1)(X4-Xśr4) |
(X1-Xśr1)2 |
(X4-Xśr4)2 |
|
6 |
35 |
-4 |
-5 |
20 |
16 |
25 |
|
8 |
35 |
-2 |
-5 |
10 |
4 |
25 |
|
10 |
38 |
0 |
-2 |
0 |
0 |
4 |
|
10 |
40 |
0 |
0 |
0 |
0 |
0 |
|
8 |
41 |
-2 |
1 |
-2 |
4 |
1 |
|
10 |
42 |
0 |
2 |
0 |
0 |
4 |
|
12 |
42 |
2 |
2 |
4 |
4 |
4 |
|
10 |
43 |
0 |
3 |
0 |
0 |
9 |
|
12 |
44 |
2 |
4 |
8 |
4 |
16 |
|
14 |
40 |
4 |
0 |
0 |
16 |
0 |
suma |
100 |
400 |
|
|
40 |
48 |
88 |
średnia |
10 |
40 |
|
|
pierwiastek |
6,93 |
9,38 |
|
|
|
|
|
|
iloczyn |
64,99 |
|
|
|
|
|
|
r14 |
0,62 |
Metoda analizy współczynników korelacji
W tej metodzie wybieramy zmienne objaśniające silnie skorelowane z ze zmienną objaśnianą, a słabo skorelowane między sobą. Do analizy używamy wektora R0 i macierzy R.
Dla danego poziomu istotności γ oraz (m-2) stopni swobody, gdzie m to ilość obserwacji wyznacza się krytyczną wartość współczynnika korelacji r* :
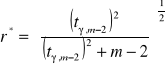
Ekonometra może sam arbitralnie ustalić wartość krytyczną r*.
Procedura ustalania zmiennych objaśniających wygląda następująco:
Ze zbioru potencjalnych zmiennych objaśniających usuwa się wszystkie dla których | ri | ≤ r* uznając, że są za mało skorelowane ze zmienną objaśnianą
Z pozostałych zmiennych wybranych do objaśniania wybieramy Xi tą, która ma największą korelację ze zmienną objaśnianą | ri | = max { |rk| ; k = 1, 2,… m}
Eliminujemy teraz wszystkie zmienne Xj, które są zbyt mocno skorelowane z wybraną zmienną Xi , tzn te dla których zachodzi |rij| > r* .
Postępowanie opisane w punktach 1, 2, 3 powtarzamy aż do wyczerpania wszystkich potencjalnych zmiennych objaśniających.
Przykład 4 (Nowak str 19)
Chcemy wyjaśnić wielkość spożycia mięsa przy pomocy z spożycia innych produktów:
Y - spożycie mięsa - zmienna objaśniana
X1 - artykuły zbożowe, X2 - ziemniaki, X3 - warzywa, X4 - owoce, X5 - tłuszcze, X6 - ryby, X7 - mleko, X8 - jajka.
Na podstawie danych statystycznych z 28 krajów obliczono odpowiednie korelacje:
|
-0,59 |
|
|
1 |
-0,09 |
0,35 |
-0,17 |
-0,26 |
-0,40 |
-0,16 |
-0,55 |
|
-0,06 |
|
|
-0,09 |
1 |
-0,06 |
-0,38 |
0,00 |
0,15 |
0,22 |
0,11 |
|
0,08 |
|
|
0,35 |
-0,06 |
1 |
0,33 |
-0,11 |
-0,20 |
-0,45 |
-0,02 |
R0 = |
0,13 |
|
R = |
-0,17 |
-0,38 |
0,33 |
1 |
0,20 |
-0,07 |
-0,44 |
0,07 |
|
0,54 |
|
|
-0,26 |
0,00 |
-0,11 |
0,20 |
1 |
0,22 |
0,17 |
-0,11 |
|
-0,15 |
|
|
-0,40 |
0,15 |
-0,20 |
-0,07 |
0,22 |
1 |
-0,19 |
0,47 |
|
-0,10 |
|
|
-0,16 |
0,22 |
-0,45 |
-0,44 |
0,17 |
-0,19 |
1 |
0,05 |
|
0,72 |
|
|
-0,55 |
0,11 |
-0,02 |
0,07 |
-0,11 |
0,47 |
0,05 |
1 |
Z tablic testu t-Studenta dla poziomu istotności γ = 0,10 oraz dla (m-2) = 26 stopni swobody odczytujemy wartość krytyczną t0,1 ; 26 = 1,706.
Następnie obliczamy wartość krytyczną współczynnika korelacji:
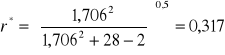
Eliminujemy najpierw wszystkie zmienne zbyt słabo skorelowane ze zmienną objaśnianą, czyli zmienne X2, X3, X4, X6, X7.
Z pozostałych wybieramy pierwszą zmienną objaśniającą czyli najsilniej skorelowaną ze zmienną objaśnianą. Wybieramy X8.
Eliminujemy teraz zmienne X zbyt silnie skorelowane ze zmienną X8 czyli spełniające |r8j|>0,317. Wyeliminowana zostaje X1. Jako druga zmienna objaśniająca zostaje przyjęta X5.
Ostatecznie przyjmujemy dwie zmienne objaśniające: X5, X8.
Y = 0 + 1X5 + 2X8 + .
Dobór zmiennych objaśniających (metoda Helwiga)
Ilość zmiennych objaśniających nie może być zbyt duża. Musimy mieć kryterium według którego będziemy je wybierać.
Przypuśćmy, że zmienne X1, X2, … Xn są kandydatkami na zmienne objaśniające. Wybierzemy te zmienne, które mają największą pojemność informacyjną.
Niech rij oznacza współczynnik korelacji liniowej Perasona między zmiennymi Xi , Xj ; rj zaś między Xj , Y.
Niech S oznacza podzbiór zbioru {1, 2, … n}
Oznaczenie
- indywidualna pojemność informacyjna nośnika Xj , j należy do S:
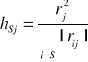
- integralna pojemność informacyjna podzbioru S:
![]()
Przykład 3
Dla zmiennej objaśnianej Y wybrano dwie zmienne objaśniające X1, X2 .
Wyliczone zostały dla nich macierze współczynników korelacji:
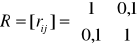
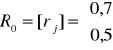
Wybrać optymalny w sensie Hellwiga zbiór zmiennych objaśniających.
H1 = h11 = 0,49 = (0,7)2/ 1 ;
H2 = h22 = 0,25 = (0,5)2/ 1 ;
h{1,2}1 = ( 0,49 ) / (1 + 0,1 ) = 0,445
h{1,2}2 = ( 0,25 ) / (1 + 0,1 ) = 0,227
H{1,2} = h{1,2}1 + h{1,2}2 = 0,672
W rozważanym przypadku optymalnym w sensie Hellwiga jest zbiór { X1 , X2 } jako zbiór objaśniający.
Wykład 2
Nieliniowe modele ekonometryczne
W ekonometrii często wykorzystujemy modele liniowe gdyż:
mają prostą interpretację ekonomiczną
są łatwe w estymacji
łatwa jest ich statystyczna weryfikacja
często są wystarczająco dobrym przybliżeniem rzeczywistości ekonomicznej
wiele modeli nieliniowych daje się sprowadzić do postaci liniowej (linearyzować).
Najprostszym przykładem jest model liniowy jednorównaniowy:
Y = a0 + a1X1 + a2X2 + … + anXn + (1)
gdzie: Y - zmienna objaśniania,
Xi - zmienne objaśniające, i = 1, 2, … n
ai - nieznane parametry strukturalne modelu, i = 0, 1, … n
- składnik losowy.
Naszym celem jest oszacowanie parametrów modelu ai , i = 0, 1, … n.
W równaniu (1) zarówno zmienne objaśniające Xi jak i parametry strukturalne ai , pojawiają się w sposób liniowy. Jeśli model opisujący zależność między zmienną objaśnianą i zmiennymi objaśniającymi nie jest postaci (1), to jest to model nieliniowy, trudniejszy do analizy. Ponieważ jednak naszym celem jest oszacowanie parametrów strukturalnych, więc uznamy, ze model jest prosty jeśli będzie liniowy ze względu na parametry (nie musi być liniowy ze względu na zmienne). W dalszych rozważaniach będziemy klasyfikowali modele na liniowe ze względu na parametry strukturalne i nieliniowe ze względu na te parametry.
Przykład 1.
Y = a + bX + cZ + ; model liniowy ze względu na parametry i zmienne,
Y = a + bX + cX2 + ; model liniowy ze względu na parametry i nieliniowy ze względu na zmienne,
Y = a + bX + b2Z + ; model nieliniowy ze względu na parametry i liniowy ze względu na zmienne,
Y2 = a + bX + b2X2 + ; model nieliniowy ze względu na parametry i zmienne.
Ogólna postać modelu liniowego ze względu na parametry ma postać:
g(Y) = a0 + a1f1(X) + a2f2(X) + … + anfn(X) + (2)
gdzie: Y - zmienna objaśniania,
X = (X1, X2,… Xn) - wektor zmiennych objaśniających
ai - nieznane parametry strukturalne modelu, i = 0, 1, … n
- składnik losowy.
Jeśli g(Y) = Y, to mówimy, że (2) jest modelem bezpośrednio liniowym. Jeśli g jest funkcja odwracalną to (2) jest linearyzcją (sprowadzeniem do postaci liniowej) modelu (2a).
Y = g-1{a0 + a1f1(X) + a2f2(X) + … + anfn(X) + (2a)
Model (2a) nazwiemy modelem linearyzowanym.
Przykład 2.
Badamy model (wykładniczo hiperboliczny) postaci:
![]()
; gdzie d, h > 0 (3a)
Model (3a) jest modelem linearyzowalnym. Logarytmując obustronnie równanie (3a) przechodzimy do modelu (3b) postaci:
ln (Y) = ln(d) + b/X + ln(h) (3b)
Przyjmując oznaczenia: a = ln(d), = ln(h) sprowadzamy równanie (3b) do postaci liniowej ze względu na parametry:
ln(Y) = a + b/X + (
Używając metody wyznaczania parametrów w modelu liniowym, możemy obliczyć â estymator parametru a. Powstaje jednak pytanie czy exp(â) jest dobrym estymatorem parametru d. Przy odpowiednich założeniach (klasycznych założeniach stochastycznych) exp(â) jest zgodnym estymatorem parametru d. Jest to jednak estymator obciążony.
Jak widać na podstawie przykładu 2, możemy wyznaczać parametry strukturalne modelu linearyzowanego. Podobnie możemy postępować w ogólnym przypadku równania (2). Zagadnienie wyznaczania oryginalnych parametrów modelu przed linearyzacją, na podstawie estymatorów ai parametrów modelu linearyzowanego, nazywamy zagadnieniem identyfikacji parametrów oryginalnych.
Model liniowy czy nieliniowy? Jaki model powinniśmy zastosować dla opisu badanego zjawiska, zbioru zaobserwowanych danych? Nie istnieją jednolite reguły postępowania. Musimy posłużyć naszą wiedzą ekonomiczną, doświadczeniem związanym z budową modeli ekonometrycznych, testami statystycznymi.
Przyrost krańcowy i elastyczność.
Przyrost krańcowy zmiennej objaśnianej Y względem zmiennej objaśniającej Xi to pochodna cząstkowa:
![]()
Przyrost krańcowy interpretujemy jako proporcję: przyrostu wielkości Y do przyrostu wielkości Xi, przy małym przyroście Xi i niezmienionych pozostałych wielkościach zmiennych objaśnianych. W przypadku, gdy przyrost krańcowy jest stałą niezależną od wszystkich zmiennych objaśniających to zmienna Xi w modelu pojawia się w sposób liniowy, zaś współczynnik przy Xi jest równy przyrostowi krańcowemu. Jeśli przyrost krańcowy nie jest wielkością stałą, to Xi w modelu występuje w sposób nieliniowy.
Elastyczność cząstkowa jest również miarą określającą zmienność zmiennej objaśnianej w zależności od zmienności zmiennej objaśniającej Xi. Elastyczność to iloczyn przyrostu krańcowego i proporcji Xi do Y:
![]()
W modelu liniowym EY|Xi = ai · (Xi / Y).
Przykład 3
Model potęgowy: Y = a · Xb ·
Linearyzujemy logarytmując obie strony równania: ln(Y) = ln(a) + b·ln(X) + ln()
Wartość krańcowa dla modelu potęgowego wynosi: a · b · Xb-1 ·
Elastyczność Y względem X wynosi: b
Przykład 4
Rozważmy model postaci: Y = a + b·ln(X) + , przy założeniu , że X>0.
Wartość krańcową Y względem X: dY/dX = b/X
Obliczmy elastyczność Y względem X: dY/dX · X/Y = b/X · X/Y = b/Y
Typowe modele liniowe ze względu na parametry - przykłady
W modelach liniowych ze względy na parametry, szacowanie parametrów weryfikacja modeli i prognozowanie dokonywana jest tak jak w modelach liniowych przy odpowiednim przedefiniowaniu zmiennych. Zmienne przedefiniowane nazywamy zmiennymi pomocniczymi.
Model wielomianowy
Zmienna Y objaśniana jest za pomocą wyrażenia wielomianowego względem zmiennej X. W praktyce n=1,2,3. Dla n=2 model funkcji kwadratowej:
Y = a0 + a1X + a2X2 (4)
Równanie (4) może reprezentować funkcję przeciętnego kosztu w zależności od X wielkości produkcji. W tym wypadku zakładamy, że: a0 > 0, a2 > 0.
Model logarytmiczny (półlogarytmiczny): Y = a0 + a1ln(X) + a2ln(Z) +
Model hiperboliczny: Y = a0 + a1/X + a2*Z +
Modele logarytmiczny i hiperboliczny, są wykorzystywane w analizie konsumpcji jako modele o wykresach będących krzywymi Engla, gdzie Y to konsumpcja, X - dochód, Z - inny parametr.
Model z interakcjami: Y = a0 + a1·X + a2·Z + a3·X·Z +
Ogólnie modele z interakcjami uwzględniają to, że wpływ zmiany jednej zmiennej objaśniającej zależy od wartości przyjmowanej przez inne zmienne objaśniające. Uwzględnienie w modelu iloczynu zmiennych objaśniających jest jednym z najprostszych modelu tego typu.
Pochodna cząstkowa Y po X: dY/dX = a1 + a3·Z , czyli jest liniową funkcją Z. Jeśli Z będzie interpretowane jako czas Z = t, to krańcowy przyrost MY|X = a1 + a3·t, będzie liniową funkcją czasu.
Modele linearyzowalne ze względu na parametry strukturalne:
Model potęgowy (podwójnie logarytmiczny, logarytmiczno-liniowy).
Y = a · Xb · Zc · exp() lub ln(Y) = ln(a) + b*ln(X) + c*ln(Z) +
Jest to jeden z bardziej popularnych w ekonometrii modeli nieliniowych. Stosowany jest między innymi jako ekonometryczna funkcja produkcji Cobba-Douglasa lub jako ekonometryczna funkcja popytu.
Model wykładniczy (półlogarytmiczny)
Y = exp(a + b·X + ) lub ln(Y) = a + b·X +
Model wykładniczy stosuje się zwykle do ilustracji wykładniczego wzrostu zmiennej Y względem zmiennej X.
Model S-krzywej (wykładniczo-hiperboliczny)
Y = exp(a + b/X + ) lub ln(Y) = a + b/X +
Jeśli X jest interpretowane jako czas X=t, to model stosuje się jako model trendu o wykresie zbliżonym do krzywej logistycznej.
Składniki losowe i estymacja modelu
Modele liniowe względem parametrów szacujemy klasyczną metodą najmniejszych kwadratów (KMNK). Jeżeli model podlegał linearyzacji, to przekształceniu podlega również losowe zaburzenie. Możemy stosować metodę najmniejszych kwadratów jeśli przekształcone zaburzenie losowe spełnia wymagania KMNK.
Np. badając model: Y = exp(b·X) · ,
sprowadzamy go do postaci liniowej przekształceniem logarytmicznym: ln(Y) = b*X +ln()
Założenia KMNK wymagają by zmienna ln() miała rozkład normalny o wartości oczekiwanej zero. Oznacza to, że sama zmienna losowa ma rozkład logarytmiczno-normalny i że w modelu jest zaburzeniem multyplikatywnym, a nie addytywnym.
Funkcja logistyczna i model logitowy
Klasyczna postać modelu krzywej logistycznej to:
![]()
; gdzie a>0, b>1, g>0.
Funkcja logistyczna ma następujące własności:
![]()
, czyli a - to parametr określający poziom nasycenia, maksymalny poziom wartości Y
dla t = 0 zachodzi ![]()
Yt ma punkt przegięcia dla t = ln(b)/g
Funkcja logistyczna ma zastosowanie przy modelowaniu długookresowego wzrostu liczby ludności, reprezentacji wielkości sprzedaży nowego produktu na rynku. Popularność modelu logistycznego zaowocowała powstaniem specyficznych metod estymacji parametrów modelu. Funkcja logistyczna ma zastosowanie przy modelowaniu zmiennych jakościowych tj. przyjmujących wartości z przedziału [0,1]. Jeden z możliwych modeli dla tego typu zmiennej ma postać:
![]()
ta postać to pewien typ funkcji logistycznej. Na przykład P może oznaczać procent gospodarstw domowych posiadających jakieś dobro w danej grupie dochodowej, zaś zmienna X to średnia dochodu w dane grupie dochodowej. Ten model wygodnie jest linearyzować przez posługiwanie się zmienną: ln(P/(1-P))
zachodzi bowiem ln( P / (1-P) ) = a + b·X + oraz należy ona do całego przedziału (-∞, +∞).
Model ten nazywa się modelem logitowym. Logitem nazywa się wielkość ln( P / (1-P) ).
X nazywa się wielkością objaśniającą logit.
Funkcje Törnquista
Funkcje Törnquista należą do rodziny funkcji o wykresie należącej do rodziny krzywych Engla. Przedstawiają wydatki w funkcji dochodów konsumenta. Wyróżniamy cztery typy funkcji Törnquista w zależności od rodzaju potrzeb zaspokajanych konsumpcją określonych dóbr.
![]()
; a>0; c>0; b<-c; 0<X≤c lub X>-b; dobra i usługi niższego rzędu.
![]()
; a>0; b>0; X>0; dobra podstawowe (pierwszej potrzeby.
![]()
; a>0; b>0; c>0; X≥c ; dobra wyższego rzędu (dalszej potrzeby).
![]()
; a>0; b>0; c>0; X≥c ; dobra i usługi luksusowe.
Modele segmentowe
Jeżeli w analizie szeregów czasowych możemy wyodrębnić podokresy, w których zbiory obserwacji łatwo opisują się różnymi modelami ekonometrycznymi, to tworzymy model segmentowy, inny model (segment) na każdym podokresie. Element szeregu czasowego kończący jeden segment i jednocześnie zaczynający następny nazywamy punktem zwrotnym.
Najprostszym przypadkiem jest model kawałkami liniowy, każdy segment to model trendu liniowego.
Przykład 5
Dane tworzą szereg czasowy: Y1, Y2,…Yn. Rozpoznajemy (np. obserwując wykres szeregu czasowego) dwa punkty zwrotne t1 , t2 . Na trzech przedziałach czasowych budujemy trzy segmenty trendu liniowego:
Yt = a0 + a1·t + ; dla t < t1 ,
Yt = b0 + b1·t + ; dla t1 ≤ t < t2 ,
Yt = c0 + c1·t + ; dla t2 ≤ t ,
Funkcja produkcji
Funkcja produkcji wyraża zależność jaka zachodzi między wielkością wytworzonego produktu Y, a czynnikami mającymi wpływ na produkcję X1, X2,…Xn oraz zaburzeniem losowym .
Y = f(X1, X2,…Xn, )
W dalszych rozważaniach ograniczymy się do dwóch czynników: L - nakładów pracy oraz K - kapitału.
Własności funkcji produkcji
Funkcja produkcji zwykle jest funkcją nieliniową. W dalszym opisie dla uproszczenia opisu pominiemy zaburzenie losowe oraz przyjmiemy zależność:
Y = f(K,L), gdzie Y>0, K>0, L>0.
Wykres funkcji produkcji tworzy powierzchnię w R3, a dokładnie mówiąc w dodatniej oktancie R3. Może na powierzchni wykresu rozpatrywać warstwice, dla każdej ustalonej wielkości produkcji Y=Y0. Te linie warstwic będziemy nazywać liniami stałej produkcji (izokwantami produkcji).
Równanie izokwanty ma postać: f(K,L) = Y0.
W dalszych rozważaniach zakładamy, że funkcja produkcji jest odpowiednio gładka, a mianowicie, że jest dwukrotnie różniczkowalna oraz, że wykres izokwanty jest wypukły (tak, jak wypukły jest wykres funkcji x2). Wypukłość izokwanty oznacza, że jeśli (K1,L1) oraz (K2,L2) dają taką samą wielkość produkcji:
czyli f(K1,L1) = f(K2,L2) = Y0 oraz 0<a<1
to a·f(K1,L1) + (1-a)·f(K2,L2) ≥ Y0
Założenia, które powinna spełniać funkcja produkcji:
Produkcyjność krańcowa czynnika produkcji jest dodatnia, czyli pochodne cząstkowe spełniają: fK>0, fL>0.
Warunek 1. oznacza, że nakłady produkcyjne są efektywne, zwiększenie danego czynnika powoduje wzrost produkcji.
Produkcyjność krańcowa jest malejąca względem nakładów danego czynnika, czyli pochodne cząstkowe spełniają: fKK<0, fLL<0.
Warunek 2. oznacza, że krańcowe przyrosty maleją w miarę wzrostu danego nakładu, przy nie zmieniającym się drugim nakładzie.
Krańcowa produkcyjność jednego czynnika wzrasta przy wzroście drugiego czynnika, czyli pochodne mieszane fKL = fLK > 0.
Warunek 3. oznacza, że krańcowe przyrosty rosną przy wzroście obu nakładów.
Funkcja f jest jednorodna, czyli: f(aK,al.) = ar·f(K,L), dla a>0.
Jednorodność funkcji produkcji oznacza można określi, jak zareaguje produkcja na zwiększenie wielkości nakładów. Dla r=1 jest to wzrost proporcjonalny. Dla r>1, jest rosnąca skala produkcji. Dla r<1, malejąca skala produkcji.
Czynniki produkcji są wzajemnie zastępowalne (zachodzi substytucja czynników produkcji).
Miarą stopnia substytucji jest krańcowa stopa substytucji czyli pochodna dK/dL lub pochodna dL/dK. Zakładamy, że te wielkości są ujemne.
Jako krańcową stopę wzajemnej substytucji (KSS) między K i L określamy współczynnik nachylenia izokwanty względem osi L:
KSS = dK/dL = -( fL/fK )
Współczynnik nachylenia izokwanty względem osi K wynosi:
1/KSS = dL/dK = -( fK/fL)
Na podstawie KSS możemy określi o ile powinien się zmienić nakład jednego czynnika, gdy drugi ulegnie zmianie o małą wielkość tak, by produkcję utrzymać na tym samym poziomie.
Jeśli KSS = -0,2 to przy spadku (L) nakładu pracy o jednostkę, należy zwiększyć nakład (K) kapitału o 0,2 jednostki, zaś przy spadku (K) nakładu kapitału o jednostkę, należy zwiększyć nakład (L) pracy o 5 jednostek.
Przykład 6
Dana jest funkcja produkcji Y = 2·(KL)0,5. Zbadać czy spełnia ona warunki nałożone na funkcję produkcji? Obliczyć fK , fL , KSS dla K = 1, L = 4.
Znaczącą rolę w ekonometrii odgrywa funkcja produkcji Cobba-Douglasa postaci:
Y = a0·X1a1· X1a2·… X1an· ;
gdzie ai > 0 dla 0 ≤ i ≤ n. Jest to przykład potęgowego modelu ekonometrycznego.
Zbadamy funkcję produkcji Cobba-Douglasa dla przypadki dwuwymiarowego:
Y = a·Kb·Lc· ; dla a>0 ; 0 < b, c < 1.
Do estymacji parametrów strukturalnych wykonujemy transformację logarytmiczną i dostajemy:
ln(Y) = ln(a) + b·ln(K) + c·ln(L) + ;
Czy spełnia ona wymogi nakładane na funkcję produkcji?
fK = a·b·Kb-1·Lc > 0 ; fL = a·c·Kb·Lc-1 > 0 ; produkcyjności krańcowe są dodatnie
fKK = a·b·(b-1)·Kb-2·Lc < 0 ; fLL = a·c·(c-1)·Kb·Lc-2 < 0 ; produkcyjności krańcowe są malejące
fKL = fLK = a·b·c·Kb-1·Lc > 0 ; produkcyjność jednego czynnika rośnie przy zwiększeniu nakładów drugiego;
f(d·K, d·L) = db+c ·f(K,L); czyli jest jednorodna stopnia (b+c);
KSS = -(fL/fK) = -(cK/bL) = -(c/b)·U ; gdzie U = K/L to współczynnik technicznego uzbrojenia pracy,
Wykład 3-4
Funkcja produkcji
Ogólna postać funkcji produkcji: y = f(x1, x2,…, xn, ) ;
gdzie:
y - wielkość produkcji
x1, x2,…, xn - wielkości czynników produkcji
- składnik losowy
Funkcja produkcji jest podstawowym narzędziem do badania zależności między wielkością produkcji, a wielkościami czynników produkcji. Funkcja produkcji może mieć rozmaite postacie analityczne. Zazwyczaj wymaga się by miała ona pewne podstawowe własności. Często jednak stosuje się również funkcje nie spełniających tych wymagań.
Trzy najczęściej występujące postaci funkcji produkcji to funkcja:
liniowa - y^t = a0 + a1x1t + a2x2t + … + anxnt ;
wielomianowa drugiego stopnia - y^t = a0 + a1x1t + a2x21t ;
potęgowa - ![]()
;
Szczególne znaczenie ze względu na spełnianie wymaganych warunków, ma funkcja produkcji Cobba-Douglasa.
Przykład 10.1 [Borkowski, Dudek, Szczesny]
Nr gospodarstwa |
Produkcja końcowa y |
Środki trwałe x1 |
Środki obrotowe x2 |
1 |
27.052 |
171.744 |
18.745 |
|
|
|
|
Na podstawie danych z tabeli 10.1 obliczono parametry strukturalne funkcji produkcji dla modelu liniowego, potęgowego (Cobba-Douglasa) i wielomianowego stopnia drugiego:
Liczymy produkt całkowity dla gospodarstwa nr 19 dla każdego modelu, zgodnie z oszacowaniami tego modelu.
Wartości rzeczywiste wynoszą: y = 69.898 ; x1 = 216.130 ; x2 = 33.963 .
Dostajemy wyliczenia:
Dla modelu liniowego: y^ = 16.206,28 + 0,1159∙216.130 + 0,6146∙33.963 = 62.133,8 ;
Dla modelu potęgowego: y^ = 8,32 ∙ 216.1300,3166 ∙ 33.9630,4857 = 64.536,3 ;
Dla modelu wielomianowego: y^ = -11.618,8 + 2,04 ∙ 33.963 - 0,000004 ∙ (33.963)2 = 53.051,8 .
Obliczone wartości teoretyczne są różne. Najbliższa wartości faktycznej jest wartość oszacowana na podstawie potęgowej funkcji produkcji.
Produkt przeciętny to stosunek wielkości teoretycznej produktu całkowitego do nakładu wielkości czynnika produkcji xi przy ustalonych wielkościach pozostałych nakladów:
![]()
W badanych gospodarstwach w modelu potęgowym, dla gospodarstwa nr 19 przy danych nakładach środków trwałych i obrotowych osiągnięto produkt przeciętny:
PPx1(216.130; 33.963) = 64.536,3 / 216.130 = 0,30
PPx2(216.130; 33.963) = 64.536,3 / 33.963= 1,90
W badanych gospodarstwach z 1 złotówki środków trwałych uzyskiwano przeciętnie 0,30zł produkcji końcowej. Z z 1 złotówki środków obrotowych uzyskiwano przeciętnie 1,90zł produkcji końcowej.
Rachunek marginalny (krańcowy)
Interesuje nas wpływ marginalny (krańcowy) daneo czynnika na produkcyjność tego czynnika.
Przyrost krańcowy to odpowiednia pochodna cząstkowa:
![]()
Jeśli przyrost krańcowy jest stałą to zmienna Xi w modelu występuje w sposób liniowy.
Przykład
Model liniowy: y = 0 + 1x1 + 2x2 + ; ![]()
Przykład
Model potęgowy: ![]()
Przykład 10.1 (cd)
Przyrosty krańcowe produkcji względem nakładów na środki obrotowe obliczone na podstawie oszacowanych modeli ekonometrycznych przy stałym poziomie wartości środków trwałych dla wybranych gospodarstw:
Przyrost krańcowy MY|Xi można interpretować jako wielkość przyrostu zmiennej Y, gdy zmienna Xi wzrośnie o jednostkę ceteris paribus (pozostałe zmienne pozostaną bez zmian).
Elastyczność cząstkowa to odpowiednia logarytmiczna pochodna cząstkowa:
![]()
Jeśli elastyczność cząstkowa jest stałą to zmienna Xi w modelu występuje w sposób potęgowy. Elastyczność cząstkową MY|Xi można interpretować jako wielkość przyrostu względnego (procentowego) zmiennej Y, gdy zmienna Xi wzrośnie o jeden procent ceteris paribus (pozostałe zmienne pozostaną bez zmian).
Przykład
Model potęgowy (logarytmiczno-liniowy): y = x1x2γe ; ![]()
Do oszacowania elastyczności cząstkowej często używa się następującego wzoru:
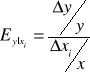
Przykład 10.1 (cd)
Dla gospodarstwa nr 21 znamy wielkości y = 42.491; x1 = 26.569 z roku 1999 (poprzedniego). Obliczamy elastyczność cząstkową:
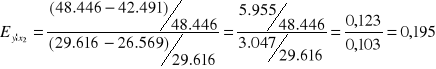
Efekt skali produkcji (elastyczność skali produkcji)
Efektem skali produkcji nazywamy sumę wszystkich elastyczności cząstkowych:
![]()
Wykład 5-6
Wielorównaniowe modele ekonometryczne
Przy analizie złożonych zjawisk ekonometrycznych model jednorównaniowy tłumaczący kształtowanie się jednej zmiennej objaśnianej może być niewystarczający. Może być tak, że pojedyncze równanie jest częścią układu relacji opisywanego zespołem relacji. W takim wypadku konstruujemy model wielorównaniowy - zespół równań. Każde z równań wyjaśnia kształtowanie się jednej zmiennej objaśnianej. Ze względu na sprzężenie między wielkościami występującymi w modelu, zmienna objaśniana w jednym równaniu, może być objaśniającą w innym równaniu.
Wyróżniamy dwa podstawowe sposoby zapisu modeli wielorównaniowych. Zapis w postaci strukturalnej i zapis w postaci zredukowanej.
Postać strukturalna oddaje strukturę związków między zmiennymi. Każde równanie w tej postaci objaśnia jedną zmienną pozostałymi zmiennymi. Postać strukturalna jest „naturalną” postacią modelu.
Przypomnienie
Zmienne pojawiające się w równaniach modelu dzielimy na:
zmienne objaśniane, objaśniające;
zmienne endogeniczne, egzogeniczne;
zmienne bieżące, opóźnione.
Podział na zmienne objaśniane i objaśniające, to podział określany na poziomie pojedynczego równania.
Podział na zmienne endogeniczne i egzogeniczne, to podział określany na poziomie całego modelu. Zmienne endogeniczne to te, które są objaśniane modelem (w jakimś równaniu modelu). Zmienne egzogeniczne określane są poza modelem (nie są objaśniane żadnym równaniem).
W dynamicznym modelu wielorównaniowym mogą występować zmienne z różnych okresów. Endogeniczne i egzogeniczne zmienne mogą być nieopóźnione, czyli z okresu bieżącego, jak i opóźnione, czyli z okresów wcześniejszych.
Zmienne endogeniczne nieopóźnione nazywa się zmiennymi łącznie współzależnymi.
Zmienne egzogeniczne i opóźnione endogeniczne nazywamy zmiennymi z góry ustalonymi, na ich podstawie wyliczamy wartości obecne zmiennych endogennych.
Zmienne |
Nieopóźnione |
Opóźnione |
Endogeniczne |
Łącznie współzależne |
|
Egzogeniczne |
|
Z góry ustalone |
Podział na zmienne łącznie współzależne i z góry ustalone jest ważny z względu na szacowanie parametrów modelu.
Zazwyczaj równania modelu są unormowane, czyli tak zbudowane by współczynnik przy zmiennej endogenicznej nieopóźnionej objaśnianej w danym równaniu był równy 1.
W postać zredukowanej modelu w każdym równaniu występuje tylko jedna zmienna endogeniczna nieopóźniona, ta która jest wyjaśniana równaniem, wszystkie pozostałe zmienne są z góry ustalone. Postać zredukowana jest wygodna do szacowania parametrów modelu.
Przykład 1
Rozpatrujemy model ekonometryczny dany równaniami:
Ct = 0 + 1·Yt + t (1)
Yt = Ct + It + Gt (2)
Gdzie Ct - zagregowana konsumpcja,
Yt - dochód narodowy,
t - składnik losowy,
It - inwestycje,
Gt - wydatki rządowe.
Równanie (1) jest równaniem stochastycznym (uwzględniającym czynnik losowy). Opisuje wielkość zagregowanej konsumpcji przy pomocy wielkości dochodu narodowego zaburzonego czynnikiem losowym.
Równanie (2) ma charakter bilansowy. Wiąże dochód narodowy z konsumpcją, inwestycjami i wydatkami rządowymi.
Model wyjaśnia wielkości opisywane w chwili t. Nie pojawiają się żadne wielkości z innych chwil, nie ma wielkości opóźnionych.
Ct , Yt są zmiennymi endogenicznymi nieopóźnionymi.
Gt , It są zmiennymi egzogenicznymi nieopóźnionymi.
W równaniu (1) Ct jest zmienną objaśnianą, Yt zmienną objaśniającą.
W równaniu (2) Yt jest zmienną objaśnianą, Ct , It , Gt zmiennymi objaśniającymi.
Zmiennymi z góry ustalonymi są nieopóźnione zmienne egzogeniczne It , Gt .
Przykład 2
Rozpatrujemy model ekonometryczny dany równaniami:
Ct = 0 + 1 · Yt + 1t (3)
Yt = 0 + 1·Ct + 2·It-1 + 2t (4)
Gdzie Ct - zagregowana konsumpcja,
Yt - dochód narodowy,
1t , 2t - składniki losowe,
It - inwestycje,
Model wyjaśnia wielkości opisywane w chwili t.
Równanie (3) ma taką samą postać ja równanie (1).
Równanie (4) wiąże wielkość dochodu z konsumpcją i poziomem inwestycji w roku poprzednim. Uwzględnia wpływ czynnika losowego.
Ct , Yt są zmiennymi endogennymi nieopóźnionymi. Gt , It są zmiennymi egzogennymi nieopóźnionymi, zaś It-1 jest zmienną egzogenną opóźnioną.
W równaniu (4) Yt jest zmienną objaśnianą, Ct oraz zmienna opóźniona It-1 są zmiennymi objaśniającymi.
Jedyną zmienną z góry ustaloną w modelu jest opóźniona zmienna egzogeniczna It-1 .
Przykład 3
Jeślibyśmy zmodyfikowali przykład 2 uznając, że poziom dochodu Yt objaśnia Ct-1 konsumpcja z roku ubiegłego, a nie Ct konsumpcja z roku bieżącego, to model miałby postać:
Ct = 0 + 1·Yt + 1t (5)
Yt = 0 + 1·Ct-1 + 2·It-1 + 2t (6)
W tym modelu nieopóźnione zmienne endogeniczne są takie same jak w modelu z przykładu 2. Zbiór zmiennych z góry ustalonych tworzą zaś opóźnione o rok: konsumpcja z roku ubiegłego Ct-1 (zmienna endogeniczna) oraz inwestycje z roku ubiegłego It-1 (zmienna egzogeniczna).
Postać strukturalna modelu.
Oznaczmy:
yti - obserwacja i-tej zmiennej endogenicznej w chwili t
ztj - obserwacja j-tej zmiennej z góry ustalonej w chwili t;
jeśli w równaniu występują stałe, to wprowadzamy fikcyjną zmienną stale równą jeden
i = 1, 2,…, m; j = 1, 2,…, k;
![]()
![]()
……
![]()
Przenoszą wszystkie zmienne współzależne i z góry ustalone na jedną stronę dostajemy:
![]()
![]()
……
![]()
Wprowadzając zapis macierzowy możemy postać strukturalną modelu zapisać równaniem macierzowym:
BYt + Zt = t ; t = 1, 2, …
gdzie:
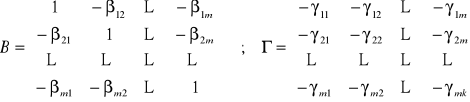
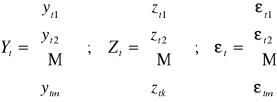
Przykład 4
Niech Yt = (Y1t , Y2t)T dwuwymiarowy wektor zmiennych endogenicznych oraz niech Zt = (1 , Z1t , Z2t , Z3t)T czterowymiarowy wektor zmiennych egzogenicznych rozszerzony przez dodanie stałej do wektora trzywymiarowego.
Niech model ekonometryczny ma postać:
Y1t = 12·Y2t + γ10 + γ11·Z1t + γ12·Z2t +γ13·Z3t + 1t
Y2t = 21·Y1t + γ20 + γ21·Z1t + γ22·Z2t +γ23·Z3t + 2t
Postać powyższa jest postacią strukturalną modelu.
Przenosząc zmienne egzogeniczne zmienne współzależne i z góry ustalone na lewą stronę, możemy przedstawić model w postaci macierzowej:
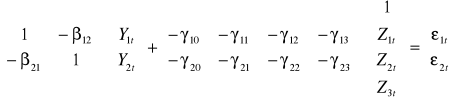
B·Yt + ·Zt = (7)
To postać strukturalna modelu w zapisie macierzowym.
Postać zredukowana modelu
W postaci zredukowanej zmiennymi objaśniającymi są jedynie zmienne z góry ustalone. W postaci macierzowej:
B·Yt + ·Zt = t
B-1·B ·Yt + B-1··Zt = B-1·t
Yt = -B-1··Zt + B-1·t
Yt = ·Zt + t
gdzie: = -B-1·· ; t = B-1·t ;
Przykład 5
Badamy model strukturalny złożony z dwóch równań:
kt = 12 zt + 13 it + 1 + 1t
zt = 21 kt + 22 pt + 2 + 2t
Gdzie:
kt - wartość majątku trwałego w okresie t;
zt - liczba zatrudnionych w okresie t;
it - wartość nakładów inwestycyjnych w okresie t;
pt - wielkość produkcji w okresie t;
jt - wielkość składnika losowego w okresie t równania j-tego.
Postać macierzowa modelu strukturalnego:
kt - 12 zt - 13 it - 1 = 1t
-21 kt + zt - 22 pt - 2 = 2t
B·Yt + ·Zt = t
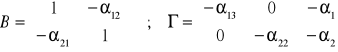
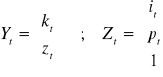
Postać zredukowana: Yt = ·Zt + t
= -B-1·· ; musimy najpierw obliczyć det (B) = 1 + 21 12 ;
a więc
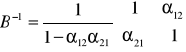
skąd
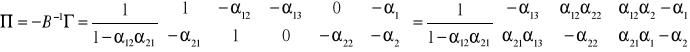
Klasyfikacja modeli wielorównaniowych.
Modele wielorównaniowe dzielimy na trzy rozłączne klasy ze względu na powiązania występujące między nieopóźnionymi zmiennymi endogenicznymi:
modele proste,
modele rekurencyjne,
modele o równaniach współzależnych.
Model jest modelem prostym jeśli zmienne endogeniczne nieopóźnione nie są ze sobą wzajemnie powiązane.
Model jest modelem rekurencyjnym jeśli powstaje łańcuch zmiennych endogenicznych nieopóźnionych. W równaniach objaśniających zmienną Ykt pojawiają się zmienne Yjt dla j<k, nie pojawiają się zaś dla j>k.
Model jest modelem o zmiennych współzależnych jeśli nie jest ani modelem prostym, ani rekurencyjnym. W tym modelu pojawiają się zmienne nieopóźnione endogeniczne jednocześnie od siebie zależne.
Proste metody ustalania z jakim modelem mamy do czynienia.
Metoda wykorzystująca schemat strzałkowy
Rysujemy graf zorientowany, którego wierzchołki numerujemy zmiennymi endogenicznymi nieopóźnionymi. Z wierzchołka Yi do wierzchołka Yk rysujemy strzałkę skierowaną, jeśli zmienna Yi jest zmienną objaśniającą w równaniu wyjaśniającym dla zmiennej Yk.
Jeśli w grafie nie ma żadnych strzałek to jest to model prosty. Jeśli strzałki tworzą powiązania bez pętli, to jest to model rekurencyjny. Jeśli pojawia się przynajmniej jedna pętla to jest to model o równaniach współzależnych.
Metoda wykorzystująca kształt macierzy parametrów B.
Jeżeli możemy tak przenumerować zmienne i równania w modelu, by macierz współczynników przy nieopóźnionych zmiennych endogenicznych była:
diagonalna, to rozważany model jest modelem prostym,
trójkątna, to rozważany model jest modelem rekurencyjnym,
jeśli nie możemy osiągnąć ani macierzy diagonalnej, ani trójkątnej to model jest modelem o równaniach współzależnych.
Przykład 5 Rozważamy model z przykładu 2 zmieniając oznaczenia parametrów i dokonując przekształceń:
Ct = 0 + 1 · Yt + 1t (3)
Yt = 0 + 1·Ct + 2·It-1 + 2t (4)
Ct - 1·Yt = 0 + 1t (3`)
-1·Ct + Yt = 0 + 2·It-1 + 2t (4')
Ct + 12·Yt = γ10 + 1t (3``)
21·Ct + Yt = γ20 + γ21·It-1 + 2t (4'')
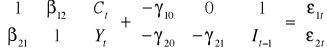
Macierz współczynników B przez zmianę numeracji nie da się sprowadzić do postaci diagonalnej, ani trójkątnej. Rozważany model jest więc modelem o równaniach współzależnych.
Posługując się schematem strzałkowym dostajemy:
Ct ↔Yt
A więc również widzimy, że jest to modelem o równaniach współzależnych.
Jest to również model dynamiczny, w równaniach pojawiają się wartości opóźnione.
Przykład 6 Rozważamy model z przykładu 3 zmieniając oznaczenia parametrów:
Ct = 0 + 1 · Yt + 1t (5)
Yt = 0 + 1·Ct-1 + 2·It-1 + 2t (6)
Ct + 12·Yt = γ10 + 1t (5`)
Yt = γ20 + γ21·Ct-1 + γ22·It-1 + 2t (6')
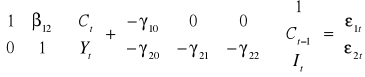
Macierz współczynników B jest w postaci trójkątnej. Rozważany model jest więc modelem rekurencyjnym.
Posługując się schematem strzałkowym dostajemy:
Yt → Ct
A więc również widzimy, że jest to modelem rekurencyjny.
Jest to również model dynamiczny, w równaniach pojawiają się wartości opóźnione.
Przykład 7
Badamy model dany równaniami:
Y1t = 10 + 11X1t + 12Y2t + 1t (11)
Y2t = 20 + 21X1t + 22Y1t + 2t (12)
Wyznacz zmienne endogeniczne, egzogeniczne, objaśniane i objaśniające, z góry ustalone.
Czy w modelu występują zmienne opóźnione?
Czy to jest model dynamiczny, czy statyczny?
Jaka jest postać strukturalna tego modelu w zapisie macierzowym?
Odpowiedź:
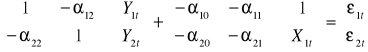
Jaki to jest typ modelu ze względu na charakter powiązań między zmiennymi endogenicznymi nieopóźnionymi?
Odpowiedź na podstawie postaci macierzy współczynników przy zmiennych endogenicznych nieobciążonych - model o równaniach łącznie współzależnych.
Y1 ↔ Y2
Odpowiedź na podstawie schematu strzałowego.
Przykład 8
Badamy model dany równaniami:
Y1t = 10 + 11X1t + 12Y2,(t-1) + 1t (13)
Y2t = 21X1t + 22Y1t + 2t (14)
Czy jest to model statyczny czy dynamiczny?
Dynamiczny. Co prawda nie występuje samodzielnie czynnik czasu, ale są zmienne opóźnione.
Czy w modelu są zmienne endogeniczne nieopóźnione?
W każdym modelu są zmienne endogeniczne nieopóźnione. W tym modelu to są: Y1t , Y2t .
Czy w modelu są zmienne endogeniczne opóźnione?
Jest : Y2,(t-1) .
Czy w modelu są zmienne egzogeniczne nieopóźnione?
Są: 1 , X1t . Komentarz: stała 1 jest traktowana jak stała zmienna egzogeniczna.
Czy w modelu są zmienne egzogeniczne opóźnione?
W tym modelu nie ma.
Jaki to jest model ze względu na charakter powiązań między zmiennymi endogenicznymi nieopoźnionymi?
To jest model o równaniach rekurencyjnych. Macierz współczynników przy zmiennych nieopóźnionych endogenicznych jest trójkątna. W schemacie strzałowym są strzałki lecz nie ma pętli.
Są dwie zmienne endogeniczne Y1 , Y2 . Są dwie zmienne egzogeniczne 1 , X1 .
Estymacja parametrów modeli wielorównaniowych
W modelu jednorównaniowym, przy spełnieniu odpowiednich założeń, do estymacji parametrów strukturalnych posługujemy się metodą najmniejszych kwadratów (MNK).
W modelu wielorównaniowym niestety nie zawsze możemy tak postąpić.
Kiedy możemy? Możemy w modelu prostym. Brak tu powiązań między zmiennymi endogenicznymi nieopóźnionymi występującymi w poszczególnych równaniach modelu. Każde równanie możemy traktować tak, jakby było osobnym modelem jednorównaniowym. W każdym równaniu, jeżeli tylko spełnione są założenia MNK, szacujemy parametry strukturalne metodą najmniejszych kwadratów (MNK).
W tym wypadku mówimy o metodzie estymacji pojedynczej, po kolei estymowaliśmy parametry równanie po równaniu.
W przypadku modelu rekurencyjnego możemy postąpić następująco. Przenumerowujemy równania tak, by w pierwszym występowała tylko jedna zmienna endogeniczna nieopóźniona. W kolejnych zaś równaniach dochodziła następna zmienna endogeniczna nieopóźniona.
(a) Y1t = 10 + 11·X1t + 1t
(b) Y2t = 20 + 21·X2t + 22·Y1t + 2t
(c) Y3t = 30 + 31·X2t + 32·Y1t + 33·Y1t + 3t
Parametry równania (a) szacujemy standardowo metodą MNK.
Niech:
(a') Y^1t = ^10 + ^11·X1t
Równanie teoretyczne wyliczone na podstawie obserwacji zmiennej Y1.
Parametry równania (b) szacując na podstawie obserwacji Y2 i wartości teoretycznych Y^1 (zamiast Y1). W ten sposób omijamy trudności związane z występowaniem zmiennej Y1 (losowość).
Analogicznie postępujemy z kolejnymi równaniami. Do estymacji parametrów kolejnego równania, pozbywamy się kolejnych zmiennych endogenicznych nieopóźnionych, wstawiając w ich miejsce ich estymaty. Tak krok po kroku dostajemy estymaty nieobciążone parametrów strukturalnych kolejnych równań.
Jak postępujemy, gdy model jest modelem o równaniach łącznie współzależnych. Sprowadzamy model do postaci zredukowanej. W postaci zredukowanej badany model jest modelem prostym. Jeśli składniki losowe z różnych równań są niezależne stosujemy do każdego z nich metodę najmniejszych kwadratów.
Wykład 7
Podstawy analizy szeregów czasowych.
Modele ekonometryczne dzielimy na dynamiczne i statyczne.
Dynamiczne modele ekonometryczne pozwalają na badanie zmian obserwowanego zjawiska w czasie. Cechą modeli dynamicznych jest uwzględnienie wpływu czasu w sposób jawny, w tym również poprzez uwzględnienie zmieniających się w czasie relacji między zmiennymi. Wyróżnimy dwa typy modeli dynamicznych:
modele dla których jedną ze zmiennych objaśniających (egzogenicznych) jest czas (zazwyczaj oznaczany przez t = 1, 2,…,n)
w tej grupie wyróżniamy modele z czasem jako jedyną zmienną objaśniającą, są to rozmaitego typu modele trendu (modele tendencji rozwojowej);
modele w których wpływ czasu uwzględniony jest poprzez zmienne opóźnione.
Modele trendu
Trend to trwała tendencja wzrostowa lub spadkowa dla poziomu określanego zjawiska. Wygodne do opisu i badania są następujące analityczne modele trendu:
Trend liniowy: yt = a + b · t +
Trend wykładniczy: yt = a · bt ·
Trend potęgowy: yt = a · tb ·
Trend logarytmiczny: yt = a + b · ln(t) +
Trend logistyczny ![]()
; gdzie a>0, b>1, g>0.
Modele trendu 2-5 są modelami nieliniowymi, ale jak zauważyliśmy na wcześniejszym wykładzie są linearyzowalne. Stąd ich popularność w ekonometrii. Po linearyzacji, metodą najmniejszych kwadratów możemy estymować parametry równań. Jeśli obserwowana jest zmienność tendencji wraz z upływem czasu, to staramy się stosować modele segmentowe do opisu tendencji.
Przykład 1
Po zlogarytmowaniu modelu trendu wykładniczego (2.) dostajemy równanie:
ln(yt) = ln(a) + t · ln(b) + ln(
po podstawieniu:
zt = ln(yt); A = ln(a); B = ln(b); ln(
dostajemy
zt = A + t · B +
Załóżmy, że metodą najmniejszych kwadratów, na podstawie obserwacji, dokonujemy estymacji parametrów:
A^ = 1,25; B^ = 0,25.
Tak więc za estymatory parametrów a, b przyjmujemy:
a^ = exp(1,25) = 3,49; b^ = exp(0,25) = 1,28.
Jak już wielokrotnie zauważyliśmy wartość poznawcza modelu trendu nie jest duża. Może być on używany do prognozowania lub wyznaczania kierunku i tempa zmian. Często używany jest w syntetycznej analizie dynamiki zjawiska.
Modele ze zmiennymi opóźnionymi
Zmienne opóźnione zarówno objaśniające jak i objaśniane występują bardzo często w modelach ekonometrycznych. Często wpływ zmiennych objaśniających nie jest natychmiastowy jak np. zmiana wielkości sprzedaży pod wpływem reklamy, inflacji czy wzrostu zarobków.
Wśród przyczyn występowania opóźnienia wymienia się między innymi:
Przyczyny psychologiczne: przyzwyczajenia, bezwładność zachowań, koszt dostosowania, niepewność stałości zmian;
Przyczyny technologiczne: zmiany technologii wymagają czasu, często upewnienia się w trwałości trendu zmian;
Przyczyny instytucjonalno-prawne: zawarte umowy, zobowiązania, kontrakty, lokaty.
Model z rozkładem opóźnień z jedną zmienną objaśniającą:
yt = + 0 · xt + 1 · xt-1 + … + n · xt-n + t
W tym modelu jest tylko jedna zmienna wyjaśniająca, ale wartość zmiennej wyjaśnianej jest opisywana przez zmienną wyjaśnianą i jej wartości opóźnione. Współczynniki 1, 2, …, n mierzą wpływ kolejnych opóźnień na zmiennej objaśniającej na wielkość zmiennej objaśnianej. Zazwyczaj wpływ wartości opóźnionych jest coraz mniejszy. Często jako wystarczające przybliżenie w modelu przyjmujemy wpływ tylko kilku opóźnień.
Model w którym przyjmujemy, że opóźnienie wynosi co najwyżej dwa okresy:
yt = a + 0 · xt + 1 · xt-1 + t
Model w którym dopuszczamy nieskończoną ilość opóźnień:
yt = a + 0 · xt + 1 · xt-1 + … + n · xt-n + …+ t
Współczynnik 0 nazywamy mnożnikiem krótkookresowym (krótkookresową krańcową skłonnością do konsumpcji), określa on średnią zmianę zmiennej objaśnianej Y wynikająca z jednostkowej zmiany zmiennej objaśniającej X dokonanej w tym samym czasie co obserwowana zmiana Y.
Zazwyczaj sądzimy, że wpływ zmiennej X maleje z czasem, czyli kolejne współczynniki i są coraz mniejsze co do wartości bezwzględnej.
Sumę wszystkich współczynników:
= 0 + 1 + … + n
nazywamy mnożnikiem długookresowym i interpretujemy jako zmianę zmiennej objaśnianej „y” pod wpływem długookresowej jednostkowej zmiany - jednostkowego przyrostu wszystkich wartości bieżących i opóźnionych, zmiennej objaśniającej.
Przykład 2
Pracownik dostając podwyżkę zwiększa swoją konsumpcję. Robi to jednak z opóźnieniem. Przypuśćmy, że następujący model opisuje wielkość wydatków na konsumpcję:
Ct = A + 0,5 · Yt + 0,25 · Yt-1 + 0,1 · Yt-2 + t
gdzie Ct - wielkość wydatków na konsumpcję w chwili t ;
Yt - dochód w chwili t,
A - stała.
Przypuśćmy, że pracownik mający dotychczas stałe zarobki w wysokości Y zł, dostał podwyżkę w wysokości K zł. Jak będzie zmieniać się jego konsumpcja?
Jeden miesiąc przed podwyżką i wcześniej - miesiąc (t-1), (t-2), (t-3):
Ct-1 = A + 0,5·Y + 0,25·Y + 0,1·Y + t-1 = A + 0,85·Y + t-1 = C + t-1
Ct-2 = A + 0,5·Y + 0,25·Y + 0,1·Y + t-2 = C + t-2
Ct-3 = A + 0,5·Y + 0,25·Y + 0,1·Y + t-3 = C + t-3
W miesiącu podwyżki - miesiąc t
Ct = A + 0,5·(K+Y) + 0,25·Y + 0,1·Y + t = C + 0,5·K + t
Miesiąc po podwyżce - miesiąc (t + 1)
Ct+1 = A + 0,5·(K+Y) + 0,25·(K+Y) + 0,1·Y + t+1 = C + 0,5·K + 0,25·K + t+1 = C + 0,75·K + t+1
Dwa miesiące po podwyżce i później - miesiąc (t+2), (t+3), (t+4):
Ct+2 = A + 0,5·(K+Y) + 0,25·(K+Y) + 0,1·(K+Y) + t+2 = C + 0,75·K + 0,1·K +t+2 = C + 0,85·K + t+2
Ct+3 = A + 0,5·(K+Y) + 0,25·(K+Y) + 0,1·(K+Y) + t+3 = C + 0,85·K + t+3
Ct+4 = A + 0,5·(K+Y) + 0,25·(K+Y) + 0,1·(K+Y) + t+4 = C + 0,85·K + t+4
W pierwszym miesiącu wydatki wzrosną o 0,5·K. W drugim dodatkowo o 0,25·K. W trzecim jeszcze o 0,1·K. Czyli w wzrost dochodów o 1 złotówkę spowoduje natychmiastowy wzrost wydatków o 50 groszy. Po miesiącu wydatki wzrosną o 75 groszy, zaś długookresowy wzrost (po dwóch miesiącach) wyniesie 85 groszy.
Mnożnik krótkookresowy wynosi więc 0,5. Mnożnik długookresowy zaś 0,5 + 0,25 + 0,1 = 0,85.
Przyrosty względne to:
Względny przyrost natychmiastowy (w miesiącu podwyżki): ![]()
czyli 58,8% ogólnego efektu wzrostu konsumpcji;
Względny przyrost po miesiącu od podwyżki: ![]()
czyli 88,2% ogólnego efektu wzrostu konsumpcji;
Względny przyrost po 2 miesiącach od podwyżki: ![]()
czyli 100% ogólnego efektu wzrostu konsumpcji. Nastąpił już cały efekt wywołany podwyżką.
Przykład 2 (cd) przykład liczbowy
Zakładamy model opisany w przykładzie 2. Jan Kowalski dostał podwyżkę w wysokości 400 zł. Obliczyć jak bezwzględnie i względnie wzrastała konsumpcja pana Jana w kolejnych miesiącach po podwyżce.
W miesiącu podwyżki konsumpcja wzrosła o 0,5 · 400 = 200 zł. W pierwszym miesiącu po podwyżce konsumpcja wzrosła o kolejne 0,25 · 400 = 100 zł. W drugim miesiącu po podwyżce konsumpcja wzrosła o kolejne 0,1 · 400 = 40 zł.
Całkowity wzrost konsumpcji po dwóch miesiącach to: 200 + 100 + 40 = 340 zł.
Kolejne przyrosty względne to:
Miesiąc 0: ![]()
;
Miesiąc 1: ![]()
;
Miesiąc 2: ![]()
Koniec przykładu 2.
Model autoregresyjny
Jeżeli zmienną objaśniającą jest opóźniona o jeden okres zmienna wyjaśniana:
Yt = a + b · Yt-1 + t ;
to model taki nazywamy modelem autoregresyjnym pierwszego rzędu.
Model z n opóźnieniami- model autoregresyjny n-tego rzędu ma postać:
Yt = a + b1 · Yt-1 + b2 · Yt-2 +…+ bn · Yt-n + t ;
Przykład 3 (model uproszczony)
Załóżmy, że posługujemy się następującym modelem opisującym popyt na pieniądz w zależności od oczekiwanej stopy procentowej:
Yt = a + b·Rt + t
gdzie Yt - popyt na pieniądz w okresie t
Rt - oczekiwana w okresie t (długookresowa) stopa procentowa (stopa procentowa, która będzie obowiązywać w okresie t+1).
Rozważany model ekonometryczny związany jest z hipotezą mówiącą, że popyt na pieniądz zależy od długookresowej stopy procentowej. W okresie t nie znamy jednak Rt, znamy jedynie rt aktualną w okresie t stopę procentową. Przyjmujemy następującą hipotezę co do kształtowania się oczekiwanej długookresowej stopy procentowej:
Rt - Rt-1 = g · (rt - Rt-1)
gdzie:
rt - faktyczna stopa procentowa w chwili t
g - współczynnik korygujący, 0 < g < 1.
Ta hipoteza mówi, że przedmioty gospodarcze korygują swe oczekiwania, uwzględniając dotychczasowe doświadczenia.
Model pozwala oszacować stopę procentową R i użyć ją w modelu opisującym kształtowanie się popytu na pieniądz.
Przykład 3 (cd) przykład liczbowy
W ubiegłym miesiącu (t-1) oczekiwaliśmy, że stopa procentowa wyniesie 4,2%. Jednak po miesiącu okazało się, że wynosi tylko 3,8%. Współczynnik korygujący w naszym modelu wynosi g = 0,8.
Zgodnie z naszym modelem jako oczekiwaną stopę procentową przyjmiemy:
Rt - Rt-1 = g · (rt - Rt-1)
Rt = Rt-1 + g · (rt - Rt-1)
Rt = Rt-1 + g · rt + (1-g) · Rt-1
Rt = 0,8 · 3,8% + 0,2 · 4,2% = 3,04% + 0,84% = 3,88%
Taki model będący przykładem modelu autoregresyjnego, nazywamy modelem oczekiwań adaptacyjnych.
Koniec przykładu 3.
Jeżeli w modelu występują zarówno opóźnienia zmiennej objaśnianej jak i objaśniającej to nazywamy go autoregresyjnym modelem z rozkładem opóźnień:
Yt = a + b1 · Yt-1 + b2 · Yt-2 + … + bk · Yt-k + c0 · Xt + c1 · Xt-1 + … + cn · Xt-n + t .
Przykład 4
Ct = a + b1 · Ct-1 + b2 · Ct-2 + c0 · PKBt + c1 · PKBt-1 + t .
Model tłumaczący wielkość zagregowanej konsumpcji, wielkością konsumpcji opóźnionej do dwóch okresów oraz wielkością produktu krajowego brutto z obecnego okresu i o jeden opóźnionego.
Model z nieskończonym rozkładem opóźnień
Model Koycka
Przyjmujemy, że w modelu występuje nieskończony rozkład opóźnień:
yt = a + c0 · xt + c1 · xt-1 + … + cn · xt-n + … + t .
Nieskończony rozkład opóźnień może opisywać sytuację, gdy nie jest nam znana wielkość opóźnienia.
Można by budować model sekwencyjnie ze wzrastającą ilością opóźnień metodą najmniejszych kwadratów (MNK), aż do chwili, gdy kolejne opóźnienie okazałoby się nieistotne. Jest to jednak metoda żmudna i pracochłonna. Dodatkowo wzrasta ilość parametrów do szacowania, maleje ilość stopni swobody. Zmienne opóźnione mogą być współliniowe.
Jeśli założymy, że parametry ck maleją w sposób geometryczny, czyli, że zachodzi równanie:
ck = c0 · k dla k = 0, 1, 2, … , gdzie 0 < < 1.
To możemy przejść do modelu nazywanego modelem Koycka
Przekształcamy:
yt = a + c0·xt + c0·1·xt-1 + … + c0·n·xt-n + … + t
yt = a + c0·xt - ·a + · a + c0·1·xt-1 + … + c0·n·xt-n + … + ·t-1 - ·t-1 + t
yt = a + c0·xt - ·a + ·( a + c0·xt-1 + … + c0·n·xt-n + … + t-1 ) + t - ·t-1
yt = a·(1-) + c0·xt + ·yt-1 + (t - ·t-1) .
yt = b + c0·xt + ·yt-1 + t .
gdzie:
b = a·(1-) ; t = (t - ·t-1) .
Parametr nazywamy stopą zaniku rozkładu opóźnień.
Tak przekształcony model nazywamy modelem Koycka. Przekształcenie nazywamy transformacją Koycka. Transformacja Koycka przeprowadziła od modelu z nieskończonym rozkładem opóźnień do modelu z opóźnioną o jeden okres zmienna objaśniana, a więc do modelu autoregresjnego.
Mnożnik długookresowy w modelu Koycka wynosi:
![]()
Przykład 5
Załóżmy, że zagregowana funkcja konsumpcji Ct w makroekonomicznym modelu równowagi wyrażana jest przez bieżącą i przez opóźnione wartości dochodów do dyspozycji Yt.
Zakładamy, że współczynniki tej funkcji są dodatnie, malejące geometrycznie. Możemy więc zastosować transformację Koycka, a więc możemy uznać, że zachodzi równanie:
Ct = a · (1 - ) + b0 · Yt + · Ct-1 + t
Oszacowany na podstawie danych z lat 1964 - 1994 model dla gospodarki USA ma postać w mld USD:
Ct^ = -38,11 + 0,52 · Yt + , · Ct-1
(0,12) (0,12)
R2 = 0,988
Wrócimy teraz do modelu wyjściowego:
Ct = a + c0·Yt + c0·1·Yt-1 + … + c0·n·Yt-n + … + t
Możemy wyznaczyć estymaty parametrów modelu:
= 0,46 ;
a · (1 - ) = -38,11 skąd a = -38,11 / (1 - 0,46) = -38,11 / 0,54 = -70,57 ;
b0 = 0,52 ; skąd bn = 0,52 · (0,46)n ;
b1 = 0,2392;
b2 = 0,11;
b3 = 0,0506
Skąd dostajemy równanie:
Ct^ = -70,57 + 0,52 · Yt + , · Yt-1 + , · Yt-2 + , · Yt-3 + …
Z mnożnikiem długookresowym b = b0 / (1 - ) = 0,52 / (1 - 0,46) = 0,52 / 0,54 = 0,96 .
Czyli wzrost dochodów do dyspozycji o 1 mld USD powoduje ostatecznie w długim okresie czasu wzrost konsumpcji o 0,96 mld USD. Mnożnik krótkookresowy wynosi zaś 0,52 a więc zachodzi duża bezwładność wydatków względem dochodu.
Wykład 8
Badanie własności odchyleń losowych
Szacowaniu parametrów modelu ekonometrycznego dokonujemy na podstawie założeń MNK. Czy przyjęcie tych założeń było słuszne? Czy trafnie został dobrany model analityczny? Skupimy się teraz na analizie odchyleń losowych w modelu. Narzędziem będą testy statystyczne. Będziemy weryfikować hipotezy związane z szacowaniem ciągu reszt odchyleń losowych modelu.
Badanie losowości
Weryfikacja hipotezy o losowości rozkładu odchyleń losowych ma na celu ocenę trafności doboru postaci analitycznej modelu.
Weryfikujemy hipotezę H0 przeciwko hipotezie alternatywnej H1:
H0 : Y^ = f(X1, X2,…, Xn)
H1 : Y^ ≠ f(X1, X2,…, Xn)
Do weryfikacji posłużymy się testem serii.
Jeśli model budowany jest na podstawie danych dynamicznych szeregujemy reszty według kolejności czasu.
Jeśli model budowany jest na podstawie danych przekrojowych szeregujemy reszty według rosnącej wartości zmiennej objaśniającej. Jeśli jest kilka zmiennych objaśniających to według wybranej zmiennej objaśniającej.
Dla uporządkowanego ciągu reszt obliczamy ilość serii. Serią nazywamy podciąg reszt o tym samym znaku.
Z tablic statystycznych testu liczby serii dla n1 liczby reszt dodatnich, n2 liczby reszt ujemnych oraz przyjętego poziomu istotności γ (γ /2 dla test lewostronnego, (1 - γ /2) dla test u prawostronnego) odczytujemy wartości krytyczne S*1 , S*2 określający zbiór wartości krytycznych.
Jeśli S*1 < S < S*2 to nie ma podstaw do odrzucenia hipotezy H0. W przeciwnym razie odrzucamy hipotezę H0 rozkład odchyleń uznajemy za nielosowy i uznajemy, że postać modelu została źle dobrana.
Przykład (P26 Nowak)
Produkcja przedsiębiorstwa w tys. sztuk (X) w latach 1960-1982 podana jest w poniższej tabeli. Zbudowany został model trendu liniowego oraz oszacowane parametry:
x^ = 172 + 3,04 · t
t |
xt |
x^t |
et |
1 |
158 |
175,04 |
-17,04 |
2 |
163 |
178,08 |
-15,08 |
3 |
176 |
181,12 |
-5,12 |
4 |
185 |
184,16 |
0,84 |
5 |
188 |
187,20 |
0,80 |
6 |
198 |
190,24 |
7,76 |
7 |
199 |
193,28 |
5,72 |
8 |
201 |
196,32 |
4,68 |
9 |
205 |
199,36 |
5,64 |
10 |
211 |
202,40 |
8,60 |
11 |
216 |
205,44 |
10,56 |
12 |
214 |
208,48 |
5,52 |
13 |
215 |
211,52 |
3,48 |
14 |
220 |
214,56 |
5,44 |
15 |
223 |
217,60 |
5,40 |
16 |
224 |
220,64 |
3,36 |
17 |
223 |
223,68 |
-0,68 |
18 |
224 |
226,72 |
-2,72 |
19 |
226 |
229,76 |
-3,76 |
20 |
230 |
232,80 |
-2,80 |
21 |
229 |
235,84 |
-6,84 |
22 |
233 |
238,88 |
-5,88 |
23 |
234 |
241,92 |
-7,92 |
Na poziomie istotności γ = 0,10 zweryfikować hipotezę o liniowości modelu tendencji rozwojowej produkcji:
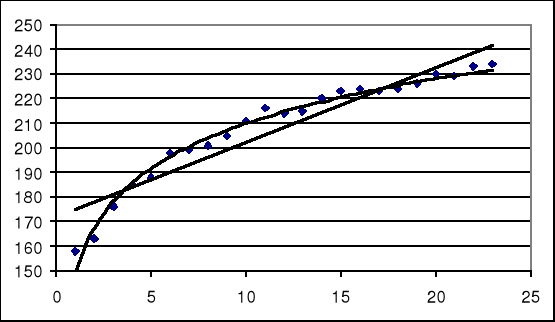
H0 : X^ = a0 + a1 · t ;
H1 : X^ ≠ a0 + a1 · t ;
Obliczamy reszty et.
Wyznaczamy ilość serii. Są trzy serie S = 3.
Dla danych n1 = 10 ; n2 = 13 (n1 = 13 ; n2 = 10) ; γ = 0,05 ; (1-γ = 0,95 odnajdujemy w tablicach serii wartości krytyczne:
S*1 = 8 ; S*2 = 16 .
Ponieważ S = 3 < S*1 = 8 odrzucamy hipotezę H0 o liniowości trendu.
Decydujemy się na zmianę postaci analitycznej modelu tendencji rozwojowej (trendu). Budujemy model trendu logarytmicznego. Po oszacowaniu parametrów dostajemy model:
x^ = 149,73 + 60,3 · log(t)
t |
xt |
x^t |
et |
1 |
158 |
149,73 |
8,27 |
2 |
163 |
167,88 |
-4,88 |
3 |
176 |
178,50 |
-2,50 |
4 |
185 |
186,03 |
-1,03 |
5 |
188 |
191,88 |
-3,88 |
6 |
198 |
196,65 |
1,35 |
7 |
199 |
200,69 |
-1,69 |
8 |
201 |
204,19 |
-3,19 |
9 |
205 |
207,27 |
-2,27 |
10 |
211 |
210,03 |
0,97 |
11 |
216 |
212,53 |
3,47 |
12 |
214 |
214,80 |
-0,80 |
13 |
215 |
216,90 |
-1,90 |
14 |
220 |
218,84 |
1,16 |
15 |
223 |
220,65 |
2,35 |
16 |
224 |
222,34 |
1,66 |
17 |
223 |
223,93 |
-0,93 |
18 |
224 |
225,42 |
-1,42 |
19 |
226 |
226,84 |
-0,84 |
20 |
230 |
228,18 |
1,82 |
21 |
229 |
229,46 |
-0,46 |
22 |
233 |
230,68 |
2,32 |
23 |
234 |
231,84 |
2,16 |
Na poziomie istotności γ = 0,10 weryfikujemy hipotezę o logarytmicznym modelu tendencji rozwojowej produkcji:
H0 : X^ = a0 + a1 · log(t) ;
H1 : X^ ≠ a0 + a1 · log(t) ;
Obliczamy reszty et.
Wyznaczamy ilość serii. Jest jedenaście serii S = 11.
Dla danych n1 = 10 ; n2 = 13 (n1 = 13 ; n2 = 10) ; γ = 0,05 ; (1-γ = 0,95 odnajdujemy w tablicach serii wartości krytyczne:
S*1 = 8 ; S*2 = 16 .
Ponieważ S*1 = 8 < S = 11 < S*2 = 16 nie ma podstaw do odrzucenia hipotezy H0 o logarytmicznej postaci trendu.
Wykład 9
Analiza przepływów międzygałęziowych
Analiza przepływów międzygałęziowych (PM) to rodzaj rachunku makroekonomicznego związanego z badaniem złożonych struktur ekonomicznych. Punktem wyjścia jest bilans gospodarczy w postaci umożliwiającej ilościowe ujęcie zależności między elementami tych struktur. Analizę PM nazywa się również analizą nakładów i wyników lub analizą input-output.
Twórcą analizy przepływów międzygałęziowych jest Wasily Leontieff (początki lat 30 XXw). Za prace związane z PM dostał w 1973 roku nagrodę Nobla z ekonomii.
Uproszczona tablica przepływów międzygałęziowych (TPM)
Sfery produkcji materialnej (produkcja dóbr i usług materialnych).
Dla systemu zamkniętego (bez import, exportu, amortyzacji).
i |
Xi |
xij |
Yi |
|||
|
|
1 |
2 |
… |
n |
|
1 |
X1 |
x11 |
x12 |
… |
x1n |
Y1 |
2 |
X2 |
x21 |
x22 |
… |
x2n |
Y2 |
… |
… |
… |
… |
… |
… |
… |
n |
Xn |
xn1 |
xn2 |
… |
xnn |
Yn |
|
x0j |
x01 |
x02 |
… |
x0n |
|
|
Zj |
Z1 |
Z2 |
… |
Zn |
|
|
Xj |
X1 |
X2 |
… |
Xn |
|
Zakładamy, że występuje n gałęzi gospodarki. Przyjmujemy oznaczenia, i, j = 1, 2, 3, … n :
Xi - wartość produktu globalnego i-tej gałęzi gospodarki ;
xij - przepływ z gałęzi i do gałęzi j ;
Yi - wartość produktu finalnego gałęzi i-tej ;
x0i - płace gałęzi i-tej ;
Zi - zysk gałęzi i-tej ;
Di - wartość dodana gałęzi i-tej .
Zachodzą następujące zależności:
xi1 + xi2 + … + xin - to zużycie produkcyjne wyrobów gałęzi i-tej ;
Yi - to produkt końcowy: eksport, na konsumpcja, inwestycje… ;
Produkt końcowy odpowiada wartości popytu końcowego.
Zużycie produkcyjne odpowiada wartości popytu pośredniego.
Wiersz i-ty odpowiada działalności i-tej gałęzi jako producenta. Bilans działalności i-tej gałęzi ma postać równania podziału:
Xi = xi1 + xi2 + … + xin + Yi ;
Kolumny w tabeli opisują proces produkcji, wartości produktów zużywanych przez daną gałąź. Suma przepływów do j-tej gałęzi, to koszt poniesiony przez gałąź na zakup towarów potrzebnych do jej procesu produkcyjnego. Ta suma to KMj - koszty materiałowe:
KMj = x1j + x2j + … + xnj ;
Koszty materiałowe KMj wraz z płacami x0j dają Kj łączny koszt produkcji:
Kj = x0j + KMj ;
Różnica między wartością wielkością produkcji globalnej, a poniesionymi kosztami to zysk danej gałęzi:
Zj = Xj - Kj ;
Wartością dodaną Dj w j-tej gałęzi produkcji nazywaną też produkcją czystą, jest różnica między wartością produkcji globalnej, a kosztami materiałowymi.
Tak więc wartość dodana to płace i zysk:
Dj = Xj - (x1j + x2j + … + xnj) = x0j + Zj ;
Kolumny w tabeli przepływów międzygałęziowych opisują bilans kosztów i zysków gałęzi, co możemy zapisać równaniem kosztów dla j-tej gałęzi. Suma wszystkich składników w kolumnie daje wartość produktu globalnego danej gałęzi. Równanie to nazywamy równaniem kosztów:
Xj = x0j + x1j + x2j + … + xnj + Zj ;
Łączną produkcję globalną całego systemu możemy obliczyć na podstawie gałęziowych bilansów podziału:
![]()
Możemy też obliczyć na podstawie gałęziowych bilansów kosztów:
![]()
Skąd dostajemy równanie wiążące płace i zyski z produktem finalnym:
![]()
Gdy tabela przepływów międzygałęziowych opisuje całą gospodarkę, ostatnie równanie jest warunkiem równowagi ogólnej. Strony równania opisują produkt krajowy (lub dochód narodowy). Jedna strona równania (lewa) to opis podażowy (rzeczowy). Druga strona (prawa) t opis popytowy (pieniężny).
Lewa strona (podażowa) odnosi się do wyprodukowanych towarów lecz jest wyrażona wartościowo w określonych cenach. Zmiana cen, przy niezmienionej wielkości rzeczowej, zmienia wartość lewej strony równania.
Prawa strona określa środki pieniężne: wynagrodzenia, podatki, dywidendy, fundusze przeznaczone na rozwój przedsiębiorstw. Zmiana poziomu płac lub podatków zmienia prawą stronę równania.
Jak widać zmiana jednej ze stron równania narusza równowagę i w rezultacie powoduje zmiany po drugiej stronie równania (np. zmiany inflacyjne).
Przykład 1 (dane z przykładu 13.1 Ekonometria SGH)
Trójgałęziowy system gospodarczy.
i |
Xi |
|
xij |
|
Yi |
1 |
500 |
50 |
195 |
0 |
255 |
2 |
300 |
100 |
0 |
90 |
110 |
3 |
150 |
80 |
45 |
15 |
10 |
|
x0j |
200 |
30 |
15 |
|
|
Zj |
70 |
30 |
30 |
|
|
Xj |
500 |
300 |
150 |
|
Bilans podziału produkcji globalnej gałęzi 1:
500 = 50 + 195 + 0 + 255
Bilans kosztów w gałęzi 2:
300 = 195 + 0 + 45 + 30 + 30
Czy spełniony jest warunek równowagi?
255 + 110 + 10 = 200 + 70 + 30 + 30 + 15 + 30
Tak warunek równowagi jest spełniony.
Rozpatrzmy teraz tabelę przepływów międzygałęziowych dla systemu otwartego. Uwzględniamy w tabeli import, export, amortyzację. Oraz uwzględniając podział produktu finalnego zgodnie z jego przeznaczeniem: spożycie, inwestycje brutto, przyrost środków obrotowych i rezerw, eksport.
i |
Xi |
xij |
Yi
|
||||||||||||
|
|
1 |
2 |
… |
n |
Spożycie (1) |
Inwestycje (2) |
śr.obrot rez. (2) |
Eksport (4) |
||||||
1 |
X1 |
x11 |
x12 |
… |
x1n |
Y1(1) |
Y1(2) |
Y1(3) |
Y1(4) |
||||||
2 |
X2 |
x21 |
x22 |
… |
x2n |
Y2(1) |
Y2(2) |
Y2(3) |
Y2(4) |
||||||
|
… |
… |
… |
… |
… |
… |
… |
… |
… |
||||||
n |
Xn |
xn1 |
xn2 |
… |
xnn |
Yn(1) |
Yn(2) |
Yn(3) |
Yn(4) |
||||||
n+1 |
import |
xn+1,1 |
xn+1,2 |
… |
xn+1,n |
xn+1(1) |
xn+1(2) |
xn+1(3) |
xn+1(4) |
||||||
n+2 |
amortyz. |
xn+2,1 |
xn+2,2 |
… |
xn+2,n |
|
|
|
|
||||||
|
x01 |
x02 |
… |
x0n |
|
|
|
|
|||||||
|
Z1 |
Z2 |
… |
Zn |
|
|
|
|
|||||||
|
X1 |
X2 |
… |
Xn |
|
|
|
|
|||||||
Koszty materialne KMAj dla gałęzi j-tej to koszty materiałowe krajowe i importowe oraz amortyzacja.
KMAj = x1j + x2j + … + xnj + xn+1,j + xn+2,j ;
Zaś koszt ogólny produkcji uwzględniający płace to Kj :
Kj = x0j + x1j + x2j + … + xnj + xn+1,j + xn+2,j ;
Zysk jest różnicą między wartością wytworzoną produkcji globalnej, a poniesionymi kosztami:
Zj = Xj - Kj = Xj - (x0j + x1j + x2j + … + xnj + xn+1,j + xn+2,j)
Wartość dodana (produkcja czysta) to różnica między wartością produkcji globalnej a kosztami materialnymi, czyli :
Dj = Xj - (x1j + x2j + … + xnj + xn+1,j + xn+2,j) = x0j + Zj ;
Równanie kosztów (kolumna) dla j-tej gałęzi ma postać:
Xj = x0j + x1j + x2j + … + xnj + xn+1,j + xn+2,j + Zj ;
Zaś równanie podziału produkcji (wiersz) dla i-tej gałęzi ma postać:
Xi = xi1 + xi2 + … + xin + Yi(1) + Yi(2) + Yi(3) + Yi(4) ;
Warunek równowagi systemu ma więc postać:
![]()
lub postać:
![]()
(*)
Dochód narodowy, produkt krajowy
Jeśli analiza przepływów międzygałęziowych dotyczy całej gospodarki to równanie (*) pozwala nam wnioskować o głównych miernikach działalności gospodarczej w skali makro.
Obie strony równania ukazują wartość dochodu narodowego wytworzonego brutto: lewa strona kierunki zużycia, prawa źródła powstania.
Przyjmijmy oznaczenia:
DN - dochód narodowy ;
P - podzielony (do dyspozycji) ;
W - wytworzony ;
B - brutto ;
N - netto ;
AM - amortyzacja -
![]()
SHZ - saldo handlu zagranicznego
![]()
Posługując się równaniem (*) na podstawie tabeli przepływów międzygałęziowych możemy obliczyć dochód narodowy wytworzony brutto:
![]()
czyli dochód narodowy wytworzony brutto może być liczony jako suma: wartości dodanej (produkcji czystej) w gałęziach produkcji materiałowej oraz amortyzacji środków trwałych.
Uwzględniając znane z ekonomii zależności:
DNB = DNN + AM
DNP = DNW - SHZ
DNWB = DNWN + AM
Otrzymujemy:
![]()
czyli dochód narodowy wytworzony netto może być liczony jako wartość dodana (produkcja czysta) w gałęziach produkcji materiałowej.
A ponieważ
DNPB = DNWB - SHZ =
![]()
z równania (*) dostajemy
![]()
![]()
Czyli dochód narodowy podzielony (do dyspozycji) możemy obliczać ze wzorów:
![]()
(a)
Oraz
![]()
(b)
Wniosek:
Dochód narodowy wytworzony brutto to suma wartości dodanej (produkcji czystej) w gałęziach produkcji materialnej i amortyzacji.
Dochód narodowy wytworzony (netto) to suma wartości dodanej (produkcji czystej) w gałęziach produkcji materialnej (bez amortyzacji).
Dochód narodowy podzielony (do dyspozycji) to dochód narodowy wytworzony skorygowany o saldo obrotów z zagranicą.
Wzory (a) i (b) pokazują strukturę podziału dochodu narodowego, składniki popytu końcowego: krajowe i importowane dobra konsumpcyjne, inwestycyjne, przeznaczone na zwiększenie środków obrotowych, rezerw. Przy dochodzie brutto inwestycje obejmują wartość odtworzenia środków trwałych (inwestycje brutto). Przy dochodzie netto, od wartości inwestycji odliczana jest amortyzacja (inwestycje netto).
Przedstawione mierniki: produkt globalny i dochód narodowy do lat 90 były podstawowymi miernikami działalności gospodarczej stosowanymi w Polsce. Obliczenia prowadzono na podstawie danych dotyczących produkcji jednostek gospodarki narodowej zaliczonych do sfery materialnej, według systemu Material Product System (MSP).
Przykład 2 (dane z przykładu 13.2 Ekonometria SGH)
W statystycznych danych zbiorczy często pojawia się rubryka „sumy niezbilansowane”. W obliczeniach musimy je uwzględnić.
Bilans dla tradycyjnego podziału n=7 działów produkcji materialnej: 1-przemysł, 2-budownictwo, 3-rolnictwo, 4-leśnictwio, 5-transport i łączność, 6-handel, 7-pozostałe gałęzie produkcji materialnej i gospodarka komunalna.
Dane w bilionach zł. cenach bieżących, zaokrąglone do 3 miejsc po przecinku. Dane zblokowane. Dodatkowo wiersz i kolumna sum niezbilansowanych, obliczone przez agregację danych indywidualnych.
Tabela przepływów międzygałęziowych gospodarki Polski w roku 1989 (GUS) mln zł
i |
Xi |
xij |
sumy |
Yi |
Yi |
Yi |
Yi |
1 |
|
|
|
|
|
|
|
|
197,549 |
80,813 |
-1,385 |
54,092 |
17,010 |
25,270 |
21,749 |
n |
|
|
|
|
|
|
|
|
sumy |
-0,761 |
|
|
|
|
|
|
import |
10,294 |
|
3,077 |
2,341 |
0,912 |
0,834 |
|
amortyzacja |
2,252 |
|
|
|
|
|
|
x0j |
47,328 |
|
|
|
|
|
|
Zj |
57,623 |
|
|
|
|
|
|
Xj |
197,549 |
|
|
|
|
|
Na podstawie tabeli obliczyć produkt globalny w Polsce w roku 1989.
Licząc metodą gałęziowych bilansów podziału (sumując w wierszach) dostajemy
X1 + … + Xn = 80,813 - 1,385 + +54,092 + 17,010 + 25,270 + 21,749 = 197,549
Licząc metodą gałęziowych bilansów kosztów (sumując w kolumnach) dostajemy :
X1 + … + Xn = 80,813 - 0,761 + 10,294 + 2,252 + 47,328 + 57,623 + 197,549 = 197,549
![]()
DNWB = DNWN + AM = 104,951 + 2,252 = 107,203
DNPB = DNWB - SHZ = ![]()
= 54,092 + 17,01 + 25,27 + 3,077 + 2,341 + 0,912 = 102,702
![]()
= 102,702 - 2,252 = 100,450
Równość:
DNW = DNP + SHZ
jest spełniona z dokładnością do sum niezbilansowanych:
DNW = 104,951
DNP = 100,450
SHZ = 21,749 - (10,294 +3,077 + 2,341 + 0,912) = 5,125
104,951 - 0,761 = 100,450 + 5,125 - 1,385.
Wykład 10
Analiza przepływów międzygałęziowych (cd)
Produkt globalny i dochód narodowy były podstawowymi miernikami działalności gospodarczej w Polsce do początku lat 90. Obliczenia prowadzono według systemu MPS (Material Product System) uwzględniającego produkcję jednostek gospodarki narodowej zaliczonych do sfery produkcji materialnej. Obecnie uwzględnia się również mierniki wartość globalną i produkt krajowy (brutto, netto) liczone według systemu SNA (System of National Accounts).
Wartość globalna (WG) to całkowita wartość dóbr i usług wytworzonych w ciągu roku w gospodarce (nie tylko dóbr materialnych). Wartość globalna to produkt globalny powiększony o wartość wytworzonych usług i innych dóbr niematerialnych.
Czyli zachodzi równanie:
WG = PG + WGU
(Wartość globalna) = (Produkt globalny) + (Wartość globalna usług niematerialnych)
Gdzie WGU to wartość globalna usług niematerialnych.
Produkt krajowy brutto (PKB) to wartość globalna pomniejszona o wartości zużycia pośredniego materialnego i niematerialnego.
PKB = DNWB + WGU - W1 - W2
Gdzie:
PKB - Produkt krajowy brutto
DNWB - Dochód narodowy wytworzony brutto
WGU - Wartość globalna usług niematerialnych
W1 - Wartość usług niematerialnych zużytych w sferze materialnej
W2 - Wartość wyrobów i usług zużytych poza sferą materialną
Produkt krajowy netto to produkt krajowy brutto pomniejszony o amortyzację.
Produkt narodowy brutto (PNB) to wartość PKB zmodyfikowana o saldo dochodów przekazanych za granicę i otrzymanych z zagranicy z tytułu działalności gospodarczej.
Związki między systemem rachunków MPS i SNA ilustruje poniższa tabela:
|
Zużycie pośrednie w sferze produkcji |
Zużycie końcowe |
|
|
dóbr i usług materialnych |
usług niematerialnych |
|
Produkcja dóbr i usług materialnych |
A |
B |
C |
Produkcja usług niematerialnych |
D |
E |
F |
Zachodzą związki:
PG = A + B + C (MPS)
WGU = D + E + F (rachunek SNA)
WG = PG + WGU = A + B + C + D + E + F (liczone wg SNA)
W1 = D ; W2 = B + E (rachunek SNA)
Widzimy więc, że pierwszy wiersz powyższej tabeli (bloki A, B, C) to schematyczny odpowiednik TPM czyli tabeli przepływów międzygałęziowych. Blok A to odpowiednik macierzy X TPM, zaś B i C to odpowiednik wektora Y produktu końcowego.
Tak więc:
DNWB = B + C (rachunek MPS)
PKB = C + F (rachunek SNA)
Skąd:
PKB = DNWB + F - B
Wyznaczając:
F - B = D+E+F -D -(B+E) = WGU -D -(B+E) = WGU - W1 -W2
Dostajemy:
PKB = DNWB + WGU - W1 - W2
Przykład 1 (kontynuacja przykładu 2 z wykładu 9) (dane z przykładu 13.2, 13.3 Ekonometria SGH)
(Rocznik statystyczny 1992, wartości dla roku 1989)
Dane z przykładu 2 wykład 6 uzupełniamy tabelą gdzie brakujące dane są uzupełnione na podstawie Rocznika Statystycznego 1992:
WGU = 22,842 (wartość globalna usług niematerialnych)
W1 = 2,934 (usługi niematerialne zużyte w sferze materialnej)
W2 = 2,158 + 6,635 = 8,793 (łączna wartość usług i wyrobów zużytych poza sferą materialną)
|
Zużycie pośrednie w sferze produkcji |
Zużycie końcowe |
|
|
dóbr i usług materialnych |
usług niematerialnych |
|
Produkcja dóbr i usług materialnych |
A = 90,346 |
B = 6,635 |
C = 100,568 |
Produkcja usług niematerialnych |
D = 2,934 |
E = 2,158 |
F = 17,750 |
Obliczyć WG wartość globalną i PKB produkt krajowy brutto dla roku 1989
WG = PG + WGU = 197,549 + 22,842 = 220,391
PKB = DNWB + WGU - W1 - W2 = (6,635 + 100,568) + 22,842 - 2,934 - 8,793 = 118,318
Wskaźniki efektywności działalności gospodarczej
Tablica przepływów międzygałęziowych (TMP) umożliwia policzenie niektórych syntetycznych współczynników charakteryzujących procesy produkcji zarówno w gałęziach produkcji jak i w całym systemie gospodarczym.
Współczynnik materiałochłonności mj produkcji globalnej w j-tej gałęzi produkcji (koszty materiałowe do produktu globalnego):
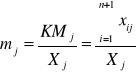
Współczynnik materiałochłonności m produkcji globalnej dla całej gospodarki:
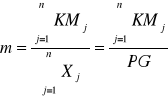
Współczynnik importochłonności impj j-tej gałęzi produkcji (materiały importowane do produktu globalnego):
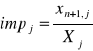
Współczynnik importochłonności imp produkcji dla całej gospodarki:
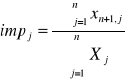
Współczynnik rentowności produkcji rj j-tej gałęzi produkcji:
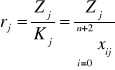
W publikacjach statystycznych TPM, czyli tablica przepływów międzygałęziowych często uzupełniana jest informacjami dotyczącymi zatrudnienia i wartości produkcyjnego majątku trwałego w poszczególnych gałęziach.
Przyjmijmy oznaczenia:
Lj - liczba pracowników zatrudnionych w j-tej gałęzi ;
STj - wartość produkcyjnych środków trwałych w j-tej gałęzi.
Możemy określić następujące współczynniki:
Pracochłonność produkcji j-tej gałęzi = ![]()
Wydajność pracy w j-tej gałęzi = ![]()
Majątkochłonność produkcji j-tej gałęzi = ![]()
Produktywność majątku trwałego w j-tej gałęzi = ![]()
Techniczne uzbrojenie pracy w j-tej gałęzi = ![]()
|
|
xij |
|
|||
i |
Xi |
1 |
2 |
3 |
4 |
razem |
1 |
255 |
30 |
0 |
58 |
30 |
118 |
2 |
340 |
50 |
40 |
45 |
0 |
135 |
3 |
285 |
25 |
50 |
60 |
30 |
165 |
4 |
195 |
20 |
30 |
0 |
40 |
90 |
5 |
import |
24 |
35 |
30 |
10 |
99 |
6 |
amort. |
25 |
42 |
28 |
15 |
110 |
|
płace |
55 |
120 |
45 |
52 |
272 |
|
zysk |
26 |
23 |
19 |
18 |
86 |
|
Xj |
255 |
340 |
285 |
195 |
1075 |
|
Lj |
8,2 |
9,5 |
10,2 |
12,5 |
40,4 |
|
STj |
83 |
92 |
105 |
80 |
360 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
xij |
|
|||
i |
|
1 |
2 |
3 |
4 |
razem |
1 |
materiałochłonność |
0,584 |
0,456 |
0,677 |
0,564 |
0,565 |
2 |
Rentowność |
0,114 |
0,073 |
0,071 |
0,102 |
0,087 |
3 |
Importochłonność |
0,094 |
0,103 |
0,105 |
0,051 |
0,092 |
4 |
Majątkochłonność |
0,325 |
0,271 |
0,368 |
0,410 |
0,335 |
5 |
Produktywność środków trwałych |
3,072 |
3,696 |
2,714 |
2,438 |
2,986 |
6 |
Pracochłonność |
0,032 |
0,028 |
0,036 |
0,064 |
0,038 |
|
Techniczne uzbrojenie pracy |
10,122 |
9,684 |
10,294 |
6,400 |
8,911 |
|
Wydajność pracy |
31,098 |
35,789 |
27,941 |
15,600 |
26,609 |
Wykład 11
Model Leontiefa
Tablica przepływów międzygałęziowych Leontiefa pozwala opisać procesy wytwórcze za pomocą relacji między nakładami (kolumny), a wynikami (wiersze) dla poszczególnych gałęzi systemu gospodarczego (relacje input-output). Założenie modelu - te relacje są stałe w czasie.
Na podstawie TPM budujemy macierz A = [aij]nxn zwaną macierzą struktury kosztów.
Niech aij i-ty współczynnik kosztów dla j-tej gałęzi:
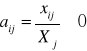
i,j = 1, 2,… n.
aij nazywamy również współczynnikiem bezpośredniej materiałochłonności.
Suma współczynników aij w kolumnie równa jest współczynnikowi mj materiałochłonności dla j-tej gałęzi:
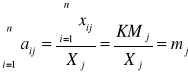
gdzie: KMj to koszty materiałowe. Będziemy zakładać, że mj < 1.
Przykład 1 (cd przykładu 1 wykład 9) macierz struktury kosztów A:
a11 = 50/500 = 0,1 |
a12 = 195/300 = 0,65 |
a13 = 0/150 = 0 |
a21 = 100/500 = 0,2 |
a22 = 0/300 = 0 |
a23 = 90/150 = 0,6 |
a31 = 80/500 = 0,16 |
a32 = 45/300 = 0,15 |
a33 = 15/150 = 0,1 |

Współczynniki materiałochłonności wynoszą odpowiednio:
m1 = 0,1+0,2+0,16 = 0,46; m2 = 0,65+0+0,15 = 0,8; m3 = 0+0,6+0,1 = 0,7.
Macierz struktury kosztów A oraz współczynników kosztów aij używana jest do opisania zależności między produkcją globalną i produkcją końcową.
Równania podziału:
X1 = x11 + x12 +…+ x1n + Y1 ;
X2 = x21 + x22 +…+ x2n + Y2 ;
……
Xn = xn1 + xn2 +…+ xnn + Yn ;
Wykorzystując zależność xij = aijXj , w równaniach podziału dostajemy:
X1 = a11X1 + a12X2 +…+ a1nXn + Y1 ;
X2 = a21X1 + a22X2 +…+ a2nXn + Y2 ;
……
Xn = an1X1 + an2X2 +…+ annXn + Yn ;
Przenosząc wszystkie wyrażenia z X na lewą stronę dostajemy:
X1 - a11X1 - a12X2 -…- a1nXn = Y1 ;
X2 - a21X1 - a22X2 -…- a2nXn = Y2 ;
……
Xn - an1X1 - an2X2 -…- annXn = Yn ;
Po uporządkowaniu względem indeksu Xj :
(1 - a11)X1 - a12X2 -…- a1nXn = Y1 ;
- a21X1 + (1- a22)X2 -…- a2nXn = Y2 ;
……
- an1X1 - an2X2 -…+ (1- ann)Xn = Yn ;
I w postaci macierzowej:
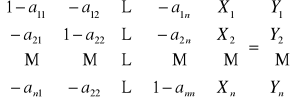
oraz równoważnie:
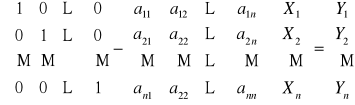
czyli:
(I - A)X = Y
Powyższe równanie nazywamy modelem Leontiefa. Macierz (I-A) nazywamy macierzą Leontiefa.
gdzie:
I - macierz jednostkowa (nxn);
A - macierz struktury kosztów (nxn);
X - wektor produkcji globalnej (n);
Y - wektor produkcji finalnej (n).
Model Leontiefa służy do określania wielkości produkcji finalnej, dla ustalonej produkcji globalnej lub określania produkcji globalnej koniecznej do osiągnięcia wymaganej produkcji finalnej.
Model Leontiefa jest jednorodny i addytywny:
jednorodność: (I-A) aX = a(I-A) X = aY
addytywność: (I-A) (X' + X'') = (I-A)X' + (I-A)X'' = Y' + Y''
Wniosek
Do obliczenia przyrostu produktu finalnego wynikającego z danego przyrostu produktu globalnego, wystarczy znajomość samego przyrostu produktu globalnego.
Istotnie:
(I-A) (X + X) = (I-A)X + (I-A) X = Y + Y,
skąd:
(I-A) X = Y,
Model Leontiefa pozwala więc łatwo wnioskować o skutkach względnej lub absolutnej zmiany produktu globalnego.
Przykład 2 (cd przykładu 1) Wyznaczenie macierzy Leontiefa
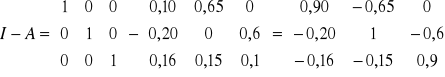
Przykład 3 (cd przykładu 1) Wyznaczenie produktu finalnego dla danego produktu globalnego.
Niech XT = [500 300 150]
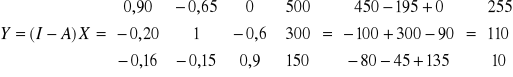
Wynik jest zgodny z danymi z przykładu 1 wykład 9.
Przykład 4 (cd przykładu 1)
O ile wzrośnie produkt finalny jeśli wiadomo, że produkt globalny w każdej gałęzi wzrośnie o 5%?
X'T = 1,05·XT = 1,05 [500 300 150] = [525 315 157,5]
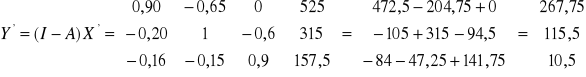
Y'T = 1,05·YT = 1,05 [255 110 10] = [267,8 115,5 10,5]
Przykład 5 (cd przykładu 1)
O ile wzrośnie produkt finalny jeśli wiadomo, że produkt globalny X zmieni się o X?
XT = [50 20 -10]
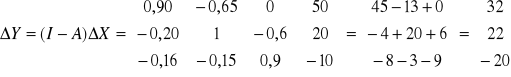
Ekonomiczna interpretacja aij elementów macierzy Leontiefa.
Niech XT = [0 … 0 1 0 … 0] przyrost o jednostkę na j-tym miejscu, to
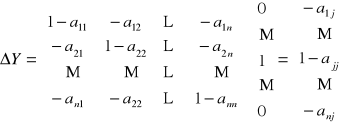
Przyrost produktu finalnego Y w tym przypadku jest równy j-tej kolumnie macierzy Leontiefa (I-A).
Jednostkowy przyrost j-tego produktu globalnego, powoduje zmianę produktu finalnego we wszystkich gałęziach. Zmiana w I-tej gałęzi jest równa i-temu elementowi j-tej kolumny macierzy Leontiefa (I-A). Czyli dla i≠j wzrost produkcji globalnej w gałęzi j powoduje spadek produktu finalnego gałęzi i o wielkość aij oraz wzrost produktu finalnego w gałęzi j o wielkość (1-ajj).
Przykład 6 (cd przykładu 1)
Jaka zmiana w produkcji finalnej nastąpi w wyniku jednostkowego zwiększenia produkcji globalnej w gałęzi 3.
Odpowiedź:
Trzecia kolumna opisuje odpowiednią zmianę produkcji:
Produkt finalny gałęzi 1 będzie bez zmian;
Produkt finalny gałęzi 2 zmniejszy się o 0,6;
Produkt finalny gałęzi 3 zwiększy się o 0,9.
Uwaga
Założyliśmy, że:
aij ≥ 0 dla każdego i, j;
suma aij po i, czy suma w kolumnie macierzy A, jest mniejsza od 1;
Te założenia gwarantują odwracalność macierzy Leontiefa (I-A) czyli istnienie macierzy (I-A)-1. Mnożąc lewostronnie
(I - A)X = Y
przez (I-A)-1 dostajemy:
(I-A)-1(I-A)X = (I-A)-1Y
Skąd:
(I-A)-1Y = X.
czyli postać modelu Leontiefa pozwalającego określać wektor produkcji globalnej na podstawie produkcji finalnej.
Ta postać modelu Leontiefa jest również jednorodna i addytywna względem produkcji finalnej:
jednorodność: (I-A)-1 aY = a(I-A)-1 Y = aX
addytywność: (I-A)-1 (Y' + Y'') = (I-A)-1 Y' + (I-A)-1 Y'' = X' + X''
Wniosek
(I-A)-1 Y = X,
Przykład 7 (cd przykładu 1)
Obliczyć macierz odwrotną do macierzy Leontiefa
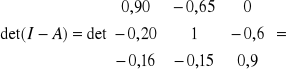
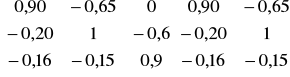
=![]()
= 0,81 - 0,0624 - 0,081 -0,117 = 0,5496 = det(I-A)
Mając obliczony wyznacznik liczymy macierz odwrotną:
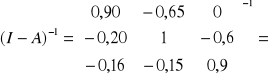
|
+[1·0,9-(-0,6)(-0,15)] |
-[(-0,65) ·0,9-0·(-0,15)] |
+[(-0,65)(-0,6)-0·(-1)] |
=1/0,5496 |
-[(-0,2)·0,9-(-0,6)(-0,16)] |
+[0,9·0,9-0·(-0,16)] |
-[0,9·(-0,6)-0·(-0,2)] |
|
+[(-0,2)(-0,15)-1·(-0,16)] |
-[(-0,2)(-0,15)-1·(-0,16)] |
+[0,9·1-(-0,65)(-0,2)] |
|
0,81 |
0,585 |
0,39 |
=1/0,5496 |
0,276 |
0,81 |
0,54 |
|
0,19 |
0,239 |
0,77 |
|
1,474 |
1,064 |
0,710 |
(I-A)-1 = |
0,502 |
1,474 |
0,983 |
|
0,346 |
0,435 |
1,401 |
Przykład 7 (cd przykładu 1)
Obliczmy wielkość produkcji globalnej X przy której wektor produkcji finalnej YT = [255 110 10].
|
1,47 |
1,06 |
0,71 |
|
255 |
|
500 |
X=(I-A)-1Y= |
0,50 |
1,47 |
0,98 |
|
110 |
= |
300 |
|
0,35 |
0,43 |
1,40 |
|
10 |
|
150 |
|
1,47·255+1,06·110+0,71·10 |
|
500 |
= |
0,5·255+1,47·110+0,98·10 |
= |
300 |
|
0,35·255+0,43·110+1,4·10 |
|
150 |
A więc jest zgodność z danymi początkowymi.
Przykład 8 (cd przykładu 1)
O ile musi zwiększyć się produkt globalny by produkt finalny zwiększył się o 7%.
Odpowiedź
Z jednorodności modelu Leontiefa, wiemy, że produkt globalny też musi zwiększyć się o 7%.
Przykład 9 (cd przykładu 1)
Jaka musi być zmiana produktu globalnego by nastąpiła zmiana produktu finalnego o YT = [10 -5 0].
Odpowiedź
|
1,47 |
0,50 |
0,35 |
|
10 |
|
12,23 |
X = |
1,06 |
1,47 |
0,43 |
|
-5 |
= |
3,28 |
|
0,71 |
0,98 |
1,40 |
|
0 |
|
2,18 |
Musi nastąpić wzrost X = [12,33 3,28 2,18].
Ekonomiczna interpretacja macierzy odwrotnej do macierzy Leontiefa (I-A)-1
Oznaczmy B = [bij]nxn = (I-A)-1. Macierz B nazywamy macierzą współczynników pełnej materiałochłonności. Elementy bij nazywamy współczynnikami pełnej materiałochłonności, bij to wartość o ile musi wzrosnąć j-ty produkt globalny, by i-ty produkt finalny wzrósł o jednostkę przy niezmienionych pozostałych produktach finalnych.
Niech YT = [0 … 0 1 0 … 0] przyrost o jednostkę na j-tym miejscu, to
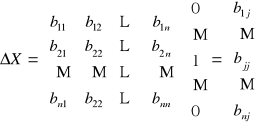
Wektor j-ty określa o ile musi zwiększyć się produkcja globalna, by w j-tej gałęzi nastąpił jednostkowy wzrost produktu finalnego przy niezmienionym produkcie finalnym w pozostałych gałęziach.
Prognozowanie na podstawie modelu Leontiefa.
Na podstawie bilansu przepływów międzygałęziowych wyznaczmy: macierz X, macierz A, macierz (I-A), macierz (I-A)-1. Zakładamy, że wyznaczone macierze są stałe w rozpatrywanym czasie i będą takie same w okresie na który, wykonywana jest prognoza.
Prognoza I rodzaju.
Na podstawie oceny możliwości wytwórczych systemu ekonomicznego określamy wielkość produktu globalnego X. Przy pomocy modelu Leontiefa prognozujemy wielkość produktu finalnego Y:
Y = (I-A) X
Prognoza II rodzaju.
Na podstawie oceny przyszłego zapotrzebowania na produkt finalny określamy wielkość wektora produktu finalnego Y. Przy pomocy modelu Leontiefa wyznaczamy wielkość wymaganego produktu globalnego X niezbędnego do wyprodukowania wymaganego wektora produkcji finalnej Y:
X = (I-A)-1 Y
Prognoza mieszana.
Na podstawie oceny przyszłego zapotrzebowania na produkt finalny części gałęzi produkcji oraz na podstawie oceny możliwości wytwórczych pozostałych gałęzi, przy pomocy modelu Leontiefa ustalamy pozostałe wielkości wektorów produkcji globalnej i finalnej.
Przykład 10 (cd przykładu 1)
Zakładamy, że dane z przykładu 1 dotyczyły okresu t. Badamy zachowanie się sytemu gospodarczego w następnym okresie, czyli w okresie (t+1). Na podstawie danych ekonomicznych oceniamy, że produkt globalny w gałęzi 3 nie zmieni się, zaś w gałęziach 1 i 2 wzrośnie o 10%. Jaki będzie produkt finalny w okresie (t+1)?
Rozwiązanie
Produkt globalny w okresie (t+1) wyniesie:
XTt+1 = [550 330 150]
Produkt finalny w okresie (t+1) wyniesie:
|
0,9 |
-0,65 |
0 |
|
550,00 |
|
280,5 |
Yt+1 = |
-0,2 |
1 |
-0,6 |
|
330,00 |
= |
130,0 |
|
-0,16 |
-0,15 |
0,9 |
|
150,00 |
|
-2,5 |
Z wykonanej prognozy I rodzaju wynika, że do zrealizowania zakładanej produkcji globalnej potrzebny jest import produktów gałęzi. Do zaspokojenia popytu pośredniego potrzeba produktów gałęzi 3 o wartości 2,5 jednostki.
Przykład 11 (cd przykładu 1)
Chcemy uniknąć konieczności importu towarów z gałęzi 3. Jaki powinien być wektor produkcji globalnej, tak by wektor produkcji finalnej wynosił:
YTt+1 = [280,5 130,0 0]
Rozwiązanie
Wyznaczamy prognozę II rodzaju dla ustalonego wektora produkcji finalnej:
|
1,47 |
1,06 |
0,71 |
|
280,5 |
|
551,77 |
Xt+1 = |
0,50 |
1,47 |
0,98 |
|
130,0 |
= |
332,46 |
|
0,35 |
0,43 |
1,40 |
|
0,0 |
|
153,50 |
Unikniemy konieczności importu, jeśli wektor produkcji globalnej XTt+1 wyniesie [551,77 332,46 153,50].
Zwiększając produkcję globalną:
działu pierwszego o (551,77 - 500)/500 % = 10,35% zamiast 10%,
działu drugiego o (332,46 - 330)/300 % = 10,82% zamiast 10%,
działu trzeciego o (153 - 150)/150 % = 2,34% zamiast 0%
unikniemy konieczności importu.
Przykład 12 (cd przykładu 1)
Prognoza mieszana na okres (t+1).
Sądzimy, że:
w dziale 3 nie zmieni się produkcja globalna ani popyt końcowy, czyli X3 = 0, Y3 = 0;
w dziale 2 zwiększy się popyt końcowy o wartość równą 10 jednostek, czyli Y2 = 10;
Musimy wyznaczyć pozostałe wielkości: X1, X2 , Y1. Z modelu Leontiefa otrzymujemy układ równań:
(I-A) X = Y
czyli:
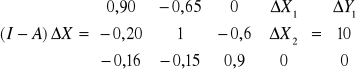
0,9 X1 -0,65 X2 = Y1
-0,2 X1 + X2 =
-0,16 X1 -0,15 X2 =
Skąd dostajemy:
X1 = , X2 = , Y1 = -12,58
Tak więc przy poczynionych założeniach sądzimy, że system gospodarczy będzie opisywany wektorami:
XTt+1 = [-7,89 8,42 0] ; YTt+1 = [-12,58 10 0].
XTt+1 = [492,11 308,42 150] ; YTt+1 = [242,42 120 10].
Ekonometria I Eko II W1
49 / 49