A⊂ Ω to P(A)=![]()
Rachunek prawdopodobieństwa 29.10.2005
Klasyczny model r-ku pr-stwa
D - doświadczenie losowe
Ω - przestrzeń zdarzeń elementarnych - zbiór wszystkich pojedynczych wyników doświadczenia losowego
W klasycznym modelu r-ku pr-stwa zakłada się że przestrzeń zdarzeń elementarnych Ω jest zbiorem skończonym i każdy wynik doświadczenia losowego jest jednakowo prawdopodobny tj. Ω = {ω1, ω2……ωn} i ∀ 1 ≤ i ≤ n, P ({ω1}) = 1/n
W tym modelu przez zdarzenie losowe rozumiemy dowolny podzbiór Ω
A zdarzenie losowe <=> A ⊂ Ω
2Ω rodzina wszystkich podzbiorów Ω
A∈ 2Ω <=> A ⊂ Ω
Np.:
Ω= {1,2,3}
2Ω={φ, {1} {2}, {1,2}, {1,3}, {2,3}, {1,2,3}}
A⊂ Ω to P(A)=![]()
![]()
- liczba elementów zbioru A
W urnie jest M kul ponumerowanych liczbami 1,2……M losujemy n razy opisz przestrzeń zdarzeń elementarnych tego doświadczenia losowego
1) losowanie bez zwracania
n≤M
próbka uporządkowana
ω=(a1, a2,…an) : ai≠aj dla i≠j
a=1,2……M
W tym przypadku ωjest n-wyrazową wariacją bez powtórzeń zbioru M-elementowego
Ω={ω:ω=(a1, a2,…an) : ai≠aj dla i≠j
a=1,2……M
Ω= M (M-1)(M-2)*(M-n+1)=(M)n
próbka nieuporzadkowana
ω=[a1, a2,…an] : ai≠aj dla i≠j
a=1,2……M
W tym przypadku ω jest to n-elementowa kombinacja bez powtórzeń zbioru M-elementowego
n-elementowy podzbiór złożony z różnych elementów ze zbioru M-elementowego
Ω={ω: ω=[a1, a2,…an] : ai≠aj dla i≠j}
a=1,2……M
![]()
M!=1*2*…M 0!=1
2)losowanie ze zwracaniem
a) próbka uporządkowana
ω=(a1, a2,…an) : ai=1,2,…M
W tym przypadku ω jest n-wyrazową wariacją z powtórzeniami zbioru M-elementowego
Ω={ω:ω=(a1, a2,…an) : ai=1,2,…M
![]()
b)próbka nieuporządkowana
ω=[a1, a2,…an] : ai=1,2,…M i=1,2…n
W tym przypadku ω jest to n-elementowa kombinacja z powtórzeniami zbioru M-elementowego
![]()
Rzucamy tak długo moneta aż pojawi się orzeł. Przestrzeń zdarzeń tego doświadczenia jest następująca:
Ω={O, RO, RRO, RRRO,…..}
Zbiór wyników tego doświadczenia losowego jest zbiorem przeliczalnym tzn. elementy tego zbioru możemy ustawić w ciąg nieskończony
Wykres…..
Przestrzeń Ω jest zbiorem nieskończonym, który nie jest zbiorem przeliczalnym.
Ogólny model r-ku pr-stwa
D - doświadczenie losowe
Ω - przestrzeń zdarzeń elementarnych - zbiór wszystkich pojedynczych wyników doświadczenia losowego D (Ω- zbiór nieskończony, przeliczalny lub nieprzeliczalny
F - rodzina podzbioru zbioru Ω spełniającego następujące warunki
1) Ω∈F
2) jeżeli A∈F to A' = Ω\ A∈F
3) ![]()
Wtedy F nazywamy σ (sigma) podzbioru Ω
Przez zdarzenie losowe będziemy rozumieć dowolny podzbiór Ω tj. F= 2Ω
Funkcję P: F→[0,1] spełniającą warunki:
P(Ω)=1 to unormowanie miary (pr-stwo zdarzenia pewnego równa się 1)
∀ ![]()
Ai ∧Aj≠φ dla i≠ j zachodzi równość:
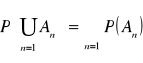
Przeliczalna addytywność nazywamy funkcję pr-stwa lub pr-stw lub miara probabilistyczną
Uporządkowaną trójkę: (Ω, F, P) nazywamy przestrzenią probabilistyczną → jest modelem matematycznym doświadczenia losowego
Pojecie zmiennej losowej
Niech (Ω, F, P) przestrzeń probabilistyczna funkcji X' : Ω spełnia warunki ∀a∈R {ω∈Ω : X(ω)<a}∈F nazywamy zmienną losową określoną na przestrzeni probabilistycznej (Ω, F, P)
(Nieprecyzyjna definicja zmiennej losowej)
Przez zmienną losową rozumiemy dowolną funkcję określona na Ω o wartościach R (X : Ω→R)
Oznaczenie Fx - dystrybuanta zmiennej losowej X
Funkcję Fx : R→[0,1]
∀x∈R Fx(x)=P {ω∈Ω X(ω)<x}=P(X<x)
Nazywamy dystrybuantą zmiennej losowej x
Dystrybuanta jest charakterystyką funkcyjną zmiennej losowej.
Zmienne losowe skokowe (dyskretne)
Niech X zmienna losowa określona na przestrzeni probabilistycznej (Ω, F, P)
χ=x (Ω)= {x (ω):ω∈Ω}
Mówimy, że X jest zmienną losową skokowa (dyskretną) jeżeli jej zbiór wartości χ jest zbiorem skończonym lub przeliczalnym tj.
χ={x1, x2,…xn} lub χ ={x1, x2,x3…}
pi=P(X=x i) x i∈χ
Zbiór {(xi, P) : xi⊂χ, pi=P(X=x i) nazywamy rozkładem pr-stwa zmiennej losowej X
Przykłady zmiennych losowych skokowych
1) X∼Poiss (λ),>0
P(X=k)= e -λ *![]()
, k=1,2…..
Zbiorem wartości tej zmiennej jest zbiór wszystkich liczb całkowitych nieujemnych (≥0)
2)X∼Bin (n,p), n∈N, 0≤P≤1
Zmienna losowa X ma rozkład binominalny (2- mianowy) o parametrach n, p
P(X=k)= ![]()
k=0,1….n
Zmienne losowe ciągłe
Mówimy, że X jest zmienną losową ciągłą jeśli istnieje funkcja f : R→R+ , taka, że ∀x∈R
Fx (x)= 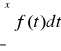
Funkcje f nazywamy funkcją gęstości pr-stwa zmiennej losowej x
Przykłady zmiennej losowej ciągłej
X∼Exp (α), α>0
Zmienna losowa X ma rozkład wykładniczy (eksponencjalny) z parametrem α
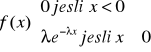
Wykres…..
X∼N (m,σ) m ∈R, σ >0![]()
Wykres…..
Charakterystyki liczbowe zmiennych losowych
E(X) - wartość średnia lub wartość oczekiwana zmiennej X
X - zmienna losowa skokowa
χ={x1, x2,…xn}
Pi=P(X=x i), i=1,2…. (P=pr-stwo)
wtedy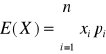
b) χ={x1, x2,x3 …}
Pi=P(X=x i), i=1,2,3….
Wtedy 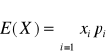
przy założeniu, że szereg stojący po prawej stronie równości definicyjnej jest zbieżny bezwzględnie tj. że 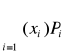
<∞
X zmienna losowa ciągła o funkcji gęstości pr-stwa f
Wtedy 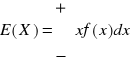
przy założeniu, że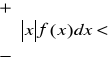
Twierdzenie o własnościach wartości średnich
Niech X1, X2, X3 zmienne losowe określone na tej samej przestrzeni probabilistycznej (Ω, F, P), zakładamy, że istnieją(są skończone) E(X1), E(X2) , E(X) wtedy istnieje wartość średnia
∃ E(X1+X2) i zachodzi równość E(X1+X2) = E(X1) + E(X2)
∀a∈R ∃ E(aX) i zachodzi równość E(aX)=aE(X)
∀c∈R E(c)=c
Wartość średnia (oczekiwana) jest najważniejszą charakterystyka zmiennej losowej
12.11.2005
Liczbę mk: E(Xk) nazywamy k-tym momentem zmiennej losowej X
Definicja
X zmienna losowa taka, że (istnieje) ∃ E(X2) <∞
D2(X) var (x), σ2(x) wariancja zmiennej losowej X
D2(X) := E((X)-E(X))2
Stwierdzenie 1
Zakładamy, że ∃ E(X2) <∞
D2(X) := E(X2)-(E(X))2
![]()
D2(aX+b)=a2D2(X)
Dowód
a) 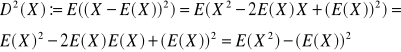
b) 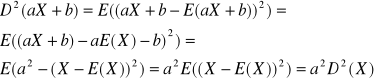
Liczbę „mi” μ : = E((X-E(X))k) nazywamy k-tym momentem centralnym zmiennej losoej X
Wielowymiarowe zmienne losowe
Niech X1, X2, X3 zmienne losowe określone na tej samej przestrzeni probabilistycznej (Ω, F, P) wtedy X:=( X1, X2,….. Xn) nazywamy n-wymiarową zmienna losową (lub n-wymiarowym wektorem losowym) określoną na przestrzeni probabilistycznej (Ω, F, P)
X:=( X1, X2,….. Xn) n-wymiarowa zmienna losowa. Załóżmy, że
∀ 1 ≤ i ≤ n ∃ E(X i) <∞
Wtedy:
E(X)=E((X1,X2….Xn):=(E(X1),E(X2).....E(Xn))
Oprócz charakterystyk liczbowych pojedynczych zmiennych losowych zdefiniowano charakterystyki liczbowe pary zmiennych losowych mówiącą o ich powiązaniach. Zależność pomiędzy zmiennymi losowymi mierzymy za pomocą kowariancji
i współczynnika korelacji.
Definicja
X i Y zmienne losowe takie, że
∃ E(X2), E(Y2) <∞
Cov (X,Y) : = E((X-E(X))(Y-E(Y)))
Odchylenie standardowe 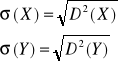
Definicja
Przy założeniach definicji poprzedniej
![]()
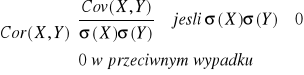
współczynnik korelacji
Współczynnik korelacji jest to kowariancja odniesiona do iloczynu odchyleń standardowych - unormowana kowariancja.
Definicja
X1, X2,….Xn zmienne losowe określone na tej samej przestrzeni probabilistycznej (Ω, F, P). Mówimy, że zmienne losowe X1, X2, ….Xn są niezależne jeśli:
∀ x1,x2,….xn ∈ R zachodzi równość
P(X1<x1, X2<x2….. Xn<xn)= P(X1<x1)….P(Xn<xn)
Pojęcie niezależności jest fundamentalnym pojęciem probabilistyki. Pojęcie to wyodrębnia teorię pr-stwa z teorii funkcji rzeczywistej (z analizy matematycznej).
Twierdzenie
X1, X2,….Xn zmienne losowe E(X1,X2….Xn)=E(X1)….E(Xn)
Wniosek
Jeżeli X1, X2,…Xn zmienne losowe, to wtedy D2(X1,X2…Xn)= D2(X1)+ D2(X2)+…+ D2(Xn)
Pojęcie macierzy kowariancyjnej
Definicja
X=(X1,X2….Xn) n-wymiarowa zmienna losowa, zakładamy, że
∀ 1 ≤ i ≤ n ∃ E(X i2) ⊂ ∞
Macierz [Cov(Xi, Yj)]n, i,,j=1 nazywamy macierzą kowariancyjną n-wymiarowej zmiennej losowej X=(X1…..Xn)
Stwierdzenie
X, Y zmienne losowe takie, ze ∃ E(X2), E(Y2) <∞
a) Cov (X, Y)= E(X-Y)-E(X)E(Y)
b) jusli X, Y nielalezne zmienne losowe to cor (X,Y)=0 (Cov(X,Y)=0)
Dowód
Cov (X.Y) =E((X-E(X))(Y-E(Y)))=E(XY-XE(Y)-E(X)Y+E(X)E(Y)=
E(X*Y)-E(X)E(Y)-E(X)E(Y)+E(X)E(Y)=
E(XY)-E(X)E(Y)
X,Y zmienne niezależne => E(XY)=E(X)E(Y) =>Cov (X,Y) = E(X-Y)-E(X)E(Y)=0
=>cor(X,Y)=0
UWAGA!
Stwierdzenie odwrotne do punktu b) nie zachodzi tzn. jeśli cor(X,Y)=0 to nie wynika z tego, ze zmienne x,Y są niezależne
X - cecha mieszana populacji generalnej
x - zmienna losowa
Fx(x,θ) - dystrybuanta θ - parametr rozkładu
Fx(x,θ)=P(X<x) ∀a∈R
(X1,X2….Xn) n-wymiarowa zmienna losowa, zakładamy, że
∀ 1 ≤ i ≤ n Xi∼X ( zmienna losowa Xi ma taki sam rozklad jak zmienna losowa X) oraz że zmienne losowe X1,X2….Xn nazywamy n - elementową próba losową (prostą)
Estymacja (szacowanie) punktowe. Estymatory i ich podstawowe właściwości.
W przypadku gdy rozkład badanej populacji cechy mierzalnej nie jest znany zachodzi często potrzeba oszacowania pewnych parametrów tego rozkładu. Niech rozkład badanej cech X populacji zależy od nieznanego parametru θ („teta”). Parametr ten będziemy szacować (estymować) na podstawie n- elementowej próby prostej (X1,X2….Xn) pobranej z tej populacji g(X1,X2….Xn) będące funkcja próby losowej (X1,X2….Xn) nazywamy statystykami. Rozkład pr-stwa takiej zmiennej zależy od postaci funkcji g oraz od rozkładu zmiennej X1,X2….Xn
Każdą statystykę ![]()
, której wartości przyjmujemy jako oceny nieznanego parametru θ nazywamy estymatorem parametru θ. Otrzymana na podstawie jednej konkretnej realizacji próby wartość estymatora nazywamy oceną (oszacowaniem) tego parametru.
Własności estymatorów
Mówimy, ze estymator ![]()
parametru θ jest zgodny, jeśli
∀ε>0 ![]()
Własność zgodności oznacza, ze dla dostatecznie dużych liczności próby estymatora przyjmuje z dużym pr-stwem wartości bliskie estymowanemu parametrowi θ.
Estymatorem zgodnym nieznanej wartości oczekiwanej θ = E(X) < ∞ dowolnego rozkładu jest statystyka ![]()
Estymator ![]()
nazywamy estymatorem nieobciążonym parametrem θ jeśli ∀ n∈N E![]()
=θ n
jeśli istnieje E![]()
i E![]()
to mówimy, ze estymator ![]()
jest estymatorem obciążonym parametrem ![]()
Liczbę Bn(θ):E(![]()
) - θ nazywamy obciążeniem estymatora ![]()
Jeśli ![]()
to mówimy, że estymator ![]()
jest estymatorem asymptotycznie nieobciążonym parametru θ.
Metody otrzymywanie estymatorów
Metoda momentów
Jeśli mamy próbę losowa (X1,X2….Xn) to możemy określić tzw. momenty z próby w sposób analogiczny do definicji momentów zmiennej losowej
mk=E(Xk) k=1,2….
Ak![]()
nazywamy k-tym momentem próby losowej
Ak![]()
Podobnie określamy momenty centralne „mi” μk = E((X-E(X))k)
k-ty moment centralny zmiennej losowej X ![]()
zazywamy k-tym momentem centralnym próby losowej (X1,X2….Xn)
μk = E((X-E(X))2)=D2(X)
![]()
drugi moment centralny próby losowej (X1,X2….Xn)
Sn2=B2
Sn2 jest estymatorem (obciążonym) wariancji cech populacji (rozkładu)
Metoda momentów jest najstarszą metodą szacowania parametrów. Polega ona na tym, że do szacowania parametrów populacji generalnej używamy odpowiednich momentów z próby lub ich funkcji
Jeśli chcemy oszacować wartość średnią to ponieważ jest to pierwszy moment jako estymatora używamy I momentu z próby. Chcąc oszacować wariancję, która jest II momentem centralnym jako estymatora używamy II momentu centralnego z próby
Metoda momentów charakteryzuje się dużą prostota ale estymatory uzyskane przy pomocy tej metody nie mają na ogół dobrych własności. Są z reguły estymatorami obciążonymi poza estymatorem ![]()
![]()
jest estymatorem obciążonym wariancją σ2 (σ2=D2(X))
![]()
jest estymatorem nieobciążonym wariancji wariancją σ2 (σ2=D2(X))
Estymatory Sn2 i Sn*2 sa estymatorami nieznanych wariancji σ2 (σ2=D2(X))
Estymacja przedziałowa 26.11.2005
Estymacja przedziałowa parametru θ polega na znalezieniu 2 statystyk θ1=θ1(X1,X2….Xn) i θ2=θ2(X1,X2….Xn) spełniających warunki:
P(θ1(X1,….Xn)< θ < θ2(X1, ….Xn)=1-α, gdzie 1-α jest liczbą bliską jedności
Szukamy przedziału (θ1, θ2), którego końcami są zmienne losowe, a który zawiera nieznany parametr θ z pr-stwem równym 1-α.
Przedział (θ1, θ2) nazywamy przedziałem ufności a pr-stwo 1-α poziomem ufności (lub współczynnikiem ufności)
Z definicji przedziału ufności końce tego przedziału są zmiennymi losowymi. Nieznana wartość parametru θ może być więc pokryta przez ten losowy przedział albo też nie. Jeżeli jednak dla różnych zaobserwowanych próbek losowych (x1,x2….xn) znajdziemy wiele realizacji przedziału ufności to częstość tych które będą zawierać rzeczywistą wartość parametru θ w dużej liczbie tych realizacji będzie w przybliżeniu równa 1-α
MODEL I
Przedział ufności dla średniej normalnej gdy wariancja jest znana
Niech cecha X elementów populacji generalnej ma rozkład N(m, σ) tzn., że 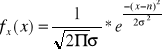
, ∀x∈R
E(X)=m, D2(X)= σ2, m∈R, σ>0, m-nieznane, σ-znane
Niech (X1, X2….Xn) prosta próba losowa pobrana z populacji normalnej o rozkładzie normalnym N(m, σ) tzn.,
∀ 1 ≤ i ≤ n Xi∼X oraz zmienne losowe X1, X2….Xn są (stochastycznie) niezależne.
Z r-ku pr-stwa wiadomo, że statystyka ![]()
ma rozkład normalny (![]()
)
![]()
∼ N(![]()
)
Stąd wynika, że zmienna standaryzowana 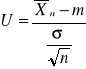
∼ N (0,1)
W tablicach rozkładu normalnego można znaleźć uα spełniającą warunek P(-uα<U< uα)=1-α
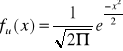
∀x∈R
Wykres
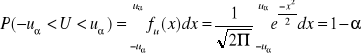
![]()
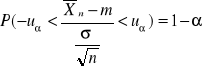
Rozwiązujemy powyższą nierówność względem m
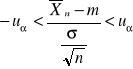
![]()
![]()
Powyższe 3 nierówności są równoznaczne
Stąd mamy:
P(![]()
)=1-α
Z powyższej równości otrzymujemy wzór na przedział ufności dla średniej normalnej n gdy σ2 jest znane na poziomie ufności 1-α
![]()
przedział ufności
Długość tego przedziału jest równa ![]()
Długość przedziału ufności dla średniej normalnej jest proporcjonalna do odchylenia standardowego σ a odwrotnie proporcjonalna do ![]()
α |
0,1 |
0,005 |
0,0495 |
0,01 |
0,001 |
u |
1,645 |
1,96 |
2 |
2,576 |
3,291 |
1-α |
90% |
95% |
95,05% |
99% |
99,9% |
Na poziomie ufności 1-α=95% przedział ufności dla średniej normalnej m, gody σ2 jest znane wyraża się wzorem ![]()
Otrzymany w tym modelu przedział ufności dla średniej normalnej stosuje się w przypadku próby dużej o liczebności n ≥30 wtedy wariancję σ2 można ocenić na podstawie wartości nieobciążonego estymatora wariancji![]()
Przykład 1
Z pewnej populacji dorosłych mężczyzn wylosowano n=100 zmierzono ich wzrost. Otrzymano następujące sumy
![]()
Znajdź realizacje przedziałów ufności dla średniej normalnej na poziomie ufności 95% i 99%
Zał: wzrost ma rozkład normalny
![]()
![]()
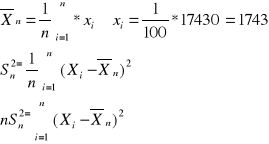
![]()
![]()
![]()
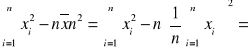
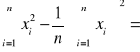
3057149-1/100*(17430)2=19100
Ponieważ próba jest liczna to:
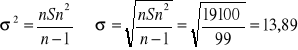
1-α=95% uα=1,96
(174,3-1,96*![]()
, 174,3+1,96*![]()
)
(170,72 , 177,88)
Model II
Przedział ufności dla średniej normalnej gdy wariancja jest nieznana
Zakładamy, że cecha X ma rozkład N(m, σ), gdzie m, σ nieznane
(X1,X2….Xn) prosta próba losowa pobrana z tej populacji. Można pokazać ze statystyki ![]()
i nSn2 są stochastycznie niezależne oraz ![]()
∼ χ2(n-1)
Definicja X1,X2….Xn niezależne zmienne losowe takie, że
∀ 1 ≤ i ≤ n Xi∼N (0, 1) wtedy mówimy, że zmienne losowe χ2(n)=X12+X22….+Xn2 ma rozkład chi kwadrat z n stopniami swobody
Rozkład χ2 został wprowadzony przez Karla Pearsona. Rozkład χ2 jest rozkładem stablicowanym.
Tworzymy 2 nowe zmienne losowe:
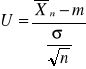
∼N (0, λ)
![]()
∼χ2(n-1)
Definicja (Rozkład t-Studenta)
Niech U∼N (0,1), V∼χ2(k), zakładamy, że zmienne U i V są niezależne. Wtedy mówimy, że zmienna losowa 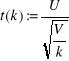
ma rozkład t-Studenta z k stopniami swobody
Rozkład ten został wprowadzony przez W. Gosset (1976-1937) używającego pseudonimu Student.
Zgodnie z powyższa definicją zmienna losowa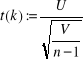
∼t(n-1)
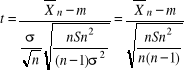
∼t(n-1)
W tablicach rozkładu t-Studenta można znaleźć wartość tα=t(α, n-1) spełniające warunek
P(-tα<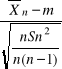
< tα )= 1-α
Poniższa nierówność
-tα<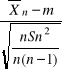
< tα
jest równa następującej podwójnej nierówności
-tα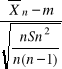
<![]()
< tα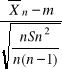
A to jest równoważne:
![]()
-tα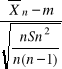
<m< ![]()
+tα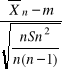
Stąd otrzymujemy
P(![]()
-tα![]()
<m< ![]()
+tα![]()
)=1-α
Z powyższego wzoru mamy, że przedział (![]()
-tα![]()
<m< ![]()
+tα![]()
) jest przedziałem ufności dla średniej normalnej m gdy σjest nieznane na poziomie ufności 1- α
Przedział ten ma zastosowanie gdy dysponujemy próbą małej liczności n≤30
Przedział ufności dla wariancji i odchylenia standardowego 10.12.2005
Model I
Cecha X elementów populacji generalnej ma rozkład N (m, σ), gdzie m, σ są nieznane
Próba jest liczności n≤50
Konstrukcję przedziałów oprzemy na statystyce
![]()
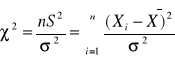
Która ma rozkład chi - kwadrat z (n-1) stopniami swobody. Rozkład ten oznaczamy przez χ2 (n-1). Wtedy:
![]()
Liczby χ2 (½α, n-1) i χ2 (1-½α, n-1) nazywamy kwadratami rzędu ½α i 1-½α rozkładu χ2 z n-1, ½α,
Wykres 1
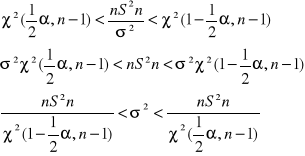
Stąd mamy ze prawdopodobieństwo
P(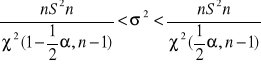
)=1-α
Otrzymaliśmy wzór na przedział ufności dla wariancji σ2 na poziomie ufności 1- α
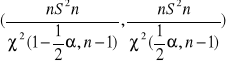
Stąd mamy ze pr-stwo
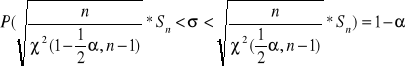
Otrzymaliśmy wzór na przedział ufności dla odchylenia standardowego σ2 na poziomie ufności 1-α
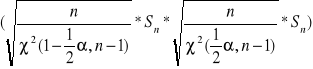
Model II
Cecha X elementu populacji generalnej ma rozkład N (m, σ), gdzie m, σ są nieznane
Próba jest liczności n≥50
W przypadku tego modelu można wykorzystać fakt, że statystyka 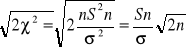
Ma w przybliżeniu rozkład N(![]()
1) zatem
![]()
Gdzie ![]()
jest kwantylem rzędu ![]()
rozkładu N(0, 1)
Rozwiązujemy następujące podwójne nierówności ze względu na σ
![]()
![]()
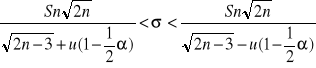
Stąd mamy wzór na przedział ufności dla σ na poziomie ufności 1-α
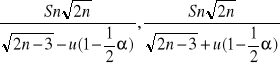
Elementy rachunku prawdopodobieństwa
Rozkład Snedecora
Rozkładem Snedecora ze stopniami swobody (r1,r2) nazywamy rozkład pr-stwa iloraz
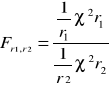
Gdzie ![]()
, ![]()
SA niezależnymi zmiennymi losowymi o rozkładzie![]()
stopniami swobody odpowiednio
E![]()
![]()
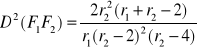
Wykres 2
Rozkład ten jest rozkładem stablicowanym
Dla danych prawdopodobieństw α i ustalonych liczb stopni swobody α(r1, r2) dana jest wartość
![]()
Twierdzenia o rozkładzie sumy nierealnych zmiennych losowych
Twierdzenie 1
Niech X1, X2……Xn niezależne zmienne losowe takie, że ∀ 1≤ i≤ n Xi ~N(m,σ)
Wtedy zmienne losowe ![]()
Xi ~N(m1+ m2+….+ mn , ![]()
)
Z twierdzenia 1 wynika:
Jeśli X1, X2……Xn niezależne zmienne losowe takie, że ∀ 1≤ i < n Xi ~N(m,σ) wtedy
![]()
Xi ~N(nm, ![]()
)
Twierdzenie 2
X1, X2 niezależne zmienne losowe takie, że Xi ~N(mi,σi), i=1,2
Wtedy zmienna losowa Z=X1-X2 ~ N(m1-m2, ![]()
)
Stąd wynika, że jeśli X1, X2 niezależne zmienne losowe takie, że Xi ~N(m,σ), i=1,2 Wtedy zmienna losowa Z=X1-X2 ~ N(0, ![]()
)
Twierdzenie 3
X1, X2……Xn niezależne zmienne losowe takie, że ∀ 1 i ≤ n Xi ~N(m,σ)
Wtedy ![]()
Xi ~N(![]()
(m1 +….+ mn) , ![]()
)
Weryfikacja hipotez statystycznych
Obok zagadnień estymacji 2 podstawowym działem wnioskowania statystycznego jest weryfikacja hipotez statystycznych
Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawidłowości lub fałszywości którego wnioskuje się w oparciu o pobraną próbkę. Hipotezy które dotyczą wyłącznie wartości parametru (parametrów) określanej klasy rozkładów nazywamy hipotezami parametrycznymi
Np.:
Cecha X ~N(0,σ)
Wysuwamy hipotezę σ =1
Każdą hipotezę, która nie jest parametryczna nazywamy nieparametryczną.
Np.:
Niech T oznacza czas między 2 kolejnymi zgłoszeniami do centrali telefonicznej. Wysuwamy hipotezę, że T ma rozkład wykładniczy.
Jeżeli hipoteza parametryczna precyzuje dokładnie wartość wszystkich parametrów rozkładu badanej cechy to nazywamy ją hipotezą prostą, w przeciwnym wypadku mówimy o hipotezie złożonej. Weryfikację postawionych hipotez statystycznych przeprowadzamy w oparciu o próby losowe.
Metodą postępowania, która każdej realizacji próbki (x1, x2….xn) przyporządkowuje z ustalonym pr-stwem decyzję przyjęcia lub odrzucenia sprawdzonej hipotezy nazywamy testem statystycznym. W praktyce przy weryfikacji hipotez postępuje się w ten sposób że oprócz weryfikowanej hipotezy H0 wyróżnia się inną hipotezę H1, która najczęściej wynika z celu badania statystycznego (zwana jest hipotezą alternatywną)
H1 jest taką hipotezą, którą w danym zagadnieniu skłonni jesteśmy przyjąć jeśli weryfikowaną hipotezę H0 należy odrzucić
W celu zbudowania testu do weryfikacji postawionej H0 należy wybrać odpowiednią funkcję próby losowej „delta” δ(X1, X2…..Xn) nazywamy statystyką testową.
Przy pobieraniu różnych próbek nawet tej samej liczności funkcja ta przyjmuje na ogół różne wartości. Jedne z nich będą świadczyły o zgodności weryfikacji z hipotezą a inne będą przemawiać przeciw tej hipotezie. Zachodzi więc konieczność podziału zbioru wszystkich wartości, które może przyjąć statystyka testowa.
δ(X1, X2…..Xn) ma 2 dopełniające się zbiory W i W', takie, że jeśli δ(X1, X2…..Xn) є W to hipotezę odrzucamy
Jeżeli δ(X1, X2…..Xn) є W' to hipotezę przyjmujemy. Zbiór W nazywamy zbiorem krytycznym lub zbiorem odrzuceń hipotezy. Zbiór W' nazywamy zbiorem przyjęć.
Weryfikując daną hipotezę statystyczną H0 w oparciu o zaobserwowane wyniki próbki ponosimy zawsze pewne ryzyko podjęcia błędnej decyzji. Wynika to stąd że na podstawie próbki nigdy nie mamy całkowitej informacji o zbiorowości z której została pobrana próbka. W wyniku testowania hipotezy statystycznej możemy podjąć poprawna decyzję albo popełnić 1 z 2 następujących błędów:
możemy odrzucić weryfikowana hipotezę H0 wtedy gdy jest ona w rzeczywistości prawidłowa - błąd I rodzaju
możemy przyjąć weryfikowaną H0 jako prawdziwą podczas gdy jest ona fałszywa czyli jeśli prawdziwa jest hipoteza alternatywna H1- błąd II rodzaju
Pr-stwo błędu I rodzaju nazywamy poziomem istotności i oznaczamy α . Pr-stwo błędu II rodzaju oznaczamy β
Pożądane jest aby pr-stwo błędów obu rodzajów uczynić możliwie małym. Nie można jednak zmniejszać jednocześnie obydwu rodzajów błędów przy ustalonej liczności próby
Weryfikacja hipotez dotycząca wartości średniej 7.01.2006
MODEL I
Badana cecha X populacji generalnej ma rozkład N(m, σ), gdzie σ >0 jest znane.
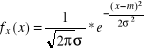
E(X)=m, D2(X)= σ2
Weryfikujemy hipotezę H0:m=m0 wobec hipotezy alternatywnej
H1:m=m1 < m0
H1:m=m1 > m0
H1:m=m1 ≠ m0
Poziom istotności α, 0<α<1
Do weryfikacji hipotezy H0 użyjemy statystyki ![]()
, która przy prawdziwości hipotezy H0:m=m0 ma rozkład N(0,1)
Jeśli H1:m=m1 < m0 to zbiorem krytycznym W jest przedział [(1-α), +∞), gdzie u(1-α) jest kwantylem rzędu 1-α rozkładu N(0,1)
konstrukcja testu do weryfikacji hipotezy H0:m=m0 wobec hipotezy alternatywnej H1:m=m1 < m0 na poziomie istotności α
Wykres...
Jeśli H1:m=m1 ≠ m0 to zbiorem krytycznym W jest suma przedziałów (-∞, u(1-α/2)] ∪[(1-α/2) +∞)
Wykres....
Jeśli wartość statystyki U jest obliczana dla próbki uobl należy do zbioru krytycznego W to weryfikowaną hipotezę H0 odrzucamy a przyjmujemy hipotezę alternatywną H1. W przeciwnym przypadku nie ma podstaw do odrzucenia weryfikowanej hipotezy H0.
Przyklad
Z populacji w której badana cecha X ma rozkład normalny X ~N(m,4) wylosowano próbkę o liczności n=9. Na poziomie istotności α=0,05 zweryfikować hipotezę H0: m=2 wobec hipotezy H1m=m1 < 2 jesli średnia z próbki wynosi ![]()
=1,4
![]()
![]()
H1m=m1 < m0=2 to zbiór krytyczny W=(-∞, u(1-α)]=(-∞, u(0,95)]= (-∞,-1,64]
MODEL II
Badana cecha X populacji generalnej ma rozkład N(m, σ), gdzie m, σ nieznane.
Weryfikujemy hipotezę H0:m=m0 wobec hipotezy alternatywnej
a) H1:m=m1 ≠ m0
b) H1:m=m1 > m0
c)H1:m=m1 < m0
Poziom istotności α, 0<α<1
Do weryfikacji hipotezy H0 użyjemy statystyki ![]()
, która przy prawdziwości hipotezy H0:m=m0 ma rozkład t-Studenta z n-1 stopniami swobody.
Jeśli m1 > m0 to zbiorem krytycznym jest przedział [t(1- α, n-1), +∞), gdzie t(1- α, n-1) jest kwantylem rzędu 1-α rozkładu t-Studenta z n-1 stopniami swobody
Jeśli m1 < m0 to zbiorem krytycznym jest przedział (-∞, - t(1- α, n-1)]
Jeśli m1 ≠ m0 to zbiorem krytycznym jest przedział (-∞, - t(1- α/2, n-1)]∪[ t(1- α/2, n-1), +∞), gdzie t(1- α/2, n-1) jest kwantylem rzędu 1- α/2 rozkładu t- Studenta z n-1 stopniami swobody.
Jeśli wartość tobl statystyki t obliczona dla danej próbki należy do zbioru krytycznego W wtedy weryfikowaną hipotezę H0 odrzucamy na korzyść hipotezy alternatywnej H1. W przeciwnym przypadku nie ma podstaw do odrzucenia weryfikowanej hipotezy H0.
Testy istotności dla wariancji
Niech badana cecha X populacji generalnej ma rozkład N(m, σ), gdzie m, σ nieznane.
Weryfikujemy hipotezę H0:σ 2 =σ20 wobec hipotezy alternatywnej
a) H1: σ 2 =σ21 ≠σ 20
b) H1: σ 2 =σ21 > σ 20
c)H1: σ 2 =σ21 < σ 20
Poziom istotności α, 0<α<1, n≤50
Do weryfikacji hipotezy H0 użyjemy statystyki ![]()
, która przy prawdziwości hipotezy H0 ma rozkład χ2 (n-1). Jeśli H1: σ 2 =σ21 > σ 20 wtedy zbiorem krytycznym W jest przedział [χ2(1-α, n-1), +∞) gdzie χ2(1-α, n-1) jest kwantylem rzędu 1-α z n-1 stopniami swobody
Wykres...
Jeśli H1: σ 2 =σ21 < σ 20 to W (0, χ2(α, n-1)
Wykres...
Jeśli H1: σ 2 =σ21 ≠σ 20 to W (0, (1/2α, n-1)] ∪ [(1-1/2α, n-1), +∞)
Jesli obliczona z próbki wartość statystyki ![]()
należy do zbioru krytycznego W to weryfikowaną hipotezę H0 odrzucamy i przyjmujemy hipotezę alternatywną. W przeciwnym przypadku nie ma podstaw do jej odrzucenia.
UWAGA
Ponieważ tablice rozkładu χ2 podają wartości kwantyli dla n≤50 to rozpatrzony model stosujemy przy założeniu, że próbka jest o liczności n≤50
Przykład
W celu oszacowania dokładności pomiaru wykonanych pewnym przyrządem dokonano n=8 pomiarów i otrzymano następujące wyniki: 18,17; 19,21; 18,05; 18,14; 18,19; 18,22; 18,06; 18,08;
α=0,05 H0; σ 2 =σ20 przeciw hipotezie alternatywnej:
a) H1: σ 2 =σ21 ≠σ 20
b) H1: σ 2 =σ21 > σ 20
c)H1: σ 2 =σ21 < σ 20
Poziom istotności α, 0<α<1, n>50
Do weryfikacji hipotezy H0 wykorzystamy jak w poprzednim modelu statystykę ![]()
oraz fakt, że statystyka 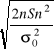
ma w przybliżeniu rozkład N(![]()
, 1)
Do weryfikacji H0 użyjemy statystyki ![]()
, która ma w przybliżeniu rozkład N(0,1)
1) jeśli H1: σ 2 =σ21 > σ 20 to zbiorem krytycznym W jest przedział [u(1-α), +∞), gdzie u(1-α) jest kwantylem rzędu 1-α rozkładu N(0,1)
2) jeśli H1: σ 2 =σ21 < σ 20 to zbiorem krytycznym W jest przedział (-∞, - u(1-α)]
3) jeśli H1: σ 2 =σ21 ≠σ 20 to zbiorem krytycznym W jest przedział ((-∞, - u(1-α/2)]∪[ u(1-α/2), +∞)