ANALIZA ZALEŻNOŚCI DWÓCH ZMIENNYCH.
REGRESJA LINIOWA.
I. Współczynnik korelacji próbkowej
Niech ![]()
będzie próbką cechy dwuwymiarowej ![]()
.
Będziemy badali zależność Y od X.
X = zmienna niezależna ( zmienna objaśniająca ),
Y = zmienna zależna ( zmienna objaśniana ),
Wykres rozproszenia - graficzne przedstawienie próbki w postaci punktów na płaszczyźnie Oxy.
Przykład. Wyniki kolokwium i egzaminu końcowego
Definicja. Niech ![]()
będzie próbą losową. Współczynnikiem korelacji z próby losowej nazywamy zmienną losową
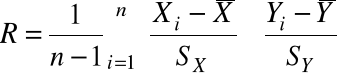
,
gdzie ![]()
i ![]()
oznaczają średnią i odchylenie standardowe dla ![]()
, a ![]()
i ![]()
oznaczają średnią i odchylenie standardowe dla ![]()
.
( np. 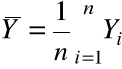
, 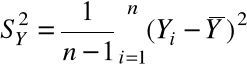
, ![]()
)
Współczynnikiem korelacji próbkowej nazywamy wartość R obliczoną dla próbki ![]()
:
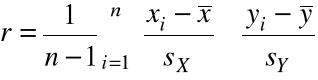
Własności współczynnika korelacji próbkowej :
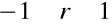
.
2. Jeśli ![]()
, to wszystkie punkty wykresu rozproszenia leżą na prostej o dodatnim współczynniku kierunkowym, tzn. istnieje dodatnia zależność liniowa między zmiennymi x i y próbki.
3. Jeśli ![]()
, to wszystkie punkty wykresu rozproszenia leżą na prostej o ujemnym współczynniku kierunkowym, tzn. istnieje ujemna zależność liniowa między zmiennymi x i y próbki.
4. Wartości r bliskie -1 lub 1 wskazują, że wykres rozproszenia jest skupiony wokół prostej.
Prosta regresji. Metoda najmniejszych
kwadratów.
Problem: w jaki sposób dopasować „najlepiej” do wykresu rozproszenia, tzn. do ![]()
, linię prostą ?
Niech ![]()
, ![]()
, będzie równaniem prostej „dopasowanej” do punktów ![]()
, ![]()
wykresu rozproszenia.
( ![]()
= współczynnik kierunkowy, ![]()
= wyraz wolny )
Wówczas ![]()
= przybliżenie wartości ![]()
na podstawie zmiennej niezależnej ![]()
uzyskane z zależności liniowej.
Błąd oszacowania ![]()
nazywamy wartością resztową lub rezyduum.
Miarą dopasowania prostej do próbki (punktów wykresu rozproszenia ) jest
suma kwadratów błędów ( rezyduów ):
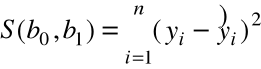
= 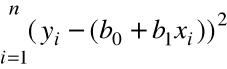
.
Prostą dla której ![]()
osiąga wartość minimalną nazywamy prostą regresji lub też prostą wyznaczoną metodą najmniejszych kwadratów.
Współczynniki prostej regresji ![]()
wyznaczamy
z warunku koniecznego minimum funkcji ![]()
, tzn. przyrównując do zera obie pochodne cząstkowe.
Rozwiązując ten układ 2 równań liniowych otrzymujemy:
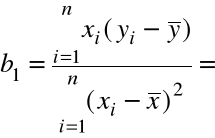
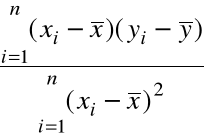
=
= 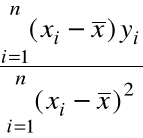
, (1)
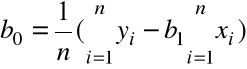
= ![]()
, (2)
gdzie 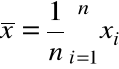
, 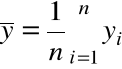
.
Wartość ![]()
nazywamy wartością przewidywaną zmiennej objaśnianej (zależnej) przy pomocy prostej regresji na podstawie zmiennej objaśniającej ( niezależnej ) x.
Określimy współczynnik determinacji.
Ocena „dobroci” dopasowania prostej regresji ?
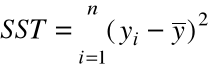
= całkowita suma kwadratów
( Total Sum of Squares )
( miara zmienności samych ![]()
.
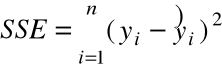
= suma kwadratów błędów
( Error Sum of Squares ),
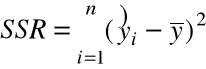
= regresyjna ( modelowa ) suma
kwadratów ( Regression ( Model )
Sum of Squares
( miara zmienności ![]()
.
Można pokazać:
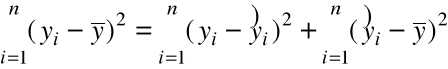
.
![]()
= ![]()
+ ![]()
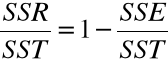
= współczynnik determinacji.
Im mniejsze SSE tym wykres rozproszenia skupiony bardziej wokół prostej regresji.
Współczynnik determinacji jest miarą stopnia dopasowania prostej regresji do wykresu rozproszenia
( ocenia jakość tego dopasowania ), określa stopień, w jakim zależność liniowa między zmienną objaśnianą a objaśniającą wyjaśnia zmienność wykresu rozproszenia.
Wartość współczynnika determinacji jest ściśle związana
z wartością współczynnika korelacji próbkowej.
Stwierdzenie.
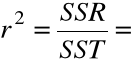
![]()
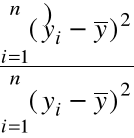
= zmienność wyjaśniona
przez model/ zmienność całkowita
Przykład. - wydruk z pakietu SAS.
( prosta regresji, ![]()
)
Model zależności liniowej (model regresji
liniowej)
Załóżmy, że próbka ![]()
jest realizacją
próby losowej ![]()
, gdzie
![]()
, ![]()
,
oraz ![]()
są niezależnymi zmiennymi losowymi
o wartości średniej 0 i wariancji ![]()
, a znane liczby ![]()
nie wszystkie są jednakowe.
Prostą ![]()
nazywamy prostą regresji
współczynnik![]()
= wyraz wolny prostej regresji
współczynnik![]()
= współczynnik kierunkowy prostej
regresji
zmienne losowe ![]()
= losowe błędy w modelu
wariancja ![]()
= wariancja błędów w modelu
Własności zmiennej losowej ![]()
, ![]()
,
![]()
![]()
= ![]()
.
Var(![]()
= Var![]()
= Var(![]()
Założenia:
Obserwujemy wartości zmiennych
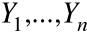
.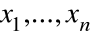
są znane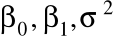
są nieznanymi parametrami modelu
Cel eksperymentu - wnioskowanie na temat
parametrów modelu
Naturalne estymatory ![]()
otrzymujemy metodą najmniejszych kwadratów, wstawiając we wzorach (1), (2) zmienne losowe ![]()
zamiast ich wartości ![]()
, ![]()
,
![]()
= ![]()
,
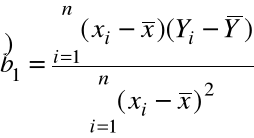
= 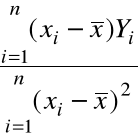
.
Własności estymatorów ![]()
, ![]()
:
Twierdzenie.
(i) ![]()
, ![]()
,
Var(
=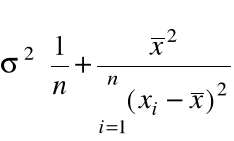
, (3)
Var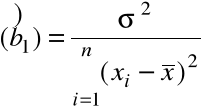
, (4)
Jeśli
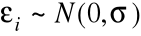
, i = 1,..,n, to
![]()
, ![]()
mają rozkłady normalne o wartościach średnich i wariancjach określonych w (i) i (ii).
Estymator ![]()
:
Definicja. Błędem średniokwadratowym ![]()
nazywamy estymator wariancji ![]()
określony następująco
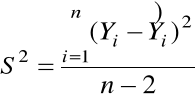
= 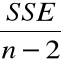
.
Liczbę ![]()
nazywamy liczbą stopni swobody rezyduów.
Stwierdzenie. ![]()
jest nieobciążonym estymatorem ![]()
, tzn.
![]()
.
![]()
= estymator ![]()
.
Wniosek. (i) Nieobciążonym estymatorem Var(![]()
jest 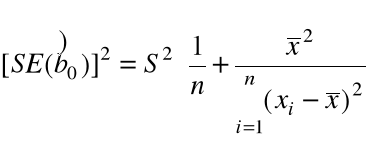
![]()
= 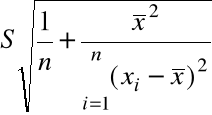
nazywamy błędem standardowym estymatora ![]()
, gdyż na mocy (3) ![]()
= estymator ![]()
= ![]()
(ii) Nieobciążonym estymatorem Var(![]()
jest
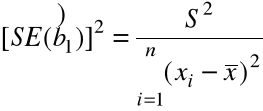
![]()
= 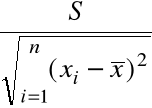
nazywamy błędem standardowym estymatora ![]()
, gdyż na mocy (4) ![]()
= estymator ![]()
= ![]()
.
Twierdzenie. Jeśli ![]()
, i = 1,..,n, to
(i) 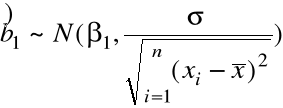
,
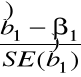
~ ![]()
,
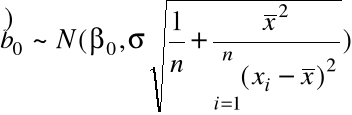
, skąd:
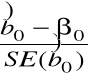
~ ![]()
.
Przedział ufności na poziomie ufności ![]()
dla współczynnika ![]()
:
[![]()
![]()
]
Przedział ufności na poziomie ufności ![]()
dla współczynnika ![]()
:
[![]()
![]()
]
Testowanie hipotezy o wartości współczynnika ![]()
(A) ![]()
,
gdzie ![]()
jest ustaloną liczbą.
Statystyka testowa
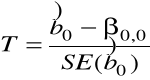
= ![]()
/(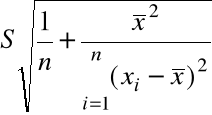
)
Jeśli ![]()
prawdziwa, to T ![]()
.
![]()
(a) ![]()
, ![]()
.
Obszar krytyczny C = ![]()
.
(b) ![]()
, ![]()
.
Obszar krytyczny C = ![]()
.
(c) ![]()
, ![]()
Obszar krytyczny C = ![]()
.
Testowanie hipotezy o wartości współczynnika ![]()
(B) ![]()
,
gdzie ![]()
jest ustaloną liczbą.
Statystyka testowa
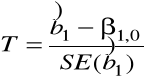
= 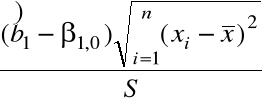
Jeśli ![]()
prawdziwa, to T ![]()
.
![]()
(a) ![]()
, ![]()
.
Obszar krytyczny C = ![]()
.
(b) ![]()
, ![]()
.
Obszar krytyczny C = ![]()
.
(c) ![]()
, ![]()
.
Obszar krytyczny C = ![]()
.
(C) ![]()
, ![]()
Statystyka testowa
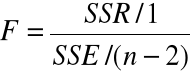
Jeśli ![]()
prawdziwa, to F ma rozkład F Snedecora o
1, n-2 stopniach swobody.
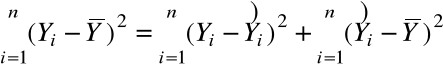
.
SST = SSE + SSR
n-1 = n-2 + 1
(Liczby stopni swobody SSx = liczba niezależnych zmiennych zmniejszona o liczbę ograniczeń występujących w określeniu SSx).
![]()
, ![]()
,
Obszar krytyczny testu: ![]()
.
![]()
Zauważmy, że ![]()
, stąd test jest szczególnym przypadkiem testu z (B) gdy ![]()
![]()
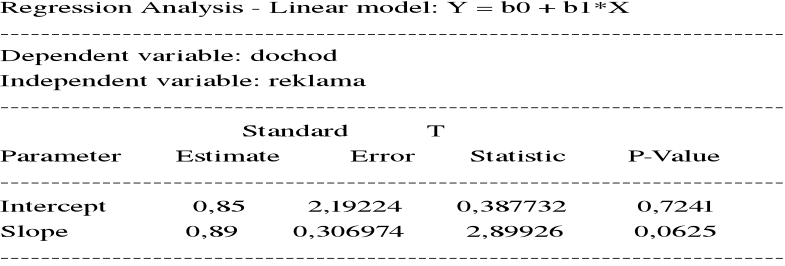
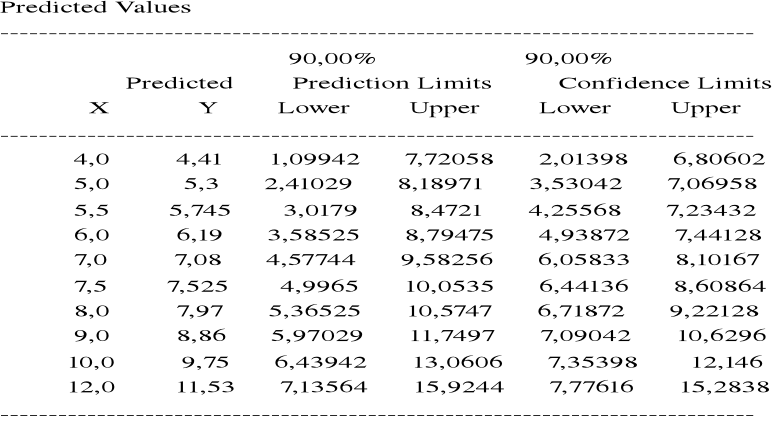
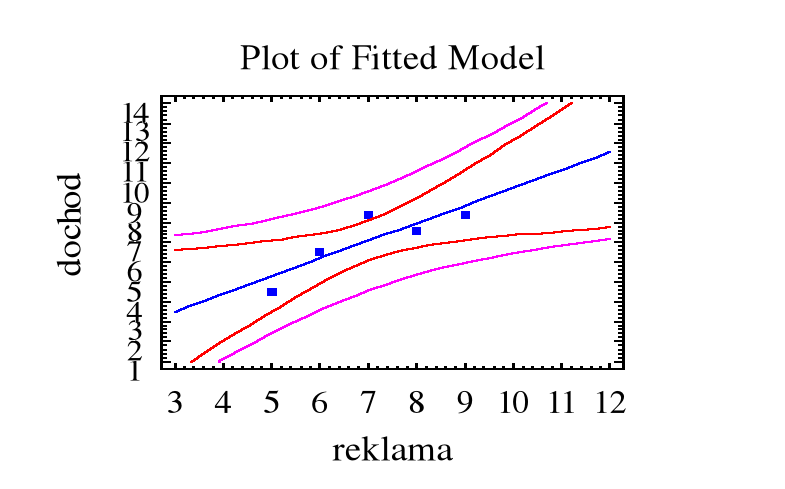
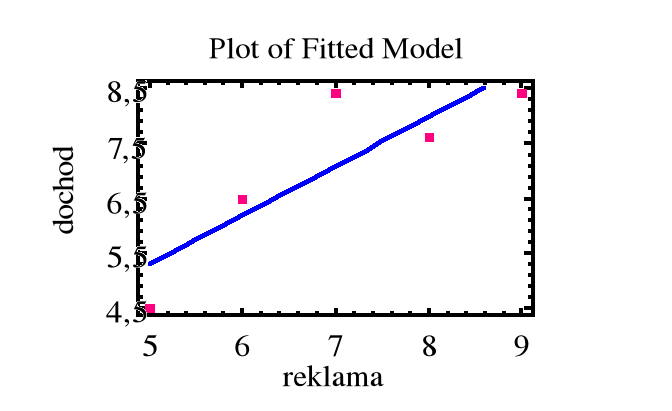
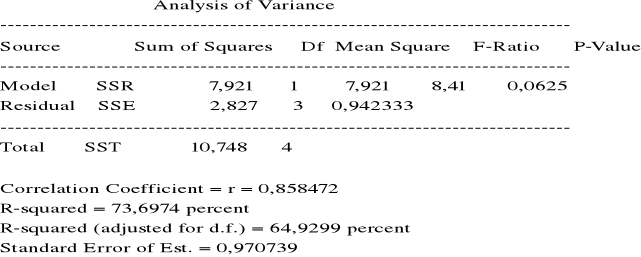
Przykład. Zanotowano miesięczne wydatki na reklamę ( w 10000 złotych ) pewnego artykułu oraz miesięczne dochody ze sprzedaży artykułu ( w 100000 zł ) :
Miesiąc i : 1 2 3 4 5
Reklama xi : 5 6 7 8 9
Dochód yi : 4,5 6,5 8,4 7,6 8,4
![]()
= 7,0 ![]()
= 7,08 sX = 1,58 sY = 1,64
Współczynnik korelacji próbkowej:
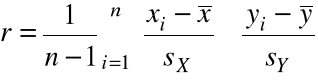
= 0,858
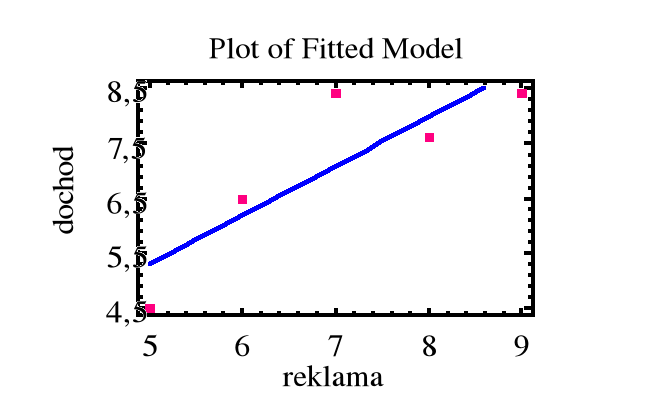
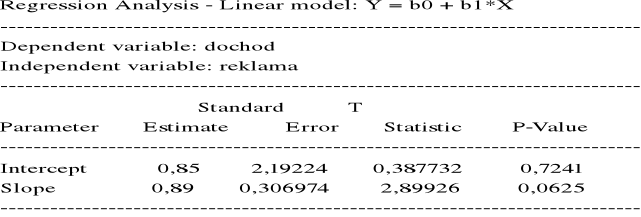
Dopasowana prosta regresji: y = b0 + b1x
b1 = 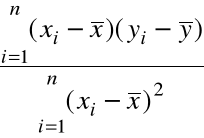
= 0,89
b0 = ![]()
= 7,08 - 0,89 x 7 = 0,85
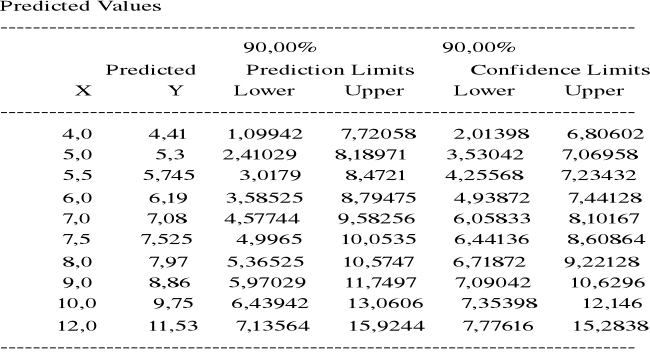
Przewidywany dochód ze sprzedaży przy wydatku na reklamę x = 10 (x 10000 zł ) wynosi
![]()
= 0,85 + 0,89 x 10 = 9,75 ( x 100000 zł ).
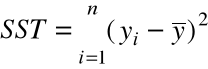
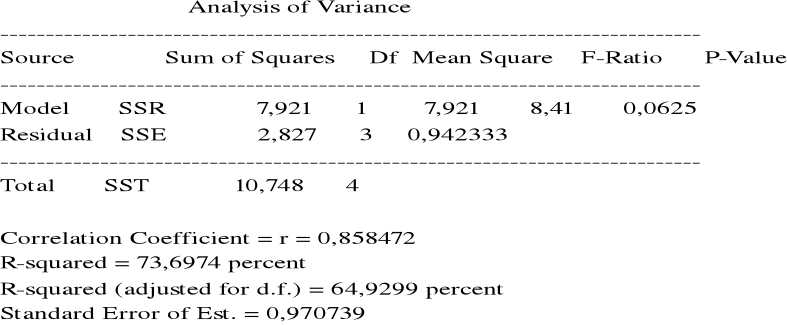
= 10,748
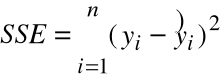
= 2,827
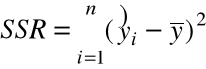
= 7,921
R2 = 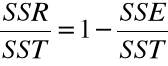
= współczynnik determinacji.
R2 = 0,737
Zmienność dochodu w prawie 74% wyjaśniona przez zmienność wydatków ma reklamę.
Zmienność wydatków na reklamę w 74% określa zmienność dochodu.
Założenie: model liniowy zależności dochodu od wydatków na reklamę
![]()
Prognoza wartości ![]()
na podstawie ![]()
.
Obserwowane ![]()
.
![]()
, ![]()
.
Nieobserwowane ![]()
![]()
![]()
, (5)
gdzie ![]()
są niezależnymi zmiennymi losowymi o rozkładach ![]()
.
Zadania:
(a) ocena ( estymacja ) wartości średniej ![]()
=
![]()
zmiennej objaśnianej w sytuacji, gdy zmienna
objaśniająca ![]()
jest równa ![]()
.
(b) przewidywanie ( prognoza ) wartości ![]()
.
(a) Obliczając wartość średnią obu stron (5) mamy:
![]()
= ![]()
= ![]()
.
Stąd naturalnym oszacowaniem ![]()
jest
![]()
= ![]()
.
![]()
= ![]()
(6)
Zatem ![]()
jest nieobciążonym estymatorem ![]()
.
![]()
= Var(![]()
) = Var(![]()
).
Można pokazać, że ![]()
są nieskorelowane, stąd
![]()
= 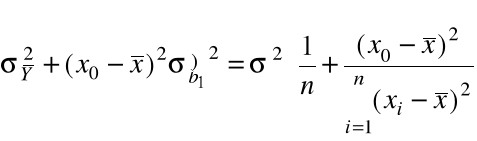
(7)
Błąd standardowy estymatora ![]()
definiujemy jako
![]()
= 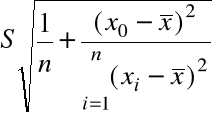
.
Twierdzenie. Estymator ![]()
wartości średniej ![]()
zmiennej objaśnianej Y dla wartości zmiennej objaśniającej ![]()
ma rozkład normalny o wartości średniej i wariancji postaci (6) i (7), odpowiednio. Ponadto,
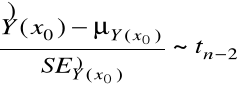
.
Wniosek. Przedział ufności na poziomie ufności ![]()
dla ![]()
ma krańce
![]()
.
Długość przedziału nie jest stała, (wynosi ![]()
![]()
) , zależy od ![]()
, im dalej od ![]()
tym bardziej ocena staje się niedokładna.
(b) Prognoza (przewidywanie) ![]()
.
Niech ![]()
będzie oceną (prognozą) ![]()
. Zmienne
losowe ![]()
, ![]()
są niezależne, więc wariancja ich
różnicy ma postać:
![]()
= ![]()
![]()
![]()
=
= 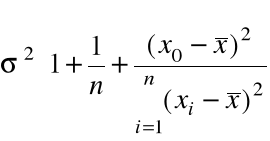
.
Stąd naturalnym estymatorem standardowego odchylenia ![]()
jest tzw. błąd standardowy
![]()
jest
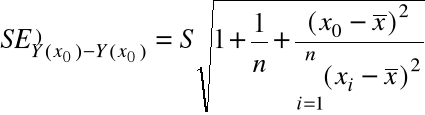
.
Twierdzenie. Zmienna losowa ![]()
ma rozkład normalny ![]()
, oraz
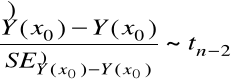
.
Wniosek. Przedział ufności na poziomie ufności ![]()
dla zmiennej ![]()
ma krańce
![]()
.
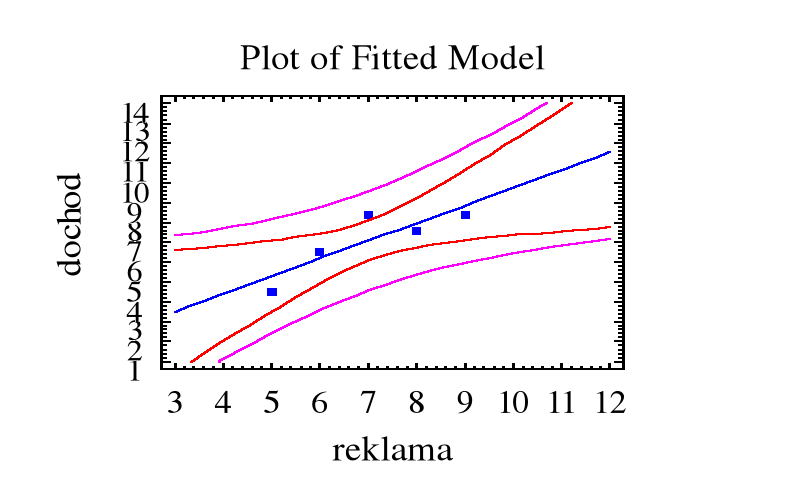
Przykład. Prosta regresji dla miesięcznego dochodu ze sprzedaży artykułu w zależności od miesięcznego wydatku na reklamę:
y = 0,85 + 0,89x
Stąd prognozowany dochód przy wydatku na reklamę x0 = 10 ( x 10000 zł.) oraz jednocześnie estymowana ( przewidywana ) wartość średnia dochodu na podstawie miesięcznych wydatków na reklamę x0 = 10 ( x 10000 zł.)
![]()
(x 100000 zł. )
Przedział ufności na poziomie ufności 0,90 dla :
(a) ![]()
ma granice 9,75 ![]()
![]()
,
gdzie ![]()
= 2,353, ![]()
= 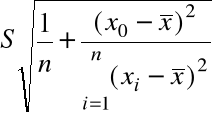
,
S = ![]()
0,9423,
![]()
= 0,9423 x (1/5 + (10 - 7)2/10)1/2 = 0,9883
granice 90% przedziału ufności dla ![]()
:
9,75 - 2,353 x 0,9883 = 7,354
9,75 + 2,353 x 0,9883 = 12,146
(b) granice 90% przedziału ufności dla prognozy zmiennej ![]()
:
9,75 ![]()
,
gdzie 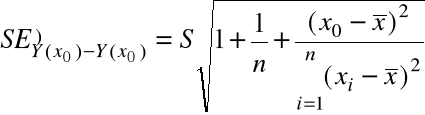
=
0,9423 x (1 +1/5 + (10 - 7)2/10)1/2 = 1,3655.
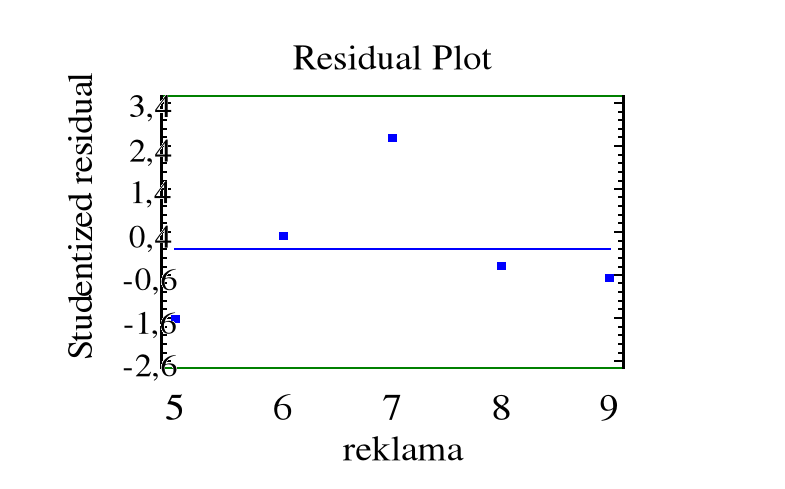
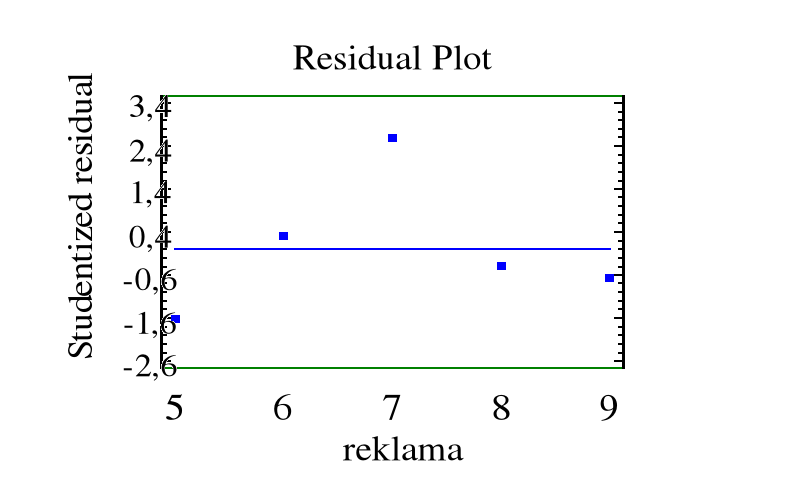
Analiza wartości resztowych ( rezyduów )
Poprawność testów dotyczących parametrów modelu oraz prognozy przyszłych zmiennych zależy istotnie od poprawności przyjętego modelu liniowego:
![]()
, ![]()
(8)
Wartość resztowa (rezyduum):
![]()
jest przybliżeniem błędu
![]()
.
Jeśli model (8) jest poprawny, błędy mają rozkład normalny, to rezyduua zachowują się w przybliżeniu tak jak ciąg niezależnych zmiennych losowych o rozkładzie normalnym. W szczególności, wykres rezyduów względem numeru porządkowego powinien przedstawiać „chmurę” punktów skupioną wokół osi Ox, bez wyraźnej struktury czy tendencji.
Stwierdzenie. Wariancja rezyduum ma postać:
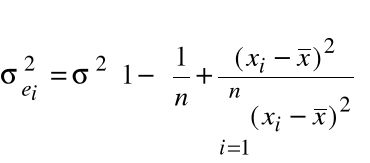
.
Błąd standardowy rezyduum definiujemy
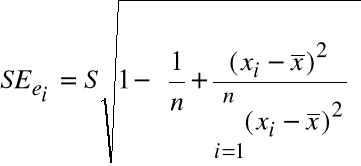
.
Oraz studentyzowane rezyduum 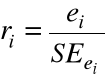
, ![]()
Przy małej liczbie obserwacji i dużym rozproszeniu zmiennej objaśniającej błędy ![]()
mogą odbiegać znacznie od błędu S.
Badanie odstępstw od modelu:
Załóżmy, że model liniowy jest prawdziwy
( zachodzi związek (8) ), ale rozkład błędów różni się znacznie od normalnego rozkładu. Wówczas odkryjemy to analizując histogram oraz wykres kwantylowy rezyduów bądź studentyzowanych rezyduów. W przypadku rozkładu normalnego punkty wykresu kwantylowego będą skupiały się wokół pewnej prostej.
(b) Załóżmy, że model nie jest prawdziwy. Zachodzi związek ![]()
ale funkcja regresji ![]()
nie jest postaci ![]()
. Odstępstwo tego typu często udaje się odczytać z wykresu rezyduów. Rys. (a)-(b) sporządzone są dla obserwacji modelu ![]()
. Rys. (c)-(d) wykonany dla obserwacji modelu ![]()
, gdzie regresja jest liniowa, ale błędy nie są niezależne, kolejne ![]()
jest ujemnie zależne od ![]()
.
(c) Prawdziwy model zależności jest sprowadzalny do modelu liniowego, np. zależność ![]()
, i = 1, ... , n, sprowadzamy do modelu liniowego wprowadzając nowe zmienne objaśniające: ![]()
. Jeśli regresja jest liniowa względem współczynników ![]()
, to na ogół udaje się znaleźć przekształcenie ![]()
, które prowadzi do modelu w przybliżeniu liniowego, np. jeśli zależność y od x jest dodatnia i opisana przez funkcję wklęsłą, to próbujemy zastosować funkcje ![]()
lub ![]()
.
(d) Funkcja regresji jest liniowa ( równość (8) spełniona), ale wariancja błędów nie jest stała: Var(![]()
. Wówczas modyfikujemy kryterium najmniejszych kwadratów - zamiast minimalizacji sumy kwadratów błędów
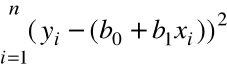
,
minimalizujemy ważoną sumę kwadratów błędów:
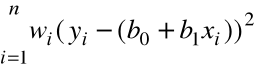
.
Waga ![]()
powinna być tym mniejsza im większa jest wariancja błędu ![]()
. Przyjmujemy: ![]()
lub ![]()
( gdy ![]()
nie jest znane ).
Często ![]()
= wartość przewidywana dla i-tej obserwacji w modelu regresji z tą samą zmienną objaśniającą, gdy za wartości zmiennej objaśnianej przyjmuje się wartości
rezyduów.
(e) Model jest nieadekwatny ze względu na występowanie innych lub większej ilości zmiennych objaśniających.
Wyszukiwarka
Podobne podstrony:
kol3(maj), PJWSTK, 0sem, SAD
SAD e 03.01.2006 v1, PJWSTK, 0sem, SAD
SAD k3 zadania pomocnicze, PJWSTK, 0sem, SAD, SAD inne, kolokwia
sadreg2-egzamin, PJWSTK, 0sem, SAD
sad11hipotezy, PJWSTK, 0sem, SAD
sad7(3), PJWSTK, 0sem, SAD
zasady, PJWSTK, 0sem, SAD
SAD e 09.02.2007, PJWSTK, 0sem, SAD
sad13p(1), PJWSTK, 0sem, SAD
sad11pp(02), PJWSTK, 0sem, SAD
sad8(2), PJWSTK, 0sem, SAD
SADegzamin2003, PJWSTK, 0sem, SAD
SAD e xx.09.2003 v2, PJWSTK, 0sem, SAD
SAD e 30.01.2009 v2, PJWSTK, 0sem, SAD, egzaminy
SAD e 03.01.2006 v2, PJWSTK, 0sem, SAD
sad9p(02), PJWSTK, 0sem, SAD
więcej podobnych podstron