Opis istniejących algorytmów upraszczania.
Charakterystyka i klasyfikacja.
Wszystkie elementy liniowe w procedurach kartograficznych wykorzystujących komputer przedstawione są za pomocą ciągu punktów, łączonych odcinkami prostymi bądź odcinkami krzywych wyższego rzędu. Zatem w większości przypadków problem upraszczania kształtu, jako jeden z aspektów generalizacji elementów liniowych, sprowadza się do odpowiedniej redukcji liczby punktów tworzących daną linię. Algorytmy dostarczane z opcją upraszczania umożliwiają usuwanie niepotrzebnych informacji o współrzędnych. Cyfrowe przedstawienie cech kartograficznych powinno być dokładne w swojej prezentacji cechy, a także skuteczne pod względem pozostawienia najmniejszej liczby punktów koniecznych dla przedstawienia charakteru linii. Operatory upraszczania będą wybierać właściwość lub ukształtowanie punktów do pozostawienia lub będą odrzucać punkty zbyteczne rozważając ich znaczenie w opisaniu charakteru linii. Przy badaniu linii bierzemy pod uwagę jej krętość, którą opisują następujące parametry: całkowita zmiana załamań; przeciętna zmiana załamań na cal; przeciętna zmiana załamań na kąt; suma dodatnich albo ujemnych kątów; całkowita liczba dodatnich albo ujemnych kątów; całkowita liczba dodatnich albo ujemnych przebiegów; całkowita liczba przebiegów (oczek); i średnia długość przebiegów.
Rysunek 5.1 Upraszczanie. Punkty podświetlane przez strzałkę są usuwane.
Pierwsze algorytmy upraszczania pojawiły się w połowie lat 60-tych (Tobler, 1966). W tym okresie rozwijało się wiele technik usuwających niepotrzebne łańcuchy par współrzędnych (x, y). Możliwość automatycznego upraszczania obiektów liniowych wykorzystywano nie tylko dla potrzeb kartografii, ale także informatyki, teledetekcji i matematyki. Stopień ich skomplikowania był bardzo zróżnicowany, zarówno geometrycznie jak i obliczeniowo. Spośród algorytmów upraszczania obiektów liniowych wyodrębniono pięć kategorii procesów. Klasyfikacja ta wykorzystuje ilość zdygitalizowanych linii, użytych w procesie, jako metodę porównania (Tabela 4.1). Procesy te składały się z (a) niezależne procedury punktowe, (b) lokalne procedury przetwarzania, (c) procedury bezwarunkowego rozszerzonego przetwarzania lokalnego, (d) procedury warunkowego rozszerzonego przetwarzania lokalnego i (e) procedury globalne.
Tabela 5.1 Klasyfikacja algorytmów używanych do upraszczania digitalizowanych linii
Kategoria 1: Niezależne algorytmy punktowe.
Nie wyjaśniają stosunków matematycznych z sąsiadującymi parami współrzędnych; działają niezależnie od topologii.
Przykłady: n-ta procedura punktowa (Tobler 1964)
przypadkowy wybór punktów ( Robinson , i inni 1978 )
Kategoria 2: Lokalne procedury przetwarzania.
Używają właściwości bezpośrednio sąsiadujących punktów do określonego wyboru lub odrzucenia.
Przykłady: odległość między punktami (McMaster 1987a)
kątowa zmiana między punktami (McMaster 1987a)
algorytm Jenksa (McMaster 1983b)
Kategoria 3: Procedury warunkowego rozszerzonego przetwarzania lokalnego
Badają nie tylko bezpośrednio sąsiadujące współrzędne i oceniają grupy linii. Obszar badań zależy od odległości, kąta lub liczby kryteriów punktowych.
Przykłady: algorytm Lang'a (Lang 1969)
algorytm Opheim'a (Opheim 1982)
algorytm Johannsen'a (Johannsen 1973)
algorytm Deveau'a (Deveau 1985)
algorytm Roberge'a (Roberge 1985)
Kategoria 4: Procedury bezwarunkowego rozszerzonego przetwarzania lokalnego
Badają nie tylko bezpośrednio sąsiadujące współrzędne i oceniają grupy linii. Obszar badań jest ograniczony przez geomorfologiczną komplikację linii, nie przez kryteria algorytmów.
Przykład: algorytm Reumann-Witkam'a (Reumann i Witkam 1974)
Kategoria 5: Procedury globalne
Rozważają całą linię lub wyszczególniony w przetwarzaniu segment linii. Iteracyjnie wybiera krytyczne punkty. Przykład: algorytm Douglasa (Douglas i Peucker 1973), algorytm Chrobaka uwzględniający odległość strzałki od cięciwy w segmencie upraszczanej linii, bada długości boków trójkąta elementarnego w celu ustalenia czytelności rysunku upraszczanego.
Duża liczba algorytmów ograniczenia liczby punktów tworzących daną linię pozwala na powstanie różnych ich klasyfikacji. Algorytmy upraszczania podzielono również na trzy zasadnicze grupy:
Aproksymacja linii funkcjami matematycznymi.
Metoda aproksymacji wiąże się z wyborem funkcji matematycznej będącej przybliżeniem danej linii, lub kilku funkcji aproksymujących oddzielne fragmenty linii krzywych określonych przez ustaloną liczbę punktów. Powstało kilka sposobów zawierających się w tej metodzie. Dwa z nich oparte są na wyznaczeniu długości odcinków krzywej, gdzie odcinki te mają ustaloną liczbę punktów rejestracji. Pierwszy bierze pod uwagę ważone środki każdego z odcinków jako punkty aproksymacji. Przybliżenie generalizowanej linii powstaje poprzez połączenie w ten sposób środków ważonych. Realizacja tego sposobu daje jednak zbyt kanciastą linię i powoduje nadmierną redukcję punktów. Drugi sposób rozpatruje w charakterze punktów aproksymacji nie ważone środki każdego zbioru kolejnych „n” punktów, gdzie „n” jest liczbą wyznaczoną przez użytkownika. Plusem tej metody jest fakt, iż wszystkie oryginalnie zarejestrowane punkty używane są do stworzenia zgeneralizowanego obrazu. Jednak powoduje ona częste deformacje obrazu linii w pobliżu punktów końcowych poszczególnych odcinków. Te dwa sposoby powodują zazwyczaj duże uproszczenie linii w stosunku do oryginału. Ich wykorzystanie w procesie generalizacji musi być bardzo ostrożne. Bardziej skomplikowany sposób bazuje na zastępowaniu punktów zarejestrowanej krzywej przez punkty końcowe zadanych odcinków różnych pseudo-hiperbol.
Eliminacja punktów przy pomocy jednego lub więcej kryteriów.
Metoda ta dotyczy eliminacji punktów linii w oparciu o jedno lub więcej kryteriów. Można zaznaczyć, że dla tego sposobu opracowano zdecydowanie najwięcej rozwiązań. Podzielić je można na cztery zasadnicze grupy:
selekcję punktów,
sposób tolerancyjnej odległości,
sposób tolerancyjnego pola trójkąta oraz
sposób tolerancyjnego odchylenia kątowego punktu przegięcia krzywej.
Selekcja punktów, jako najprostsza procedura rekonstrukcji kształtu linii, polega na wyborze co n-tego punktu z całego zbioru punktów opisującego linię, przy czym „n” jest liczbą całkowitą, z góry ustaloną przez użytkownika. Generalizacja wg. tego sposobu ma poważne mankamenty, gdyż mogą zostać pominięte niektóre istotne punkty i w związku z tym zatracone zostanę geograficzne cechy obiektu. Jest to procedura bardzo prosta, szybka i tania, jednak z kartograficznego punktu widzenia nie do przyjęcia. Sposób tolerancyjnej odległości wykorzystuje jedynie te punkty, których odległość od ostatniego wybranego punktu jest większa od ustalonej wartości. Powoduje to opuszczenie części punktów. Mankamentem tej metody jest utrata wypukłości linii, poza tym wybór punktu początkowego decyduje o wyniku końcowym. Do grupy tych procedur zalicza się również generalizacja metodą obliczania strzałki punktu ekstremalnego linii. Upraszczanie linii polega na opuszczeniu kolejnych punktów, do których wystawiona strzałka jest mniejsza od wartości tolerancji.
Generalizacja bazująca na tolerancyjnych polach trójkątów sprowadza się do obliczenia pól trójkątów tworzonych w oparciu o trzy przegięcia linii krzywej. Upraszczanie polega na opuszczaniu wygięcia krzywej, na którym opisany trójkąt ma pole mniejsze od przyjętego za graniczne. Pola liczy się zwykle ze wzoru Herona, a tolerancje określa się empirycznie, odpowiednio do zmiany skali.
Metoda tolerancyjnego odchylenia kątowego punktu przegięcia krzywej polega na obliczeniu różnicy kątowej między kierunkami na dwa następujące punkty krzywej. Przy uproszczeniu wymagane jest obliczenie różnicy między kątami i jeżeli jest ona mniejsza od wartości tolerancyjnej, usunięcia punktu środkowego.
Omówione metody nie w pełni odpowiadają wymogą generalizacji kartograficznej, ponieważ wybór punktów dokonywany jest w sposób czysto mechaniczny, często bez uwzględnienia własności geograficznych obiektów.
Wykrycie i przedstawienie charakterystycznych cech reprezentowanych przez obiekt liniowy.
Obiektywna generalizacja wymaga jednoznacznego określenia geograficznych właściwości wszystkich obiektów i zjawisk podlegających przedstawieniu na mapie i ujęcia ich w formie sformalizowanego opisu. Posłużyć mogą do tego specjalnie dobrane kryteria istotności. Dla elementów punktowych nie stanowi to zbytniego problemu. Trudności pojawiają się dopiero przy liniowych elementach treści mapy. Można zadać pytanie:, w jaki sposób dobierać cechy obiektów dla kryterium istotności przy generalizacji np. sieci rzecznej, linii brzegowej, sieci drogowej czy poziomic? Na podstawie doświadczenia można by powiedzieć, że nie jest możliwe wybranie jednolitych cech, które byłyby dla wszystkich takich elementów. Można jednak zaryzykować pogląd, że w charakterze uniwersalnego kryterium należy przyjąć genetyczne cechy tych obiektów. W celu obiektywnego scharakteryzowania znaczenia poszczególnych punktów generalizowanego elementu liniowego przyjąć można kryteria uwzględniające geograficzne cechy tych punktów. Na przykład dla linii brzegowej przyjęte kryteria można podzielić na grupy: geologiczno-genetyczne, komunikacyjne, gospodarcze i osadnicze. Wybrane kryteria należy następnie pogrupować oraz ustalić wartość progową sum cech charakteryzujących dany punkt, która klasyfikuje go do umieszczenia na liście punktów „istotnych”. Głównym mankamentem tej metody jest zbyt duży nakład pracy poniesiony w przypadku jej szerszego zastosowania.
Algorytmy upraszczania obiektów liniowych.
Algorytm Toblera
Tobler (1996) opracował jeden z pierwszych operatorów upraszczania w generalizacji, który wybierał, co n-tą parę współrzędnych. Zdaniem McMastera (1987), ta forma niezależnego algorytmu punktowego nie była możliwą do zaakceptowania metodą uzyskiwania wyników o wysokiej jakości. Tobler opracował również procedury przetwarzania liniowego z wykorzystaniem charakterystyk przyległych par współrzędnych dla kryterium upraszczania. Punkty, których wzajemne odległości są mniejsze niż grubość linii użytej do przedstawienia na mapie, są eliminowane.
Algorytmy Jenks'a
Rysunek 5.2 ilustruje dwie lokalne procedury przetwarzania: odległość prostopadła i algorytmy tolerancji kątowej. Algorytm odległości (rysunek 5.2a), opisany przez Jenks'a (1981) działa on w oparciu o triadę par współrzędnych. Po pierwsze, linia prostopadła jest zbudowana od linii łączącej pierwszy i trzeci punkt triady do punktu pośredniego. Jeśli ta odległość jest większa niż zdefiniowana przez użytkownika tolerancja, punkt pozostaje. Jeśli obliczona odległość jest mniejsza niż tolerancja, drugi punkt jest eliminowany, ponieważ jest za blisko prostego odcinka linii. W istocie, ma to mały wpływ na geometrię lub geomorfologię linii. Ilustracja (algorytm odległości prostopadłej) pokazuje kolejność kroków, w których punkt (p2) najpierw pozostaje a później, w drugim zestawieniu punktów (p2, p3 i p4) jest eliminowany. Prawa strona ilustracji (B) przedstawia podobny algorytm, ale z tolerancją kątową mierzoną między połączonymi wektorami p1 i p3 i p1 i p2.
Algorytm upraszczania Langa.
Algorytm Langa jest przykładem lokalnej procedury przetwarzania, jest przedstawiony na rysunku 5.3 (Lang 1969). Algorytm Lang'a wymaga dwóch wartości tolerancji zdefiniowanych przez użytkownika: (1) liczba punktów "patrz naprzód" (n) przy badaniu i (2) parametru tolerancji odległości (t). W tym szczególnym przykładzie, liczba punktów "patrz naprzód" jest równa 7 a tolerancja odległości jest oznaczona przez t. Utworzony zostaje wektor łączący p1 i p8 (n + 7) i obliczana jest prostopadła odległość do wszystkich punktów pośrednich. Jeżeli którakolwiek z 6 (n - 1) pośrednich odległości jest większych niż tolerancja, wektor wybiera następny punkt, do p7 (łącząc p1 i p7). Następnie jeszcze raz, gdy co najmniej jeden z pośrednich punktów przewyższa parametr odległości, punkt końcowy cofa się do p6, następnie przez p5 i w końcu p4. Tutaj, oba punkty pośrednie, p2 i p3, zawierają się w granicy tolerancji t, a więc p4 pozostaje, natomiast p2 i p3 są eliminowane. Rysunek 5.3 b (góra) ilustruje następny krok w algorytmie Lang'a, gdzie p4 jest teraz początkiem a p11 (n + 7) jest końcem. Pomiar odległości prostopadłej do punktów pośrednich (p5 do p10) daje w rezultacie w pierwszym punkcie przekroczenie parametru tolerancji i jest wybierany nowy punkt końcowy (p10). Jednak, wszystkie punkty pośrednie między p4 i p10 - nowe punkty końcowe, mieszczą się w granicy tolerancji i są eliminowane. Wektor jest teraz budowany między p10 i p17 (n + 7) i ten odcinek linii jest teraz przetwarzany. W testach geometrycznych algorytmu, Lang udowodnił, że jest on doskonały w zachowaniu pierwotnych właściwości geometrycznych linii. ( McMaster 1987b). Do kategorii warunkowych rozszerzonych przetwarzań lokalnych zaliczyć można także podejście Opheima, które opiera się na zastosowaniu koła o średnicy x w obszarze poszukiwań. Jeśli linia znajduje się poza tym obszarem tworzony jest nowy obszar z zachowaniem punktu końcowego.
Rysunek 5.2 Upraszczanie lokalne wg. Algorytmu Jenksa. Ilustracja algorytmów odległości prostopadłej i tolerancji kątowej.
Algorytm Reumanna - Witkama
W algorytmie Reumanna - Witkama obszar poszukiwań determinują dwie proste równoległe o zadanym odstępie. Linia generalizowana jest przetwarzana dopóty, dopóki nie przetnie którejś z prostych równoległych. Reumann i Witkam opracowali również algorytm tzw. rozbioru rozszerzonego, zapewniający rygorystyczną definicje linii ograniczającej. Algorytm ten jest bardzo efektywny czasowo, ale trudny do kontroli. Można go stosować tylko przy małym zakresie tolerancji.
Algorytm upraszczania Douglas'a
Algorytm Douglas'a opiera się na podejściu całościowym. McMaster przedstawił ten algorytm jako jedną z bardziej solidnych kartograficznych propozycji, ale też jeden z gorszych algorytmów pod względem wymaganych kosztów. Rysunek 5.4 (część A-I) przedstawia kilka całkowitych iteracji algorytmu Douglas'a. Zauważmy, że w tej próbce digitalizowana linia ma 40 par współrzędnych. W każdej iteracji muszą być zidentyfikowane dwa punkty: punkt początkowy (lub "kotwica"), który jest ustalony i punkt końcowy (lub "pływak"), który się przemieszcza. W 4.4a, pierwszym krokiem algorytmu, jest ustalenie "korytarza" (przedziału) tolerancji między "kotwicą" a "pływakiem" (kolejno p1 do p40). Szerokość tego "korytarza", przedstawiona za pomocą cieniowanego bloku, jest obliczana jako podwójna szerokość t1, zdefiniowanej przez użytkownika wartości tolerancji. "Korytarz" ten może być geometrycznie zilustrowany jako dwa równoległe pasy o długości t1 po obu stronach wektora (łączącego "kotwicę" i "pływak"). Oblicza się odległości prostopadłe dla wszystkich punktów pośrednich (p2 do p39) i dla każdej iteracji a maksymalną odległość - razem z towarzyszącą parą współrzędnych - zachowuje się. Na rysunku 5.4 A, ta maksymalna odległość jest obliczana dla p32. Ponieważ punkt ten jest na zewnątrz zdefiniowanego przez użytkownika "korytarza", przetwarzanie jest kontynuowane a pozycja p32 jest umieszczana w stosie. W drugiej iteracji (rysunek 5.4 B), "kotwicą" pozostaje p1, ale nowym "pływakiem" zostaje p32 - maksymalna odległość prostopadła obliczona na rysunku 5.4 A. "Korytarz" jest teraz umieszczany pomiędzy p1 i p32 a wszystkie pośrednie odległości są obliczane. W tej iteracji, maksymalna odległość (do p23) jest też na zewnątrz korytarza. Przetwarzanie trwa i p23 jest umieszczany w stosie. Następnie (rysunek 5.4 C) wszystkie punkty pośrednie między "kotwicą" (p1) a "pływakiem" (p23) są przeliczane, przy czym p4 (maksymalna odległość) też jest na zewnątrz korytarza. Po umieszczeniu p4 w stosie, powyżej p32 i p23, pomiędzy p1 i p4 proces trwa nadal (rysunek 5.4 D). Tutaj, ponieważ p2 jest jeszcze na zewnątrz korytarza, jest wybierany nowy "pływak" (p2). Algorytm Douglas'a wybierałby teraz p2 ("kotwica" = p1 i "pływak" = p2) jako " punkt do zachowania”, ponieważ proces nie może dłużej trwać (rysunek 5.4 E). W tym stadium algorytmu, jest wybierana nowa "kotwica" (p2) i ostatni punkt w stosie (p4) jest wybierany jako "pływak" (rysunek 5.4 F). Ponieważ punkt pośredni (p3) jest teraz w granicach "korytarza", jest on uważany za nieistotny geometrycznie i jest usuwany, podczas gdy p4 jest zachowywany. Znowu nowy punkt (p23), który jest wybierany ze stosu, jest lokowany jako "pływak", podczas gdy p4 staje się nową "kotwicą". Punkt p10 jest teraz wyznaczony jako najbardziej oddalony od linii i znajdujący się na zewnątrz "korytarza" (rysunek 5.4 G). Przy użyciu tej techniki przetwarzania sekcyjnego linii, te punkty, które leżą w granicach "korytarza" są eliminowane, podczas gdy te obliczane jako krytyczne dla geometrii są zachowywane (rysunek 5.4 I). Ostatecznie będzie przetwarzany odcinek linii pomiędzy p23 i p32 (rysunek 5.4 H) i p32 a p40. Ten nowy ruchomy punkt końcowy staje się nowym początkiem i algorytm działa nadal. Procedura Douglas'a może być najbardziej odpowiednia dla wymagań dokładnego odwzorowania jak również dla tworzenie cyfrowych baz danych dla celów analitycznych. Dla mniej surowych wymagań — upraszczanie danych wektorowych dla wsparcia graficzno rastrowych pokazów — bardziej skuteczna rachunkowo procedura, jak np. procedura algorytmów tolerancji Langa (1969) jest prawdopodobnie użyteczniejsza.
Rysunek 5.3 A. Algorytm Langa.
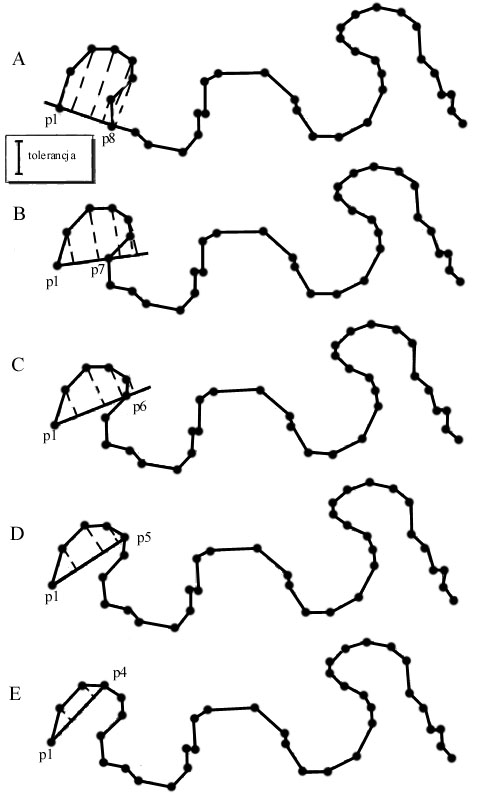
Rysunek 5.3 B. Algorytm upraszczania Lang'a. Punkty „w przód” i tolerancja odległościowa kierują pracą algorytmu. Prostopadłe odległości między punktem początkowym i końcowym punktem ruchomym (punkt początkowy + „w przód”) są obliczane, aby ocenić czy jakiekolwiek punkty przekraczają próg odległości. Jeżeli dojdzie do tego, wybierany jest nowy ruchomy punkt końcowy aż do momentu, kiedy wszystkie punkty nie znajdą się w granicach tego progu. Ten nowy ruchomy punkt końcowy staje się nowym początkiem i algorytm działa nadal.
Rysunek 5.4 cz.I. Algorytm Douglas'a.
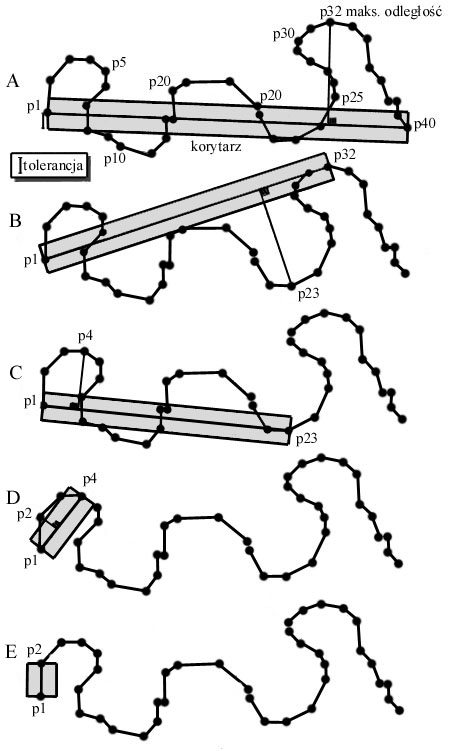
Rysunek 5.4 cz.II. Algorytm upraszczania Douglas'a.
Metoda Chrobaka
Jest to metoda upraszczania linii łamanych otwartych i zamkniętych zależna od skali mapy i sposobu prezentacji rysunku (monitor komputera, mapa „papierowa”). W metodzie upraszczania linii zachowana jest hierarchia jej wierzchołków i ich topologia. Hierarchię wierzchołków linii pierwotnej określa się z jej kształtu na podstawie tzw. ekstremów lokalnych wyznaczanych w przedziałach zamkniętych (tworzonych z sąsiednich wierzchołków - niezmienników procesu przekształcenia). Pierwsze dwa wierzchołki - niezmienniki to początek i koniec, w hierarchii o najwyższej pozycji na linii upraszczanej, następne pary niezmienników tworzy się przy wykorzystaniu trójkąta elementarnego. Wierzchołki początku i końca tworzą zarazem bok podstawy trójkąta a trzeci na linii upraszczanej wyznacza punkt, który z wszystkich punktów w przedziale zachowuje największą wysokość w trójkącie i spełnia warunek dla najkrótszej długości εj trójkąta elementarnego. Znając podstawę trójkąta (utworzoną przez początek i koniec linii), jego trzeci wierzchołek wyznacza punkt, który spełnia w trójkącie warunki:
1) długości boków są co najmniej równe najkrótszej długości εj - trójkąta elementarnego,
wysokość ma największą z możliwych długości w badanym przedziale.
Wyznaczony trzeci wierzchołek trójkąta to w hierarchii kolejny (po początku i końcu linii) niezmiennik procesu upraszczania. W ten sposób otrzymujemy dwie pary niezmienników: początek - trzeci punkt i koniec - trzeci punkt (kolejność wyboru tzn. początek - trzeci następnie koniec - trzeci lub odwrotnie nie ma wpływu na wynik końcowy procesu upraszczania linii). Postępując analogicznie dla tych par (budując przedziały na linii pierwotnej) tworzymy następne pary wierzchołków - niezmienników linii upraszczanej. Koniec etapu wyboru niezmienników - wierzchołków nastąpi wtedy gdy zachowując kolejność wynikającą z hierarchii wierzchołków, przy użyciu trójkąta sprawdzimy wszystkie punkty należące do linii upraszczanej. Zastosowany w procesie trójkąt pozwala zachować topologię wierzchołków linii, gdyż podstawę trójkąta zawsze wyznaczają dwa wierzchołki - niezmienniki a trzeci zachowuje sąsiedztwo względem wierzchołków - niezmienników linii pierwotnej.
W metodzie upraszczania linii jako wzorzec do ustalania jej wierzchołków - niezmienników zastosowano elementarny trójkąt, którego najkrótszą długość boku określa zależność:
εj = s Mj
gdzie: s - miara progowa rozpoznawalności rysunku (nie zależna od skali mapy),
Mj - mianownik skali mapy opracowywanej.
W ustalaniu wartości - s uczestniczy:
rozpoznawalność rysunku linii pojedynczej o grubości 0,1mm, zdefiniowana przez Saliszczewa,
wielkość piksela przyjęta przez Szwajcarskie Towarzystwo Kartograficzne,
dokładność II grupy szczegółów liniowych na mapie, określonych normami branżowymi GUGiK.
Na podstawie określonych w punktach „a”, „b” i „c” wartości, ustalono miarę długości - s :
s1 = 0,5mm, dla rysunku mapy klasycznej („papierowej” jako nośniku obrazu),
s2 = 0,6mm, dla rysunku prezentowanego w monitorze komputera.
Po wyborze wierzchołków niezmienników linii pierwotnej, etapem następnym procesu upraszczania jest zbadanie linii pierwotnej w przedziałach utworzonych z sąsiednich wierzchołków - niezmienników linii. W przedziałach tych łańcuch punktów linii pierwotnej badany jest na okoliczność, kiedy można zastąpić go:
- cięciwą utworzoną przez początek i koniec przedziału,
- dwoma odcinkami łączącymi początek i koniec przedziału z nowym pośrednim punktem (nie będącym niezmiennikiem) leżącym na jednym z boków badanego przedziału linii pierwotnej.
Metoda upraszczania w przedziale badanym zapewnia odpowiedz jednoznaczną jak przekształcić łańcuch punktów linii, otóż suma boków gdy mniejsza jest od 2εj to po upraszczaniu łańcuch punktów reprezentuje cięciwa. Dla przypadku, gdy w przedziale suma boków jest równa lub większa od 2εj możliwe jest utworzenie nowego punktu. Aby punkt utworzyć proces iteracyjny dla aproksymacji liniowej musi być zbieżny. Ma miejsce to wówczas, gdy w przedziale zmienne niezależne przyrostów współrzędnych punktów sąsiednich mają stały znak. W przypadku gdy różne są znaki przyrostów współrzędnych (tzn. proces iteracyjny jest rozbieżny), łańcuch punktów przedziału badanego linii pierwotnej po upraszczaniu zastąpi cięciwa.
Ostatnim etapem metody upraszczania linii jest ocena dokładności procesu. Jest ona możliwa dzięki następującym faktom:
- wybór i usuwanie wierzchołków są określone jednoznacznie,
- kształt linii pierwotnej (przed generalizacją) różni się najmniej od rzeczywistości, jest zatem znana zmienna losowa opisująca najbardziej prawdopodobny przebieg linii,
- każde uogólnienie (uproszczenie) jest opisane wierzchołkami linii pierwotnej,
- określone są jednoznacznie najkrótsze odległości pomiędzy odrzucanymi punktami a pozostającymi wierzchołkami linii pierwotnej, które to odległości są zarazem pozornymi błędami procesu.
Wykorzystując prawo przenoszenia się błędów i jeden stopień swobody dla n - odrzucanych wierzchołków, określany zostaje błąd średni procesu linii upraszczanej. Znając dokładność danych przed upraszczaniem i błąd procesu można wyznaczyć, zgodnie z prawem przenoszenia błędów, błąd danych po procesie.
W metodzie tej użytkownik ustala długość εj dla opracowywanej skali 1 : Mj przez wprowadzenie do programu mianownika skali mapy oraz jednej z wartości si (i = 1, 2). Pozostałe czynności - upraszczania linii i oceny dokładności procesu - wykonywane są automatycznie.
Hierarchiczne podejście Cromley'a do upraszczania liniowego.
Metoda upraszczania digitalizowanych linii zaproponowana przez Cromley'a (1991) nosi nazwę hierarchicznego upraszczania liniowego. W hierarchicznym upraszczaniu liniowym, różne wersje upraszczania tych samych cech liniowych przy różnych poziomach tolerancji są przechowywane w strukturze drzewa. Często, różne poziomy drzewa są rozwijane na podstawie algorytmu Douglas'a. Rysunki 5.5 i 5.6 ilustrują to pojęcie. Korzystając z próbki 27 punktowej digitalizowanej linii, wektor zbudowany jest między p1 i p27, dokładnie jak w przykładzie Douglas'a. Punkt 16, który ma największą prostopadłą odległość od tego wektora, jest użyty do podziału początkowego odcinka linii na dwie części (odcinek1: punkty 1-16 i odcinek 2: punkty 16-27 na rysunku 5.6). W granicach drzewa, zarówno punkt 16 jak i towarzysząca jemu wartość przemieszczenia (180.27) są ulokowane na najwyższym poziomie (rysunek 5.6). W następnej iteracji, punkt 5 jest wybierany jako mający maksymalną odległość (wartość przesunięcia 100.82) od wektora łączącego punkty 1-16 (pierwszy odcinek), a punkt 21 jest wybierany jako mający maksymalną odległość (wartość przesunięcia 63.45) od wektora łączącego punkty 16-27 (drugi odcinek). Ten tok postępowania jest kontynuowany na trzecim poziomie iteracji (wybierane są punkty 2, 12, 17 i 25) i czwartym (wybierane są punkty 4, 9, 14, 18, 24 i 26). Dodatkowe trzy iteracje są przedstawione w strukturze drzewa na rysunku 5.6. Jak demonstruje Cromley, jeśli zostało rozwinięte drzewo upraszczania, to poprawa par współrzędnych, dla wymaganego poziomu generalizacji staje już prostszym problemem. Zachowywane są tylko te pary współrzędnych z wartością większą niż wymagana tolerancja. Gdyby na przykład, zdefiniowana przez użytkownika tolerancja była równa 17 jednostek, wtedy byłyby zachowywane tylko punkty: 16 (wartość atrybutu = 180.27), 5 (wartość atrybutu = 100.82), 21 (wartość atrybutu = 63.45) i punkty 2, 12 i 9. Dwa punkty końcowe (punkt 1 i punkt 27) też byłyby zachowane. Dolna część rysunku 5.5 ilustruje wersję upraszczania linii oryginalnej przy użyciu tych ośmiu punktów.
Rysunek 5.5 Hierarchiczne upraszczanie Cromley'a. Oryginalna 27- punktowa linia i jej 8- punktowa uproszczona prezentacja.
Geometria pasmowego drzewa Buttenfield.
Buttenfield twierdzi, że trudności w generalizowaniu linii wynikają z faktu, że wierzchołki są funkcjami semantyki geometrii określonego obiektu i skali roboczej. Innymi słowy dwa identyczne obiekty geometryczne niekoniecznie musza przejść taka samą zmianę.
Buttenfield (1991) zademonstrowała wykorzystanie oznaczenia struktury geometrycznej linii jako środek do kontroli procesu liniowej generalizacji. Dokładne oznaczenie położenia mogłoby kierować procesem generalizacji przez rozpoznawanie wartości różnic w tolerancji algorytmu dla każdej cechy, lub wybór topologicznego składnika cechy. Metoda ta dotyczy określenia ilości informacji zawartej w digitalizowanej linii. Technika ta może być używana do dzielenia na odcinki linii zgodnie z ich strukturą oznaczenia opartą na ich faktycznej geometrii, ażeby móc dostosować parametry tolerancji algorytmów upraszczania do każdego obszaru. Podział linii w tej metodzie jest powiązany z geometrią pasmowego drzewa Buttenfield (Buttenfield 1985). Rysunek 5.7 przedstawia tą samą linię co powyżej, podzieloną na dwie części przez maksymalną prostopadłą dwusieczną punktu 16. Początkowym poziomem geometrii jest pas 0. Na drugim poziomie, dwa odcinki linii, pas 01 i pas 02, są przetwarzane oddzielnie. Na każdym poziomie, można obliczyć kilka miar geometrycznych. Na przykład, długość pasa (L) jest maksymalną długością ograniczonego prostokąta. Szerokość pasa, maksymalne odchylenie i wskaźnik segmentacji też mogą być obliczone. Przy użyciu tych miar, właściwości geometryczne pasa na każdym poziomie mogą być określone i użyte do modyfikowania wartości tolerancji.
Rysunek 5.6 Drzewo upraszczania Cromley'a. Drzewo upraszczania wygenerowane jako wynik upraszczania 27-punktowej linii z rysunku 5.5.
Rysunek 5.7 Geometria drzewa pasmowego Buttenfield. Pasy 0, 01, i 02 generowane w wyniku powstawania maksymalnych prostopadłych dwusiecznych na 27-punktowej linii Cromley'a.
8
Wyszukiwarka
Podobne podstrony:
Opis istniejących algorytmów upraszczania
karto ściągaII, Kartografia tematyczna
Algorytmy upraszczania
CZYTANIE MAPY, Kartografia tematyczna
sciaga tematyczna-egz 2, Kartografia tematyczna
sciaga tematyczna-2egz, Kartografia tematyczna
karto tematyczna- od olki, Kartografia tematyczna
sciaga karto, Kartografia tematyczna
kartografia tematyczna
Wyklady Kartografia tematyczna
Kartografia Tematyczna
projekty - tematy + opis, Zarządzanie UE Katowice - licencjat - materiały, zarządzanie UE Katowice -
WYTYCZNE TECHNICZNE K 1 4 (1983 Opracowanie pierworysu rzeźby terenu z istniejących materiałów kar
opis algorytmu do l100 BT6YWRU2YMH3VC7JYF5ZRO452DOIDYTSOLA6JFI
więcej podobnych podstron