Komunikacja procesora z innymi elementami architektury komputera 13
Rozdział 1.
Komunikacja procesora z innymi elementami architektury komputera
Każda z opisanych w tym rozdziale konfiguracji sprzętowych posiada centralny ośrodek zarządzania, którym jest procesor. Najnowsze osiągnięcia w technologii produkcji układów scalonych pozwalają na realizację coraz to potężniejszych mikroprocesorów. Jednak bez względu na szerokość ich magistral, częstotliwość pracy czy wielkość zintegrowanej w układzie pamięci, pierwotna zasada działania pozostaje — przynajmniej na razie — bez większych zmian.
Procesor
Rozwój mikroelektroniki i technologii sprzyja opracowywaniu coraz to potężniejszych mikroprocesorów. Postęp w miniaturyzacji pozwala na zwiększenie stopnia upakowania i wzrost częstotliwości taktującej. Dobrze opanowana jest technika 0,35 um a już obserwuje się przejście w kierunku 0,25 um. To dzięki temu nieustannemu zmniejszaniu rozmiarów elementarnych tranzystorów (mimo stałego wzrostu ich liczby) pobór mocy nowych procesorów mieści się jeszcze w granicach zdrowego rozsądku.
Konstrukcja komputera PC podlega również stałej ewolucji, wymuszanej głównie przez wymagania nakładane ze strony współczesnego oprogramowania. „Pamięciożerne" aplikacje i rozszerzenia multimedialne są w stanie zniwelować każdą sprzętową inwestycję.
14
Anatomia PC
Rynek przyjmuje z wdzięcznością nowe opracowania procesorów gdyż częsty brak kompatybilności z poprzednimi modelami zmusza do wymiany płyt głównych i stanowi dźwignię napędową do nowych zakupów.
Niezależnie od częstotliwości taktującej i charakterystycznych dla danej firmy rozwiązań indywidualnych każdy mikroprocesor da się przedstawić jako zespół współpracujących ze sobą bloków funkcjonalnych (rysunek 1.1).
Rysunek 1.1
Schemat blokowy procesora
Architektura komputera PC zakłada bardzo silną więź mikroprocesora z pamięcią operacyjną. W niej to bowiem przechowywane są dane i rozkazy, tam też odsyła się wyniki obliczeń. Za współpracę z pamięcią odpowiada wyizolowany blok komunikacyjny (BU — Bus Unit). Połączenie realizowane jest zwykle w formie dwóch odseparowanych od siebie magistral: oddzielnie dla danych (w tym kodu) i adresów. Zarządzanie ruchem na magistralach gwarantują dodatkowe sygnały sterujące.
Konieczność zapewnienia płynnego funkcjonowania procesora wymaga, by dane do wykonania (kod programowy) pobierane były w większych porcjach i gromadzone w kolejce, gdzie oczekują na wykonanie. Każdy ze spoczywających tu bajtów stanowi pewną zakodowaną informację o koniecznych do wykonania operacjach. Odtworzenie tej informacji odbywa się w bloku dekodera (IU - Instruction Unit). Praca tego układu wspomagana jest często przez obszerną podręczną pamięć stałą (ROM), w której zawarty jest słownik tłumaczący przyjmowane kody rozkazowe na sekwencje ukrywających się pod nimi operacji.
Rozkodowane instrukcje przekazywane są do właściwego układu wykonawczego (EU -Execution Unit), gdzie realizowana jest operacja określona danym kodem rozkazowym. Znaczna część powszechnie używanego kodu pracuje na liczbach stałoprzecinkowych
Komunikacja procesora z innymi elementami architektury komputera 15
(Integer) i podlega obróbce w module ALU (Arithmetic-Logic Unii) sterowanego z bloku CU (Control Unit). Jeśli jednak rozkaz dotyczył obiektów zmiennoprzecinkowych jego realizacja w stałoprzecinkowych układach logicznych zajęłaby zbyt wiele czasu. W takim wypadku przekazuje się go do wyspecjalizowanej jednostki zmiennoprzecinkowej (FPU - Floating Point Unit).
Rozkazy posługują się zwykle pewnymi argumentami (parametry funkcji, na przykład składniki przy dodawaniu), które również trzeba pobrać z pamięci operacyjnej. Często wymaga się, by wynik operacji przesłać pod określony adres. Obsługę tego rodzaju życzeń bierze na siebie jednostka adresowania (AU — Addressing Unit). Względy natury technicznej (stronicowanie i segmentacja) powodują, iż dostęp do pamięci operacyjnej wymaga pewnych dodatkowych nakładów, których realizacji poświęca się jednostkę zarządzania pamięcią (MMU - Memory Management Unit).
Rozwinięcie przedstawionego powyżej ogólnego schematu blokowego do postaci bardziej szczegółowej nastąpi przy okazji omawiania różnic w konkretnych modelach procesorów.
Przetwarzanie rozkazów
Obraz architektury współczesnych procesorów jest wynikiem wpływów wielu czynników. Stała pogoń za wzrostem mocy obliczeniowej zmusza do szukania nowych dróg. Nie wszystkie z nich są tak nowatorskie jak mogłoby się wydawać. Wiele z rozwiązań ma swoje pierwowzory w procesorach dużych maszyn, które ujrzały światło dzienne na długo przed komputerami klasy PC. Wspomniany, w poprzednim punkcie, klasyczny model mikroprocesora był dobry jeszcze przed kilkoma laty. Mocno zarysowany podział na wyspecjalizowane bloki nie zawsze da się zastosować do współczesnych konstrukcji i ulega stopniowemu rozmyciu.
Słownictwo w tej dziedzinie wzbogaciło się o szereg nowych, często tajemniczo brzmiących, zwrotów. W publikowanych pracach teoretycznych nie zawsze panuje zgodność poglądów. Głębokie zazębianie się zagadnień teoretycznych z konkretnymi rozwiązaniami sprzętowymi prowadzi do sporów odnośnie definiowanych określeń (kwestią sporną jest nawet sprecyzowanie zakresu obejmowanego pojęciem architektura). W tej części rozdziału omówione zostaną skrótowo podstawowe pojęcia z tego zakresu.
RISC i CISC
Termin RISC (Reduced Instntction Set Computer) zrodził się w toku prac nad projektem „801" firmy IBM1 i oznaczał tendencję do ograniczania listy rozkazów procesora do niewielu błyskawicznie wykonywanych instrukcji. Realizacja każdej z nich była wynikiem odwołania się do wyspecjalizowanego obwodu elektronicznego, który nie tracił
1 Idea podchwycona została przez wielu innych projektantów i utrwalona między innymi w projektach: AMD 29000, HP PA-RISC, Intel 860 i 960 oraz IBM RS/6000.
16 Anatomia PC
czasu na tłumaczenie rozkazu. Rozpisanie algorytmu wykonywanego programu, który przecież składał się z operacji dużo bardziej skomplikowanych niż przepisanie z rejestru do rejestru, należało do obowiązków kompilatora. Warto zwrócić uwagę, że system taki wyzwala ogromne obciążenie magistrali pamięciowej - kod przetłumaczony przez kompilator znajduje się przecież w pamięci operacyjnej i każdy z elementarnych „klocków" musi zostać pobrany przez procesor. Prędkość przetwarzania jest bardzo duża i taka musi też być przepustowość magistrali. Problem ten rozwiązuje się współcześnie przez zastosowanie szybkich pamięci podręcznych (LI i L2). Spore uproszczenie konstrukcji typu RISC zawdzięcza się stałej długości wszystkich mikrorozkazów. Istnieją jednak projekty procesorów (na przykład „Thumb" firmy ARM) dopuszczające zmienną długość instrukcji.
Odmienny punkt widzenia reprezentuje filozofia CISC (Complex Instruction Set Computer) dominująca w rodzinach x86 Intela i 680xx Motoroli. Procesory budowane według tej zasady biorą na siebie coraz to większe zadania. Pobierany z pamięci pojedynczy rozkaz wywołuje szereg kompleksowych działań. Czas opracowywania takiego polecenia może dochodzić nawet do kilkudziesięciu cykli zegarowych. Kod programu jest bardzo zwarty a proces jego transportu do procesora znacznie mniej krytyczny.
Jakkolwiek oba pojęcia definiowały początkowo kategorie przeciwstawne, to obecnie coraz trudniej jednoznacznie przypisać dany procesor do jednej nich. Ostry podział na RISC i CISC ma coraz mniejszy sens. Można co najwyżej mówić o pewnych cechach architektury a i to wyłącznie w odniesieniu do fragmentów określonej konstrukcji. Klasyczny przykład stanowią procesory K6 i Pentium Pro. Chociaż same zaliczają się do grupy CISC (akceptują przecież na swym wejściu złożone instrukcje x86), wyposażone są w dekoder tłumaczący na wewnętrzny kod mikroprocesora a więc ich jądro pracuje w trybie RISC (RISC Kernel). Uznawany za członka rodziny RISC procesor PowerPC 601 może z kolei poszczycić się chyba zbyt nadmierną jak na „zredukowaną" (R — Reduced) liczbą rozkazów: samych rozgałęzień można naliczyć ponad 150. Łatwiejsze do sklasyfikowania są typy Pentium oraz Ml (podobnie jak ich mutacje z rozszerzeniami MMX) przetwarzające dostarczany kod w sposób bezpośredni (Native Code).
Pipeline
Niezależnie od powyższej klasyfikacji każdy procesor można porównać do zakładu produkcyjnego, który z dostarczonych materiałów (dane w pamięci) wytwarza według określonego algorytmu (kod programu) pewien określony produkt wyjściowy (inny stan danych). Analogia ta pozwala na sięgnięcie do jednego z bardziej rewolucyjnych pomysłów racjonalizatorskich - taśmy produkcyjnej. Wprowadzona po raz pierwszy w zakładach Forda idea podzielenia cyklu produkcyjnego na wiele małych i szybkich operacji wydaje się pozornie bezużyteczna: czas pracy nad produktem nie ulega przecież zmianie (może się nawet wydłużyć jeśli szwankują połączenia między poszczególnymi etapami). Nie o ten czas tu jednak chodzi, ale o zwiększenie przepustowości.
Przeniesienie powyższej idei na grunt architektury mikroprocesorów odbyło się po raz pierwszy w roku 1960 podczas prac nad projektem IBM procesora klasy Mainframe typu 7030; mikroprocesory dołączyły dopiero w 20 lat później. Charakterystyczny jest
Komunikacja procesora z innymi elementami architektury komputera
17
podział czasu pracy nad pojedynczym rozkazem na wyraźnie zarysowane fazy. Symboliczna taśma produkcyjna nazywana jest tutaj potokiem przetwarzającym (Pipeline lub w skrócie Pipę) a jej poszczególne punkty stopniami (Pipeline Stages).
Rysunek 1.2.
Idea potokowego
przetwarzanie
danych
u FAZA |
FAZA |
FAZA |
u F«A,, |
FAZA j |
*~T |
2 |
' 3 " |
4 |
5 |
Rozkaz (n) |
Rozkaz (n-1) |
Rozkaz (n-2) |
Rozkaz (n-3) |
Rozkaz (n-4) |
Rozkaz (n+1) |
Rozkaz W |
Rozkaz (n-1) |
Rozkaz (n-2) |
Rozkaz (n-3) |
Rozkaz (n+2) |
Rozkaz (n+1) |
Rozkaz , W |
Rozkaz (n-1) |
Rozkaz (n-2) |
Rozkaz (n+3) |
Rozkaz (n+2) |
Rozkaz (n+D |
Rozkaz W |
Rozkaz (n-1) |
Rozkaz (n+4) |
Rozkaz (n+3) |
Rozkaz (n+2) |
Rozkaz (n+1) |
Rozkaz : w. |
ZEGAR CPU
Potok pracuje jednocześnie nad kilkoma rozkazami a każdy z nich znajduje się w innej fazie wykonania. Chociaż czas przetwarzania każdego z nich wynosi pewną wielokrotność okresu zegara taktującego, w każdym jego cyklu taśmę opuszcza kompletny produkt finalny. Nie inaczej pracuje taśma montażowa w fabryce samochodów - mimo, że co minutę zjeżdża z niej gotowy samochód, czas jego montażu może wynosić wiele godzin.
Połączenia pomiędzy poszczególnymi stacjami mogą być elastyczne, co pozwala na zmniejszenie dyscypliny całej taśmy. Czas przebywania rozkazu w poszczególnych stopniach zależy często od czynników zewnętrznych i ścisłe przestrzeganie reżimu czasowego nie zawsze jest możliwe. W punktach krytycznych montowane są więc małe magazyny pośrednie (bufory) nazywane też kolejkami (Queue).
Stopień rozdrobnienia takiej linii produkcyjnej (ilość stopni) nazywany jest też głębokością potoku. Wielkość ta ma fundamentalne znaczenie dla kluczowych parametrów procesora. Rozbicie procesu produkcyjnego na bardzo wiele małych operacji pozwala na ich przyspieszenie - dwaj robotnicy przykręcający po jednym kole pracują szybciej niż jeden, który musi zamontować dwa. W przeniesieniu na grunt architektury procesora oznacza to możliwość zwiększenie częstotliwości taktującej i ogólnej wydajności. Poszczególne stacje mogą pracować wręcz szybciej niż wynika to z wymiaru zewnętrznego zegara (Super-Pipeline). Model powyższy nie bierze jednak pod uwagę sytuacji awaryjnych a analogia do taśmy produkcyjnej nie znajduje tutaj pełnego zastosowania. Międzystopniowa kontrola jakości może po prostu odrzucić wadliwy wyrób na dowol-
18
Anatomia PC
nym etapie przetwarzania. Odbywa się to bez większej szkody dla całej taśmy. Inaczej jest jednak w przypadku procesorów. Stwierdzenie błędu (na przykład opracowywana właśnie instrukcja sprowadza się do dzielenia przez zero) oznacza konieczność oczyszczenia całego potoku. Punkt w którym taka sytuacja została rozpoznana znajduje się z natury rzeczy daleko od wejścia, a na pewno tym dalej im więcej stopni ma potok. Dodatkowym czynnikiem ograniczającym wzrost wydajności wraz z rozdrobnieniem potoku są wzajemne uzależnienia pomiędzy instrukcjami oraz konflikty w wykorzystaniu zasobów zewnętrznych. Zagadnienia te omówione zostaną bardziej szczegółowo w dalszej części rozdziału.
Dla zanalizowania powyższej zależności przeprowadzone zostały różnorodne badania symulacyjne. Wyniki testów wykazują, iż istnieje wartość optymalna głębokości leżąca w okolicy liczby 8. Taki też wymiar mają potoki przetwarzające większości procesorów (tabela 1.1).
Tabela 1.1.
Liczba stopni w potokach współczesnych procesorów
CPU |
P54C |
P55C |
P-Pro |
P-II |
Ml |
M2 |
K5 |
K6 |
Liczba stopni w potoku |
5 |
6/8* |
12 |
12/14* |
7 |
1 |
1 |
6 |
Druga z podanych wartości obowiązuje dla instrukcji MMX |
||||||||
Procesory wyposażone w potok pracują nad kolejnymi rozkazami według ściśle określonego schematu. Przetwarzana instrukcja przesuwa się wzdłuż linii produkcyjnej zaliczając kolejne etapy. Niezależnie od różnic w architekturze, należą do nich zawsze cztery podstawowe czynności: pobranie, dekodowanie, wykonanie i zakończenie. Każda z nich może być rozpisana na kilka czynności bardziej elementarnych, na przykład: pobranie wstępne i pobranie właściwe, wykonanie część pierwsza i następne itp.
Faza pierwsza: pobranie (Prefetch, PF)
Zakładamy obecność kodu w kolejce rozkazowej procesora. Zapełniane tej kolejki odbywa się poprzez sięganie do pamięci podręcznej LI. Jeśli rozkaz znajduje się w pamięci operacyjnej uruchamiana jest procedura zapełniania linijki pamięci podręcznej LI, z ewentualnym uwzględnieniem pośredniej pamięci L2.
Faza druga: dekodowanie (Decode, DE)
W pierwszej części tej fazy analizowany jest kod operacyjny instrukcji i jeśli to konieczne separuje się przedrostki i argumenty. W drugiej części oblicza się adres efektywny argumentów (jeśli takowe występują).
Komunikacja procesora z innymi elementami architektury komputera 19
Faza trzecia: wykonanie (Execute, EX)
W fazie tej następuje fizyczny dostęp do pamięci w celu pobrania ewentualnych argumentów rozkazu oraz operacje na argumentach określane kodem instrukcji.
Faza czwarta: zakończenie i zapisanie wyników (Write Back, WB)2
Wynik operacji wykonanej w fazie EX umieszczany jest w miejscu określonym w kodzie rozkazowym (rejestry lub pamięć). Na zakończenie przywracany jest stan początkowy wewnętrznych (niewidocznych dla użytkownika i programisty) układów procesora oraz ustawiane są bity sygnalizujące pewne stany charakterystyczne dla zakończonej właśnie operacji (znaczniki, słowa stanu itp.).
Przyjrzyjmy się bliżej poszczególnym etapom przetwarzania następującego rozkazu:
add ax, [bx] ; dodaj zawartość rejestru AX do zawartości komórki, ; której adres znajdziesz w BX, wynik prześlij do AX
Faza PF - pobranie kodu instrukcji.
Faza DE - określenie czynności do wykonania, obliczenie adresu efektywnego
dla drugiego argumentu (16xDS)+BXFaza EX - dostęp do komórki pamięci o adresie (16xDS)+BX, operacja doda
wania do AX.Faza WB — umieszczenie wyniku w AX, ustawienie flag.
Techniki przyspieszania
Wzrost mocy obliczeniowej mierzy się ilością wykonywanych operacji w jednostce czasu. Zwiększanie częstotliwości taktującej (skrócenie czasu trwania pojedynczego cyklu) jest najbardziej oczywistym czynnikiem gwarantującym przyrost wydajności (pod warunkiem, iż nadążają układy otaczające procesor, głównie systemy pamięciowe). Na określonym etapie rozwoju technologii, dalszy wzrost częstotliwości taktującej nie jest już możliwy i trzeba sięgać do innych rozwiązań. Jeśli trzymać się analogii do zakładu produkcyjnego, ogromne możliwości drzemią zawsze we właściwej „organizacji pracy" i różnych drobnych usprawnieniach. W świecie mikroprocesorów należą do nich między innymi: techniki superskalarne, przemianowywanie rejestrów, przepowiadanie rozgałęzień i odpowiednie (zoptymalizowane pod kątem konstrukcji wewnętrznej danego procesora) przygotowanie kodu.
Techniki superskalarne
Jeśli nie można zwiększyć wydajności pojedynczej linii produkcyjnej należy wybudować drugą. Procesor taki nosi miano superskalarnego. Uruchomienie dodatkowych, równoległych linii produkcyjnych gwarantuje oczywiście zwielokrotnienie produkcji. Model taki nie sprawdza się jednak na gruncie mikroprocesorów. Strumień rozkazów do wy-
Literatura angielskojęzyczna używa też często terminu Retii-e (spoczynek).
20 Anatomia PC
konania naszpikowany jest wzajemnymi uzależnieniami i pełen punktów rozgałęzień. Ponadto pracujące równolegle taśmy produkcyjne procesora (potoki) nie stanowią niezależnych obiektów, korzystają bowiem z wielu wspólnych elementów architektury (choćby rejestrów). Te i inne ograniczenia powodują, iż dołożenie więcej niż jednego potoku nie wpływa już w istotnej mierze na wzrost wydajności. Zwielokrotniona (przynajmniej teoretycznie) moc obliczeniowa procesora konsumowana jest w większości przez wewnętrzny system komunikacji międzypotokowej.
Zdecydowana większość dominujących obecnie na rynku procesorów posiada więc dwa równoległe kanały przetwarzające dane typu Integer (określane zwykle symbolami U i V). Jednostka zmiennoprzecinkowa (FPU - Floating Point Unii) została już stosunkowo dawno (w czasach 8087) wydzielona z właściwej struktury logicznej i ma swoje własne życie wewnętrzne. Można śmiało powiedzieć, iż stanowi ona trzeci równoległy potok.
Z napływającego do procesora strumienia rozkazów odławiane są te, które operują na danych zmiennoprzecinkowych i kierowane do właściwego im potoku. Reszta kodu podlega przetwarzaniu w sekcji Integer. To, który z rozkazów nich ląduje w ciągu U, a który w ciągu V stanowi wynik pracy układu rozdzielacza. Istniejące reguły rozdziału wynikają głównie z drobnych różnic w budowie wewnętrznej U i V oraz z wymogów synchronizacji potoków. Możliwość niezależnego (asynchronicznego) doprowadzania do końca instrukcji równocześnie zapoczątkowanych w dwóch potokach (Out of Order Completion) nie jest bowiem cechą każdego procesora. Warunki takie ma na przykład M2 Cyrixa, natomiast architektura Intel-MMX wymaga synchronicznej pracy obu linii. Jeśli jest to niemożliwe (na przykład oczekiwanie na wyniki pośrednie) drugi potok zostaje zatrzymany.
Przemianowywanie rejestrów
Wykonywany przez procesor program stanowi w najbardziej korzystnym przypadku sekwencję instrukcji, które dają się naprzemiennie kierować do potoków U i V. Technika taka nosi miano parowania rozkazów. Nie wszystkie rozkazy podlegają parowaniu i nie zawsze przez ich równoległe wykonywania można cokolwiek przyspieszyć. Rozkazy odwołujące się do tych samych lokalizacji pamięci lub oceniające status procesora nie mogą być przecież wykonywane wcześniej niż to wynika z ich naturalnego położenia w sekwencji kodu. Najczęstsza przyczyna uzależnień leży jednak w zazębieniach powstałych skutkiem odwoływania się do tych samych programowych rejestrów procesora.
Przykładowy ciąg instrukcja asemblera:
mov bx, ax ; -> do potoku U add ax, ex ; -> do potoku V
prowadzi do powstania uzależnienia od rejestru AX. Przepisanie stanu CX do AX w drugiej z podanej pary instrukcji nie może być przeprowadzone wcześniej niż zakończenie realizacji odczytu AX w pierwszej instrukcji pary. Opisana sytuacja stanowi przykład uzależnienia typu WAR (Write After Read- najpierw odczyt, później zapis).
Komunikacja procesora z innymi elementami architektury komputera
21
Akumulator (AX) . «H
Rejestr bazowy (BX) j BH Rejestr licznika (CX) Rejestr danych (DX)
Wskaźnik stosu
Wskaźnik bazowy
Indeksowanie źródła
Indeksowanie celu
Rysunek 1.3.
Zestaw rejestrów procesora
AL
b,5... bs b7 ... b„
Segment danych
Segment kodu
Segment stosu
Segment dodatkowy
Zestaw znaczników Wskaźnik instrukcji
b,5... b8 b7 ... b„
FLAGS
Dwie następujące kolejno po sobie instrukcje dostępu do rejestru mogą w zależności od trybu dostępu (zapis/odczyt) prowadzić do czterech stanów zebranych w tabeli l .2.
Tabela 1.2.
Sekwencje rozkazów, których nie można parować
Typ zależności |
RAR (Read After Read) |
RAW (Read After Write) |
RAW (Read After Write) |
WAR (Write After Read) |
WAW (Write After Write) |
Przykład |
add bx, ax mov ex, ax |
add ax, bx mov ex, ax |
mov ax, bx mov [mem] , ax |
mov bx, ax add ax, ex |
mov ax, [mem] add ax, bx |
Rozwiązanie |
Dual Pipę Access |
Result Forwarding |
Operand Forwarding |
Register Renaming |
Register Renaming |
Pierwsza kolumna symbolizuje dwa następujące po sobie (w kodzie programu) a jednocześnie występujące (w przypadku rozesłania do potoków U i V) cykle odczytu zawartości rejestru AX. Nie mamy to do czynienia z hazardem danych a uzależnienie tego typu jest stosunkowo łatwe do usunięcia poprzez wbudowanie podwójnych portów odczytu dla rejestrów. Dzięki takiemu usprawnieniu stan każdego z rejestrów może być pobierany niezależnie i jednocześnie przez U i V.
Istotne problemy wywołują sekwencje rozkazów w dalszych kolumnach. Dwie ostatnie prezentują sytuacje powstałą w wyniku próby jednoczesnego zapisu rejestru generowane przez potoki U i V. Prostym sposobem wyjścia z tej opresji jest tymczasowe podstawienie dodatkowego rejestru pomocniczego (rysunek 1.4), tak by nie zamazywać wartości zapisanej jako wcześniejsza. Technika ta nazywa się przemianowywaniem rejestrów (Register Renaming).
Różne procesory posługują się tą techniką w mniejszym lub większym zakresie. W najprostszej formie procesor wyposaża się w zestaw dodatkowych rejestrów, które stoją do dyspozycji jednostki sterującej. W razie napotkania pary rozkazów powodującej uzależnienie typu WAR:
mov bx, ax add ax, ex
22
Anatomia PC
Rysunek 1.4.
Idea
przemianowywania
rejestrów
HS V-BR .,
Dl
układ sterowania dokonuje szybkiego podstawienia: AX •=> RegO BX <=> Regl CX o Reg2
Jeśli teraz dokonać przemianowania
AX •=> Reg3 to można bez trudu wykonać równolegle operacje:
Regl := RegO || Reg3 := Reg2 + RegO
Liczba stojących do dyspozycji tej techniki rejestrów jest różna w zależności od modelu i typu procesora. Pentium i Pentium MMX nie mają ich wcale a AMD-K6 dysponuje zestawem 48 (tabela 1.3).
Tabela 1.3.
Liczba przemianowanych rejestrów
CPU |
P54C |
P55C |
P-Pro |
M1.M2 |
K5 |
K6 |
Liczba przemianowanych rejestrów |
8 + 0 |
8 + 0 |
8 + 32 |
8 + 24 |
8 + 8 |
8 + 40 |
Komunikacja procesora z innymi elementami architektury komputera 23
Trudności innego typu występują w sytuacjach przedstawionych symbolicznie jako zależności RAW. Nie ma tutaj kolizji przy zapisie do rejestru lecz pojawia się konieczność oczekiwania na wynik wcześniejszej operacji (obliczenia lub przesłania). Aby tego uniknąć, potok potencjalnie narażony na stratę czasu sam przeprowadza równolegle tą samą operację. Jeśli jest to obliczenie, technika nazywana jest Result Forwarding, a jeśli przesłanie mówimy o Operand Forwarding.
Przepowiadanie
Wykorzystanie pełnych mocy obliczeniowej procesorów wyposażonych w potoki przetwarzające (pipeline) wymaga stałego zasilania instrukcjami. Program, którego realizacja przebiega kolejno od jednej instrukcji do następnej nie stwarza w tym zakresie żadnych problemów. Również bezwarunkowe skoki typu go to mają jasno określony punkt docelowy. Kłopoty pojawiają się w momencie napotkania warunkowej instrukcji rozgałęzienia kiedy to dalsza realizacja programu może w zależności od spełnienia określonych warunków przebiegać sekwencyjnie dalej lub też przemieścić się do odległego obszaru kodu.
Mimo iż nie jest wiadomo która z instrukcji będzie wykonywana jako następna po problematycznej i f potok musi zostać czymś napełniony. Problem przybiera na sile wraz ze wzrostem długości pipeline; coraz więcej operacji tkwi już głęboko w systemie przetwarzania, choć nie do końca wiadomo czy słusznie. Ostateczne rozstrzygnięcie warunku zawartego w i f odbywa się w najlepszym razie w okolicach środka potoku. Może się więc zdarzyć, iż wszystko to co jest za instrukcją warunkową należy usunąć. Oczyszczenie całego skomplikowanego aparatu przetwarzającego ze zbędnych wyników pośrednich zajmuje dłuższą chwilę3. Krok taki jest z punktu widzenia wydajności procesora ogromną stratą czasu.
Dodatkowe opóźnienia mogą również powstawać w systemach pobierania rozkazów, a zwłaszcza w procesorach z jądrem RISC. Dekodery tych procesorów rozkładające instrukcje x86 na drobne mikrooperacje też muszą pracować z dużą wydajnością. Oczekują więc nieprzerwanego dopływu przetwarzanego materiału od układów współpracy z pamięcią podręczną i magistralami. Od systemu pobierania kolejnych instrukcji x86, czy to z przeznaczeniem na rozkład na mikrokroki (RISC) czy też do bezpośredniego przetworzenia wymaga się więc również orientacji w zamiarach programu.
Stosowane w praktyce próby rozwiązania tego dylematu grupują się wokół dwóch podstawowych sposobów rozumowania:
Dalszy bieg programu można z większym lub mniejszym powodzeniem spróbo
wać przewidzieć (Branch Predictiori).W przypadku rozgałęzienia podąża się na wszelki wypadek w obydwu kierun
kach (Multiple Paths ofExecutiori).
3 Dla K6 wynosi l - 4 cykle zegarowe, M2 karany jest 5 cyklami natomiast Pentium-Pro ze względu na długość potoku musi czekać aż 15 cykli.
24
Anatomia PC
Oba punkty podejścia mają swoje dobre i złe strony. Prawdopodobieństwo właściwego przepowiedzenia jest zawsze mniejsze od jedności a prowadzenie programu kilkoma ścieżkami jednocześnie4 prowadzi do ogromnej komplikacji sprzętowej. Powielaniu podlegają nie tylko jednostki wykonawcze ale i dekodery oraz systemy pamięci podręcznej. Wielokrotnie zagnieżdżone lub następujące szybko po sobie pętle szybko uporają się z każdą ilością zasobów sprzętowych. Wybranie przypuszczalnie słusznej drogi i jej realizacja (Speculative Execution) też niesie z sobą sporą dozę komplikacji całego systemu. Wyniki wszystkich operacji lądują w buforach pośrednich bowiem nie wolno jeszcze przecież niczego zmieniać w świecie poza procesorem (zapis do pamięci wywołany sekwencją programu, która nigdy nie miała być wykonana miałby przecież katastrofalne skutki).
Współczesne procesory korzystają w większości z techniki przepowiadania biegu programu a stopień komplikacji stosowanych systemów odpowiada z grubsza uzyskiwanym wynikom. Podstawową strukturą informacyjną tych układów jest tablica BTB (Branch Target Buffer) - rysunek 1.5. Jest to szybka podręczna pamięć asocjacyjna grupująca zwykle 128 - 1024 rekordów. Każdy z wierszy zawiera w sobie informacje o jednym z punktów rozgałęzienia programu. BTB w najprostszej formie to zestaw adresów instrukcji skoków i adresów tych skoków. Dodatkowo zapamiętywany jest status danej linijki (V: Yalid) oraz omawiane poniżej bity opisujące zachowanie się instrukcji (H],m:HistoryBits).
Rysunek 1.5
Struktura tablicy BTB
Branch Target Buffer
Program
InstrukcjaJ
InstrukcjaJ
HIH}||Adf9sin5trakqiJ |
Adres lnsWI«L7| |
Instrukcjo (skok)
lnstrukcja_4
Instrukcjajj
2|[
lnstmkcja_6
lnstrukcja_7
lnstrukcja_8
lnstrukcja_9 (skok)
InstrukcjaJO
InstrukcjaJ 1
HIBjIj Adresifistrakd |
Attes stoku | |
InstrukcjaJ 2
InstrukcjaJS
InstrukcjaJ 4
W tablicy umieszczane są tylko te instrukcje (w miarę dostępnego w buforze miejsca), które już się wykonały, innymi słowy takie, których zachowanie zostało zaobserwowane i udokumentowane. Średnia ilość trafnych przepowiedni pozostaje w ścisłym związku z rozmiarami tablicy BTB. Statystyczna analiza typowych programów prowadzi do wyznaczenia następujących współczynników:
Idea wcielona w życie w niektórych modelach procesorów IBM (na przykład 3033).
Komunikacja procesora z innymi elementami architektury komputera
25
Rozmiar BTB |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
2048 |
Średnia ilość trafnych przepowiedni [%] |
40 |
50 |
65 |
72 |
78 |
80 |
85 |
87 |
System nadzorujący pobieranie kolejnych bajtów rozkazowych może więc w wypadku napotkania rozgałęzienia zwrócić się do tabeli BTB z zapytaniem o przewidywany dalszy bieg programu. Wiarygodność uzyskanej odpowiedzi zależy oczywiście nie tylko od samych rozmiarów tabeli. Choć istnieje wiele ciekawych sposobów podejścia do tego zagadnienia tylko kilka z nich znalazło praktyczne zastosowanie. We wszystkich przypadkach instrukcje rozgałęzień opatruje się dodatkową sygnaturą, zwykle nie dłuższą od 2 bitów. W nich to próbuje się zawrzeć, w mniej lub bardziej udany sposób „charakter i osobowość" danego rozgałęzienia. Stosowane algorytmy przepowiadania różnią się miedzy sobą w sposobie wykorzystania tej niezmiernie ograniczonej porcji informacji.
Metoda statyczna
Stosowany jest zwykle jeden bit a jego ustawienie odbywa się stosunkowo wcześnie bo jeszcze w fazie kompilacji. Faktyczny przebieg programu nie jest w stanie już nic zmienić. Metoda szybka, tania i mało skuteczna.
Metody dynamiczne
Metody tej grupy operują na jednym lub dwóch bitach, którymi manipuluje się w fazie wykonywania programu. Jednym z możliwych punktów podejścia jest przyjęcie założenia o powtarzalności przebiegu. Każdemu rozgałęzieniu towarzyszy jeden bit informacyjny, który podlega ustawieniu na l jeśli nastąpił skok. Proste przejście przez rozwidlenie (do kolejnej w szeregu instrukcji) kwitowane jest wyzerowaniem tego bitu. Jeśli w wyniku dalszego wykonywania programu znajdziemy się ponownie w tym samym punkcie, system przewidywania typuje wynik zgodny z poprzednio utrwalonym zachowaniem. Stan taki utrzymuje się do czasu pierwszego błędu w przepowiedni (typowe wyjście z wielokrotnej pętli po spełnieniu określonego warunku), co powoduje zmianę wartości bitu kontrolnego.
Bardziej rozbudowana logika wkomponowana jest w układy dwubitowe.
Sygnatura |
Opis |
00 |
Mocne założenie o braku skoku |
01 |
Słabe założenie o braku skoku |
10 |
Słabe założenie o skoku |
11 |
Mocne założenie o skoku |
Punktem wyjściowym algorytmu jest przyjęcie założenia, że wszystkie po raz pierwszy napotkane rozgałęzienia nie prowadzą do skoków. Opatruje się je sygnaturą „00" i przystępuje do wykonywania programu. Pierwsze przejście przez dane rozwidlenie zgodnie
26 Anatomia PC
z przepowiednią (brak skoku) nie modyfikuje sygnatury i nadal zakłada się iż stan ten utrzyma się do następnego razu. Jak długo rozgałęzienie istotnie nie nastąpi, układ typuje prawidłowo. Jeżeli jednak dojdzie do skoku, mamy pierwsze niepowodzenie. W odpowiedzi na nie system zmienia stan sygnatury na „01" ale nadal zakłada, że kolejne skoki nie będą miały miejsca. Następna ocena odbywa się w trakcie kolejnego przejścia. Jeśli skok istotnie się nie powtórzył, następuje powrót do stanu „00". W przeciwnym razie instrukcja opatrywana jest sygnaturą „l l". Układ pozostaje w tym stanie tak długo, jak długo skoki istotnie mają miejsce. Gdy po raz pierwszy nastąpi pomyłka modyfikuje się sygnaturę do postaci „10". System przepowiadania nadal jest zdania, iż następnym razem skok będzie jednak miał miejsce i taką też odpowiedź zwraca. Gdy przewidywanie było słuszne następuje powrót do postaci „11" z mocnym przekonaniem o dalszych skokach, jeżeli jednak system pomylił się powtórnie, sygnatura przechodzi do stanu „00".
Optymalizacja kodu
Jeżeli zna się dobrze szczegóły konstrukcyjne konkretnego procesora można próbować tak pisać program (już w fazie doboru algorytmu i podejścia do problemu a potem na etapie kompilacji) by wykorzystać dobre strony konstrukcji a ominąć punkty słabe. Optymalizacja kodu jest konieczna w przypadku Intel-Pentium, gdyż nie radzi on sobie (potoki synchroniczne) z doborem parowanych instrukcji. Procesor ten pobiera po prostu kolejne instrukcje z sekwencji programowej i (jeśli spełniają tylko pewne warunki wstępne) rozsyła je na chybił trafił do potoków U i V. Powstające uzależnienia nie są neutralizowane poprzez podmianę rejestrów i jeden z potoków po prostu czeka na zakończenie pracy (ew. udostępnienie wyników) w drugim.
Dostęp do pamięci
Zadaniem procesora jest przetwarzanie danych w złożonych w pamięci; tam też znajduje się kod realizowanego programu. CPU bardzo intensywnie współpracuje z układami pamięciowymi i bez nich nie może się obejść. Wykonywane operacje mają charakter dwukierunkowy: zapis lub odczyt. Przy zapisie procesor wystawia słowo na magistralę danych a stosowny adres na magistralę adresową. Podczas odczytu końcówki adresowe CPU definiują punkt odniesienia w pamięci a zawartość tej właśnie komórki zdejmowana jest przez procesor z magistrali danych. Nad sprawnym przebiegiem takich operacji czuwają oczywiście różne układy towarzyszące, których rytm pracy wyznaczają sygnały kontrolno-sterujące wytwarzane przez sam procesor. Kilka poniższych uwag ma pomóc Czytelnikowi w wyjaśnienie zachodzących przy tym zjawisk. Mają one kluczowe znaczenie dla zrozumienia działania CPU.
Procesory 16-bitowe pierwszej generacji (począwszy na modelu 8088 a skończywszy na układzie 80186) miały 20 końcówek adresowych. Architektura logiczna wyznaczała podział pamięci na 64 kB segmenty. Mechanizm adresowania składał się z dwóch rejestrów 16-bitowych: jeden określał początek segmentu (Segment) a drugi odległość punktu od tego początku (Offset). Para rejestrów Segment i Offset wyznaczała tzw. adres logiczny. Konieczność dopasowania tej logicznej struktury (16+16) do wymiaru 20-bitowej magistrali adresowej wyznaczyła następujący sposób przeliczenia:
Komunikacja procesora z innymi elementami architektury komputera 27_
Adres fizyczny = 16 x Segment + Offset
Generowany według powyższej formuły adres fizyczny (tutaj 20-bitowy) wystawiany był na magistralę adresową. Operacja mnożenia przez 16 stanowi w dziedzinie liczb binarnych przesunięcie w lewo o 4 pozycje - tak z 16 bitów robi się potrzebne 20. Powstające z prawej strony dodatkowe pozycje wypełnia się zerami a do uzyskanej w ten sposób liczby 20-bitowej dodaje się zawartość rejestru Offset.
Warto w tym miejscu wspomnieć o tzw. adresie liniowym. Stanowi on również efekt działania mechanizmu segmentacji w trakcie przetwarzania adresu logicznego. Adres jest liniowy dlatego, ponieważ bezpośredni system adresowania segmentu (w rejestrze segmentowym zawarty jest adres segmentu) gwarantuje, iż segment o adresie wyższym znajduje się fizycznie wyżej w pamięci. Jeśli omawiany w dalszej części rozdziału mechanizm stronicowania jest wyłączony (i pamięć wirtualna nieaktywna), adres liniowy odwzorowywany jest wprost w adres fizyczny: 20, 24 lub 32 bitowy, zależnie od szerokości magistrali. Aktywacja przestrzeni wirtualnej powoduje, iż mechanizm stronicowania odwzorowuje adres liniowy w adres fizyczny.
Generacja procesorów 16-bitowych wyposażonych w 20-końcówkową magistralę adresową operowała w przestrzeni fizycznej o rozmiarze l MB (220). Wyjątek stanowił model 80286 dysponujący 24 liniami adresowymi i obejmujący tym samym przestrzeń 16 MB (224). Procesory 32-bitowe (począwszy od 80386DX) mają już 32 końcówki adresowe co pozwala na pokrycie zakresu 4 GB (232).
Architektura nowoczesnych procesorów 32-bitowych ulegała licznym przeobrażeniom a implementacja nowych, dostosowanych do współczesnych wymogów trybów pracy spowodowała sporą komplikację w przeliczeniach adresów logicznych, którymi operuje program, na rzeczywisty stan końcówek adresowych CPU. Wyróżnić należy trzy podstawowe tryby pracy procesora:
Tryb rzeczywisty (Real Modę}. Procesor 32-bitowy przełącza się w stan odwzo-
rowujący zachowanie jednostki 16-bitowej. Zawartość rejestru segmentowego
przesuwana jest o 4 pozycje binarne w lewo i dodawana do zawartości rejestru
przesunięcia (16xSegment + Offset). Wynik stanowi liczbę 20-bitową, która jest
po prostu wystawiana na magistralę adresową. Proszę zwrócić uwagę, iż kon
strukcja adresu według takiej reguły prowadzi do wieloznaczności. Różne pary
liczb Segment:Offset mogą dawać jednakowy wynik i odwoływać się do tej samej
komórki pamięci. W trybach chronionych jest to z różnych względów wyklu
czone.Tryb chroniony (Protected Modę). Tryb ten wprowadzony został (począwszy od
modelu 80286) w celu ochrony poszczególnych zadań pracujących pod kontrolą
wielozadaniowego (multitasking) systemu operacyjnego. Całość jest zaimplemen-
towana jako czteropoziomowy system uprawnień. Układy sprzętowe wbudowane
w procesor kontrolują odwołania do danych oraz kodu i wydają (lub odmawiają)
zezwolenia na dostęp. Wzrost bezpieczeństwa okupuje się stosunkowo dużą
komplikacją w obliczaniu adresu.
28 Anatomia PC
• Tryb wirtualny procesora 8086 (Yirtual 8086 Modę). Tryb dostępny jest w układach rodziny Intel począwszy od modelu 80386. Koncepcja trybu wirtualnego stanowi kombinację dwóch wcześniej omówionych trybów. System operacyjny wykorzystujący tą możliwość pracy stawia do dyspozycji wykonywanych programów bardzo interesujące środowisko. Każdy z programów użytkowych widzi swój własny procesor 8086 pracujący w trybie rzeczywistym. System jako całość dysponuje jednak zaczerpniętymi z trybu chronionego mechanizmami gwarantującymi odpowiedni dobór praw dostępu do zasobów i uniemożliwiającymi wzajemne kolizje pomiędzy współ-uczestniczącymi zadaniami.
Najbardziej istotną innowacją (oprócz architektury 32-bitowej) wprowadzoną do rodziny procesorów Intela począwszy od modelu 80386 jest jednak jednostka stronicowania (Paging Unit). W kolejnej części rozdziału zostaną omówione możliwości jakie oferuje to rozszerzenie.
Adresowanie
Znana z trybu rzeczywistego prosta projekcja zawartości rejestrów segmentowych i przesunięcia na adres fizyczny zatraca się wyraźnie w chronionych trybach pracy. Wspomniane rejestry są od siebie całkowicie odseparowane i chociaż nadal dostępne programowo, interpretacja ich zawartości jest zupełnie inna.
Rejestr segmentowy stanowi teraz selektor segmentu a nie wprost jego adres. 13 najstarszych pozycji tego rejestru stanowi wskaźnik do 8-bajtowej struktury opisującej dany segment (Segment Descriptor). Z pozostałych trzech bitów dwa poświęcone zostały na implementację czteropoziomowego systemu praw dostępu do segmentu a jeden określa czy wspomniany powyżej wskaźnik odnosi się do tzw. tablicy lokalnej czy globalnej. Rekordami w tych tablicach są właśnie deskryptory segmentów. Każdy z nich zawiera jednoznaczną informację o lokalizacji segmentu w pamięci i jego rozmiarach. W ten sposób definiowany jest spójny obszar o adresie początkowym wyznaczanym liczbą 32-bitową. Na liczbę określającą rozmiar takiego bloku przeznaczone zostało pole 20-bito-we. Istnieją dwie możliwości interpretowania liczby w tym polu. W trybie 1:1 (granulacja l B) rozmiar maksymalny wynosi po prostu 220=1 MB. Gdyba jednak przyjąć jednostkę 4 kB (granulacja 4 kB), rozmiar segmentu może sięgać do 220x212 = 232 = 4 GB. Informacja o tym, która z konwencji jest aktualnie obowiązująca zawarta jest w des-kryptorze.
Adres logiczny do którego odwołuje się procesor 32-bitowy budowany jest ze złożenia zawartości 16-bitowego rejestru segmentowego i 32-bitowego rejestru przesunięcia. W przypadku granulacji 4 kB maksymalny wymiar segmentu wynosi 4 GB. Liczba możliwych segmentów wynosi 214 (213 deskryptorów lokalnych i tyle samo globalnych) co daje w sumie astronomiczną objętość 64 TB (214x232). Właściwie już jeden taki segment stanowi wielkość optymalną: 4 GB przestrzeni adresowej zaspokaja przy obecnym rozwoju techniki PC najbardziej wygórowane wymagania. Rozwiązanie takie, określane jako „płaski model pamięci" stosowane jest w systemie Windows NT.
Komunikacja procesora z innymi elementami architektury komputera 2S_
Segmenty l MB (granulacja bajtowa) pozwalają na utworzenie przestrzeni wirtualnej
rozmiarze 16 GB (2l4x220). Utworzenie pamięci operacyjnej o takiej pojemności
w oparciu o półprzewodnikowe układy scalone jest absolutnie nierealne. Sarno zasilaniesterowanie zespołu l 000 układów SIMM (16 MB) nastręczało by zbyt wiele trudności
technicznych, nie mówiąc o kosztach. Jest więc rzeczą oczywistą, iż nie wszystkie
segmenty jednocześnie mogą być przechowywane w pamięci operacyjnej. Część z nich
składuje się więc (Swapping) na znacznie tańszym nośniku magnetycznym (zwykle
dysk twardy). Duża pamięć wirtualna realizowana jest więc jako złożenie małej i szyb
kiej pamięci RAM i obszernej pamięci masowej.
System operacyjny nadzoruje mechanizm składowania ustawiając odpowiednie znaczniki w tabelach deskryptorów. Jeśli procesor żąda dostępu do takiego „odłożonego na bok" segmentu, sprzęt wyzwala tzw. wyjątek (Exception), będący odpowiednikiem przerwania OxOb. Wzywany jest podprogram obsługi przerwania, który sprowadza potrzebny segment z dysku do pamięci.
Omówione powyżej składowanie segmentów pozwala na wykorzystanie znacznie większego wycinka logicznej przestrzeni adresowej procesora niż wymiar fizycznie obecnej pamięci operacyjnej. Mechanizm ten nie jest jednak pozbawiony wad. Proszę zwrócić uwagę, iż elementarną jednostką wymiany informacji pomiędzy pamięcią RAM a pamięcią masową jest segment. Jego rozmiar niekoniecznie musi odpowiadać strukturze przetwarzanych obiektów. Obszerne bloki danych typowe dla zagadnień numerycznych, moduły dużych programów, mapy bitowe i im podobne lokowane są w dużych segmentach. Zwięzłe procedury, bloki danych krótkich programów umieszcza się oczywiście w dopasowanych do ich rozmiarów mniejszych segmentach.
Potrzeba sprowadzenia do pamięci jednego z dużych segmentów może oznaczać konieczność zwolnienia miejsca zajmowanego przez szereg mniejszych bloków. Jeśli przetwarzane zagadnienie wymaga naprzemiennego sięgania do sprowadzanego właśnie dużego segmentu oraz wyeksportowanych przed chwilą segmentów mniejszych (klasyczny przykład: kompaktowy kod obsługi bazy danych i obszerne struktury samych danych) rozpoczyna się intensywny proces wymiany informacji pomiędzy dyskiem a pamięcią. Operacje takie pochłaniają oczywiście znaczną część mocy obliczeniowej.
Opisany problem staje się szczególnie dotkliwy w komputerach skąpo wyposażonych w pamięć RAM. Należy przecież pamiętać, iż tylko pewna część pamięci operacyjnej może być oddana do dyspozycji mechanizmu obsługującego zrzuty na dysk. Wolna przestrzeń to reszta, która pozostaje po rozlokowaniu kodu i danych systemu operacyjnego oraz sterowników i innych niezbędnych elementów. Może się wręcz zdarzyć, iż segment po który chcemy aktualnie sięgnąć nie mieści się w ogóle w wolnej przestrzeni. Uruchamiana jest wtedy skomplikowana procedura analizująca stopień wykorzystania obecnego w pamięci kodu i podejmuje się decyzję, które z jego fragmentów mogą być odesłane na dysk.
Powyższe względy zadecydowały o konieczności poszukiwania bardziej efektywnej metody zagospodarowania oferowanej przez nowoczesny procesor wirtualnej przestrzeni adresowej. Opracowany system określany jest mianem stronicowania.
30
Anatomia PC
Stronicowanie
Stronicowanie (Paging) stanowi specyficzną funkcję odwzorowującą ogrom przestrzeni wirtualnej na stosunkowo wąskie pole pamięci RAM plus obszar udostępniany przez pamięć masową. Odwzorowanie to odbywa się za pośrednictwem małych porcji zwanych stronami (Pages). Rozmiar stron jest stały i wynosi 4 kB. W przypadku omawianego tutaj modelu 80386, wielkość ta jest „zaszyta" we wnętrzu CPU i nie może być zmieniana. Niektóre procesory najnowszej generacji (na przykład Pentium) pozwalają na pewne odstępstwa od tej reguły. Można w nich wybrać jeden z dwóch rozmiarów stron: standardowy 4 kB lub rozszerzony 4 MB.
Procesor może ale nie musi korzystać z mechanizmu stronicowania. Odpowiedni „wyłącznik" zamontowany jest w jednym z rejestrów konfiguracyjnych (bit PG w rejestrze CRO). Samo ustawienie PG oznacza jedynie inną interpretację adresów i jeszcze niczego nie załatwia. To system operacyjny musi brać na siebie obsługę całego związanego z tym mechanizmu. Jeśli stronicowanie jest aktywne, adres logiczny podlega dwustopniowym przekształceniom (rysunek 1.6).
Rysunek 1.6.
Schemat tworzenia adresu fizycznego przy włączonym stronicowaniu
_4_JS*$*i |
|
^J|jMU«- |
.""'."óft |
^.a.^...a.^ji.Ł.8.^jj |
|
|
Descrfptor |
|
|
|
|
• * • |
|
|
|
|
Segnenl Dascriptor < |
1 |
|
|
|
i i ł |
|
|
|
|
|
|
|
Adres logiczny
Adres liniowy
.Adres fizyczny
W pierwszej fazie odbywa się opisany wcześniej proces segmentacji. 16-bitowy selektor segmentu wskazuje na rekord adresowy w tablicy deskryptorów. Do uzyskanego w ten sposób adresu podstawy dodaje się 32-bitowe przesunięcie. Dopiero generowany w powyższy sposób adres liniowy (rysunek 1.7) podlega transformacji na fizyczny adres obiektu. Transformacja ta stanowi sedno mechanizmu stronicowania a jej istota rzeczy polega na innej interpretacji adresu liniowego (rysunek 1.8).
Rysunek 1.7.
32-bitowy adres liniowy
Katalog (DiR)
' Przesunięcie (OFFSET) '
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 O
Komunikacja procesora z Innymi elementami architektury komputera
31
Rysunek 1.8.
Interpretacja 32-bitowego adresu liniowego
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 O
PASĘ
Page 1023 |
|
Page2Q47 |
|
PageX7i |
Page 1022 |
|
Page 2046 |
|
Paga 3070 |
3 |
|
\ |
|
^ |
Page 2 |
|
Page 1026 |
|
Page2QSO |
Pagel |
|
Paga 1025 |
|
Pags2049 |
PagtO |
|
Paga 1024 |
|
Paga204B |
o
32-bitowe słowo adresowe podzielone jest na trzy grupy. W pierwszych dziesięciu najstarszych bitach przechowywany jest numer rekordu w katalogu stron (Page Directory). Katalog zawiera l 024 takich rekordów a każdy z nich wskazuje na tablicę stron (Page Tables). Pierwszy rekord w katalogu stron wskazuje adres bazowy tablicy stron o numerach 0-1 023, drugi dotyczy tablicy l 024 - 2 047 a ostatni odnosi się do stron o numerach l 047 552 - l 048 575. 10 kolejnych bitów adresu liniowego (Page) wskazuje na jeden z l 024 rekordów w danej tablicy. Same rekordy w tablicach stron stanowią z kolei wskaźniki do stron, z których każda ma wymiar 4 kB.
Adresowany obiekt ulokowany jest w obrębie danej strony. Jego dokładna pozycja ustalana jest na podstawie pola Offset, tj. dwunastu najmłodszych bitów adresu liniowego (2l2 = 4kB).
Caching
Coraz szybciej taktowane procesory wymagają coraz szybszych układów pamięci. Czas przetwarzania prostego rozkazu nie jest zwykle dłuższy od pojedynczego cyklu zegarowego (5 ns przy częstotliwości 200 MHz). Pamięć operacyjna współczesnych komputerów PC zbudowana jest z układów scalonych DRAM, które cechuje czas dostępu większy o rząd wielkości. Na cóż zdać się może procesor pracujący z tak dużą prędkością, jeśli czas oczekiwania na kolejną porcję danych wynosi w najlepszym razie 50 ns. Istnieją oczywiście typy pamięci (SRAM - Static RAM) mogące sprostać takim wymaganiom, ale ze względów ekonomicznych (są kilkanaście razy droższe) nie można z nich zbudować całej pamięci operacyjnej.
32
Anatomia PC
Dla zlikwidowania tego wąskiego gardła wprowadzona została pamięć podręczna stanowiąca bufor o krótkim czasie dostępu (poniżej 10 ns). Rozwiązanie to jest ekonomicznie uzasadnionym kompromisem: duża i tania pamięć główna wspierana jest przez małą, szybką i nie aż tak drogą pamięć podręczną (Cache).
Rysunek 1.9.
Pamięć podręczna wspomaga pamięć główną
CPU
Pamięć Cache
Kontroler Cache
Pamięć
Rozwiązanie takie nie było by możliwe, gdyby nie jedna cenna właściwość przetwarzanego przez komputery PC kodu: jest on stosunkowo spójny. Procesor „porusza się" przez dłuższy czas w tym samym rejonie pamięci a nie skacze chaotycznie po całym obszarze. Analizowane rozkazy ułożone są w pamięci sekwencyjnie (nie licząc oczywiście rozgałęzień i skoków) a bloki danych też nie są świadomie rozpraszane po całej przestrzeni adresowej. Rozważania teoretyczne i symulacje doprowadziły do wyznaczenia przybliżonych rozmiarów takiego obszaru. Można przyjąć z prawdopodobieństwem równym 0,9 iż większość odwołać do pamięci będzie się mieścić w bloku nie przekraczającym 16 kB. Tabela 1.4 prezentuje rozmiary pamięci podręcznej stosowanej w aktualnie produkowanych procesorach.
Tabela 1.4.
Rozmiar pamięci podręcznej stosowanej w aktualnie produkowanych procesorach
CPU |
P54C |
P55C |
P-Pro |
P-II |
Ml |
M2 |
#5 |
K6 |
Ll-kodfkBJ |
8 |
16 |
8 |
16 |
16* |
64* |
16 |
32 |
LI- dane [kB] |
8 |
16 |
8 |
16 |
|
|
8 |
32 |
L2 [kB] |
- |
- |
256/512 |
256/512 |
- |
- |
- |
- |
* Wspólny dla kodu i danych, ponadto 256 bajtów Instruction Linę Cache |
||||||||
Komunikacja procesora z innymi elementami architektury komputera 33
Topologie
Buforowe działanie pamięci podręcznej osiąga się umieszczając ją „po drodze" lub „przy drodze" do pamięci głównej. Niezależnie od różnic w strategii dostępu oraz realizowanych algorytmach, w chwili obecnej występują w świecie PC trzy podstawowe układy topologiczne.
W układzie konwencjonalnym (często określany nazwą Look-Aside) - rysunek 1.10 -z którym mamy do czynienia w procesorach x86 i Pentium, pamięć podręczna dołączona jest równolegle do magistrali pamięciowej. Widać wyraźnie, iż procesor odwołuje do pamięci cache wykorzystując magistralę pamięciową: częstotliwości pracy cache jest więc taka sama jak pamięci głównej, jedynie czas dostępu może ulec skróceniu.
Rysunek 1.10.
Układ
konwencjonalny (Look-Aside) podłączenia pamięci podręcznej
Drugi sposób podłączenia przedstawiony na rysunku 1.11 określany jest mianem Look-Through lub Inline Cache. Procesor, zanim sięgnie do pamięci głównej, napotyka układ pamięci podręcznej. Ta z kolei, sprzężona jest z pamięcią główną poprzez właściwą magistralę pamięciową. Cache może więc być taktowany z prędkością większą niż sama magistrala pamięciowa, na przykład dwa razy szybciej - takie rozwiązanie zastosowano w procesorze Pentium II.
Rysunek 1.11.
Układ Look-Through podłączenia pamięci podręcznej
CPU
k-> Cache l*—* RAM l
Oddzielenie pamięci podręcznej od magistrali pamięciowej ma miejsce w procesorze Pentium Pro - architektura tego typu znana jest pod nazwą Backside (rysunek 1.12). Kontroler pamięci podręcznej osadzony jest na strukturze procesora i ma (poprzez zestaw wydzielonych końcówek) bezpośrednie połączenie z pamięcią podręczną. Częstotliwości taktowania magistral są od siebie absolutnie niezależne.
Rysunek 1.12.
Układ Backside podłączenia pamięci podręcznej
RAM
CPU
h > Cache l
34
Anatomia PC
Organizacja pamięci podręcznej
Pamięć podręczna zorganizowana jest w linijki (Cache Lines) o rozmiarach 16 lub 32 bajtów. Jest to najmniejsza porcja informacji, jaką pamięć podręczna wymienia z pamięcią główną. System taki narzucony został dla zwiększenia wydajności. Większość kontrolerów magistral realizuje zwielokrotniony cykl dostępu (Bursf) bardzo szybko. Pamięć podręczna „widzi" pamięć główną jako zbiór linijek, te z kolei pogrupowane są w zespoły zwane stronami (Pages). Informacja o tym, które z linijek RAM znajdują się aktualnie w pamięci cache przechowywana jest w katalogu pamięci podręcznej TRAM (TAG-RAM). Sposób odwzorowywania linijek i stron pamięci głównej w bloku pamięci podręcznej może przebiegać na jeden z trzech omówionych poniżej sposobów.
Mapowanie bezpośrednie (Direct Mapped)
Implementacja tego typu jest najprostszą z możliwych i można ją również rozpatrywać jako przypadek szczególny układu asocjacji zespołowej (1-Way-Set). Pamięć główna podzielona jest na strony zgodne z rozmiarem bloku pamięci podręcznej.
Rysunek 1.13.
Mapowanie bezpośrednie
o |
|
C |
o |
|
c |
J2 |
STRONA |
ca |
^ |
STRONA |
co |
.c |
0 |
c |
.£ |
1 |
c lj |
Pamięć główna
.
&
Pamięć podręczna
W linijce O pamięci podręcznej znajduje się zawsze jakaś linijka O pewnej strony pamięci RAM. Prostota konstrukcji i szybkość odszukiwania informacji (wystarczy przeprowadzić tylko jedną operację porównania) są jedynymi zaletami takiego systemu. Układ cechuje niestety brak elastyczności i mała efektywność, szczególnie jeśli dochodzi do częstych skoków poza granicami stron. Jeżeli pamięć podręczna przechowuje linijkę n jakiejś strony a system żąda dostarczenia linijki n strony następnej, kontroler musi usunąć ją z pamięci, chociaż jest prawie pewne iż w chwilę potem system odwoła się do niej ponownie.
Pełna asocjacja (Fully Associative)
Organizacja z pełną asocjacją (rysunek 1.14) pozwala na składowanie dowolnej linijki RAM w dowolnym miejscu pamięci podręcznej. W modelu tym nie ma symbolicznego podziału na strony pamięci a operuje się wyłącznie linijkami.
Ta optymalnie elastyczna organizacja ma jednak dużą wadę: odszukanie informacji w pamięci podręcznej wymaga przeglądnięcia całego katalogu TRAM, bowiem poszukiwana linijka może być na dowolnej pozycji. Konstrukcje tego typu mają uzasadnienie ekonomiczne dla bloków pamięci podręcznej nie przekraczających 4 kB.
35
Komunikacja procesora z innymi elementami architektury komputera
Rysunek 1.1 4. |
|
|
||||
|
|
|
|
|
|
|
Pełna asocjacja |
o i? |
s |
CM .S |
|
c: 2 |
Pamięć |
|
'c •J |
'E 13 |
c: L-J |
|
•g i_t |
główna |
Pamięć podręczna
Asocjacja zespołowa (Set Associative)
Stanowi kombinację rozwiązań przedstawionych powyżej. Cechą charakterystyczną architektury tego typu jest podział pamięci podręcznej na równe porcje, zwykle 2 lub 4 zwane kanałami (Ways) - rysunek 1.15.
Rysunek 1.15.
Asocjacja zespołowa
O |
|
c |
O |
|
c |
2 |
STRONA |
co _^ |
3 |
STRONA |
J? |
1- |
0 |
c |
i- |
1 |
C |
^ |
|
ZJ |
^j |
|
_J |
Pamięć główna
2
&
Pamięć podręczna
Kanał-O
Kanał-1
Wymiar strony w pamięci RAM odpowiada rozmiarowi kanału w pamięci cache. Każdy z kanałów administrowany jest zgodnie z regułami obowiązującymi dla organizacji typu „mapowanie bezpośrednie". System kontroli trafień (Hit/Miss) ogranicza się do przeprowadzenia dwóch (2-Way-Sef) lub maksymalnie czterech (4-Way-Sef) porównań: linijka o określonym numerze może znajdować się tylko w jednej z dwóch (czterech) dopuszczalnych lokalizacji.
Reakcja pamięci podręcznej na żądanie udostępnienia danych zależy od implementacji oraz od faktu, czy poszukiwane dane są w niej istotnie zawarte. Obecność danych w pamięci cache nazywa się trafieniem (Cache Hit) i nie wymaga sięgania do pamięci głównej. W sytuacji odwrotnej (Cache Miss) uruchamiana jest magistrala pamięciowa i do pamięci podręcznej sprowadzana jest nowa linijka.
Cykle zapisu do pamięci mogą uwzględniać na swej drodze obecność pamięci cache (Write Back) lub ją omijać (Write Through).
36
Anatomia PC
Write Through
Implementacja tego typu powoduje, iż zapis wyzwala zawsze cykl dostępu do pamięci głównej, niezależnie od tego, czy dana linijka obecna jest w cache czy nie. W razie trafienia (Cache Hit) odbywa się oczywiście również i aktualizacja.
Write Back
Pamięć podręczna pracująca w tym trybie zbiera wszystkie cykle zapisu i aktualizuje swoją zawartość ale nie zawartość pamięci głównej. Dzieje się to dopiero na konkretne żądanie wyrażone przez instrukcję programową (rozkaz WBINYO: Write Back and Invalid Data Cache), sygnał sprzętowy na linii -FLUSH lub w wyniku braku trafienia w fazie odczytu. Zapis do pamięci ma miejsce w czasie gdy wolna jest szyna systemowa (a procesor przetwarza kod zawarty np. w pamięci podręcznej poziomu pierwszego). Metoda taka gwarantuje oczywiście dużą wydajność ale jednocześnie komplikuje układ.
Pamięć podręczna procesora 80386
Jako konkretny przykład omawianych zagadnień przedstawiona zostanie konstrukcja pamięci podręcznej procesora 80386. Model ten wyposażony został w zintegrowany czterokanałowy kontroler cache (4-Way-Set) obsługujący blok 16 kB pamięci SRAM zorganizowanej w linijki 16-bajtowe.
1 • DW IDouble Wofdl . 32 bity 1-' bity A3-A2 adresu wskazują na 16 bajtów jedno z czterech DW ^ |
|||
|
|
1 |
|
|
|
|
|
'$,»;,.&«*, - |
Dan« |
DaiW' . -"• |
- '.',; "ftll» '/ ,"1 |
|
|
|
f |
+ „ |
< »• |
|
|
Rysunek 1.16.
DW
DW
DW
DW
Organizacja linijki pamięci cache
Generowany we wnętrzu procesora 32-bitowy adres lokalizacji w pamięci (rysunek 1.17) przejmowany jest przez kontroler podręcznej, który dokonuje jego rozkładu na trzy składniki:
B31-BI2 :Tag
Bn-B4 :Set
B3 - bo : Byte
Rysunek 1.17.
32-bitowy adres lokalizacji w pamięci
r
TT
TT
31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 O
Na pełnowartościowy wpis do pamięci podręcznej składają się dwa ściśle ze sobą powiązane komponenty:
Komunikacja procesora z innymi elementami architektury komputera
37
Rekord w pamięci cache (16-bajtowa linijka)
Rekord w katalogu pamięci cache
Katalog jest strukturą informacyjną, przy pomocy której kontroler zarządza danymi w pamięci podręcznej. Każda 16-bajtowa linijka stanowi elementarny obiekt opisany przez powiązany z nią rekord. Rekord zawiera w sobie 20-bitowy adres TAG oraz kilka dodatkowych pól bitowych służących dla celów organizacyjnych.
Rysunek 1.18.
Rekord w katalogu pamięci podręcznej
Adres
20 bitów (adres TAG)
3 bity (LRU)
Sam katalog zlokalizowany jest (fizycznie) we wnętrzu kontrolera, który oddaje na ten cel fragment pamięci SRAM. Uwaga ta dotyczy oczywiście pamięci L-1 (Level One Cache) zintegrowanej w strukturze CPU. Na pamięć podręczną poziomu drugiego L-2 (Level Two Cache), która umieszczana jest na płycie głównej, składa się większa liczba układów scalonych niż wynikało by to z prostego rachunku „pamięć całkowita L-2/ pamięć pojedynczego układu". Obowiązek prowadzenie katalogu (TAG-RAM) pociąga za sobą oczywiście konieczność instalacji kilku ponadplanowych układów SDRAM.
Katalog pamięci podręcznej procesora 80386 (rysunek 1.19) jest czterokanałowy (WayO - Way3). Każdy z kanałów stanowi tabelę o 256 wierszach i 22 kolumnach. Wiersze tabeli przechowują adres TAG odpowiadający danej 16-bajtowej linijce. Cztery tabele opisują w sumie 16 kB pamięci cache (4 Ways x 256 Sets x 16 Byte). Dodatkowy bit WP (Write Protecf) implementuje mechanizm blokady zapisu a pole VAL (Valid) określa aktualność danych.
Rysunek 1.19.
Katalog pamięci podręcznej procesora 80386
|
Adres TAG |
r |
• v - v |
w AL |
A" SfflO |
|
i |
|
|
Setl |
|
i |
|
|
<. Ś |
|
|
|
|
% S*1 '59 ffi |
-JftMfa I |
iu |
|
|
•8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
T Set 255 |
|
|
|
|
WayO
Way1
Way2
Way3
LRU
Pozycja wiersza w tabelach WayO — Way3 wyznaczana jest przez bity Al l - A4 słowa adresowego (Set-Address). Adres TAG stanowi centralny fragment mechanizmu umożliwiającego jednoznaczne określenie trafienia (Cache Hit). Mechanizm blokady zapisu (WP) uruchamiany jest na czas trwania operacji wypełniania linijki (Cache Linę FilT), tak by procesor nie mógł zamazywać przedwcześnie jej zawartości.
38
Anatomia PC
Określenie trafienia
Procesor sięga do żądanej lokalizacji w pamięci wystawiając 32-bitowy adres na swoją szynę adresową. Adres ten przejmowany jest przez kontroler cache i rozkładany na trzy omówione wcześniej elementy: TAG, SET i BYTE. Składnik TAG przekazywany jest natychmiast do komparatora adresowego TAG natomiast 8-bitowa część Ali - A4 skierowana zostaje do katalogu (Cache Directory) powodując uaktywnienie wszystkich czterech kanałów (Way-0 — Way-3).
Bufor / Selektor
(bity A2-A3 wybierają z linijki 128 bitowej jeden z czterech DW)
Rysunek 1.20.
Określenie trafienia
Odszukany w katalogu adres TAG przekazywany jest do komparatora i porównywany z fragmentem A31 — A12 pobranym z szyny adresowej. Porównanie odbywa się dla każdego z czterech kanałów oddzielnie. Wycinek Ali - A4 magistrali kierowany jest równolegle do obwodów pamięci podręcznej przechowującej linijki z danymi. Proces przebiega przez wszystkie kanały równolegle, stosownie do aktualnej selekcji w katalogu. Pamięć wystawia za każdym razem jedną z zaadresowanych w ten sposób linijek. Informacja ta przejmowana jest tymczasowo przez bufor separujący obwody pamięci podręcznej od magistrali danych. Jeśli poszukiwana informacja znajduje się w jakimś kanale, dochodzi do zgodności adresów TAG. Na sygnał z komparatora 32-bitowy fragment zawartości bufora (jedna czwarta część 16 bajtowej linijki wyizolowana przez bity A2 - A3) odkładany jest na magistralę a cały układ generuje sygnał trafienia (Cache Hit). Bity AO — A l nie podlegają ocenie.
Komunikacja procesora z innymi elementami architektury komputera 39
Decyzja o wymianie linijki (LRU)
Stwierdzenie braku obecności określonej linijki w pamięci podręcznej (Cache Miss) pociąga za sobą konieczność jej sprowadzenia z pamięci głównej. Kontroler cache musi przygotować na ten cel jedno wolne miejsce, a jeżeli wszystkie są zajęte, określić która z obecnych w pamięci podręcznej linijek może zostać usunięta. Algorytm wyboru bazuje na obserwacji zakresu wykorzystania zmagazynowanej dotychczas informacji. Skuteczność działania takiego aparatu zależy w dużej mierze od stopnia jego rozbudowania.
Kontroler cache procesora 80386 posługuje się trzema bitami LRU (Last Recently Used), które przechowywane są w połączeniu z rekordami katalogu TAG. Częstotliwość dostępu do informacji każdego z kanałów rejestrowana jest podczas ciągłej pracy układu:
Jeżeli ostatni dostęp do kanału Way-0 lub Way-1 okazał się trafieniem, usta
wiany jest bit LRU-B0.Jeżeli wybrany został kanał Way-0 ustawia się bit LRU-B,, a dla Way-1 bit ten
ulega wyzerowaniu.Jeżeli trafienie miało miejsce w kanale Way-2 lub Way-3, bit LRU-B0 zostaje
wyzerowany.Trafienie w kanale Way-2 oznaczane jest ustawieniem, a trafienie w kanale
Way-3 wyzerowaniem bitu LRU-B2.
Bity LRU aktualizowane są w następstwie każdego cyklu dostępu. Reset (lub Start) powoduje wyzerowanie wszystkich bitów LRU. Gdy kontroler stwierdzi brak trafienia, linijka zawierająca żądaną informację sprowadzana jest do pamięci podręcznej w miejsce określane przez algorytm pracujący według schematu przedstawionego na rysunku 1.21.
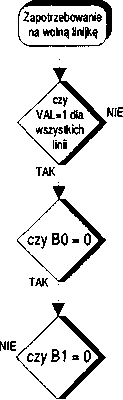
Jeśli brak jest wolnych pól w pamięci podręcznej, analizowane są bity LRU przynależne do danego adresu SET. Algorytm przesuwa się wzdłuż naszkicowanego powyżej drzewa logicznego i oznacza jedną z linijek jako przeznaczoną do usunięcia. W tak przygotowane miejsce sprowadzana jest z pamięci głównej żądana informacja (Cache Linę Fill).
Opisana tu metoda bazująca na algorytmie LRU stosowana jest w większości omawianych w tej książce procesorów. Dzięki niej usuwana jest ta linijka, która spoczywała bezużytecznie przez najdłuższy czas.
Inną drogą poszli twórcy procesora AMD-K5 implementując prosty algorytm opierający się na losowym wyborze wolnego miejsca (Pseudo Rondom Replacement Policy). Badania statystyczne i symulacje wykazały, iż skuteczność działania takich metod nie odbiega znacznie od wyników uzyskiwanych przy pracy z LRU. Do niewątpliwych zalet układów tego typu należy zaliczyć szybkość działania i prostotę (eliminuje się bity LRU i cały mechanizm związany z ich zarządzaniem).
40
Anatomia PC
Rysunek 1.21.
Algorytm sprowadzania linijki do pamięci cache
NIE
Wymienić lnie 1 o statusie VAL=0 l
TAK
i
I Wymienić linijkę l wMokuWay-0 l
Wymienić linijkę | wUokuWay-2
Wymienić linijkę wblokuWay-1
I
Wymienić linijkę l wblokuWay-3 |
Zakres pokrywany przez pamięć podręczną
Zlokalizowana we wnętrzu procesora pamięć podręczna LI przyspiesza dostęp do bloków pamięci poziomu wyższego, który stanowi zależnie od konstrukcji pamięć operacyjna lub pamięć podręczna drugiego poziomu (L2). Dobroczynne działanie cache polegające na skróceniu czasu dostępu do kolejnego wyższego bloku w hierarchii możliwe jest do osiągnięcia tylko w pewnym zakresie adresów. Zarówno rozmiar pamięci podręcznej jak i szczegóły konstrukcyjne kontrolera ograniczają rozmiar tego obszaru (Cacheable Ared).
Z faktu tego warto zdawać sobie sprawę planując rozbudowę komputera. Obszar pokrywany przez CPU (wraz z LI) nie ma zwykle większego znaczenia, gdyż ograniczenie stanowi kontroler L2 zlokalizowany we wnętrzu układów sterujących na płycie głównej. Obecność pewnej liczby podstawek SIMM lub DIMM nie gwarantuje automatycznie, iż umieszczone w nich moduły pamięci o rozmiarze dopuszczonym przez dokumentację będą spełniały należycie swe funkcje. Również procesory Pentium II (wyposażone w cache drugiego poziomu) mają określone ograniczenia. Rozszerzenie pamięci powyżej bariery pokrywanej przez cache objawia się spowolnieniem komputera i ma skutek odwrotny od zamierzonego.
Płyty główne z podstawką typu „7" (Pentium, Pentium MMX itp.) bazują zwykle na jednym z zestawów (Chip-Set) firmy Intel. Będące już na wymarciu układy typu TX obejmują przestrzeń do 64 MB. Prawie całkowicie znikły już modele bazujące na układach HX, które gwarantowały (po umieszczeniu dodatkowego układu TAG-RAM) pokrycie obszaru do 512 MB.
Komunikacja procesora z innymi elementami architektury komputera
41
Dla potrzeb nowych procesorów „pentium-podobnych" współpracujących z magistralą 100 MHz stworzona została nowa generacja produktów (tabela l .5). Zestawy układów scalonych nie pochodzą w tym wypadku od firmy Intel, która nie jest zainteresowana rozbudową nurtu 100 MHz na bazie innej niż Pentium II. Układy VIA-MVP3 pozwalają na pokrycie (zależnie od rozmiarów L2 i trybu pracy WB lub WT) obszaru do 512 MB a zestawy ALi-V obejmuje przestrzeń 128 MB.
Tabela 1.5.
Maksymalny rozmiar pamięci cacheowany przez chipsety współpracujące z procesorem Pentium
Chip-Set |
VIA MVP3 L2=512kB |
VIA MVP3 L2=1024kB |
VIA MVP3 L2=2048kB |
ALiV L2=512/1024kB |
Write Back |
64 MB |
128 MB |
256 MB |
128 MB |
Write Through |
128 MB |
256 MB |
512 MB |
128 MB |
Procesor Pentium II (wraz ze swym LI) jest w stanie pokryć obszar do 64 GB. Zintegrowany z procesorem kontroler pamięci podręcznej L2 ogranicza ten obszar (zależnie od modelu) do 512 MB lub 4 GB. Do grupy pierwszej zaliczane są wszystkie procesory poniżej 300 MHz i pewna część modeli taktowanych zegarem 333 MHz. Procesory Pentium 11/333 oznaczone numerami SL2QH i SL2S5 oraz wszystkie wersje 350 MHz i 400 MHz należą do grupy drugiej.
Nie mniej ważną rolę odgrywa architektura wewnętrzna układów płyty głównej, gdyż to one właśnie realizują dostęp procesora do pamięci operacyjnej (tabela 1.6).
Tabela 1.6.
Maksymalny rozmiar pamięci cacheowany przez chipsety współpracujące z procesorem Pentium II
Chip-Set |
440EX |
440FX, LX, BX |
440GX |
440NX |
Cacheable Area |
256 MB |
1 GB |
2 GB |
8 GB |
Obsługa przestrzeni adresowej l/O
Przestrzeń adresowa procesorów dzieli się na obszar pamięci oraz na obszar wejścia/ wyjścia (I/O — Input/Outpuf). Różnica widoczna jest zarówno od strony programowej jak i sprzętowej.
Rozkazy maszynowe odwołujące się do pamięci (np. MOV mem, reg) operują w pierwszym z tych obszarów. Dwa specjalne rozkazy odwołań do portów (in i out) obsługują drugi z nich. Warto dodać, że rozkazy in i OUT operują wyłącznie za pośrednictwem akumulatorów, tj. nie można przesłać zawartości pamięci bezpośrednio do portu lub skierować zawartość portu do pamięci. Przestrzeń adresowa pamięci nie ma jak wiadomo takich ograniczeń. Podczas operacji na portach ignorowane są ponadto stany
42
Anatomia PC
rejestrów segmentowych. Przestrzeń I/O można więc sobie wyobrazić jako oddzielny segment 64 kB, do którego można się zwracać wyłącznie za pośrednictwem instrukcji IN i OUT.
Procesor dysponuje mechanizmem sygnalizacyjnym jednoznacznie informującym otoczenie o tym, czy aktualne odwołanie odnosi się do pamięci czy też do przestrzeni I/O. Funkcje tę spełniają odpowiednie sygnały sterujące.
W przestrzeni I/O rozmieszczane są zwykle rejestry konfiguracyjne (zestawy przełączników binarnych) sterujące pracą różnych układów otaczających procesor lub wręcz samego procesora. Dostęp do tych rejestrów odbywa się za pośrednictwem instrukcji maszynowych IN oraz out, mówimy wówczas o tzw. I/O-mapped I/O. Oczywiście nic nie stoi na przeszkodzie by te same rejestry umieścić w przestrzeni adresowej procesora i odwoływać się do nich poprzez rozkazy maszynowe MOV itp. Rozwiązanie tego typu nosi miano Memory-mapped I/O. Układy logiczne kontrolera magistrali kierują i tak wszelkie odwołania do właściwej lokalizacji: pamięci lub portów.
Procesor 8086
Zapis i odczyt portów nie różni się zasadniczo od analogicznych cykli dostępu do pamięci. Procesor sygnalizuje potrzebę sięgnięcia do portu poprzez specyficzny stan sygnałów sterujących ~S2, ~S1 i ~SO.
|
~S2 |
~S1 |
~so |
Odczyt portu |
0 |
0 |
1 |
Zapis do portu |
0 |
1 |
0 |
Procesor 8086 może zaadresować 65 536 (64 K) portów, tak więc cztery najwyższe linie adresowe (A)9 - A]6) są zawsze równe zero. W komputerach PC-kompatybilnych używa się ponadto wyłącznie pierwszych l 024 portów (OxOOOh - 0x3ffh).
Procesory 80386 i 80486
Procesory te mogą zaadresować:
65 536 (64 K) portów 8-bitowych o adresach rozpoczynających się od O, l, 2 do 65535
lub:
32 768 (32 K) portów 16-bitowych o adresach rozpoczynających się od O, 2, 4 do 65534
lub:
16 384 (16 K) portów 32-bitowych o adresach rozpoczynających się od O, 4, 8 do 65532
Komunikacja procesora z innymi elementami architektury komputera
43
Dopuszczalne jest mieszanie portów o różnych wymiarach, ale sumaryczna długość w przeliczeniu na bajty nie może przekraczać 64 K. Stan końcówki M/-IO sygnalizuje wybór przestrzeni adresowej:
|
M/-IO |
Odwołanie do pamięci |
1 |
Odwołanie do I/O |
0 |
Kierunek transmisji rozpoznawany jest w klasyczny sposób znany z cykli dostępu do pamięci:
|
W/~R |
Zapis do portu |
1 |
Odczyt portu |
0 |
Ze względu na wymóg kompatybilności „w dół" (486 -> 386 -» 286) procesor 80486 blokuje adresy portów Oxf8h - Oxffh używane we wcześniejszych modelach jako kanał komunikacyjny CPU-MPU (koprocesor). Dostęp do przestrzeni I/O odbywa się z pominięciem pamięci podręcznej (zarówno zapis jak i odczyt portów). W trakcie pisania do portów nie korzysta się z buforów zapisu procesora.
Pentium
Zakres przestrzeni I/O zgodna jest z procesorem 80486 (64 K portów 8-bitowych lub ekwiwalent). Na uwagę zasługuje jedynie fakt, iż w cyklach dostępu do portów bierze udział w najlepszym razie połowa szerokości 64-bitowej magistrali danych. Cykle takie omijają również pamięć podręczną oraz wszelkie bufory zapisu.
Funkcje kontrolne i sterujące
Współczesne procesory posiadają szereg wbudowanych funkcji kontrolnych i sterujących. Mechanizmy te należy podzielić na następujące grupy:
Systemy sterowania. Zaliczamy do nich wszelkie rejestry konfiguracyjne, których
stan określa aktualny tryb pracy procesora i pozwala na wybór różnorodnych
opcji. Liczna grupa tych rejestrów jest wspólna dla większości znanych proceso
rów, istniejąjednak pewne specyficzne rozwiązania znane tylko w obrębie danego
modelu lub producenta (np. grupa rejestrów obecna jedynie w Pentium Pro).Systemy śledzenia i nadzoru. Zestaw funkcji ułatwiających śledzenie (Debug)
przebiegu wykonywanego programu na poziomie sprzętu. Grupa ta obejmuje
również mechanizmy ułatwiające ocenę wydajności przetwarzania (Performance
Monitoring) oraz wszelkiego rodzaju stopery i układy pomiaru czasu (Timers).
44 Anatomia PC
Systemy diagnostyczne. Stanowią wewnętrzne systemy kontrolne pierwszego poziomu i ułatwiają wykrywanie błędów w pracy wewnętrznych systemów CPU. Do grupy tej należy również zaliczyć tryb JTAG (począwszy od 80486 SOMHz). Na systemy kontrolne CPU składają się: ogólny tester wewnętrzny (BIST), systemy kontroli TLB i pamięci podręcznej oraz mechanizm przejścia w stan wysokiej impedancji. Konkretna implementacja danych funkcji zależy od producenta i wersji procesora, część z nich została wprowadzona dopiero na określonym etapie rozwoju. Aby nie zaciemniać obrazu, podamy jedynie krótki przegląd tych układów.
BIST
BIST (Built In Self Test) stanowi zestaw testów wewnętrznych obejmujących między innymi układy logiczne, wewnętrzną pamięć ROM procesora oraz częściowo pamięć podręczną i TLB.
Funkcja aktywuje się w następujących okolicznościach:
Jeśli wejście AHOLD utrzymywane jest w stanie wysokim przez czas dłuższy od
dwóch cykli zegarowych CLK.
Po powrocie sygnału RESET do stanu niskiego
Czas trwania testu wynosi około 220 cykli zegara. Wynik testu odkładany jest w rejestrze EAX. Ocena OxOOOOOOOOb wskazuje na wynik bezbłędny, każda inna wartość dyskwalifikuje procesor.
Kontrola TLB
Funkcja służy kontroli układu TLB i wprowadzona została po raz pierwszy w modelu 80386. Interfejs sterujący zbudowany jest w oparciu o rejestry TR6 i TR7. Kontrola polega na zapisie rekordu do TLB i odczycie kontrolnym z porównaniem (TLB-Lookup).
Kontrola pamięci podręcznej
System kontroli pamięci podręcznej procesora (On-Chip Cache) sterowany jest grupą rejestrów kontrolnych TR3 - TR5. Rejestry te stanowią porty umożliwiające bezpośredni dostęp do pamięci podręcznej. Można dzięki temu przeprowadzić następujące funkcje kontrolne: zapis i odczyt bufora, zapis i odczyt cache, oczyszczenie pamięci podręcznej (Cache Flush).
Przejście w stan wysokiej impedancji
Funkcja służy do lokalizowania usterek i przeprowadzania testów układów otoczenia procesora. Odpowiada w przybliżeniu wyjęciu CPU z podstawki, bowiem wszystkie końcówki wyjściowe i dwukierunkowe (warunkowe wyjście lub wejście) przechodzą w stan wysokiej impedancji i nie mają wpływu na stan przyłączonych do nich linii.
Komunikacja procesora z innymi elementami architektury komputera
45
JTAG
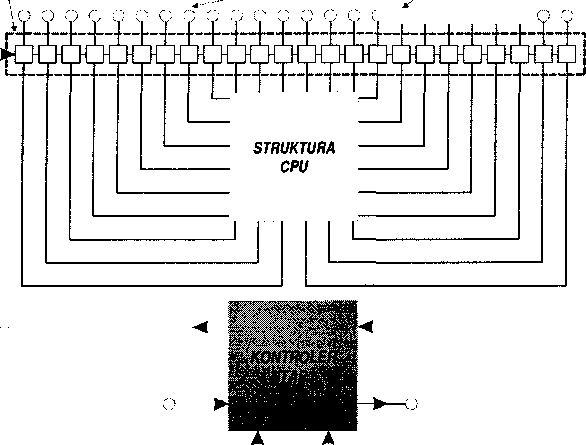
JTAG (nazywany też Boundary Scan Test) stanowi potężny system diagnostyczny używany głównie w fazie projektowania i testowania układów otoczenia procesora. Warto podkreślić, iż omawiany tu mechanizm ma znaczenie wyłącznie dla producentów sprzętu. Chociaż użytkownik komputera nie ma najmniejszej potrzeby uciekania się do funkcji oferowanych przez ten system, wyjaśnimy w tym punkcie jego elementarne cechy. JTAG wprowadzony został po raz pierwszy do modelu 80486-50 pracującym wtedy jeszcze bez wewnętrznego podwajacza częstotliwości. Wszystkie późniejsze wersje tego procesora (DX2-50, SX-xx i wzwyż) oraz ich następcy miały już zaimplementowany JTAG.
System pozwala widzieć procesor jako „czarną skrzynkę" z pewną ilością wyprowadzeń. Istota rzeczy polega na tym, że stan dowolnej końcówki można nie tylko ustawić (oddziaływanie procesora na układy otaczające) ale i odczytać (ocena działania układów zewnętrznych).
Rysunek 1.22.
Procesor w obudowie
Końcówki zewnętrzne (wyprowadzenia)
Aby umożliwić taki tryb pracy należy odseparować „właściwą" strukturę procesora od świata zewnętrznego. W istocie rzeczy, każde wyprowadzenie obudowy nie jest bezpośrednio połączone ze swym logicznym punktem docelowym lecz przebiega przez pole komórek BST.
Rysunek 1.23.
Każde
wyprowadzenie przechodzi przez pole BST
Końcówki
zewnętrzne
CPU
Dla zapewnienia efektywnej kontroli nad polem komórek BST zostały one połączone w jeden szereg, a pracę całego systemu nadzoruje specjalny kontroler TĄP (Test Access Port). Dostęp do kontrolera odbywa się za pośrednictwem czterech końcówek: TMS, TDI, TDO i TCK.
46
Anatomia PC
Rysunek1,24.
Dostęp do kontrolera TĄP umożliwiają końcówki TMS, TDI, TDO i TCK
TDI
Rejestr BST
Końcówki zewnętrzne procesora.
\
TDO
) O O Q O O C
TMS TCK
TCK Test Clock, końcówka wejściowa. Wejście zegarowe sygnału taktującego
kontrolera TĄP.
TDI Test Data Input, końcówka wejściowa. Punkt wejściowy rejestru BST
i kontrolera TĄP. Podawana tędy informacja zostaje wprowadzana synchronicznie z zegarem TCK.
TDO Test Data Output, końcówka wyjściowa. Stanowi wylot rejestru
przesuwnego i punkt wyprowadzania danych od kontrolera. Proces odbywa się synchronicznie z impulsami zegarowymi TCK. Kontrolery TĄP mogą być łączone w szereg, co daje możliwość efektywnego testowania grupy urządzeń, np. płyt głównych systemów multiprocesorowych. Wyjście TDO kierowanie jest wówczas na wejście TDI kolejnego układu kaskady.
TMS Test Modę Select, końcówka wejściowa. Wymuszenie wysokiego stanu
logicznego na tym wejściu powoduje uruchomienie całego układu JTAG. Przetrzymanie stanu wysokiego przez okres powyżej pięciu cykli zegarowych procesora oznacza reset dla kontrolera TĄP i powrót do domyślnej konfiguracji.
Komunikacja procesora z innymi elementami architektury komputera
47
Częstotliwość taktowania
Częstotliwość taktowania procesora leży w ścisłym związku z zegarem magistrali i stanowi jego wielokrotność. Wartość mnożnika ustalana jest poprzez stan specjalnych końcówek sterujących (BF) procesora. Obecna powszechnie w komputerach PC magistrala PCI narzuca limit na częstotliwość szyny wewnętrznej wynoszący 66 MHz, połowę tej częstotliwości stanowi zegar taktujący magistralę PCI (33 MHz). Układy peryferyjne zgodne ze standardem PCI muszą pracować niezawodnie przy tej częstotliwości.
CPU generacji 586 obarczone są sporą wadą: nie wiedzą jaka jest ich właściwa częstotliwość taktowania. Procesor przyjmuje na swoje wejście pewną częstotliwość zegarową i powiela ją zgodnie z wartością zakodowaną na końcówkach BF. Liczba takich końcówek wynosi zależnie od modelu od jednej do trzech a ich położenie zaznaczone jest na poniższym rysunku 1.25.
Rysunek 1.25
Położenie końcówek BF
17 !S l! 20 H Z2 23 a H Z« *T 2« 21 M 31 JI 33 » » M 37
Widok od strony końcówek
coc
/ Pin 1
Właściwe ustawienie mnożnika leży w gestii płyty głównej, która dysponuje zwykle zestawem zwor konfiguracyjnych. Sytuację pogarsza fakt, iż różne typy procesorów interpretują tą samą kombinację poziomów na wejściach BF na różne sposoby. Ustawienie BFO = BF1 = l oznacza dla klasycznego Pentium współczynnik 1,5 (100 MHz przy magistrali 66 MHz), a dla Pentium MMX i AMD-K6 wartość 3,5 (233 MHz dla tej samej częstotliwości magistrali).
Sama obecność końcówki w procesorze to dopiero połowa sukcesu. Musi być również możliwość sterowania jej poziomem logicznym czyli fizyczne połączenie odpowiedniego styku na podstawce ze zworą. Końcówka „wisząca w powietrzu" zachowuje się jak logiczna jedynka. Aktualny przykład to rzadko obecne w starszych płytach wyprowadzenie BF2 niezbędne dla procesora AMD-K6 przewidzianego do pracy z częstotliwością 266 MHz. Maksymalna wartość mnożnika bez udziału BF2 sięga jedynie do x3,5 co ogranicza wartość zegara CPU do 233 MHz.
48
Anatomia PC
Warto również wspomnieć o istotnym szczególe konstrukcyjnym różniącym procesory Pentium i Pentium MMX. Modele standardowe mają wewnętrzne rezystory podciągające poziom napięcia na wyprowadzeniach BFO i BF1 (Pull-up). Wraz z pojawieniem się serii MMX firma Intel zdecydowała się na wprowadzenie zmiany: końcówka BFO wyposażona została w rezystor sprowadzający do masy (Pull-down). Poziomowanie linii BF1 nie uległo przy tym zmianie. Często jedynym ratunkiem dla posiadaczy nieco starszych płyt głównych borykających się z problemami właściwych mnożników jest sięgnięcie po multimetr, pomiar napięć na końcówkach BF i ewentualna ingerencja przy pomocy lutownicy i zewnętrznych rezystorów.
Tabela 1.7.
Wartości mnożników dla podstawowych typów procesorów
BFO (Pin Y33) |
BF1 (Pin X34) |
BF2 (Pin W35) |
Pentium |
Pentium MMX |
AMDK6 |
Cyrix M2 |
0 |
0 |
1 |
2,5 |
2,5 |
2,5 |
2,5 |
1 |
0 |
1 |
3 |
3 |
3 |
3 |
0 |
1 |
1 |
2 |
2 |
2 |
2 |
1 |
1 |
1 |
1,5 |
3,5 |
3,5 |
3,5 |
0 |
0 |
0 |
- |
- |
4,5 |
- |
1 |
0 |
0 |
- |
- |
5 |
- |
0 |
1 |
0 |
- |
- |
4 |
- |
1 |
1 |
0 |
- |
- |
5,5 |
- |
Nie tylko procesory ale i układy je otaczające (Chip-Sef) pracują coraz szybciej. Sprzyja temu rozwój nowych typów pamięci (na przykład SDRAM) oraz modyfikacje standardu PCI (powyżej 33 MHz). Na rynku pojawiają się coraz częściej płyty główne dopuszczające taktowanie magistrali z prędkościami 75, 83 a ostatnio 100 MHz. Ta mnogość częstotliwości w połączeniu z szerokim zakresem mnożników daje szerokie pole dla różnych (nie zawsze rozsądnych) eksperymentów.
Nominalną częstotliwość taktowania procesora można zwykle osiągnąć na kilka sposobów, na przykład:
Magistrala |
Mnożnik |
CPU -200 MHz |
66 MHz |
3 |
198 MHz (standard) |
75 MHz |
2,5 |
187 MHz |
83 MHz |
2,5 |
207 MHz |
Podobnie można postępować w przypadku modelu 233 MHz. Podniesienie częstotliwości magistrali należy zawsze przedkładać nad przyspieszeniem zegara samego procesora:
Komunikacja procesora z innymi elementami architektury komputera
49
Magistrala |
Mnożnik |
CPU -233 MHz |
66MHz |
3,5 |
23 IMHz (standard) |
75MHz |
3 |
225 MHz (lepiej) |
Niektórym trudno oprzeć się pokusie by wypróbować również następujące kombinacje:
Magistrala |
Mnożnik |
Zegar CPU |
75 MHz |
3 |
225 MHz (zamiast 200) |
83 MHz |
2,5 |
249 MHz (zamiast 233) |
75 MHz |
3,5 |
262 MHz (zamiast 233) |
Dwie ostatnie opcje należy stanowczo odradzić, chociaż obserwowane wyniki (mierzone programami typu benchmark) są często imponujące: 10 - 20%. Przyrost mocy obliczeniowej osiągany na poziomie aplikacji nie jest jednak aż tak znaczący by usprawiedliwić ryzyko trwałego uszkodzenia procesora lub innych elementów.
Operacjom wymuszania zwiększonej częstotliwości pracy poddają się również procesory Pentium II, chociaż zważywszy na ich cenę należałoby odradzać wszelkich nierozsądnych eksperymentów. Manipulować można w zasadzie5 zarówno zegarem taktującym procesor (mnożnik) jak częstotliwością pracy magistrali (66 lub 100 MHz). Szczególna ostrożność zalecana jest w przypadku procesorów P-II-Celeron. Model 266 MHz ma trwale ustawiony mnożnik x4 i nie reaguje na ustawienie zwor konfiguracyjnych płyty. Ponieważ procesory tego typu przewidziane są do współpracy z magistralą 66 MHz, nie wolno zmuszać ich do współdziałania z szyną taktowaną zegarem 100 MHz bowiem powstającej nadwyżki (400 zamiast 266 MHz) i tak nie da się skompensować. To samo odnosi się do modelu Celeron-300 zmuszanego do pracy z szybkością 450 MHz.
Zasilanie
Właściwe napięcie zasilania procesora typu Pentium Pro i Pentium II dobierane jest przez BIOS automatycznie na podstawie odczytania informacji dostarczanych przez CPU (kodowanie przy pomocy bloku końcówek konfiguracyjnych). Procesory rodziny Pentium (włączając w to również odmianę MMX) nie mają mechanizmu automatycznej konfiguracji napięcia zasilającego i obowiązek ten spoczywa na użytkowniku. W praktyce zagadnienie to sprowadza się do odpowiedniego ustawienia zwór konfiguracyjnych (zgodnie z instrukcją dołączoną do płyty). W obiegu spotkać można trzy rodzaje płyt głównych dla procesorów zgodnych z Pentium:
• Płyty z podstawką typu 4 (Socket Type 4) przeznaczona do obsługi najstarszej odmiany Pentium - modeli 60 i 66 MHz.
.Niektóre operacje wymagają użycia lutownicy, szczegóły na odpowiednich stronach Internetu.
50 Anatomia PC
Płyty wyposażone w podstawkę typu 5 (Socket Type 5) skonstruowane dla CPU
drugiej generacji. Procesory tego typu taktowane były do częstotliwości 133 MHz
i zasilane napięciem 3.3 V przy stosunkowo ograniczonym poborze prądu. Stero
wanie mnożnikiem częstotliwości sprowadzało się do wyboru jednego z dwóch
stanów końcówki BFO (xl,5 lub x2).Najszerzej rozpowszechniona jest generacja płyt z podstawką typu 7 (Socket
Type 7), której specyfikacja dopuszcza maksymalną częstotliwość taktowania
równą 266 MHz. Płyty tej grupy występują w trzech wariantach:
Brak możliwości wymuszenia na stabilizatorze napięcia 2.8 V przy jedno
czesnym braku podstawki modułu dodatkowego regulatora (VRM).Płyta ma wspomniane powyżej gniazdo i brakujące napięcie 2,8 V można
wytworzyć przy użyciu modułu dodatkowego regulatora VRM.Oryginalny stabilizator napięcia dysponuje opcją 2,8 V.
Wszystkie płyty z podstawką typu 7 mają już wyprowadzone nie tylko końcówki BFO ale i BF1 co poszerza zakres możliwych wartości mnożnika częstotliwości taktowania wnętrza procesora.
Kłopoty związane z mnogością poziomów napięć wynikły z konieczności rozdzielenia obwodów zasilających jądro procesora (VCORE) od członów współpracujących z magistralami (Vi/0). Nieustający wyścig częstotliwości taktujących powoduje przecież wzrost energii rozpraszanej na ciepło i wzrost temperatury struktur półprzewodnikowych do niebezpiecznych wartości. Jeśli tych niekorzystnych zjawisk nie można zahamować na drodze minimalizowania rozmiarów (przejście do technologii 0.25um i dalej), trzeba zmniejszyć prąd pobierany przez obwody procesora. Nie można jednak zmniejszać poziomów napięć wystawianych na magistralę, gdyż grozi to zachwianiem równowagi na liniach przesyłowych. Jedynym rozsądnym kompromisem jest rozdzielenie tych obwodów i operowanie poziomami optymalnymi dla każdego z nich. Linia zasilania Vj/o musi doprowadzać napięcie w zakresie około 3,2 V. Obniżenie poziomu vcore o kilkanaście procent (do wysokości około 2,8 V) daje zadowalający efekt w zakresie częstotliwości do 233 MHz włącznie. Różnica powyżej l V (poziom 2,1 V) wymagana jest dla procesorów osiągających zakres 266 - 300 MHz. Niestety każdy z producentów preferuje własne, uznane za optymalne, poziomy napięć (tabela 1.8). Zdarza się nawet, że te same procesory mają nadrukowane różne wartości napięć w zależności od serii, z której pochodzą.
Producenci płyt głównych usiłują zapanować nad tym zamętem wyposażając programy BIOS w coraz to przemyślniejsze algorytmy rozpoznawania typów procesora. Sytuację ratuje nieco fakt, iż procesory o rozdzielonych obwodach zasilania (Split- Yoltage) meldują się przy pomocy specjalnej końcówki yccidetect • Płyta zostaje poinformowana o konieczności doprowadzenia dwóch różnych napięć, ich wielkość jednak trudna jest do określenia w sposób automatyczny i leży w gestii użytkownika. Zamieszanie wprowadzają „rodzynki" typu AMD-K6/233 opatrzone napisem 3,3VCore/3,3VI/O, które meldują się jako Split-Yoltage. Większość płyt nie jest oczywiście przygotowana na taką okoliczność, bowiem zakres napięć vcqre kończy się w punkcie 3.2V.
Komunikacja procesora z innymi elementami architektury komputera
51
Tabela 1.8.
Typowe napięcia zasilania dla podstawowych typów procesorów
CPU |
P54C |
P55C |
Ml |
M2 |
K5 |
K6 |
vCOREm |
3,3' (3,135-3,6) |
2,8 (2,7-2,9) |
3.3 (3,15-3,6) |
2,9 (2,8-3,0) |
3,52 (3,45-3,6) |
2,9" (2,755-3,045) |
VI/0[V] |
|
3,3 (3,135-3,6) |
|
3,3 (3,135-3,465) |
|
3,3 (3,135-3,6) |
Podstawka |
Socket 7 |
Socket 7 |
Socket 7 |
Socket 7 |
Socket 7 |
Socket 7 |
' Wersja STD (Standard): 3,3 V, w wersji VRE 3,45 V Jądro procesora w wersji 233 MHz zasilane jest napięciem 3,2 V (3,1 - 3,3), natomiast w modelu 266 MHz napięciem 2,1 V. |
||||||
Dobre i uniwersalne płyty potrafią podać (chociaż nie zawsze jest to odnotowane w dokumentacji) każde napięcie z przedziału 2,0 — 3,5 V (w odstępach 0,1 V). Sztandarowy przykład stanowią produkty serii TX97 firmy ASUS (rysunek 1.26).
'O
Rysunek 1.26.
Zwory
konfiguracyjne na płycie ASUS serii TX97 umożliwiają ustawienie napiąć zasilających z dokładnością do 0,1 V
3.4WP54C
3.5WP54C
ol [o o ol
S g
U [iliiłl
3.0V
3.1 V
3.3V
o
. o <a-N>
CD T~ C\J
g i g 2.9V
3.2V
Ol
II
2.8V
t—> r~\ *•**
Q — Q
2.7V
2.6V
2.5V
2.4V
S
TT W Q Q > > >
2.3V
I
O ffi fl <j> O ¥1 O O ,51
S | e 2.1V
s S
II
2.2V
CD
2.0V
o J *| ł ffl łl o ffi 41 o o}qJ oa op o J>[o|
I
O G Ol <j> O Ol O Q Ol
O <S O l * <j> OI O <j>. Ol
5 S
s S
III
Q
>
o ojop o d [o p o l jg| q f
Potwierdzenie poprawności danego ustawienia znaleźć można w programie BlOS-Setup na stronie Power Management w punkcie zatytułowanym YCORE Yoltage.
Ilość energii zużywanej przez procesor zależy w dużej mierze od jego aktywności. Szczytowe obciążenie występuje podczas przetwarzania materiału MPEG a minimalne w stanie oczekiwania na reakcję użytkownika. Ponieważ bieg jałowy jest różnie implementowany przez różne systemy operacyjne, pobór prądu w oczekiwaniu na komendę
52
Anatomia PC
(System Prompf) jest dużo mniejszy w NT i OS/2 niż w Windows 95. Istotne różnice zaobserwować można również po zamianie typu procesora.
|
NT4-Prompt |
DOS-Prompt |
Intel-MMX 233 MHz |
4.9A |
5.2A |
AMD-K6 233 MHz |
7.2A |
1.9A |
Obciążenie linii V//0 jest oczywiście dużo mniejsze niż źródła vcore- Typowy rozkład wartości przedstawia poniższe porównanie.
|
ycore/ icore |
vi/q/ Ii/o |
Intel-MMX233 MHz |
2,8 V 76,7 A |
3,3V/0,8A |
AMD-K6233MHz |
3,2 VI 9,5 A |
3,3V / 0,5A |
Obniżanie napięcia zasilania CPU prowadzi zwykle do niestabilnej pracy ale nie szkodzi procesorowi i warto z pewnością pokusić się o taką próbę. Niektóre modele procesorów bardzo dobrze znoszą takie zabiegi (na przykład AMD-K6-233, CPUID Stepping 2 opisany jako vcore - 3,2V). Redukcja poziomu napięcia do wartości 2,8V pozwala na ograniczenie poboru mocy z 34W do 27W. Operacja przynosi efektywny spadek temperatury mierzonej na powierzchni obudowy o 5°C.
Przegląd architektury procesorów
Wnętrze współczesnego komputera klasy PC zawiera w sobie szereg produktów najróżniejszych firm. Oferta jest tak bogata, że w niektórych dziedzinach nie sposób byłoby nawet wymienić wszystkich znaczących producentów. Nie dotyczy to jednak procesorów. Rynek opanowany jest przez trzy firmy, z których jedna zdominowała w zasadzie całą resztę.
Można śmiało zaryzykować stwierdzenie, iż zaglądając do statystycznego PC-ta nowej generacji odkryjemy w nim jeden z opisanych w tym rozdziale procesorów. Krótkie przedstawienie każdego z nich obejmuje zwięzły opis, schemat blokowy i tabelarycznie ujęte główne cechy architektury.
Omówione zostaną produkty następujących firm:
AMD (rodzina K5 i K6)
IBM/Cyrix(MliM2)
Intel (Pentium, Pentium MMX, Pentium Pro, Pentium II)
Komunikacja procesora z Innymi elementami architektury komputera
53
Procesory AMD
Rodzina K5
Procesor AM5K86 (K5) jest pierwszym niezależnym projektem AMD. Poprzednie modele z serii 386 i 486 kopiowały w mniejszym lub większym stopniu oryginały Intela. Jądro procesora K5 opiera się na superskalarnej architekturze RISC. Napływający strumień rozkazów x86 analizowany jest przez dekoder i tłumaczony na ciąg elementarnych operacji (mikrorozkazów) w wewnętrznym kodzie procesora. W terminologii AMD takie elementarne rozkazy RISC noszą miano ROP (RISC Operations). Rozkazy proste tłumaczone są przez dekoder pracujący w szybkim trybie (Fast Patii), a rozkazy bardziej skomplikowane wymagają odwołania się do sekwencera rozwijającego odpowiednią sekwencję ROP z pamięci stałej EPROM. Niezależnie od sposobu kodowania cegiełki ROP mają zawsze stałą długość.
Rysunek 1.27.
Schemat blokowy procesora K5
Adres ^
32
Dane
L1 Code Cache: 16kB
Branch Prediction
AMD, K5
Byte Oueue |
|
|
|
|
|
|
|
|
|
|
|
64
Decoder
o> u
•e
0>
Sterowanie
m
Zegar
RS |
RS |
RS |
RS |
RS |
|
Branch |
Storę & Load |
Storę Load |
ALU-1 |
ALU-2 |
FP |
T 4^*i ! , . |
|||||
L1 Data Cache: 8kB
Wypływający z dekodera strumień ROP kierowany jest do jednostek wykonawczych -K5 dysponuje sześcioma jednostkami: dwoma arytmetyczno-logicznymi dla liczb całkowitych, jedną dla zmiennoprzecinkowych, dwoma kanałami dla obsługi operacji typu Load/Store i jedną do przetwarzania instrukcji rozgałęzień. Nad właściwym rozdziałem ROP do odpowiednich jednostek czuwa system dystrybucji (Dispatcher), który jest
54 Anatomia PC
w stanie rozesłać w jednym cyklu zegarowym maksymalnie cztery mikrorozkazy. Jeśli dana jednostka jest aktualnie zajęta, skierowane do niej mikrokody oczekują w kolejce RS (Reservation Statiori). Zdecydowana większość ROP może być kierowana do dowolnej z dwóch jednostek ALU a tylko nieliczne z nich wymagają obsługi przez konkretną jednostkę.
Duża wydajność procesora gwarantowana jest jedynie w sytuacji stałego i pełnego wykorzystania wszystkich jednostek wykonawczych. W trosce o nieprzerwany dopływ ROP do tych układów procesor wyposażony został w szereg dodatkowych mechanizmów wspomagających. Do głównych z nich zaliczyć należy opisane wcześniej systemy Register Renaming oraz Data Forwarding. Procesor przetwarza w miarę możliwości również poza kolejnością (Out of Order Executiori) a zlokalizowany u wylotu potoku 16-stopniowy bufor RÓB (Reorder Buffer) troszczy się o ich ponowne uszeregowanie zgodnie z pozycją zajmowaną w realizowanej sekwencji x86.
System przewidywania rozgałęzień zapamiętuje l 024 adresów skoków i gwarantuje współczynnik trafienia 75%. Napotkanie rozgałęzienia powoduje iż pobieranie kolejnych instrukcji odbywa się w kierunku typowanym przez układ przepowiadania. Instrukcje są dekodowane i wykonywane ale ich wyniki przechowuje się w buforze RÓB do czasu potwierdzenia słuszności przypuszczalnie wybranej drogi. Jeśli przewidywanie okaże się fałszywe, procesor traci 3 takty zegara potrzebne na opróżnienie potoków, rejestrów i buforów.
Pamięć podręczna procesora podzielona jest na wyizolowane bloki obsługujące w niezależny sposób dane i kod. K5 przeznacza dla kodu 16 kB, co stanowi wartość dwukrotnie większą niż oferowana przez Pentium. Każdy z zapamiętywanych bajtów opatrzony jest dodatkową 5-bitową sygnaturą (Pre-Code Bits) będącą wynikiem pracy układu dekodowania wstępnego. W ten sposób ulega skróceniu czas przebywania instrukcji w układzie właściwego dekodera. Pamięć podręczna danych zajmuje 8 kB. System pamięci cache zorganizowany jest w 32-bajtowe linijki, jednak najmniejszą porcją informacji wymienianej z pamięcią operacyjną stanowią dwie takie linijki. Magistrala przystosowana jest więc w naturalny sposób do obsługi adresów leżących na granicy 64-bajtów (Q-Word). Próba dostępu do obiektu leżącego „gdzieś pomiędzy" rozkładana jest przez większość procesorów na dwa cykle. K5 potrafi jednak wygenerować taki zestaw sygnałów sterujących (Split Linę Access) by omawiany problem nie wystąpił.
Układ sterowania pamięcią podręczną procesora K5 (zarówno dla kodu jak i dla danych) prowadzi podwójny (Dual Tagged) system katalogów. W jednym z nich przechowywane są adresy fizyczne a w drugim adresy liniowe. Osiągane w ten sposób znaczne przyspieszenie dostępu do pamięci cache okupywane jest koniecznością dodatkowego rozbudowania układów sterujących dla potrzeb nadzorowania spójności (Cache Tag Recovery) dwóch systemów adresowania.
Komunikacja procesora z innymi elementami architektury komputera
55
Tabela 1.9.
Podstawowe dane procesorów K5
|
PR-100 PR-133 PR-166 |
Architektura |
RISC |
Zegar CPU [MHz] |
100 100 116 |
Magistrala [MHz] |
66 66 66 |
Mnożnik (BF) |
1 ,5 (BF= 1 ) 1 ,5 (BF 1 /BFO= 1 0) 1 ,75 (BF 1 /BFO=00) |
Ll-Cache (kod) |
16 kB, 1 bank, 4 x Associative, Dual Tags (linear + phys.), Linę Cache 32 bajty |
Ll-Cache (dane) |
8 kB, 4 Banks, 4x Associatwe, Dual Tags, MESI, WB, Linę Cache 32 bajty |
L2-Cache |
Brak wbudowanej pamięci podręcznej drugiego poziomu |
Pipe-Lines |
6 |
Pipe-Line Stages |
5 |
Out of Order Execution |
', 16 |
Branch History Table |
1024 |
Branch Target Buffer |
1024 |
vcore[v] |
3.52 |
VI/0[V] |
|
Pobór mocy, typ. [W] |
12,6 10,6 12,3 |
Return Stack |
K |
Renaming Registers |
v^ |
Performance Monitoring |
J |
Time Stamp Counter |
^ |
Podstawka |
Socket 7, P54C |
System niezgodny z Pentium |
|
Rodzina K6
Projekt tego procesora nie jest w zasadzie dziełem AMD lecz przejęty został wraz z zakupioną firmą NexGen. Połączenie okazało się niezmiernie korzystne dla obydwu stron. Rozwijana przez NexGen nowoczesna technologia6 została zaadaptowana dla potrzeb niezmiernie chłonnego rynku komputerów klasy PC i wypromowana przez firmę, która wprawdzie zdobyła już pozycję w tym sektorze ale nadal nie dysponowała „okrętem flagowym" mogącym skutecznie odpierać nieustające ataki konkurencji.
6 Płyta główna zdolna do przyjęcia procesora NexGen bazowała na specjalnie opracowywanych do tego celu układach scalonych (Chip-Set). Winę za to ponosiła całkowita niezgodność z architekturami „Intelopodobnymi", np. specjalna super szybka magistrala łącząca procesor z pamięcią podręczną L-2.
56
Anatomia PC
Tak więc zakupiony procesor (wtedy jeszcze o nazwie Nx686) został na tyle przebudowany by dać się umieścić w podstawce Socket-7 typowej płyty głównej w miejsce zwykłego P54C. Uzyskany produkt końcowy otrzymał nazwę handlową K6, co miało stanowić nawiązanie do sprzedawanego do tej pory przez AMD własnego opracowania znanego pod symbolem K5.
AMD, K6
Brand< Load Storę lnt.X Int.Y MMX
Rysunek 1,28.
Schemat blokowy procesora K6
K6 jest konstrukcją bardzo nowoczesną i pod wieloma względami przewyższa swoich konkurentów. Jądro procesora pracuje w trybie RISC bowiem operacje w kodzie x86 rozkładane są na krótkie kody wewnętrzne noszące miano RISC86. Układ dekodera jest niezmiernie wydajny i pobierając 16 bajtów kodu x86 na raz produkuje do 4 mikroin-strukcji w ramach jednego cyklu zegarowego. Mikroinstrukcje opuszczając dekoder spływają do zbiornika pośredniego (Scheduler), gdzie oczekują na zwolnienie właściwej dla danego rozkazu jednostki przetwarzające. Procesor dysponuje sześcioma takim układami: dwoma dla operacji typu Integer, po jednym dla przesłań do i z pamięci, zmiennoprzecinkową i MMX. Wszystkie jednostki za wyjątkiem dwóch ostatnich7 mogą przetwarzać mikrokody RISC równolegle i jednocześnie.
7 Projekt jednostki MMX przejęty został od Intela na mocy wzajemnej umowy licencyjnej. Koncepcja wyklucza jednoczesną pracę MMX i FPU bowiem obydwa bloki korzystają ze wspólnych rejestrów.
Komunikacja procesora z innymi elementami architektury komputera
57
Wzajemne uzależnienia kodu w strumieniach równoległych rozwiązywane są poprzez przemianowywanie rejestrów. Do dyspozycji tej funkcji oddano 32 dodatkowe rejestry 32-bitowe. Układ przepowiadania rozgałęzień śledzi zachowanie 8 192 instrukcji rozgałęzień przez co cechuje się bardzo dużą dokładnością trafień.
Procesor wyposażony został w 64 kB pamięci podręcznej, po 32 kB dla kodu i danych co stanowi wartość czterokrotnie większą niż w przypadku Pentium i dwukrotnie większą niż Pentium MMX. Na uwagę zasługuje również organizacja pamięci pośredniej jednostki MMU. Tablice TLB (Transaction Lookaside Buffer) dla kodu są w stanie zapamiętać do 128 rekordów (dla porównania Pentium Pro tylko 32).
Tabela 1.10.
Podstawowe dane procesorów K6
|
166 | 200 233 266' 300' |
Architektura |
RISC 86 |
Zegar CPU [MHz] |
166 200 233 266 300 |
Magistrala [MHz] |
66 66 66 66 66 |
Mnożnik (BF) |
2,5 3,0 3,5 4,0 4,5 |
Ll-Cache (kod)[kB] |
32 kB, 2x Associative |
Ll-Cache (dane) [kB] |
32 kB, 2x Associative, WB |
L2-Cache on Chip |
« |
Pipe-Lines |
7 |
Pipe-Line Stages |
6 (FP: 7) |
Out of Order Exectition |
S |
Branch History Table |
8192 |
Branch Target Buffer |
16 |
vcore[v] |
2,9(2,76-3,05)2,9(2,76-3,05) 3,2(3,1-3,3) 2,1 2,1 |
Vvo[V] |
3,3(3,14-3,6) 3,3(3,14-3,6) 3,3(3,14-3,6) 3,3 3,3 |
P obór mocy, ty p. [W] |
10 12 17 6 (max. 11,5) 7 (max. 12,5) |
Return Stack |
16 |
Renaming Registers |
48 (8 + 40) |
Performance Monitoring |
x |
Time Stamp Counter |
« |
Podstawka |
Socket 7, P55C |
Wykonywane w technologii 0,25 (im. |
|
58
Anatomia PC
Rodzina K6-2
W połowie roku 1998 na rynku pojawiły się procesory K6 dostosowane do pracy z magistralą 100 MHz. Firma AMD rzuciła w ten sposób wyraźne wyzwanie monopolistycznej polityce Intela ukierunkowanej na rozwój linii Pentium II i uśmiercenie szeroko rozpowszechnionej podstawki typu 7. Ponieważ obowiązująca w tym zakresie specyfikacja dopuszczała maksymalną częstotliwość szyny wynoszącą 66 MHz, nowy „wynalazek" propagowany jest jako podstawka Super 7 (Socket Super 7).
Tabela 1.11.
Podstawowe dane procesorów K6-2
|
266 300 |
Architektura |
RISC 86 |
Zegar CPU [MHz] |
266 300 |
Magistrala [MHz] |
100/66 100/66 |
Mnożnik (BF) |
2,5/4,0 3,0/4,5 |
Ll-Cache (kod) [kB] |
32 kB, 2x Associative |
Ll-Cache (dane) [kB] |
32 kB, 2x Associative, WB |
L2-Cache on Chip |
X |
Pipe-Lines |
7 |
Pipe-Line Stages |
6 (FP: 7) |
Out of Order Execution |
^ |
Branch History Table |
8192 |
Branch Target Buffer |
16 |
vcore[v] |
2,2 2,2 |
V,/0[V] |
3,3 3,3 |
Pobór mocy, typ./max. [W] |
8,85/14,7 10,35/17,2 |
Return Stack |
16 |
Renaming Registers |
48 (8 + 40) |
Performance Monitoring |
X |
Time Stamp Counter |
X |
Podstawka |
Socket Super? |
Nie trzeba dodawać, że prawidłowe rozpoznanie i skonfigurowanie procesora AMD K6-2 wymaga wsparcia ze strony BIOS w jednej z najbardziej aktualnych wersji. Jeśli nie jest możliwe wgranie nowej wersji (Flash-BIOS) lub ewentualna wymiana pamięci EPROM można próbować się posłużyć programem konfiguracyjnym SETK6.EXE.
Komunikacja procesora z innymi elementami architektury komputera 59^
Na straconej pozycji są posiadacze płyt pozbawionych wyprowadzenia końcówki BF-2 co uniemożliwia ustawienie mnożnika powyżej x3,5. Zwracać też należy uwagę na dostateczną wydajność źródła prądowego: procesory tej serii czerpią około 10 A.
Procesory K6-2 mogą współpracować zarówno z magistralą 66 MHz jak i 100 MHz. Układy sterujące (Chip-Sei) do tych ostatnich pochodzą wyłącznie od producentów konkurujących z Intelem, bowiem polityka tej firmy nie przewiduje przyszłości dla magistrali 100 MHz doprowadzanej do podstawki typu 7. Warto zwrócić uwagę, że modele 100 MHz różnią się istotnie od wersji 66 MHz. Nowość (a zarazem pewien problem techniczny) stanowi uniezależnienie częstotliwości szyny głównej od PCI i AGP. Dotychczas, częstotliwości 33 MHz, taktująca magistralę PCI, uzyskiwana była przez prosty podział zegara magistrali procesora (66 MHz : 2). Z kolei szyna AGP otrzymywała pełny przebieg 66 MHz. Przebiegi były ze sobą wspaniale zsynchronizowane, bowiem wywodziły się ze wspólnego źródła. Ten prosty mechanizm podziału stosowany jest także w przypadku magistrali 75 MHz lub 83 MHz, co znoszą z różnym szczęściem układy peryferyjne PCI i AGP (gwarancja działania obejmuje zakres do 33 MHz). Na rynku znajduje się duża liczba płyt głównych pozwalających na manipulację częstotliwościami magistral w zakresie wybiegającym często poza zdrowy rozsądek. Należy pamiętać, iż podnoszenie ponad miarę częstotliwości magistrali PCI zagraża nie tylko kartom graficznym i innym urządzeniom PCI ale ma również ujemne skutki dla kontrolera IDE, co może się objawiać sporadycznymi błędami zapisu i odczytu dysków.
Poważna trudność powstaje w momencie, gdy częstotliwość przebiegu wyjściowego (magistrala CPU) wynosi 100 MHz. Z takiego źródła niełatwo uzyskać zsynchronizowane przebiegi 33 MHz i 66 MHz. Stosuje się dwa sposoby podejścia do tego problemu. Pierwszy z nich to asynchroniczny tryb pracy: magistrala główna i procesor mają własny zegar 100 MHz, a szyna AGP wyposażona zostaje w generator 66 MHz, z którego sygnał po podziale przez 2 posyła się na magistralę PCI. Rozwiązanie drugie to tzw. tryb pseudosynchroniczny polegający na przemyślnym wyprowadzaniu (poprzez kolejne dzielenia i mnożenia) potrzebnych częstotliwości (66 i 33 MHz) z zegara 100 MHz. Tryb asynchroniczny ma istotną wadę: połączenie i współpraca magistral taktowanych różnymi częstotliwościami wymaga stosowania buforów pośrednich przechowujących dane. Skomplikowany na pozór tryb pseudosynchroniczny gwarantuje lepsze sprzężenie, bowiem mimo nierównomiemości cyklów ich wzajemne przesunięcia są jednoznacznie zdefiniowane i kontrolery magistral mogą lepiej przewidzieć stosowne momenty dla wymiany danych.
Magistrala 100 MHz nie jest jedyną nowością wprowadzoną do procesorów AMD K6-2. Drugim istotnym elementem jest rozszerzenie o funkcje określane mianem 3DNOW!. W trosce o zmniejszenie dystansu dzielącego K6 od Pentium II (zwłaszcza w zakresie działań na liczbach zmiennoprzecinkowych) zmodyfikowano jednostkę FPU. 3DNOW! to zestaw dodatkowych rozkazów uzupełniających funkcje MMX. Dopuszczalne jest mieszanie rozkazów obydwu typów w ramach tej samej aplikacji. Znana z systemu MMX idea grupowego przetwarzania danych SIMD (Single Instmction Multiple Data) znalazła tu zastosowanie w odniesieniu do liczb zmiennoprzecinkowych. Lwia część rozkazów 3DNOW! operuje na rejestrach 64-bitowych, których zawartość interpretowana jest według schematu przedstawionego na rysunku 1.29.
60 Anatomia PC
31 30 23 22 O 30
Rysunek 1.29.
S Exponenta Maniysa S Exponenta Mantysa
Sposób
interpretacji 63 °
rejestrów
64-bitowych
Dla każdej z liczb przeznacza się 32 bity: l bit na znak, 23 bity na mantysę i 8 bitów na eksponentę. Powyższy sposób kodowania pozwala na przetwarzanie liczb z zakresu 1038 do l O'38 z dokładnością 2'24.
Platformą łączącą nowe rozkazy 3DNOW! z aplikacjami multimedialnymi (główny nacisk kładzie się na funkcje 3D) stanowi system DirectX w wersji 6.0. Wyniki osiągane przez duet K6-2 i Direct3D/6 stanowią poważne zagrożenie dla pozycji zajmowanej dotychczas przez procesor Pentium II.
Procesory Cyrix Rodzina 6x86 (M1)
Omawiany w tym punkcie procesor stanowi wspólne dzieło firm Cyrix, IBM i SGS Thompson. Jako bardzo oryginalny projekt zdołał znaleźć dla siebie miejsce na rynku PC, głównie ze względu na bardzo konkurencyjną cenę. Całkowita zgodność z Pentium jest niestety mocno problematyczna. Procesorom Cyrix brak jest funkcji wewnętrznego stopera TSC (Time Stamp Counter) oraz możliwości nadzoru (Performance Monitoring).
Licznik czasu TSC, chociaż nie stanowi obowiązkowego elementu architektury x86, jest chętnie wykorzystywany przez różne aplikacje. Jego fizyczna nieobecność w systemie może, zależnie od stylu programowania, zaowocować różnymi skutkami ubocznymi.
Mocno ograniczone są funkcje śledzenia a praca w systemie multiprocesorowym możliwa jest wyłącznie zgodnie z koncepcją OpenPIC, która całkowicie nie pasuje do modułu APIC zintegrowanego z procesorami Pentium. Sporo kłopotów przysparza brak instrukcji CPU-ID a właściwie jej zablokowanie. Niektóre aplikacje sprawdzaj ą bowiem przed przystąpieniem do pracy typ CPU zainstalowanego w systemie. Procesor 6x86 w konfiguracji standardowej nie zna kodu tego rozkazu i system zatrzymuje się sygnalizując błąd, tak jak w przypadku napotkania instrukcji o zabronionym kodzie. Konfigurację procesora można na szczęście zmienić. Dokonuje się tego np. przy pomocy programu CX86!8. Ustawiona konfiguracja obowiązuje do następnego restartu systemu. Powyższe uwagi odnoszą się wyłącznie do procesorów serii 6x86 i nie dotyczą następnej generacji tj. MX i M2.
Użytkownicy przywykli do jasno zdefiniowanej częstotliwości taktowania procesora mogą być nieco zagubieni, gdyż produkty IBM/Cyrix znakowane są w odmienny sposób.
Wywołanie programu: cx86 ! mapenO cpuiden
Komunikacja procesora z innymi elementami architektury komputera
61
Na obudowie drukowany jest współczynnik PR (Pentium Rating), który jest równoważnikiem mocy obliczeniowej danego CPU w odniesieniu do procesora Pentium. W przeszłości do liczby PR dołączany był często znak „+" mający wskazywać na zależność „lepszy lub co najmniej równy". Wyniki pracy programów testowych typu Benchmark potwierdzają na ogół prawo do noszenia stosownej etykiety P-xxx+. Przedstawiciel rodziny 6x86 P-166 osiąga istotnie wyniki porównywalne z Pentium 166:
|
Sysmark NT |
Sysmark 95 |
6x86133MHzP-166+ |
455 |
450 |
Pentium 166MHz |
433 |
464 |
Pomiary przeprowadzone wśród dalszych członków rodziny procesorów prowadzą do ustanowienia następującego przyporządkowania:
Cyrix |
100MHzP-120+ |
110MHzP-133+ |
120MHzP-150+ |
133MHzP-166+ |
Intel |
Pentium 1 20 MHz |
Pentium 133 MHz |
Pentium ISOMHz |
Pentium 166MHz |
Warto więc przyjrzeć się dokładniej jakich to sztuczek używa procesor Cyrix, by mimo mniejszych częstotliwości taktowania osiągać tę samą wydajność co jego główny konkurent.
Główną specjalnością tej architektury jest niewątpliwie jednolita pamięć podręczna dla kodu i danych (Unified Cache). Koncepcja ta umożliwia większą elastyczność (a za razem i prędkość) w zarządzaniu pamięcią podręczną a niebezpieczeństwo wzajemnego wyrzucania się partii kodu i danych (Trashing) likwidowane jest poprzez wprowadzenia małej, 256 bajtowej pamięci podręcznej (Instruction Linę Cache) dedykowanej wyłącznie dla kodu rozkazów. Dostęp do 16 kB pamięci podręcznej możliwy jest dla obydwu potoków jednocześnie (Dual Ported).
Realizacja instrukcji x86 odbywa się w sposób naturalny — jądro procesora pracuje w trybie CISC. Przetwarzanie ma miejsce w dwóch równoległych potokach (oznaczanych przez Cyrix jako X i Y). Potoki są siedmiostopniowe przy czym w dwóch spośród nich (ID - Instruction Decode i AC - Address Calculation) wyodrębnia się jeszcze stopnie pośrednie (ID l, ID2 oraz AC1 i AC2) taktowane podwójną częstotliwością zegara.
Pierwszy stopień (IF - Instruction Fetch) jest wspólny dla obydwu potoków i pobiera w jednym cyklu zegara 16 bajtów kodu. Jednocześnie sprawdza się, czy w załadowanych właśnie instrukcjach nie występują rozkazy skoków. W przypadku rozgałęzień bezwarunkowych pobierany jest również kod z punktu na który wskazuje adres skoku. Przepowiadanie rozgałęzień instrukcji warunkowych odbywa się przy pomocy 256 wierszowej tabeli BTB (plus dwa bity charakteryzujące skok). Aby nie tracić czasu w wypadku pomyłki pobiera się również na wszelki wypadek fragment kodu z drugiego punktu, odrzuconego przez układ przepowiadania.
62
Anatomia PC
Rysunek 1.30 Schemat blokowy procesora 6M<M» Adres 4^ 32 Dane 4*** 64 Sterowanie |
|
^'64r 32 3 £ <? 2 0 l Adres |
Cyrix,6x86(M1) |
|
|
BUS Interface Unit |
|
Cache Unit L1 Unifled Cache F 'amiśas Cach (16kB) dla kodu (256 bajtów) |
4 4 5 ' UJ Q> 2 |
|
|
|
frtrtjhi32-' |
|
|
|
|
, _, |
|
|
|
|
i IF ! |
|
|
|
|
ID-1 j |
|
|
|
|
ID-2 ID-2 i , k |
|
|
|
|
AC-1 AC-1 |
|
|
|
|
AC-2 AC-2 ! ^ |
|
|
|
|
! EX EX j j |
|
|
|
|
j WB WB ! l |
|
Zegar * |
|
|
^dresl' ,2 l-Adres niow/i ^liniowy |
|
|
|
|
Memory Management Unit |
|
|
|
|
fizyczny/ 32 Adres fizyczn^ 32 'X" Y |
|
Potoki równoległe Cyrixa nie są synchronizowane. Bezrobotny potok Y nie czeka (w przeciwieństwie do Pentium) na ukończenie przetwarzania w X i może wykonywać inny fragment kodu (poza kolejnością), choćby jeden z przepowiadanych kierunków biegu programu. Powstające przy tym zależności likwiduje się przy pomocy przemiano-wywania rejestrów, których jest w sumie 32.
Spore różnice w stosunku do Pentium można odnaleźć w jednostce zarządzania pamięcią (MMU). Bufor TLB zawiera 128 rekordów (Pentium: 96) a pamięć podręczna w której przechowywane są katalogi dostępu do stron pamięci (Page Directory Table) daje się programowo aktywować i dezaktywować. Niezmiernie oryginalny jest ośmio-stopniowy Yictim Buffer, forma kosza na śmieci, gdzie lądują usuwane z TLB odwołania do stron. Rekordy takie dają się szybciej odtworzyć bowiem nie zostały jeszcze fizycznie skasowane. Cyrix radzi sobie również świetnie ze stronami pamięci o wymiarach innych niż Intelowskie 4 kB i 4 MB. Następujące po sobie strony dają się połączyć w jedną całość, co przynosi ogromne skrócenie czasu dostępu.
Na zakończenie warto wreszcie wspomnieć o łączonych cyklach zapisu (Write Gather-ing). System dostępu do magistrali jest w stanie łączyć następujące po sobie odwołania do pamięci. W ten sposób żądania zapisu bajtów, słów i dwusłów grupowane są w pojedynczy blok i wykonywane w szybkim trybie 64 bitowym.
Komunikacja procesora z innymi elementami architektury komputera
63
Tabela 1.12.
Podstawowe dane procesorów 6x86 (Ml)
|
PR 150+ PR 166+ |
PR 200+ |
Architektura |
x86 Native |
|
Zegar CPU [MHzJ |
120 133 |
150 |
Magistrala [MHz] |
60 66 |
75*" |
Mnożnik (BF) |
2 2 |
2 |
Ll-Cache |
16 kB Unified Cache (Code + Data), 4x Associative, 512 Lines. 256 bajtów Instruction Linę Cache (8 Lines) |
|
L2-Cache on Chip |
X |
|
Pipe-Lines |
2 ( + FP) |
|
Pipe-Line Stages |
7 |
|
Oul of Order Execution |
^ |
|
Branch History Table |
512 |
|
Branch Target Buffer |
256 |
|
VcORE[V] |
3,3* (2,8)* |
|
y no m |
3,3 |
|
Pobór mocy, typ. [W] |
16,8 18 |
21 |
Return Stack |
8 |
|
Renaming Registers |
^ (8 + 24) |
|
Performance Monitoring |
X |
|
Time Stamp Counter |
X |
|
Podstawka |
Socket 7 |
|
Modele serii Ml wykonywane w technologii 0,65 (im zajmują 394 mm2 struktury krzemowej (Die) Nowe układy serii MIR charakteryzują się mniejszym poborem mocy i wymagają dwóch napięć zasilających (Split Yoltage). Wykonywane w technologii 0,5 urn (PR-120...PR-166) lub nawet 0,44 (im (PR-200) zajmująjedynie 204 mm2. Praca w tym trybie wymaga wsparcia ze strony płyty głównej (standardowa częstotliwość maksymalna dla magistrali wynosi jedynie 66 MHz) |
||
Rodzina M2
Historia współpracy i wzajemnych kontaktów pomiędzy firmami Cyrix i IBM jest bardzo zawikłana, co znajduje wyraźne odbicie w systemie oznaczeń procesorów. Opracowany w firmie Cyrix pierwowzór rodziny całej rodziny (6x86) nosił przez pewien czas przydomek Ml. Procesor Cyrix M2 stanowi w zasadzie rozwinięcie modelu 6x86 (Ml) poprzez wzbogacenie o większą pamięć podręczną (64 kB zamiast 16 kB). Producent pozostał wierny idei wspólnej pamięci podręcznej dla danych i kodu (Unified Cache). Zachowany został również odseparowany wycinek pamięci cache z przeznaczeniem
64
Anatomia PC
wyłącznie na kod (256 bajtów). Najistotniejsza innowacja to rozszerzenie o zestaw rozkazów MMX, których realizacja odbywa się w bloku funkcyjnym zintegrowanym z jednostką zmiennoprzecinkową. Przez pewien czas procesory tej rodziny nosiły nawet przydomek MX (zamiast M2).
Mimo przejęcia firmy Cyrix przez National Semiconductor obowiązuje nadal umowa partnerska z IBM. To właśnie na liniach produkcyjnych IBM powstają aktualnie procesory tej serii. Część produkcji opatrywana jest znakiem firmowym IBM a część wraca do Cyrixa. Specjaliści od marketingu firmy Cyrix uznali, że używany przez pewien czas przyrostek M2 (poprzez asocjację z Pentium II) lepiej nadaje się do promocji wyrobów niż wysłużony przyrostek MX, kojarzący się wyłącznie z wszechobecnym standardem MMX. Dla zwiększenia efektu zamieniono dodatkowo M2 na M-II i tak powstało aktualne oznaczenie M-II-300, pod którym ukrywa się wprawdzie jednostka z rodziny 6x86 ale o mocy obliczeniowej sięgającej (przynajmniej w zakresie aplikacji biurowych) poziomu Pentium II taktowanego zegarem 300 MHz. Ten sam procesor (a przynajmniej jego półprzewodnikowa struktura) trafia na rynek pod znakiem firmowym IBM jako 6x86MX-PR 266. IBM stosuje ponadto inną technikę pakowania chipów do obudów. Zamiast klasycznej formy łączenia przy pomocy cienkich drutów (Bonding), płytka półprzewodnikowa osadzana jest na matrycy punktów lutowniczych (Flip Chip*). To skrócenie wyprowadzeń (zredukowanie indukcyjności i zmniejszenie przesłuchów między-połączeniowych) pozwala na podniesienie częstotliwości taktowania.
Rysunek 1.31.
Schemat blokowy
procesora
6x86MX(M2)
Cyrix, M2
Adres ^ - |
BUS Interface Unit |
|
Cache Unit LI Unified Cache (64kB) |
Pamięć Cache dla kodu (256 bajtów) |
|
|
iiii^iiMidCililiii ^^mjpiiiiippp 3 S s Adre |
|
|
32 Dane 64 Sterowanie •4- - > Zegar |
|
|
|
|
|
|
|
|l "li "|i |
OJ J ^ 128 ,2 32 Ą M 'l |
|
|
|
CPU-Core |
|
|
|
|
BTB INT |
FPU MMX |
|
|
|
|