img213

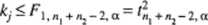
(11.30)
gdzie a oznacza przyjęty poziom istotności.
Przy takim postępowaniu rozważany obiekt może być zaliczony do jednej z dwóch danych zbiorowości, do obu zbiorowości albo wreszcie do żadnej z nich. Za pomocą relacji (11.30) otrzymujemy wokół każdego z obu środków v, i v2 pewien obszar rozrzutu (rozproszenia), który z prawdopodobieństwem (1-a) zawiera w sobie obiekty rzeczywiście należące do rozpatrywanych klas.
Jeśli jednak chcemy w każdym przypadku podać jednoznaczne rozwiązanie problemu różnicowania, a więc jeśli szukamy najprawdopodobniejszej diagnozy, to trzeba się zdecydować na klasę o najmniejszej wartości kf.
gdy k{ < k2. wtedy klasa 1, gdy k{ > k2, wtedy klasa 2, gdy k{ = k2, wtedy klasa 1 lub klasa 2.
W przypadku, gdy pr/.y takiej dyskryminacji mają być uwzględnione tzw. prawdopodobieństwa aprioryczne /?, i p2, gdy zatem zakłada się z góry, z jakim prawdopodobieństwem dany obiekt należy do klasy 1 lub do klasy 2, wówczas dobrze jest korzystać z wielkości

(11.31)
Rozważany obiekt przydziela się do klasy z najmniejszą wartością /,. W przypadku p\ = p2 ta reguła decyzyjna jest identyczna z uprzednią regułą.
Bardzo często pojawiającym się problemem jest możliwość zmniejszenia liczby rozpatrywanych cech pierwotnych6. Optimum jest bowiem uzyskanie przy możliwie najmniejszej liczbie cech możliwie największej miary dyskryminacyjnej.
W celu rozwiązania tego problemu określamy tzw. niezbędności poszczególnych cech )>•. Niezbędność U, cechy y, definiuje się jako wielkość, o jaką zmniejsza się miara dyskryminacyjna 7’2, gdy ze zbioru wszystkich cech wyeliminuje się cechę yp

6 Proponujemy Czytelnikowi porównanie opisanego poniżej sposobu redukcji cech z metodami przedstawionymi w rozdziale dotyczącym regresji wielokrotnej. Wnioski mogą być pouczające!
(11.32)
213
Wyszukiwarka
Podobne podstrony:
2. przyjęcie poziomu istotności 3. sprawdzenie założeń wybranego
KIEDY: 13 maja 2017 r. START: godz. 11:30 GDZIE: Prywatna Wyższa Szkoła Nauk Społecznych, Komputerow
WPŁYW MUZYKOTERAPII NA SAMOOCENĘ NIEDOSTOSOWANYCH SPOŁECZNIE Przyjęto poziom istotności p < 0,1 d
102 Tablica 11 Wartości krytyczne statystyki uK Poziom istotności co Postać hipotezy
2009 11 30 WYKŁAD [2] (33) Stosowanie zastrzyków długodziałających przy zapobieganiu rui Bardzo podo
2009 11 30 WYKŁAD (35) Stosowanie zastrzyków długodziałających przy zapobieganiu rui _• Bardzo podob
2- Poziom zmiany: zmienianym obiektem może być praktyka edukacyjna oraz postawa badacza. Cykl zmiany
74804 ScanImage004 (11) WPROWADZENIEsa# mf &ms && vss& om Wybór najlepszego algorytm
mikro1 Oznaczanie gronkowcowego dumping factor metodą szkiełkową Z powierzchnią komórek gronkowców m
DSC00145 (30) onsekwencją finansowania deficytu budżetowego przy pomocy długu publice jest (może być
DSC00742 // X Dowolną linię poziomą zdjęcia 1 jlJ , na płaszczyzną przedmiotu £ może byc wybran
Abstrakcja (2) Abstrakcja jako cecha obiektowości może być rozpatrywana również na innych poziomach
Obciążenie bezwzględne oznacza ilość energii wydatkowanej przez organizm w jednostce czasu (moc). Mo
więcej podobnych podstron