img258

wprowadzenie odpowiednich mierników, określających globalna dokładność predykcji oraz szacujących istotność cząstkowych współczynników regresji.
Dokładność danego równania regresji wielokrotnej możemy określić za pomocą „odległości” między y, oraz yh czyli za pomocą różnic (y, - y,-), a ściślej — kwadratów tych różnic.
Sumę
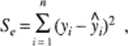
(12.8)
gdzie n oznacza liczebność próby, nazywa się suma kwadratów odchyleń od regresji lub resztowa suma kwadratów. Natomiast wielkość
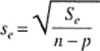
(12.9)
nazywa się błędem standardowym predykcji; jest ona miara dokładności przewidywania na podstawie równania
y = b0 + b]xl+b2x2 + ... + bpxp .
Im wartość se jest mniejsza, tym mniejsze różnice występują między przewidywanymi na podstawie równania regresji i obserwowanymi wartościami cechy Y. Można również wykazać, że j; jest estymatorem wariancji zmiennej losowej e, występującej w równaniu (12.1).
Określanie błędu standardowego predykcji na podstawie wartości Se danej wzorem (12.8), jest o tyle niewygodne, że najpierw należy uzyskać oceny cząstkowych współczynników regresji b0, b{.....bp, następnie wyliczyć z równania regresji wartości prze
widywane y, i dopiero wtedy zastosować wzór (12.8). Prościej jest obliczyć Se ze wzoru:
n
(12.10)
S' = 2y}-R0o,b bp) ,
1=1
w którym pierwszy składnik oznacza sumę kwadratów obserwacji cechy Y (czyli zmiennej
zależnej), natomiast drugi składnik R (b0. bt.....bp) to tzw. redukcja sumy kwadratów
w wyniku dopasowania wymienionych w nawiasach stałych.
Wiclkoć redukcji oblicza się ze wzoru:
(12.11)
K (V h\ v = bTw = b0lyi + />, +... + bp 'Lxpiyi
258
Wyszukiwarka
Podobne podstrony:
78180 Image0011 (13) W odpowiedzi na poczynania globalnych sił ekonomicznych oraz w c
img1 Wprowadzenie Organizacja W3C opracowało CSS (kaskadowe arkusze stylów) CSS odpowiada za określe
skanuj0024 (95) dojściach i dojazdach do obszaru wodnego, odpowiednimi znakami określającymi przyczy
img085 (zobacz określenie wielomianu dokładnie tak samo Jak wyżej. P_ na eteonie HI ) 1 rozumować ni
str11 (21) rowanie zespołu prowadnic na cel odbywało się przez odpowiednie ustawienie wozu boiowego,
1. Wprowadzenie 1.1. Zarysowanie problemu Określenie aktualnego stanu cieków i rzek jest niezwykle w
odpowiada celom określonym w strategii jednostki oraz w polityce zapewnienia jakości, a także uwzglę
wykłady z polskiej składni�6 16 Wprowadzenie do składni4. Istota komunikatu językowego: predykacja K
P1070058 136 CtfU II- Rożwfrzinlł I odpowied/i_____ W celu określenia ciśnienia p w dowolnym punkcie
więcej podobnych podstron