192 193
1‘)2
asocjacyjną (Content Addressable Memory = CAlł), przeznaczoną głównie dla dużych systemów wyszukiwania inforoS^ji. - ' ftimlęć z dostępem cyklicznym
li puilęci tej informacja krąży w obwodzie zamkniętym i określony bit do.iLQ.tiiy Jest tylko raz na jeden cykl obiegu. Półprzewodnikową pamięć cykliczną stanowi rejestr SISO z możliwością zwierania wejścia z wyjściom w calu utworzenia pętli cyrkulacyjnej. Korzysta się tu ze specjalnie zaprojektowanych rejestrów ŁiOS, statycznych lub dynamicznych, o pojemnościach od J2 do ponad 2048 bitów.
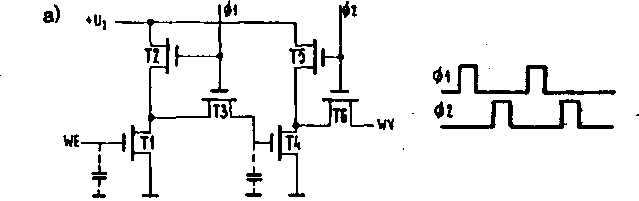
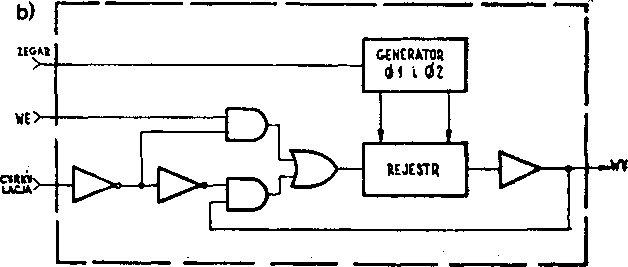
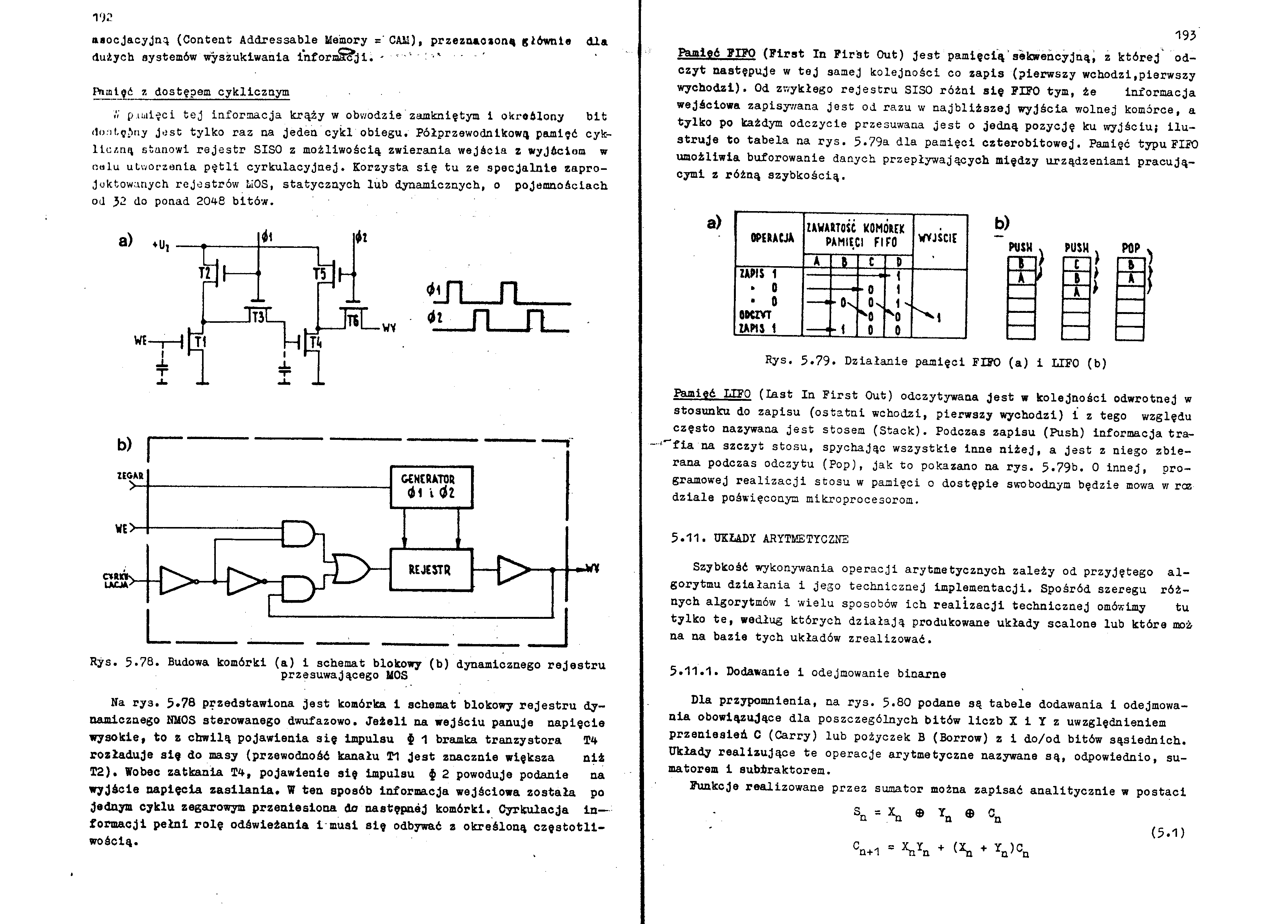
Rys. 5.78. Budowa komórki (a) i schemat blokowy (b) dynamicznego rejestru
przesuwającego MOS
Na ry3. 5*78 przedstawiona jest komórka 1 schemat blokowy rejestru dynamicznego NMOS sterowanego dwufazowo. Jeżeli na wejściu panuje napięcie wysokie, to z chwilą pojawienia się Impulsu $ 1 bramka tranzystora T4 rozładuje się do masy (przewodność kanału Tl jest znacznie większa niż T2). Wobec zatkania T4, pojawienie się impulsu i 2 powoduje podanie na wyjście napięcia zasilania. W ten sposób informacja wejściowa została po jednym cyklu zegarowym przeniesiona do następnej komórki. Cyrkulacja in— formacji pełni rolę odświeżania imusl się odbywać z określoną częstotliwością.
Pamięć FIFO (First In FirSt Out) jest pamięcią'sekwencyjną, z której" odczyt następuje w tej samej kolejności co zapis (pierwszy wchodzi.pierwszy wychodzi). Od zwykłego rejestru SISO różni się FIFO tym, że informacja wejściowa zapisywana jest od razu w najbliższej wyjścia wolnej komórce, a tylko po każdym odczycie przesuwana jest o jedną pozycję ku wyjściuj ilustruje to tabela na rys, 5*79a dla pamięci czterobitowej. Pamięć typu FIFO umożliwia buforowanie danych przepływających między urządzeniami pracującymi z różną szybkością.

Rys. 5.79. Działanie pamięci FISO (a) i LIFO (b)
a)
Pamięć UFO (Iast In First Out) odczytywana Jest w kolejności odwrotnej w stosunku do zapisu (ostatni wchodzi, pierwszy wychodzi) i z tego względu często nazywana jest stosem (Stack). Podczas zapisu (Push) informacja tra-‘"fia na szczyt stosu, spychając wszystkie inne niżej, a jest z niego zbierana podczas odczytu (Pop), jak to pokazano na rys. 5.79b. 0 innej, programowej realizacji stosu w pamięci o dostępie swobodnym będzie mowa w rcz dziale poświęconym mikroprocesorom.
5.11. UKŁADY ARYTMETYCZNE
Szybkość wykonywania operacji arytmetycznych zależy od przyjętego algorytmu działania i jego technicznej implementacji. Spośród szeregu różnych algorytmów i wielu sposobów ich realizacji technicznej omówimy tu tylko te, według których działają produkowane układy scalone lub które moż na na bazie tych układów zrealizować.
5.11.1. Dodawanie 1 odejmowanie binarne
Dla przypomnienia, na rys. 5.80 podane są tabele dodawania i odejmowania obowiązujące dla poszczególnych bitów liczb X i Y z uwzględnieniem przeniesień C (Carry) lub pożyczek B (Borrow) z i do/od bitów sąsiednich. Układy realizujące te operacje arytmetyczne nazywane są, odpowiednio, sumatorem 1 subtraktorem.
(5-1)
Funkcje realizowane przez sumator można zapisać analitycznie w postaci SQ = XQ © Yn ® Cn
Cn+1 = V» + <*n + VCn
Wyszukiwarka
Podobne podstrony:
192 193 asocjacyjną (Content Addressable Memory = CAlł), przeznaozoną głównie dla dużych systemów wy
Przedsiębiorstwo turystyczne w gospodarce wolnorynkowej G Gołembski (192) 193 2. Źródła danych dl
s 192 193 ROZDZIAŁ 6192 c) jest konsultantem współpracującym z Centrum Edukacji
192 193 Oznaczenie 1- b xbxc xt Wymiary Pole przekroju h c t r e a A mm cm cm2 40x40x20x
2002 Sygn: P 191, P 192, P 193 114. Disce Disce puer : podręcznik do łaciny
192 193 45. Jeżeli przedmiot o wysokości 6 cm, umieszczony w odległości 0,9 m od soczew ki skupiając
192,193 192 Pomoc ii In uzależnionych Przeciętny narkoman zazwyczaj jest odtruwany wielokrotnie Czas
192,193 192Teorie literatury XX M 1959: Unłerwegs zu Sprache (W drodze do języka) Martina Heideggera
CCF20120104�001 " 192 193 skich, możemy wyróżniać składnię rzeczownika lub prr. miotnika, skład
address mask=maska adresu address matrix=macierz adresu address memory=pamięć adresowa address
192 193 45. Jeżeli przedmiot o wysokości 6 cm, umieszczony w odległości 0,9 m od socze l i skup
192,193 192 Pomoc dla uzależnionych Przeciętny narkoman zazwyczaj jest odtruwany wielokrotni Czasem
więcej podobnych podstron