dupa0085
odchylają się wartości zaobserwowane od oszacowanych za pomocą funkcji regresji i stąd jest nazywany średnim błędem szacunku.
(3.37)
Se(Y) = y]Sc7(Y)
oraz
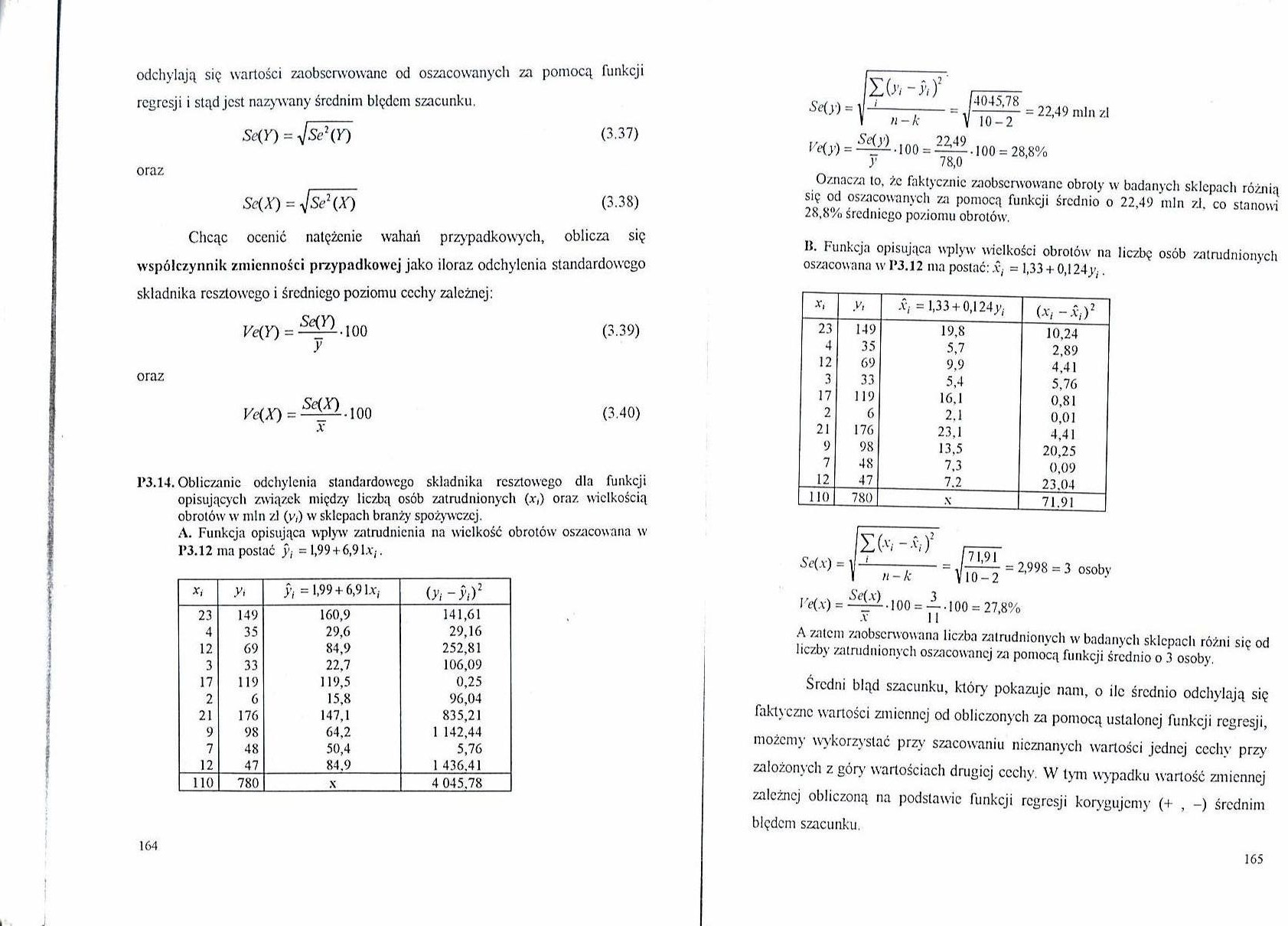
Se(X) = ^Sc\X) (3.38)
Chcąc ocenić natężenie wahań przypadkowych, oblicza się współczynnik zmienności przypadkowej jako iloraz odchylenia standardowego składnika resztowego i średniego poziomu cechy zależnej:
Ve(Y) = —(3.39)
y
oraz
KeW =^r^-100 (3.40)
jc
P3.14. Obliczanie odchylenia standardowego składnika resztowego dla funkcji opisujących związek między liczbą osób zatrudnionych (x,) oraz wielkością obrotów w min zl (w) w sklepach branży spożywczej.
A. Funkcja opisująca wpływ zatrudnienia na wielkość obrotów oszacowana w P3.12 ma postać y; = 1,99 + 6,9 l.v(.
|
X,i |
y> |
)'i =1,99 + 6,9 l.v(. |
O-t-P/)2 |
|
23 |
149 |
160,9 |
141,61 |
|
4 |
35 |
29,6 |
29,16 |
|
12 |
69 |
84,9 |
252,81 |
|
3 |
33 |
11.1 |
106,09 |
|
17 |
119 |
119,5 |
0,25 |
|
2 |
6 |
15,8 |
96,04 |
|
21 |
176 |
147,1 |
835,21 |
|
9 |
98 |
64.2 |
1 142,44 |
|
7 |
48 |
50,4 |
5,76 |
|
12 |
47 |
84.9 |
1 436.41 |
|
110 |
780 |
X |
4 045.78 |
- \2
Se(y) = ^
n-k
14045,78 _ V 10-2
,49 min zl
[/.w- v) _ 400 = 400 = 28,8%
jr 78,0
Oznacza to. że faktycznie zaobserwowane obroty w badanych sklepach różnią się od oszacowanych za pomocą funkcji średnio o 22,49 min zl. co stanowi 28,8% średniego poziomu obrotów.
B. Funkcja opisująca wpływ wielkości obrotów na liczbę osób zatrudnionych oszacowana w 1*3.12 ma postać: x, = 1,33 + 0,124y(.
Se(x) =
2,998 = 3 osoby
|
X, |
y, |
.v; = 1,33 + 0,124^ | |
|
23 |
149 |
19,8 |
10,24 |
|
4 |
35 |
5,7 |
2,89 |
|
12 |
69 |
9.9 |
4,41 |
|
3 |
33 |
5,4 |
5,76 |
|
17 |
119 |
16.1 |
0,81 |
|
2 |
6 |
2.1 |
0,01 |
|
21 |
176 |
23.1 |
4,41 |
|
9 |
98 |
13.5 |
20,25 |
|
7 |
48 |
7.3 |
0,09 |
|
12 |
47 |
7.2 |
23.04 |
|
110 |
780 |
X |
71.91 |
165
W.y) = • 100 = — • 100 = 27,8%
x 11
A zatem zaobserwowana liczba zatrudnionych w badanych sklepach różni się od liczby zatrudnionych oszacowanej za pomocą funkcji średnio o 3 osoby.
Średni błąd szacunku, który' pokazuje nam, o ile średnio odchylają się faktyczne wartości zmiennej od obliczonych za pomocą ustalonej funkcji regresji,
możemy wykorzystać przy szacowaniu nieznanych wartości jednej cechy przy założonych z góry wartościach drugiej cechy. W tym wypadku wartość zmiennej zależnej obliczoną na podstawie funkcji regresji korygujemy (+ , -) średnim błędem szacunku.
Wyszukiwarka
Podobne podstrony:
• suma odchyleń poszczególnych wartości cechy od średniej równa się
Spełnia warunek xran<xw<xm„. Suma odchyleń poszczególnych wartości cechy od średniej równa się
1. Wariancja (5Z) - średnia arytmetyczna kwadratów odchyleń poszczególnych wartości cechy od średnie
W zakresie modeli bryłowych rozróżnia się dwie drogi ich tworzenia [1]: • za pomoc
img17 Stałe Stałe można zdefiniować za pomocą funkcji define(). Raz zdefiniowana wartość stały
skanuj0610 pcja konkurencyjna odnosi się do i kluczowych czynników sukcesu za pomocą analizy fa
S5001347 W jaki sposób omawia się z dzieckiem trening za pomocą planu punktowego? Ważne jest, by wyj
Scan10498 Patyczek do szaszłyków dokładamy do drucika w odległości 2 cm od środka. za
skanowanie0005 (137) analizatorem spalin. Pizy negatywnym wyniku dopuszcza się wykonanie testu czujn
1S. W pobudzonym teście redukcji NBT wartości niższe od 40% dowodzą: *) prawidłowej funkcji komórek
więcej podobnych podstron