Analiza statystyczna z wykorzystaniem pakietu
SPSS 8.0 PL Wersja standardowa
Narzędzia graficzne wykorzystywane do analizy statystycznej
Do graficznej analizy danych wykorzystywane są narzędzia zgrupowane w rozwijanym menu o nazwie Wykresy. Wykresami służącymi do ogólnej prezentacji danych są wykresy
słupkowy (dla danych typu kategorie)
liniowy (np. dla szeregów czasowych)
warstwowy (do wykreślania wartości wielu zmiennych)
kołowy (dla danych typu kategorie)
max-min (np. wykresy notowań giełdowych)
Wykresami zawierającymi elementy analizy statystycznej są wykresy
skrzynkowy (dla zestawów danych odpowiadających różnym kategoriom)
Pareto (słupkowy, uprządkowany)
Wykresy do analizy statystycznej zestawów danych
słupki błędu (wartości średnie zestawów danych wraz z błędami oceny)
rozrzutu (pole rozrzutu XY)
histogram
P-P (wykres do weryfikacji postaci rozkładu prawdopodobieństwa)
K-K(wykres do weryfikacji postaci rozkładu prawdopodobieństwa)
Wykresy do analizy szeregów czasowych
sekwencyjny
szeregi czasowe (trzy rodzaje wykresów)
Ponadto można wykonać wykresy kart kontrolnych wykorzystywanych w Statystycznym Sterowaniu Jakością
Informacje o każdym z wykresów (po angielsku) uzyskujemy korzystając z opcji Wykresy|Galeria.
Wskazane powyżej wykresy tworzone są automatycznie po wskazaniu odpowiednich danych (w oknach dialogowych).
Można też tworzyć wykresy własne korzystając z opcji Wykresy|Interaktywne. Uruchamiane jest specjalne narzędzie pozwalające na stworzenie wykresów następujących rodzjów:
słupkowy
punktowy
liniowy
wstęgowy
linii rzutowania
kołowy (trzech rodzajów)
skrzynkowy
słupki błędu
histogram
rozrzutu
Wykresy wykonywane automatycznie można poddać prostej edycji (po dwukrotnym kliknięciu). Wykresy tworzone interaktywnie można poddać skomplikowanej obróbce wykorzystując zestaw narzędzi graficznych dostępnych w narzędziu do interaktywnego tworzenia wykresów.
Analiza danych statystycznych z wykorzystaniem opcji Statystyka|Opis statystyczny
Poleceniem Statystyka|Opis statystyczny wykonywane są podstawowe obliczenia statystyczne typowe dla statystyki opisowej. Możemy korzystać z następujących opcji:
Częstości
Statystyki opisowe
Eksploracja
Tabele krzyżowe
Raporty warstwowe
Podsumowania obserwacji
Raport w wierszach
Raport w kolumnach
Analiza danych z wykorzystaniem opcji Statystyka|Opis statystyczny|Częstości
Cel: Wstępna analiza danych statystycznych. Szczególnie przydatna do opisu danych dotyczących kategorii.
Używane statystyki
częstości występowania poszczególnych wartości obserwacji
udział procentowy (indywidualny i skumulowany) poszczególnych wartości obserwacji
suma wartości obserwacji
wartość średnia i jej odchylenie standardowe
wariancja i odchylenie standardowe
mediana i kwartyle
wartość modalna (dla kategorii)
skośność i kurtoza z ich odchyleniami standardowymi
rozstęp, wartość minimalna, wartość maksymalna
percentyle (określone przez użytkownika)
Możliwość analizy danych przedziałowych (dane środki przedziałów)
Stosowane wykresy
wykres słupkowy
wykres kołowy
histogram (z opcjonalną krzywą gęstości rozkładu normalnego)
Analiza danych z wykorzystaniem opcji Statystyka|Opis statystyczny|Statystyki opisowe
Cel: Statystyczna analiza porównawcza wielu zmiennych. Wyznaczane są wartości charakterystyk statystycznych wielu zmiennych, a następnie przedstawiane we wspólnych tabelach porównawczych.
Używane statystyki
wartość średnia i jej odchylenie standardowe
suma wartości obserwacji
wariancja i odchylenie standardowe
skośność i kurtoza z ich odchyleniami standardowymi
rozstęp, wartość minimalna, wartość maksymalna
Wyniki obliczeń dla poszczególnych zmiennych są przedstawiane w kolejności odpowiadającej
kolejności przyjętych do analizy zmiennych (domyślnie)
alfabetycznej kolejności nazw zmiennych
wzrastających wartości średnich
malejących wartości średnich
Możliwe jest wyliczanie standaryzowanych wartości obserwacji
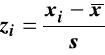
i zapisanie ich w edytorze danych jako nowe zmienne.
Analiza danych z wykorzystaniem opcji Statystyka|Opis statystyczny|Eksploracja
Cel: Statystyczna analiza porównawcza obserwacji (przypadków) opisanych wieloma zmiennymi, a w tym zmiennymi o charakterze kategorii. Opcja Eksploracja jest szczególnie przydatna, gdy rozkłady danych liczbowych nie są rozkładami normalnymi.
Używane statystyki
wartość średnia i jej odchylenie standardowe
przedział ufności dla średniej (dolna i górna granica) na poziomie ufności 95%
5% średnia obcięta
mediana
wariancja i odchylenie standardowe
skośność i kurtoza z ich odchyleniami standardowymi
rozstęp, wartość minimalna, wartość maksymalna
rozstęp ćwiartkowy
M-estymatory (Hubera, Andrew'a, Hampela, Tukeya dwuwaźony)
wartości skrajne (5 największych i 5 najmniejszych z etykietami)
percentyle (5, 10, 25, 50, 75, 90, 95) obliczane w różny sposób (w tym kwartyle jako tzw. zawiasy Tukey'a)
Stosowane wykresy
wykres „łodyga - liście” (w trybie znakowym)
wykres skrzynkowy (Tukey'a)
histogramy (dla każdej z kategorii)
wykresy w siatce rozkładu normalnego (kwantylowy, kwantylowy bez trendu) wraz z wynikami analizy statystycznej przy pomocy testów Kołmogorowa-Smirnowa (z uzupełnieniem Lillieforsa) oraz Shapiro-Wilka (dla 50 lub mniej obserwacji)
wykresy pozwalające porównać wariancje zmiennych dla różnych analizowanych kategorii danych wraz z testem Levene'a jednorodności wariancji (różne wersje testu)
Uwaga: Jeżeli opisane są również zmiennymi o charakterze kategorii, to powyższa analiza przeprowadzana jest oddzielnie dla każdej kategorii.
Jeżeli dane nie są opisane rozkładem normalnym można przeprowadzić transformację danych korzystając z następujących przekształceń:
logarytmicznego (logarytm naturalny)
odwrotność pierwiastka kwadratowego
odwrotność
pierwiastek kwadratowy
kwadrat
sześcian
Weryfikacja hipotez o postaci rozkładu prawdopodobieństwa
Hipotezy o postaci rozkładu prawdopodobieństwa mogą być weryfikowane przy pomocy narzędzi:
Wykresy|P-P
Wykresy|Q-Q
W obu przypadkach weryfikacja dokonywana jest wizualnie.
W przypadku wykresu P-P:
na osi x zaznaczone są oceny (dla kolejnych pomiarów) empirycznej dystrybuanty
na osi y zaznaczone są wyliczone odpowiednie wartości dystrybuanty teoretycznej
W przypadku wykresu K-K:
na osi x zaznaczone są wartości obserwacji (dla kolejnych pomiarów)
na osi y zaznaczone są wyliczone wartości oczekiwane odpowiednich statystyk pozycyjnych
Dane mogą być przedstawiane na siatkach prawdopodobieństwa następujących rozkładów:
normalnego
wykładniczego
Weibulla
Pareto
lognormalnego
beta
gamma
logistycznego
Laplace'a
równomiernego
pół-normalnego
chi-kwadrat (należy podać liczbę stopni swobody)
t-Studenta (należy podać liczbę stopni swobody)
Dla wybranego rozkładu program dokonuje estymacji parametrów rozkładu na podstawie danych źródłowych, a następnie wpisuje dane na odpowiedni wykres.
Jeżeli rozkład został właściwie wybrany, to opisujące dane punkty powinny ułożyć się wzdłuż prostej.
Program SPSS tworzy wykresy dwu rodzajów: typowy dla siatki prawdopodobieństwa oraz tzw. bez trendu, na którym zaznaczane są odchylenia od założonej linii prostej.
O.Hryniewicz: Analiza statystyczna - komputery (8 godz.) 54
Wyszukiwarka
Podobne podstrony:
AnaLIZA STATYSTYCZNA 8 wykład4, Analiza statystyczna z wykorzystaniem pakietu
Ekonometryczna analiza - absolwenci (45 stron), Ekonometryczna analiza liczby absolwentów akademii m
METODY STATYSTYCZNE WYKORZYSTYWANE W PLANOWANIU I PRZEPROWADZANIU EKSPERYMENTU NAUKOWEGO
Analiza moliwoci wykorzystania pyt gipsowo kartonowych jako materiau wykoczeniowego w budownictwie d
5 Weryfikacja hipotez statystycznych z wykorzystaniem testˇw parametrycznych
rola analizy w toku wykorzystywania informacji (6 str), Finanse i bankowość, finanse cd student
25 Kardas Analiza efektywnosci wykorzystania maszyn
2009 06 Analiza obrazu z wykorzystaniem ImageJ [Grafika]
Metody analizy finansowej wykorzystywane w przedsiębiorstwach turystycznych S Bronowicki
Teoria badania statystycznego oraz pakiety statystyczne
PRZEMOC SEKSUALNA WOBEC DZIECI Informacja statystyczna do pakietu Daphne III 1
L2 PAA Modelowanie układu regulacji automatycznej z wykorzystaniem pakietu MATLAB Simulink(1)
Symulacja układów sterowania z wykorzystaniem pakietu MATLAB, PWr W9 Energetyka stopień inż, III Sem
więcej podobnych podstron