3784500539
238 Jarosław Gramacki, Artur Gramacki
Rys. 6. Wzajemne położenie tytułów książek w 2-wymiarowej przestrzeni konceptów
Przyjęta aproksymacja rzędu 2 miała oczywisty cel dydaktyczny uzasadniony dodatkowo charakterem danych. W praktyce należałoby przyjąć nieco większą wartość. Nie istnieją niestety precyzyjne wskazówki dotyczących optymalnego wyboru tej liczby. W praktycznych zastosowaniach przyjmuje się ich liczbę jako „około 10%” oryginalnej wymiarowości. Stosuje się również podejście znane na przykład z analizy PCA (ang. principal components analysis), polegające na analizie tzw. wykresu osuwiskowego (ang. scree plot)1.
Zupełnie innym problemem, którego tu nie omawiamy, jest procedura grupowania danych w k-wymiarowej przestrzeni. Nic nie stoi jednak na przeszkodzie, aby użyć tu dowolnego algorytmu grupowania (np. znanego algorytmu k-średnich z odpowiednią do zadania miarą podobieństwa). Podejście to zastosowane zostanie w dalszej części pracy dotyczącej generowania podsumowań.
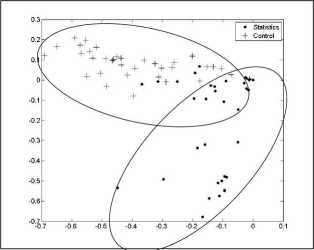
3.2.3. Przykład 2
Wykonajmy jeszcze jeden ciekawy eksperyment. Na rysunku 7a pokazano stopień wypełnienia macierzy TDM (tej z poprzedniego przykładu). Dwa wskazane owalem termy występują w bardzo wielu dokumentach. Zidentyfikowano je jako „ControF oraz „Statistics / StatisticaF. Fakt ten z pewnością ułatwia poprawne grupowanie, biorąc pod uwagę tematykę obu grup tytułów. Usuńmy je jednak z macierzy. Po wykonaniu analogicznej jak w pierwszym przykładzie analizy widać, że grupowanie się jednorodnych tematycznie tytułów również jest widoczne (rysunek 7b). Dla tytułów z grupy ^Statistics" umieszczono na wykresie ich numery zgodne z tymi z tabeli 8, celem łatwiejszej ich identyfikacji. Jak widać, niektóre pozycje „odjechały” w stronę drugiej kategorii -najbardziej tytuły o numerach 10, 22, 32 (wyróżniono je większą czcionką). Powodem tego jest fakt, że brzmią one jak ... tytuły z dziedziny „Control & Systems Theory”, a nie „Statistics”. Przykładowo pozycję 22 „Statistieał Design and Analysis of Experiments" większość osób, biorąc pod uwagę tylko jej tytuł, zaklasyfikuje do dziedziny „Control & Systems Theory”.
Ponadto z rysunku 7b można odczytać, że tytuły z grupy „Statistics” (pomijając wspomniane trzy wartości odstające) są dużo bardziej podobne do siebie niż tytuły z drugiej grupy. Innymi słowy ich „semantyczny rozrzut” jest dużo mniejszy - tytuły z tej dziedziny są bardziej lingwistycznie jednolite!
PCA jest, z matematycznego punktu widzenia, silnie pow iązane z rozkładem SVD.
Wyszukiwarka
Podobne podstrony:
21338 skanuj0008 BWPatfKMKSfflPI—B1 rfo brz# Rys.3.3 Wzajemne położenie części spawanych nie powinno
234 Jarosław Gramacki, Artur Gramacki opisane w poprzednich rozdziałach. Następnym krokiem jest znal
236 Jarosław Grainacki. Artur Gramacki 43 [C] Practical Methods for Optimal Contro
240 Jarosław Gramacki. Artur Gramacki Tabela 10. Przykładowy dokument, który należy podsumować:
242 Jarosław Grainacki, Artur Gramacki Tabela 11. Wynik podsumowania tekstu z tabeli 10 w postaci 3
244 Jarosław Gramacki. Artur Gramacki5. Oracle Text Moduł Oracle Text (OT) to instalowany jako opcja
228 Jarosław Gramacki, Artur Gramacki 0
230 Jarosław Gramacki. Artur Gramacki2.1. Stop lista Procedura usuwania słów nieistotnych jest
232 Jarosław Gramacki. Artur Gramacki3.1. Struktura TF*IDF Główna modyfikacja podstawowej struktury
P1050870 c> Rys. 14. Zrekonstruowane wzajemne położenie kontynentów Ameryki Południowej i Alryki
282 (13) Rys. 15 5. Wzajemne położenie powierzchni zliczenia i pasa pozycyjnego. Istnienie błędu gru
a/ b/ Rys. 2.6. Rzuty prostej a) poziomej i b) czołowej Wzajemne położenie dwóch prostych w przestrz
slajd2 (56) Wzajemne położenie elementów -przynależność -równoległość
slajd3 (56) Wzajemne położenie elementów •przynależność ■ prosta punkt płaszczyzna płaszczyzna
więcej podobnych podstron