Programowanie równoległe i rozproszone – opracowanie lab nr 1
OpenMP (ang. Open Multi-Processing) – wieloplatformowy interfejs programowania aplikacji
(API) umożliwiający tworzenie programów komputerowych dla systemów wieloprocesorowych z
pamięcią dzieloną. Może być wykorzystywany w językach programowania C, C++ i Fortran na
wielu architekturach, m.in. Unix i Microsoft Windows. Składa się ze zbioru dyrektyw
kompilatora, bibliotek oraz zmiennych środowiskowych mających wpływ na sposób
wykonywania się programu.
Dzięki temu, że standard OpenMP został uzgodniony przez głównych producentów sprzętu i
oprogramowania komputerowego, charakteryzuje się on przenośnością, skalowalnością,
elastycznością i prostotą użycia. Dlatego może być stosowany do tworzenia aplikacji
równoległych dla różnych platform, od komputerów klasy PC po superkomputery.
OpenMP można stosować do tworzenia aplikacji równoległych na klastrach komputerów
wieloprocesorowych. W tym przypadku zwykle stosuje się rozwiązanie hybrydowe, w którym
programy są uruchamiane na klastrach komputerowych pod kontrolą alternatywnego interfejsu
MPI, natomiast do urównoleglenia pracy węzłów klastrów wykorzystuje się OpenMP.
Alternatywny sposób polega na zastosowaniu specjalnych rozszerzeń OpenMP dla systemów
pozbawionych pamięci współdzielonej (np. Cluster OpenMP Intela).
Kompilacja
Przykład kompilacji dla kompilatora Intel C++:
$ icc -openmp program.cpp -o program
Przykład kompilacji dla kompilatora GCC:
$ g++ -fopenmp program.cpp -o program
Uruchomienie programu dla czterech wątków:
$ env OMP_NUM_THREADS=4 ./program
Proces kompilacji OpenMP (
https://iwomp.zih.tu-dresden.de/downloads/OpenMP-
Front End – odczytanie kodu źródłowego, sprawdzenie czy jest wolny od błędu, przygotowanie
kodu pośredniego. (Czytanie i sprawdzanie dyrektyw OpenMP, czy dyrektywa jest w
odpowiednim miejscu, czy pętla jest dozwolona, niektóre błędy mogą nie być uznane za błąd!
Tworzy kod pośredni z adnotacjami OpenMP do dalszego obsłużenia).
Middle End – jak najlepsza analiza i optymalizacja kodu. (Tłumaczenie sekcji, pętli, dodawanie
niejawnych barier, łączenie sąsiednich obszarów równoległych i barier [redundancja]).
Back End – przetłumaczenie konstrukcji OpenMP na wielowątkowy kod
Każdy wątek potrzebuje własnego stosu.
Konstrukcje związane ze współdzieleniem pracy:
•
omp for lub omp do – używane do rozdzielania iteracji pętli pomiędzy wątki, zwane
także konstrukcjami pętli.
•
sections – przypisanie następujących po sobie, ale niezależnych bloków kodu do
różnych wątków
•
single – wyszczególnienie bloku kodu, który będzie przetwarzany przez tylko jeden
wątek, z barierą na końcu

•
master – podobne do single, przy czym kod jest przetwarzany tylko przez wątek
główny, bez bariery na końcu
Klauzule atrybutów współdzielenia danych
•
shared – dane współdzielone, co oznacza, że są widoczne i dostępne dla wszystkich
wątków jednocześnie. Domyślnie wszystkie zmienne w regionie współdzielonej pracy są
shared z wyjątkiem licznika iteracji pętli.
•
private – dane są prywatne dla każdego wątku, co oznacza, że każdy wątek posiada
lokalną kopię i używa jej jako zmienną tymczasową. Prywatne zmienne nie są
inicjalizowane, ich wartość nie jest udostępniana do użycia poza regionem
przetwarzanym równolegle. Domyślnie liczniki iteracji pętli są prywatne.
•
default – pozwala programiście ustawiać domyślny zasięg zmiennych wewnątrz
równolegle przetwarzanego regionu, poprzez użycie shared, private lub none. Opcja
none zmusza programistę do deklarowania każdej zmiennej.
Klauzule synchronizacji
•
critical section – zawarty blok kodu będzie przetwarzany przez tylko jeden wątek w
danym czasie, a nie jednocześnie przez kilka. Jest często używany do ochrony
współdzielonych danych przed błędnym stanem.
•
atomic – podobne do critical section, ale informuje kompilator aby zostały użyte
specjalne instrukcje sprzętowe dla zapewnienia lepszej wydajności. Kompilatory mogą
zignorować tę sugestię od użytkownika i użyć critical section.
•
ordered – zawarty blok jest przetwarzany w porządku, w którym iteracje są
uruchamiane w sekwencyjnej pętli.
•
barrier – każdy wątek czeka, zanim wszystkie inne wątki osiągną ten punkt.
Konstrukcje współdzielące prace posiadają ukrytą synchronizację barier na końcu.
•
nowait – ustala, że wątek kompletujący przyporządkowaną mu pracę, może pracować
bez czekania na inne wątki przed zakończeniem. W przypadku braku tej klauzuli, wątki
przeprowadzają synchronizację bariery na końcu bloku pracy współdzielonej.
Klauzule planowania
•
schedule(type, chunk) – Jest to użyteczne, jeśli konstrukcja współdzieląca prace jest
pętlą do lub for. Określa sposób podziału pętli na części wykonywane równolegle.
Parametr „type” określający sposób rozdziału iteracji jest obowiązkowy. Drugi parametr
„chunk” jest opcjonalny. Określa on wielkość równolegle przetwarzanej części. Musi być
liczbą całkowitą. Poszczególne wątki w blokach są rozmiaru „chunk”, do których
przydzielane są iteracje. Typy planowania to:
1. static – Tutaj, każdy z wątków posiada przypisane iteracje przed uruchomieniem
iteracji pętli. Domyślnie, iteracje są dzielone po równo między wątki. Określenie
całkowitej wartości dla parametru „chunk” spowoduje przydzielenie tej ilości
następujących po sobie iteracji do konkretnego wątku. Jeżeli programista pominie
parametr „chunk”, zbiór iteracji zostanie podzielony na podzbiory o wielkości (w
przybliżeniu) równej liczba_iteracji/liczba_wątków, a każdy wątek otrzyma przynajmniej
jeden podzbiór.
2. dynamic – Tutaj, pewna ilość iteracji jest przypisywana do mniejszej ilości wątków. Gdy
konkretny wątek skończy swoją iterację, pobiera następną z pozostałych wolnych
iteracji. Ostatni podzbiór może mieć mniejszą wielkość niż ta określona przez parametr
„chunk”. Parametr „chunk” definiuje ilość iteracji, które są przyporządkowywane do

wątku za każdym razem. Gdy „chunk” nie jest określony, wówczas podzbiory są
jednoelementowe.
3. guided – Duży fragment następujących po sobie iteracji jest przypisywany do każdego
wątku dynamicznie (jak powyżej). Rozmiar fragmentu zmniejsza się wykładniczo, wraz
z każdą pomyślną alokacją, do minimalnego rozmiaru zdefiniowanego w parametrze
„chunk”. Jeśli programista ustawi parametr „chunk” na 1, to rozmiar każdego zbioru jest
opisany algorytmem: liczba_nieprzydzielonych_iteracji/liczba_wątków. Wartość ta
zmierza do 1. Adekwatnie, jeśli „chunk” ustalony zostaje na m gdzie m>1, to rozmiar
porcji ustalany jest podobnie jak wyżej, lecz nie może on stać się mniejszy od m.
Wyjątkiem jest jedynie ostatnia porcja. Może ona być mniejsza od zadanej wielkości.
Domyślny „chunk” (gdy nie jest ustalony) jest równy 1.
4. auto – System samodzielnie określa podział zrównoleglenia zadania.
5. runtime – Ta opcja zezwala na określanie na wykorzystywanie powyższych możliwości
w trakcie działania programu. Przekazywanie jest powiązane ze zmienną środowiskową
OMP_SCHEDULE:
$ export OMP_SCHEDULE="dynamic"
$ export OMP_SCHEDULE="guided,4"
Kontrola IF
•
if – Powoduje, że wątki zrównoleglają zadanie tylko wtedy gdy warunek jest spełniony.
W innym wypadku blok kodu jest przetwarzany szeregowo.
Inicjalizacja
•
firstprivate – we wszystkich wątkach przypisywane są wartości początkowe, takie jak
przed wejściem do bloku równoległego.
•
zmiennym lastprivate po zakończeniu bloku równoległego przypisywana jest ich
wartość końcowa w bloku równoległym (tak jakby był on wykonywany sekwencyjnie).
•
threadprivate – uczynienie ze zmiennych globalnych, zmiennych prywatnych wątków,
z ich zachowaniem pomiędzy różnymi blokami równoległymi.
Redukcja
•
reduction(operator | intrinsic: list) – zmienna posiada lokalną kopię w każdym wątku,
lecz wartości lokalnych kopii są podsumowywane (redukowane) do współdzielonej
globalnie zmiennej. Jest to bardzo użyteczne, jeśli dana operacja (ustalona w
parametrze „operator” dla tego przypadku) pracuje na interaktywnym typie danych,
takim, że jego wartość podczas konkretnej iteracji zależy od jego wartości w
poprzedniej. Ogólnie, kroki, które prowadzą do operacyjnej inkrementacji są
zrównoleglane, ale wątki gromadzą się i czekają na zaktualizowanie danych, dzięki temu
inkrementacja następuje w dobrym porządku co zapobiega błędnym stanom. Jest to
wymagane na przykład, przy całkowaniu numerycznym funkcji i równaniach
różniczkowych.
Inne
•
flush – Punkt, w którym kompilator upewnia się, że wszystkie wątki w obszarze
równoległym mają takie samo pojęcie o zmiennych podanych w parametrze

•
master – Uruchamiane jedynie przez wątek główny (wątek zarządzający resztą podczas
przetwarzania dyrektywy OpenMP) Żadna niewidoczna bariera nie występuje, inne wątki
nie muszą jej osiągnąć.
Zalety i wady
•
Zalety
•
Prostota – nie ma potrzeby przejmowania się przesyłaniem wiadomości, jak w
MPI
•
Układ danych i dekompozycja jest obsługiwana automatycznie przez dyrektywy
•
Równoległość inkrementacyjna – można pracować na jednej porcji programu w
jednym czasie, nie są potrzebne drastyczne zmiany kodu
•
Zunifikowany kod dla szeregowych i równoległych aplikacji – konstrukcje
OpenMP są traktowane jako komentarz podczas kompilacji przy użyciu
sekwencyjnego kompilatora
•
Oryginalny (szeregowy) kod na ogół nie potrzebuje zmian przy jego
zrównoleglaniu przy użyciu OpenMP. Redukuje to szanse nieumyślnego
wprowadzenia błędów przy konwersji.
•
Zarówno grubo-, jak i drobnoziarnista równoległość jest możliwa.
•
Wady
•
Obecnie działa wydajnie jedynie przy platformach wieloprocesorowych z pamięcią
współdzieloną (zobacz jednak Cluster OpenMP Intela).
•
Wymaga kompilatora wspierającego OpenMP.
•
Skalowalność jest limitowana przez architekturę pamięci.
•
Brakuje niezawodnej obsługi błędów.
•
Brakuje drobno-ziarnistych mechanizmów kontroli przypisania wątku do
procesora.
Zasady określania ilości wątków:
1. ustalenie liczby wątków przy pomocy klauzuli num_threads, np.:
#pragma omp parallel num_threads(2)
2. wywołanie funkcji omp_set_num_threads, np.:
omp_set_num_threads(4);
3. ustalenie zmiennej środowiskowej OMP_NUM_THREADS, np.:
$ set OMP_NUM_THREADS = 1;
4. w pozostałych przypadkach liczba wątków jest ustalana przez implementację OpenMP w
danym systemie – zazwyczaj liczba procesorów w komputerze,
5. istnieje możliwość dynamicznego ustalania liczby wątków.
Zmienne środowiskowe:
OMP_DYNAMIC [TRUE/FALSE] – dynamiczne przydzielenie liczby wątków w równoległym
obszarze
OMP_NESTED [TRUE/FALSE] – zagnieżdżona współbieżność
OMP_NUM_THREADS [INT] – maksymalna liczba wątków we współbieżnym obszarze
OMP_SCHEDULE [STATIC/DYNAMIC/GUIDED/RUNTIME [, chunk]] – tylko gdy ustawiona
klauzula shedule(runtime), dla dyrektyw for lub parallel for, ustala sposób podziału iteracji
pomiędzy wątki
Kiedy petla się nie zrównolegli?
•
Komputer z jednym procesorem,
•
Klauzula if nie została spełniona,
•
Włączony jest dynamiczny przydział liczby procesorów i system zdecyduje, że tylko
jeden procesor jest w stanie obsłużyć pętle,
•
Liczba wątków ustawiona na wartość 1.
Hyper-threading – implementacja wielowątkowości współbieżnej opracowana przez firmę
Intel i stosowana w procesorach Atom, Core i3, Core i5, Core i7, Pentium 4.
Hyper-threading służy zwiększeniu wydajności obliczeń prowadzonych równolegle przez
mikroprocesory. Dla każdego fizycznego rdzenia procesora system operacyjny przypisuje dwa
procesory wirtualne, a następnie dzieli obciążenie obliczeniami między nimi, jeżeli jest to
możliwe. Hyper-threading wymaga nie tylko wsparcia ze strony systemu operacyjnego, ale
również oprogramowania zoptymalizowanego specjalnie dla obsługi tej technologii. Intel zaleca
wyłączanie jej, jeżeli używany jest system operacyjny bez takiej optymalizacji.
OpenMP przydziela jeden wątek na rdzeń. Jeżeli HT jest włączony to w takim wypadku
przydzielane są dwa wątki na jeden rdzeń. Trzeba pamiętać o tym, że naszym ograniczeniem
jest pamięć dzielona (za
https://www.msi.umn.edu/sites/default/files/OpenMP.tutorial_1.pdf
slajd 18).
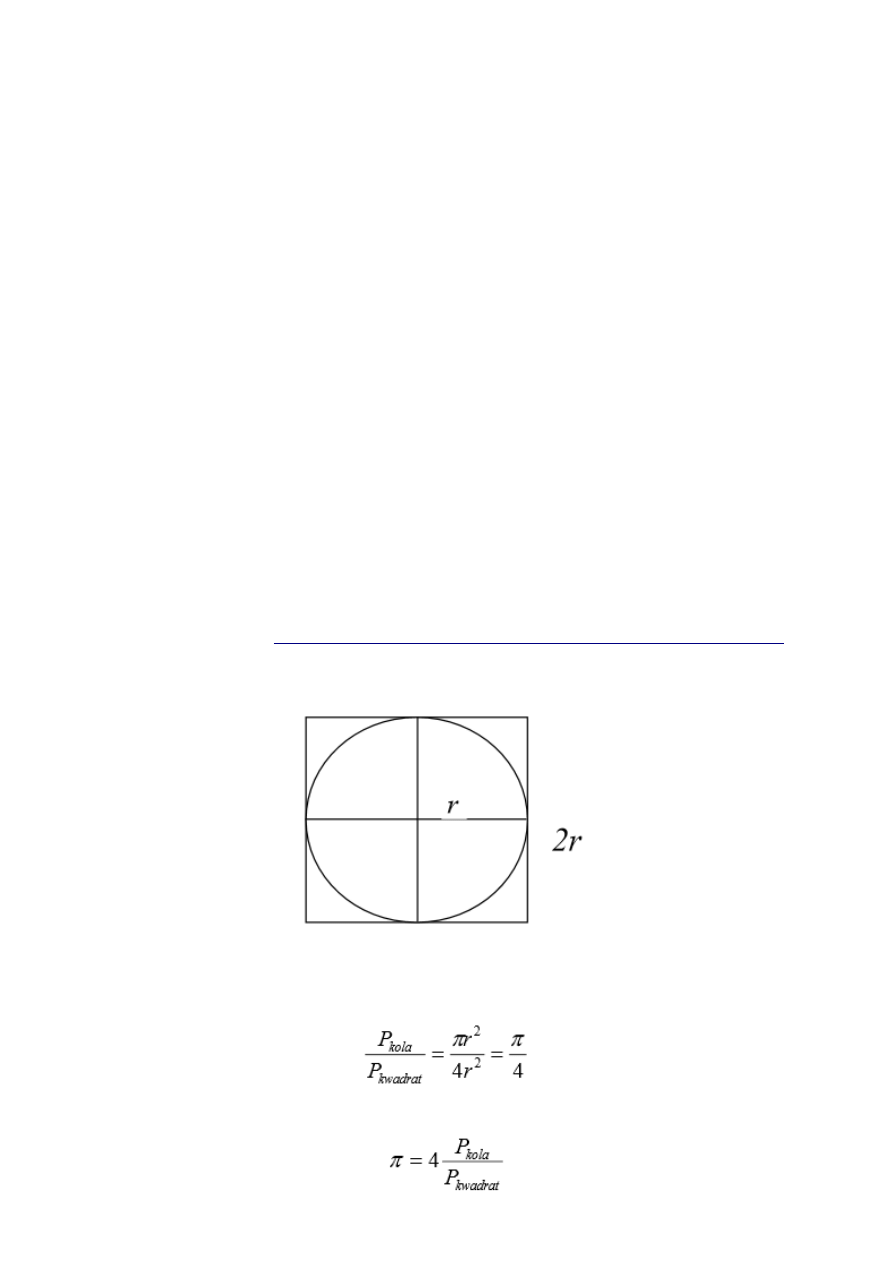
PI metodą Monte Carlo
Pole kwadratu = 4r
2
Pole koła = ∏*r
2
więc:
i dalej, mając pole koła i kwadratu można obliczyć:
Pola można otrzymać stosując metodę MC.
1. Losuje się n punktów z opisanego na tym kole kwadratu - dla koła o R = 1 współrzędne
wierzchołków (-1,-1), (-1,1), (1,1), (1,-1).
2. Po wylosowaniu każdego z tych punktów trzeba sprawdzić, czy jego współrzędne spełniają
powyższą nierówność (tj. czy punkt należy do koła).
Wynikiem losowania jest informacja, że z n wszystkich prób k było trafionych, zatem pole koła
wynosi
więc PI = 4 * liczba trafionych / liczba_wszystkich
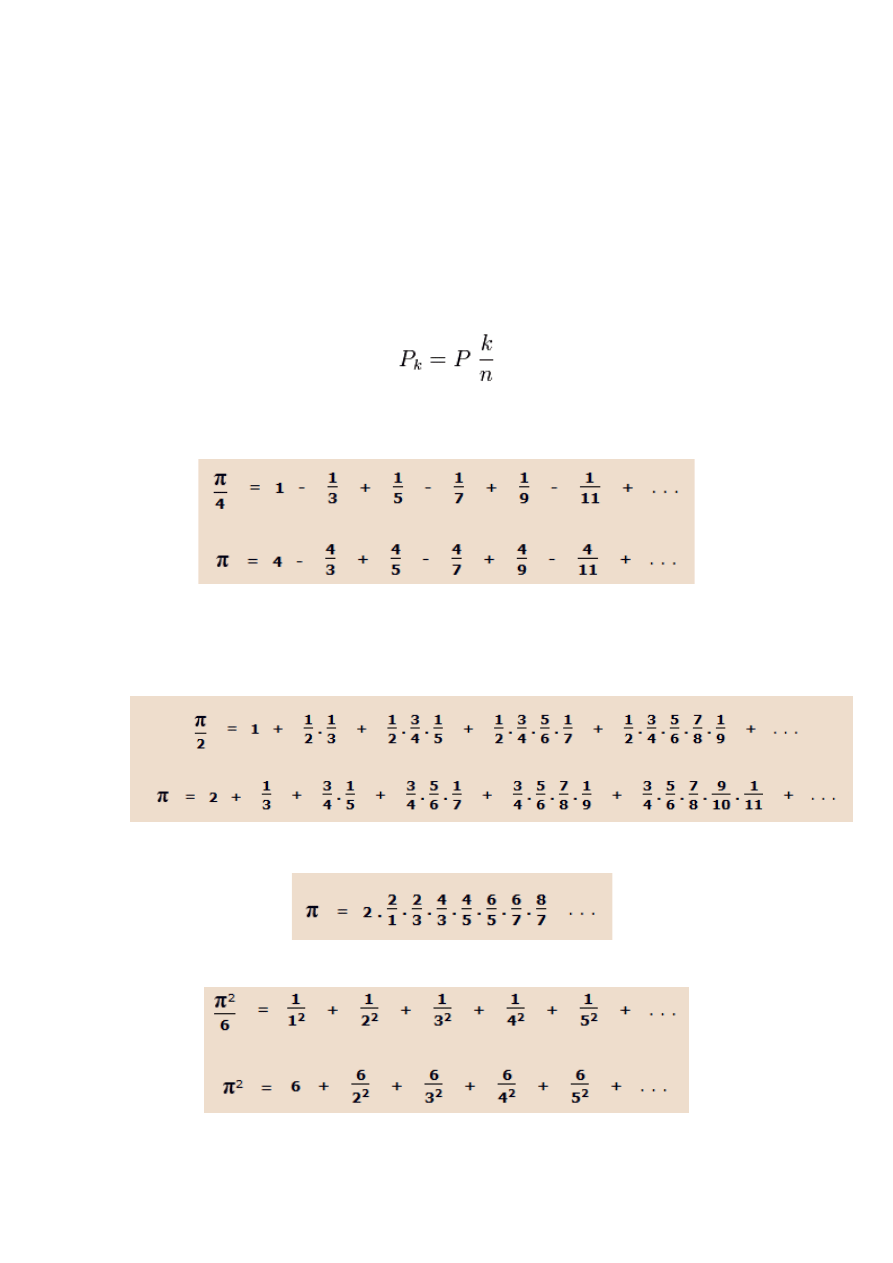
Inne metody:
1.
Wzór ten, odkryty przez Leibniza, otrzymuje się po rozwinięciu w szereg Maclaurina funkcji
y = arctg x i podstawieniu x = 1 ( arctg 1 = ∏/4 ).
2.
To także rozwinięcie w szereg Maclaurina, ale tym razem funkcji y = arcsin x arcsin 1 = ∏/2 ).
3.
Wzór odkryty przez Johna Wallisa
4.
To rozwinięcie, odkryte przez Eulera, otrzymuje się z teorii tzw. szeregów trygonometrycznych.

Pytania:
- co to openmp
- wady i zalety open mp
- co jest wydajniejsze zmienne prywatne czy współdzielone?
Prywatne. Chodzi o to, że nie tracimy czasu na synchronizację.
- różnice między first private oraz private
- kiedy pętla się nie z równolegli
- jak przebiega proces kompilacji Openmp
- w jaki sposób można wyznaczyć liczbę PI (nie chodzi tutaj o Monte Carlo)
- czy openMP zrównoległa na wątkach, czy procesach,
- jak określić na ilu watkach ma zrównoleglić
- jeśli nie określimy to na ilu się wykona
- co w przypadku gdy mamy hyper-threading
Document Outline
- Klauzule atrybutów współdzielenia danych
- Klauzule synchronizacji
- Klauzule planowania
- Kontrola IF
- Inicjalizacja
- Redukcja
- Inne
- Zalety i wady
Wyszukiwarka
Podobne podstrony:
OpenMP lab1 opracowanie odpowiedz
finanse lokalne opracowane odpowiedzi, Różne Dokumenty, MARKETING EKONOMIA ZARZĄDZANIE
MPI lab4 opracowanie odpowiedz
PODSTAWY PRAWA, Prawo - test (opracowane odpowiedzi), 1
OPRACOWANE ODPOWIEDZI id 337615 Nieznany
CUDA lab2 opracowanie odpowiedz
Zbiór2 pytań wraz z opracowanymi odpowiedziami z przedmiot
opracowane odpowiedzi do zestawu 2
opracowane odpowiedzi na pytani Nieznany
finanse lokalne opracowane odpowiedzi--ściaga, Różne Dokumenty, MARKETING EKONOMIA ZARZĄDZANIE
prawo test opracowanie odpowiedzi 15, Agh kier. gig. rok 3 sem 6, podziemka podsadzka, sem VI, Prawo
Opracowane odpowiedzi część
opracowane odpowiedzi, MRiT-Mechanika i Budowa Maszyn, Fizyka
kolo opracowanie odpowiedzi
Egzamin Podstawy Projektowania 12 opracowane odpowiedzi
OPRACOWANE ODPOWIEDZI
opracowane odpowiedzi do zestawu 1
więcej podobnych podstron