Modelowanie komputerowe w badaniach wstępnych, przedklinicznych i klinicznych.
Zgodnie z informacją przedstawioną w poprzednich wykładach badania kliczniczne obejmują cztery
najważniejsze etapy przedstawione poniżej.
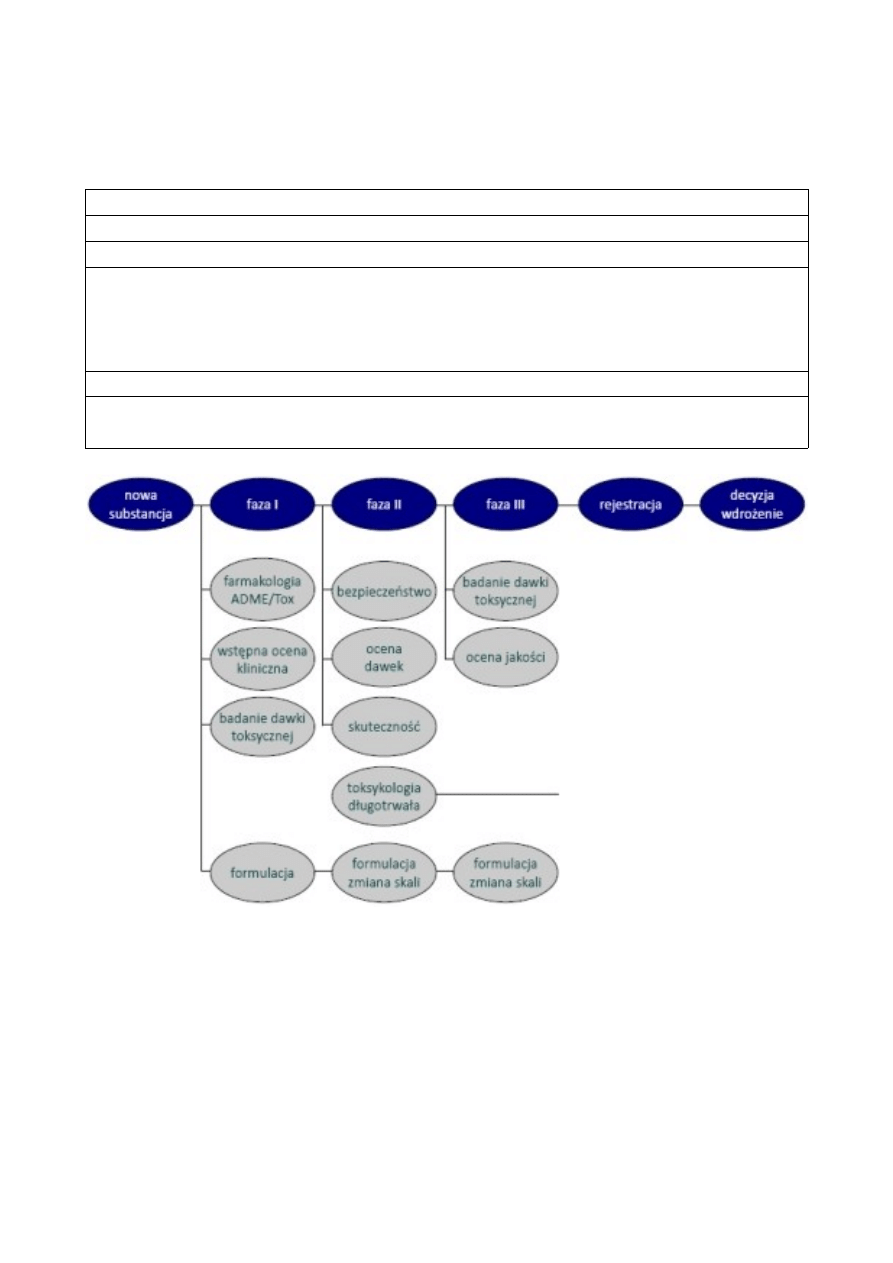
Tabela 1. Etapy badań klinicznych:
●
badania przedkliniczne (in vitro i na zwierzętach)
●
faza I - na niewielkiej grupie (20-80) zdrowych ochotników; ma na celu zbadanie bezpieczeństwa,
toksyczności, farmakokinetyki i farmakodynamiki terapii. W badaniach nad niektórymi lekami
(np. przeciwnowotworowymi czy anty-HIV) w tej fazie badań biorą udział pacjenci w
zaawansowanym stadium choroby.
●
faza II - na większej grupie (20-300); ma na celu zbadanie klinicznej skuteczności terapii.
●
faza III - randomizowane badania na dużej grupie (300–3000 lub więcej) pacjentów; ma na celu
pełną ocenę skuteczności nowej terapii.
Niekiedy jako kolejną, czwartą fazę badań klinicznych określa się badania post-marketingowe, a więc
wykonywane już po wprowadzeniu leku na rynek. Badania te obejmują ocenę bezpieczeństwa stosowania
leku w szerokiej, nieizolowanej populacji tak charakterystycznej dla badań klinicznych faz I-III oraz
badania farmakoekonomiczne, polegające na ocenie porównawczej leków i schematów leczenia lub też
porównanie farmakoterapii z nieleczeniem - jak w przypadku filozofii BSC (ang. Best Supportive Care), a
więc dostarczenie osobom w terminalnych stadiach chorób nowotworowych najlepszej możliwej terapii
wspomagającej bez wdrażania chemo- lub radioterapii. Co ważne z punktu widzenia omawianego tematu -
tu także wykorzystuje się techniki modelowania komputerowego.
Rozwój metod modelowania matematycznego i ich praktyczna realizacja z wykorzystaniem
komputerowych jednostek obliczeniowych daje możliwość ograniczenia potrzeby stosowania zwierząt
laboratoryjnych na wczesnych etapach badań nad lekiem, niemniej jednak całkowite ich wyeliminowanie
nie jest możliwe. Jak już wcześniej wspomniano, ze względów naukowych i praktycznych (trudności w
skalowaniu wyników badań zwierzęcych na ludzi), postuluje się wykorzystanie izolowanych komórek
ludzkich (np. komórki wątroby - enterocyty, całych narządów lub w miarę możliwości i z zachowaniem
obowiązujących - bardzo ścisłych - reguł, przeprowadzanie badań na ludziach. Otrzymane na ich
podstawie wyniki są wykorzystywane jako dane wstępne do budowania generalnych modeli zachowań leku
w organizmie. Wykorzystywane na tym etapie programy wykorzystują gotowy zestaw modeli - zarówno
farmakokinetycznych jak i farmakodynamicznych. Najczęściej wykorzystywane programy - WinNonlin,
Nonmem czy moduły wbudowane do zaawansowanych pakietów statystycznych (S-Plus) umożliwiają także
definiowanie własnych algorytmów, co jest często wykorzystywane w działach rozwoju firm
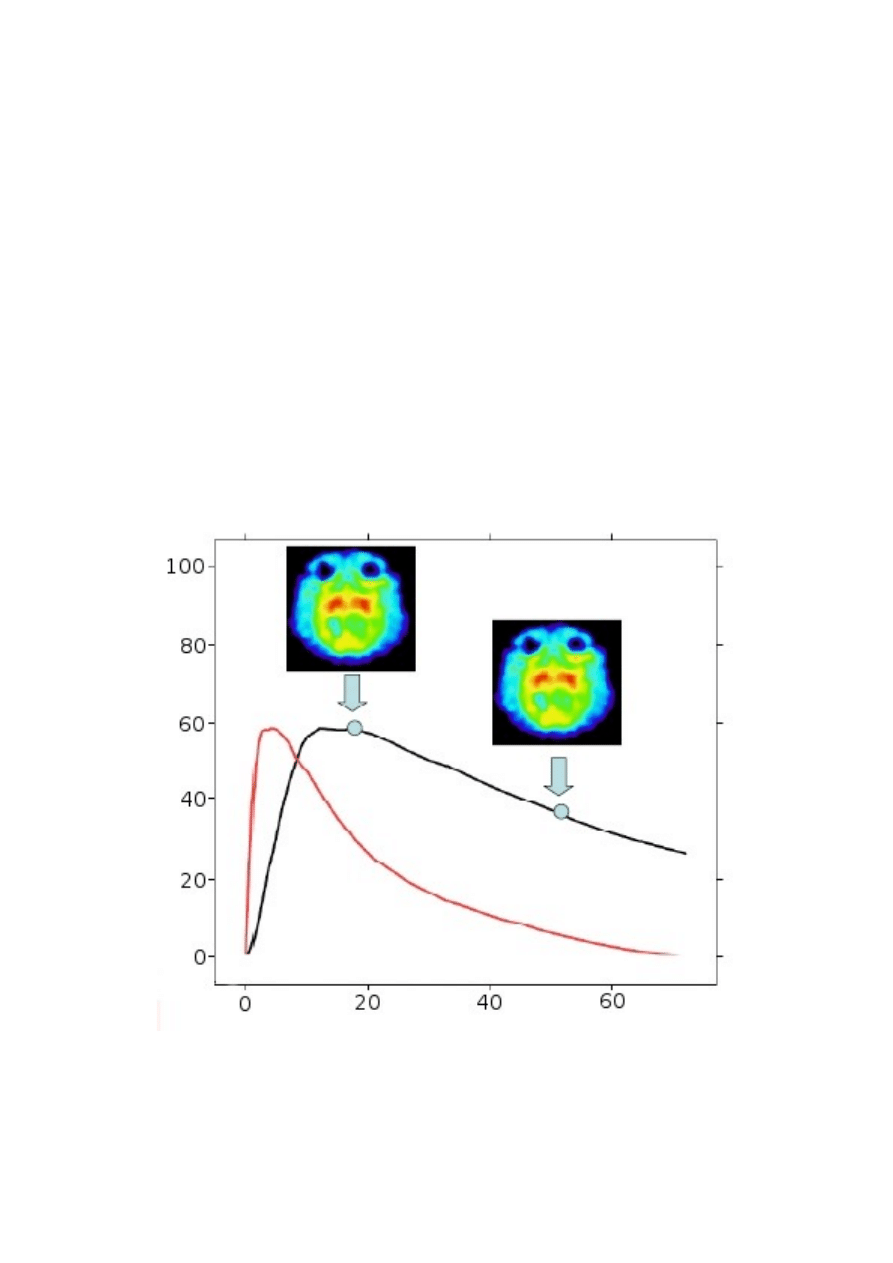
farmaceutycznych. Kolejny przykład ich wykorzystania to skalowanie PK-PD, a więc poszukiwanie
zależności między stężeniem leku we krwi (lub ogólnie - ilością leku w organizmie), a siłą odpowiedzi
farmakologicznej, a także poszukiwanie zależności między danymi uzyskiwanymi w warunkach in vitro
oraz ich przenoszenie na warunki in vivo.
wykres - zależność PK/PD

Wszystkie opisane powyżej przykłady obejmowały modelowanie indywidualne, dla poszczególnych
jednostek. Obecnie wyzwaniem staje się raczej uzyskanie wyników dla wirtualnych populacji,
uwzględniających zmienność międzyjednostkową. Jest to o tyle ważne, że w realnych warunkach lek nie
jest wykorzystywany jedynie w wąskich grupach, tak jak to ma miejsce w trakcie badań klinicznych. Jak
można się domyślać należy się spodziewać różnic we wszystkich elementach definiujących zachowanie
leku w organizmie - wchłanianiu, dystrybucji, metabolizmie i wydalaniu w różnych grupach populacjach
zróżnicowanych pod względem wieku (różnice w fizjologii poszczególnych narządów np. wątroby, jelit u
dzieci), płci, rasy, budowy fizycznej (powierzchnia ciała, waga, wzrost, BMI) czy też konstytucji
genetycznej (np. zróżnicowana aktywność enzymów metabolizujących leki). Jeszcze inaczej wygląda to w
przypadku osób chorych, u których szeroko pojęty metabolizm może być drastycznie zmieniony (cukrzyca,
celiakia). Najczęstsze postępowanie pomagające modelować zmienność w populacji (ang. PBPK modeling)
to wykorzystywanie bibliotek danych zawierających informacje charakteryzujących określone populacje.
Są to najczęściej bardzo obszerne zbiory, z których odpowiednie algorytmy pobierają dane w trakcie
symulacji lub analiz typu what if (co jeśli). Dzięki wbudowanym modelom chorób możliwe jest również
symulowanie zachowań leku w populacji osób chorych. Najbardziej znane programy komputerowe -
wykorzystane na tych etapach - to Simcyp, Gastro+ czy PK Sim. Już z poprzedniego zdania wynika, iż
stosowane są one równolegle do wszystkich faz badań klinicznych - choć w różnych celach. Najczęściej
chodzi o przeniesienie wyników badań na zdrowych ochotnikach na szersze populacje.
Nieco inne zastosowanie mają również istniejące wirtualne modele chorób (cukrzyca, nadciśnienie i inne),
możliwe do wykorzystania jako biblioteki zewnętrzne. Ich potencjalną rolą jest obserwacja zachowań
organizmu (jako całości) na zmieniające się warunki - w tym również podanie leku.
W trakcie badań klinicznych konieczne jest stosowanie programów wspomagających, jednak są to raczej
systemy analizy danych niż ich generowania w procesie symulacji, dlatego nie zostaną przedstawione w
tym omówieniu.
Jak wspomniano powyżej systemy komputerowe są również wykorzystywane w trakcie czwartej - ostatniej
fazy badań klinicznych. Gromadzone wtedy dane (co jest obowiązkiem firm farmaceutycznych
wprowadzających lek na rynek) pozwalają na ocenę skuteczności preparatu i stosowanych schematów
terapeutycznych, co z kolei może zostać wykorzystane do badań farmakoekonomicznych. Wymagania
stawiane tego typu badaniom wymuszają różnicowanie populacji otrzymującej różnorodne schematy
terapeutyczne, co w praktyce jest bardzo trudne lub niemożliwe (np. w przypadku chorób
nowotworowych). W takim przypadku istnieje możliwość wykorzystania systemów matematycznych lub
opartych na sztucznej inteligencji pozwalających na przeprowadzanie analizy typu what if, a więc
wirtualnego podania innego leku o ocena różnic terapeutycznych schematu realnego i zamodelowanego.
Równolegle z badaniami klinicznymi oceniającymi m.in. skuteczność, bezpieczną dawkę i inne parametry
leku oraz planowanych schematów terapii, prowadzone są doświadczenia nad formulacją. Na tym etapie
wykorzystuje się bardzo intensywnie dane uzyskane na wcześniejszych etapach prac nad lekiem, które
wpływają na planowaną - dostępną lub optymalną - drogę podania oraz postać leku. W przypadku
substancji, które ze względu na swoje właściwości fizykochemiczne (słaba rozpuszczalność lub
przenikalność przez bariery biologiczne co warunkuje niską biodostępność) lub z innych względów (np.

działanie toksyczne lub konieczność ominięcia danego odcinka przewodu pokarmowego lub nawet
specjalnej drogi podania np. wziewnej) wymagają wyspecjalizowanych formulacji, prace w laboratoriach
technologicznych są niekiedy niezwykle żmudne i kosztowne. Z tego właśnie powodu zarówno kompanie
farmaceutyczne jak i firmy wyspecjalizowane w dostarczaniu półproduktów wykorzystywanych w trakcie
sporządzania postaci leku (np. kapsułki) coraz intensywniej stosują w trakcie praz doświadczalnych
metody modelowania komputerowego. Przykładem podobnego jest zarówno stosowanie modeli
mechanistycznych będących częścią większego systemu komputerowego (choćby wspomniany wcześniej
Simcyp) jak i wyspecjalizowane modele oparte o wspomniane wcześniej algorytmy sztucznej inteligencji,
np. sztuczne sieci neuronowe. Jest to szczególnie przydatne w sytuacji kiedy dana postać leku może
zawierać substancje potencjalnie toksyczne (np. w dużym stężeniu) lub nie ma gotowych algorytmów
poszukiwania zestawu poszczególnych składników, jak to ma miejsce w przypadku chociażby mikroemulsji.
Dzięki możliwości uczenia się na kolejnych przykładach tego typu systemy mogą poprawiać swoją
skuteczność wraz ze wzrostem ilości dostępnych informacji. Podejście, w którym system obliczeniowy
staje się niejako partnerem badacza w procesie optymalizacji formulacji, staje się dzisiaj coraz bardziej
popularnym rozumieniem sposobu wykorzystania narzędzi in silico.
Powyższe opracowanie nie wyczerpuje wszystkich dostępnych i coraz powszechniej wykorzystywanych
systemów modelowania komputerowego, jak również ich możliwych zastosowań. Niemniej jednak stanowi
przegląd metod i wskazuje na rosnącą rolę szeroko pojętego modelowana matematycznego w naukach
biologicznych, a szczególnie w procesie badań nad lekiem. Techniki te stają się coraz szerzej
wykorzystywane w celu zwiększenia efektywności opracowania leku. Możliwości percepcyjne maszyn
znacznie przekraczają ludzką zdolność do całościowego ogarniania problemu, co przynosi korzyści w
postaci automatycznej akwizycji i przetwarzania wiedzy pozwalając skupić się na najistotniejszych
aspektach opracowywanego zagadnienia. Wg dzisiejszego stanu wiedzy jesteśmy wciąż daleko od pełnego
zrozumienia wszystkich procesów wpływających na lek i jego działanie w organizmie. Każda skuteczna
technologia pozwalająca na efektywniejsze pogłębianie i wykorzystanie tej wiedzy jest więc cenna i
skrzętnie wykorzystywana, jak właśnie m.in. metody in silico.
Wyszukiwarka
Podobne podstrony:
Modelowanie komputerowe w badaniach wstępnych, przedklinicznych i klinicznych
Modelowanie komputerowe w badaniach wstępnych, przedklinicznych i klinicznych
Modelowanie komputerowe w badaniach nad lekiem
Pośmiertna dyfuzja tlenku węgla do mięśni i krwi - badania wstępne, Forensic science, Medycyna sądow
BADANIE WSTĘPNE BTLS
badania wstepne, STUDIA -PRYWATNE, Różności
Skierowanie na badania wstepne - wzor, Różne Dokumenty, KADROWE
skierowanie pracownika na badania wstepne, dot. pracy
badania lekarskie, Skierowanie pracownika na badania wstępne - chomik reflex, Dokumenty i formularze
Modelowanie komputerowe
Korzystne efekty dodania kwasów tłuszczowych omega 3 do leczenia przeciwdepresyjnego w depresji leko
Karol Sapieha mgr praca domowa modelowanie komputerowe w praktyce in ynierskiej
badania wstępne
KOMPUTEROWE BADANIE ROZWINI
Alprazolam w leczeniu lęku uogólnionego z towarzyszącymi objawami depresyjnymi (badanie wstępne)
Wykł BADANIA KLINICZNO KONTROLNE I PRZEKROJOWE
więcej podobnych podstron