www.hakin9.org
hakin9 Nr 6/2006
34
Narzędzia
S
formułowanie polityki bezpieczeństwa
wiąże się bezpośrednio z takimi czyn-
nościami jak konfiguracja zapory oraz
przygotowanie infrastruktury monitorowania
logów w celu wykrycia ewentualnych nad-
użyć. Niestety, administratorzy zapominają
często o pewnej istotnej sprawie: otóż zapory
ogniowe (tak jak wszystkie inne urządzenia
przetwarzające) są zawodne. Istnieje spo-
ra liczba dobrze znanych błędów w różnych
produktach tego typu, zarówno komercyjnych
jak i wywodzących się z ruchu Open Source.
Zapory są często dzielone na dwie kategorie
w odniesieniu do początkowych założeń kon-
figuracyjnych. Kategoria pierwsza zakłada,
że wszystko to na co nie ma bezpośredniego
przyzwolenia jest zabronione. Drugie podej-
ście opiera się na twierdzeniu, że wszystko
to, co nie jest w bezpośredni sposób zabro-
nione, jest dozwolone. Patrząc z historyczne-
go punktu widzenia, w przeszłości bardziej
popularna była forma druga (tzw. zapory po-
zwalające), jednak wraz z rozwojem Interne-
tu i pojawianiem się coraz większej liczby za-
grożeń podejście pierwsze zaczęło zyskiwać
coraz więcej zwolenników i stało się równo-
prawną alternatywą. Przy takim podejściu
mamy zazwyczaj do czynienia z tzw. białą li-
stą zasad (ang. white-listing rules), które de-
finiują dozwolone akcje. Lista ta jest ogra-
niczona pojedynczą zasadą złap-wszystko
(ang. catch-all), która blokuje wszystkie nie-
pożądane akcje. Pojęcie zasada (ang. rule)
w odniesieniu do zapory, to pewien opis (za-
pisany w formacie zależnym od konkretnego
produktu), który stanowi wskazówkę odno-
śnie traktowania określonego typu ruchu w
sieci. Na przykład, moglibyśmy zdefiniować
Analiza Naruszeń
i Egzekwowanie Polityki
Bezpieczeństwa
Arrigo Triulzi, Antonio Merola
stopień trudności
W artykule przedstawiamy możliwości wykorzystania Systemu
Detekcji Włamań Sieciowych (ang. Network Intrusion Detection
System, NIDS) jako narzędzia do weryfikacji specyficznych
rodzajów awarii zapory oraz jako mechanizmu wspomagającego
egzekwowanie polityki bezpieczeństwa.
Z artykułu dowiesz się...
• wykrywać naruszenia polityki bezpieczeństwa w
odniesieniu do reguł zapory,
• wykrywać błędy w konfiguracji zapory,
• stosować mechanizmy egzekwowania polityki
bezpieczeństwa.
Powinieś wiedzieć...
• posiadać przynajmniej podstawową wiedzę na
temat zapór ogniowych oraz narzędzi IDS,
• znać obsługę narzędzi OpenBSD pf oraz
Snort.
Różnicowa Analiza Pracy Zapory
hakin9 Nr 6/2006
www.hakin9.org
35
następującą zasadę: zezwalaj na
dostęp do naszej zewnętrznej wi-
tryny korporacyjnej z wewnętrznej
sieci. Tak określona zasada jest ty-
powym przykładem wpisu do białej
listy, jako że definiuje ona pewne
dozwolone i przewidziane zacho-
wanie. Zadanie zapory polega na
dopasowaniu każdego ruchu poja-
wiającego się w sieci do wpisów na
swojej białej liście. Jeśli dopasowa-
nie będzie udane, ruch zostanie au-
tomatycznie przepuszczony; w każ-
dym innym przypadku ruch zosta-
nie zablokowany i fakt ten zostanie
odnotowany (najprawdopodobniej
w postaci wpisu do loga).
Zastanówmy się jednak co się
stanie gdy zapora ulegnie awarii. I
właśnie w tym momencie pojawia
się problem: okazuje się ruch, któ-
ry powinien być zablokowany może
bez żadnego problemu wpływać do
naszej sieci. Spowodowane jest to
oczywiście brakiem aktywności re-
guły złap-wszystko. Awaria zapory
wiąże się też zazwyczaj z nieprawi-
dłowym działaniem mechanizmu ra-
portowania. Innymi słowy: oprócz te-
go, że podejrzane pakiety mogą bez
problemu penetrować zakątki naszej
sieci, to na dodatek nie pozostanie
po nich żaden namacalny ślad. Sy-
tuację tę można wyobrazić sobie ja-
ko strażnika, który zasnął na służ-
bie: docelowa reguła (np. zatrzy-
muj na wejściu wszystkie obce oso-
by) jest aktywna, ale nie egzekwo-
wana ze względu na błąd systemu
(strażnik zasnął). Podsumowując, je-
śli przyjmiemy możliwość wystąpie-
nia błędów w zaporze, to nie może-
my pokładać w tym mechanizmie ca-
łego zaufania odnośnie wykrywania
włamań do naszej sieci. W związku z
tym potrzebujemy jakiegoś dodatko-
wego mechanizmu, który byłby od-
powiedzialny za monitorowanie za-
chowania firewalla.
Konfiguracja zapory:
projektowanie
Sposoby konfiguracji zapory ewolu-
ują. Na początku proces ten był po-
strzegany jako czarna magia (ob-
sługa dostępna wyłącznie z pozio-
mu linii komend). Na dzień dzisiej-
szym firewalle oferują użytkowni-
kom zaawansowane interfejsy gra-
ficzne typu pokaż i przyciśnij. Za-
pory stały się również bardziej po-
pularne w kręgach mniej doświad-
czonych użytkowników – mamy tu
do czynienia z tzw. personalnymi fi-
rewallami, które można instalować
na indywidualnych stacjach robo-
czych. W niniejszym artykule sku-
pimy się na bardziej zaawansowa-
nych produktach, przeznaczonych
do ochrony dużych sieci korpora-
cyjnych.
Transformacja mechanizmów
obsługi konfiguracji zapór, od linii
poleceń do zaawansowanych inter-
fejsów graficznych sprawiła, że do
obsługi mechanizmów zabezpie-
czeń sieci korporacyjnej nie potrze-
ba już wysokce wykwalifikowanych
pracowników – dla firmy jest to nie-
wątpliwie duża oszczędność. Jed-
nak z drugiej strony, brak specja-
listycznej wiedzy mści się w przy-
padku kiedy zapora ulega awarii.
W ekstremalnych sytuacjach sła-
bo wykwalifikowany pracownik mo-
że w ogóle nie zauważyć, że coś
się popsuło..
Przy projektowaniu konfigura-
cji firewalla dobrą praktyką jest bez-
pośrednie tłumaczenie reguł opisa-
nych w ramach polityki bezpieczeń-
stwa danej organizacji na reguły za-
pory. Prosta, acz efektywna polityka
bezpieczeństwa polega na zabloko-
waniu bezpośredniego dostępu z ze-
wnętrznych sieci do wewnętrznego
intranetu firmy, przy czym cały do-
zwolony ruch przechodzi przez tzw.
pełnomocników (ang. Proxies). Za-
daniem pełnomocników jest prze-
chwytywanie i weryfikacja różnych
typów ruchu w sieci (e-mail, web,
FTP, itd.) i transfer tego ruchu do
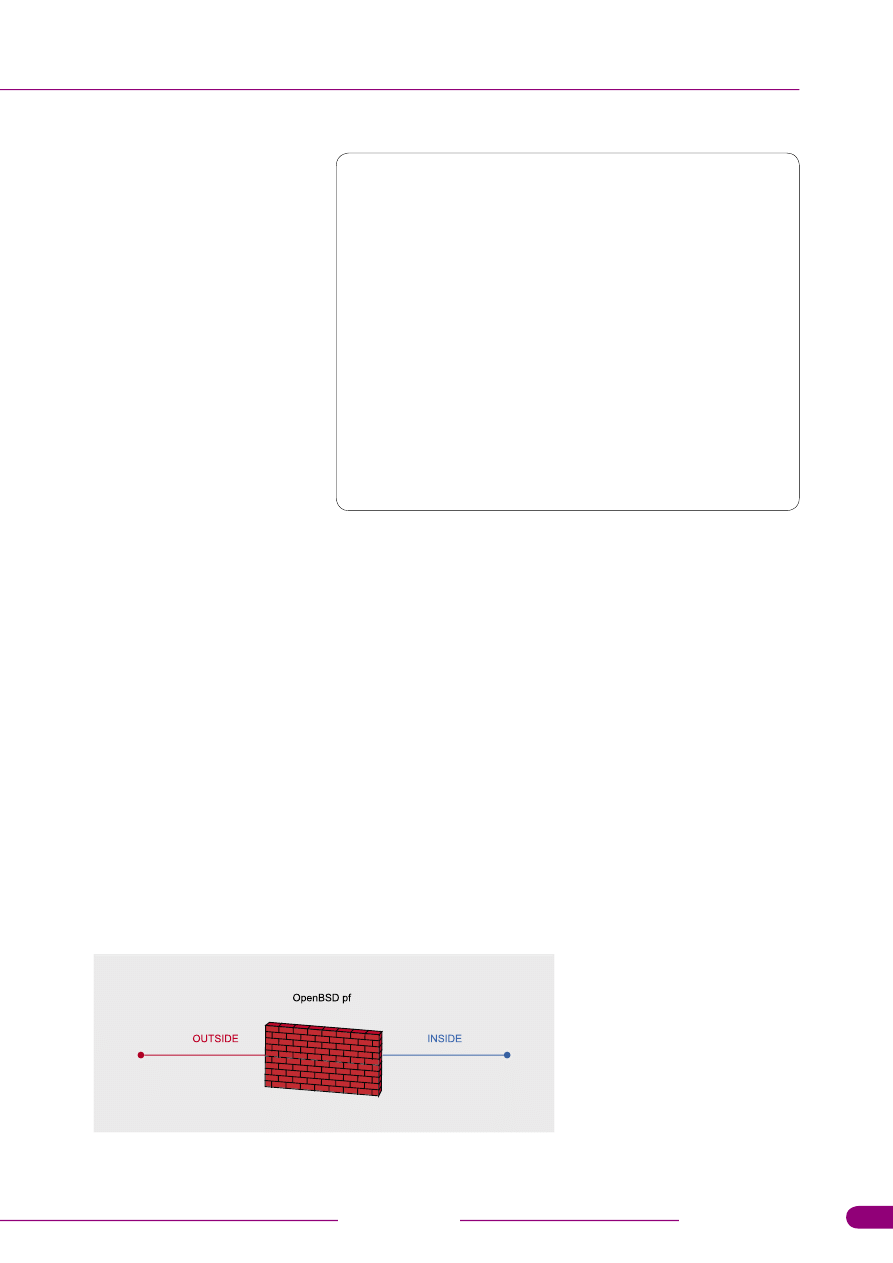
Rysunek 1.
Uproszczona struktura sieci postrzegana z punku widzenia
zapory
Listing 1.
Konfiguracja narzędzia OpenBSD pf
ext_if
=
"ne1"
int_if
=
"ne2"
ext_office
=
"10.105.0.0/16"
int_lan
=
"192.168.10.0/24"
int_hosts_auth
=
"{ 192.168.10.167/32, 192.168.10.168/32, 192.168.10.189/32,
192.168.10.190/32, 192.168.10.213/32, 192.168.10.214/
32, 192.168.10.215/32 }"
(
...
)
#Ten wpis będzie blokował cały ruch wchodzący na obydwu interfejsach
block in all
(
...
)
#Ten wpis pozwala wewnętrznym hostom int_hosts_auth odwoływać się do sieci
10.105/16
pass
in
on
$
int_if
proto
tcp
from
$
int_hosts_auth
to
$
ext_office
keep
state
flags
S
/
SA
pass
out
on
$
ext_if
proto
tcp
from
$
int_hosts_auth
to
$
ext_office
modulate
state
flags
S
/
SA
(
...
)
hakin9 Nr 6/2006
www.hakin9.org
Narzędzia
36
właściwych punktów przeznaczenia.
Procedura taka powinna być stoso-
wana zarówno dla ruchu wchodzą-
cego jak i wychodzącego.
Oczywiście i tutaj zdarzają się
tzw. wyjątki prezesa. To ostatnie
określenie wiąże się z faktem, że
wspomniane wyjątki łączą się za-
zwyczaj z dodatkowymi wymagania-
mi ze strony managementu (na przy-
kład żądanie dostępu do wewnętrz-
nej sieci z domu, lub w trakcie podró-
ży). Aby uzyskać tego typu niestan-
dardowe efekty trzeba dodać do za-
pory dodatkowe reguły. Z czasem
wyjątki się mnożą i wolno aczkol-
wiek nieuchronnie polityka prywat-
ności staje się coraz bardziej złożo-
na, co z kolei sprawia trudności przy
monitorowaniu.
Struktura sieci z punktu widze-
nia zapory powinna być jak naj-
prostsza; preferuje się tu wyodręb-
nienie dwóch warstw: wewnętrznej
i zewnętrznej. Oczywiście w prak-
tyce rzeczywistość jest bardziej
skomplikowana – firewalle posiada-
ją zazwyczaj zarówno wielokrotne
warstwy wewnętrzne (np. kilka pod-
sieci w jednej firmie) jak i zewnętrz-
ne (np. połączenia obsługiwane
przez różne podmioty ISP). Zjawi-
sko tego typu wiąże się z często
stosowaną praktyką pakowania jak
największej liczby usług w ramach
pojedynczego systemu. Jako przy-
kład można przytoczyć tu chociaż-
by systemy oferowane przez firmę
Cisco, gdzie router może służyć ja-
ko zapora, switch będź koncentra-
tor linii telefonicznej – wszystko to
w zależności od tego jakie karty
rozszerzeń dołączymy do urządze-
nia. W ramach niniejszego artykułu
będziemy rozważać urządzenie re-
prezentujące zaporę opartą na re-
gułach, która działa w kontekście
dwóch warstw: wewnętrznej i ze-
wnętrznej (patrz Rysunek 1).
Rozważmy
prostą
zaporę
przedstawioną na Listingu 1. Za-
pora ta opiera się na narzędziu
OpenBSD pf. W tym przykładzie
wewnętrzna warstwa sieci jest zde-
finiowana jako 192.168.10/24, zaś
cała reszta oznacza warstwę ze-
wnętrzną. W warstwie wewnętrznej
definiujemy adres 10.105/16 jako
zdalną sieć biurową, do której nale-
ży zapewnić dostęp użytkownikom.
Podstawowa zasada naszej polity-
ki bezpieczeństwa mówi, że połą-
czenia przychodzące są dozwolo-
ne tylko wtedy gdy pojawiły się jako
odpowiedzi na żądania wychodzą-
ce z hostów podłączonych do sieci
wewnętrznej. W konfiguracji mamy
wpisy definiujące dziury oraz wyra-
żenia block in all. Zakładamy rów-
nież, że zapora OpenBSD zosta-
ła poprawnie skonfigurowana – w
taki sposób, że może działać jako
router, wliczając w to weryfikację
konfiguracji sieciowych adresów IP.
Aby uzyskać ten efekt należy umie-
ścić wpis net.inet.ip.forwarding=1
w pliku /etc/sysctl.conf, oraz wpis
pf=YES w pliku /etc/rc.conf.local.
Dzięki temu pf będzie się automa-
tycznie włączał i wczytywał swoją
konfigurację przy każdym bootowa-
niu systemu.
Przedstawione wyżej zasa-
dy tworzą mechanizm autoryza-
cji dla przepływu ruchu pomię-
dzy określonymi hostami w sieci
192.168.10/24 oraz dowolnym ho-
stem z sieci 10.105/16. Klauzula
block in all
będzie blokować każ-
dą inną próbę dostępu. Z teoretycz-
nego punktu widzenia, na tym eta-
pie możemy śmiało powiedzieć, że
żadne nielegalne pakiety nie po-
winny opuścić naszej wewnętrznej
sieci. Pozostaje nam jeszcze konfi-
guracja mechanizmu logowania; je-
śli wykonamy ten dodatkowy krok
to wszelkie próby naruszenia zdefi-
niowanych powyżej reguł będą wy-
słane do odpowiednich hostów lo-
gujących gdzie będzie je można
monitorować.
Różnicowa Analiza
Pracy Zapory
Posiadając konfigurację i przykła-
dową sieć powinniśmy pomyśleć od
wprowadzeniu dodatkowych mecha-
nizmów monitorowania w celu wyła-
pania defektów w działaniu zapory.
Optymalnie byłoby sprawdzać czy
każda z reguł określonych w konfigu-
racji została zachowana, ze szcze-
gólnym uwzględnieniem reguły blo-
kującej niepożądany ruch.
W tej sytuacji potrzebna nam
będzie możliwość porównywania
w czasie rzeczywistym ruchu ze-
wnętrznego z ruchem wewnętrznym
i mechanizmu alarmowania jeśli wy-
niki porównania nie będą odpowia-
dać naszym regułom. W tym ce-
lu zmodyfikujemy nasz prosty dia-
gram architektury sieci dodając dwa
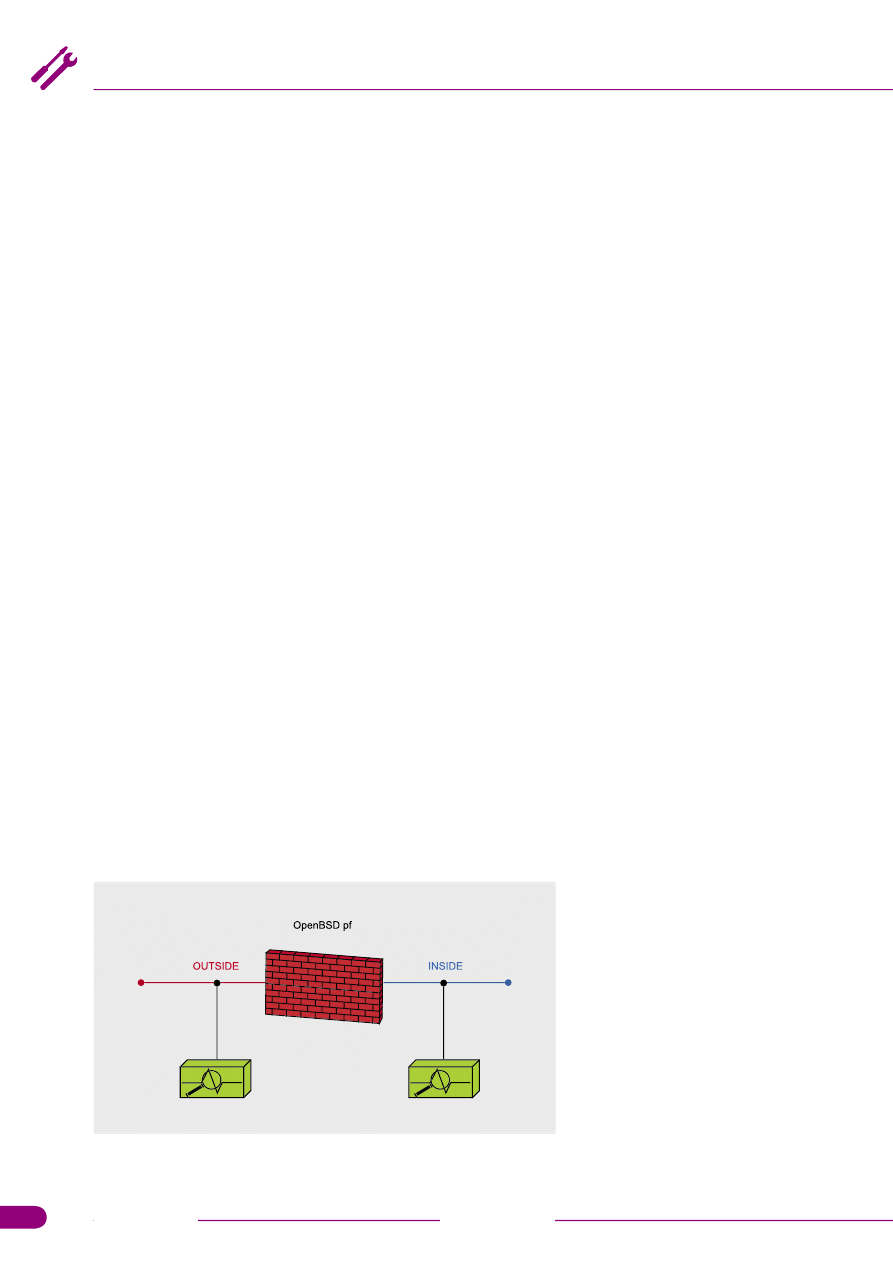
punkty monitorujące (patrz: Rysu-
nek 2).
We wspomnianych punktach mo-
nitorujących możemy podłączyć do-
wolny Systemu Detekcji Włamań
(ang. Intrusion Detection System,
NIDS), dla którego określimy wyma-
gane zasady. W punktach tych mo-
żemy zastosować zarówno mecha-
nizm odzwierciedlania portów jak i
TAPy w celu przekazania ruchu do
IDS (patrz: ramka Kopiowanie ru-
chu).
Rysunek 2.
Uproszczony schemat przykładowej sieci rozszerzony o punkty
monitorujące

Różnicowa Analiza Pracy Zapory
hakin9 Nr 6/2006
www.hakin9.org
37
W ramiach niniejszego artyku-
łu jako NIDS użyjemy narzędzia
Snort. Przedstawione tu techniki
mogą być z powodzeniem stosowa-
ne w połączeniu z dowolnym, pro-
gramowalnym narzędziem NIDS
dostępnym na rynku. Na tym eta-
pie najczęściej występującym błę-
dem koncepcyjnym jest ograniczo-
ne myślenie w kategoriach jedne-
go kierunku przepływu ruchu. Co
prawda wykracza to trochę poza
ramy niniejszego artykułu, jednak
postaramy się przedstawić kilka
faktów mocno przemawiających za
tym aby monitorować również ruch
wychodzący. Po pierwsze, warto
wziąć pod uwagę, że najnowsze
wirusy dla systemu Windows, któ-
re oprócz generowania ogromnej
ilości wychodzących wiadomości
email (do których załączone są za-
zwyczaj poufne pliki), otwierają tyl-
ne furtki czy wręcz próbują się bez-
pośrednio połączyć do zewnętrz-
nych systemów. Działanie takie,
określone jest jako dzwonienie do
domu (ang. calling home), może
prowadzić do całkowitego przeję-
cia przez twórcę (lub twórców) wi-
rusa kontroli nad komputerem ofia-
ry. Zainfekowany komputer mo-
że być później nadużywany w nie-
malże dowolny sposób: poczynając
od rozsyłania spamu lub blokowa-
nia sieci IRC, a kończąc na włama-
niach do innych, zewnętrznych sys-
temów lub przechwytywania waż-
nych informacji przy pomocy urzą-
dzeń takich jak drukarki, serwe-
ry druku, narzędzia monitorowania
sieci lub źle skonfigurowane opro-
gramowanie.
Gdybyśmy rozważali jedynie ruch
przychodzący, oczywiste byłoby, że
wystarczyłby pojedynczy sensor w
wewnętrznej warstwie naszej sieci.
Sensor ten byłby zaprogramowany
tak, aby sygnalizować wszelkie błę-
dy w konfiguracji zapory w sytuacji
kiedy teoretycznie niedopuszczalny
ruch pojawia się w naszej wewnętrz-
nej sieci. Biorąc pod uwagę wysoce
prawdopodobną możliwość pojawie-
nia się niepożądanego ruchu w dru-
gą stronę, należy uznać zasadność
istnienia zewnętrznego sensora.
Konfiguracja NIDS
– sensor wewnętrzny
Zajmijmy się teraz konfiguracją we-
wnętrznego sensora. Zbiór reguł bę-
dzie określony tu bardzo prosto:
• Zmienna $INSIDE definiuje pod-
sieć 192.168.10/24, którą określi-
liśmy wcześniej jako sieć biuro-
wą.
• Zmienna $OUTSIDE definiuje
wszystko inne: !$INSIDE (sym-
bol wykrzyknika jest używany w
Snort do reprezentacji logiczne-
go operatora not).
W następnym kroku rozważymy wy-
jątki określone w konfiguracji zapo-
ry:
• Zmienna $EXTERNAL_OFFICE
jest zdefiniowana jako sieć, do
której autoryzujemy bezpośred-
Kopiowanie ruchu
Aby analizować lub monitorować ruch w sieci trzeba najpierw uzyskać do niego
dostęp; aby sprostać temu zadaniu można wykorzystać hub, SPAN lub TAP. Naj-
bardziej popularna metoda węszenia przepływających pakietów opiera się na hu-
bie – urządzeniu, które potrafi powtarzać pakiety na wszystkich interfejsach. W tej
sytuacji wystarczy dla danego sensora bądź sondy przełączyć interfejs na działa-
nie w tryb masowym (ang. promiscuous mode) – i sprawa załatwiona. Oczywiście,
w sieciach korporacyjnych nie korzysta się z hubów; ze względu na wysoki stopień
zaawansowania tych topologii wykorzystuje się w tym przypadku raczej switche
bądź routery. W takim odniesieniu do śledzenia ruchu należy zaadoptować SPAN
lub TAP. Przyjrzyjmy się różnicom w tych rozwiązaniach. SPAN (skrót od angiel-
skiej nazwy Switched Port Analyzer) określany jest również mianem odzwierciedla-
nia portów. Mechanizm ten jest bardzo prosty i polega na konfiguracji przełączania
portu pod który podłączony będzie sensor lub sonda, tak aby odbierał on ruch z in-
nych portów. Mimo swojej prostoty i faktu, iż mechanizm ten jest wspierany niemal-
że przez wszystkich producentów sprzętu sieciowego, dochodzą tu do głosu pewne
niedogodności: chociażby problem dużego obciążenia sieci, który powoduje prze-
rwy w dostawie pakietów do docelowego portu SPAN; co więcej – również błędne
pakiety oraz występowanie błędów w pierwszej i drugiej warstwie zazwyczaj też łą-
czy się z występowaniem kłopotów. Inny problem wiąże się z pojemnością: na przy-
kład aby rejestrować pełny, dwókierunkowy ruch na każdym łączu o przepustowo-
ści 100 Mbps, SPAN port musiałby mieć pojemność 200 Mbps. Jeśli chcemy unik-
nąć wymienionych tu kłopotów warto rozważyć wykorzystanie TAP.
TAP (skrót od angielskiej nazwy Test Access Port), jest dedykowanym urzą-
dzeniem, zaprojektowanym w celach monitoringowych. Jest to port stałego do-
stępu, pozwalający podłączyć sensor lub sondę w celu pasywnego monitorowa-
nia. TAP przechwytuje pełny ruch - włącznie z błędami i obsługuje dane w trybie
full-duplex, przy czy strumień danych jest rozbity na dwie linie: TX i RX. Ze względu
na ostatni z wymienionych faktów, w celu odtworzenia oryginalnego ruchu potrze-
ba dwóch interfejsów sieciowych; ten sam efekt można uzyskać korzystając z wir-
tualnego interfejsu (więcej szczegółów na ten temat można znaleźć pod adresem
http://sourceforge.net/projects/bonding). Alternatywna opcja polega na tym aby
użyć narzędzia mergecap (lub czegoś podobnego) w celu stworzenia pojedyncze-
go przepływu z dwóch strumieni danych. Można również podłączyć TAP do switcha
zaś sensor/sondę podpiąć do odzwierciedlonego portu na tym switchu, albo sko-
rzystać z agregatora w postaci portu TAP, dzięki czemu monitorowany port będzie
odbierał cały, połączony strumień ruchu. W sytuacji kiedy mamy do czynienia z za-
awansowaną architekturą sieci wyposażoną w duża liczbę różnego rodzaju sond,
warto rozważyć wykorzystanie sprzętu nowej generacji, takiego jak aparaty wypo-
sażone w wielokrotne łącza sieciowe dla rozproszonych analizatorów. W ramach
dopełnienia zaprezentowanej w tym miejscu zwięzłej analizy metodologii kopiowa-
nia ruchu w sieci, na Rysunku 4 można zapoznać się z typowym schematem podłą-
czenia TAP. Osobom zainteresowanym sugerujemy również przejrzenie poradnika
opisującego zasady rozmieszczania systemów typu IDS, dostępnego pod adresem
http://www.snort.org/docs/#deploy.
hakin9 Nr 6/2006
www.hakin9.org
Narzędzia
38
nie połączenia, (konkretna war-
tość: 10.105/16).
• Zmienna $INT_HOSTS_AUTH
określa zbiór wewnętrznych syste-
mów, które mogą łączyć się bez-
pośrednio z siecią zewnętrzną. W
notacji Snort zbiór taki zapisze-
my to jako listę adresów umiesz-
czonych w nawiasach kwadra-
towych i rozdzielonych przecin-
kami np. [192.168.10.167,...]. Na
końcu zdefiniujemy kilka oczywi-
stych punktów docelowych, które
będą umieszczone w naszej we-
wnętrznej sieci: web proxy, ser-
wer mailowy oraz serwer DNS.
Zakładamy, że wszystkie te ser-
wisy są zlokalizowane na hoście
192.168.1.1, umieszczonym po ze-
wnętrznej stronie zapory (general-
nie jest to bardzo kiepskie rozwią-
zanie – w świecie rzeczywistym
usługi te powinny być zlokalizowa-
ne w strefie ściśle strzeżonej – w
odniesieniu do niniejszego tekstu
zaakceptujemy takie rozwiązanie
ze względu na jego prostotę).
Przyjmijmy więc co następuje:
• Zmienna $SERVICES określa
hosta na którym uruchomione są
wspomniane wyżej serwisy (ad-
res: 192.168.1.1).
W tym miejscu mamy już wszyst-
kie potrzebne informacje potrzeb-
ne do zapisania odpowiednich re-
guł (patrz: Listing 3). Reguły te bę-
dą się odnosić do sieci zaprezento-
wanej na Rysunku 3. Należy zwró-
cić w tym miejscu uwagę na istot-
ność porządku definicji reguł, jako
że chcemy aby reguły przepusz-
czające miały wyższy priorytet
niż końcowa reguła złap-wszyst-
ko. Wato też wspomnieć, iż w ce-
lu poprawnej obsługi przedstawio-
nego tu pliku konfiguracji narzędzie
Snort należy uruchomić z opcją -o.
Dzięki przekazaniu tej opcji silnik
obsługi reguł będzie działał w try-
bie pass, log, alert. Przedstawiony
zbiór reguł jest bardzo mały i przez
to nie było okazji wykorzystać tu
wielu bardzo przydatnych właści-
wości narzędzia Snort (np. obsłu-
gi wtyczek czy też standardowego
zbioru sygnatur).
Dodawanie reguł IDS do
wewnętrznego sensora
Warto zapytać się w tym miejscu o
wbudowane reguły Snorta: czy jest
sens aby ich używać? Odpowiedź
zależy od lokalnej konfiguracji syste-
mu. Jeśli planujemy użyć Snorta tyl-
ko w celu sprawdzania integralności
naszej zapory, to wspomniane regu-
ły nie są konieczne. Jednak z drugiej
strony, jeśli już mamy zainstalowane
narzędzie NIDS, to czemu nie sko-
rzystać z jego rozszerzonych moż-
liwości?
Za dobrą praktykę uważa się
dodawanie lokalnych reguł na po-
czątku pliku z definicją reguł stan-
dardowych (snort.conf). Przy za-
chowaniu takiej kolejności Snort
będzie najpierw brał pod uwagę
nasze reguły przepuszczające, da-
lej zastosuje swoje reguły standar-
dowe, zaś na końcu zaaplikuje re-
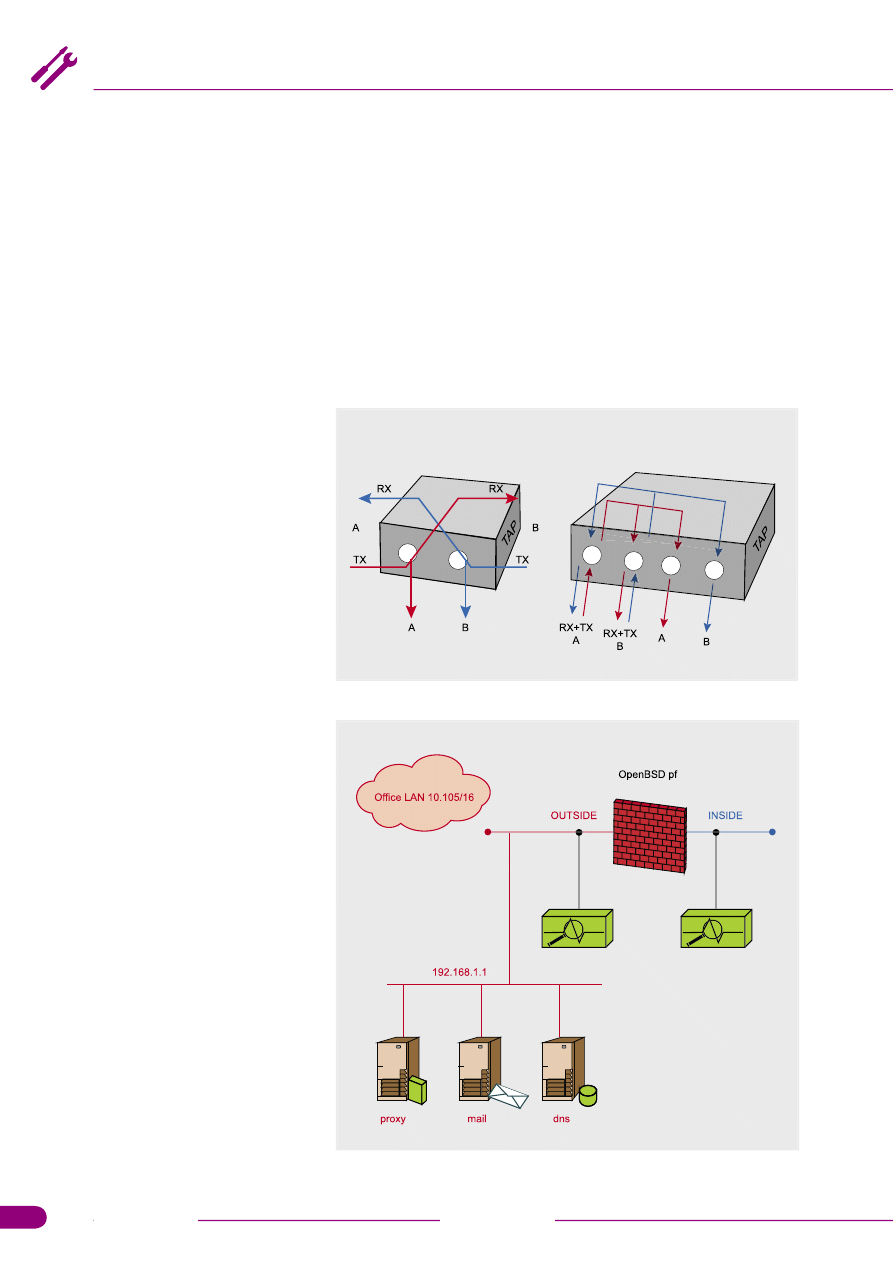
Rysunek 3.
Schemat podłączenia TAP
Rysunek 4.
Uproszczona sieć ze zdefiniowanym punktem monitorowania

Różnicowa Analiza Pracy Zapory
hakin9 Nr 6/2006
www.hakin9.org
39
gułę złap-wszystko. Bardziej docie-
kliwi czytelnicy mogą zapytać się w
tym miejscu czego można spodzie-
wać się po wbudowanych regułach
Snorta. Jakiego rodzaju ruch mo-
gą one zablokować? Otóż reguły te
są bardzo dobre w wychwytywaniu
trojanów atakujących systemy z ro-
dziny Windows. Co prawda, w przy-
padku dobrze skonfigurowanego fi-
rewalla połączenia wychodzące ze
strony tych złośliwych programów
pozostaną najprawdopodobniej za-
blokowane, i infekcja systemu po-
zostanie niezauważona na pozio-
mie NIDS. Przykładowo, w przy-
padku konfiguracji naszej zapory,
połączenie wychodzące z hosta
172.16.12.1 na porcie 54321, naj-
prawdopodobniej nigdy nie będzie
widoczne poza NIDS. Jednak gdy
zapora z jakichś przyczyn przesta-
nie działać to dzwonienie do domu
wykonywane przez trojana będzie
niezwłocznie zauważone.
Konfiguracja NIDS
– sensor zewnętrzny
Główną różnicą pomiędzy we-
wnętrznym i zewnętrznym sensorem
jest to, że ten drugi jest wystawiony
na przysłowiową dzicz Fakt sprawia,
że sensor ten jest idealnym kandy-
datem na wykorzystanie wszystkich
standardowych reguł NIDS oferowa-
nych przez Snorta; jedynie filtrowa-
niem ustawiamy na minimalny po-
ziom (można je nawet wyłączyć – ze
względu na to, że filtrowanie jest za-
zwyczaj i tak wykonywane po stro-
nie ISP w celu minimalizacji liczby
ataków).
Docelowy zbiór reguł jest nie-
malże identyczny jak w przypad-
ku sensora wewnętrznego – jedy-
na różnica polega na tym, że nie
sygnalizujemy wychodzenia we-
wnętrznego ruchu do zewnętrznej
sieci. Jest to kluczowy aspekt, któ-
ry nadaje sens różnicowej analizie
działania zapory i pozwala wykry-
wać usterki w konfiguracji – w od-
niesieniu do ruchu w obie strony.
Przykładowa konfiguracja senso-
ra pokazana jest na Listingu 3 (de-
finicje są identyczne jak na Listin-
gu 2).
Obsługa NAT
Ściśle mówiąc, systemy Tłumacze-
nia Adresów Sieciowych (ang. Ne-
twork Address Translation, NAT) w
odniesieniu do specyfikacji TCP/IP
nie powinny w ogóle istnieć. Wią-
że się to z jednym z piedestałów
na których spoczywa standard
TCP/IP, a mianowicie: jedna ma-
szyna, jeden adres IP. Generalnie
NAT nie jest niczym więcej jak od-
wzorowaniem wielu-do-jednego, w
którym wartość adresu IP pobrana
z prywatnego zakresu (zdefiniowa-
nego w RFC1918) jest przekształ-
cana przez zaporę transformującą
na pojedynczy, publiczny adres IP,
zanim pakiety zostaną wysłane do
Internetu. Podejście takie ma wiele
zalet: pozwala zmniejszyć ilość wy-
korzystywanych adresów IP (jeden
IP reprezentuje wiele maszyn), ale
ponad wszystko – tworzy dodatko-
wą barierę dla intruzów, którzy pró-
bują infiltrować dany system z ze-
wnątrz.
Powodem popularności syste-
mu NAT w społeczności specjali-
stów od bezpieczeństwa sieci jest
to, że sprawia on, iż bardzo trud-
no jest odwzorować sieć schowa-
ną za zaporą, jako że wszystkie
połączenia przychodzące z ze-
wnątrz nie będą miały odpowia-
dających wpisów w tablicy odwzo-
rowań firewalla (zakładamy że nie
odbywa się przekierowywanie por-
tów, które pozwala w sposób prze-
zroczysty odwzorować port w pu-
blicznym adresie IP zapory na port
w prywatnym adresie – za zaporą).
Listing 2.
Konfiguracja narzędzia Snort: sensor wewnętrzny
#
# Sensor wewnętrzny – przekazać flagę ’-o’ przy uruchamianiu narzędzia Snort
#
# Definicje zmiennych
#
var INSIDE
[
192.168.10.0/24
]
var OUTSIDE !
$INSIDE
var SERVICES
[
192.168.1.1/32
]
var PROXY_PORT 8080
# TCP
var SMTP_PORT 25
# TCP
var DNS_PORT 53
# TCP/UDP
var EXTERNAL_OFFICE
[
10.105.0.0/16
]
var INT_HOSTS_AUTH
[
192.168.10.167,192.168.10.168,192.168.10.189,\
192.168.10.190,192.168.10.213,192.168.10.214,192.168.10.215
]
#
# W pierwszej kolejności obsługujemy reguły “przepuszczające”; zakładamy, że
mamy do czynienia
# z dobrze zachowującym się systemem, w którym połączenia wychodzą z portów
# nieuprzywilejowanych.
#
pass tcp
$INSIDE
1023: <>
$SERVICES
$PROXY_PORT
pass tcp
$INSIDE
1023: <>
$SERVICES
$SMTP_PORT
# Następujący wpis zakłada używanie nowoczesnej biblioteki do obsługi
resolvera (np. sport != 53)
pass tcp
$INSIDE
1023: <>
$SERVICES
$DNS_PORT
pass udp
$INSIDE
1023: <>
$SERVICES
$DNS_PORT
pass tcp
$INT_HOSTS_AUTH
1023: <>
$EXTERNAL_OFFICE
any
#
# Reguła “złap-wszystko”, zapisywanie sesji. W tym miejscu
# monitorujemy zewnętrzny ruch wchodzący do zapory. Podobna
# reguła będzie utworzona dla ruch przepływającego w drugą stronę.
#
var SESSION_TTL 60
# Jak długo trzymamy sesję?
alert tcp
$OUTSIDE
any ->
$INSIDE
any
(
\
msg:
"Firewall error - disallowed external traffic on int net"
\
tag: session,
$SESSION_TTL
, seconds; \
rev:1; \
)

hakin9 Nr 6/2006
www.hakin9.org
Narzędzia
40
Oczywiście NAT nie jest trudnością
nie do przebrnięcia (dostęp można
uzyskać na przykład przy pomocy
pełnomocników lub wykorzystując
schemat ataku man in the middle),
jednak dzięki wykorzystaniu tego
mechanizmu poprzeczka dla jest
zawieszona dość wysoko.
Skutkiem ubocznym przy stoso-
waniu NAT jest to, że nasze defini-
cje sieci wewnętrznej i zewnętrznej
stają się nieco mętne. Podstawową
tego przyczyną jest fakt, że dopó-
ki korzystamy z zapory, każdy ad-
res wewnętrzny staje się adresem
prywatnym i przez to (zgodnie z za-
leceniem RFC1918) – nie można
się do niego odwoływać. To z ko-
lei oznacza, że router nie powinien
akceptować żadnych adresów z za-
kresu RFC1918, czyniąc niemożli-
wym wysłanie jakiegokolwiek pa-
kietu z publicznego do prywatne-
go IP. Fakt ten nie oznacza, że na-
sza reguła opisująca działanie we-
wnętrznego sensora jest zła, ponie-
waż wewnętrzny zakres adresów
RFC1918 ciągle będzie otrzymy-
wał pakiety z publicznych adresów.
Zapora nie tłumaczy zewnętrznych
adresów w ruchu przychodzącym,
ona jedynie ponownie odwzoro-
wuje docelowe adresy przy uży-
ciu transformacji (IPext, dportext) !
(IPint, dportint), dla każdego połą-
czenia, które pochodzi z wewnątrz.
W rezultacie otrzymamy komunikat
o błędzie – zarówno na zaporze jak
i w NAT. Wynika to z tego, że każ-
de połączenie, które nie przychodzi
z jednego z zewnętrznych autory-
zowanych hostów nigdy nie powin-
no być przepuszczone – niezależ-
nie od tego czy NAT jest włączony
czy nie. A co w tej sytuacji stanie
sie z zewnętrznym sensorem? Czy
nadal jest sens monitorować we-
wnętrzne adresy w odniesieniu do
sieci zewnętrznej? Oczywiście, że
tak! Jeśli wewnętrzny adres jest wi-
doczny na zewnętrznej sieci, to ma-
my do czynienia z naruszeniem za-
sad RFC1918, gdyż te nie pozwala-
ją przekazywać zabronionych adre-
sów do Internetu. W takim wypadku
reguła złap-wszystko wykryje błęd-
ne funkcjonowanie silnika NAT.
Ciągle brakuje nam jedne-
go szczegółu: fakt, że łapiemy we-
wnętrzne adresy na zewnętrznej sie-
ci jest niewystarczający. Jeśli NAT
jest aktywny i działa, to może się
okazać, że naruszamy zasady wła-
snej zapory. Wróćmy do reguł zde-
finiowanych w sekcji 2. Należy w
tym miejscu dobrze zrozumieć, że
przy używaniu NAT cały wychodzą-
cy ruch jest poddawany transforma-
cji (IPint, sportint) ! (IPfw, sportfw),
gdzie Ipfw jest możliwym do prze-
kierowania (publicznym) adresem
IP przypisanym do zapory, zaś spor-
tfw jest losowym, docelowym por-
tem przypisanym przez silnik NAT.
Wszystko to oznacza, że wszystkie
reguły powinny być zastosowane ze
zmienną $INTERNAL odwzorowaną
na publiczny adres IP zapory.
Wreszcie, stosowanie NAT pro-
wadzi do pewnego olbrzymiego
skrótu: otóż tracimy w tym przy-
padku możliwość monitorowania
naszych specyficznych reguł “prze-
puszczających”, które zdefiniowali-
śmy pomiędzy określonymi syste-
mami wewnętrznymi a siecią ze-
wnętrzną. Niedogodność ta wyni-
ka z faktu, iż silnik NAT (zakłada-
jąc, że działa poprawnie) sprawia,
że wszystkie wewnętrzne adresy
IP wyglądają jak jeden zewnętrzny
Listing 3.
Konfiguracja narzędzia Snort: sensor zewnętrzny
#
# Sensor wewnętrzny – przekazać flagę ’-o’ przy uruchamianiu narzędzia Snort
#
# Definicje zmiennych
#
var INSIDE
[
192.168.10.0/24
]
var OUTSIDE !
$INSIDE
var SERVICES
[
192.168.1.1/32
]
var PROXY_PORT 8080
# TCP
var SMTP_PORT 25
# TCP
var DNS_PORT 53
# TCP/UDP
var EXTERNAL_OFFICE
[
10.105.0.0/16
]
var INT_HOSTS_AUTH
[
192.168.10.167,192.168.10.168,192.168.10.189,\
192.168.10.190,192.168.10.213,192.168.10.214,192.168.10.215
]
#
# W pierwszej kolejności obsługujemy reguły “przepuszczające”; zakładamy, że
mamy do czynienia
# z dobrze zachowującym się systemem, w którym połączenia wychodzą z portów
# nieuprzywilejowanych.
#
pass tcp
$INSIDE
1023: <>
$SERVICES
$PROXY_PORT
pass tcp
$INSIDE
1023: <>
$SERVICES
$SMTP_PORT
# Następujący wpis zakłada używanie nowoczesnej biblioteki do obsługi
resolvera (np. sport != 53)
pass tcp
$INSIDE
1023: <>
$SERVICES
$DNS_PORT
pass udp
$INSIDE
1023: <>
$SERVICES
$DNS_PORT
pass tcp
$INT_HOSTS_AUTH
1023: <>
$EXTERNAL_OFFICE
any
#
# Reguła “złap-wszystko”, zapisywanie sesji. W tym miejscu
# monitorujemy zewnętrzny ruch wchodzący do zapory. Podobna
# reguła będzie utworzona dla ruch przepływającego w drugą stronę.
#
var SESSION_TTL 60
# Jak długo trzymamy sesję?
alert tcp
$INSIDE
any ->
$OUTSIDE
any
(
\
msg:
"Firewall error - disallowed internal traffic on ext net"
\
tag: session,
$SESSION_TTL
, seconds; \
rev:1; \
)

Różnicowa Analiza Pracy Zapory
hakin9 Nr 6/2006
www.hakin9.org
41
adres zapory. Tracimy w tym przy-
padku wartość zmiennej $INTER-
NAL_AUTH. Na rozwiązanie tego
problemu nie ma niestety konkret-
nej recepty: pozostaje nam jedy-
nie polegać na regułach wewnętrz-
nych, czyli stwierdzić, że reguły
przepuszczające dla wewnętrznej
konfiguracji będą we właściwy spo-
sób kontrolować adresy IP (patrz:
Listing 4).
Konkluzja
W momencie kiedy obydwa opisa-
ne wyżej sensory zbierają informa-
cje możemy zastosować technikę
połączenia logów w celu porówna-
nia oczekiwanych wyników (nie po-
winno się pojawić nic poza stan-
dardowymi ostrzeżeniami Snorta)
z aktualnym wyjściem. Jeśli w od-
powiedni sposób zastosujemy syn-
chronizację NTP, logi mogą być
monitorowane równolegle zaś waż-
ne informacje przekazywane bar-
dzo szybko.
Celem różnicowej analizy pra-
cy zapory jest uzyskanie możliwo-
ści monitorowania nieoczekiwa-
nych awarii softwarowych firewal-
la. Technika ta przyczynia się rów-
nież do skuteczniejszego wykry-
wania błędów w konfiguracji zapo-
ry, gdyż przy jej stosowaniu regu-
ły bezpieczeństwa zapisuje się w
co najmniej dwóch różnych nota-
cjach (niektórzy specjaliści stosu-
ją różne rodzaje narzędzi NIDS dla
wewnętrznych i zewnętrznych sen-
sorów).
Wdrożenie prezentowanego roz-
wiązania pociąga za sobą również
efekt “wymuszenia polityki” - szcze-
gólnie przydatny w firmach, gdzie
zazwyczaj zdefiniowane są dwie
grupy odpowiedzialności, zwane
odpowiednio NOC i SOC (skró-
ty od angielskich nazw: Network
Operation Center i Security Ope-
ration Center). Grupa NOC jest od-
powiedzialna za zarządzanie i kon-
figurację urządzeń, takich jak route-
ry, firewalle itd., zaś zadaniem SOC
jest monitorowanie logów opisują-
cych ruch w sieci, wygenerowanych
przez IDSy, sondy RMON lub inne
narzędzia o podobnym przeznacze-
niu. W takim kontekście, różnicowa
analiza pracy zapory automatycz-
nie zacieśnia współpracę pomiędzy
obydwoma wspomnianymi podmio-
tami – oprócz tego, że i jedni i dru-
dzy muszą tworzyć spójne reguły
dla dwóch systemów, to NOC czer-
pie korzyści z informacji na temat
błędów firewalla, zaś SOC ma wię-
cej okazji na wyłapywanie naruszeń
polityki bezpieczeństwa.
Prezentowana technika oferuje
duże pole do manewru jeśli chodzi
o rozszerzenia i nowe kierunki roz-
woju. Prowadząc dalsze badania w
tym temacie warto by się zastano-
wić nad możliwością monitorowania
usterek zapory w czasie rzeczywi-
stym – na bazie integracji wyjścia
generowanego przez Snorta (lub
inne, dowolne narzędzie NIDS) z
centralną, zorientowaną-na-pozy-
cję konsolą. Ta pozycyjna orienta-
cja oznacza w tym przypadku to, iż
konsola jest skonfigurowana na ba-
zie wiedzy o lokacji sensorów, dzię-
ki czemu błędy zapory mogą być
poprawnie raportowane jako we-
wnętrzne, zewnętrzne, związane z
silnikiem NAT itd.
Na sam koniec warto zauważyć,
ze opisany rodzaj analizy można
również z powodzeniem stosować
w odniesieniu do serwisów proxy
uruchamianych na serwerze – cho-
ciażby po to aby być pewnym, że
połączenia z tymi serwisami działa-
ją poprawnie w obie strony. l
Listing 4.
Konfiguracja zewnętrznego sensora ze wsparciem dla NAT
#
# Sensor wewnętrzny ze wsparciem dla NAT
# Przekazać flagę ’-o’ przy uruchamianiu narzędzia Snort
#
# Definicje zmiennych
#
var OUTSIDE !
$INSIDE
var FWEXTIP
[
172.16.1.1/32
]
var INSIDE
[
192.168.10.0/24,
$FWEXTIP
]
var SERVICES
[
192.168.1.1/32
]
var PROXY_PORT 8080
# TCP
var SMTP_PORT 25
# TCP
var DNS_PORT 53
# TCP/UDP
var EXTERNAL_OFFICE
[
10.105.0.0/16
]
#
# Należy pamiętać, że większość implementacji NAT mapuje źródłowy port
# na port nieuprzywilejowany, niezależnie do portu oryginalnego.
#
pass tcp
$FWEXTIP
1023: <>
$SERVICES
$PROXY_PORT
pass tcp
$FWEXTIP
1023: <>
$SERVICES
$SMTP_PORT
pass tcp
$FWEXTIP
1023: <>
$SERVICES
$DNS_PORT
pass udp
$FWEXTIP
1023: <>
$SERVICES
$DNS_PORT
#
# Poniższa reguła jest teraz o wiele słabsza – cała sieć wewnętrzna
# jest obsługiwana poprzez NAT.
#
pass tcp
$FWEXTIP
1023: <>
$EXTERNAL_OFFICE
any
#
# Reguła “złap-wszystko”, zapisywanie sesji.
# Monitoruje wewnętrzny ruch na zewnętrznej sieci.
var SESSION_TTL 60
# Jak długo trzymamy sesję?
alert tcp
$INSIDE
any ->
$OUTSIDE
any
(
\
msg:
"Firewall error - disallowed internal traffic on ext net"
\
tag: session,
$SESSION_TTL
, seconds; \
rev:1; \
)
W Sieci
• http://www.openbsd.org/faq/pf
• http://www.snort.org
Wyszukiwarka
Podobne podstrony:
2006 01 Analiza bezpieczeństwa komunikatora internetowego z wykorzystaniem platformy Linux [Bezpiecz
Kamiński, Tomasz Miejsce Chin w polityce bezpieczeństwa Unii Europejskiej (2006)
Polityka bezpieczenstwa
2006 06 Wstęp do Scrum [Inzynieria Oprogramowania]
polityka bezpieczeństwa informacji
2006 06 nowotwory slinianek trzustki
Polityka bezp. Wykład 20.02.2011r, Sudia - Bezpieczeństwo Wewnętrzne, Semestr II, Polityka Bezpiecze
Uwarunkowania polityki bezpieczeństwa Rosji, Bezpieczeństwo nardowe, Polityka Bezpieczeństwa
Analiza popytu i optymalna polityka cenowa
PN EN 12697 7 2006 06 30
Nowe centra potęgi gospodarczej i politycznej, Bezpieczeństwo Narodowe, Międzynarodowe stosunki poli
NAJWAZNIEJSZE WYDARZENIA ZWIAZANE Z POLITYKĄ BEZPIECZEŃSTWA UE, Bezpieczeństwo Wewnętrzne - Studia,
V pbp, POLITYKA BEZPIECZEŃSTWA POLSKI - Lasoń
06 Analizowanie ukladow elektry Nieznany (2)
06 Analiza ryzyka [tryb zgodnos Nieznany
06 analizaw wrazliwosci
polityka bezpieczeństwa w sieciach komputerowych, Pomoce naukowe, studia, informatyka
więcej podobnych podstron