
Prezentacja 1
SM- synteza mowy,
ARG -
automatyczne rozpoznawanie głosów,
ARM- automatyczne rozpoznawanie mowy,
ARMIS-
rodzaj ARM rozpoznajacy izolowane słowa,
ARMC - rodzaj ARM rozpoznajacy mowe ciagla,
ASV-
automatyczna weryfikacja mówcy,
ASI- automatycz
na identyfikacja mówcy,
Zalety systemów wykorzystujących informacje przekazywane za pośrednictwem sygnału mowy:
sterowanie i przekazywanie danych głosem może być realizowane znacznie szybciej niż za
pomocą klawiatury alfanumerycznej,
przekazywanie informa
cji do maszyny za pomocą sygnału mowy umożliwia zwolnienie rąk
operatora,
czas reakcji głosowej jest znacznie krótszy niż reakcji ruchowej, co jest ważne w systemach
alarmowych uruchamianych głosem,
przekazywanie informacji głosem może mieć miejsce w różnych, nietypowych sytuacjach i
położeniach operatora,
układy sterowania głosem pozwoliłyby w znacznym stopniu złagodzić skutki kalectwa osób
niepełnosprawnych,
sterowanie głosem nie wymaga od operatora specjalnego przygotowania ani treningu.
Rozpoznawanie mowy -
> słowa
Rozpoznawanie języka -> nazwa języka
Rozpoznawanie mówcy -> imię mówcy
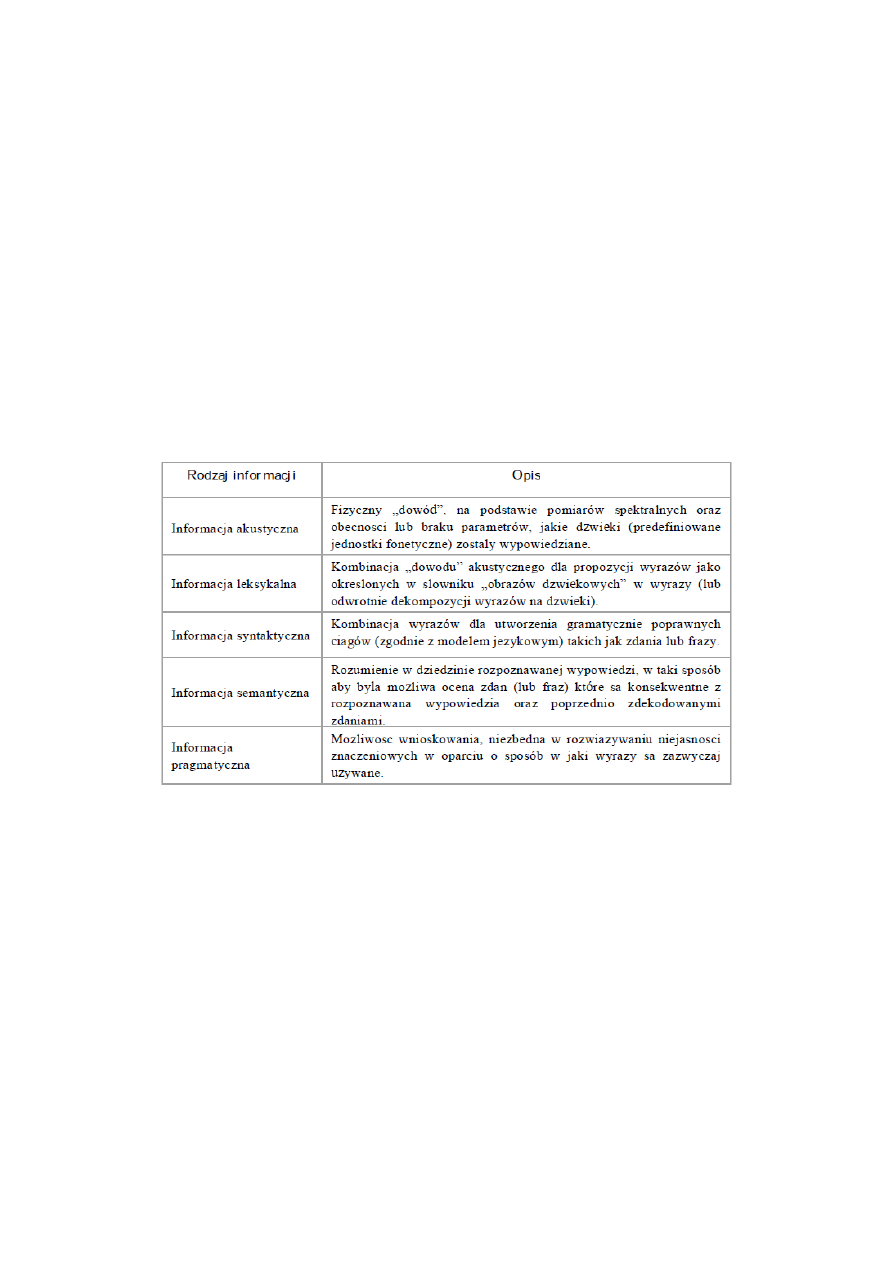
Schemat blokowy systemu ARM/ARG:
1.
Przetwarzanie wstępne- mające za zadanie zamianę sygnału akustycznego na postać
cyfrową,
Odbiór sygnalu mowy
Wzmocnienie sygnalu i normalizacja mocy
Ograniczenie pasma czestotliwosci
Przetwarzanie A/C (analogowo - kodowe)
2. Blok ekstrakcji -
gdzie tworzone sa obrazy wypowiedzi jako macierzy parametrów, które
niosą informacje o tresci wypowiedzi, mozliwie niezalezna od indywidualnych cech glosu
mówcy,
3. Blok uczenia i klasyfikacji -
gdzie w oparciu o okreslony algorytm decyzyjny porównywane
sa nadchodzace ciagi obrazów ze znajdujacymi sie w pamieci wzorcami (tworzonymi
wczesniej w procesie uczenia).
Na rysunku przedstawiono przyklad schematu blokowego systemu ARM
z uwzględnieniem
segmentacji. Sygnal wejsciowy jest przetwarzany na postac cyfrowa a nastepnie podawany
niezaleznie do dwóch bloków: segmentacji i opisu parametrycznego.
Blok segmentacji ma za zadanie wykrycie w przychodzacym sygnale granicy segmentu i w postaci
znacznika czasowego przekazanie tej informacji
do bloku ekstrakcji parametrów.

Automatyczna weryfikacja mówcy - jest prostszym zadaniem, gdyż konieczne jest tylko porównanie
sygnalu testowego z sygnalem odniesienia i podjecie „binarnej” decyzji, czy oba pochodza od tego
samego mówcy.
Automatyczna identyfikacja mówcy - wymaga wyboru, który sposród N znanych glosów najlepiej
odpowiada glosowi testowemu. Poniewaz potrzebnych jest N decyzji, blad prawidlowej identyfikacji
rosnie wraz z N dla automatycznej
identyfikacji mówcy, podczas, gdy w systemach automatycznej
weryfikacji jest
niezalezny od ilosci mówców.
W ARG możemy wyróżnić dwa przypadki:
Zbiór otwarty (open set)- glos rozpoznawany moze nie znajdowac sie posród zachowanych
wzorców, co wymaga podjecia decyzji, ze zaden wzorzec nie odpowiada sygnalowi
testowemu.
Zbiór zamknięty (closed- set)- gdy badane sa tylko glosy użytkowników,
Błąd fałszywej akceptacji (FA)- gdy system niepoprawnie zaakceptuje oszusta w systemie
weryfikacji lub zidentyfikuje mówce jako inna osobe w systemie identyfikacji.
Błąd fałszywego odrzucenia (FR)- gdy system niepoprawnie zaakceptuje oszusta w systemie
weryfikacji lub zidentyfikuje mówce jako inna osobe w systemie identyfikacji.
Prezentacja 2
Blok wstępnego przetwarzania:
1. Przetwarzanie A/C (analogowo
– cyfrowe)
Pierwszym etapem komputerowej analizy sygnalu akustycznego jest jego rejestracja oraz
zamiana na postac cyfrowa za pomoca przetwornika.
Wybór czestotliwosci próbkowania okresla górna czestotliwosc pasma rejestrowanego
sygnalu. Przyjecie zbyt malej czestotliwosci próbkowania moze prowadzic do trudnosci
identyfikacji tych
segmentów, o których informacja moze byc zawarta w wyzszych wartościach
czestotliwosci, natomiast zbyt duza czestotliwosc próbkowania nadmiernie rozszerza
analizowane pasmo i
powoduje wzrost nakladów obliczeniowych.
W cyfrowym przetwarzaniu mowy stosuje
się czestotliwosci próbkowania z zakresu: 8kHz-
32kHz (pasmo czestotliwosci sygnalu mowy ma okolo 16kHz).
2. Preemfaza
Tak zwane formanty ( maksima widma niosace informacje o rezonansach traktu głosowego)
maja zwykle znacznie nizsza amplitude dla wyzszych czestotliwosci. Aby wiec otrzymać
podobna amplitude wszystkich fo
rmantów, spróbkowany sygnal poddawany jest najczęściej
wstepnej filtracji, która w najprostszym przypadku ma postac preemfazy. Mozna to
zrealizowac, poprzez filtracje sygnalu mowy filtrem pierwszego rzedu typu FIR.
3. Okienkowanie
Kolejnym etapem wstepnego przetwarzania sygnalu mowy zwanym okienkowaniem jest
wybór fragmentu sygnalu dla którego obliczany jest wektor parametrów. W systemach ARM
najczesciej stosuje sie okno Hamminga.
Kryteria wyboru parametrów
Skuteczność - wyznaczona w tzw. sile dyskryminacyjnej. Dzwieki opisane tymi parametrami sa lepiej
rozrózniane przez dalsze procedury rozpoznawania
Łatwość pomiaru - kryterium to jest zwiazane ze zlozonoscia procedur pomiarowych, co ma wpływ
m.in. na koszty. Przykladowo pomiar, w charakterze parametru, amp
litudy jest znacznie prostszy niż
ekstrakcja formantu.
Stabilność - kryterium to oznacza, ze zakresy zmiennosci mierzonych (ekstrahowanych) parametrów
mieszcza sie w okreslonych przedzialach zmiennosci sytuacyjnej lub czasowej
Odporność na zakłócenia - kryterium to oznacza stopien wrazliwosci parametrów na zmiany i
poziom zaklócen wnoszonych przez otoczenie, w którym jest rejestrowany sygnal mowy, jak i na
zakłócenia wprowadzane przez tor transmisyjny.
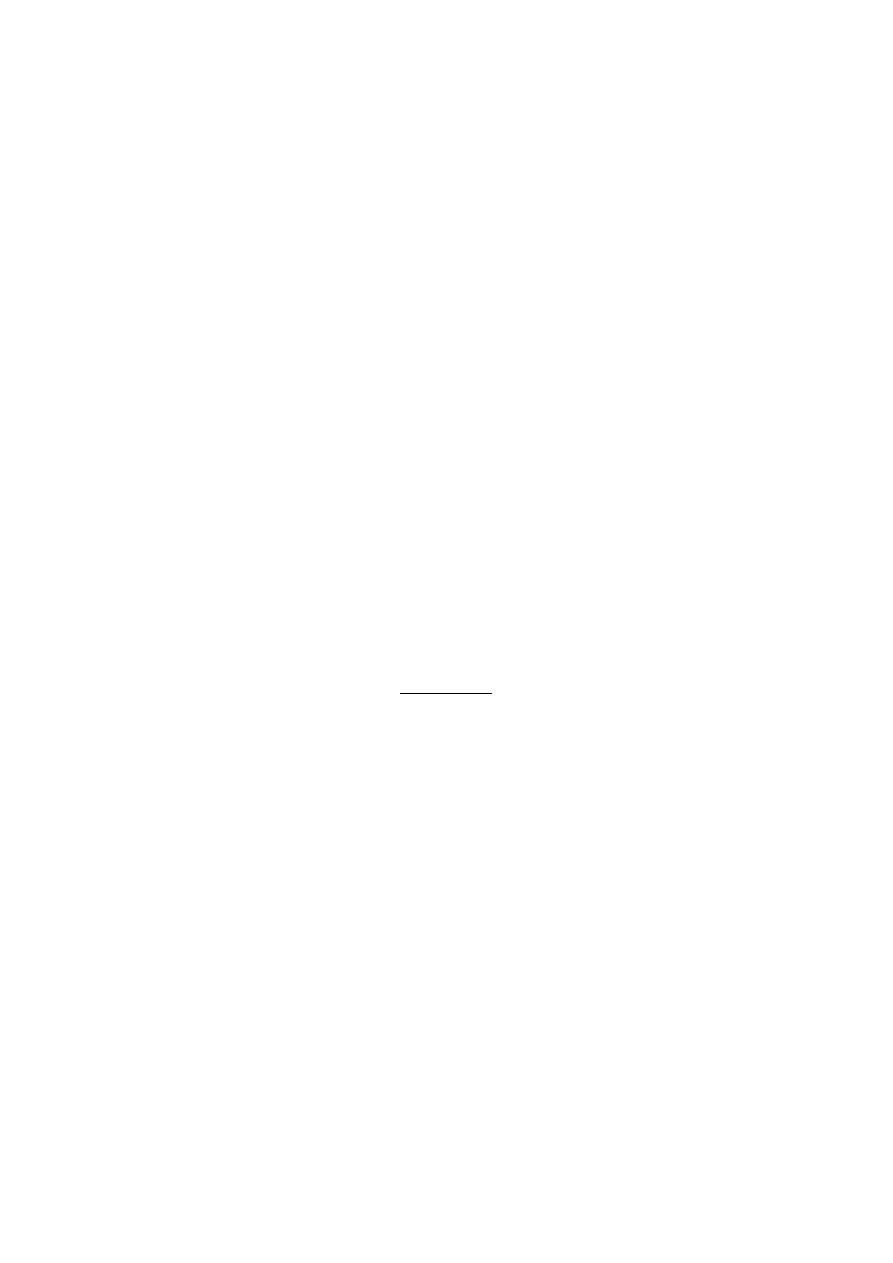
Parametry w dziedzinie czasu
Istnieja dwie grupy para
metrów mozliwych do uzyskania bezposrednio ze struktury czasowej sygnalu:
Pierwsza zwiazana jest z tzw. makrostruktura sygnalu i odnosi sie do wielkosci
rozciagajacych sie na cale elementy fonetyczne (fonemy, sylaby, wyrazy a nawet zdania) a
ich pomiar dokonywany jest najczesciej w ramach konturowego modelu analizy.
Do grupy tej zaliczamy m.in. natezenie w funkcji czasu i przebieg obwiedni amplitudowej. Jest
bezpośrednio powiazana z mikrostruktura czasowa sygnalu mowy i zaliczamy do nich m.in.
parametry zwiazane z analiza przejsc przez zero sygnalu mow (czestotliwosci
a Rice’a) oraz
interwaly pomiedzy przejsciami przez zero.
Parametry w dziedzinie częstotliwości
Krótkoterminowa analiza widmowa jest tradycyjnie jedna z najwazniejszych metod obróbki sygnalu
mowy. Podstawowym zalozeniem lezacym u podstaw dowolnej metody a
nalizy krótkoterminowej jest
fakt, ze dla dluzszego przedzialu czasu sygnal mowy jest niestacjonarny, natomiast dla odpowiednio
krótkich odcinków czasu (tzw. okienek czasowych) moze byc uwazany za stacjonarny.
Krótkoterminowe widmo mowy zawiera prawie wszystkie informacje zawarte w sygnale mowy i
stanowi podstawe dla wielu innych metod parametryzacji sygnalu. Jedna z metod uzyskiwania widma
krótkoterminowego zwana dyskretna transformata Fouriera (DFT), polega na obliczeniu widma
dynamiczneg z wykorzystanie
m efektywnych algorytmów przetwarzania, zwanych szybkimi
transformatami Fouri (FFT).
LFC-
liniowe parametry częstotliwości; Liniowe parametry czestotliwosciowe LFC (Linear Frequency
Coefficients) wyznaczane sa najczesciej w sposób analogowy za pomoca banku filtrów pasmowych
lub w sposób cyfrowy za pomoca transformaty FFT.
MFC-
melowe parametry częstotliwości
Parametry cepstralne- sygnal mowy mozna przedstawic jako odpowiedz kanalu losowego,
przedstawionego w postaci odpowiednio pobudzonego kanalu liniowego o parametrach zmiennych w
czasie.
Centrowanie parametrów cepstralnych- Po wyznaczeniu, parametry cepstralne moga zostać
wycentrowane, tzn. sredni wektor cepstralny odejmowany jest kolejno od wszystkich
wektorów.
Redukcja wektorów cepstralnych- polega na normalizacji zmian wartosci parametrów.
Prezentacja 3
Dopasowanie czasowe i normalizacja
Na wyjsciu modułu parametryzacji systemów rozpoznawania mowy otrzymujemy krótkoterminowe
(rzedu 10ms ramki) wektory parametrów. Rozpoznawana wypowiedz jest dosc zlozona i zawiera
sekwencje wektorów parametrów reprezentujacych krótkoterminowe reprezentacje akustyczne
sygnalu mowy. Problem zwiazany jest z porównaniem sekwencji wektorów parametrów sygnalu mowy
dla róznych interpretacji tej samej wypowiedzi (tj. wyrazu, frazy, zdania), które rzadko artykułowane sa
z tym samym tempem (szybkoscia mówienia). Stad nalezy znormalizowac czas wypowiedzi przed jej
pózniejszym porównaniem i rozpoznaniem.
Najprostszym sposobem dla rozwiazania problemu dopasowania czasowego i normalizacji je technika
normalizacji liniowej. Równanie normalizacji liniowej zaklada, ze czas trwania wypowiedzi jest
niezalezny od artykułowanych dzwieków.
Ogólny schemat dopasowania
Ogólny schemat dopasowania i normalizacji czasowej wykorzystuje dwie funkcje które odnosza sie
do odstepów czasowych dwóch obrazów sygnalu mowy na osi czasu. (Przykład slajd 5)
Dla uzupelnienia definicji miary odleglosci pary obrazów musimy jeszcze okreslic sciezke. Istnieje
wiele par mozliwych funkcji. Kluczowym zagadnieniem je
st wiec okreslenie która mozliwa sciezka
powinna byc wybrana , taka, ze odleglosc moze byc mierzona w spójny sposób. Jednym naturalnym i
czesto stosowanym wyborem jest zdefiniowanie funkcji jako minimum funkcji po wszystkich mozliwych
sciezkach. Dla rozwiazania tego problemu stosuje sie techniki programowania dynamicznego.

Kwantyzacja wektorowa (VQ)
Zalety:
Zredukowana objetosc przechowywanej informacji spektralnej,
Zredukowana ilosc obliczen niezbedna przy wyznaczaniu podobienstw analizowanych
wektorów parametrów
Dyskretna reprezentacja dzwieków mowy
Wady:
Nieodlaczne znieksztalcenia przy reprezentacji aktualnie analizowanego wektora
Rozmiar danych niezbednych do przechowania ksiazki kodowej ma czesto duze rozmiary
Do zbudowania książki kodowej (VQ) potrzebujemy:
Duzego zbioru wektorów skladajacego sie na zbiór uczący,
Miary podobienstwa lub odleglosci pomiedzy para wektorów aby móc pogrupowac zbiór
wektorów uczących i poklasyfikowac wektory na poszczególne klasy ksiazki kodowej,
Procedury wyznaczania
centroidów
Procedury klasyfikacji dokonujacej wyboru wektora z ksiazki kodowej najblizszego do wektora
wejściowego i wykorzystujacej indeks ksiazki kodowej jako wynikowa reprezentacje
Grupowanie wektorów uczących:
1.
Inicjalizacja: Arbitralny wybór M wektorów (poczatkowo sposród l wektorów zbioru uczacego)
jako poczatkowy zbiór slów kodowych w ksiazce kodowej.
2. Poszukiwanie najblizszego sasiada: Dla kazdego wektora uczacego znajdowane jest
najblizsze slowo kodowe w aktualnej ksiazce kodowej (zgodnie ze zdefiniowana miara
odleglosci), nastepnie wektor ten przypisywany jest do korespondujacej komórki (powiazanej
z najblizszym slowem kodowym).
3.
Uaktualnienie centroidów: Uaktualniane jest slowo kodowe w kazdej komórce z
wykorzystaniem centroidów wektorów uczacych powiazanych z komórka.
4.
Iteracja: Powtórzenie kroków 2 oraz 3 az do chwili gdy srednia odleglosc bedzie mniejsza od
zalozonego progu.
Algorytm podziału binarnego.
Pomimo, ze powyzszy alorytm rekurencyjny dziala dobrze, wykazano, ze korzystne jest
zaprojektowanie M- wektorowej ksiazki kodowej etapami tj. najpierw zaprojektowanie 1-wektorowej
ksiazki kodowej, nastepnie korzystajac z metody podzialu slów kodowych rozpoczac poszukiwania 2-
wektorowej książki kodowej i dalsze kontynuowanie podzialu az do uzyskania M-wektorowej ksiazki
kodowej. Procedura ta zwana jest algorytmem podzialu binarnego.
Procedura klasyfikacji wektorowej- polega na pelnym przeszukaniu ksiazki kodowej w celu
znalezienia najlepszego odpowiednika.
Prezentacja 4
Systemy rozpoznawania obraz
ów:
Strukturalne (syntaktyczne)
O logicznych kryteriach decyzyjnych
O statystycznych kryteriach decyzyjnych
Statyczne algorytmy rozpoznawania:
1. Parametryczne
-
algorytm Bayesa i jego modyfikacje
-
HMM (Hidden Markov Models)
-
ANN (Artificial Neural Networks)
-
SVM (Support Vector Machines)
-
GMM (Gaussian Mixture Models)
2. Nieparametryczne
-
NN (najblizszy sasiad)
-
k-NN (k-
najblizszych sasiadów)
-
NM (najblizsza srednia)
Opis niektórych algorytmów na slajdach 6-12.
Prezentacja 5
HMM, pięciostanowy proces Markowa- Rozwazmy system który moze byc opisany w kazdej chwili
czasu jako znajdujacy sie w zbiorze charakterystycznych stanów. W równych, dyskretnych odstepach
czasu, nastepuje zmiana stanu (z mozliwoscia powrotu do tego samego stanu) zgodnie ze zbiorem
prawdopodobienstw zwiazanych z każdym stanem.
Uczenie modelu sprowadza sie do optymalizowania parametrów HMM. Najczesciej stosowany jest
algorytm wprowadzony przez Bauma i Welcha i znany pod nazwa algorytmu Forward- Backward.
Uczenie modelu opisane na slajdach 5-15.
W ogólnym przypadku mozna powiedziec, ze problem rozpoznawania w modelach Markowa
sprowadza
się do wyznaczenia prawdopodobienstwa ciagu obserwacji dla danego modelu. Przyjety
sposób rozpoznawania zalezy od typu rozpoznawanych sygnalów i w przypadku rozpoznawania
segmentów izolowanych moze sprowadzac sie do obliczenia prawdopodobienstwa i wybrania modelu,
dla którego jest ono najwieksze. Bardziej zlozonym zagadnieniem okazuje sie byc rozpoznawanie
sygnalów ciaglych.
Algorytm opisany na slajdach 17-22.
Prezentacja 6
ARM problem interdyscyplinarny:
Prz
etwarzanie sygnałów- efektywny i niezawodny proces ekstrakcji niezbednej informacji z
sygnalu mowy. W przetwarzaniu sygnalów uwzgledniona jest zarówno analiza widmowa do
opisu cech sygnalu mowy zmieniających sie w czasie jak i przetwarzanie wstepne majace na
celu uniezaleznienie uzytecznego sygnalu mowy od warunków akustycznych srodowiska.
Fizyka/ akustyka- Pozwala zrozumiec zaleznosc pomiedzy fizycznym sygnalem mowy
(mechanizm traktu glosowego czlowieka) a fizjologicznym mechanizmem wytwarzania mowy
a sposobem jej percepcji (mechanizm slyszenia).
Rozpoznawanie obrazu-
zbiór algorytmów wykorzystywanych do klasyfikacji danych w celu
stworzenia jednego lub wiecej prototypów wzorców oraz ich porównania na podstawie miar
parametrycznych.
Teoria informacji i komunikacji -
nowoczesnych algorytmów kodowania i dekodowania (np.
wlaczajac programowanie dynamiczne, algorytmy akwizycji i skladowania danych,
dekodowanie Viterbiego etc.) wykorzystywane do przeszukania obszernego ale skonczonego
ukladu w celu znalezienia n
ajlepszej „sciezki”-tzn. rozpoznanej sekwencji slów.
Lingwistyka - Zwiazek pomiedzy dzwiekami (fonologia), slowami w jezyku (syntaktyka),
znaczeniem wypowiadanych slów (semantyka) oraz sensem wyznaczonym ze znaczenia.
Metodologia gramatyki i rozbiór jezykowy równiez zawieraja sie w tej dyscyplinie.
Fizjologia-
Rozumienie mechanizmów wyzszego rzedu w centralnym ukladzie nerwowym
czlowieka czyli wytwarzania mowy oraz jej percepcji przez czlowieka. Wiele nowoczesnych
technik próbuje umiescic ten rodzaj wiedzy w
ramach sieci neuronowych.
Informatyka-
Badania efektywnych algorytmów implementacji programowej lub sprzetowej
różnych metod wykorzystywanych w rzeczywistych systemach rozpoznawania mowy.
Psychologia -
Nauka rozumienia czynników umozliwiajacych wykorzystanie przez czlowieka
technologii dozadan praktycznych.
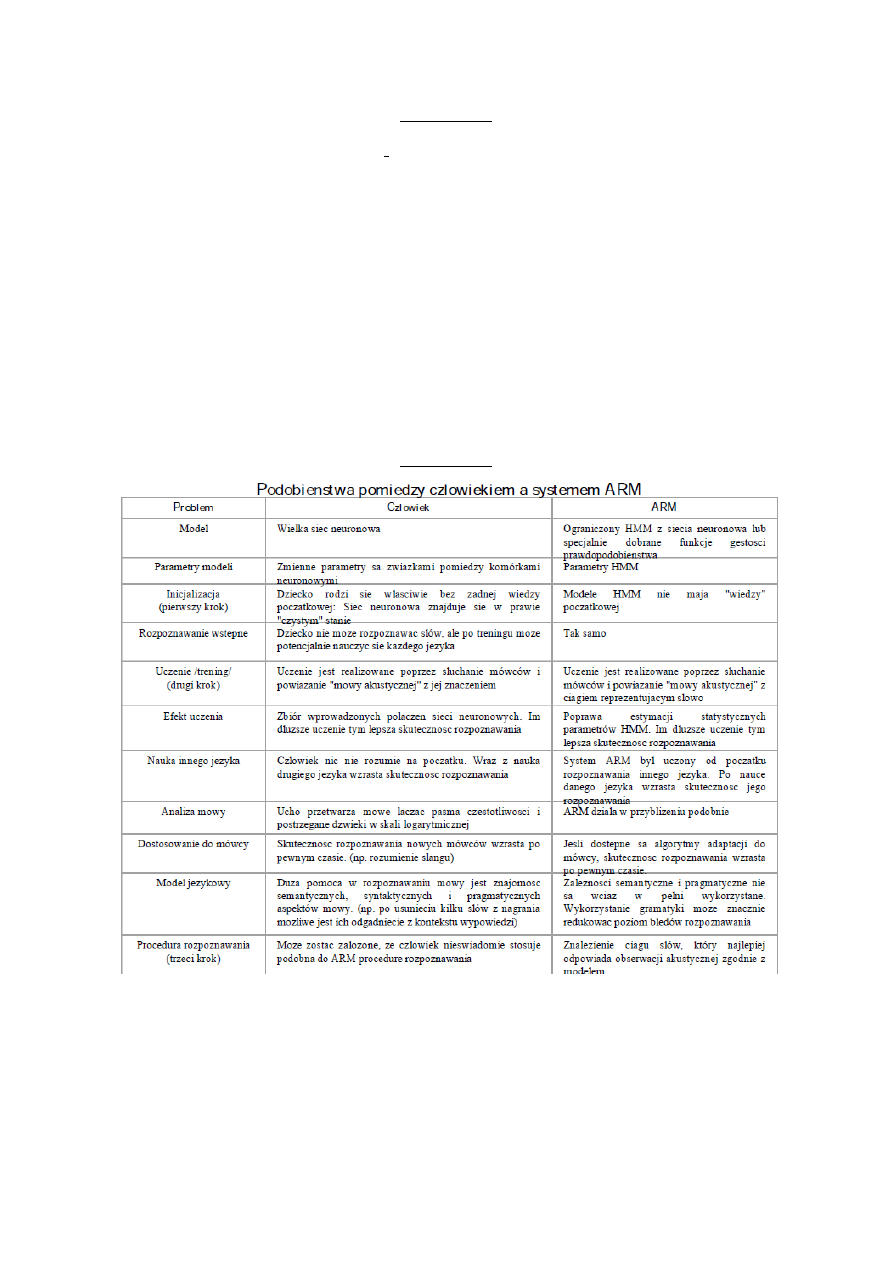
Rodzaje informacji wykorzystywanych w ARM:
Procedury rozpoznawania mowy:
z dołu do góry (bottom-up)- Najbardziej standardowa procedura w której proces najnizszego
rzedu (tj. detekcja parametrów, dekodowanie fonemów) poprzedza procesy wyzszego rzedu
(dekodowanie leksykalne, modelowanie jezykowe) dokonywane jest w sposób sekwencyjny.
z góry do dołu (top-down)- Model jezykowy generuje w oparciu o sygnal mowy hipotezy,
nastepnie syntaktycznie i semantycznie sensowne wypowiedzi budowane sa na podstawie
wyników porównania wyrazów. Pokazane zostalo, ze czesto stosuje sie integracje porównania
jednostek, dekodowania leksykalnego oraz modulu analizy syntaktycznej w jednym bloku.
wspólnej płaszczyzny (blackboard)- W tym podejsciu wszystkie zródla informacji
analizowane sa niezaleznie. Paradygmat hipoteza-
test sluzy jako glówne medium komunikacji
pomiedzy zródlami informacji. Kazde zródlo opiera sie o dane uzyskane w oparciu o
wystepujace na wspólnej plaszczyznie obrazy które odpowiadaja rozwiazaniom okreslonym w
zródlach. System dziala wiec asynchronicznie.
Rozpoznawania obrazów i akustyczno- fonetyczna - Trzy glówne kroki w modelu
rozpoznawania obrazów to: pomiar parametrów (w którym obraz testowy jest tworzony),
porównanie obrazów oraz podjecie decyzji. Funkcja bloku pomiaru parametrów jest
prezentacja odpowiednich zdarzen akustycznych sygnalu mowy w formie zwartych,
wydajnych wektorów parametrów mowy. Podobnie w modelu akustyczno-fonetycznym
rozpoznawania pierwszy krok procesu tj. pomiar parametrów, jest zasadniczo identyczny jak
w modelu rozpoznawania obrazów, pomimo, ze dalsze kroki obu podejsc znaczaco się róznia.

Skutecznosc systemów rozpoznawania mowy jest oceniana poprzez porównanie prawdziwej oraz
rozpoznanej przez system sekwencji elementów. Liczba dodanych elementów oznacza liczbe
rozpoznanych przez system elementów nieobecnych w prawdziwej sekwencji. Liczba pominietych
elementów to liczba wypowiedzianych przez mówce elementów nie odnotowanych w rozpoznanej
przez system sekwencji elementów.
Miary skutecznosci
wykorzystywane sa zarówno w systemach rozpoznawania wykorzystujacych
fonemy jako jednostki podstawowe jak i w systemach rozpoznawa calych wyrazów (elementem
rozpoznawania jest wiec wtedy odpowiednio fonem i wyraz). Przy tym oczywiscie wysoka skutecznosc
rozpoznawania fonemów moze przekladac sie na skutecznosc rozpoznawania calych wyrazów. Tak
wiec w pierwszej kolejnosci system rozpoznawania powinien byc oceniany na podstawie modelu
akustycznego o parametrach dobranych dla skutecznosci ro
zpoznawania fonemów bez uwzglednienia
gramatyki.
WER (word error rate)-
Najpowszechniej stosowana miara skutecznosci systemów. Jest
p
rocentowym stosunkiem liczby zamienionych, dodanych oraz pominietych wyrazów do liczby
wyrazów w rozpoznawanym zdaniu.
Prezentacja 7
Same tabelki i wykresy :P
Prezentacja 8
Model przejść międzydifonowych
Korzystne relacje przy przyjeciu difonów jako jednostek rozpoznawania zachodza dla jednej z
najpowszechniej wykorzystywanych we wspólczesnych algorytmach ARM technik opierajacych sie o
niejawne procesy Markowa jaka jest metoda programowania dynamicznego zwana algorytmem
Viterbiego. Ma ona szczególnie korzystne cechy zwlaszcza w odniesieniu do analizy sygnalów
ciaglych. W procesie rozpoznawania otrzymujemy ciag obserwacji,
które w naszym systemie
odpowiadaja wektorom parametrów dla kolejnych wykrytych w analizowanej wypowiedzi diafonów -
stanów niejawnego procesu Markowa. Zadaniem algorytmu jest znalezienie jednego „najlepszego”
ciągu stanów dla danego ciagu obserwacji.
Sieć neuronowa jako estymator prawdopodobieństwa a priori
Wsród wielu sposobów wykorzystania sztucznych sieci neuronowych najstarszym i najlepiej opisanym
jest
rozpoznawanie wzorców. Na wejscie sieci podawany jest wektor wejściowy. Opisuje on
rozpoznawany
obiekt. W przypadku sygnalów akustycznych jest to wektor cech akustycznych czyli
parametryczny opis sygnalu akustycznego. Moze to byc zbiór współczynników Fouriera, predykcji
liniowej lub rozklad interwalów czasowych. Pamietac nalezy o tym, ze sygnal akustyczny jest
próbkowany w oknach dlatego liczba wejsc sieci zalezy od liczby okien i liczby parametrów w oknie.
Podstawowym elementem jest model neuronu McCullo
ch’a - Pitts’a.
Prezentacja 9
Schemat bud
owy urządzenia AGD z funkcją automatycznego rozpoznawania mowy
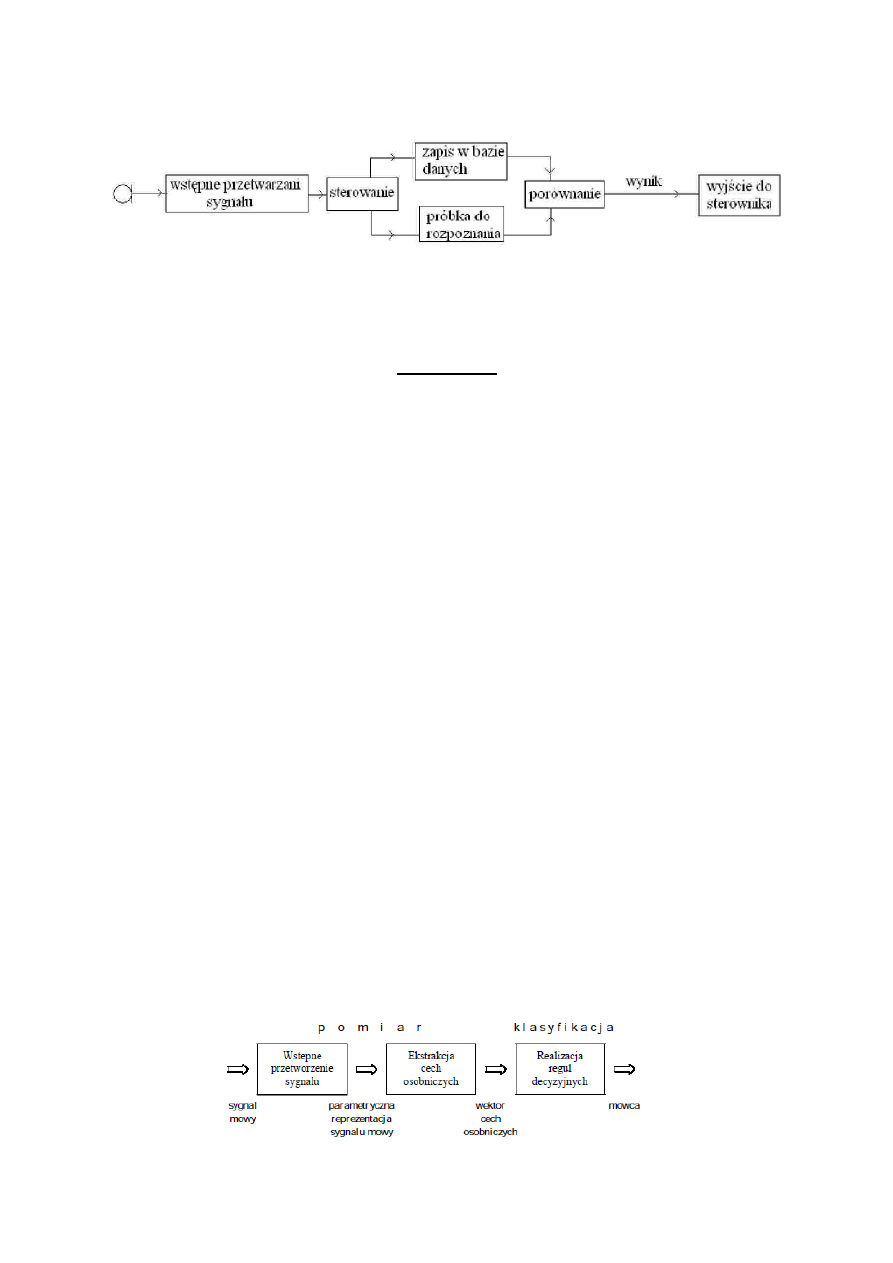
Schemat funkcjonalny
systemu ARM w urządzeniu AGD
Układ do rozpoznawania mowy SRI-07 - jest to kompletny i programowalny podzespól sluzacy do
realizacji funkcji rozpoznawania mowy. Zestaw ten pracuje w trybie zaleznym od mówcy, tzn. najpierw
nagrywa sie slowa (albo wypowiedzi), a nastepnie uklad je rozpoznaje. Dzieki temu mozna
wykorzystać dzialanie zestawu do sterowania innym urzadzeniem.
Prezentacja 10
Biometria
– zautomatyzowane rozpoznawanie osób na podstawie cech biologicznych lub
behawioralnych.
Obejmuje rozpoznawanie osób m.in. na podstawie: odcisków palców, glosu,
siatkówki oka, badan krwi, badan antropologicznych, badan struktury kodu DNA. Mozliwe jest
stosowanie równiez innych technik biometrycznych lub ich pochodnych: sposób chodzenia, odciski
dloni, itp. Metody biometryczne moga byc stosowane jako dodatkowe zabezpieczenie przy metodach
identyfikcji osób.
Zastosowanie:
Dokumenty biometryczne
Na calym swiecie kraje tworza polityczne i prawne warunki dla stopniowego wprowadzenia
dokumentów biometrycznych. Zgodnie z zaleceniami dane z obszaru dla czytnika
automatycznego, zdjecie twarzy, dwa odciski linii papilarnych oraz podpis elektroniczny beda
przechowywane w chipie.
Kryminalistyka
U
niwersalny zespól metod i srodków, który pozwolilby w warunkach wzrastajacej
przestepczosci nie tylko na optymalne wykrywanie sprawców przestepstw, lecz takze na
jednoznaczne i nie budzace watpliwosci udowadnianie im winy.
Badania fonoskopijne- sa nowoczesnym dzialem kryminalistyki, zajmujacym sie problematyka
ustalania tozsamosci czlowieka na podstawie analizy pewnych cech akustycznych zawartych sygnale
mowy.
Metody rozpoznawania
głosów:
subiektywna-
Polega na rozpoznawaniu mówców przez sluchaczy na podstawie próbek
głosów. Sluchacze nie sa na ogól w stanie wymienic kryteriów lezacych u podstaw ich decyzji.
zobiektywizowana (metoda wzrokowa)-
Polega na porównywaniu przez ekspertów obrazów
wypowiedzi,
czyli spektrogramów otrzymanych na podstawie analizy spektrograficznej
kreslonej frazy, jednakowej dla wszystkich badanych glosów.
obiektywna (metoda automatyczna)- Metoda ARG polega na realizacji regul decyzyjnych na
mierzalnych w sposób obiektywny cechach sygnalu mowy w celu okreslenia, czy dana
wypowiedz nalezy do określonego mówcy.
Automatyczne rozpoznawanie glosu (ARG) to proces polegajacy na rozpoznaniu osoby mówiącej na
podstawie indywidualnych informacji osobniczych zawartych w falach dźwiękowych wypowiedzi
danego mówcy. Podstawowy podzial systemów ARG jest uzalezniony od nastepujacych czynników:
rodzaju i ilosci analizowanego materialu akustycznego, oraz od sposobu analizy pobranych próbek
glosu.

Systemy zalezne i niezalezne od tresci wypowiedzi
Kolejnym sposobem podzialu metod rozpoznawania mówców jest podzial na systemy zalezne i
niezalezne od tekstu wypowiedzi. Systemy niezalezne od tekstu wypowiedzi wychwytuja z
wypowiedzi danego mówcy jego specyficzne cechy osobnicze zawarte w glosie bez wzgledu na to, co
on mówi. Specyfika systemów zaleznych od tekstu polega na tym, ze mówca wypowiada jedna,
konkretnie ustalona wczesniej sentencje slowna i to na jej podstawie zostaje odpowiednio
zidentyfikowany.
Klasyczny proces weryfikacji glosu mozna schematycznie przedstawic jako dwie procedury:
procedurę uczenia gdzie tworzone sa modele mówców oraz model tla
procedure rozpoznawania
gdzie sparametryzowane próbki glosu porównywane sa ze
stworzonymi wczesniej modelami i podejmowana jest decyzja o akceptacji badz odrzuceniu
tozsamosci mówcy
Schemat procesu weryfikacji głosu
Sygnal mowy jest najpierw poddawany preemfazie. Celem preemfazy jest uwypuklenie wyższych
czestotliwosci widma sygnalu mowy, które sa tlumione w procesie artykulacji. Po okienkowaniu oknem
Hamminga wyznaczana jest szybka transformata Fouriera (FFT). Modul FFT przemnażany jest przez
bank filtrów melowych w celu wygladzenia i uzyskania obwiedni spektrum w skali audytoryjnej. Po
przejsciu na dB jako krok koncowy procedury parametry
zacji stosowana była dyskretna transformata
cosinusowa dajac wspólczynniki cepstralne. Tak uzyskane wektory parametrów podawane byly do
procedury klasyfikacji.
Krzywa ROC-
relative operating characteristic; określa stopę porawnych decyzji systemu
Krzywa DET-
detection error tradeoff; standardowy sposób prezentacji jakosci systemów ARG oraz
ARM.
Prezentacja 11
U
rzadzenie mówiace zostałow wynazleione w 1791r. przez Wolfganga von Kempelena. Urzadzenie
skladalo sie z miecha wzbudzajacego strumien powietrza podawanego z kolei na wibrujace jezyki
spelniajace funkcje strun (wiazadel) glosowych. Kanal glosowy imitowala
rurka elastyczna, która przez
odpowiednie manipulowanie (ucisk dlonia) powodowala generacje róznych dzwieków (20 dźwięków
mowy). Urzadzenie zawieralo dwie komory imitujace kanal nosowy oraz dwie dzwigienki, za pomoca
których mozna bylo sterowac generacja glosek tracych.
Mozna wyróznic trzy zródla sygnalu mowy:
trakt glosowy czlowieka, dokonujacy mowy;
systemy techniczne o prostej strukturze, dokonujace mowy;
syntezatory mowy dokonujace mowy na drodze modelowania procesu artykulacji.
Tekst moze byc analizowany jako jedna z form bardzo efektywnego kodowania mowy z duza jednak
mozliwoscia jego interpretowania pod wzgledem stylu, intonacji, tempa, rytmu itp.
Relacja miedzy tekstem pisanym i mówionym jest jednak czesto niezwykle zlozona, szczególnie, gdy
mamy do czynienia z tekstami z dodatkowymi opisami. Modul analizy tekstu okresla typ i strukture
przetwarzanego dokumentu, dokonuje konwersji nieortogr
aficznych znaków, rozbioru gramatycznego,
analizy syntaktycznej, leksykalnej.
Modul ten powinien dostarczyc cala informacje dotyczaca tekstu, nie bedaca w swej naturze
fonetyczna, majaca jednak wplyw na dzialanie modulu fonetycznego.
W najprostszych syste
mach modul ten dokonuje konwersji znaków nieortograficznych np. liczby.
Bardziej rozwiniete systemy dokonuja analizy
znaków takich jak spacje, znaków przestankowych itp. w
celu dokonania bardziej
szczególowej analizy syntaktycznej i semantycznej tekstu podzielonego na
zdania.
Normalizacja tekstu
polega na ujednoliceniu konwersji symboli, liczb i znaków nieortograficznych w
transkrypcji ortograficznej, w postaci umozliwiajacej nastepnie ich konwersje na ciag znaków
transkrypcji fonetycznej.

Analiza lingwistyczna tekstu obejmuje wybrane elementy syntaktyczne i semantyczne takie jak
slowo, fraza, zdanie, wypowiedz by ocenic ich wpływ na sama wymowe i cechy prozodyczne.
Modul syntezy mowy generuje akustyczny sygnal mowy, na podstawie sekwencji okreslonych
fon
emów uzyskanych na podstawie przetwarzania tekstu, wzorców iloczasowych, konturu
melodycznego i obwiedni amplitudy.
Modelowanie obwiedni widma
– statyczne:
Stewart(1922)
– 2 filtry formantowe pobudzane przebiegiem piloksztaltnym
Voder (Dunn,1939)
– 10 szeregowo polaczonych filtrów pasmowych pobudzanych badz
przebiegiem okresowym, badz szumowym.
Elektroniczne syntezatory formantowe- Opieraly sie na modelowaniu funkcji przenoszenia toru
glosowego w dziedzinie
czestotliwosci za pomoca filtrów dolnoprzepustowych.
Synteza artykulacyja- modelowanie narzadu artykulacyjnego w oparciu o rejestrowane obrazy
przekrojów toru glosowego w nadziei, ze uzyska sie prostsze reguly odwzorowywania zmian polozenia
elementów artykulacyjnych.
Dla kazdej gloski utworzono zestaw
przekrojów cylindrycznych o odpowiednio dobranych
powierzchniach. Przyjeto liniowe odwzorowywanie zmian konfiguracji toru glosowego przy przejsciu
miedzy gloskami. Wyniki byly jednak gorsze od ówczesnych syntezatorów formantowych.
Synteza konkatenacyjna- podstawowym elementem sa wycinki rzeczywistego sygnalu mowy
zarejestrowane w bazie danych i laczone ze sobą odpowiednio do przetwarzanego tekstu.
Atrakcyjnosc tej metody polega przede wszystkim w tym, ze nie sa potrzebne rozbudowane reguly
oraz ze dzieki
operowaniu rzeczywistym sygnalem mowy laczone ze soba segmenty zachowują
stosunkowo naturalne brzmienie.
Problemy: Wybór jednostek , stworzenie bazy jednostek, rozmiary bazy, jak okreslic optymalny system
wyboru i laczenia ze soba segmentów, jak modyfikowac cechy prozodyczne ztworzonego lancucha
segmentów.
Difon- element zawierajacy w calosci przejscie miedzy gloskami, poprzedzone czescia gloski
poprzedzajacej i zakonczone czescia gloski nastepujacej.
Zastosowanie syntezy mowy:
Uslugi telekomunikacyjne,
portale głosowe, nauka jezyków, dostep do tekstów pisanych dla osób
niewidomych, ulatwienie komunikacji werbalnej osobom z zaburzeniami mowy, w dwustronnej
komunikacji werbalnej czlowiek-
maszyna, człowiek – człowiek, automatyczny tłumacz.
Prezentacja 12
Problemy przy projektowaniu akustycznej bazy danych:

Style wypowiedzi do baz danych:
Mowa naturalna-
nagrywana w sytuacjach codziennych rozmów na tematy wybrane przez
mówce
Mowa laboratoryjna-
nagrywana w sytuacjach kontrolowanych i artykulowana w sposób
bardziej formalny.
Czytanie izolowanych fonemów- wypowiedz izolowanego fonemu jest generalnie
wykorzystana jako wzór do porównania wypowiedzi tego samego fonemu w mowie ciaglej.
Czytanie izolowanych słów- moze obejmowac zarówno istniejace wyrazy jak i slowa "bez
sensu" lingwistycznego które sa jednak uzyteczne do badan nad efektami koartykulacyjnymi
poszczególnych fonemów w róznych kontekstach.
Czytanie izolowanych fraz-
przykladem tego typu fraz moga być przypadki gdy zalezy nam
na bardziej naturalnej niz w izolowanych slowach wypowiedzi
Czytanie fragmentów tekstu- dotyczy czytania kilku zdan powiazanych semantycznie.
Podejscie to wpływa korzystnie na naturalnosc mowy. Zdania moga pochodzic z ksiazki lub
gazety i moga posiadac szczególna strukture fonetyczna lub syntaktyczna.
Mowa quasi spontaniczna- slownictwo, syntaktyka i wypowiadanie jest kontrolowane. Baza
jest generalnie
tworzona dla celów komercyjnych. Typowym przykladem jest czytanie wyrazen
alfanumerycznych,
pozostawiajace mówcy zupelna dowolnosc sposobu wypowiedzi. Ma to
miejsce w przypadku numerów telefonicznych: czasem czytanych jako sekwencja pojedy
czych cyfr lub jako grupy cyfr.
Mowa spontaniczna dotyczaca okreslonego temat-
wypowiedź sprowokowana; Rózne
procedury sa wykorzystywane do "wymuszenia" dyskusji, jednakze przy pozostawieniu
mówcy mozliwosci wypowiedzi swobodnej i naturalnej.
Mowa wywolywana metoda " Czarnoksieznika z Krainy Oz"- Idea metody jest dosc prosta:
operator (tzw. "czarnoksieznik") nasladuje zachowanie komputera w symulacji rozmowy
czlowiek-komputer. Dla zachowania realizmu tej symulacji musza byc spelnione dwa warunki:
symulowany system powinien miec cechy odpowiadajace ludzkim ograniczeniom (np. po
pytaniu czas odpowiedzi czlowieka jest inny niz komputera), po drugie zachowanie operatora
w przypadku
niejasnych pytan lub bledów powinno zostac dokladnie okreslone dla
zagwarantowania porównywalnych warunków symulacji. Metoda ta byla wykorzystana przy
tworzeniu bazy ATIS.
Mowa spontaniczna -
Mówca ma dowolnosc w wyborze tematu rozmowy i slownictwa w celu
uzyskania najbardziej naturalnej wypowiedzi. W celu unikniecia wplywu emocjonalnego
warunków nagran na mówce, czesto nagrania prowadzi sie podczas przerw relaksacyjnych w
nagraniach. W innych przypadkach
mówca proszony jest o przypomnienie sobie sytuacji z
przeszlosci lub o rozmowe z bliskimi lub znajomymi osobami.
Akustyczne bazy danych:
Babel-
Projekt jest wspólnym Europejskim przedsiewzieciem pod patronatem fundacji
Copernicus w sklad którego wchodza osrodki naukowe z europy zachodniej i srodkowej.
Celem projektu jest stworzenie wielojezycznej bazy danych dla pieciu (najbardziej
rozpowszechnionych) jezyków srodkowoeuropejskich: bulgarskiego, estonskiego, polskiego,
rumunskiego i wegierskiego.
Speech DAT- Jako platforme nagrywajaca wykorzystano komputer Pentium II z systemem
operacyjnym Windows 98, wyposazony w karte dzwiekowa, duzy dysk twardy oraz karte ISDN
AVM A1 z oprogramowaniem ADA (Automatic Database Acquisition). Sygnaly sa nagrywane
z czestotliwoscia próbkowania 8kHz na 8 bitach kwantyzacji i zapisywane jako pliki bez
naglówka w standardzie a-law. Do kazdego pliku z sygnalem dolaczany jest plik opisowy w
formacie SAM, zawierajacy informacje o sygnale, warunkach i czasie
nagrania, mówcy oraz
tresci wypowiedzi. Zapis fonetyczny przeprowadzany jest zg dnie ze standardem SAMPA
(Speech Assesment Methods Phonetic Alphabet).
Proces weryfikacji jakosciowej bazy przebiegal w dwóch etapach:
Weryfikacja subiektywna- wszystkie sesje nagraniowe
zostały przesluchane i ocenione
prze
z sluchaczy kontrolerów. Sesje niepelne lub niskiej jakosci kierowano do ponownego
nagrania lub odrzucano.
Weryfikacja obiektywna -material akustyczny poddano ocenie obiektywnej w oparciu o trzy
podstawowe wspólczynniki sygnalu: wartosc wspólczynnika przesterowania, sredniej wartosci
próbek oraz stosunku sygnal/szum.

Współczynnik przesterowania- zdefiniowany jest jako stosunek liczby próbek w pliku, które maja
wartosc maksymalna lub minimalna do calkowitej liczby pr
óbek.
Stosunek s
ygnał/szum- syganł zostaje podzielony na okna o dlugosci 10 ms w których liczona jest
energia po uprzednim odjeciu s
redniej wartosci próbki od wszystkich próbek sygnalu. Zalozono, ze 5%
okien
zawierających najnizsza energie zawieraja szum tla. Stosunek sygnal/szum otrzymywano jako
stosunek sredniej
wartości energii we wszystkich oknach do sredniej wartosci energii w oknach
zawierajacych najnizsza energie.
Wyszukiwarka
Podobne podstrony:
Bazy danych kolo 2 1 id 81756 Nieznany
biochemia kolo id 86264 Nieznany (2)
Kompozyty na kolo id 243183 Nieznany
FP 30 kolo id 180395 Nieznany
kolo 5 id 239706 Nieznany
letni 2013 I e kolo id 267392 Nieznany
zestawy pytan kolo 1 id 589534 Nieznany
fizyka kolo id 176858 Nieznany
3 kolo id 33745 Nieznany (2)
ergonomia kolo id 163080 Nieznany
Aplikacja webworks 2 id 67048 Nieznany
Kolo 2 2 id 239743 Nieznany
Aplikacja webworks 3 id 67049 Nieznany
hermeneutyka skroty kolo id 200 Nieznany
dodatkowe pytania kolo 2 id 138 Nieznany
3 kolo B id 33749 Nieznany (2)
Betony Spoiwa kolo I id 83081 Nieznany
Kolo 1 id 239733 Nieznany
3 kolo A id 33747 Nieznany
więcej podobnych podstron