
P
OLITECHNIKA
W
ROCŁAWSKA
W
YDZIAŁOWY
Z
AKŁAD
I
NFORMATYKI
W
YDZIAŁ
I
NFORMATYKI I
Z
ARZ DZANIA
Wybrze e Wyspia skiego 27, 50-370 Wrocław
Praca Magisterska
METODY TESTOWANIA KODU OPROGRAMOWANIA.
BADANIE NIEZAWODNO CI OPROGRAMOWANIA.
Kamil Olszewski
Promotor:
dr hab. in . prof. nadzw. P.Wr. Ireneusz Jó wiak
Ocena:
Wrocław 2003

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
2
Temat pracy:
Metody testowania kodu oprogramowania.
Badanie niezawodno ci oprogramowania.
Streszczenie
Praca prezentuje aktualny stan wiedzy na temat testowania w procesie wytwarzania
oprogramowania, zarówno w nurcie metodyk ci kich jak i lekkich, kład c szczególny nacisk
na problem testowania kodu. Przedstawia równie zagadnienie jako ci i niezawodno ci
oprogramowania z punktu widzenia testowania kodu.
Celem pracy jest wytworzenie narz dzia wspomagaj cego modelowanie niezawodno ci
oprogramowania na podstawie danych testowych z wykorzystaniem metod sztucznej
inteligencji.
Title:
Software code testing methods.
Software reliability research.
Abstract
This paper shows the current level of knowledge on the subject of testing in software
development process both in heavy and agile methodologies. It emphasizes the code’s testing
problem and presents the issue of software quality and reliability as well, from the code’s
testing point of view.
The purpose of the work is to create an instrument to support software reliability
modeling on the ground of test data and with utilization of artificial intelligence methods.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
3
SPIS TRE CI
WST P
6
1. TESTOWANIE KODU W PROCESIE WYTWARZANIA OPROGRAMOWANIA 8
1.1. Wprowadzenie
8
1.2. Testowanie według metodyk ci kich
10
1.3. Testowanie według metodyk lekkich
13
1.4. Porównanie podej cia do testowania w metodykach ci kich i lekkich
15
2. METODY TESTOWANIA KODU
17
2.1. Wprowadzenie
17
2.2. Testowanie strukturalne i funkcjonalne
19
2.3. Testowanie jednostkowe
20
2.4. Testowanie integracyjne
21
2.5. Testowanie systemowe
21
2.6. Testowanie akceptacyjne
21
3. TESTOWANIE KODU DLA ZAPEWNIENIA NIEZAWODNO CI
OPROGRAMOWANIA
23
3.1. Wprowadzenie
23
3.2. Niezawodno sprz tu a niezawodno oprogramowania
25
3.3. Normy niezawodno ci
26
3.3.1. Podstawowe informacje o normach
26
3.3.2. Normy dotycz ce jako ci i niezawodno ci oprogramowania
28
3.4. Modele niezawodno ci oprogramowania
30
3.4.1. Przegl d modeli niezawodno ci oprogramowania
30
3.4.2. Wymagania modeli niezawodno ci oprogramowania
33
4. PROGNOZOWANIE NIEZAWODNO CI OPROGRAMOWANIA
35
4.1. Wprowadzenie
35
4.2. Metody sztucznej inteligencji w badaniu niezawodno ci
35
4.2.1. Zastosowania algorytmów genetycznych
35
4.2.2. Zastosowania sieci neuronowych
39
4.3. Prognozowanie niezawodno ci
41
4.4. Zastosowania
43
ZAKO CZENIE
48
LITERATURA
50
BIBLIOGRAFIA ELEKTRONICZNA
52

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
4
DODATEK A
53
DODATEK B
56
DODATEK C
60

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
5
SPIS RYSUNKÓW
Rys. 1.1. Fazy i etapy (przepływy) w metodyce RUP
12
Rys. 1.2. Fazy i etapy (przepływy) w metodyce USDP
12
Rys. 2.1. Testowanie w procesie wytwarzania oprogramowania – model „V”
18
Rys. 3.1. Zale no intensywno ci uszkodze od czasu w systemach technicznych
25
Rys. 3.2. Zale no intensywno ci uszkodze od czasu w oprogramowaniu
26
Rys. 4.1. Schemat dwuwarstwowej sieci jednokierunkowej
40
Rys. 4.2. Liczno klas przy podziale na 8
42
Rys. 4.3. Liczno klas przy podziale na 12
42
Rys. 4.4. Okno programu z wynikami testowania i prognozy sieci po wyuczeniu
44
Rys. 4.5. Ustalenie prognozy sieci dla warto ci granicznych
45
Rys. 4.6. Podział okresu badanego i okresu prognozy na 5 klas
46
Rys. 4.7. Podział okresu badanego i okresu prognozy na 8 klas
46
Rys. A.1. Graficzna reprezentacja zbioru 1
55
Rys. A.2. Graficzna reprezentacja zbioru 2
55
Rys. B.1. Pocz tkowy interfejs programu.
56
Rys. B.2. Interfejs programu po załadowaniu danych testowych.
57
Rys. B.3. Okno wprowadzania parametrów sieci neuronowej
57
Rys. B.4. Okno wprowadzania parametrów uczenia sieci neuronowej
58
Rys. B.5. Okno wprowadzania liczby klas podziału danych
59
Rys. B.6. Wykres liczno ci klas i wzór krzywej trendu
59
SPIS TABEL
Tab. 1.1. Historia in ynierii oprogramowania
9
Tab. 1.2. Porównanie ról osób w zespole projektowym według metodyk XP i RUP
16
Tab. 1.2. Porównanie ról osób w zespole projektowym według metodyk XP i RUP (c.d.) 16
Tab. 3.1. Normy i standardy niezawodno ci oprogramowania
28
Tab. 3.2. Modele niezawodno ci oprogramowania uwzgl dniaj ce intensywno
uszkodze
31
Tab. 3.3. Modele niezawodno ci oprogramowania typu NHPP
32
Tab. 3.4. Zało enia modeli niezawodno ci oprogramowania
33
Tab. 3.5. Wymagania modeli niezawodno ci oprogramowania dotycz ce danych
wej ciowych
34
Tab. 4.1. Porównanie wyników rozwi za dla algorytmu numerycznego i genetycznego 38

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
6
WST P
Systemy informatyczne, z wyj tkiem najprostszych aplikacji, powstaj według przyj tej
metodyki, w procesie wytwarzania oprogramowania.
1
W in ynierii oprogramowania
2
[16]
w czasie kilkudziesi ciu lat jej istnienia wypracowano wiele ró nych procesów i metodyk.
Bardzo wa nym etapem ka dego procesu jest testowanie.
Zwłaszcza w USA zagadnienia jako ci, niezawodno ci i testowania oprogramowania s
przedmiotem bada wielu naukowców [2], [6], [7], [18], [19], [22], [26], [28], [29], [43],
[46]. Na szczególn uwag zasługuj prace [28], [29], [39], które powstały w Software
Assurance Technology Center przy NASA. Dostarczaj bowiem wielu informacji na temat
praktycznego wykorzystania modeli niezawodno ci w zastosowaniu do oprogramowania.
W Polsce natomiast istnieje tylko kilka o rodków naukowych zajmuj cych si tym tematem.
S to przede wszystkim: Politechnika Gda ska, Akademia Górniczo–Hutnicza, Akademia
Morska w Gdyni, Wydziałowy Zakład Informatyki Politechniki Wrocławskiej.
Je li za chodzi o literatur z zakresu testowania i niezawodno ci oprogramowania, to
pozycje polskoj zyczne stanowi nikły procent wszystkich prac obecnie dost pnych. Do tych
najwa niejszych mo na zaliczy podr cznik Górskiego [12], Jaszkiewicza [16], oraz
przetłumaczone z j zyka angielskiego i wydane przez Mikom ksi ki: Pattona [26], Becka [3]
oraz przez Helion: ksi ka Maguire’a [19]. Ksi ki Górskiego i Jaszkiewicza kompleksowo
traktuj o jednej z wa niejszych dziedzin informatyki, jak jest in ynieria oprogramowania.
Testowanie, jako element tej in ynierii, oczywi cie znajduje w nich swoje miejsce, jednak
z oczywistych powodów
3
nie jest omawiany zbyt dogł bnie. Natomiast inne jest podej cie
autorów Pattona i Maguire’a: ich ksi ki s pisane bezpo rednim j zykiem i na bazie wielu
przykładów poruszaj zagadnienia bardzo konkretne i praktyczne. Na uwag zasługuje
równie wydana ostatnio przez Mikom praca Szejki [31]. Jest to jedna z nielicznych ksi ek
z zakresu testowania i niezawodno ci oprogramowania napisanych w j zyku polskim. Nie ma
natomiast obecnie polskich ksi ek, które traktowałyby etap testowania jako pole do prac
badawczych.
Dlatego niniejsza praca powstała w du ej mierze dzi ki wykorzystaniu materiałów: prac
i dokumentów angielskoj zycznych pobranych z Internetu [2], [3], [6], [7], [8], [18], [22],
[41], [43], [45], [46], [48]. Szczególn warto maj prace poruszaj ce zagadnienia
nowatorskie, odpowiedniki polskich prac magisterskich i rozpraw doktorskich oraz
dokumenty publikowane w elektronicznej prasie bran owej, np. w katalogach Elsevier
i innych. Wszystkie te dokumenty s wyszczególnione w literaturze na ko cu pracy.
Przegl d dost pnych publikacji stał si powodem napisania tej pracy z dziedziny
testowania i badania niezawodno ci oprogramowania, poniewa małe liczby pozycji
polskoj zycznych stanowi powa ny brak w rodzimej literaturze informatycznej.
Niezwykle interesuj ca i godna uwagi okazała si praca po wi cona predykcji
czasowych szeregów wyst pie bł dów w fazie testowania [7], która stała si inspiracj tre ci
1
Ang. software development process.
2
Jako in ynieri oprogramowania nale y tu rozumie wiedz techniczn dotycz c faz cyklu ycia
oprogramowania, której celem jest wytworzenie wysokiej jako ci oprogramowania.
3
Prace dotycz ce cało ci in ynierii oprogramowania nie mog traktowa dokładnie o ka dym jej aspekcie
z powodu ograniczonej obj to ci publikacji.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
7
czwartego rozdziału. Ilustracj jego tre ci jest symulacja sieci neuronowej wzorowana na
do wiadczeniu opisanym w pracy [7].
Celem pracy jest wytworzenie narz dzia wspomagaj cego modelowanie niezawodno ci
oprogramowania na podstawie danych testowych z wykorzystaniem metod sztucznej
inteligencji.
Zakres pracy obejmuje teoretyczne opracowanie zagadnie zwi zanych z testowaniem,
niezawodno ci i jako ci produktu informatycznego, jakim jest oprogramowanie oraz
praktyczne przedstawienie mo liwo ci okre lania i modelowania niezawodno ci
oprogramowania za pomoc programu komputerowego.
Zawarto pracy przedstawia si nast puj co. Rozdział pierwszy jest wprowadzeniem
w zagadnienia zwi zane z miejscem etapu testowania w procesie wytwarzania
oprogramowania. Dokonany został przegl d najbardziej znanych metodyk z punktu widzenia
etapu testowania. Przegl d dotyczy zarówno metodyk ci kich, jak i, zyskuj cych ostatnio
coraz wi ksze zainteresowanie, metodyk lekkich,
4
tzw. agile methodologies.
Rozdział drugi pod tytułem: „Metody testowania kodu” stanowi studium obecnie
stosowanych metod testowania kodu oprogramowania – od testowania jednostkowego do
testowania akceptacyjnego, wł czaj c w to równie testowanie strukturalne i funkcjonalne.
Metody te b d omówione z punktu widzenia zarówno metodyk ci kich jak i lekkich.
Rozdział trzeci pod tytułem: „Testowanie kodu dla zapewnienia niezawodno ci
oprogramowania” jest merytoryczn kontynuacj rozdziału poprzedniego. Wprowadza
poj cie niezawodno ci, jako po redniego celu etapu testowania, którego celem ostatecznym
jest poprawa jako ci wytwarzanego oprogramowania. Na jego tre składa si równie
przegl d krajowych i mi dzynarodowych norm zwi zanych z jako ci i niezawodno ci
oprogramowania.
Rozdział czwarty pod tytułem: „Prognozowanie niezawodno ci oprogramowania” wraz
z rozdziałem trzecim stanowi najwa niejsz cz
pracy. Zawiera opis praktycznego
zastosowania wyników uzyskanych na etapie testowania do okre lania i prognozowania
niezawodno ci oprogramowania z u yciem metod statystycznych, jak równie
z powodzeniem znajduj cych tu zastosowanie metod sztucznej inteligencji i metod
hybrydowych. Ta cz
pracy zilustrowana jest programem symuluj cym działanie sieci
neuronowej zastosowanej do predykcji szeregu czasowego wyst pie bł dów
w oprogramowaniu, wspomagaj cej wyznaczanie jego niezawodno ci poprzez okre lenie
przyszłej liczby awarii w kolejnych jednostkach czasu. Badania te dotyczyły przede
wszystkim dokładno ci predykcji liczby awarii. Ponadto miały wykaza mo liwo estymacji
parametrów trendu wykładniczego dla tych samych danych testowych. Wyniki uzyskane
podczas przeprowadzonych bada oraz dyskusja uzyskanych wyników zostały umieszczone
w tre ci rozdziału czwartego.
Zako czenie jest podsumowaniem zawarto ci pracy. W tej cz ci zostały omówione
przyj te zało enia oraz została przedstawiona propozycja kierunków dalszych bada , jakie
pojawiły si w trakcie realizacji pracy.
Na samym ko cu pracy zostały zamieszczone dodatki. Zawieraj one kolejno: dodatek
A – wykaz danych testowych, które posłu yły do wykonania wymienionych powy ej bada ,
dodatek B – opis działania programu wykorzystanego w badaniach w rozdziale czwartym
oraz dodatek C – zawarto płyty CD doł czonej do pracy.
4
Zob. przypis 15.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
8
1. TESTOWANIE
KODU
W
PROCESIE
WYTWARZANIA
OPROGRAMOWANIA
1.1. Wprowadzenie
In ynieria Oprogramowania w czasie kilkudziesi ciu lat swojego istnienia od połowy
lat sze dziesi tych [16] wypracowała ró ne metodyki wytwarzania oprogramowania. Celem
ich było znalezienie i zdefiniowanie takiego zestawu czynno ci, których wykonanie
doprowadziłoby do wytworzenia oprogramowania jako produktu niezawodnego,
spełniaj cego wymagania klienta, zgodnego ze specyfikacj oraz mieszcz cego si
w planowanym harmonogramie i bud ecie [49]. W ten sposób powstało wiele ró nych
procesów wytwarzania oprogramowania. W [16] wyró nia si nast puj ce metodyki: model
kaskadowy,
5
realizacja kierowana dokumentami,
6
prototypowanie,
7
programowanie
odkrywcze,
8
realizacja przyrostowa,
9
model spiralny,
10
formalne transformacje.
11
The
Rational Unified Process
12
i Unified Software Development Process.
13
Wszystkie te procesy
nale do grupy tzw. metodyk ci kich.
14
Istnieje równie szereg tak zwanych metodyk
lekkich:
15
Extreme Programming,
16
Crystal,
17
Adaptive Software Development, Scrum
18
[30],
Feature Driven Development
19
oraz Dynamic System Development Method
20
[2], [3], [4], [6],
[8], [14], [30], [34], [40], [43], [46]. Metodyki lekkie zyskuj ostatnio coraz wi ksz
popularno w ród projektantów i programistów. Wybór metodyki dla konkretnego projektu
zale y od takich czynników, jak: przeznaczenie tworzonego systemu, jego wielko ,
umiej tno ci, do wiadczenie i zgranie członków zespołu projektowego, programistycznego,
itd.
Oprogramowanie powstaj ce w procesie wytwarzania nie jest wył cznie kodem
zapisanym w okre lonym j zyku programowania. W ka dej fazie i na ka dym etapie powstaje
fragment oprogramowania, który nale y przetestowa , aby wykaza , czy jest on zgodny ze
swoj specyfikacj . W zale no ci od tego, czy testuje si oprogramowanie istniej ce
w postaci wymaga u ytkowych, specyfikacji systemu, konstrukcji architektonicznej,
konstrukcji szczegółowej czy kodu [12], stosuje si odpowiednie rodzaje testów. Wi cej na
temat ró nych metod testowania b dzie mowa w rozdziale drugim.
In ynieria oprogramowania musiała stawia czoła bł dom w oprogramowaniu przez
cały czas swojego istnienia. Dzieje si tak równie dzisiaj. Tabela 1.1. przedstawia histori
5
Ang. waterfall.
6
Ang. document-driven.
7
Ang. prototyping.
8
Ang. exploratory programming.
9
Ang. incremental development.
10
Ang. spiral model.
11
Ang. formal transformations.
12
Produkt firmy Rational Software.
13
Pol. ujednolicony proces wytwarzania oprogramowania.
14
Poj cie „metodyki ci kie” pojawiło si w odpowiedzi na okre lenie „metodyki lekkie” (przyp. 15), jako ich
w pewnym sensie przeciwie stwo.
15
Ang. Agile Methodologies, agile – zwinny, sprawny; w angielskiej nomenklaturze zmieniono okre lenie light
na agile, w polskiej pozostało okre lenie: „metodyki lekkie”.
16
Pol. programowanie ekstremalne.
17
Według jej twórcy, Alistair’a Cockburn’a, Crystal jest raczej rodzin metodologii ni pojedyncz metodyk .
18
Pierwsza ksi ka o metodyce Scrum [30] ukazała si w pa dzierniku 2001.
19
Pol. wytwarzanie sterowane cechami; autorzy: Peter Coad (z TogetherSoft), Jeff de Luca.
20
Pol. dynamiczna metoda wytwarzania systemów, przygotowana przez konsorcjum przedsi biorstw Wielkiej
Brytanii.
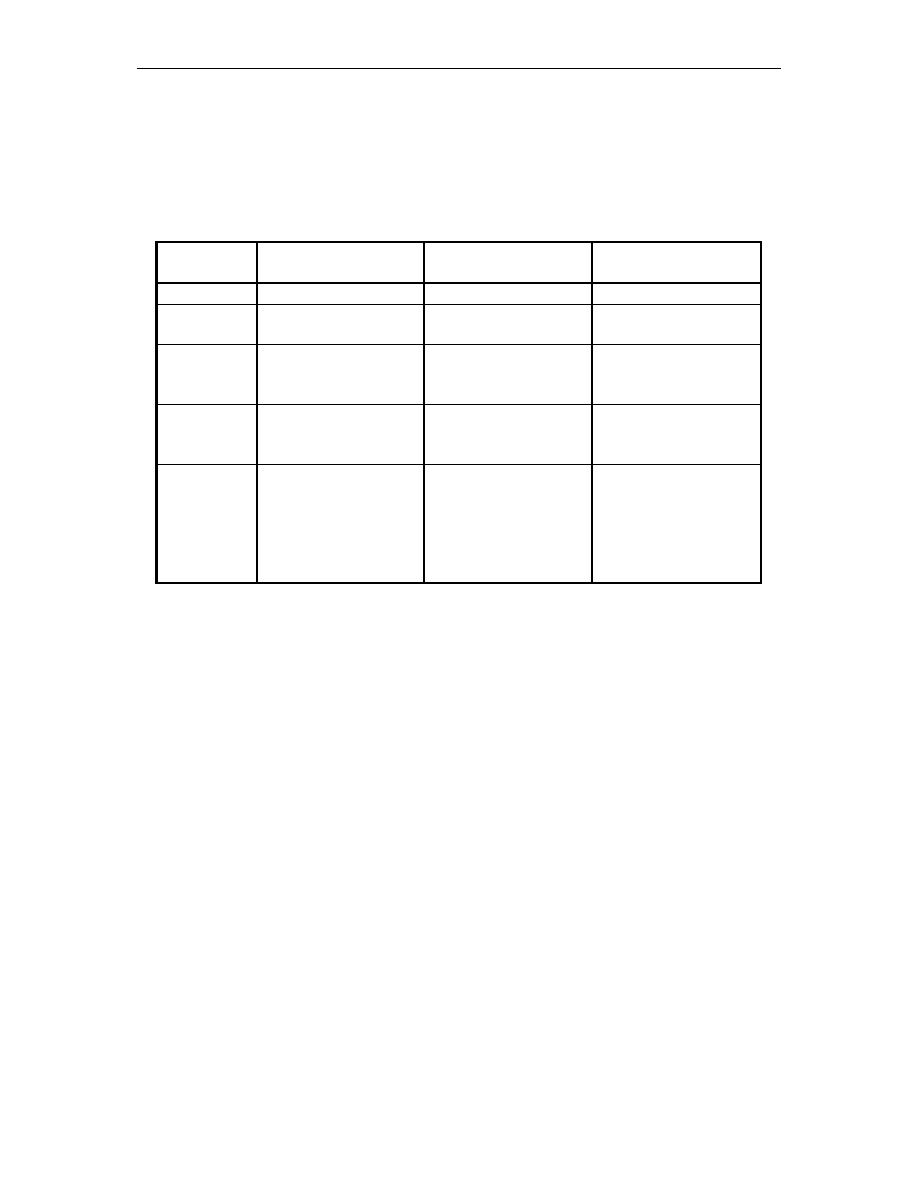
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
9
in ynierii oprogramowania [42]. Przykładowo, wiersz trzeci okre la, e w latach 1970–1990,
istniej cymi programami były w wi kszo ci olbrzymie systemy oraz komputery dla mas,
pojawiaj ce si bł dy były wyniszczaj ce i uznane zostały za rzecz zwykł , natomiast
in yniera oprogramowania była w tych latach w rozkwicie.
Lata
Programy
Bł dy
In ynieria
oprogramowania
1950 – 1960 programy dla siebie
niewielkie bł dy
nie istnieje
1960 – 1970
du e systemy
kosztowne bł dy,
pocz tki kryzysu
rodzi si
1970 – 1990
olbrzymie systemy
oraz komputery dla
mas
wyniszczaj ce bł dy,
uznanie bł dów za
rzecz zwykł
w rozkwicie
1990 – 2003
nic ju nie mo emy
bez komputerów
kryzys
oprogramowania
w rozkwicie
nadal kwitnie
przyszło
bł dnie
zaprogramowane
komputery
przeprogramowuj
ludzi do własnych
potrzeb
trudno ci z bł dami
w ludziach
powstaje in ynieria
oprogramowania
genetycznego ludzi
W pracy po wi conej metodykom RUP oraz XP [6] okre lono, e celem wprowadzenia
procesu wytwarzania oprogramowania jest obawa, e:
•
projekt doprowadzi do wytworzenia złego produktu, lub produktu gorszej
jako ci;
•
projekt b dzie miał opó nienia;
•
projekt b dzie wymagał 80 godzin pracy w tygodniu;
•
podczas realizacji projektu nie uda si wypełni zobowi za w nim
zawartych;
•
praca nad projektem nie dostarczy przyjemnych chwil i satysfakcji;
Obawy te motywuj do wytworzenia procesu, który ograniczy projektantom
i programistom pole działania i wymusi dokładnie okre lone wyniki. Ograniczenia i dane
wyniki okre la si na podstawie posiadanych do wiadcze , wybieraj c to, co poprzednio
udało si wykona , w nadziei, e uda si ponownie i zabierze obawy na przyszło . Gdy
przeanalizuje si udane projekty, mo na zauwa y , e chocia w szczegółach ró niły si
mi dzy sob , maj w istocie podobny kształt. Ten kształt jest dobrze opisany przez RUP.
Bjarne Stroustrup, twórca j zyka C++, stwierdził w 1991 roku: „Projektowanie
i programowanie s działalno ci (zaj ciem) człowieka; je li si o tym zapomni, wtedy
wszystko jest stracone” [6]. Je eli za jest to działalno człowieka, to nieuchronnie staje si
podatna na bł dy. Nie chc c o tym zapomnie , w ka dej metodyce stosuje si ró nego rodzaju
testy, których celem jest znalezienie i wyeliminowanie jak najwi kszej ilo ci bł dów. Nie
tylko sam etap testowania, ale wła ciwie cało podejmowanych aktywno ci w procesie słu y
Tab. 1.1.
Historia in ynierii oprogramowania

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
10
temu pierwszorz dnemu celowi: wytworzeniu niezawodnego oprogramowania, na ile to tylko
jest mo liwe.
Chc c mówi o testowaniu nie mo na tego czyni w oderwaniu od procesu
wytwarzania oprogramowania, w którym ma ono miejsce. Nie ma ani jednego przepływu
(w metodykach ci kich), jak równie nie ma wła ciwie adnej aktywno ci projektowej czy
programistycznej (w metodykach lekkich) bez testowania. Testowanie ma miejsce we
wszystkich procesach, ale idea, jak ka dy z nich realizuje powoduje, e nacisk kładziony na
ten etap mo e, i cz sto jest, zró nicowany. Zró nicowanie to wida szczególnie mi dzy
metodykami ci kimi i lekkimi.
Podział na metodyki lekkie i ci kie pojawił si w sposób naturalny po tym, jak
metodyki lekkie zacz to wprowadza i według nich wytwarza oprogramowanie. Poj cie
„lekko ci” i „ci ko ci” dotyczy technik w nich stosowanych. W metodykach ci kich du
wag przywi zuje si do wykonywania bie cej dokumentacji projektu, co zabiera jego
wykonawcom bardzo wiele czasu. Metodyki lekkie nie s całkowicie pozbawione obci enia
dokumentacji, ale zdecydowanie maj go mniej do uniesienia. Ró nica ta ma na pewno swoje
ródło mi dzy innymi w roli klienta w procesie wytwarzania. W metodykach ci kich
wył cznie pierwszy etap słu y pozyskaniu informacji o tym, jakiego systemu spodziewa si
klient i sporz dzeniu nieformalnego zapisu, z którego w dalszych etapach uzyskuje si coraz
to bardziej formaln posta , a do gotowego produktu. Natomiast w metodykach lekkich rol
klienta jest by obecnym podczas wszystkich etapów wytwarzania. Do niego nale y tak e
bie ca kontrola wyników testów jednostkowych i akceptacyjnych
21
oraz zgłaszanie
ewentualnych uwag, aby proces wytwarzania oprogramowania nieustannie posuwał si
w wyznaczonym kierunku, do celu.
Dokładniej ró nice i podobie stwa w podej ciu do testowania w metodykach ci kich
i lekkich opisane s w nast pnych podrozdziałach. Do porównania zostały wybrane
z metodyk ci kich: RUP, a z metodyk lekkich XP. S one bowiem kluczowymi
metodykami
22
ka da w swojej klasie, a porównanie ich stanowi przegl d tego, co dzieje si
obecnie w in ynierii oprogramowania.
1.2. Testowanie według metodyk ci kich
Spo ród wymienionych w podrozdziale 1.1 metodyk ci kich do dalszych rozwa a
zostały wybrane metodyki USDP i RUP. Obie te metodyki s metodykami generycznymi.
Oznacza to, e na ich podstawie mo na tworzy inne metodyki, które chocia podło e maj
wspólne, to jednak w konkretnej realizacji mog si ró ni . Tak wła nie powstała
licencjonowana metodyka RUP, wywodz ca si z darmowej USDP, która stanowi szkielet
23
dla metodyki RUP, znajduj cej si na ni szym poziomie abstrakcji.
USDP i inne wywodz ce si z niej metodyki, w tym RUP, stanowi klas procesów
iteracyjnych, rozszerzalnych i sterowanych przypadkami u ycia
24
[15], [16]. Iteracyjno tych
procesów polega na wykonywaniu w jednym kroku przej cia przez wszystkie fazy. Ka da
iteracja ko czy si wykonaniem odpowiednich testów.
25
Rozszerzalno polega na tym, e
ka da iteracja chocia przechodzi wci przez te same etapy, ko czy si wykonaniem
i przetestowaniem coraz to nowej funkcjonalno ci systemu. Teoretycznie istnieje mo liwo
wykonywania dowolnej ilo ci iteracji. Sterowanie przypadkami u ycia okre la sposób
21
Zob. rozdział drugi.
22
Mo na to stwierdzi np. na podstawie ilo ci publikacji na temat metodyk wytwarzania oprogramowania.
23
Ang. framework.
24
Ang. use-case driven, metoda wprowadzona przez Jacobsona w 1993.
25
W zale no ci od fazy, w jakiej miała miejsce iteracja, wykonuje si ró ne testy.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
11
podej cia do wytwarzania du ych systemów. Polega na tym, e w pierwszej kolejno ci
identyfikuje si klasy zewn trzne wzgl dem systemu. Klas zewn trzn mo e by
u ytkownik lub np. inny system. Nast pnie okre la si funkcje w systemie wykorzystywane
przez klasy zewn trzne. Tworzony jest wi c opis systemu z punktu widzenia poszczególnych
klas [16]. Ka dy przypadek u ycia zamyka w sobie odr bn funkcjonalno istotn dla klas
zewn trznych lub innych przypadków u ycia.
Przypadek testowy jest okre leniem analogicznym do poj cia przypadku u ycia.
Bowiem przypadki testowe tworzy si wła nie na podstawie przypadków u ycia. Celem
wykonywania przypadków testowych jest sprawdzenie, czy odpowiadaj cy mu przypadek
u ycia realizuje swoje funkcje zgodnie ze specyfikacj . Przypadki testowe wykonuje si na
etapie testowania w ramach testowania funkcjonalnego.
26
USDP zawiera pi przepływów (etapów): specyfikacja wymaga , analiza,
projektowanie, implementacja i testowanie. W metodyce RUP przepływów jest wi cej i s
one nieco inaczej podzielone
27
[6]. RUP ł czy ze sob etapy analizy i projektowania oraz
wprowadza pi dodatkowych etapów wzgl dem tego, co było w USDP: modelowanie
biznesowe,
28
zarz dzanie konfiguracj i zmianami
29
, zarz dzanie projektem
30
, zarz dzanie
rodowiskiem,
31
zarz dzanie rozmieszczeniem.
32
RUP mo e podlega dalszemu
uszczegóławianiu. Przepływy w procesie RUP stanowi jego realizacj [6], [49]. Przepływy
mog by ci sze, lub l ejsze. Zale y to od sposobu dostosowania RUP do potrzeb danego
procesu. Jednak w porównaniu z metodykami lekkimi pozostaj tak naprawd ci kie [49].
Etap testowania wyst puje podobnie w obu metodykach, dlatego b dzie omówiony wspólnie.
W metodykach USDP i RUP wyró nia si 4 fazy: zapocz tkowanie, opracowanie,
konstrukcja i przej cie
33
[6], [34]. Fazy dziel si na iteracje, a przej cie ka dej iteracji polega
na wykonaniu aktywno ci wszystkich etapów. Istotne jest to, aby podczas iteracji zespół
projektowy nie skupiał si na jednym fragmencie systemu, ale równocze nie wykonywał
wszystkie główne podsystemy. Na ka d iteracj składa si wysiłek wszystkich członków
zespołu, ka dy z nich buduje swoj cz
projektu. Na koniec iteracji wszystkie cz ci s
integrowane. Długo , tzn. czas trwania ka dej iteracji zale y od rodzaju projektu, jednak
bardziej zaleca si krótsze ni dłu sze iteracje. Dla wi kszo ci projektów 1 do 2 tygodni
zawsze powinno wystarczy [6].
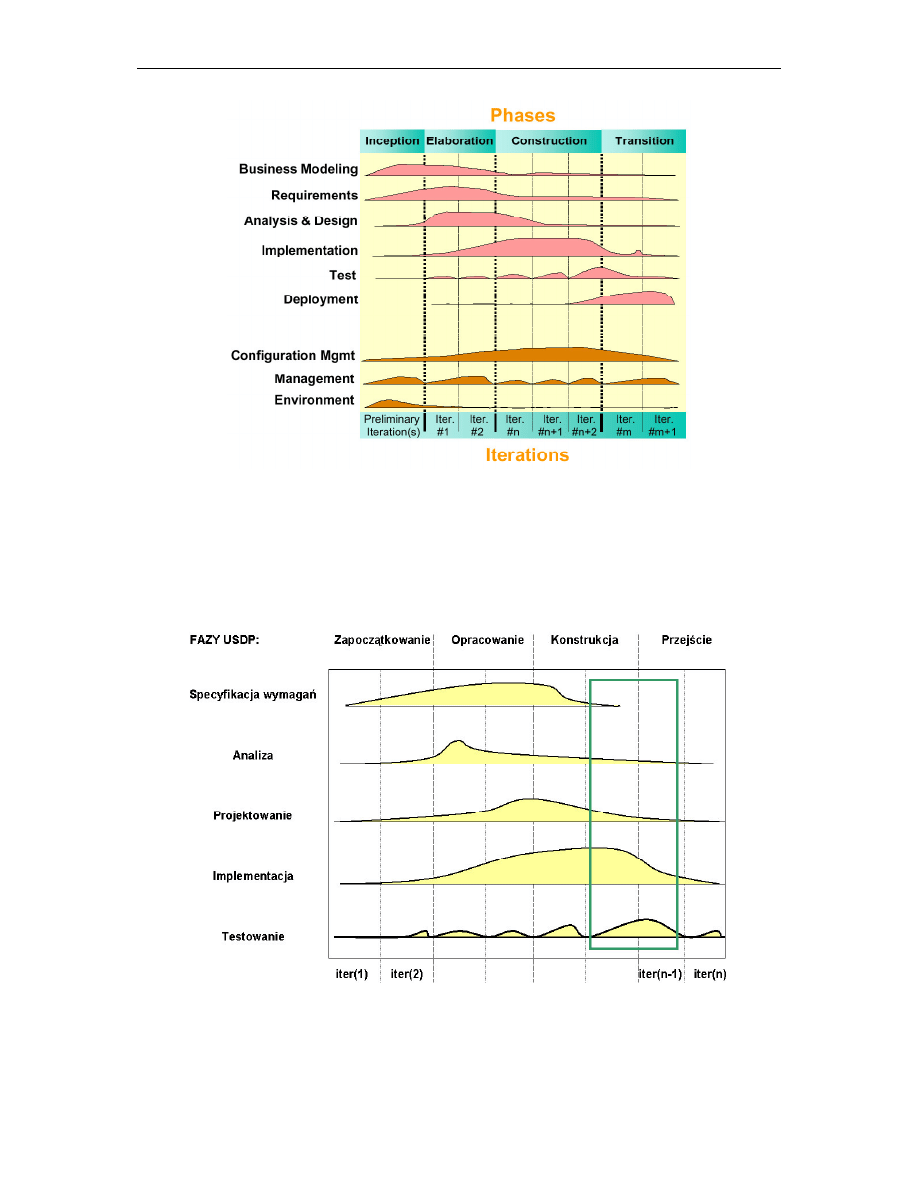
Rysunek 1.1 przedstawia fazy i etapy w metodyce RUP. Wida na nim, e etap
testowania ma szczególne nasilenie na granicy faz konstrukcji i przej cia, gdzie ilo
zaimplementowanego kodu jest ju znaczna. Etap implementacji ko czy si ju w połowie
fazy przej cia. Warto jednak zwróci uwag , e tak naprawd w ka dej fazie wykonuje si
testowanie, poniewa ka da iteracja ko czy si powstaniem tzw. buildu, który wymaga
sprawdzenia. Build jest działaj cym fragmentem systemu, który cz sto wykorzystuje si do
weryfikacji przez odbiorc systemu w celu okre lenia kierunku dalszej pracy nad rozwijaniem
systemu.
26
Zob. rozdział drugi.
27
Por. rysunki 1.1 i 1.2.
28
Zrozumienie i okre lenie potrzeb i wymaga informatyzowanego biznesu (przedsi biorstwa).
29
Zachowywanie cie ek wytwarzania wszystkich wersji systemu.
30
Zarz dzanie harmonogramem i zasobami.
31
Ustawianie i utrzymanie rodowiska projektowego.
32
Czynno ci zwi zane z wydaniem produktu.
33
Ang. inception phase, elaboration phase, construction phase, transition phase.
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
12
Rys. 1.1.
Fazy i etapy (przepływy) w metodyce RUP
Dla porównania z metodyk RUP, rysunek 1.2 przedstawia fazy i przepływy
w metodyce USDP oraz miejsce (zaznaczone ramk ), w którym aktywno ci etapu testowania
s najwi ksze i najbardziej nasilone.
Rys. 1.2.
Fazy i etapy (przepływy) w metodyce USDP

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
13
Oprogramowanie podlega testowaniu w ka dej formie swojego istnienia: od
specyfikacji wymaga poprzez analiz i projektowanie, a po etap, w którym testuje si
gotowy produkt. Testowanie, jako etap rozło ony w czasie mo e dotyczy ró nych aspektów
oprogramowania.
34
W metodykach ci kich etap testowania traktuje si jako osobn aktywno
podejmowan przez testerów, tj. specjalnie wyznaczone do tego osoby z zespołu
projektowego. Po etapie kodowania, gdy programi ci wytworz kolejny fragment kodu
system lub jeszcze jego jest przekazywany testerom i poddawany testom. Celem testowania
jest wykrycie jak najwi kszej ilo ci bł dów.
1.3. Testowanie według metodyk lekkich
Pojawienie si metodyk lekkich wymagało od projektantów i programistów zmiany
dotychczasowej mentalno ci i sposobu podej cia do wytwarzania oprogramowania. Poprzez
specjalne techniki stosowane w tych metodykach testowanie, a zwłaszcza testowanie kodu
zyskało nowe znaczenie.
Najcz ciej wykorzystywan i najbardziej znan metodyk w ród metodyk lekkich
o wci wzrastaj cej popularno ci jest XP [38]. Twórca analizy strukturalnej, Tom de Marco
[20] okre la XP jako przełom w in ynierii oprogramowania [10]. Przełom ten mógł si
dokona dzi ki zastosowaniu w tej metodyce przedstawionych poni ej okre lonych praktyk
wytwarzania oprogramowania:
• Klient na miejscu
Klient ma pełn kontrol nad procesem rozwoju oprogramowania. Ci gła
obecno klienta stwarza programistom szans szybkiego rozwi zywania
napotykanych problemów i wyja niania w tpliwo ci dotycz cych cech
funkcjonalnych budowanego systemu. Klient aktywnie uczestniczy mi dzy
innymi w tworzeniu testów akceptacyjnych.
• Cz ste wydania
Kolejne wersje systemu buduje si na zasadzie przyrostów i dostarcza klientowi
w mo liwie krótkich cyklach (1-2 miesi ce). W ten sposób klient ma szans
lepszego poznania swoich potrzeb i wcze niej mo e skorygowa swoje
wymagania wobec systemu.
35
• Programowanie parami
Para programistów pracuje wspólnie przy jednym komputerze nad wykonaniem
okre lonego zadania. Taki sposób pracy oznacza de facto ci głe przegl dy kodu
(w XP zrezygnowano z formalnych przegl dów artefaktów).
• Ci gła integracja
Kod tworzony przez par programistów powinien by integrowany z cało ci
systemu tak cz sto, jak jest to tylko mo liwe. Przy ka dej integracji dodawana jest
nowa funkcjonalno do systemu.
• Refaktoryzacja
Oznacza ona przebudow kodu. Tworzony kod oraz struktura systemu ulegaj
iteracyjnemu poprawianiu i ulepszaniu przy zachowaniu zbudowanej
34
Ró ne metody testowania, zale ne od postaci, w jakiej wyst puje oprogramowania, s dokładniej omówione
w rozdziale drugim.
35
Patrz tak e p. 3.5 (testowanie akceptacyjne).

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
14
funkcjonalno ci. celem takiego działania jest uzyskanie przejrzystego,
komunikatywnego kodu, pozbywanie si powielonego kodu oraz zmniejszenie
ryzyka pojawienia si kolizji w trakcie procesu integracji [46].
• Testowanie
Proces kodowania zostaje zawsze poprzedzony przygotowaniem przypadków
testowych. Taki sposób pracy powoduje, e system jest w pełni zrozumiały dla
programistów, czego efektem jest wykonanie prostszej implementacji. XP kładzie
nacisk zarówno na testy jednostkowe, jak i akceptacyjne. Wa nym wymaganiem
jest automatyzacja wszystkich testów. Konieczno taka wynika z cz stych
integracji (ka da integracja systemu ko czy si wykonaniem wszystkich
istniej cych testów) oraz licznych refaktoryzacji. Dlatego metodyki te cz sto
okre la si mianem metodyk sterowanych testami.
Opisane podej cie pozwala utrzyma wysok jako wytwarzanego oprogramowania
przez cały okres prowadzonych nad nim prac.
W metodyce XP oraz innych metodykach lekkich mo na wyró ni takie praktyki,
w których znaczenie „sterowania testami” zostało posuni te jeszcze dalej. Ich nadrz dnym
celem jest wytwarzanie oprogramowania od pocz tku pozbawionego bł dów. Nie oznacza to
oczywi cie tego, e programi ci nie b d popełnia bł dów podczas pisania, ale stosowanie
testów jednostkowych na bie co nie pozwoli wytworzy du ej ilo ci niepoprawnego kodu,
którego testowanie i korekta okazałaby si niezmiernie czasochłonna, albo nawet niemo liwa.
Jedn z takich praktyk jest podej cie Test Driven Development
36
[47]. Jeden z twórców
podej cia sterowanego testami, Kent Beck [2], [3], [4], pionier na polu metodyk lekkich
przedstawia jego zało enia i praktyki.
Wytwarzanie sterowane testami jest praktyk efektywnego pisania i rozwijania
u ytecznego kodu. Chocia nazwa mo e sugerowa główny nacisk tej metodyki na
testowanie, jest ona jednak przede wszystkim projektowaniem: skupia uwag programistów
na wytwarzaniu kodu wył cznie zgodnego ze specyfikacj i unikaniu tworzenia kodu ponad
to, co jest konieczne i potrzebne.
37
U ywaj c tej techniki, programi ci rozpoczynaj tworzenie fragmentów kodu od
napisania dla nich testów. Nast pnie, gdy kod przejdzie testy pomy lnie, jest poddawany
refaktoryzacji i wszystko rozpoczyna si od nowa. TDD stwarza pewien rytm wytwarzania,
który upraszcza rozwijanie „szczupłego”, u ytecznego i w pełni przetestowanego kodu [41].
Na zako czenie mo na przytoczy słowa wiatowej sławy twórcy algorytmów, Dijkstry
[6]: „...jako człowiek powoli my l cy mam bardzo mał głow i lepiej b dzie je li naucz si
z tym y , respektowa moje ograniczenia i raczej ufa im, ni próbowa je ignorowa , aby
pó niej, mimo pró nego wysiłku, by ukaranym przez popełnienie bł du.”
Je li równocze nie próbuje si wykona wiele aktywno ci bez sprawdzania wyników, to
mo na przewidzie , e nie udadz si . Dlatego wybiera si i stawia małe kroki i ka dy z nich
testuje przed wykonaniem nast pnego. Dobry proces u ywa metod podobnych do metod
naukowych. Pierwszy krok jest niczym innym, jak hipotez . Ka d hipotez sprawdza si
empirycznie, za pomoc fizycznych eksperymentów. Dopiero gdy odpowiednia ilo testów
potwierdzi hipotez , mo na wybra nast pny krok. Jest to podstawowa motywacja dla
wszystkich metod iteracyjnych [6].
36
Pol. wytwarzanie sterowane testami.
37
Ang. over-engineering.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
15
1.4. Porównanie podej cia do testowania w metodykach ci kich
i lekkich
Podobie stwa i ró nice w podej ciu do testowania w metodykach ci kich i lekkich
mo na pokaza , jak to było ju w podrozdziałach 1.2 i 1.3 na przykładzie RUP oraz XP.
Warto w tym celu si gn do informacji ródłowych. Rational Software Corporation wraz
z Object Mentor Inc. [44] wydali elektroniczny przewodnik po RUP i XP [36]. Przewodnik
ten, który powstał we współpracy obu firm jest ródłem rzetelnych informacji na temat obu
sposobów podej cia do wytwarzania oprogramowania.
Wytwarzanie oprogramowania jest aktywno ci ludzk , która przekształca surow
intelektualn wizj w namacalny, wykonywalny kod. Z wyj tkiem najprostszych systemów,
wytwarzanie warto ciowego oprogramowania wymaga wysiłku grupy ludzi, z których cz
jest koderami, cz
testerami lub innymi członkami wnosz cymi swoje umiej tno ci
i perspektywy do wspólnego wysiłku. Ludzie wchodz cy w skład zespołu maj ró ne
przyzwyczajenia i sposoby pracy. Proces wytwarzania oprogramowania wprowadza
okre lenie i ujednolicenie wykonywanych aktywno ci, wdra a je i umo liwia porozumienie
mi dzy ró nymi członkami zespołu.
Rational Unified Process i Extreme Programming s wła nie takimi procesami.
W swojej istocie maj wiele podobie stw: oba uznaj wytwarzanie za aktywno ludzk i oba
d
do wytwarzania oprogramowania coraz lepiej i szybciej. Ponadto w swoim działaniu
wykazuj podobne aktywno ci:
•
Wytwarzanie koncentruje si na rozbudowie systemu poprzez małe iteracje
i jest procesem ci głym.
•
Iteracje zale od fazy, w której wyst puj ; ich ilo i dokładno zwi ksza
si przez cały cykl ycia projektu.
•
Wykonywalny kod jest przegl dany jako pierwotny produkt wraz ze
wszystkimi artefaktami. Artefakty s półproduktami procesu wytwarzania
oprogramowania, które pomagaj uzyska produkt finalny. Artefakty
pomagaj równie uzyska porozumienie pomi dzy członkami zespołu.
W rzeczywisto ci, patrz c z zewn trz na zespół pracuj cy według metodyki RUP,
mo na odnie wra enie, e post puj według XP i na odwrót.
Oczywi cie istnieje wiele ró nic mi dzy RUP a XP. Przede wszystkim RUP jest
metodyk generyczn , a nie konkretnym procesem, tak jak XP i mo e by dostosowywany do
aktualnych potrzeb projektantów. RUP i XP s całkiem podobne w swoich zasadach, ale
ró ne w zakresie działania. XP skupia si przede wszystkim na dynamikach mi dzyludzkich
(ang. social dynamics) wewn trz małych zespołów projektowo-programistycznych, podczas
gdy RUP równie mocno kładzie nacisk na kontekst otaczaj cy, wł czaj c w to zespoły
zarz dzaj ce zespołami projektowymi.
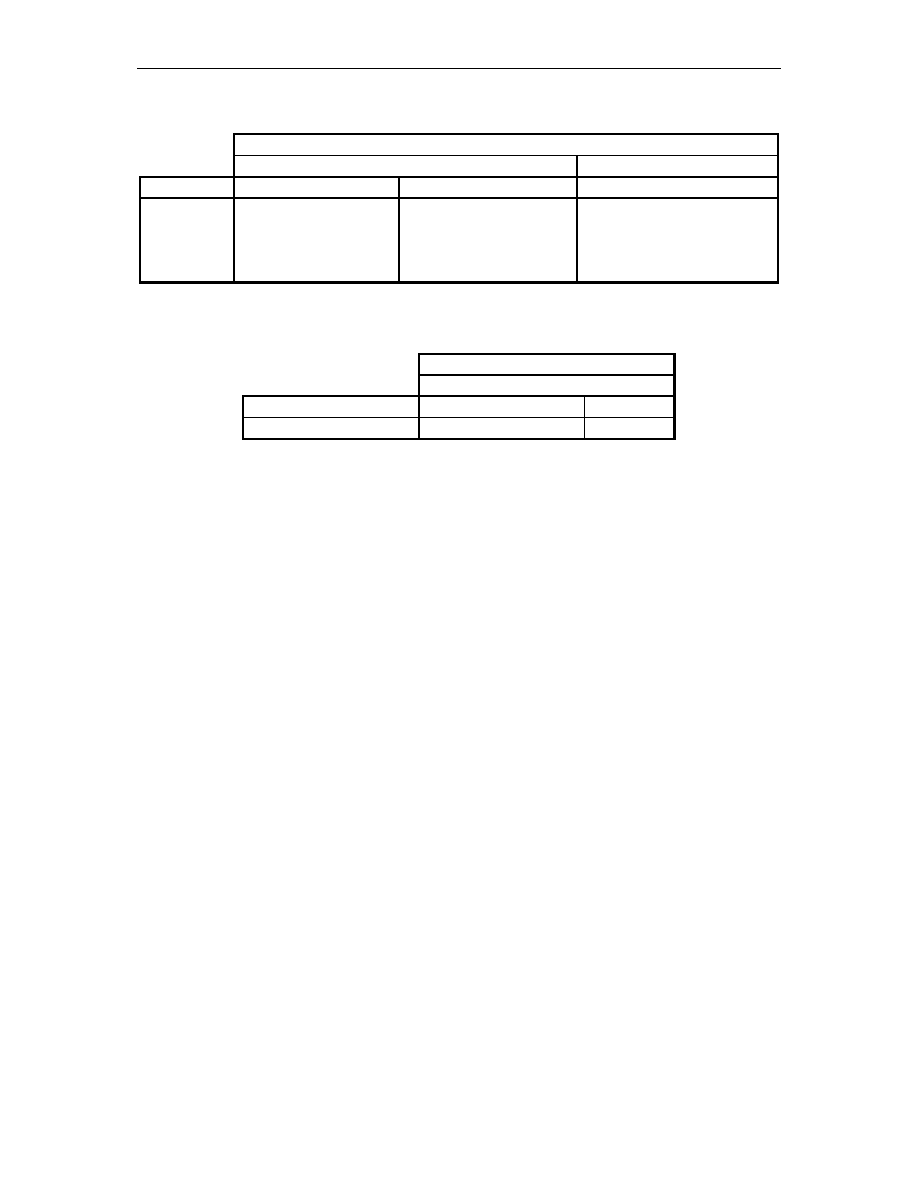
Tabele 1.2 i 1.3 przedstawiaj porównanie ról osób zwi zanych z wytwarzaniem
oprogramowania w metodykach RUP i XP. W wierszach wyszczególnione s role osób
wchodz cych w skład zespołów. Np. wiersz ostatni zawiera wykaz ról osób w metodyce
RUP: specyfikator wymaga (ang. Requirements Specifier), analityk systemowy (ang. System
Analyst) i mened er projektu (ang. Project Manager). Te trzy role odpowiadaj jednej roli
w metodyce XP: klientowi (ang. Customer).
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
16
Tab. 1.2.
Porównanie ról osób w zespole projektowym według metodyk XP i RUP
Whole Team
XP Customer Team
XP Developer Team
XP Roles
Customer
Tester
Programmer
RUP Roles
• Requirements
specifier
• System Analyst
• Project Manager
• Test Analyst
• Tester
• Test System
Administrator
• Implementer
• Designer
• Integrator
• System Administrator
Whole Team
XP Organization
XP Roles
Tracker
Coach
RUP Roles
Project Manager
–
RUP za USDP wprowadza cztery fazy: zapocz tkowanie, opracowanie, konstrukcja
i przej cie [6], [34]. W ka dej fazie wprowadza si i kładzie nacisk na ró ne aktywno ci:
okre lenie modelu biznesowego, okre lenie technicznego otoczenia, wytwarzanie systemu
oraz przej cie do w pełni funkcjonalnego u ytkowania. W XP fazy nie wyst puj w ogóle, ale
czynno ci projektowe mog by wykonywane w kolejno ci, jaka akurat wynika z potrzeb
projektu [37].
W XP identyfikuje si kilka praktyk, które kształtuj prac zespołu wytwórczego, ale za
to nie ingeruje si w sprawy otoczenia. Natomiast RUP nie okre la szczegółów pracy
i kształtu zespołu, ale wiele decyduje w kwestach otoczenia projektu. Pod tym wzgl dem XP
i RUP s procesami uzupełniaj cymi si wzajemnie.
Opisana w podrozdziale 1.2 metodyka RUP nale y do grupy metodyk ci kich. Jest
ponadto metodyk generyczn , czyli daje mo liwo dostosowania si do specyficznych
wymaga danego projektu.
W pracy [6] została opisana implementacja nowej metodyki na bazie RUP, któr
nazwano dX. Metodyka dX miała by minimaln , mo liwie lekk implementacj RUP.
Podstawy i zało enia nowej metodyki zostały zaczerpni te z prac m.in. Cunningham’a [47],
Beck’a [2], [3], [4], Jeffries’a [48], prekursorów metodyk lekkich oraz innych projektantów
i metodologów oprogramowania [39]. Udana próba adaptacji RUP do indywidualnych
potrzeb dały pocz tek nowej metodyce. Sukcesy projektów wytworzonych według tej
metodyki pokazały, e mo liwy jest kompromis mi dzy ci kim podej ciem, jakim wydaje
si by RUP a podej ciem lekkim, wzorowanym na XP.
Tab. 1.2.
Porównanie ról osób w zespole projektowym według metodyk XP i RUP (c.d.)

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
17
2. METODY TESTOWANIA KODU
2.1. Wprowadzenie
W rozdziale pierwszym wyja niona została ró nica pomi dzy oprogramowaniem
rozumianym jako kompletny produkt powstały w procesie wytwarzania oprogramowania
a kodem zapisanym w konkretnym j zyku programowania, b d cym jedynie cz ci
oprogramowania, chocia bardzo istotn .
W tym rozdziale na pocz tku wyja nione zostan podstawowe poj cia zwi zane
z dziedzin testowania oprogramowania. Nast pnie zostan dokładniej przedstawione metody
testowania samego kodu, problemy z nimi zwi zane oraz inne metody testowania na
wy szych poziomach wytwarzania oprogramowania.
38
Zagadnienia, które trudno pomin mówi c o testowaniu to poj cie bł du, awarii
i defektu. Bł d definiuje si jako zdarzenie zainicjowane przez człowieka lub rodowisko
programu, powoduj ce, e kod produkuje jaki nieoczekiwany rezultat; mówi c inaczej,
zachowuje si niezgodnie ze specyfikacj . Gdy program nie jest w stanie wykona co
najmniej jednej ze swoich funkcji, wówczas jest to awaria.
Defekt natomiast, to pomyłka
popełniona na dowolnym etapie cyklu ycia oprogramowania przez projektanta lub
programist . Podsumowuj c: bł d ujawnia si poprzez awari programu, a powstaje
w wyniku defektu w działaniu człowieka. Testowanie definiuje si jako eksperymentowanie
z programem lub poszczególnymi jego komponentami. Podczas tych eksperymentów
wykorzystuje si specjalnie dobrane dane testowe i porównuje uzyskane wyniki z wynikami
przewidywanymi. Testowanie ma na celu doprowadzenie do awarii systemu, by ujawni
ukryte w nim ewentualne bł dy [12].
Etap testowania uznawany jest za najtrudniejsze zadanie podejmowane w całym
procesie wytwarzania oprogramowania. Jest niezwykle istotne, aby czynno ci testowe były
podj te od samego pocz tku ycia projektu. Uwa a si , e 1$ zaoszcz dzony kosztem
testowania w pocz tkowych fazach poci ga za sob kwot 1000$ na wykrycie i usuni cie
bł du w fazach pó niejszych [45]. Mimo du ego wysiłku wkładanego w przygotowanie
i podejmowanie aktywno ci testowych, etap ten nie daje gwarancji, e przetestowane
oprogramowanie b dzie wolne od bł dów. W przypadku du ych systemów wiele bł dów
znajduje si ju po wydaniu produktu. Firmy o utwierdzonej renomie na rynku
oprogramowania zapewniaj w swoich produktach mo liwo zgłaszania przez klientów
znalezionych przez nich bł dów podczas u ytkowania systemu. Ta informacja zwrotna jest
wykorzystywana przy kolejnych wydaniach systemu do wyeliminowania znalezionych
bł dów. Przykładem mog by produkty firmy Microsoft: np. w Windows XP jest
wprowadzono mechanizm przesyłania informacji o bł dzie zaraz po jego wyst pieniu, je li
u ytkownik wyrazi zgod i posiada dost p do sieci Internet.
Mówi c o testowaniu, cz sto u ywa si takich poj jak przypadek testowy czy
kryterium zako czenia testu. Przypadek testowy to konkretne zachowanie si programu,
wybrane do testowania spo ród wielu mo liwych. Kryterium zako czenia testu umo liwia
podj cie decyzji, czy ilo wykonanych testów jest wystarczaj ca, tzn. czy udało si
zaobserwowa dostateczn ilo zachowa [12].
38
„Poziom wytwarzania oprogramowania” jest poj ciem nieformalnym. Jak wiadomo, na ró nych etapach
wytwarzania, oprogramowanie wyst puje w ró nej formie: od ogólnych i nieformalnych zapisów na etapie
specyfikacji wymaga (poziom najwy szy), poprzez modele analizy, projektu, a po kod (poziom najni szy).
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
18
Wykonywane testy mog podlega ocenie. Jedn z metod oceny jest technika
zasiewania bł dów [12]. Polega ona na celowym wprowadzeniu bł dów do kodu i mierzeniu,
w jakim stopniu dany test wykrywa te bł dy. Cz sto przy tej okazji wykrywane s bł dy
istniej ce w kodzie przed zasianiem.
Prof. Wiszniewski [12] tak definiuje i wprowadza poj cia ró nych metod testowania:
najni szy poziom eksperymentowania z wykonywalnym kodem wytwarzanego produktu
(programu, systemu) nazywa si testowaniem jednostkowym. Testowanie jednostkowe polega
na wykonywaniu pojedynczych funkcji lub innych fragmentów kodu w oderwaniu od reszty
systemu. Powy ej tego poziomu realizowane jest testowanie integracyjne, gdzie
przetestowane jednostki kodu s stopniowo ł czone w wi ksz cało , a nast pnie ponownie
testowane ju jako grupa jednostek. Proces ł czenia i testowania jest powtarzany a do
powstania całego systemu. Eksperymenty s wówczas prowadzone w docelowym rodowisku
programu. Ten najwy szy poziom eksperymentowania nazywany jest testowaniem
systemowym [12]. Ponadto wyró ni mo na jeszcze inne rodzaje testowania: testowania
niezale ne i testowanie akceptacyjne [12]. Niezale ne polega na tym, e testowania kodu nie
wykonuje jego twórca (programista), ale inna osoba niekoniecznie nawet zwi zana z tym
konkretnym projektem. Je li ta sama osoba jest jednocze nie programist i testerem danego
fragmentu kodu, wówczas istnieje zagro enie tendencyjnego podej cia i niezamierzonego
pomini cia kontroli pewnych aspektów. Na samym ko cu, przed „oddaniem” systemu,
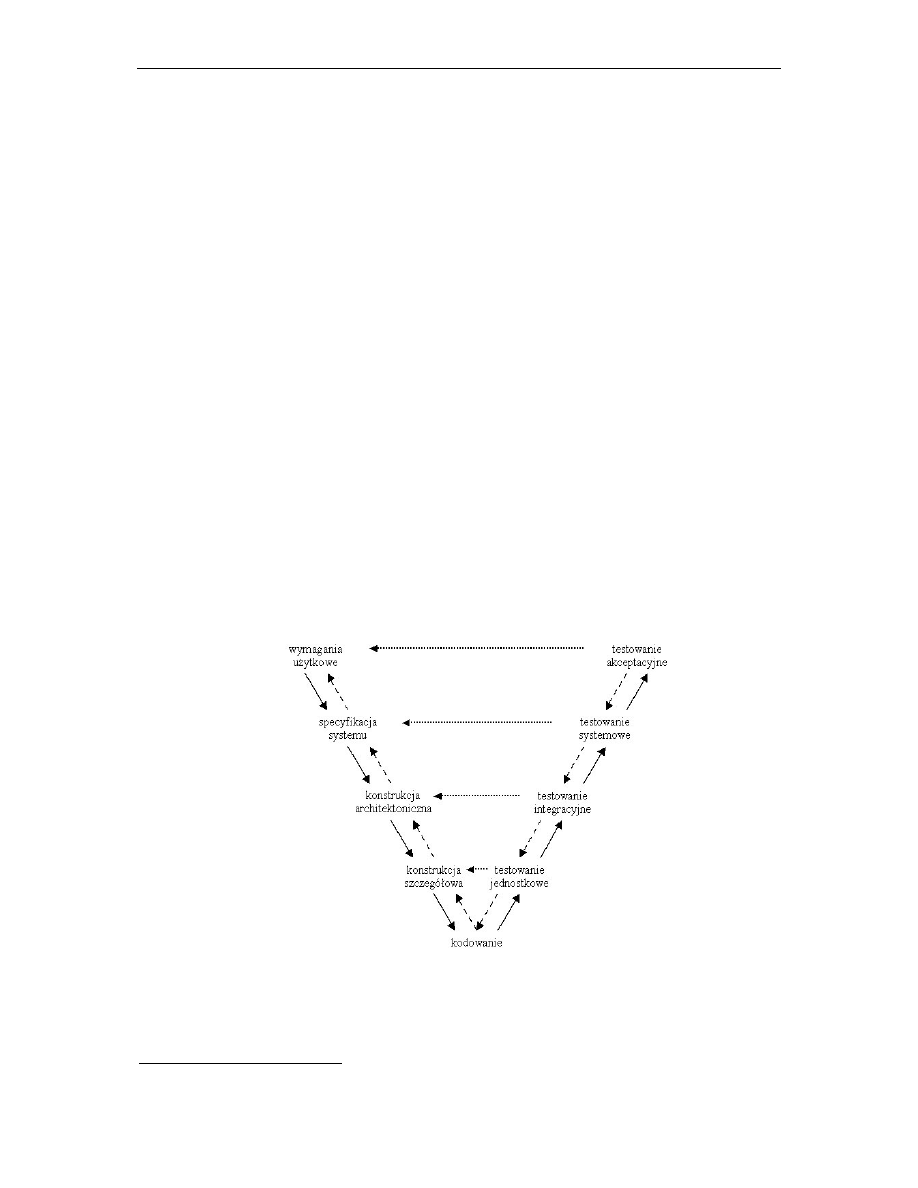
wykonuje si jeszcze testowanie akceptacyjne. Ilustruje to rysunek 2.1, który przedstawia
model „V”, miejsce testowania w procesie wytwarzania oprogramowania. Strzałki o liniach
ci głych oznaczaj kierunek wytwarzania, o liniach kreskowanych – lokalizacj bł du, a
o liniach kropkowanych – kierunek weryfikacji. Z rysunku mo na odczyta , e kodowanie
jest etapem wykonywanym na podstawie konstrukcji szczegółowej,
39
po czym wykonywane
jest testowanie jednostkowe, którego zadaniem jest weryfikacja kodu na podstawie
konstrukcji szczegółowej [12].
Rys. 2.1.
Testowanie w procesie wytwarzania oprogramowania – model „V”
39
Konstrukcja szczegółowa jest odpowiednikiem etapu projektowania w USDP i RUP.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
19
W podrozdziałach 2.2 i nast pnych zostały zamieszczone definicje i opisy
poszczególnych rodzajów testowania.
2.2. Testowanie strukturalne i funkcjonalne
Poj cia te ci le wi
si odpowiednio: funkcjonalne z metodami „czarnej skrzynki”
oraz strukturalne – „białej skrzynki” [16].
Dla metod realizowanych na zasadzie „czarnej skrzynki” ka dy przypadek testowy
40
opisany jest przez par <wej cie, wyj cie>. Dobór warto ci pary wykonuje si wył cznie na
podstawie specyfikacji systemu i wymaga analizy jego semantyki. Testowanie t metod
polega na porównaniu, czy dla danego wej cia otrzymane wyj cie jest prawidłowe. Przypadki
testowe tworzy si na podstawie przypadków u ycia okre lanych ju na etapie specyfikacji
wymaga systemu.
Testowanie metod białej skrzynki polega na przebadaniu elementów struktury
programu, np. pojedynczych instrukcji, czy cie ek z wybraniem odpowiednich danych
testowych.
Istnieje kilka kryteriów dostateczno ci
41
[18], które okre laj , na ile dany zbiór
przypadków testowych pokrywa kod programu. Kryteria te mog by sklasyfikowane ze
wzgl du na ródło informacji u ytej do sporz dzenia testów (specyfikacja systemu lub sam
program) lub ze wzgl du na sam rodzaj testowania. W pracy [18] u yto tzw. testów pokrycia
według strukturalnego kryterium pokrycia, a konkretnie pokrycia rozgał zie .
Definicja spełniania kryterium pokrycia: zbiór P cie ek wykonywania spełnia
kryterium pokrycia rozgał zie wtedy i tylko wtedy, gdy dla ka dej kraw dzi e w grafie
przepływu istnieje co najmniej jedna cie ka p w P, taka e P zawiera kraw d e.
Zaproponowano nast puj cy algorytm pokrycia rozgał zie :
1.
Wygeneruj wektor testowy według wybranego mechanizmu generacji;
2.
Je li jaka nowa gał została odkryta przez ten wektor, wówczas ilo prób
ustaw na 0, je li nie, ilo prób zwi ksz o 1;
3.
Je li ilo prób jest wi ksza od maksymalnej dozwolonej, wówczas
wykonaj rozszerzenie zakresu;
4.
Oblicz potencjał dla ka dej gał zi wektora testowego;
5.
Znajd gał ‘i’ o najwi kszej warto ci potencjału;
6.
Porównaj bie c najwi ksz warto potencjału z poprzedni . Je li bie ca
jest wi ksza, wówczas ilo prób ustaw na 0 i wykonaj redukcj zakresu ze
wzgl du na gał ‘i’;
7.
Je li dane pokrycie nie jest osi gni te, id do kroku 1;
Warto zwana potencjałem (pkt 5 algorytmu) jest miar dopasowania gał zi i została
wprowadzona w pracy [18]. Ponadto pomysłem autorów było, aby podczas testowania
wydoby u yteczne informacje o strukturze i w poł czeniu ze zmieniaj c si informacj
o stopniu pokrycia testów okre li warto bie cego potencjału gał zi. Warto ta posłu yła
do nakierowania testów typu „czarnej skrzynki” na gał zie mało b d w ogóle nie pokryte.
40
Zob. rozdział pierwszy.
41
Ang. adequacy criteria.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
20
Zaproponowano nowe podej cie zwane „wzmocnionymi gał ziami”,
42
które pomaga
ustawi w centrum uwagi gał zie trudniejsze do pokrycia. Porównano wyniki pokrycia testów
„czarnej skrzynki” (losowych) z u yciem i bez u ycia nowego podej cia. Wyniki pokazały, e
proste u ycie techniki nakierowania znacz co poprawiło pokrycie, szczególnie w przypadku
programów o zło onych strukturalnie własno ciach.
Graficzna reprezentacja tego algorytmu w postaci schematu blokowego dost pna jest
w pracy [18].
2.3. Testowanie jednostkowe
Norma definiuje testowanie jednostkowe jako testowanie pojedynczych jednostek
sprz tu czy oprogramowania lub powi zanych ze sob grup jednostek [32].
Testowanie jednostkowe stosuje si do weryfikacji konkretnych fragmentów kodu
w celu okre lenia zgodno ci strukturalnej i semantycznej ze specyfikacj , a zatem
z wykorzystaniem metod strukturalnych i funkcjonalnych. Tu odbywa si najbardziej
szczegółowa ocena pracy programisty odpowiedzialnego za kodowanie danego fragmentu
programu [12]. Poniewa programista posiada najlepsz wiedz na temat wytworzonego kodu
oraz istniej cych w nim niuansów
43
[12], wydaje si , e powinien uczestniczy
w wykonywaniu testów jednostkowych. Ze wzgl du jednak na opisywane ju wy ej
zagadnienie testowania niezale nego, konieczne jest zaanga owanie dodatkowo „osób
trzecich” do projektowania i wykonywania tego zadania.
Wida , jak istotne jest tutaj planowe i systematyczne podej cie oraz szczególne
zwrócenie uwagi na to, czy badana jednostka spełnia kryteria zako czenia testu oraz czy jest
gotowa do integracji. Je li podczas badania tej gotowo ci wyjd na jaw jakie bł dy, wówczas
wykonuje si tzw. testy regresywne, które polegaj na ponownym wykonaniu testowania
jednostkowego dla tych konkretnych jednostek [12].
W testowaniu jednostkowym cz sto wykorzystuje si techniki automatycznego
testowania. Daj one mo liwo przeprowadzania wielu testów z du ilo ci danych według
tego samego scenariusza [12]. Automatyczne testowanie wspomagane jest programami
narz dziowymi. Przykładowo, takim programem wspomagaj cym testowanie jest xUnit
44
[10], [33], dosy szeroko stosowany, zwłaszcza w metodykach lekkich.
Nacisk kładziony na testowanie jednostkowe mo e by zró nicowany w zale no ci od
przyj tego procesu wytwarzania oprogramowania. W metodykach lekkich jest to czynno
o kluczowym znaczeniu dla powodzenia przedsi wzi cia.
45
Najbardziej znanym przykładem metodyki lekkiej jest XP. W tej metodyce, przed
przyst pieniem do kodowania, przygotowuje si przypadki testowe. Dzi ki temu system jest
w pełni zrozumiały dla programistów, czego efektem jest wykonanie prostszej implementacji.
Dodatkowo wymaga si dokonywania automatyzacji wszystkich testów, co z kolei
podyktowane jest wykonywaniem cz stych integracji (ka da integracja systemu ko czy si
wykonaniem wszystkich istniej cych testów) oraz licznych refaktoryzacji.
46
Dzi ki takiemu
42
Ang. magnifying branches.
43
Dotyczy takich zagadnie , jak np. fizyczne rozmieszczenie elementów w pami ci, szczegóły organizacji
i konwersji ró nych typów danych, predykaty u yte w instrukcjach steruj cych itp.
44
Nazwa xUnit okre la rodzin aplikacji testowych dla ró nych rodowisk programistycznych: np. dla Javy jest
to JUnit, dla C++ – CppUnit, dla PHP – PhpUnit, dla Perla – PerlUnit, dla Smalltalk – SUnit, itd. Jej głównym
zastosowaniem jest tworzenie i wykonywanie powtarzalnych testów jednostkowych. Historycznie najwcze niej
powstał SUnit, napisany przez Kenta Becka.
45
Zob. rozdział drugi.
46
Zob. podrozdział 1.3, hasło: „Refaktoryzacja”.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
21
podej ciu udaje si utrzyma wysok jako wytwarzanego oprogramowania przez cały okres
prowadzonych nad nim prac [48].
2.4. Testowanie integracyjne
Testowanie integracyjne wykonuje si dla grupy co najmniej dwu jednostek
poł czonych ze sob i realizuj cych wspólnie jak bardziej zło on funkcj . Sprawdzaniu
podlegaj dwa aspekty tej grupy: interfejs ł cz cy jej elementy i wspólnie realizowana
funkcja. Dobór przypadków testowych i kryterium zako czenia testu s w zasadzie takie, jak
w testowaniu jednostkowym. Lokalizacja i eliminacja bł dów wymaga dobrej znajomo ci
struktury oraz do wiadcze zebranych w trakcie dotychczasowej integracji grupy, dlatego
znajduj tu zastosowanie metody „białej skrzynki”, metody strukturalne.
Ł czenie jednostek w wi ksz cało podlega pewnej strategii integracji. Mo na
wyró ni dwa typy strategii: przyrostowe i skokowe. Strategia przyrostowa polega na tym, e
do tworzonej cało ci doł cza si za ka dym razem tylko jedn przetestowan jednostk ;
strategia skokowa za polega na równoczesnym poł czeniu wszystkich lub wi kszej ilo ci
wybranych jednostek.
Wi cej na temat tych strategii oraz ró nych podej , jakie si w nich stosuje mo na
znale w literaturze [12].
2.5. Testowanie systemowe
Dzi ki czynno ciom testowania systemowego mo na okre li , czy wszystkie poł czone
komponenty systemu współpracuj ze sob tak, e działaj cy system jako cało jest zgodny
ze specyfikacj .
Testowaniu podlega funkcjonalno systemu z punktu widzenia interakcji
z u ytkownikiem i rodowiskiem. Testowanie systemowe nie mo e by zaliczone, je li oka e
si , e system nie realizuje w pełni swoich okre lonych funkcji. Przypadki testowe oraz
szczegóły wykonywania czynno ci testowych zale od wymaga u ytkowych, specyfikacji
systemu i jego konkretnych zastosowa .
W [12] wyró nia si kilka kategorii testowania systemowego, m.in.: testy u yteczno ci,
testy pami ci, testy instalacji, testy niezawodno ciowe i inne.
2.6. Testowanie akceptacyjne
Testowanie akceptacyjne po swoim zako czeniu powinno wykaza , e zostały
spełnione kryteria akceptacji, okre laj ce wszystkie funkcjonalne i pozafunkcjonalne
własno ci produktu. Istotnie ró ni si od testowania systemowego tym, e bardziej jest to
demonstracja systemu, a nie jego badanie. Mo na wyró ni dwa rodzaje testowania
akceptacyjnego: akceptacja fazowa i ostateczna [12].
Akceptacja fazowa ma na celu wykazanie cz ciowej realizacji wymaga , zakłada
cz sty kontakt z odbiorc systemu, aby móc na bie co kontrolowa , czy prace nad projektem
posuwaj si w kierunku zgodnym z jego oczekiwaniami.
Akceptacja ostateczna jest potwierdzeniem wywi zania si twórcy systemu z kontraktu
z klientem. Jest to czynno jednorazowa, zako czona formaln akceptacj produktu przez
klienta.
Podobnie, jak testowanie jednostkowe, testowanie akceptacyjne jest wa nym aspektem
metodyk lekkich, w tym programowania ekstremalnego. W metodyce XP wypracowano kilka

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
22
postulatów, których spełnienie umo liwia w bardzo szybki i efektywny sposób wykonywa
ten rodzaj testów [10].
Odbiorca systemu, dzi ki swojej aktywnej roli, mo e w pełni kontrolowa przebieg prac
projektowych. Mo e tak e uczestniczy w podejmowaniu decyzji podczas tworzenia
i wykonywania testów akceptacyjnych. Ponadto równie d y si do tego, aby nowe wydania
systemu pojawiały si na tyle cz sto (w odst pach 1–2 miesi cznych), aby klient miał szans
lepszego poznania własnych potrzeb i wcze niej mógł skorygowa swoje wymagania [10].

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
23
3. TESTOWANIE KODU DLA ZAPEWNIENIA NIEZAWODNO CI
OPROGRAMOWANIA
3.1. Wprowadzenie
W rozdziale drugim zostały wyja nione ró ne metody testowania oprogramowania,
których u ywa si w poszczególnych fazach procesu wytwarzania.
W tym rozdziale omówiony zostanie wpływ, jaki ma etap testowania na niezawodno
oprogramowania. Wpływ ten mo e by wi kszy lub mniejszy, a zale y przede wszystkim od
decyzji zespołu projektowego, który na podstawie wyników testowania oprogramowania
podejmuje okre lone kroki naprawcze w celu wyeliminowania znalezionych bł dów.
Wykonywanie aktywno ci testowych nie stanowi bowiem celu i warto ci samo dla siebie, ale
okazuje si bardzo istotne po odpowiednim wykorzystaniu.
Skoro za testowanie ma wpływ na niezawodno , to ma równie wpływ na jako
oprogramowania, poniewa niezawodno jest elementem jako ci produktu informatycznego
[28], [29].
Norma IEEE 610.12-1990 definiuje niezawodno oprogramowania jako zdolno
systemu lub komponentu do wykonywania okre lonych funkcji w okre lonych warunkach i
w okre lonym czasie.
Podstawow miar niezawodno ci obiektu w przedziale czasu
[ ]
t
,
0 jest
prawdopodobie stwo [5]:
)
(
)
(
t
T
P
t
R
≥
=
,
0
≥
t
(3.1)
nazywane krótko niezawodno ci obiektu. R jako funkcja czasu t bywa te nazywana
funkcj niezawodno ci.
Funkcja, która dla ka dego ustalonego
0
≥
t
przyjmuje warto prawdopodobie stwa,
e obiekt w chwili t jest uszkodzony:
( )
t
R
t
T
P
t
F
−
=
<
=
1
)
(
)
(
(3.2)
nosi nazw funkcji zawodno ci. Rozszerzenie funkcji zawodno ci na cał prost
(
)
∞
∞
− , przez przyj cie
0
)
(
=
t
F
dla
0
<
t
jest dystrybuant zmiennej losowej T.
Je eli funkcja niezawodno ci jest absolutnie ci gła, to mo na j przedstawi w postaci:
( )
( )
du
u
f
t
R
t
∞
=
,
0
≥
t
(3.3)
Funkcja f spełniaj ca warunek (3.3.) nazywa si g sto ci prawdopodobie stwa. We
wszystkich punktach ci gło ci g sto prawdopodobie stwa mo e by wyra ona jako
pochodna:
( )
( )
[ ]
( )
[ ]
t
R
dt
d
t
F
dt
d
t
f
−
=
=
(3.4)
Je li istnieje g sto prawdopodobie stwa, to mo na okre li czwart kolejn
charakterystyk funkcyjn czasu zdatno ci, jak jest intensywno uszkodze :

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
24
( )
( )
[
]
( )
( )
t
R
t
f
t
R
dt
d
t
=
−
=
ln
λ
(3.5)
Korzystaj c ze wzoru Taylora otrzymuje si nast puj ce przybli enie:
( )
( ) (
)
t
t
t
R
t
R
t
f
∆
∆
+
−
≈
(3.6)
oraz:
( ) ( ) (
)
( )
t
t
R
t
t
R
t
R
t
∆
∆
+
−
≈
λ
(3.7)
Ze wzoru (3.6) wynika, e g sto prawdopodobie stwa mo na interpretowa jako
spadek niezawodno ci w małym przedziale czasowym o długo ci t, a z (3.7) wynika, e
intensywno uszkodze to wzgl dny spadek niezawodno ci w takim przedziale. W populacji
obiektów na tyle licznej, aby mo na zało y funkcjonowanie prawa wielkich liczb ze wzoru
(3.6) wynika, jaka cz
obiektów ulegnie uszkodzeniu w przedziale czasowym t gdy jako
podstaw przyjmie si liczb wszystkich zdatnych obiektów na pocz tku
(
)
0
=
t
, natomiast
z (3.7) mo na okre li t cz
w stosunku do obiektów zdatnych w chwili t. Typowy
przebieg funkcji dla systemów technicznych i informatycznych przedstawiaj rysunki 3.1
i 3.2.
U ywa si równie tzw. funkcji wiod cej:
( )
( )
[ ]
( )
du
u
t
R
t
t
=
−
=
Λ
0
ln
λ
,
0
≥
t
(3.8)
któr mo na interpretowa jako informuj c o wyczerpywaniu si „zapasu
niezawodno ci” obiektu.
Ka d z wymienionych pi ciu funkcji charakteryzuj cych czas zdatno ci obiektu mo na
wyrazi przez dowoln inn spo ród nich. Uprzywilejowan rol w opisie niezawodno ci
obiektów odgrywaj : funkcja niezawodno ci i intensywno uszkodze . Zale no ci mi dzy
charakterystykami funkcyjnymi czasu zdatno ci pozwalaj na otrzymywanie ró norakich
informacji o czasie zdatno ci obiektów technicznych z danej populacji, w drodze
matematycznego przetworzenia informacji empirycznych posiadanych lub najłatwiejszych do
uzyskania [5].
Testowanie jest podstawow czynno ci dla wyznaczania niezawodno ci systemu.
Dostarcza bowiem danych na temat testowanego oprogramowania, lub jego fragmentu. Na
podstawie tych danych mo na okre la takie charakterystyki, jak: ilo wykrytych bł dów,
rednia ilo bł dów w jednostce czasu, redni czas mi dzy awariami itp. Nast pnie na
podstawie tych charakterystyk mo na podejmowa próby okre lania przyszłego zachowania
si badanego oprogramowania. Wi cej na temat prognozowania przyszłego zachowania si
systemu b dzie mowa w rozdziale 4.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
25
3.2. Niezawodno sprz tu a niezawodno oprogramowania
Ró nice mi dzy niezawodno ci sprz tu i oprogramowania wynikaj bezpo rednio
z ró nic mi dzy samym sprz tem i oprogramowaniem. Mog mie one wpływ na zasadno
stosowania modeli niezawodno ci sprz tu do oprogramowania.
ródłem awarii w oprogramowaniu jest bł d na etapie projektowania, podczas gdy
awarie sprz towe s skutkiem fizycznego zu ycia, defektu wytworzenia lub słabej jako ci
materiału. W sytuacjach awarii sprz tu, uszkodzony element jest usuwany i zast powany
nowym o tych samych parametrach technicznych. Bł dy projektowe elementów fizycznych s
zwykle usuwane przed wdro eniem systemu technicznego.
W przypadku oprogramowania poprawia si wył cznie wadliwy komponent
i podmienia uszkodzony moduł we wszystkich kopiach programu. Proces naprawy mo e by
niedoskonały i, usuwaj c pewne bł dy, wprowadzi nowe.
Czas poprawiania oprogramowania nieprawidłowo wlicza si do czasu
mi dzyawaryjnego, poniewa zało enia modeli uwzgl dniaj czas ci głej pracy.
W przypadku sprz tu czas kalendarzowy zwykle odpowiada czasowi pracy. Dla
oprogramowania natomiast, czas mi dzyawaryjny mie ci si w czasie kalendarzowym
i cz sto nie pokrywa si z czasem pracy.
S tak e inne problemy dotycz ce poprawy oprogramowania w procesie wytwarzania.
Je li na przykład nie b dzie wykonywana cisła kontrola konfiguracji, wówczas mo e si
zdarzy tak sytuacja, e po przetestowaniu i wykazaniu bł dów poprawiona zostanie
niewła ciwa, tj. która z poprzednich wersji programu. Poprawa nie uwzgl dni wtedy
wyst puj cych w tej wersji wcze niejszych bł dów. Je li równie nie wykona si testów
regresji, oprogramowanie mo e zawiera dodatkowe bł dy. Współczynniki modeli
niezawodno ci, ogólnie rzecz bior c, nie uwzgl dniaj takich i tego typu przypadków.
Rysunki 3.1 i 3.2 przedstawiaj zale no intensywno ci uszkodze od czasu
w systemach technicznych i oprogramowaniu.
λ
wytworzenie
u ywanie
zu ycie
t
Rys. 3.1.
Zale no intensywno ci uszkodze od czasu
w systemach technicznych

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
26
Niezawodno sprz tu mo e zmienia si w pocz tkowym i ko cowym okresie pracy
urz dzenia, ilustruje to rysunek 3.1. Niezawodno oprogramowania natomiast zmniejsza si
w całym okresie ycia programu – od powstania i przetestowania, poprzez wszystkie kolejne
wersje, a do porzucenia, gdy dalszy rozwój jest nieopłacalny. Oprogramowanie nie wykazuje
zu ycia i nie ma dodatkowych bł dów z tego powodu. Uszkodzenia prowadz ce do awarii
mog mie wiele przyczyn: nieprawidłowy model logiczny, bł dne zało enia, niezrozumiałe
lub niewła ciwie okre lone wymagania, nieprawidłowy opis danych wej ciowych lub inne
jeszcze bł dy popełnione podczas wytwarzania [28]. Przyjmuje si , e rozkład awarii
oprogramowania jest malej cy podczas testowania i w miar stabilny w czasie u ywania.
Rozkład uszkodze oprogramowania pokrywa si z rozkładem bł dów przy projektowaniu
sprz tu. W wielu przypadkach bł dy w projektowaniu sprz tu i oprogramowania s
systematyczne, poniewa powoduj , e system zachowuje si nieprawidłowo, gdy pojawiaj
si pewne dane wej ciowe lub okre lone warunki otoczenia. Podczas gdy zwykłe przyczyny
awarii sprz tu trac na wa no ci [28], a zło ono zintegrowanych układów ro nie, coraz
wi ksze znaczenie maj bł dy popełniane na etapie projektowania sprz tu. Niektórzy eksperci
z dziedziny niezawodno ci twierdz , e zagadnienia niezawodno ci sprz tu i oprogramowania
upodabniaj si do siebie [9].
3.3. Normy niezawodno ci
3.3.1. Podstawowe informacje o normach
Według [35] norma jest to wszelka wypowied dotycz ca tego, co „powinno by ”,
w szczególno ci za wyra aj ca wskazanie (zalecenie, dyrektyw ) okre lonego sposobu
post powania w okre lonej sytuacji. Ka da norma wyznacza obowi zek (powinno ) takiego,
a nie innego zachowania si w danych warunkach, zwłaszcza podj cia lub zaniechania
pewnych czynno ci, w celu spowodowania stanu rzeczy uznanego za pozytywny lub
po dany ze wzgl du na przyj te warto ci, np. dobro społeczne. Wypowiedzi zaliczane do
norm zawieraj zazwyczaj tzw. zwroty normatywne, np.: „trzeba”, „powinien”, „nale y”,
„musi”. Post powanie niezgodne z norm wi e si zwykle z okre lonymi sankcjami.
Zale nie od typu tych sankcji wyró nia si 4 główne grupy norm (systemów normatywnych):
relatywne, moralne, obyczajowe i prawne. Normy jako reguły zachowania si ludzi ró nicuje
si na 2 grupy: normy techniczne – kieruj ce post powaniem w procesie opanowywania
przyrody i wytwarzania dóbr materialnych, oraz normy społeczne – reguluj ce zachowanie
si jednostki w stosunku do innych jednostek, do zbiorowo ci społecznych, np. grupy, klasy
społecznej lub całego społecze stwa oraz do siebie samej. Całokształt norm uformowanych
i uwarunkowanych społecznie i historycznie, prawnie utrwalonych i zwyczajowo przyj tych
λ
integracja
u ywanie
porzucenie
t
i testowanie
Rys. 3.2.
Zale no intensywno ci uszkodze od czasu
w oprogramowaniu

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
27
stanowi podstaw społecznej kontroli zachowania si ludzi. Szczególne znaczenie społeczne
ma norma prawna.
W powy szej definicji warto zwróci uwag na nast puj ce zdanie: „normy jako reguły
zachowania si ludzi ró nicuje si na 2 grupy: normy techniczne – kieruj ce post powaniem
w procesie opanowywania przyrody i wytwarzania dóbr materialnych”.
Normy, którym podlega proces testowania i badania niezawodno ci oprogramowania,
s to w my l tej definicji – normy techniczne. Równie w [35] definiuje si techniczn norm
jako przepis pisemny, zazwyczaj powszechnie dost pny, b d cy wynikiem normalizacji.
Zwykle dokument techniczny (norma fakultatywna, tj. dobrowolna) lub techniczno-prawny
(norma obligatoryjna, tj. obowi zuj ca), przyj ty na zasadzie konsensu (porozumienia
polegaj cego na braku stałego sprzeciwu znacz cej cz ci zainteresowanych danym
zagadnieniem stron) i zatwierdzony przez odpowiedni jednostk administracyjn lub
prawn , ustala, do powszechnego i stałego u ytku, zasady post powania lub cechy
charakterystyczne wyrobów, procesów lub usług. Zastosowanie postanowie zawartych
w normie pozwala na uzyskanie optymalnego stopnia uporz dkowania w normalizowanej
dziedzinie. Normy powinny by oparte na trwałych osi gni ciach nauki, techniki i praktyki
oraz przyczynia si do uzyskania maksymalnych korzy ci społecznych. Normy dzieli si na:
znaczeniowe (np. normy terminologiczne, normy jednostek miar), przedmiotowe (normy
wyrobu, okre laj ce wymagania, których spełnienie przez wyrób stanowi o jego
funkcjonalno ci) i czynno ciowe (normy metod bada , normy procesu, normy usługi).
Normami powszechnie dost pnymi s normy mi dzynarodowe, przyj te i zatwierdzone przez
Mi dzynarodow Organizacj Normalizacyjn (normy ISO) lub Mi dzynarodow Komisj
Elektrotechniczn (normy IEC), zalecane przez GATT jako najbardziej skuteczny rodek
zapobiegania powstawaniu barier technicznych w handlu mi dzynarodowym i stosowane
szczególnie w krajach, których krajowe organizacje normalizacyjne s członkami
odpowiednich organizacji mi dzynarodowych. Normy regionalne, stosowane w danym
regionie geograficznym, ekonomicznym lub politycznym, przyj te i zatwierdzone przez
odpowiedni regionaln organizacj normalizacyjn , tj. przez CEN, CENELEC i ETSI
(norma europejska), ARSO (African Regional Organization for Standardization), ASMO
(Arab Organization for Standardization and Metrology), COPANT (Pan-American Technical
Standards Commission) i PASC (Pacific Area Standards Congress), normy krajowe,
stosowane na terenie danego kraju. Istniej równie normy nie spełniaj ce warunku
powszechnej dost pno ci, jak normy zakładowe (normy przedsi biorstw). Charakter norm
maj równie dokumenty normatywne opracowywane przez mi dzynarodowe, regionalne lub
krajowe organizacje naukowe, techniczne i inne, np. dokumenty Komisji Kodeksu
ywno ciowego FAO/WHO. W Polsce wyst puj obecnie Polskie Normy (PN), normy
bran owe (BN), stosowane w przedsi biorstwach danej bran y (obecnie stopniowo
zast powane normami PN), oraz normy zakładowe (ZN), stosowane w jednym lub kilku
przedsi biorstwach. W normalizacyjnych systemach mi dzynarodowych oraz w wi kszo ci
systemów regionalnych i krajowych normy s dobrowolne.
Polska Norma (PN), wymieniona wy ej i zdefiniowana równie w [35] jest to krajowa
norma techniczna ustanawiana przez Polski Komitet Normalizacyjny. Jest norm dobrowoln .
Polskie Normy okre laj wymagania stawiane wyrobom lub procesom, metody bada oraz
sposoby wykonywania ró nych czynno ci, głównie w zakresie: ochrony ycia i zdrowia,
bezpiecze stwa pracy i u ytkowania wyrobów oraz ochrony mienia i rodowiska;
podstawowych cech jako ciowych wspólnych dla asortymentowych grup wyrobów (w tym
wła ciwo ci techniczno-u ytkowych paliw, energii, materiałów i surowców powszechnie
stosowanych w produkcji i obrocie handlowym); głównie parametrów, typoszeregów,
wymiarów przył czeniowych i innych danych technicznych zwi zanych z klasyfikacj
rodzajow i jako ciow oraz zamienno ci wymiarow i funkcjonaln wyrobów;

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
28
projektowania obiektów budowlanych oraz warunków ich wykonania i odbioru; dokumentacji
technicznej. Polskie Normy okre laj ponadto powszechnie u ywane poj cia, nazwy,
oznaczenia i symbole w podanych wy ej dziedzinach, a tak e metody prowadzenia
działalno ci normalizacyjnej i certyfikacyjnej. Pierwsz Polsk Norm wydano w 1925; do
1939 PN nie miały mocy prawnej, a od 1953 były zatwierdzane kolejno przez Pa stw.
Komisj Planowania Gospodarczego, Polski Komitet Normalizacyjny (od 1961), Polski
Komitet Normalizacji i Miar (od 1972), Polski Komitet Normalizacji, Miar i Jako ci (od
1979), Polski Komitet Normalizacyjny (od 1994).
3.3.2. Normy dotycz ce jako ci i niezawodno ci oprogramowania
Istnieje wiele ró nych modeli jako ci oprogramowania, ale niemal we wszystkich
modelach niezawodno jest jednym z kryteriów jako ci, jej atrybutem. Norma ISO 9126
definiuje sze charakterystyk jako ci, z których jedn jest wła nie niezawodno . Wynika
z tego, e oprogramowanie o dobrej jako ci jest produktem o wysokiej niezawodno ci [29].
Tabela 3.1 zawiera wyszczególnienie najcz ciej stosowanych norm i standardów
w ka dej fazie cyklu ycia oprogramowania.
Tab. 3.1.
Normy i standardy niezawodno ci oprogramowania
Norma
Opis
IEEE Std982.2-1988
okre la odniesienie niezawodno ci do ró nych faz cyklu ycia
oprogramowania;
IEEE 730-1998
(ang.) Standard for Software Quality Assurance Plans;
(pol.) Standard dotycz cy planów zapewnienia jako ci;
IEEE 828-1998
(ang.) Standard for Software Configuration Management Plans;
(pol.) Standard dotycz cy planów konfiguracji zarz dzania;
IEEE 829-1998
(ang.) Standard for Software Test Documentation;
(pol.) Standard dotycz cy dokumentacji testowej;
IEEE 830-1998
(ang.) Recommended Practice for Software Requirements
Specifications;
(pol.) Zalecane czynno ci podczas specyfikacji wymaga
oprogramowania;
IEEE 1008-1987
(ang.) Standard for Software Unit Testing;
(pol.) Standard dotycz cy testowania jednostkowego;
IEEE 1012-1998
(ang.) Standard for Software Verification and Validation;
(pol.) Standard dotycz cy weryfikacji i walidacji oprogramowania;
IEEE 1016-1998
(ang.) Recommended Practice for Software Design Descriptions;
(pol.) Standard dotycz cy
IEEE 1219-1998
(ang.) Standard for Software Maintenance;
(pol.) Standard dotycz cy utrzymania i piel gnacji oprogramowania;
IEEE 12207.0-1996
(ang.) Standard for Information Technology: Software life cycle
processes;
(pol.) Standard dotycz cy technologii informatycznej: procesy
w cyklu ycia oprogramowania.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
29
Standardy, jako dokumenty wydawane przez instytucje zajmuj ce si standaryzacj , s
dokumentami płatnymi. Dlatego dost p do zatwierdzonych i obowi zuj cych norm jest
ograniczony. Ka da norma, zanim zostanie zatwierdzona w swoim ostatecznym brzmieniu
bywa kilkakrotnie wydawana w postaci tzw. draftu. Draft charakteryzuje si tym, e jest
bezpłatny, natomiast nie gwarantuje całkowitej zgodno ci z norm , która na jego podstawie
b dzie wydana.
Jako przykład jednej z norm wyszczególnionych w tabeli 3.1, zostanie poni ej
dokładniej przedstawiony standard IEEE 829-1998 dotycz cy dokumentacji testowej.
Celem standardu IEEE 829-1998 dotycz cego dokumentacji testowej jest opisanie
formy i zawarto ci zbioru dokumentów testowych oprogramowania. Ustandaryzowany
dokument testowy przynosi wiele, mi dzy innymi nast puj cych, korzy ci:
•
umo liwia łatwiejsz komunikacj wewn trz i poza zespołow poprzez
wprowadzenie wspólnej płaszczyzny odniesienia;
•
definiuje kompletn list czynno ci do wykonania przy wykonywaniu
i dokumentacji testowania;
•
umo liwia ocen wykonania dokumentacji testowej;
•
zwi ksza mo liwo ci zarz dzania całym etapem testowania.
Standard IEEE 829-1998 okre la form i zawarto nast puj cego zbioru dokumentów:
1.
Plan testu – opisuje zakres, podej cie, zasoby i harmonogram aktywno ci
testowych. Okre la elementy, które podlegaj testowaniu, cechy, które b d
i nie b d testowane, zadania testowe do wykonania, personel
odpowiedzialny za ka de zadanie, wymagane szkolenie, ryzyko i inne.
2.
Projekt specyfikacji testu – okre la cechy, które maj by przetestowane
przez wyznaczone do tego testy. Identyfikuje równie przypadki testowe,
procedury testowe i kryteria zako czenia testu.
3.
Specyfikacja przypadków testowych – opisuje aktualne warto ci u ywane
jako wej cie i warto ci
dane na wyj ciu w przypadku testowym.
Przypadek testowy okre la wszystkie ograniczenia wynikowe procedur
testowych dla u ycia tego konkretnego przypadku testowego. Przypadki
testowe s odseparowane od projektu testu, aby umo liwi ich ponowne
wykorzystanie.
4.
Specyfikacja procedur testowych – opisuje kroki wymagane przy
obsłudze systemu oraz aktywno ci przypadków testowych
eby
zaimplementowa zwi zany z nimi projekt testu. Procedury testowe s
oddzielone od projektu specyfikacji testów, poniewa s przeznaczone do
wykonywania krok po kroku.
5.
Log testowy – jest wykorzystywany do zapisywania efektów
wyst puj cych podczas testowania, takich jak np. znalezione bł dy.
6.
Raport incydentów – opisuje ka de zdarzenie, jakie miało miejsce podczas
testowania, wymagaj ce dalszego post powania. W raportach zaznacza si
takie zdarzenia, jak defekty czy dania naprawy.
7.
Podsumowanie testu – podsumowuje aktywno ci testowe zwi zane z jedn
lub wi cej specyfikacj testu.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
30
Jak ju było wspomniane w punkcie 3.3.1, oprócz norm i standardów
mi dzynarodowych istniej równie normy krajowe. Jednym ze standardów krajowych
dotycz cych zagadnie testowania jest standard brytyjski BS 7925-2. Standard ten definiuje
generyczny proces testowania, jak równie techniki projektowania przypadków testowych
i miary pokrycia przy testowaniu komponentów. Wi cej na temat tej normy mo na znale
w dost pnych w Internecie przewodnikach po normach i standardach.
Standardy mog wpływa na popraw jako ci wytwarzanego oprogramowania. Przede
wszystkim okre laj reguły, których spełnienie prowadzi do powstawania produktu zgodnego
z normami i specyfikacj danego systemu. Standardy wymagaj od wytwórców stosowania
procesów udokumentowanych, formalnych, rygorystycznych, narzuconych i powtarzalnych.
Takie podej cie na pewno wi e si z podj ciem dodatkowych czynno ci, np. cisłego
dokumentowania prac. S jednak systemy, których wytwarzanie nie mo e odbywa si
z pomini ciem norm, np. projekty NASA [29].
3.4. Modele niezawodno ci oprogramowania
3.4.1. Przegl d modeli niezawodno ci oprogramowania
In ynieria
niezawodno ci
oprogramowania
wykorzystuje
model
systemu
informatycznego bazuj cy na danych testowych pochodz cych z tego systemu, aby
dostarczy pomiarów do badania niezawodno ci. Matematyczne i statystyczne funkcje
u ywane w modelowaniu niezawodno ci stosuj kilka kroków obliczeniowych. Parametry
równa wewn trz modeli estymuje si u ywaj c takich technik, jak metoda najmniejszych
kwadratów lub metoda najwi kszej wiarygodno ci [17], [28]. Nast pnie stosuje si modele,
najcz ciej w formie równa wykładniczych. Weryfikacja tego, czy dany model jest wła ciwy
dla okre lonego zbioru danych testowych mo e wymaga iteracyjnego wykonania
i przeanalizowania jego funkcji. Kolejno mo na dokona predykcji ilo ci pozostałych
uszkodze , lub czasu do nast pnej awarii, obliczaj c dla predykcji odległo ci czasowe.
Tabele 3.2 i 3.3 przedstawiaj algorytmy kilku najcz ciej stosowanych modeli
niezawodno ci oprogramowania [27]. Tabela 3.2 dotyczy modeli uwzgl dniaj cych
intensywno uszkodze . Tabela 3.3. zawiera opis modeli typu NHPP (ang. Non-homogenous
Poisson process
).
W tabeli 3.2 wykorzystuje si symbole o nast puj cych oznaczeniach:
α
– estymowany parametr g sto ci rozkładu prawdopodobie stwa;
φ
– stała okre laj ca znaczenie uszkodzenia dla całego systemu;
N
– pocz tkowa liczba uszkodze w programie;
t
i
– czas mi dzy (i
−1) a i-t awari ;
D
– pocz tkowy współczynnik cz sto ci awarii programu;
k
– parametr rozkładu prawdopodobie stwa w modelu J-M, (0
<k<1);
p
– prawdopodobie stwo usuni cia awarii;
ξ(i) = β
0
+
β
1
i lub
β
0
+
β
1
i
2
;
ω
– pocz tkowa g sto awarii w programie;
β
1
– stosunek liczby wykonanych instrukcji (bez powtórze ) do liczby wszystkich
instrukcji;
β
2
– stała rozmiaru;

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
31
β
3
(t) – liczba uszkodze naprawionych w jednostce czasu w stosunku do liczby
instrukcji;
Podobnie, jak wy ej, tabela 3.3 zawiera nast puj ce symbole:
MVF – funkcja warto ci rednich;
m(t) – spodziewana ilo bł dów wykrytych do czasu t, równa MVF;
a(t) – funkcja wyst pie bł dów, np. całkowita liczba bł dów w oprogramowaniu
wł czaj c w to wykryte bł dy w czasie t
b(t) – liczba wykrytych bł dów w stosunku do liczby wszystkich bł dów w czasie t
t
i
– czas mi dzy (i
−1) a i-t awari ;
a
– całkowita liczba awarii w programie;
c
– współczynnik kompresji testowania;
T
– redni czas do wyst pienia awarii na pocz tku testowania;
n
– całkowita liczba wyst pie awarii w ci gu całego czasu u ytkowania programu;
Modele niezawodno ci oprogramowania bazuj na dwóch rodzajach danych: na ilo ci
awarii w danym okresie czasu lub na długo ci czasu mi dzy awariami.
Modele niezawodno ci oprogramowania s ju w wi kszo ci dobrze poznane
i stosowane od lat 80-tych.
Rozkłady wykładnicze s stosowane niemal wył cznie do prognozowania
niezawodno ci sprz tu elektronicznego. Funkcja g sto ci prawdopodobie stwa zmiennej
losowej X w rozkładzie wykładniczym wyra a si wzorem:
( )
t
e
x
f
λ
λ
−
=
Ten rozkład mo e by wybrany wtedy i tylko wtedy, gdy przyjmie si zało enie stałego
współczynnika intensywno ci uszkodze
λ.
Tab. 3.2.
Modele niezawodno ci oprogramowania uwzgl dniaj ce intensywno uszkodze
Typ modelu
Funkcja g sto ci
f(t
i
)
Funkcja niezawodno ci
R(t
I
) = 1 – F(t
i
)
Intensywno
λλλλ(t
i
)
Jeli ski-Moranda φ[N−(i−1)]exp
(
−φ(N−(i−1))t
i
)
Exp(
−φ(N−i+1)t
i
)
φ[N−(i−1)]
Schick-Wolverton φ[N−(i−1)]t
i
exp
(
−(φ[N−(i−1)]t
i
2
)
/2)
Exp(
−(φ[N−(i−1)]t
i
2
)
/2)
φ[N−(i−1)]t
i
Jeli ski-Moranda
geometryczny
Dk
i
−1
exp(
−Dk
i
−1
t
i
)
Exp(
−Dk
i
−1
t
i
)
Exp(
−Dk
i
−1
)
Goel-Okumoto
φ[N−p(i−1)]exp
(
−φ[N−p(i−1)]t
i
)
Exp(
−φ[N−p(i−1)]t
i
)
φ[N−p(i−1)]
Littlewood-Verrall α[ξ(i)/(t
i
+
ξ(i)]
α
[1
/
(t
i
+
ξ(i))]
∞
{
α[ξ(i)/(s+ξ(i)]
α
t
i
[1
/(s+ξ(i))]}ds
α/(t
i
+
ξ(i))
Shooman
brak
brak
t
i
ω −[od 0 do
t
i
β
3
(s)ds]
β
1
β
2
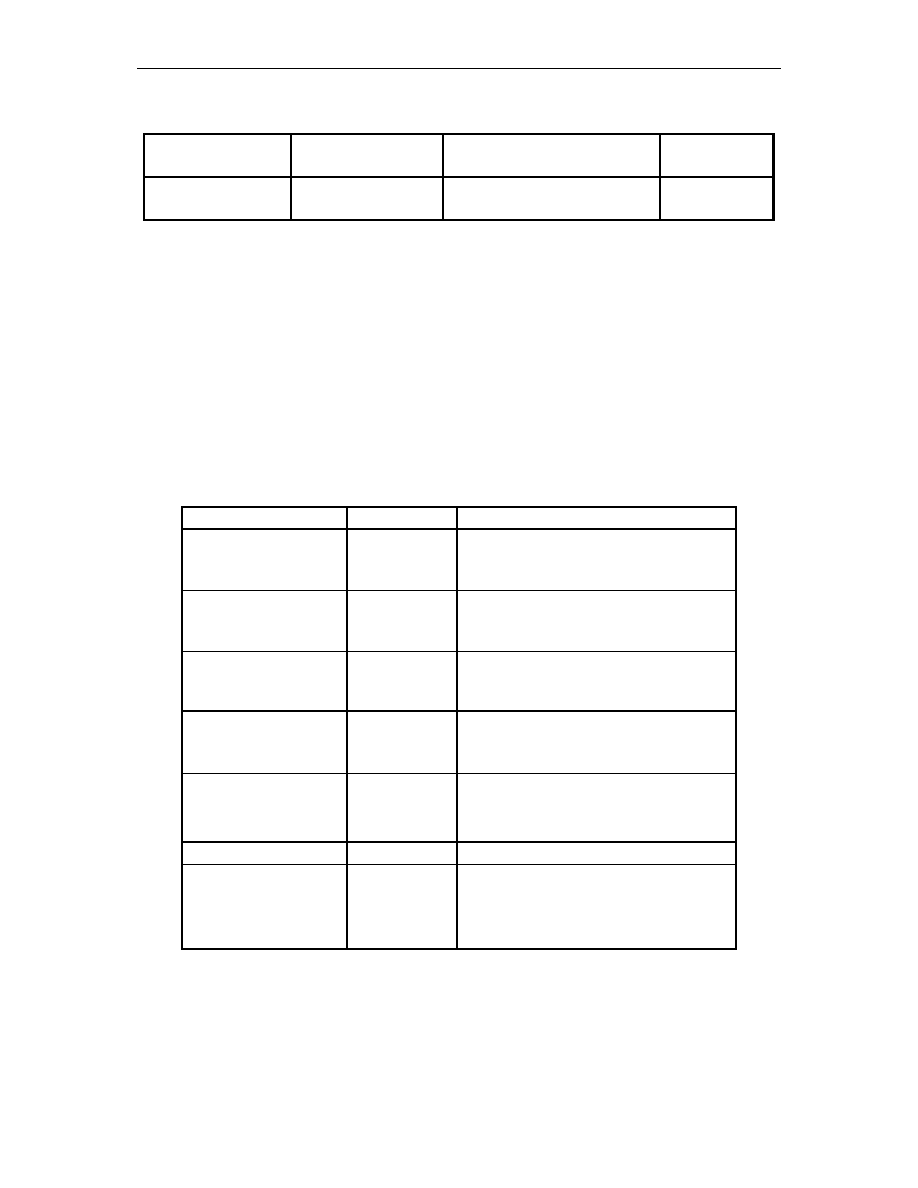
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
32
Tab. 3.2.
Modele niezawodno ci oprogramowania uwzgl dniaj ce intensywno uszkodze
Typ modelu
Funkcja g sto ci
f(t
i
)
Funkcja niezawodno ci
R(t
I
) = 1 – F(t
i
)
Intensywno
λλλλ(t
i
)
Weibull
(
β(t−γ)
β−1
/θ
β
)exp
(
−((t−γ)/θ)
β
)
Exp(
−((t−γ)/θ)
β
)
(
β(t−γ)
β−1
/θ
β
)
W ród modeli wykorzystuj cych rozkład wykładniczy s takie, jak: Musa Basic,
Jeli ski-Moranda De-eutrophication, Non-homogenous Poisson process (NHPP), Goel-
Okumoto, Schneidewind, i modele hiperwykładnicze. W przypadku tych modeli awarie
z przeszło ci nie maj wpływu na przyszł niezawodno .
Model Weibulla jest uogólnieniem dla rozkładów: gamma, lognormal, wykładniczego
lub normalnego w zale no ci od warto ci parametru
β.
Model Musy u ywa modelu logarytmicznego i zakłada zró nicowan cz sto
wyst powania bł dów. Shooman u ywa rozkładu dwumianowego, a Littlewood-Verrall
u ywa statystyk bayesowskich [24]. Dla modeli bayesowskich, istotna jest pami , tzn.
przeszłe awarie maj wpływ na obecn i przyszł cz sto awarii.
Tab. 3.3.
Modele niezawodno ci oprogramowania typu NHPP
Nazwa modelu
Typ modelu
MVF
Goel-Okumoto (G-O)
wkl sły
m(t) = a(1
−exp(−bt))
a(t) = a
b(t) = b
Schneidewind
wkl sły
m(t) = (a
/b)(1−exp(−bt))
a(t) = a
b(t) = b
Duane Growth
wkl sły lub
S-kształtny
m(t) = at
b
a(t) = a
b(t) = b
Opó niony
S-kształtny
(Yamada)
S-kształtny
m(t) = a(1
−(1+bt)exp(−bt))
a(t) = a
b(t) = b
2
t
/(1+bt)
Sztywny S-kształtny
(Ohba)
wkl sły
m(t) = a(1
−exp(−bt))/(1+βexp(−bt))
a(t) = a
b(t) = b
/(1+βexp(−bt))
Musa Basic
wkl sły
m(t) =
β
0
(1
−exp(−β
1
t))
Musa Log
wkl sły
m(t) = a(1
−exp(−ct/nT))
a = k
/Σ
i
k
=1
(1
−exp(−ct
i
/nT))
c = (1
/knT)Σ
i
k
=1
t
i
+(a/knT)Σ
i
k
=1
t
i
exp(
−ct
i
/nT)

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
33
3.4.2. Wymagania modeli niezawodno ci oprogramowania
Modele niezawodno ci oprogramowania wymagaj spełnienia pewnych zało e , aby
obliczenia wykonywane za pomoc tych modeli były wła ciwe. W tabeli 3.4 zostały
wyszczególnione zało enia dotycz ce niektórych modeli. Wyst puj ce w tej tabeli poj cie
„podstawowe zało enia” oznacza, e model wymaga nast puj cych zało e :
1. Oprogramowanie jest u ywane w podobnych warunkach do tych, w których
dokonuje si predykcji niezawodno ci.
2. Ka de uszkodzenie z danej klasy uszkodze jest wykrywane z jednakowym
prawdopodobie stwem.
3. Awarie zdarzaj si niezale nie od wykrywanych uszkodze .
Tab. 3.4.
Zało enia modeli niezawodno ci oprogramowania
Nazwa
modelu
Zało enia
Musa Basic
Wykładniczy
Stosowany
po integracji
systemu
1. Podstawowe zało enia.
2. Skumulowana liczba bł dów do czasu t, M(t), o rozkładzie Poissona
o MVC:
µ(t) = β
0
[1-exp
-(
β1t)
] gdzie
β
0
,
β
1
> 0.
µ(t) takie e spodziewana
liczba wyst pie awarii dla dowolnego odcinka czasu jest
proporcjonalna do spodziewanej liczby nie wykrytych uszkodze w tym
czasie.
3. Czas mi dzy awariami wyra ony w cyklach zegara CPU.
4. Wszystkie bł dy maj jednakowy współczynnik bł du (szkodliwo ci).
5. Pocz tkowa liczba bł dów jest sko czona.
6. Współczynnik cz sto ci bł du maleje jednostajnie po ka dym
poprawionym bł dzie, współczynnik bł du w czasie jest stały.
7. MVC: spodziewana liczba wyst pie awarii w czasie jest
proporcjonalna do liczby nie wykrytych uszkodze w tym czasie.
8. Czasy mi dzy awariami maj rozkład bliski wykładniczemu
(intensywno uszkodze jest stała).
9. Ilo ci zasobów wykorzystywanych do testowania (personel, sprz t,
czas) s stałe w odcinkach czasu obserwacji testowanego
oprogramowania.
Musa Log
Stosowany
od testowania
jednostkowego
do testowania
systemowego
1. Podstawowe zało enia.
2. Niesko czona liczba pocz tkowych bł dów.
3. Jest logarytmiczny: oczekiwana liczba awarii w czasie jest
logarytmiczn funkcj czasu.
4. NHPP. Z funkcj intensywno ci malej c wykładniczo. Wcze niej
odkryte bł dy maj wi kszy wpływ na redukcj funkcji cz sto ci awarii.
5. Z powodu 3, intensywno awarii maleje wykładniczo z oczekiwan
empiryczn liczb awarii.
6. Skumulowana liczba awarii do czasu t, m(t), ma rozkład Poissona.
7. Ka de uszkodzenie z danej klasy uszkodze jest wykrywane
z jednakowym prawdopodobie stwem
8. Awarie zdarzaj si niezale nie od wykrywanych uszkodze .
9. Współczynnik cz sto ci bł du jest stały; bł dy maj zró nicowany
współczynnik bł du (szkodliwo ci).

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
34
Ró ne modele niezawodno ci oprogramowania maj zastosowanie do danych
w odpowiedniej postaci. W tabeli 3.5 znajduje si wykaz wymaganej postaci danych
wej ciowych dla danego modelu.
Tab. 3.5.
Wymagania modeli niezawodno ci oprogramowania dotycz ce danych wej ciowych
Data
Model
Czas mi dzy awariami: x
1
, x
2
,... x
n
lub chwile czasowe wyst pie
awarii: t
1
, t
2
,.. t
n
, gdzie: x
i
= t
i
– t
(i-1)
, i =1 ,…, n, t
0
= 0.
Musa basic dla
czasu wykonania;
Musa-Okumoto
logarytmiczny.
Liczby uszkodze w ka dym okresie testowania, f
1
, f
2
,..., f
n
Schneidewind
Tabele 3.2, 3.3, 3.4 oraz 3.5 s przydatne przy wyborze modelu niezawodno ci dla
okre lonego zbioru danych testowych. Wszystkie modele s okre lone dla konkretnych typów
danych wej ciowych. S one równie przeznaczone do stosowania w okre lonych etapach
cyklu ycia oprogramowania.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
35
4. PROGNOZOWANIE NIEZAWODNO CI OPROGRAMOWANIA
4.1. Wprowadzenie
W rozdziale trzecim został omówiony wpływ etapu testowania na niezawodno
oprogramowania. Testowanie jest bowiem zestawem czynno ci, których wykonanie dostarcza
danych niezb dnych do oszacowania obecnej i przyszłej niezawodno ci oprogramowania.
Wpływ ten, jak zostało powiedziane, mo e by wi kszy lub mniejszy zale nie od decyzji
zespołu projektowego, który na podstawie wyników testowania oprogramowania podejmuje
okre lone kroki naprawcze w celu wyeliminowania znalezionych bł dów. W zwi zku z tym,
informacja na temat przyszłych wyst pie bł dów jest bardzo oczekiwana, pozwala bowiem
dokładniej zaplanowa wykonywane czynno ci naprawcze, przewidywa ich czas trwania
i przez to wymagany koszt akcji naprawczych.
W tym rozdziale omówione zostanie zagadnienie prognozowania niezawodno ci.
Prognozowanie, o którym mowa, najcz ciej bazuje na modelach rozkładu niezawodno ci
charakterystycznych dla danego oprogramowania. Prognozowa mo na równie
wykorzystuj c metody sztucznej inteligencji i o tym w wi kszo ci traktuje dalsza cz
rozdziału. W podrozdziale 4.4 przedstawiony zostanie program wyznaczaj cy charakterystyki
niezawodno ci oprogramowania na podstawie zestawu danych pochodz cych z testowania.
Program ten w swoim działaniu wykorzystuje równie metody sztucznej inteligencji,
a dokładnie sie neuronow . Wyniki działania programu b d porównane z tradycyjnymi
metodami wyznaczania charakterystyk niezawodno ci.
4.2. Metody sztucznej inteligencji w badaniu niezawodno ci
4.2.1. Zastosowania algorytmów genetycznych
Dla du ej klasy wa nych zada nie opracowano dot d dostatecznie szybkich
algorytmów ich rozwi zania. Wiele z nich to zadania optymalizacji.
Ogólnie jak kolwiek czynno do wykonania mo na przedstawi jako rozwi zywanie
zadania, co mo na z kolei rozumie jako przeszukiwanie przestrzeni mo liwych rozwi za .
Poniewa cz sto oczekuje si znale najlepsze rozwi zanie, mo na uwa a to zadanie za
proces optymalizacji. W małych przestrzeniach klasyczne metody pełnego przeszukiwania
zwykle wystarczaj . W wi kszych przestrzeniach trzeba stosowa specjalizowane metody
sztucznej inteligencji. W ród nich znajduj si algorytmy genetyczne. S to algorytmy
stochastyczne, których sposób przeszukiwania na laduje pewne procesy naturalne:
dziedziczenie genetyczne i darwinowsk walk o prze ycie.
Do opisu algorytmów genetycznych u ywa si słownictwa zapo yczonego z genetyki
naturalnej. Mówi si o osobnikach w populacji. Cz sto osobniki te s tak e nazywane
ła cuchami lub chromosomami. Chromosomy składaj si z genów (cech, znaków,
dekoderów) uszeregowanych liniowo. Ka dy gen decyduje o dziedziczno ci jednej lub kilku
cech. Geny pewnych typów s umieszczone w pewnych miejscach chromosomu, zwanych
pozycj . Jakakolwiek cecha osobnika (taka jak kolor włosów) objawia si inaczej – gen jest
w kilku stanach, zwanych allelami (warto ciami cech).
Ka dy genotyp (tutaj: pojedynczy chromosom) reprezentuje potencjalne rozwi zanie
zadania. Znaczenie poszczególnego chromosomu, tzn. jego fenotyp, jest definiowane
zewn trznie przez u ytkownika. Proces ewolucyjny zachodz cy w populacji chromosomów
odpowiada przeszukiwaniu przestrzeni poszczególnych rozwi za . Takie przeszukiwanie

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
36
wymaga pogodzenia dwóch, w sposób oczywisty sprzecznych celów: skorzystania
z najlepszych dotychczasowych rozwi za i szerokiego przebadania przeszukiwanej
przestrzeni. Metoda wzrostu jest przykładem strategii, która korzysta z najlepszego
dotychczasowego rozwi zania w celu jego poprawienia. Przeszukiwanie losowe jest
natomiast przykładem strategii, która korzysta z najlepszego dotychczasowego rozwi zania
w celu jego poprawienia. Przeszukiwanie losowe jest natomiast typowym przykładem
strategii, w której bada si przeszukiwan przestrze , nie zwracaj c uwagi na jej obiecuj ce
regiony. Algorytmy genetyczne s klas ogólniejszych metod przeszukiwania (niezale nych
od dziedziny), w których utrzymuje si mo liwie jak najlepsz równowag mi dzy szerokim
badaniem przestrzeni a korzystaniem z wcze niejszych wyników.
Algorytmy genetyczne były z powodzeniem stosowane w zadaniach optymalizacji,
takich jak wytyczanie trasy poł cze kablowych, harmonogramowanie, sterowanie
adaptacyjne, rozgrywanie gier, modelowanie poznawcze, zadania transportowe, zadanie
komiwoja era, sterowanie optymalne, optymalizacja obsługi pyta w bazie danych itp. [11],
[23].
W pracy [1] przedstawiono zastosowanie algorytmu genetycznego wspomaganego
technik symulowanego wy arzania [11], [23] do ustalenia parametrów rozkładu
niezawodno ci. Do bada został wybrany model Jeli skiego–Morandy dla zbioru danych
testowych Musa’y [1], [7]. Zbiór tych danych testowych jest przedstawiony w dodatku A.
Model Jeli skiego–Morandy (J-M) jest modelem wykładniczym,
47
co oznacza, e
system, który jest nim opisywany w momencie rozpocz cia testowania ma N uszkodze
pocz tkowych, a ka de uszkodzenie ma taki sam współczynnik intensywno ci wyst powania
λ
. Zało enia modelu (J-M) zostały wyszczególnione w nast puj cych punktach:
1. Współczynnik detekcji uszkodze jest wprost proporcjonalny do ilo ci
uszkodze znajduj cych si w danej chwili w oprogramowaniu.
2. Współczynnik detekcji uszkodze pozostaje stały w czasie pomi dzy
wyst pieniami uszkodze .
3. Uszkodzenia s naprawiane natychmiastowo, bez wprowadzania nowych
bł dów.
4. Oprogramowanie jest u ywane w podobny sposób, w jaki wykonywana jest
predykcja niezawodno ci.
5. Ka de uszkodzenie ma jednakowe prawdopodobie stwo wyst pienia
wzgl dem innych uszkodze z danej klasy.
6. Awarie podczas wyst pienia uszkodze s niezale ne.
Przyj wszy te zało enia mo na zauwa y , e zmienna
1
−
−
=
i
i
i
t
t
x
,
N
i
,...,
1
=
oznaczaj ca odst py czasowe mi dzy kolejnymi wyst pieniami uszkodze , jest niezale n
zmienn o rozkładzie wykładniczym.
Niech
( )
i
t
f
b dzie funkcj g sto ci prawdopodobie stwa dla warto ci czasu
i
t ,
wówczas:
( )
[
]
( )
[
]
(
)
i
i
i
x
i
N
i
N
t
x
f
1
exp
1
1
−
−
−
−
−
=
−
φ
φ
(4.1)
47
Zob. punkt 3.5.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
37
funkcja dystrybuanty:
( )
(
)
i
i
i
t
t
F
λ
−
−
=
exp
1
(4.2)
oraz:
( )
[
]
i
i
N
λ
φ
1
1
1
=
−
−
,
(4.3)
gdzie:
i
λ
jest współczynnikiem intensywno ci uszkodze .
Poniewa ten model wykładniczy jest typu dwumianowego, dlatego z równa
(4.2) i (4.3) wynika:
( )
( )
(
)
t
N
t
φ
µ
−
−
=
exp
1
(4.4)
( )
( )
(
)
t
N
t
φ
φ
λ
−
=
exp
(4.5)
gdzie:
( )
t
µ
jest funkcj warto ci rednich, a
( )
t
λ
jest funkcj intensywno ci uszkodze .
Jest to model o wyra nie sko czonej liczbie awarii:
( )
( )
(
)
N
t
N
t
t
t
=
−
−
=
∞
→
∞
→
φ
µ
exp
1
lim
lim
(4.6)
Estymacja modelu i predykcja niezawodno ci przedstawia si nast puj co. Maksymalne
oszacowanie prawdopodobie stwa (MOP), obliczone z poł czonej g sto ci
{ }
i
x jest
rozwi zaniem nast puj cych równa :
( )
=
=
−
−
=
N
i
i
N
i
i
x
i
x
N
N
1
1
1
ˆ
ˆ
φ
(4.7)
( )
( )
−
−
=
−
−
=
=
=
N
i
i
N
i
i
N
i
x
i
x
N
N
i
N
1
1
1
1
1
ˆ
1
ˆ
1
(4.8)
Za pomoc programu komputerowego
48
wyznaczono Nˆ z równania (4.8) a nast pnie
podstawiono do (4.7) w celu znalezienia maksymalnych warto obu estymatorów Nˆ i
φ
ˆ .
Z powy szych równa (4.7) i (4.8) mo na otrzyma ró ne miary niezawodno ci poprzez
podstawienie za Nˆ i
φ
ˆ w danej funkcji, np. redni czas do wyst pienia awarii
(
)
MTTF dla
(
)
1
+
N
uszkodzenia:
48
Algorytm został podany w pracy [1].
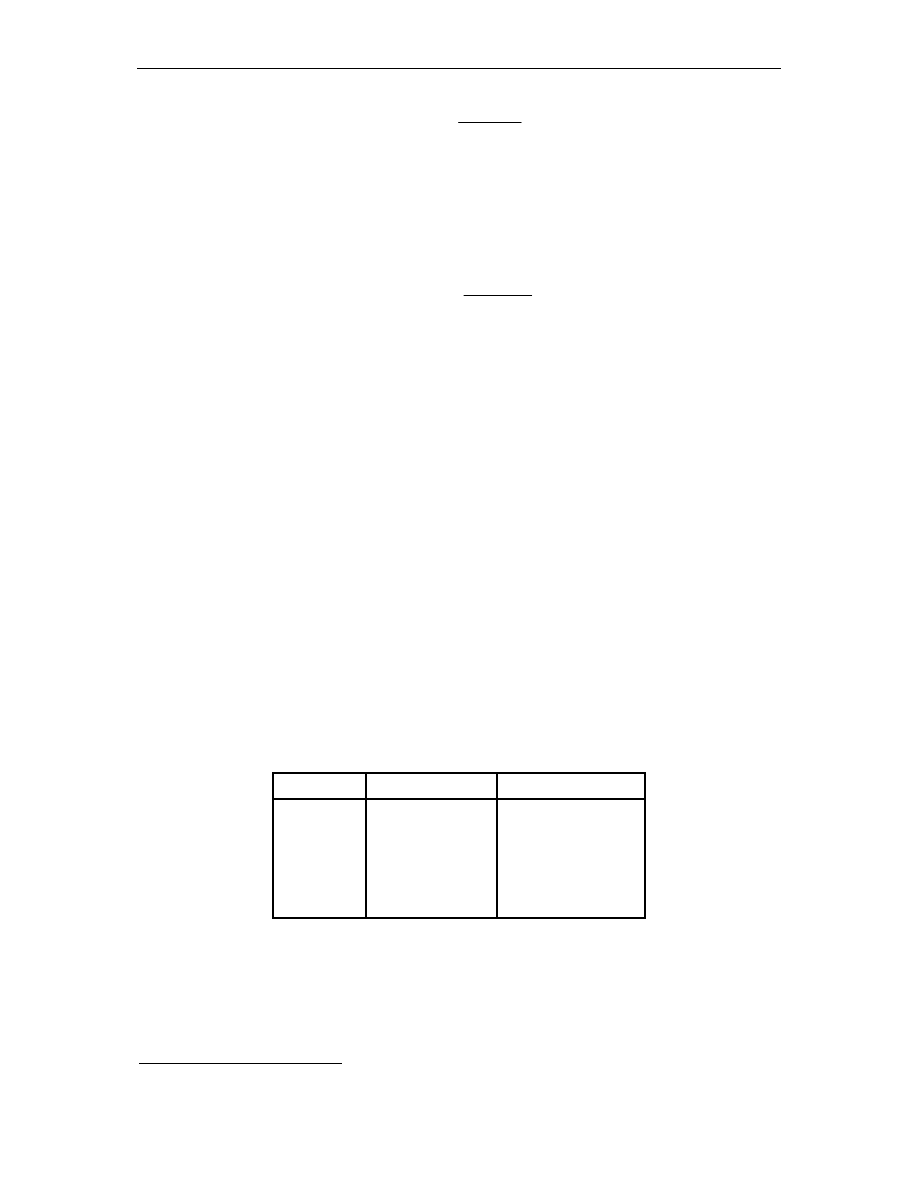
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
38
(
)
N
N
TF
T
M
−
=
ˆ
ˆ
1
ˆ
φ
(4.9)
W pracy [1] postawiono nast puj cy problem: przeprowadzi minimalizacj funkcji
(
)
MTTF . Zastosowano minimalizacj numeryczn oraz hybrydowy algorytm symulowanego
wy arzania, a konkretnie: hybrydowa technika przeszukiwania stochastycznego (HSST).
49
Minimalizacja numeryczna:
(
)
N
N
i
N
K
MTTF
i
−
+
−
=
ˆ
1
ˆ
λ
(4.10)
gdzie K jest współczynnikiem wygładzenia.
Ograniczenia minimalizacji s nast puj ce:
007
.
0
002
.
0
≤
≤
i
λ
150
35
≤
≤ N
100
1
≤
≤ i
200
ˆ
1
≤
≤ N
100
90
≤
≤ K
N
N
≥
ˆ
i
N
≥
ˆ
Szczegóły realizacji hybrydowego algorytmu genetycznego mo na znale w pracy [1].
Wyniki porównawcze przedstawiono w tabeli 4.1.
Nˆ
MTTF (model)
MTTF (HSST)
40
200
214,2
50
350
256,5
60
300
321,3
70
500
428,4
80
550
642,6
90
1100
1285,0
Liczno populacji zastosowanego algorytmu genetycznego wynosiła 40 osobników.
Algorytm pracował przez 50 iteracji (pokole ).
Analiza danych przeprowadzone za pomoc MTTF dla modelu J-M wykazała, e
poziom zaszumienia danych jest pocz tkowo niewielki, ale wzrasta do znacz cego. Algorytm
genetyczny bazuj cy na HSST wykazał dobre cechy jako narz dzie do wygładzonej estymacji
49
Ang. Hybrid Stochastic Search Technique.
Tab. 4.1.
Porównanie wyników rozwi za dla algorytmu numerycznego i genetycznego

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
39
wa nych parametrów rozkładu, takich jak
λ
,
φ
i inne. Znalezione warto ci MTTF s
dokładniejsze dla mniej zaszumionych danych. Jednak e mo na wywnioskowa , e przy
wi kszej ilo ci eksperymentów, wprowadzaj c zmienne ograniczenia współczynnika korekcji
w przedstawionym modelu J-M, by mo e uda si uzyska lepsze wygładzenie nawet
w przypadku du ego szumu. Wykresy danych oraz szczegółowe wyniki bada znajduj si
w pracy [1].
4.2.2. Zastosowania sieci neuronowych
Sztuczne sieci neuronowe, zwane w skrócie sieciami neuronowymi, stanowi
intensywnie rozwijaj c si dziedzin wiedzy stosowan w wielu obszarach nauki. Maj
wła ciwo ci po dane w wielu zastosowaniach praktycznych: stanowi uniwersalny układ
aproksymacyjny odwzorowuj cy wielowymiarowe zbiory danych, maj zdolno uogólniania
nabytej wiedzy, stanowi c pod tym wzgl dem system sztucznej inteligencji. Podstaw
działania sieci s algorytmy ucz ce, umo liwiaj ce zaprojektowanie odpowiedniej struktury
sieci i dobór parametrów tej struktury, dopasowanych do problemu podlegaj cego
rozwi zaniu.
Badania systemów nerwowych istot ywych s i nadal stanowi istotny czynnik post pu
w dziedzinie teorii systemów i ich zastosowa w praktyce. Ju w 1943 roku McCulloch i Pitts
[21] opracowali model komórki nerwowej, którego idea przetrwała lata i stanowi do dzisiaj
podstawowe ogniwo wi kszo ci u ywanych modeli. Istotnym elementem tego modelu jest
sumowanie sygnałów wej ciowych z odpowiedni wag i poddanie otrzymanej sumy
działaniu nieliniowej funkcji aktywacji. W efekcie sygnał wyj ciowy neuronu jest okre lony
w postaci:
( )
i
i
net
f
y
=
(4.11)
gdzie:
=
=
N
j
j
ij
i
x
W
net
1
(4.12)
przy czym
j
x
(
)
N
j
,...,
2
,
1
=
reprezentuj sygnały wej ciowe, a
ij
W odpowiednie
współczynniki wagowe, zwane wagami synaptycznymi lub w skrócie wagami. Przy dodatniej
warto ci waga przekazuje sygnał pobudzaj cy, przy ujemnej – gasz cy. Funkcja aktywacji
( )
f
mo e mie ró n posta ; w modelu pierwotnym McCullocha–Pittsa jest to funkcja typu
skoku jednostkowego [13], [25].
Sposoby poł czenia neuronów mi dzy sob i ich wzajemnego współdziałania
spowodowały powstanie ró nych typów sieci.
50
Ka dy typ sieci jest z kolei ci le powi zany
z odpowiedni metod doboru wag, tj. z metod uczenia.
Jednym z takich typów sieci jest sie jednokierunkowa wielowarstwowa, która
charakteryzuje si wyst powaniem co najmniej jednej warstwy ukrytej neuronów,
po rednicz cej w przekazywaniu sygnałów mi dzy w złami wej ciowymi a warstw
wyj ciow . Sygnały wej ciowe s podawane na pierwsz warstw ukryt neuronów, a te
z kolei stanowi sygnały ródłowe dla kolejnej warstwy. Rysunek 4.1 przedstawia typowy
przykład sieci jednokierunkowej dwuwarstwowej.
50
W [25] wyró nia si : sieci wielowarstwowe (takie jak sie zaimplementowana w tej pracy), sieci o radialnych
funkcjach bazowych, sieci rekurencyjne, w tym: sie Hopfielda, sie BAM, i in. oraz sieci samoorganizuj ce si .

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
40
Rys. 4.1.
Schemat dwuwarstwowej sieci jednokierunkowej
Wyst puj tu poł czenia pełne mi dzy warstwami. W szczególno ci w niektórych
zastosowaniach pewne poł czenia mi dzyneuronowe mog nie wyst powa i mówi si
wówczas o poł czeniu cz ciowym, lokalnym. Neurony warstw ukrytych stanowi bardzo
istotny element sieci, umo liwiaj cy uwzgl dnienie zwi zków mi dzy sygnałami,
wynikaj cymi z zale no ci statystycznych wy szego rz du [25].
Sie zaimplementowana w pracy jest wła nie sieci wielowarstwow z jedn warstw
ukryt . Funkcja aktywacji wyst puj ca w neuronach warstwy ukrytej i wyj ciowej jest
funkcj sigmoidaln :
( )
)
exp(
1
1
net
net
f
⋅
−
+
=
β
(4.13)
gdzie
β
jest współczynnikiem przyjmuj cym warto z przedziału
[ ]
1
,
0 , natomiast net
jest tzw. wzbudzeniem neuronu, wyra onym przez równanie (4.12). Uczenie sieci odbywa si
z wykorzystaniem algorytmu propagacji wstecznej z mechanizmem momentum. Jest to tzw.
uczenie z nauczycielem [13], [25]. Sie uczona jest za pomoc wzorców. Wzorzec ucz cy jest
to para <wej cie, wyj cie>, gdzie wej cie to pewna liczba kolejnych warto ci szeregu,
a wyj cie jest nast pn warto ci w tym szeregu. Liczba wej odpowiada ilo ci neuronów
w warstwie wej ciowej. Bł d uczenia jest to ró nica pomi dzy
danym wyj ciem,
a warto ci na wyj ciu sieci. Wielko bł du wykorzystywana jest do odpowiedniej
modyfikacji wag. Bł dy dla ka dej k-tej jednostki wyj ciowej oblicza si według
nast puj cego wzoru:
(
) ( )
k
k
k
k
net
f
o
y
'
−
=
δ
(4.14)
gdzie
k
δ
oznacza bł d dla k-tej jednostki wyj ciowej,
k
y jest danym wyj ciem, a
k
o
wyj ciem otrzymanym ze wzoru (4.13) dla k-tej jednostki wyj ciowej.
W nieco odmienny, chocia podobny sposób oblicza si bł dy dla jednostek ukrytych
[25]. Obliczone bł dy wykorzystuje si w procesie uczenia, tzn. do modyfikacji wag.
W algorytmie propagacji wstecznej dla warstwy ukrytej odbywa si to według wzoru:
w
i
w
w
j
k
kj
kj
∆
+
+
=
γ
αδ
(4.15)
gdzie
kj
w oznacza wag poł czenia mi dzy k-t jednostk w warstwie wyj ciowej a j-t
jednostk w warstwie ukrytej,
k
δ
oznacza bł d dla k-tej jednostki wyj ciowej,
α
jest
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
41
współczynnikiem uczenia,
j
i jest wyj ciem z warstwy ukrytej,
γ
jest współczynnikiem
momentum, a w
∆ to ró nica wag w poprzednim i bie cym kroku.
Analogicznie modyfikuje si wagi w warstwie ukrytej. W ten sposób sie uczy si na
podstawie krótkiej „historii” prognozowa kolejne warto ci.
Wykorzystanie momentum w algorytmie uczenia (człon
w
∆
γ
) pozwala bardziej
efektywnie przeprowadza czynno ci uczenia. Mechanizm momentum polega na
uwzgl dnianiu przy uczeniu, tj. przy modyfikacji wag, poprzednich warto ci wag, aby zmiany
miały bardziej „bezwładny” charakter. Mechanizm ten ogranicza chaotyczne poruszanie si
algorytmu po przestrzeni stanów (rozwi za ).
Badania przeprowadzone za pomoc tej sieci oraz wyniki i wnioski b d przedstawione
w dalszej cz ci, w podrozdziale 4.4.
4.3. Prognozowanie niezawodno ci
Prognozowanie niezawodno ci wi e si bezpo rednio z przewidywaniem liczby
bł dów w testowanym oprogramowaniu na podstawie bie cych danych o bł dach.
Przedstawione poni ej podej cie dotyczy danych testowych wyszczególnionych w dodatku
A (zbiór 2).
Wykres na rysunku A.2 przedstawia czasy mi dzy kolejnymi wyst pieniami bł dów
w badanym oprogramowaniu. O pionowa wykresu to unormowany (do warto ci z przedziału
[ ]
1
,
0 ) czas mi dzy kolejnymi wyst pieniami bł dów, natomiast o pozioma to kolejne
wyst pienia bł dów. Małe warto ci oznaczaj krótkie odcinki czasu mi dzy bł dami, a wi c
du cz sto bł dów i na odwrót. Na wykresie wida , e szereg czasowy jest niejednorodny.
Mo na wyznaczy co najmniej trzy przedziały, w których z osobna charakterystyka szeregu
jest podobna. Pierwszy przedział to warto ci od 1 do około 50, drugi to warto ci od około 51
do około 115 i trzeci to warto ci od około 116 do 163 (do ko ca). W ka dym przedziale
amplituda skoków warto ci jest coraz wi ksza. Szczególnie du a jest w otoczeniu punktu 147.
Słuszne zatem wydaje si przypuszczenie, e kolejne warto ci byłyby jeszcze wi ksze.
Prowadzi to do wniosku, e szereg staje si coraz bardziej chaotyczny, czyli
nieprzewidywalny. W zwi zku z tym prognoza takiego szeregu nie ma sensu.
Mo na jednak prognozowa inne charakterystyki tego szeregu po odpowiednim
dostosowaniu go do wymaga prognozy. Na pocz tku obliczony został ł czny czas, w którym
wyst piły wszystkie awarie. Nast pnie czas ten został podzielony na równe przedziały
klasowe, tzn. identycznie długo trwaj ce okresy czasu. Wybór ilo ci klas jest okre lony
zasad znan w statystyce, która mówi, e:
n
k
n
≤
≤
2
,
gdzie:
k oznacza ilo klas;
n oznacza ilo obserwacji.
Poniewa liczba wszystkich obserwacji jest równa 163 dla badanego przypadku,
otrzymuje si warunek na ilo klas:
12
7
≤
≤ k
, dla
Z
k
∈
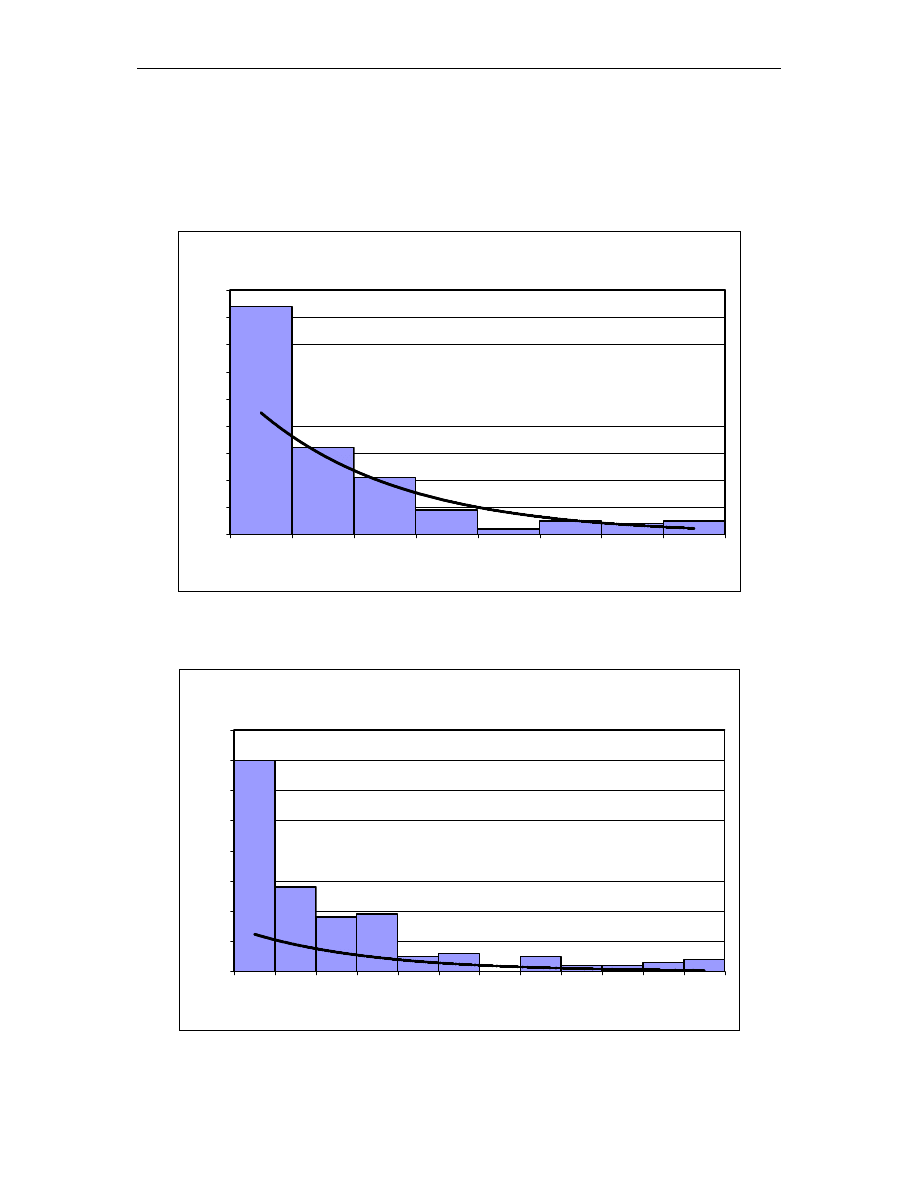
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
42
Po przejrzeniu wszystkich podziałów, do porównania wybrane zostały podziały na 8
i na 12 klas. Nast pnie dla ka dego podziału zostały wyznaczone liczby punktów szeregu,
które znalazły si w klasach. Rysunki 4.2 i 4.3 przedstawiaj wykresy liczno ci klas dla
podziału na 8 i na 12 klas. O pionowa wykresu to liczby elementów szeregu, które zostały
przydzielone do odpowiedniej klasy, natomiast o pozioma to kolejne klasy.
Podział na 8 klas
y = 68,772e
-0,428x
R
2
= 0,7103
0
10
20
30
40
50
60
70
80
90
1
2
3
4
5
6
7
8
Klasy
Li
cz
no
k
la
s
Rys. 4.2.
Liczno klas przy podziale na 8
Podział na 12 klas
y = 17,104e
-0,3281x
R
2
= 0,0632
0
10
20
30
40
50
60
70
80
1
2
3
4
5
6
7
8
9
10
11
12
Klasy
Li
cz
no
k
la
s
Rys. 4.3.
Liczno klas przy podziale na 12

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
43
Na wykresach (rys. 4.2 i rys 4.3) zaznaczone zostały tak e linie trendu (linie
pogrubione). Ponadto dla ka dego podziału obliczono nast puj ce charakterystyki ci gu klas:
dla podziału na 8 klas:
•
rednia
5
•
odchylenie standardowe
2,28
•
współczynnik zmienno ci
45,6 %
dla podziału na 12 klas:
•
rednia
3,375
•
odchylenie standardowe
1,87
•
współczynnik zmienno ci
55,3 %
Oba szeregi wykazuj du zmienno , a pod koniec stabilizuj si . Z tego powodu
powy sze charakterystyki zostały wyznaczone dla pi ciu ostatnich klas.
rednia jest redni arytmetyczn , natomiast współczynnik zmienno ci to iloraz
odchylenia standardowego przez redni . Na podstawie tych charakterystyk mo na
prognozowa kolejne warto ci. Tymi warto ciami s liczno ci nast pnych klas, czyli liczby
awarii w kolejnym okresie czasu.
Po wyznaczeniu powy szych charakterystyk prognoza jest natychmiastowa: kolejn
warto ci jest rednia. Zatem dla podziału na 8 prognoza wynosi: 5, tzn. w kolejnym odcinku
czasu o długo ci
8
1
całego czasu trwania badania, nale y si spodziewa około 5 awarii;
podobnie dla podziału na 12 kolejn warto ci b dzie: 3, tzn. w kolejnym odcinku czasu
o długo ci
12
1
całego czasu trwania badania, nale y si spodziewa około 3 awarii, poniewa
liczno jest warto ci całkowit .
Warto
2
R
oznacza procentowe dopasowanie modelu (tutaj wykładniczego) do danych
empirycznych.
2
R
dla rys. 4.2 wynosi 0,71 i oznacza dopasowanie do danych empirycznych
w 71%; dla rys. 4.3 dopasowanie jest w 6%.
W dalszej cz ci rozdziału, podj ta zostanie próba prognozy szeregu warto ci za
pomoc implementacji sieci neuronowej.
4.4. Zastosowania
W tej cz ci pracy zostan przedstawione badania przeprowadzone za pomoc
programu implementuj cego sie neuronow , opisan dokładnie w podpunkcie 4.2.2.
Program korzystaj c z prognozy sieci neuronowej wyznacza liczb awarii w kolejnych
odcinkach czasu. Badania zostały przeprowadzone na podstawie danych testowych
przedstawionych w zbiorze 2 w dodatku A.
Dokładny opis instalacji i obsługi programu znajduje si w dodatku B na ko cu pracy.
Badania obejmuj przetestowanie skuteczno ci uczenia sieci neuronowych z ró nymi
parametrami struktury i uczenia oraz wyznaczenie dla ka dego powstałego szeregu prognozy
liczby awarii w kolejnych odcinkach czasu.
Przykładowy wykres szeregu (zbiór 2 w dodatku A) po wyuczeniu sieci i wykonaniu
predykcji przedstawia rysunek 4.4.
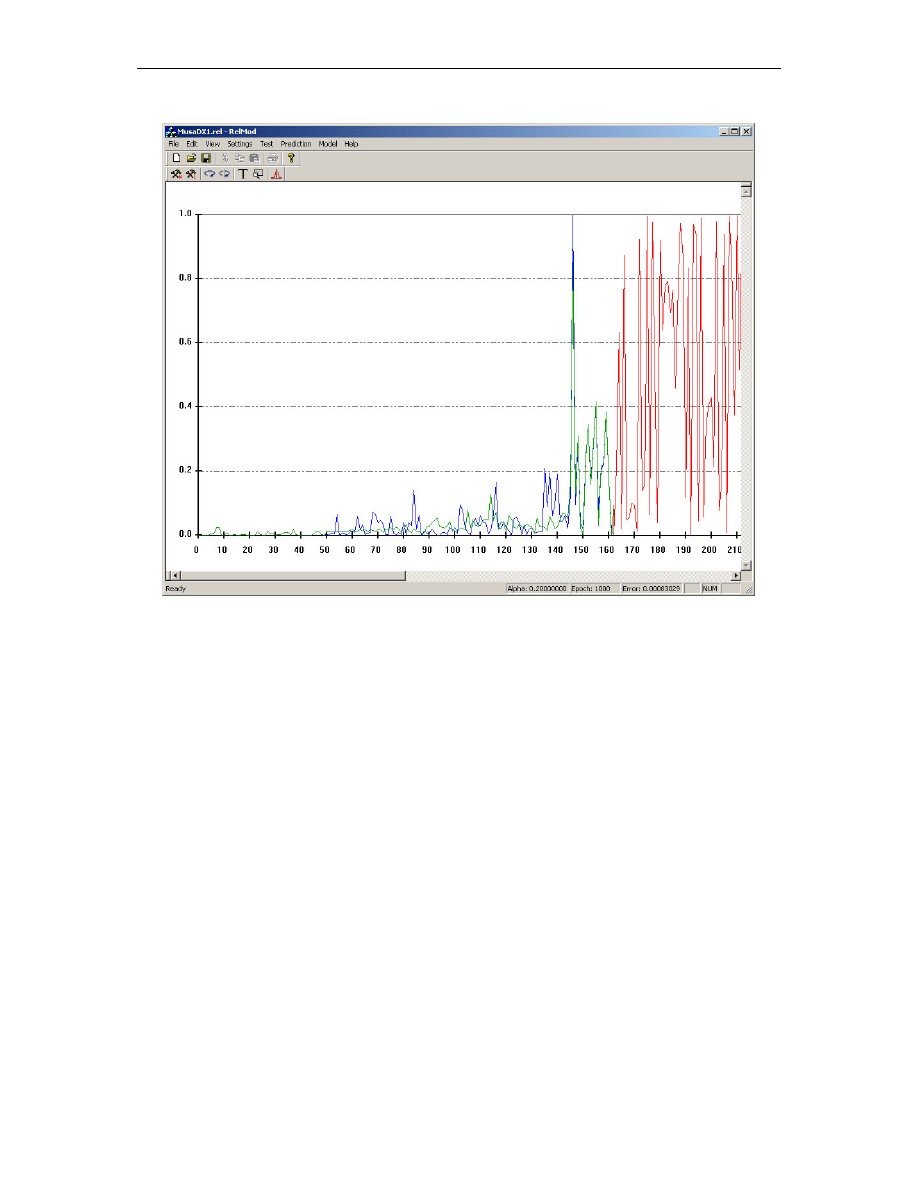
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
44
Rys. 4.4.
Okno programu z wynikami testowania i prognozy sieci po wyuczeniu
Na rysunku 4.4 przedstawione s trzy krzywe oznaczaj ce kolejno: kolor niebieski –
dane ródłowe, zielony – testowanie wyuczenia sieci i czerwony – predykcj szeregu. Sie
była uczona przez 1000 epok, a bł d wyuczenia wynosi 0,00083. Współczynnik (uczenia)
został wybrany jako stała warto równa 0.2.
Wida , e prognoza przeprowadzona przez sie neuronow (warto ci od 163 do ko ca)
oddaje charakter krzywej. Jak ju była mowa w podpunkcie 4.2.2, sie zaimplementowana
w pracy, czyli perceptron wielowarstwowy ma zdolno aproksymacji uczonych warto ci
(wzorców ucz cych), co wida w postaci krzywej prognozowanej. Zatem mo na si
spodziewa , e funkcja realizowana przez sie b dzie miała działanie u redniaj ce. Gdy
przeprowadzi si prognoz jeszcze dalej, wówczas krzywa przewidywana b dzie si stawała
coraz mniej zró nicowana, a do momentu ustalenia poziomu dla pewnej warto ci granicznej
(tutaj: około 340), gdzie nie byłoby ju adnych zmian. Ilustruje to rysunek 4.5. Wida wi c,
e nie da si z powodzeniem stosowa sieci neuronowych do predykcji długoterminowych.
Sie daje przybli one i mo liwe do zaakceptowania wyniki wył cznie dla blisko poło onych
prognozowanych warto ci (tutaj: około 100 najbli szych warto ci).
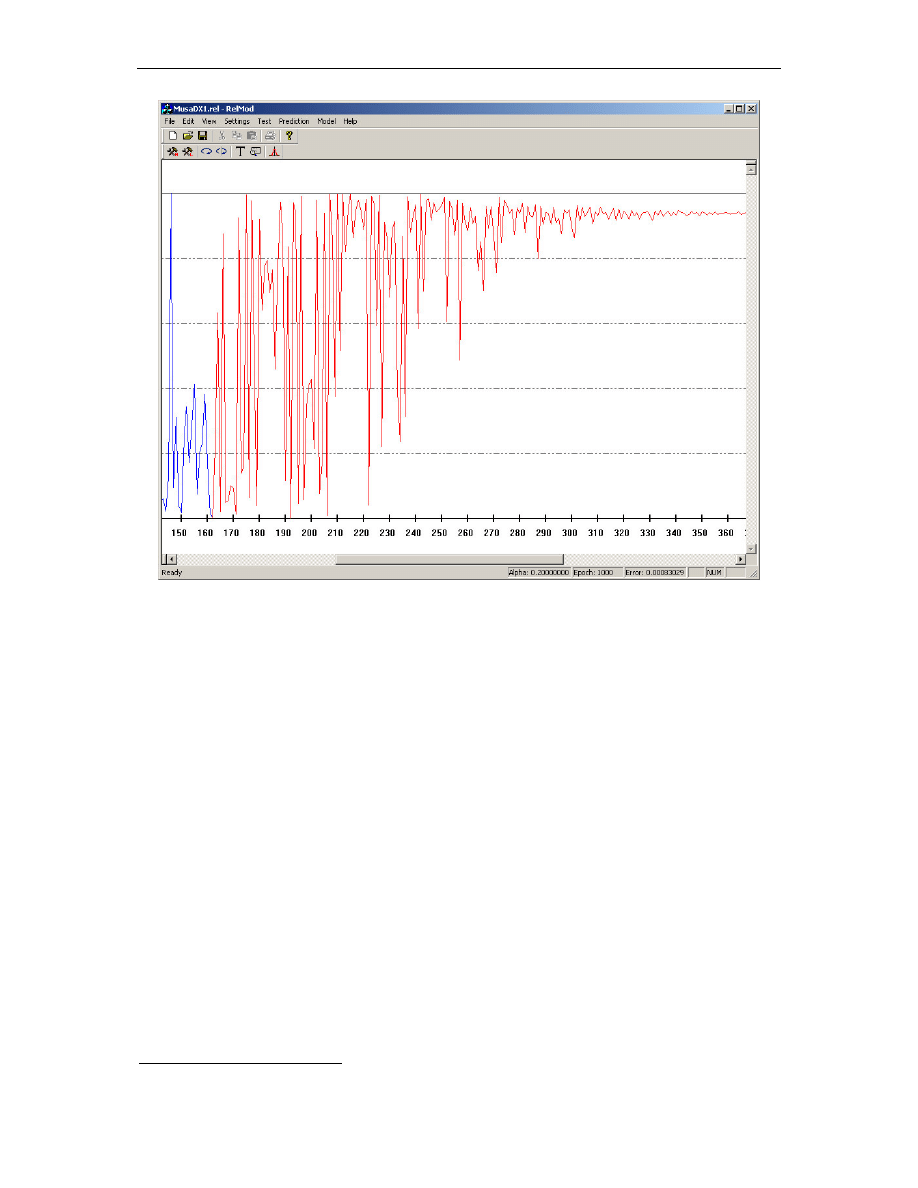
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
45
Rys. 4.5.
Ustalenie prognozy sieci dla warto ci granicznych
Mo na przypuszcza , e sie prognozowałaby z jeszcze mniejszym bł dem dla zbioru
danych o łagodniejszym przebiegu. Zastosowanie wi c tej sieci mo na by znale dla tych
samych danych, ale odpowiednio dostosowanych do jej mo liwo ci. Dostosowanie danych
mo na by uzyska poprzez wyznaczenie pewnych charakterystyk tego zbioru tak, jak to
zostało zrobione w podpunkcie 4.3. Prognozowanie na przykład krzywej przedstawiaj cej
współczynnik zmienno ci dla konkretnego podziału na klasy byłoby pod wzgl dem
mo liwo ci du o łatwiejsze dla sieci. Poziom zró nicowania takiej charakterystyki byłby
du o ni szy. Dzi ki temu sie neuronowa byłaby w stanie nauczy si przebiegu tej
łagodniejszej funkcji, aby móc j prognozowa . Mimo uproszczenia badanej funkcji, takie
podej cie wci miałoby du warto pod wzgl dem u yteczno ci w procesie wytwarzania
oprogramowania. Pozwalałoby bowiem przewidywa zró nicowanie charakterystyk badanego
rozkładu i wyznacza cz sto ci wyst powania bł dów w kolejnych klasach (w kolejnych
okresach czasu).
51
Byłoby zatem pomocne w podejmowaniu decyzji o aktywno ciach etapu
testowania, o spodziewanej wielko ci pracy do wykonania, okre lonej poprzez liczb bł dów
do wykrycia, a wi c równie o obci eniu poszczególnych członków zespołu projektowego.
Obci enie zespołu przekłada si bezpo rednio na aspekt finansowy projektu, co jest ju
bardzo znacz ce.
Wi cej na temat predykcji za pomoc sieci neuronowych mo na znale w literaturze
[7], [13], [25].
51
Por. podrozdział 4.3.
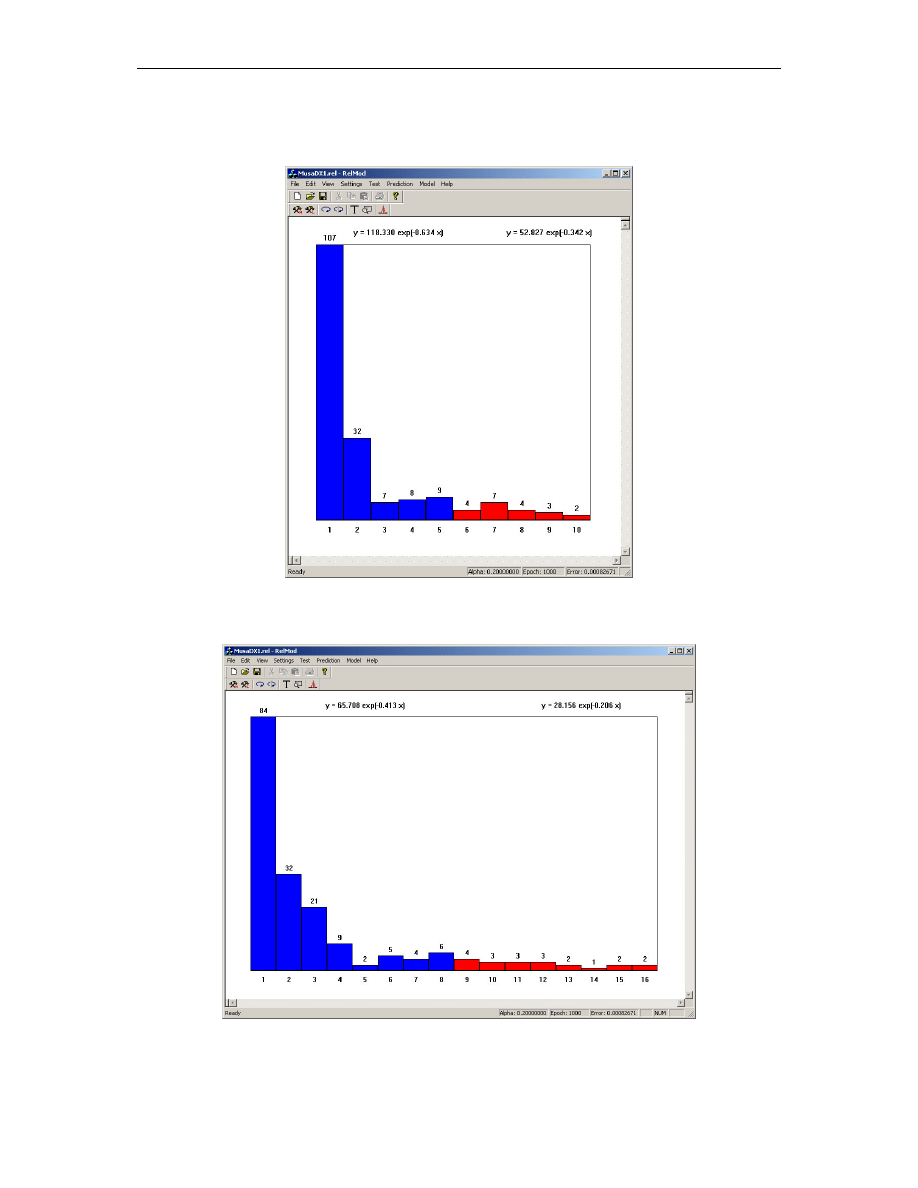
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
46
Dla szeregu przedstawionego na rys. 4.4 mo na wyznaczy prognoz liczby awarii
w kolejnych odcinkach czasu. Przedstawiaj to rysunki 4.6 i 4.7.
Rys. 4.6.
Podział okresu badanego i okresu prognozy na 5 klas
Rys. 4.7.
Podział okresu badanego i okresu prognozy na 8 klas

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
47
Kolorem niebieskim oznaczono liczby awarii w badanym okresie podzielonym na
jednakowe odcinki czasu: rys 4.6 – 5 odcinków, rys. 4.7 – 8 odcinków. Kolorem czerwonym
oznaczono liczby awarii w prognozowanym okresie, podzielonym odpowiednio na takie same
odcinki czasu. Długo okresu prognozy odpowiada długo ci okresu badanego, co
przedstawia jednakowa liczba klas obu kolorów. Przykładowo, gdyby badania ilo ci awarii
były prowadzone przez jeden miesi c, to prognoza liczby awarii byłaby na przyszły miesi c.
Ponadto na ka dym z rysunków umieszczono po dwa równania trendu wykładniczego. Ka de
równanie z lewej strony dotyczy okresu badanego, natomiast ka de prawe równanie dotyczy
całego okresu (badanego i prognozowanego). Dwa równania dotycz ce tego samego rysunku
ró ni si mi dzy sob w nieistotny sposób, tj. parametry obu równa s porównywalne, co
potwierdzałoby du y stopie zgodno ci warto ci prognozowanych z danymi oryginalnymi.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
48
ZAKO CZENIE
Cel, jaki postawiono w pracy, został zrealizowany. Udało si bowiem zaimplementowa
narz dzie, które wspomaga czynno ci prognozowania liczby awarii w kolejnych odcinkach
czasu, a przez to modelowania niezawodno ci oprogramowania na podstawie danych,
pochodz cych z testowania oprogramowania. Wytworzone narz dzie w swoim działaniu
wykorzystuje jedn z metod sztucznej inteligencji, tj. sieci neuronowe. Głównym powodem
wykorzystania do tego zagadnienia wła nie tej metody jest zdolno wielowarstwowej sieci
neuronowej (perceptronu wielowarstwowego) do aproksymacji uczonych wzorców. Wyniki,
jakie uzyskano poprzez wykorzystanie narz dzia do wspomagania badania niezawodno ci
oprogramowania pozwala przypuszcza , e sieci neuronowe wielowarstwowe stanowi dobr
metod prognozowania. Metoda ta wymaga jednak szczególnego podej cia i specjalnego
przygotowania danych wej ciowych. Badania pokazały, e pierwotna posta danych,
przedstawiaj ca kolejne odcinki czasowe mi dzy wyst pieniami awarii w oprogramowaniu
nie nadaje si do zastosowania w narz dziu opartym o mechanizm sieci neuronowych. Nie
pozwala bowiem prognozowa przyszłych wyst pie awarii w takim stopniu dokładno ci,
jaki byłby zadowalaj cy.
Podczas bada sie wykazywała swój charakter aproksymacyjny, co w tej sytuacji nie
miało zastosowania, gdy to samo mo na było uzyska korzystaj c z tradycyjnych metod
statystycznych, jak to zostało przedstawione w pracy, w podrozdziale 4.3. W zwi zku z tym
postawiono przypuszczenie, e zastosowanie sieci neuronowych w predykcji szeregów
czasowych awarii oprogramowania jest dobrym kierunkiem bada , pod warunkiem przyj cia
ogranicze na posta szeregu. Ograniczenia dotycz przede wszystkim współczynnika
zmienno ci, jaki mo na wyznaczy dla ka dego szeregu czasowego. Im wi ksza b dzie
bowiem warto współczynnika zmienno ci, tym trudniej b dzie sieci nauczy si predykcji
danego szeregu. Prace nad zastosowaniem sieci neuronowych do problemów predykcji wci
trwaj .
W rozdziale czwartym pokazano, e spo ród wybranych metod sztucznej inteligencji,
równie algorytmy genetyczne udaje si z powodzeniem wykorzystywa do wspomagania
estymacji parametrów rozkładu niezawodno ci. Zdolno ci algorytmów genetycznych do
przeszukiwania przestrzeni rozwi za zostały potwierdzone przeprowadzonymi badaniami
w podrozdziale 4.2.1.
Niezawodno oprogramowania korzysta z bogatego aparatu matematycznego, jaki
został wypracowany przy niezawodno ci systemów technicznych (hardware’owych). Aparat
ten pozwala si z powodzeniem stosowa w systemach informatycznych (software’owych).
Jednak proces modelowania niezawodno ci oprogramowania jest zadaniem trudnym
i stawiaj cym du e wyzwanie. Z jednej strony jest tak dlatego, e uszkodzenia
w oprogramowaniu maj zró nicowany charakter intensywno ci wyst pie oraz stopnia
szkodliwo ci dla cało ci systemu. Z drugiej strony metody wykorzystywane do znajdywania
i usuwania awarii s równie zró nicowane i zale ne od takich czynników jak: etap w cyklu
ycia oprogramowania, w którym znajduje si badany system, czy te po rednio zwi zanych
z tym etapem danych testowych, na których bazuje proces modelowania niezawodno ci.
Przegl d metodyk wytwarzania oprogramowania przedstawiony w rozdziale pierwszym
daje podstawy, by przypuszcza , e in ynieria oprogramowania b dzie si rozwija
w kierunku metodyk lekkich. Nie mo na jednak wnioskowa zbyt daleko, e metodyki
ci kie b d całkiem zarzucone. Metodyki ci kie od wielu lat przynosz konkretne

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
49
wymierne korzy ci w postaci udanych projektów. S ponadto wspierane komercyjnymi
rozwi zaniami przez takie firmy, jak: Rational Software Corporation czy Together Software
Corporation. Raczej nale y si spodziewa poszukiwania kompromisu mi dzy metodykami
ci kimi i lekkimi, jak to zostało pokazane w podrozdziale 1.4. Tak, jak w wielu dziedzinach
informatyki, tak samo tutaj wydajne okazuj si metody hybrydowe, które ł cz ró ne
techniki i podej cia, aby uzyska najlepsze mo liwe wyniki. Przykładem metod hybrydowych
jest proces RUP, który pozwala dostosowa si do potrzeb konkretnego projektu i wybra
optymalny proces wytwarzania oprogramowania.
W zwi zku z rozwojem metodyk lekkich zyskuje na znaczeniu technika automatyzacji
testów szeroko stosowana w tych metodykach. W tej dziedzinie wci jest wiele do zrobienia.
Mo na bowiem równie tutaj stosowa metody hybrydowe, wspomagane osi gni ciami
sztucznej inteligencji. Metody te mo na by wykorzystywa , np. do automatycznego
generowania testów na podstawie kodu, czy te obustronnego współdziałania kodu
oprogramowania i testów tak, jak to si obecnie odbywa na nowoczesnych platformach
programistycznych, gdzie wyst puje sprz enie mi dzy kodem i specyfikacj systemu.
Informatyzacja post puj ca w ka dej dziedzinie ycia powoduje i b dzie powodowa
coraz wi ksz liczb powstaj cych systemów informatycznych. Wymagania stoj ce przed
tymi systemami b d równie coraz wi ksze. Nie ominie to wymaga dotycz cych jako ci
i niezawodno ci oprogramowania. Dlatego wydaje si , e niezawodno oprogramowania jest
tak dziedzin in ynierii oprogramowania, która na wiele lat zapewnia pole do podejmowania
prac badawczych.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
50
LITERATURA
Praca powstała z wykorzystaniem nast puj cych pozycji ksi kowych i materiałów
elektronicznych:
[1] Ahuja Sona, Mishra Guru Saran, Agam Prasad Tyagi, Jelinski – Moranda Model for
Software Reliability Prediction and its G.A. based Optimised Simulation
Trajectory.
[2] Beck Kent, Test Driven Development: By Example, The Addison Wesley Signature
Series, Pearson Education, Boston 2003.
[3] Beck Kent, Wydajne programowanie – Extreme programming, Mikom, Warszawa
2001.
[4] Beck Kent, Extreme Programming Explained: Embrace Change, Longman Higher
Education, 2000.
[5] Bobrowski Dobiesław, Modele i metody matematyczne teorii niezawodno ci
w przykładach i zadaniach, WNT, Warszawa 1985.
[6] Booch Grady, Martin Robert C, Newkirk James, Object Oriented Analysis and Design
with Applications, 2d. ed., Copyright © 1998, by Addison Wesley Longman, Inc.
[7] Cai Kai-Yuan, Cai Lin, Wang Wei-Dong, Yu Zhou-Yi, Zhang David, On the neural
network approach in software reliability modeling, Elsevier 58 (2001).
[8] Cockburn Alistair, Agile Software Development: The Cooperative Game, Cockburn &
Highsmith, Series Editors, 2000.
[9] Friedman Michael A., Voas Jeffrey M., Software Assessment: Reliability, Safety,
Testability, John Wiley & Sons, Inc., 1995.
[10] Gabor Maciej, Nawrocki Jerzy, Walter Bartosz, Testowanie ekstremalne i narz dzia
xUnit, Politechnika Pozna ska, praca w ramach grantu 91-378/02-BW.
[11] Goldberg D. E., Algorytmy genetyczne i ich zastosowania, WNT, Warszawa 1995.
[12] Górski Andrzej red., In ynieria oprogramowania w projekcie informatycznym, praca
zbiorowa, wyd. II, Mikom, Warszawa 2000.
[13] Hertz John, Krogh Anders, Palmer G. Richard, Wst p do teorii oblicze neuronowych,
wyd. II, WNT, Warszawa 1995.
[14] Highsmith Jim, Helping organizations leverage IT for competitive advantage and
business success, Cutter Consortium, 2001.
[15] Jacobson Ivar, Object-oriented software engineering: A use case driven approach,
Addison-Wesley, 1992.
[16] Jaszkiewicz Andrzej, In ynieria oprogramowania, Helion, Gliwice 1997.
[17] Jó wiak Ireneusz, Zastosowanie modelu hazardów proporcjonalnych Weibulla
w badaniach niezawodno ci systemów technicznych, Wydawnictwo Politechniki
Wrocławskiej, Wrocław 1991.
[18] Kantamneni Harish V., Pillai Sanjay R., Malaiya Yashwant K., Structurally Guided
Black Box Testing, Department of Computer Science Colorado State University.
[19] Maguire Steve, Niezawodno oprogramowania, tyt. oryginału: Writing solid code:
Microsoft's techniques for developing bug-free C programs, Helion 2002.
[20] De Marco Tom, Structured analysis and systems specification, Prentice-Hall, 1979.
[21] McCulloch W. S., Pitts W. H., A logical calculus of ideas immanent in nervous activity,
Bull. Math. Biophysics, Vol. 5, 1943.
[22] McGregor John D., Testing a Software Product Line, Pittsburgh, 2001.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
51
[23] Michalewicz Zbigniew, Algorytmy genetyczne + struktury danych = programy
ewolucyjne, wyd. II, WNT, Warszawa 1999.
[24] Narkhede Dinesh D., Verma A.K., Bayesian Model for Software Reliability, Indian
Institute of Technology, Bombay 2002.
[25] Osowski Stanisław, Sieci neuronowe w uj ciu algorytmicznym, WNT, Warszawa 1996.
[26] Patton Ron, Testowanie oprogramowania, Mikom, Warszawa 2002.
[27] Pham Hoang, Software Reliability, Springer, 2000.
[28] Rosenberg Linda, Brennan Dennis, Application and Improvement of Software
Reliability Models, Software Assurance Technology Center, 2001.
[29] Rosenberg Linda, Hammer Ted, Shaw Jack, Software metrics and reliability, Software
Assurance Technology Center, 1998.
[30] Schwaber Ken, Beedle Mike, Martin Robert C., Agile Software Development with
SCRUM, Mike Beedle Prentice Hall, 2001.
[31] Szejko Stanisław, Metody wytwarzania oprogramowania, Mikom, wyd. 1, Warszawa
2002.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
52
BIBLIOGRAFIA ELEKTRONICZNA
[32] ANSI/IEEE Standard Glossary of Software Engineering Terminology, IEEE Std
610.12-1990, New York: Institute of Electrical and Electronics Engineers, Inc.,
1990.
[33] Beck Kent, JUnit Documentation.
*
[34] Materiały do wykładu: Projektowanie Systemów Informatycznych II, Wydziałowy
Zakład Informatyki, Wydział Informatyki i Zarz dzania Politechniki
Wrocławskiej.
[35] Multimedialna Nowa Encyklopedia Powszechna PWN, Wydawnictwo Naukowe PWN
S.A., Warszawa 1999.
[36] RUP XP Plug-In ®, Version 2002.05.20.10, Copyright © 2002 Object Mentor Inc.,
Rational Software Corporation.
*
[37]
http://ciclamino.dibe.unige.it/xp2000/summaries/EcksteinSummary.htm
[38]
http://www.agilealliance.com
[39]
http://www.cutter.com/consultants/
[40]
http://www.dsdm.org
[41]
http://www.industriallogic.com/
[42]
http://www.ipipan.gda.pl/~stefan/Elblag/Inzynieria/Slajdy/03-03a.pdf
[43]
http://www.martinfowler.com/articles/newMethodology.html
[44]
http://www.objectmentor.com/home
[45]
http://www.qestest.com/principl.htm
[46]
http://www.refactoring.com
[47]
http://www.xp2001.org/tutorial/cunningham.html
[48]
http://www.xprogramming.com/software.htm
[49]
http://xp.c2.com/RationalUnifiedProcess.html
*
Materiały dost pne na płycie CD doł czonej do pracy.

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
53
DODATEK A
Poni ej zostały przedstawione dane testowe, które posłu yły do wykonania bada
omówionych w rozdziale czwartym. Dane testowe pochodz z prac [1] oraz [7]. S to dwa
niezale ne szeregi czasowe reprezentuj ce wyst pienia awarii oprogramowania w czasie
testowania. W poni szym zestawieniu zostały podane w postaci oryginalnej, natomiast do
wykonywanych bada zostały dostosowane poprzez unormowanie, tzn. ka da warto
szeregu została podzielona przez maksymaln warto szeregu. Dzi ki temu, ka dy element
szeregu zawiera si w przedziale
[ ]
1
,
0 . W pracach nie podano, jakie dokładnie s to dane,
sk d pochodz i w jakich s jednostkach, jednak wydaje si , e jednostki nie maj znaczenia,
gdy dane zostan unormowane.
Zbiór 1 (z pracy [1]):
1.
3
36. 65
71. 44
106. 1247
2.
30
37. 176
72. 129
107. 943
3.
113
38. 58
73. 810
108. 700
4.
81
39. 457
74. 290
109. 875
5.
115
40. 300
75. 300
110. 245
6.
9
41. 97
76. 529
111. 729
7.
2
42. 263
77. 281
112. 1897
8.
91
43. 452
78. 160
113. 447
9.
112
44. 255
79. 828
114. 386
10. 15
45. 197
80. 1011
115. 446
11. 138
46. 193
81. 445
116. 122
12. 50
47. 6
82. 296
117. 990
13. 77
48. 79
83. 1755
118. 948
14. 24
49. 816
84. 1064
119. 1082
15. 108
50. 1351
85. 1783
120. 22
16. 88
51. 148
86. 860
121. 75
17. 670
52. 21
87. 983
122. 482
18. 120
53. 233
88. 707
123. 5509
19. 26
54. 134
89. 33
124. 100
20. 114
55. 357
90. 868
125. 10
21. 325
56. 193
91. 724
126. 1071
22. 55
57. 236
92. 2323
127. 371
23. 242
58. 31
93. 2930
128. 790
24. 68
59. 369
94. 1461
129. 6150
25. 422
60. 748
95. 843
130. 3321
26. 180
61. 0
96. 12
131. 1045
27. 10
62. 232
97. 261
132. 648
28. 1146
63. 330
98. 1800
133. 5485
29. 600
64. 365
99. 865
134. 1160
30. 15
65. 1222
100. 1435
135. 1864
31. 36
66. 543
101. 30
136. 4116
32. 4
67. 10
102. 143
33. 0
68. 16
103. 108
34. 8
69. 429
104. 0
35. 227
70. 379
105. 3110

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
54
Zbiór 2 (z pracy [7]):
1.
320
36. 41632
71. 177395
106. 44494
141. 864000
2.
1439
37. 4160
72. 214622
107. 10506
142. 202600
3.
9000
38. 82040
73. 156400
108. 177240
143. 203400
4.
2880
39. 13189
74. 16800
109. 241487
144. 277680
5.
5700
40. 3426
75. 10800
110. 143028
145. 105000
6.
21800
41. 5833
76. 267000
111. 273564
146. 580080
7.
26800
42. 640
77. 34513
112. 189391
147. 4533960
8.
113540
43. 640
78. 7680
113. 172800
148. 432000
9.
112137
44. 2880
79. 37667
114. 21600
149. 1411200
10. 660
45. 110
80. 11100
115. 64800
150. 172800
11. 2700
46. 22080
81. 187200
116. 302400
151. 86400
12. 28793
47. 60654
82. 18000
117. 752188
152. 1123200
13. 2173
48. 52163
83. 178200
118. 86400
153. 1555200
14. 7263
49. 12546
84. 144000
119. 100800
154. 777600
15. 10865
50. 784
85. 639200
120. 194400
155. 1296000
16. 4230
51. 10193
86. 86400
121. 115200
156. 1872000
17. 8460
52. 7841
87. 288000
122. 64800
157. 335600
18. 14805
53. 31365
88. 320
123. 3600
158. 921600
19. 11844
54. 24313
89. 57600
124. 230400
159. 1036800
20. 5361
55. 298890
90. 28800
125. 259200
160. 1728000
21. 6553
56. 1280
91. 18000
126. 183600
161. 777600
22. 6499
57. 22099
92. 88640
127. 3600
162. 57600
23. 3124
58. 19150
93. 43200
128. 144000
163. 17280
24. 51323
59. 2611
94. 4160
129. 14400
25. 17017
60. 39170
95. 3200
130. 86400
26. 1890
61. 55794
96. 42800
131. 110100
27. 5400
62. 42632
97. 43600
132. 28800
28. 62313
63. 267600
98. 10560
133. 43200
29. 24826
64. 87074
99. 115200
134. 57600
30. 26335
65. 149606
100. 86400
135. 48800
31. 363
66. 14400
101. 57699
136. 950400
32. 13989
67. 34560
102. 28800
137. 400400
33. 15058
68. 39600
103. 432000
138. 883800
34. 32377
69. 334395
104. 345600
139. 273600
35. 41632
70. 296015
105. 115200
140. 432000
Na podstawie tego szeregu (rys. A.2) mo na przypuszcza , e zawiera dane testowe
fragmentu lub cało ci programu istniej cego w formach o zró nicowanych stopniach
zaawansowania.
Na wykresie wida , e szereg czasowy jest niejednorodny. Mo na wyznaczy co
najmniej trzy przedziały, w których z osobna charakterystyka szeregu jest podobna. Pierwszy
przedział to warto ci od 1 do około 50, drugi to warto ci od około 51 do około 115 i trzeci to
warto ci od około 116 do 163 (do ko ca). W ka dym przedziale amplituda skoków warto ci
jest coraz wi ksza.
Małe warto ci oznaczaj krótkie odcinki czasu mi dzy bł dami, a wi c du cz sto
bł dów i na odwrót. Mo na zatem przypuszcza , e pierwsza cz
dotyczy testowania
oprogramowania w której z faz pocz tkowych, druga cz
to faza
β
, natomiast trzecia
cz
– faza
α
. St d wła nie im czas testowania jest dłu szy, tym warto ci szeregu staj si
coraz wi ksze, a tak e coraz bardziej chaotyczne.
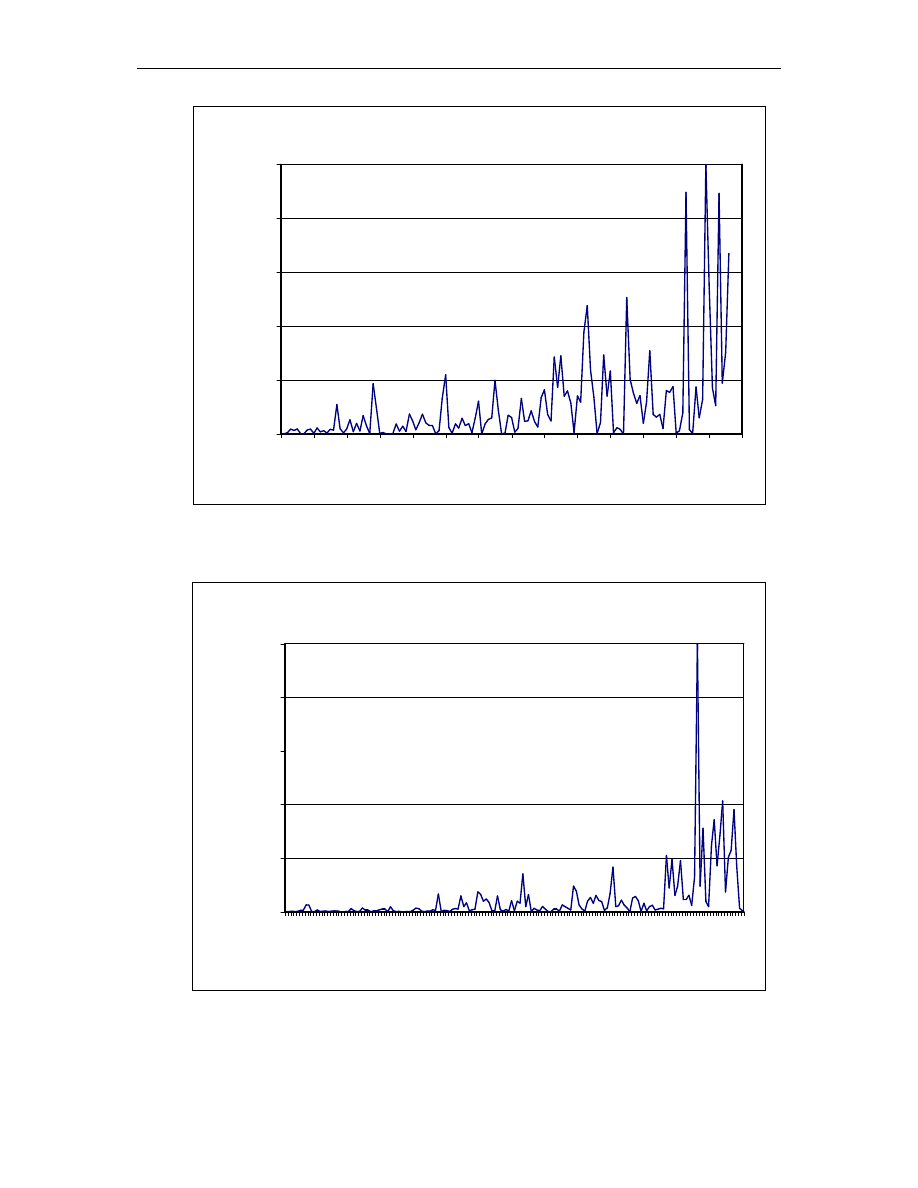
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
55
Zbiór 1
0,00
0,20
0,40
0,60
0,80
1,00
0
10
20
30
40
50
60
70
80
90
100 110 120 130 140
Odcinki czasu pomi dzy kolejnymi bł dami
U
no
rm
ow
an
y
cz
as
m
i
dz
y
bł
da
m
i
Rys. A.1.
Graficzna reprezentacja zbioru 1
Zbiór 2
0,0
0,2
0,4
0,6
0,8
1,0
1 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161
Odcinki czasu pomi dzy kolejnymi bł dami
U
no
rm
ow
an
y
cz
as
m
i
dz
y
bł
da
m
i
Rys. A.2.
Graficzna reprezentacja zbioru 2
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
56
DODATEK B
W tej cz ci pracy przedstawiony jest program RelMod, który został napisany
specjalnie do przeprowadzenia bada omówionych w podrozdziale 4.4. Nazwa programu to
skrót od angielskich słów: Reliability Modeling (modelowanie niezawodno ci).
Charakterystyka programu została przedstawiona poni ej w punktach.
•
Wymagania sprz towe i systemowe
•
komputer PC, procesor klasy Pentium z zegarem co najmniej 500 MHz (dla
zapewnienia akceptowalnej szybko ci oblicze );
•
system operacyjny Windows 2000, XP;
•
wielko pami ci na dysku (na program + pliki danych): około 3 MB;
•
wielko pami ci RAM: zgodnie z wymaganiami systemu operacyjnego
Windows 2000 lub XP;
•
Instrukcja obsługi programu
Rysunek B.1 przedstawia interfejs programu zaraz po uruchomieniu.
Rys. B.1.
Pocz tkowy interfejs programu.
Program został napisany w oparciu o architektur dokument / widok SDI (ang. single
document interface). Zostały w nim wykorzystane standardowe klasy MFC, dlatego sposób
korzystania z programu jest zbli ony do sposobu obsługi wi kszo ci aplikacji dla Windows.
Belki narz dziowe udost pniaj te same opcje, które s dost pne w menu programu, dlatego
w dalszej cz ci instrukcji dokładnie zostan omówione funkcje wył cznie przycisków na
belkach narz dziowych. Górna belka narz dziowa nie wymaga dokładnego opisu.
Najwa niejszy jest przycisk otwarcia pliku z danymi
– pozwala wczyta z pliku dane
potrzebne do dalszego działania programu. Rysunek B.2 przedstawia interfejs programu po
wczytaniu przygotowanego pliku z danymi (zbiór 2 w dodatku A):
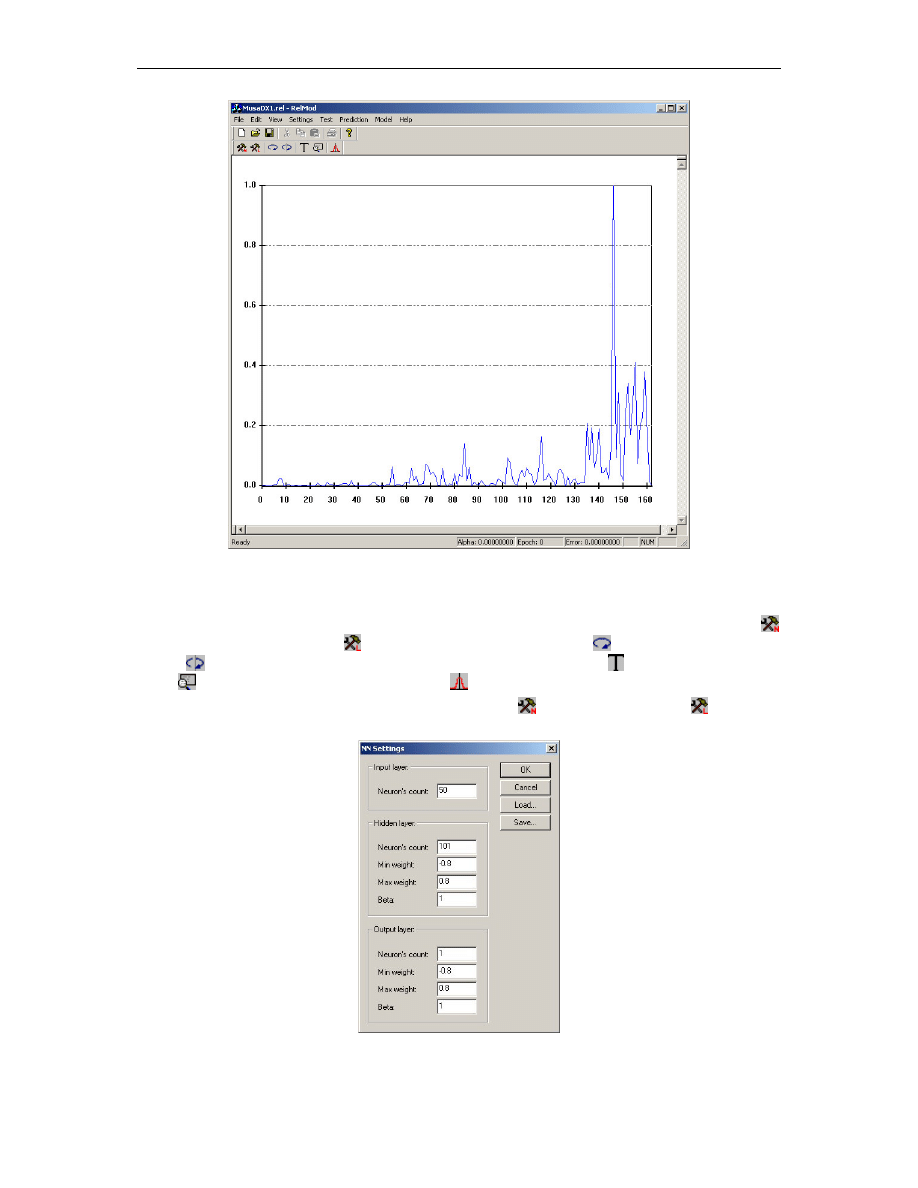
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
57
Rys. B.2.
Interfejs programu po załadowaniu danych testowych.
Druga belka narz dziowa zawiera przyciski uruchamiaj ce kolejno (od lewej):
ustawienia sieci neuronowej, ustawienia parametrów uczenia, wykonanie pojedynczej
epoki, uruchomienie uczenia sieci do spełnienia warunku stopu, testowanie wyuczenia
sieci, predykcja szeregu wyst pie awarii, wyznaczenie modelu niezawodno ci danych.
Przyciski ustawie parametrów sieci neuronowej i parametrów uczenia wywołuj
nast puj ce okna:
Rys. B.3.
Okno wprowadzania parametrów sieci neuronowej
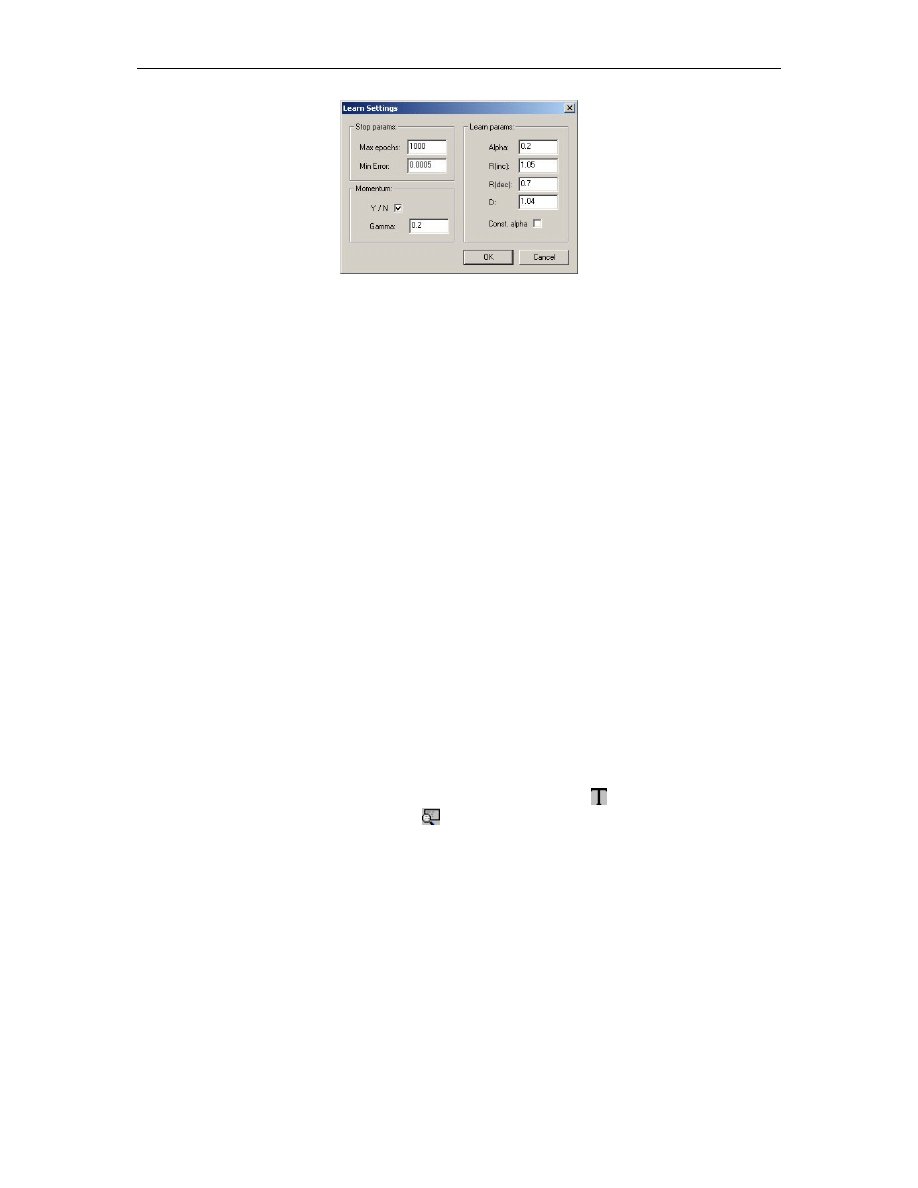
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
58
Rys. B.4.
Okno wprowadzania parametrów uczenia sieci neuronowej
Najpierw wprowadza si parametry sieci neuronowej, takie jak: liczby neuronów
w warstwach, zakres losowania wag dla ka dej warstwy oraz parametr
β
[13], [25]. Mo na
równie wczyta sie neuronow z pliku lub zapisa do pliku.
Nast pnie ustala si parametry uczenia sieci takie, jak: współczynnik uczenia,
współczynniki adaptacji parametru uczenia, współczynnik momentum oraz parametry
zatrzymania algorytmu, czyli maksymalna ilo wykonanych epok i minimalny bł d
wyuczenia [13], [25].
Adaptacja współczynnika uczenia do wyników procesu uczenia sieci polega na
zmniejszaniu warto ci współczynnika, gdy bł d wyuczenia maleje w kolejnych krokach
i zwi kszaniu, gdy bł d ro nie. Mechanizm ten, nazywany adaptacyjnym współczynnikiem
uczenia, jest dokładnie opisany w literaturze [13], [25].
Parametry struktury sieci oraz algorytmu uczenia zostały przyj te podobnie jak w pracy
[7]. Zazwyczaj liczb neuronów ukrytych przyjmuje si jako redni arytmetyczn lub
geometryczn liczby neuronów w warstwach wej ciowej i wyj ciowej. W tym jednak
przypadku, gdy w warstwie wyj ciowej znajduje si tylko jeden neuron, przyj to inn zasad
doboru ilo ci neuronów ukrytych. Jest to podwojona liczba neuronów wej ciowych plus
jeden. Zasada ta została przyj ta zgodnie z prac [7]. Algorytm uczenia zastosowany
w programie, tj. algorytm propagacji wstecznej jest bardzo cz sto u ywanym algorytmem
uczenia sieci wielowarstwowych, ze wzgl du na swoj przejrzysto i wzgl dn prostot
implementacji; jest ponadto bardzo dobrze opisany niemal we wszystkich ksi kach
dotycz cych sieci neuronowych [13], [25].
Po dłu szym uczeniu sieci, tj. po podawaniu na jej wej cie du ej liczby wzorców
ucz cych, mo na przetestowa stopie tego wyuczenia (przycisk ) oraz dokona predykcji
przyszłych warto ci szeregu (przycisk
). Predykcja warto ci polega na sukcesywnym
podawaniu na wej cie sieci ostatnich warto ci szeregu i odczytywanie z wyj cia sieci warto ci
przewidywanej. Nast pnie warto prognozowana doł cza si do szeregu jako kolejny
element. Nale y si tak przesuwa prognozuj c kolejne elementy szeregu.
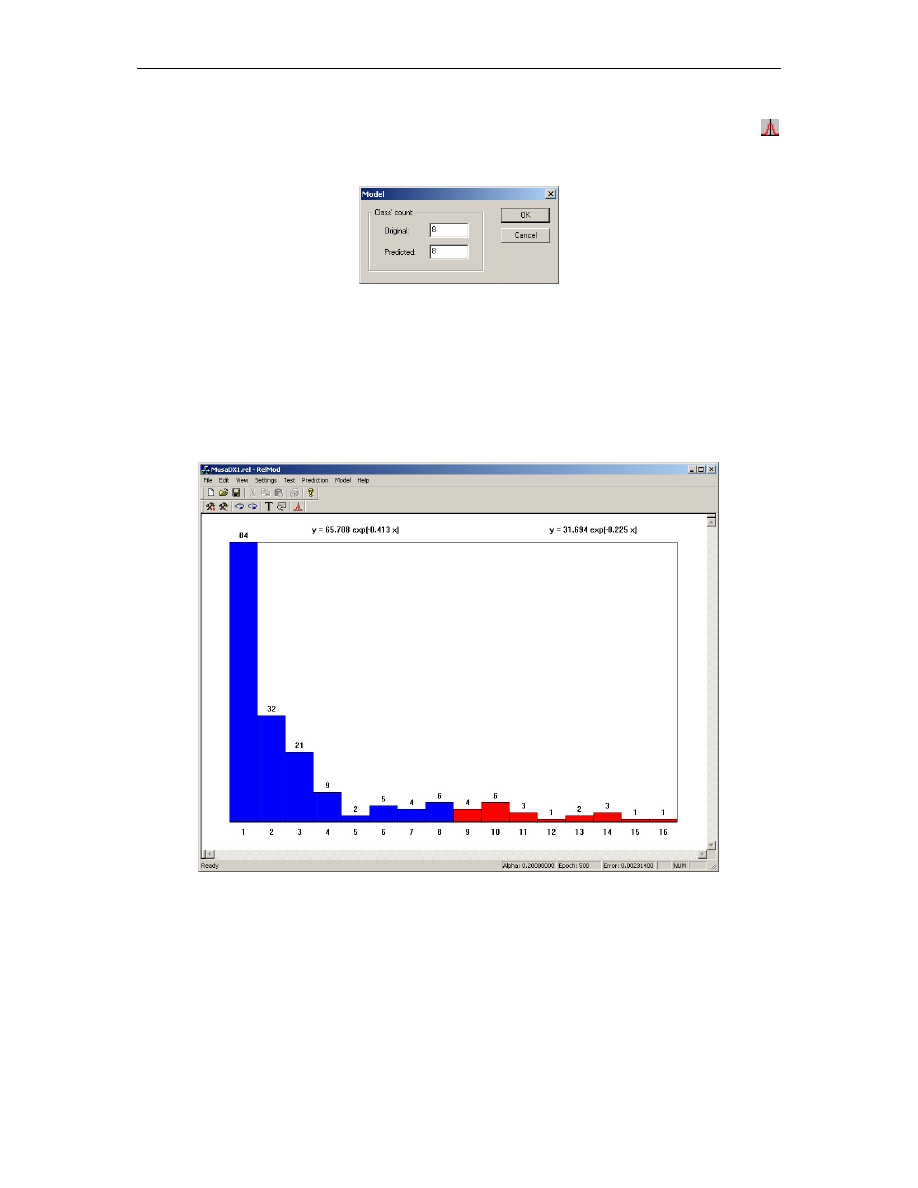
Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
59
Program pozwala tak e wyznaczy prognoz liczby awarii w kolejnych odcinkach
czasu na podstawie aktualnie wczytanych danych. Po wywołaniu tej funkcji przyciskiem
wy wietla si okno przedstawione na rysunku B.5.
Rys. B.5.
Okno wprowadzania liczby klas podziału danych
Wprowadzona warto musi si zawiera w przedziale
[ ]
50
;
2
. W pierwszym polu
wprowadza si liczb klas, na które b dzie podzielony szereg wzorcowy, natomiast w drugim
liczb klas dla szeregu wypredykowanego. Klasa oznacza jednakowy dla całego podziału
odcinek czasu. Po zatwierdzeniu wy wietla si wykres jak na rysunku B.6.
Rys. B.6.
Wykres liczno ci klas i wzór krzywej trendu
Równanie z lewej strony dotyczy okresu badanego, natomiast prawe równanie dotyczy
całego okresu (badanego i prognozowanego).

Metody testowania kodu oprogramowania. Badanie niezawodno ci oprogramowania.
60
DODATEK C
Zawarto płyty CD doł czonej do pracy:
1.
Dokument pracy magisterskiej w formacie pdf.
2.
Darmowy program Adobe Acrobat Reader w wersji 5.0.5 CE do odczytu
plików w formacie pdf.
3.
Program napisany w Visual C++ 6.0 dla systemu Windows 2000 oraz XP
(opisany w dodatku B).
4.
Niektóre materiały wykorzystane w pracy, w literaturze oznaczone
numerami: [33], [36].
Wyszukiwarka
Podobne podstrony:
głuchowski,inżynieria oprogamowania S, METODYKI I PROCESY PRODUKCJI OPROGRAMOWANIA
Metody testowania hipotez ewolucyjnych, Psychologia, biologia, ewolucyjna
Metody testowania zabezpieczen w sieciach WiFi 4TG WoDzUu
Mikrofalowka, Kuchenka mikrofalowa-metody testowania i naprawa głównych podzespołów, Kuchenka mikrof
Metody ankietowe i analiza tekstu w badaniach JOS
metody testowania, wypracowania
Metody-zad[1]. dom., Studia, Badania marketingowe, ankiety
METODY TESTOWANIA
Metody testowania hipotez ewolucyjnych, Psychologia, biologia, ewolucyjna
Metody testowania zabezpieczen w sieciach WiFi 4TG WoDzUu
Java Obsluga wyjatkow, usuwanie bledow i testowanie kodu
Java Obsluga wyjatkow usuwanie bledow i testowanie kodu javaob
Java Obsluga wyjatkow usuwanie bledow i testowanie kodu
Java Obsluga wyjatkow, usuwanie bledow i testowanie kodu
Java Obsluga wyjatkow usuwanie bledow i testowanie kodu 2
Java Obsluga wyjatkow usuwanie bledow i testowanie kodu javaob
2008 06 Java Microedition – metody integracji aplikacji [Inzynieria Oprogramowania]
więcej podobnych podstron