
04
Metodyka i Techniki Programowania
Procesy i wątki
dr inż. Rafał Stankiewicz
2008-03-10
Krótkie wprowadzenie.
Procesem jest każdy program, który został uruchomiony i jest wykonywany. Każdy proces ma odrębne niezależne
struktury danych, kodu, rejestry, stosy itd. Proces jest niezależnym bytem w systemie i może działać niezależnie od
innych procesów (z wyjątkiem sytuacji, gdy celowo zaprogramowano mechanizmy współpracy między procesami).
Wątek jest tworzony jest wewnątrz procesu i wykorzystuje jego zasoby. Dla wątku tworzone są na nowo tylko
niezbędne struktury resztę współdzieli z innymi wątkami/procesem. Przykładowo, zmiany wykonane na zmiennych
globalnych są widoczne w innych wątkach, ze wszystkimi tego skutkami.
PROCESY
Każdy proces ma swój unikalny identyfikator w systemie – PID (ang. Process identifier). Procesy w systemie UNIX
powstają poprzez mechanizm rozwidlania procesów. Każdy nowy proces jest tworzony przez inny proces. Proces
tworzący zwany jest procesem macierzystym, a proces nowy – potomnym. Dla każdego procesu można więc podać
identyfikator procesu, który go utworzył – PPID (ang. Parent PID). Więcej o rozwidlaniu procesów poniżej.
Wyświetlenie listy procesów w systemie umożliwia polecenie ps. Poszczególne opcje pozwalają na wyświetlenie
różnorodnych informacji o procesie. Szczegółowo o możliwościach polecenia ps, opcjach i wyświetlanych
informacjach można przeczytać np. w manualu (man ps).
Proces może zostać uruchomiony:
na pierwszym planie (np.: ./program), wówczas przez czas działania programu nie ma dostępu do
wiersza poleceń terminala. Proces przejmuje kontrolę nad standardowym wejściem (stdin).
w tle (np.: ./program &), wówczas proces działa niejako na drugim planie nie blokując dostępu do
terminala (można wykonywać inne polecenia, uruchamiać inne procesy).
Możliwe jest wymuszenie przerwania działania procesu w dowolnym momencie przez wysłanie do niego
odpowiedniego sygnału. Do wysyłania sygnałów służą:
komenda kill [-signal] pid
pewne kombinacje klawiszy np.: ^C – wysłanie sygnału INT (interrupt) do procesu – przerywa działanie
bieżącego procesu działającego na pierwszym planie
Działający proces może zostać zatrzymany (uśpiony) na pewien czas. Proces wówczas nie jest wykonywany (nie
jest mu przydzielany czas procesora). Zatrzymanie procesu następuje poprzez wysłanie do niego sygnału TSTP lub
STOP. Sygnał TSTP można wysłać do procesu przez naciśnięcie kombinacji klawiszy ^Z (pod warunkiem, że proces
działa na pierwszym planie).
Uśpiony proces może zostać ponownie przywrócony do działania. Można tego dokonać wysyłając do procesu sygnał
CONT. Oprócz komendy kill można też użyć jedno z dwóch poleceń:
fg – przywrócenie do działania na pierwszy plan
bg – przywrócenie do działania w tle.
Ponadto, poleceniem fg można przenieść na pierwszy plan proces działający w tle.
Użyteczne jest polecenie jobs które wyświetla listę procesów uśpionych oraz działających w tle.
Jak już wspomniano, procesy tworzone są przy pomocy tego samego mechanizmu – rozwidlania procesów
(wywołanie funkcji fork). Jeżeli proces wywoła funkcję fork, wówczas w systemie powstanie nowy proces
(potomny) będący jego kopią. Dla każdego procesu zawsze można określić, który inny proces go utworzył (z
wyjątkiem procesu init). W momencie utworzenia proces otrzymuje swój unikalny identyfikator PID przydzielony
przez system. Nie da się przewidzieć wartości PID. Proces init jest pierwszym procesem powstającym przy starcie
systemu. Jedynie proces init ma zawsze taki sam numer PID równy 1. Każdy proces dziedziczy też od swojego
rodzica jego identyfikator jako PPID.
Do uzyskania wartości PID oraz PPID procesu służą następujące funkcje języka C:
pid_t getpid();
pid_t getppid();
Do rozwidlania procesów służy funkcja:
pid_t fork();
Funkcja fork zwraca wartość zero w procesie potomnym, natomiast w procesie tworzącym (macierzystym)
zwracana jest wartość identyfikatora PID utworzonego procesu (w ten sposób proces macierzysty zna PID
swojego potomka). W przypadku, gdy nie udało się utworzyć procesu potomnego zwracana jest wartość –1.
Przykład
Przykład przedstawia mechanizm rozwidlania procesów i przydzielania identyfikatorów PID, PPID.
Załóżmy, że kod programu rower.c jest następujący (pominięto biblioteki):
main(){
int a;
a=fork();
sleep(2);
printf(”%d\n”,a);
return 0;
}
Kolejne etapy wykonania procesu wyglądają nastepująco:
./rower
PID=1202
PPID=1097
a=fork();
./rower
PID=1298
PPID=1202
a=0
a=1298
1
2
3
proces macierzysty
(parent, “rodzic”)
proces potomny
(child, “dziecko”)
sleep(2);
printf(”%d\n”,a);
return 0;
sleep(2);
printf(”%d\n”,a);
return 0;
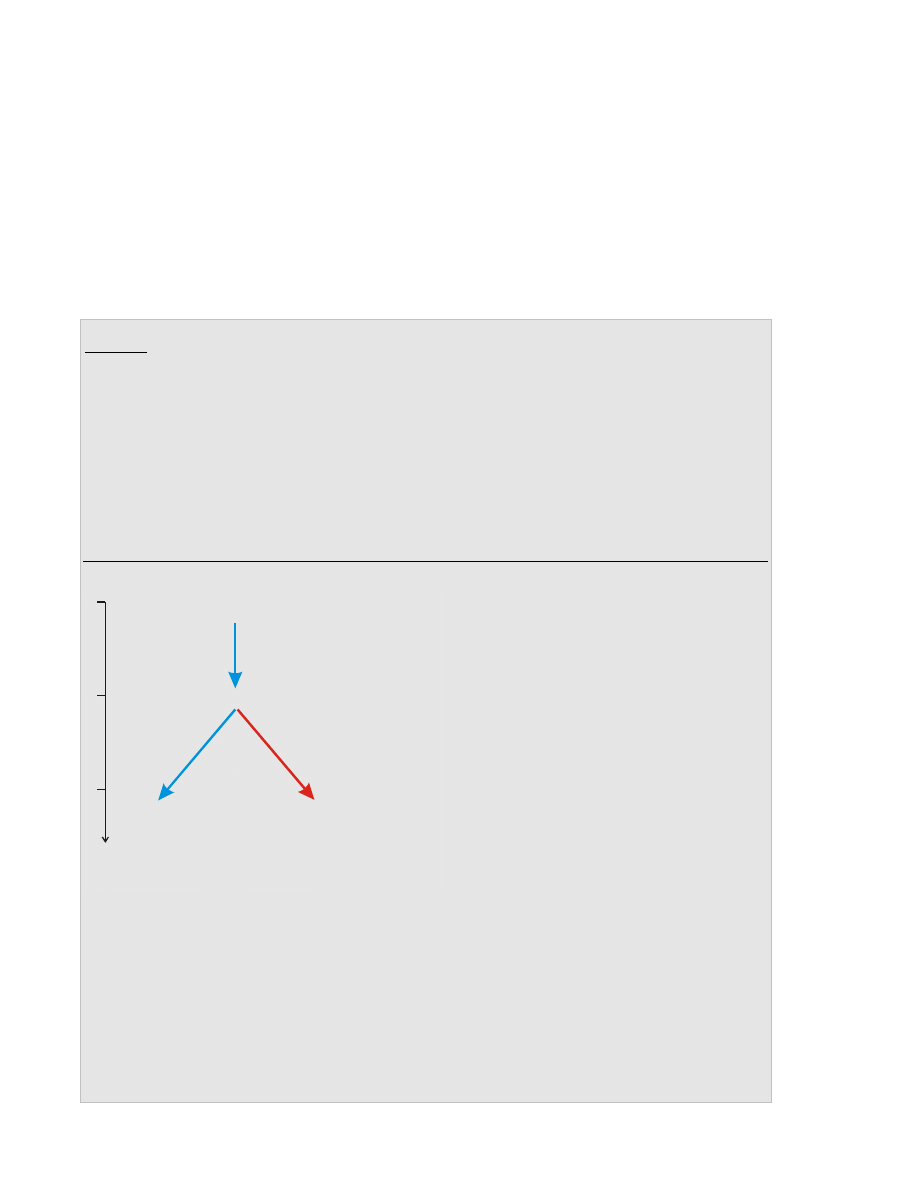
W chwili (1) uruchomiono program ./rower. Interpreter poleceń (shell) miał PID równy 1097.
Procesowi ./rower przydzielony został PID=1202, zaś jego PPID jest równy PID-owi procesu
shell’a – 1097.
W chwili (2) proces ./rower wykonał funkcję fork() i utworzył w systemie swoją nową kopię.
Nowy proces zwany jest procesem potomnym, zaś proces, który wywołał funkcję fork()
procesem macierzystym. Nowo powstałemu procesowi został przydzielony PID równy 1298. Jego
PPID jest równy PID-owi procesu macierzystego, czyli 1202.
Funkcja fork() zwróciła w procesie macierzystym wartość 1298 (PID potomka), zaś w procesie
potomnym wartość 0. Oznacza to, że w chwili (3) wartości zmiennej a w obu procesach będą
odpowiednio 1298 i 0.

Obydwa procesy mają ten sam kod i są niejako na tym samym etapie wykonywania swojego kodu.
Kolejną operacją, jaką wykonają obydwa procesy będzie funkcja sleep(2). Następnie oba procesy
wykonają funkcję printf i zakończą swoje działanie.
Mechanizm rozwidlania procesów powoduje utworzenie tylko kopii procesu, co daje ograniczone możliwości
tworzenia różnorodnych procesów. Aby było możliwe uruchamianie innych programów konieczny jest jeszcze
mechanizm podmiany kodu procesu.
Przykładowo, gdy uruchamiamy program ls, w pierwszej chwili powstaje kopia procesu naszego shell’a, której kod
jest następnie podmieniany na kod programu ls.
Każdy proces może w dowolnym momencie podmienić swój kod na inny (czyli zupełnie zmienić swoje własności i
funkcje). W momencie podmiany kodu nie zmieniają się identyfikatory procesu. Kod procesu, który „decyduje się” na
podmianę swojego kodu (oraz jego zestaw zmiennch) są bezpowrotnie tracone i zastępowane nowym kodem i
nowymi strukturami danych.
Dostępna jest rodzina funkcji w języku C służących do podmiany kodu. Jedną z nich jest funkcja
int execl(const char *path, const char *arg0, ..., const char *argn, char *
/*NULL*/);
Oczekiwanie na zakończenie procesów potomnych
Procesy macierzysty i potomny powinny kończyć swoje działanie w kolejności odwrotnej niż powstawały., tzn.
proces macierzysty nie powinien zakończyć się wcześniej niż jego procesy potomne. Jednakże jest to możliwe. Jeśliby
się tak stało, PPID w procesie potomnym utraci ważność (nie ma już procesu o takim identyfikatorze). Istnieje
niebezpieczeństwo, że zwolniony identyfikator procesu zostanie przydzielony przez system innemu procesowi.
Dlatego też „osierocony” proces zostaje przejęty przez proces init, a jego PPID ustawiony na 1. Sytuacja taka jest
jednak nienormalna (w niektórych systemach osierocone procesy nie mogą się poprawnie zakończyć i pozostają w
systemie jako tzw. procesy-duchy, zajmujące niepotrzebnie zasoby komputera).
Należy zapewnić, aby proces macierzysty poczekał na zakończenie swoich procesów potomnych i odebrał od nich
kod zakończenia procesu. W tym celu proces macierzysty powinien wywołać funkcję wait tyle razy ile utworzył
procesów potomnych. Funkcja ta ma następującą składnię:
#include <sys/types.h>
#include <sys/wait.h>
int wait(int *stat_loc);
Funkcja zwraca identyfikator zakończonego procesu potomnego lub -1 jeżeli wszystkie procesy potomne się już
zakończyły. Jedno wywołanie funkcji wait oczekuje tylko na zakończenie jednego procesu potomnego. Jeżeli nie
wiemy ile mamy procesów potomnych, należy wykonywać w pętli funkcję wait, aż do momentu, kiedy zwróci
wartość -1 (nie ma już procesów potomnych).
W zmiennej wskazywanej przez stat_loc zapisywana jest liczba szesnastkowa w postaci: XXYY, gdzie XX to kod
zakończenia procesu potomnego, zaś YY to numer sygnału, który spowodował zakończenie procesu potomnego lub
0, jeśli proces zakończył się samodzielnie.
WĄTKI
Technicznie, wątek to niezależny strumień instrukcji, który może być wykonywany jednocześnie z innym
strumieniem instrukcji danego procesu. Jest to jak gdyby „procedura”, która może zostać wykonana niezależnie od
głównego części danego procesu.
Czym jest wątek i czym różni się od procesu można zobrazować w następujący sposób:

Pojedynczy proces (bez wątków) wykonując swoją główną cześć kodu (funkcja main) może wywoływać
inne funkcje. Opuszcza wówczas wykonywanie programu głównego i „przechodzi” do wykonania kodu
wywołanej funkcji. Po skończeniu wykonywania funkcji wraca do wykonywania głównej części kodu.
Wątek można sobie wyobrazić jako wywołanie funkcji, przy czym program główny jest wykonywany
dalej, równolegle z wątkiem. Proces wywołujący wątek i sam wątek (wywołana funkcja) wykonują się
równocześnie.
Z kolei nowy proces (powstały w wyniku rozwidlania procesów) jest natomiast zupełnie niezależny od
procesu, który go utworzył. Wszystkie struktury danych, kodu, rejestry itp. ma niezależne i odrębne.
Stwarza to szereg nowych możliwości, z których najważniejsze jest tworzenie procesów o różnym kodzie
(dzięki mechanizmowi podmiany kodu).
Jak już wspomniano, wątek tworzony jest wewnątrz procesu i wykorzystuje jego zasoby. Dla wątku tworzone są
tylko niezbędne struktury takie jak: wskaźnik stosu, rejestry, ustawienia planowania CPU, zestaw obsługi sygnałów,
dane specyficzne dla wątku (ID wątki, itd.) Resztę struktur procesu wątek współdzieli z innymi wątkami/procesem.
Wątek istnieje dopóki istnieje proces go tworzący lub do momentu kiedy sam się zakończy lub jego działanie
zostanie przerwane z zewnątrz (np. przez proces tworzący lub przez sygnał wysłany przez zupełnie inny proces).
Realizacja wątków i możliwość programowania ich w języku C jest wspierana (pod UNIX-em) przez bibliotekę
pthreads.h, która definiuje około 60 funkcji niezbędnych do tworzenia i obsługi wątków.
Podstawową motywacją do wykorzystania wątków jest zwiększenie potencjalnej efektywności programu. W
porównaniu do procesów (aplikacji wieloprocesowych) wątki mają mniejsze wymagania związane z ich obsługą i
tworzeniem, przez co są szybsze i wydajniejsze (korzystają ze wspólnych obszarów pamięci współdzielą część
zmiennych, pliki itp.) Wątki mają zastosowanie w tworzeniu dużych aplikacji wielowątkowych, w których wiele
operacji musi wykonywać się jednocześnie. Aplikacje takie mogą być tworzone również jako wieloprocesowe (przy
użyciu współpracujących procesów) jednak zakres możliwości jest inny.
Przykładem sytuacji, w której rozwidlania procesów (wieloporcesowości) nie da się zastąpić wielowątkowością jest
chociażby uruchamianie programów w interpretera poleceń (shell-a). Używany shell najpierw wykonuje funkcję
fork (tworzy swoją kopię) a następnie podmienia kod tej kopii na kod programu, który uruchamiamy. Bez
rozwidlania procesów byłoby to niemożliwe (wszystkie programy musiałyby być niejako z góry wbudowane we
„wszechpotężny” wielowątkowy system operacyjny).
SYGNAŁY
Sygnał to informacja dla procesu, że wystąpiło jakieś zdarzenie. Sygnały są wysyłane przez:
jądro do procesu,
proces do innego procesu.
Sygnały są zwykle asynchroniczne tzn. nie da się przewidzieć momentu ich pojawienia się. Proces może w dowolnym
momencie otrzymać sygnał. Winien wówczas przerwać pracę i zareagować na otrzymany sygnał (wykonać
odpowiednie operacje). Dlatego też sygnały nazywa się inaczej przerwaniami programowymi.
W systemie UNIX do każdego typu sygnału przypisane są określone czynności domyślne, które powinien wykonać
proces po otrzymaniu danego sygnału. Mogą to być:
zatrzymanie procesu
zakończenie procesu
zakończenie procesu z zapisaniem obrazu pamięci (utworzenie pliku core)
ignorowanie
Sygnał można wysłać:
poleceniem kill
kill -signal pid
np.: kill -INT 2367
Listę sygnałów można wypisać poleceniem kill -l
funkcją kill
int kill(int pid, int sig);
naciskając klawisz terminala (patrz tabela)
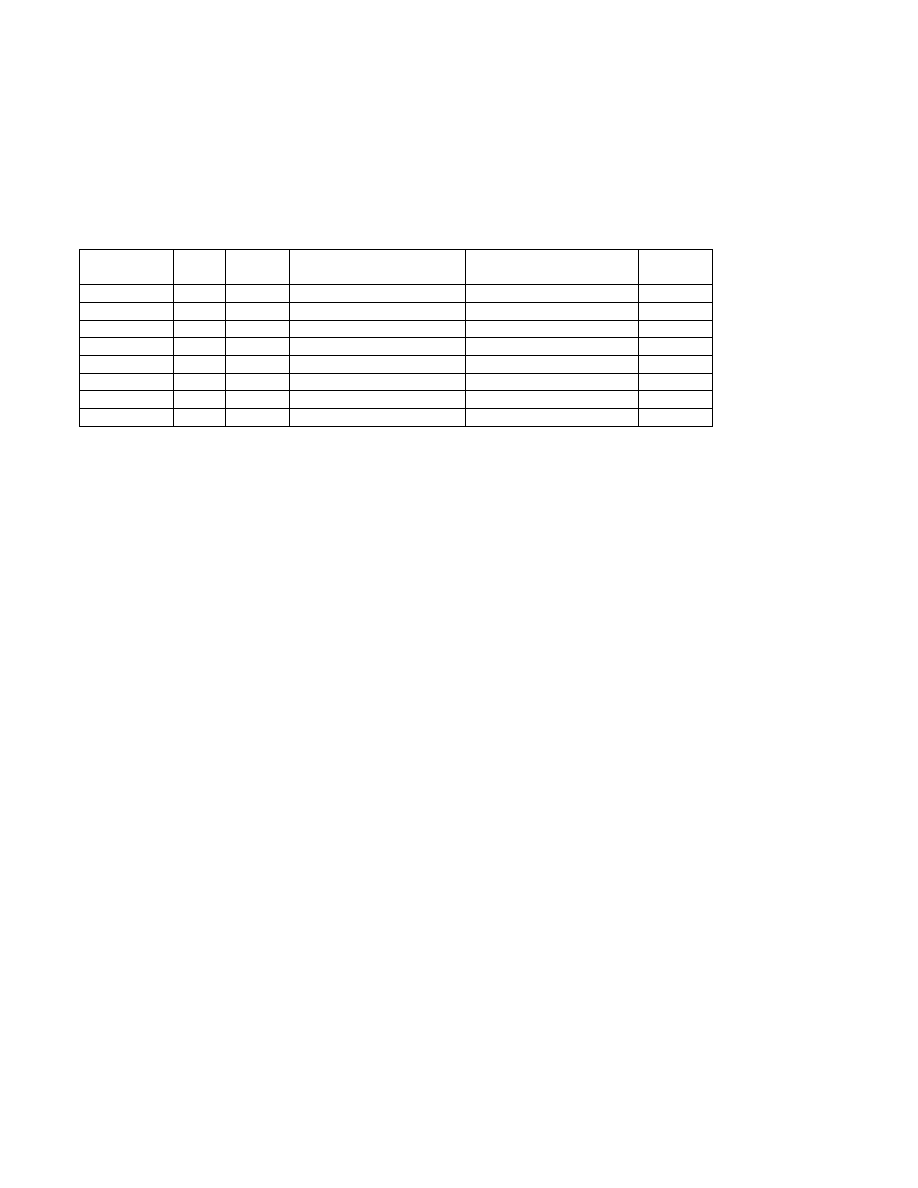
przez jądro: błędy operacji, adresacji, arytmetyczne, pojawienie się wysokopriorytetowych danych w gnieździe
itp.
Każdy proces może zawierać swoje funkcje do obsługi sygnałów (nie będziemy się tym jednak zajmować). Proces
może w związku z tym również ignorować sygnały. Istnieją dwa sygnały, tzw. niezawodne, które działają zawsze:
SIGKILL i SIGSTOP.
Przykłady sygnałów:
SIGNAL
ID
Action
Event
Command
Key
SIGHUP
1
Exit
Hangup
kill -HUP pid
SIGINT
2
Exit
Interrupt
kill -INT pid
^C
SIGQUIT
3
Core
Quit
kill -QUIT pid
^\
SIGKILL
9
Exit
Killed
kill -9 pid
SIGPIPE
13 Exit
Broken Pipe
kill -PIPE pid
SIGTERM
15 Exit
Terminated
kill -TERM pid
SIGSTOP
23 Stop
Stopped (signal)
kill -STOP pid
SIGTSTP
24 Stop
Stopped (user)
kill -TSTP pid
^Z ^Y
Wyszukiwarka
Podobne podstrony:
Lab 05 procesy
Lab 05 Wprowadzenie do jezyka C
Lab 05 Obliczenia w C id 257534 Nieznany
WDA LAB 3, WAT, semestr III, Wprowadzenie do automatyki
05 procesyid 5808 Nieznany (2)
lab 05 analiza widmowa
SO 2 PROCESY I WATKI
Lab 05 2011 2012
MP Lab 05 Opory lokalne, Mechanika płynów
fiz lab 05
lab 05
lab. 05 - baron, Chemia fizyczna AGH laborki, lab 5
lab peim, PG, rok1, fizyka, Laborki, Laborki, parzy, fizyka laborki, lab 05
Procesy, wątki
CMS Lab 05 Moduly
lab 05
więcej podobnych podstron