
Metody statystyczne w analizie
danych marketingowych
Magdalena Jabłońska
mjablonska2@swps.edu.pl

Kwestie organizacyjne:
•
E-learning:
-
hasło: predyktor
•
Obecność:
-
2 nieobecności

Zaliczenie
•
Moduł: 45 z 100 punktów
-
Test: 25 punktów
-
Raport z badań: 15 punktów
-
Zadanie domowe: 5 punktów
•
Zakres pytań: prezentacje + informacje
przekazane podczas ćwiczeń

Tematyka poruszana podczas zajęć:
1.
Marketing i pytania statystyczne.
2.
Ogólny model liniowy i regresja wieloraka.
3.
Regresja logistyczna.
4.
Metody
redukcji
wymiarów
(analiza
głównych
składowych, analiza czynnikowa).
5.
Pozycjonowanie (analiza dyskryminacyjna, skalowanie).
6.
Metody klasyfikacji (segmentacja, analiza skupień,
analiza drzew hierarchicznych).
7.
Podsumowanie zajęć, prezentacje.


Badania marketingowe
(Definicja American Marketing Association):
funkcja wiążąca konsumenta, klienta i opinię publiczną z
menedżerem
marketingu
poprzez
informację
wykorzystywaną do
•
identyfikowania i wykorzystywania marketingowych
szans i zagrożeń,
•
tworzenia,
doskonalenia
i
oceny
działań
marketingowych,
•
monitorowania wyników marketingu.
Badanie marketingowe: określa jakie informacje są
niezbędne, projektuje metodę zbierania informacji, wdraża
proces
zbierania
danych,
analizuje
wyniki,
komunikuje wyniki oraz wnioski
Eric Schmidt
„Co każde dwa dni
tworzymy
tyle
informacji co od
początku cywilizacji
do 2003 roku”.
Eksploracja danych
Data Mining
•
Analiza (często ogromnych) zbiorów danych
obserwacyjnych w celu znalezienia nieoczekiwanych
związków i podsumowania danych w oryginalny
sposób
•
Tak aby były zarówno zrozumiałe, jak i przydatne
dla ich właściciela

Typowe zadania w analizie danych:
Klasyfikacja: ocena cech nowego obiektu i
przewidywanie do jakiej wcześniej zdefiniowanej klasy
będzie należał.
– np. skoring finansowy dla kredytów, skoring marketingowy
akceptacji nowej oferty, przynależność do grupy segmentacyjnej.
Estymacja: ocena wartości pewnej ciągłej zmiennej na
podstawie innych zmiennych.
-
np. ocena wartości transakcji z konsumentem (life – time value
CLV
)
Predykcja: przewidywanie przyszłych wartości na
podstawie danych historycznych (może to być estymacja
lub klasyfikacja)
-
np. przewidywanie akceptacji nowych ofert, ryzyko odejścia,
przyszłe wartości kursów akcji

Tworzenie reguł asocjacyjnych: poszukiwanie zależności, które
da się przedstawić w postaci „jeżeli A, to B”.
- np. przygotowywanie ofert cross – selling i up – selling, organizacja
towaru na półkach
Łączenie w grupy (clustering): poszukiwanie grup obiektów,
które pod jakimś względem są podobne do siebie i łączenie ich
grupy (liczba grup nie jest znana z góry)
- np. poszukiwanie segmentów konsumentów, analiza podobieństwa
produktów
Tworzenie profili: opisywanie zależności w zbiorze danych w
sposób ułatwiające zrozumienie
- np. opis cech wyborców głosujących na polityków danej partii, opis cech
osób często kupujących produkt X
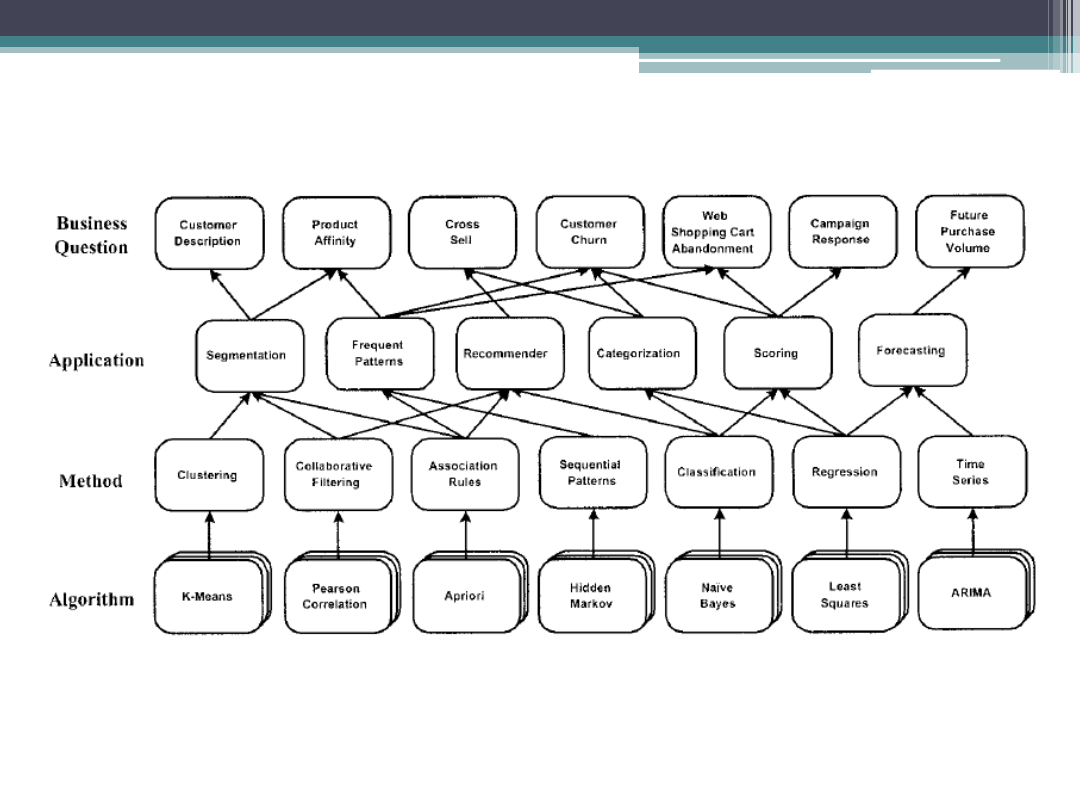
Analizy danych i pytania marketingowe
Metody wykorzystywane w analizie danych:
Metody matematyczne, wykorzystujące operacje na wartościach
cech obiektów:
regresja liniowa, regresja logistyczna, analiza dyskryminacyjna,
analiza głównych składowych, sieci neuronowe, klasyfikacja bayesowska
Metody dystansowe, polegają na znalezieniu najbliższych
sąsiadów (najbardziej podobne) i określeniu cech obiektu na
podstawie cech sąsiadów
hierarchiczna analiza skupień, analiza skupień metodą k –
średnich, skalowanie wielowymiarowe
Metody logiczne – łączą informacje z próby wykorzystując
operatory prawda / fałsz
analiza drzew hierarchicznych
Metody matematyczne
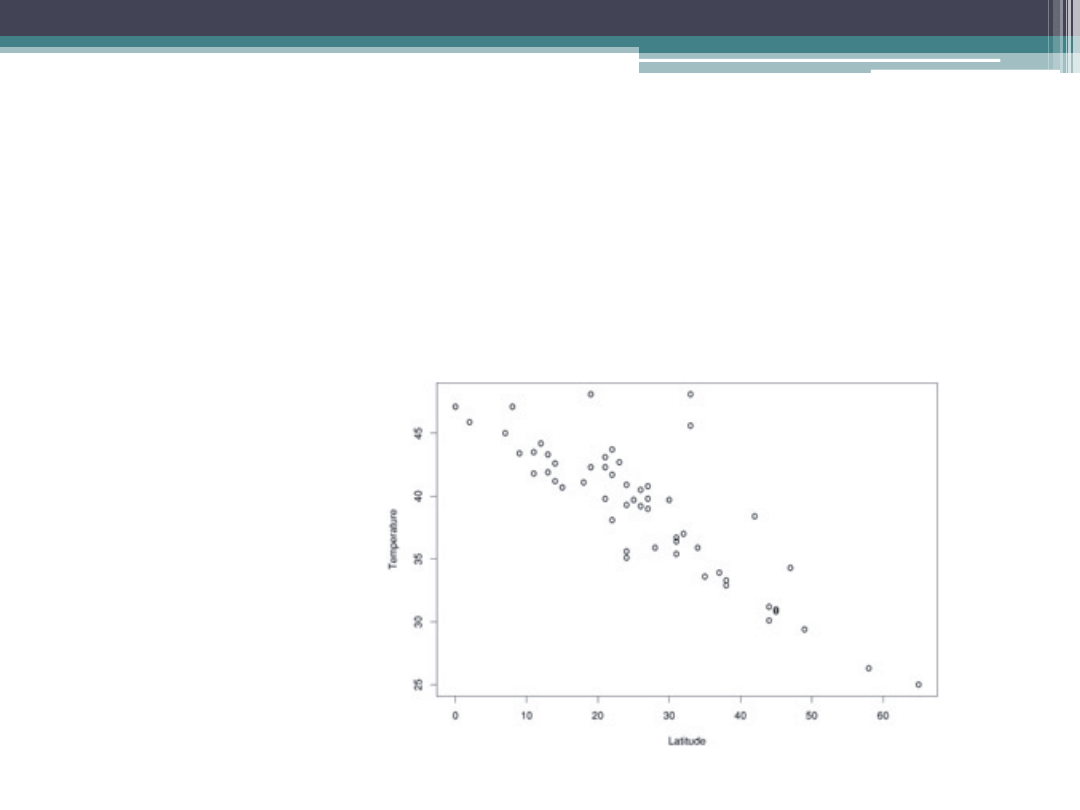
Regresja liniowa
Przykład: Temperatura w miastach amerykańskich jest
zależna liniowo od szerokości geograficznej na północ

1. Czym jest model?
Model jest równaniem, zmienna zależna ma charakter ilościowy, zmienne
niezależne są ilościowe, zmienne jakościowe mogą być wykorzystane jako
wskaźnikowe
2. Algorytm budowania modelu
Metoda najmniejszych kwadratów – minimalizacja sumy kwadratów
odchyleń wartości wykorzystanych do modelowania od wartości w modelu
3. Wynik modelowania
Równanie, opisujące wartości zmiennej zależnej jako liniową kombinacją
zmiennych niezależnych
4 Wskaźnik dopasowania modelu
Wartość R kwadrat, czyli proporcja sumy kwadratów dla wartości
opisanych przez równanie regresji do całkowitej sumy kwadratów
(najczęściej w wersji skorygowanej, po uwzględnieniu liczby obiektów i
liczby predyktorów)

5. Upraszczanie modelu
Zmiana liczby predyktorów (na podstawie wartości testu F i ew.
testu t)
6. Założenia
Dane o charakterze przedziałowym (?), predyktory nie są
współliniowe (VIF i tolerancja), reszty mają rozkład normalny
(warto przeprowadzić analizę reszt)
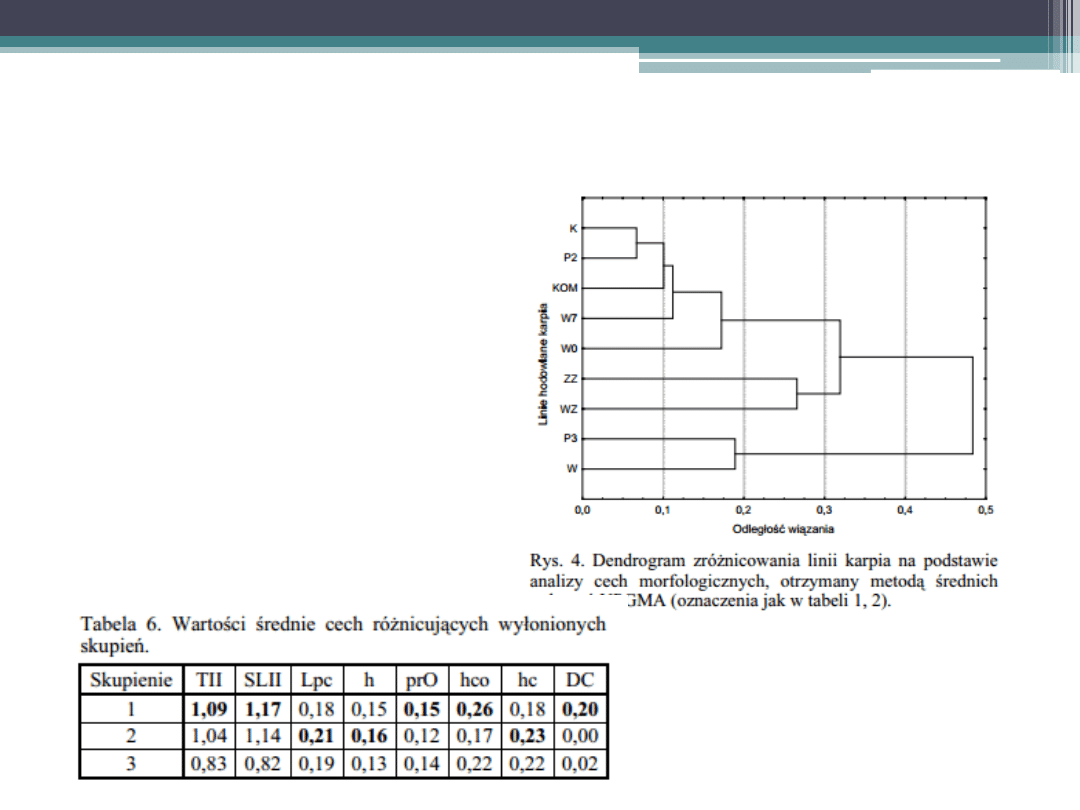
Model dystansowy:
Hierarchiczna analiza skupień
Przykład
Jak bardzo karpie różnią się
między sobą
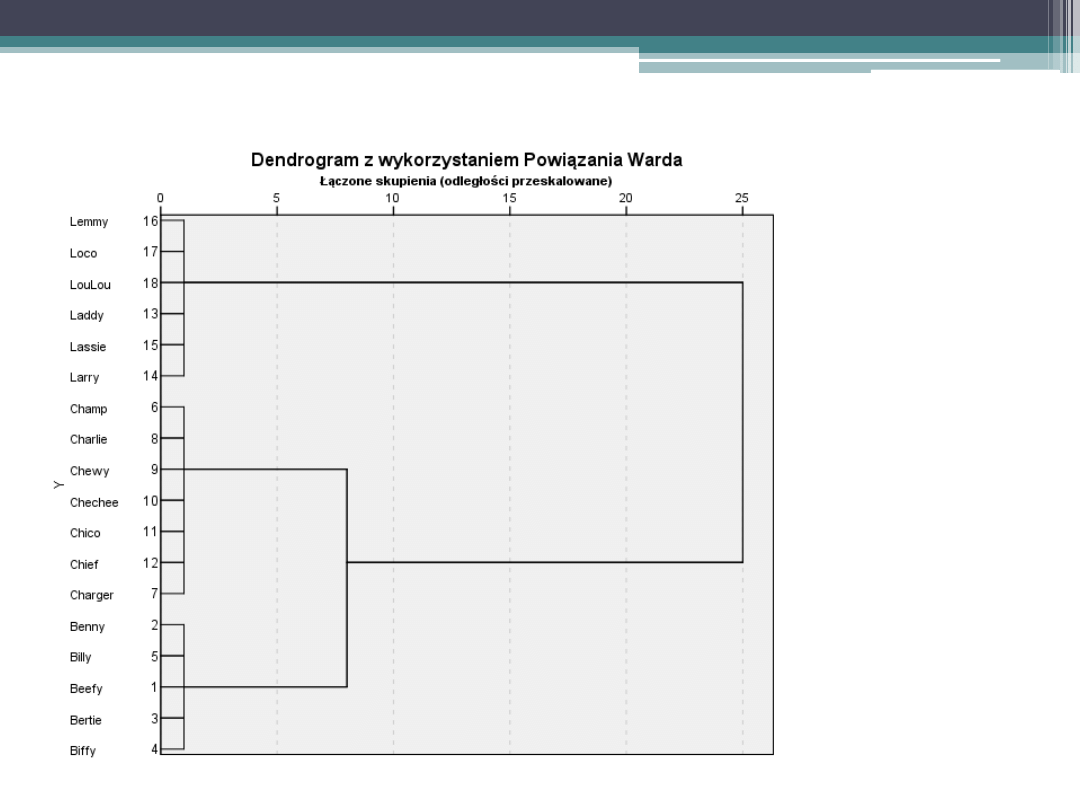
Plik:
small-
cluster.sav
Jak bardzo psy różnią się między sobą?
1. Czym jest model?
Model jest grafem obrazującym relacje podobieństwa między
testowanymi obiektami
2. Algorytm budowania modelu
Kolejne kroki łączenia obiektów w pary na podstawie wyliczonych
wartości „geometrycznego podobieństwa” w przestrzeni N-1 wymiarowej

3. Wynik modelowania
Najważniejszym wynikiem modelowania jest dendrogram obrazujący
kolejność łączenia obiektów oraz odległości między nimi (także w
postaci tabeli jako przegląd aglomeracji)
4. Wskaźnik dopasowania modelu
Jako wskaźnik dopasowania modelu można wykorzystać testy F dla
poszczególnych analizowanych zmiennych po przypisaniu badanym
obiektom kategorii skupień
5. Upraszczanie modelu
HAS przedstawia podobieństw między wszystkimi obiektami wychodząc
od N skupień (tyle ile jest obiektów) do jednego skupienia. Trudno jest
podać analityczne metody odcięcia drzewa skupień na jakimś poziomie
6. Założenia
Wykonanie HAS jest możliwe, gdy liczba danych jest odpowiednio
większa od liczby wymiarów (50%) oraz gdy jest sensowne traktowanie
relacji między obiektami jako odległości
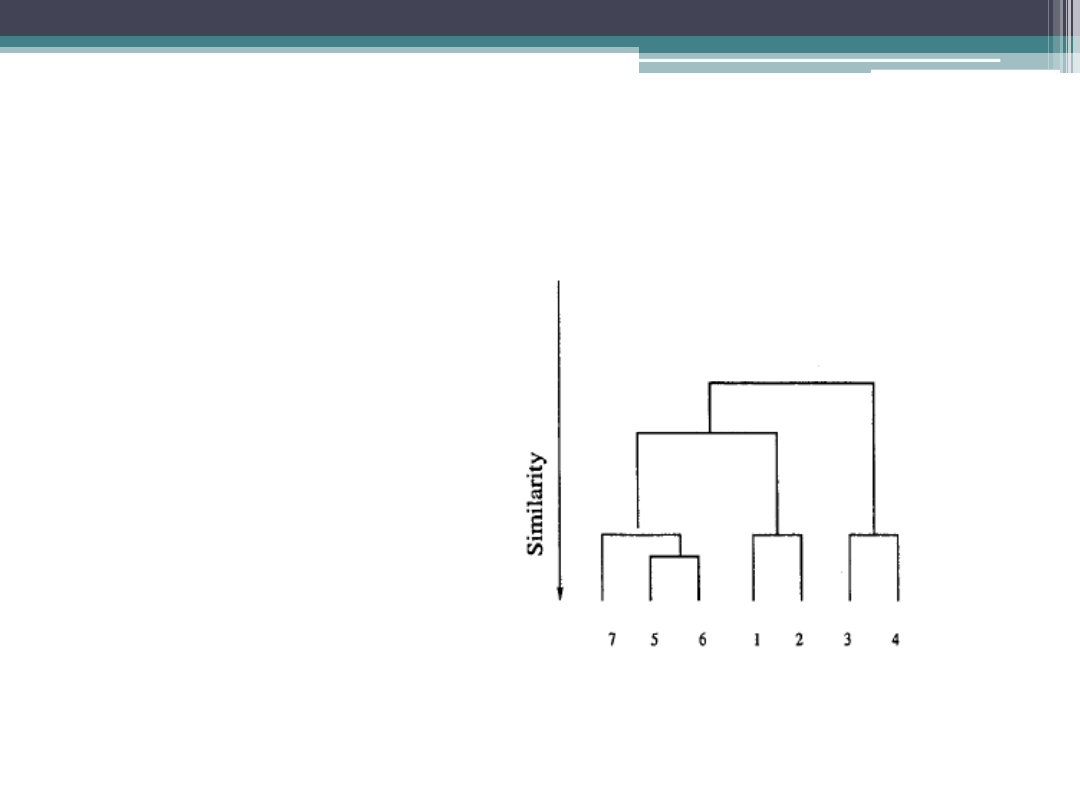
Ad 1. Algorytm budowania modelu: dendrogram jest
tworzony w wyniku iteracji, czyli analizy podobieństwa w
kolejnych krokach.
Analiza podobieństwa jest zależna od definicji metryki
podobieństwa (jak w MDS)
Podobieństwo między ob. 5 i ob. 6 jest wyższe niż między 3 i 4
(linie pionowe na dendrogramie są krótsze)
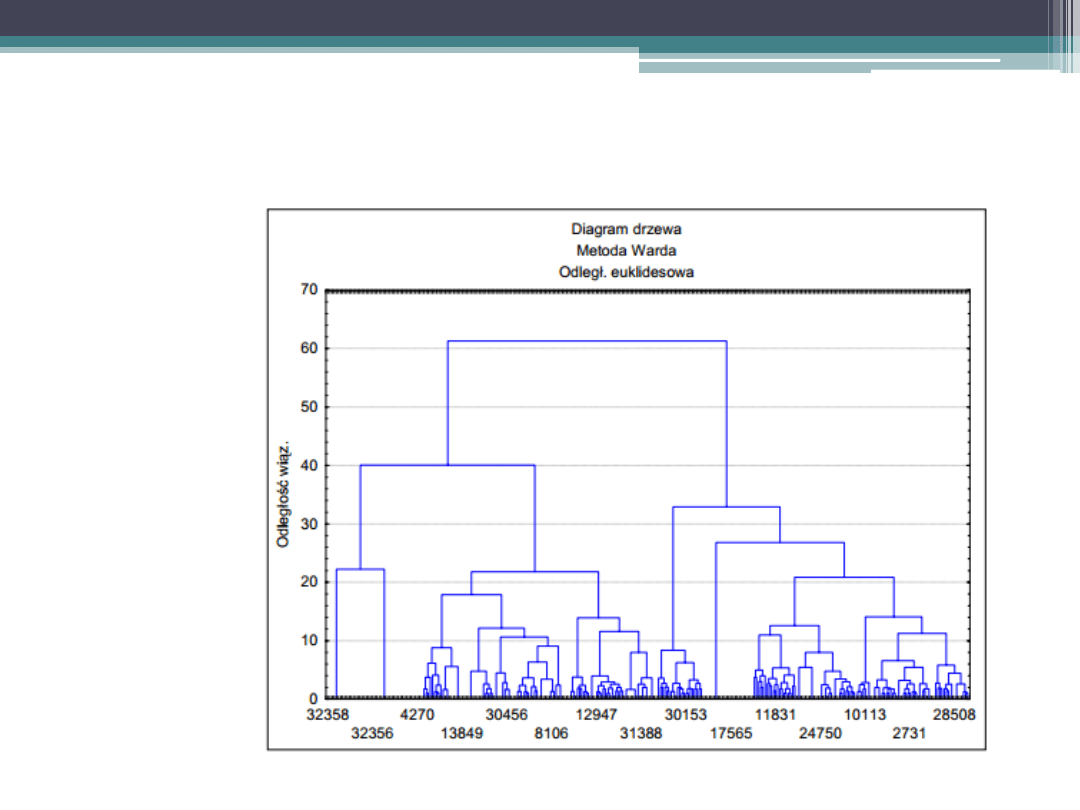
Ad 2. Wynik modelowania: klienci banku połączeni w
hierarchiczne grupy
Jak można wykorzystać te dane, aby uzyskać maksimum korzyści?
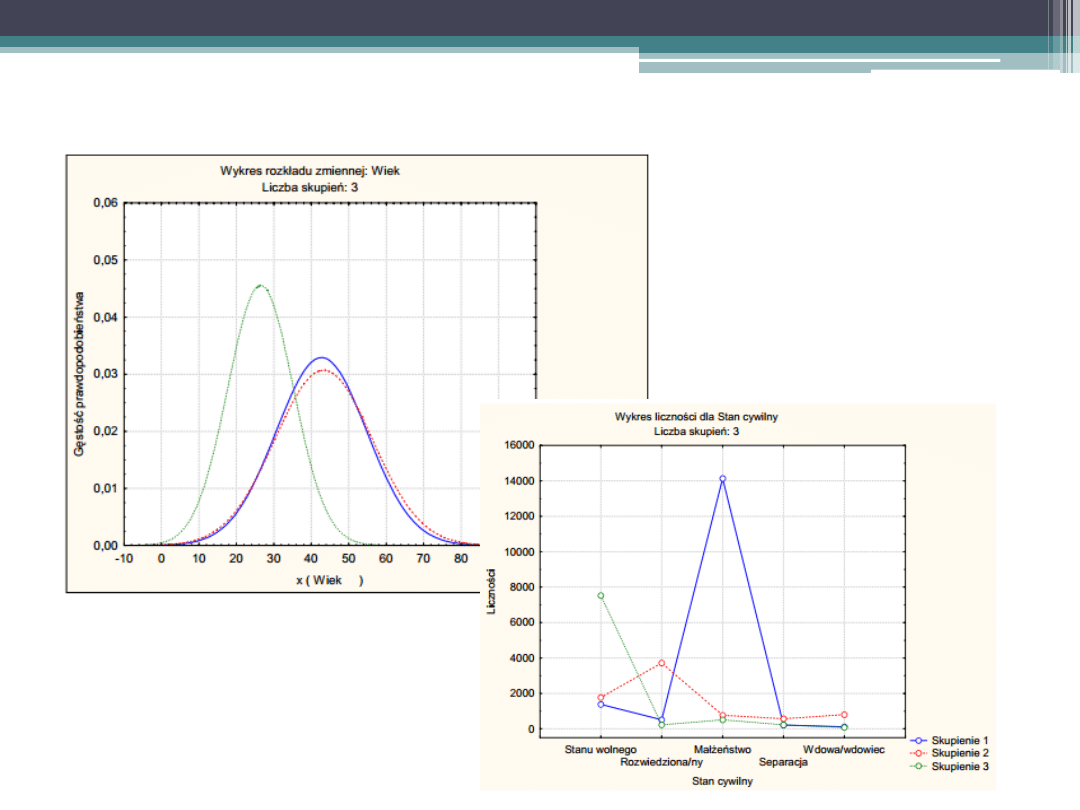
Po podziale badanych obiektów na grupy można sprawdzić, jakie są
cechy (wartości wymiarów) w tych grupach
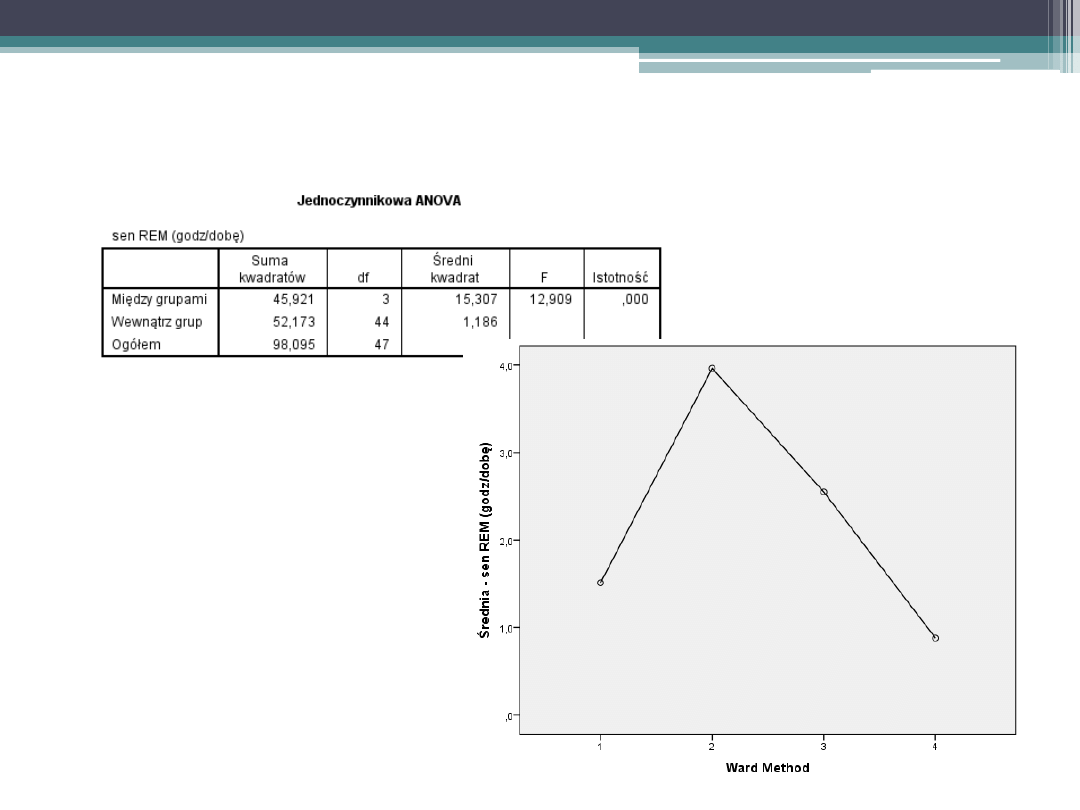
Ad 3. Wskaźnik dopasowania: skupienia można potraktować
jako kategorie (zmienne niezależne) w Anova i sprawdzić czy
tak utworzone grupy istotnie różnią się między sobą
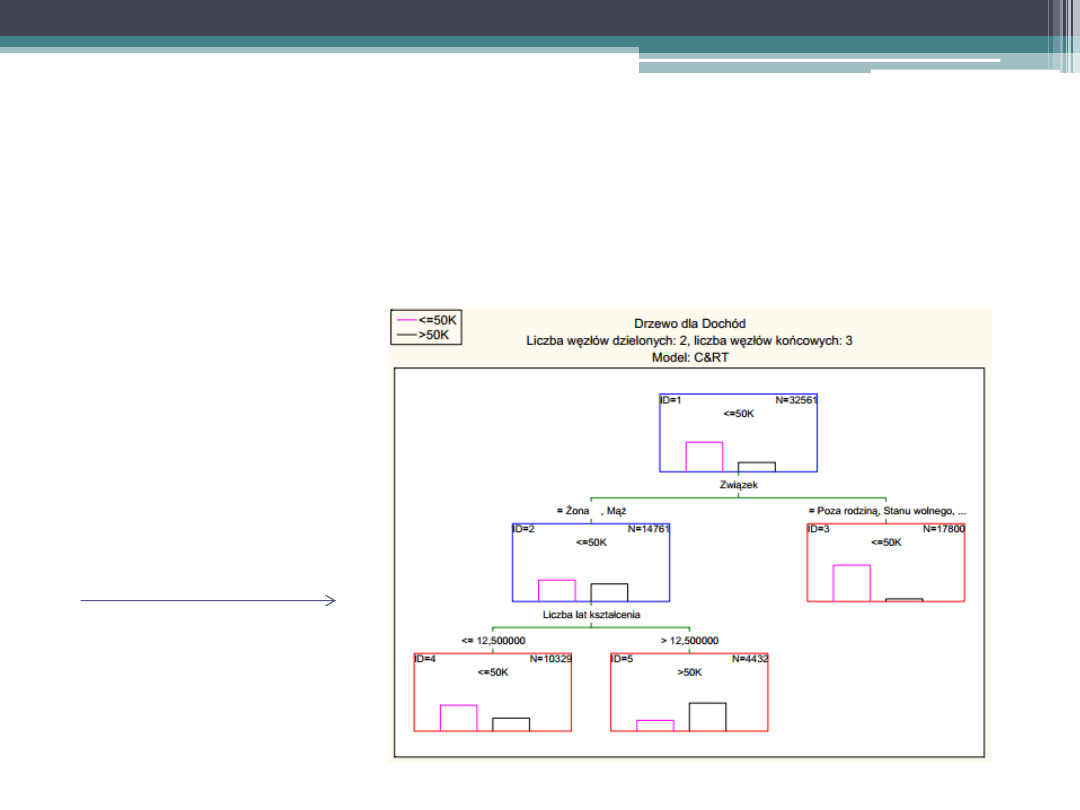
Metody logiczne
Analiza drzew hierarchicznych
Drzewa wykorzystywane są głównie w przypadku
segmentacji
Dochód w zależności
od cech
demograficznych
1. Czym jest model?
Hierarchiczny graf obrazujący przynależność do kategorii jakościowej
zmiennej zależnej na podstawie wartości zmiennych niezależnych, które
mogą być jakościowe i ilościowe
2. Algorytm budowania modelu
Model najczęściej tworzony jest przez rekurencyjne tworzenie drzewa, w
którym każdy obiekt jest końcowym „liściem” a potem drzewo jest
przycinane, tak, aby utrzymać na odpowiednim poziomie procent
poprawnych klasyfikacji

5. Upraszczanie modelu
Upraszczanie modelu polega na przycinaniu drzewa i z reguły jest
wykonywane automatycznie przez algorytm obliczeniowy
6. Założenia
Zmienna zależna musi być jakościowa. Nie ma założeń, co do
charakteru ZN (choć może być potrzeba równoważenia zbioru
danych).
3. Wynik modelowania
Wynikiem modelowania jest graf obrazujący drzewo, który może być
przestawiony także w postaci reguł „Jeżeli …., to …”
4. Wskaźnik dopasowania modelu
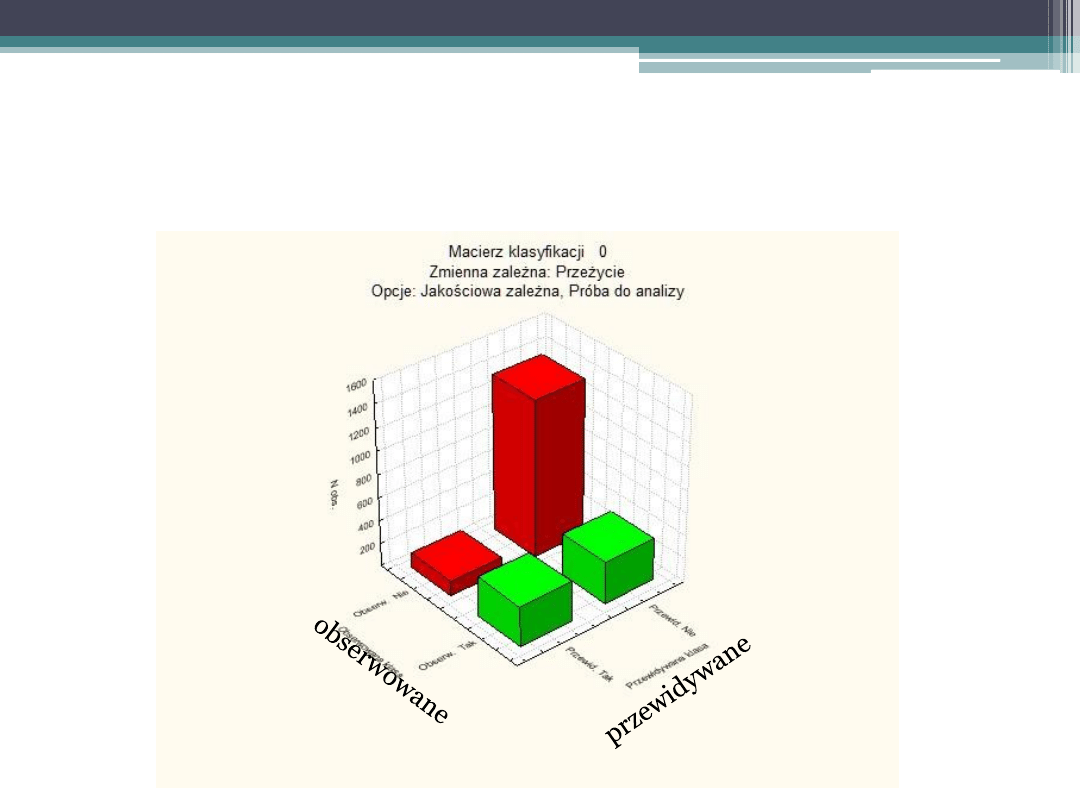
Podstawowym wskaźnikiem modelu jest procent poprawnych i
błędnych klasyfikacji (czasem także możliwe jest obliczenie kosztów
takich klasyfikacji i ważności predykatów)
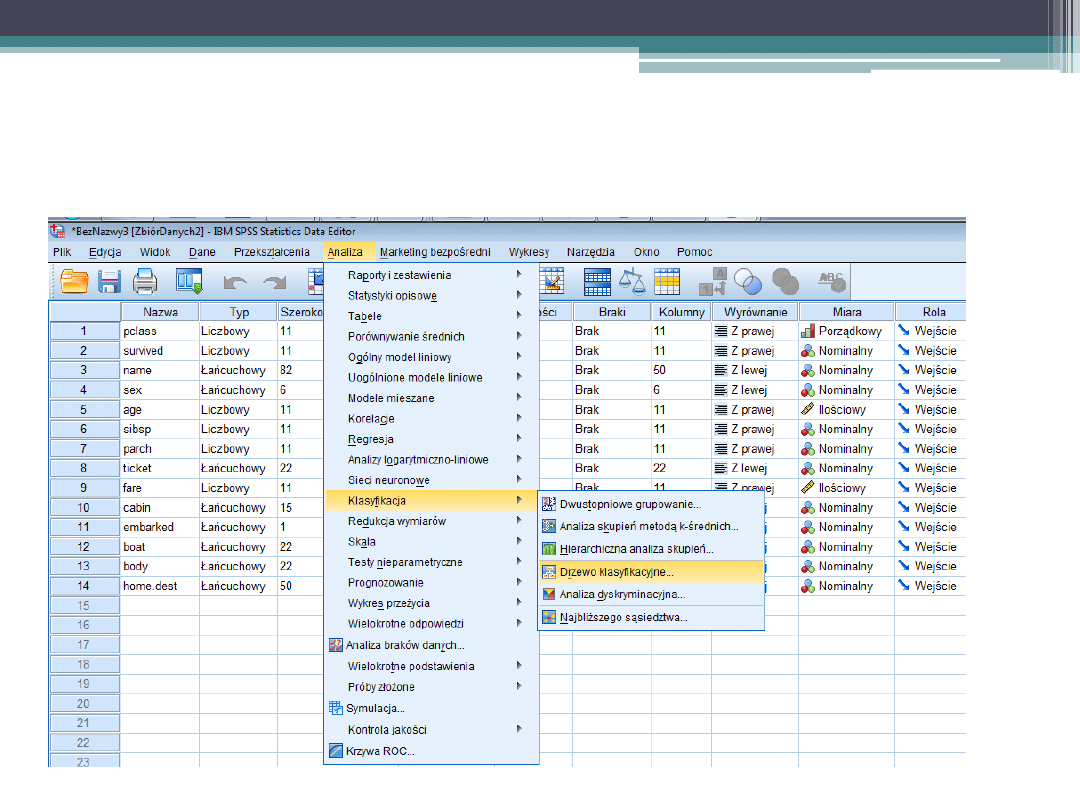
SPSS 22
Analiza drzew hierarchicznych

SPSS 22
Analiza drzew hierarchicznych
Definiujemy wybrane
zmienne.
UWAGA!
Zmienna zależna musi
być kategorialna
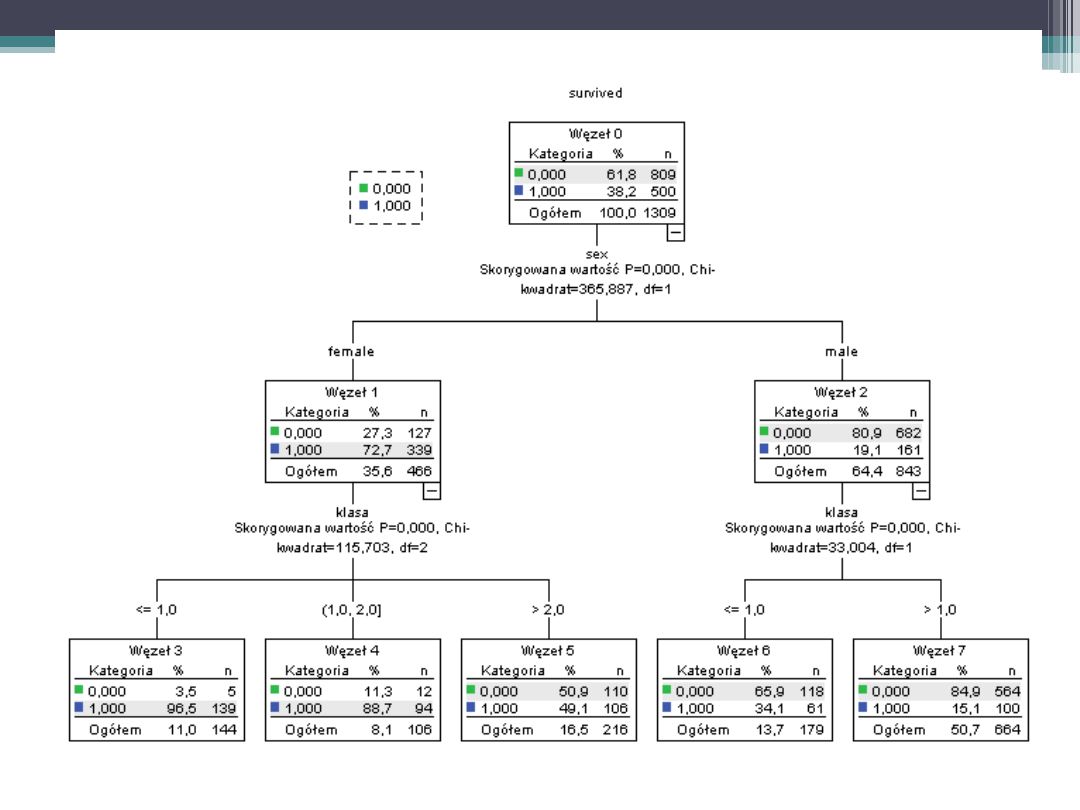
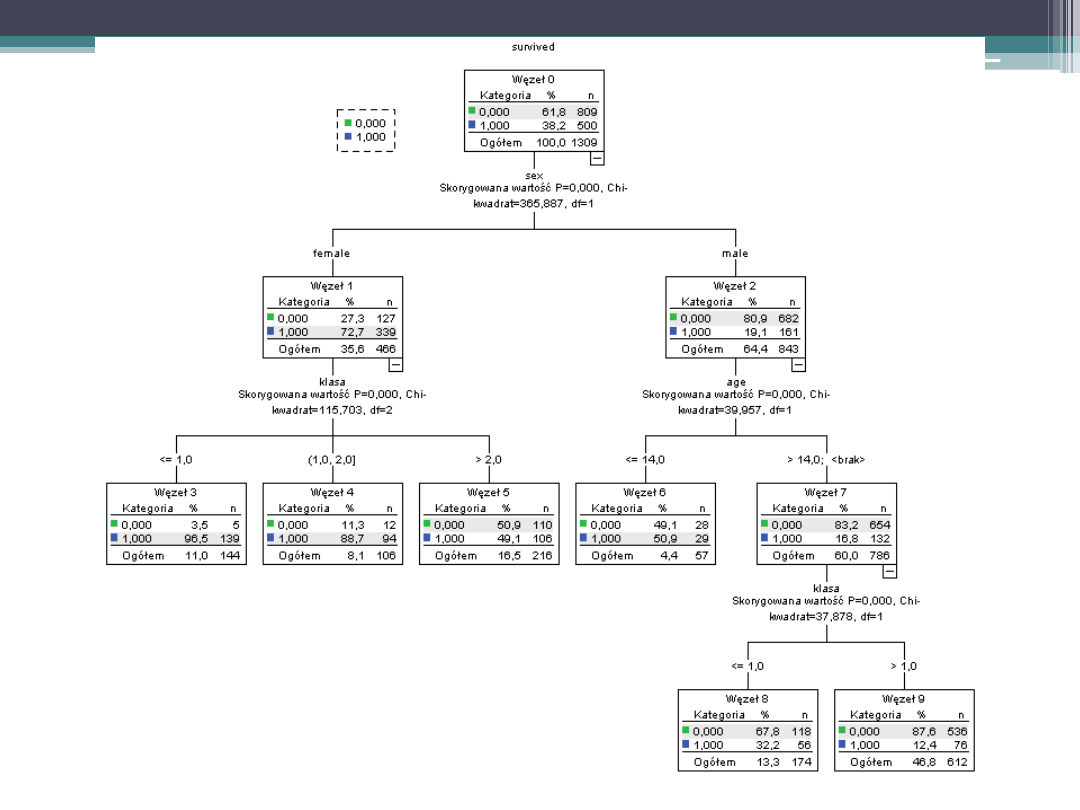
+ dodano zmienną age
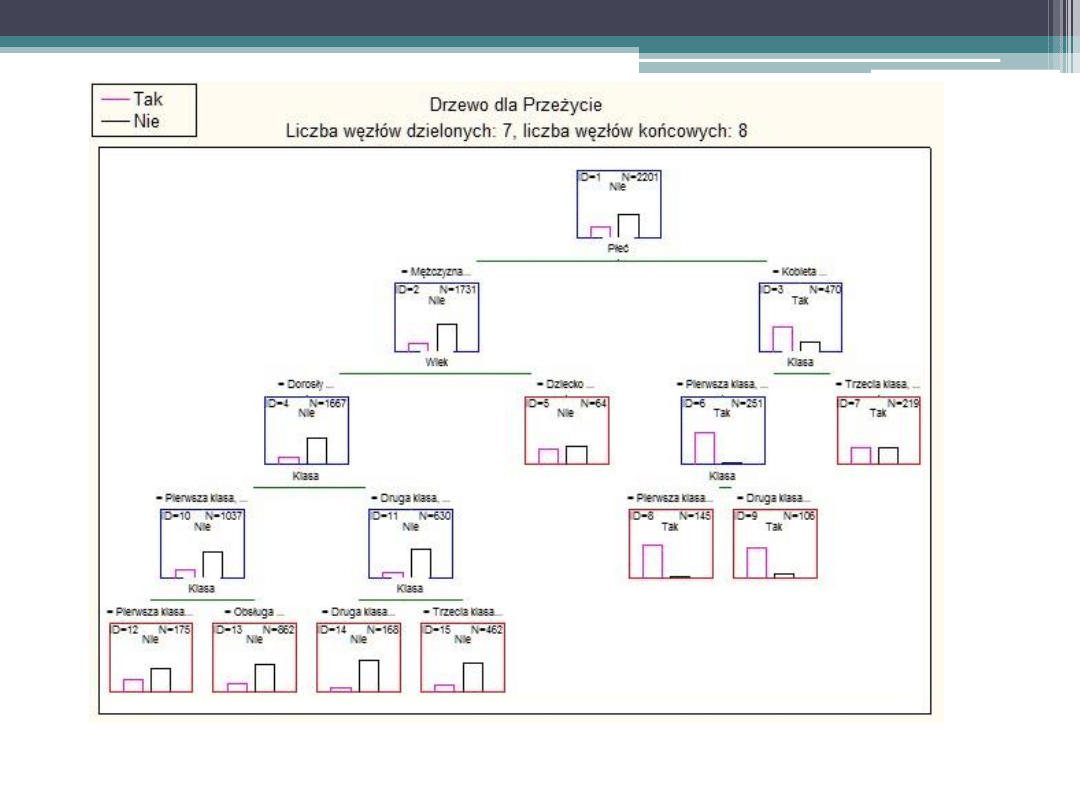
Ta
k
Ta
k
Ni
e
Ni
e
Wyniki drzewa można opisać przy pomocy reguł:
Jeżeli A i B i C …, to X (gdzie X jest nazwą kategorii)
Ocena drzewa – wykres klasyfikacji
Metody sprawdzania dopasowania modelu klasyfikacji
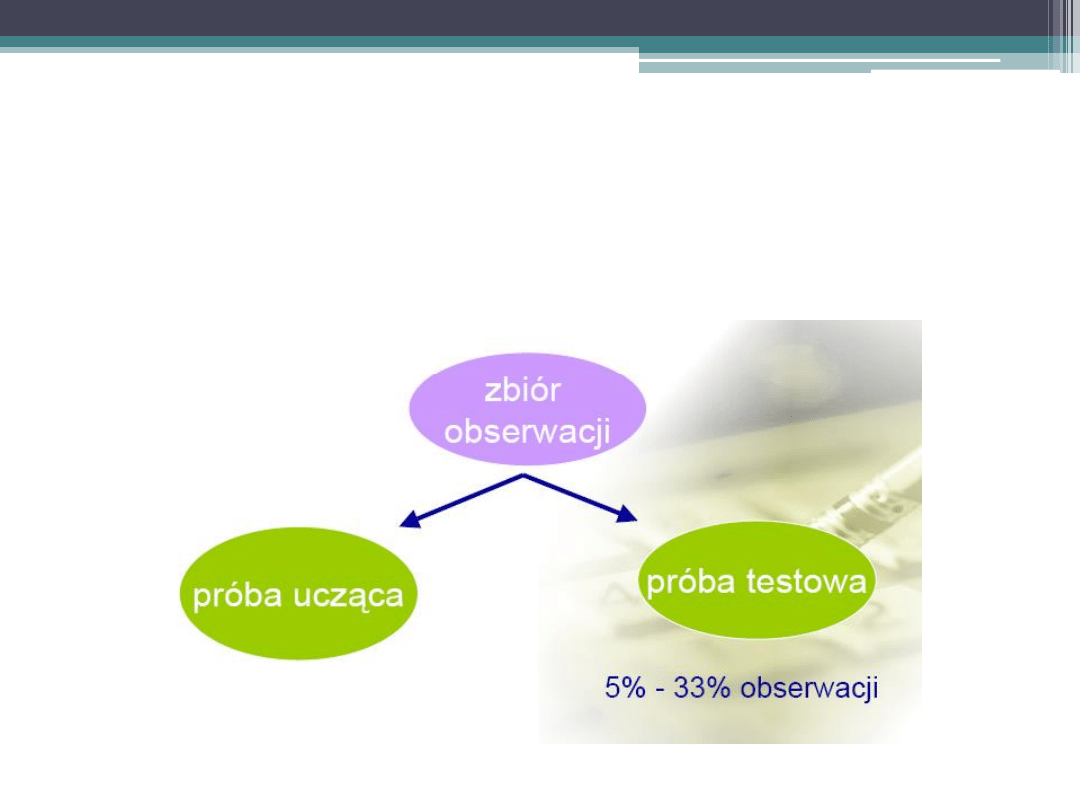
1. Podział na próbę uczącą i próbę testową
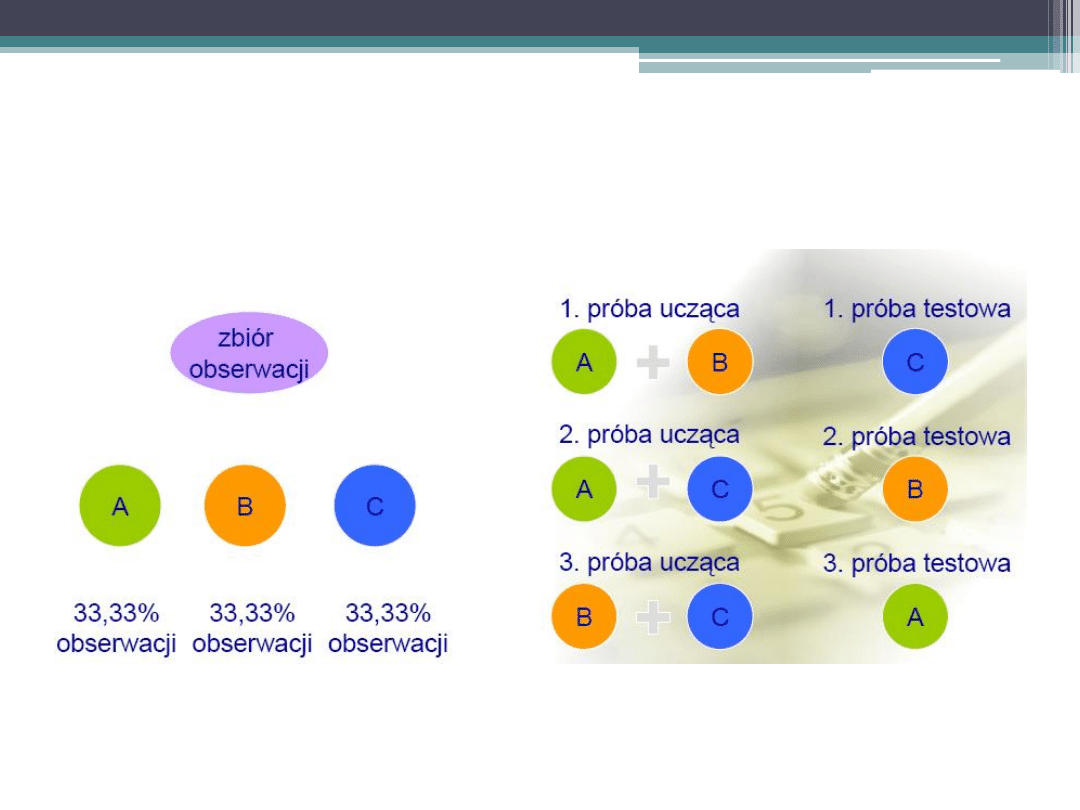
Walidacja krzyżowa
Wyszukiwarka
Podobne podstrony:
Metody analizy danych
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
Metody analizy danych
Braki danych, Informatyka SGGW, Semestr 4, Metody analizy danych
metody analizy danych dane ilosciowe
Wymagania pierwszego projektu, Informatyka SGGW, Semestr 4, Metody analizy danych
Prof Kukuła tekst HD, Informatyka SGGW, Semestr 4, Metody analizy danych
Informatyka-MAD Wszczesny, Informatyka SGGW, Semestr 4, Metody analizy danych, Wykład 1
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
Mikroekonometria Modele i metody analizy danych indywidualnych RedGruszczynski Marek
Baza danych upraszcza i przyspiesza analizę danych, Dokumenty do szkoły, przedszkola; inne, Metody,
Metody analizy marketingowej (11 stron) MBERX2CDYBFRDHFYSGAGUADABWYZUFX3F7GEV6A
Informacja o analizowanych danych, Akademia Ekonomiczna w Katowicach, Zarzadzanie, Semestr III, Bada
więcej podobnych podstron