


Politechnika Poznańska
Wydział Informatyki i Zarządzania
Kierunek: Informatyka
Specjalność: Inteligentne Systemy Wspomagania Decyzji
Praca magisterska
Krzysztof Dondajewski
INTERAKTYWNY SYSTEM REGUŁOWEJ
ANALIZY DANYCH MARKETINGOWYCH
DOTYCZĄCYCH SATYSFAKCJI KLIENTA
Promotor:
prof. dr hab. inż. Roman Słowiński
Poznań 2004

SPIS TREŚCI
SPIS TREŚCI ............................................................................................................................................. 4
1
WSTĘP.............................................................................................................................................. 5
2
CEL I ZAKRES PRACY................................................................................................................. 8
3
PRZEGLĄD WYBRANYCH ZAGADNIEŃ ANALIZY SATYSFAKCJI KLIENTA (ASK) 10
3.1
S
POSOBY ANALIZY SATYSFAKCJI KLIENTA
.............................................................................. 10
3.1.1
Badanie poziomu zadowolenia klienta............................................................................... 10
3.1.2
Indeks satysfakcji klienta ................................................................................................... 12
3.1.3
Zarządzanie relacjami z klientem....................................................................................... 13
3.2
ASK
PRZY WYKORZYSTANIU REGUŁ DECYZYJNYCH
............................................................... 14
3.2.1
Elementy teorii zbiorów przybliżonych i indukcji reguł decyzyjnych................................. 14
3.2.2
Wprowadzenie do metodologii ASK w oparciu o reguły decyzyjne ................................... 22
3.2.3
Formalne przedstawienie metodologii............................................................................... 22
3.3
T
ECHNOLOGIA ANALIZY WIELOWYMIAROWYCH DANYCH
OLAP............................................ 25
3.3.1
Terminologia i przykłady ................................................................................................... 25
3.3.2
Zastosowanie ..................................................................................................................... 27
4
PROPOZYCJE ROZSZERZEŃ METODOLOGII ASK W OPARCIU O REGUŁY
DECYZYJNE........................................................................................................................................... 28
4.1
P
RZYKŁAD DANYCH WEJŚCIOWYCH DO ANALIZY SATYSFAKCJI KLIENTA
................................ 28
4.2
T
ESTOWANIE STRATEGII INTERWENCJI
.................................................................................... 29
4.2.1
Przykład analizy danych metodą testowania strategii interwencji .................................... 29
4.2.2
Algorytm testowania strategii interwencji ......................................................................... 31
4.2.3
Możliwe zastosowania i kierunki rozwoju.......................................................................... 31
4.3
S
ZUKANIE STRATEGII INTERWENCJI
......................................................................................... 32
4.3.1
Przykład analizy danych metodą szukania strategii interwencji........................................ 32
4.3.2
Algorytm szukania strategii interwencji............................................................................. 33
4.3.3
Możliwe zastosowania i kierunki rozwoju.......................................................................... 34
4.4
P
OŁĄCZENIE
OLAP
I
DRSA
DO ANALIZY SATYSFAKCJI KLIENTA
........................................... 34
5
PROJEKT SYSTEMU I IMPLEMENTACJA............................................................................ 38
5.1
A
RCHITEKTURA SYSTEMU I WYKORZYSTANE TECHNOLOGIE
................................................... 38
5.2
E
LEMENTY SYSTEMU I POWIĄZANIA MIĘDZY NIMI
................................................................... 39
5.2.1
Moduł komunikacji z bazą danych ..................................................................................... 40
5.2.2
Moduły do prezentacji atrybutów i przykładów ................................................................. 41
5.2.3
Moduł do prezentacji reguł ................................................................................................ 42
5.2.4
Moduły prezentacji danych OLAP ..................................................................................... 43
5.2.5
Moduły do analizy satysfakcji klienta ................................................................................ 43
6
STUDIUM PRZYPADKÓW – EKSPERYMENT I WYNIKI................................................... 45
6.1
D
ANE WEJŚCIOWE PRZEZNACZONE DO ANALIZY SATYSFAKCJI KLIENTA
................................. 45
6.2
P
RZEBIEG EKSPERYMENTU
...................................................................................................... 46
6.2.1
Etap 1 – prezentacja danych marketingowych do analizy ................................................. 48
6.2.2
Etap 2 – analiza metodą szukania strategii interwencji..................................................... 51
6.2.3
Etap 3 – analiza metodą testowania strategii interwencji ................................................. 54
6.2.4
Etap 4 – badanie oczekiwanej efektywności strategii interwencji ..................................... 57
6.3
K
OŃCOWE WNIOSKI
................................................................................................................. 61
7
PODSUMOWANIE I WNIOSKI.................................................................................................. 62
BIBLIOGRAFIA ..................................................................................................................................... 65
DODATEK A – WYKAZ TABEL I RYSUNKÓW .............................................................................. 67
DODATEK B – PRZEWODNIK INSTALACYJNY UŻYTKOWNIKA........................................... 68
DODATEK C – PRZEWODNIK INSTALACYJNY PROGRAMISTY ............................................ 70
DODATEK D – SPIS CD ........................................................................................................................ 71

5
1 Wstęp
Strategia każdej firmy, działającej na rynku konkurencyjnym opiera się na
utrzymywaniu i pozyskiwaniu nabywców swojego produktu lub usługi. Ze
strategicznego punktu widzenia wynika więc, że najważniejsi dla firmy są klienci,
ponieważ to oni decydują tak naprawdę o sukcesie firmy. W warunkach nasilającej się
konkurencji najważniejszym czynnikiem wpływającym na zdobycie klienta i
zatrzymanie go, a co za tym idzie – sukces przedsiębiorstwa, staje się zadowolenie
klienta.
Co tak naprawdę kryje się pod pojęciem „satysfakcja klienta” (ang. Customer
Satisfaction)? Klienci od dawna już nie płacą za produkt w sensie fizycznym, ale za to,
co w produkcie czy usłudze cenią i czego od niego/niej oczekują. W wyniku zakupu i
korzystania z produktu/usługi klient zaspokaja lub nie swoje oczekiwania. W
końcowym efekcie może on być niezadowolony (jego oczekiwania były większe),
zadowolony (oczekiwania spełniają się) lub bardzo zadowolony (oczekiwania były
mniejsze) [26]. Usatysfakcjonowani klienci są bardziej lojalni i dzielą się swoimi
korzystnymi opiniami o produkcie/usłudze z innymi, natomiast obniżenie poziomu ich
satysfakcji zmniejsza prawdopodobieństwo ponownego zakupu, a szansa na to, że nie
odejdą redukuje się do kilkunastu procent [15]. Stopień satysfakcji staje się jednym z
najlepszych wskaźników przyszłych zysków firmy oraz dużą pomocą w ustalaniu
strategii przedsiębiorstwa oraz zwiększaniu wpływów i udziału w rynku. Wszystko to
wskazuje na celowość badań ukierunkowanych na poznanie stopnia satysfakcji
klientów.
Pojawia się problem sprawnego i wiarygodnego badania tej satysfakcji ze
względu na wpływ różnorodnych czynników, czy zależność od dziedziny życia. Firmy
posiadają szereg własnych informacji bądź mają możliwość ich zgromadzenia,
najczęściej przez indywidualne wywiady grupowe, wywiady telefoniczne oraz ankiety
pocztowe. Aby dokonać najlepszej i najbardziej obiektywnej analizy satysfakcji klienta
(ASK) stosuje się wiele metod badawczych zarówno ilościowych jak i jakościowych,
m.in.: analizę poziomu sprzedaży, analizę utraty klientów, analizę reklamacji lub
kontrolowany zakup [6]. Podejmowane są próby ujednolicenia sposobów określających
stopień satysfakcji klienta, czego przykładem może być amerykański indeks satysfakcji

6
klienta (ang. American Customer Satisfaction Index) [26] oraz jego odpowiednik
szwedzki (ang. Swedish Customer Satisfaction Barometr). Wymienione indeksy oparte
są na modelu opracowanym przez C. Fornella [14], którego podstawą jest analizowanie
satysfakcji klienta w oparciu o trzy grupy czynników, tj. postrzeganą jakość,
oczekiwaną jakość i postrzeganą wartość oraz powiązania i zależności między nimi.
Otrzymywane informacje można skutecznie wykorzystać do analizy zadowolenia
odbiorców, ale są one bezwartościowe, jeśli nie są systematycznie analizowane, nie
wyciąga się z nich wniosków i nie wprowadza w życie.
Najczęstszą i najpopularniejszą formą zbierania potrzebnych informacji przez
firmy jest opracowywanie kwestionariuszy i przeprowadzanie ankiet. Pozwalają one na
wyróżnienie czynników satysfakcjonujących i
niesatysfakcjonujących klienta,
tkwiących w samym produkcie/usłudze, oraz na ocenę różnorodnych cech
produktu/usługi. Otrzymane rezultaty (dane marketingowe) można łatwo przedstawić
w postaci tabeli zwanej tablicą decyzyjną; wiersze tej tablicy zawierają uzyskane
ankiety, a kolumny kryteria oceny. Na przecięciu wiersza i kolumny znajduje się ocena
produktu/usługi ze względu na dane kryterium. Opisany powyżej model danych stanowi
typowe dane wejściowe dla metody eksploracji danych i odkrywania wiedzy opartej na
teorii zbiorów przybliżonych (ang. Rough Set Theory) zaproponowanej przez Z.
Pawlaka [20]. Podstawą filozofii zbiorów przybliżonych jest wyrażenie wiedzy o
klasyfikacji obiektów ze względu na zmienną niezależną (zwaną decyzją) za pomocą
wiedzy o klasyfikacji obiektów ze względu na zbiór zmiennych zależnych (kryteria
ocen). To wyrażenie jednej wiedzy w kategoriach innej nosi nazwę przybliżenia (ang.
approximation). Teoria ta podaje również definicje jakości przybliżenia klasyfikacji
oraz zależności występujących w danych [8][20][21]. Wynikiem analizy danych za
pomocą teorii zbiorów przybliżonych jest zbiór reguł decyzyjnych, które stanowią
zwartą reprezentację wiedzy zawartej w danych.
W zakresie poszukiwania metod i sposobów skutecznego pomiaru stopnia
satysfakcji klientów wiele jest jeszcze możliwości ich doskonalenia. Dostępne na rynku
narzędzia są najczęściej bardzo kosztowne, a same metody analizy nie są wolne od wad.
Konieczne jest więc ciągłe poszukiwanie takich sposobów pomiaru, które pozwalałyby
na osiągnięcie możliwie najwyższej skuteczności i wiarygodności przy możliwie
największej prostocie wykonania i ograniczonych kosztach. Wydaje się, że
przeprowadzanie ankiet spełnia dwa ostatnie warunki. Niniejsza praca podejmuje

7
powyższe wyzwanie z zamiarem wykorzystania podejścia zbiorów przybliżonych do
analizy wyników ankiet. Celem pracy jest sprawdzenie, czy reguły decyzyjne mogą być
pomocne w analizie satysfakcji klienta i czy możliwa jest ocena skuteczności strategii
interwencji opracowanej na podstawie uzyskanych reguł.

8
2 Cel i zakres pracy
Podstawowym celem mojej pracy było stworzenie interaktywnego systemu
wykorzystującego metodę analizy danych marketingowych dotyczących satysfakcji
klienta (kwestionariuszy, ankiet) w oparciu o teorię zbiorów przybliżonych z relacją
dominacji. W systemie należało dodatkowo zaimplementować metodologię badania
wpływu strategii interwencji wywiedzionej z reguł decyzyjnych [7], prezentację
otrzymanych wyników, a także sam algorytm indukcji satysfakcjonującego zbioru
reguł.
W ramach pracy inżynierskiej wykonanej w 2003r. na Politechnice Poznańskiej,
powstał system GoalProject [1][19] wspierający szeroko pojętą eksplorację danych.
Zawiera on m.in. moduł dostępu do danych pozwalający na odczyt/zapis plików z
tablicą decyzyjną (ISF) i ze zbiorem reguł decyzyjnych (RLS) do pamięci i do bazy
danych (MySQL) oraz moduł obliczeniowy generujący redukty i reguły decyzyjne. Aby
uniknąć powtórnego pisania powtarzalnych części systemu ustalono, że tworzony
program będzie komunikował się z GoalProject-em poprzez bazę danych MySQL i
wyciągał z niej potrzebne dane - wykorzysta się tym samym zaimplementowane już
parsery plików oraz algorytmy generowania reguł.
Ważnym elementem pracy jest odpowiedni wybór technologii programistycznej.
Ponieważ moim celem było stworzenie aplikacji wieloplatformowej, łatwo dostępnej i
darmowej, mój wybór padł na Javę. Takie założenie dodatkowo przyczyni się do
łatwiejszego rozbudowywania i dostępności systemu w przyszłości, bez ponoszenia
dodatkowych kosztów.
Główne cele projektu przedstawiają się następująco:
• stworzenie systemu regułowej analizy danych marketingowych dotyczących
satysfakcji klienta, obejmujące:
o
implementację zaproponowanej w pracy [7] metodologii badania
wpływu strategii interwencji wywiedzionej z reguł decyzyjnych,
o
opracowanie i implementację własnych propozycji i pomysłów
wykorzystania reguł decyzyjnych do analizy satysfakcji klienta,

9
• wykorzystanie systemu GoalProject
o
wczytywanie plików z danymi wejściowymi (ISF/RLS),
o
algorytmy generowania reguł,
• implementację modułu prezentacji otrzymywanych wyników analizy,
• dobre udokumentowanie pracy.
Główne założenia projektu:
• „otwartość” oprogramowania – umożliwienie łatwej rozbudowy systemu w
przyszłości,
• „przenośność” oprogramowania – możliwość uruchamiana na różnych
platformach systemowych,
• „ergonomiczność” oprogramowania – umożliwienie łatwego i możliwie
najprostszego korzystania z systemu,
• niezawodność oprogramowania,
• spójność i uniwersalność modułów.
Powyższym celom i założeniom podporządkowana jest struktura pracy złożonej
z 7 rozdziałów. W rozdziale 3 dokonano przeglądu istniejących sposobów analizy
satysfakcji klienta i nowego podejścia wykorzystującego reguły decyzyjne, a także
zaprezentowano technologię OLAP. Rozdział 4 zawiera propozycje rozszerzeń
metodologii ASK w oparciu o reguły decyzyjne. Dokładny opis powstałej aplikacji
można znaleźć w rozdziale 5. Natomiast przykład jej zastosowania w postaci
przeprowadzonego eksperymentu znajduje się w rozdziale 6. Pracę kończą 4 dodatki,
wśród których są przewodnik instalacyjny użytkownika i programisty.

10
3 Przegląd wybranych zagadnień Analizy Satysfakcji
Klienta (ASK)
Rozdział ten zawiera opis wybranych zagadnień z problematyki pracy i
dotychczasowy stan wiedzy w danym zakresie. Omówione zostały najpopularniejsze
metody badania satysfakcji klienta stosowane w praktyce, a także nowa metodologia
wykorzystująca do tego celu reguły decyzyjne. W rozdziale przedstawiono również
elementy wykorzystane w stworzonym w ramach pracy magisterskiej systemie: bardzo
efektywną i przejrzystą formę wielowymiarowej prezentacji danych, a także
zastosowanie języka SQL oraz systemu zarządzania bazą danych MySQL.
3.1 Sposoby analizy satysfakcji klienta
Uzyskanie przez przedsiębiorstwo przewagi konkurencyjnej w silnie zmiennym
otoczeniu wymaga ciągłego analizowania sytuacji rynkowej i wyprzedzania
konkurentów. W tych działaniach podstawową kategorią jest zaspokajanie potrzeb
klienta i jego (możliwie jak największe) zadowolenie. Przedstawione w tym rozdziale
metody pomiaru stopnia zadowolenia klienta, zarówno ilościowe, jakościowe i
wielowariantowe, dostarczają przedsiębiorstwu informacji do oceny satysfakcji klienta.
Ze względu na przedstawione ograniczenia tych metod konieczne jest jednak
doskonalenie ich i propagowanie w środowisku decydentów podejmujących
strategiczne decyzje rynkowe.
3.1.1 Badanie poziomu zadowolenia klienta
• Analiza poziomu sprzedaży
Ogólna analiza sprzedaży pozwala na wyznaczenie wzrostu lub spadku
sprzedaży w określonych okresach. Na poziomie pojedynczego klienta poziom
sprzedaży to analiza liczby transakcji zawartych z danym klientem w określonym
czasie oraz ich wartość pieniężna. Niestety metoda ta nie pozwala w pełni określić
poziomu zadowolenia klienta – daje jedynie ogólny pogląd na liczbę klientów
dokonujących zakupu.
Trzeba sobie zadać pytania: Czy wysoka sprzedaż oznacza zadowolenie
klientów? Czy klient dokonujący stałych zakupów jest zadowolony i pozostanie

11
lojalny wobec firmy w przyszłości? W tym przypadku nie można odpowiedzieć na
nie jednoznacznie. Wysoka sprzedaż może oznaczać zadowolenie klientów, ale
również może być wynikiem obniżek cen i promocji w danym okresie czasu.
Natomiast stałe zakupy dokonywane przez klientów mogą być spowodowane
przyzwyczajeniem lub brakiem czasu na zakupy w innej konkurencyjnej firmie.
• Analiza utraty klientów
Analiza utraty klientów jest metodą badania niezadowolenia klientów. Jeżeli
zmniejsza się liczba klientów firmy to można zakładać, że są oni niezadowoleni z jej
usług, produktów lub obsługi. Należy wtedy na bieżąco analizować ich utratę i
próbować odpowiedzieć na pytanie, dlaczego tak się dzieje, a następnie
przeciwdziałać takim sytuacjom w przyszłości.
• Analiza reklamacji
Reklamacje to cenna informacja dla firmy. W rzeczywistości reklamacje
składane przez klientów nie są dobrze odbierane przez firmy i traktowane jako
krytyka ich działań. Firma musi jednak wyciągać wnioski ze składanych skarg i
zażaleń. Z analiz wynika bowiem, że jeżeli klient zgłasza swoje niezadowolenie to
oznacza, że zależy mu na współpracy z firmą i jest do niej przywiązany. Natomiast
klient niezadowolony nie traci czasu na składanie reklamacji i woli przejść do
konkurencyjnej firmy.
• Analiza kontrolowanego zakupu
Kontrolowany zakup może być badany przez wprowadzenie klienta – aktora
(osoby zatrudnionej z zewnątrz) do udziału w zakupie. Taki klient przechodzi przez
wszystkie etapy sprzedaży i obsługi posprzedażowej, notując na bieżąco swoje
odczucia, potrzeby i uwagi. Analiza informacji zebranych w ten sposób pozwala
stwierdzić, co spodoba się potencjalnemu klientowi, a co może spowodować spadek
jego zadowolenia.
Drugą metodą analizy kontrolowanego zakupu jest zakup przez klienta –
pracownika firmy. Metoda sprowadza się do tego, że pracownik ma do wyboru
zakup produktu w sklepie firmowym z określoną zniżką lub takiego samego
produktu w konkurencyjnej firmie. Po dokonanym zakupie analizuje się, co wybrał
pracownik i jakimi kryteriami kierował się przy zakupie.

12
3.1.2 Indeks satysfakcji klienta
Indeks satysfakcji klienta [26] (ang. Customer Satisfaction Index – CSI) pozwala
na analizę poziomu zadowolenia klienta pod względem każdej cechy istotnej z punktu
widzenia satysfakcji klienta jak i całości produktu/usługi. Jest również doskonałym
narzędziem do podejmowania decyzji związanych ze strategią marketingową firmy,
ponieważ pozwala analizować zmiany preferencji i oceniać poziom satysfakcji z
produktów konkurencyjnych. Dokładniej CSI daje odpowiedź na pytania: jakie są
oczekiwania klienta co do produktu/usługi, które z tych oczekiwań mają największą
wartość dla klienta, w jakim stopniu nasz produkt lub konkurencyjny spełnia te
oczekiwania, oraz w które elementy należy inwestować i rozwijać, a które są
przeinwestowane.
W analizie można wyróżnić trzy etapy:
• Etap I – wtórna eksploracja
Celem tego etapu jest zdefiniowanie cech, które mają być oceniane i
wyeliminowanie niepotrzebnych elementów badania. W praktyce wiele informacji
posiada sama firma, dlatego też w tym etapie przeprowadza się analizę informacji
dostępnych wewnątrz firmy prowadząc rozmowy z pracownikami poszczególnych
działów (sprzedaży, marketingu, produkcji). W wyniku definiowane są czynniki
generujące zadowolenie lub niezadowolenie klienta oraz kryteria, którymi kierują
się nabywcy.
• Etap II – budowa kwestionariusza
Budowa kwestionariusza polega na umieszczaniu w nim odpowiednich pytań
dotyczących czynników satysfakcji klienta, zdefiniowanych w pierwszym etapie,
dających się zwymiarować za pomocą skali Likerta (od 1 do 5). Respondenci
dodatkowo nadają powyższym czynnikom wagi, co w rezultacie powoduje, że
otrzymana ocena konkretnego czynnika jest miara ważoną. Ponieważ stworzenie
dobrego kwestionariusza nie jest rzeczą trywialną, więc istnieją różne podejścia
tworzenia takich kwestionariuszy, przykładem może być amerykański lub szwedzki
indeks satysfakcji klienta [10].
• Etap III – prezentacja i analiza wyników
Ogólny ważony CSI jest miarą średnią z ważonych ocen wszystkich czynników.
Procedura wyliczania ważonych ocen każdego czynnika jest dokonywana dla

13
każdego respondenta, natomiast miara CSI wykonywana jest dla danej firmy jak
również dla każdej firmy konkurencyjnej, co umożliwia dokonywanie
pozycjonowania firm pod względem ich atrakcyjności dla klientów.
Skonstruowany indeks zadowolenia klienta przedstawiany jest również w
powiązaniu z przychodami firmy. Przychody wynikające z zadowolenia klienta
opisuje się w postaci funkcji zależnej od kształtowania się tego indeksu. Funkcja
jest z założenia rosnąca, co oznacza, że im wyższy jest indeks tym przedsiębiorstwo
osiąga wyższe przychody.
Na sam koniec należy zaznaczyć, że omawiana w tym punkcie metoda badania
satysfakcji klienta nie jest bez wad i ma swoje ograniczenia. Jej stosowanie wymaga
systematycznego prowadzenia badań rynkowych. Poza tym wyższy indeks zadowolenia
klienta może, lecz nie musi, oznaczać wyższych przychodów ze sprzedaży i-tego
produktu. Ograniczeniem jest to, że przyjmuje się teoretyczne założenia dotyczące
tworzenia indeksu – wielowariantową ocenę produktu przez klienta przy użyciu n
różnych parametrów oraz uwzględnienie znaczenia każdego z parametrów przez
przyporządkowanie mu odpowiedniego współczynnika znaczenia (wagi). Dodatkowo
należy zapewnić porównywalność parametrów i ich wag.
3.1.3 Zarządzanie relacjami z klientem
Zarządzanie relacjami klienta [4] (ang. Customer Relationship
Management – CRM) to koncepcja określana mianem strategii, której głównym celem
jest budowanie długotrwałych i pozytywnych relacji z klientami. Program ten obejmuje
zarówno same przedsiębiorstwo, jak i jego partnerów rynkowych (dostawców,
uczestników kanałów dystrybucji, klientów) tworząc w ten sposób tzw. sieć wartości.
Na strategie składają się cztery etapy: zdefiniowanie wartości dla klienta, kreowanie
wartości dla klienta, komunikowanie wartości dostarczonej klientom (dotarcie do
wybranych klientów, umiejętność kształtowania ich oczekiwań i wsłuchiwania się w ich
potrzeby), dostarczanie klientom oczekiwanej wartości.
Takie rozwiązanie pozwala firmom na podnoszenie zadowolenia klientów, na lepsze
utrzymanie ich najbardziej wartościowych klientów i zdobywanie nowych w tym
samym czasie. Ponieważ bardzo trudnym staje się rozpoznanie potrzeb i preferencji
klientów, to około 55% wdrożonych programów nie przyniosło oczekiwanych korzyści.

14
3.2 ASK przy wykorzystaniu reguł decyzyjnych
Reguły decyzyjne są wynikiem eksploracji danych i stanowią pewien rodzaj
odkrytej wiedzy. Zawierają one informacje o regularnościach w danych z przeszłości,
ale mogą być również bardzo użyteczne w podejmowaniu decyzji w przyszłości.
Przykładowo w odniesieniu do medycyny reguła z jednej strony ukazuje zależności
między objawami a chorobą, ale może także pomagać w diagnozowaniu nowych
pacjentów. Dodatkowo taka reguła może nam podpowiedzieć określoną strategię
interwencji, która umożliwi osiągnięcie wyznaczonego celu – dla opisywanego
przypadku medycznego z reguły możemy się dowiedzieć, co zrobić, aby zwiększyć
wyleczalność z danej choroby.
W punkcie tym zostały przedstawione elementy teorii zbiorów przybliżonych
oraz indukcji reguł decyzyjnych, a także elementy metodologii badania oczekiwanej
efektywności strategii interwencji, której dokładny opis można znaleźć w artykule [7].
3.2.1 Elementy teorii zbiorów przybliżonych i indukcji reguł decyzyjnych
a. Wprowadzenie
Teoria zbiorów przybliżonych [8][20][23][24][25] jest jednym z podejść
rozumienia pojęcia zbioru, natomiast z praktycznego punktu widzenia teoria ta jest
nową metodą analizy danych. W klasycznej teorii mnogości, zbiór jest definiowany
poprzez swoje elementy, przy czym nie jest tu potrzebna żadna dodatkowa wiedza o
elementach uniwersum, z których tworzymy zbiory. W teorii zbiorów przybliżonych
przeciwnie, zakłada się, iż istnieją pewne dane o elementach uniwersum i dane te są
wykorzystywane w tworzeniu zbiorów. Elementy, o których mamy identyczną
informację są nierozróżnialne i tworzą tzw. zbiory elementarne. Stanowią one podstawę
rozumowań w teorii zbiorów przybliżonych. Suma dowolnych zbiorów elementarnych
jest nazywana zbiorem definiowalnym. Zbiory, które nie są zbiorami definiowalnymi
nazywane są zbiorami przybliżonymi.
Oczywiście, zbiory definiowalne można jednoznacznie scharakteryzować
poprzez własności ich elementów, natomiast zbiorów przybliżonych nie można
scharakteryzować w ten sposób. Np. zbiór „liczb parzystych” jest pojęciem
definiowalnym (ostrym), gdyż każdą liczbę naturalną możemy jednoznacznie
zaklasyfikować jako parzystą lub nieparzystą. Natomiast zbiór „zdolnych studentów”

15
jest pojęciem przybliżonym (nieostrym), gdyż nie o każdym studencie możemy
jednoznacznie twierdzić, iż jest on zdolny czy też nie. Dlatego w teorii zbiorów
przybliżonych wprowadza się pojęcia dolnego i górnego przybliżenia zbioru, które
pozwalają każdy zbiór niedefiniowalny (przybliżony) scharakteryzować za pomocą dwu
zbiorów definiowalnych
− jego dolnego i górnego przybliżenia.
b. Zbiory przybliżone – pojęcia podstawowe
System informacyjny, jest parą
)
,
,
,
(
f
V
A
U
, gdzie U jest niepustym i
skończonym zbiorem obiektów zwanym uniwersum, A jest niepustym i skończonym
zbiorem atrybutów.
U
A
a
a
V
V
∈
=
,
a
V jest dziedziną atrybutu a
∈
A, oraz
V
A
U
f
→
×
:
jest funkcją informacyjną, taką, że
∀
a
∈
A, x
∈
U, f(a,x)
∈
a
V
. Jeżeli w systemie
informacyjnym wyróżniamy rozłączne zbiory atrybutów warunkowych C i atrybutów
decyzyjnych D (gdzie A=C
∪
D), to system taki nazywany jest tablicą decyzyjną.
Z każdym podzbiorem atrybutów P
⊆
A związana jest binarna relacja I(P),
nazywana relacją nierozróżnialności, zdefiniowana jako:
I(P) = {(x,y)
∈U×U : f(a,x)=f(a,y), ∀a∈P}
Jeśli (x,y)
∈
I(P) to obiekty x i y są nierozróżnialne ze względu na podzbiór atrybutów P
(relacja nierozróżnialności jest relacją równoważności). P(x) oznacza klasę abstrakcji
relacji I(P) zawierającą obiekt x i nazywane są zbiorami P-elementarnymi.
Niech
)
,
,
,
(
f
V
A
U
S
=
będzie systemem informacyjnym, X niepustym
podzbiorem U oraz P
⊆
A. Celem jest opisanie zbioru X w kategoriach wartości
atrybutów z P. Prowadzi to zdefiniowania dwóch zbiorów
( )
X
P
i
( )
X
P
, nazywanych
odpowiednio P-dolnym przybliżeniem i P-górnym przybliżeniem X, zdefiniowanych
jako:
( )
}
)
(
:
{
X
x
P
U
x
X
P
⊆
∈
=
( )
( )
{
}
∅
≠
∩
∈
=
X
x
P
U
x
X
P
:
Zbiór (różnica między górnym a dolnym przybliżeniem) BN
P
(X) =
( )
X
P
–
( )
X
P
jest
nazywany P-brzegiem zbioru X. Dolne przybliżenie
( )
X
P
zbioru X jest zbiorem
obiektów, które można z pewnością zaliczyć do X na podstawie zbioru atrybutów P (w
świetle posiadanej wiedzy mogą być zaklasyfikowane jednoznacznie do rozważanego
zbioru), podczas gdy obiekty z
( )
X
P
mogą być tylko uznane za możliwie należące do

16
X, na podstawie atrybutów P (nie można ich wykluczyć, w świetle posiadanej wiedzy, z
danego zbioru). P-brzeg BN
P
(X) zawiera obiekty, których nie można jednoznacznie
przydzielić do X z uwagi na sprzeczny opis w terminach atrybutów P. Natomiast
obiekty z U\
( )
X
P
z pewnością nie należą do X. O zbiorze X mówimy, że jest
P-przybliżony, jeśli BN
P
(X)
≠
∅
(gdy jego obszar brzegowy jest niepusty) w
przeciwnym razie jest on P-definiowalny (dokładny). Zauważmy też, że konstrukcja
przybliżeń ma charakter obliczeń granularnych, gdyż operuje na blokach obiektów
nierozróżnialnych przez atrybuty P, czyli na zbiorach P-elementarnych.
Wiersze tablicy decyzyjnej określają reguły decyzyjne, które można wyrazić w
postaci wyrażeń „jeżeli…,to…”:
Ψ
→
Φ
, gdzie
m
Φ
∧
∧
Φ
∧
Φ
=
Φ
...
2
1
jest częścią
warunkową reguły, a
Ψ jej częścią decyzyjną. Każda reguła decyzyjna wyznacza
decyzje, które musza być podjęte, jeśli warunki podane w tablicy są spełnione. Reguły
decyzyjne są ściśle związane z przybliżeniami. Dolne przybliżenia klas decyzyjnych
wyznaczają deterministyczne reguły decyzyjne, to jest takie reguły, które jednoznacznie
wyznaczają decyzje na podstawie warunków; zaś górne przybliżenia klas decyzyjnych
wyznaczają niedeterministyczne reguły decyzyjne, to jest reguły nie wyznaczające
jednoznacznie decyzji na podstawie warunków.
Atrybuty z dziedziną uporządkowaną według preferencji nazywane są
kryteriami, ponieważ dotyczą oceny w określonej skali preferencji. Przykład natomiast
to wiersz tablicy decyzyjnej, czyli obiekt z opisem i przydziałem do klasy.
c. Podejście zbiorów przybliżonych oparte na relacji dominacji
Ogólnie semantyczna korelacja między kryteriami warunkowymi a decyzyjnymi
wymaga, by obiekt x dominujący obiekt y na wszystkich kryteriach warunkowych (tzn.
x mający oceny co najmniej tak dobre jak y na wszystkich kryteriach warunkowych)
powinien również dominować y na wszystkich kryteriach decyzyjnych (tzn. x powinien
być oceniony co najmniej tak dobrze jak y na wszystkich kryteriach decyzyjnych).
Zasada ta zwana jest zasadą dominacji (lub zasadą Pareto) i jest to jedyna obiektywna
zasada wielokryterialnego porównywania obiektów, której racjonalności nikt nie
podważa.
Każda reguła decyzyjna określona jest przez profil warunkowy i profil
decyzyjny, które są wektorami wartości progowych na wybranych atrybutach i

17
kryteriach, odpowiednio, po stronie warunkowej i decyzyjnej. Mówimy, że jeden profil
dominuje drugi, jeśli oba profile mają takie same wartości na zwykłych atrybutach, a
wartości kryteriów pierwszego profilu są nie gorsze od wartości kryteriów drugiego
profilu.
Zachowując oznaczenia, przyjmiemy ponadto, że X
C
=
∏
=
C
q
q
V
1
i X
D
=
∏
=
D
q
q
V
1
oznaczają odpowiednio, przestrzenie atrybutów warunkowych i decyzyjnych. Punkty
przestrzeni X
C
i X
D
są wektorami możliwych ocen obiektów, odpowiednio, za pomocą
atrybutów warunkowych C={1,…,|C|} i decyzyjnych D={1,…,|D|}. Ocena obiektu x na
atrybucie q
∈
A jest oznaczona przez x
q
. Relacja nierozróżnialności na U ze względu na
zbiór atrybutów decyzyjnych D dokonuje podziału U na skończoną liczbę klas
decyzyjnych Cl={Cl
t
, t=1,...,n}. Każdy obiekt x
∈
U należy do jednej i tylko jednej klasy
Cl
t
∈
Cl. Załóżmy bez utraty ogólności, że wszystkie atrybuty warunkowe w C i
decyzyjne w D są kryteriami, oraz że C i D są skorelowane semantycznie.
Niech
q
f
będzie relacją słabej preferencji na U (zwaną też relacją
przewyższania) reprezentującą preferencję na zbiorze obiektów ze względu na
kryterium q
∈
{C
∪
D}; x
q
q
f
y
q
oznacza, że “x
q
jest co najmniej tak dobry jak y
q
ze
względu na kryterium q”. Z drugiej strony mówimy, że x dominuje y ze względu na
P
⊆
C (x P-dominuje y) w przestrzeni atrybutów warunkowych X
P
(oznaczenie: xD
P
y)
jeśli x
q
q
f
y
q
dla wszystkich kryteriów q
∈
P. Zakładając, bez utraty ogólności, że
dziedziny wszystkich kryteriów są liczbowe, tzn. X
q
⊆
R dla każdego q
∈
C, oraz, że są
uporządkowane w ten sposób, że preferencja rośnie z wartością, można powiedzieć, że
xD
P
y jest równoważne: x
q
≥
y
q
dla wszystkich q
∈
P, P
⊆
C. Zauważmy, że dla każdego
x
∈
X
P
, xD
P
x, tzn. P-dominacja jest zwrotna. Analogiczną definicję dominacji można
sformułować dla przestrzeni atrybutów decyzyjnych X
R
(oznaczenie: xD
R
y), R
⊆
D.
Relacje dominacji xD
P
y i xD
R
y (P
⊆
C i R
⊆
D) są stwierdzeniami
ukierunkowanymi, w których x jest podmiotem a y jest obiektem odniesienia. Jeśli
x
∈
X
P
jest obiektem odniesienia, P
⊆
C, to można zdefiniować zbiór obiektów y
∈
X
P
P-
dominujących x, zwany zbiorem P-dominującym:
D
P
+
(x)={y
∈U: yD
P
x}. Jeśli x
∈
X
P
jest
podmiotem, P
⊆
C, to można zdefiniować zbiór obiektów y
∈
X
P
P-zdominowanych przez
x, zwany zbiorem P-zdominowanym:
D
P
−
(x)={y
∈U: xD
P
y}.

18
Jeśli chodzi o przestrzeń atrybutów decyzyjnych X
R
, R
⊆D, to relacja
R-dominacji pozwala na zdefiniowanie zbiorów: Cl
x
R
≥
={y
∈U: yD
R
x},
Cl
x
R
≤
={y
∈U: xD
R
y}.
q
t
Cl
={x
∈
X
D
: x
q
=t
q
} jest klasą decyzyjną ze względu na pojedyncze kryterium
decyzyjne q
∈
D. Cl
x
R
≥
nazywamy złożeniem klas „w górę”, a Cl
x
R
≤
, złożeniem klas „w
dół”. Jeśli x
∈
Cl
x
R
≥
, to x należy do klasy
q
t
Cl
, x
q
=t
q
, lub lepszej, na każdym kryterium
decyzyjnym q
∈
R. Jeśli z kolei x
∈
Cl
x
R
≤
, to x należy do klasy
q
t
Cl
, x
q
=t
q
, lub gorszej, na
każdym kryterium decyzyjnym q
∈
R. Złożenia klas w górę i w dół odpowiadają
pozytywnym i negatywnym stożkom dominacji w X
R
, z początkiem w punkcie x o
współrzędnych [
q
t
Cl
, x
q
=t
q
, q
∈
R].
d. Podejście zbiorów przybliżonych oparte na dominacji – DRSA
W sytuacjach praktycznych zbiór D atrybutów decyzyjnych jest zazwyczaj
jednoelementowy, D={d}. Przyjmijmy to założenie, aczkolwiek nie jest ono konieczne
dla DRSA. Atrybut decyzyjny d dokonuje, tak samo jak poprzednio zbiór D, podziału U
na skończona liczbę klas decyzyjnych Cl={Cl
t
, t=1,...,n}. Także tutaj, im wyższy numer
klasy, tym lepsza klasa. Złożenia klas decyzyjnych w górę i w dół sprowadzają się,
odpowiednio, do:
U
t
s
s
t
Cl
Cl
≥
≥
=
,
U
t
s
s
t
Cl
Cl
≤
≤
=
, t=1,...,n,
co odpowiada określeniom: „klasa co najmniej Cl
t
” i „klasa co najwyżej Cl
t
”.
Zauważmy, że
U
Cl =
≥
1
,
U
Cl
n
=
≤
, oraz dla t=2,...,n mamy Cl
t
≥
=U– Cl
t
≤
−1
, tzn. wszystkie
obiekty nie należące do klasy Cl
t
lub lepszej, należą do klasy Cl
t-1
lub gorszej.
Wyjaśnijmy jak pojęcie zbioru przybliżonego zostało uogólnione w podejściu
DRSA w celu umożliwienia obliczeń granularnych na stożkach dominacji. Dla danego
zbioru kryteriów P
⊆C, zaliczenie obiektu x∈U do złożenia klas w górę Cl
t
≥
, t=2,…,n,
jest niespójne z zasadą dominacji, gdy zachodzi jedna z poniższych sytuacji:
• obiekt x należy do klasy Cl
t
lub lepszej, lecz jest P-zdominowany przez obiekt y
należący do klasy gorszej od Cl
t
, tzn. x
∈Cl
t
≥
lecz
)
(
x
D
P
+
∩
≤
−1
t
Cl
≠∅,

19
• obiekt x należy do klasy gorszej od Cl
t
lecz
P-dominuje obiekt y należący do
klasy
Cl
t
lub lepszej, tzn.
x
∉Cl
t
≥
lecz
)
(
x
D
P
−
∩Cl
t
≥
≠∅.
Jeśli dla danego zbioru kryteriów
P
⊆C, zaliczenie x∈U do Cl
t
≥
,
t=2,…,n, jest niespójne
z zasadą dominacji, to mówimy, że
x należy do Cl
t
≥
z pewną wątpliwością. Zatem, x
należy do Cl
t
≥
bez wątpliwości
, biorąc pod uwagę P
⊆C, jeśli x∈Cl
t
≥
i nie ma
niespójności z zasadą dominacji. To oznacza, że wszystkie obiekty
P-dominujące x
należą do Cl
t
≥
, tzn.
)
(
x
D
P
+
⊆Cl
t
≥
. Ponadto, x być może należy do Cl
t
≥
, biorąc pod
uwagę
P
⊆C, gdy zachodzi jedna z poniższych sytuacji:
• zgodnie z decyzją d, x należy do Cl
t
≥
,
• zgodnie z decyzją d, x nie należy do Cl
t
≥
, lecz obiekt ten jest niespójny w sensie
zasady dominacji z obiektem
y należącym do Cl
t
≥
.
Używając pojęcia wątpliwości,
x być może należy do Cl
t
≥
, biorąc pod uwagę
P
⊆C, jeśli x należy do Cl
t
≥
z wątpliwością lub bez. Ze względu na zwrotność relacji
dominacji
D
P
, powyższe sytuacje mogą być podsumowane następująco: biorąc pod
uwagę
P
⊆C, x być może należy do klasy Cl
t
lub lepszej, jeśli wśród obiektów
P-zdominowanych przez x istnieje obiekt y należący do klasy Cl
t
lub lepszej, tzn.
)
(
x
D
P
−
∩Cl
t
≥
≠∅.
Dla
P
⊆C, zbiór wszystkich obiektów należących bez wątpliwości do Cl
t
≥
tworzy
P-dolne przybliżenie złożenia klas Cl
t
≥
, oznaczone przez
)
(Cl
P
t
≥
; natomiast
zbiór wszystkich obiektów należących być może do Cl
t
≥
tworzy
P-górne przybliżenie
złożenia klas Cl
t
≥
, oznaczone przez
)
(Cl
P
t
≥
:
)
(Cl
P
t
≥
={
x
∈U:
)
(
x
D
P
+
⊆ Cl
t
≥
},
)
(Cl
P
t
≥
={
x
∈
U:
)
(
x
D
P
−
∩Cl
t
≥
≠∅
},
t=2,…,n
Analogicznie można zdefiniować
P-dolne przybliżenie i P-górne przybliżenie złożenia
klas Cl
t
≤
:
)
(Cl
P
t
≤
={
x
∈U:
)
(
x
D
P
−
⊆ Cl
t
≤
},
)
(Cl
P
t
≤
={
x
∈U:
)
(
x
D
P
+
∩Cl
t
≤
≠∅
},
t=1,...,n-1
20
e. Indukcja reguł decyzyjnych
Zdefiniowane w poprzednim punkcie przybliżenia złożeń klas decyzyjnych „w
górę” i „w dół” są punktem wyjścia dla indukcyjnego generowania reguł decyzyjnych
opartych na dominacji. Dla danego złożenia klas Cl
t
≥
, reguły decyzyjne indukowane
przy założeniu, że obiekty należące do dolnego przybliżenia
)
(Cl
P
t
≥
są pozytywne, a
wszystkie inne negatywne, zalecają przydział do „klasy
Cl
t
lub lepszej”. Analogicznie,
dla danego złożenia klas
≤
s
Cl , reguły decyzyjne indukowane przy założeniu, że obiekty
należące do dolnego przybliżenia
)
(
≤
s
Cl
P
są pozytywne, a wszystkie inne negatywne,
zalecają przydział do „klasy Cl
s
lub gorszej”. Z drugiej strony, reguły decyzyjne
indukowane przy założeniu, że obiekty należące do przekroju
)
(
)
(
≥
≤
∩
t
s
Cl
P
Cl
P
są
pozytywne, a wszystkie inne negatywne, zalecają przydział do ciągu dwóch lub więcej
klas od
Cl
s
do
Cl
t
(
s<t).
W celu uwzględnienia porządku preferencyjnego, zaproponowano reguły
decyzyjne o składni opartej na dominacji. W zależności od źródła obiektów
pozytywnych w procedurze indukcji reguł, rozpatruje się następujące typy reguł:
1) D≥-reguły pewne, dla których obiektami pozytywnymi są obiekty należące do
)
(Cl
P
t
≥
:
Jeżeli x
q1
f
q1
r
q1
oraz x
q2
f
q2
r
q2
oraz … x
qp
f
qp
r
qp
,
to x należy do Cl
t
≥
,
gdzie dla każdego
w
q
,z
q
∈X
q
, “
w
q
f
q
z
q
” oznacza, że “
w
q
jest co najmniej tak dobry
jak
z
q
”,
2) D≥-reguły możliwe, dla których obiektami pozytywnymi są obiekty należące do
)
(Cl
P
t
≥
:
Jeżeli x
q1
f
q1
r
q1
oraz x
q2
f
q2
r
q2
oraz … x
qp
f
qp
r
qp
,
to x być może należy do
Cl
t
≥
,
3) D≤-reguły pewne, dla których obiektami pozytywnymi są obiekty należące do
)
(Cl
P
t
≤
:
Jeżeli x
q1
p
q1
r
q1
oraz x
q2
p
q2
r
q2
oraz … x
qp
p
qp
r
qp
,
to x należy do Cl
t
≤
,
gdzie dla każdego
w
q
,z
q
∈X
q
, “
w
q
p
q
z
q
” oznacza, że “
w
q
jest co najwyżej tak
dobry jak
z
q
”,
4) D≤-reguły możliwe, dla których obiektami pozytywnymi są obiekty należące do
)
(Cl
P
t
≤
:
Jeżeli x
q1
p
q1
r
q1
oraz x
q2
p
q2
r
q2
oraz … x
qp
p
qp
r
qp
,
to x być może należy do
Cl
t
≤
,

21
5) D≥≤-reguły przybliżone, dla których obiektami pozytywnymi są obiekty
należące do
)
(
)
(
≥
≤
∩
t
s
Cl
P
Cl
P
(
s<t): Jeżeli x
q1
f
q1
r
q1
oraz... x
qk
f
qk
r
qk
oraz
x
qk+1
p
qk+1
r
qk+1
oraz ... x
qp
p
qp
r
qp
,
to x należy do Cl
s
∪Cl
s+1
∪…∪Cl
t
.
W części warunkowej D≥≤-reguł przybliżonych możemy mieć warunki “x
q
f
q
r
q
” i
“
x
q
p
q
r'
q
”, gdzie
r
q
≤r'
q
, dla tego samego kryterium
q
∈C. Ponadto, jeśli r
q
=
r'
q
, to te dwa
warunki sprowadzają się do “
x
q
∼
q
r
q
”, gdzie dla każdego
w
q
,z
q
∈X
q
, “
w
q
∼
q
z
q
” oznacza, że
“
w
q
jest nierozróżnialny z
z
q
”.
Reguły decyzyjne typu 1) i 3) reprezentują wiedzę pewną wyindukowaną z
tablicy decyzyjnej, podczas gdy reguły typu 2) i 4) reprezentują wiedzę możliwą (być
może wątpliwą), a reguły typu 5) reprezentują wiedzę wątpliwą. Ponadto, reguły typu 1)
i 3) są dokładne, jeśli nie pokrywają obiektów spoza klas wskazanych w części
decyzyjnej; w przeciwnym razie są one probabilistyczne. Reguła probabilistyczna jest
scharakteryzowana przez współczynnik wiarygodności, określający
prawdopodobieństwo, że obiekt spełniający część warunkową reguły spełnia również
jej część decyzyjną. Aby go czytelnie zapisać wprowadźmy na początek pewne
oznaczenia:
)
(
Φ
m
będzie oznaczać zbiór obiektów spełniających wyrażenie
warunkowe
Φ ,
)
(
Ψ
m
zbiór obiektów należących do klasy decyzyjnej Ψ ,
)
(
Φ
m
to
liczba obiektów spełniających część warunkową reguły, a
)
(
)
(
Ψ
∩
Φ
m
m
to liczba
obiektów spełniających zarówno część warunkową jak i decyzyjną reguły. Drugą
natomiast zaufanie reguły lub inaczej jej pewność:
)
(
)
(
)
(
)
,
(
Φ
Ψ
∩
Φ
=
m
m
m
U
r
conf
Zakres tej miary zawiera się w przedziale <0, 1> i jeśli otrzymaną wartość pomnożymy
razy 100% to można ją interpretować jako prawdopodobieństwo przynależności
obiektów do danej klasy
Ψ przy spełnionych warunkach Φ .
Inną miarą jest siła reguły definiowana przez liczbę obiektów pokrywanych
przez część warunkową reguły i należących do zalecanej klasy (spełniających jej część
decyzyjną):
)
(
)
(
)
,
(
Ψ
∩
Φ
=
m
m
U
r
strength

22
3.2.2 Wprowadzenie do metodologii ASK w oparciu o reguły decyzyjne
Załóżmy, że mam przykładowy zbiór danych
U
w postaci tablicy decyzyjnej.
Indukujemy z niego zbiór reguł decyzyjnych informujący nas o występujących
regularnościach w danych. Dodatkowo posiadamy inny zbiór danych
'
U
, w
szczególnym przypadku może się on pokrywać z
U
, na którym chcemy sprawdzić
wywiedzioną z reguł strategię interwencji. W wyniku jej zastosowania na zbiorze
'
U
otrzymujemy nowy zbiór
''
U
. Jeśli odnieść to do rzeczywistości to przykładowo w
medycynie mamy zbiór pacjentów i strategię w postaci leczenia objawów powiązanych
z chorobą w celu wyleczenia pacjenta. Innym przykładem może być dziedzina
marketingu i zbioru danych w postaci klientów oraz strategii polegającej na zmianach
ocen produktów/usług przez klientów w celu zwiększenia liczby zadowolonych.
W szczególności przypuśćmy, że mamy regułę decyzyjną wyidukowaną ze
zbioru
U
postaci: „jeśli pewien składnik
α jest obecny we krwi pacjenta, to pacjent
jest zdrowy” z zaufaniem
)
,
( U
r
conf
. Zależy nam oczywiście na jak największej liczbie
zdrowych pacjentów. Strategia wywiedziona z takiej reguły nakazuje nam „wstrzyknąć
składnik
α do krwi tym pacjentom, którzy go nie mają i są chorzy”. W tym momencie
nasuwa się pytanie o oczekiwany procentowy wzrost zdrowych pacjentów po
zastosowaniu takiego rodzaju leczenia (co nam da zastosowanie takiej właśnie strategii
interwencji). Formalny zapis powyższej metodologii został zaproponowany w [7] i jest
przedstawiony w kolejnym podpunkcie. Należy zaznaczyć, że całość propozycji opiera
się na hipotezie homogeniczności (jednorodności) zbiorów
U
i
'
U
.
3.2.3 Formalne przedstawienie metodologii
Niech dana będzie reguła
r , dla której liczona będzie miara skuteczności
wywiedzionej strategii interwencji:
Ψ
→
Φ
∧
∧
Φ
∧
Φ
≡
n
r
...
2
1
W odniesieniu do medycyny powyższą regułę można zapisać w postaci „jeżeli składniki
A
1
i
A
2
… i
A
n
są obecne we krwi pacjenta, to pacjent jest zdrowy” z
prawdopodobieństwem
)
,
( U
r
conf
.
Załóżmy, że strategią dla tej reguły będzie leczenie
T - „wprowadź składnik A
1
i
A
2
… i
A
n
do krwi pacjentom, którzy nie mają tych składników i są chorzy”. Leczenie
T może
być w takim przypadku dodatkowo rozbite na pewne bardziej szczegółowe leczenia
23
T
P
– „wprowadź tylko składniki
A
i
(
N
P
i
⊆
∈
) do krwi pacjentom, którzy nie mają
żadnego ze składników
A
i
(
P
i
∈
), ale mają składniki
A
j
(
P
j
∉ ) i są chorzy”. W takim
przypadku dla każdego
N
P
⊆ można zadać pytanie, jaki będzie oczekiwany wzrost
liczby zdrowych pacjentów po zastosowaniu leczenia
T
P
?
W oparciu o powyższe rozważania i wprowadzone wcześniej oznaczenia
oczekiwany wzrost liczby zdrowych pacjentów można wyliczyć następująco:
'
)
(
'
)
(
'
)
(
'
)
,
(
)
(
U
m
m
m
U
r
conf
i
P
i
i
P
i
P
Ψ
¬
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
¬
×
=
Ψ
∉
∈
I
I
δ
Ten sam wzór można zapisać inaczej:
'
)
(
'
)
(
'
)
(
'
)
(
'
)
(
'
)
(
)
(
)
(
)
(
U
m
m
m
m
m
m
m
m
i
P
i
i
P
i
i
N
i
i
N
i
P
Ψ
¬
×
Ψ
¬
Ψ
¬
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
¬
×
⎥⎦
⎤
⎢⎣
⎡
Φ
Ψ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
=
Ψ
∉
∈
∈
∈
I
I
I
I
δ
'
)
(
'
)
'
,
(
)
,
(
)
(
U
m
U
s
conf
U
r
conf
P
P
Ψ
¬
×
×
=
Ψ
δ
, gdzie
(
)
( )
i
P
i
i
P
i
P
s
Φ
∧
∧
Φ
¬
∧
→
Ψ
¬
≡
∉
∈
Na podstawie powyższej formuły można zdefiniować wskaźnik efektywności
stworzonej strategii pod względem konsekwencji reguły decyzyjnej r , wyidukowanej
ze zbioru
U
i zastosowanej na
i
P
i
Φ
∧
∈
w zbiorze
'
U
:
)
'
,
(
)
,
(
)
'
,
,
(
U
s
conf
U
r
conf
U
U
r
E
P
P
×
=
Ψ
Oczekiwany wzrost liczy zdrowych pacjentów można wyrazić także formułą:
'
)
(
'
)
(
'
)
(
'
)
(
'
)
(
'
)
(
'
)
(
'
)
(
)
(
)
(
)
(
U
m
m
m
m
m
m
m
m
m
m
i
P
i
i
P
i
i
P
i
i
P
i
i
P
i
i
P
i
i
N
i
i
N
i
P
⎥⎦
⎤
⎢⎣
⎡
Φ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
¬
×
×
⎥⎦
⎤
⎢⎣
⎡
Φ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
¬
Ψ
¬
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
¬
×
⎥⎦
⎤
⎢⎣
⎡
Φ
Ψ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
=
Ψ
∉
∈
∉
∈
∉
∈
∈
∈
I
I
I
I
I
I
I
I
δ
'
)
(
'
)
(
'
)
'
,
(
)
,
(
)
(
U
m
m
U
t
conf
U
r
conf
i
P
i
i
P
i
P
P
⎥⎦
⎤
⎢⎣
⎡
Φ
∩
⎥⎦
⎤
⎢⎣
⎡
Φ
¬
×
×
=
Ψ
∉
∈
I
I
δ
, gdzie
(
)
( )
Ψ
¬
→
Φ
∧
∧
Φ
¬
∧
≡
∉
∈
i
P
i
i
P
i
P
t

24
Na bazie powyższych wyliczeń można zdefiniować inny indeks – efektywności
wywiedzionej strategii pod względem przesłanki reguły decyzyjnej r , wyidukowanej
ze zbioru
U
i zastosowanej na
i
P
i
Φ
∧
∈
w zbiorze
'
U
:
)
'
,
(
)
,
(
)
'
,
,
(
U
t
conf
U
r
conf
U
U
r
E
P
P
×
=
Φ
Podsumowując, oczekiwany wzrost liczby zdrowych pacjentów po zastosowaniu
leczenia
T będzie równy:
∑
⊆
Ψ
=
Ψ
N
P
P
)
(
)
(
δ
δ
Opisywana metodologia wprowadza jeszcze dwa współczynniki pomocne w
mierzeniu oczekiwanej efektywności strategii interwencji opartej na regułach
decyzyjnych. Pierwszy z nich określa udział (wkład) warunku
N
i
i
∈
Φ ,
użytego w
strategii bazującej na regule
r i jest ilorazem sumy oczekiwanych wzrostów
)
(
Ψ
P
δ
na
skutek leczeń
T
P
i liczności zbioru
P, dla wszystkich P zawierających i:
∑
∈
⊆
Ψ
=
Φ
P
i
N
P
P
i
P
c
:
)
(
)
(
δ
Drugi natomiast definiuje kompletną skuteczność warunku
N
i
i
∈
Φ ,
użytego w tej
strategii:
∑
∈
⊆
Ψ
=
Φ
P
i
N
P
P
i
P
U
U
r
E
I
:
)
'
,
,
(
)
(
Opisana tutaj metodologia jest jednym ze sposobów wykorzystania odkrytej
wiedzy. Pokazuje jak tworzyć strategie bazujące na regułach decyzyjnych
wyidukowanych z danych, a także jak mierzyć oczekiwaną efektywność ich stosowania.
Całe działanie sprowadza się do 3 kroków:
1) Indukcja reguł decyzyjnych w zbiorze
U
,
2) Interwencja (modyfikacja) w zbiorze
'
U
tak, aby w rezultacie otrzymać
pożądane wyniki,
3) Przejście ze zbioru
'
U
do zbioru
''
U
na skutek interwencji dokonanej w
kroku 2.

25
3.3 Technologia analizy wielowymiarowych danych OLAP
Technologia OLAP (ang. On-line Analytic Processing) jest bardzo dynamicznie
rozwijającym się narzędziem do interakcyjnego tworzenia, zarządzania i analizy danych
postrzeganych jako struktury wielowymiarowe [5]. Podstawowymi korzyściami
wynikającymi ze struktur wielowymiarowych do przechowywania informacji to
przejrzysta reprezentacja wiedzy i znaczenie efektywnościowe. Interakcyjna eksploracja
i zgłębianie danych to najpopularniejsze wykorzystanie techniki OLAP. Należy
zauważyć, że pomimo swej nazwy (on-line) analizy nie muszą być przeprowadzane na
bieżąco (w czasie rzeczywistym).
Systemy wykorzystujące tę technikę możemy traktować nie tylko jako sposób na
dokonywanie wszechstronnych analiz danych, ale jako sposób na odkrywanie wiedzy.
Mogą one operować na dowolnym typie nieprzetworzonej informacji, nawet informacji
nie ujętej w określone struktury, oraz mogą być stosowane do przeglądania i
zestawiania danych generowanych za pomocą OLAP w celu dostarczenia bardziej
dogłębnej, a często również bardziej wieloaspektowej wiedzy.
Rezultaty osiągane technikami OLAP mogą mieć bardzo prostą postać (np. tablice
liczebności, statystyki opisowe, proste tabele krzyżowe) lub nieco bardziej złożoną (np.
mogą uwzględniać pewnie korekty, usuwanie odstających obserwacji lub inne metody
filtracji danych).
3.3.1 Terminologia i przykłady
Dana wielowymiarowa (ang. cube, multi-dimensional array) jest zbiorem
komórek danej (ang. cell) zlokalizowanych w przestrzeni wielowymiarowej, określonej
przez wymiary (ang. dimension) danej.
Pojedyncza komórka wyznaczona przez zbiór wartości wymiarów reprezentuje miarę
danej w określonym punkcie przestrzeni – np. ilość towarów lub obrót ze sprzedaży, są
nazwane miarą.
Wymiary danych są strukturalnymi i w ogólności złożonymi atrybutami grupującymi
elementy (ang. member) tego samego typu, np. wymiar czasu jest zbiorem elementów:
dekada, rok, kwartał, miesiąc, tydzień, dzień, godzina. W typowych zastosowaniach
rolę wymiarów pełnią czas, lokalizacja i typ produktu. Operacja grupowanie dla
wskazanych wymiarów tworzy i wylicza tzw. agregaty.
26
Wymiary mogą być wewnętrznie złożone i opisane za pomocą wielu atrybutów, a
atrybuty mogą pozostawać w pewnych zależnościach, tworząc hierarchię atrybutów, np.
dla miejsca sprzedaży hierarchia może przyjąć postać klient-miasto-województwo.
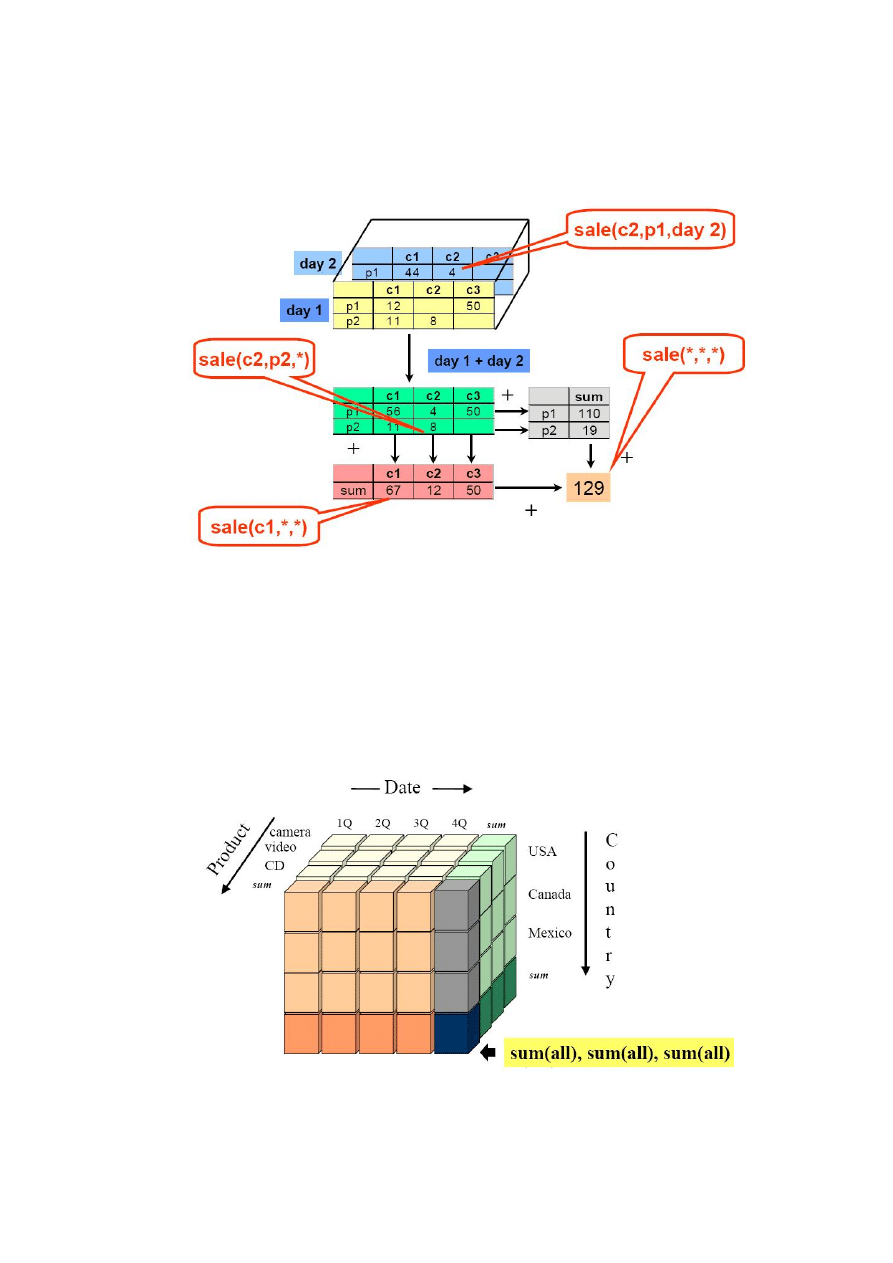
Rys. 1 Struktura danych wielowymiarowych z wykorzystaniem agregacji
(źródło: T.Morzy)
Formą prezentacji jest kostka danych (Rys. 1 i 2). Pozwala to na swobodne
manipulowanie perspektywami analizy, przechodzenie od danych ogólnych do coraz
bardziej szczegółowych, wybieranie do analizy dowolnego fragmentu danych,
filtrowanie wymiarów według dowolnych kryteriów.
Rys. 2 Przykładowa kostka danych OLAP
(źródło: T.Morzy)

27
Najpopularniejsze metody analizy:
• wyznaczanie punktu centralnego (ang. pivoting) – polega na wskazaniu miary i
wybraniu wymiarów, w których ma ona być zaprezentowana, np. country=USA,
• eksploracja danych w górę lub w dół (rozwijanie (ang. drill-down), zwijanie
(ang. roll-up lub drill-up)) wzdłuż hierarchii wymiarów. Powoduje to
zwiększenie lub zmniejszenie stopnia szczegółowości analizy, np. rozwijanie lub
zwijanie hierarchii czasu,
• obracanie (ang. rotating) – pozwala na analizę miary w kolejnych wymiarach
danej, np. obrót kostki o
°
90
w lewo,
• projekcja (ang. slice and dice) – polega na wycinaniu wybranych fragmentów
danej wielowymiarowej. W rezultacie następuje zmniejszenie liczby wymiarów
i agregacja danych,
• ranking (ang. ranking) – np. wg wzrostu miary lub jej agregatu.
3.3.2 Zastosowanie
OLAP jest jedną z popularnych metod do aktywnego wykorzystywania
informacji gromadzonych w firmach. Istnieje wiele danych w przedsiębiorstwie, które
opisane są przez kilka wymiarów jednocześnie, np. czas, produkt, region, klient,
dostawca. Wartościowe informacje biznesowe powstają najczęściej dopiero po
połączeniu pojedynczych danych w wielowymiarowej strukturze. Możliwość dokładnej
analizy takich informacji pozwala na poprawę jakości procesu podejmowania decyzji,
co w konsekwencji może wpłynąć na zwiększenie stopnia satysfakcji klientów.
Narzędzia OLAP mogą być również integrowane z systemami baz danych
(korporacyjnymi) tworząc magazyny danych [29] i umożliwiając analitykom i
menedżerom śledzenie wydajności przedsiębiorstwa (np. różnych aspektów procesu
produkcyjnego lub ilości i rodzajów transakcji przeprowadzanych w różnych
oddziałach) lub rynku. Wynikiem analizy może być dotarcie do tak niezbędnych
informacji jak trendy, relacje czy wartości charakterystyczne. W ten sposób otrzymuje
się natychmiastowe odpowiedzi na najistotniejsze pytania biznesowe oraz wsparcie w
podejmowaniu decyzji krótko i długookresowych.
28
4 Propozycje rozszerzeń metodologii ASK w oparciu o
reguły decyzyjne
W rozdziale tym można się zaznajomić z propozycjami rozszerzeń podejścia do
analizy satysfakcji klienta, które wykorzystuje mechanizm reguł decyzyjnych. Próbują
one odpowiedzieć na pytanie, co należy zrobić, aby jak największa liczba obiektów
zmieniła swój obecny przydział do klasy na klasę przynajmniej o jeden lepszą. W opisie
wykorzystano przykładowe dane ankietowe przedstawione na samym wstępie rozdziału.
Opisaną wcześniej technologię OLAP można powiązać z teorią zbiorów przybliżonych,
co daje w rezultacie bogate narzędzie do prezentacji i analizy danych opisane poniżej.
4.1 Przykład danych wejściowych do analizy satysfakcji klienta
Przedstawiony w tym punkcie prosty problem będzie kanwą wykorzystaną do
opisu proponowanego narzędzia. Przypuśćmy, że dysponujemy danymi ankietowymi
uzyskanymi od kilku osób na temat oceny Polskiej Kolei Państwowej (PKP). W
ankiecie respondenci dokonywali oceny PKP według sześciu kryteriów a następnie
wyrażali ogólną satysfakcję z usług PKP dokonując przydziału do odpowiedniej klasy.
Definicja problemu wygląda następująco:
• Kryteria: rozkład jazdy, punktualność, wygoda, czystość, obsługa, cena
• Skala ocen kryteriów: bardzo źle (1), źle (2), dostatecznie (3), dobrze (4), bardzo
dobrze(5)
• Klasa: przeciętna (1), standard (2), komfort (3)
Wyniki ankiety (posortowane rosnąco wg przydziału do klas):
Tabela 1 Wyniki ankiety PKP
Odp. Rozkład jazdy Punktualność Wygoda Czystość Obsługa Cena Klasa
1
4 4 3 3 3 2 1
2
3 3 1 1 2 1 1
3
4 3 3 2 4 3 1
4
4 3 3 2 3 3 1
5
1 4 3 2 3 3 2
6
3 2 2 3 4 3 2
7
3 2 2 2 5 3 2
8
4 3 5 5 5 4 3
9
4 4 4 4 5 4 3

29
Dla przedstawionego problemu, przy pomocy programu 4eMka2, wygenerowano reguły
decyzyjne (opcja Minimal Cover Algorithm - DomLEM), które znajdują się poniżej:
Tabela 2 Reguły decyzyjne dla ankiety PKP
Nr Reguła
Liczba przykł.
wspierających
Relatywna
siła [%]
Przykłady
pokrywane
1 (Cena <= 2) => (Klasa <= 1)
2
50
1,2
2
(Obsługa <= 4) & (Czystość <=2) & (Punktualność<=2)
=> (Klasa <= 1)
3 75
2,3,4
3 (Cena <= 3) => (Klasa <= 2)
7
100
1,2,3,4,5,6,7
4 (Czystość >= 4) => (Klasa >= 3)
2
100
8,9
5 (Obsługa >= 5) => (Klasa => 2)
3
60
7,8,9
6 (Cena => 2) & (Czystość => 3) => (Klasa => 2)
3
60
6,8,9
7 (Punktualność => 4) & (Cena => 3) => (Klasa => 2)
2
40
5,9
4.2 Testowanie strategii interwencji
Dla przypomnienia reguła mówi o minimalnych warunkach, których spełnienie
powoduje, że spełniona jest również jej część decyzyjna. Z regułą związane jest również
wsparcie wyrażone przez liczbę przykładów, które ona pokrywa (spełniona jest część
warunkowa i część decyzyjna). Analiza w tej metodzie polega na hipotetycznej zmianie
warunku(ów) elementarnych w danej regule i sprawdzeniu jak ta zmiana wpłynęła na
liczbę przykładów pokrywanych przez regułę, czy ich liczba się zwiększyła czy
zmniejszyła i w jakim stopniu. Innymi słowy przy pomocy reguły definiujemy pewną
strategię interwencji i testujemy jej wpływ. Można sobie zadać pytania – co nam to
daje? Jak interpretować otrzymany w rezultacie wynik? Odpowiedź na te pytania
znajduje się w poniższym przykładzie analizy danych proponowaną metodą.
4.2.1 Przykład analizy danych metodą testowania strategii interwencji
Ponieważ najlepiej coś tłumaczyć na przykładzie, dlatego poniżej znajduje się
przykładowa analiza danych metodą testowania strategii interwencji (ang. Strategy of
Intervention Test), bazująca na wynikach ankiety PKP (Tabela 1) i przeprowadzona dla
reguły nr 5 (Tabela 2):
• Reguła nr 5 mówi, że jeżeli Obsługa PKP jest oceniana na co najmniej 5 to
następuje przydział PKP do Klasy co najmniej 2. Przykłady z tablicy decyzyjnej,
które ją wspierają to 7,8 i 9.

30
• Zmieniając hipotetycznie warunek elementarny reguły (w tym przypadku tylko
jeden) np. na Obsługa>=3 (ocena Obsługi PKP na co najmniej 3) można
zauważyć, że taka reguła, a dokładniej jej część warunkowa (na tym etapie
analizy pomija się część decyzyjną reguły), pokrywa oprócz wcześniejszych
przykładów również przykłady nr 1, 3, 4, 5 i 6. Jak interpretować ten przyrost?
Otrzymany wynik wskazuje ilu klientów PKP, którzy aktualnie oceniają
Obsługę na co najmniej 3 po jej zmianie na co najmniej 5 (jeśli spowoduje się u
nich taką zmianę oceny przez zastosowanie testowanej strategii interwencji)
może zmienić przydział do Klasy na co najmniej 2.
• Z ankiety PKP wynika, że klienci nr 5 i 6 przydzielają już teraz PKP do Klasy 2,
więc zmiana oceny Obsługi u nich nic nie zmieni, dlatego pomija się ich w
dalszej analizie. Odwrotnie jest w przypadku klientów nr 1, 3 i 4, którzy obecnie
przydzielają PKP do Klasy 1 – oznacza to, że po zmianie oceny Obsługi z 3 na
co najmniej 5 zgodnie z regułą nr 6 zmienią przydział z Klasy 1 na co najmniej
2.
• Ponieważ analizowana reguła nie jest jedyną w zbiorze reguł, dlatego trzeba też
mieć wzgląd na możliwe niezgodności występujące w zbiorze. Dla danej reguły
za takie niezgodności uznaje się wszystkie takie reguły, których część decyzyjna
jest negacją decyzji wybranej reguły – dla relacji „co najmniej” oznaczać będzie
to relację „co najwyżej” klasa o jeden niższa (np. dla Klasa>=2 zaprzeczeniem
będzie Klasa<=1) i odwrotnie, dla „co najwyżej” będzie to „co najmniej” klasa
o jeden wyższa. Ponadto reguły niezgodne to takie, które będą nadal pokrywać
wybrane przykłady po hipotetycznej zmianie ich oceny na danych kryteriach.
• Dla analizowanej reguły możliwie niezgodne są wszystkie reguły, których część
decyzyjna ma postać: co najwyżej 1 (Klasa<=1) – w analizowanym zbiorze
mogą to być reguły nr 1 i 2. Rozpatruje się każdy przykład osobno. Przykłady nr
3 i 4 nie są pokrywane przez regułę 1, ponieważ ich ocena Ceny wynosi 3, ani
przez regułę nr 2 po hipotetycznej zmianie oceny Obsługi na co najmniej 5.
Sytuacja jest inna dla klienta nr 1, gdyż pokrywa go reguła nr 1 (ocenia Cenę na
2). Należy pozbyć się niezgodności przez dodanie dodatkowego wymogu, że dla
tego konkretnego przykładu ocena Ceny musi być co najmniej 3. W tym
momencie nastąpiły dwie hipotetyczne zmiany, dalej postępuje się podobnie i
sprawdza czy po tych zmianach nadal są reguły, które są niezgodne.

31
• Podsumowując powyższą analizę okazuje się, że ze wszystkich ankietowanych,
którzy oceniają aktualnie Obsługę PKP na co najmniej 3, po zastosowaniu
strategii i zmianie ich ocen na tym kryterium na co najmniej 5, trzech zmieni
swój przydział z Klasy 1 na co najmniej 2, przy dodatkowym wymogu dla
klienta nr 1, że należy spowodować dodatkowo zmianę oceny Ceny z 2 na co
najmniej 3.
4.2.2 Algorytm testowania strategii interwencji
Dokładny algorytm postępowania w tej metodzie wygląda następująco:
• Określ interesującą Cię strategię interwencji przez wskazanie reguły do analizy,
• Zmodyfikuj według uznania warunek/warunki wybranej reguły,
• Wyszukaj wszystkie przykłady, które pokrywa zmieniona część warunkowa
reguły decyzyjnej,
• Dokonaj hipotetycznej zmiany wartości w znalezionych przykładach na tych
kryteriach, dla których zostały zmienione warunki reguły,
• Dla wybranej reguły znajdź reguły, które mogą być niezgodne,
• Dla każdego przykładu z osobna przeglądaj zbiór tych reguł i sprawdzaj, czy nie
jest pokrywany przez którąś z nich,
• Jeśli tak jest (reguła niezgodna) to dodaj dodatkowy wymóg, jaki musi być
spełniony dla tego przykładu taki, żeby reguła go nie pokrywała (np. negacja
pierwszego warunku w regule),
• Dokonaj kolejnej hipotetycznej zmiany w przykładzie będącej wynikiem
nałożenia dodatkowego wymogu i kontynuuj przeglądanie zbioru możliwych
niezgodnych reguł.
4.2.3 Możliwe zastosowania i kierunki rozwoju
Opisane tutaj podejście pozwala w łatwy sposób zdefiniować konkretną strategię
interwencji, która jest interesująca z punktu widzenia przedsiębiorstwa i wskazać, co
należy zrobić (jakich zmian dokonać w ocenach satysfakcji klientów), aby dała ona
zamierzone rezultaty. Dla przykładu firma może być zainteresowana zwiększeniem
liczby klientów, którzy przydzielaliby ją do klasy najwyższej. W metodzie testowania

32
strategii interwencji wystarczy wskazać regułę odpowiadającą zamierzonej strategii i
zmianami na warunkach tej reguły sterować liczbą i rodzajem klientów, którzy zostaną
jej poddani.
Należy zauważyć, że w zbiorze wszystkich reguł będzie się znajdować
przynajmniej kilka reguł, które będą odpowiadać określonej przez nas strategii. W
rezultacie możemy otrzymać kila różnych rozwiązań. Dodatkowo, w rzeczywistości, z
każdą zmianą oceny satysfakcji klienta związany jest pewien koszt zależny od
kryterium, na którym ta zmiana jest dokonywana. Wskazane by więc było określenie
dla każdego kryterium kosztów zmian na jego wartościach, co umożliwiłoby
wprowadzenie elementu optymalizacji i wyboru najlepszej strategii – jak największy
wzrost liczby klientów przy jak najmniejszym koszcie koniecznych zmian.
4.3 Szukanie strategii interwencji
W metodzie szukania strategii interwencji zaczynamy analizę nie od zbioru
reguł, ale od zbioru przykładów. Wybieramy konkretny przykład i wskazujemy
konkretną decyzję. Celem tego podejścia jest wskazanie zmian, jakich należy dokonać,
aby dany przykład miał określoną decyzję – poszukanie możliwej strategii interwencji,
która pozwoli osiągnąć zamierzony cel. Dokonuje się tego na podstawie zbioru reguł
decyzyjnych.
4.3.1 Przykład analizy danych metodą szukania strategii interwencji
W celu wyjaśnienia metody dokonano przykładowej analizy danych metodą
szukania strategii interwencji (ang. Strategy of Intervention Search) w oparciu o ankietę
PKP (Tabela 1) i zbiór reguł decyzyjnych (Tabela 2):
• Do analizy ze zbioru danych wejściowych wybrany został przykład (klient) nr 2.
• Interesuje nas strategia interwencji mająca na celu zmianę przydziału PKP tego
klienta do Klasy co najmniej 2. Chcemy wiedzieć, co musimy zrobić, aby tak się
stało.
• Należy w tym celu przeanalizować zbiór reguł i wybrać takie, których decyzja
odpowiada określonej strategii; w tym przypadku będą to wszystkie reguły z
decyzją Klasa>=2 (nr 5, 6 i 7). Każda z takich reguł jest jednym z możliwych
rozwiązań.

33
• Tak jak w metodzie testowania strategii interwencji również i tutaj mogą
występować niezgodności w zbiorze reguł decyzyjnych. W naszym przykładzie
mogą ją ewentualnie wprowadzać reguły o decyzji Klasa<=1 (nr 1 i 2).
• Reguła nr 5 wskazuje, że jeżeli Obsługa PKP jest oceniona na co najmniej 5 to
PKP zostaje przydzielone do Klasy co najmniej 2. Wybrany klient ocenia to
kryterium na 2, a więc zmieniając ocenę na co najmniej 5 według tej reguły,
spowoduje się, że zmieni on przydział z Klasy 1 na co najmniej 2.
• Należy zauważyć, że po zmianie oceny Obsługi analizowany klient nr 2 spełnia
część warunkową już tylko reguły nr 1 (niezgodność). Reguła nr 1 pokazuje, że
Cena musi być co najmniej 3, żeby nie pokrywała przykładu.
• Analizując regułę nr 6 tak samo jak nr 5 okazuje się, że trzeba zmienić ocenę
Ceny i Czystości z 1 na co najmniej 3. Po tych hipotetycznych zmianach klient
nie będzie już pokrywany przez żadną ze niezgodnych reguł.
• Dla reguły nr 7 postępując analogicznie jak w dwóch powyższych przypadkach
otrzymujemy, że należy zmienić ocenę Punktualności z 3 na co najmniej 4 i
Ceny z 1 na co najmniej 3. Po takich zmianach nie zachodzi już żadna
niezgodność.
• Podsumowując, w końcowym rezultacie otrzymujemy trzy różne rozwiązania –
strategie interwencji (z 3 reguł). Klient nr 2 zmieni przydział z Klasy 1 na co
najmniej 2 jeśli: spowodujemy u niego zmianę oceny Obsługi na co najmniej 5 i
Ceny na co najmniej 3 lub Czystości i Ceny na co najmniej 3 lub Punktualności
na co najmniej 4 i Ceny na co najmniej 3.
4.3.2 Algorytm szukania strategii interwencji
Dokładny algorytm tej metody przedstawia się następująco:
• Wybierz interesujący Cię przykład w danych wejściowych,
• Określ interesującą Cię strategię interwencji przez wskazanie decyzji,
• Znajdź w zbiorze reguł decyzyjnych takie, które odpowiadają pożądanej decyzji,
tzn. ich część decyzyjna pokrywa się ze wskazaną decyzją. Każda ze
znalezionych reguł stanowi jedno z możliwych rozwiązań strategicznych,

34
• Znajdź w zbiorze reguł decyzyjnych reguły mogące stanowić niezgodność dla
reguł znalezionych w poprzednim kroku – negacja wskazanej decyzji,
• Dla każdego znalezionego rozwiązania dokonaj hipotetycznej zmiany wartości
w wybranym przykładzie na tych kryteriach, które wskazują zmienione warunki
reguły,
• Przejrzyj zbiór reguł, które mogą wprowadzać niezgodność dla
zmodyfikowanego przykładu i sprawdzaj, czy nie jest pokrywany przez którąś z
nich,
• Jeśli tak jest (reguła niezgodna) to dodaj dodatkowy wymóg, jaki musi być
spełniony dla tego przykładu taki, żeby reguła go nie pokrywała (np. negacja
pierwszego warunku w regule),
• Dokonaj kolejnej hipotetycznej zmiany w przykładzie będącej wynikiem
nałożenia dodatkowego wymogu i kontynuuj przeglądanie zbioru możliwych
niezgodnych reguł.
4.3.3 Możliwe zastosowania i kierunki rozwoju
Powyższa metodologia pozwala firmie sprawdzić możliwe sposoby osiągnięcia
zamierzonego celu dla interesującego ją klienta, np. takim ogólnym celem może być
chęć zwiększyć przez niego ogólnej oceny firmy. Ponieważ strategii interwencji może
być dużo (zależy to od zbioru reguł decyzyjnych) wskazane jest wprowadzenie kosztów
zmian dla poszczególnych kryteriów, co umożliwi w końcowym efekcie posortowanie
otrzymanych wyników względem kosztu przeprowadzenia strategii.
Podejście to można rozwinąć również na kilka przykładów i przeprowadzać
analizę nie dla pojedynczego przypadku, ale dla pewnej grupy (klastra), którą sami
ustalamy, np. wg konkretnej wartości jakiegoś kryterium lub decyzji. W tym przypadku
rozwiązania będą dotyczyć zmian satysfakcji dla wszystkich wskazanych klientów.
4.4 Połączenie OLAP i DRSA do analizy satysfakcji klienta
W trakcie licznych konsultacji z projektantami platformy GoalProject [2]
narodziła się idea wykorzystania do badania satysfakcji klienta opisanej wcześniej
technologii analizy wielowymiarowych danych OLAP i teorii zbiorów przybliżonych
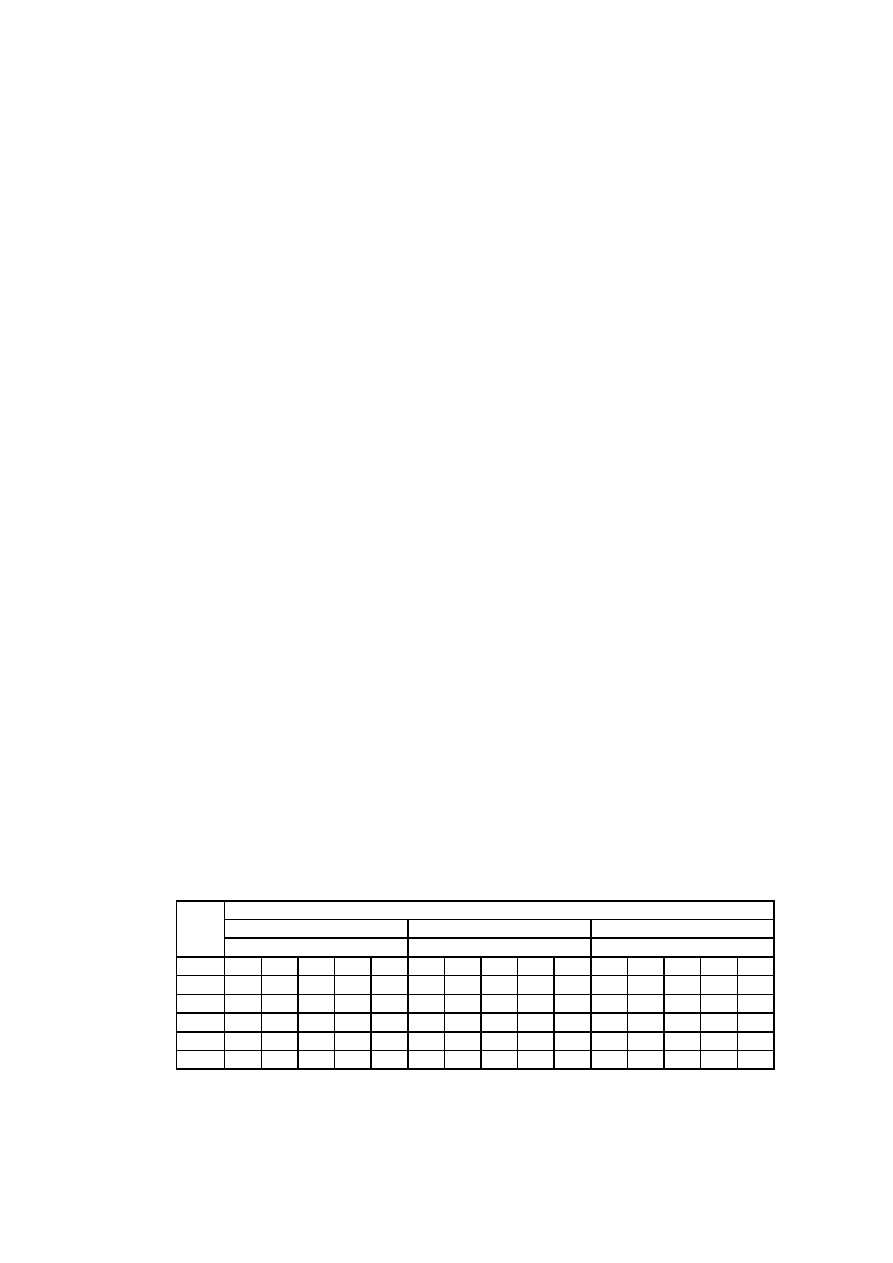
35
DRSA. W rezultacie powstała metodologia bezpośredniej analizy satysfakcji przy
użyciu teorii zbiorów przybliżonych bazujących na relacji dominacji [7][24]
(ang. On-Line Satisfaction Analysis using Dominancie-based Rough Set Approach) i
pozwalająca na tworzenie OLAP-owych raportów w oparciu o tablicę decyzyjną.
Dzięki połączeniu OLAP i DRSA dane z tablicy decyzyjnej można
zaprezentować w innej postaci – wielowymiarowej tabeli. Wymiary są wewnętrznie
złożone i opisane za pomocą wielu atrybutów (typu wyliczeniowego). Wartościami tych
wymiarów, w oparciu o teorię zbiorów przybliżonych, są możliwe wartości z dziedziny
atrybutów przyjmujące postać:
• wartość atrybutu = kolejna wartość z dziedziny atrybutu (wartość równa),
• wartość atrybutu >= kolejna wartość z dziedziny atrybutu (wartość co najmniej),
• wartość atrybutu <= kolejna wartość z dziedziny atrybutu (wartość co najwyżej).
Pojedyncza komórka w wielowymiarowej tabeli wyznaczona przez zbiór
wartości wymiarów reprezentuje miarę danej w określonym punkcie przestrzeni. W
opisywanej metodologii są wykorzystywane dwie takie miary:
• liczność (ang. count),
• decyzja
„Liczność” pozwala zliczać w danej komórce liczbę przykładów z tablicy
decyzyjnej, które przyjmują odpowiednie wartości na kryteriach (atrybutach)
zdefiniowanych jako wymiary w tabeli dla tej komórki. Poniżej znajduje się
przykład tabeli wielowymiarowej (Tabela 3), stworzonej na podstawie tablicy
decyzyjnej PKP (Tabela 1), dla której zostały określone trzy wymiary: Cena,
Punktualność i Wygoda oraz wartość co najmniej:
Tabela 3 Przykład połączenia OLAP i DRSA - liczność
Cena
>=1 >=2 >=3 >=4 >=5 >=1 >=2 >=3 >=4 >=5 >=1 >=2 >=3 >=4 >=5
>= 1
7
>= 2
3
>= 3
7
5
2
>= 4
1
1
>= 5
Wygoda
Wygoda
Punktualność
>= 3
>= 4
>= 2
Wygoda
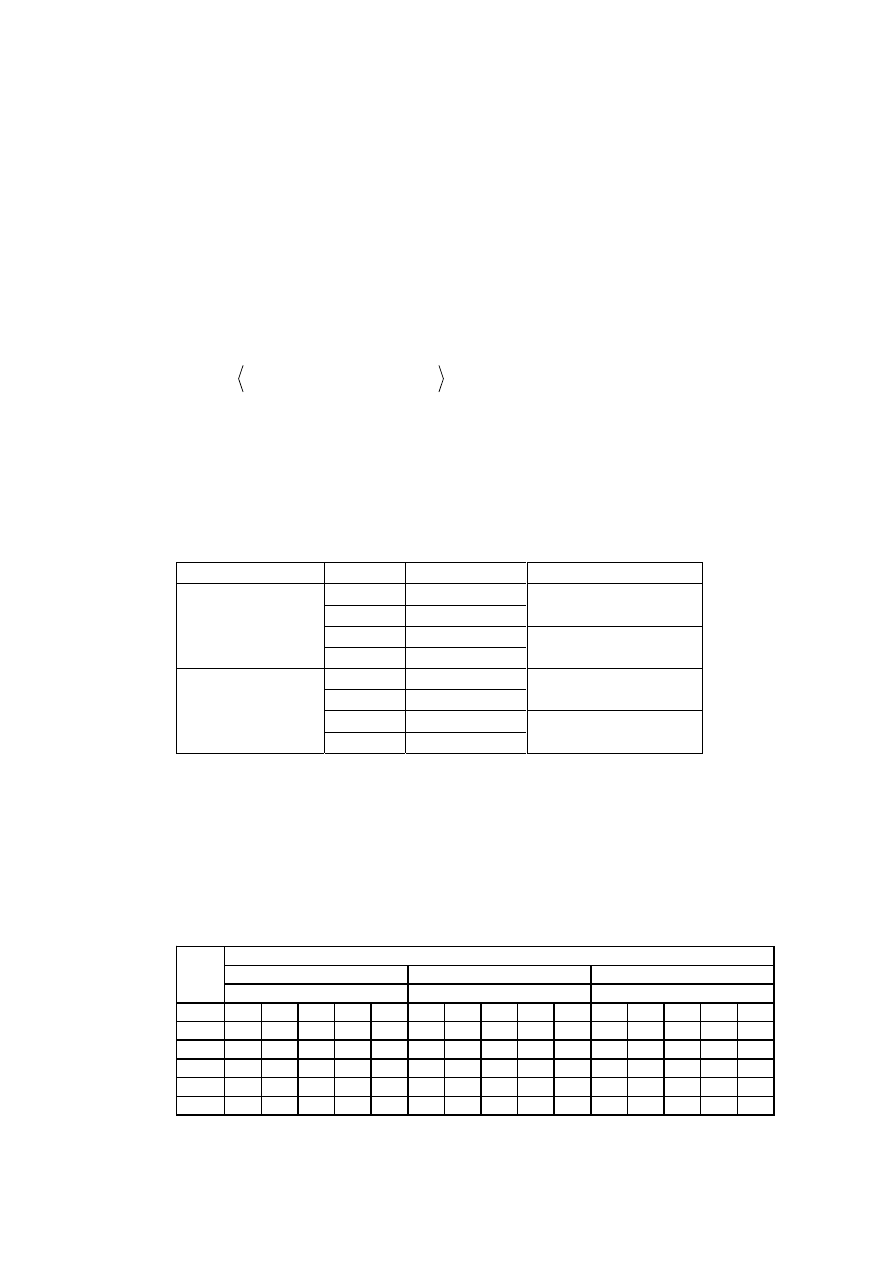
36
„Decyzja” wykorzystuje atrybut decyzyjny z tablicy decyzyjnej, a w komórkach
tabeli wielowymiarowej znajdują się jego wartości (decyzje) zależne od sposobu
dodatkowo wybranego podejścia. Każdej komórce tabeli odpowiada zbiór
przykładów
N
z tablicy decyzyjnej przyjmujących odpowiednie wartości
wymiarów dla tej komórki. Dla danej komórki postępowanie rozpoczynamy od
wyznaczenia dla każdego przykładu z
N
zbioru decyzji przykładów, które go
dominują
+
P
D i zbioru decyzji przykładów zdominowanych przez niego
−
P
D . Oba
wyznaczone zbiory służą do wyznaczenia przedziału decyzji dla danego przykładu
postaci
)
(
max
),
(
min
−
+
P
P
D
dec
D
dec
. Pozwala to wykryć przykłady niespójne w
tablicy decyzyjnej – w przypadku, gdy przykład będzie spójny to obie wartości
(decyzje) będę równe.
Dla dalszych rozważań przyjmuje się
)
(
min
+
≡
P
D
dec
L
oraz
)
(
min
−
≡
P
D
dec
R
.
Do wyboru jest 8 podejść uwzględniając różne wartości wymiarów (Tabela 4).
Tabela 4 Podejścia dla miary - decyzja
Podejście Typ
reguł Wartość wymiaru
Miara w komórce
pewne co
najmniej
>=
pewne co
najwyżej <=
i
N
i
L
∈
∀
min
możliwe co
najmniej
>=
w górę (ang. upward
decision)
możliwe co
najwyżej <=
i
N
i
R
∈
∀
min
pewne co
najmniej
>=
pewne co
najwyżej <=
i
N
i
L
∈
∀
max
możliwe co
najmniej
>=
w dół (ang. downward
decision)
możliwe co
najwyżej <=
i
N
i
R
∈
∀
max
Z powyższej tabeli wynika, że sposób wyliczania miary zależy od trzech
czynników: wybranego podejścia, typu reguł i typu wartości wymiaru. W tabeli
poniżej (Tabela 5) zawiera przykład wielowymiarowej tabeli dla decyzji w górę,
reguł pewnych i wartości dla wymiarów co najmniej:
Tabela 5 Przykład połączenia OLAP i DRSA – decyzja
Cena
>=1 >=2 >=3 >=4 >=5 >=1 >=2 >=3 >=4 >=5 >=1 >=2 >=3 >=4 >=5
>= 1
1
>= 2
1
>= 3
1
1
2
>= 4
3
3
>= 5
Wygoda
Wygoda
Punktualność
>= 3
>= 4
>= 2
Wygoda

37
Podsumowując, wielowymiarowe tabele opisane powyżej pozwalają w prosty
sposób określić dane do wizualizacji i jej formę m.in. przez sterowanie szczegółowością
prezentowanych danych. Taki rodzaj prezentacji danych może być bardzo pomocny
przy analizie satysfakcji klienta, ponieważ najczęściej ma na nią wpływ kilka
czynników (wymiarów), np. płeć, wiek. Przykładowa analiza mogłaby mieć wtedy
postać: prezentacja rozkładu oceny
Obsługi przez klientów w rozróżnieniu na płeć i
przedziały wiekowe. Dodatkowo wymiary wraz z wartościami można traktować jak
część warunkową reguły – spełnienie jej warunków spowoduje, że pojawi się wartość
miary w danej komórce tabeli.
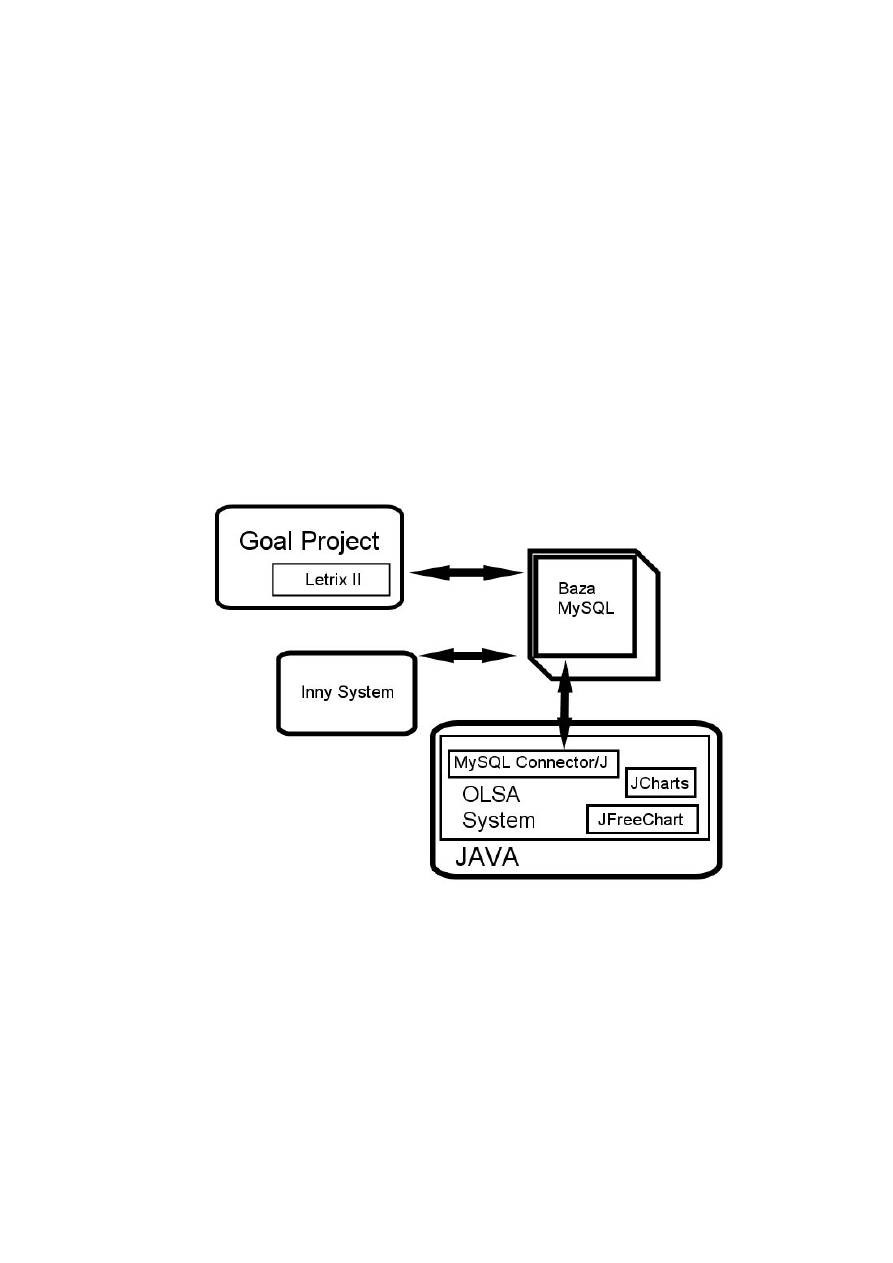
38
5 Projekt systemu i implementacja
Rozdział omawia stworzony w ramach pracy magisterskiej system regułowej
analizy danych marketingowych dotyczących satysfakcji klienta – OLSA System
(ang. On-Line Satisfaction Analysis System). Można tutaj zapoznać się z projektem
systemu, środowiskiem realizacji, wykorzystywanymi bibliotekami oraz innymi
systemami i oczywiście zasadą działania całego systemu.
5.1 Architektura systemu i wykorzystane technologie
Na w pełni działający system składają się trzy duże bloki: stworzony w ramach
tej pracy OLSA System, baza danych MySQL oraz system analityczny dla eksploracji
danych o nazwie GoalProject (Rys. 3):
Rys. 3 Architektura systemu OLSA i wykorzystane technologie
Centrum całego systemu jest baza danych, która stanowi pewien pomost między
dwoma systemami i umożliwia wymianę między nimi danych. Ze względu na
początkowe założenia co do systemu: otwartość i przenośność, a także na fakt, że miał
on współpracować z platformą GoalProject, wybrano łatwy w obsłudze i szybki system
zarządzania bazą danych MySQL [18]. Jest to bardzo popularna, dynamicznie się

39
rozwijająca i co ważne darmowa baza danych spełniająca powyższe założenia
(wykorzystano najnowszą wersję w wersji 5.0.0a).
Do wczytywania danych z plików lub generacji danych wejściowych dla
systemu OLSA posłużono się projektem zrealizowany w ramach dwóch prac
inżynierskich – GoalProject [1][19]. Architektura klient-serwer tego sytemu pozwala na
uruchomienie przetwarzania z dowolnego miejsca na świecie. Klient odpowiada za
zarządzanie i komunikację z użytkownikiem, natomiast odległy serwer (bazujący na
technologii Letrix II [16]) za uruchamianie obliczeń i zwracanie wyników do klienta.
Jedną z możliwości jest zapisanie tych wyników w odpowiednich tabelach w bazie
danych, do której mogą mieć dostęp inne systemy/aplikacje znajdujący się w różnych
miejscach na świecie.
Jedną z takich aplikacji jest stworzony w ramach tej pracy magisterskiej OLSA
System. Aby spełnić założenia do jej stworzenia wykorzystano język JAVA [11][22],
który obecnie jest najbardziej rozwijającym się środowiskiem do tworzenia aplikacji (w
większości JAVA Swing do tworzenia interfejsów [3][27]). Należy zaznaczyć, że
główną jego cechą jest fakt, że to język interpretowany a nie kompilowany – oznacza
to, że do uruchomienia programów w nim napisanych wymagana jest maszyna
wirtualna (JavaVM) pracująca w danym środowisku, jednak dzięki temu nie ważne jest
na jakim sprzęcie będzie uruchamiana aplikacja.
System do komunikacji z bazą danych MySQL korzysta ze specjalnej do tego celu
biblioteki napisanej w Javie – MySQL Connector/J [17], która dostarcza odpowiedni
interfejs i funkcje do zapisu i odczytu danych. Dodatkowo do systemu OLSA dołączone
są dwie inne biblioteki odpowiedzialne za wizualizację danych w postaci wykresów:
JFreeChart [13] oraz JCharts [12]. Wszystkie wymienione biblioteki są oczywiście w
pełni darmowe.
5.2 Elementy systemu i powiązania między nimi
Zasadę działania aplikacji w postaci poszczególnych elementów systemu (ich
dokładniejszy opis można znaleźć właśnie w tym punkcie) i powiązań między nimi
przedstawiono na rysunku poniżej (Rys. 4):
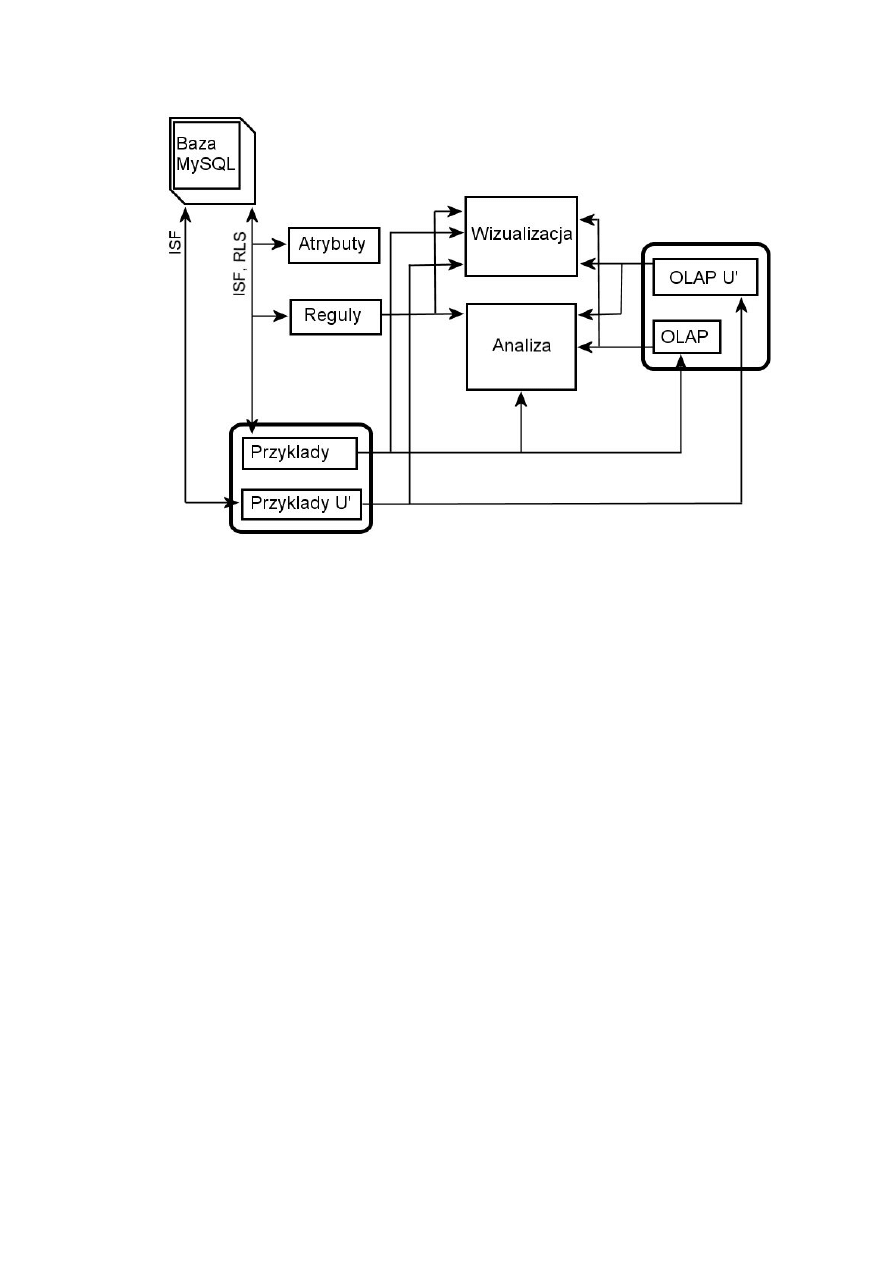
40
Rys. 4 Elementy systemu OLSA i ich powiązania
5.2.1 Moduł komunikacji z bazą danych
Moduł komunikacji z bazą danych (Rys. 5) wykorzystuje do tego celu darmową
bibliotekę MySQL Connector/Java [17], udostępnioną przez twórców darmowej bazy
danych MySQL [18]. Dzięki temu istnieje możliwość wczytywania do OLSA System
danych wejściowych umieszczonych przez system GoalProject w bazie danych: plików
ze zdefiniowanymi problemami (ISF) i z regułami (RLS) do odpowiednich struktur w
aplikacji. Należy zaznaczyć, że aplikacja i baza danych mogą znajdować się zarówno na
jednym komputerze jak i w różnych częściach świata. Biorąc to pod uwagę, a także
podobną zasadę, jeśli chodzi o GoalProject daje to możliwość bardzo dużego
rozproszenia działania wszystkich elementów i dokonywanych obliczeń oraz analiz.
Schemat tabel w bazie danych zależny jest od systemu GoalProject, dlatego nie
uległ zmianom, a dostosowany do niego został system OLSA. Aby ułatwić i uprościć
zarządzanie danymi struktury do ich przechowywania w Javie swoim „wyglądem”,
możliwościami i udostępnionymi funkcjami odpowiadają tym z GoalProject
(funkcjonalność funkcji jest praktycznie identyczna łącznie z nazwami). Jedynie na

41
potrzeby OLSA System struktury zostały dodatkowo rozszerzone o pewne nowe
funkcje.
5.2.2 Moduły do prezentacji atrybutów i przykładów
Wczytywany problem (plik ISF) to zbiór przykładów – obiektów opisanych
atrybutami, z których jeden stanowi atrybut decyzyjny. W aplikacji są dostępne moduły
umożliwiające wyświetlenie tego problemu w przejrzystej i czytelnej postaci – tabelach
z odpowiednimi danymi. Należy wspomnieć, że istnieje możliwość wgrania dwóch
plików z przykładami: jeden z nich jest bazowy a drugi dodatkowy (może być ten sam),
wykorzystywany/wymagany przez metodę badania oczekiwanej efektywności
zastosowania strategii interwencji wywiedzionej z reguł (punkt 3.2). Jak wynika z
Rys. 4 dla obu przypadków są dostępne podobne opcje w programie.
Moduł do prezentacji atrybutów (Rys. 10) przedstawia ich charakterystykę:
nazwę atrybutu, kierunek preferencji, typ i możliwe wartości jakie przyjmuje, czy jest
opisowy oraz czy jest to atrybut decyzyjny. Dodatkowo w prosty sposób można
wskazać, który z atrybutów ma być decyzyjnym.
Właściwe dane w obu przypadkach plików wyświetlane są w postaci prostej
tablicy decyzyjnej (Rys. 9), w której wiersze to przykłady, a kolumny to kryteria ocen
(atrybuty). Wskazując konkretny przykład (dla pliku bazowego) można rozpocząć jego
analizę metodą szukania strategii interwencji (punkt 4.3). Wykorzystanie bazy MySQL
do przechowywania danych pozwoliło stworzyć dodatkowy mechanizm umożliwiający
przedstawienie ich w praktycznie dowolnej postaci (ograniczonej tabelą
dwuwymiarową). Mechanizm ten wykorzystuje język zapytań do bazy danych
SQL [28], dzięki któremu można sprecyzować dokładnie, jakie dane mają być
zaprezentowane w tabeli – które z atrybutów i przykładów. Dokonuje się tego przez
zapisanie prostego zapytania, w którym podaje się atrybuty oraz odpowiednie warunki
filtracji dla przykładów (Rys. 8). Takie zapytanie dla ankiety PKP (Tabela 1) może
mieć postać:
SELECT id, example_name, punktualnosc, wygoda, cena, klasa FROM pkp WHERE klasa > 2
Odpowiednie słowa kluczowe (pogrubione) określają, co wyświetlić (SELECT), skąd
(FROM) i przy jakich ograniczeniach (WHERE). Aby w aplikacji była możliwość
kontroli tego, co faktycznie jest wczytywane z bazy danych wprowadzono dwa
obowiązkowe pola w zapytaniu identyfikujące w sposób jednoznaczny dany przykład:

42
identyfikator (id) oraz jego nazwę (example_name). Należy wspomnieć, że symbol
gwiazdki (*) w zapytaniu SQL oznacza, że pobiera się z bazy danych wszystkie
kolumny. W wyniku tego zapytania w tabeli zostaną wyświetlone przykłady z ankiety
PKP o przydziale do klasy co najmniej 2 i opisane tylko 4 atrybutami w tym jednym
decyzyjnym plus pola je identyfikujące. Dodanie możliwości generacji reguł (przez
dodatkową komunikację z systemem GoalProject) dla tak przefiltrowanych danych
wejściowych jest jednym ze sposobów na rozszerzenie aplikacji w przyszłości i większe
możliwości ich analizy.
Aplikacja OLSA pozwala również wizualizować dane z plików w postaci dwóch
wykresów: zwykłego liniowego XY (Rys. 13 i 14) oraz tak zwanego radarowego. Na
pierwszym wykresie na osi X umieszczone są kryteria opisujące przykłady natomiast
oś Y zawiera ich znormalizowane wartości od 0 do 100% na tych kryteriach. Drugi
wykres różni się od pierwszego tym, że każde kryterium znajduje się na osobnej osi, a
wszystkie zbiegają się centralnym punkcie odpowiadającemu 0%. Istnieje więc tyle osi
ile jest kryteriów i gdy umieści się na wykresie przykłady to wszystko wyglądem
przypomina właśnie radar. W obu wizualizacjach zastosowano darmowe komponenty
napisane w Javie: JFreeChart dla liniowego oraz JCharts dla radarowego.
Podsumowując moduły odpowiedzialne za prezentację problemu pozwalają na:
• wczytanie dwóch plików z problemem: bazowego i dodatkowego,
• wyświetlanie atrybutów i ich charakterystyki oraz wybór atrybutu decyzyjnego,
• wyświetlanie przykładów w postaci prostej tablicy decyzyjnej,
• łatwe wskazanie danych do prezentacji przy pomocy języka zapytań SQL,
• wizualizację przykładów w postaci wykresu liniowego i radarowego,
• rozpoczęcie analizy danych metodą szukania strategii interwencji.
5.2.3 Moduł do prezentacji reguł
Reguły decyzyjne dla pliku bazowego, podobnie jak przykłady, są wczytywane
z bazy danych (ich generacja odbywa się po stronie platformy GoalProject) i
prezentowane z podziałem na część warunkową i decyzyjną. Dodatkowo z każdą regułą
związana jest jej pewność oraz wsparcie, czyli liczba przykładów, które ona pokrywa –
ich lista pojawia się po wskazaniu danej reguły (Rys. 11). Istnieje możliwość

43
stworzenia filtra dla reguł m.in. w celu ograniczenia ich liczby. Można ustawić
maksymalną długość reguły, tzn. maksymalną liczbę warunków elementarnych oraz jej
minimalne wsparcie (Rys. 12). Dodanie nowych metod filtracji reguł jest kolejnym ze
sposobów na rozszerzenie aplikacji i większe możliwości przy ich wyświetlaniu.
Wskazanie określonej reguły umożliwia: wizualizację przykładów ją
wspierających na wykresach, rozpoczęcie analizy metodą testowania strategii
interwencji (punkt 4.2) lub szacowania efektywności strategii wywiedzionej z reguł
(punkt 3.2). Dla drugiej metody wymagane jest wczytanie dodatkowego pliku z danymi.
5.2.4 Moduły prezentacji danych OLAP
Moduły prezentacji danych OLAP implementują sposób analizy danych będący
połączeniem wielowymiarowych tabel OLAP oraz teorii zbiorów przybliżonych DRSA
omówiony w punkcie 4.4 pracy (Rys. 17). W oknie ustawień (Rys. 16) definiuje się
wymiary tabeli (kryteria opisujące przykłady), wartości dla wymiarów oraz
analizowaną miarę (jest ich jedenaście). Ten sposób wizualizacji danych jest dostępny
zarówno dla pliku bazowego jak i dodatkowego.
Wskazanie określonej komórki w tabeli OLAP dla pliku bazowego umożliwia
wykonanie identycznych operacji jak w przypadku wybrania reguły. Ponieważ wymiary
stanowią jakby część warunkową reguły, dlatego dodatkowo po wybraniu metod
analizy koniecznym staje się podanie części decyzyjnej, dla wizualizacji wykresowej
podanie tej części nie jest obowiązkowe (dla tak stworzonej reguły obliczany jest
współczynnik wiarygodności) – Rys. 18. Dla przykładu dodatkowego nie ma analizy
metodą szukania strategii, ponieważ do tego celu wymagane są reguły, a te dotyczą
bazowego.
5.2.5 Moduły do analizy satysfakcji klienta
Moduły do analizy danych są dostępne z różnych miejsc w aplikacji, co
zwiększa jej funkcjonalność i daje większą swobodę w pracy z programem.
Umożliwiają one analizę satysfakcji klienta różnymi sposobami: metodą szukania lub
testowania strategii interwencji (punkt 4.3 lub 4.2) oraz metodą badania oczekiwanej
efektywności strategii interwencji wywiedzonych z reguł (punkt 3.2).

44
W module do analizy metodą szukania strategii (Rys. 15) dla danego przykładu
wskazuje się decyzję, którą miałby on uzyskać. W wyniku obliczeń otrzymuje się
proponowane strategie interwencji w postaci reguł decyzyjnych. Po wybraniu
konkretnego sposobu działania (reguły) pojawia się informacja o dodatkowych
wymogach, jakie muszą zostać dla niego spełnione, aby dany przykład zmienił decyzję
w pożądany sposób.
Postępowanie w module dla metody testowania strategii interwencji (Rys. 19)
jest bardzo podobne jak w metodzie wyżej, ale dotyczy oczywiście reguły. Tutaj
zmienia się warunki elementarne w regule ustalając w ten sposób rodzaj i motyw
strategii działania, a w rezultacie otrzymuje się zbiór nowych przykładów, dla których
można ją ewentualnie zastosować. Po wskazaniu już konkretnego przykładu pojawia się
dodatkowa informacja o wymogach, jakie należy spełnić, aby uzyskać zamierzony cel
określony przez strategię.
Ostatni moduł analizy satysfakcji klienta umożliwia określenie reguły, na
podstawie której będą tworzone strategie interwencji, a następnie obliczenie
oczekiwanych efektywności w przypadku ich zastosowania (Rys. 20). Pierwszy krok
odbywa się przez wybranie warunków elementarnych na podstawie których będzie
wywiedziona strategia. W drugim kroku następują odpowiednie obliczenia, w wyniku
których otrzymuje się wartości współczynników charakteryzujących daną strategię.
Istnieje również możliwość wybrania opcji, która umożliwi od razu wykonanie obliczeń
dla wszystkich kombinacji warunków elementarnych, a tym samym dla kilku
możliwych strategii interwencji jednocześnie. Końcowe wyniki prezentowane są w
tabeli, a dokładniejszy przebieg obliczeń w formie tekstowej.
45
6 Studium przypadków – eksperyment i wyniki
Rozdział zawiera przebieg wykonanego eksperymentu, którego celem było
przedstawienie przykładu praktycznego zastosowania powstałej aplikacji OLSA
System. Otrzymane wyniki zostały poddane analizie i odpowiednio zinterpretowane, a
rezultaty badań znajdują się w tej części pracy.
6.1 Dane wejściowe przeznaczone do analizy satysfakcji klienta
Pewien włoski magazyn „Anna” przeprowadził wśród swoich czytelników
ankietę dotyczącą oceny jego tematycznej zawartości. Respondenci mieli za zadanie
ocenić je w skali od 1 do 5 (kierunek preferencji to zysk) pod względem różnych
tematów poruszanych na łamach pisma odpowiadających kryteriom w problemie
(Tabela 6). Na końcu wyrażali ogólną opinię na temat jego zawartości.
Zadaniem ankiety było zapoznanie się z rzeczywistym zadowoleniem czytelników
czasopisma i zdobycie danych, które byłyby pomocne w określeniu działań mających
na celu zwiększenie satysfakcji klientów i zdobycie nowych.
Tabela 6 Kryteria oceny magazynu "Anna"
Kryterium Oznaczenie Kryterium
Oznaczenie
Bieżące Wydarzenia
B1
Telewizja
B14
Społeczeństwo B2 Listy
do
Gazety
B15
Moda B3
Odpowiedzi
Ekspertów
B16
Sprzęt B4
Małżeństwo B17
Uroda B5 Seks
B18
Kuchnia B6
Uczucia
i
Emocje B19
Zdrowie B7
Psychologia
i
Testy
B20
Meble B8 Praca
B21
Podróże B9 Ekonomia
B22
Osobistości B10 Internet
B23
Sztuka i Kultura
B11
Dzieci
B24
Kino B12
Domowe
Zwierzęta B25
Muzyka
B13
Kwiaty i Rośliny B26
Ogólna
ocena
magazynu
C
Plik ISF z wynikami ankiety znajduje się na dołączonej płycie CD w katalogu
„CD/Install/GoalProject/ScriptsSamples/Survey/Magazines/…” (łącznie zawiera 23
przykłady opisane 27 kryteriami).
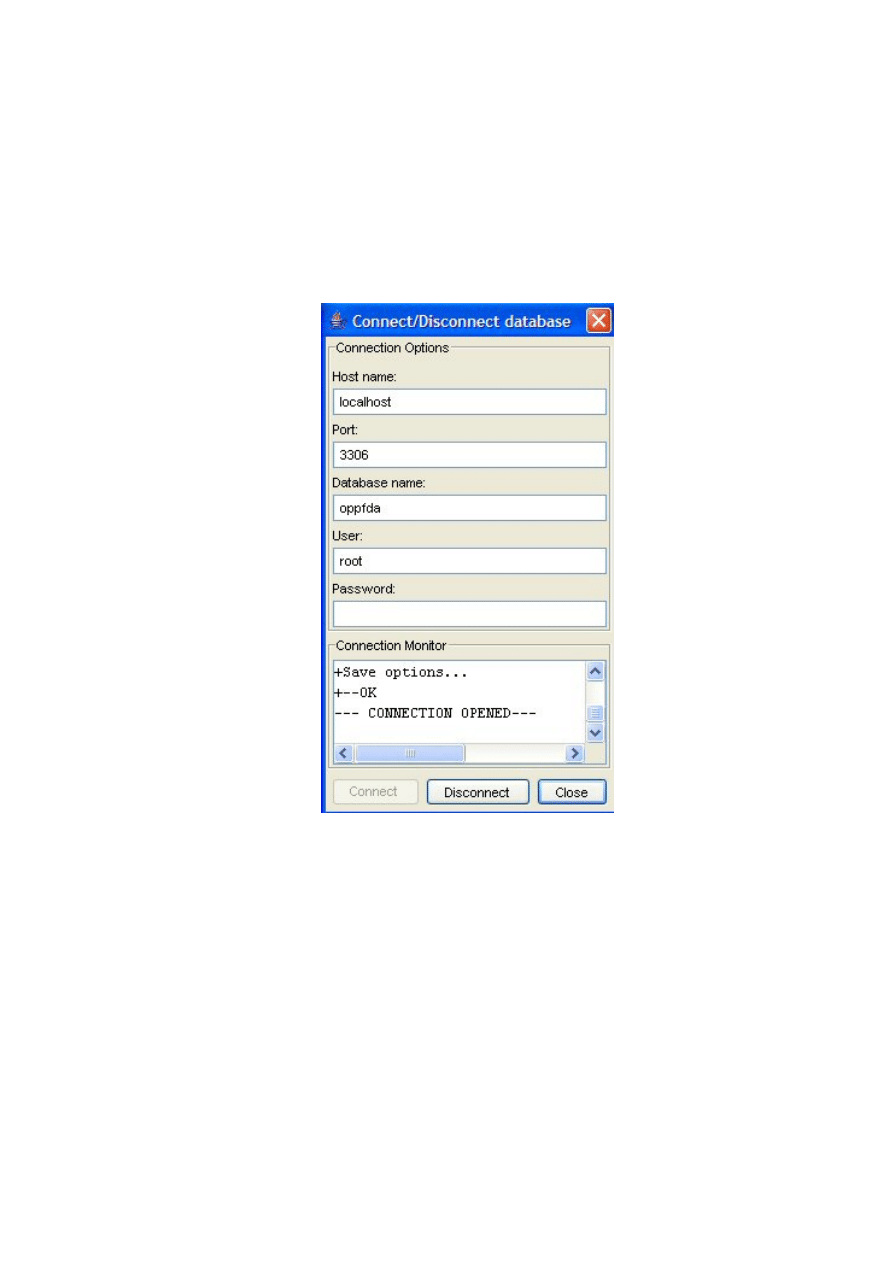
46
6.2 Przebieg eksperymentu
Przeprowadzany eksperyment zakłada, że dane wejściowe w postaci wyników
ankiety zostały już wczytane do bazy danych przez system GoalProject, a następnie
wygenerowano dla nich reguły decyzyjne. Pracę z systemem OLSA można więc
rozpocząć od połączenia z bazą danych, gdzie znajduje się problem, podając
odpowiednie opcje połączenia [File->Database...] (Rys. 5):
Rys. 5 Moduł komunikacji z bazą danych
Kolejnym krokiem po udanym połączeniu z bazą danych jest oczywiście wczytanie
pliku z danymi do analizy [File->Open file…] (Rys. 6) – w tym przypadku będą to
wyniki ankiety magazynu „Anna”. Ponieważ w bazie znajdują się wygenerowane
reguły dla tego pliku to zostaną one automatycznie wgrane do aplikacji.
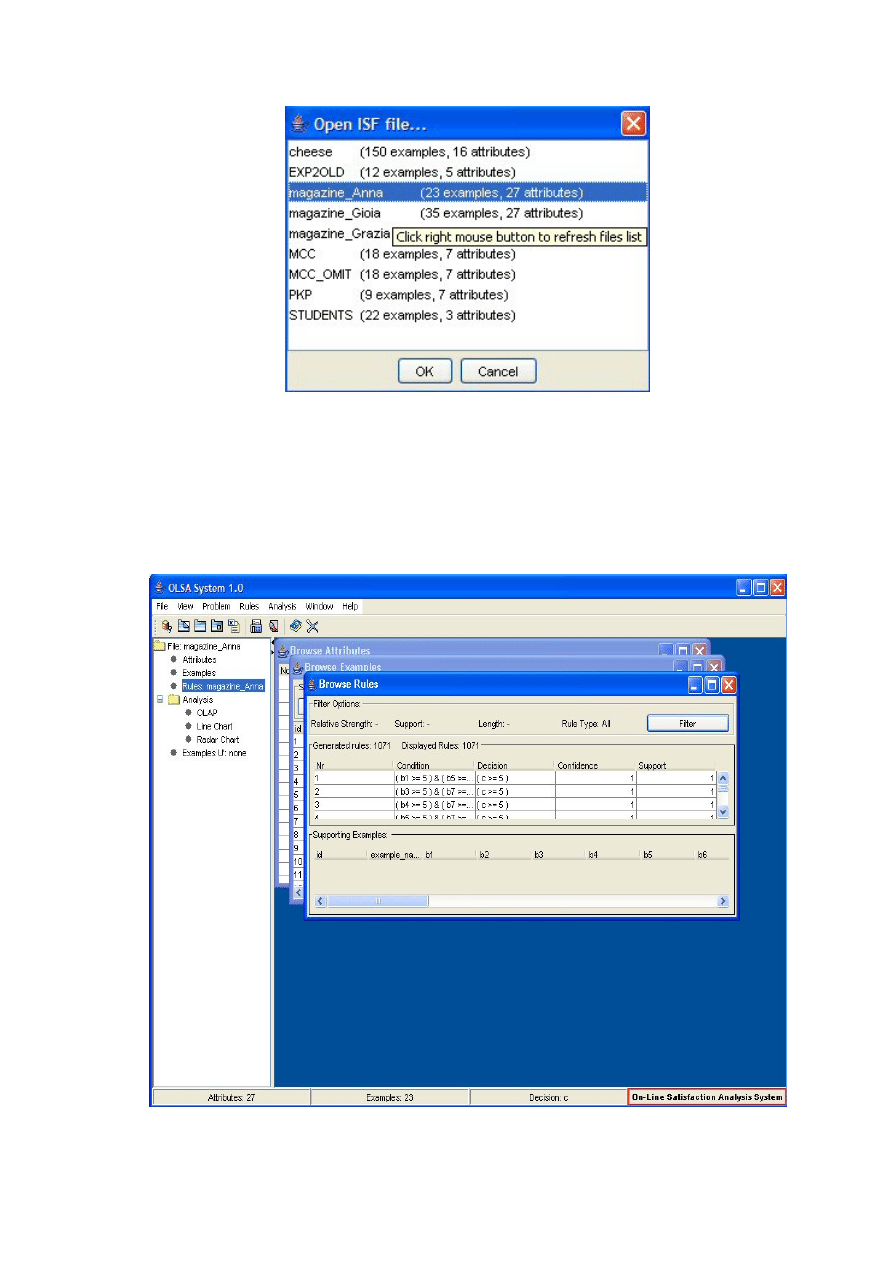
47
Rys. 6 Moduł do wczytywania danych wejściowych
W tym momencie można rozpocząć analizę danych, co zostało przedstawione poniżej w
postaci kolejnych etapów pracy z systemem OLSA. Dostęp do odpowiednich opcji
możliwy jest z paska menu, paska narzędziowego, szczegółowego drzewa projektu oraz
przy pomocy skrótów klawiszowych (Rys. 7).
Rys. 7 Aplikacja OLSA System 1.0
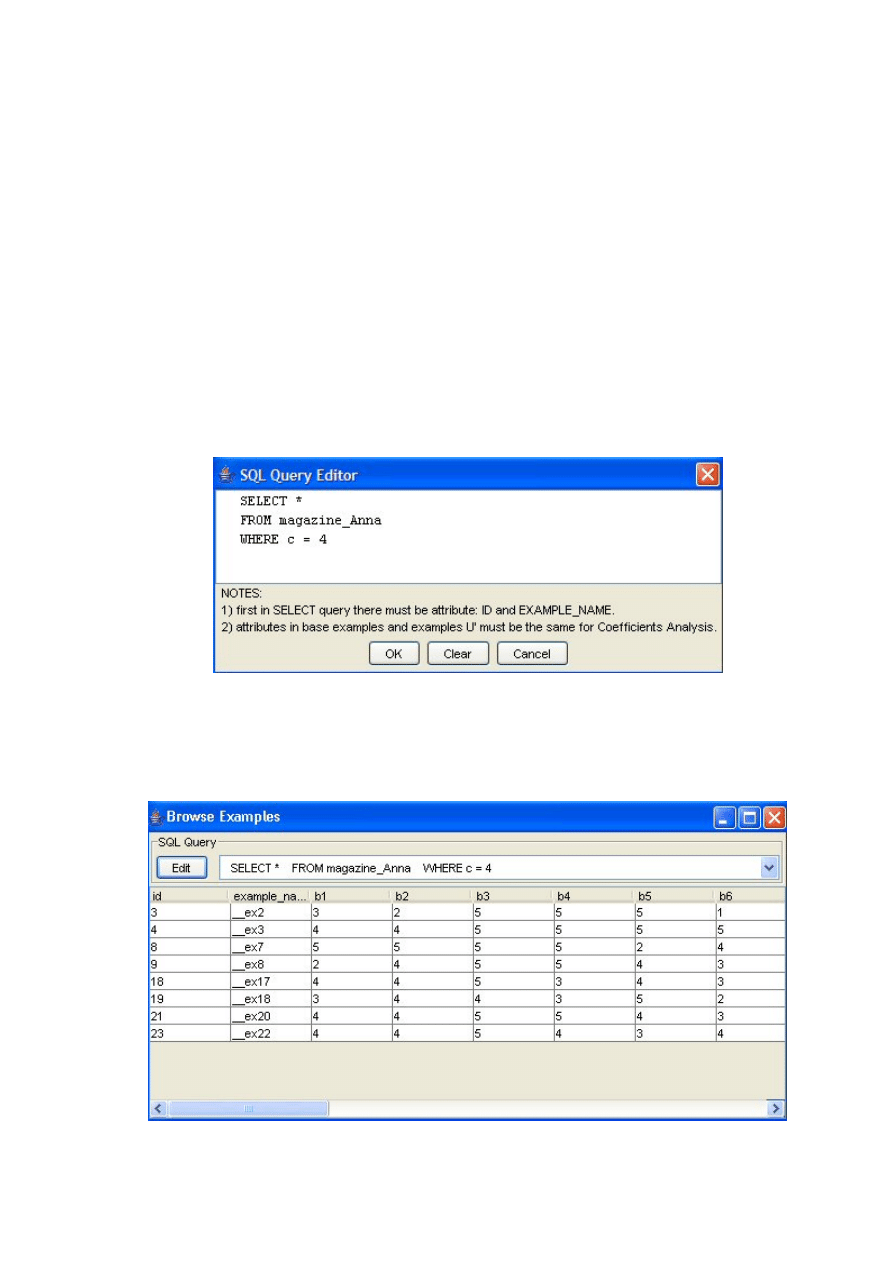
48
6.2.1 Etap 1 – prezentacja danych marketingowych do analizy
Danymi marketingowymi dla magazyny „Anna” są odpowiedzi respondentów
na ankietę dotyczącą jego zawartości. Właścicielom magazynu zależy na wzroście
liczby czytelników oceniających ogólną zawartość czasopisma najwyżej, tzn. na 5.
Naszym celem jest znalezienie takich strategii interwencji, których zastosowanie
pozwoli na osiągnięcie zamierzonych celów – wykorzystamy do tego system OLSA.
Można się spodziewać, że na początku będzie to najłatwiejsze i najmniej kosztowne u
czytelników, którzy obecnie oceniają go na 4. Aby przekonać się ilu ich jest,
przefiltrujmy zbiór danych właśnie do takich przykładów. Taką filtrację dokonuje się w
bardzo prosty sposób wydając odpowiednie zapytanie do bazy danych wyciągające z
niej interesujące użytkownika przykłady [opcja Edit SQL Query] (Rys. 8):
Rys. 8 Wybór z klasy c=4
Okazuje się, że ze wszystkich 23 ankietowanych czytelników ośmiu jest takich, którzy
oceniają ogólną zawartość magazynu na 4 (Rys. 9).
Rys. 9 Prezentacja przykładów dla klasy c=4
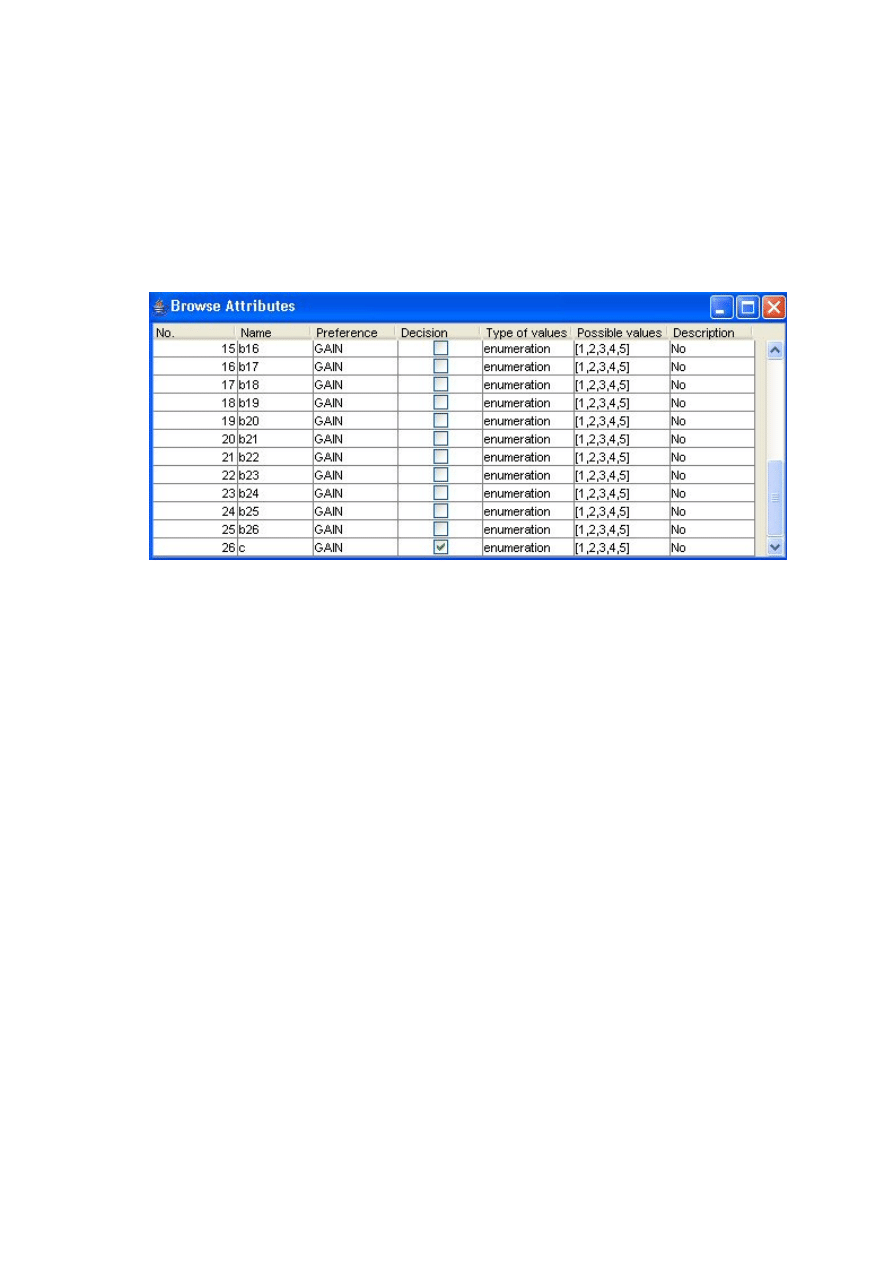
49
Aplikacja OLSA System daje użytkownikowi ogromne możliwości, jeśli chodzi
o prezentacje problemu i jego własności. Przykłady dodatkowo można obrazować w
postaci dwóch wykresów oraz technologii OLAP i DRSA. Poza przykładami można
podejrzeć dokładną charakterystykę atrybutów (kryteriów), możliwe wartości jakie
mogą przyjmować, kierunek preferencji i wskazać, który z nich ma być decyzyjnym
(Rys. 10).
Rys. 10 Moduł prezentacji atrybutów
Ponieważ cała analiza danych marketingowych oraz metody szukania strategii
interwencji bazują na wygenerowanych regułach decyzyjnych, dlatego dużo zależy od
sposobu ich generacji, tj. algorytmu oraz własności danej reguły: zaufania oraz
wsparcia. Aktualnie w systemie GoalProject zaimplementowany jest prosty algorytm
generujący wszystkie możliwe reguły, który dla analizowanego problemu 23
przykładów i 27 kryteriów stworzył aż 1071 reguł. Istnieje także możliwość wczytania
do bazy danych przez GoalProject reguł wygenerowanych w innych programach przy
pomocy różnych algorytmów lub przez późniejsze dodanie do aplikacji OLSA System
komunikacji z GoalProject-em i generację reguł np. dla przefiltrowanych przykładów.
Dla każdej z reguł prezentowane są jej własności oraz lista przykładów, które ona
pokrywa. Należy zaznaczyć, że liczba przykładów w kolumnie „Support” nie zawsze
musi być równa faktycznej liczbie wyświetlanych przykładów pokrywanych przez tą
regułę. Pierwsza wartość dotyczy reguły wczytanej z bazy danych i wygenerowanej dla
całego zbioru przykładów, natomiast druga dotyczy już przypadku, który analizujemy w
aplikacji i modyfikujemy, np. po filtracji przykładów będą wyświetlane tylko te, które
spełniają warunki filtru, zazwyczaj będzie ich mniej (Rys. 11):
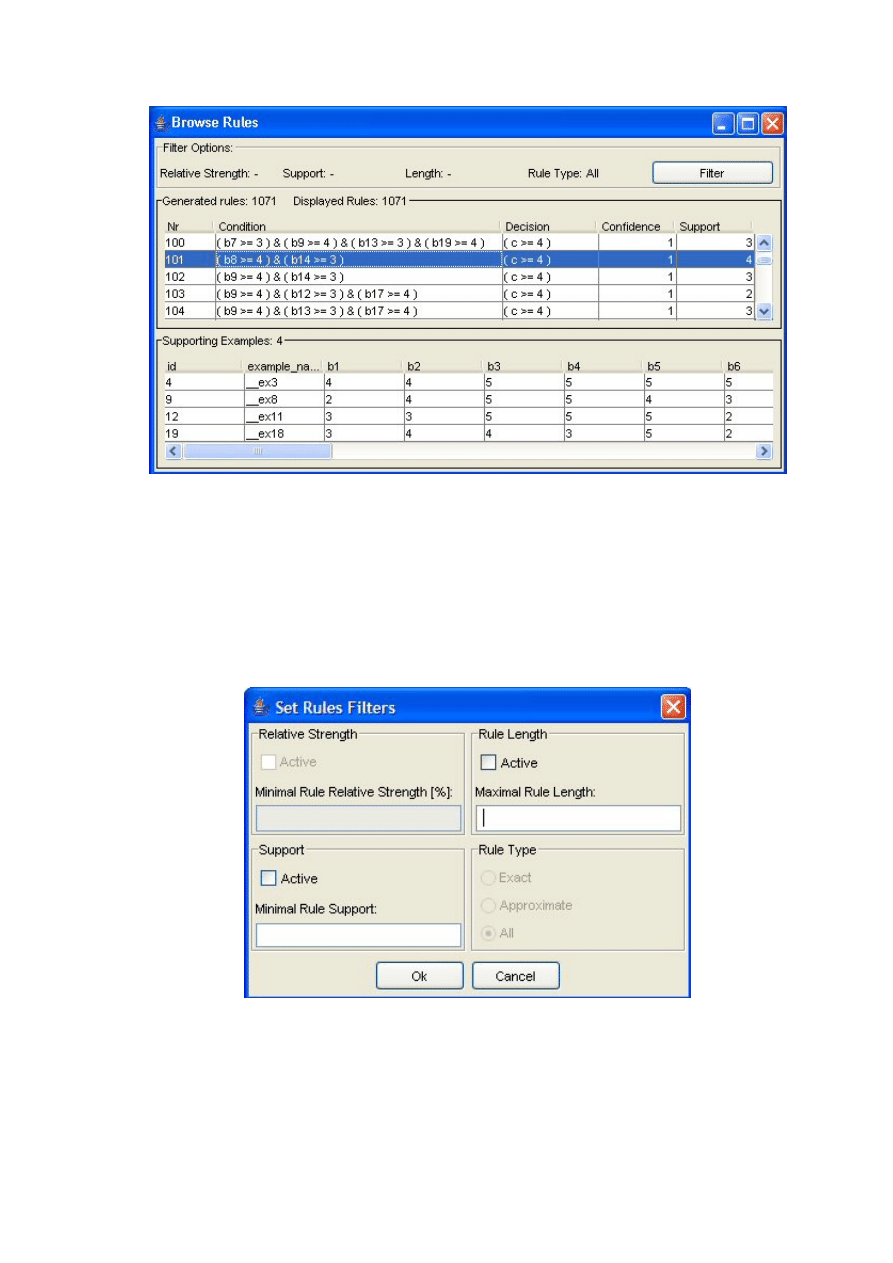
50
Rys. 11 Moduł prezentacji reguł
Przy bardzo dużej liczbie reguł sensowna analiza jest mocno utrudniona lub wręcz
niemożliwa. Aby strategie interwencji wywiedzione z reguł decyzyjnych były jak
najbardziej wiarygodne można dokonać filtracji reguł wg dwóch kryteriów:
minimalnego wsparcia reguły oraz maksymalnej liczby warunków elementarnych
(długości reguły) [opcja Filter Options] (Rys. 12):
Rys. 12 Moduł do filtrowania reguł
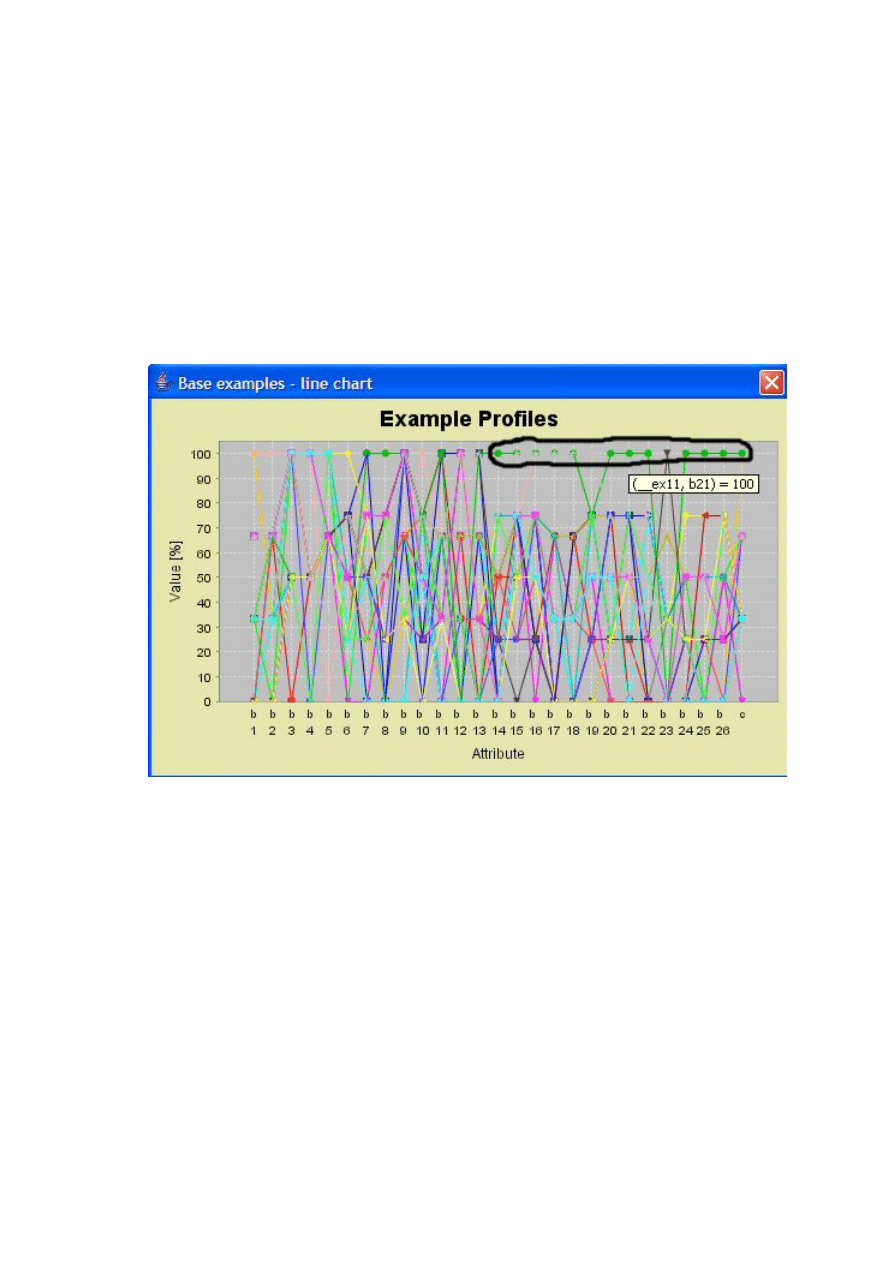
51
6.2.2 Etap 2 – analiza metodą szukania strategii interwencji
Załóżmy, że magazyn „Anna” jest zainteresowany zwiększeniem ogólnej oceny
jego zawartości z 4 na 5 dla konkretnych ankietowanych. Pytanie, jakie może się
nasunąć w tym momencie to, dla których z nich będzie to łatwe, a dla których
trudniejsze? Teoretycznie im więcej lepszych ocen na poszczególnych kryteriach tym
wyższa ogólna ocena końcowa. Dlatego należy szukać takich czytelników, którzy mają
jak najwyższe oceny tematycznej zawartości czasopisma. Pomocna w tej sytuacji może
być wizualizacja przykładów na wykresie [Analysis->Line Chart->Examples] (Rys. 13):
Rys. 13 Moduł wykresu liniowego
Zaznaczony fragment wykresu wskazuje, że powyższe warunki spełnia m.in.
respondent oznaczony numerem 11 (example_name = __ex11), ponieważ na dużej
ilości kryteriów ma on wysoką ocenę. Powyższy rysunek jest niestety nieczytelny. Z
pomocą przychodzi w takiej sytuacji możliwość filtracji przykładów. Dokonajmy takiej
filtracji i wyświetlmy tylko tą część przykładów, która wizualnie ma wysokie oceny na
dużej ilości kryteriów: nr 7, 11, 22:
SELECT * FROM magazine_Anna WHERE example_name IN (‘__ex7’, ‘__ex11’, ‘__ex22’)
Okazuje się, że największą liczbę kryteriów z najwyższymi ocenami ma przykład nr 11
(kolor niebieski) – aż 20, mniej bo 13 ma przykład nr 7 (kolor czerwony), a 10 nr 22
(kolor zielony) – Rys. 14:
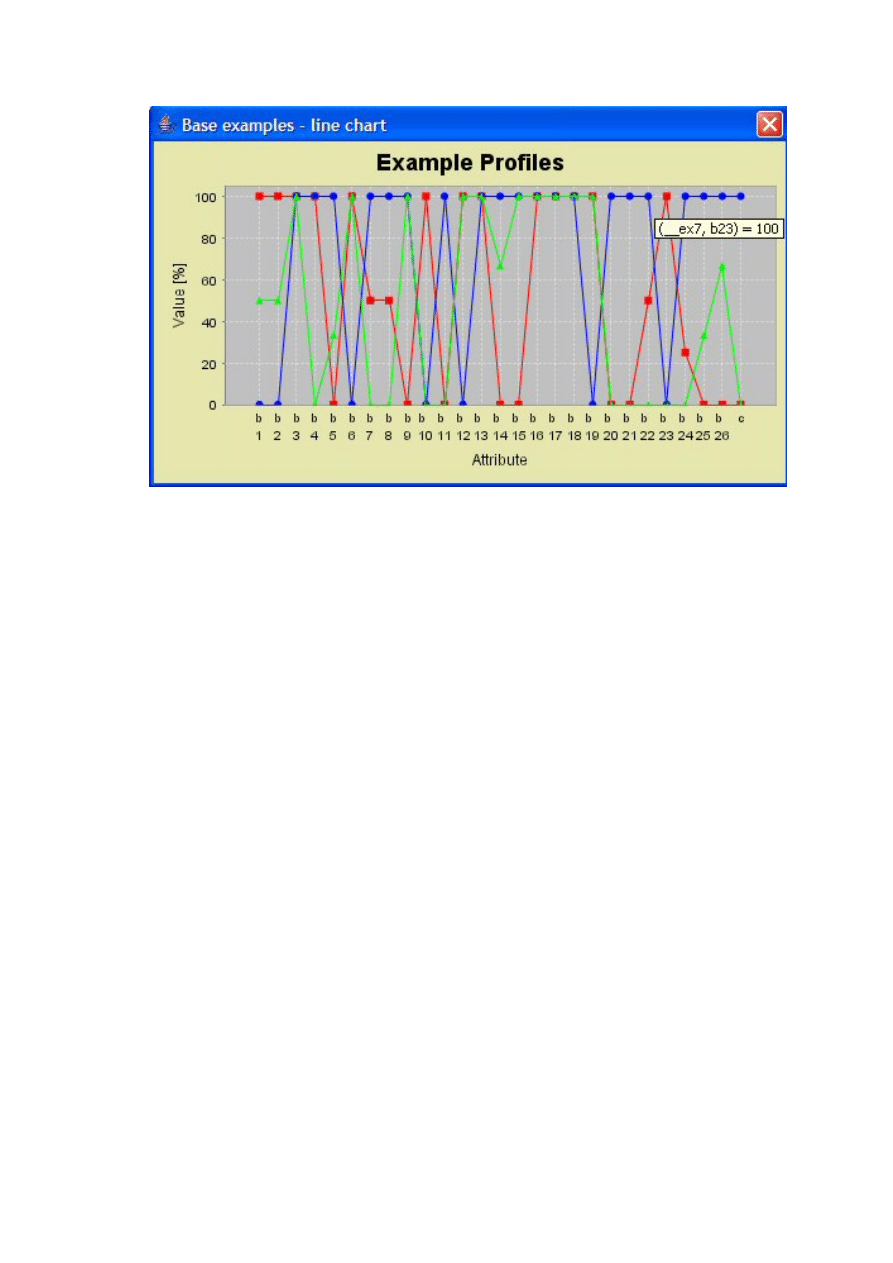
52
Rys. 14 Wykres liniowy dla przykładów: __ex7, __ex11, __ex22
Czytelnik nr 11 ocenia już ogólną zawartość magazynu na 5, więc do analizy
wybieramy respondenta nr 7. Przekonajmy się, co należy zrobić, aby zmienił on ogólną
ocenę zawartości magazynu z 4 na 5 wykorzystując do tego celu metodą szukania
strategii interwencji.
Po wskazaniu w tabeli decyzyjnej interesującego nas przykładu i wybraniu
metody szukania strategii [opcja
Search of strategy pod prawym przyciskiem myszki]
określamy decyzję co najmniej 5 i uruchamiamy obliczenia. W ich wyniku
otrzymujemy aż 43 reguły – możliwe strategie interwencji, których zastosowanie
pozwoli na zmianę ogólnej oceny z 4 na 5, a wśród której poszukujemy najlepszej. Nie
można zapomnieć o niezgodnościach w zbiorze reguł, które w tym przypadku nie
występują (Rys. 15).
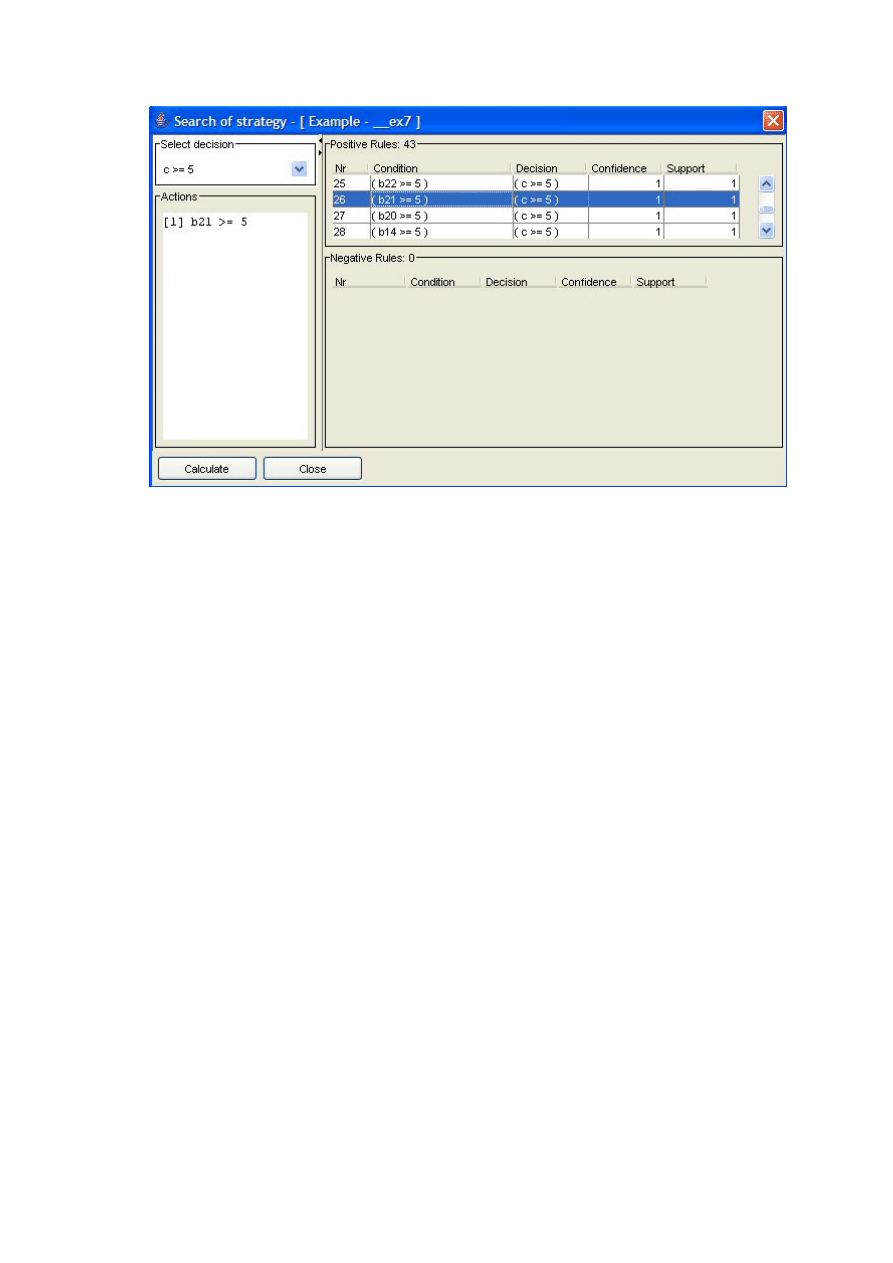
53
Rys. 15 Moduł szukania strategii interwencji
Ponieważ dla czasopisma „Anna” ważne jest osiągnięcie celu jak najmniejszym
wysiłkiem i kosztem ustalono, że pod uwagę będą brane reguły o minimalnej liczbie
warunków elementarnych. Takie postępowanie jest zrozumiałe, gdyż w konsekwencji
będzie to równoważne małym zmianom na kryteriach przy zastosowaniu strategii
wywiedzionej z takich reguł. Wśród otrzymanych rezultatów znajduje się 8 reguł
(propozycji strategii interwencji) posiadających tylko jeden warunek elementarny.
Dla przykładu strategia wywiedziona z reguły nr 26 mówi, że wybrany przez nas
czytelnik będzie oceniał zawartość czasopisma na 5, jeśli jego ocena na kryterium
Praca będzie wynosić co najmniej 5 – aktualnie ocenia on je tylko na 3. Dla magazynu
oznacza to, że jeśli chce on, aby ten właśnie respondent zmienił ogólną ocenę
zawartości magazynu, musi spowodować podwyższenie jego oceny z 3 na 5 na
kryterium
Praca.
Aby powyższa analiza miała sens należy założyć, że magazyn „Anna” wie jak
nakłonić czytelników do zmiany ich oceny na poszczególnych kryteriach. Gdyby z
każdym kryterium i określoną zmianą na nim powiązać koszt to otrzymane 43 strategie
można by było posortować po koszcie od najmniej kosztownej do najbardziej.
Zastosowana strategia daje odpowiedzi na pytania tylko dla konkretnego jednego
przykładu. Docelowo jej stosowanie powinno dotyczyć pewnej grupy obiektów
pogrupowanych według określonych zasad (np. ogólną oceną zawartości magazynu
54
równą 4) i odpowiadać na pytanie, co należałoby zrobić, aby wszyscy z tej grupy
zmienili ogólną ocenę na 5 (jedna z możliwości rozbudowy OLSA System w
przyszłości). Wówczas przy zastosowaniu wskazanej strategii interwencji magazyn
zyskałby dodatkową grupę klientów (nie tylko jednego) oceniającą jego zawartość
najwyżej.
6.2.3 Etap 3 – analiza metodą testowania strategii interwencji
W rzeczywistości bardzo często tematy dotyczące kina, muzyki, itp. nie są przez
czytelników rozróżniane, a traktowane jako szeroko pojęta rozrywka. Magazyn „Anna”,
przy drugim podejściu analizy danych ankietowych w systemie OLSA, bazuje właśnie
na takim przypuszczeniu. Istnieje duża szansa, że respondenci bardzo podobnie ocenili
zawartość czasopisma na trzech kryteriach:
Sztuka i Kultura, Kino oraz Muzyka. Do
sprawdzenia tego wykorzystamy prezentację danych w postaci wielowymiarowej tabeli
OLAP i DRSA [Analysis->OLAP Settings->Examples]. Określamy więc, co chcemy
mieć zaprezentowane i w jakiej postaci: trzy wymienione kryteria jako wymiary,
wartości wymiarów (co najmniej) oraz miarę liczności (Rys. 16):
Rys. 16 Moduł definiowania wymiarów i miary dla OLAP
W rezultacie otrzymujemy wielowymiarową tabelę danych. W pojedynczej komórce
znajduje się liczba czytelników magazynu, którzy oceniają jego zawartość zgodnie z
wartościami wymiarów określonymi dla danej komórki (rys. 17).
55
Rys. 17 Moduł prezentacji danych wielowymiarowych OLAP
Rozkład wartości pokazuje, że przypuszczenie się potwierdza, ale nie w całości. Oceny
zawartości tematycznej na tych kryteriach są bardzo zbliżone, ale praktycznie w
większości przypadków istnieje różnica w wartości oceny na jednym z trzech
kryterium, a dla dwóch pozostałych jest identyczna.
Powyższa analiza może być wyjściem do metody testowania strategii [opcja
Test
of strategy pod prawym przyciskiem myszki]. Cel jest taki sam – zmiana ogólnej oceny
zawartości tematycznej magazynu przez czytelników z 4 na 5 przy jak najmniejszej
ilości działań z tym związanych. Kierując się ponownie jak najwyższą oceną na jak
największej liczbie kryteriów zastosujemy metodologię dla komórki określonej
wymiarami:
Sztuka i Kultura, Kino oraz Muzyka co najmniej 4 (wartości wymiarów,
tzn. część warunkową reguły spełnia przykład nr 10). Następnie należy określić cel
strategii (część decyzyjną) – dla danego wyboru obliczany jest współczynnik
wiarygodności reguły. Dla decyzji co najmniej 5 otrzymujemy końcową postać reguły:
(b11>=3)&(b12>=4)&(b13>=4) => (c>=5) i współczynnik równy 0% (Rys. 18).
Oznacza to, że strategie wywiedzione z takiej reguły będą miały zerową wiarygodność.
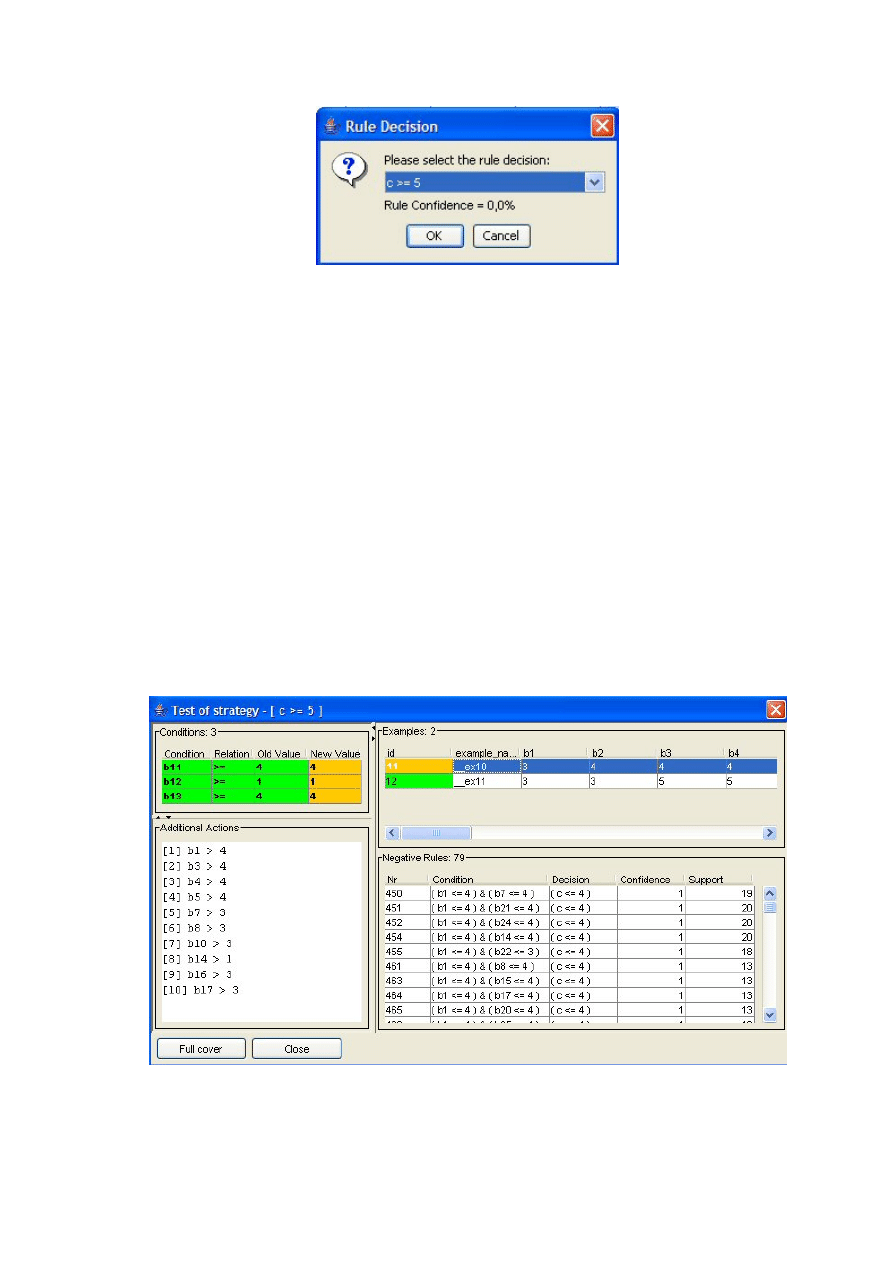
56
Rys. 18 Wybór celu strategii (części decyzyjnej reguły)
Należy więc poszukać takiej reguły która będzie miała dodatkowo, oprócz przyjętej
wyżej zasady, jak największy współczynnik wiarygodności (najlepiej 100%). Jako
kompromis przyjmijmy regułę postaci: (b11>=4)&(b12>=1)&(b13>=4) => (c>=5) ze
współczynnikiem równym 50%, która pokrywa przykłady: nr 10 oraz nr 11 (ocenia już
magazyn najwyżej).
Aby wymieniony przykład nr 10 był pokrywany przez tą regułę, tzn. dany czytelnik
zmienił swoją ogólną ocenę na najwyższą, należy jeszcze sprawdzić czy w zbiorze
wszystkich reguł nie ma niezgodności. Okazuje się, że takie są i żeby się ich pozbyć
należy dodatkowo wymóc u niego zmianę oceny na wielu innych kryteriach (Rys. 19).
Zgodnie z tą regułą wywiedziona z niej strategia interwencji o wiarygodności 50%
mówi, że czytelnik nr 10 może zmienić ogólną ocenę zawartości czasopisma „Anna”
pod warunkiem jego zmian oceny na wskazanych dodatkowych kryteriach.
Rys. 19 Moduł testowania strategii interwencji

57
Dokonajmy teraz zmiany wartości na jednym z warunków elementarnych reguły
i sprawdźmy (przetestujmy) czy istnieją inne przykłady, które pokryłaby część
warunkowa reguły w zmienionej postaci. Okazuje się, że gdy zmienimy warunek
(b13>=4) na (b13>=2) to poza respondentami nr 10 i 1 pokrywani są także nr 3 oraz 9.
Co to dla nas oznacza? Otóż, jeśli magazyn „Anna” chciałby zmienić ogólną ocenę
czytelnika nr 3 lub 9 na najwyższą musiałby spowodować zmianę jego oceny na
kryterium
Muzyka z obecnej równej 2 na 4 zgodnie ze strategią interwencji
wywiedzioną z tej reguły oraz dodatkowo, aby zlikwidować niezgodności, zmianę na
wskazanych kryteriach.
Analizę metodą opisaną w tym podpunkcie można przeprowadzić także dla
reguły już wygenerowanej po jej wskazaniu w tabeli z wczytanymi regułami. Wówczas
nie dokonujemy „ręcznego” wyboru celu strategii interwencji (części decyzyjnej),
ponieważ taka reguła już go posiada i owy cel definiujemy wskazując odpowiednią dla
nas regułę decyzyjną.
6.2.4 Etap 4 – badanie oczekiwanej efektywności strategii interwencji
Wyidukowany zbiór reguł wczytany razem z wynikami ankiety magazynu
„Anna” informuje o występujących w niej regularnościach i zależnościach.
Dotychczasowa analiza dotyczyła jednego zbioru czytelników. Załóżmy, że posiadamy
dwa zbiory danych: podstawowy
U czyli wyniki ankiety czasopisma oraz dodatkowy
U’, na których chcemy sprawdzić efektywność strategii wywiedzionej z reguł
wyidukowanych ze zbioru, a który w tym przypadku jest tym samym zbiorem
(oczywiście może być inny oparty na tych samych kryteriach).
Do aplikacji OLSA System należy wczytać podstawowy plik z problemem: przykłady i
reguły [File->Open file] oraz dodatkowy plik pokrywający się w tym przypadku z
pierwszym [File->Open examples U’].
Ponieważ celem strategii włoskiego magazynu jest wzrost liczby czytelników
oceniających ogólnie jego zawartość najwyżej, należy wybrać taką regułę decyzyjną,
która pozwoli osiągnąć zamierzony cel, a dokładniej strategie interwencji z niej
wywiedzione. Przypuśćmy, że właściciele czasopisma chcą tym razem oprzeć działania
na dwóch kryteriach:
Moda oraz Zdrowie i ograniczyć ewentualne zmiany ocen
czytelników tylko na tych dwóch tematach. Kierując się tymi założeniami do dalszej
analizy wybieramy regułę
r postaci: (b3>=5)&(b7>=5) => (c>=5), tzn. jeżeli ocena
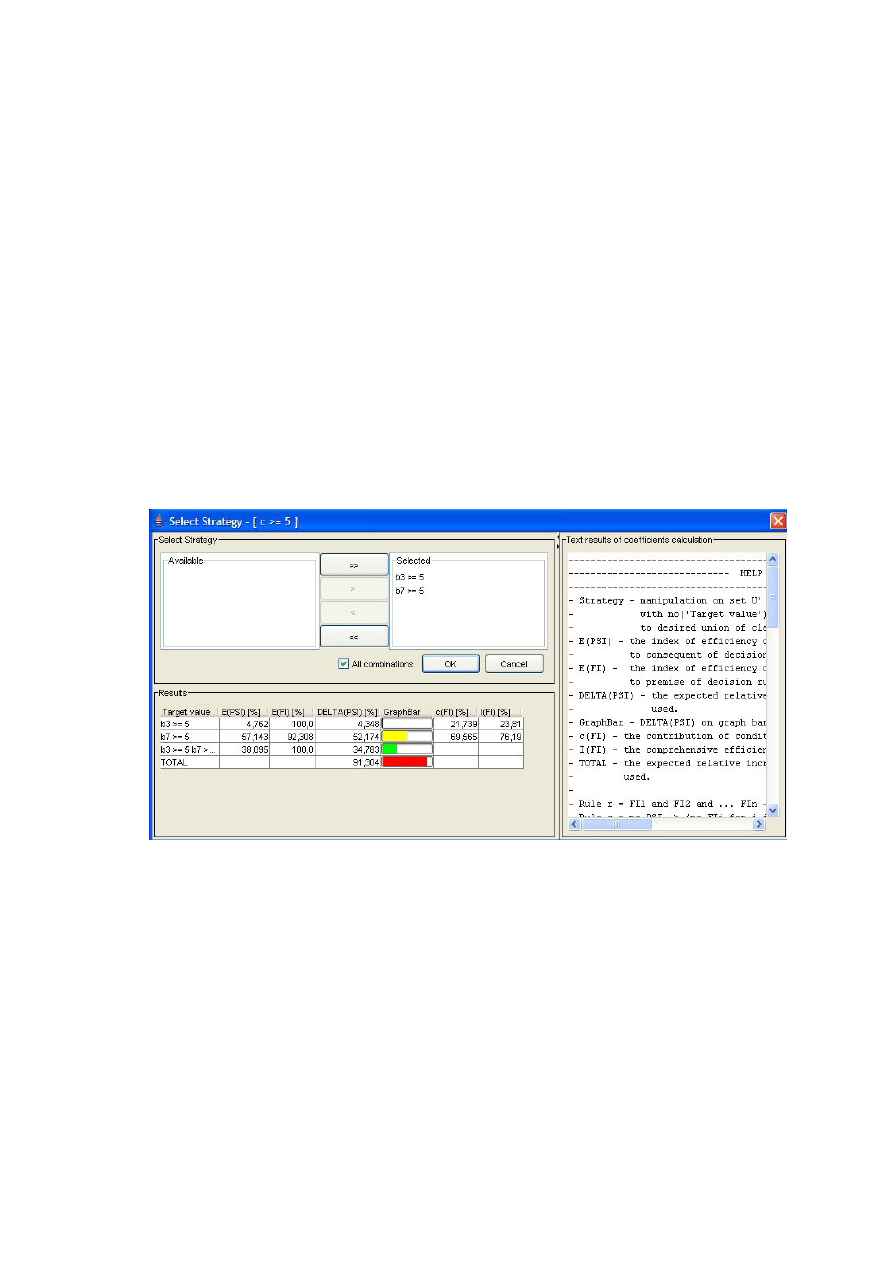
58
Mody i Zdrowia będzie co najmniej 5 to czytelnik oceni magazyn na co najmniej 5
[opcja
Calculate Coefficients pod prawym przyciskiem myszki].
W kolejnym kroku określamy, przez wybór odpowiednich warunków elementarnych,
postać badanej strategii wywiedzionej z reguły. Przez strategię będziemy rozumieć w
tym przypadku manipulację na zbiorze
U’ mającą na celu transformację przykładów z
¬
(„Target value”) & („Selected” \ ”Target value”) do pożądanych klas decyzyjnej.
Jeśli dla przykładu wybralibyśmy tylko pierwszy (b3>=5) to oznaczałoby to, że badamy
oczekiwaną efektywność strategii interwencji dla przykładów, które nie spełniają tego
warunku elementarnego (b3<=4), natomiast spełniają drugi nie wybrany (b7>=5) i
oczywiście oceniają magazyn na mniej niż 5 (c<=4). Nasza analiza zakłada sprawdzenie
efektywności wszystkich możliwych strategii interwencji wywiedzionej ze wskazanej
reguły, więc wybieramy wszystkie warunki elementarne i zaznaczamy opcję –
wszystkie kombinacje (Rys. 20):
Rys. 20 Moduł badania efektywności strategii interwencji wywiedzionej z reguł
Zanim przejdziemy do interpretacji wyników przypomnijmy znaczenie
poszczególnych współczynników (wszystkie wartości wyrażone są w procentach i im są
one większe tym lepiej) – dokładny opis omawianej metody można znaleźć w
punkcie 3.2:
• E(PSI) – wskaźnik efektywności stworzonej strategii ze względu na
konsekwencję (część decyzyjną) danej reguły
r,

59
• E(FI) – wskaźnik efektywności wywiedzionej strategii ze względu na przesłanki
(część warunkową) danej reguły decyzyjnej
r,
• DELTA(PSI) – oczekiwany wzrost liczby obiektów po zastosowaniu
pojedynczej strategii interwencji,
• c(FI) – wskaźnik określający udział (wkład) danego warunku użytego w
strategiach bazujących na regule
r,
• I(FI) – wskaźnik określający kompletną skuteczność warunku użytego w
strategiach bazujących na regule
r,
• TOTAL – całkowity oczekiwany wzrost liczby obiektów po zastosowaniu
łącznej strategii interwencji wywiedzionej z danej reguły
r, polegającej na
jednoczesnej zmianie wielu warunków.
W rezultacie obliczeń otrzymujemy trzy możliwe strategie interwencji, które
nakazują odpowiednio (Rys. 21):
• Strategia 1 – zmienić ocenę na kryterium Moda na co najmniej 5 wszystkim tym
czytelnikom, którzy oceniają ją obecnie na co najwyżej 4 i oceniają zawartość
tematyczną magazynu na kryterium
Zdrowie na co najmniej 5, a ogólną ocenę
czasopisma mają równą co najwyżej 4,
• Strategia 2 – zmienić ocenę na kryterium Zdrowie na co najmniej 5 wszystkim
tym czytelnikom, którzy oceniają je obecnie na co najwyżej 4 i oceniają
zawartość tematyczną magazynu na kryterium
Moda na co najmniej 5, a ogólną
ocenę czasopisma mają równą co najwyżej 4,
• Strategia 3 – zmienić oceny na kryteriach Moda oraz Zdrowie na co najmniej 5
wszystkim tym czytelnikom, którzy oceniają je obecnie na co najwyżej 4, a
ogólną ocenę czasopisma mają równą co najwyżej 4. Należy zauważyć, że tej
strategii nie można tak naprawdę zrealizować.

60
Rys. 21 Graficzna reprezentacja reguły i wywiedzionych z niej strategii interwencji
Teraz można postawić pytanie o oczekiwany procentowy wzrost czytelników magazynu
„Anna” oceniających jego zawartość najwyżej po zastosowaniu każdej ze znalezionych
strategii interwencji i rzeczywistą efektywność każdej z nich. Okazuje się, że działania
podjęte zgodnie ze strategią nr 1 spowodują znikomy wzrost czytelników (4,35%).
Najbardziej efektywną dla nas jest natomiast strategia nr 2, której zastosowanie da nam
wzrost ponad połowy ankietowanych (52,17%) ze zbioru
U’. Ostatnia proponowana
strategia interwencji powoduje, że 34,78% respondentów zwiększy swoją ogólną ocenę
z 4 na 5.
Jeśli chodzi o wartości wskaźników dla warunków elementarnych to dla pierwszego
(b3>=5) są one bardzo małe: 21,74% (
c(FI)) oraz 23,81% (I(FI)), a bardzo duże dla
drugiego (b7>=5): 69,56% (
c(FI)) oraz 76,19% (I(FI)). Wynika to oczywiście z faktu,
że strategie, w których udział ma warunek pierwszy są mało efektywne (nr 1 i 3),
natomiast drugi wchodzi w skład bardzo efektywnej strategii nr 2.
Podsumowując, w wyniku badania efektywności strategii interwencji
wywiedzionej z wybranej na początku reguły
r, otrzymano trzy możliwe strategie o
różnych efektywnościach. Jednoczesne zastosowanie wszystkich pozwoli magazynowi
„Anna” osiągnąć zamierzony cel w 91,3%, tj. najwyższą ogólną ocenę jego zawartości
przez ewentualne zmiany tylko na dwóch kryteriach:
Moda i Zdrowie, dla 91,3%
respondentów ze zbioru
U’. Pomijamy w tym przypadku sprawę kosztów takich zmian
dla poszczególnych strategii i kryteriów.

61
6.3 Końcowe wnioski
Przeprowadzony eksperyment, na rzeczywistych danych ankietowych włoskiego
magazynu „Anna”, pozwolił zapoznać się z możliwościami i zastosowaniem aplikacji
OLSA System. Na początku został określony cel eksperymentu, a następnie przy
wykorzystaniu trzech podejść analizy danych zawartych w programie, próbowano
znaleźć sposoby jego osiągnięcia. W rezultacie otrzymano propozycje działań w postaci
konkretnych strategii interwencji różniących się między sobą w zależności od
postawionych przez czasopismo dodatkowych wymagań i wybranej metody. Bardzo
pomocna okazała się różnorodność sposobów prezentacji analizowanych danych, m. in.
na wykresie (w metodzie szukania strategii) i w tabeli wielowymiarowej (dla metody
testowania strategii).
Otrzymane wyniki zawierają już określone działania, jakie musi podjąć
czasopismo, aby zwiększyła się ogólna ocena jego zawartości przez czytelników (na
najwyższą równą 5). Przebieg eksperymentu pokazał, że punktem wyjściowym analizy
może być konkretny czytelnik magazynu (wtedy poszukujemy dla niego najlepszej
strategii), jak i zamierzona strategia interwencji (wówczas testujemy jej zastosowanie
oraz oczekiwaną efektywność). Wadą metod szukania oraz testowania strategii
interwencji jest to, że obliczenia dotyczą jedynie pojedynczego ankietowanego
natomiast trzecia z metod, w przeciwieństwie do pozostałych dwóch, bada oczekiwaną
efektywność dla określonej grupy ankietowanych. Należy zaznaczyć, że bardzo
przydatne byłoby wprowadzenie kosztów zmian ocen na poszczególnych kryteriach,
dzięki czemu pojawiłby się element wyboru między efektywnością a kosztem
zastosowania strategii interwencji.

62
7 Podsumowanie i wnioski
W ramach pracy magisterskiej powstał zaawansowany system wspomagania
decyzji – OLSA System, który reprezentuje nowoczesne podejście do analizy
satysfakcji klienta. Do tego celu została w nim wykorzystana teoria zbiorów
przybliżonych, a w szczególności reguły decyzyjne. W systemie zaproponowano
następujące trzy warianty analizy: badanie oczekiwanej efektywności strategii
interwencji, poszukiwanie strategii interwencji oraz testowanie strategii interwencji.
Przeprowadzony eksperyment pozwolił udowodnić zasadność motywacji
wykorzystania do ASK wiedzy odkrytej właśnie w postaci reguł. Otrzymane wyniki
udowodniły, że każdy z trzech zaprezentowanych wariantów analizy danych
marketingowych (ankiet), pozwolił osiągnąć zamierzony cel i w rezultacie dał
odpowiedź na postawione pytania – propozycje działań w postaci konkretnych strategii
interwencji. Ponieważ brakuje tutaj elementów dotyczących kosztów takich strategii,
dlatego trudno ocenić rzeczywiste ich zastosowanie i wybranie tej najlepszej. Aplikacja
daje możliwość zarówno poszukiwania strategii dla konkretnego przykładu jak i
testowania efektywności strategii już zamierzonej, co jest jej dużą zaletą.
Wykorzystanie technologii OLAP w połączeniu z DRSA umożliwiło stworzenie
rozbudowanego narzędzia do prezentacji analizowanych danych w postaci tabeli
wielowymiarowej. W programie wykorzystano również inne formy prezentacji danych,
m.in. proste tabele dwuwymiarowe i wykresy. To wszystko wpłynęło na przejrzystość,
czytelność i funkcjonalność interfejsu mimo jego dużej złożoności.
Wszystkie zadania postawione na początku pracy (punkt 2) zostały
zrealizowane. Udało się osiągnąć następujące cele:
• stworzyć „otwarty” i „ergonomiczny” system regułowej analizy danych
marketingowych dotyczących satysfakcji klienta,
• zaimplementować metodologię badania wpływu strategii interwencji
wywiedzionej z reguł decyzyjnych,
• zaprojektować i zaimplementować własne rozszerzenia (w postaci algorytmów)
metodologii ASK w oparciu o reguły decyzyjne: metodę testowania oraz
szukania strategii interwencji,

63
• do wczytywania danych wejściowych oraz generacji reguł decyzyjnych
wykorzystać istniejący już system eksploracji danych GoalProject,
• stworzyć bardzo rozbudowany, ale przejrzysty interfejs użytkownika łączący w
sobie czytelną i przejrzystą prezentację problemu oraz dużą funkcjonalność,
• przeprowadzić eksperyment, przeanalizować otrzymane wyniki i wyciągnąć z
nich odpowiednie wnioski,
• utworzyć dokumentację systemu OLSA.
Stworzony system OLSA ze względu na swoją otwartość ma wiele możliwości
rozbudowy (część z nich opisano w treści pracy). Jednym z kierunków dalszego
rozwoju pracy może być skupienie się na metodach analizy danych
zaimplementowanych w aplikacji i ich rozwijanie. Ponieważ w rzeczywistości
spowodowanie zmian oceny/ocen satysfakcji klienta kosztuje, należałoby wprowadzić
funkcję kosztu zmiany zależną od kryterium, na którym ta zmiana jest dokonywana
(określenie dla każdego kryterium kosztów zmian na jego wartościach). Pozwoliłoby to
w przyszłości dokonywać wyboru najlepszej znalezionej strategii interwencji pod
względem kosztu jej przeprowadzenia – jak największy wzrost liczby klientów przy jak
najmniejszym koszcie koniecznych zmian (elementy optymalizacji), a także tak
naprawdę ocenić przydatność powstałego systemu. Ponadto dla metody szukania
strategii interwencji bardzo funkcjonalne wydaje się podejście jej poszukiwania nie
tylko dla pojedynczego przykładu, ale pewnej wcześniej wybranej grupy.
Przy ewentualnym rozwijaniu OLSA System należy zwrócić również uwagę na
interfejs i jego doskonalenie. Mimo dużej funkcjonalności oraz złożoności nie jest on na
pewno idealny. Jedna z propozycji to bardziej zaawansowana komunikacja z systemem
GoalProject nie tylko przez bazę danych (pośrednio), ale przez wydawanie poleceń
(bezpośrednio), np. przy generowaniu reguł. Inne możliwości to m.in. bardziej
interakcyjne prezentacje w postaci wykresów, dodanie nowych filtrów dla reguł, czy
wyświetlanie kryteriów w postaci OLAP nie tylko typu wyliczeniowego (więcej w pliku
TODO.pdf na dołączonej płycie CD).
Ponieważ wykorzystane narzędzia i systemy są w pełni darmowe można
zastanowić się również nad ewentualnym udostępnieniem całego projektu w sieci i jego
rozwojem jako system
Open Source. Pozwoliłoby to na rozwijanie aplikacji przez wielu

64
programistów, a tym samym na dodawanie kolejnych elementów oraz doskonalenie już
istniejących.

65
BIBLIOGRAFIA
[1] Biedziński J., Biedziński M., Boński P., Lepkowski L.,
Praca inżynierska:
Otwarta platforma programowa dla systemów eksploracji danych, Politechnika
Poznańska, Poznań 2003
[2] Błaszczyński J., Dembczynski K.,
Otwarta platforma programistyczna dla
systemów analizy danych, Raport Politechniki Poznańskiej RB-034/03, 2003
[3] CodeGuru, http://www.codeguru.com/java/Swing/JTable/index.shtml
[4] CRM,
Customer Relationship Management, http://www.e-crm.int.pl
[5] Date C.J.,
An Introduction to Database Systems, Addison Wesley Longman,
Massachusetts 2000
[6] Dejnak A.,
Psychologia kontaktu z klientem - zadowolenie klienta i lojalność,
Psychologia i Rzeczywistość nr 4/2002
http://www.psycholog.alleluja.pl/tekst.php?numer=465
[7] Greco S., Matarazzo B., Pappalardo N., Słowiński R.,
Measuring expected effects
of interventions based on decision rules, Journal of Experimental and Theoretical
Artificial Intelligence, 2004 (w druku)
[8] Greco S., Matarazzo B., Słowiński R.,
Rough Set Analysis of Preference-Ordered
Data, [In]: J.J. Alpigini, J.F. Peters, A. Skowron, N. Zhong (eds.), Rough Sets and
Current Trends in Computing. LNAI 2475, Springer-Verlag, Berlin, 2002, 44-59
[9] Greco S., Matarazzo B., Slowinski R., Stefanowski J.,
Variable consistency model
of dominance based rough set approach, [In]: W.Ziarko, Y.Yao: Rough Sets and
Current Trends in Computing, LNAI 2005, Springer-Verlag, Berlin, 2001, pp.
170-181
[10] Grigoroudis E., Siskos Y.,
A survey of customer satisfaction barometers: Some
result from the transportation-communications sector, European Journal of
Operational Research 152 (2004), 334-353
[11] Java Sun Microsystems, http://java.sun.com
[12] JCharts,
A free Java chart library, http://jcharts.krysalis.org/,
http://sourceforge.net/projects/jcharts/
[13] JFreeChart,
A free Java chart library, http://www.jfree.org/jfreechart/
[14] Johnson M.D., Fornell C.,
A framework for comparing customer satisfaction
across individuals and product categories, Journal of Economic Psychology 12
(1991), 267-286
[15] Kessler S.,
Measuring And Managing Customer Satisfaction, ASQ Quality Press,
Wisconsin 1996
[16] Letrix, http://www-idss.cs.put.poznan.pl/~goalproject/letrixII-webpage/index.html
[17] MySQL Connector/J, http://dev.mysql.com/
[18] MySQL, http://www.mysql.com
[19]
Otwarta Platforma Programowa Dla Eksploracji Danych,
http://www-idss.cs.put.poznan.pl/~goalproject/
[20] Pawlak Z.,
Rough Sets, International Journal of Information and Computer
Sciences 11 (1982), 341-356
[21] Roy B.,
Wielokryterialne wspomaganie decyzji, WNT Warszawa 1990
[22] Rumiński J.,
Język Java – podstawy programowania, 1999
[23] Słowiński R., Greco S., Matarazzo B.,
Induction of decision rules for explanation
and support of multicriteria choice and ranking, DSTIS, Warszawa 2001
[24] Słowiński R., Greco S., Matarazzo B., Rough set based decision support. Chapter
16 in: Burke E., Kendall G., eds:
Introductory Tutorials on Optimization, Search
and Decision Support Methodologies. Kluwer Academic Publishers, Boston, 2004

66
[25] Słowiński R., Greco S., Matarazzo B.,
Rough sets theory for multicriteria decision
analysis, European Journal of Operational Research 129 (2001), 1-47
[26] Sydra E., Góreczka M.,
Indeks Satysfakcji Klienta (CSI) jako jeden z elementów
wpływających na kreowanie strategii przedsiębiorstwa, Strategie.info.pl
http://ww.strategie.info.pl/artykuly/1023.htm, 2004
[27] The Java Developers Almanac 1.4, http://javaalmanac.com/egs/index.html
[28] W3 Schools,
SQL Tutorial, http://www.w3schools.com/sql/default.asp
[29] Wrembel R., Królikowski Z., Morzy M.,
Pro Dialog 10: Magazyny danych – stan
obecny i kierunki rozwoju, Wydawnictwo NAKOM, Poznań 2000, 75-93

67
Dodatek A – Wykaz tabel i rysunków
TABELE
Tabela 1 Wyniki ankiety PKP ........................................................................................ 28
Tabela 2 Reguły decyzyjne dla ankiety PKP.................................................................. 29
Tabela 3 Przykład połączenia OLAP i DRSA - liczność................................................ 35
Tabela 4 Podejścia dla miary - decyzja .......................................................................... 36
Tabela 5 Przykład połączenia OLAP i DRSA – decyzja................................................ 36
Tabela 6 Kryteria oceny magazynu "Anna" ................................................................... 45
RYSUNKI
Rys. 1 Struktura danych wielowymiarowych z wykorzystaniem agregacji ................... 26
Rys. 2 Przykładowa kostka danych OLAP..................................................................... 26
Rys. 3 Architektura systemu OLSA i wykorzystane technologie .................................. 38
Rys. 4 Elementy systemu OLSA i ich powiązania ......................................................... 40
Rys. 5 Moduł komunikacji z bazą danych...................................................................... 46
Rys. 6 Moduł do wczytywania danych wejściowych ..................................................... 47
Rys. 7 Aplikacja OLSA System 1.0 ............................................................................... 47
Rys. 8 Wybór z klasy c=4............................................................................................... 48
Rys. 9 Prezentacja przykładów dla klasy c=4................................................................. 48
Rys. 10 Moduł prezentacji atrybutów............................................................................. 49
Rys. 11 Moduł prezentacji reguł..................................................................................... 50
Rys. 12 Moduł do filtrowania reguł................................................................................ 50
Rys. 13 Moduł wykresu liniowego ................................................................................. 51
Rys. 14 Wykres liniowy dla przykładów: __ex7, __ex11, __ex22 ................................ 52
Rys. 15 Moduł szukania strategii interwencji................................................................. 53
Rys. 16 Moduł definiowania wymiarów i miary dla OLAP........................................... 54
Rys. 17 Moduł prezentacji danych wielowymiarowych OLAP ..................................... 55
Rys. 18 Wybór celu strategii (części decyzyjnej reguły)................................................ 56
Rys. 19 Moduł testowania strategii interwencji.............................................................. 56
Rys. 20 Moduł badania efektywności strategii interwencji wywiedzionej z reguł ........ 58
Rys. 21 Graficzna reprezentacja reguły i wywiedzionych z niej strategii interwencji... 60

68
Dodatek B – Przewodnik instalacyjny użytkownika
Poniżej została przedstawiona krok po kroku instalacja systemu OLSA oraz
elementów z nim związanych dla użytkownika końcowego:
1) Instalacja bazy danych MySQL
• Zainstalować MySQL w wersji 5.0 (wersja instalacyjna znajduje się w
CD\Install\MySQL\mysql-5.0.0a-alpha-win.zip).
• W katalogu gdzie został zainstalowany MySQL należy uruchomić
..\mysql-5.0.0-alpha\bin\mysql.exe.
• Należy stworzyć nową bazę danych o nazwie „oppfda” (Open Programming
Platform for Data Analysis) poleceniem
create database oppfda;
.
• Należy uruchomić skrypt tworzący odpowiednie tabele w bazie danych. Treść
skryptu znajduje się w plikach:
isf.sql oraz rls.sql w katalogu
CD\Install\GoalProject\MySQL-tables\. Komenda uruchamiająca skrypt z
konsoli MySQL (mysql.exe) :
\. Ścieżka_dostępu_do_skryptu (po kropce musi
być spacja).
• Istnieje możliwość wykorzystania przykładowej bazy danych „oppfda”
znajdującej się na dołączonej do pracy płycie CD. Wystarczy wgrać zawartość
katalogu
CD\Install\GoalProject\MySQL-database\ (katalog oppfda) do
odpowiedniego katalogu w MySQL -
..\mysql-5.0.0-alpha\data\.
2) Instalacja systemu GoalProject
• Zainstalować maszynę wirtualną Microsoft .NET Framework w wersji 1.0.3705
(nie może być wyższa) – plik
CD\Install\DotNetFx\dotnetredist.exe.
• Kolejne etapy instalacji samego systemu znajdują się w pliku
CD\Install\GoalProject\Install-GoalProject.pdf. Należy wykonać kroki z
pominięciem punktu 1.1.1 (wszystkie pliki zaznaczone na niebiesko znajdują się
w katalogu
CD\Install\GoalProject\BIN\ natomiast przykładowe skrypty
ScriptsSamples można znaleźć w
CD\Install\GoalProject\ScriptsSamples\).
3) Instalacja środowiska JAVA
• Zainstalować maszynę wirtualną JAVA w wersji 1.4.2_05 – plik
CD\Install\Java\j2re-1_4_2_05-windows-i586-p.exe.
4) Instalacja aplikacji OLSA System

69
• Należy przegrać katalog CD\Application\ w dowolnie wybrane miejsce.
• Aplikację uruchamia plik OLSA System 1.0.bat.
• Przykład korzystania z systemu został opisany w punkcie 6 (Studium
przypadków) oraz w podręczniku użytkownika zamieszonym na CD.

70
Dodatek C – Przewodnik instalacyjny programisty
Poniżej została przedstawiona krok po kroku instalacja wszystkich elementów
dla programisty systemu OLSA:
1) Instalacja bazy danych MySQL oraz systemu GoalProject
• Postępowanie identycznie jak w podpunktach 1) i 2) z dodatku B.
2) Instalacja maszyny wirtualnej JAVA lub środowiska JAVA SDK
• Zainstalować maszynę wirtualną JAVA – plik CD\Install\Java\j2re-1_4_2_05-
windows-i586-p.exe lub maszynę wirtualną JAVA z SDK (ang. Software
Development Kit) w wersji 1.4.2_05 – plik
CD\Programs\Java\j2sdk-1_4_2_05-
windows-i586-p.exe.
3) Instalacja środowiska programistycznego Eclipse SDK i projektu OLSA System
• Zainstalować
środowisko do programowania w Javie – plik
CD\Programs\Eclipse SDK\eclipse-SDK-3.0-win32.zip.
• Po uruchomieniu należy wskazać katalog do przechowywania projektów
(najlepiej zostawić domyślny).
• Należy przegrać katalog projektu OLSA System z kodem źródłowym do
wybranego wcześniej katalogu projektów – plik
CD\Sources\OLSASystem.rar.
• Przegrać pliki JAR znajdujące się w katalogu
..\eclipse\workspace\OLSASystem\OLSASystem\lib\ do odpowiedniego katalogu
z JAVĄ (np.
..\j2sdk1.4.2_05\jre\lib\ext\).
4) Eclipse SDK 3.0
• Stworzyć nowy projekt JAVA w Eclipse [File->New->Projekt->JavaProject] i
jako nazwę wpisujemy
OLSASystem, a następnie wybieramy opcje Next i Finish.
• Należy ustawić konfigurację kompilacji projektu OLSA System [opcja Run]. W
oknie konfiguracji należy wybrać opcję
New dla Java Apllication, określić
nazwę projektu i główną klasę w projekcie (
OLSASystem.Application).
• Po wykonaniu powyższych kroków można dokonywać zmian w kodzie projektu
OLSA System oraz dokonywać kompilacji.
• Generacja pliku JAR odbywa się przez wybór opcji File->Export->JARFile i
wskazanie co ma dokładnie zawierać.

71
Dodatek D – Spis CD
Płyta CD-ROM dołączona do pracy magisterskiej zawiera:
1) gotową do uruchomienia aplikację OLSA System 1.0 w postaci pliku JAR z
wymaganymi bibliotekami oraz plikiem uruchamiającym,
2) dokumentację aplikacji OLSA System 1.0 w postaci HTML (wygenerowaną
przy pomocy JavaDoc) oraz inne dokumenty:
• możliwości i propozycje rozwoju aplikacji OLSA System 1.0 (TODO),
• podręcznik użytkownika,
• manuale i tutoriale dla JAVY i MySQL,
• dotyczące zagadnień DRSA i Satysfakcji Klienta,
3) programy do instalacji w systemie operacyjnym wymagane dla poprawnego
działania aplikacji OLSA System 1.0:
• maszynę wirtualną Microsoft DotNet oraz JAVY,
• system GoalProject z przykładowymi problemami, skryptami i bazą danych,
• biblioteki i komponenty wykorzystywane w aplikacji OLSA System 1.0,
• system zarządzania baza danych MySQL w wersji 5.0.0a,
4) dodatkowe programy dla programistów JAVY i MySQL:
• darmowe środowisko do programowania w JAVIE – Eclipse 3.0, w której został
stworzony system OLSA,
• środowisko JAVA SDK 1.4.2 dla programistów,
• MySQL w wersji 4.0.13 i programy pomocne przy zarządzaniu bazą danych,
5) kod źródłowy aplikacji OLSA System 1.0,
6) elektroniczną wersję pracy magisterskiej z rysunkami JPG w niej
wykorzystywanymi.
Wyszukiwarka
Podobne podstrony:
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
Interaktywny system regułowej analizy danych marketingowych dotyczących satysfakcji klienta
1 Metody analizy danych w marketingu
17 Rejestracja i analiza danych dotyczących z k
Analiza danych w Systemach Informacji Przestrzennej
Informacja o analizowanych danych, Akademia Ekonomiczna w Katowicach, Zarzadzanie, Semestr III, Bada
systemy analizy danych
17 Rejestracja i analiza danych dotyczących z k
SPSS paca domowa 1 odpowiedzi, Studia, Kognitywistyka UMK, I Semestr, Statystyczna analiza danych
Systemy dydaktyczne - analiza porównawcza, UAM Pedagogika, I rok, Dydaktyka ogólna
Analiza danych wyjściowych
Metody analizy danych
Analiza działań marketingowych Kawasaki popr
Cierpiałkowska Koncepcje interakcyjne i systemowe oraz ich znaczenie dla psychologii klinicznej
Sciaga3, Cyfrowa Analiza Danych
podział marzeny, WZG 1, WYKAZ ZMIAN DANYCH EWIDENCYJNYCH DOTYCZĄCYCH DZIAŁKI
więcej podobnych podstron